参与赖氨酸脱羧作用的多肽的表达及其方法和应用与流程
尸胺是参与产生多种产物的平台化合物。尸胺可以通过微生物中的赖氨酸的脱羧作用合成。赖氨酸脱羧酶是通过从赖氨酸去除羧基来催化产生尸胺的酶。例如,在大肠杆菌(E.coli)中,尸胺是通过两种赖氨酸脱羧酶多肽CadA和LdcC直接从L-赖氨酸生物合成的。
目前,尸胺的生物合成利用两种策略进行:发酵生产或体外酶催化。在L-赖氨酸的发酵生产路径中,将赖氨酸脱羧酶,通常为CadA或LdcC,添加至赖氨酸生成细菌菌株(例如谷氨酸棒杆菌(Corynebacterium glutamicum)和大肠杆菌),以便将赖氨酸生物合成途径延长至尸胺生物合成途径。或者,对于体外酶催化,可以将细菌工程化或诱导以产生赖氨酸脱羧酶,通常为CadA或LdcC,然后其可以用于通过脱羧作用将赖氨酸转化为尸胺。
但是,尸胺的生产目前是有限的并且导致低收率。因此,需要以较高收率生产尸胺的方法。
发明概述
本发明的一方面涉及一种多肽,其包含铜绿假单胞菌(P.aeruginosa)多肽Ldc2的一个或多个突变体、由铜绿假单胞菌(P.aeruginosa)多肽Ldc2的一个或多个突变体组成、或者基本上由铜绿假单胞菌(P.aeruginosa)多肽Ldc2的一个或多个突变体组成。如本文所用,铜绿假单胞菌多肽Ldc2称作“铜绿假单胞菌Ldc2”、“Ldc2”或“Ldc2多肽”,并且具有SEQ ID NO:4的氨基酸序列。
本发明的另一方面涉及编码一个或多个第一多肽的第一多核苷酸,所述第一多肽包含一个或多个第二多肽、由一个或多个第二多肽组成或者基本上由一个或多个第二多肽组成,所述第二多肽选自Ldc2、Ldc2片段和Ldc2突变体,其中所述第一多核苷酸包含分别编码一个或多个第二多肽的一个或多个第二多核苷酸;当有多个第一多肽时,每个第一多肽可以相同或不同;当有多个第二多肽时,每个第二多肽可以相同或不同;当有多个第二多核苷酸时,每个第二多核苷酸可以相同或不同;所述一个或多个第一多肽可以单独表达或作为融合蛋白表达;并且当第二多肽为Ldc2时,至少一个相应的编码所述第二多肽的第二多核苷酸包含突变的铜绿假单胞菌ldc2基因、由突变的铜绿假单胞菌ldc2基因组成或者基本上由突变的铜绿假单胞菌ldc2基因组成。如本文所用,铜绿假单胞菌ldc2基因称作“铜绿假单胞菌ldc2”或“ldc2”,并且具有SEQ ID NO:3的多核苷酸序列。ldc2突变体的实例编码Ldc2,并且可以是密码子优化的ldc2(例如,ldc2-co1(SEQ ID NO:17))。
本发明的另一方面涉及编码一个或多个第三多肽的第三多核苷酸,所述第三多肽包含一个或多个第四多肽、由一个或多个第四多肽组成或者基本上由一个或多个第四多肽组成,所述第四多肽选自Ldc2(SEQ ID NO:4)、Ldc2的片段和Ldc2的突变体;其中所述第三多核苷酸包含分别编码一个或多个第四多肽的一个或多个第四多核苷酸;当有多个第三多肽时,每个第三多肽可以相同或不同;当有多个第四多肽时,每个第四多肽可以相同或不同;当有多个第四多核苷酸时,每个第四多核苷酸可以相同或不同;并且所述一个或多个第三多肽可以单独表达或作为融合蛋白表达。在某些实施方案中,所述多核苷酸包含ldc2、由ldc2组成或者基本上由ldc2组成。
本发明的另一方面涉及第一表达质粒载体,其包含编码一个或多个第五多肽的第五多核苷酸、由编码一个或多个第五多肽的第五多核苷酸组成或者基本上由编码一个或多个第五多肽的第五多核苷酸组成,所述第五多肽包含一个或多个第六多肽、由一个或多个第六多肽组成或者基本上由一个或多个第六多肽组成,所述第六多肽选自Ldc2、Ldc2的片段和Ldc2的突变体;以及能够在宿主细胞中自主复制的骨架质粒。在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。
本发明的另一方面涉及第二表达质粒载体,其包含编码一个或多个第七多肽的第七多核苷酸、由编码一个或多个第七多肽的第七多核苷酸组成或者基本上由编码一个或多个第七多肽的第七多核苷酸组成,所述第七多肽包含一个或多个第八多肽、由一个或多个第八多肽组成或者基本上由一个或多个第八多肽组成,所述第八多肽选自Ldc2、Ldc2的片段和Ldc2的突变体;以及能够在宿主细胞中自主复制的骨架质粒。在某些实施方案中,所述宿主细胞不是铜绿假单胞菌细胞。
本发明的另一方面涉及在宿主细胞中包含所述第一表达质粒载体的第一转化体。在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。
本发明的另一方面涉及在宿主细胞中包含所述第二表达质粒载体的第二转化体。在某些实施方案中,所述宿主细胞不是铜绿假单胞菌细胞。
本发明的另一方面涉及包含如本文公开的第一或第三多核苷酸的第一突变宿主细胞,其中所述第一或第三多核苷酸已整合入所述宿主细胞的染色体。在某些实施方案中,所述宿主细胞不是铜绿假单胞菌细胞。在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。
本发明的另一方面涉及一种制备一个或多个第九多肽的方法,所述第九多肽选自Ldc2、Ldc2的片段和Ldc2的突变体,所述方法包括获得如本文所述的第一转化体、第二转化体或第一突变宿主细胞,在有效表达所述一个或多个第九多肽的条件下培养所述第一转化体、第二转化体或第一突变宿主细胞,以及收获所述一个或多个第九多肽。
本发明的另一方面涉及一种制备尸胺的方法,所述方法包括培养如本文所述的第一转化体、第二转化体或第一突变宿主细胞,利用获得自培养第一转化体、第二转化体或第一突变宿主细胞的培养物对赖氨酸进行脱羧来制备尸胺,以及提取并纯化尸胺。
本发明的另一方面涉及制备自如本文公开制备的生物基尸胺的聚酰胺和1,5-二异氰酸戊烷(1,5-diisocyanatopentane)及其组合物和制备方法。
附图说明
图1:利用国家生物技术信息中心(NCBI)基本局部比对搜索工具(BLAST)产生自对大肠杆菌蛋白CadA(高亮)的序列相似性搜索的蛋白树。
图2:利用BLAST产生自对大肠杆菌蛋白LdcC(高亮)的序列相似性搜索的蛋白树。
图3:用来构建包含具有SEQ ID NO:1的序列的铜绿假单胞菌基因(此后“ldc1”)或根据本发明的实施方案的ldc2的重组表达质粒载体的聚合酶链反应(PCR)引物序列,以及用来构建SEQ ID NO:5的启动子序列的引物序列(psyn-1和psyn-2)。
图4:用来表达具有SEQ ID NO:2的序列的铜绿假单胞菌蛋白(此后“Ldc1”)和根据本发明的实施方案的Ldc2蛋白的重组表达质粒载体图。A)pCIB10的载体图;B)pCIB45的载体图;C)pCIB46的载体图;D)pCIB47的载体图;以及E)pCIB48的载体图。
图5:来自不同物种的赖氨酸脱羧酶多肽的一部分序列的序列比对,包括大肠杆菌LdcC、宋内志贺菌(Shigella sonnei)CadA、肠道沙门氏菌(Salmonella enterica)赖氨酸脱羧酶、大肠杆菌CadA和铜绿假单胞菌Ldc2,具有保守丝氨酸(方框区)。
图6:来自不同物种的赖氨酸脱羧酶多肽的一部分序列的序列比对,包括大肠杆菌LdcC、宋内志贺菌CadA、肠道沙门氏菌赖氨酸脱羧酶、大肠杆菌CadA和铜绿假单胞菌Ldc2,具有保守天冬酰胺和丝氨酸(方框区)。
发明详述
以下描述为充分理解和实施本公开的实施方案提供具体细节。但是,本领域技术人员会理解,没有这些细节也可以实施本公开。在其他情况下,未详细示出或描述公知的结构和功能以避免不必要地模糊本公开的实施方案的描述。
铜绿假单胞菌Ldc2(登录:WP_014603046.1)在BLAST搜索中表征为β-消除裂解酶多肽。铜绿假单胞菌Ldc2与已知的大肠杆菌赖氨酸脱羧酶CadA和LdcC具有低序列相似性(分别为39.44%和38.71%序列相同性)。BLAST搜索结果未显示Ldc2是赖氨酸脱羧酶。
部分由于低基因表达和不溶性蛋白,假单胞菌(Pseudomonas)蛋白在大肠杆菌中的功能性异源表达是具有挑战性的(West,1988)。例如,以前表征的铜绿假单胞菌赖氨酸脱羧酶Ldc1(SEQ ID NO:2,登录:EME94559.1)在大肠杆菌中的异源表达未导致增加的尸胺生成,尽管其BLAST结果显示其是赖氨酸脱羧酶家族的推定成员(相应的铜绿假单胞菌基因为ldc1(SEQ ID NO:1))。
如本文公开的,意外地发现铜绿假单胞菌Ldc2的异源表达导致意外高产量的尸胺生成,表达Ldc2的大肠杆菌表现出比表达大肠杆菌赖氨酸脱羧酶CadA的大肠杆菌更高的尸胺产量(参见例如实施例5)。在其他宿主细胞(例如,蜂房哈夫尼菌(H.alvei))中表达铜绿假单胞菌Ldc2也导致与大肠杆菌CadA表达相比意外地更高产量的尸胺生成(参见例如实施例5)。此外,意外地发现本文公开的Ldc2突变多肽的表达导致高尸胺生成。
本发明的一方面涉及一种多肽,其包含Ldc2的一个或多个突变体、由Ldc2的一个或多个突变体组成或者基本上由Ldc2的一个或多个突变体组成。Ldc2的突变体可以包括对SEQ ID NO:4的氨基酸序列的一个或多个氨基酸的缺失、取代、添加和/或插入,同时Ldc2的突变体提供与Ldc2基本上相同的功能(即Ldc2的突变体具有与Ldc2相比约80%或更高的赖氨酸脱羧酶活性;与Ldc2相比约90%或更高的赖氨酸脱羧酶活性;与Ldc2相比约95%或更高的赖氨酸脱羧酶活性;与Ldc2相比约97%或更高的赖氨酸脱羧酶活性;与Ldc2相比约99%或更高的赖氨酸脱羧酶活性;或者与Ldc2相比约100%或更高的赖氨酸脱羧酶活性)。
Ldc2突变体的实例包括但不限于SEQ ID NO:6(Ldc2S111C),SEQ ID NO:11(Ldc2N262T),SEQ ID NO:12(Ldc2K265N),SEQ ID NO:13(Ldc2S111C/N262T),SEQ ID NO:14(Ldc2S111C/K265N),SEQ ID NO:15(Ldc2N262T/K265N),SEQ ID NO:16(Ldc2S111C/N262T/K265N),Ldc2的同源多肽,Ldc2S111C的同源多肽(例如Ldc2S111X),Ldc2N262T的同源多肽(例如Ldc2N262X’),Ldc2K265N的同源多肽(例如Ldc2K265X’),Ldc2S111C/N262T的同源多肽(例如Ldc2S111X/N262X’),Ldc2S111C/K265N的同源多肽(例如Ldc2S111X/K265X”),Ldc2N262T/K265N的同源多肽(例如Ldc2N262X’/K265X”),以及Ldc2S111C/N262T/K265N的同源多肽(例如Ldc2S111X/N262X’/K265X”)。X为不是丝氨酸的任何氨基酸,X’为不是天冬酰胺的任何氨基酸,并且X”为不是赖氨酸的任何氨基酸。如本文所用,同源多肽与所述多肽至少约90%、至少约95%、至少约97%、至少约98%或至少约99%同源。当Ldc2突变体具有多个突变时,每个突变可以相同或不同。
如本文所用,包含特定多肽序列的多肽可以包括所述特定多肽序列的片段和/或突变体,同时仍提供与所述完整原始未突变的特定多肽序列基本上相同的功能。多肽的片段表示所述多肽的一部分,其提供与所述完整多肽基本上相同的功能。特定多肽序列的突变体的实例包括对所述特定多肽序列的一个或多个氨基酸的缺失、取代、添加和/或插入。例如,Ldc2的片段或突变体具有Ldc2多肽的基本上相同的功能(例如赖氨酸脱羧酶活性)。
本发明的另一方面涉及编码一个或多个第一多肽的第一多核苷酸,所述第一多肽包含一个或多个第二多肽、由一个或多个第二多肽组成或者基本上由一个或多个第二多肽组成,所述第二多肽选自Ldc2、Ldc2的片段和Ldc2的突变体;其中所述第一多核苷酸包含分别编码一个或多个第二多肽的一个或多个第二多核苷酸;当有多个第一多肽时,每个第一多肽可以相同或不同;当有多个第二多肽时,每个第二多肽可以相同或不同;当有多个第二多核苷酸时,每个第二多核苷酸可以相同或不同;所述一个或多个第一多肽可以单独表达或作为融合蛋白表达;并且当第二多肽为Ldc2时,至少一个相应的编码所述第二多肽的第二多核苷酸包含突变的ldc2、由突变的ldc2组成或者基本上由突变的ldc2组成。ldc2突变体的实例编码Ldc2,并且可以是密码子优化的ldc2(例如ldc2-co1(SEQ ID NO:17))。
Ldc2的突变体与上文所述相同。例如,没有限制,Ldc2的突变体包含在选自111、262和265的一个或多个氨基酸位置具有突变的Ldc2、由在选自111、262和265的一个或多个氨基酸位置具有突变的Ldc2组成或者基本上由在选自111、262和265的一个或多个氨基酸位置具有突变的Ldc2组成(如上文所述,例如SEQ ID NO:6(Ldc2S111C)、SEQ ID NO:11(Ldc2N262T)、SEQ ID NO:12(Ldc2K265N)、SEQ ID NO:13(Ldc2S111C/N262T)、SEQ ID NO:14(Ldc2S111C/K265N)、SEQ ID NO:15(Ldc2N262T/K265N)、SEQ ID NO:16(Ldc2S111C/N262T/K265N)、Ldc2S111X、Ldc2N262X’、Ldc2K265X”、Ldc2S111X/N262X’、Ldc2S111X/K265X”、Ldc2N262X’/K265X”以及Ldc2S111X/N262X’/K265X”)。
在一个实施方案中,所述第二多肽是Ldc2的突变体,并且相应的编码所述第二多肽的第二多核苷酸是编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3)),包含选自以下的一个或多个合适的核苷酸突变的密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17)):在核苷酸位置331处的突变、在核苷酸位置332处的突变、在核苷酸位置333处的突变、在核苷酸位置784处的突变、在核苷酸位置785处的突变、在核苷酸位置786处的突变、在核苷酸位置793处的突变、在核苷酸位置794处的突变以及在核苷酸位置795处的突变。
在另一实施方案中,所述第二多肽是Ldc2的突变体,并且相应的编码所述第二多肽的第二多核苷酸是编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),包含选自以下的一个或多个合适的核苷酸突变的密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17)):在核苷酸位置332处的突变、在核苷酸位置785处的突变以及在核苷酸位置795处的突变。在某些实例中,没有限制,在位置332处的核苷酸可以突变为G,在位置785处的核苷酸可以突变为C,并且在位置795处的核苷酸可以突变为T或C。
在另一实施方案中,所述第二多肽为Ldc2,并且相应的第二多核苷酸为不是ldc2(SEQ ID NO:3)且编码Ldc2的多核苷酸。这类第二多核苷酸的实例包括但不限于密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17)。
在某些实施方案中,所述第二多核苷酸的实例包括但不限于SEQ ID NO:17(ldc2-co1)、SEQ ID NO:18(ldc2-co1C332G)、SEQ ID NO:19(ldc2-co1A785C)、SEQ ID NO:20(ldc2-co1A795C)、SEQ ID NO:21(ldc2-co1C332G/A785C)、SEQ ID NO:22(ldc2-co1C332G/A795C)、SEQ ID NO:23(ldc2-co1A785C/A795C)以及SEQ ID NO:24(ldc2-co1C332G/A785C/A795C)。
在某些实施方案中,所述第一和第二多核苷酸可以是重组或非天然存在的多核苷酸。在某些实施方案中,所述第一和第二多核苷酸可以是cDNA。在某些实施方案中,所述第一和第二多核苷酸是通过为了在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达进行密码子优化获得的。
如本文所用的核苷酸序列、多核苷酸和DNA分子不限于功能区,并且可以包括表达抑制区、编码区、前导序列、外显子、内含子和表达盒的至少一个(参见例如Papadakis et al.,"Promoters and Control Elements:Designing Expression Cassettes for Gene Therapy,"Current Gene Therapy(2004),4,89-113)。此外,核苷酸序列或多核苷酸可以包括双链DNA或单链DNA(即构成双链DNA的正义链和反义链),或者RNA。包含特定多核苷酸序列的多核苷酸可以包括所述特定多核苷酸序列的片段和/或突变体。多核苷酸的片段表示编码多肽的多核苷酸的一部分,其提供与所述完整多核苷酸编码的多肽基本上相同的功能。特定多核苷酸序列的突变体的实例包括天然存在的等位基因突变体;人工突变体;以及通过对所述特定多核苷酸序列的一个或多个核苷酸的缺失、取代、添加和/或插入获得的多核苷酸序列。应当理解,特定多核苷酸序列的这类片段和/或突变体编码多肽,所述多肽具有与原始的特定多核苷酸序列编码的多肽基本上相同的功能。例如,ldc2的片段和/或突变体编码具有基本上相同的Ldc2的功能(例如赖氨酸脱羧酶活性)的多肽。
本发明的另一方面涉及编码一个或多个第三多肽的第三多核苷酸,所述第三多肽包含一个或多个第四多肽、由一个或多个第四多肽组成或者基本上由一个或多个第四多肽组成,所述第四多肽选自Ldc2、Ldc2的片段和Ldc2的突变体;其中所述第三多核苷酸包含分别编码一个或多个第四多肽的一个或多个第四多核苷酸;当有多个第三多肽时,每个第三多肽可以相同或不同;当有多个第四多肽时,每个第四多肽可以相同或不同;当有多个第四多核苷酸时,每个第四多核苷酸可以相同或不同;并且所述一个或多个第三多肽可以单独表达或作为融合蛋白表达。在某些实施方案中,所述第三和第四多核苷酸是重组或非天然存在的多核苷酸。在某些实施方案中,所述第三和第四多核苷酸为cDNA。在某些实施方案中,所述第三和第四多核苷酸可以是通过为了在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达进行密码子优化获得的。密码子优化的编码Ldc2的ldc2的实例为SEQ ID NO:17(ldc2-co1)。在某些实施方案中,所述第三多核苷酸包含铜绿假单胞菌ldc2(SEQ ID NO:3)、其片段和/或其突变体,由铜绿假单胞菌ldc2(SEQ ID NO:3)、其片段和/或其突变体组成,或者基本上由铜绿假单胞菌ldc2(SEQ ID NO:3)、其片段和/或其突变体组成。当所述第四多肽是Ldc2的突变体时,它们与上文所述相同,并且相应的第四多核苷酸与上文所述相同。所述第四多核苷酸的实例进一步包括但不限于编码Ldc2的多核苷酸(例如ldc2及其突变体,如SEQ ID NO:17(ldc2-co1))。
密码子优化是可以用来通过增加感兴趣基因的翻译效率来最大化生物体中蛋白表达的技术。由于突变偏差和自然选择,不同生物体常表现出对编码相同氨基酸的几个密码子中的一个的特别偏好。例如,在快速生长的微生物如大肠杆菌中,最佳密码子反映它们各自基因组tRNA池的组成。因此,可以用相同氨基酸但是在快速生长的微生物中具有高频率的密码子代替氨基酸的低频率密码子。因此,优化的DNA序列的表达在快速生长的微生物中提高。参见例如密码子优化技术综述http://www.guptalab.org/shubhg/pdf/shubhra_codon.pdf,其全文加入本文参考。如本文提供的,可以将多核苷酸序列进行密码子优化用于在特定微生物(包括但不限于大肠杆菌、蜂房哈夫尼菌和铜绿假单胞菌)中的最佳多肽表达。
在某些实施方案中,多核苷酸的突变体可以获得自所述多核苷酸的密码子优化以减少其鸟嘌呤(G)和胞嘧啶(C)多核苷酸含量,用于提高蛋白表达。如果其碱基的50%或更多是G或C,则认为基因组是富含GC的。感兴趣的多核苷酸序列中的高GC含量可以导致在mRNA中形成二级结构,其可以导致中断的翻译和较低水平的表达。因此,将编码序列中的G和C残基变为A和T残基而不改变氨基酸可以提供较高的表达水平。
据认为铜绿假单胞菌ldc2是富含GC的,因为其碱基超过66%为G或C。在一些实施方案中,可以将多核苷酸优化以包含这样的鸟嘌呤和胞嘧啶多核苷酸含量,其包含所述多核苷酸的总多核苷酸含量的少于约60%、少于约55%、少于约50%、少于约45%或少于约40%。在一些实施方案中,优化以包含特定鸟嘌呤和胞嘧啶多核苷酸含量的多核苷酸可以是铜绿假单胞菌ldc2。
如本文进一步显示的,Ldc2突变体Ldc2S111C(SEQ ID NO:6)的异源表达已导致意外高的尸胺生成,表达Ldc2S111C的大肠杆菌表现出比表达大肠杆菌赖氨酸脱羧酶CadA或野生型Ldc2的大肠杆菌更高的尸胺产量(例如参见表3)。虽然在Ldc2中氨基酸位置111处的丝氨酸在来自不同物种的赖氨酸脱羧酶中是保守的(例如参见图5),但是Ldc2S111C在氨基酸位置111处包含为半胱氨酸的突变。在某些实施方案中,可以将Ldc2中氨基酸位置111处的丝氨酸突变为任何其他氨基酸(即Ldc2S111X)。例如,没有限制,X可以为丙氨酸、精氨酸、天冬酰胺、天冬氨酸、半胱氨酸、谷氨酰胺、谷氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、甲硫氨酸、苯丙氨酸、脯氨酸、苏氨酸、色氨酸、酪氨酸或缬氨酸;优选地,X为丙氨酸、甘氨酸、异亮氨酸、亮氨酸、甲硫氨酸、苏氨酸、酪氨酸或缬氨酸;更优选X为甲硫氨酸、苏氨酸或酪氨酸。
在某些实施方案中,编码Ldc2S111C的多核苷酸包含在核苷酸位置332处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置332处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置332处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置332处的核苷酸突变为G(例如ldc2-co1C332G(SEQ ID NO:18))。
在某些实施方案中,编码Ldc2S111C的多核苷酸包含在核苷酸位置332和333处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置332和333处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置332和333处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置332处的核苷酸突变为G并且可以将位置333处的核苷酸突变为T或C。
在某些实施方案中,编码Ldc2S111X的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸具有选自以下的一个或多个合适的核苷酸突变:在核苷酸位置331处的突变、在核苷酸位置332处的突变以及在核苷酸位置333处的突变。
在某些实施方案中,编码Ldc2S111C或Ldc2S111X的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
如本文进一步显示的,另一Ldc2突变体Ldc2N262T(SEQ ID NO:11)的异源表达也导致意外高的尸胺生成,表达密码子Ldc2N262T的大肠杆菌表现出比表达大肠杆菌赖氨酸脱羧酶野生型Ldc2的大肠杆菌更高的尸胺产量(例如参见表4)。虽然在Ldc2中氨基酸位置262处的天冬酰胺在来自不同物种的赖氨酸脱羧酶中是保守的(例如参见图6),但是Ldc2N262T在氨基酸位置262处包含突变。在某些实施方案中,可以将Ldc2中氨基酸位置262处的天冬酰胺突变为任何其他氨基酸(即Ldc2N262X’)。例如,没有限制,X’可以为丙氨酸、精氨酸、天冬氨酸、半胱氨酸、谷氨酰胺、谷氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、甲硫氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸或缬氨酸。在某些实施方案中,X’优选为具有极性不带电侧链的氨基酸,例如但不限于丝氨酸、苏氨酸或谷氨酰胺。
在某些实施方案中,编码Ldc2N262T的多核苷酸包含在核苷酸位置785处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置785处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置785处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置785处的核苷酸突变为C(例如ldc2-co1A785C(SEQ ID NO:19))。
在某些实施方案中,编码Ldc2N262T的多核苷酸包含在核苷酸位置785和786处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置785和786处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置785和786处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置785处的核苷酸突变为C并且可以将位置786处的核苷酸突变为T、C、A或G。
在某些实施方案中,编码Ldc2N262X’的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸具有选自以下的一个或多个合适的核苷酸突变:在核苷酸位置784处的突变、在核苷酸位置785处的突变以及在核苷酸位置786处的突变。
在某些实施方案中,编码Ldc2N262T或Ldc2N262X’的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
如本文进一步显示的,Ldc2突变体Ldc2K265N(SEQ ID NO:12)的异源表达也导致意外高的尸胺生成,表达Ldc2K265N的大肠杆菌表现出比表达野生型Ldc2的大肠杆菌更高的尸胺产量(例如参见表5)。虽然在Ldc2中氨基酸位置265处的赖氨酸在来自不同物种的赖氨酸脱羧酶中是保守的(例如参见图6),但是Ldc2K265N在位置262处包含突变。在某些实施方案中,可以将Ldc2的位置265处的赖氨酸突变为任何其他氨基酸(即Ldc2K265X”)。例如,没有限制,X’可以为丙氨酸、精氨酸、天冬酰胺、天冬氨酸、半胱氨酸、谷氨酰胺、谷氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、甲硫氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸或缬氨酸;优选具有极性不带电侧链的氨基酸如丝氨酸、苏氨酸、天冬酰胺或谷氨酰胺。
在某些实施方案中,编码Ldc2K265N的多核苷酸包含在核苷酸位置795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置795处的核苷酸突变为T或C(例如ldc2-co1A795C(SEQ ID NO:20))。
在某些实施方案中,编码Ldc2K265X”的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸具有选自以下的一个或多个合适的核苷酸突变:在核苷酸位置793处的突变、在核苷酸位置794处的突变以及在核苷酸位置795处的突变。
在某些实施方案中,编码Ldc2K265N或Ldc2K265X”的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
在某些实施方案中,Ldc2的突变体(也可以称作“Ldc2突变体”)可以在SEQ ID NO:4的序列中的一个以上的氨基酸处包含突变。在某些实施方案中,Ldc2的突变体是包含SEQ ID NO:13(Ldc2S111C/N262T)的双突变体,其在氨基酸位置111和262处具有突变。在某些实施方案中,可以将Ldc2中在氨基酸位置111处的丝氨酸和在氨基酸位置262处的天冬酰胺突变为任何其他氨基酸(Ldc2S111X/N262X’)。X和X’可以相同或不同,并且与上文所述相同。
在某些实施方案中,编码Ldc2S111C/N262T的多核苷酸包含在核苷酸位置332和785处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置332和785处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置332和785处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置332处的核苷酸突变为G并且可以将位置785处的核苷酸突变为C(例如ldc2-co1C332G/A785C(SEQ ID NO:21))。
在某些实施方案中,编码Ldc2S111C/N262T的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含如上文对编码Ldc2S111C的多核苷酸描述的一个或多个突变以及如上文对编码Ldc2N262T的多核苷酸描述的一个或多个突变。
在某些实施方案中,编码Ldc2S111X/N262X’的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含选自以下的一个或多个合适的核苷酸突变:在核苷酸位置331处的突变、在核苷酸位置332处的突变、在核苷酸位置333处的突变、在核苷酸位置784处的突变、在核苷酸位置785处的突变以及在核苷酸位置786处的突变。
在某些实施方案中,编码Ldc2S111C/N262T或Ldc2S111X/N262X’的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
在某些实施方案中,Ldc2的突变体是包含SEQ ID NO:14(Ldc2S111C/K265N)的双突变体,其在氨基酸位置111和265处具有突变。在某些实施方案中,可以将在氨基酸位置111处的丝氨酸和在氨基酸位置265处的赖氨酸突变为任何其他氨基酸(Ldc2S111X/N265X”)。X和X”可以相同或不同,并且与上文所述相同。
在某些实施方案中,编码Ldc2S111C/K265N的多核苷酸包含在核苷酸位置332和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置332和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置332和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。
在某些实施方案中,编码Ldc2S111C/K265N的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含如上文对编码Ldc2S111C的多核苷酸描述的一个或多个突变以及如上文对编码Ldc2K265N的多核苷酸描述的一个或多个突变。在某些实施方案中,可以将位置332处的核苷酸突变为G并且可以将位置795处的核苷酸突变为T或C(例如ldc2-co1C332G/A795C(SEQ ID NO:22))。
在某些实施方案中,编码Ldc2S111X/K265X”的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸具有选自以下的一个或多个合适的核苷酸突变:在核苷酸位置331处的突变、在核苷酸位置332处的突变、在核苷酸位置333处的突变、在核苷酸位置793处的突变、在核苷酸位置794处的突变以及在核苷酸位置795处的突变。
在某些实施方案中,编码Ldc2S111C/K265N或Ldc2S111X/K265X”的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
在某些实施方案中,Ldc2的突变体是包含SEQ ID NO:15(Ldc2N262T/K265N)的双突变体,其在氨基酸位置262和265处具有突变。在某些实施方案中,可以将在氨基酸位置262处的天冬酰胺和在氨基酸位置265处的赖氨酸突变为任何其他氨基酸(Ldc2N262X’/K265X”)。X’和X”可以相同或不同,并且与上文所述相同。
在某些实施方案中,编码Ldc2N262T/K265N的多核苷酸包含在核苷酸位置785和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置785和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置785和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,可以将位置785处的核苷酸突变为C并且可以将位置795处的核苷酸突变为T或C(例如ldc2-co1A785C/A795C(SEQ ID NO:23))。
在某些实施方案中,编码Ldc2N262T/K265N的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含如上文对编码Ldc2N262T的多核苷酸描述的一个或多个突变以及如上文对编码Ldc2K265N的多核苷酸描述的一个或多个突变。
在某些实施方案中,编码Ldc2N262X’/K265X”的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含选自以下的一个或多个合适的核苷酸突变:在核苷酸位置784处的突变、在核苷酸位置785处的突变、在核苷酸位置786处的突变、在核苷酸位置793处的突变、在核苷酸位置794处的突变以及在核苷酸位置795处的突变。
在某些实施方案中,编码Ldc2N262T/K265N或Ldc2N262X’/K265X”的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
在某些实施方案中,Ldc2的突变体是包含SEQ ID NO:16(Ldc2S111C/N262T/K265N)的三突变体,其在氨基酸位置111、262和265处具有突变。在某些实施方案中,可以将在氨基酸位置111处的丝氨酸、在氨基酸位置262处的天冬酰胺和在氨基酸位置265处的赖氨酸突变为任何其他氨基酸(S111X/N262X’/K265X”)。X、X’和X”可以相同或不同,并且与上文所述相同。
在某些实施方案中,编码Ldc2S111C/N262T/K265N的多核苷酸包含在核苷酸位置332、785和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由在核苷酸位置332、785和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由在核苷酸位置332、785和795处具有突变的编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成。在某些实施方案中,在位置332处的核苷酸可以突变为G,在位置785处的核苷酸可以突变为C并且在位置795处的核苷酸可以突变为T或C。
在某些实施方案中,编码Ldc2S111C/N262T/K265N的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含如上文对编码Ldc2S111C的多核苷酸描述的一个或多个突变、如上文对编码Ldc2N262T的多核苷酸描述的一个或多个突变以及如上文对编码Ldc2K265N的多核苷酸描述的一个或多个突变(例如ldc2-co1C332G/A785C/A795C(SEQ ID NO:24))。
在某些实施方案中,编码Ldc2S111X/N262X’/K265X”的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含选自以下的一个或多个合适的核苷酸突变:在核苷酸位置331处的突变、在核苷酸位置332处的突变、在核苷酸位置333处的突变、在核苷酸位置784处的突变、在核苷酸位置785处的突变、在核苷酸位置786处的突变、在核苷酸位置793处的突变、在核苷酸位置794处的突变以及在核苷酸位置795处的突变。
在某些实施方案中,编码Ldc2S111C/N262T/K265N或Ldc2S111X/N262X’/K265X”的多核苷酸可以进行进一步的密码子优化,用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)中的最佳多肽表达。
在某些实施方案中,Ldc2的突变体(SEQ ID NO:4)包含选自以下的一个或多个突变:在氨基酸位置111处的为X的突变、在氨基酸位置262处的为X’的突变以及在氨基酸位置265处的为X”的突变(即“Ldc2111/262/265”)。在某些实施方案中,X、X’和X”独立地选自丙氨酸、精氨酸、天冬酰胺、天冬氨酸、半胱氨酸、谷氨酰胺、谷氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、甲硫氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸;并且条件是X不是丝氨酸,X’不是天冬酰胺,而且X”不是赖氨酸。
因此,编码Ldc2 111/262/265的多核苷酸包含编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))、由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成或者基本上由编码Ldc2的多核苷酸(例如ldc2(SEQ ID NO:3),密码子优化的ldc2(例如ldc2-co1,SEQ ID NO:17))组成,所述编码Ldc2的多核苷酸包含选自以下的一个或多个合适的核苷酸突变:在核苷酸位置331处的突变、在核苷酸位置332处的突变、在核苷酸位置333处的突变、在核苷酸位置784处的突变、在核苷酸位置785处的突变、在核苷酸位置786处的突变、在核苷酸位置793处的突变、在核苷酸位置794处的突变以及在核苷酸位置795处的突变。
在某些实施方案中,本文描述的多核苷酸可以是重组或非天然存在的多核苷酸序列。在某些实施方案中,所述多核苷酸序列可以是cDNA。
本发明的另一方面涉及第一表达质粒载体,其包含编码一个或多个第五多肽的第五多核苷酸、由编码一个或多个第五多肽的第五多核苷酸组成或者基本上由编码一个或多个第五多肽的第五多核苷酸组成,所述第五多肽包含一个或多个第六多肽、由一个或多个第六多肽组成或者基本上由一个或多个第六多肽组成,所述第六多肽选自Ldc2、Ldc2的片段或Ldc2的突变体;以及能够在宿主细胞中自主复制的骨架质粒。第六多核苷酸编码第六多肽。在某些实施方案中,所述第五多核苷酸与上文所述第一多核苷酸相同,所述第五多肽与上文所述第一多肽相同,所述第六多核苷酸与上文所述第二多肽相同,并且所述第六多肽与上文所述第二多核苷酸相同。在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。在某些实施方案中,所述宿主细胞不是铜绿假单胞菌细胞。
在某些实施方案中,所述第一表达质粒载体还包含中和对宿主细胞有害的毒素多肽的抗毒素多核苷酸,以及任选存在的编码所述毒素多肽的毒素多核苷酸。毒素和抗毒素多核苷酸以及毒素多肽与下文进一步描述的相同。
本发明的另一方面涉及第二表达质粒载体,其包含编码一个或多个第七多肽的第七多核苷酸、由编码一个或多个第七多肽的第七多核苷酸组成或者基本上由编码一个或多个第七多肽的第七多核苷酸组成,所述第七多肽包含一个或多个第八多肽、由一个或多个第八多肽组成或者基本上由一个或多个第八多肽组成,所述第八多肽选自Ldc2、Ldc2的片段和Ldc2的突变体;以及能够在宿主细胞中自主复制的骨架质粒。第八多核苷酸编码第八多肽。在某些实施方案中,所述第七多核苷酸与上文所述第三多核苷酸相同,所述第七多肽与上文所述第三多肽相同,所述第八多核苷酸与上文所述第四多肽相同,并且所述第八多肽与上文所述第四多核苷酸相同。在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。在某些实施方案中,所述宿主细胞不是铜绿假单胞菌细胞。
在某些实施方案中,利用包含突变体ldc2(例如ldc2-co1(SEQ ID NO:17))的第二表达质粒载体异源表达Ldc2导致与利用包含ldc2的第二表达质粒载体异源表达Ldc2相同或更大的尸胺生成。在某些实施方案中,当在宿主细胞中表达时,Ldc2的片段或突变体表现出赖氨酸脱羧酶活性和/或增加尸胺生成。在某些实施方案中,在宿主细胞中异源表达Ldc2的片段或突变体导致与Ldc2的异源表达相同或更大的尸胺生成。
在某些实施方案中,第二表达质粒载体还包含中和对宿主细胞有害的毒素多肽的抗毒素多核苷酸,以及任选存在的编码所述毒素多肽的毒素多核苷酸。毒素和抗毒素多核苷酸以及毒素多肽与下文进一步描述的相同。
如本文所用,术语“宿主细胞”指微生物细胞,其可能是可以用表达质粒载体转化的任何细胞(例如,假单胞菌(例如铜绿假单胞菌)、埃希氏菌(例如大肠杆菌)、棒杆菌(例如谷氨酸棒杆菌)、芽孢杆菌、哈夫尼菌(例如蜂房哈夫尼菌)、短杆菌、乳杆菌(例如戊糖乳杆菌(Lactobacillus pentosus)、植物乳杆菌(Lactobacillus plantarum)、Lactobacillus saerimneri)、乳球菌(例如乳酸乳球菌(Lactococcus lactis)、乳酸乳球菌乳脂亚种(Lactococcus lactis ssp.cremoris)、乳酸乳球菌乳酸亚种(Lactococcus lactis ssp.lactis))和链球菌(例如嗜热链球菌(Streptococcus thermophilus)))。在某些实施方案中,所述宿主细胞可以为不是铜绿假单胞菌细胞的任何细胞。
大肠杆菌细胞可以是任何衍生自大肠杆菌K12(例如MG1655、W3110、DH10b、DH1、BW2952和由其衍生的菌株)或大肠杆菌B的大肠杆菌菌株,或者由其衍生的菌株。
在某些实施方案中,宿主细胞可以包含一个或多个内源质粒。在某些实施方案中,宿主细胞不含内源质粒。如本文所用,术语“治愈”表示从宿主细胞去除一个或多个内源质粒。在某些实施方案中,可以通过从宿主细胞去除所有内源质粒来“治愈”宿主细胞的所有内源质粒。在某些实施方案中,可以通过仅去除从细胞靶向去除的一个或多个内源质粒来“治愈”宿主细胞的一个或多个内源质粒。
在某些实施方案中,宿主细胞可以是包含编码特定毒素/抗毒素基因对的内源质粒的原核细胞(例如是蜂房哈夫尼菌)。这类毒素/抗毒素基因对在维持遗传信息和应激反应具有作用。(参见Wertz et al.“Chimeric nature of two plasmids of Hafnia alvei encoding the bacteriocins alveicins A and B.”Journal of Bacteriology,(2004)186:1598-1605)。只要细胞具有包含抗毒素基因的一个或多个质粒,通过所述一个或多个质粒连续表达的抗毒素中和毒素以保持细胞存活。在某些原核生物中,抗毒素蛋白比毒素蛋白更快降解。如果包含抗毒素基因的质粒从细胞丢失,毒素蛋白在细胞中会比抗毒素蛋白存在的时间更长,并且杀死或抑制细胞的生长。因此,优选维持包含抗毒素或毒素/抗毒素基因的质粒以保持宿主细胞存活。
如本文所用,毒素/抗毒素基因对具有两个基因,一个是表达对宿主细胞有毒的多肽的毒素基因,而另一个是中和宿主细胞中的有毒多肽的抗毒素基因。毒素/抗毒素基因对的实例包括但不限于abt/abi基因对和aat/aai基因对,它们的片段以及它们的突变体。在一些实施方案中,毒素多核苷酸序列包含SEQ ID NO:7或SEQ ID NO:9的核苷酸序列、它们的片段或它们的突变体,由SEQ ID NO:7或SEQ ID NO:9的核苷酸序列、它们的片段或它们的突变体组成,或者基本上由SEQ ID NO:7或SEQ ID NO:9的核苷酸序列、它们的片段或它们的突变体组成。在一些实施方案中,抗毒素多核苷酸序列包含SEQ ID NO:8或SEQ ID NO:10的核苷酸序列、它们的片段或它们的突变体,由SEQ ID NO:8或SEQ ID NO:10的核苷酸序列、它们的片段或它们的突变体组成,或者基本上由SEQ ID NO:8或SEQ ID NO:10的核苷酸序列、它们的片段或它们的突变体组成。
在某些实施方案中,宿主细胞可以是任何蜂房哈夫尼菌菌株,例如不含内源质粒的蜂房哈夫尼菌菌株或包含内源质粒的蜂房哈夫尼菌菌株。例如,宿主细胞可以是包含一个或多个pAlvA质粒的蜂房哈夫尼菌菌株或其治愈菌株(pAlvA-菌株),或者包含一个或多个pAlvB质粒的蜂房哈夫尼菌菌株及其治愈菌株(pAlvB-菌株)。
在某些实施方案中,本文公开的表达质粒载体(例如第一或第二表达质粒载体)可以进一步包含选自abi基因、aai基因、它们的突变和片段的一个或多个抗毒素基因,和/或选自abt/abi基因对和aat/aai基因对以及它们的突变和片段的一个或多个毒素/抗毒素基因对。例如,在某些实施方案中,表达质粒载体(例如第一和第二表达质粒载体)可以进一步包含中和对宿主细胞有害的毒素多肽的抗毒素多核苷酸,以及编码所述毒素多肽的毒素多核苷酸序列。
在某些实施方案中,宿主细胞是适合用于工业规模或大规模生产的工业菌株。例如,工业菌株可以在发酵罐中培养。培养规模可以从数百升至数百万升。在另一方面,实验室菌株通常在几升或更少中培养。在某些实施方案中,工业菌株可以比实验室菌株在更简单或更经济的培养基中生长。
能够在宿主细胞中自主复制的骨架质粒可能是可以在宿主细胞中复制的任何质粒。在一实施方案中,表达质粒载体包含可以在大肠杆菌中复制的骨架质粒。在另一实施方案中,表达质粒载体包含可以在蜂房哈夫尼菌中复制的骨架质粒。骨架质粒的实例包括但不限于可以在大肠杆菌菌株中复制的骨架质粒,例如pUC(例如pUC18和pUC19质粒)、pBR322、pSC101、p15a、pACYC、pET和pSC101质粒,以及由其衍生的质粒。
在某些实施方案中,多核苷酸的突变体可以得自针对特定微生物(例如大肠杆菌、蜂房哈夫尼菌或铜绿假单胞菌)的多核苷酸的密码子优化,以增强多肽表达。
启动子是启动特定基因转录的DNA区域。在某些实施方案中,表达质粒载体可以包含一个或多个启动子多核苷酸序列。例如,包含SEQ ID NO:5的多核苷酸序列、由SEQ ID NO:5的多核苷酸序列组成或者基本上由SEQ ID NO:5的多核苷酸序列组成的启动子多核苷酸序列可以位于多核苷酸上游。在某些实施方案中,可以利用引物psyn-1和psyn-2(见图3)合成启动子序列并进一步插入pUC18。在一些实施方案中,表达质粒载体可以包含一个或多个lac启动子多核苷酸序列以及一个或多个合成启动子多核苷酸序列。在一些实施方案中,表达质粒载体可以仅包含一个lac启动子多核苷酸序列或一个合成启动子序列。
本发明的另一方面涉及在宿主细胞中包含本文公开的第一表达质粒载体的第一转化体,其中第一表达质粒载体包含、由以下组成或基本上由以下组成:
编码一个或多个第五多肽的第五多核苷酸,所述第五多肽包含一个或多个第六多肽、由一个或多个第六多肽组成或者基本上由一个或多个第六多肽组成,所述第六多肽选自Ldc2、Ldc2的片段和Ldc2的突变体;以及
能够在宿主细胞中自主复制的骨架质粒。
第六多核苷酸编码第六多肽。宿主细胞、第五多核苷酸、第五多肽、第六多核苷酸和第六多肽与上文所述相同。
如本文所用,转化体是已通过将一个或多个表达质粒载体引入宿主细胞而被改变的宿主细胞。在某些实施方案中,通过转化将表达质粒载体引入表现出对质粒载体具有感受态的宿主细胞来获得转化体。
在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。在一实例中,第六多肽为Ldc2,第六多核苷酸编码第六多肽并且是突变的ldc2,例如用于在特定微生物(例如大肠杆菌、蜂房哈夫尼菌)中的最佳多肽表达的密码子优化的ldc2(例如ldc2-co1)。
在某些实施方案中,所述宿主细胞不是铜绿假单胞菌细胞。
本发明的另一方面涉及在宿主细胞中包含第二表达质粒载体的第二转化体,其中表达质粒载体包含、由以下组成或基本上由以下组成:
编码一个或多个第七多肽的第七多核苷酸,所述第七多肽包含一个或多个第八多肽、由一个或多个第八多肽组成或者基本上由一个或多个第八多肽组成,所述第八多肽选自Ldc2、Ldc2的片段和Ldc2的突变体。
第八多核苷酸编码第八多肽。宿主细胞、第七多核苷酸、第七多肽、第七多核苷酸和第八多肽与上文所述相同。
在某些实施方案中,所述宿主细胞是铜绿假单胞菌细胞。
在某些实施方案中,宿主细胞不是铜绿假单胞菌细胞,第八多肽为Ldc2,第八多核苷酸编码第八多肽并且不是ldc2,例如用于在宿主细胞(例如大肠杆菌、蜂房哈夫尼菌)中的最佳多肽表达的密码子优化的ldc2(例如ldc2-co1)。
在某些实施方案中,转化入本文公开的转化体(例如第一或第二转化体)的表达质粒载体(例如第一或第二表达质粒载体)进一步包含中和对宿主细胞有害的毒素多肽的抗毒素多核苷酸,以及任选存在的编码毒素多肽的毒素多核苷酸,并且可以通过将表达质粒载体(包含编码毒素多肽的毒素多核苷酸序列,以及任选存在的中和毒素多肽的抗毒素多核苷酸)引入宿主细胞来进一步改变转化体。
本发明的另一方面涉及包含如本文公开的第一或第三多核苷酸的第一突变宿主细胞,其中所述第一或第三多核苷酸已整合入所述宿主细胞的染色体。所述第一或第三多核苷酸与上文所述相同。
在某些实施方案中,所述第一或第三多核苷酸已如上文所述进行密码子优化。在某些实施方案中,所述第一或第三多核苷酸编码一个或多个多肽,所述多肽包含Ldc2和/或一个或多个Ldc2突变体、由Ldc2和/或一个或多个Ldc2突变体组成或者基本上由Ldc2和/或一个或多个Ldc2突变体组成,所述一个或多个Ldc2突变体选自SEQ ID NO:6(Ldc2S111C)、SEQ ID NO:11(Ldc2N262T)、SEQ ID NO:12(Ldc2K265N)、SEQ ID NO:13(Ldc2S111C/N262T)、SEQ ID NO:14(Ldc2S111C/K265N)、SEQ ID NO:15(Ldc2N262T/K265N)、SEQ ID NO:16(Ldc2S111C/N262T/K265N)和Ldc2 111/262/265。
在某些实施方案中,可以根据PCR介导的基因置换方法将第一或第三多核苷酸整合入宿主细胞染色体(参见例如PCR介导的基因置换方法的综述Datsenko,2000,其全文并入本文参考)。还可以通过其他合适方法产生整合的染色体。
本发明的另一方面涉及一种制备铜绿假单胞菌Ldc2、Ldc2的片段或Ldc2的突变体的方法,所述方法包括:
获得如本文公开的第一转化体、第二转化体和/或第一突变宿主细胞(例如第一和/或第二转化体);
在有效表达多肽的条件下培养第一转化体、第二转化体和/或第一突变宿主细胞;以及
收获多肽。
可以利用包含碳源和非碳营养源的培养基培养第一转化体、第二转化体和/或第一突变宿主细胞。碳源的实例包括但不限于糖(例如碳水化合物如葡萄糖和果糖)、油和/或脂肪、脂肪酸、和/或其衍生物。油和脂肪可以包含具有10个或更多个碳原子的饱和和/或不饱和脂肪酸,例如椰子油、棕榈油、棕榈仁油等。脂肪酸可以是饱和和/或不饱和脂肪酸,例如己酸、辛酸、癸酸、月桂酸、油酸、棕榈酸、亚油酸、亚麻酸、肉豆蔻酸等。脂肪酸衍生物的实例包括但不限于其酯及盐。非碳源的实例包括但不限于氮源、无机盐和其他有机营养源。
例如,培养基可以包含转化体和/或突变宿主细胞可吸收的碳源,任选具有选自氮源、无机盐和另一有机营养源的一种或多种其他源。在某些实施方案中,氮源的重量百分比是培养基的约0.01%-约0.1%。氮源的实例可以包含氨、铵盐(例如氯化铵、硫酸铵和磷酸铵)、蛋白胨、肉膏、酵母提取物等。无机盐的实例包括但不限于磷酸二氢钾、磷酸氢二钾、磷酸镁、硫酸镁、氯化钠等。其他有机营养源的实例包括但不限于氨基酸(例如甘氨酸、丙氨酸、丝氨酸、苏氨酸和脯氨酸)、维生素(例如维生素B1、维生素B12和维生素C)等。
培养可以在任何温度下进行,只要细胞可以生长,并且优选在约20℃-约40℃或约35℃。培养时间可以为约1天、约2天、约3天、约4天、约5天、约6天、约7天、约8天、约9天或约10天。
在一实施方案中,将第一转化体、第二转化体和/或第一突变宿主细胞在包含肽、蛋白胨、维生素(例如B族维生素)、痕量元素(例如氮、硫、镁)和矿物质的培养基中培养。这类培养基的实例包括但不限于包含悬浮于水(例如蒸馏或去离子)中的胰蛋白胨、酵母提取物和NaCl的通常已知的Lysogeny肉汤(LB)培养基。
本发明的另一方面涉及一种制备尸胺(1,5-戊二胺)的方法,所述方法包括:
1a)培养如本文公开的第一转化体、第二转化体和/或第一突变宿主细胞;
1b)利用获得自步骤1a的培养物对赖氨酸进行脱羧来制备尸胺;以及
1c)利用获得自步骤1b的培养物提取和纯化尸胺。
培养第一转化体、第二转化体和/或第一突变宿主细胞可以包括如上文所述培养转化体或突变宿主细胞的步骤。
如本文所用,“利用获得自步骤1a的培养物”可以包括获得自步骤1a的培养物的进一步加工。例如,利用缓冲溶液稀释培养物;离心培养物以收集细胞;将细胞重悬于缓冲溶液中;或者将细胞裂解为细胞裂解物;或/和从细胞裂解物纯化赖氨酸脱羧酶。
在另一实施方案中,所述方法的步骤1c进一步包括以下步骤:
1c1)分离获得自步骤1b的反应的固体和液体组分;
1c2)将获得自步骤1c1的液体组分的pH调整至约14或更高;
1c3)从获得自步骤1c2的液体组分去除水;以及
1c4)回收尸胺。
在步骤1c1中,分离步骤1b的反应的固体和液体组分可以通过常规离心和/或过滤完成。
在步骤1c2中,可以通过添加碱如NaOH来调整步骤1c1的液体组分的pH。NaOH可以作为固体和/或溶液(例如水性溶液)添加。
在步骤1c3中,可以通过在环境压力或真空下蒸馏来去除水。
在步骤1c4中,可以通过在环境压力或真空下蒸馏来回收尸胺。
本发明的另一方面涉及根据本文公开的方法制备的生物基尸胺。
如本文所用,“生物基”化合物表示在标准ASTM D6866下认为化合物是生物基的。
本发明的另一方面涉及具有结构1的结构的聚酰胺:
包括其立体异构体,其中:
m=4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21或22;
n=4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21或22;
j=约100~约1000000;并且
所述聚酰胺制备自具有碳数目m的一个或多个二胺以及具有碳数目n的一个或多个二羧酸,所述二胺和二羧酸中至少一个包含标准ASTM D6866下的生物基碳,并且每个二胺或二羧酸的m或n可以相同或不同。
在一实施方案中,所述二胺为生物基尸胺,更优选根据本文公开的方法制备的生物基尸胺。二羧酸的实例包括但不限于C10二羧酸、C11二羧酸、C12二羧酸、C13二羧酸、C14二羧酸、C16二羧酸、C18二羧酸和它们的任何组合。在某些实施方案中,全部或部分Cn二羧酸是生物基的。
在另一实施方案中,所述聚酰胺具有上述结构,其中:
所述聚酰胺是通过使生物基尸胺与一个或多个二羧酸反应形成的,更优选生物基尸胺是根据本文公开的方法制备的;
n=4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21或22;
j=约100-约1000000,约1000-约100000或约1000-约10000;并且
所述二羧酸包含标准ASTM D6866下的生物基碳。
本发明的另一方面涉及一种制备本文公开的聚酰胺的方法,所述方法包括根据本文公开的方法将生物基尸胺制备为Cm二胺。
在一实施方案中,所述方法进一步包括制备一种或多种生物基Cn二羧酸。
在另一实施方案中,所述方法进一步包括通过使生物基尸胺与一个或多个生物基Cn二羧酸反应来制备聚酰胺。
本发明的另一方面涉及一种包含本文公开的一种或多种聚酰胺的组合物。
在一实施方案中,所述二胺为生物基尸胺,更优选根据本文公开的方法制备的生物基尸胺。二羧酸的实例包括但不限于C10二羧酸、C11二羧酸、C12二羧酸、C13二羧酸、C14二羧酸、C16二羧酸、C18二羧酸和它们的任何组合。在某些实施方案中,全部或部分Cn二羧酸是生物基的。
在另一实施方案中,所述聚酰胺具有上述结构,其中:
所述聚酰胺是通过使生物基尸胺与一个或多个二羧酸反应形成的,更优选生物基尸胺是根据本文公开的方法制备的;
n=4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21或22;
j=约100-约1000000,约1000-约100000或约1000-约10000;并且
所述二羧酸包含标准ASTM D6866下的生物基碳。
本发明的另一方面涉及一种制备1,5-二异氰酸戊烷的方法,所述方法包括:
2a)制备如本文公开的生物基尸胺;以及
2b)将获得自步骤2a的生物基尸胺转化为1,5-二异氰酸戊烷。
步骤2b可以包括利用任何已知的方法将二胺转化为异氰酸盐/酯。所述方法的实例是传统光气法,其包括一步高温光气法(即在高温下混合光气与二胺以获得异氰酸盐/酯),改进的两步光气法,以及三光气法,其中使用三光气代替光气。还有不使用光气作为原料的其他方法。所述方法的实例是使用CO2代替光气的己二胺羰基化:将CO2添加至伯胺和有机碱的溶液中,然后将适当量的磷亲电试剂添加至反应溶液中以起始放热的脱水反应,获得异氰酸盐/酯。另一实例是氨基甲酸酯热分解法,其中将伯胺转化为氨基甲酸酯,然后将氨基甲酸酯加热至分解并产生异氰酸盐/酯。
用于氨基酸、多肽、碱基序列和核酸的缩写是基于IUPAC-IUB Communication on Biochemical Nomenclature,Eur.J.Biochem.,138:9(1984),"Guideline for Preparing Specifications Including Base Sequences and Amino Acid Sequences"(United States Patent and Trademark Office)中指定的缩写,以及这个技术领域中常用的那些缩写。
除非上下文另有明确要求,在整个说明书和权利要求书中,单词“包含”、“包括”等在包容的意义上解释(即在“包括但不限于”的意义上),与排他性或穷尽性意义相反。在本申请中使用时,单词“本文”、“以上”、“以下”、“上文”和相似输入的单词指作为整体的本申请,不是指本申请的任何特定部分。在上下文允许时,上文详细描述中使用单数或复数的单词还可以分别包括复数或单数。关于两个或更多个项目的列表的单词“或”和“和/或”涵盖单词的所有以下解释:列表中的任何项目,列表中的所有项目,以及列表中的项目的任何组合。
以下实施例意图说明本发明的各种实施方案。因此,讨论的具体实施方案不应当理解为限制本发明的范围。本领域技术人员会清楚可以进行各种等价、改变和修改而不背离本发明的范围,并且应当理解这类等价实施方案包括在本文中。此外,本公开中引用的所有参考文献均以其全文加入本文参考,就如在本文中完整示出一样。
实施例
实施例1.铜绿假单胞菌多肽序列与大肠杆菌CadA或LdcC赖氨酸脱羧酶序列不相似。
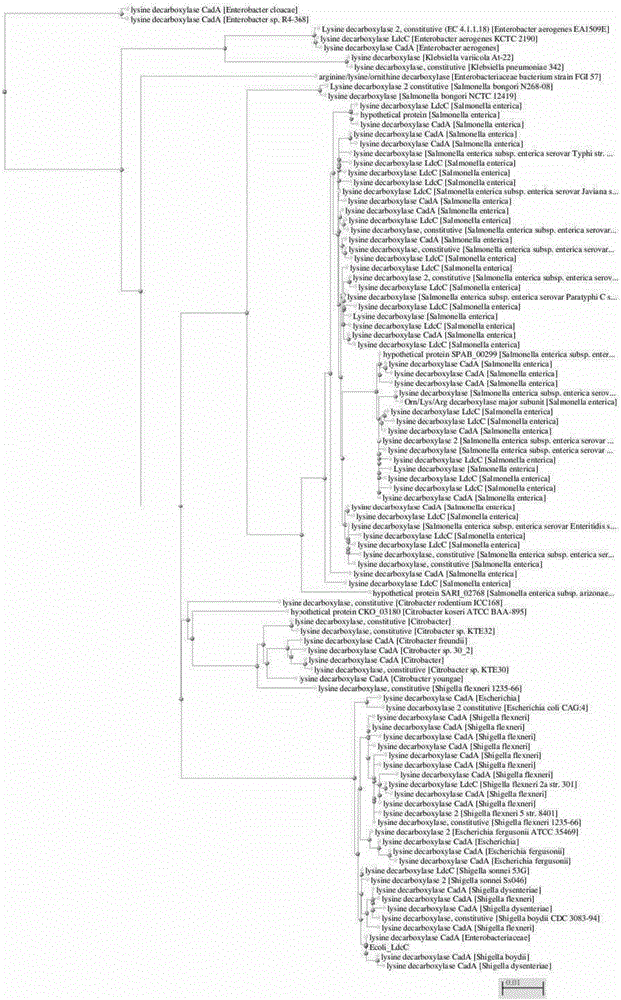
为了鉴定新的赖氨酸脱羧酶,将大肠杆菌赖氨酸脱羧酶多肽CadA和LdcC用作BLAST查询以从不是大肠杆菌的生物鉴定相似的蛋白序列。使用非冗余(nr)多肽序列数据库,并且从搜索排除大肠杆菌(taxid:562)。显示具有相似序列的多肽的BLAST结果在图1中示出为CadA的蛋白树,在图2中示出为LdcC的蛋白树。值得注意的是,如图1和2中说明的,来自假单胞菌(例如铜绿假单胞菌)的赖氨酸脱羧酶在BLAST搜索结果中未显现。
实施例2.铜绿假单胞菌ldc1和ldc2表达质粒载体以及大肠杆菌菌株的构建。
铜绿假单胞菌PAO1(登录号:NC_002516)的基因组DNA购自DSMZ(Leibniz Institute DSMZ-German Collection of Microorganisms and Cell Cultures)(DSM No.22644)并且用作PCR的模板DNA。基于来自铜绿假单胞菌PA21_ST175(登录号:EME94559.1)的基因(将其命名为ldc1)设计PCR引物ldc1-1和ldc1-2(图3)。ldc1的核苷酸序列在SEQ ID NO:1中提供并且Ldc1蛋白序列在SEQ ID NO:2中提供。Ldc1-1和ldc1-2引物用来扩增ldc1(SEQ ID NO:1)。
基于来自铜绿假单胞菌RP73(登录号:WP_014603046.1)的基因(将其命名为ldc2)设计PCR引物ldc2-1和ldc2-2(图3)。ldc2的核苷酸序列在SEQ ID NO:3中提供并且Ldc2蛋白序列在SEQ ID NO:4中提供。引物ldc2-1和ldc2-2用来扩增ldc2(SEQ ID NO:3)。
构建包含ldc1或ldc2基因的重组表达质粒载体。将各自的基因插入pUC18质粒载体或包含合成启动子的pUC18质粒载体(pCIB10)(图4A)。利用PCR引物psyn-1和psyn-2(图3)合成合成启动子序列(SEQ ID NO:5)。引物psyn-1包含启动子序列和与pUC18同源的序列,引物psyn-2包含与pUC18同源的序列。将这两个PCR引物用来扩增一部分pUC18,其包括来自质粒的插入合成启动子序列下游的多克隆位点。限制性酶EcoRI和ScaI用来消化扩增的包含合成启动子的DNA,将其进一步连接入pUC18以构建pCIB10(图4A,合成启动子显示为“Pcp25”)。用限制性酶SacI和XbaI消化扩增的ldc1和ldc2的DNA片段并将其连接入pUC18以构建pCIB45(图4B)和pCIB48(图4E),或者将其连接入pCIB10以构建pCIB46(图4C)和pCIB47(图4D)。
通过将pCIB45-48转化入大肠杆菌MG1655K12来构建细菌菌株。将pUC18转化入大肠杆菌MG1655K12作为阴性对照。
实施例3.通过在大肠杆菌中异源表达铜绿假单胞菌Ldc1和Ldc2来制备尸胺。
使包含空载体或者铜绿假单胞菌ldc1或ldc2重组表达质粒载体(分别为菌株CIB45-46和CIB 47-48)的每个大肠杆菌菌株的单一菌落在具有氨苄西林(100μg/mL)的Lysogeny肉汤(LB)培养基中于37℃在4mL培养物中生长过夜。第二天,将每个培养物接种入4mL的具有氨苄西林(100μg/mL)的新鲜LB培养基至0.05的最终光密度(OD),在吸光度600nm下测量(OD600)。使每个培养物在30℃下生长4小时,然后添加赖氨酸-HCl和磷酸吡哆醛(PLP)分别至20g/L和0.1mM的终浓度。使每个培养物生长额外的24小时,然后测量最终OD600和尸胺浓度。利用核磁共振(NMR)鉴定并定量尸胺(表1)。
表1.通过在大肠杆菌中异源表达铜绿假单胞菌Ldc1和Ldc2来制备尸胺。
如表1中提供的,表达铜绿假单胞菌Ldc2(CIB47和48)的大肠杆菌菌株与表达铜绿假单胞菌Ldc1(CIB45和CIB46)的大肠杆菌菌株相比表现出产生更高产量的尸胺。表达Ldc1的菌株全部表现出比阴性对照(N.C.)少的尸胺生成产量。因此,这些结果证实铜绿假单胞菌Ldc2在大肠杆菌中的异源表达影响尸胺生成。
实施例4.在大肠杆菌和蜂房哈夫尼菌菌株中密码子优化的铜绿假单胞菌ldc2重组表达质粒载体的构建。
将ldc2基因的核苷酸序列密码子优化用于在大肠杆菌中表达(ldc2-co1,SEQ ID NO:17)。利用限制性酶SacI和XbaI将密码子优化的序列克隆入pUC18和pCIB10以分别产生质粒pCIB65和pCIB66。通过将野生型大肠杆菌cadA克隆入pUC18和pCIB10以分别产生pCIB60和pCIB61来构建阳性对照。将质粒pCIB60和pCIB65转化入大肠杆菌MG1655K12以产生菌株CIB60和CIB65。将质粒pCIB61和pCIB66转化入蜂房哈夫尼菌以产生菌株CIB61和CIB66。
实施例5.通过大肠杆菌和蜂房哈夫尼菌中表达的铜绿假单胞菌Ldc2和大肠杆菌CadA产生尸胺。
使每个大肠杆菌和蜂房哈夫尼菌菌株(菌株CIB48、CIB60、CIB61、CIB65和CIB66)的单一菌落在具有氨苄西林(100μg/mL)的LB培养基中于29℃在2.5mL培养物中生长过夜。将用空载体pUC18转化的大肠杆菌和蜂房哈夫尼菌用作阴性对照。第二天,具有氨苄西林(100μg/mL)的基本培养基并且赖氨酸-HCl和PLP分别至20g/L和0.1mM的终浓度。将每个培养物在37℃温育5小时。从每个培养物采集1毫升的样品以利用NMR定量尸胺生成。
表2.通过大肠杆菌和蜂房哈夫尼菌中表达的铜绿假单胞菌Ldc2和大肠杆菌CadA产生的尸胺。
如表2中提供的,与表达CadA蛋白的大肠杆菌细胞(5.81g/kg)相比,产生自ldc2或ldc2-co1DNA的表达Ldc2蛋白的大肠杆菌细胞表现出更高的尸胺生成产量(6.02g/kg和6.54g/kg)。值得注意的是,与产生自ldc2DNA的表达Ldc2蛋白的大肠杆菌细胞(6.02g/kg)相比,产生自ldc2-co1DNA的表达Ldc2蛋白的大肠杆菌细胞表现出更高的尸胺生成产量(6.54g/kg)。此外,与表达CadA蛋白的蜂房哈夫尼菌细胞(6.62g/kg)相比,表达Ldc2蛋白的蜂房哈夫尼菌细胞(产生自ldc2-co1DNA)表现出更高的尸胺生成产量(9.60g/kg)。
实施例6.铜绿假单胞菌Ldc2S111C突变体的构建和表达。
如图5中提供的序列比对所示,在铜绿假单胞菌Ldc2中氨基酸位置111处的丝氨酸在来自不同物种包括大肠杆菌、宋内志贺菌和肠道沙门氏菌的赖氨酸脱羧酶中是保守的。通过在核苷酸332处产生点突变(ldc2-co1C332G(SEQ ID NO:18))来突变密码子优化的铜绿假单胞菌ldc2基因(SEQ ID NO:17),这导致用半胱氨酸取代在氨基酸111处的丝氨酸(Ldc2S111C)(SEQ ID NO:6)。利用限制性酶SacI和XbaI将ldc2-co1 C332G(SEQ ID NO:18)克隆入pUC18和pCIB10以分别产生质粒pCIB67和pCIB68。将质粒pCIB67转化入大肠杆菌MG1655K12以产生菌株CIB67,并且将pCIB68转化入蜂房哈夫尼菌以产生菌株CIB68。如实施例5所述进行确定生成的实验。简单地说,使每个菌株的单一菌落在具有氨苄西林(100μg/mL)的LB培养基中于29℃在2.5mL培养物中生长过夜。第二天,向2.5mL基本培养基补充氨苄西林(100μg/mL)以及赖氨酸-HCl和PLP分别至20g/L和0.1mM的终浓度。将每个培养物在37℃温育5小时。从每个培养物采集1毫升的样品以利用NMR定量尸胺生成。
表3.通过大肠杆菌和蜂房哈夫尼菌中表达的铜绿假单胞菌Ldc2S111C和大肠杆菌CadA产生的尸胺。
如表3所示,与表达野生型Ldc2蛋白的大肠杆菌细胞(6.54g/kg)相比,表达Ldc2S111C突变蛋白的大肠杆菌细胞表现出高得多的尸胺生成产量(9.88g/kg)。
实施例7.铜绿假单胞菌Ldc2N262T突变体的构建和表达。
如图6中提供的序列比对所示,在铜绿假单胞菌Ldc2中氨基酸位置262处的天冬酰胺在来自不同物种包括大肠杆菌、宋内志贺菌、肠道沙门氏菌的赖氨酸脱羧酶中是保守的。通过在核苷酸785处产生点突变(ldc2-co1A785C(SEQ ID NO:19))来突变ldc2-co1(SEQ ID NO:17),这导致用苏氨酸取代在氨基酸262处的天冬酰胺(Ldc2N262T)(SEQ ID NO:11)。利用限制性酶SacI和XbaI将ldc2-co1A785C(SEQ ID NO:19)克隆入pUC18和pCIB10以产生质粒pCIB75。将质粒pCIB75转化入大肠杆菌MG1655K12以产生菌株CIB75。
如实施例5所述进行确定生成的实验。简单地说,使每个菌株的单一菌落在具有氨苄西林(100μg/mL)的LB培养基中于29℃在2.5mL培养物中生长过夜。第二天,向2.5mL基本培养基补充100μg/mL氨苄西林以及赖氨酸-HCl和PLP分别至20g/L和0.1mM的终浓度。将每个培养物在37℃温育5小时。从每个培养物采集1毫升的样品以利用NMR定量尸胺生成。表4.通过大肠杆菌中表达的铜绿假单胞菌Ldc2N262T产生的尸胺。
如表4所示,与表达野生型Ldc2蛋白的大肠杆菌菌株(6.25g/kg)相比,表达Ldc2N262T突变蛋白的大肠杆菌菌株表现出高得多的尸胺生成产量(14.5g/kg)。
实施例8.铜绿假单胞菌Ldc2K265N突变体的构建和表达。
如图6中提供的序列比对所示,在铜绿假单胞菌Ldc2中氨基酸位置265处的赖氨酸在来自不同物种包括大肠杆菌、宋内志贺菌、肠道沙门氏菌的赖氨酸脱羧酶中是保守的。通过在核苷酸795处产生点突变(ldc2-co1A795C(SEQ ID NO:20))来突变ldc2-co1(SEQ ID NO:17),这导致用天冬酰胺取代在氨基酸265处的赖氨酸(Ldc2K265N)(SEQ ID NO:12)。利用限制性酶SacI和XbaI将ldc2-co1A795C(SEQ ID NO:20)克隆入pUC18和pCIB10以产生质粒pCIB76。将质粒pCIB76转化入大肠杆菌MG1655K12以产生菌株CIB76。
如实施例5所述进行确定生成的实验。简单地说,使每个菌株的单一菌落在具有氨苄西林(100μg/mL)的LB培养基中于29℃在2.5mL培养物中生长过夜。第二天,向2.5mL基本培养基补充100μg/mL氨苄西林以及赖氨酸-HCl和PLP分别至20g/L和0.1mM的终浓度。将每个培养物在37℃温育5小时。从每个培养物采集1毫升的样品以利用NMR定量尸胺生成。
表5.通过大肠杆菌中表达的铜绿假单胞菌Ldc2K265N产生的尸胺。
如表5所示,与表达野生型Ldc2蛋白的细胞(4.73g/kg)相比,表达Ldc2K265N突变蛋白的大肠杆菌细胞表现出高得多的尸胺生成产量(10.1g/kg)。
实施例9.ldc2整合入大肠杆菌染色体以及Ldc2的表达。
根据如Datsenko et al,2000中描述的PCR介导的基因置换方法进行ldc2整合入大肠杆菌染色体。铜绿假单胞菌的ldc2-co1基因(SEQ ID NO:17)在recA基因的基因座整合入大肠杆菌MG1655染色体。通过利用缝纫PCR将4个片段融合在一起来构建这个敲除盒:1)recA上游的400bp区,2)ldc2基因,3)使得能够产生氯霉素抗性的cat基因,以及4)recA下游的400bp区。将敲除盒转化入包含pKD46Red重组酶表达质粒的MG1655。使转化体在氯霉素平板上生长以鉴定成功整合,并且利用菌落PCR和测序验证基因中断。将分离的具有期望整合的一个菌落标记为CIB96。
如实施例5所述进行验证整合和证实尸胺生成的从染色体表达Ldc2的实验。简单地说,使单一菌落在具有氯霉素(25μg/mL)的LB培养基中于29℃在2.5mL培养物中生长过夜。第二天,向2.5mL基本培养基补充25μg/mL氯霉素以及赖氨酸-HCl和PLP分别至20g/L和0.1mM的终浓度。将每个培养物在37℃温育过夜。从每个培养物采集1毫升的样品以利用NMR定量尸胺生成。
表6.通过具有ldc2整合染色体的大肠杆菌中表达的铜绿假单胞菌Ldc2产生的尸胺。
如表6所示,与阴性对照(没有整合染色体的大肠杆菌细胞)(0.10g/kg)相比,包含整合入染色体的ldc2-co1且表达Ldc2蛋白的大肠杆菌细胞表现出高得多的尸胺生成产量(5.98g/kg)。
序列表
SEQ ID:NO 1(ldc1 DNA序列)
ATGCCCTACGAAGCCGATGACTATCTTTCCCGGCACTTCCAGACCAGCGGCACCGACCTGGCGCGGAAGGTCGACGAACTGGCGGCCCTTGCGGCTCCCGGCGACAGCCCCAATCTCGCGCTCTACCGCGAGATGCTCTTCACCGTGACGCGCATGGCCCAGGCCGACCGCAACCGCTGGGACGCCAAGATCATGCTGCAGACCCTGCGCGAGATGGAGCATGCCTTCAGCGTCCTCGAGCAGTTCAAGCGGCGACGCAAGGTCACCGTGTTCGGCTCGGCGCGCACGCCGGTCGAACATCCGGTCTATGCCCTGGCGCGCAAGCTGGGCGAGGAACTGGCCCGCTACGACCTGATGGTGATCACCGGCGCCGGCGGCGGCATCATGGCCGCCGCCCACGAAGGCGCCGGGCTGGAGAACAGCCTGGGCTTCAACATCACCCTGCCCTTCGAGCAGCACGCCAACCATACGGTGGACGGCAGCGGCAACCTGCTGTCGTTCCACTTTTTCTTCCTGCGCAAGCTGTTCTTCGTCAAGGAAGCCGACGCCCTGGTGCTCTGCCCCGGCGGCTTCGGCACCCTCGACGAGGCACTGGAAGTGCTGACCCTGGTACAGACCGGCAAGAGTCCGCTGGTGCCGATCGTGCTGCTCGACCAGCCGGGCGGCCGCTACTGGGAACACGCCCTGGAGTTCATGCAGGAACAGTTGCTGGAGAATCACTATATCCTGCCGGCCGACATGCGCCTGATGCGCCTGGTGCATTCGGCCGAAGACGCGGTGAAGGAAATCGCCCAGTTCTACCGCAACTTCCACTCCAGCCGCTGGCTGAAAGGCACTTTCGTGATTCGCCTGAACCACGCCCTGAACGAAGCCGCGCTGGCGCACCTGCACGAACACTTCGCCAGCCTCTGCCTGAGCGGCGGCTTCCAGCAGCAGGCCTACAGCGAGCAGGAACAGGACGAACCGGAGTTCCGCAACCTGACCCGCCTCGCCTTCGTGTTCAACGGGCGCGACCAGGGGCGGCTGCGGGAATTGCTGGACTACATCAACCTGCCGGAAAACTGGGACTGA
SEQ ID:NO 2(Ldc1蛋白序列)
SEQ ID:NO 3(ldc2 DNA序列)
ATGTATAAAGACCTCAAATTTCCCGTCCTCATCGTCCATCGCGACATCAAGGCCGACACCGTTGCCGGCGAACGCGTGCGGGGCATCGCCCACGAACTGGAGCAGGACGGCTTCAGCATTCTCTCCACCGCCAGCTCCGCCGAGGGGCGCATCGTCGCTTCCACCCACCACGGCCTGGCCTGCATTCTGGTCGCCGCCGAAGGTGCCGGGGAAAACCAGCGCCTGCTGCAGGATGTGGTCGAACTGATCCGCGTGGCCCGCGTGCGGGCGCCGCAATTGCCGATCTTCGCCCTCGGCGAGCAGGTGACCATCGAGAACGCGCCGGCCGAGTCCATGGCCGACCTGCACCAGTTGCGCGGCATCCTCTACCTGTTCGAAGACACCGTGCCGTTCCTCGCCCGCCAGGTCGCCCGGGCGGCGCGCAACTACCTGGCCGGGCTGCTGCCGCCATTCTTCCGTGCGCTGGTCGAGCACACCGCGCAGTCCAACTATTCCTGGCATACGCCGGGCCACGGCGGCGGTGTCGCCTATCGCAAGAGTCCGGTGGGACAGGCGTTCCACCAGTTCTTCGGGGAGAACACGCTGCGTTCCGACCTGTCGGTCTCGGTCCCCGAGCTGGGATCGCTGCTCGACCATACCGGCCCCCTGGCCGAGGCCGAGGACCGTGCCGCGCGCAATTTCGGCGCCGACCATACCTTCTTCGTGATCAATGGCACTTCCACCGCGAACAAGATCGTCTGGCACTCCATGGTCGGTCGCGAAGACCTGGTGCTGGTGGACCGCAACTGCCACAAGTCGATCCTCCACTCGATCATCATGACCGGGGCGATACCGCTCTACCTGACTCCGGAACGCAACGAACTGGGGATCATCGGGCCGATCCCGCTGAGCGAATTCAGCAAGCAGTCGATCGCCGCGAAGATCGCCGCCAGCCCGCTGGCGCGCGGCCGCGAGCCGAAGGTGAAGCTGGCGGTGGTGACTAACTCCACCTACGACGGCCTGTGCTACAACGCCGAGCTGATCAAGCAGACCCTCGGCGACAGCGTCGAGGTGTTGCACTTCGACGAGGCTTGGTACGCCTATGCCGCGTTCCACGAGTTCTACGACGGACGCTATGGCATGGGCACCTCGCGCAGCGAGGAGGGACCCCTGGTGTTCGCCACCCACTCCACGCACAAGATGCTCGCCGCCTTCAGCCAGGCCTCGATGATCCACGTGCAGGATGGCGGGACCCGGAAGCTGGACGTGGCGCGCTTCAACGAAGCCTTCATGATGCACATCTCGACCTCGCCGCAGTACGGCATCATCGCTTCGCTGGACGTGGCTTCGGCGATGATGGAAGGGCCCGCCGGGCGTTCGCTGATCCAGGAGACCTTCGACGAGGCCCTCAGCTTCCGCCGGGCCCTGGCCAACGTACGGCAGAACCTGGACCGGAACGACTGGTGGTTCGGCGTCTGGCAGCCGGAGCAGGTGGAGGGCACCGACCAGGTCGGCACCCATGACTGGGTGCTGGAGCCGAGCGCCGACTGGCACGGCTTCGGCGATATCGCCGAAGACTACGTGCTGCTCGACCCGATCAAGGTCACCCTGACCACCCCGGGCCTGAGCGCTGGCGGCAAGCTCAGCGAGCAGGGGATTCCGGCCGCCATCGTCAGCCGCTTCCTCTGGGAGCGCGGGCTGGTGGTGGAGAAAACCGGTCTCTACTCCTTCCTGGTGCTGTTCTCGATGGGCATCACCAAGGGCAAGTGGAGCACCCTGGTCACCGAACTGCTCGAATTCAAGCGCTGTTACGACGCCAACCTGCCGCTGCTTGACGTCTTGCCCTCCGTGGCCCAGGCCGGCGGCAAGCGCTACAACGGAGTGGGCCTGCGCGACCTCAGCGACGCCATGCACGCCAGCTACCGCGACAACGCCACGGCGAAGGCCATGAAGCGCATGTACACGGTGCTGCCGGAGGTCGCGATGCGGCCGTCCGAGGCCTACGACAAGCTGGTGCGCGGCGAGGTCGAGGCGGTACCGATCGCTCGGTTGGAAGGGCGCATCGCGGCCGTCATGCTGGTACCCTATCCGCCGGGTATCCCGCTGATCATGCCGGGTGAGCGCTTCACCGAGGCGACCCGCTCGATCCTCGACTATCTCGAGTTCGCGCGGACCTTCGAGCGCGCCTTCCCTGGTTTCGACTCCGATGTGCATGGCCTGCAGCATCAGGACGGACCGTCCGGGCGCTGCTATACCGTTGAATGCATAAAGGAATGA
SEQ ID:NO 4(Ldc2蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAESMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRNCHKSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 5(合成启动子)
agtttattcttgacatgtagtgagggggctggtataat
SEQ ID:NO 6(Ldc2 S111C蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAECMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRNCHKSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID NO:7(aat DNA序列)
>gb|AY271828.1|:385-1717蜂房哈夫尼菌质粒pAlvA,完整序列
SEQ ID NO:8(aai DNA序列)
>gb|AY271828.1|:1734-2069蜂房哈夫尼菌质粒pAlvA,完整序列
SEQ ID NO:9(abt DNA序列)
>gb|AY271829.1|:384-1566蜂房哈夫尼菌质粒pAlvB,完整序列
SEQ ID NO:10(abi DNA序列)
>gb|AY271829.1|:1583-1918蜂房哈夫尼菌质粒pAlvB,完整序列
SEQ ID:NO 11(Ldc2 N262T蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAESMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRTCHKSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 12(Ldc2 K265N蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAESMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRNCHNSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 13(Ldc2 S111C/N262T蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAECMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRTCHKSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 14(Ldc2 S111C/K265N蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAECMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRNCHNSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 15(Ldc2 N262T/K265N蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAESMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRTCHNSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 16(Ldc2 S111C/N262T/K265N蛋白序列)
MYKDLKFPVLIVHRDIKADTVAGERVRGIAHELEQDGFSILSTASSAEGRIVASTHHGLACILVAAEGAGENQRLLQDVVELIRVARVRAPQLPIFALGEQVTIENAPAECMADLHQLRGILYLFEDTVPFLARQVARAARNYLAGLLPPFFRALVEHTAQSNYSWHTPGHGGGVAYRKSPVGQAFHQFFGENTLRSDLSVSVPELGSLLDHTGPLAEAEDRAARNFGADHTFFVINGTSTANKIVWHSMVGREDLVLVDRTCHNSILHSIIMTGAIPLYLTPERNELGIIGPIPLSEFSKQSIAAKIAASPLARGREPKVKLAVVTNSTYDGLCYNAELIKQTLGDSVEVLHFDEAWYAYAAFHEFYDGRYGMGTSRSEEGPLVFATHSTHKMLAAFSQASMIHVQDGGTRKLDVARFNEAFMMHISTSPQYGIIASLDVASAMMEGPAGRSLIQETFDEALSFRRALANVRQNLDRNDWWFGVWQPEQVEGTDQVGTHDWVLEPSADWHGFGDIAEDYVLLDPIKVTLTTPGLSAGGKLSEQGIPAAIVSRFLWERGLVVEKTGLYSFLVLFSMGITKGKWSTLVTELLEFKRCYDANLPLLDVLPSVAQAGGKRYNGVGLRDLSDAMHASYRDNATAKAMKRMYTVLPEVAMRPSEAYDKLVRGEVEAVPIARLEGRIAAVMLVPYPPGIPLIMPGERFTEATRSILDYLEFARTFERAFPGFDSDVHGLQHQDGPSGRCYTVECIKE
SEQ ID:NO 17(ldc2-co1 DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATCTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTAACTGTCACAAATCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 18(ldc2-co1 C332G DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATGTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTAACTGTCACAAATCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 19(ldc2-co1 A785C DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATCTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTACCTGTCACAAATCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 20(ldc2-co1 A795C DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATCTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTAACTGTCACAACTCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 21(ldc2-co1 C332G/A785C DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATGTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTACCTGTCACAAATCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 22(ldc2-co1 C332G/A795C DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATGTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTAACTGTCACAACTCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 23(ldc2-co1 A785C/A795C DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATCTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTACCTGTCACAACTCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
SEQ ID:NO 24(ldc2-co1 C332G/A785C/A795C DNA序列)
ATGTACAAAGATCTGAAATTCCCTGTTCTGATTGTACACCGCGATATCAAGGCGGACACGGTAGCCGGCGAGCGTGTTCGCGGTATTGCCCACGAACTCGAACAAGACGGCTTTAGCATTCTCTCTACGGCGTCTTCTGCGGAAGGCCGCATTGTGGCTAGCACGCACCACGGTCTCGCCTGCATCCTCGTGGCAGCTGAGGGTGCGGGTGAGAATCAGCGTCTGCTCCAAGACGTGGTTGAGCTGATCCGTGTAGCTCGCGTCCGTGCGCCACAGCTCCCGATCTTCGCGCTGGGCGAACAGGTGACTATTGAAAACGCGCCTGCCGAATGTATGGCCGACCTGCACCAGCTCCGCGGCATTCTGTATCTCTTCGAGGATACTGTCCCGTTCCTGGCACGTCAGGTTGCACGCGCAGCGCGTAACTACCTCGCTGGCCTCCTCCCGCCATTCTTCCGTGCACTCGTGGAGCACACGGCCCAAAGCAATTACTCTTGGCACACCCCGGGTCACGGTGGTGGTGTCGCTTACCGTAAATCTCCGGTAGGTCAAGCTTTCCACCAGTTCTTTGGCGAGAATACCCTCCGCTCTGACCTGTCTGTTAGCGTTCCAGAGCTGGGCAGCCTGCTGGATCACACTGGCCCTCTCGCGGAAGCAGAGGATCGTGCCGCTCGCAATTTCGGTGCGGACCACACCTTCTTTGTCATCAATGGTACCTCTACTGCGAACAAAATCGTTTGGCACTCTATGGTTGGTCGCGAGGACCTGGTGCTGGTCGATCGTACCTGTCACAACTCTATTCTGCACTCCATTATCATGACGGGTGCTATCCCACTGTACCTGACTCCGGAACGCAACGAACTGGGTATTATCGGCCCTATTCCACTCTCCGAGTTTTCTAAACAATCTATCGCAGCAAAAATTGCCGCCTCCCCACTCGCGCGTGGTCGTGAACCGAAAGTTAAACTGGCTGTCGTTACCAACTCTACCTATGACGGTCTGTGTTACAACGCGGAACTGATCAAACAAACCCTCGGCGACTCTGTCGAGGTACTGCATTTCGACGAGGCTTGGTATGCTTATGCGGCGTTTCACGAGTTCTACGACGGCCGCTACGGTATGGGCACTTCTCGTTCCGAAGAGGGTCCGCTGGTCTTTGCTACCCATTCTACCCACAAGATGCTCGCGGCTTTTTCCCAAGCTAGCATGATTCACGTTCAGGATGGTGGTACGCGCAAGCTGGACGTCGCCCGCTTTAACGAAGCCTTTATGATGCACATCAGCACCTCTCCACAGTACGGCATCATTGCGTCTCTCGATGTCGCAAGCGCTATGATGGAAGGTCCTGCCGGTCGTAGCCTGATCCAAGAGACGTTCGATGAGGCGCTGTCCTTCCGTCGTGCTCTGGCGAATGTCCGTCAGAACCTGGACCGTAATGATTGGTGGTTCGGTGTCTGGCAACCGGAGCAGGTTGAGGGCACCGACCAGGTAGGTACTCACGACTGGGTTCTCGAGCCTAGCGCGGACTGGCATGGTTTTGGTGACATTGCGGAGGATTACGTTCTCCTCGATCCTATCAAAGTTACCCTGACCACCCCAGGTCTGAGCGCTGGCGGTAAACTCTCTGAACAAGGCATCCCGGCAGCTATCGTTAGCCGTTTCCTGTGGGAACGTGGTCTGGTGGTCGAGAAAACGGGTCTGTACTCTTTCCTGGTTCTGTTCTCCATGGGTATCACGAAAGGCAAATGGTCTACTCTGGTTACCGAGCTGCTCGAATTCAAACGCTGTTACGACGCGAATCTGCCACTCCTGGATGTGCTGCCTTCTGTAGCGCAGGCGGGTGGTAAACGCTATAACGGTGTAGGTCTGCGTGATCTGTCCGATGCCATGCACGCTTCTTATCGTGACAATGCCACGGCGAAGGCCATGAAGCGTATGTATACGGTGCTCCCGGAAGTAGCCATGCGCCCGTCCGAAGCTTATGATAAGCTCGTACGCGGTGAAGTCGAAGCTGTTCCTATTGCACGTCTCGAGGGTCGTATTGCGGCGGTTATGCTGGTTCCGTACCCGCCAGGTATCCCGCTCATTATGCCGGGTGAACGTTTTACTGAAGCTACCCGCTCCATTCTGGACTATCTGGAGTTTGCCCGTACCTTCGAGCGCGCGTTCCCGGGCTTTGACTCTGATGTTCACGGCCTCCAACATCAAGATGGCCCGTCTGGCCGTTGTTATACCGTTGAATGCATCAAGGAATAA
参考文献
下文列出的参考文献、专利和公开的专利申请以及上文说明书中引用的所有参考文献以其全文加入本文参考,就如在本文中完整示出的一样。
1.West SE and Iglewski BH(1988).Codon usage in Pseudomonas aeruginosa.Nucleic Acids Res 16:9323-9335.
2.Wertz et al.Chimeric nature of two plasmids of H.alvei encoding the bacteriocins alveicins A and B.Journal of Bacteriology,(2004)186:1598-1605.3.Datsenko KA&Wanner BL(2000).One-step inactivation of chromosomal genes in Escherichia coli K-12 using PCR products.PNAS:6640-6645.
4.Papadakis et al.,Promoters and Control Elements:Designing Expression Cassettes for Gene Therapy.Current Gene Therapy(2004),4,89-113.
序列表
<110> 凯赛生物产业有限公司
<120> 参与赖氨酸脱羧作用的多肽的表达及其方法和应用
<130> 77705-8005
<160> 24
<170> PatentIn version 3.5
<210> 1
<211> 1071
<212> DNA
<213> Pseudomonas aeruginosa
<400> 1
atgccctacg aagccgatga ctatctttcc cggcacttcc agaccagcgg caccgacctg 60
gcgcggaagg tcgacgaact ggcggccctt gcggctcccg gcgacagccc caatctcgcg 120
ctctaccgcg agatgctctt caccgtgacg cgcatggccc aggccgaccg caaccgctgg 180
gacgccaaga tcatgctgca gaccctgcgc gagatggagc atgccttcag cgtcctcgag 240
cagttcaagc ggcgacgcaa ggtcaccgtg ttcggctcgg cgcgcacgcc ggtcgaacat 300
ccggtctatg ccctggcgcg caagctgggc gaggaactgg cccgctacga cctgatggtg 360
atcaccggcg ccggcggcgg catcatggcc gccgcccacg aaggcgccgg gctggagaac 420
agcctgggct tcaacatcac cctgcccttc gagcagcacg ccaaccatac ggtggacggc 480
agcggcaacc tgctgtcgtt ccactttttc ttcctgcgca agctgttctt cgtcaaggaa 540
gccgacgccc tggtgctctg ccccggcggc ttcggcaccc tcgacgaggc actggaagtg 600
ctgaccctgg tacagaccgg caagagtccg ctggtgccga tcgtgctgct cgaccagccg 660
ggcggccgct actgggaaca cgccctggag ttcatgcagg aacagttgct ggagaatcac 720
tatatcctgc cggccgacat gcgcctgatg cgcctggtgc attcggccga agacgcggtg 780
aaggaaatcg cccagttcta ccgcaacttc cactccagcc gctggctgaa aggcactttc 840
gtgattcgcc tgaaccacgc cctgaacgaa gccgcgctgg cgcacctgca cgaacacttc 900
gccagcctct gcctgagcgg cggcttccag cagcaggcct acagcgagca ggaacaggac 960
gaaccggagt tccgcaacct gacccgcctc gccttcgtgt tcaacgggcg cgaccagggg 1020
cggctgcggg aattgctgga ctacatcaac ctgccggaaa actgggactg a 1071
<210> 2
<211> 438
<212> PRT
<213> Pseudomonas aeruginosa
<400> 2
Met Ala Ala Leu Asp Glu Leu Arg Gln Val Ala Pro Ser Ile Pro Leu
1 5 10 15
Phe Leu Leu Phe Arg Gln Leu Arg Ile Glu Gln Leu Ser Ser Gln Leu
20 25 30
Leu Asp Glu Val Gln Gly Cys Phe Asn Leu Ala Ala Gly Pro Ala Arg
35 40 45
Phe Ile Ala Glu Arg Ile Asp Ser Asp Leu Arg Glu Trp Arg Ala Pro
50 55 60
Ala Gly Pro Arg Arg Leu Arg Asp Tyr Ala Pro Pro Val Pro Arg Thr
65 70 75 80
Pro Val Ser Ala Arg Tyr Asn Gly Arg Ala Arg Leu Asp Leu Ala Pro
85 90 95
Ala Lys Gln Trp Arg Ile Gly Ser Gly Ser Thr Ala Glu Arg Leu Ala
100 105 110
Thr Pro Leu Asn Asp Leu Ser Thr Ala Tyr Arg Lys Thr Ser Ala Gly
115 120 125
Ala Pro Ala Ala His Ala Gly Asp Ile Ala Glu Ala Phe Arg Arg Ala
130 135 140
Leu Trp Glu Ala Ala Ala Arg Leu Ala Arg Glu Asp Gly Asp Thr Trp
145 150 155 160
Phe Phe Glu Ile Leu Arg Gly Asn Pro Gly Pro Gly Ile Glu Ala Gly
165 170 175
Arg Glu Thr Pro Ala Lys Arg Trp His Gly Leu Ala Glu Thr Leu Asp
180 185 190
Ser Ser Pro Arg Leu Asp Pro Leu Arg Val Ala Leu Ser Ala Pro Gly
195 200 205
Leu Asp Ser Arg Gly Arg Pro Ala Ser Phe Gly Val Pro Ala Ala Val
210 215 220
Val Cys Arg Tyr Leu Arg Arg His Gly Ile Ala Pro Leu Arg Thr Gly
225 230 235 240
Asp Tyr Arg Phe Leu Leu Leu Phe Pro Gln Gly Ala Arg Ala Glu His
245 250 255
Ala Gln Pro Leu Val Asp Arg Leu Cys Glu Phe Lys Arg Arg His Asp
260 265 270
Asp Asp Ala Pro Leu Lys Gln Val Leu Pro Glu Leu Leu Asp Ser Ser
275 280 285
Pro Leu Tyr Arg Tyr Ile Gly Leu Arg Glu Leu Cys Ala Met Ile His
290 295 300
Glu Ala Ser Leu Arg Leu His Leu Thr Ala Leu Ala Asp Ala Ala Ala
305 310 315 320
Arg Thr Ala Gly His Ala Ala Leu Ala Pro Ala Thr Val Tyr Gly His
325 330 335
Leu Val Arg Asp Glu Thr Glu Ala Val Ala Ile Asp Arg Leu Gly Gly
340 345 350
Arg Val Val Ala Ser Leu Val Gly Val His Pro Ala Ala Thr Pro Leu
355 360 365
Leu Leu Pro Gly Glu Arg Val Ala Glu Glu Ser Pro Ala Leu Ile Asp
370 375 380
Tyr Leu Leu Ala Leu Gln Ala Phe Gly Glu His Phe Pro Gly Phe Ala
385 390 395 400
Pro Glu Leu Gln Gly Ile Glu Ile Asp Glu Arg Gly Arg Tyr Arg Val
405 410 415
Arg Cys Val Arg Pro Ala Ala Leu Ala Arg Gly Ser Val Leu Arg Leu
420 425 430
Ala Thr Arg Arg Pro Asp
435
<210> 3
<211> 2256
<212> DNA
<213> Pseudomnas aeruginosa
<400> 3
atgtataaag acctcaaatt tcccgtcctc atcgtccatc gcgacatcaa ggccgacacc 60
gttgccggcg aacgcgtgcg gggcatcgcc cacgaactgg agcaggacgg cttcagcatt 120
ctctccaccg ccagctccgc cgaggggcgc atcgtcgctt ccacccacca cggcctggcc 180
tgcattctgg tcgccgccga aggtgccggg gaaaaccagc gcctgctgca ggatgtggtc 240
gaactgatcc gcgtggcccg cgtgcgggcg ccgcaattgc cgatcttcgc cctcggcgag 300
caggtgacca tcgagaacgc gccggccgag tccatggccg acctgcacca gttgcgcggc 360
atcctctacc tgttcgaaga caccgtgccg ttcctcgccc gccaggtcgc ccgggcggcg 420
cgcaactacc tggccgggct gctgccgcca ttcttccgtg cgctggtcga gcacaccgcg 480
cagtccaact attcctggca tacgccgggc cacggcggcg gtgtcgccta tcgcaagagt 540
ccggtgggac aggcgttcca ccagttcttc ggggagaaca cgctgcgttc cgacctgtcg 600
gtctcggtcc ccgagctggg atcgctgctc gaccataccg gccccctggc cgaggccgag 660
gaccgtgccg cgcgcaattt cggcgccgac cataccttct tcgtgatcaa tggcacttcc 720
accgcgaaca agatcgtctg gcactccatg gtcggtcgcg aagacctggt gctggtggac 780
cgcaactgcc acaagtcgat cctccactcg atcatcatga ccggggcgat accgctctac 840
ctgactccgg aacgcaacga actggggatc atcgggccga tcccgctgag cgaattcagc 900
aagcagtcga tcgccgcgaa gatcgccgcc agcccgctgg cgcgcggccg cgagccgaag 960
gtgaagctgg cggtggtgac taactccacc tacgacggcc tgtgctacaa cgccgagctg 1020
atcaagcaga ccctcggcga cagcgtcgag gtgttgcact tcgacgaggc ttggtacgcc 1080
tatgccgcgt tccacgagtt ctacgacgga cgctatggca tgggcacctc gcgcagcgag 1140
gagggacccc tggtgttcgc cacccactcc acgcacaaga tgctcgccgc cttcagccag 1200
gcctcgatga tccacgtgca ggatggcggg acccggaagc tggacgtggc gcgcttcaac 1260
gaagccttca tgatgcacat ctcgacctcg ccgcagtacg gcatcatcgc ttcgctggac 1320
gtggcttcgg cgatgatgga agggcccgcc gggcgttcgc tgatccagga gaccttcgac 1380
gaggccctca gcttccgccg ggccctggcc aacgtacggc agaacctgga ccggaacgac 1440
tggtggttcg gcgtctggca gccggagcag gtggagggca ccgaccaggt cggcacccat 1500
gactgggtgc tggagccgag cgccgactgg cacggcttcg gcgatatcgc cgaagactac 1560
gtgctgctcg acccgatcaa ggtcaccctg accaccccgg gcctgagcgc tggcggcaag 1620
ctcagcgagc aggggattcc ggccgccatc gtcagccgct tcctctggga gcgcgggctg 1680
gtggtggaga aaaccggtct ctactccttc ctggtgctgt tctcgatggg catcaccaag 1740
ggcaagtgga gcaccctggt caccgaactg ctcgaattca agcgctgtta cgacgccaac 1800
ctgccgctgc ttgacgtctt gccctccgtg gcccaggccg gcggcaagcg ctacaacgga 1860
gtgggcctgc gcgacctcag cgacgccatg cacgccagct accgcgacaa cgccacggcg 1920
aaggccatga agcgcatgta cacggtgctg ccggaggtcg cgatgcggcc gtccgaggcc 1980
tacgacaagc tggtgcgcgg cgaggtcgag gcggtaccga tcgctcggtt ggaagggcgc 2040
atcgcggccg tcatgctggt accctatccg ccgggtatcc cgctgatcat gccgggtgag 2100
cgcttcaccg aggcgacccg ctcgatcctc gactatctcg agttcgcgcg gaccttcgag 2160
cgcgccttcc ctggtttcga ctccgatgtg catggcctgc agcatcagga cggaccgtcc 2220
gggcgctgct ataccgttga atgcataaag gaatga 2256
<210> 4
<211> 751
<212> PRT
<213> Pseudomonas aeruginosa
<400> 4
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Ser Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Asn Cys His Lys Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 5
<211> 38
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 5
agtttattct tgacatgtag tgagggggct ggtataat 38
<210> 6
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 6
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Cys Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Asn Cys His Lys Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 7
<211> 1333
<212> DNA
<213> Hafnia alvei
<400> 7
ttgactttgt taaaagtcag gcataagatc aaaatactgt atatataaca atgtatttat 60
atacagtatt ttatactttt tatctaacgt cagagagggc aatattatga gtggtggaga 120
tggcaagggt cacaatagtg gagcacatga ttccggtggc agcattaatg gaacttctgg 180
gaaaggtggg ccatcaagcg gaggagcatc agataattct gggtggagtt cggaaaataa 240
cccgtggggc ggtggtaact cgggaatgat tggtggcagt caaggaggta acggagctaa 300
tcatggtggc gaaaatacat cttctaacta tgggaaagat gtatcacgcc aaatcggtga 360
tgcgatagcc agaaaggaag gcatcaatcc gaaaatattc actgggtact ttatccgttc 420
agatggatat ttgatcggaa taacgccact tgtcagtggt gatgcctttg gcgttaatct 480
tggcctgttc aataacaatc aaaatagtag tagtgaaaat aagggatgga atggaaggaa 540
tggagatggc attaaaaata gtagccaagg tggatggaag attaaaacta atgaacttac 600
ttcaaaccaa gtagctgctg ctaaatccgt tccagaacct aaaaatagta aatattataa 660
gtccatgaga gaagctagcg atgaggttat taattctaat ttaaaccaag ggcatggagt 720
tggtgaggca gctagagctg aaagagatta cagagaaaaa gtaaagaacg caatcaatga 780
taatagtccc aatgtgctac aggatgctat taaatttaca gcagattttt ataaggaagt 840
ttttaacgct tacggagaaa aagccgaaaa actagccaag ttattagctg atcaagctaa 900
aggtaaaaag atccgcaatg tagaagatgc attgaaatct tatgaaaaac acaaggctaa 960
cattaacaaa aaaatcaatg cgaaagatcg cgaagctatc gccaaggctt tggagtctat 1020
ggatgtagaa aaagccgcaa aaaatatatc caagttcagc aaaggactag gttgggttgg 1080
cccagctatc gatataactg attggtttac agaattatac aaagcagtga aaactgataa 1140
ttggagatct ctttatgtta aaactgaaac tattgcagta gggctagctg caacccatgt 1200
caccgcctta gcattcagtg ctgtcttggg tgggcctata ggtattttag gttatggttt 1260
gattatggct ggggttgggg cgttagttaa cgagacaata gttgacgagg caaataaggt 1320
cattgggatt taa 1333
<210> 8
<211> 336
<212> DNA
<213> Hafnia alvei
<400> 8
ctatatttta gcggtcacat tttttatttc aaaacaaaca gaaagaacac caataggaat 60
tgatgtcata aaaataaaaa taaaatacaa agtcattaaa tatgtttttg gcacaccatc 120
cttaaaaaaa cctgttttcc aaaattcttt tttcgtatat ctaagcgctg ctttctctat 180
tagaaaccga gagaaaggaa atagaatagc gctagccaaa ccaaagattc tgagcgcaat 240
tattttaggt tcgtcatcac cataactggc gtaaagaata caagcagcca taaagtatcc 300
ccaaaacata ttatgtatgt aatatttcct tgtcat 336
<210> 9
<211> 1077
<212> DNA
<213> Hafnia alvei
<400> 9
atgagtggtg gagacggtaa aggtcacaat agtggagcac atgattccgg tggcagcatt 60
aatggaactt cggggaaagg tggacctgat tctggtggcg gatattggga caaccatcca 120
catattacaa tcaccggtgg acgggaagta ggtcaagggg gagctggtat caactggggt 180
ggtggttctg gtcatggtaa cggcgggggc tcagttgcca tccaagaata taacacgagt 240
aaatatccta acacgggagg atttcctcct cttggagacg ctagctggct gttaaatcct 300
ccaaaatggt cggttattga agtaaaatca gaaaactcag catggcgctc ttatattact 360
catgttcaag gtcatgttta caaattgact tttgatggta cgggtaagct cattgatacc 420
gcgtatgtta attatgaacc cagtgatgat actcgttgga gcccgcttaa aagttttaaa 480
tataataaag gaaccgctga aaaacaggtt agggatgcca ttaacaatga aaaagaagca 540
gttaaggacg ctgttaaatt tactgcagac ttctataaag aggtttttaa ggtttacgga 600
gaaaaagccg agaagctcgc taagttatta gcagatcaag ctaaaggcaa aaaggttcgc 660
aacgtagaag atgccttgaa atcttatgaa aaatataaga ctaacattaa caaaaaaatc 720
aatgcgaaag atcgcgaagc tattgctaaa gccttggagt ctatggatgt aggaaaagcc 780
gcaaaaaata tagccaagtt cagtaaagga ctaggttggg ttggccctgc tatcgatata 840
actgattggt ttacagaatt atacaaggca gtggaaactg ataattggag atctttttat 900
gttaaaactg aaactattgc agtagggcta gctgcaaccc atgttgccgc cttggcattc 960
agcgctgtct tgggtgggcc tgtaggtatt ttgggttatg gtttgattat ggctggggtt 1020
ggggcgttag ttaatgagac aatagttgac gaggcaaata aggttattgg gctttaa 1077
<210> 10
<211> 336
<212> DNA
<213> Hafnia alvei
<400> 10
ctataattta gcggtcacat tttttatttc aaaaaaaaca gaaataacac ctataggaat 60
tgatgtcata aaaataaaaa ttaaatacaa agtcattaaa tatgtttttg gcacgccatc 120
cttaaaaaaa ccagtttccc aaaattcttt tttcgtatat ctaagcgcgg ttttctctat 180
taaaaaccga gagaaaggga ataggatagc actagccaaa ccaaagattc tgagcgcaat 240
tattttaggt tcgttatccc cataactggc gtaaagaata caaacagcca taaagtaccc 300
ccaaaacata ttatgtatat aatatttcct tgtcat 336
<210> 11
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 11
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Ser Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Thr Cys His Lys Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 12
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 12
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Ser Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Asn Cys His Asn Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 13
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 13
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Cys Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Thr Cys His Lys Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 14
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 14
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Cys Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Asn Cys His Asn Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 15
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 15
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Ser Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Thr Cys His Asn Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 16
<211> 751
<212> PRT
<213> artificial
<220>
<223> synthetic, synthesized
<400> 16
Met Tyr Lys Asp Leu Lys Phe Pro Val Leu Ile Val His Arg Asp Ile
1 5 10 15
Lys Ala Asp Thr Val Ala Gly Glu Arg Val Arg Gly Ile Ala His Glu
20 25 30
Leu Glu Gln Asp Gly Phe Ser Ile Leu Ser Thr Ala Ser Ser Ala Glu
35 40 45
Gly Arg Ile Val Ala Ser Thr His His Gly Leu Ala Cys Ile Leu Val
50 55 60
Ala Ala Glu Gly Ala Gly Glu Asn Gln Arg Leu Leu Gln Asp Val Val
65 70 75 80
Glu Leu Ile Arg Val Ala Arg Val Arg Ala Pro Gln Leu Pro Ile Phe
85 90 95
Ala Leu Gly Glu Gln Val Thr Ile Glu Asn Ala Pro Ala Glu Cys Met
100 105 110
Ala Asp Leu His Gln Leu Arg Gly Ile Leu Tyr Leu Phe Glu Asp Thr
115 120 125
Val Pro Phe Leu Ala Arg Gln Val Ala Arg Ala Ala Arg Asn Tyr Leu
130 135 140
Ala Gly Leu Leu Pro Pro Phe Phe Arg Ala Leu Val Glu His Thr Ala
145 150 155 160
Gln Ser Asn Tyr Ser Trp His Thr Pro Gly His Gly Gly Gly Val Ala
165 170 175
Tyr Arg Lys Ser Pro Val Gly Gln Ala Phe His Gln Phe Phe Gly Glu
180 185 190
Asn Thr Leu Arg Ser Asp Leu Ser Val Ser Val Pro Glu Leu Gly Ser
195 200 205
Leu Leu Asp His Thr Gly Pro Leu Ala Glu Ala Glu Asp Arg Ala Ala
210 215 220
Arg Asn Phe Gly Ala Asp His Thr Phe Phe Val Ile Asn Gly Thr Ser
225 230 235 240
Thr Ala Asn Lys Ile Val Trp His Ser Met Val Gly Arg Glu Asp Leu
245 250 255
Val Leu Val Asp Arg Thr Cys His Asn Ser Ile Leu His Ser Ile Ile
260 265 270
Met Thr Gly Ala Ile Pro Leu Tyr Leu Thr Pro Glu Arg Asn Glu Leu
275 280 285
Gly Ile Ile Gly Pro Ile Pro Leu Ser Glu Phe Ser Lys Gln Ser Ile
290 295 300
Ala Ala Lys Ile Ala Ala Ser Pro Leu Ala Arg Gly Arg Glu Pro Lys
305 310 315 320
Val Lys Leu Ala Val Val Thr Asn Ser Thr Tyr Asp Gly Leu Cys Tyr
325 330 335
Asn Ala Glu Leu Ile Lys Gln Thr Leu Gly Asp Ser Val Glu Val Leu
340 345 350
His Phe Asp Glu Ala Trp Tyr Ala Tyr Ala Ala Phe His Glu Phe Tyr
355 360 365
Asp Gly Arg Tyr Gly Met Gly Thr Ser Arg Ser Glu Glu Gly Pro Leu
370 375 380
Val Phe Ala Thr His Ser Thr His Lys Met Leu Ala Ala Phe Ser Gln
385 390 395 400
Ala Ser Met Ile His Val Gln Asp Gly Gly Thr Arg Lys Leu Asp Val
405 410 415
Ala Arg Phe Asn Glu Ala Phe Met Met His Ile Ser Thr Ser Pro Gln
420 425 430
Tyr Gly Ile Ile Ala Ser Leu Asp Val Ala Ser Ala Met Met Glu Gly
435 440 445
Pro Ala Gly Arg Ser Leu Ile Gln Glu Thr Phe Asp Glu Ala Leu Ser
450 455 460
Phe Arg Arg Ala Leu Ala Asn Val Arg Gln Asn Leu Asp Arg Asn Asp
465 470 475 480
Trp Trp Phe Gly Val Trp Gln Pro Glu Gln Val Glu Gly Thr Asp Gln
485 490 495
Val Gly Thr His Asp Trp Val Leu Glu Pro Ser Ala Asp Trp His Gly
500 505 510
Phe Gly Asp Ile Ala Glu Asp Tyr Val Leu Leu Asp Pro Ile Lys Val
515 520 525
Thr Leu Thr Thr Pro Gly Leu Ser Ala Gly Gly Lys Leu Ser Glu Gln
530 535 540
Gly Ile Pro Ala Ala Ile Val Ser Arg Phe Leu Trp Glu Arg Gly Leu
545 550 555 560
Val Val Glu Lys Thr Gly Leu Tyr Ser Phe Leu Val Leu Phe Ser Met
565 570 575
Gly Ile Thr Lys Gly Lys Trp Ser Thr Leu Val Thr Glu Leu Leu Glu
580 585 590
Phe Lys Arg Cys Tyr Asp Ala Asn Leu Pro Leu Leu Asp Val Leu Pro
595 600 605
Ser Val Ala Gln Ala Gly Gly Lys Arg Tyr Asn Gly Val Gly Leu Arg
610 615 620
Asp Leu Ser Asp Ala Met His Ala Ser Tyr Arg Asp Asn Ala Thr Ala
625 630 635 640
Lys Ala Met Lys Arg Met Tyr Thr Val Leu Pro Glu Val Ala Met Arg
645 650 655
Pro Ser Glu Ala Tyr Asp Lys Leu Val Arg Gly Glu Val Glu Ala Val
660 665 670
Pro Ile Ala Arg Leu Glu Gly Arg Ile Ala Ala Val Met Leu Val Pro
675 680 685
Tyr Pro Pro Gly Ile Pro Leu Ile Met Pro Gly Glu Arg Phe Thr Glu
690 695 700
Ala Thr Arg Ser Ile Leu Asp Tyr Leu Glu Phe Ala Arg Thr Phe Glu
705 710 715 720
Arg Ala Phe Pro Gly Phe Asp Ser Asp Val His Gly Leu Gln His Gln
725 730 735
Asp Gly Pro Ser Gly Arg Cys Tyr Thr Val Glu Cys Ile Lys Glu
740 745 750
<210> 17
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 17
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tctatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtaactgtc acaaatctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 18
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 18
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tgtatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtaactgtc acaaatctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 19
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 19
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tctatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtacctgtc acaaatctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 20
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 20
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tctatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtaactgtc acaactctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 21
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 21
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tgtatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtacctgtc acaaatctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 22
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 22
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tgtatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtaactgtc acaactctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 23
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 23
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tctatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtacctgtc acaactctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
<210> 24
<211> 2256
<212> DNA
<213> artificial
<220>
<223> synthetic, synthesized
<400> 24
atgtacaaag atctgaaatt ccctgttctg attgtacacc gcgatatcaa ggcggacacg 60
gtagccggcg agcgtgttcg cggtattgcc cacgaactcg aacaagacgg ctttagcatt 120
ctctctacgg cgtcttctgc ggaaggccgc attgtggcta gcacgcacca cggtctcgcc 180
tgcatcctcg tggcagctga gggtgcgggt gagaatcagc gtctgctcca agacgtggtt 240
gagctgatcc gtgtagctcg cgtccgtgcg ccacagctcc cgatcttcgc gctgggcgaa 300
caggtgacta ttgaaaacgc gcctgccgaa tgtatggccg acctgcacca gctccgcggc 360
attctgtatc tcttcgagga tactgtcccg ttcctggcac gtcaggttgc acgcgcagcg 420
cgtaactacc tcgctggcct cctcccgcca ttcttccgtg cactcgtgga gcacacggcc 480
caaagcaatt actcttggca caccccgggt cacggtggtg gtgtcgctta ccgtaaatct 540
ccggtaggtc aagctttcca ccagttcttt ggcgagaata ccctccgctc tgacctgtct 600
gttagcgttc cagagctggg cagcctgctg gatcacactg gccctctcgc ggaagcagag 660
gatcgtgccg ctcgcaattt cggtgcggac cacaccttct ttgtcatcaa tggtacctct 720
actgcgaaca aaatcgtttg gcactctatg gttggtcgcg aggacctggt gctggtcgat 780
cgtacctgtc acaactctat tctgcactcc attatcatga cgggtgctat cccactgtac 840
ctgactccgg aacgcaacga actgggtatt atcggcccta ttccactctc cgagttttct 900
aaacaatcta tcgcagcaaa aattgccgcc tccccactcg cgcgtggtcg tgaaccgaaa 960
gttaaactgg ctgtcgttac caactctacc tatgacggtc tgtgttacaa cgcggaactg 1020
atcaaacaaa ccctcggcga ctctgtcgag gtactgcatt tcgacgaggc ttggtatgct 1080
tatgcggcgt ttcacgagtt ctacgacggc cgctacggta tgggcacttc tcgttccgaa 1140
gagggtccgc tggtctttgc tacccattct acccacaaga tgctcgcggc tttttcccaa 1200
gctagcatga ttcacgttca ggatggtggt acgcgcaagc tggacgtcgc ccgctttaac 1260
gaagccttta tgatgcacat cagcacctct ccacagtacg gcatcattgc gtctctcgat 1320
gtcgcaagcg ctatgatgga aggtcctgcc ggtcgtagcc tgatccaaga gacgttcgat 1380
gaggcgctgt ccttccgtcg tgctctggcg aatgtccgtc agaacctgga ccgtaatgat 1440
tggtggttcg gtgtctggca accggagcag gttgagggca ccgaccaggt aggtactcac 1500
gactgggttc tcgagcctag cgcggactgg catggttttg gtgacattgc ggaggattac 1560
gttctcctcg atcctatcaa agttaccctg accaccccag gtctgagcgc tggcggtaaa 1620
ctctctgaac aaggcatccc ggcagctatc gttagccgtt tcctgtggga acgtggtctg 1680
gtggtcgaga aaacgggtct gtactctttc ctggttctgt tctccatggg tatcacgaaa 1740
ggcaaatggt ctactctggt taccgagctg ctcgaattca aacgctgtta cgacgcgaat 1800
ctgccactcc tggatgtgct gccttctgta gcgcaggcgg gtggtaaacg ctataacggt 1860
gtaggtctgc gtgatctgtc cgatgccatg cacgcttctt atcgtgacaa tgccacggcg 1920
aaggccatga agcgtatgta tacggtgctc ccggaagtag ccatgcgccc gtccgaagct 1980
tatgataagc tcgtacgcgg tgaagtcgaa gctgttccta ttgcacgtct cgagggtcgt 2040
attgcggcgg ttatgctggt tccgtacccg ccaggtatcc cgctcattat gccgggtgaa 2100
cgttttactg aagctacccg ctccattctg gactatctgg agtttgcccg taccttcgag 2160
cgcgcgttcc cgggctttga ctctgatgtt cacggcctcc aacatcaaga tggcccgtct 2220
ggccgttgtt ataccgttga atgcatcaag gaataa 2256
- 还没有人留言评论。精彩留言会获得点赞!