一种用于生成短视频的方法与装置与流程
本发明涉及计算机技术领域,尤其涉及一种生成短视频的技术。
背景技术:
在现有技术中,输入法主要包括emoji、颜文字、表情图、gif图等以图片的形式存在的表情,而在论坛、微博等由用户生成内容的场景下,主要包括以各种静态或动态图片形式存在的表情。这种表情均是固定的单张图片或gif图,用户在发送表情时,直接选择发送即可。
然而由于表情图所蕴含的内容是固定的,若用户想要对此进行补充,或希望声情并茂地表达与该表情图对应的情感时,则需要单独地输入文字或语音等来加重情感表达。进一步地,用户也可以单独制作短视频来作为新的表情图,然而一般的短视频制作需要用户拍摄一段短视频并将其转换为表情图,或是利用图像处理软件将多个图片、视频、音频或字幕进行组合,这种方法对于用户而言过于复杂,相比直接发送表情图而言,制作成本较高。因此,用户仍然习惯采用各自独立的表情图、语音、文字等来表达内容,从而导致了表达效率较低且形式单一。
技术实现要素:
本发明的目的是提供一种用于生成短视频的方法与装置。
根据本发明的一个方面,提供了一种用于生成短视频的方法,其中,该方法包括以下步骤:
a获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;
b根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;
c根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;
d根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。
可选地,所述步骤c包括:
-根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
可选地,所述步骤c包括:
-根据所述语音信息的语音特征和/或语义特征,结合所述语音信息的语音长度,确定与所述图片和/或所述字幕信息所对应的展示特效。
可选地,该方法还包括:
x根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片;
其中,该方法还包括:
-根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
可选地,所述步骤x包括:
x1确定与所述图片相关联的相关图片数量;
-根据所述语音信息、所述图片以及所述相关图片数量,确定与所述图片相关联的一个或多个相关图片。
可选地,所述步骤x1包括以下至少任一项:
-根据所述语音信息的语音长度,确定与所述图片相关联的相关图片数量;
-根据所述语音信息的语音特征,确定与所述图片相关联的相关图片数量;
-根据所述语音信息的语义特征,确定与所述图片相关联的相关图片数量。
可选地,该方法还包括:
-获取所述用户的一个或多个历史语音信息,确定与所述用户相对应的用户语音特征库;
其中,所述步骤c包括:
-根据所述用户语音特征库,确定与所述语音信息相对应的语音特征;
-根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
可选地,该方法还包括:
-根据所述短视频所对应的应用的相关配置信息,将所述短视频转存为一种或多种应用可用格式;
-将所述短视频以所述应用可用格式添加在所述应用中。
可选地,所述展示特效包括一种或多种动态效果。
根据本发明的另一方面,还提供了一种用于生成短视频的生成装置,其中,所述生成装置包括:
获取装置,用于获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;
字幕确定装置,用于根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;
特效确定装置,用于根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;
视频生成装置,用于根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。
可选地,所述特效确定装置用于:
-根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
可选地,所述特效确定装置用于:
-根据所述语音信息的语音特征和/或语义特征,结合所述语音信息的语音长度,确定与所述图片和/或所述字幕信息所对应的展示特效。
可选地,所述生成装置还包括:
相关图片确定装置,用于根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片;
其中,所述生成装置还包括:
相关视频生成装置,用于根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
可选地,所述相关图片确定装置包括:
数量确定单元,用于确定与所述图片相关联的相关图片数量;
关联确定单元,用于根据所述语音信息、所述图片以及所述相关图片数量,确定与所述图片相关联的一个或多个相关图片。
可选地,所述数量确定单元用于以下至少任一项:
-根据所述语音信息的语音长度,确定与所述图片相关联的相关图片数量;
-根据所述语音信息的语音特征,确定与所述图片相关联的相关图片数量;
-根据所述语音信息的语义特征,确定与所述图片相关联的相关图片数量。
可选地,所述生成装置还包括:
历史获取装置,用于获取所述用户的一个或多个历史语音信息,确定与所述用户相对应的用户语音特征库;
其中,所述特效确定装置用于:
-根据所述用户语音特征库,确定与所述语音信息相对应的语音特征;
-根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
可选地,所述生成装置还包括:
转存装置,用于根据所述短视频所对应的应用的相关配置信息,将所述短视频转存为一种或多种应用可用格式;
添加装置,用于将所述短视频以所述应用可用格式添加在所述应用中。
可选地,所述展示特效包括一种或多种动态效果。
根据本发明的又一方面,还提供了一种输入设备,包括如上述任一项所述的生成装置。
与现有技术相比,本发明获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。从而,本发明通过根据所述语音信息的语音特征和/或语意特征,确定与所述图片和/或所述字幕信息所对应的展示特效,将图片转换为短视频,能够更加富有创造性地表达情感,提高了输入行为的多样性,增加了图片的趣味性、智能性,使得用户的表现形式更加丰富且具有吸引力,改善了用户体验。
而且,本发明还可以根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,确定与所述图片和/或所述字幕信息所对应的展示特效;或者,根据所述语音信息的语音特征和/或语义特征,结合所述语音信息的语音长度,确定与所述图片和/或所述字幕信息所对应的展示特效。从而本发明使得所确定的展示特效与图片与语音更加贴合,提高了表现效果及可视性,进一步提高了吸引力,改善了用户体验。
而且,本发明还可以根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片;根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。从而,本发明能够为用户生成多种相关短视频,减少了用户寻找图片的操作,提高了获取信息的效率,提供给用户更多的选择,进一步提高了吸引力,改善了用户体验。
而且,本发明还可以获取所述用户的一个或多个历史语音信息,确定与所述用户相对应的用户语音特征库;根据所述用户语音特征库,确定与所述语音信息相对应的语音特征;根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。从而,本发明使得所提取的语音特征更加准确,所确定的展示特效也就更符合用户的需求。
而且,本发明还可以根据所述短视频所对应的应用的相关配置信息,将所述短视频转存为一种或多种应用可用格式;将所述短视频以所述应用可用格式添加在所述应用中。从而,本发明丰富了应用内信息表达的表现形式,使得用户的信息表达形式丰富且更有吸引力。例如,可将短视频作为表情等进行添加,因此,本发明可以让用户边看到表情图边听到语音,并结合展示特效来理解对方的情感表达,使加入真人语音的表情动态图像形式丰富且更有吸引力。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1示出根据本发明一个方面的一种用于生成短视频的生成装置示意图;
图2示出根据本发明的一个优选实施例的一种用于生成短视频的生成装置示意图;
图3示出根据本发明另一个方面的一种用于生成短视频的方法流程图;
图4示出根据本发明的一个优选实施例的一种用于生成短视频的方法流程图。
附图中相同或相似的附图标记代表相同或相似的部件。
具体实施方式
在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各项操作描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。此外,各项操作的顺序可以被重新安排。当其操作完成时所述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。所述处理可以对应于方法、函数、规程、子例程、子程序等等。
在上下文中所称“生成装置”即为“计算机设备”,也称为“电脑”,是指可以通过运行预定程序或指令来执行数值计算和/或逻辑计算等预定处理过程的智能电子设备,其可以包括处理器与存储器,由处理器执行在存储器中预存的存续指令来执行预定处理过程,或是由asic、fpga、dsp等硬件执行预定处理过程,或是由上述二者组合来实现。
所述计算机设备包括用户设备和/或网络设备。其中,所述用户设备包括但不限于电脑、智能手机、pda等;所述网络设备包括但不限于单个网络服务器、多个网络服务器组成的服务器组或基于云计算(cloudcomputing)的由大量计算机或网络服务器构成的云,其中,云计算是分布式计算的一种,由一群松散耦合的计算机集组成的一个超级虚拟计算机。其中,所述计算机设备可单独运行来实现本发明,也可接入网络并通过与网络中的其他计算机设备的交互操作来实现本发明。其中,所述计算机设备所处的网络包括但不限于互联网、广域网、城域网、局域网、vpn网络等。
本领域技术人员应能理解,本发明中所述的“生成装置”可以仅是用户设备,即由用户设备来执行相应的操作;也可以是由用户设备与网络设备或服务器相集成来组成,即由用户设备与网络设备相配合来执行相应的操作。
需要说明的是,所述用户设备、网络设备和网络等仅为举例,其他现有的或今后可能出现的计算机设备或网络如可适用于本发明,也应包含在本发明保护范围以内,并以引用方式包含于此。
需要说明的是,优选地,本发明所述的“生成装置”可包含在各类设备(如输入设备)、各类应用(如输入法),或包含各类应用的装置中(如包含在输入法中的装置)。其中,本发明所述的生成装置可由计算机设备的生产厂商或销售服务商预先安装至该计算机设备,也可由计算机设备从服务器加载到计算机设备。本领域技术人员应能理解,任何可用于实现本发明中的功能的装置,无论是否被加载至计算机设备中,均包含在本发明的保护范围内。
在此,本领域技术人员应能理解,本发明可应用于移动端与非移动端,例如,当用户使用手机或pc时,均可利用本发明所述的方法或装置来进行提供与呈现。
这里所公开的具体结构和功能细节仅仅是代表性的,并且是用于描述本发明的示例性实施例的目的。但是本发明可以通过许多替换形式来具体实现,并且不应当被解释成仅仅受限于这里所阐述的实施例。
应当理解的是,虽然在这里可能使用了术语“第一”、“第二”等等来描述各个单元,但是这些单元不应当受这些术语限制。使用这些术语仅仅是为了将一个单元与另一个单元进行区分。举例来说,在不背离示例性实施例的范围的情况下,第一单元可以被称为第二单元,并且类似地第二单元可以被称为第一单元。这里所使用的术语“和/或”包括其中一个或更多所列出的相关联项目的任意和所有组合。
这里所使用的术语仅仅是为了描述具体实施例而不意图限制示例性实施例。除非上下文明确地另有所指,否则这里所使用的单数形式“一个”、“一项”还意图包括复数。还应当理解的是,这里所使用的术语“包括”和/或“包含”规定所陈述的特征、整数、步骤、操作、单元和/或组件的存在,而不排除存在或添加一个或更多其他特征、整数、步骤、操作、单元、组件和/或其组合。
还应当提到的是,在一些替换实现方式中,所提到的功能/动作可以按照不同于附图中标示的顺序发生。举例来说,取决于所涉及的功能/动作,相继示出的两幅图实际上可以基本上同时执行或者有时可以按照相反的顺序来执行。
下面结合附图对本发明作进一步详细描述。
图1示出根据本发明一个方面的一种用于生成短视频的生成装置示意图;其中,所述生成装置包括获取装置1、字幕确定装置2、特效确定装置3、视频生成装置4。
具体地,所述获取装置1获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;所述字幕确定装置2根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;所述特效确定装置3根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;所述视频生成装置4根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。
所述获取装置1获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息。
具体地,所述获取装置1可以通过调用内置缺省图片、获取用户通过上传或拍摄等的方式所提供的图片、通过搜索的方式从网络上搜索到图片、通过下载的方式下载图片等一种或多种方式,获取一个或多个图片。所述图片可以实时获取,也可以预先获取。所述图片包括静态图片(如采用jpg、bmp等格式的图片)和/或动态图片(如采用gif等格式的图片)。
所述获取装置1通过实时录音或调用历史录音等方式,获取用户对所述一个或多个图片的一个或多个语音信息。在此,本领域技术人员应能理解,一张图片可以对应于一个或多个语音信息,一个语音信息也可以对应于一张或多张图片。所述图片与语音信息的关联关系可以根据用户的设置进行确定。
例如,所述用户选择了内置中的一张图片,然后按下录音键,录制了一段语音信息,则该语音信息即与该图片相对应;然后,用户又录制了一段语音信息,则这两段语音信息均与该图片对应。
或者,例如,所述用户从网上下载了两张图片,然后同时选择了这两张图片,并与另一段语音信息相关联,则这段语音信息即与这两张图片同时相关联。
所述字幕确定装置2根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息。
具体地,所述字幕确定装置2通过语音识别,识别出所述语音信息的语音内容,然后,确定与所识别的语音内容相对应的文字,以作为与所述语音信息相对应的字幕信息。
优选地,所述字幕确定装置2还可以结合所述语音信息的长度,来确定是否对所述字幕信息进行分行等;所述字幕确定装置2可以根据所述语音信息的语音内容,结合所述语音信息中的语音特征,如声调、节奏等,来确定所述字幕信息中的标点、分行等内容;所述字幕确定装置2还可以与所述用户进行交互,为所述用户提供校对输入功能,以便于所述用户对所述字幕信息进行校对。
优选地,所述字幕确定装置2可以自行进行语音特征、语音长度等的分析;也可以与所述特效确定装置3交互,根据所述特效确定装置3对语音特征/语义特征/展示特效等的反馈,来迭代调整所述字幕信息的分行、标点等内容。
所述特效确定装置3根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,所述特效确定装置3对所述语音信息进行分析,以确定所述语音信息的语音特征和/或语义特征。
其中,所述语音特征包括但不限于声调、节奏、音色等;例如通过对所述语音信息的波形分析,得知该语音信息的声音高低变化和/或节奏等;通过对所述语音信息的频谱和/或语谱的分析,得知该语音信息的音色,如粗犷、尖细、低沉、奶气、清脆等等;由于所述语音信息的声调、节奏、音色等是不断变化的,还可以根据上述变化来确定用户语气的变化,如突然提高音量或降低音量等。
所述语义特征即为所述用户的所述语音的含义。如“我很高兴”则表达了积极的情绪,“这东西不好”则表达了消极的情绪等等。
然后,所述特效确定装置3根据所述语音信息的语音特征和/或语义特征,从预置的特效中选择一个或多个以作为与所述图片和/或所述字幕信息相对应的展示特效,或者通过与服务器或其他第三方设备相交互,获取与所述图片和/或所述字幕信息相对应的展示特效。
其中,所述展示特效中包括作用于所述图片的展示特效、作用于所述字幕信息的展示特效或者同时作用于所述图片和字幕信息的展示特效。所述展示特效中包括但不限于静态效果和/或动态效果。其中,作用于所述字幕信息的静态效果例如字体、颜色等,作用于所述图片的静态效果例如附加装饰图片、附加装饰文字、增加图片纹理、图片变色等。所述动态效果包括但不限于渐变、浮动、闪烁等。
例如,若所述用户的语音特征表示用户说话声音时大时小,展示字幕会随着说话一大一小不断变化;若所述用户的语音特征表示用户说话的音色奶声奶气,则展示华康娃娃体字幕等。
例如,对所述用户的语义特征进行分析,若用户说“爱你”,则图片或字幕上出现一颗一闪一闪的心;若用户说“晚安”,则表情图加渐变蒙层逐渐变成黑色以实现关灯的效果。
优选地,所述特效确定装置3根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,所述特效确定装置3还可以对所述图片进行分析,以确定所述图片的图片特征,其中,所述图片特征包括但不限于图片名称、图片说明、图片色彩、动态信息(如gif动态图片)、图片内容等。
然后,所述特效确定装置3根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,将上述多种因素综合考虑,以确定与所述图片和/或所述字幕信息所对应的展示特效。
例如,若所述图片特征为图片色彩较暗,而用户的语音特征为音调轻快,则所确定的展示特效为:将所述字幕以跳跃的形式展示,且为字幕加上颜色较浅的轮廓等。
例如,若所述图片特征为图片中已经包含了心形图案,则当用户说“爱你”时,不再将“图片或字幕上出现一颗一闪一闪的心”作为展示特效,而是在图片上添加玫瑰花。
优选地,所述特效确定装置3根据所述语音信息的语音特征和/或语义特征,结合所述语音信息的语音长度,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,所述语音长度即为所述语音信息的时长。所述特效确定装置3可以在考虑所述语音长度的基础上,来确定符合所述语音特征和/或语义特征的展示特效。
例如,若一条语音的语义长度为3秒,而某个动态展示特效循环一次需要5秒,则不采用该展示特效;反之,若某个动态展示特效循环一次需要3秒,则可以结合所述语音特征和/或语义特征来确定是否选择该展示特效。
所述视频生成装置4根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。
具体地,所述视频生成装置4将所述图片以及所述语音信息一起生成包含语音与图像的短视频,并将所述字幕信息以及所述展示特效加入到该短视频中。例如,若所述图像为动态图像,可以生成一个包含了字幕信息以及展示特效的短视频,图片的播放进程与语音进程相一致;若所述图像为静态图像,可以生成一个包含了字幕信息以及展示特效的短视频,图片可以作为背景,而动态的是字幕信息以及展示特效,且动态的部分随着语音进程进行。
所述短视频可以被保存、收藏、发送等。
优选地,所述生成装置还包括历史获取装置(未示出),其中,所述历史获取装置获取所述用户的一个或多个历史语音信息,确定与所述用户相对应的用户语音特征库;所述特效确定装置3根据所述用户语音特征库,确定与所述语音信息相对应的语音特征;根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,所述历史获取装置通过直接与用户交互以获取所述用户的一个或多个历史语音信息,或者与其他能够提供该用户历史语音信息的设备相交互,以获取所述用户的一个或多个历史语音信息。在此,所述历史语音信息可以是用户在其他场景或其他应用中所提供的语音信息;所述历史语音信息可以对应于已确认的或未确认的语音特征和/或语义特征。
然后,所述历史获取装置根据所述历史语音信息,建立与所述用户相对应的用户语音特征库,例如,通过对多个历史语音信息的分析与统计,得到该用户的常用音调、非普通音调、音色、节奏等,以建立与该用户相对应的用户语音特征库。
然后,所述特效确定装置3可以根据所述用户语音特征库,通过将所述用户的当前语音与该用户语音特征库相匹配或对比,以确定与所述用户的当前语音信息相对应的语音特征。
然后,所述特效确定装置3根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
优选地,所述生成装置还包括转存装置(未示出)和添加装置(未示出);其中,所述转存装置根据所述短视频所对应的应用的相关配置信息,将所述短视频转存为一种或多种应用可用格式;所述添加装置将所述短视频以所述应用可用格式添加在所述应用中。
具体地,所述转存装置可以根据所述短视频所对应的应用的相关配置信息,确定该应用所需求的一种或多种应用可用格式;并将所述短视频转存为所述应用可用格式;例如,若所述应用为输入法,则可将所述短视频转存为动态图片类格式,以作为动态图片表情;若所述应用为微博等,则可将其转存为一种或多种的可用视频格式,以作为短视频发送。
然后,所述添加装置将所述短视频以所述应用可用格式添加在所述应用中,供用户进行后续调用。
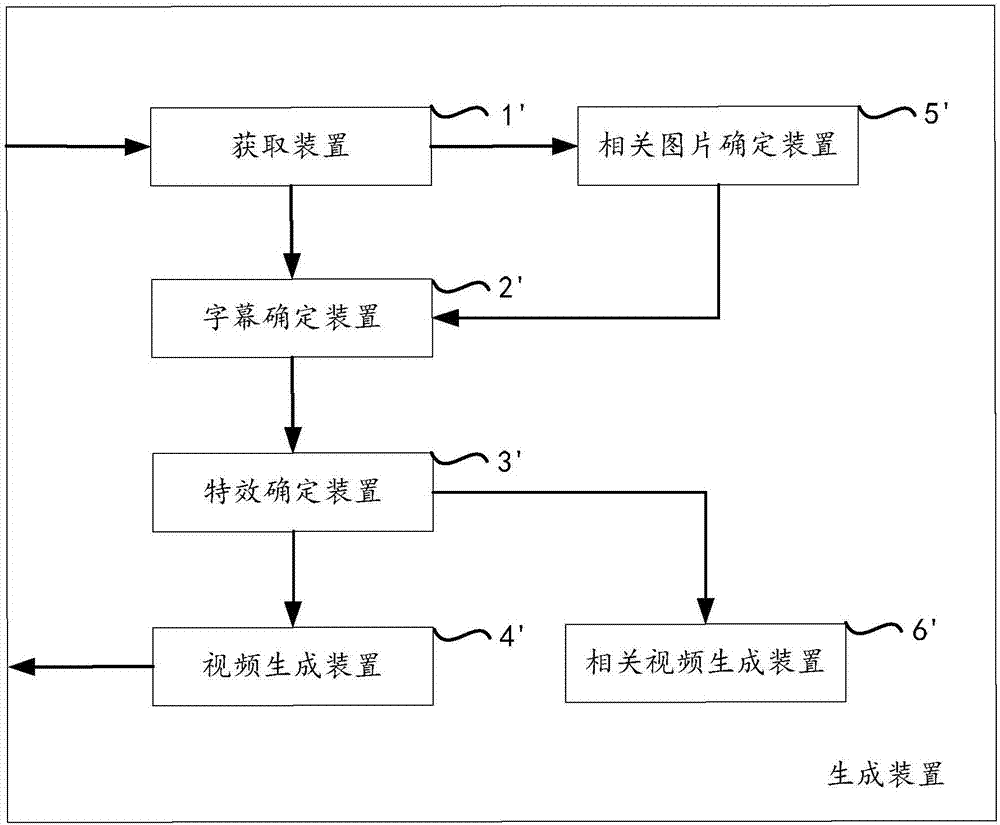
图2示出根据本发明的一个优选实施例的一种用于生成短视频的生成装置示意图;其中,所述生成装置包括获取装置1’、字幕确定装置2’、特效确定装置3’、视频生成装置4’、相关图片确定装置5’、相关视频生成装置6’。
具体地,所述获取装置1’获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;所述字幕确定装置2’根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;所述特效确定装置3’根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;所述视频生成装置4’根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频;所述相关图片确定装置5’根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片;所述相关视频生成装置6’根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
所述相关图片确定装置5’根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片。
具体地,所述相关图片确定装置5’根据所述语音信息的语音特征和/或语义特征,并结合所述图片的图片特征,来确定与上述语音信息和所述图片在内容或特征上相关联的一个或多个相关图片。
其中,所述语音特征包括但不限于声调、节奏、音色等;所述语义特征即为所述用户的所述语音的含义。所述图片特征包括但不限于图片名称、图片说明、图片色彩、动态信息(如gif动态图片)、图片内容等。
其中,所述相关图片与所述语音信息/所述图片在内容或主题上相关联;或者,所述相关图片与所述图片在色调上相关联等。
例如,若所述语音信息为:“很棒啊!”,所述图片为“鼓掌”,则可以推荐以“很棒”为主题的其他图片,如“翘起拇指”、“欢呼”等,或者可以选择以不同角色为主题的鼓掌图片或类似图片,如“兔斯基鼓掌”、“兔斯基点赞”、“ac娘点赞”等。
优选地,所述相关图片确定装置5’还可以从所选择的相关图片中进一步筛选出优选相关图片。例如,继上例,可以仅将同一主题的相关图片挑选出来,作为优选相关图片,如“兔斯基鼓掌”和“兔斯基点赞”;或者,可以将相关图片中色调类似的图片挑选出来,作为优选相关图片,如具有相同的背景色或主题颜色等。
所述相关视频生成装置6’根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
具体地,所述相关视频生成装置6’可以根据所述特效确定装置3’为所述图片所确定的展示特效,来所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。或者,所述相关视频生成装置6’可以将所述相关图片、语音信息、所述图片重新发给所述字幕确定装置2’(如图2所示),以供所述字幕确定装置2’为上述内容重新确定展示特效,在此,确定所述展示特效的方法与图1中对应装置的确定方法相同或相似,故在此不再赘述。
然后,所述相关视频生成装置6’根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
其中,所述相关短视频可以是对应于“字幕信息、展示特效、一张所述相关图片、所述语音信息”,即将所述字幕信息、所述展示特效、所述语音信息分别添加到某张相关图片中,以生成相关短视频;
所述相关短视频还可以对应于“字幕信息、展示特效、多张所述相关图片、所述语音信息”,即将所述字幕信息、所述展示特效、所述语音信息添加到多张相关图片中,使得多张相关图片能够连续播放,以形成一个动态相关短视频;
所述相关短视频还可以对应于“字幕信息、展示特效、所述图片以及一张或多张所述相关图片、所述语音信息”,即将所述图片以及一张或多张相关图片作为待处理的图片,并将所述字幕信息、所述展示特效、所述语音信息添加到上述待处理的图片中,使得多张待处理的图片能够连续播放,以形成一个动态相关短视频等。
优选地,所述相关图片确定装置5’包括数量确定单元(未示出)以及关联确定单元(未示出);其中,所述数量确定单元确定与所述图片相关联的相关图片数量;所述关联确定单元根据所述语音信息、所述图片以及所述相关图片数量,确定与所述图片相关联的一个或多个相关图片。
具体地,所述数量确定单元通过按照预设置的方式,确定与所述图片相关联的相关图片数量;或者,更优选地,基于以下一种或多种方式,确定与所述图片相关联的相关图片数量:
-根据所述语音信息的语音长度,确定与所述图片相关联的相关图片数量:例如,若所述语音长度为5秒,则所述相关图片数量确定为5;若所述语音长度为10秒,则所述相关图片数量确定为10;
-根据所述语音信息的语音特征,确定与所述图片相关联的相关图片数量:例如,若所述语音特征显示发生了2次或多次的语调变换(如高音转低音,低音转高音等),则提高所确定的相关图片数量;
-根据所述语音信息的语义特征,确定与所述图片相关联的相关图片数量:例如,若所述语义特征显示出包含了多个语义关键词,则可根据不同的关键词,确定不同的相关图片,因此,相关图片数量会更多。
所述关联确定单元在根据所述语音信息的语音特征和/或语义特征,并结合所述图片的图片特征的基础上,来确定与上述语音信息和所述图片在内容或特征上相关联的、符合上述相关图片数量要求的一张或多张相关图片。
图3示出根据本发明另一个方面的一种用于生成短视频的方法流程图。具体地,在步骤s1中,所述生成装置获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;在步骤s2中,所述生成装置根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;在步骤s3中,所述生成装置根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;在步骤s4中,所述生成装置根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。
在步骤s1中,所述生成装置获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息。
具体地,在步骤s1中,所述生成装置可以通过调用内置缺省图片、获取用户通过上传或拍摄等的方式所提供的图片、通过搜索的方式从网络上搜索到图片、通过下载的方式下载图片等一种或多种方式,获取一个或多个图片。所述图片可以实时获取,也可以预先获取。所述图片包括静态图片(如采用jpg、bmp等格式的图片)和/或动态图片(如采用gif等格式的图片)。
在步骤s1中,所述生成装置通过实时录音或调用历史录音等方式,获取用户对所述一个或多个图片的一个或多个语音信息。在此,本领域技术人员应能理解,一张图片可以对应于一个或多个语音信息,一个语音信息也可以对应于一张或多张图片。所述图片与语音信息的关联关系可以根据用户的设置进行确定。
例如,所述用户选择了内置中的一张图片,然后按下录音键,录制了一段语音信息,则该语音信息即与该图片相对应;然后,用户又录制了一段语音信息,则这两段语音信息均与该图片对应。
或者,例如,所述用户从网上下载了两张图片,然后同时选择了这两张图片,并与另一段语音信息相关联,则这段语音信息即与这两张图片同时相关联。
在步骤s2中,所述生成装置根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息。
具体地,在步骤s2中,所述生成装置通过语音识别,识别出所述语音信息的语音内容,然后,确定与所识别的语音内容相对应的文字,以作为与所述语音信息相对应的字幕信息。
优选地,在步骤s2中,所述生成装置还可以结合所述语音信息的长度,来确定是否对所述字幕信息进行分行等;在步骤s2中,所述生成装置可以根据所述语音信息的语音内容,结合所述语音信息中的语音特征,如声调、节奏等,来确定所述字幕信息中的标点、分行等内容;所述生成装置还可以与所述用户进行交互,为所述用户提供校对输入功能,以便于所述用户对所述字幕信息进行校对。
优选地,在步骤s2中,所述生成装置可以自行进行语音特征、语音长度等的分析;也可以与从步骤s3的执行结果中获得反馈,根据所述步骤s3对语音特征/语义特征/展示特效等的反馈,来迭代调整所述字幕信息的分行、标点等内容。
在步骤s3中,所述生成装置根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,在步骤s3中,所述生成装置对所述语音信息进行分析,以确定所述语音信息的语音特征和/或语义特征。
其中,所述语音特征包括但不限于声调、节奏、音色等;例如通过对所述语音信息的波形分析,得知该语音信息的声音高低变化和/或节奏等;通过对所述语音信息的频谱和/或语谱的分析,得知该语音信息的音色,如粗犷、尖细、低沉、奶气、清脆等等;由于所述语音信息的声调、节奏、音色等是不断变化的,还可以根据上述变化来确定用户语气的变化,如突然提高音量或降低音量等。
所述语义特征即为所述用户的所述语音的含义。如“我很高兴”则表达了积极的情绪,“这东西不好”则表达了消极的情绪等等。
然后,在步骤s3中,所述生成装置根据所述语音信息的语音特征和/或语义特征,从预置的特效中选择一个或多个以作为与所述图片和/或所述字幕信息相对应的展示特效,或者通过与服务器或其他第三方设备相交互,获取与所述图片和/或所述字幕信息相对应的展示特效。
其中,所述展示特效中包括作用于所述图片的展示特效、作用于所述字幕信息的展示特效或者同时作用于所述图片和字幕信息的展示特效。所述展示特效中包括但不限于静态效果和/或动态效果。其中,作用于所述字幕信息的静态效果例如字体、颜色等,作用于所述图片的静态效果例如附加装饰图片、附加装饰文字、增加图片纹理、图片变色等。所述动态效果包括但不限于渐变、浮动、闪烁等。
例如,若所述用户的语音特征表示用户说话声音时大时小,展示字幕会随着说话一大一小不断变化;若所述用户的语音特征表示用户说话的音色奶声奶气,则展示华康娃娃体字幕等。
例如,对所述用户的语义特征进行分析,若用户说“爱你”,则图片或字幕上出现一颗一闪一闪的心;若用户说“晚安”,则表情图加渐变蒙层逐渐变成黑色以实现关灯的效果。
优选地,在步骤s3中,所述生成装置根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,在步骤s3中,所述生成装置还可以对所述图片进行分析,以确定所述图片的图片特征,其中,所述图片特征包括但不限于图片名称、图片说明、图片色彩、动态信息(如gif动态图片)、图片内容等。
然后,在步骤s3中,所述生成装置根据所述语音信息的语音特征和/或语义特征,结合根据所述图片的图片特征,将上述多种因素综合考虑,以确定与所述图片和/或所述字幕信息所对应的展示特效。
例如,若所述图片特征为图片色彩较暗,而用户的语音特征为音调轻快,则所确定的展示特效为:将所述字幕以跳跃的形式展示,且为字幕加上颜色较浅的轮廓等。
例如,若所述图片特征为图片中已经包含了心形图案,则当用户说“爱你”时,不再将“图片或字幕上出现一颗一闪一闪的心”作为展示特效,而是在图片上添加玫瑰花。
优选地,在步骤s3中,所述生成装置根据所述语音信息的语音特征和/或语义特征,结合所述语音信息的语音长度,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,所述语音长度即为所述语音信息的时长。在步骤s3中,所述生成装置可以在考虑所述语音长度的基础上,来确定符合所述语音特征和/或语义特征的展示特效。
例如,若一条语音的语义长度为3秒,而某个动态展示特效循环一次需要5秒,则不采用该展示特效;反之,若某个动态展示特效循环一次需要3秒,则可以结合所述语音特征和/或语义特征来确定是否选择该展示特效。
在步骤s4中,所述生成装置根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频。
具体地,在步骤s4中,所述生成装置将所述图片以及所述语音信息一起生成包含语音与图像的短视频,并将所述字幕信息以及所述展示特效加入到该短视频中。例如,若所述图像为动态图像,可以生成一个包含了字幕信息以及展示特效的短视频,图片的播放进程与语音进程相一致;若所述图像为静态图像,可以生成一个包含了字幕信息以及展示特效的短视频,图片可以作为背景,而动态的是字幕信息以及展示特效,且动态的部分随着语音进程进行。
所述短视频可以被保存、收藏、发送等。
优选地,所述方法还包括步骤s7(未示出),其中,所在步骤s7中,所述生成装置获取所述用户的一个或多个历史语音信息,确定与所述用户相对应的用户语音特征库;在步骤s3中,所述生成装置根据所述用户语音特征库,确定与所述语音信息相对应的语音特征;根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
具体地,在步骤s7中,所述生成装置通过直接与用户交互以获取所述用户的一个或多个历史语音信息,或者与其他能够提供该用户历史语音信息的设备相交互,以获取所述用户的一个或多个历史语音信息。在此,所述历史语音信息可以是用户在其他场景或其他应用中所提供的语音信息;所述历史语音信息可以对应于已确认的或未确认的语音特征和/或语义特征。
然后,在步骤s7中,所述生成装置根据所述历史语音信息,建立与所述用户相对应的用户语音特征库,例如,通过对多个历史语音信息的分析与统计,得到该用户的常用音调、非普通音调、音色、节奏等,以建立与该用户相对应的用户语音特征库。
然后,在步骤s7中,所述生成装置可以根据所述用户语音特征库,通过将所述用户的当前语音与该用户语音特征库相匹配或对比,以确定与所述用户的当前语音信息相对应的语音特征。
然后,在步骤s3中,所述生成装置根据所述语音特征和/或所述语音信息的语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效。
优选地,所述方法还包括步骤s8(未示出)和步骤s9(未示出);其中,在步骤s8中,所述生成装置根据所述短视频所对应的应用的相关配置信息,将所述短视频转存为一种或多种应用可用格式;在步骤s9中,所述生成装置将所述短视频以所述应用可用格式添加在所述应用中。
具体地,在步骤s8中,所述生成装置可以根据所述短视频所对应的应用的相关配置信息,确定该应用所需求的一种或多种应用可用格式;并将所述短视频转存为所述应用可用格式;例如,若所述应用为输入法,则可将所述短视频转存为动态图片类格式,以作为动态图片表情;若所述应用为微博等,则可将其转存为一种或多种的可用视频格式,以作为短视频发送。
然后,在步骤s9中,所述生成装置将所述短视频以所述应用可用格式添加在所述应用中,供用户进行后续调用。
图4示出根据本发明的一个优选实施例的一种用于生成短视频的方法流程图。
具体地,在步骤s1’中,所述生成装置获取一个或多个图片以及用户对所述一个或多个图片的一个或多个语音信息;在步骤s2’中,所述生成装置根据所述语音信息的内容,确定与所述语音信息相对应的字幕信息;在步骤s3’中,所述生成装置根据所述语音信息的语音特征和/或语义特征,确定与所述图片和/或所述字幕信息所对应的展示特效;在步骤s3’中,所述生成装置根据所述字幕信息以及所述展示特效,将所述图片与语音信息生成短视频;在步骤s5’中,所述生成装置根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片;在步骤s6’中,所述生成装置根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
在步骤s5’中,所述生成装置根据所述语音信息以及所述图片,确定与所述图片相关联的一个或多个相关图片。
具体地,在步骤s5’中,所述生成装置根据所述语音信息的语音特征和/或语义特征,并结合所述图片的图片特征,来确定与上述语音信息和所述图片在内容或特征上相关联的一个或多个相关图片。
其中,所述语音特征包括但不限于声调、节奏、音色等;所述语义特征即为所述用户的所述语音的含义。所述图片特征包括但不限于图片名称、图片说明、图片色彩、动态信息(如gif动态图片)、图片内容等。
其中,所述相关图片与所述语音信息/所述图片在内容或主题上相关联;或者,所述相关图片与所述图片在色调上相关联等。
例如,若所述语音信息为:“很棒啊!”,所述图片为“鼓掌”,则可以推荐以“很棒”为主题的其他图片,如“翘起拇指”、“欢呼”等,或者可以选择以不同角色为主题的鼓掌图片或类似图片,如“兔斯基鼓掌”、“兔斯基点赞”、“ac娘点赞”等。
优选地,在步骤s5’中,所述生成装置还可以从所选择的相关图片中进一步筛选出优选相关图片。例如,继上例,可以仅将同一主题的相关图片挑选出来,作为优选相关图片,如“兔斯基鼓掌”和“兔斯基点赞”;或者,可以将相关图片中色调类似的图片挑选出来,作为优选相关图片,如具有相同的背景色或主题颜色等。
在步骤s6’中,所述生成装置根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
具体地,在步骤s6’中,所述生成装置可以根据所述步骤s3’为所述图片所确定的展示特效,来所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。或者,所在步骤s6’中,所述生成装置可以将所述相关图片、语音信息、所述图片重新执行步骤s2’(如图2所示),以供所述步骤s2’为上述内容重新确定展示特效,在此,确定所述展示特效的方法与图3中对应装置的确定方法相同或相似,故在此不再赘述。
然后,在步骤s6’中,所述生成装置根据所述字幕信息以及所述展示特效,将所述图片、所述相关图片与所述语音信息,生成一个或多个相关短视频。
其中,所述相关短视频可以是对应于“字幕信息、展示特效、一张所述相关图片、所述语音信息”,即将所述字幕信息、所述展示特效、所述语音信息分别添加到某张相关图片中,以生成相关短视频;
所述相关短视频还可以对应于“字幕信息、展示特效、多张所述相关图片、所述语音信息”,即将所述字幕信息、所述展示特效、所述语音信息添加到多张相关图片中,使得多张相关图片能够连续播放,以形成一个动态相关短视频;
所述相关短视频还可以对应于“字幕信息、展示特效、所述图片以及一张或多张所述相关图片、所述语音信息”,即将所述图片以及一张或多张相关图片作为待处理的图片,并将所述字幕信息、所述展示特效、所述语音信息添加到上述待处理的图片中,使得多张待处理的图片能够连续播放,以形成一个动态相关短视频等。
优选地,所述步骤s5’包括步骤s51’(未示出)以及步骤s52’(未示出);其中,在步骤s51’中,所述生成装置确定与所述图片相关联的相关图片数量;在步骤s52’中,所述生成装置根据所述语音信息、所述图片以及所述相关图片数量,确定与所述图片相关联的一个或多个相关图片。
具体地,在步骤s51’中,所述生成装置通过按照预设置的方式,确定与所述图片相关联的相关图片数量;或者,更优选地,基于以下一种或多种方式,确定与所述图片相关联的相关图片数量:
-根据所述语音信息的语音长度,确定与所述图片相关联的相关图片数量:例如,若所述语音长度为5秒,则所述相关图片数量确定为5;若所述语音长度为10秒,则所述相关图片数量确定为10;
-根据所述语音信息的语音特征,确定与所述图片相关联的相关图片数量:例如,若所述语音特征显示发生了2次或多次的语调变换(如高音转低音,低音转高音等),则提高所确定的相关图片数量;
-根据所述语音信息的语义特征,确定与所述图片相关联的相关图片数量:例如,若所述语义特征显示出包含了多个语义关键词,则可根据不同的关键词,确定不同的相关图片,因此,相关图片数量会更多。
在步骤s52’中,所述生成装置在根据所述语音信息的语音特征和/或语义特征,并结合所述图片的图片特征的基础上,来确定与上述语音信息和所述图片在内容或特征上相关联的、符合上述相关图片数量要求的一张或多张相关图片。
需要注意的是,本发明可在软件和/或软件与硬件的组合体中被实施,例如,可采用专用集成电路(asic)、通用目的计算机或任何其他类似硬件设备来实现。在一个实施例中,本发明的软件程序可以通过处理器执行以实现上文所述步骤或功能。同样地,本发明的软件程序(包括相关的数据结构)可以被存储到计算机可读记录介质中,例如,ram存储器,磁或光驱动器或软磁盘及类似设备。另外,本发明的一些步骤或功能可采用硬件来实现,例如,作为与处理器配合从而执行各个步骤或功能的电路。
另外,本发明的一部分可被应用为计算机程序产品,例如计算机程序指令,当其被计算机执行时,通过该计算机的操作,可以调用或提供根据本发明的方法和/或技术方案。而调用本发明的方法的程序指令,可能被存储在固定的或可移动的记录介质中,和/或通过广播或其他信号承载媒体中的数据流而被传输,和/或被存储在根据所述程序指令运行的计算机设备的工作存储器中。在此,根据本发明的一个实施例包括一个装置,该装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发该装置运行基于前述根据本发明的多个实施例的方法和/或技术方案。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。装置权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 还没有人留言评论。精彩留言会获得点赞!