发送装置、发送方法、接收装置、接收方法、信息处理装置和信息处理方法与流程
本技术涉及一种发送装置、一种发送方法、一种接收装置、一种接收方法、一种信息处理装置和一种信息处理方法,并且具体地,涉及一种传输字幕文本信息以及图像数据的发送装置等。
背景技术:
通常,例如,在遵从数字视频广播(dvb)的广播等中,执行使用位图数据发送字幕信息的操作。近年来,已经提出了使用文本字符代码(即,基于文本)发送字幕信息的想法。在这种情况下,根据分辨率在接收侧执行字体扩展。
另外,提出了在基于文本发送字幕信息的情况下将定时信息附加到文本信息的想法。万维网联盟(w3c)已经建议了定时文本标记语言(ttml)作为文本信息的示例(参考专利文献1)。
引用列表
专利文献
专利文献1:日本专利申请公开第2002-169885号
技术实现要素:
本发明要解决的问题
本技术的目的是确保可以在接收侧适当地执行利用字幕文本信息的处理。
解决问题的方法
本技术的概念是一种发送装置,包括:视频编码单元,被配置为生成具有编码图像数据的视频流;字幕编码单元,被配置为生成具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息的字幕流;以及发送单元,被配置为发送包括视频流和字幕流的具有预定格式的容器。
在本技术中,由视频编码单元生成具有编码图像数据的视频流。由字幕编码单元生成字幕流。字幕流具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息。
例如,元信息可以包括用于识别每个话语的发话者的标识符。在这种情况下,例如,元信息可以进一步包括每个话语的发话者的属性信息。例如,字幕流可以具有字幕文本信息和元信息,作为ttml数据或具有ttml派生格式的数据。
包括视频流和字幕流的具有预定格式的容器由发送单元传输。例如,容器可以是数字广播标准中采用的传输流(mpeg-2ts)。可替换地,例如,容器可以是用于互联网传送等的mp4或具有不同格式的容器。
如上所述,在本技术中,除了与预定数量的发话者的话语相对应的字幕文本信息之外,字幕流还具有用于分析每个话语的元信息。因此,在接收侧,可以参照元信息更适当地执行字幕文本信息的处理。
此外,本技术的另一概念是一种接收装置,包括:接收单元,被配置为接收包括视频流和字幕流的具有预定格式的容器,该视频流具有编码图像数据,该字幕流具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息;信息提取单元,被配置为从字幕流中提取字幕文本信息和元信息;以及信息处理单元,被配置为利用所提取的字幕文本信息和元信息执行处理。
在本技术中,由接收单元接收具有预定格式的容器。该容器至少包括具有编码图像数据的视频流和具有与预定数量的发话者的话语相对应的字幕文本信息及用于分析每个话语的元信息的字幕流。
由信息处理单元从字幕流中提取字幕文本信息和元信息。然后由信息处理单元利用所提取的字幕文本信息和元信息执行处理。例如,元信息可以包括用于识别每个话语的发话者的标识符。在这种情况下,例如,元信息可以进一步包括每个话语的发话者的属性信息。
例如,信息处理单元可以参考元信息并且对字幕文本信息执行语义分析和语境化,以便为每个发话者创建个人概要或字幕概要,或将每个话语的字幕翻译成另一种语言。
此外,例如,信息处理单元可以被配置为:将字幕文本信息和元信息发送到外部装置;并且从外部装置接收通过参考元信息对字幕文本信息执行的语义分析和语境化而创建的每个发话者的个人概要或字幕概要,或者通过参考元信息对字幕文本信息执行的语义分析和语境化而获得的将每个话语的字幕翻译成另一种语言的结果。
如上所述,在本技术中,使用用于分析每个话语的元信息以及与预定数量的发话者的话语相对应的字幕文本信息来执行处理。因此,可以参照元信息更适当地执行字幕文本信息的处理。
此外,本技术的另一概念是一种信息处理装置,包括:接收单元,被配置为从外部装置接收与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息;信息处理单元,被配置为利用字幕文本信息和元信息执行处理;以及发送单元,被配置为将处理结果发送到外部装置。
在本技术中,由接收单元从外部装置接收与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息。由信息处理单元利用字幕文本信息和元信息执行处理。例如,信息处理单元可以参考元信息,并对字幕文本信息执行语义分析和语境化,以便为每个发话者创建个人概要或字幕概要,或将每个话语的字幕翻译成另一种语言。由发送单元将处理的结果发送到外部装置。
如上所述,在本技术中,使用从外部装置接收的与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息来执行处理,并且将结果发送到外部装置。因此,可以减少外部装置的处理负荷。
本发明的效果
根据本技术,可以更适当地在接收侧执行字幕文本信息的处理。注意,本说明书中描述的效果仅是示例,并且本发明的效果不限于这些效果。还可以获得额外的效果。
附图说明
[图1]是示出作为实施方式的发送/接收系统的示例性配置的框图。
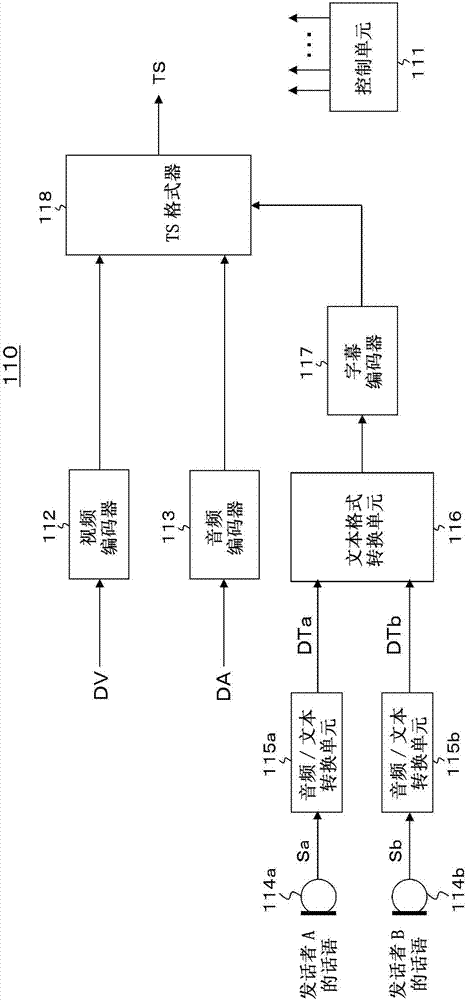
[图2]是示出广播传输系统的流生成单元的示例性配置的框图。
[图3]是用于说明ttml结构的示图。
[图4]是示出存在于ttml结构的报头(头部)中的相应元素(即元数据、样式和布局)的示例性结构的示图。
[图5]是示出ttml结构的主体的示例性结构的示图。
[图6]是示出电视接收机的示例性配置的框图。
[图7]是用于说明字幕流分析单元的操作的示图。
[图8]是用于说明在信息处理单元中为每个发话者生成个人概要的处理的示例性过程的示图。
[图9]是示出对话的文本示例的示图。
[图10]是示出示例性字/划分处理和示例性语境/语义分析处理的示图。
[图11]是示出示例性字/划分处理和示例性语境/语义分析处理的示图。
[图12]是示出从电视接收机发送到外部装置的ttml元数据和ttml主体的示例的示图。
具体实施方式
在后文中,将描述用于实施本发明的模式(在后文中称为“实施方式”)。请注意,描述将按以下顺序提供:
1、实施方式
2、变化
<1、实施方式>
[发送/接收系统的示例性配置]
图1是示出作为实施方式的发送/接收系统10的示例性配置的示图。发送/接收系统10包括广播传输系统100和电视接收机200。广播传输系统100通过广播波发送作为多路复用流的传输流ts。
传输流ts至少具有视频流和字幕流。视频流具有编码图像数据。字幕流具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息。在本实施方式中,元信息包括用于识别每个话语的发话者的标识符和每个话语的发话者的属性信息。注意,可以仅包括标识符,作为元信息,或者可以包括诸如关于每个话语的环境的信息的其他类型的信息,作为元信息。
电视接收机200使用广播波接收从广播传输系统100发送的传输流ts。如上所述,传输流ts至少具有视频流和字幕流。注意,在一些情况下,传输流ts可以包括音频流。除了与预定数量的发话者的话语相对应的字幕文本信息之外,字幕流还包括用于分析每个话语的元信息。
电视接收机200对视频流执行解码处理以获得图像数据,并且对从字幕流中提取的字幕文本信息进行解码处理以获得字幕(标题)的位图数据。然后,电视接收机200将字幕(标题)的位图数据叠加在图像数据上,并且显示经过字幕叠加的图像。
此外,电视接收机200使用从字幕流中提取的字幕文本信息和元信息,获取每个发话者的个人概要或字幕概要、或者将每个话语的字幕翻译成另一种语言的结果。电视接收机200本身执行为每个发话者生成个人概要或字幕概要的处理,或者将每个话语的字幕翻译成另一种语言的处理。可替换地,电视接收机200使云端上的外部装置(即,经由网络连接的外部装置)执行这些处理。
例如,电视接收机200根据用户的选择操作,将所获取的每个发话者的个人概要或字幕概要、或者所获取的每个话语的字幕翻译成另一种语言的结果叠加在图像上,并且显示经过叠加的图像。
[广播传输系统的流生成单元的示例性配置]
图2是示出广播传输系统100的流生成单元110的示例性配置的示图。流生成单元110具有控制单元111、视频编码器112、音频编码器113、麦克风114a和114b、音频/文本转换单元115a和115b、文本格式转换单元116、字幕编码器117以及ts格式器(多路复用器)118。
例如,控制单元111被配置为包括中央处理单元(cpu),并且控制流生成单元110的每个部件的操作。图像数据dv被输入到视频编码器112。视频编码器112编码图像数据dv以生成包括pes数据包的视频流,在pes数据包中,编码图像数据设置在有效载荷中。音频数据da被输入到音频编码器113。音频编码器113编码音频数据da以生成包括pes数据包的音频流,在pes数据包中,编码音频数据被设置在有效载荷中。
麦克风114a将发话者a的话语转换为音频数据sa。音频/文本转换单元115a将音频数据sa转换为文本数据(字符代码)dta,作为字幕信息。麦克风114b将发话者b的话语转换为音频数据sb。音频/文本转换单元115b将音频数据sb转换为文本数据(字符代码)dtb,作为字幕信息。音频/文本转换单元115b和115b中的转换处理可以手动或自动执行。此外,音频数据sa和sb块可以与音频数据da并行地输入到音频编码器113。
作为字幕信息的文本数据dta和dtb块被输入到文本格式转换单元116,并且获得具有预定格式的字幕文本信息。文本信息的示例包括ttml和ttml派生格式。本实施方式基于ttml的前提。
图3是示出ttml结构的示图。ttml是基于xml描述的。相应的元素,即元数据、样式和布局,存在于报头(头部)中。图4(a)是示出元数据(ttm:ttml元数据)的示例性结构的示图。元数据包括有关元数据的标题的信息和有关版权的信息。
此外,元数据包括与用于识别发话者a和发话者b的标识符相关联的发话者的属性信息项。项‘voice_id=“a”’表示发话者a的标识符,并且包括‘sex=“m”’、‘age=“30”’、‘char=“mild”’以及‘language_id=“english”’的属性信息与该标识符相关联地设置。项‘sex=“m”’表示性别是男性。项‘age=“30”’表示年龄是30。项‘char=“mild”’表示个性温和。项‘language_id=“english”’表示语言是英语。
此外,项‘voice_id=“b”’表示发话者b的标识符,并且包括‘sex=“f”、‘age=“25”’、‘char=“smart”&“sharp”’以及‘language_id=“english”’的属性信息与该标识符相关联地设置。项‘性别=“f”’表示性别是女性。项‘age=“25”’表示年龄是25。项‘char=“smart”&“sharp”’表示个性聪明并且机灵。项‘language_id=“english”’表示该语言是英语。
注意,所示类型的属性信息仅是示例。并非所有这些都需要设置,并且可以设置其他类型的属性信息。另外,在示出的示例中,尽管包括发话者a和发话者b的属性信息项,但是可以包括与发话者a和发话者b的话语有关的其他信息项,例如,诸如地点和时间的环境信息。
图4(b)是示出样式(tts:ttml样式)的示例性结构的示图。样式包括诸如颜色、字体(fontfamily)、大小(fontsize)和对齐(textalign)的信息项以及标识符(id)。图4(c)是示出布局(区域:ttml布局)的示例性结构的示图。布局包括诸如范围(extent)、偏移(padding)、背景颜色(backgroundcolor)和对齐(displayalign)的信息项以及设置字幕的区域的标识符(id)。
图5是示出主体的示例性结构的示图。在所示的示例中,包括关于三个字幕的信息项,即,字幕1(subtitle1)、字幕2(subtitle2)和字幕3(subtitle3)。对于每个字幕,与显示开始定时和显示结束定时一起描述文本数据,并且描述与文本数据相对应的发话者的标识符。例如,关于字幕1(subtitle1),显示开始定时是“0.76s”,显示结束定时是“3.45s”,文本数据是“看起来是悖论,不是吗,”,并且标识符是“a”,表示发话者a。
此外,关于字幕2(subtitle2),显示开始定时是“5.0s”,显示结束定时是“10.0s”,文本数据是“形成在视网膜上<br/>的图像应当是倒转的?”,并且标识符是“b”,表示发话者b。此外,关于字幕3(subtitle3),显示开始定时是“10.0s”,显示结束定时是“16.0s”,文本数据是“这是令人困惑的,为什么<br/>我们看到的东西不是颠倒的?”,并且标识符是“a”,表示发话者a。
返回图2,字幕编码器117将由文本格式转换单元116获得的ttml转换为各种段,并且生成包括pes数据包的字幕流,在pes数据包中这些段设置在有效载荷中。注意,代替将ttml放置在段上并将段设置在pes数据包的有效载荷中,也可以直接将ttml设置在pes数据包的有效载荷中。
ts格式器118通过将由视频编码器112生成的视频流、由音频编码器113生成的音频流和由字幕编码器117生成的字幕流转换为传输数据包来执行多路复用,并获得传输流ts作为多路复用流。
将简要描述图2所示的流生成单元110的操作。图像数据dv提供至视频编码器112。在视频编码器112中,图像数据dv被编码,并且生成包括视频pes数据包的视频流(pes流),其中编码图像数据保存在有效载荷中。视频流提供至ts格式器118。
此外,音频数据da提供至音频编码器113。在音频编码器113中,对音频数据da进行编码,并且生成包括具有编码音频数据的音频pes数据包的音频流(pes流)。音频流提供至ts格式器118。
此外,作为与发话者a的话语相对应并且由音频/文本转换单元115a获得的字幕信息的文本数据(字符代码)dta,以及作为与发话者b的话语相对应并且由音频/文本转换单元115b获得的字幕信息的文本数据(字符代码)dtb提供至文本格式转换单元116。
在文本格式转换单元116中,基于作为字幕信息的文本数据dta和dtb2块,获得作为字幕文本信息的ttml。在ttml中,用于识别发话者a和发话者b的标识符与相应字幕的文本数据块相关联地描述(参照图5)。另外,在ttml中,发话者的属性信息项等与用于识别发话者a和发话者b的标识符相关联地描述(参考图4(a))。ttml提供至字幕编码器117。
在字幕编码器117中,ttml被转换为各种段,并且生成包括pes数据包的字幕流,其中这些段设置在pes数据包的有效载荷中,ttml直接设置在有效载荷中。字幕流提供至ts格式器118。
在ts格式器118中,由视频编码器112生成的视频流、由音频编码器113生成的音频流以及由字幕编码器117生成的字幕流被转换为传输数据包并被多路复用,并且生成传输流ts作为多路复用流。通过广播波从发送单元(未示出)发送传输流ts。
[电视接收机的示例性配置]
图6是示出电视接收机200的示例性配置的示图。电视接收机200具有接收单元201、ts分析单元(多路解复用器)202、视频解码器203、视频叠加单元204、面板驱动电路205、以及显示面板206。电视接收机200还具有音频解码器207、音频输出电路208和扬声器209。
电视接收机200还具有字幕流分析单元210、文本解码显示处理单元211和信息处理单元212。电视接收机200还具有cpu221、闪存rom222、dram223、内部总线224、遥控接收单元225和遥控发送器226。
cpu221控制电视接收机200的每个部件的操作。闪存rom222容纳控制软件并存储数据。dram223构成cpu221的工作区域。cpu221扩展从dram223上的闪存rom222读取的软件和数据,以启动软件,并且控制电视接收机200的每个部件。
遥控接收单元225接收从遥控发送器226发送的遥控信号(遥控代码),并将遥控代码提供至cpu221。cpu221基于遥控代码控制电视接收机200的每个部件。cpu221、闪存rom222和dram223连接到内部总线224。
接收单元201通过广播波接收从广播传输系统100发送的传输流ts。如上所述,传输流ts包括视频流、音频流和字幕流。ts分析单元202从传输流ts中提取相应流,即,视频流、音频流和字幕流。
音频解码器207对由ts分析单元202提取的音频流执行解码处理,以获得音频数据。音频输出电路208对音频数据进行诸如d/a转换和放大的必要处理,并将经处理的音频数据提供至扬声器209。视频解码器203对由ts分析单元202提取的视频流执行解码处理,以获得图像数据。
字幕流分析单元210对由ts分析单元202提取的字幕流中包括的ttml进行分类,取出文本信息和显示相关信息,并将这些信息项发送到文本解码显示处理单元211。字幕流分析单元210还取出文本信息和语义分析元信息,并将这些信息项发送到信息处理单元212。
将进一步描述字幕流分析单元210。如图7(a)所示,ttml包括ttml报头(ttml头部)和ttml主体,并且相应元素(即,ttml元数据、ttml样式和ttml布局)存在于ttml报头中。
如图7(b)所示,字幕流分析单元210从ttml取出ttml样式、ttml布局和ttml主体,并将其发送到文本解码显示处理单元211。此外,如图7(b)所示,字幕流分析单元210从ttml取出ttml元数据和ttml主体,并将其发送到信息处理单元212。
返回图6,文本解码显示处理单元211对文本信息和显示相关信息(ttml样式、ttml布局和ttml主体)执行解码处理,以获得要叠加在图像数据上的每个区域的位图数据。
视频叠加单元204将从文本解码显示处理单元211获得的每个区域的位图数据叠加在由视频解码器203获得的图像数据上。面板驱动电路205基于视频叠加单元204获得的显示图像数据,驱动显示面板206。例如,显示面板206包括液晶显示器(lcd)、有机电致发光显示器(有机el显示器)等。
信息处理单元212执行文本信息和语义分析元信息(ttml元数据和ttml主体)的处理,并输出处理结果。该处理的示例包括为每个发话者生成个人概要和字幕概要的处理,以及将每个话语的字幕翻译成另一种语言的处理。在这种情况下,信息处理单元212获得用于显示处理结果的位图数据。
图8是用于说明在信息处理单元212中为每个发话者生成个人概要的处理的示例性过程的示图。下面的描述基于如图9(a)和图9(b)所示的场景1和场景2中的发话者a和b之间的对话的文本示例。
首先,作为步骤1,执行字/划分处理。图10(a)是示出与场景1中的发话者a和b的字幕相关的示例性字/划分处理的示图。图11(a)是示出与场景2中的发话者a和b的字幕相关的示例性字/划分处理的示图。
接下来,作为步骤2,执行语境/语义分析处理。图10(b)是示出与场景1中的发话者a和b的字幕相关的示例性语境/语义分析处理的示图。图11(b)是示出与场景2中的发话者a和b的字幕相关的示例性语境/语义分析处理的示图。注意,语境/语义分析处理的结果构成每个发话者的字幕概要。在执行生成每个发话者的字幕概要的处理的情况下,信息处理单元212输出例如语境/语义分析处理的结果。注意,信息处理单元212的输出可以采取文本的形式。在这种情况下,文本输出经过文本解码显示处理单元211以进行位图转换,并且被提供至视频叠加单元204。
接下来,作为步骤3,执行使用发话者标识符创建字符的概要的处理。场景1中的标识符“a”和场景2中的标识符“a”表示同一个人。类似地,场景1中的标识符“b”和场景2中的标识符“b”表示同一个人。由于在场景1和场景2中提供了发话者的标识符,所以可以识别出个人的个性和本质根据场景而变化。缺少标识符导致场景1中的发话者a和场景2中的发话者b是同一个人这一误解。发话者的标识符的存在使能够识别并且可以获得准确的个人概要。
接下来,作为步骤4,添加发话者的属性信息项,并且执行在程序中创建字符的概要的处理。因此,添加使用ttml元数据(参照图4(a))传输的发话者a和b的属性信息项,从而估计个人的最终概要。
在示出的示例中,如下生成发话者a的个人概要:“一个勤奋、富有成效的男人,讲日语并且具有有条理的个性。他是习惯于诸如飞机的交通工具的那种人,并且处事冷静”。此外,如下生成发话者b的个人概要:“一个讲日语的中年男子,并且通常倾向于无牵挂的。但是,当他乘坐飞机时,他变成感到紧张的那种人”。
注意,虽然省略了详细的描述,但是即使在信息处理单元212中执行将每个话语的字幕翻译成另一种语言的处理的情况下,也可以基于发话者的标识符,执行基于发话者的翻译。此外,参考每个发话者的属性信息,可以根据诸如性别、年龄、个性、口语等的信息更适当地执行翻译成另一种语言。
返回图6,视频叠加单元204根据用户的显示选择操作,将由文本解码显示处理单元211获得的每个区域的位图数据叠加在由视频解码器203获得的图像数据上。此外,视频叠加单元204根据用户的显示选择操作,将由信息处理单元212获得的处理结果的位图数据叠加在由视频解码器203获得的图像数据上。
面板驱动电路205基于由视频叠加单元204获得的显示图像数据来驱动显示面板206。显示面板206包括例如液晶显示器(lcd)、有机电致发光显示器(有机el显示器)等。
将简要描述图6所示的电视接收机200的操作。在接收单元201中,接收从广播传输系统100通过广播波发送的传输流ts。传输流ts包括视频流、音频流和字幕流。
由ts分析单元202提取的视频流提供至视频解码器203。在视频解码器203中,对视频流执行解码处理,并获得图像数据。图像数据提供至视频叠加单元204。另外,由ts分析单元202提取的字幕流提供至字幕流分析单元210。在字幕流分析单元210中,将包括在字幕流中的ttml分类。
然后,在字幕流分析单元210中,将ttml样式、ttml布局和ttml主体取出作为文本信息和显示相关信息,并提供至文本解码显示处理单元211。另外,在字幕流分析单元210中,将ttml元数据和ttml主体取出作为文本信息和语义分析元信息,并提供至信息处理单元212。
在文本解码显示处理单元211中,对作为文本信息和显示相关信息的ttml样式、ttml布局和ttml主体进行解码处理,并且获得要叠加在图像数据上的每个区域的位图数据。位图数据提供至视频叠加单元204。在视频叠加单元204中,由文本解码显示处理单元211获得的每个区域的位图数据,根据用户的显示选择操作叠加在由视频解码器203获得的图像数据上。
由视频叠加单元204获得的显示图像数据提供至面板驱动电路205。在面板驱动电路205中,基于显示图像数据驱动显示面板206。因此,图像显示在显示面板206上,并且字幕(标题)根据用户的显示选择操作而叠加在该图像上,以用于显示。
此外,在信息处理单元212中,执行作为文本信息和语义分析元信息的ttml元数据和ttml主体的处理,并且获得用于显示处理结果的位图数据。该处理的示例包括为每个发话者生成个人概要和字幕概要的处理,以及将每个话语的字幕翻译成另一种语言的处理。
位图数据提供至视频叠加单元204。在视频叠加单元204中,由信息处理单元212获得的处理结果的位图数据,根据用户的显示选择操作叠加在由视频解码器203获得的图像数据上。因此,根据用户的显示选择操作,将处理结果(例如,每个发话者的个人概要和字幕概要,或将每个话语的字幕翻译成另一种语言的结果)叠加在显示面板206上显示的图像上。
此外,由ts分析单元202提取的音频流提供至音频解码器207。在音频解码器207中,对音频流执行解码处理,并获得音频数据。
音频数据提供至音频输出电路208。在音频输出电路208中,对音频数据执行诸如d/a转换和放大的必要处理。然后,经处理的音频数据提供至扬声器209。因此,从扬声器209获得与显示面板206上显示的图像相对应的音频输出。
注意,在上述示例中,文本信息和语义分析元信息(ttml元数据和ttml主体)的处理由设置在电视接收机200中的信息处理单元执行。可替换地,该处理可以由云上的外部装置(即,经由网络连接的外部装置)执行。
通信单元213经由网络向外部装置300发送由字幕流分析单元210取出的文本信息和语义分析元信息(ttml元数据和ttml主体),并且从外部装置300接收用于显示处理结果的位图数据(例如,每个发话者的个人概要和字幕概要、或将每个话语的字幕翻译成另一种语言的结果)。
位图数据提供至视频叠加单元204。在视频叠加单元204中,由通信单元213接收的处理结果的位图数据,根据用户的显示选择操作叠加在由视频解码器203获得的图像数据上。因此,即使在如上所述由外部装置300执行处理的情况下,处理结果(例如,每个发话者的个人概要和字幕概要,或者将每个话语的字幕转换为另一种语言的结果)根据用户的显示选择操作而叠加在显示面板206上显示的图像上。
外部装置300具有通信单元301和信息处理单元302。通信单元301经由网络从电视接收机200接收文本信息和语义分析元信息(ttml元数据和ttml主体),并且将这些信息项提供至信息处理单元302。通信单元301还经由网络向电视接收机200发送指示从信息处理单元302提供的处理结果的位图数据。
例如,通信单元213将ttml元数据和ttml主体放置在mp4容器中,并将mp4容器发送到外部装置300。注意,在这种情况下,在字/短语划分之后获得的文本列表可以与发话者的标识符一起设置在ttml主体中。以这种方式,在外部装置300中减少了字/短语划分的处理时间。图12(a)和图12(b)是示出从通信单元213发送到外部装置300的ttml元数据和ttml主体的示例的示图。
图12(b)是在电视接收机200中执行字/短语划分的情况下的ttml主体的示例。可替换地,可以将接收的ttml主体如同没有经受字/短语划分一样从通信单元213发送到外部装置300。
注意,在外部装置300中的信息处理之后获得的处理结果可以以文本格式输入到电视接收机200的通信单元213。在这种情况下,通信单元213的输出经过文本解码显示处理单元211以进行位图转换,并提供至视频叠加单元204。
信息处理单元302被配置为与电视接收机200中的上述信息处理单元212相似。信息处理单元302执行从通信单元301提供的文本信息和语义分析元信息(ttml元数据和ttml主体)的处理,并将指示处理结果的位图数据提供至通信单元301。
如上所述,在图1所示的发送/接收系统10中,除了与预定数量的发话者的话语相对应的字幕文本信息之外,字幕流还具有用于分析每个话语的元信息。因此,在接收侧,可以参考元信息适当地执行字幕文本信息的处理(例如,为每个发话者生成个人概要和字幕概要的处理以及将每个话语的字幕翻译成另一种语言的处理)。
<2、变化>
注意,在以上实施方式中描述的示例中,ttml用作字幕文本信息。然而,本技术不限于该示例,并且可以使用具有与ttml中的信息等同的信息的其他类型的定时文本信息。例如,可以使用ttml派生的格式。
此外,在以上实施方式中描述的示例中,发送/接收系统10包括广播传输系统100和电视接收机200。然而,可以应用本技术的发送/接收系统的配置不限于这个示例。例如,对应于电视接收机200的部分可以被配置为通过诸如高清晰度多媒体接口(hdmi)的数字接口耦接在一起的机顶盒和监视器。请注意,“hdmi”是注册商标。
此外,本技术也可以如下配置。
(1)一种发送装置,包括:
视频编码单元,被配置为生成具有编码图像数据的视频流;
字幕编码单元,被配置为生成具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息的字幕流;以及
发送单元,被配置为发送包括视频流和字幕流的具有预定格式的容器。
(2)根据(1)所述的发送装置,其中,
元信息包括用于识别每个话语的发话者的标识符。
(3)根据(2)所述的发送装置,其中,
元信息进一步包括每个话语的发话者的属性信息。
(4)根据(1)至(3)中任一项所述的发送装置,其中,
字幕流具有字幕文本信息和元信息,作为ttml数据或具有ttml派生格式的数据。
(5)一种发送方法,包括:
视频编码步骤,生成具有编码图像数据的视频流;
字幕编码步骤,生成具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息的字幕流;以及
发送步骤,由发送单元发送包括视频流和字幕流的具有预定格式的容器。
(6)一种接收装置,包括:
接收单元,被配置为接收包括视频流和字幕流的具有预定格式的容器,该视频流具有编码图像数据,该字幕流具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息;
信息提取单元,被配置为从字幕流中提取字幕文本信息和元信息;以及
信息处理单元,被配置为利用所提取的字幕文本信息和元信息执行处理。
(7)根据(6)所述的接收装置,其中,
元信息包括用于识别每个话语的发话者的标识符。
(8)根据(7)所述的接收装置,其中,
元信息进一步包括每个话语的发话者的属性信息。
(9)根据(6)至(8)中任一项所述的接收装置,其中,
信息处理单元参考元信息并且对字幕文本信息执行语义分析和语境化,以便为每个发话者创建个人概要或字幕概要,或将每个话语的字幕翻译成另一种语言。
(10)根据(6)至(8)中任一项所述的接收装置,其中,
信息处理单元被配置为:
将字幕文本信息和元信息发送到外部装置;并且
从外部装置接收通过参考元信息对字幕文本信息执行的语义分析和语境化而创建的每个发话者的个人概要或字幕概要,或者通过参考元信息对字幕文本信息执行的语义分析和语境化而获得的将每个话语的字幕翻译成另一种语言的结果。
(11)一种接收方法,包括:
接收步骤,由接收单元接收包括视频流和字幕流的具有预定格式的容器,该视频流具有编码图像数据,该字幕流具有与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息;
信息提取步骤,从字幕流中提取字幕文本信息和元信息;以及
信息处理步骤,利用所提取的字幕文本信息和元信息执行处理。
(12)一种信息处理装置,包括:
接收单元,被配置为从外部装置接收与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息;
信息处理单元,被配置为利用字幕文本信息和元信息执行处理;以及
发送单元,被配置为将处理的结果发送到外部装置。
(13)根据(12)所述的信息处理装置,其中,
信息处理单元参考元信息并且对字幕文本信息执行语义分析和语境化,以便为每个发话者创建个人概要或字幕概要,或将每个话语的字幕翻译成另一种语言。
(14)一种信息处理方法,包括:
接收步骤,由接收单元从外部装置接收与预定数量的发话者的话语相对应的字幕文本信息和用于分析每个话语的元信息;
信息处理步骤,利用字幕文本信息和元信息执行处理;以及
发送步骤,由发送单元将处理的结果发送到外部装置。
本技术的主要特征在于,除了与预定数量的发话者的话语相对应的字幕文本信息之外,字幕流还具有用于分析每个话语的元信息,使得可以在接收侧适当地执行字幕文本信息的处理(参照图2、图4以及图5)。
附图标记列表
10发送/接收系统
100广播传输系统
110流生成单元
111控制单元
112视频编码器
113音频编码器
114a、114b麦克风
115a、115b音频/文本转换单元
116文本格式转换单元
117字幕编码器
118ts格式器(多路复用器)
200电视接收机
201接收单元
202ts分析单元(多路解复用器)
203视频解码器
204视频叠加单元
205面板驱动电路
206显示面板
207音频解码器
208音频输出电路
209扬声器
210字幕流分析单元
211文本解码显示处理单元
212信息处理单元
213通信单元
300外部装置
301通信单元
302信息处理单元
221cpu。
- 还没有人留言评论。精彩留言会获得点赞!