声音区间检测装置、声音区间检测方法以及记录介质与流程
本发明涉及声音区间检测装置、声音区间检测方法以及记录介质。
背景技术:
公知有一种从声音信号检测包括对由说话人发出的语音进行表示的语音信号的语音区间的技术。
例如,zhang,x.-l.,wu,j.,“deepbeliefnetworksbasedvoiceactivitydetection”,ieeetransactionsonaudio,speech,andlanguageprocessing,vol.21,no.4,pp697-710,(2013)公开了一种使用dbn(deepbeliefnetwork:深度信念网络)从声音信号检测语音区间的方法。
在使用上述的文献所公开的方法从声音信号检测出语音区间时,是该声音信号中的区间,有时包括对由说话人以外的声源发出的噪声声音进行表示的噪声声音信号但不包含语音信号的区间被误检测为语音区间。
因为误检测语音区间,而产生了以下那样的问题。例如,在从长时间录音的声音数据中只检测人说话的部分而想要只对检测出的声音数据进行再生的情况下,如果误检测了语音区间,则需要对不必要的声音数据也进行再生。另外,例如在一边对声音进行录音(输入)、一边想要实时执行语音的声音识别的情况下,由于误检测语音区间,会导致在不是语音时也执行声音识别,大量消耗必要以上的资源(计算量)。
另外,在语音区间的检测精度低的情况下,产生了以下那样的问题。例如,由于检测出的对象有时不是人声而是噪声、环境音,所以在重听检测到的声音数据时,要使用不必要的时间。另外,例如说话的部分未被检测而从检测结果中缺失,导致漏听需要进行重听的声音数据。并且,由于语音区间的检测精度低,所以有时发声区间的前端、一部分未被检测而从检测结果中缺失,该情况下,当将该检测结果的声音数据作为输入数据进行了声音识别时,成为识别精度降低的理由之一。
因此,要求使语音区间的检测精度提高。
技术实现要素:
本发明基于上述情况,其目的在于,提供使根据声音信号来检测包括对由说话人发出的语音进行表示的语音信号的语音区间时的检测精度提高的声音区间检测装置、声音区间检测方法以及记录介质。
本发明涉及一种声音区间检测装置,其中,具备:处理器;以及存储器,构成为通过执行该存储器中存储的命令,使得上述处理器执行以下的处理:从靶声音信号检测包括特定声音信号的特定声音区间,上述特定声音信号表示在比特定时间长的时间持续发出的同一子音的音素的状态,通过从上述靶声音信号至少除去检测出的上述特定声音区间,来从该靶声音信号检测包括语音信号的语音区间,上述语音信号表示由说话人发出的语音。
另外,本发明涉及一种由声音区间检测装置执行的方法,其中,上述声音区间检测装置具备:处理器;以及存储器,存储由上述处理器执行的命令,上述方法包括以下步骤:从靶声音信号检测包括特定声音信号的特定声音区间,上述特定声音信号表示在比特定时间长的时间持续发出的同一子音的音素的状态,通过从上述靶声音信号至少除去检测出的上述特定声音区间,来从该靶声音信号检测包括语音信号的语音区间,上述语音信号表示由说话人发出的语音。
并且,本发明涉及一种记录介质,是非暂时性且存储有计算机可读取的程序的记录介质,通过具备处理器和存储由该处理器执行的命令的存储器的声音区间检测装置的上述处理器来执行以下处理:
从靶声音信号检测包括特定声音信号的特定声音区间,上述特定声音信号表示在比特定时间长的时间持续发出的同一子音的音素的状态,
通过从上述靶声音信号至少除去检测出的上述特定声音区间,来从该靶声音信号检测包括语音信号的语音区间,上述语音信号表示由说话人发出的语音。
附图说明
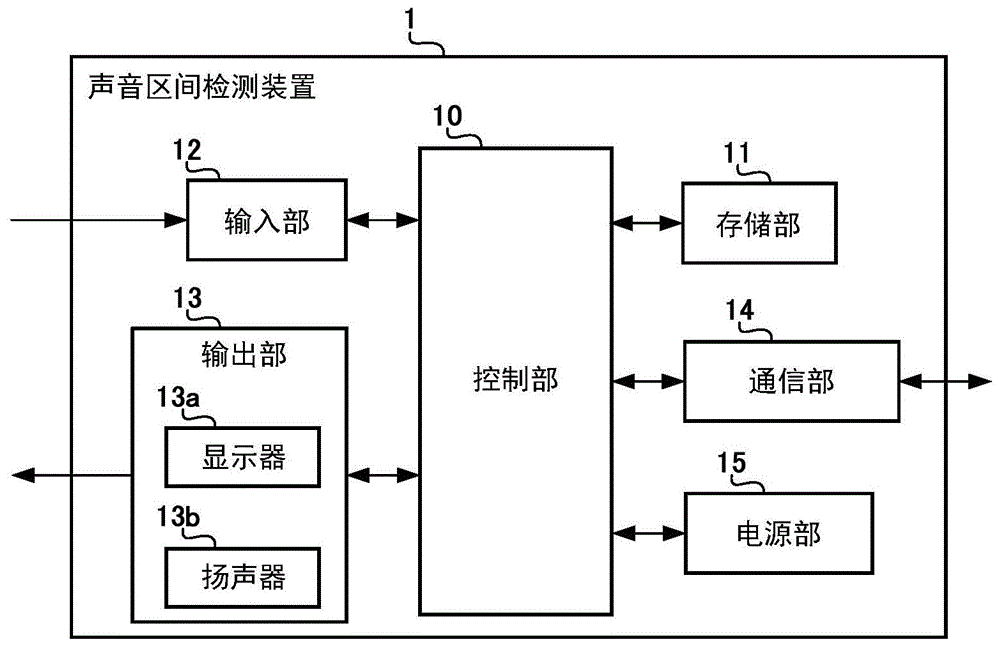
图1是表示本发明的实施方式涉及的声音区间检测装置的物理结构的图。
图2是表示本发明的实施方式涉及的声音区间检测装置的功能结构的图。
图3是用于对本发明的实施方式涉及的声音区间检测装置所执行的帧的设定以及候补区间的设定进行说明的图。
图4是表示本发明的实施方式涉及的nn(neuralnetwork)的构成例的图。
图5是用于对本发明的实施方式涉及的声音区间检测装置所执行的特定声音区间的检测以及语音区间的检测进行说明的图。
图6是用于对本发明的实施方式涉及的声音区间检测装置所执行的检测信息的输出进行说明的图。
图7是用于对本发明的实施方式涉及的声音区间检测装置所执行的声音区间检测处理进行说明的流程图。
图8是用于对本发明的实施方式涉及的声音区间检测装置所执行的候补区间取得处理进行说明的流程图。
图9是用于对本发明的实施方式涉及的声音区间检测装置所执行的语音区间取得处理进行说明的流程图。
具体实施方式
以下,参照附图对本发明的实施方式涉及的声音区间检测装置进行说明。在图中,对相互相同或者等同的构成赋予相互相同的附图标记。
图1所示的声音区间检测装置1从靶声音信号检测包括对说话人发出的语音进行表示的语音信号的语音区间。作为靶声音信号的具体例,可举出表示会议的声音的声音信号、表示演讲的声音的声音信号、表示电视播放的声音的声音信号、表示广播的声音的声音信号等。
声音区间检测装置1具备控制部10、存储部11、输入部12、输出部13、通信部14、以及电源部15。
控制部10具备cpu(centralprocessingunit),根据存储部11中存储的程序以及数据,执行包括后述的声音区间检测处理的各种处理。控制部10经由指令以及数据的传送路径即未图示的系统总线与声音区间检测装置1的各部连接,统一控制声音区间检测装置1整体。
存储部11具备rom(readonlymemory)、ram(randomaccessmemory)、hdd(harddiskdrive)、闪存等非易失性的外部存储装置,存储控制部10为了执行各种处理而使用的程序以及数据,并且存储通过控制部10执行各种处理而生成或者取得的数据。具体而言,存储部11存储有控制部10执行的控制程序。另外,存储部11存储有表示靶声音信号的靶声音数据。声音区间检测装置1从pc(personalcomputer)、智能手机等外部的信息处理装置取得通过该信息处理装置使用麦克风对靶声音信号进行录音而生成的靶声音数据,并存储到存储部11所具备的外部存储装置。
存储部11具备的ram作为控制部10的工作区域发挥功能。即,控制部10将存储部11中存储的程序以及数据向ram读出,通过参照读出的程序以及数据来执行各种处理。
输入部12具备键盘、触摸面板、操作按钮等输入装置,根据用户的操作来接受各种指示,并将接受到的指示向控制部10供给。具体而言,输入部12根据用户的操作来接受用于指定靶声音数据的指示、用于使语音区间的检测开始的指示。
输出部13具备显示器13a和扬声器13b,根据控制部10的控制,将包括对语音区间的检测结果进行表示的检测信息的各种信息以用户能够识别的形态输出。具体而言,输出部13根据控制部10的控制,在显示器13a显示对语音区间的检测结果进行表示的检测图像作为检测信息,从扬声器13b输出包括检测出的语音区间的声音信号作为检测信息。
通信部14根据控制部10的控制,与pc、智能手机等外部的信息处理装置之间经由lan(localareanetwork)、因特网等通信网进行无线通信,与该外部的信息处理装置之间收发数据。具体而言,通信部14从pc、智能手机等外部的信息处理装置接收由该信息处理装置生成的靶声音数据,并将接收到的靶声音数据向存储部11供给。
电源部15具备蓄电池等电源、以及控制该电源的电源控制电路,根据控制部10的控制,向声音区间检测装置1的各部供给电力。
具备上述的物理结构的声音区间检测装置1在功能上如图2所示,具备靶声音数据取得部100、帧设定部101、候补区间取得部102、nn存储部103、概率信息存储部104、语音区间取得部105、以及检测信息输出部106。
靶声音数据取得部100、帧设定部101、候补区间取得部102、语音区间取得部105以及检测信息输出部106由控制部10实现。具体而言,控制部10通过执行存储部11中存储的控制程序来控制声音区间检测装置1,由此作为这些各部发挥功能。nn存储部103以及概率信息存储部104由存储部11实现。具体而言,nn存储部103以及概率信息存储部104被构建于存储部11所具备的外部存储装置的存储区域。
靶声音数据取得部100从存储部11所具备的外部存储装置取得由该外部存储装置存储的靶声音数据。
帧设定部101向由靶声音数据取得部100取得的靶声音数据所表示的靶声音信号中设定时间上连续的多个帧。帧是时间长度为帧长的时间窗。帧长是预先设定的时间长度。以下,参照图3对帧设定部101执行的帧的设定进行说明。
图3中示出了表示靶声音信号的声音波形的波形图。在图3所示的波形图中,纵轴表示声音波形的振幅的大小,横轴表示时间t。以下,如图3所示,以从靶声音信号的前端到末尾的时间长度为t的情况为例来进行说明。
帧设定部101将开始时刻与靶声音信号的前端一致且时间长度为帧长f的时间窗设定为靶声音信号中的最初的帧即第0帧。靶声音信号中的最初的帧是该靶声音信号中的帧之中的开始时刻最早的帧。在设定了第0帧之后,帧设定部101判断是否开始时刻是比一个帧的开始时刻靠后移动长度g的时刻、且时间长度为帧长f的时间窗的结束时刻是比靶声音信号的末尾靠后的时刻,当判定为该结束时刻不是比靶声音信号的末尾靠后的时刻时,通过反复执行将该时间窗设定为该一个帧的紧后的帧的处理直到判定为该结束时刻是比靶声音信号的末尾靠后的时刻为止,由此在靶声音信号中设定时间上连续的多个帧。帧设定部101在判定为开始时刻是比一个帧的开始时刻靠后移动长度g的时刻、且时间长度为帧长f的时间窗的结束时刻是比靶声音信号的末尾靠后的时刻时,结束向靶声音信号中设定帧的处理。移动长度g是预先设定的时间长度。靶声音信号中的一个帧的紧后的帧是该靶声音信号中的帧之中的开始时刻紧接着该一个帧晚的帧。
以下,如图3所示,以由帧设定部101在靶声音信号中设定了第0帧~第(m-1)帧的m个帧的情况为例来进行说明。第0帧~第(m-1)帧都是时间长度为帧长f。如图3所示,第1帧~第(m-1)帧的各帧是开始时刻比紧前的帧的开始时刻靠后移动长度g的时刻。靶声音信号中的一个帧的紧前的帧是该靶声音信号中的帧之中的开始时刻紧接着该一个帧早的帧。例如,第1帧的开始时刻是比第1帧的紧前的帧即第0帧的开始时刻靠后移动长度g的时刻。
帧长f以及移动长度g使用实验等任意的方法被预先设定为帧长f比移动长度g长。在本实施方式中,帧长f被设定为25ms,移动长度g被设定为10ms。由于帧长f比移动长度g长,所以各帧与紧后的帧重复时间长度(f-g)。
返回到图2,候补区间取得部102在靶声音信号中设定候补区间。如后述那样,声音区间检测装置1从由候补区间取得部102设定的候补区间检测语音区间。候补区间取得部102如图2所示,具备后验概率取得部102a、第1帧判定部102b以及候补区间设定部102c。
后验概率取得部102a针对由帧设定部101设定的每个帧,取得帧所包含的声音信号表示各音素的各状态的后验概率。
音素的状态是将音素沿时间方向细分的单位。按每个音素,预先设定了音素的状态的数。以下,以各音素的状态的数被设定为3的情况为例来进行设定。例如,音素“a”被分为包括该音素的发音开始时的第1状态“a1”、包括该音素的发音结束时的第3状态“a3”、以及作为该第1状态“a1”与该第3状态“a3”的中间状态的第2状态“a2”这3个状态。
以下,以使用单声道模型作为声学模型的情况为例来进行说明。声学模型将音素的频率特性模型化。单声道模型是按每1个音素生成的声学模型,是不取决于邻接的音素、即将与前后的音素的状态的状态迁移固定化了的声学模型。后验概率取得部102a按每个帧取得帧所包含的声音信号分别表示单声道模型中的各音素的3个状态的后验概率。在将单声道模型中利用的全部音素的数设为q个的情况下,存在(3×q)个状态。后验概率取得部102a取得与(3×q)个状态分别对应的后验概率。
在本实施方式中,将作为识别符的索引与各音素的各状态唯一建立对应。
后验概率取得部102a使用由nn存储部103存储的、图4所示的nn103a来取得后验概率。nn103a输出声音信号表示单声道模型中的各音素的各状态的后验概率。具体而言,nn103a的输入层的各单元in1~inv分别与mfcc(mel-frequencycepstrumcoefficient:梅尔频率倒谱系数)的各维预先对应,nn103a的输出层的各单元io1~iow分别与单声道模型中的各音素的各状态对应。nn103a响应于mfcc作为声音信号的声学特征量被输入至输入层这一情况,从输出层输出该声音信号表示各音素的各状态的后验概率。
后验概率取得部102a将一个帧所包含的声音信号向mfcc变换,取得该mfcc作为该声音信号的声学特征量,并将所取得的mfcc的各维的值分别输入至与各维对应的nn103a的输入层的单元in1~inv,通过将响应于该输入而由nn103a的输出层的各单元io1~iow输出的输出值输入至软最大值(softmax)函数,由此取得该声音信号表示单声道模型中的各音素的各状态的后验概率。
后验概率取得部102a将对各帧所包含的声音信号表示各音素的各状态的后验概率进行表示的概率信息向概率信息存储部104供给并进行存储。另外,后验概率取得部102a将概率信息向第1帧判定部102b供给。
返回到图2,第1帧判定部102b针对靶声音信号中的每个帧,判定预先设定的第1判定条件在帧中是否成立。第1判定条件在帧所包含的声音信号表示与声音对应的各音素的各状态的后验概率的总和比该声音信号表示与无音对应的各音素的各状态的后验概率的总和大的情况下成立。即,第1判定条件在下述的式(1)成立的情况下成立。第1帧判定部102b通过判定式(1)是否成立,来判定第1判定条件是否成立。如「藤田悠哉,磯健一,“音素エントロピーを利用した背景発話に頑健なdnnに基づく音声区間検出”,研究報告音声言語情報処理(slp),vol.2016-slp-112,no.9,pp.1-6,(2016.7」所记载那样,当在一个帧中第1判定条件成立的情况下,该一个帧中包含语音信号的可能性高。另一方面,当在一个帧中第1判定条件不成立的情况下,该一个帧中包含语音信号的可能性低。
【数式1】
在式(1)中,s表示具有作为识别符与各音素的各状态对应的索引中的、与声音所对应的音素的状态建立了对应的索引作为要素的集合。n表示具有作为识别符与各音素的各状态对应的索引中的、与无音所对应的音素的状态建立了对应的索引作为要素的集合。p(i|x(tj))表示具有声学特征量x(tj)的声音信号对与索引i对应的音素的状态进行表示的后验概率。声学特征量x(tj)表示开始时刻为时刻tj的帧所包含的声音信号的声学特征量。
第1帧判定部102b基于从后验概率取得部102a供给的概率信息来取得后验概率p(i|x(tj)),并基于所取得的后验概率p(i|x(tj))来判定式(1)是否成立。式(1)中的声学特征量x(tj)是后验概率取得部102a通过对开始时刻为时刻tj的帧所包含的声音信号进行变换而取得的mfcc,后验概率p(i|x(tj))是后验概率取得部102a通过将该mfcc输入至nn103a而取得的、该声音信号表示与索引i对应的音素的状态的后验概率。第1帧判定部102b将表示判定结果的信息向候补区间设定部102c供给。
候补区间设定部102c在靶声音信号中设定候补区间。具体而言,候补区间设定部102c将是靶声音信号中的区间、且由第1帧判定部102b判定为在该区间所包含的全部帧中第1判定条件成立的区间设定为候补区间。其中,也可以使用「大淵康成,武田龍,神田直之,“統計的雑音抑圧法の強調的適用による雑音環境下音声区間検出”,電子情報通信学会技術研究報告:信学技報,vol.2012-slp-94,no.18,pp.101-106,(2012.12)」所记载的方法来设定候补区间的前端以及末尾。
如上所述,当在一个帧中第1判定条件成立的情况下,该一个帧包含语音信号的可能性高,当在该一个帧中第1判定条件不成立的情况下,该一个帧包含语音信号的可能性低。由于候补区间所包含的帧都由第1帧判定部102b判定为第1判定条件成立,所以候补区间中包含语音信号的可能性高。另一方面,靶声音信号中的候补区间以外的区间包含语音信号的可能性低。
以下,如图3所示,以候补区间设定部102c在靶声音信号中设定了第1候补区间~第p候补区间这p个候补区间的情况为例来进行说明。第1候补区间~第p候补区间所包含的帧都是在该帧中由第1帧判定部102b判定为第1判定条件成立的帧。例如,第1候补区间如图3所示,包括第1帧~第k帧这k个帧,第1帧~第k帧都是由第1帧判定部102b判定为第1判定条件成立的帧。
返回到图2,nn存储部103存储表示nn103a的数据。nn103a通过在pc、智能手机等外部的信息处理装置中,使用声音文集作为教师数据,进行基于误差逆传播法等任意方法的机械学习来生成。声音文集是表示由多个说话人发出的声音的大量的声音数据的集合体。声音区间检测装置1经由通信部14从外部的信息处理装置接收表示由该外部的信息处理装置生成的nn103a的数据,并将接收到的数据储存到nn存储部103。
概率信息存储部104存储从后验概率取得部102a供给的概率信息。概率信息存储部104将所存储的概率信息向语音区间取得部105供给。
语音区间取得部105从由候补区间取得部102取得的候补区间检测语音区间。
如上所述,候补区间中包括语音信号的可能性高,另一方面,靶声音信号中的候补区间以外的区间包括语音信号的可能性低。语音区间取得部105通过从候补区间检测语音区间,由此与从靶声音信号整体检测语音区间的情况相比,能够抑制检测精度的降低,并且降低处理负荷。
候补区间中包括语音信号的可能性高,另一方面,存在包括对由说话人以外的声源发出的噪声声音进行表示的噪声声音信号的可能性。作为噪声声音的具体例,可举出换气扇的工作音、空调装置的工作音、冰箱的工作音等。
语音区间取得部105检测出候补区间中的、包含噪声声音信号但不包含语音信号的可能性高的区间以外的区间作为语音区间。
具体而言,语音区间取得部105从候补区间检测包括特定声音信号的特定声音区间,该特定声音信号表示在比预先设定的特定时间长的时间持续发音的同一子音的音素的状态,将候补区间中的被检测出的特定声音区间以外的区间检测为语音区间。
特定时间通过任意的方法,根据各子音的音素的各状态的持续长度的平均值而预先设定。各子音的音素的各状态的持续长度是由说话人发出各子音的音素的各状态的时间长度。具体而言,特定时间根据下述的式(2)来设定。
l=aa+2×sd···(2)
在式(2)中,l表示特定时间。aa表示各子音的音素的各状态的持续长度的平均值。sd表示各子音的音素的各状态的持续长度的标准偏差。各子音的音素的各状态的持续长度的平均值aa以及各子音的音素的各状态的持续长度的标准偏差sd根据声音文集中的各子音的音素的各状态的持续长度的分布来取得。
当候补区间中包括噪声声音信号的情况下,该噪声声音信号是子音的音素的可能性高,是母音的音素的可能性低。另外,在说话人发出子音的音素的情况下,说话人在比特定时间长的时间持续发出该子音的音素的可能性低。因此,表示在比特定时间长的时间持续发出的同一子音的音素的状态的特定声音信号是噪声声音信号的可能性高,特定声音区间包括噪声声音信号但不包括语音信号的可能性高。语音区间取得部105通过将候补区间中的特定声音区间以外的区间检测为语音区间,能够降低将包括噪声声音信号但不包括语音信号的区间误检测为语音区间的可能性,使语音区间的检测精度提高。
语音区间取得部105将候补区间中的特定声音区间以外的区间中的、时间长度为预先设定的判定时间以上的区间检测为语音区间。
判定时间通过实验等任意的方法被预先设定。具体而言,在本实施方式中,通过对各音素的持续长度的平均值乘以0.1而得到的时间长度被设定为判定时间。各音素的持续长度的平均值根据声音文集中的各音素的持续长度的分布来取得。
在说话人发出语音的情况下,说话人在比判定时间短的时间发出该发音声音的可能性低。因此,候补区间中的特定声音区间以外的区间中的、时间长度比判定时间短的区间是发音声音区间的可能性低,是包括噪声声音信号但不包括语音信号的可能性高。语音区间取得部105通过将候补区间中的特定声音以外的区间中的、时间长度为判定时间以上的区间检测为语音区间,能够降低将包括噪声声音信号但不包括语音信号的区间误检测为语音区间的可能性,使语音区间的检测精度提高。
如图2所示,语音区间取得部105具备相关系数计算部105a、第2帧判定部105b、特定声音区间检测部105c、以及语音区间检测部105d。
相关系数计算部105a针对各候补区间中的每个帧,计算对帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布、与该帧的紧前的帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布的相关程度进行表示的相关系数。具体而言,相关系数计算部105a根据下述的式(3)来计算相关系数。其中,对于各候补区间中的最初的帧而言,由于不存在该最初的帧的紧前的帧,所以被从相关系数计算部105a的相关系数的计算对象排除。
【数式2】
在式(3)中,ρ(tj)是对开始时刻为时刻tj的帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布、与该帧的紧前的帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布的相关程度进行表示的相关系数。c表示具有作为识别符而与各音素的各状态对应的索引中的、与子音的音素的状态对应的索引作为要素的集合。p(i|x(tj))表示具有声学特征量x(tj)的声音信号对与索引i建立了对应的音素的状态进行表示的后验概率。声学特征量x(tj)表示开始时刻为时刻tj的帧所包含的声音信号的声学特征量。av(p(tj))表示开始时刻为时刻tj的帧所包含的声音信号对各子音的音素的各状态进行表示的后验概率的相加平均。p(i|x(tj-1))表示具有声学特征量x(tj-1)的声音信号对与索引i建立了对应的音素的状态进行表示的后验概率。声学特征量x(tj-1)表示开始时刻为时刻tj-1的帧所包含的声音信号的声学特征量。时刻tj-1是开始时刻为tj的帧的紧前的帧的开始时刻。即,开始时刻为时刻tj-1的帧是开始时刻为tj的帧的紧前的帧。av(p(tj-1))表示开始时刻为时刻tj-1的帧所包含的声音信号对各子音的音素的各状态进行表示的后验概率的相加平均。
相关系数计算部105a从概率信息存储部104取得由概率信息存储部104存储的概率信息,基于所取得的概率信息来取得后验概率p(i|x(tj))、后验概率p(i|x(tj-1))、相加平均av(p(tj-1))以及相加平均av(p(tj)),计算相关系数。
具体而言,声学特征量x(tj)是通过后验概率取得部102a对开始时刻为时刻tj的帧所包含的声音信号进行变换而取得的mfcc,后验概率p(i|x(tj))是通过后验概率取得部102a将该mfcc输入至nn103a而取得的、该声音信号表示与索引i对应的音素的状态的后验概率。另外,声学特征量x(tj-1)是通过后验概率取得部102a对开始时刻为时刻tj-1的帧所包含的声音信号进行变换而取得的mfcc,后验概率p(i|x(tj-1))是通过后验概率取得部102a将该mfcc输入至nn103a而取得、该声音信号表示与索引i对应的音素的状态的后验概率。
通过计算由后验概率取得部102a将对开始时刻为时刻tj的帧所包含的声音信号进行变换而取得的mfcc输入至nn103a所取得的、该声音信号表示各子音的音素的各状态的后验概率的相加平均来取得相加平均av(p(tj))。通过计算由后验概率取得部102a将对开始时刻为时刻tj-1的帧所包含的声音信号进行变换而取得的mfcc输入至nn103a所取得的、该声音信号表示各子音的音素的各状态的后验概率的相加平均来取得相加平均av(p(tj-1))。
相关系数计算部105a将表示计算出的相关系数的信息向第2帧判定部105b供给。
第2帧判定部105b针对各候补区间中的每个帧,基于预先设定的第2判定条件是否成立来判定帧是否包括与表示该帧的紧前的帧所包括的子音的音素的状态的声音信号相同的声音信号。第2判定条件在由相关系数计算部105a计算出的相关系数为预先设定的判定阈值以上的情况下成立。判定阈值通过实验等任意的方法预先设定。当在一个帧中第2判定条件成立的情况下,该一个帧包括与表示该一个帧的紧前的帧所包含的子音的音素的状态的声音信号相同的声音信号。另一方面,当在一个帧中第2判定条件不成立的情况下,该一个帧不包含与表示该一个帧的紧前的帧所包含的子音的音素的状态的声音信号相同的声音信号。
此外,从相关系数计算部105a涉及的相关系数的计算对象排除了的各候补区间中的最初的帧被从第2帧判定部105b涉及的判定的对象中排除。第2帧判定部105b将表示判定结果的信息向特定声音区间检测部105c供给。
特定声音区间检测部105c将是候补区间中的区间、且由第2帧判定部105b判定为在该区间所包含的全部帧中第2判定条件成立的区间中的、包括比预先设定的特定个数多的个数的帧的区间检测为特定声音区间。特定个数按照下述的式(4),根据特定时间被预先设定。
l=f+(y-1)×g···(4)
在式(4)中,y表示特定个数。l表示特定时间。f表示帧长。g表示移动长度。特定个数相当于具有特定时间的时间长度的区间所包含的时间上连续的帧的数。因此,当是候补区间中的区间、且由第2帧判定部105b判定为在该区间所包含的全部帧中第2判定条件成立的区间包含比特定个数多的个数的帧的情况下,该区间包括对在比特定时间长的时间持续发出的同一子音的状态进行表示的特定声音信号。
以下,如图5所示,以在由候补区间取得部102设定的第1候补区间~第p候补区间中包括:含有被判定为第2判定条件成立的比特定个数多的个数的帧的区间、和含有被判定为第2判定条件成立的特定个数以下的个数的帧的区间的情况为例来进行说明。特定声音区间检测部105c如图5所示,将这些区间中的、含有被判定为第2判定条件成立的比特定个数多的个数的帧的区间检测为特定声音区间。
返回到图2,语音区间检测部105d将候补区间中的由特定声音区间检测部105c检测出的特定声音区间以外的区间中的、时间长度为判定时间以上的区间检测为语音区间。
以下,如图5所示,以第1候补区间~第p候补区间中的特定声音以外的区间包含时间长度为判定时间以上的区间、和时间长度比判定时间短的区间的情况为例来进行说明。语音区间检测部105d如图5所示,将这些区间中的时间长度为判定时间以上的区间检测为特定声音区间。
返回到图2,检测信息输出部106使输出部13输出表示由语音区间检测部105d对语音区间的检测结果的检测信息。具体而言,检测信息输出部106如图6所示,使输出部13所具备的显示器13a显示表示由语音区间检测部105d对语音区间的检测结果的检测图像ww作为检测信息,使输出部13所具备的扬声器13b输出包括由语音区间检测部105d检测出的语音区间的声音信号作为检测信息。
如图6所示,检测图像ww包括表示靶声音信号的声音波形的图像、和表示检测出的语音区间的图像。在由语音区间检测部105d检测出多个语音区间的情况下,检测信息输出部106使扬声器13b从包括开始时刻晚的语音区间的声音信号按顺序连续输出包括检测出的各语音区间的声音信号。
此外,在通过语音区间检测部105d未检测到语音区间的情况下,检测信息输出部106使输出部13输出对未检测到语音区间这一情况进行报告的非检测信息。具体而言,检测信息输出部106使显示器13a显示对“没有检测到语音区间。”这一消息进行表示的图像作为非检测信息,使扬声器13b输出对“没有检测到语音区间。”这一消息进行表示的声音信号作为非检测信息。
以下,参照图7~图9的流程图,对具备上述的物理/功能结构的声音区间检测装置1所执行的声音区间检测处理进行说明。
声音区间检测装置1经由通信部14从pc、智能手机等外部的信息处理装置接收由该外部的信息处理装置生成的靶声音数据,并预先存储到存储部11。
在该状态下,若用户通过操作输入部12而指示了语音区间的检测开始,则控制部10开始图7的流程图所示的声音区间检测处理。
若开始了声音区间检测处理,则首先靶声音数据取得部100取得存储部11中存储的靶声音数据(步骤s101)。帧设定部101在通过步骤s101取得的靶声音数据所表示的靶声音信号中设定时间上连续的多个帧(步骤s102)。具体而言,在步骤s102中,帧设定部101在将开始时刻与靶声音信号的前端一致且时间长度为帧长f的时间窗设定为靶声音信号中的最初的帧即第0帧之后,判定是否是开始时刻比一个帧的开始时刻靠后移动长度g的时刻且时间长度为帧长f的时间窗的结束时刻是比靶声音信号的末尾靠后的时刻,当判定为该结束时刻不是比靶声音信号的末尾靠后的时刻时,通过反复执行将该时间窗设定为该一个帧的紧后的帧的处理,直至判定为该结束时刻是比靶声音信号的末尾靠后的时刻为止,由此在靶声音信号中设定时间上连续的多个帧。
在执行了步骤s102的处理之后,候补区间取得部102执行候补区间取得处理(步骤s103)。以下,参照图8的流程图对步骤s103的候补区间取得处理进行说明。
如果开始了候补区间取得处理,则首先候补区间取得部102将在步骤s101中取得的靶声音数据所表示的靶声音信号中的最初的帧指定为处理对象的帧(步骤s201)。
在执行了步骤s201的处理之后,后验概率取得部102a取得被指定的处理对象的帧所包含的声音信号表示各音素的各状态的后验概率(步骤s202)。具体而言,后验概率取得部102a将处理对象的帧所包含的声音信号向mfcc变换,并将该mfcc输入至由nn存储部103存储的nn103a的输入层,通过响应于该输入而将由nn103a的输出层的各单元io1~iow输出的输出值输入至软最大值函数来取得该处理对象的帧所包含的声音信号表示各音素的各状态的后验概率。后验概率取得部102a使表示所取得的后验概率的概率信息存储于概率信息存储部104。
第1帧判定部102b通过基于在步骤s202中取得的后验概率判定上述的式(1)是否成立来判定在所指定的处理对象的帧中第1判定条件是否成立(步骤s203)。
在执行了步骤s203的处理之后,候补区间取得部102判定是否将在步骤s101中取得的靶声音数据所表示的靶声音信号中的全部帧都已指定为处理对象的帧(步骤s204)。如果判定为靶声音信号中的帧之中存在尚未被指定为处理对象的帧的帧(步骤s204;否),则候补区间取得部102将靶声音信号中的帧之中的当前被指定为处理对象的帧的帧的紧后的帧指定为处理对象的帧(步骤s206),处理返回到步骤s202。
候补区间取得部102变更被指定为处理对象的帧的帧,并且反复进行步骤s202~s204的处理直到在步骤s204中判定为是为止,由此针对靶声音信号中的每个帧,取得帧所包含的声音信号表示各音素的各状态的后验概率,并判定在帧中第1判定条件是否成立。
在步骤s204中,如果判定为已经将靶声音信号中的全部帧指定为处理对象的帧(步骤s204;是),则候补区间设定部102c将是靶声音信号中的区间且在步骤s203中判定为在该区间所包含的全部的帧中第1判定条件成立的区间指定为候补区间(步骤s205),结束候补区间取得处理。此外,当不存在是靶声音信号中的区间且被判定为在该区间所包含的全部帧中第1判定条件成立的区间的情况下,候补区间设定部102c判定为没有检测到语音区间而结束声音区间检测处理。
返回到图7,当在步骤s103中执行了候补区间取得处理之后,语音区间取得部105执行语音区间取得处理(步骤s104)。以下,参照图9的流程图对步骤s104的语音区间取得处理进行说明。
如果开始了语音区间取得处理,则首先语音区间取得部105将在步骤s205中设定于靶声音信号中的候补区间之中的最初的候补区间指定为处理对象的候补区间(步骤s301)。靶声音信号中的候补区间之中的最初的候补区间是该靶声音信号中的候补区间之中的开始时刻最早的候补区间。在执行了步骤s301的处理之后,语音区间取得部105将所指定的处理对象的候补区间中的帧之中的最初的帧的紧后的帧指定为处理对象的帧(步骤s302)。
在执行了步骤s302的处理之后,相关系数计算部105a根据上述的式(3)来计算对被指定的处理对象的帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布、与该处理对象的帧的紧前的帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布的相关程度进行表示的相关系数(步骤s303)。
在执行了步骤s303的处理之后,第2帧判定部105b通过判定在步骤s303中计算出的相关系数是否为判定阈值以上来判定在被指定的处理对象的帧中第2判定条件是否成立(步骤s304)。
在执行了步骤s304的处理之后,语音区间取得部105判定是否已经将被指定的处理对象的候补区间中的帧之中的、该处理对象的候补区间中的最初的帧以外的全部帧都指定为处理对象的帧(步骤s305)。如果判定为在处理对象的候补区间中的帧之中的该处理对象的候补区间中的最初的帧以外存在尚未被指定为处理对象的帧的帧(步骤s305;否),则语音区间取得部105将该处理对象的候补区间中的帧之中的当前被指定为处理对象的帧的帧的紧后的帧指定为处理对象的帧(步骤s309),处理返回到步骤s303。
语音区间取得部105变更被指定为处理对象的帧的帧,并且反复进行步骤s303~s305的处理直到在步骤s305中判定为是为止,由此针对被指定的处理对象的候补区间中的最初的帧以外的每个帧,计算帧所涉及的相关系数,判定在帧中第2判定条件是否成立。
在步骤s305中,如果判定为在被指定的处理对象的候补区间中的帧之中,已经将该处理对象的候补区间中的最初的帧以外的全部帧都指定为处理对象的帧(步骤s305;是),则特定声音区间检测部105c将是该处理对象的候补区间中的区间且在步骤s304中判定为在该区间所包含的全部帧中第2判定条件成立、包括比特定个数多的个数的帧的区间检测为特定声音区间(步骤s306)。
在执行了步骤s306的处理之后,语音区间检测部105d将被指定的处理对象的候补区间中的在步骤s306中检测出的特定声音区间以外的区间中的、时间长度比判定时间长的区间检测为语音区间(步骤s307)。
在执行了步骤s307的处理之后,语音区间取得部105判定是否已经将在步骤s205中设定的候补区间中的全部候补区间都指定为处理对象的候补区间(步骤s308)。如果判定为在步骤s205中设定的候补区间中存在尚未被指定为处理对象的候补区间的候补区间(步骤s308;否),则语音区间取得部105将在步骤s205中设定的候补区间之中的、当前被指定为处理对象的候补区间的候补区间的紧后的候补区间指定为处理对象的候补区间(步骤s310),处理返回到步骤s302。一个候补区间的紧后的候补区间是开始时刻紧接着该一个候补区间晚的候补区间。
语音区间取得部105变更被指定为处理对象的候补区间的候补区间,并且反复进行步骤s302~s308的处理直到在步骤s308中判定为是为止,由此针对在步骤s205中设定的每个候补区间,检测候补区间所包含的语音区间。
在步骤s308中,如果判定为已经将在步骤s205中设定的全部候补区间都指定为处理对象的候补区间(步骤s308;是),则语音区间取得部105结束语音区间取得处理。
返回到图7,在步骤s104中执行了语音区间取得处理之后,检测信息输出部106使输出部13输出对步骤s104中的语音区间的检测结果进行表示的检测信息(步骤s105),结束声音区间检测处理。具体而言,在步骤s105中,检测信息输出部106使输出部13所具备的显示器13a显示对步骤s104中的语音区间的检测结果进行表示的检测图像ww作为检测信息,使输出部13所具备的扬声器13b输出包括在步骤s104中检测出的语音区间的声音信号作为检测信息。此外,当在步骤s104中没有检测到语音区间的情况下,检测信息输出部106使输出部13输出非检测信息。
如以上说明那样,声音区间检测装置1从靶声音信号中的候补区间检测出包括特定声音信号的特定声音区间,该特定声音信号表示在比特定时间长的时间持续发出的同一子音的音素的状态,并将候补区间中的被检测出的特定声音区间以外的区间检测为语音区间。根据这样的构成,能够降低将包含噪声声音信号但不包含语音信号的区间误检测为语音区间的可能性,使语音区间的检测精度提高。
另外,声音区间检测装置1将候补区间中的特定声音区间以外的区间之中的、时间长度为判定时间以上的区间检测为语音区间。根据这样的构成,能够降低将包含噪声声音信号但不包含语音信号的区间误检测为语音区间的可能性,使语音区间的检测精度提高。
以上,对本发明的实施方式进行了说明,但上述实施方式只是一个例子,本发明的应用范围并不限于此。即,本发明的实施方式能够进行各种应用,所有的实施方式都包含于本发明的范围。
例如,在上述实施方式中,说明了靶声音数据取得部100从存储部11取得预先存储于存储部11的靶声音数据的情况。但是,这只不过是一个例子,靶声音数据取得部100能够通过任意的方法来取得靶声音数据。例如,声音区间检测装置1可以构成为具备麦克风,靶声音数据取得部100通过向该麦克风录制靶声音信号而生成靶声音数据,并从该麦克风取得所生成的靶声音数据。
另外,在上述实施方式中,说明了后验概率取得部102a使用由nn存储部103存储的nn103a来取得后验概率的情况。但是,这只不过是一个例子,后验概率取得部102a可以通过任意的方法来取得后验概率。例如,后验概率取得部102a可以使用hmm(hiddenmarkovmodel)来取得后验概率。hmm是用于基于声音信号来大致推断成为输出该声音信号的源的音素的状态的模型。hmm使用将表示时间状态的摇摆的迁移概率、和从各状态输出被输入的声学特征量的后验概率作为参数的标准模式。hmm若被输入帧所包含的声音信号的声学特征量,则以将多个高斯分布加权相加后的混合高斯分布的形式输出从各音素的各状态输出该声学特征量的后验概率的概率分布。
另外,在上述实施方式中,说明了使用单声道模型作为声学模型的情况。但是,这只不过是一个例子,能够使用任意的声学模型。例如,作为声学模型,也可以使用双音节模型。双音节模型是按每2个音素生成的声学模型,是取决于邻接的音素的声学模型。双音节模型是考虑了与前后一方的音素的状态的状态迁移的声学模型。或者,作为声学模型,也可以使用三音节模型。三音节模型是按每3个音素生成的声学模型,是取决于邻接的音素的声学模型。三音节模型是考虑了与前后两方的音素的状态的状态迁移的声学模型。
另外,在上述实施方式中,说明了后验概率取得部102a针对每个帧取得帧所包含的声音信号表示单声道模型中的各音素的3个状态每一个的后验概率的情况。但是,这只不过是一个例子,后验概率取得部102a也可以取得各帧所包含的声音信号表示双音节模型中的各音素的3个状态每一个的后验概率。此外,该情况下,只要预先将nn103a的输出层的各单元io1~iow分别与双音节模型中的各音素的各状态建立对应即可。或者,后验概率取得部102a也可以取得各帧所包含的声音信号表示三音节模型中的各音素的3个状态每一个的后验概率。此外,该情况下,只要预先将nn103a的输出层的各单元io1~iow分别与三音节模型中的各音素的各状态建立对应即可。或者,后验概率取得部102a可以取得各帧所包含的声音信号表示各音素的后验概率。此外,该情况下,只要预先将nn103a的输出层的各单元io1~iow分别与各音素建立对应即可。
另外,在上述实施方式中,说明了根据上述的式(2)来设定特定时间的情况。但是,这只不过是一个例子,特定时间能够根据各子音的音素的各状态的持续长度的平均值,通过任意的方法来设定。例如,可以将各子音的音素的各状态的持续长度的平均值的2倍的时间长度设定为特定时间。
另外,在上述实施方式中,说明了相关系数计算部105a针对候补区间中的每个帧,根据上述的式(3)来计算对帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布、与该帧的紧前的帧所包含的声音信号表示各子音的音素的各状态的后验概率的概率分布的相关程度进行表示的相关系数的情况。但是,这只不过是一个例子,相关系数计算部105a能够通过任意的方法来计算相关系数。
另外,在上述实施方式中,说明了检测信息输出部106使显示器13a显示检测图像ww作为检测信息、使扬声器13b输出包括检测到的语音区间的声音信号作为检测信息的情况。但是,这只不过是一个例子,检测信息输出部106能够通过任意的方法输出检测信息。例如,声音区间检测装置1可以构成为具备对纸、塑料等打印介质打印打印图像的打印装置,检测信息输出部106使该打印装置向打印介质打印表示由语音区间检测部105d对语音区间的检测结果的打印图像作为检测信息,来输出检测信息。作为表示由语音区间检测部105d对语音区间的检测结果的打印图像的具体例,可举出包括表示靶声音信号的声音波形的图像、和表示检测出的语音区间的图像的打印图像。
另外,在上述实施方式中,说明了声音区间检测装置1在进行了语音区间的检测之后输出表示该检测的结果的检测信息的情况。但是,这只不过是一个例子,声音区间检测装置1能够在进行了语音区间的检测之后,执行与该检测的结果对应的任意的处理。例如,声音区间检测装置1可以在进行了语音区间的检测之后,将检测出的语音区间所包含的声音信号作为对象来执行声音识别。或者,声音区间检测装置1可以在进行了语音区间的检测之后,将检测出的语音区间所包含的声音信号作为对象,来执行基于声音信号的说话人的感情识别。
此外,对于能够提供为预先具备用于实现本发明涉及的功能的构成的声音区间检测装置而言,当然能够通过程序的应用,来使pc、智能手机等现有的信息处理装置作为本发明涉及的声音区间检测装置发挥功能。即,通过将用于实现本发明涉及的声音区间检测装置的各功能构成的程序应用为能够由控制现有的信息处理装置的cpu等执行,由此可使该现有的信息处理装置作为本发明涉及的声音区间检测装置发挥功能。
此外,这样的程序的应用方法是任意的。能够将程序例如储存到软盘、cd(compactdisc)-rom、dvd(digitalversatiledisc)-rom、存储卡等计算机可读取的存储介质而应用。并且,也能够将程序叠加于载波,并经由因特网等通信介质来应用。例如,可以将程序公布到通信网络上的公告板(bbs:bulletinboardsystem)来进行分发。而且,也可以构成为通过起动该程序,在os(operatingsystem)的控制下,与其他应用程序同样地执行,由此能够执行上述的处理。
以上,对本发明的优选实施方式进行了说明,但本发明并不限定于该特定的实施方式,本发明包括技术方案所记载的发明及其等同的范围。
- 还没有人留言评论。精彩留言会获得点赞!