一种单点故障的处理方法及装置与流程
本发明属于单点故障技术领域,尤其涉及一种单点故障的处理方法及装置。
背景技术:
在云计算产业中,大部分的架构都是集中式管理,即由一个总控中心负责管理一系列的资源,这种集中式管理架构中存在的一个问题是作为总控中心的管理节点,由于断电等原因会导致出现单点故障,进而导致整个集中式管理系统瘫痪。
目前处理管理节点的单点故障的方式是:搭建集群,通过搭建多个管理节点,每个管理节点都可以作为备份总控中心,当作为总控中心的管理节点发生单点故障时,作为备份总控中心的管理节点代替发生单点故障的管理节点,用于负责管理一系列的资源。使得即使一个管理节点发生单点故障,也可以通过其他管理节点继续进行工作,解决了管理节点的单点故障问题。
通过搭建集群的方式处理管理节点的单点故障时,针对搭建的每一个管理节点,分别对应一个数据库,构成数据库集群。由于每个管理节点都可以作为总控中心,用于管理一系列的资源,以供多个计算节点的调用,且一个计算节点从管理节点处获取到的内容应该相同,因此,数据库集群内的多个数据库,应该具有一致性。
现有技术中处理管理节点的单点故障问题时,由于需要建立多个管理节点,每一个管理节点对应一台物理机,且需要为每个管理节点建立一个数据库,因此,搭建的系统架构复杂,增加了系统成本,而且需要维护各个数据库之间的数据一致性,因此后期系统维护困难,增加系统维护成本。
技术实现要素:
有鉴于此,本发明的目的在于提供一种单点故障的处理方法及装置,以解决现有技术中在处理管理节点的单点故障问题时,存在的系统架构复杂、系统成本高且维护困难的问题。
技术方案如下:
本发明提供一种单点故障的处理方法,应用在第一节点中,所述处理方法包括:
接收安装在虚拟机内部的第二节点发送的心跳信号;其中,所述虚拟机运行于共享存储内;
根据所述心跳信号,判断所述第二节点是否发生单点故障;
判断是,则重启所述虚拟机。
优选地,所述接收安装在虚拟机内部的第二节点发送的心跳信号后,还包括:
记录接收到所述心跳信号的产生时间;
其中,所述根据所述心跳信号,判断所述第二节点是否发生单点故障,包括:
查找上一次接收到的所述心跳信号的产生时间,得到第一时间;
计算当前时间与所述第一时间之间的差值;其中,所述当前时间为所述第一节点的系统时间;
判断所述差值是否大于预设时间值;
是,则所述第二节点发生单点故障。
优选地,所述重启所述虚拟机,包括:
调用应用程序编程接口或命令行界面;
向所述应用程序编程接口或所述命令行界面,输入重启命令。
优选地,在执行所述调用应用程序编程接口或命令行界面步骤前,还包括:
在所述共享存储内,查找是否存在与所述虚拟机对应的存储锁;
若不存在,则调用应用程序编程接口或命令行界面;
若存在,则间隔预设时长后,重新执行根据所述心跳信号,判断所述第二节点是否发生单点故障的步骤。
本发明还提供一种单点故障的处理装置,所述处理装置包括:
接收单元,用于接收安装在虚拟机内部的第二节点发送的心跳信号;其中,所述虚拟机运行于共享存储内;
判断单元,用于根据所述心跳信号,判断所述第二节点是否发生单点故障;
重启单元,用于当所述判断单元判断结果为是时,重启所述虚拟机。
优选地,还包括:
记录单元,用于记录接收到所述心跳信号的产生时间;
其中,所述判断单元,还包括:
查找子单元,用于查找上一次接收到的所述心跳信号的产生时间,得到第一时间;
计算子单元,用于计算当前时间与所述第一时间之间的差值;其中,所述当前时间为所述第一节点的系统时间;
判断子单元,用于判断所述差值是否大于预设时间值;
是,则所述第二节点发生单点故障。
优选地,所述重启单元包括:
调用子单元,用于调用应用程序编程接口或命令行界面;
输入子单元,用于向所述应用程序编程接口或所述命令行界面,输入重启命令。
优选地,还包括:
查找单元,用于在所述共享存储内,查找是否存在与所述虚拟机对应的存储锁;
若不存在,则调用所述调用子单元;
若存在,则间隔预设时长后,调用所述判断单元。
与现有技术相比,本发明的第一节点接收安装在虚拟机内部的第二节点发送的心跳信号,仅根据所述心跳信号,即可判断所述第二节点是否发生单点故障,发生单点故障时,第一节点重启所述虚拟机,以克服安装在虚拟机内部的第二节点发生的单点故障问题。相较于现有技术需要额外建立多个管理节点以及与多个管理节点对应的数据库,本申请并不需要改变原本的集中式管理系统架构,而仅仅是将原本安装在物理机内的第一节点,改进为安装在虚拟机内,并依据心跳机制,即可判断第二节点是否发生单点故障。大大降低了集中式管理系统的复杂度,且降低了系统成本。
此外,由于本发明中虚拟机是运行在共享存储内,所有第一节点都可以直接从共享存储内获取相应的数据,可以满足数据的一致性。相较于现有技术为了满足数据的一致性,需要后期对数据库集群内的多个数据库进行维护的这一技术方案,大大降低了系统维护难度,降低了系统维护成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种单点故障的处理方法的流程图;
图2是本发明实施例提供的另一种单点故障的处理方法的流程图;
图3是本发明实施例提供的一种单点故障的处理装置的结构图;
图4是本发明实施例提供的另一种单点故障的处理装置的结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,其示出了本发明实施例提供的一种单点故障的处理方法的流程图,所述处理方法应用在第一节点中,包括:
S101、接收安装在虚拟机内部的第二节点发送的心跳信号;其中,所述虚拟机运行于共享存储内;
在基于云平台的集中式管理架构中,管理节点作为总控中心负责管理一系列的资源,与管理节点连接的有多个彼此间相互独立的计算节点,每个计算节点分别从管理节点处获取资源,进行各自的处理。本实施例中,第一节点为计算节点,第二节点为管理节点。
现有技术中,在建立基于云平台的集中式管理架构时,管理节点和多个计算节点,分别都是基于物理机建立的。
本实施例中,需要将原本安装在物理机内的管理节点,改进为安装在虚拟机内,即首先需要创建一个虚拟机,并且在新创建的虚拟机上安装管理节点。然后,利用虚拟机,重新搭建基于云平台的集中式管理架构。其中,所述虚拟机运行于共享存储内,使得所述虚拟机对与所述管理节点建立连接的所有计算节点,都可见。
此处共享存储可以为创建虚拟机的物理机自带的存储器,也可以为外接的存储器,只要能够满足存储需求即可,本实施例并不对共享存储进行限定。
基于云平台的架构一般支持心跳机制,但并不是所有的云平台架构都存在心跳机制,当建立的云平台架构不存在心跳机制时,则需要进一步安装心跳机制。
本实施例利用管理节点和计算节点之间的心跳机制,即管理节点周期性向与所述管理节点连接的计算节点发送心跳信号,计算节点接收安装在虚拟机内部的管理节点发送的心跳信号。
S102、根据所述心跳信号,判断所述第二节点是否发生单点故障;
判断是,则执行步骤S103;
S103、重启所述虚拟机。
计算节点根据接收到的所述心跳信号,判断所述管理节点是否发生了单点故障,例如管理节点由于断电发生了宕机。
判断是,则重启所述虚拟机。
可选地,本实施例中,可以从基于云平台的集中式管理架构中,选择至少两个计算节点,用于接收管理节点发送的心跳信号,并用于判断所述管理节点是否发生了单点故障。避免只通过一个计算节点,接收管理节点发送的心跳信号时,计算节点本身发生单点故障,而不能或者误判断管理节点发生单点故障的问题产生。
从上述技术方案可知,第一节点接收安装在虚拟机内部的第二节点发送的心跳信号,仅根据所述心跳信号,即可判断所述第二节点是否发生单点故障,发生单点故障时,第一节点重启所述虚拟机,以克服安装在虚拟机内部的第二节点发生的单点故障问题。相较于现有技术需要额外建立多个管理节点以及与多个管理节点对应的数据库,本申请并不需要改变原本的集中式管理系统架构,而仅仅是将原本安装在物理机内的第一节点,改进为安装在虚拟机内,并依据心跳机制,即可判断第二节点是否发生单点故障。大大降低了集中式管理系统的复杂度,且降低了系统成本。
此外,由于本发明中虚拟机是运行在共享存储内,所有第一节点都可以直接从共享存储内获取相应的数据,可以满足数据的一致性。相较于现有技术为了满足数据的一致性,需要后期对数据库集群内的多个数据库进行维护的这一技术方案,大大降低了系统维护难度,降低了系统维护成本。请参阅图2,其示出了本发明实施例提供的另一种单点故障的处理方法的流程图,所述处理方法包括:
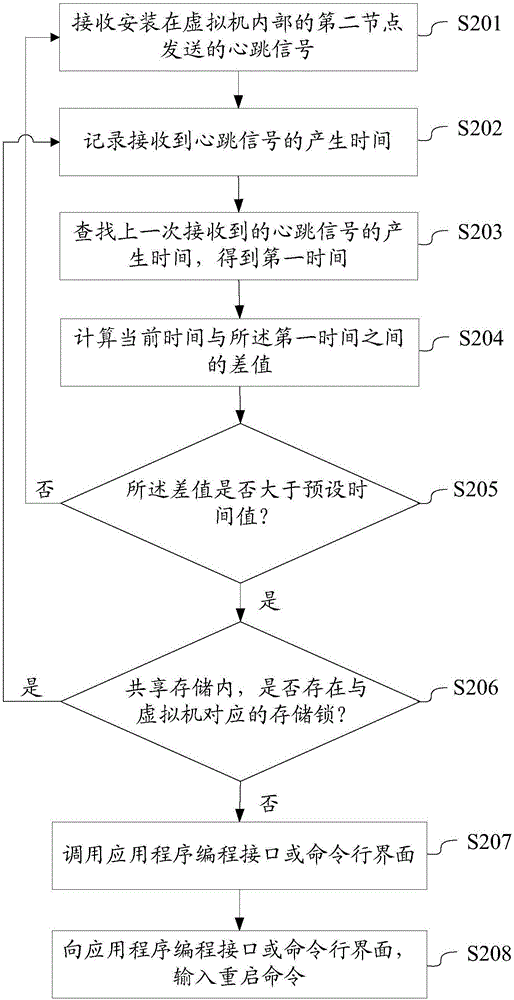
S201、接收安装在虚拟机内部的第二节点发送的心跳信号;其中,所述虚拟机运行于共享存储内;
步骤S201与上一实施例中的步骤S101相同,此处不再赘述。
S202、记录接收到所述心跳信号的产生时间;
计算节点接收到管理节点发送的心跳信号后,同时记录接收到此心跳信号的时间;
其中,计算节点每次接收到管理节点发送的心跳信号,分别都记录在预设区域内,即预定区域内记录有每次接收到的心跳信号的产生时间;
当然还可以,计算节点在接收到管理节点发送的心跳信号,记录的此次心跳信号的产生时间,覆盖上一次接收到的心跳信号的产生时间,即预定区域内仅记录有最近一次接收到的心跳信号的产生时间,节省了计算节点自身的存储空间。
S203、查找上一次接收到的所述心跳信号的产生时间,得到第一时间;
此处的上一次指的是最近一次。
S204、计算当前时间与所述第一时间之间的差值;其中,所述当前时间为所述第一节点的系统时间;
当前时间指的是计算节点的系统时钟的时间,与计算机上的系统时间类似;
S205、判断所述差值是否大于预设时间值;
是,则执行S206。
预设时间值根据管理节点发送心跳信号的周期不同,设置为不同的值。例如,管理节点发送心跳信号的周期是1s,那么预设时间值可以设置为1.5s,管理节点发送心跳信号的周期为2s,那么预设时间值可以设置为2.5s。
判断系统时间与第一时间的差值大于预设时间值,则说明计算节点在一个时间周期内没有接收到管理节点发送的心跳信号,即管理节点没有按预设的周期向计算节点发送心跳信号,管理节点发生了单点故障。
S206、在所述共享存储内,查找是否存在与所述虚拟机对应的存储锁;
云平台自身的一项功能特性是虚拟机正常启动后,在虚拟机运行的共享存储空间内,会存在与所述虚拟机一一对应的存储锁,而当虚拟机宕机时,将释放存储锁,即共享存储空间内,将不存在与此虚拟机对应的存储锁。
针对计算节点而言,在其判断管理节点发生了单点故障后,在对此单点故障进行处理前,先在所述共享存储内,查找是否存在与所述虚拟机对应的存储锁;
若不存在,则执行S207;
若不存在,则说明此管理节点发生的单点故障还未被处理。
若存在,则间隔预设时长后,重新执行步骤S202及其后续步骤;
若共享存储内,存在与所述虚拟机对应的存储锁,则说明安装有管理节点的虚拟机重新启动成功,进而安装在此虚拟机内部的管理节点恢复了正常功能,即其他的计算节点已经成功地处理了此次管理节点发生的单点故障。那么此计算节点不对此次管理节点的单点故障进行处理,避免对管理节点发生的单点故障,多个计算节点同时都进行处理的问题产生。
间隔预设时长后,重新执行根据所述心跳信号,判断所述第二节点是否发生单点故障的步骤,即重新判断管理节点是否发生了单点故障。
S207、调用应用程序编程接口或命令行界面;
计算节点在判断管理节点发生单点故障后,可以自动调用应用程序编程接口API或命令行界面CLI;
当然,计算节点在判断出管理节点发生单点故障后,可以发出故障报警信号,用于告知用户管理节点发生了故障;
用户在计算节点发出故障报警信号后,可以通过操作计算节点的方式,调用应用程序编程接口API或命令行界面CLI。
S208、向所述应用程序编程接口或所述命令行界面,输入重启命令。
从上述技术方案可知,本实施例中第一节点接收安装在虚拟机内部的第二节点发送的心跳信号,仅根据所述心跳信号,即可判断所述第二节点是否发生单点故障,发生单点故障时,第一节点重启所述虚拟机,以克服安装在虚拟机内部的第二节点发生的单点故障问题。相较于现有技术需要额外建立多个管理节点以及与多个管理节点对应的数据库,本申请并不需要改变原本的集中式管理系统架构,而仅仅是将原本安装在物理机内的第一节点,改进为安装在虚拟机内,并依据心跳机制,即可判断第二节点是否发生单点故障。大大降低了集中式管理系统的复杂度,且降低了系统成本。
此外,由于本发明中虚拟机是运行在共享存储内,所有第一节点都可以直接从共享存储内获取相应的数据,可以满足数据的一致性。相较于现有技术为了满足数据的一致性,需要后期对数据库集群内的多个数据库进行维护的这一技术方案,大大降低了系统维护难度,降低了系统维护成本。
同时,在对管理节点发生的单点故障进行处理前,先在所述共享存储内,查找是否存在与所述虚拟机对应的存储锁,只有不存在时,计算节点才对管理节点发生的单点故障进行处理,而当存在时,不对管理节点发生的单点故障进行处理,重新判断管理节点是否发生了单点故障。避免了多个计算节点同时都对管理节点发生的单点故障进行处理的问题产生。
对应图1所示的一种单点故障的处理方法,本发明还提供了一种单点故障的处理装置,其结构示意图请参阅图3所示,本实施例提供的一种单点故障的处理装置包括:
接收单元11、判断单元12和重启单元13;
所述接收单元11,用于接收安装在虚拟机内部的第二节点发送的心跳信号;其中,所述虚拟机运行于共享存储内;
所述判断单元12,用于根据所述心跳信号,判断所述第二节点是否发生单点故障;
所述重启单元13,用于当所述判断单元判断结果为是时,重启所述虚拟机。
从上述技术方案可知,本申请公开的一种单点故障的处理装置中,判断单元根据接收单元接收到的安装在虚拟机内部的第二节点发送的心跳信号,判断第二节点是否发生了单点故障,当判断发生了单点故障时,利用重启单元重启虚拟机,以克服安装在虚拟机内部的第二节点发生的单点故障问题。本实施例中,并不改变原有的系统架构,即实现了对第二节点发生的单点故障的处理,降低了系统的复杂度、系统成本以及维护成本。
对应图2所示的一种单点故障的处理方法,本发明还提供了另一种单点故障的处理装置,其结构示意图请参阅图4所示,本实施例提供的另一种单点故障的处理装置包括:
接收单元11、判断单元12、重启单元13、记录单元14和查找单元15;
优选地,所述判断单元12,包括:
查找子单元21、计算子单元22和判断子单元23;
优选地,所述重启单元13,包括:
调用子单元31和输入子单元32;
所述接收单元11,用于接收安装在虚拟机内部的第二节点发送的心跳信号;其中,所述虚拟机运行于共享存储内;
所述记录单元14,用于记录接收到所述心跳信号的产生时间;
所述查找子单元21,用于查找上一次接收到的所述心跳信号的产生时间,得到第一时间;
所述计算子单元22,用于计算当前时间与所述第一时间之间的差值;其中,所述当前时间为所述第一节点的系统时间;
所述判断子单元23,用于判断所述差值是否大于预设时间值;
是,则调用所述查找单元15;
所述查找单元15,用于在所述共享存储内,查找是否存在与所述虚拟机对应的存储锁;
若不存在,则调用所述重启单元13;
若存在,则间隔预设时长后,调用所述判断单元12;
其中,所述重启单元13中的所述调用子单元31,用于调用应用程序编程接口或命令行界面;
所述重启单元13中的所述输入子单元32,用于向所述应用程序编程接口或所述命令行界面,输入重启命令。
从上述技术方案可知,本申请公开的一种单点故障的处理装置中,判断单元根据接收单元接收到的安装在虚拟机内部的第二节点发送的心跳信号,判断第二节点是否发生了单点故障,当判断发生了单点故障时,利用重启单元重启虚拟机,以克服安装在虚拟机内部的第二节点发生的单点故障问题。本实施例中,并不改变原有的系统架构,即实现了对第二节点发生的单点故障的处理,降低了系统的复杂度、系统成本以及维护成本。
且,在对管理节点发生的单点故障进行处理前,先在所述共享存储内,利用查找单元查找是否存在与所述虚拟机对应的存储锁,只有不存在时,计算节点才对管理节点发生的单点故障进行处理,而当存在时,不对管理节点发生的单点故障进行处理,重新判断管理节点是否发生了单点故障。避免了多个计算节点同时都对管理节点发生的单点故障进行处理的问题产生。
对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于方法类实施例而言,由于其与设备实施例基本相似,所以描述的比较简单,相关之处参见设备实施例的部分说明即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!