机器人的声纹服务系统及其服务控制方法与流程
本发明涉及声纹检测技术领域,尤其涉及一种机器人的声纹服务系统及其服务控制方法。
背景技术:
所谓声纹,是用电声学仪器显示的携带言语信息的声波频谱。现代科学研究表明,声纹不仅具有特定性,而且有相对稳定性的特点。成年以后,人的声音可保持长期相对稳定不变。实验证明,无论讲话者是故意模仿他人声音和语气,还是耳语轻声讲话,即使模仿得惟妙惟肖,其声纹却始终不相同。
现有技术中,机器人常常无法无法自动辨别用户,因此无法为用户提供针对性的服务。
技术实现要素:
针对上述技术中存在的不足之处,本发明提供一种结构简单、操作方便的机器人的声纹服务系统及其服务控制方法,能够自动辨识用户,能为不同用户提供针对性的服务。
为了达到上述目的,本发明一种机器人的声纹服务系统,包括设置在机器人内部的
语音输出模块,输出两种形式的语音,一种为自主向周围播放需要的语音,另一种为由语音解析模块获得的结果交给扬声器向周围播放语音;
引导模块,引导用户根据语音输出模块播放的提示音进行录音;
语音输入模块,接收周围声音、麦克风录音,且存储音频文件;
语音解析模块,处理语音输入模块的音频文件,将处理的结果交给语音输出模块;
声纹记录模块,将语音输入模块所存储的音频文件建立声音模型;
声纹识别模块,由语音输入模块所存储的音频文件匹配声纹记录模块所存储的声音模型,并判定用户身份;
业务模块,根据声纹记录模块提供的声音模型进行对应的操作处理;
所述语音输出模块播放第一个提示语音,询问用户要录入的声纹身份,所述引导模块引导用户进行声纹身份的录音,所述语音输入模块接收用户录音后存储音频文件,所述语音解析模块对语音输入模块内的音频文件进行解析处理,若解析失败,则语音输出模块播放第一个提示语音;若解析成功,则语音输出模块播放下一个提示语音,所述引导模块再次引导用户进行再次录音,循环多次后,所述语音解析模块将多个音频文件发送给声纹记录模块,所述声纹记录模块将多个音频文件建立为一个声音模型,存储为用户的声纹身份,且声音模型存储在声纹库中;建立好多个声音模型后,用户根据语音输出模块播放的提示语音后说话,所述声纹识别模块将语音输入模块所存储的音频文件与声纹记录模块所存储的声音模型进行对比,判定用户身份后,业务模块执行对应的操作处理。
其中,所述声纹身份包括儿童、少年、中年和老年,且所述少年、中年和老年均为非儿童身份。
其中,所述业务模块包括音乐播放单元和视频播放单元,所述音乐播放单元播放的内容包括儿歌、流行歌曲、革命歌曲和古典歌曲;若声纹识别模块判定用户身份为儿童,则播放儿歌;若声纹识别模块判定用户为少年,则播放流行歌曲;若声纹识别模块判定用户为中年,则播放革命歌曲;若声纹识别模块判定用户身份为老年,则播放古典歌曲;所述视频播放单元播放的内容包括动画和非动画,若声纹识别模块判定用户身份为儿童,则播放动画;若声纹识别模块判定用户身份为非儿童,则播放非动画。
其中,所述业务模块还包括游戏单元和学习单元,所述游戏单元包括游戏界面和游戏管理;若声纹识别模块判定用户身份为儿童,则游戏界面运行;若声纹识别模块判定用户身份为非儿童,则游戏管理执行管理儿童游戏时间和游戏类型;所述学习单元包括学习界面和学习管理,若声纹识别模块判定用户身份为儿童,则学习界面运行;若声纹识别模块判定用户身份为非儿童,则学习管理执行管理儿童学习时间和学习内容。
为了实现上述目的,本发明还提供一种机器人的声纹服务控制方法,包括声纹记录步骤和声纹识别步骤,所述声纹记录步骤包括以下具体步骤:
步骤A1,语音输出模块播放第一个提示语音,询问用户要录入的声纹身份;
步骤A2,引导模块对用户进行声纹引导,且用户开始对声纹身份录音;
步骤A3,语音输入模块开启识别录音,录入用户声纹身份,且存储音频文件;
步骤A4,语音解析模块对语音输入模块存储后的音频文件进行解析,若语音解析模块解析成功,获取声纹身份,则执行步骤A5;若语音解析模块解析不成功,无法获取声纹身份,则跳转回步骤A1;
步骤A5,语音输入模块关闭识别录音;
步骤A6,语音解析模块第一次成功获取音频文件,且语音输出模块播放第二个提示语音,并重复循环步骤A2-A5五次,直至语音解析模块得到用户六个音频文件;
步骤A7,声纹记录模块综合用户的六个音频文件建立一个声纹模型,声纹模型存储在声纹库中,且一个声纹模型建立一个用户身份;
步骤A8,语音输出模块播放第三个提示语音,提醒用户该机器人已成功记录用户的声纹身份。
其中,所述声纹识别步骤包括以下具体步骤:
步骤B1,启动机器人;
步骤B2,开始说话,且语音输入模块开启识别录音;
步骤B3,声纹识别模块对比语音输入模块的音频文件和声纹库中的声纹模型后判定用户身份;
步骤B4,业务模块根据用户身份进行对应的操作处理。
其中,首次使用该机器人时,所述步骤A1前还需要完成以下具体步骤:引导界面内设有声纹按钮,打开系统的引导界面后,点击声纹按钮,由声纹按钮进入后,引导界面设有添加声纹身份按钮,点击添加声纹身份按钮。
其中,所述步骤A6中,在重复循环步骤A2-A5中,若语音解析模块解析到的六个音频文件的声纹特点都一致,则将六个音频文件建立成声纹模型并存储;若语音解析模块解析到的六个音频文件中存在声纹特点不一致,则剔除掉声纹特点不一致的音频文件,并跳转回步骤A2。
其中,在所述步骤A8后,多个用户依次进行录音,声纹记录模块建立多个声纹模型,且所述多个声纹模型均存储在声纹库中。
其中,所述步骤B3具体为:根据语音输入模块的音频文件,声纹识别模块对声纹库中的第一个声纹模型进行查询对比,若对比成功,声纹识别模块读取语音输入模块的音频文件,且判定用户身份;若对比不成功,声纹识别模块对声纹库中的第二个声纹模型进行查询对比,直至对比成功。
本发明的有益效果是:
与现有技术相比,本发明的机器人的声纹服务系统及其服务控制方法,通过设置在机器人的语音输出模块、引导模块、语音输入模块、语音解析模块、声纹记录模块和声纹识别模块的配合,语音输入模块接收声音,语音输出模块播放提示语音,引导模块能够引导用户根据语音输出模块播放的提示音进行录音,语音解析模块能够处理语音输入模块的音频文件,声纹记录模块将语音输入模块所存储的音频文件建立声音模型,且声纹识别模块能将语音输入模块所存储的音频文件匹配声纹记录模块所存储的声音模型,并判定用户身份,实现用户的声纹记录和识别功能,使得声纹可作为一种可存储且可读取的数据,且业务模块可根据声纹记录模块提供的声音模型进行对应的操作处理,针对不同用户身份,实现不同的服务。
附图说明
图1为本发明机器人的声纹服务系统的方框示意图;
图2为本发明机器人的声纹服务控制方法中的声纹记录步骤的方框流程图;
图3为本发明机器人的声纹服务控制方法中的声纹识别步骤的方框流程图。
主要元件符号说明如下:
1、语音输出模块 2、引导模块
3、语音输入模块 4、语音解析模块
5、声纹记录模块 6、声纹识别模块
7、业务模块 71、音乐播放单元
72、视频播放单元 73、游戏单元
74、学习单元。
具体实施方式
为了更清楚地表述本发明,下面结合附图对本发明作进一步地描述。
参阅图1,本发明机器人的声纹服务系统,包括设置在机器人内部的
语音输出模块1,输出两种形式的语音,一种为自主向周围播放需要的语音,另一种为由语音解析模块4获得的结果交给扬声器向周围播放语音;
引导模块2,引导用户根据语音输出模块1播放的提示音进行录音;
语音输入模块3,接收周围声音、麦克风录音,且存储音频文件;
语音解析模块4,处理语音输入模块3的音频文件,将处理的结果交给语音输出模块1;
声纹记录模块5,将语音输入模块3所存储的音频文件建立声音模型;
声纹识别模块6,由语音输入模块3所存储的音频文件匹配声纹记录模块5所存储的声音模型,并判定用户身份;
业务模块7,根据声纹记录模块5提供的声音模型进行对应的操作处理;
语音输出模块1播放第一个提示语音,询问用户要录入的声纹身份,引导模块2引导用户进行声纹身份的录音,语音输入模块3接收用户录音后存储音频文件,语音解析模块4对语音输入模块3内的音频文件进行解析处理,若解析失败,则语音输出模块1播放第一个提示语音;若解析成功,则语音输出模块1播放下一个提示语音,引导模块2再次引导用户进行再次录音,循环多次后,语音解析模块4将多个音频文件发送给声纹记录模块5,声纹记录模块5将多个音频文件建立为一个声音模型,存储为用户的声纹身份,且声音模型存储在声纹库中;建立好多个声音模型后,用户根据语音输出模块1播放的提示语音后说话,声纹识别模块6将语音输入模块3所存储的音频文件与声纹记录模块5所存储的声音模型进行对比,判定用户身份后,业务模块7执行对应的操作处理。
业务模块7根据用户身份执行对应的操作处理,主要是指,如用户身份为儿童,那么对应的操作处理即为儿童播放儿歌,或者播放动画,或者儿童可以操作游戏界面,或者儿童可以操作学习界面;如用户身份为非儿童,那么对应的操作处理即为播放非儿歌,包括少年爱听的流行歌曲、中年爱听的六七十年代的革命歌曲和老年人爱听的古典歌曲或者五十年代的歌曲。
与现有技术相比,本发明的机器人的声纹服务系统,通过设置在机器人的语音输出模块1、引导模块2、语音输入模块3、语音解析模块4、声纹记录模块5和声纹识别模块6的配合,语音输入模块3接收声音,语音输出模块1播放提示语音,引导模块2能够引导用户根据语音输出模块1播放的提示音进行录音,语音解析模块4能够处理语音输入模块3的音频文件,声纹记录模块5将语音输入模块3所存储的音频文件建立声音模型,且声纹识别模块6能将语音输入模块3所存储的音频文件匹配声纹记录模块5所存储的声音模型,并判定用户身份,实现用户的声纹记录和识别功能,使得声纹可作为一种可存储且可读取的数据,且业务模块7可根据声纹记录模块5提供的声音模型进行对应的操作处理,针对不同用户身份,实现不同的服务。
本实施例中,声纹身份包括儿童、少年、中年和老年,且少年、中年和老年均为非儿童身份。当然,声纹身份并不局限于上述各个身份,也可以是其他类型的身份。本案主要针对以家庭为主体的各个不同身份的进行业务操作,当然也可以以一个班,一个家族,一个公司等不同主体的团体,本案的机器人在进行声纹识别后所进行的功能操作包括了音乐播放,视频播放,游戏,学习等。
本实施例中,业务模块7包括音乐播放单元和视频播放单元,音乐播放单元播放的内容包括儿歌、流行歌曲、革命歌曲和古典歌曲;若声纹识别模块6判定用户身份为儿童,则播放儿歌;若声纹识别模块6判定用户为少年,则播放流行歌曲;若声纹识别模块6判定用户为中年,则播放革命歌曲;若声纹识别模块6判定用户身份为老年,则播放古典歌曲;视频播放单元播放的内容包括动画和非动画,若声纹识别模块6判定用户身份为儿童,则播放动画;若声纹识别模块6判定用户身份为非儿童,则播放非动画。
本实施例中,业务模块7还包括游戏单元和学习单元,游戏单元包括游戏界面和游戏管理;若声纹识别模块6判定用户身份为儿童,则游戏界面运行;若声纹识别模块6判定用户身份为非儿童,则游戏管理执行管理儿童游戏时间和游戏类型;学习单元包括学习界面和学习管理,若声纹识别模块6判定用户身份为儿童,则学习界面运行;若声纹识别模块6判定用户身份为非儿童,则学习管理执行管理儿童学习时间和学习内容。
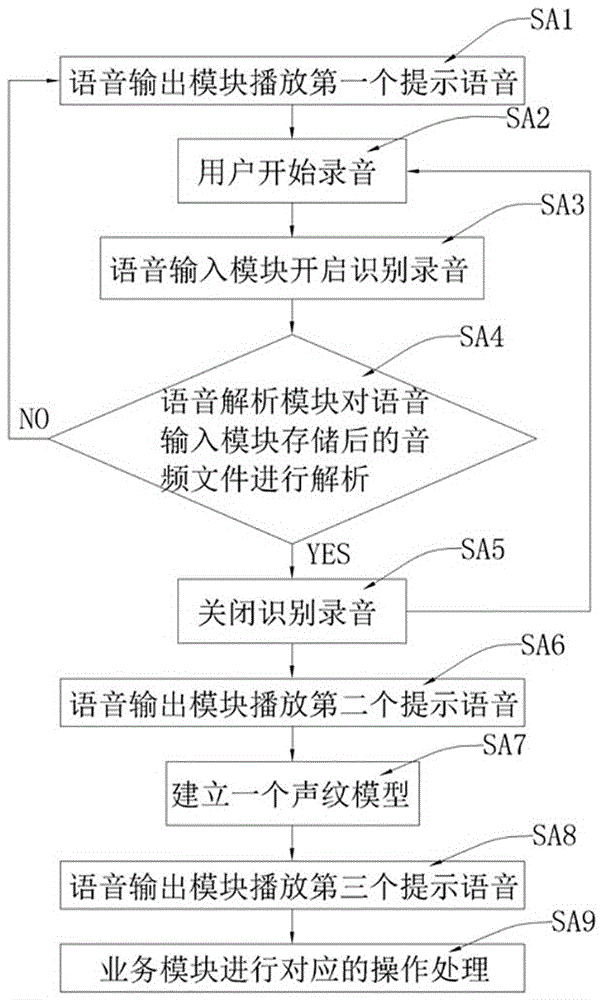
请参阅图2-3,为了实现上述目的,本发明还提供一种机器人的声纹服务控制方法,包括声纹记录步骤和声纹识别步骤,声纹记录步骤包括以下具体步骤:
步骤SA1,语音输出模块播放第一个提示语音,询问用户要录入的声纹身份;
步骤SA2,引导模块对用户进行声纹引导,且用户开始对声纹身份录音;
步骤SA3,语音输入模块开启识别录音,录入用户声纹身份,且存储音频文件;
步骤SA4,语音解析模块对语音输入模块存储后的音频文件进行解析,若语音解析模块解析成功,获取声纹身份,则执行步骤SA5;若语音解析模块解析不成功,无法获取声纹身份,则跳转回步骤SA1;
步骤SA5,语音输入模块关闭识别录音;
步骤SA6,语音解析模块第一次成功获取音频文件,且语音输出模块播放第二个提示语音,并重复循环步骤SA2-SA5五次,直至语音解析模块得到用户六个音频文件;当然,本案中并不局限于获取六个音频文件,也可以是三个,循环五次后得到六个音频文件有利于提高准确率,且用户体验良好;
步骤SA7,声纹记录模块综合用户的六个音频文件建立一个声纹模型,声纹模型存储在声纹库中,且一个声纹模型建立一个用户身份;
步骤SA8,语音输出模块播放第三个提示语音,提醒用户该机器人已成功记录用户的声纹身份。
本实施例中,声纹识别步骤包括以下具体步骤:
步骤SB1,启动机器人;
步骤SB2,开始说话,且语音输入模块开启识别录音;
步骤SB3,声纹识别模块对比语音输入模块的音频文件和声纹库中的声纹模型后判定用户身份;
步骤SB4,业务模块根据用户身份进行对应的操作处理。
本实施例中,首次使用该机器人时,步骤A1前还需要完成以下具体步骤:引导界面内设有声纹按钮,打开系统的引导界面后,点击声纹按钮,由声纹按钮进入后,引导界面设有添加声纹身份按钮,点击添加声纹身份按钮。用户首次使用时,需要录入声纹身份,再次使用时,机器人内部已经存储有声纹身份,因此只需声纹识别模块对用户的声音进行识别即可。
本实施例中,步骤SA6中,在重复循环步骤SA2-SA5中,若语音解析模块解析到的六个音频文件的声纹特点都一致,则将六个音频文件建立成声纹模型并存储;若语音解析模块解析到的六个音频文件中存在声纹特点不一致,则剔除掉声纹特点不一致的音频文件,并跳转回步骤SA2。由于声纹是录取多个音频文件,每个音频文件都有可能不同,语音分析模块分析这多个音频文件,声音播放出来是波浪型的,声音高则波浪越高,没声音则是一条直线,每个人说话的语调,声音各有不同,有的先高后低,有的先低后高,这些都是声纹记录的特点,语音分析模块分析综合这多个音频文件的特征建立声纹模型,进而建立声纹库。
本实施例中,在步骤SA8后,多个用户依次进行录音,声纹记录模块建立多个声纹模型,且多个声纹模型均存储在声纹库中。
本实施例中,步骤SB3具体为:根据语音输入模块的音频文件,声纹识别模块对声纹库中的第一个声纹模型进行查询对比,若对比成功,声纹识别模块读取语音输入模块的音频文件,且判定用户身份;若对比不成功,声纹识别模块对声纹库中的第二个声纹模型进行查询对比,直至对比成功。比如第一个声纹模型为儿童,第二个声纹模型为少年,第三个声纹模型为中年,且第四个声纹模型为老年,当老年人对着机器人说话时,老年人的声音通过语音输入模块输入并存储,声纹识别模块对声纹库中的声纹模型逐一查询对比,首先查询到儿童,声纹识别模块判断老年人的音频文件不是儿童,因此声纹识别模块继续查询下一个声纹模型,即少年,而声纹识别模块判定老年人的音频文件不是少年,因此声纹识别模块继续查询下一个声纹模型,即中年,而声纹识别模块判定老年人的音频文件不是中年,因此声纹识别模块继续查询下一个声纹模型,即老年,声纹识别模块判定老年人的音频文件为老年,因此对比成功。
本发明的优势在于:与现有技术相比,本发明的机器人的声纹服务控制方法,通过设置在机器人的语音输出模块、引导模块、语音输入模块、语音解析模块、声纹记录模块和声纹识别模块的配合,语音输入模块接收声音,语音输出模块播放提示语音,引导模块能够引导用户根据语音输出模块播放的提示音进行录音,语音解析模块能够处理语音输入模块的音频文件,声纹记录模块将语音输入模块所存储的音频文件建立声音模型,且声纹识别模块能将语音输入模块所存储的音频文件匹配声纹记录模块所存储的声音模型,并判定用户身份,实现用户的声纹记录和识别功能,使得声纹可作为一种可存储且可读取的数据,且业务模块可根据声纹记录模块提供的声音模型进行对应的操作处理,针对不同用户身份,实现不同的服务。
以上公开的仅为本发明的几个具体实施例,但是本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!