LMOD3在制备口腔鳞癌诊疗制剂中的应用的制作方法
本发明属于生物医药领域,涉及LMOD3在制备口腔鳞癌诊疗制剂中的应用。
背景技术:
口腔鳞状细胞癌(oral squamous cell carcinoma,OSCC)是由上皮组织恶变而来,是口腔颌面部常见的恶性肿瘤,占口腔恶性肿瘤的80%以上。目前为止,对口腔鳞状细胞癌的治疗仍然以手术治疗为主,并辅以放射治疗和化学药物治疗。尽管随着手术方式的不断改进以及辅助手段的加强,口腔鳞状细胞癌的治疗效果也逐渐改善,但是其五年生存率仍不足50%。随着恶性相关基因研究的不断深入,肿瘤的基因治疗已经成为研究恶性肿瘤治疗的新热点。基因治疗具有选择性强、损伤小、对原发灶及转移灶均有效的优点,已经成为手术、放疗和化疗之后的新的有希望的治疗手段。
现阶段,基因治疗主要包括:基因修正、“自杀”基因的应用,反义性基因治疗以及RNA干扰(RNA interference,RNAi)技术等。其中RNAi具有高效性、高稳定性、以及便利性等优点,因此在研究基因功能、抗病毒治疗以及抗肿瘤基因治疗等方面均得到广泛的应用。RNAi作为肿瘤基因治疗的新方法,可以抑制肿瘤细胞中一些基因以及生长因子的异常表达,从而抑制肿瘤细胞的增殖促进肿瘤细胞的凋亡,在肿瘤的基因治疗中具有重要的意义。
RNAi是指具有同源性的双链NRA导致靶mNRA发生序列特异性降解的现象,是最近几年发现和发展起来的一门新兴的在转录水平上的基因阻断技术。它是真核生物中基因转录后沉默作用的重要机制之一。RNAi具有抑制作用强、稳定性高、细胞摄取相对容易等优点,在基因功能研究、抗病毒和抗肿瘤基因治疗方面均得到广泛应用。在肿瘤的发生发展过程中,多存在癌基因的过量表达,这种过量表达的癌基因可导致细胞增殖失控或凋亡受限,为肿瘤的基因治疗提供了特异的靶向分子。作为基因治疗的新工具,将RNAi应用于探寻癌症靶向相关基因,抑制肿瘤细胞中过量表达的一些因子,使与肿瘤发生发展相关的基因的表达降低从而抑制肿瘤细胞增殖和侵袭,能够大大提高肿瘤基因治疗的效果,是具有极好前景的肿瘤治疗方法。
技术实现要素:
为了弥补现有技术的不足,本发明的目的在于提供一种与口腔鳞状细胞癌发生发展相关的生物标志物,从而为口腔鳞癌的诊断和治疗提供一种分子手段。
为了实现上述目的,本发明采用如下技术方案:
本发明提供了种LMOD3基因和/或其表达产物或特异性识别LMOD3基因和/或其表达产物试剂的用途,用于制备诊断口腔鳞状细胞癌的产品。
进一步,所述特异性识别LMOD3基因和/或其表达产物的试剂选自:
特异性扩增LMOD3基因的引物;或
特异性识别LMOD3基因的探针;或
特异性结合LMOD3编码的蛋白的抗体或配体。
进一步,所述特异性扩增LMOD3基因的引物对序列如SEQ ID NO.3和SEQ ID NO.4所示。
本发明提供了一种诊断口腔鳞状细胞癌的产品,所述产品包括上面所述的试剂。
进一步,所述产品包括芯片、试剂盒或制剂。
其中,所述芯片包括基因芯片、蛋白质芯片;所述基因芯片包括固相载体以及固定在固相载体的寡核苷酸探针,所述寡核苷酸探针包括用于检测LMOD3基因转录水平的针对LMOD3基因的寡核苷酸探针;所述蛋白质芯片包括固相载体以及固定在固相载体的LMOD3蛋白的特异性抗体;所述试剂盒包括基因检测试剂盒和蛋白免疫检测试剂盒;所述基因检测试剂盒包括用于检测LMOD3基因转录水平的试剂;所述蛋白免疫检测试剂盒包括LMOD3蛋白的特异性抗体。
进一步,所述试剂盒还包括使用说明书或标签、阳性对照物、阴性对照物、缓冲剂、助剂或溶剂;所述说明书或标签注明所述试剂盒用于检测口腔鳞癌。
本发明提供了一种LMOD3基因或其表达产物的下调剂的用途,用于制备治疗口腔鳞状细胞癌的药物组合物。
进一步,所述的LMOD3基因或其表达产物的下调剂选自:核酸抑制剂、蛋白抑制剂、蛋白水解酶、蛋白结合分子,其能够在基因或蛋白水平下调LMOD3基因或其编码的蛋白的表达或活性。
进一步,所述LMOD3基因或其表达产物的下调剂为siRNA。
本发明提供了一种预防、缓解或治疗口腔鳞状细胞癌的药物组合物,所述组合物含有:
(1)如上所述的LMOD3基因或其表达产物的下调剂;和
(2)药学上可接受的载体。
本发明提供了一种筛选预防、缓解或治疗口腔鳞状细胞癌的潜在物质的方法,所述方法包括:
(1)用候选物质处理表达或含有LMOD3基因或其编码的蛋白的体系;和
(2)检测所述体系中LMOD3基因或其编码的蛋白的表达或活性。
其中,若所述候选物质可降低LMOD3基因或其编码的蛋白的表达或活性(优选显著降低,如低20%以上,较佳的低50%以上;更佳的低80%以上),则表明该物质为预防、缓解或治疗口腔鳞状细胞癌的潜在物质。
进一步,所述的候选物质包括(但不限于):针对LMOD3基因或其表达产物或其上游或下游基因或蛋白设计的干扰分子、核酸抑制物、结合分子(如抗体或配体)、小分子化合物等。
本发明提供了LMOD3基因在制备治疗口腔鳞状细胞癌的药物组合物中的应用。
本发明还提供了一种抑制细胞增殖的方法,所述方法是将LMOD3基因或其表达产物的下调剂在体外导入到肿瘤细胞中。
进一步,所述下调剂包括将针对LMOD3基因的siRNA、shRNA、反义寡核苷酸或功能缺失型基因。
本发明的优点和有益效果:
本发明首次发现了差异性表达的LMOD3与口腔鳞状细胞癌的发生发展相关,提示检测LMOD3基因表达水平可成为口腔鳞状细胞癌早期诊断的辅助诊断指标。
本发明首次发现了下调LMOD3基因表达水平可以抑制抑制癌细胞的增殖,降低癌细胞的侵袭率,从而为口腔鳞癌的干预提供了新途径。
附图说明
图1显示利用QPCR检测LMOD3基因在口腔鳞状细胞癌组织中的表达情况;
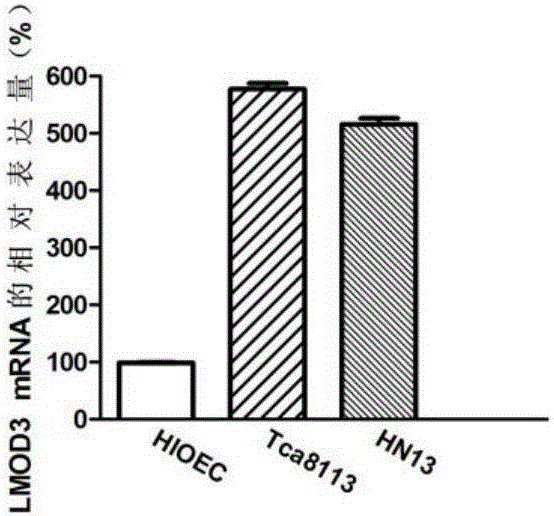
图2显示利用QPCR检测LMOD3基因在口腔鳞状细胞癌细胞中的表达情况;
图3显示利用QPCR检测siRNA对LMOD3基因表达的影响;
图4显示MTT法检测LMOD3对口腔鳞状细胞癌细胞增殖活性的影响;
图5显示利用transwell小室检测LMOD3基因对口腔鳞状细胞癌细胞侵袭的影响。
具体的实施方式
本发明经过深入的研究,首次发现了口腔鳞癌组织中LMOD3基因的表达显著高于正常粘膜组织,并且实验证明了LMOD3在口腔鳞癌细胞中也呈现高表达,下调LMOD3的表达水平可以抑制口腔鳞癌细胞的增殖和侵袭,提示LMOD3可作为诊断和治疗的靶标应用于临床。
LMOD3蛋白是一种平滑肌蛋白,该蛋白包含三个肌动蛋白结合域、一个原肌球蛋白结合域、一个富含亮氨酸重复结构域和一个WH2结构域。该蛋白在平滑肌成核反应中起催化作用,在骨骼肌肌节细肌丝的组织中也起着重要的作用。该蛋白的突变会引起杆状体肌症。
可用于本发明的LMOD3多核苷酸或蛋白(多肽)序列包括各种来源和物种的LMOD3,并且包括野生型、突变型的LMOD3,或其活性片段。在本发明的一些实施方案中,所述LMOD3来源于人类,一种代表性的人LMOD3的编码序列或氨基酸序列分别如SEQ ID NO.1和SEQ ID NO.2所示。
本发明中,术语“生物标志物”是其在组织或细胞中的表达水平与正常或健康细胞或组织的表达水平相比发生改变的任何基因或蛋白。
本发明可以利用本领域内已知的任何方法测定基因表达。本领域技术人员应当理解,测定基因表达的手段不是本发明的重要方面。可以在转录或翻译(即蛋白)水平上检测生物标记物的表达水平。
在一些实施方案中,在转录水平上检测生物标记物的表达水平。利用核酸杂交技术进行具体DNA和RNA测量的多种方法是本领域技术人员已知的。一些方法涉及电泳分离(例如,用于检测DNA的Southern印迹和用于检测RNA的Northern印迹),但是也可以在不利用电泳分离的情况下进行DNA和RNA的测量(例如,通过斑点印迹)。基因组DNA(例如,来自人)的Southern印迹可用于筛选限制性片段长度多态性(RFLP),以检测影响本发明多肽的遗传病症的存在。可以检测所有形式的RNA,包括但不限于信使RNA(mRNA)、微RNA(miRNA)、核糖体RNA(rRNA)和转运RNA(tRNA)。
本发明所述的基因芯片或基因检测试剂盒可用于检测包括LMOD3基因在内的多个基因(例如,与口腔鳞状细胞癌相关的多个基因)的表达水平。所述蛋白芯片或蛋白免疫检测试剂盒可用于检测包括LMOD3蛋白在内的多个蛋白质(例如与口腔鳞状细胞癌相关的多个蛋白质)的表达水平。将口腔鳞状细胞癌的多个标志物同时进行检测,可大大提高口腔鳞状细胞癌诊断的准确率。
术语“探针”是指能够用于测量特定基因的表达情况的分子。示例性探针包括PCR引物以及基因特异性DNA寡核苷酸探针,例如固定于微阵列基底上的微阵列探针、定量核酸酶保护检验探针、与分子条形码连接的探针、以及固定于珠上的探针。
本发明所用的术语“探针”指能与另一分子的特定序列或亚序列或其它部分结合的分子。除非另有指出,术语“探针”通常指能通过互补碱基配对与另一多核苷酸(往往称为“靶多核苷酸”)结合的多核苷酸探针。这里,所谓“互补”,只要是杂交即可,可以不是完全互补。根据杂交条件的严谨性,探针能和与该探针缺乏完全序列互补性的靶多核苷酸结合。探针可作直接或间接的标记,其范围包括引物。杂交方式,包括,但不限于:溶液相、固相、混合相或原位杂交测定法。
术语“抗体”在本文中以最广义使用,明确覆盖单克隆抗体、多克隆抗体、多特异性抗体(例如双特异性抗体)、及抗体片段、组合抗体等,只要它们展现出期望的生物学活性。
术语“单克隆抗体”在用于本文时指从一群基本上同质的抗体获得的抗体,即构成群体的各个抗体相同和/或结合相同表位,除了生产单克隆抗体的过程中可能产生的可能变体外,此类变体一般以极小量存在。此类单克隆抗体典型的包括包含结合靶物的多肽序列的抗体,其中靶物结合多肽序列是通过包括从众多多肽序列中选择单一靶物结合多肽序列在内的过程得到的。
单克隆抗体在本文中明确包括“嵌合”抗体,其中重链和/或轻链的一部分与衍生自特定物种或属于特定抗体类别或亚类的抗体中的相应序列相同或同源,而链的剩余部分与衍生自另一物种或属于另一抗体类别或亚类的抗体中的相应序列相同或同源,以及此类抗体的片段,只要它们展现出期望的生物学活性。
“完整抗体”在本文中指包含两个抗原结合区及Fc区的抗体。优选的是,完整抗体具有功能性Fc区。
“抗体片段”包含完整抗体的一部分,优选包含其抗原结合区。抗体片段的例子包括Fab、Fab′、F(ab′)2和Fv片段;双抗体(diabody);线性抗体;单链抗体分子;及由抗体片段形成的多特异性抗体。
本发明中抗LMOD3蛋白的抗体可用于免疫组织化学技术中,检测样本中LMOD3蛋白的含量,还可用于预防和治疗口腔鳞癌的特异性制剂,血样或尿液中LMOD3蛋白的直接测定可以作为肿瘤的辅助诊断和愈后的观察指标,也可作为肿瘤早期诊断的依据。抗体可以通过ELISA、Western Blot印记分析,或者与检测基团偶联,通过化学发光、同位素示踪等方法来检测。
本发明中所述的LMOD3基因或其表达产物的下调剂是指任何可降低LMOD3蛋白的活性、降低LMOD3基因或蛋白的稳定性、下调LMOD3蛋白的表达、减少LMOD3蛋白有效作用时间、或抑制LMOD3基因的转录和翻译的物质,这些物质均可用于本发明,作为对于下调LMOD3有用的物质,从而可用于预防或治疗口腔鳞癌。例如,所述的抑制剂是:核酸抑制物,蛋白抑制剂,抗体,配体,蛋白水解酶,蛋白结合分子,只要其能够在蛋白或基因水平上下调LMOD3蛋白或其编码基因的表达。
作为本发明的一种优选方式,所述的LMOD3的下调剂是一种LMOD3特异性的小干扰RNA分子(small interfering RNA,SiRNA)。如本文所用,所述的“小干扰RNA”是指一种短片段双链RNA分子,能够以同源互补序列的mRNA为靶目标降解特定的mRNA,这个过程就是RNA干扰(RNA interference)过程。小干扰RNA可以制备成双链核酸的形式,它含有一个正义链和一个反义链,这两条链仅在杂交的条件下形成双链。一个双链RNA复合物可以由相互分离的正义链和反义链来制备。因此,举例来讲,互补的正义链和反义链是化学合成的,其后可通过退火杂交,产生合成的双链RNA复合物。
在筛选有效的siRNA序列时,本发明人通过大量的比对分析,从而找出最佳的有效片段。本发明人设计合成了多种siRNA序列,并将它们分别通过转染试剂转染口腔鳞癌细胞系进行验证,结果检测出干扰效果较好的干扰分子,它们分别具有SEQ ID NO.9、SEQ ID NO.10和SEQ ID NO.11、SEQ ID NO.12的序列。
作为本发明的一种可选方式,所述的LMOD3的下调剂也可以是一种“小发夹RNA(Small hairpin RNA,shRNA)”,其是能够形成发夹结构的非编码小RNA分子,小发夹RNA能够通过RNA干扰途径来抑制基因的表达。如上述,shRNA可以由编码需要的转录物的双链DNA模板来表达。编码需要的转录物的双链DNA模板被插进一个载体,例如质粒或病毒载体,然后在体外或体内连接到一个启动子进行表达。shRNA在真核细胞内DICER酶的作用下,可被切割成小干扰RNA分子,从而进入RNAi途径。“shRNA表达载体”是指一些本领域常规用于构建shRNA结构的质粒,通常该质粒上存在“间隔序列”以及位于“间隔序列”两边的多克隆位点或供替换序列,从而人们可以将shRNA(或类似物)相应的DNA序列通过正向和反向的方式插入多克隆位点或替换其上的供替换序列,该DNA序列转录后的RNA可形成shRNA(Short Hairpin)结构。
本发明的核酸抑制物如siRNA可以化学合成,也可以通过一个重组核酸结构里的表达盒转录成单链RNA之后进行制备。siRNA等核酸抑制物,可通过采用适当的转染试剂被输送到细胞内,或还可采用本领域已知的多种技术被输送到细胞内。
基因表达载体包括非病毒载体和病毒载体,其中病毒载体包括逆转录病毒载体、腺病毒载体、慢病毒载体等。
在本发明的药物组合物中,除了除作为有效成分的上述物质(多核苷酸、抗体)之外,还能够含有药学上可接受的其它成分。作为这样的其它成分,包括(但不限于)缓冲剂、乳化剂、悬浮剂、稳定剂、防腐剂、生理食盐等。作为缓冲剂,能够使用磷酸盐、柠檬酸盐、乙酸盐等。作为乳化剂,能够使用阿拉伯树胶、海藻酸钠、西黄芪胶等。作为悬浮剂,能够使用单硬脂酸甘油、单硬脂酸铝、甲基纤维素、羧甲基纤维素、羟甲基纤维素、月桂基硫酸钠等。作为稳定剂,能够使用丙二醇、二亚乙基亚硫酸盐、抗坏血酸等。作为防腐剂,能够使用叠氮化钠、苯扎氯铵、对羟苯甲酸、氯丁醇等。
另外,除包含多核苷酸、抗体的标准品之外,也能够组合附加于多核苷酸、抗体上的标记的检测中所需要的基质、阳性对照、阴性对照、原位杂交等中所使用的对比染色用试剂(DAPI等)、抗体的检测中所需要的分子(例如,二次抗体、蛋白质G、蛋白质A)、用于试样的稀释、清洗的缓冲液等标准品,制成用于本发明的方法的试剂盒。在该试剂盒中能够包括该试剂盒的使用说明书。本发明也提供用于上述本发明的方法的试剂盒。
对于临床使用,将依照本发明的化合物或其前药形式配制成药物组合物,其配制为与其意图的施用路径,例如口服、直肠、胃肠外或其它施用模式相容。通常,通过混合活性物质与常规的药学可接受稀释剂或载体来制备药物配制剂。如本文中所使用的,语言“药学可接受载体”意图包括与药物施用相容的任何和所有溶剂、分散介质、涂层、抗细菌和抗真菌剂、吸收延迟剂等等。药学可接受稀释剂或载体的例子有水、明胶、阿拉伯树胶、乳糖、微晶纤维素、淀粉、羟基乙酸淀粉钠、磷酸氢钙、硬脂酸镁、滑石、胶体二氧化硅等等。此类介质和药剂对药学活性物质的用途是本领域中公知的。除非任何常规的介质或药剂与活性化合物不相容,涵盖其在组合物中的用途。
本发明所述药物组合物可口服给药、非胃肠道给药、通过吸入喷雾给药、局部给药、直肠给药、鼻给药、颊给药、阴道给药或通过植入的贮药装置给药。优选口服给药或注射给药。本发明药物组合物可含有任何常用的无毒可药用载体、辅料或赋形剂。在某些情况下,药用酸、碱或缓冲剂可用来调节制剂的pH以提高所配制的化合物或其给药剂型的稳定性。本文所用术语非胃肠道包括皮下、皮内、静脉内、肌内、关节内、动脉内、滑膜内、胸骨内、鞠内、损伤部位内、和颅内注射或输注技术。只要能达到目标组织,本发明所述药物组合物可以通过任何途径给予受体。
本发明的药物组合物可以用于补充内源性的LMOD3蛋白的缺失或不足,通过提高LMOD3蛋白的表达或增强LMOD3蛋白的功能,从而治疗因LMOD3蛋白减少导致的口腔鳞状细胞癌。
本发明还包括一种组合药物,所述组合药物包括上述的药物组合物、和含抗肿瘤剂的药物组合物。抗肿瘤剂的药物组合物包括但不限于免疫治疗剂如西妥昔单克隆抗体,化学治疗剂或化学放射性治疗剂如卡波铂或者是一种相关类别的铂类药物、紫杉烷或者是一种类别的紫衫烷,或者是两者。
本发明的药物还可与其他治疗口腔鳞状细胞癌的药物联用,其他治疗性化合物可以与主要的活性成分同时给药,甚至在同一组合物中同时给药。还可以以单独的组合物或与主要的活性成分不同的剂量形式单独给予其它治疗性化合物。主要成分的部分剂量可以与其它治疗性化合物同时给药,而其它剂量可以单独给药。在治疗过程中,可以根据症状的严重程度、复发的频率和治疗方案的生理应答,调整本发明药物组合物的剂量。
本发明中术语“治疗”是指以治愈、改善、稳定或预防疾病、病理状态或病症为目的对患者进行的医学管理。
本发明中术语“样本”是指从目标患者得到的组合物,其包含细胞和/或其他分子体—将进行特征化和/或识别,例如,根据物理、生化、化学和/或生理特征。例如,短语“临床样本”或“疾病样本”及其变体,是指从目标患者获得的任何样本,将预期或已知所述样本中能够获得细胞和/或分子体,例如将被特征化的生物标志物。
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,例如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring HarborLaboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。
实施例1筛选与口腔鳞状细胞癌相关的基因标志物
1、样品收集
各收集6例周围正常粘膜组织和口腔鳞状细胞癌组织,均经病理学诊断证实,所有患者术前未接受任何形式的治疗。手术切下的样本于液氮中冻存,患者均知情同意,上述所有标本的取得均通过组织伦理委员会的同意。
2、RNA样品的制备(利用QIAGEN的组织RNA提取试剂盒进行操作)
取出冻存于液氮中的组织样本,把组织样本放入已预冷的研钵中进行研磨,按照试剂盒中的说明书提取分离RNA。具体如下:
1)加入Trizol,室温放置5min;
2)加入氯仿0.2ml,用力振荡离心管,充分混匀,室温下放置5-10min;
3)12000rpm离心15min,将上层水相移到另一新的离心管中(注意不要吸到两层水相之间的蛋白物质),加入等体积的-20℃预冷的异丙醇,充分颠倒混匀,置于冰上10min;
4)12000rpm高速离15min后小心弃掉上清液,按1ml/ml Trizol的比例加入75%DEPC乙醇洗涤沉淀(4℃保存),洗涤沉淀物,振荡混匀,4℃,12000rpm离心5min;
5)弃去乙醇液体,室温下放置5min,加入DEPC水溶解沉淀;
6)用Nanodrop2000紫外分光光度计测量RNA纯度及浓度,冻存于-70℃冰箱。
3、逆转录和标记
用Low RNA Input Linear Amplification Kit将mRNA逆转录成cDNA,同时用Cy3分别标记实验组和对照组。
4、杂交
基因芯片采用Aglient公司的人全基因组表达谱芯片,每张芯片包括45015个寡核苷酸,其中有43376个人基因探针和1639个实验控制探针。按芯片使用说明书的步骤进行,温度在65℃,经17h 10r/min滚动杂交,37℃洗片。
5、数据处理
杂交后芯片用Agilent扫描仪扫描,分辨率为5μm,扫描仪自动以100%和10%PMT各扫描1次,2次结果Agilent软件自动合并。扫描图像数据采用Feature Extraction进行处理分析,得到的原始数据应用Bioconductor程序包进行后续数据处理。最后Ratio值为实验组和对照组。差异基因筛选标准:ratio≥4为上调基因,ratio≤0.25为下调基因。
6、结果
与正常粘膜组织相比,LMOD3基因在口腔鳞状细胞癌组织中的表达量显著上调。
实施例2QPCR测序验证LMOD3基因的差异表达
1、对LMOD3基因差异表达进行大样本QPCR验证。按照实施例1中的样本收集方式选择正常粘膜组织和口腔鳞状细胞癌组织各80例。
2、RNA提取步骤如实施例1所述。
3、逆转录:
1)配置10μl反应体系:
取MgCl2 2μl、10×RT Buffer 1μl、无Rnase水 3.75μl、dNTP混合液 1μl、Rnase抑制剂0.25μl、AMV反转录酶 0.5μl、寡聚dT适配子引物 0.5μl、实验样品 1μl混合
2)逆转录反应条件
按照RNA PCR Kit(AMV)Ver.3.0中逆转录反应条件进行。
42℃60min,99℃2min,5℃5min。
3)聚合酶链反应
1)引物设计
根据Genebank中LMOD3基因和GAPDH基因的编码序列设计QPCR扩增引物,由博迈德生物公司合成。具体引物序列如下:
LMOD3基因:
正向引物为5’-ATCACCACTCTCAACATC-3’(SEQ ID NO.3);
反向引物为5’-CTCAGTTAGCGTCTCATT-3’(SEQ ID NO.4)。
管家基因GAPDH的引物序列为:
正向引物:5’-CTCTGGTAAAGTGGATATTGT-3’(SEQ ID NO.5)
反向引物:5’-GGTGGAATCATATTGGAACA-3’(SEQ ID NO.6)
2)按照表1配制25μl PCR反应体系:
正(反)向引物1μl、Takara Ex Taq HS 12.5μl、模板2μl、去离子水8.5μl
3)PCR反应条件:94℃4min,(94℃20s,60℃30s、72℃30s)×30个循环。
以SYBR Green作为荧光标记物,在Light Cycler荧光定量PCR仪上进行PCR反应,通过融解曲线分析和电泳确定目的条带,ΔΔCT法进行相对定量,每个样进行3次重复实验。
5、统计学方法
以GAPDH为内参,计算口腔鳞状细胞癌组织与正常粘膜组织荧光定量RT-PCR的实验结果,采用SPSS18.0统计软件来进行统计分析,两者之间的差异采用t检验,以P<0.05具有统计学差异。
6、结果
结果如图1所示,与周围正常粘膜组织相比,LMOD3基因在口腔鳞状细胞癌组织中表达上调,差异具有统计学意义(P<0.05),同RNA-sep结果一致。
实施例3LMOD3基因在口腔鳞状细胞癌细胞系中的差异表达
1、细胞培养
口腔鳞状细胞癌细胞系Tca8113、HN13,正常粘膜上皮细胞系HIOEC购自于上海交通大学附属第九人民医院。
HIOEC的培养基为K-SFM;Tca8113、HN13的培养基为DMEM;以含10%胎牛血清和1%P/S的培养基在37℃、5%CO2、相对湿度为90%的培养箱中培养。2-3天换液1次,使用0.25%含EDTA的胰蛋白酶常规消化传代。
2、细胞总RNA的提取
1)当细胞达80-90%融合时终止培养,0.25%胰蛋白酶消化收集细胞于1.5m1EP管中,每管中加入lm1Trizol缓慢摇动破碎细胞,冰上放置10min。
2)去蛋白,去DNA:每个1.5m1EP管加入0.2ml三氯甲烷,摇晃15s,室温放置10min。4℃,12000rpm离心15min。
剩余操作步骤同组织中RNA提取过程。
3、逆转录
具体步骤同实施例2.
4、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,两者之间的差异采用t检验,认为当P<0.05时具有统计学意义。
5、结果
结果如图2所示,与正常粘膜上皮细胞相比,LMOD3基因在口腔鳞状细胞癌细胞Tca8113、HN13中表达均上调,差异具有统计学意义(P<0.05),同RNA-sep结果一致。
实施例4LMOD3基因的沉默
1、细胞培养
人口腔鳞状细胞癌细胞株Tca8113,以含10%胎牛血清和1%P/S的培养基DMEM在37℃、5%CO2、相对湿度为90%的培养箱中培养。2-3天换液1次,使用0.25%含EDTA的胰蛋白酶常规消化传代。
2、siRNA设计
针对LMOD3基因的siRNA序列:
阴性对照siRNA序列(siRNA-NC):
正义链为5’-UUCUCCGAACGUGUCACGU-3’(SEQ ID NO.7),
反义链为5’-ACGUGACACGUUCGGAGAA-3’(SEQ ID NO.8);
siRNA1-LMOD3:
正义链为5’-AGAAGUUCUUCUUGAUCUGAA-3’(SEQ ID NO.9),
反义链为5’-CAGAUCAAGAAGAACUUCUCG-3’(SEQ ID NO.10);
siRNA2-LMOD3:
正义链为5’-AAGAGAUUUAUGAUUGAAGUU-3’(SEQ ID NO.11),
反义链为5’-CUUCAAUCAUAAAUCUCUUGU-3’(SEQ ID NO.12);
将细胞按4×104/孔接种到六孔细胞培养板中,在37℃、5%CO2培养箱中细胞培养24h,在无双抗、含10%FBS的DMEM培养基中,转染按照脂质体转染试剂2000(购自于Invitrogen公司)的说明书转染。
将实验分为三组:对照组(Tca8113)、阴性对照组(siRNA-NC)和实验组(siRNA1-LMOD3、siRNA2-LMOD3),其中阴性对照组siRNA与LMOD3基因的序列无同源性,浓度为20nM/孔,同时分别进行转染。
3、QPCR检测LMOD3基因的转录水平
3.1细胞总RNA的提取
具体步骤同实施例3。
3.2逆转录步骤同实施例2。
3.3QPCR扩增步骤同实施例2。
4、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,干扰LMOD3基因表达组与对照组之间的差异采用t检验,认为当P<0.05时具有统计学意义。
5、结果
结果如图3显示,阴性对照组、阳性对照组以及siRNA2-LMOD3组,siRNA1-LMOD3组能够显著降低LMOD3基因的表达,差异具有统计学意义(P<0.05)。
实施例5ELISA检测Tca8113细胞中LMOD3的蛋白表达
应用双抗体夹心酶标免疫(Enzyme-Linked Immunosorbent Assay,ELISA)分析法测定Tca8113细胞上清中LMOD3蛋白水平。RNA干扰后第六天,分别收集三组Tca8113细胞的上清液,按照ELISA试剂盒操作流程定量检测肿瘤细胞上清液中LMOD3的浓度。
1、配置浓度为70000pg/ml的标准品,10倍稀释后,再进行2倍倍比稀释,共有7个稀释度。
2、加样:分别设空白孔、标准孔、待测样品孔。空白孔加样品稀释液50μl,余孔分别加不同浓度梯度的标准品和待测样品各50μl。轻轻晃动混匀,酶标板加上盖,37℃反应2h。
3、弃去液体,晾干。每孔加200μl VEGF-C结合物。37℃,120min后,弃去孔内液体,晾干,PBS洗板3次。
4、依序每孔加底物溶液200μl,37℃避光显色30min。
5、依序每孔加终止溶液50μl,终止反应。
6、用酶联仪在450nm波长依序测量各孔的光密度(OD值)。所有标准品和待测样品的OD值均需减去零孔的OD值以得到校正值。
7、计算样品的实际浓度。
8、结果如下表1所示,siRNA沉默Tca8113细胞的LMOD3基因,LMOD3的蛋白含量也相应降低,说明沉默LMOD3基因可以抑制LMOD3基因的表达。
表1ELISA检测不同组别细胞中的LMOD3蛋白的表达
实施例6MTT法检测Tca8113细胞增殖活性
应用MTT(Methyl thiazolyl tetrazolium,甲基噻唑基四唑)法检测LMOD3基因沉默后对Tca8113细胞增殖活性的影响。
1、细胞培养将Tca8113细胞按1×103/孔接种于96孔板,每孔100μ1,37℃,5%CO2孵箱内孵育培养。
2、细胞转染步骤同实施例3。
3、MTT检测
1)分别于转染1~7天时,弃掉各孔培养基,加入MTT(5mg/ml)20μl。继续常规培养4h。
2)吸去混合液,每孔加入DMSO 200μl,震荡10min使结晶充分溶解。在酶联免疫仪上测490nm处的光吸收值,记录结果。
4、以时间为横轴,光吸收值(OD)为纵轴绘制细胞生长曲线。
5、结果:
结果如图4所示,与对照相比,转染siRNA1-LMOD3组的细胞增殖显著降低。
实施例7Transwell细胞体外侵袭实验
RNA干扰后第六天收集不同组别的Tca8113细胞,重悬于培养液中,使细胞终浓度为2×106/ml,吸取100μl细胞悬液加入Transwell小室中。应用Transwell小室方法观察LMOD3基因沉默对Tca8113细胞侵袭性的影响。
1、将Matrigel(4μg/μl)放入4℃融化,准备冰盒(冰浴环境)。Matrigel用DMEM稀释8倍后使用。在Transwell小室滤膜(8μm孔径)的外表面涂8μg人纤粘连蛋白,置超净台内风干。
2、在6孔Transwell小室滤膜的内表面铺以100μ1/孔的Matrigel胶,37℃、5%CO2孵箱内孵育1h,形成一个基质屏障层备用。
3、在6孔板每孔内加入含20%FBS的DMEM培养液2.5m1。
4、收集对数生长期的细胞,重悬于培养液中,终浓度为2×106/ml。
5、将细胞悬液加入Transwell小室中,每孔100μ1,将小室浸于6孔板的条件培养基中,37℃、5%CO2孵箱内孵育24h。
6、将Transwell小室取出,滤膜用甲醇固定1分钟。
7、HE染色:苏木精染色3min,水洗;伊红染色10~30s,水洗。并用棉签擦掉未穿过膜的细胞。
8、显微镜下观察、照相并计数侵袭细胞数,每膜计数上下左右中5个不同视野的透过细胞数,计算平均值。每组平行设3个滤膜。
9、数据处理
用SPSS18.0软件对数据进行统计学分析。计量资料用均数±标准差表示。多个样本均数比较采用单因素方差分析,P<0.05为差异有统计学意义。
10、结果
结果如图5所示,细胞在transwell小室中培养24h后,相比其他组细胞,siRNA1-LMOD3组聚碳酸酯膜下室面的细胞数显著减少。
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
SEQUENCE LISTING
<110> 北京泱深生物信息技术有限公司
<120> LMOD3在制备口腔鳞癌诊疗制剂中的应用
<160> 12
<170> PatentIn version 3.5
<210> 1
<211> 1683
<212> DNA
<213> 人源
<400> 1
atgtcagagc acagcagaaa ttcagatcaa gaagaacttc tcgatgagga gattaatgaa 60
gatgaaatct tggccaactt gtctgctgaa gaactgaaag aactgcagtc ggaaatggaa 120
gtcatggccc ctgaccccag ccttcccgtg ggaatgattc agaaagatca aactgacaag 180
ccaccgacag gaaacttcaa tcataaatct cttgttgatt atatgtattg ggaaaaggca 240
tccaggcgca tgctggaaga ggaacgagtt cctgtcacct ttgtgaaatc cgaggaaaag 300
actcaagaag agcatgaaga aatagaaaaa cgtaataaaa atatggccca gtatttaaaa 360
gaaaagctca ataatgaaat agttgcaaat aaaagagaat caaagggcag cagcaatatc 420
caagaaacag atgaagaaga tgaagaagaa gaagatgatg atgatgacga cgaaggagaa 480
gatgatggtg aagagagtga agaaacgaac agagaagagg aaggcaaagc aaaggaacaa 540
attagaaatt gtgagaacaa ctgccagcag gtaactgaca aagcattcaa agaacagaga 600
gacagaccag aggcccaaga acaaagtgag aaaaaaatat cgaaattaga tcctaagaag 660
ttagctctag acaccagctt tttgaaggta agtacaaggc cttcaggaaa ccagacagac 720
ctggatggga gcttgaggag agttaggaaa aatgatcctg acatgaagga actcaacctg 780
aacaacattg aaaacatccc caaagaaatg ttactggact ttgtcaatgc aatgaagaaa 840
aacaagcaca tcaaaacatt cagtttagcc aatgtgggtg cagatgagaa tgtagcattt 900
gccttggcta acatgttgcg tgaaaataga agcatcacca ctctcaacat cgagtccaat 960
ttcatcacag gtaaagggat tgtggccatc atgaggtgtc tccagtttaa tgagacgcta 1020
actgagcttc ggtttcacaa tcagaggcac atgttgggtc accatgctga aatggaaata 1080
gccaggcttt tgaaggcaaa caacactctc ctgaagatgg gctaccattt tgagcttccg 1140
ggtcccagaa tggtggtcac taatctgctc accaggaatc aggataaaca aaggcagaaa 1200
cgacaggaag agcaaaaaca gcagcaactc aaggaacaga agaagctgat agccatgtta 1260
gagaatgggt tggggctgcc ccctgggatg tgggagctgt tgggaggacc caagccagat 1320
tccagaatgc aggaattctt ccagccaccg ccacctcggc ctcccaaccc ccaaaatgtc 1380
ccctttagtc aacgcagtga aatgatgaaa aagccatcgc aggccccgaa gtacaggaca 1440
gaccctgact ccttccgggt ggtgaagctg aagagaatcc agcgcaaatc tcggatgccg 1500
gaagccagag aaccacccga gaaaaccaac ctcaaagatg tcatcaaaac gctcaagcca 1560
gtgccgagaa acaggccacc cccattggtg gaaatcactc ccagagatca gctgctaaac 1620
gacattcgtc acagcagtgt cgcctatctt aaacctgtgc aactgccaaa agaactggcg 1680
taa 1683
<210> 2
<211> 560
<212> PRT
<213> 人源
<400> 2
Met Ser Glu His Ser Arg Asn Ser Asp Gln Glu Glu Leu Leu Asp Glu
1 5 10 15
Glu Ile Asn Glu Asp Glu Ile Leu Ala Asn Leu Ser Ala Glu Glu Leu
20 25 30
Lys Glu Leu Gln Ser Glu Met Glu Val Met Ala Pro Asp Pro Ser Leu
35 40 45
Pro Val Gly Met Ile Gln Lys Asp Gln Thr Asp Lys Pro Pro Thr Gly
50 55 60
Asn Phe Asn His Lys Ser Leu Val Asp Tyr Met Tyr Trp Glu Lys Ala
65 70 75 80
Ser Arg Arg Met Leu Glu Glu Glu Arg Val Pro Val Thr Phe Val Lys
85 90 95
Ser Glu Glu Lys Thr Gln Glu Glu His Glu Glu Ile Glu Lys Arg Asn
100 105 110
Lys Asn Met Ala Gln Tyr Leu Lys Glu Lys Leu Asn Asn Glu Ile Val
115 120 125
Ala Asn Lys Arg Glu Ser Lys Gly Ser Ser Asn Ile Gln Glu Thr Asp
130 135 140
Glu Glu Asp Glu Glu Glu Glu Asp Asp Asp Asp Asp Asp Glu Gly Glu
145 150 155 160
Asp Asp Gly Glu Glu Ser Glu Glu Thr Asn Arg Glu Glu Glu Gly Lys
165 170 175
Ala Lys Glu Gln Ile Arg Asn Cys Glu Asn Asn Cys Gln Gln Val Thr
180 185 190
Asp Lys Ala Phe Lys Glu Gln Arg Asp Arg Pro Glu Ala Gln Glu Gln
195 200 205
Ser Glu Lys Lys Ile Ser Lys Leu Asp Pro Lys Lys Leu Ala Leu Asp
210 215 220
Thr Ser Phe Leu Lys Val Ser Thr Arg Pro Ser Gly Asn Gln Thr Asp
225 230 235 240
Leu Asp Gly Ser Leu Arg Arg Val Arg Lys Asn Asp Pro Asp Met Lys
245 250 255
Glu Leu Asn Leu Asn Asn Ile Glu Asn Ile Pro Lys Glu Met Leu Leu
260 265 270
Asp Phe Val Asn Ala Met Lys Lys Asn Lys His Ile Lys Thr Phe Ser
275 280 285
Leu Ala Asn Val Gly Ala Asp Glu Asn Val Ala Phe Ala Leu Ala Asn
290 295 300
Met Leu Arg Glu Asn Arg Ser Ile Thr Thr Leu Asn Ile Glu Ser Asn
305 310 315 320
Phe Ile Thr Gly Lys Gly Ile Val Ala Ile Met Arg Cys Leu Gln Phe
325 330 335
Asn Glu Thr Leu Thr Glu Leu Arg Phe His Asn Gln Arg His Met Leu
340 345 350
Gly His His Ala Glu Met Glu Ile Ala Arg Leu Leu Lys Ala Asn Asn
355 360 365
Thr Leu Leu Lys Met Gly Tyr His Phe Glu Leu Pro Gly Pro Arg Met
370 375 380
Val Val Thr Asn Leu Leu Thr Arg Asn Gln Asp Lys Gln Arg Gln Lys
385 390 395 400
Arg Gln Glu Glu Gln Lys Gln Gln Gln Leu Lys Glu Gln Lys Lys Leu
405 410 415
Ile Ala Met Leu Glu Asn Gly Leu Gly Leu Pro Pro Gly Met Trp Glu
420 425 430
Leu Leu Gly Gly Pro Lys Pro Asp Ser Arg Met Gln Glu Phe Phe Gln
435 440 445
Pro Pro Pro Pro Arg Pro Pro Asn Pro Gln Asn Val Pro Phe Ser Gln
450 455 460
Arg Ser Glu Met Met Lys Lys Pro Ser Gln Ala Pro Lys Tyr Arg Thr
465 470 475 480
Asp Pro Asp Ser Phe Arg Val Val Lys Leu Lys Arg Ile Gln Arg Lys
485 490 495
Ser Arg Met Pro Glu Ala Arg Glu Pro Pro Glu Lys Thr Asn Leu Lys
500 505 510
Asp Val Ile Lys Thr Leu Lys Pro Val Pro Arg Asn Arg Pro Pro Pro
515 520 525
Leu Val Glu Ile Thr Pro Arg Asp Gln Leu Leu Asn Asp Ile Arg His
530 535 540
Ser Ser Val Ala Tyr Leu Lys Pro Val Gln Leu Pro Lys Glu Leu Ala
545 550 555 560
<210> 3
<211> 18
<212> DNA
<213> 人工序列
<400> 3
atcaccactc tcaacatc 18
<210> 4
<211> 18
<212> DNA
<213> 人工序列
<400> 4
ctcagttagc gtctcatt 18
<210> 5
<211> 21
<212> DNA
<213> 人工序列
<400> 5
ctctggtaaa gtggatattg t 21
<210> 6
<211> 20
<212> DNA
<213> 人工序列
<400> 6
ggtggaatca tattggaaca 20
<210> 7
<211> 19
<212> RNA
<213> 人工序列
<400> 7
uucuccgaac gugucacgu 19
<210> 8
<211> 19
<212> RNA
<213> 人工序列
<400> 8
acgugacacg uucggagaa 19
<210> 9
<211> 21
<212> RNA
<213> 人工序列
<400> 9
agaaguucuu cuugaucuga a 21
<210> 10
<211> 21
<212> RNA
<213> 人工序列
<400> 10
cagaucaaga agaacuucuc g 21
<210> 11
<211> 21
<212> RNA
<213> 人工序列
<400> 11
aagagauuua ugauugaagu u 21
<210> 12
<211> 21
<212> RNA
<213> 人工序列
<400> 12
cuucaaucau aaaucucuug u 21
- 还没有人留言评论。精彩留言会获得点赞!