表达和分泌系统的制作方法
本申请要求2012年7月5日提交的美国临时申请号61/668397、2013年3月15日提交的61/852483和2013年5月3日提交的61/819063的优先权的权益,所述全部专利申请在本文中以其整体引入作为参考。
发明领域
本发明涉及表达和分泌系统及其使用的方法,用于当核酸转化到用于噬菌体展示的原核细胞时表达和分泌一种Fab融合蛋白质,并当核酸转染到用于表达和纯化的真核细胞时表达和分泌不同的或者相同的Fab融合蛋白质。在本文中还提供了核酸分子、载体以及包含此类载体和核酸分子的宿主细胞。
发明背景
多肽或蛋白质在丝状噬菌体颗粒上的噬菌体展示是允许从多种肽或蛋白质的大型库中挑选具有期望特性的肽或蛋白质的体外技术(McCafferty等人,Nature,348:552-554(1990);Sidhu等人,CurrentOpinion in Biotechnology,11:610-616(2000);Smith等人,Science,228:1315-1317(1985))。可将噬菌体展示用于在丝状噬菌体颗粒的表面展示肽或蛋白质(包括抗体片段如抗体研发领域的Fab)的不同文库,然后挑选与特定的目的抗原结合的。可以通过将抗体片段的基因与噬菌体外壳蛋白的基因融合,将抗体片段展示在丝状噬菌体颗粒的表面上,产生在其表面展示编码的抗体片段的噬菌体颗粒。该技术允许从大型噬菌体文库中分离与多种抗原具有期望亲和力的抗体片段。
对于基于噬菌体的抗体研发,在功能测定法(例如目标结合、基于细胞的活性测定、体内半衰期等)中评价挑选的抗体片段及其同源IgG的特性需要通过从用于噬菌体展示的载体中分离编码HC和LC的DNA序列,并亚克隆到用于IgG表达的哺乳动物表达载体中,来将Fab重链(HC)和轻链(LC)序列重新格式化成全长IgG。亚克隆数十或数百个挑选的HC/LC对的费力方法代表了基于噬菌体的抗体研发方法的主要瓶颈。此外,一旦重新格式化,由于在最初的筛选测定中相当比例挑选的Fab没有令人满意地施行,那么增加进行该重新格式化/筛选方法的克隆的数目将极大地增加成功的最终可能性。
在本文中,我们描述了表达和分泌系统的产生,用于当转化到大肠杆菌中时驱动Fab-噬菌体融合的表达,并当转染到哺乳动物细胞中时驱动包含相同Fab片段的全长IgG的表达。我们证明,来自鼠结合免疫球蛋白(mBiP)的哺乳动物信号序列(Haas等人,Immunoglobulin heavy chain binding protein,Nature,306:387-389(1983);Munro等人,An Hsp70-like protein in the ER:identify with the 78kd glucose-regulated protein and immunoglobulin heavy chain binding protein,Cell,4:291-300(1986))可以在原核和真核细胞二者中驱动有效的蛋白质表达。使用哺乳动物mRNA剪接,去除在人IgG1HC的铰链区内插入的含噬菌体融合肽的合成的内含子,我们可以以宿主细胞依赖性方式产生两种不同的蛋白质:用于在大肠杆菌中噬菌体展示的与接头肽融合的Fab片段和哺乳动物细胞中的天然人IgG1。该技术允许挑选与来自噬菌体展示文库的目的抗原结合的Fab片段,并且可以在不需要亚克隆的情况下,在哺乳动物细胞中后续表达同源全长IgG并纯化。
发明概述
在一个方面,本发明部分基于以下实验发现(1)非原核来源的信号序列可以在原核细胞中发挥功能和(2)当mRNA加工在真核细胞,而不是原核细胞中发生时,可以以宿主细胞依赖性方式从相同的核酸分子中表达不同的Fab融合蛋白质(原核细胞中的Fab-噬菌体融合蛋白质和真核细胞中的Fab-Fc融合蛋白质)。因此,本文中描述的是这样的核酸分子以及使用方法,当将核酸转化到原核宿主细胞(例如大肠杆菌)中时在细菌中表达和分泌与用于噬菌体展示的噬菌体颗粒蛋白质、外壳蛋白或者接头蛋白融合的Fab片段,以及当将核酸转化到真核细胞(例如哺乳动物细胞)中时,在不需要亚克隆的情况下,与Fc融合的Fab片段。
在一个实施方案中,本发明提供了这样的核酸分子,其编码包含可变重链结构域(VH)的VH-HVR1、VH-HVR2和HVR3的第一多肽和/或包含可变轻链结构域的VL-HVR1、VL-HVR2和VL-HVR3的第二多肽,并且其中该核酸分子还编码在原核和真核细胞二者中发挥功能的信号序列,并且其由与第一和/或第二多肽序列有效连接的核酸序列编码,并且其中全长抗体表达自核酸分子的第一和/或第二多肽。在另一个实施方案中,第一和/或第二多肽还包含可变重链(VH)结构域和可变轻链(VL)结构域。在另外的实施方案中,VH结构域与CH1连接,并且VL结构域与CL连接。
在一个方面,本发明提供了这样的核酸分子,其编码可变重链结构域(VH)的VH-HVR1、VH-HVR2和VH-HVR3以及可变轻链结构域(VL)的VL-HVR1、VL-HVR2和VL-HVR3,并且包含原核启动子和真核启动子,所述启动子与VH的HVR和/或VL的HVR有效连接,以允许在原核和真核细胞中表达VH的HVR和VL的HVR,并且其中当通过真核细胞表达时,VH和/或VL的HVR与效用肽(utility peptide)连接,并且其中核酸还编码在原核和真核细胞二者中发挥功能的信号序列。
在另一方面,本发明提供了这样的核酸分子,其编码可变重链(VH)结构域和可变轻链(VL)结构域,并且包含原核启动子和真核启动子,所述启动子与VH结构域和/或VL结构域有效连接,以允许在原核和真核细胞中表达VH结构域和/或VL结构域,并且其中当通过真核细胞表达时,VH结构域和/或VL与效用肽连接,并且其中核酸还编码在原核和真核细胞二者中发挥功能的信号序列。
在一个实施方案中,VL和VH与效用肽连接。在另外的实施方案中,VH还与CH1连接,并且VL与CL连接。效用肽选自Fc、标签、标记和对照蛋白质(control protein)。在一个实施方案中,VL与对照蛋白质连接,并且VH与Fc连接。例如,对照蛋白质是gD蛋白质或其片段。
甚至在另外的实施方案中,本发明的第一和/或第二多肽与下述物质融合:外壳蛋白(例如,噬菌体M13、f1或fd的pI、pII、pIII、pIV、pV、pVI、pVII、pVIII、pIX和pX或其片段例如pIII蛋白质的氨基酸267-421或262-418(除非另外指明,当在本文中使用时,“pI”、“pII”、“pIII”、“pIV”、“pV”、“pVI”、“pVII”、“pVIII”、“pIX”和“pX”指全长蛋白质或其片段))、或者接头蛋白(例如亮氨酸拉链蛋白质或包含SEQ ID NO:12(cJUN(R):ASIARLEEKV KTLKAQNYELASTANMLREQ VAQLGGC)或SEQ ID NO:13(FosW(E):ASIDELQAEVEQLEERNYAL RKEVEDLQKQAEKLGGC的氨基酸序列的多肽)或其变体(修饰了SEQ ID NO:12和SEQ ID NO:13中的氨基酸,包括但不限于那些以下划线和黑体表示的氨基酸),其中变体具有氨基酸修饰,其中修饰保留或者增加了接头蛋白与另一接头蛋白或者包含选自SEQ ID NO:6(ASIARLRERVKTLRARNYELRSRANMLRERVAQLGGC)或SEQ ID NO:7(ASLDELEAEIEQLEEENYALEKEIEDLEKELEKLGGC)的氨基酸序列的多肽的亲和力)、或者包含SEQ ID NO:8(GABA-R1:EEKSRLLEKE NRELEKIIAE KEERVSELRH QLQSVGGC)或SEQ ID NO:9(GABA-R2:TSRLEGLQSE NHRLRMKITE LDKDLEEVTM QLQDVGGC)或SEQ ID NO:14(Cys:AGSC)或SEQ ID NO:15(铰链:CPPCPG)的氨基酸序列的多肽。编码外壳蛋白或接头蛋白的核酸分子包含在合成的内含子内。合成的内含子位于编码VH结构域的核酸和编码Fc的核酸之间。合成的内含子还包含编码来自IgG1的天然存在的内含子的核酸,其中天然存在的内含子选自IgG1的内含子1、内含子2或内含子3。
在一个实施方案中,本发明提供了这样的核酸分子,其中在原核细胞中,第一融合蛋白质是表达的,并且在真核细胞中,第二融合蛋白质是表达的。第一融合蛋白质和第二融合蛋白质可以是相同的或者不同的。在另外的实施方案中,第一融合蛋白质可以是Fab-噬菌体融合蛋白质(例如包含与pIII融合的VH/CH1的Fab-噬菌体融合蛋白质),并且第二融合蛋白质可以是Fab-Fc或Fab-铰链-Fc融合蛋白质(例如包含与Fc融合的VH/CH1的Fab-Fc或Fab-铰链-Fc融合蛋白质)。
在一个实施方案中,本发明提供了这样的核酸分子,其中信号序列在真核细胞中指导蛋白质分泌至内质网或者细胞外和/或其中信号序列在原核细胞中指导蛋白质分泌至周质或者细胞外。此外,可以编码信号序列的核酸序列包括,编码包含SEQ ID NO:10(XMKFTVVAAALLLLGAVRA)的氨基酸序列的核酸序列,其中X=0个氨基酸或1个或2个氨基酸(例如X=M(SEQ ID NO:3;MMKFTVVAAALLLLGAVRA;野生型mBIP)或者X=MT(SEQ ID NO:19;MTMKFTVVAAALLLLGAVRA)或X是缺失的(SEQ ID NO:20;MKFTVVAAALLLLGAVRA)或者编码mBIP(SEQ ID NO:4;ATG ATG AAA TTT ACC GTG GTG GCG GCG GCG CTG CTG CTG CTG GGC GCG GTC CGC GCG)的核酸序列及其变体、或者编码与选自SEQ ID NO:3(mBIP氨基酸序列)的氨基酸序列具有至少90%氨基酸序列同一性的氨基酸序列的核酸序列,并且其中信号序列在原核和真核细胞二者中是有功能的、或者SEQ ID NO:11(共有mBIP序列,X ATG AAN TTN ACN GTN GTN GCN GCN GCN CTN CTN CTN CTN GGN GCN GTN CGN GCN,其中N=A,T,C或G,其中X=ATG(SEQ ID NO:5;ATG ATG AAN TTN ACN GTN GTN GCN GCN GCN CTN CTN CTN CTN GGN GCN GTN CGN GCN),X=ATG ACC(SEQ ID NO:21;ATG ACC ATG AAN TTN ACN GTN GTN GCN GCN GCN CTN CTN CTN CTN GGN GCN GTN CGN GCN)或X=是缺失的(SEQ ID NO:22;ATG AAN TTN ACN GTN GTN GCN GCN GCN CTN CTN CTN CTN GGN GCN GTN CGN GCN)的核酸序列、或者选自SEQ ID NO:16(mBIP.Opt1:ATG ATG AAA TTT ACC GTT GTT GCT GCT GCT CTG CTA CTT CTT GGA GCG GTC CGC GCA),SEQ ID NO:17(mBIP.Opt2:ATG ATG AAA TTT ACT GTT GTT GCG GCT GCT CTT CTC CTT CTT GGA GCG GTC CGC GCA)和SEQ ID NO:18(mBIP.Opt3:ATG ATG AAA TTT ACT GTT GTC GCT GCT GCT CTT CTA CTT CTT GGA GCG GTC CGC GCA)的核酸序列。
在另外的实施方案中,核酸分子中合成的内含子的两侧是其5’端的编码CH1的核酸以及其3’端的编码Fc的核酸。此外,编码CH1结构域的核酸包含天然剪接供体序列的一部分,并且编码Fc的核酸包含天然剪接受体序列的一部分。备选地,编码CH1结构域的核酸包含经修饰的剪接供体序列的一部分,其中经修饰的剪接供体序列包含至少一个核酸残基的修饰,并且其中该修饰增加了剪接。
在一个实施方案中,原核启动子是phoA、Tac、Tphac或Lac启动子和/或真核启动子是CMV或SV40或莫洛尼鼠白血病病毒U3区或山羊关节炎脑炎病毒U3区或绵羊脱髓鞘脑白质炎病毒U3区或逆转录U3区序列。通过原核启动子的表达在细菌细胞中发生,并且通过真核启动子的表达在哺乳动物细胞中发生。在另外的实施方案中,细菌细胞是大肠杆菌,并且真核细胞是酵母细胞、CHO细胞、293细胞或NSO细胞。
在另一实施方案中,本发明提供了包含本文中所述的核酸分子的载体和/或包含用此类载体转化了的宿主细胞。宿主细胞可以是细菌细胞(例如大肠杆菌细胞)或真核细胞(例如酵母细胞、CHO细胞、293细胞或NSO细胞)。
在另外的实施方案中,本发明提供了产生抗体的方法,包括培养本文中所述的宿主细胞,以使核酸表达。方法还包括回收由宿主细胞表达的抗体,并且其中从宿主细胞培养基中回收抗体。
在一个方面,本发明提供了包含修饰SEQ ID NO:8、9、12、13、14或15的氨基酸序列的至少一个残基的接头蛋白。在一个实施方案中,氨基酸序列选自SEQ ID NO:6(ASIARLRERVKTLRARNYELRSRANMLRERVAQLGGC)或SEQ ID NO:7(ASLDELEAEIEQLEEENYALEKEIEDLEKELEKLGGC)。在一个实施方案中,本发明提供了编码此类接头蛋白的核酸。
在一个方面,本发明提供了在原核和真核细胞二者中发挥功能的核酸分子,其编码包含SEQ ID NO:3的氨基酸序列的mBIP多肽及其变体,或者与SEQ ID NO:3的氨基酸序列具有85%同源性的氨基酸序列的多肽。在一个实施方案中,本发明提供了在原核和真核细胞二者中表达mBIP多肽的方法,所述mBIP多肽包含SEQ ID NO:3的氨基酸序列及其变体。在一个实施方案中,本发明提供了这样的细菌细胞,其可以表达包含SEQ ID NO:3的氨基酸序列及其变体的mBIP序列。
在一个方面,本发明提供了位于编码VH结构域的核酸和编码Fc或者抗体的铰链的核酸之间的、编码抗体的CH2和CH3结构域的核酸之间的、编码抗体的铰链区和CH2结构域的核酸之间的合成的内含子。
在一个方面,本发明包含下述多肽,该多肽包含含SEQ ID NO:3的氨基酸序列的信号序列或其变体、可变重链结构域(VH)和可变轻链结构域(VL),其中VH结构域与VL结构域的氨基端连接、或者该多肽包含含SEQ ID NO:3的氨基酸序列的信号序列或其变体、可变重链结构域(VH)和可变轻链结构域(VL),其中VH结构域与VL结构域的羧基端连接、或者该多肽包含含SEQ ID NO:3的氨基酸序列的信号序列以及可变重链结构域(VH)的VH-HVR1、VH-HVR2和VH-HVR3、或者该多肽包含含SEQ ID NO:3的氨基酸序列的信号序列以及可变轻链结构域(VL)的VL-HVR1、VL-HVR2和VL-HVR3、或者该多肽包含含SEQ ID NO:3的氨基酸序列的信号序列或其变体、可变重链结构域(VH)的VH-HVR1、VH-HVR2和VH-HVR3以及可变轻链结构域(VL)的VL-HVR1、VL-HVR2和VL-HVR3。在一个实施方案中,本发明多肽是抗体或抗体片段。本发明抗体或抗体片段可选自F(ab’)2和Fv片段、双抗体和单链抗体分子。
在一个方面,本发明包括用于增强蛋白质的噬菌体展示的突变的辅助型噬菌体。在一个实施方案中,辅助型噬菌体的核苷酸序列包含pIII中的琥珀突变,其中包含琥珀突变的辅助型噬菌体增强了与pIII融合的蛋白质在噬菌体上的展示。在另外的实施方案中,在权利要求70的核苷酸序列中,琥珀突变是M13KO7核酸的核苷酸2613、2614和2616中的突变。甚至在另外的实施方案中,权利要求71的核苷酸序列,其中M13KO7核酸的核苷酸2613、2614和2616中的突变引入了琥珀终止密码子。
附图简述
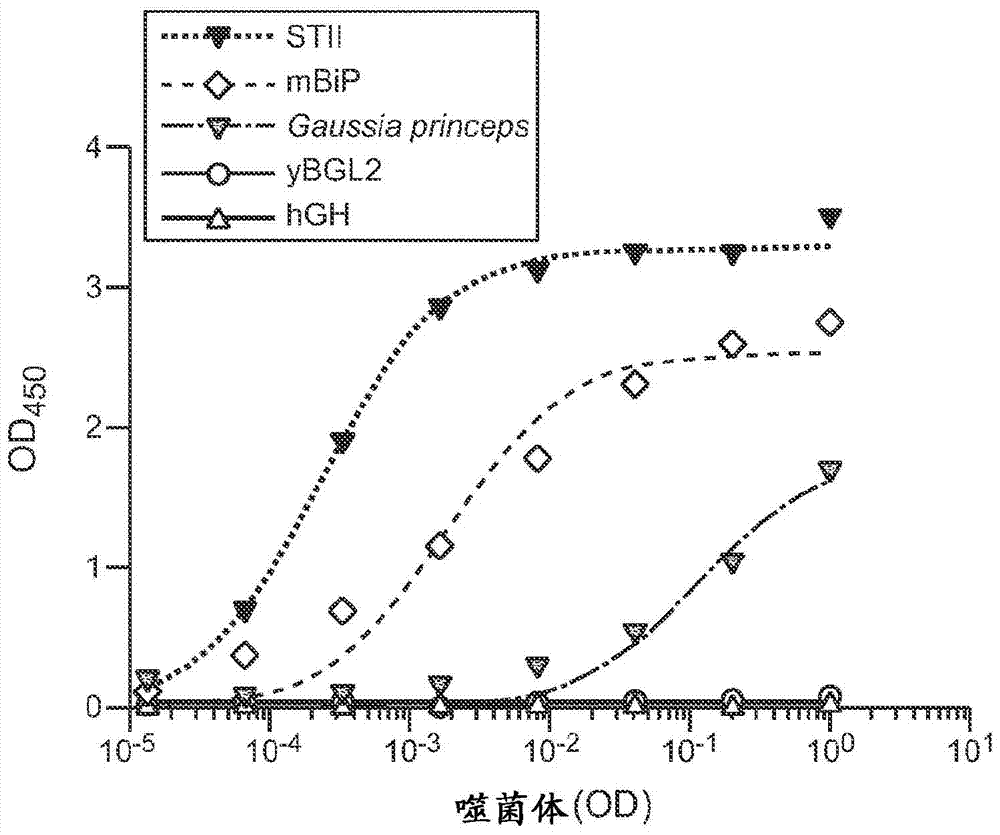
图1.(A)在4中不同真核信号序列(mBiP、Gaussia princeps、yBGL2、hGH)的控制下,展示抗-Her2Fab的经纯化的噬菌体的Her2噬菌体ELISA。将常用于噬菌粒的热稳定肠毒素II(STII)原核信号序列作为基准。(B)与野生型真核mBiP信号序列(mBiP.wt)融合的抗-Her2Fab的噬菌体展示,以及通过噬菌体文库淘选获得的密码子优化版本(mBiP.Opt1、mBiP.Opt2和mBip.Opt3(SEQ ID NOs:16-18))。
图2.(A)来自各个克隆的30mL 293细胞悬浮培养物的表达产量和(B)与真核mBiP或原核天然IgG HC(VHS)信号序列表达为融合物的hIgG1克隆的聚集统计(aggregate statistics)分析。
图3.(A)含三个天然内含子的人IgG1HC的基因组结构。内含子1紧接着在铰链区之前出现。(B)含衍生自内含子1或3的合成内含子并且含噬菌体接头融合肽的HC构建体。合成的内含子两侧是来自内含子1或3的天然内含子剪接供体(D)和受体(A)。(C)含衍生自内含子1或3的合成内含子并且含噬菌体外壳融合蛋白质的HC构建体。合成的内含子两侧是来自内含子1或3的天然内含子剪接供体(D)和受体(A)。构建体(B)和(C)二者在接头肽或噬菌体外壳蛋白序列的3’末端都含有STOP密码子。
图4.(A)来自没有内含子、含噬菌体接头肽的合成内含子(参见图3B)或者含噬菌体外壳蛋白(基因-III,参见图3C)的合成内含子的构建体的h4D5IgG的表达水平。(B)来自转染细胞的hIgG1HC的RT-PCR。正确剪接的HC mRNA的预测大小为1,650nt。在接头+内含子1构建体中的上面的条带表示未剪接的前体mRNA。在含接头-和基因-III的构建体中的下面的条带是在VH中通过隐蔽剪接供体不正确剪接的。
图5.(A)在天然内含子1剪接供体中产生的点突变,以增加哺乳动物mRNA共有剪接供体的一致性。(B)内含子剪接供体的优化消除了未剪接和不正确剪接的HC mRNA的积累和(C)哺乳动物细胞中的表达增加至没有内含子存在时观察到的水平。
图6.(A)使用pDV.5.0和野生型KO7(单价展示)或接头KO7(多价展示)调节展示。(B)在三种不同的哺乳动物细胞系中表达来自pDV.5.0的4种不同mAb。
图7.用于在原核和真核细胞中表达和分泌多肽的载体的示意图。合成的内含子可以含有接头序列或者噬菌体外壳蛋白,以及来自hIgG1的任一天然存在的内含子序列。HC和LC二者可以具有:1)ORF上游的哺乳动物和细菌启动子,2)在ORF上游的仅细菌启动子(也参见图14)或3)在ORF上游的仅哺乳动物启动子。显示了其中HC和LC二者具有两种启动子类型的构建体。含具有接头肽融合物的基因-III的构建体(pDV5.0所示)仅当合成的内含子含有接头肽融合物时存在,而当噬菌体外壳蛋白融合物在合成的内含子中存在时不存在。
图8.突变辅助型噬菌体Amber KO7的pIII的核苷酸序列(核苷酸1579至2853(SEQ ID NO:24)),以增强与pIII融合的蛋白质在M13噬菌体上的展示。Amber KO7具有在M13KO7辅助型噬菌体基因组中通过定点诱变引入的琥珀密码子。下划线残基是在M13KO7基因III的密码子346中引入琥珀终止(TAG)的核苷酸2613、2614和2616(T2613C、C2614T和A2616G)中的突变,以及在密码子345中AvrII限制位点引入的沉默突变。M13KO7的核苷酸1是独特的HpaI限制位点的第三个残基。
图9.通过使用Amber KO7辅助型噬菌体在M13噬菌体的pIII上Fab片段的增强展示。当将野生型M13KO7用于噬菌体产生时,具有野生型M13KO7的常规高展示噬菌粒(开口的菱形)驱动了比那些通过低展示噬菌粒载体(闭合的正方形)实现的Fab展示水平显著更高的Fab展示水平。使用携带pIII中琥珀突变的经修饰的M13KO7(Amber KO7)使低展示噬菌粒的展示水平(闭合的三角形)增加至了具有野生型M13KO7的高展示噬菌粒的展示水平(开口的菱形)。
图10.是显示针对固定化VEGF,选自噬菌体文库分选实施例5的天然双载体Fab-噬菌体文库的克隆的结合(通过噬菌体ELISA测量)的柱状图。四轮选择后,挑选了各个克隆,并测试噬菌体上清液与固定化抗原(VEGF)和与无关蛋白质(Her2)的结合,以评价结合特异性。
图11显示了在BIAcore T100仪器上通过Fc捕获测定法测量的,针对与VEGF的抗原结合,通过BIAcore筛选IgG格式的挑选的噬菌体克隆。将用于测序分析和噬菌体ELISA挑选的96个克隆转染到293S细胞(1mL)中,并培养7天用于IgG表达。上清液是经0.2μm过滤的,并用于在BIAcore T100仪器上通过Fc捕获测定法评价VEGF抗原结合。
图12显示了来自实施例5中VEGF淘选实验的阳性结合子的序列。显示了8个克隆的重链CDR序列,8个克隆为:VEGF50(按出现顺序分别为SEQ ID NOS 25-27)、VEGF51(按出现顺序分别为SEQ I D NOS28-30)、VEGF 52(按出现顺序分别为SEQ ID NOS 31-33)、VEGF59(按出现顺序分别为SEQ ID NOS 34-36)、VEGF55(按出现顺序分别为SEQ ID NOS 37-39)、VEGF60(按出现顺序分别为SEQ ID NOS40-42)、VEGF61(按出现顺序分别为SEQ ID NOS 43-45)和VEGF64(按出现顺序分别为SEQ ID NOS 46-48)。全部克隆都共有相同的轻链CDR序列。
图13显示了选自针对VEGF的噬菌体分选的挑选的抗-VEGF IgG抑制VEGF与其天然受体之一,VEGF-R1结合的能力。在CHO中表达来自针对VEGF分选的挑选的抗体,并将纯化的IgG用于测量挑选的克隆抑制VEGF与VEGF-R1结合的能力。一个克隆(VEGF55)以贝伐单抗(Avastin)IC50的3.5倍的IC50抑制VEGF-R1结合。
图14显示了在原核和真核细胞中用于表达和分泌多肽的载体的示意图,其中合成的内含子含pIII,以及来自hIgG1的任一天然存在的内含子序列,并且其中LC在ORF上游具有细菌启动子,并且HC在ORF上游就哺乳动物和细菌启动子二者。不同于图7中显示的载体,该载体(pDV6.5)不需要用于与噬菌体颗粒融合的额外gIII盒。产生自在大肠杆菌和哺乳动物细胞中表达的蛋白质显示于下面的载体示意图。短划线表示在哺乳动物细胞中剪接的重链转录本中的内含子。应当注意,在该载体中编码IgG1铰链的序列部分是重复的,以允许包含于大肠杆菌和哺乳动物细胞表达的蛋白质中。
图15显示了表达自pDV6.5的全长抗-VEGF IgG的特性。在100mL转染的CHO细胞培养物中表达IgG,并通过蛋白A层析纯化。显示了纯化的IgG的终产量,以及在用于测量非特异性结合的杆状病毒ELISA中的评分。还显示了噬菌体格式(噬菌体ELISA)或IgG格式(BIAcore)的每一克隆的阳性或阴性结合。
本发明实施方案的详细描述
I.定义
在本文中,术语“合成的内含子”用于定义位于编码CH1的核酸和编码铰链-Fc或Fc的核酸之间的核酸区段。“合成的内含子”可以是不编码蛋白质合成的任一核酸、编码蛋白质合成(例如噬菌体颗粒蛋白质或外壳蛋白(例如pI、pII、pIII、pIV、pV、pVI、pVII、pVIII、pIX、pX)或者接头蛋白(例如亮氨酸拉链等))的任一核酸或其组合。在一个实施方案中,“合成的内含子”包含允许剪接事件的剪接供体序列和剪接受体序列的一部分。剪接供体和剪接受体序列允许剪接事件并可以包含天然的或者合成的核酸序列。
在本文中,术语“效用多肽”用于指用于若干活动性(activities),例如用于蛋白质纯化、蛋白质标签、蛋白质标记(例如用可检测的化合物或组合物(例如放射性标记、荧光标记或酶标记)标记)的多肽。标记可以与氨基酸侧链、活化的氨基酸侧链、半胱氨酸经改造的抗体等间接缀合。例如,可以将抗体与生物素缀合,并且可以将上述三大类标记之一与亲和素或链霉亲和素缀合,或者反之亦然。生物素选择性地与链霉亲和素结合,并因此可以以这种间接方式将标记与抗体缀合。备选地,为了实现标记与多肽变体的间接缀合,将多肽变体与小的半抗原(例如,地高辛)缀合,并将上述不同类型的标记之一与抗-半抗原多肽变体(例如,抗-地高辛抗体)缀合。从而,实现标记与多肽变体的间接缀合(Hermanson,G.(1996)in Bioconjugate Techniques Academic Press,San Diego)。
当将核酸与另一核酸序列置于功能关系中时,其是“有效连接的”。例如,如果用于前序列或分泌前导序列的DNA表达为参与多肽分泌的前蛋白,那么其与用于多肽的DNA是有效连接的;如果启动子或增强子影响了序列的转录,那么其与编码序列是有效连接的;如果核糖体结合位点位于可以协助翻译的位置,那么其与编码序列是有效连接的。总之,“有效连接”意为连接的DNA序列存在于一个核酸分子中,以至于他们可以作为核酸或者以由它们表达的蛋白质相互具有功能性关系。它们可以是连续的或者不连续的。在分泌前导序列的情况下,它们通常是连续的并且在阅读相(reading phase)中。然而,增强子不必是连续的。可以在合适的限制位点通过连接反应实现连接。如果不存在此类位点,可以使用合成的寡核苷酸接头或连接体。
当编码异源蛋白质序列(例如,VH或VL区)的核酸直接插入到编码噬菌体外壳蛋白(例如,pII、pVI、pVII、pVIII或pIX)的核酸中时,VH或VL结构域与噬菌体是“连接的”。当引入到原核细胞中时,可以产生噬菌体,其中外壳蛋白可以展示VH或VL结构域。在一个实施方案中,得到的噬菌体颗粒展示了与噬菌体外壳蛋白的氨基端或羧基端融合的抗体片段。
如本文中所用,术语“连接的”或“连接”意图指两个氨基酸序列或两个核酸序列分别通过肽键或磷酸二酯键共价结合在一起,该结合可以包括结合的两个氨基酸序列或核酸序列之间任意数目的其他氨基酸或核酸序列。例如,第一和第二氨基酸序列之间可以直接肽链连接或者第一和第二氨基酸序列之间存在一个或多个氨基酸序列的连接。
如本文中所用,“连接体”意为两个或多个氨基酸长度的氨基酸序列。连接体可以由中性极性或者非极性氨基酸组成。连接体可以是例如2-100个氨基酸长度,例如2至50个氨基酸之间的长度,例如,3、5、10、15、20、25、30、35、40、45或50个氨基酸长度。连接体可以是“可切割的”,例如通过自切割或者酶促或化学切割。氨基酸序列中的切割位点以及在该位点切割的酶或化学物质是本领域熟知的,并也在本文中进行了描述。
术语“信号序列功能”指信号序列指导蛋白质分泌到ER(在真核生物中)或周质(在原核生物中)或者细胞外的生物学活性。
如本文中所用,“对照蛋白质”指测量其表达以定量蛋白质序列的展示水平的蛋白质序列。例如,该蛋白质序列可以是“表位标签”,其能使用与表位标签结合的抗-标签抗体或另一类型的亲和基质,通过亲和纯化容易地纯化VH或VL。标签多肽及其合适的各个抗体的实例包括:聚-组氨酸(聚-His)或者聚-组氨酸-甘氨酸(聚-His-gly)标签;流感HA标签多肽及其抗体12CA5[Field等人,Mol.Cell.Biol.,8:2159-2165(1988)];c-myc标签及其8F9、3C7、6E10、G4、B7和9E10抗体[Evan等人,Molecular and Cellular Biology,5:3610-3616(1985)];以及单纯疱疹病毒糖蛋白D(gD)标签及其抗体[Paborsky等人,Protein Engineering,3(6):547-553(1990)]。其他标签多肽包括Flag-肽[Hopp等人,BioTechnology,6:1204-1210(1988)];KT3表位肽[Martin等人,Science,255:192-194(1992)];α-微管蛋白表位肽[Skinner等人,J.Biol.Chem.,266:15163-15166(1991)];和T7基因10蛋白质肽标签[Lutz-Freyermuth等人,Proc.Natl.Acad.Sci.USA,87:6393-6397(1990)]。
如本文中所用,“外壳蛋白”指组成噬菌体颗粒的五种衣壳蛋白之一,包括pIII、pVI、pVII、pVIII和pIX。在一个实施方案中,可将“外壳蛋白”用于展示蛋白质或肽(参见Phage Display,A Practical Approach,Oxford University Press,由Clackson和Lowman编辑,2004,p.1-26)。在一个实施方案中,外壳蛋白可以是pIII蛋白质或者一些变体、其一部分和/或衍生物。例如,可以使用M13噬菌体pIII外壳蛋白的羧基端部分(cP3),例如编码M13噬菌体的蛋白质III的羧基端残基267-421的序列。在一个实施方案中,pIII序列包含SEQ ID NO:1:(AEDIEFASGGGSGAETVESCLAKPHTENSFTNVWKDDKTLDRYANYEGCLWNATGVVVCTGDETQCYGTWVPIGLAIPENEGGGSEGGGSEGGGSEGGGTKPPEYGDTPIPGYTYINPLDGTYPPGTEQNPANPNPSLEESQPLNTFMFQNNRFRNRQGALTVYTGTVTQGTDPVKTYYQYTPVSSKAMYDAYWNGKFRDCAFHSGFNEDPFVCEYQGQSSDLPQPPVNAGGGSGGGSGGGSEGGGSEGGGSEGGGSEGGGSGGGSGSGDFDYEKMANANKGAMTENADENALQSDAKGKLDSVATDYGAAIDGFIGDVSGLANGNGATGDFAGSNSQMAVGDGDNSPLMNNFRQYLPSLPQSVECRPFVFSAGKPYEFSIDCDKINLFRGVFAFLLYVATFMYVFSTFANILRNKES)的氨基酸序列。在一个实施方案中,pIII片段包含SEQ ID NO:2(SGGGSGSGDFDYEKMANANKGAMTENADENALQSDAKGKLDSVATDYGAAIDGFIGDVSGLANGNGATGDFAGSNSQMAQVGDGDNSPLMNNFRQYLPSLPQSVECRPFVFGAGKPYEFSIDCDKINLFRGVFAFLLYVATFMYVFSTFANILRNKES)的氨基酸序列。
如本文中所用,“接头蛋白”指在溶液中与另一接头蛋白质序列特异性相互作用的蛋白质序列。在一个实施方案中,“接头蛋白”包含异型多聚化结构域。在一个实施方案中,接头蛋白是cJUN蛋白或Fos蛋白。在另一实施方案中,接头蛋白包含SEQ ID NO:6(ASIARLRERVKTLRARNYELRSRANMLRERVAQLGGC)或SEQ ID NO:7(ASLDELEAEIEQLEEENYALEKEIEDLEKELEKLGGC)的序列。
如本文中所用,“异型多聚化结构域”指对生物分子进行改变或添加,以促进异型多聚体形式并且阻碍同型多聚体形成。相对于同型二聚体,对形成异型二聚体具有强优先性的任意异型二聚化结构域都在本发明范围内。说明性实例包括但不限于,例如美国专利申请20030078385(Arathoon等人–Genentech;描述了knob into holes);WO2007147901(等人–Novo Nordisk:描述了离子相互作用);WO 2009089004(Kannan等人–Amgen:描述了静电转向效应);WO2011/034605(Christensen等人-Genentech;描述了卷曲螺旋)。还参见,描述亮氨酸拉链的Pack,P.&Plueckthun,A.,Biochemistry 31,1579-1584(1992)或者描述螺旋-转角-螺旋基序的Pack等人,Bio/Technology 11,1271-1277(1993)。短语“异型多聚化结构域”与“异型二聚化结构域”在本文中可互换使用。
如本文中所用,术语“Fab-融合蛋白质”指原核细胞中的Fab-噬菌体融合蛋白质和/或真核细胞中的Fab-Fc融合蛋白质。Fab-Fc融合还可以是Fab-铰链-Fc融合。
在本文中,术语“抗体”以其广义使用,并包括多种抗体结构,包括但不限于单克隆抗体、多克隆抗体、多特异性抗体(例如,双特异性抗体)和抗体片段,只要它们表现出期望的抗原-结合活性。
“抗体片段”指不同于完整抗体的包含完整抗体的一部分的分子,其结合完整抗体所结合的抗原。抗体片段的实例包括但不限于Fv、Fab、Fab'、Fab’-SH、F(ab')2;双抗体、线性抗体、单链抗体分子(例如scFv);以及形成自抗体片段的多特异性抗体。
抗体的“种类”指其重链拥有的恒定结构域或恒定区的类型。存在五种主要种类的抗体:IgA、IgD、IgE、IgG和IgM,并且可将它们中的几种进一步划分成亚类(同种型),例如IgG1、IgG2、IgG3、IgG4、IgA1和IgA2。将对应于免疫球蛋白不同种类的重链恒定区分别称为α、δ、ε、γ和μ。
在本文中,术语“Fc区”用于定义含有恒定区的至少一部分的免疫球蛋白重链的羧基端区。该术语包括天然序列Fc区和变体Fc区。在一个实施方案中,人IgG重链Fc区从Cys226或者从Pro230延伸至重链的羧基端。然而,Fc区的羧基端赖氨酸(Lys447)是可以存在或者可以不存在的。在本文中除非另外指明,如在Kabat等人,Sequences of Proteins of Immunological Interest,5th Ed.Public Health Service,National Institutes of Health,Bethesda,MD,1991中所述,根据EU编码系统,也称为EU索引,编号Fc区或恒定区中的氨基酸残基。
“构架”或“FR”指不同于高变区(HVR)残基的可变区残基。可变区的FR通常由4种FR区:FR1、FR2、FR3和FR4组成。因此,在VH(或VL)中,HVR和FR序列通常在以下序列:FR1-H1(L1)-FR2-H2(L2)-FR3-H3(L3)-FR4中出现。
在本文中可互换使用的术语“全长抗体”、“完整抗体”和“全抗体”指这样的抗体,其具有与天然抗体结构基本类似的结构或者具有含如本文中所定义的Fc区的重链。
术语“宿主细胞”、“宿主细胞系”和“宿主细胞培养物”可互换使用,并指已经引入外源核酸的细胞,包括此类细胞的子代。宿主细胞包括“转化体”和“转化的细胞”,其包括最初转化的细胞及其衍生的子代(不考虑传代的次数)。子代可以在核酸含量方面与亲代细胞不完全相同,但可以含有突变。本文中包括了与筛选或挑选的最初转化的细胞具有相同功能或生物学活性的突变子代。
如本文中所用,术语“高变区”或“HVR”指在序列上高变的和/或形成结构上定义的环(“高变环”)的抗体可变区的每一区域。通常,天然的四链抗体包含六个HVR;三个在VH中(H1、H2、H3),并且三个在VL中(L1、L2、L3)。HVR通常包含来自高变环和/或来自“互补决定区”(CDR)的氨基酸残基,后者具有最高的序列可变性和/或参与抗原识别。示例性高变环存在于氨基酸残基26-32(L1)、50-52(L2)、91-96(L3)、26-32(H1)、53-55(H2)和96-101(H3)中。Chothia和Lesk,J.Mol.Biol.196:901-917(1987)。示例性CDR(CDR-L1、CDR-L2、CDR-L3、CDR-H1、CDR-H2和CDR-H3)存在于L1的氨基酸残基24-34、L2的50-56、L3的89-97、H1的31-35、H2的50-65和H3的95-102中。(Kabat等人,Sequences of Proteins of Immunological Interest,5th Ed.Public Health Service,National Institutes of Health,Bethesda,MD(1991)。)除VH中CDR1外,CDR通常包含形成高变环的氨基酸残基。CDR还包含“特异性决定残基”或“SDR”,其是接触抗原的残基。SDR包含于CDR的区域内,称为“简称-CDR”或a-CDR。示例性a-CDR(a-CDR-L1、a-CDR-L2、a-CDR-L3、a-CDR-H1、a-CDR-H2和a-CDR-H3)存在于L1的氨基酸残基31-34、L2的50-55、L3的89-96、H1的31-35B、H2的50-58和H3的95-102中。(参见Almagro and Fransson,Front.Biosci.13:1619-1633(2008)。)除非另外指明,在本文中,根据Kabat等人,同上所述,编号HVR残基以及可变区中的其他残基(例如,FR残基)。
“个体”或“受试者”是哺乳动物。哺乳动物包括但不限于,驯养的动物(例如,牛、绵羊、猫、狗和马)、灵长类动物(例如,人和非人灵长类动物如猴子)、兔和啮齿类动物(例如,小鼠和大鼠)。在某些实施方案中,个体或受试者是人。
“分离的”抗体是已经从其天然环境的组分中分离的抗体。在一些实施方案中,如通过例如电泳(例如,SDS-PAGE、等电聚焦(IEF)、毛细管电泳)或层析(例如,例子交换或反相HPLC)所测定,抗体纯化至了95%以上或者99%的纯度。对于评估抗体纯度的方法的综述,参见例如Flatman等人,J.Chromatogr.B 848:79-87(2007)。
“分离的”核酸指已经从其天然环境的组分中分离的核酸分子。分离的核酸包括在通常含有该核酸分子的细胞中含有的核酸分子,但该核酸分子在染色体外存在或者位于不同于其天然染色体位置的染色体位置。
“分离的编码抗体的核酸”指编码抗体重链和轻链(或其片段)的一个或多个核酸分子,包括单个载体或分离的载体中的该核酸分子,以及宿主细胞中在一个或多个位置存在的该核酸分子。
如本文中所用,术语“单克隆抗体”指获自基本上均一的抗体群体的抗体,即除可能的变体抗体(例如含天然发生的突变或者在单克隆抗体制备的产生期间发生的变体抗体,此类变体抗体通常以较少的量存在)外,群体包含的各个抗体相同和/或结合相同的表位。与多克隆抗体制备物(其通常包括直接针对不同决定簇(表位)的不同抗体)相反,单克隆抗体制备物的每一单克隆抗体直接针对抗原上单一的决定簇。因此,修饰语“单克隆”指获自基本上均一的抗体群体的抗体的特征,并且不应理解为需要通过任一特定方法产生该抗体。例如,可以通过多种技术制备根据本发明使用的单克隆抗体,包括但不限于杂交瘤方法、重组DNA方法、噬菌体-展示方法,以及使用含人免疫球蛋白基因座的全部或一部分的转基因动物的方法,在本文中描述了此类方法以及用于制备多克隆抗体的其他示例性方法。
“裸抗体”指不与异源部分(例如,细胞毒性部分)或放射性标记缀合的抗体。裸抗体可以存在于药物制剂中。
“天然抗体”指具有可变结构的天然存在的免疫球蛋白分子。例如,天然IgG抗体是约150,000道尔顿的异型四聚体糖蛋白,其由二硫键键合的两个相同的轻链和两个相同的重链组成。从氨基端至羧基端,每一重链具有可变区(VH),也称为可变重链结构域或重链可变区,然后是三个恒定结构域(CH1、CH2和CH3)。相似地。从氨基端至羧基端,每一轻链具有可变区(VL),也称为可变轻链结构域或轻链可变结构域,然后是恒定轻链(CL)结构域。基于其恒定结构域的氨基酸序列,可将抗体的轻链指定为两种类型(称为κ和λ)之一。
术语“包装说明书”用于指在习惯上包括在治疗产品的市售包装中的说明书,其含有涉及该治疗产品使用的有关适应症、用途、剂量、施用、组合疗法、禁忌症和/或警告的信息。
术语“可变区”或“可变结构域”指参与抗体与抗原结合的抗体重链或轻链的结构域。天然抗体的重链和轻链(分别为VH和VL)的可变结构域通常具有相似的结构,其中每一结构域包含四个保守的构架区(FR)以及三个高变区(HVR)(参见,例如Kindt等人Kuby Immunology,6th ed.,W.H.Freeman and Co.,page 91(2007)。)。单个VH或VL结构域足以赋予抗原结合特异性。此外,可以使用来自结合抗原的抗体的VH和VL结构域,以分别筛选互补性VL或VH结构域的文库来分离结合特定抗原的抗体。参见,例如Portolano等人,J.Immunol.150:880-887(1993);Clarkson等人,Nature 352:624-628(1991)。
如本文中所用,术语“载体”指能增殖与其连接的另一核酸的核酸分子。该术语包括作为自复制核酸结构的载体,以及掺入到已经引入其的宿主细胞的基因组中的载体。某些载体能指导其有效连接的核酸的表达。在本文中,此类载体称为“表达载体”。
II.详细描述
基于噬菌体的抗体研发方法使用噬菌体展示技术从各个噬菌体颗粒的大型库中挑选具有期望的结合特异性的Fab片段1-3。在该方法中,使用已建立的分子生物学技术以及特定的噬菌体展示载体产生噬菌体文库,所述噬菌体文库由Fab片段直接或间接通过主要外壳蛋白之一与M13丝状噬菌体颗粒融合组成,并含有变化的互补决定区(CDR)(Tohidkia等人,Journal of drug targeting,20:195-208(2012);Bradbury等人,Nature biotechnology,29:245-254(2011);Qi等人,Journal ofmolecular biology,417:129-143(2012))。尽管该文库理论的多样性可轻易地超过1025个独特序列,但对于给定文库,噬菌体库构建的实践局限通常限制实际的多样性为≤1011个克隆(Sidhu等人,Methods inenzymology,328:333-363(2000))。
假定起始文库可以含有基本数目的独特序列,那么挑选克隆的筛选处理量是非常重要的。对于基于噬菌体的抗体研发,在功能测定法(目标结合、基于细胞的活性测定、体内半衰期等)中彻底评价挑选的Fab及其同源全长IgG的特性,需要通过从用于展示的噬菌粒载体中分离编码HC和LC的DNA序列,并亚克隆到用于IgG表达的哺乳动物表达载体中,来将Fab重链(HC)和轻链(LC)序列重新格式化成全长IgG。亚克隆数十或数百个挑选的HC/LC对的费力方法代表了基于噬菌体的抗体研发方法的主要瓶颈。此外,一旦重新格式化,由于在最初的筛选测定中相当比例挑选的Fab没有令人满意地施行,那么增加进行该重新格式化/筛选方法的克隆的数目将极大地增加成功的最终可能性。
在本文中,我们描述了表达和分泌系统的产生,用于在原核细胞中表达和分泌一种Fab融合蛋白质,并在真核细胞中表达和分泌不同的(或相同的)Fab融合蛋白质。例如,当转化到大肠杆菌中时该表达和分泌系统驱动Fab-噬菌体融合的表达,并当转染到哺乳动物细胞中时驱动包含相同Fab片段的全长IgG的表达。我们证明,来自鼠结合免疫球蛋白(mBiP)8,9的哺乳动物信号序列可以在原核和真核细胞二者中驱动有效的蛋白质表达。使用哺乳动物mRNA剪接去除在人IgG1HC的铰链区内插入的含噬菌体融合肽的合成的内含子,我们可以以宿主细胞依赖性方式产生两种不同的蛋白质:在大肠杆菌中与用于噬菌体展示的接头肽融合的Fab片段和哺乳动物细胞中的天然人IgG1。该技术允许从噬菌体展示文库挑选与目的抗原结合的Fab片段,并且可以在不需要亚克隆的情况下,在哺乳动物细胞中后续表达和纯化同源的全长IgG。
本发明部分基于以下实验发现(1)在不削弱真核细胞中IgG表达的情况下,非细菌来源的信号序列可以以足够分选噬菌体文库的水平在原核细胞中发挥功能和(2)当mRNA加工在真核细胞,而不是原核细胞中发生时,可以以宿主细胞依赖性方式从相同的核酸分子中表达不同的Fab融合蛋白质(原核细胞中的Fab-噬菌体融合蛋白质和真核细胞中的Fab-Fc融合蛋白质)。因此,本文中描述的是这样的表达和分泌系统以及与表达和分泌系统的构建和使用相关的方法,该表达和分泌系统用于表达和分泌与用于噬菌体展示的噬菌体颗粒蛋白质、外壳蛋白或接头蛋白融合的Fab片段(在原核宿主细胞(例如大肠杆菌)中)以及在不需要亚克隆的情况下,与Fc融合的Fab片段(在真核细胞(例如哺乳动物细胞)中)。特别地,本文中描述了用于在原核细胞中表达和分泌Fab-噬菌体融合蛋白质和在真核细胞中表达和分泌Fab-Fc融合蛋白质的载体、用于在原核和真核细胞中表达和分泌蛋白质或肽的核酸分子,以及包含此类载体的宿主细胞。此外,本文中描述了使用该表达和分泌系统的方法,包括使用表达和分泌系统用于筛选和挑选针对目的蛋白质的新抗体的方法。
实施本发明的模式
除非另外指明,本发明的实践可以使用本领域技术内的分子生物学(包括重组技术)、微生物学、细胞生物学、生物化学和免疫学的常规技术。此类技术在文献中是充分说明的,例如“Molecular Cloning:A Laboratory Manual”,第二版(Sambrook等人,1989);“Oligonucleotide Synthesis”(M.J.Gait,ed.,1984);“Animal Cell Culture”(R.I.Freshney,ed.,1987);“Methods in Enzymology”(Academic Press,Inc.);“Handbook of Experimental Immunology”,第四版(D.M.Weir&C.C.Blackwell,eds.,Blackwell Science Inc.,1987);“Gene Transfer Vectors for Mammalian Cells”(J.M.Miller&M.P.Calos,eds.,1987);“Current Protocols in Molecular Biology”(F.M.Ausubel等人,eds.,1987);“PCR:The Polymerase Chain Reaction”,(Mullis等人,eds.,1994);和“Current Protocols in Immunology”(J.E.Coligan等人,eds.,1991)。
用于原核和真核细胞的表达和分泌系统
用于原核和真核细胞的表达和分泌系统涉及含用于目的蛋白质(例如IgG分子的重链或轻链)的调节和编码序列的载体,其中原核和真核启动子(例如CMV(真核)和PhoA(原核))串联排列在目的基因的上游,并且单个信号序列驱动目的蛋白质在原核和真核细胞中的表达。本发明通过使用位于IgG1的VH/CH1和铰链-Fc区之间的合成的内含子,为该载体提供了以宿主细胞依赖性方式产生两种不同融合形式的目的蛋白质的手段。
A.在原核和真核细胞中发挥功能的信号序列
构建能在原核(大肠杆菌)和真核(哺乳动物)细胞二者中表达目的蛋白质的载体的一个挑战产生自在这些细胞类型中发现的信号序列的差异。尽管在原核和真核细胞中信号序列的某些特征是广泛保守的(例如一小部分疏水残基位于序列的中间,并且极性/带电荷残基与成熟多肽氨基端的切割位点邻近),但其他特征在不同细胞类型之间多数情况下是不同的。此外,本领域已知,不同的信号序列在哺乳动物细胞中对表达水平具有显著的影响,即使这些序列都是哺乳动物来源的(Hall等人,J of Biological Chemistry,265:19996-19999(1990);Humphreys等人,Protein Expression and Purification,20:252-264(2000))。例如,细菌细胞序列通常在起始甲硫氨酸之后正好是正电荷残基(最常见的是赖氨酸),而这通常在哺乳动物信号序列中是不存在的。尽管存在已知的能在两种细胞类型中指导分泌的信号序列,但此类信号序列通常仅在一种细胞类型或者其他细胞类型中指导高水平的蛋白质分泌。
尽管极少显示细菌信号序列可以在哺乳动物细胞中表现出任何功能,但已经报道,哺乳动物来源的信号序列能驱动进入细菌周质的转运(Humphreys等人,The Protein Expression and Purification,20:252-264(2000))。然而,信号序列仅仅具有功能还不足以用于噬菌体展示和IgG表达的强双表达系统。相反,挑选的信号序列必需在两种表达系统中都发挥功能,特别是对于噬菌体展示,其中低水平的展示可能会削弱系统进行噬菌体淘选实验的能力。
本发明部分基于这样的发现,在不削弱真核细胞中IgG表达的情况下,非细菌来源的信号序列可以以足以进行噬菌体文库分选的水平在原核细胞中发挥功能。
本发明提供了可以使用的任一信号序列(包括共有信号序列),其在原核细胞中使目的多肽靶向周质以及在真核细胞中使目的多肽靶向内质网(endoplasmic/reticulum)。可以使用的信号序列包括但不限于鼠结合免疫球蛋白(mBiP)信号序列(UniProtKB:accession P20029)、来自人生长激素(hGH)的信号序列(UniProtKB:accession BIA4G6)、Gaussia princeps luciferase(UniProtKB:accession Q9BLZ2)、酵母内切-1,3-葡聚糖酶(yBGL2)(UniProtKB:accession P15703)。在一个实施方案中,信号序列是天然的或者合成的信号序列。在另外的实施方案中,合成的信号序列是经优化的信号分泌序列,与其未优化的天然信号序列比较,其以优化的水平驱动展示的水平。
如本文中所述,用于测定信号序列在原核细胞中驱动目的多肽的展示的能力的合适测定法包括,例如噬菌体ELISA。
如本文中所述,用于测定信号序列在真核细胞中驱动目的多肽表达的能力的合适测定法包括,例如将编码具有目的信号的目的多肽的哺乳动物表达载体转染到培养的哺乳动物细胞中、培养细胞一段时间、从培养的细胞中收集上清液,并通过亲和层析从上清液中纯化IgG。
B.导致宿主依赖性融合蛋白质从相同的核酸中表达的合成的内含子
本发明部分基于这样的发现,可以通过利用真核细胞而不是原核细胞中mRNA加工期间发生的内含子剪接的天然方法,以宿主细胞依赖性方法从相同的核酸分子中表达不同的Fab-融合蛋白质。
hIgG1HC恒定区的基因组序列含有三个天然内含子(图3A),内含子1、内含子2和内含子3。内含子1是位于HC可变结构域/CH1(VH/CH1)和铰链区之间的391个碱基对内含子。内含子2是位于铰链区和CH2之间的118个碱基对内含子。内含子3是位于CH2和CH3之间的97个碱基对内含子。
本发明提供了包含位于VH/CH1和铰链区之间的内含子1的载体。其他实例,包括位于VH/CH1和铰链区之间的内含子2或内含子3。对于一些载体,将编码外壳蛋白或接头蛋白的核酸插入到位于VH/CH1和铰链区之间的内含子中,在其5’端有用于内含子的天然剪接供体以及在其3’端有天然剪接受体。
其他实例包括在剪接供体的位置8之外,在位置1和5处具有替换的突变的剪接供体。
例如,可将ELISA用于分析原核细胞中的表达和分泌系统。
例如,可以将使用蛋白A和凝胶过滤层析从培养上清液中纯化的IgG用于分析真核细胞中的表达和分泌系统。
C.用于在原核和真核细胞中表达和分泌多肽的载体
可以使用本领域技术内的多种技术构建用于在原核和真核细胞中表达和分泌Fab-融合蛋白质的表达和分泌系统。
在一个方面,表达和分泌系统包含这样的载体,其包含:(1)哺乳动物启动子;(2)LC盒,其包含(从5’到3’的顺序)细菌启动子、信号序列、抗体轻链序列、对照蛋白质(gD);(3)合成盒,其包含(从5’到3’的顺序)哺乳动物聚腺苷酸化/转录终止信号、用于在原核细胞中终止转录的转录终止子序列、用于驱动HC表达的哺乳动物启动子和细菌启动子;(4)HC盒,其包含信号序列和抗体重链序列;和(5)第二合成盒,其包含哺乳动物聚腺苷酸化/转录终止信号和用于在原核细胞中终止转录的转录终止子序列。在LC和HC前的分泌信号序列可以是在原核和真核细胞二者中发挥功能的相同信号序列(例如哺乳动物mBiP信号序列)。在一个实施方案中,抗体重链序列包含合成的内含子。合成的内含子位于VH/CH1结构域(在其5’端)和铰链区(在其3’端)之间。在一个实施方案中,合成的内含子的侧翼是5’端的经优化的剪接供体序列和3’端的天然内含子1剪接受体序列。在一个实施方案中,合成的内含子包含核苷酸序列,其编码用于直接融合展示的噬菌体外壳蛋白(例如pIII)(参见图14),或者编码用于间接融合展示的在核苷酸水平与内含子1融合的接头蛋白(参见图7)。对于间接融合展示,载体还包含分离的细菌表达盒,其包含(从5’到3’的顺序)细菌启动子、细菌信号序列、具有在核苷酸水平与外壳蛋白的氨基端融合的配偶体接头肽的噬菌体外壳蛋白(例如pIII)和转录终止子序列(参见图7)。此外,上述构建体的不同实施方案是可以的,其中HC和LC受串联的哺乳动物和细菌启动子控制(参见图7)或者仅一个(例如,HC)盒受串联的哺乳动物和细菌启动子控制,而其他(例如,LC)盒仅受细菌启动子控制(参见图14)。
此外,载体包括细菌复制起点、哺乳动物复制起点、核酸,其编码用作为对照(例如gD蛋白质)的蛋白质,或者用于下述活动的蛋白质,如蛋白质纯化、蛋白质标签、蛋白质标记,例如用可检测化合物或组合物标记(例如放射性标记、荧光标记或酶促标记)。
在一个实施方案中,哺乳动物和细菌启动子以及信号序列与抗体轻链序列有效连接,并且哺乳动物和细菌启动子以及信号序列与抗体重链序列有效连接。
D.针对目的抗原挑选和筛选抗体
本发明通过噬菌体或细菌展示基于Fab的文库,提供了针对目的蛋白质筛选和挑选抗体的方法,或者通过相似方法优化已存在的抗体。可将上述双载体用于在原核细胞中筛选和挑选Fab片段,并且在不需要亚克隆的情况下,可以将挑选的Fab容易地表达为用于进一步测试的全长IgG分子。
本发明抗体
在本发明的另外方面,根据任一上述实施方案的抗体是单克隆抗体,包括嵌合的、人源化的或者人抗体。在一个实施方案中,抗体是抗体片段,例如Fv、Fab、Fab’、scFv、双抗体或F(ab’)2片段。在另一个实施方案中,抗体是全长抗体,例如完整的IgG1、IgG2、IgG3或IgG4抗体或者如本文中所定义的其他抗体种类或同种型。
在另外的方面,根据任一上述实施方案的抗体可以单独地或者组合地包含如以下章节1-7中所述的任一特性。
1.抗体亲和力
在某些实施方案中,本文中提供的抗体具有≤1μM、≤100nM、≤10nM、≤1nM、≤0.1nM、≤0.01nM或≤0.001nM(例如10-8M或以下,例如10-8M至10-13M,例如,10-9M至10-13M)的解离常数(Kd)。
在一个实施方案中,通过使用目的抗体的Fab版本以及其抗原如通过以下测定法所述的进行放射性标记的抗原结合测定法(RIA)测量Kd。在滴定系列的未标记抗原存在的情况下,通过使用最小浓度(125I)-标记的抗原平衡Fab,然后用抗-Fab抗体-包被板捕获结合的抗原,来测量Fab对抗原的溶液结合亲和力(参见,例如Chen等人,J.Mol.Biol.293:865-881(1999))。为了建立测定的条件,将多孔板(Thermo Scientific)用在50mM碳酸钠(pH 9.6)中的5μg/ml捕获抗-Fab抗体(Cappel Labs)包被过夜,并随后用在PBS中的2%(w/v)牛血清白蛋白室温(大约23℃)封闭2至5个小时。在非吸附板(Nunc#269620)中,将100pM或26pM[125I]-抗原与连续稀释的目的Fab混合(例如,与Presta等人,Cancer Res.57:4593-4599(1997)中评估抗-VEGF抗体、Fab-12一致)。然后温育目的Fab过夜;然而,可以持续温育更长的时间(例如,约65个小时),以确保达到平衡。然后,将混合物转移到捕获平板,室温温育(例如,1个小时)。然后,去除溶液,并用在PBS中的0.1%聚山梨醇酯20洗涤平板8次。当平板晾干时,加入150μl/孔的闪烁体(MICROSCINT-20TM;Packard),并在TOPCOUNT TMγ计数器(Packard)上计数10分钟。挑选产生低于或等于最大结合的20%的每一Fab的浓度,用于竞争结合测定法。
根据另一个实施方案,使用固定化抗原CM5芯片,以~10个响应单元(RU),在25℃使用或(BIAcore,Inc.,Piscataway,NJ),使用表面质子共振测定法测量Kd。简言之,根据供应商说明,使用N-乙基-N’-(3-二甲氨基丙基)-碳二亚胺盐酸盐(EDC)和:N-羟基琥珀酰亚胺(NHS)活化羧甲基化的葡聚糖生物传感器芯片(CM5,BIACORE,Inc.)。在以5μl/分钟的流速注射前,用10mM乙酸钠,pH 4.8将抗原稀释至5μg/ml(~0.2μM),以实现偶联蛋白质的大约10个响应单元(RU)。注射抗原后,注射1M乙醇胺,以封闭未反应的基团。对于动力学测量,在25℃,在具有0.05%聚山梨醇酯20(TWEEN-20TM)表面活性剂的PBS(PBST)中以大约25μl/分钟的流速注射两倍连续稀释的Fab(0.78nM至500nM)。通过同时拟合结合和解离传感图(sensorgram),使用简单的一对一Langmuir结合模型(评价软件版本3.2)计算结合速率(kon)和解离速率(koff)。将平衡的解离常数(Kd)计算为比率koff/kon。参见,例如Chen等人,J.Mol.Biol.293:865-881(1999)。如果通过上述表面质子共振测定法测定的on速率(on-rate)超过106M-1s-1,那么可以使用荧光淬灭技术来测定on-速率,在增加浓度的抗原存在的情况下,25℃,其测量PBS,pH 7.2中20nM抗-抗原抗体(Fab形式)的荧光发射强度(激发=295nm;发射=340nm,16nm带通)的增加或减少,如在如分光光度计例如装备了截流的分光光度计(Aviv Instruments)或者8000-系列SLM-AMINCO TM分光光度计(ThermoSpectronic)中使用搅拌的比色杯所测量的。
2.抗体片段
在某些实施方案中,本文中提供的抗体是抗体片段。抗体片段包括但不限于,Fab、Fab’、Fab’-SH、F(ab’)2、Fv和scFv片段,以及下述其他片段。对于某些抗体片段的综述,参见Hudson等人Nat.Med.9:129-134(2003)。对于scFv片段的综述,参见,例如Pluckthün,在The Pharmacology of Monoclonal Antibodies,vol.113,Rosenburg and Moore eds.,(Springer-Verlag,New York),pp.269-315(1994)中;还参见WO 93/16185;以及美国专利号5,571,894和5,587,458。对于包含补救受体结合表位残基并具有增加的体内半衰期的Fab和F(ab')2片段的讨论,参见美国专利号5,869,046。
双抗体是具有两个抗原结合位点的抗体片段,其可以是二价的或者双特异性的。参见,例如EP 404,097;WO 1993/01161;Hudson等人,Nat.Med.9:129-134(2003);以及Hollinger等人,Proc.Natl.Acad.Sci.USA 90:6444-6448(1993)。在Hudson等人,Nat.Med.9:129-134(2003)中还描述了三抗体和四抗体。
单结构域抗体是包含抗体的重链可变区的全部或者一部分或者轻链可变区的全部或者一部分的抗体片段。在某些实施方案中,单结构域抗体是人单结构域抗体(Domantis,Inc.,Waltham,MA;参见,例如美国专利号6,248,516B1)。
如本文中所述,可以通过多种技术制备抗体片段,包括但不限于水解消化完整抗体,以及通过重组宿主细胞(例如大肠杆菌或噬菌体)产生。
3.嵌合的和人源化抗体
在某些实施方案中,在本文中提供的抗体是嵌合抗体。某些嵌合抗体描述于例如美国专利号4,816,567;和Morrison等人,Proc.Natl.Acad.Sci.USA,81:6851-6855(1984)中。在一个实例中,嵌合抗体包含非人可变区(例如衍生自小鼠、大鼠、仓鼠、兔子或非人灵长类动物如猴子的可变区)和人恒定区。在另外的实例中,嵌合抗体是“种类转换的(class switched)”抗体,其中种类或亚类改变自亲本抗体的种类或亚类。嵌合抗体包括其抗原结合片段。
在某些实施方案中,嵌合抗体是人源化抗体。通常,人源化非人抗体,以减少对人的免疫原性,而保留亲本非人抗体的特异性和亲和性。通常,人源化抗体包含一个或多个可变区,其中HVR,例如CDR(或其部分)衍生自非人抗体,并且FR(或其部分)衍生自人抗体序列。人源化抗体任选地还包含至少一部分人恒定区。在一些实施方案中,用来自非人抗体(例如,HVR残基所衍生的抗体)的相应残基替换人源化抗体中的一些FR残基,以恢复或者改进抗体特异性或亲和力。
人源化抗体以及制备它们的方法综述于例如,Almagro和Fransson,Front.Biosci.13:1619-1633(2008)中,并且进一步描述于例如,Riechmann 等人,Nature 332:323-329(1988);Queen等人,Proc.Nat’l Acad.Sci.USA86:10029-10033(1989);美国专利号5,821,337、7,527,791、6,982,321和7,087,409;Kashmiri等人,Methods 36:25-34(2005)(描述SDR(a-CDR)嫁接);Padlan,Mol.Immunol.28:489-498(1991)(描述“重新表面化(resurfacing)”);Dall’Acqua等人,Methods 36:43-60(2005)(描述“FR改组”);以及Osbourn等人,Methods 36:61-68(2005)和Klimka等人,Br.J.Cancer,83:252-260(2000)(描述FR改组的“指导挑选”方法)中。
可用于人源化的人构架区包括但不限于:使用“最适合(best-fit)”方法挑选的构架区(参见,例如Sims等人J.Immunol.151:2296(1993));衍生自特定亚组的人抗体的轻链或重链可变区的共有序列的构架区(参见,例如Carter等人Proc.Natl.Acad.Sci.USA,89:4285(1992);和Presta等人J.Immunol.,151:2623(1993));人成熟(体细胞突变)构架区或人生殖细胞构架区(参见,例如Almagro和Fransson,Front.Biosci.13:1619-1633(2008));以及衍生自筛选FR文库的构架区(参见,例如Baca等人,J.Biol.Chem.272:10678-10684(1997)和Rosok等人,J.Biol.Chem.271:22611-22618(1996))
4.人抗体
在某些实施方案中,本文中提供的抗体是人抗体。人抗体可以使用本领域已知的多种技术产生。人抗体通常描述于van Dijk和van de Winkel,Curr.Opin.Pharmacol.5:368-74(2001)和Lonberg,Curr.Opin.Immunol.20:450-459(2008)中。
可以通过将免疫原施用给转基因动物来制备人抗体,所述转基因动物经修饰在应答抗原攻击时可以产生完整人抗体或者具有人可变区的完整抗体。此类动物通常含有人免疫球蛋白基因座的全部或一部分,所述人免疫球蛋白基因座的全部或一部分取代了内源性免疫球蛋白基因座,或者所述人免疫球蛋白基因座的全部或一部分在染色体外存在或者随机整合到动物的染色体中。在此类转基因小鼠中,内源性免疫球蛋白基因座通常是失活的。对于从转基因动物中获得人抗体的方法的综述,参见Lonberg,Nat.Biotech.23:1117-1125(2005)。还参见,例如描述XENOMOUSETM技术的美国6,075,181号和6,150,584号专利;描述技术的美国5,770,429号专利;描述K-M技术的美国7,041,870号专利,以及描述技术的公开号US 2007/0061900的美国专利申请。可以例如通过与不同的人恒定区组合,进一步修饰通过此类动物产生的来自完整抗体的人可变区。
还可以通过基于杂交瘤的方法制备人抗体。已经描述了用于人单克隆抗体产生的人骨髓瘤和小鼠-人异型骨髓瘤细胞系。(参见,例如Kozbor J.Immunol.,133:3001(1984);Brodeur等人,Monoclonal Antibody Production Techniques and Applications,pp.51-63(Marcel Dekker,Inc.,New York,1987);以及Boerner等人,J.Immunol.,147:86(1991))。在Li等人,Proc.Natl.Acad.Sci.USA,103:3557-3562(2006)中还描述了通过人B-细胞杂交瘤技术产生的人抗体。其他方法包括那些例如在美国专利号7,189,826(描述了从杂交瘤细胞系中单克隆人IgM抗体的产生)和Ni,Xiandai Mianyixue,26(4):265-268(2006)(描述了人-人杂交瘤)中描述的方法。在Vollmers和Brandlein,Histology and Histopathology,20(3):927-937(2005)以及Vollmers和Brandlein,Methods and Findings in Experimental and Clinical Pharmacology,27(3):185-91(2005)中也描述了人杂交瘤技术(Trioma技术)。
还可以通过选自人衍生的噬菌体展示文库的分离的Fv克隆可变区序列,产生人抗体。然后,可以将此类可变区序列与期望的人恒定区组合。下文描述了用于从抗体文库中挑选人抗体的技术。
5.衍生自文库的抗体
可以通过针对具有期望活性或活性的抗体筛选组合文库,来分离本发明抗体。例如,对于产生噬菌体展示文库和针对拥有期望结合特征的抗体筛选此类文库,多种方法是本领域已知的。此类方法综述于例如,Hoogenboom等人in Methods in Molecular Biology 178:1-37(O’Brien等人,ed.,Human Press,Totowa,NJ,2001)中,并且进一步描述于例如,McCafferty等人,Nature 348:552-554;Clackson等人,Nature 352:624-628(1991);Marks等人,J.Mol.Biol.222:581-597(1992);Marks和Bradbury,在Methods in Molecular Biology 248:161-175(Lo,ed.,Human Press,Totowa,NJ,2003)中;Sidhu等人,J.Mol.Biol.338(2):299-310(2004);Lee等人,J.Mol.Biol.340(5):1073-1093(2004);Fellouse,Proc.Natl.Acad.Sci.USA 101(34):12467-12472(2004);以及Lee等人,J.Immunol.Methods 284(1-2):119-132(2004)中。
在某些噬菌体展示方法中,如在Winter等人,Ann.Rev.Immunol.,12:433-455(1994)中所述,通过聚合酶链式反应(PCR)分别克隆VH和VL基因的全库,并在噬菌体文库中随机组合,然后可以对其筛选抗原结合的噬菌体。噬菌体通常展示抗体片段,单链Fv(scFv)片段或者Fab片段。在不需要构建杂交瘤的情况下,来自免疫源的文库提供了针对免疫原的高亲和力抗体。备选地,如通过Griffiths等人,EMBO J,12:725-734(1993)所述,可以克隆(例如,来自人)天然全库,以在没有任何免疫的情况下,将单一来源的抗体提供给大范围的非自身以及自身抗体。最后,如通过Hoogenboom和Winter,J.Mol.Biol.,227:381-388(1992)所述,还可以通过克隆来自干细胞的未重排V-基因区段,并使用含随机序列的PCR引物编码高度可变的CDR3区并完成体外重排合成地制备天然文库。描述人抗体噬菌体文库的专利文献包括例如:美国专利号5,750,373和美国专利公开号2005/0079574、2005/0119455、2005/0266000、2007/0117126、2007/0160598、2007/0237764、2007/0292936和2009/0002360。
在本文中,将分离自人抗体文库的抗体或抗体片段视为人抗体或人抗体片段。
6.多特异性抗体
在某些实施方案中,本文中提供的抗体是多特异性抗体,例如双特异性抗体。多特异性抗体是对至少两个不同位点具有结合特异性的单克隆抗体。在某些实施方案中,一个结合特异性针对第一抗原,并且其他结合特异性针对任一其他抗原。在某些实施方案中,双特异性抗体可以结合第一抗原的两个不同表位。还可以将双特异性抗体用于将细胞毒性剂定位于表达第一抗原的细胞。可以将双特异性抗体制备为全长抗体或抗体片段。
制备多特异性抗体的技术包括但不限于,重组共表达具有不同特异性的两个免疫球蛋白重链-轻链对(参见Milstein和Cuello,Nature 305:537(1983)、WO 93/08829和Traunecker等人,EMBO J.10:3655(1991)),以及“knob-in-hole”改造(参见,例如美国专利号No.5,731,168)。还可以通过改造用于制备抗体Fc-异型二聚体分子的静电转向效应(WO 2009/089004A1);交联两个或多个抗体或片段(参见,例如美国专利号4,676,980和Brennan等人,Science,229:81(1985));使用亮氨酸拉链产生双特异性抗体(参见,例如Kostelny等人,J.Immunol.,148(5):1547-1553(1992));使用用于制备双特异性抗体片段的“双抗体”技术(参见,例如Hollinger等人,Proc.Natl.Acad.Sci.USA,90:6444-6448(1993));和使用单链Fv(sFv)二聚体(参见,例如Gruber等人,J.Immunol.,152:5368(1994));以及如例如Tutt等人J.Immunol.147:60(1991)中所述制备三特异性抗体,来制备多特异性抗体。
本文中还包括了具有三个或多个功能性抗原结合位点的经改造的抗体,包括“章鱼抗体(Octopus antibody)”,参见例如US 2006/0025576A1。
在本文中,抗体或片段还包括“双作用FAb(Dual Acting FAb)”或“DAF”,其包含与第一抗原以及另一个不同的抗原结合的抗原结合位点(参见,例如US 2008/0069820)。
7.抗体变体
在某些实施方案中,考虑在本文中提供抗体的氨基酸序列变体。例如,可以期望改进抗体的结合亲和力和/或其他生物学特性。可以通过将合适的修饰引入到编码抗体的核苷酸序列中或者通过肽合成,来制备抗体的氨基酸序列变体。此类修饰包括例如,在抗体的氨基酸序列中缺失和/或插入和/或替换残基。可以进行缺失、插入和替换的任意组合,以得到最终的构建体,只要最终的构建体拥有期望的特征例如抗原结合即可。
a)替换、插入和缺失变体
在某些实施方案中,提供了具有一个或多个氨基酸替换的抗体变体。替换诱变的目的位点包括HVR和FR。在表1中,在标题“保守替换”下显示了保守替换。在表1中,在标题“示例性替换”下提供了更多的替换改变,并参考氨基酸侧链种类进一步描述如下。可以将氨基酸替换引入到目的抗体中,并针对期望的活性例如保留/改进的抗原结合、减少的免疫原性或者改进的ADCC或CDC,来筛选产物。
表1
可以根据常见的侧链特性分组氨基酸:
(1)疏水性:正亮氨酸、Met、Ala、Val、Leu、Ile;
(2)中性亲水性:Cys、Ser、Thr、Asn、Gln;
(3)酸性:Asp、Glu;
(4)碱性:His、Lys、Arg;
(5)影响链方向的残基:Gly、Pro;
(6)芳香族:Trp、Tyr、Phe.
非保守性替换需要将这些种类之一的成员与另一种类交换。
一种类型的替换变体涉及替换亲本抗体(例如,人源化或人抗体)的一个或多个高变区残基。通常,挑选的用于进一步研究的得到的变体相对于亲本抗体在某些生物学特性方面具有修饰(例如,改进)(例如,增加的亲和力、降低的免疫原性)和/或具有基本保留的亲本抗体的某些生物学特性。示例性替换变体是亲和力成熟的抗体,其可以是例如使用如本文中所述的那些基于噬菌体展示的亲和成熟技术常规产生的。简言之,一个或多个HVR残基是突变的,并将变体抗体展示在噬菌体上,并针对特定的生物学活性(例如结合亲和力)筛选。
可以在HVR中进行改变(例如,替换)以改进抗体亲和力。可以在HVR“热点(hotspot)”(即在体细胞成熟过程期间通过经历高频率突变的密码子编码的残基)(参见,例如Chowdhury,Methods Mol.Biol.207:179-196(2008))和/或SDR(a-CDR)中进行此类改变,并测试得到的变体VH或VL的结合亲和力。例如,Hoogenboom等人在Methods in Molecular Biology 178:1-37(O’Brien等人编辑,Human Press,Totowa,NJ,(2001))中已经描述了通过从第二文库中构建和再挑选的亲和力成熟。在亲和力成熟的一些实施方案中,通过多种方法任一(例如,易错PCR、链改组或寡核苷酸指导的诱变)将多样性引入到挑选用于成熟的可变基因中。然后产生第二文库。然后筛选文库,以鉴定具有期望亲和力的任一抗体变体。引入多样性的另一方法涉及HVR指导的方法,其中随机化几个HVR残基(例如,一次4-6个残基)。可以例如使用丙氨酸扫描诱变或者造模,特别地鉴定参与抗原结合的HVR残基。特别地,通常靶向CDR-H3和CDR-L3。
在某些实施方案中,可以在一个或多个HVR中发生替换、插入或缺失,只要此类改变不会在实质上降低抗体结合抗原的能力。例如,可以在HVR中进行不会在实质上降低结合亲和力的保守改变(例如,如本文中所提供的保守替换)。此类改变可以在HVR“热点”或SDR之外。在上文提供的变体VH和VL序列的某些实施方案,每一HVR没有改变或者含有不超过1个、2个或3个的氨基酸替换。
如由Cunningham和Wells(1989)Science,244:1081-1085所述,鉴定可以作为诱变靶标的抗体的残基或区域的有用方法称为“丙氨酸扫描诱变”。在该方法中,鉴定了残基或者靶残基组(例如,带电荷的残基如arg、asp、his、lys和glu),并用中性或带负电荷的氨基酸(例如,丙氨酸或聚丙氨酸)取代,以测定是否会影响抗体与抗原的相互作用。可以在对最初替换表现出功能敏感性的氨基酸位置处引入另外的替换。备选地或另外地,可以将抗原-抗体复合物的晶体结构用于鉴定抗体和抗原之间的接触点。可以靶向此类接触残基和邻近残基,并除去作为替换的候选。可以筛选变体,以测定它们是否含有期望的特性。
氨基酸序列插入包括一个残基至含数百个或更多残基的多肽长度的氨基端和/或羧基端融合,以及单个或多个氨基酸残基的序列内插入。末端插入的实例包括具有氨基端甲硫氨酰残基的抗体。抗体分子的其他插入变体包括抗体的氨基端或羧基端与酶(例如ADEPT)或者可以增加抗体血清半衰期的多肽的融合体。
b)糖基化变体
在某些实施方案中,本文中所提供的抗体是经改变的,以增加或者减少抗体糖基化的程度。可以通过改变氨基酸序列,以使一个或多个糖基化位点产生或去除,来常规地实现抗体糖基化位点的添加或缺失。
当抗体包含Fc区时,可以改变其连接的糖。通过哺乳动物细胞产生的天然抗体通常包含分支的、双分枝的寡糖,其通常通过N-连接于Fc区的CH2结构域的Asn297连接。参见,例如Wright等人TIBTECH15:26-32(1997)。寡糖可以包括多种糖,例如甘露糖、N-乙酰葡糖胺(GlcNAc)、半乳糖和唾液酸,以及在双分枝寡糖结构的“茎干”中与GlcNAc连接的岩藻糖。在一些实施方案中,可以在本发明抗体中进行寡糖的修饰,以产生具有某些改进特性的抗体变体。
在一个实施方案中,提供的抗体变体具有缺少与Fc区连接(直接或间接)的岩藻糖的糖结构。例如,该抗体中岩藻糖的量可以为1%至80%、1%至65%、5%至65%或者20%至40%。如WO 2008/077546中所述,例如可以相对于通过MALDI-TOF质谱测量的与Asn 297连接的全部糖结构(例如复合物、杂交物和高甘露糖结构)的总和,通过计算Asn297处糖链中岩藻糖的平均量,来测定岩藻糖的量。Asn297指位于Fc区中约位置297处的天冬酰胺残基(Fc区残基的Eu编号);然而,由于抗体中较少的序列变异,Asn297也可以位于位置297的上游或下游约±3个氨基酸,即在位置294和300之间。此类岩藻糖基化变体可以改进ADCC功能。参见,例如美国专利公开号US 2003/0157108(Presta,L.);US 2004/0093621(Kyowa Hakko Kogyo Co.,Ltd)。与“去岩藻糖基化”或“岩藻糖-缺失”抗体变体相关的文献的实例包括:US 2003/0157108;WO 2000/61739;WO 2001/29246;US 2003/0115614;US 2002/0164328;US 2004/0093621;US 2004/0132140;US 2004/0110704;US 2004/0110282;US 2004/0109865;WO 2003/085119;WO 2003/084570;WO 2005/035586;WO 2005/035778;WO2005/053742;WO2002/031140;Okazaki等人J.Mol.Biol.336:1239-1249(2004);Yamane-Ohnuki等人Biotech.Bioeng.87:614(2004)。能产生去岩藻糖基化抗体的细胞系的实例包括缺失蛋白质岩藻糖基化的Lec13CHO细胞(Ripka等人Arch.Biochem.Biophys.249:533-545(1986);US专利申请号US 2003/0157108A1,Presta,L;和WO 2004/056312A1,Adams等人,特别是在实施例11中),以及敲除细胞系,例如α-1,6-岩藻糖基转移酶基因,FUT8敲除的CHO细胞(参见,例如Yamane-Ohnuki等人Biotech.Bioeng.87:614(2004);Kanda,Y.等人,Biotechnol.Bioeng.,94(4):680-688(2006);和WO2003/085107)。
还提供了具有二等分寡糖的抗体变体,例如其中通过GlcNAc二等分与抗体的Fc区连接的双分枝寡糖。此类抗体变体可以具有减少的岩藻糖基化和/或改进的ADCC功能。此类抗体变体的实例描述于例如,WO 2003/011878(Jean-Mairet等人);美国专利号6,602,684(Umana等人);和US 2005/0123546(Umana等人)中。还提供了在与Fc区连接的寡糖中具有至少一个半乳糖残基的抗体变体。此类抗体变体具有改进的CDC功能。此类抗体变体描述于例如,WO 1997/30087(Patel等人);WO 1998/58964(Raju,S.);和WO 1999/22764(Raju,S.)中。
c)Fc区变体
在某些实施方案中,可以将一个或多个氨基酸修饰引入到本文中提供的抗体的Fc区中,从而产生Fc区变体。Fc区变体可以包含人Fc区序列(例如,人IgG1、IgG2、IgG3或IgG4Fc区),其在一个或多个氨基酸位置包含氨基酸修饰(例如替换)。
在某些实施方案中,本发明考虑了拥有一些但不是全部效应子功能的抗体变体,所述效应子功能使得该抗体变体是期望的应用候选物,其中抗体的体内半衰期是重要的,而某些效应子功能(例如补体和ADCC)是不必须的或者不利的。可以进行体外和/或体内细胞毒性测定法以确认CDC和/或ADCC活性的降低/缺失。例如,可以进行Fc受体(FcR)结合测定法,以确保抗体缺少FcγR结合(因此可能缺少ADCC活性),但保留FcRn结合能力。调节ADCC的主要细胞,NK细胞仅表达FcγRIII,而单核细胞表达FcγRI、FcγRII和FcγRIII。在Ravetch和Kinet,Annu.Rev.Immunol.9:457-492(1991)的第464页的表3中总结了造血细胞上FcR表达。评估目的分子的ADCC活性的体外测定法的非限制性实例描述于美国专利号5,500,362(参见,例如Hellstrom,I.等人Proc.Nat’l Acad.Sci.USA 83:7059-7063(1986))以及Hellstrom,I等人,Proc.Nat’l Acad.Sci.USA 82:1499-1502(1985);5,821,337(参见Bruggemann,M.等人,J.Exp.Med.166:1351-1361(1987))中。备选地,可以使用非放射性测定方法(参见,例如用于流式细胞仪(CellTechnology,Inc.Mountain View,CA)的ACTITM非放射性细胞毒性测定法;以及非放射性细胞毒性测定法(Promega,Madison,WI))。用于此类测定法的有用的效应细胞包括外周血单核细胞(PBMC)和天然杀伤(NK)细胞。备选地或另外地,可以例如在Clynes等人Proc.Nat’l Acad.Sci.USA 95:652-656(1998)中公开的动物模型中体内评估目的分子的ADCC活性。还可以实施C1q结合测定法,以确认抗体不能结合C1q并因此缺少CDC活性。参见,例如WO 2006/029879和WO 2005/100402中的C1q和C3c结合ELISA。为了评估补体活性,可以进行CDC测定法(参见,例如Gazzano-Santoro等人,J.Immunol.Methods 202:163(1996);Cragg,M.S.等人,Blood101:1045-1052(2003);和Cragg,M.S.and M.J.Glennie,Blood103:2738-2743(2004))。使用本领域已知的方法还可以进行FcRn结合和体内清除/半衰期测定(参见,例如Petkova,S.B.等人,Int’l.Immunol.18(12):1759-1769(2006))。
具有降低的效应子功能的抗体包括那些具有一个或多个Fc区残基238、265、269、270、297、327和329替换的抗体(美国专利号6,737,056)。此类Fc突变体包括在两个或两个以上氨基酸位置265、269、270、297和327处具有替换的Fc突变体,包括称为“DANA”具有残基265和297替换成丙氨酸的Fc突变体(美国专利号7,332,581)。
描述了与FcR具有改进的或者减少的结合的某些抗体变体。(参见,例如美国专利号6,737,056;WO 2004/056312,以及Shields等人,J.Biol.Chem.9(2):6591-6604(2001))。
在某些实施方案中,抗体变体包含改进ADCC的具有一个或多个氨基酸替换的Fc区,例如在Fc区的位置298、333和/或334处的替换(残基的EU编号)。
在一些实施方案中,例如如在美国专利号6,194,551、WO 99/51642和Idusogie等人J.Immunol.164:4178-4184(2000)中所述,在Fc区中进行改变,其导致改变的(即,改进的或者减少的)C1q结合和/或补体依赖性细胞毒性(CDC)。
US2005/0014934A1(Hinton等人)中描述了具有增加的半衰期以及改进了与新生儿Fc受体(FcRn)结合的抗体,其负责将母源性IgG转移给胎儿(Guyer等人,J.Immunol.117:587(1976)和Kim等人,J.Immunol.24:249(1994))。这些抗体包含其中具有一个或多个替换的Fc区,其改进了Fc区与FcRn的结合。此类Fc变体包括在一个或多个Fc区残基:238、256、265、272、286、303、305、307、311、312、317、340、356、360、362、376、378、380、382、413、424或434处具有替换,例如替换Fc区残基434的Fc变体(美国专利号7,371,826)。
也参见涉及Fc区变体的其他实例的Duncan&Winter,Nature322:738-40(1988);美国专利号5,648,260;美国专利号5,624,821;和WO 94/29351。
d)半胱氨酸改造的抗体变体
在某些实施方案中,期望的是产生半胱氨酸改造的抗体,例如“thioMAb”,其中用半胱氨酸残基替换抗体的一个或多个残基。在特定的实施方案中,替换的残基在抗体的可接近的位点存在。如在本文中进一步描述,通过用半胱氨酸替换这些残基,从而将活性硫醇基置于抗体的可接近位点,并可用于抗体与其他部分,例如药物部分或者连接体-药物部分的缀合,以产生免疫缀合物。在某些实施方案中,可以用半胱氨酸替换一个或多个以下残基之一:轻链的V205(Kabat编号);重链的A118(EU编号);以及重链Fc区的S400(EU编号)。可以例如如在美国专利号7,521,541中所述,产生半胱氨酸改造的抗体。
e)抗体衍生物
在某些实施方案中,可以进一步修饰本文中提供抗体,以含有本领域已知的且容易得到的其他非蛋白质部分。适合于衍生化抗体的部分包括但不限于水溶性聚合物。水溶性聚合物的非限制性实例包括但不限于,聚乙二醇(PEG)、乙二醇/丙二醇的共聚物、羧甲基纤维素、葡聚糖、聚乙烯醇、聚乙烯吡咯烷酮、聚-1,3-二氧戊环、聚-1,3,6-三烷、乙烯/马来酸酐共聚物、聚氨基酸(同型聚合物或者随机共聚物)以及葡聚糖或聚(N-乙烯吡咯烷酮)聚乙二醇、propropylene glycol共聚物、prolypropylene oxide/环氧乙烧共聚物、聚氧乙烯化多元醇(例如甘油)、聚乙烯醇及其混合物。由于其在水中的稳定性,聚乙二醇丙醛在生产中具有优势。聚合物可以具有任一分子量,并可以是分支的或者不分支的。可以改变与抗体连接的聚合物的数目,并且如果连接了一个以上的聚合物,它们可以是相同的或者不同的分子。总之,可以基于考虑,包括但不限于待改进抗体的特定特性或功能、是否在定义的条件下将抗体衍生物用于治疗等,确定用于衍生化的聚合物的数目和/或类型。
在另一个实施方案中,提供了可以通过暴露于放射选择性加热的抗体和非蛋白质部分的聚合物。在一个实施方案中,非蛋白质部分是碳纳米管(Kam等人,Proc.Natl.Acad.Sci.USA 102:11600-11605(2005))。放射可以是任意波长,并且包括但不限于不会伤害普通细胞的波长,但其可以使非蛋白质部分加热至可以杀死邻近抗体-非蛋白质部分的细胞的温度。
重组方法和组合物
可以使用例如如在美国专利号4,816,567中所述的重组方法和组合物产生抗体。在一个实施方案中,提供了编码本文中所述的抗体的分离的核酸。此类核酸可以编码包含抗体的VL的氨基酸序列和/或包含VH的氨基酸序列(例如,抗体的轻链和/或重链)。在另外的实施方案中,提供了包含该核酸的一个或多个载体(例如,表达载体)。在另外的实施方案中,提供了包含该核酸的宿主细胞。在一个此种实施方案中,宿主细胞包含(例如已经转化了):(1)包含编码包含抗体的VL的氨基酸序列和包含抗体的VH的氨基酸序列的核酸的载体,或(2)包含编码包含抗体的VL的氨基酸序列的核酸的第一载体和包含编码抗体的VH的氨基酸序列的核酸的第二载体。在一个实施方案中,宿主细胞是真核细胞,例如中国仓鼠卵巢(CHO)细胞或淋巴样细胞(例如,Y0、NS0、Sp20细胞)。在一个实施方案中,提供了制备抗体的方法,其中方法包括在适合于表达抗体的条件下,培养如上所提供的包含编码抗体的核酸的宿主细胞,并任选地从宿主细胞(或者宿主细胞培养基)中回收抗体。
对于抗体的重组产生,分离例如如上所述编码抗体的核酸,并插入到一个或多个载体中,用于在宿主细胞中进一步克隆和/或表达。该核酸可以是使用常规方法(例如通过使用能与编码抗体的重链和轻链的基因特异性结合的寡核苷酸探针)容易地分离和测序的。
用于克隆和表达编码抗体的载体的合适宿主细胞包括本文中所述的原核或真核细胞。例如,特别地当不需要糖基化和Fc效应子功能时,可以在细菌中产生抗体。对于在细菌中表达抗体片段和多肽,参见例如美国专利号5,648,237、5,789,199和5,840,523(还参见Charlton,Methods in Molecular Biology,Vol.248(B.K.C.Lo编辑,Humana Press,Totowa,NJ,2003),pp.245-254),描述在大肠杆菌中表达抗体片段)。表达后,可以从可溶性组分中的细菌细胞糊状物中分离抗体,并可以进一步纯化。
除原核细胞外,真核微生物如丝状真菌或酵母都是用于编码抗体的载体的合适克隆或表达宿主,包括已经“人源化了”糖基化通路的真菌和酵母菌株,导致了具有部分或全部人糖基化模式的抗体的产生。参见Gerngross,Nat.Biotech.22:1409-1414(2004)和Li等人,Nat.Biotech.24:210-215(2006)。
用于表达糖基化抗体的合适宿主细胞还可以衍生自多细胞生物(无脊椎动物和脊椎动物)。无脊椎动物的实例包括植物和昆虫细胞。已经鉴定了可以用于与昆虫细胞缀合的众多杆状病毒的菌株,特别地用于转染草地夜蛾(Spodoptera frugiperda)细胞。
也可以将植物细胞培养物用作为宿主。参见例如,美国专利号5,959,177、6,040,498、6,420,548、7,125,978和6,417,429(描述用于在转基因植物中产生抗体的PLANTIBODIESTM技术)。
还可以将脊椎动物细胞用作为宿主。例如,可以使用适合于在悬浮液中培养的哺乳动物细胞。有用的哺乳动物宿主细胞系的其他实例是通过SV40转化的猴肾CV1细胞系(COS-7);人胚肾细胞系(例如如在Graham等人,J.Gen Virol.36:59(1977)中描述的293或293细胞);仓鼠幼肾细胞(BHK);小鼠塞托利细胞(例如如在Mather,Biol.Reprod.23:243-251(1980)中所述的TM4细胞);猴肾细胞(CV1);非洲绿猴肾细胞(VERO-76);人宫颈癌细胞(HELA);犬肾细胞(MDCK;buffalo大鼠肝细胞(BRL 3A));人肺细胞(W138);人肝细胞(Hep G2);小鼠乳腺肿瘤(MMT 060562);TRI细胞,例如如在Mather等人,Annals N.Y.Acad.Sci.383:44-68(1982)中所述;MRC 5细胞;和FS4细胞。其他有用的哺乳动物宿主细胞系包括中国仓鼠卵巢(CHO)细胞,包括DHFR-CHO细胞(Urlaub等人,Proc.Natl.Acad.Sci.USA 77:4216(1980));以及骨髓瘤细胞系例如Y0、NS0和Sp2/0。对于适合用于抗体产生的某些哺乳动物宿主细胞系的综述,参见例如Yazaki和Wu,Methods in Molecular Biology,Vol.248(B.K.C.Lo编辑,Humana Press,Totowa,NJ),pp.255-268(2003)。
测定法
可以通过本领域已知的多种测定法鉴定、筛选本文中提供的抗体,或表征其物理/化学特性和/或生物学活性。
1.结合测定法和其他测定法
在一个方面,例如通过已知的方法如ELISA、Western blot等测试本发明抗体的抗原结合活性。
在另一方面,可以将竞争测定法用于鉴定与本发明抗体竞争与目的抗原结合的抗体。在某些实施方案中,该竞争抗体结合本发明抗体结合的相同表位(例如,线性或者构象表位)。在Morris(1996)“Epitope Mapping Protocols”中,在Methods in Molecular Biology vol.66(Humana Press,Totowa,NJ)中提供了用于绘制与抗体结合的表位的详细示例性方法。
在示例性竞争测定法中,在溶液中温育固定化的目的抗原,所述溶液包含与目的抗原结合的第一标记抗体(例如,本发明抗体)和待测试其与第一抗体竞争与目的抗原结合的能力的第二未标记抗体。第二抗体可以在杂交瘤上清液中存在。作为对照,在包含第一标记抗体但不包含第二未标记抗体的溶液中温育固定化的目的抗原。在允许第一抗体与目的抗原结合的条件下温育后,去除过量的未结合抗体,并测量与固定化目的抗原相关的标记的量。如果与固定化目的抗原结合的标记的量在测试样品中相对于对照样品是大幅降低的,那么表示第二抗体与第一抗体竞争与目的抗原结合。参见Harlow and Lane(1988)Antibodies:A Laboratory Manual ch.14(Cold Spring Harbor Laboratory,Cold Spring Harbor,NY)。
2.活性测定法
在一个方面,提供了鉴定其抗体具有生物学活性的测定法。还提供了在体内和/或体外具有该生物学活性的抗体。
在某些实施方案中,测试了本发明抗体的该生物学活性。
提供了以下实施例仅用于说明性目的,并不意图以任何方式限制本发明的范围。
在本说明中引用的全部专利和文献参考在此处以其整体引入作为参考。
III.实施例
下文是本发明方法和组合物的实例。应当理解,考虑到上文提供的一般描述,可以实践多种其他实施方案。
M13KO7辅助性噬菌体来自New England Biolabs。牛血清白蛋白(BSA)和Tween 20来自Sigma。酪蛋白来自Pierce。缀合了辣根过氧化物酶(HRP)的抗-M13来自Amersham Pharmacia。Maxisorp免疫板来自NUNC。四甲联苯胺(TMB)底物来自Kirkegaard and Perry Laboratories。通过Genentech,Inc.的研究组产生全部其他蛋白质抗原。
实施例1:挑选用于在原核和真核细胞中表达的信号序列
为了说明载体是否能在大肠杆菌和真核(哺乳动物)细胞二者中表达目的蛋白质,挑选了4个非细菌来源的信号序列,对于这4个非细菌来源的信号序列,存在无对照证据支持它们可以在哺乳动物细胞中发挥功能的观点。我们使用噬菌体ELISA测试了这些信号序列驱动抗-Her2(h4D5)Fab在M13噬菌体上展示的能力(图1A)。相对于细菌热稳定肠毒素II(STII)信号序列,评价了展示的水平。信号序列驱动Fab-噬菌体展示的能力差异很大,并且来自鼠结合免疫球蛋白(mBiP)的一个信号序列驱动了可以允许有效水平Fab展示的展示水平。
为了进一步改进mBiP信号序列的性能,我们使用了基于噬菌体的密码子优化方法,因为以前已经显示,通过密码子选择,可以极大地影响细菌中真核信号序列的功能(Humphreys等人,The Protein Expression and Purification,20:252-264(2000))。构建了噬菌体文库,其中mBiP信号序列在标准的噬菌粒载体中与h4D5Fab HC的氨基端融合。在仅允许沉默突变的前两个甲硫氨酸之后的每一密码子的第三个碱基中,多样化mBiP信号序列的DNA序列。针对固定化Her2的4轮固相淘选后,挑选并测序各个克隆。我们发现,挑选的克隆的共有序列在随机化位置强烈地偏向于腺嘌呤或胸腺嘧啶,而不是鸟嘌呤或胞嘧啶。在野生型mBiP序列中17个密码子的15个在第三碱基位置含有鸟嘌呤或胞嘧啶,但在分选的文库中,在60-90%的时候,17个密码子的每一个在这些位置含有腺嘌呤或胸腺嘧啶的事实突出了该结果。当在噬菌体ELISA中测试时,优化的mBiP信号序列以与原核STII信号序列相当的水平驱动h4D5Fab展示,表明mBiP信号序列可以在不会明显降低性能的情况下取代原核STII信号序列用于噬菌体展示和淘选实验。
接下来,评价了mBiP信号序列在哺乳动物细胞中支持IgG表达和分泌的能力。将编码h4D5hIgG1的HC和LC的哺乳动物表达载体(每一个都具有与氨基端融合的mBiP信号序列)共转染到悬浮的293S细胞中,并培养5天。然后收集上清液并通过亲和层析纯化IgG。与在两个链都使用天然HC信号(VHS)获得的产量(数据未显示)相当,在一个30mL培养物中,IgG的产量常规为~2.0mg。令人感兴趣地,mBiP信号序列的野生型对比密码子优化形式的使用对IgG表达水平并没有可辨别的影响(数据未显示)。凝胶过滤层析和质谱确认溶液中纯化的蛋白质>90%为单体,并且mBiP信号序列在HC和LC二者上的合适位置处是完全切割的(数据未显示)。由于已知h4D5是良好的表达子(expresser),我们相对于VHS测试了mBiP在任意选自噬菌体淘选实验的未表征克隆库上的性能。在30mL悬浮培养物中,这些克隆的平均产量为~1.0mg,并且在两种信号序列之间没有观察到显著的差异(图2A和B)。
总之,mBiP哺乳动物分泌信号序列能以足以筛选的水平在哺乳动物细胞中表达IgG,并且一旦优化了密码子,其还能在不削弱IgG表达水平的情况下在噬菌体上驱动强的Fab展示。
实施例2:在原核和真核细胞中表达改变的Fab融合体
为了以宿主细胞依赖性方式产生不同的Fab-融合蛋白质,我们试图研发了在真核细胞而不是原核细胞中mRNA加工期间发生的内含子剪接的天然方法。hIgG1HC恒定区的基因组序列含有三个天然内含子(图3A)。这些内含子的第一个(内含子1)是位于HC可变结构域(VH)和铰链区之间的384个碱基对。通过RT-PCR和测序转录本,评估了包含内含子1和表达完全剪接的mRNA的经优化的剪接供体序列的HC表达载体,并且当与LC载体共转染时,IgG1以与没有内含子的载体相当的水平表达(图5)。
为了测定与包埋在内含子1序列内的噬菌体接头肽融合的Fab片段是否分别允许在细菌中的噬菌体展示和在哺乳动物细胞中的IgG表达二者,在内含子1或内含子3的5’末端,将接头肽(图3B)或噬菌体外壳蛋白基因III(图3C)插入到h4D5HC内含子1构建体中。在接头肽的上游立即去除来自内含子1或3的天然剪接供体。当HC-接头.内含子1构建体在哺乳动物细胞中与h4D5LC共表达时,h4D5IgG的表达为不具有内含子的对照构建体的h4D5IgG表达的大约40%(对于含接头的内含子)或5%(对于含基因-III的内含子)(图4A)。RT-PCR显示,尽管正确地剪接了HC-接头mRNA部分(图4B,中间条带),显著量的mRNA或者没有剪接(图4B,上面的条带)或者在VH区中从隐蔽剪接供体中不正确剪接(图4B,下面的条带)。HC-基因-III mRNA几乎从隐蔽剪接供体中完全剪接。隐蔽剪接供体序列的沉默突变仅导致了未剪接mRNA的积累(未显示)。
考虑到当插入接头序列时有效剪接内含子的失败,我们将天然剪接供体的序列与哺乳动物mRNA剪接供体的已知共有序列比较(Stephens等人,J of Molecular Biology,228:1124-1136(1992))。如在图5中所示,来自hIgG1内含子1的天然剪接供体在8个位置中的3个与共有供体序列不同。进一步分析了位置1和5处的替换,因为这些位置比位置8更保守。产生将其中位置1和5处的碱基改变成与共有序列相匹配的突变剪接供体(供体1)(图5A),并测试这些经修饰的供体介导HC中合成内含子剪接的能力。该优化的剪接供体完全恢复了合成内含子的剪接(图5B),其中伴随着h4D5IgG表达增加至与不含内含子的对照构建体的h4D5IgG表达相匹配的水平(图5C)。无论合成内含子是否含接头肽或基因-III,并且无论合成内含子是否基于hIgG1内含子1或内含子3,都观察到了剪接和IgG表达的改进。
实施例3:产生用于原核和真核细胞的表达和分泌系统
对于双载体质粒的产生,我们使用当前用于噬菌体展示的pBR322-衍生的噬菌粒载体,pRS。该双顺反子载体由驱动抗体轻链盒及其相关的STII信号序列,以及抗体重链和及其相关的STII序列表达的细菌PhoA启动子组成。在轻链序列的末端,有用于检测在噬菌体颗粒上展示的Fab的gD表位标签。在常规噬菌粒中,重链序列仅由hIgG的VH和CH1结构域组成,并且其在核苷酸水平与效用肽融合,如噬菌体融合蛋白质,最通常是编码噬菌体外壳蛋白pIII的基因-III或接头肽。轻链和重链盒的3’末端含有用于在大肠杆菌中终止转录的λ转录终止序列。由于该载体从单个mRNA转录本中产生轻链和重链-pIII,因此在LC和HC序列之间不存在转录调节元件。该载体还含有β-内酰胺酶(bla)基因,以赋予氨苄青霉素抗性,大肠杆菌中的pMB1复制起点和用于细菌表面表达pillus的f1起点,允许被M13噬菌体感染。该载体的另一形式还包括在合适的哺乳动物细胞株中用于质粒的附加型复制的SV40复制起点。
对于构建最初的双载体(称为“pDV.6.0”),我们首先在驱动LC-HC顺反子的PhoA启动子的上游插入来自pRK(用于表达IgG和其他蛋白质的哺乳动物表达载体)的哺乳动物CMV启动子。在编码LC抗体的序列的末端,我们在gD表位标签之前插入琥珀终止密码子,当在琥珀抑制基因(Amber suppressor)的大肠杆菌菌株中展示时,允许在噬菌体上检测标记的LC。当该载体在哺乳动物细胞中表达时,表位标签是不存在的。因此,LC盒包含(以5’至3’的顺序)真核启动子、细菌启动子、信号序列、编码抗体轻链(LC)的序列和表位标签(gD)。
接下来,在HC和LC盒之间,我们插入了包含(以5’至3’的顺序)SV40哺乳动物聚腺苷酸化/转录终止信号、用于在大肠杆菌中转录终止的λ终止子序列、CMV启动子和PhoA启动子的合成盒。
接下来,在HC盒之后插入SV40哺乳动物聚腺苷酸化/转录终止信号和λ终止子序列。HC盒包含信号序列和编码抗体重链(HC)的序列。
为了允许目的融合蛋白质在原核和真核细胞二者中分泌,我们将位于LC和HC之前的STII信号序列置换成真核鼠结合免疫球蛋白(mBiP)信号序列。几种候选信号序列的筛选导致我们发现该信号序列能在需要原核表达(即,噬菌体展示)和/或真核表达(即,在哺乳动物细胞中表达IgG)的应用中发挥功能,并且在这些设置中的mBiP也如在此工作前使用的各个信号序列一样良好地运行。
为了允许在大肠杆菌中表达Fab-噬菌体和在哺乳动物细胞中表达IgG,我们在HC盒中产生了合成内含子。我们修饰了来自人IgG1内含子1或内含子3的天然内含子,以产生含用于在噬菌体颗粒上展示的融合蛋白质(基因-III)的合成内含子。在由终止密码子分离的基因-III序列之后紧接着插入来自人IgG1的内含子1(或内含子3)的基因组序列,以在大肠杆菌中产生Fab HC-p3融合物。当在大肠杆菌中表达时,在合成内含子的5’侧翼区处天然剪接供体八核苷酸的放置需要铰链区的两个氨基酸突变(E212G和P213K,Kabat编号),并且产生优化的剪接供体的突变导致了这些残基都突变成了赖氨酸。这些突变不会影响在噬菌体上展示的水平(未显示),并且由于在剪接加工期间去除了噬菌体铰链区,所以其在哺乳动物细胞中表达的全长IgG中是不存在的。
备选地,对于接头噬菌体展示的使用,我们产生了与上述pDV6.0载体相似的具有不同合成内含子的载体(在本文中称为pDV5.0,在图7中显示)。用亮氨酸拉链对(在本文中称为“接头”)的两个成员之一取代基因-III序列。在该合成内含子中,接头肽序列之后是终止密码子和内含子1或3的基因组序列。在该构建体中,我们还插入了由与亮氨酸拉链对的同源成员融合的基因-III组成的分离的细菌表达盒。将该分离的细菌表达盒引入到LC CMV启动子的上游并受PhoA启动子控制,所述分离的细菌表达盒含有STII信号序列以限制大肠杆菌的接头-基因-III表达,并在下游紧接着含有λ终止子。当在大肠杆菌中表达时,重链和轻链在周质中组装,以形成Fab,并且与重链融合的接头与pIII-接头蛋白质上的同源接头稳定结合。将该组装的Fab-接头-pIII复合物包装到噬菌体颗粒中得到了展示目的Fab的噬菌体。此外,我们产生了常规突变的KO7辅助型噬菌体,其中将配偶体接头与基因-III的氨基端融合(接头-KO7)。用接头-KO7感染携带pDV.5.0的大肠杆菌导致全部拷贝的pIII呈现在与接头融合的成熟噬菌粒上。结果,全部拷贝的pIII都可以与Fab-接头关联,而不仅仅是那些来源于pDV5的pIII拷贝。然而,在一些情况下,当寻求极高亲和力克隆时(例如,在亲和力成熟应用中),期望较低水平的展示。在该情况下,用常规KO7辅助型噬菌体感染携带pDV.5.0的大肠杆菌产生了接头-pIII(来自pDV.5.0)和已经在噬菌体颗粒上展示的野生型pIII(来自KO7辅助型噬菌体)的混合物。在该情况下,由于仅全部pIII库的一个亚集可以与接头-Fab关联,所以得到的展示水平要比使用接头-KO7时低。通过挑选合适的辅助型噬菌体调节展示水平的这种能力是本发明的独特优势。
我们评价了pDV5.0在哺乳动物细胞中表达不同IgG的能力。将来自4中不同的人IgG的HC和LC亚克隆到pDV5.0中,并在293细胞中表达。有些令人惊奇的是,pDV的整体产量一直比双质粒系统的整体产量低~10倍。然而,产量仍处于每30mL培养物~0.1-0.4mg的数量级(图6B)。该物质量足以用于常规筛选测定,并且如果需要更大量的物质,可以将其容易地提升至0.1-1L或者更高。通过凝胶过滤层析,显示溶液中IgG>90%是单体的。
实施例4:构建在基因III中具有琥珀突变的突变辅助型噬菌体M13KO7(AMBER KO7)
为了增强与pIII融合的蛋白质在M13噬菌体上的展示,我们使用定点诱变产生了突变的辅助型噬菌体Amber KO7。Amber KO7具有通过定点诱变在M13KO7辅助型噬菌体中引入的琥珀密码子。图8中显示了pIII的核苷酸序列(突变辅助型噬菌体Amber KO7的核苷酸1579至2853)。
为了产生Amber KO7,将辅助型噬菌体M13KO7用于感染大肠杆菌CJ236菌株(基因型dut-/ung-),并收获子代病毒颗粒以使用ssDNA纯化试剂盒(QIAGEN)纯化ssDNA。将合成的寡核苷酸(序列5’-GTGAATTATCACCGTCACCGACCTAGGCCATTTGGGAATTAGAGCCA-3’)(SEQ ID NO:23)用于在M13KO7中通过寡核苷酸定点诱变突变基因-III。将经诱变的DNA用于转化大肠杆菌XL1-Blue细胞(Agilent Technologies),并接种在软琼脂平板上非感染的XL1-Blue细胞菌苔上。个别地挑选噬菌斑,并将细胞培养于含50μg/ml卡那霉素的LB培养基中。使用DNA微量制备试剂盒提取双链复制形式(RF)DNA并测序,以确认琥珀终止突变的存在。通过AvrII限制性内切酶消化和RF DNA的琼脂凝胶电泳,确认群体的均一性。如Sambrook,J.等人,A Laboratory Manual,Third Edition,Cold Spring Harbor Laboratroy Press,Cold Spring Harbor,NY,2001所述进行全部重组DNA操作步骤。
通过噬菌体ELISA测量使用Amber KO7产生的在噬菌体颗粒上展示的Fab的水平。将抗原(Her2)固定化在免疫平板上,并使用野生型KO7(WT KO7)或者在pIII(Amber KO7)辅助型噬菌体中携带琥珀突变的经修饰的M13KO7,在XL1-Blue细胞中产生携带抗-Her2Fab的噬菌体。通过与小鼠抗-M13-HRP缀合物温育,然后在450nm处测量TMB底物OD,来检测结合。与当将WT KO7用于噬菌体产生时通过相同噬菌粒实现的水平(闭合的正方形)比较,Amber KO7的使用导致了低展示噬菌粒的更高展示水平(闭合的三角形)(图9)。使用Amber KO7的低展示噬菌粒展示的Fab水平(闭合的三角形)也与当使用WT KO7的高展示噬菌粒时观察到的Fab展示水平(开口的菱形)相似(图9)。
实施例5:产生用于原核和真核细胞产生仅未经处理的HC文库的表达和分泌系统,以及该系统用于噬菌体淘选的用途
除实施例3中所述的以在HC和LC二者上的原核和真核启动子为特征的直接和间接融合载体(pDV5.0和pDV6.0)外,我们还产生了经修饰的直接融合双载体构建体(图14中所示的pDV.6.5),其中Fab LC与STII信号序列融合,并且仅通过细菌PhoA启动子驱动,而Fab HC(含基因-III-合成内含子以及在哺乳动物细胞中用于表达全长hIgG1HC的hIgG Fc序列)通过真核CMV启动子和原核PhoA启动子二者驱动。将该构建体用于概述前述合成的人Fab文库(Lee,等人,Journal of Molecular Biology,340.1073-1093(2004)),其中仅将多样性引入到HC中。从该载体中表达全长IgG需要共转染编码LC的哺乳动物表达载体。
使用寡核苷酸定点(Kunkel)诱变和pDV.6.5的“终止模板”版本,产生噬菌体展示文库,其中将终止密码子(TAA)置于全部三个重链CDR中。通过在编码CDRH1、H2和H3的区域上退火的寡核苷酸的混合物,在诱变反应期间修复了这些终止,并用简并密码子在随机化挑选的位置处取代密码子。将诱变反应物电穿孔到XL1-Blue细胞中,并使用温度转换方法(37℃4小时,然后30℃36小时),在补充了Amber.KO7辅助型噬菌体、50μg/ml羧苄青霉素和25μg/ml卡那霉素的2YT培养基中培养培养物。通过用PEG/NaCl沉淀,从培养基中收获噬菌体。每一电穿孔反应使用~5μg的DNA,并且产生了1×108–7×108个转化体。
针对人血管内皮生长因子(VEGF)进行在该载体中产生的未经处理的噬菌体文库的淘选。对于噬菌体文库分选,将蛋白质抗原固定化在Maxisorp免疫平板上,并将文库进行4至5轮的结合挑选。在交替轮次中,备选地使用BSA或酪蛋白封闭板孔。使用噬菌体ELISA测定选自第3至第5轮的随机克隆,以与靶抗原(VEGF)和用于检查非特异性结合的无关蛋白质(Her2)比较结合。简言之,在1.6mL补充了Amber.KO7辅助型噬菌体的2YT培养基中过夜培养噬菌体克隆(实施例4)。将上清液与固定化抗原或无关蛋白质包被的平板在室温结合1小时。洗涤后,使用HRP缀合的抗-M13抗体(室温20分钟),然后使用TMB底物检测,来检测结合的噬菌体。我们分离了多个克隆,其对VEGF是ELISA阳性,但对无关对照蛋白质(Her2)不是ELISA阳性(图10-柱状图)。
然后,在用于表达全长hIgG1的小规模293细胞悬浮培养物中,通过与编码共有LC的哺乳动物表达载体共转染,将那些对VEGF显示出特异性的克隆的DNA用于表达全长IgG。根据厂商说明,使用Expifectamine或JetPEI转染1mL培养物,并在37℃/8%CO2温育5-7天。在30mL 293细胞中进行按比例放大的转染。
然后在BIAcore T100仪器上,在Fc捕获测定法中,将培养上清液用于筛选结合VEGF的IgG(图11)。将来自1mL培养物的IgG上清液用于筛选抗原结合。将抗-人Fc捕获抗体固定化在一系列S CM5传感器芯片(~10,000RU)上。将上清液顺次地从流动池2、3和4上流过(5μL/分钟持续4分钟),以允许捕获来自上清液的IgG(50-150RU),随后将抗原(100-1000nM)流过固定化的IgG上(30μL/分钟持续2分钟),以测量结合应答。
阳性结合物的测序显示,8种独特序列(图12中显示了重链CDR序列)具有阳性结合特性(图12)。将与噬菌体ELISA(图10)和BiaCore数据(图11)组合的测序数据(图12)用于挑选8个抗-VEGF克隆的库,用于进一步分析。
将这8个克隆的表达按比例放大至100mL中国仓鼠卵巢(CHO)细胞培养物(参见图15),并通过受体-阻断ELISA,将纯化的物质用于评价抗-VEGF克隆阻断VEGF与其同族受体之一(VEGFR1)结合的能力。在PBS/0.5%BSA/0.05%Tween-20中,使用3倍连续稀释的抗-VEGF抗体(200nM最高浓度)温育生物素化的hVEGF165(2nM)。室温温育1-2小时后,将混合物转移到VEGFR1固定化的平板中,并温育15分钟。然后通过链霉亲和素-HRP温育30分钟,然后用TMB底物显影,来检测VEGFR-1结合的VEGF,并测量IC50值。
我们鉴定了一个具有与贝伐单抗(市售的抗-VEGF抗体)的IC50相当的IC50的克隆(VEGF55)(图13)。因此,我们在都不需要亚克隆的情况下,能直接从噬菌体淘选进展到IgG表达,并将克隆库分类减少到单个候选物。
总之,这种经修饰的直接融合双载体(pDV.6.5)能在大肠杆菌中用于构建具有随机化重链和恒定轻链的噬菌体展示文库,并当补充了轻链表达载体时,还能在不亚克隆的情况下,将其在哺乳动物细胞中用于后续表达挑选的克隆为天然IgG1。由于哺乳动物CMV启动子仅存在于HC的上游,所以pDV在大肠杆菌中表达Fab LC和Fab HC-pIII二者,但在哺乳动物细胞中仅表达hIgG1HC。可以将该载体用于从结合多个抗原的未经处理合成Fab文库中挑选Fab片段,并然后通过将经修饰的直接融合双载体克隆与编码共有LC的哺乳动物表达载体共转染,在哺乳动物293和CHO细胞中,从挑选的克隆中表达全长天然hIgG1。天然IgG1获自那些进行了几种测定法的表达实验,例如那些获自通过ELISA和BIAcore显示结合活性的8个独特抗-VEGF克隆库的天然IgG1,我们在不需要从最初的噬菌体载体克隆中亚克隆HC序列的情况下,能分类单个候选物,以便以IgG格式评价候选物的溶液中性质、非特异性结合和生物学活性。
尽管出于明确理解的目的,已经通过说明和实例的方式略为详细地描述了前述发明,但不应将说明和实例理解为限制本发明的范围。在本文中引用的全部专利和科学文献的公开以其整体明确引入作为参考。
- 还没有人留言评论。精彩留言会获得点赞!