一种环状转座子复合物及其应用的制作方法
本发明涉及分子生物学与基因组学领域。更具体地,涉及一种环状转座子复合物及其应用。
背景技术:
DNA测序(DNA sequencing)作为一种重要的实验技术,在生物学研究中有着广泛的应用。早在DNA双螺旋结构被发现后不久就有人报道过DNA测序技术,但是当时的操作流程复杂,无法形成规模。随后在1977年Sanger发明了具有里程碑意义的双脱氧末端终止测序法(Sanger,F.;Nicklen,S.;Coulson,A.R.(1977),"DNA sequencing with chain-terminating inhibitors",Proceedings of the National Academy of Sciences USA,74(12):5463–5467),因其简单、快速,经过后续的不断改良,成为了相当一段时间内DNA测序的主流技术。
然而随着科学的发展,传统的Sanger测序已经不能完全满足研究的需要,对模式生物进行基因组重测序以及对一些非模式生物的基因组测序,都需要费用更低、通量更高、速度更快的测序技术,第二代测序技术(Next-generation sequencing)应运而生。与传统的Sanger测序方法相比,二代测序技术使得科学家们可以更加快速、廉价地对DNA与RNA进行测序,彻底变革了分子生物学与基因组学的研究(Quail,M.A.,I.Kozarewa,F.Smith,A.Scally,P.J.Stephens,R.Durbin,H.Swerdlow,and D.J.Turner.A large genome center’s improvements to the Illumina sequencing system.Nat.Methods 2008,5:1005-1010)。
标准的传统二代测序文库构建包括如下步骤:(i)片段化,(ii)末端修复,(iii)5’末端磷酸化,(iv)3’末端加dA,从而可与测序接头连接,(v)连接接头,(vi)通过PCR富集两端均成功连接接头的产物(如图1)(Steven R.Head,H.Kiyomi Komori,Sarah A.LaMere,Thomas Whisenant,Filip Van Nieuwerburgh,Daniel R.Salomon,and Phillip Ordoukhanian,Library construction for next-generation sequencing:Overviews and challenges.BioTechniques,2014,56:61–77)。该方法步骤较多,操作繁琐,耗时费力,因而有学者对其作出改进,将步骤(ii)~(v)整合在同一反应体系中(M Neiman,S Sundling,H P Hall,K Czene,et al.Library preparation and multiplex capture for massive parallel sequencing applications made efficient and easy.Plos One 2012,7(7):e48616-e48616)。但无论整合与否,建库过程中的3’末端加dA步骤,因为需要用Taq或exo Klenow DNA聚合酶为DNA3’端添加dA突出端,而此步骤的加3’末端dA效率较低,因此直接决定了产物两端均成功连接接头的效率较低,在很大程度上制约了建库效果。
已有学者对以上建库方法作出改进(中国发明专利:201610537963.4;发明名称:一种高效的DNA接头连接方法),使用具有不同末端结构的接头混合物与加A产物进行连接,接头混合物中的平末端、3’dT突出端、3’dG突出端,分别对应加A反应后,DNA分子末端可能具有的平末端、3’dA突出端、3’dG突出端三种结构,并分别与其连接。因此,无论DNA分子的加A效率如何,具有何种末端结构,均有与之相匹配的接头相连接,确保了分子两端添加接头效率的显著提升,有效改善了建库效率。但该方法仍然具有步骤较多、操作繁琐等缺点。
A Bhasin等发现Tn5Transposon可将任何双链DNA插入到其他DNA片段中(A Bhasin,IY Goryshin,WS Reznikoff.Hairpin formation in Tn5transposition.Journal of Biological Chemistry,1999,274(52):37021-9),唯一和必须的条件是此双链DNA的两端含19bp的特定顺序(MEDS)。Epicentre用此原理开发了将Tn5Transposon用于第一代测序的试剂盒(EZ-Tn5<KAN-2>Insertion Kit)。
在此之后Epicentre发现,Transposon可用于同时插入两条不同的DNA,只要这两条DNA链的一端有MEDS顺序,并在此基础上开发了第二代DNA测序试剂盒系列产品(TRANSPOSON END COMPOSITIONS AND METHODS FOR MODIFYING NUCLEIC ACIDS.United States Patent Application Pub.No.US 20110287435A1.)。该方法较之上文介绍的文库构建方案,步骤更加简单,易于操作,大幅缩短了建库操作时间。
但该方法亦存在缺点:该方法理论上可在断裂形成的DNA片段两端加上不同标签,但实际操作过程中,转座子插入序列的方向是随机的,具有正反两种可能,因此DNA片段两端可能带有相同的标签,无法进行下游的PCR放大。实际上,可有效利用的DNA片段仅有50%。
因此,需要开发简单、高效、易于操作、成本较低的转座子复合物及DNA文库构建技术,对于生命科研与精准医疗事业来说至关重要。
技术实现要素:
本发明的第一个目的在于提供一种环状转座子复合物,该转座子复合物可用于测序技术的基因组DNA文库构建、转录组测序文库构建。
本发明的第二个目的在于提供一种包含上述环状转座子复合物的应用。
本发明的第三个目的在于提供一种DNA文库的构建方法,通过“先插入、再切断”,一步完成“片段化——加标签”的全过程,提高建库效率,操作更简便。
为达到上述目的,本发明采用下述技术方案:
一种环状转座子复合物,所述环状转座子复合物包含Tn5转座酶和插入DNA。
本发明所述插入DNA包含转座子末端序列、2个标签序列和含酶切位点的DNA序列;所述插入DNA两端为转座子末端序列,在转座子末端序列内侧则是2个标签序列;所述2个标签序列之间为含酶切位点的DNA序列;所述含酶切位点的DNA序列包括但不限于含U的单链或双链DNA序列、含限制性酶切位点的DNA序列、含有不互补碱基对的双链DNA序列。
本发明优选的实施例中,所述环状转座子复合物有且仅有一个插入DNA。
本发明所述的插入DNA可以通过化学合成或其它分子生物学方法获得,其结构形如“转座子末端序列——第一标签序列——酶解序列——第二标签序列——转座子末端序列”,其序列中第一标签序列和第二标签序列可以相同也可以不同,组成顺序固定,且每个转座子中保证有且仅有一个插入DNA分子,因此当两个标签序列不同时,这种结构的每个转座子所能提供的,是完全精确的两个不同的标签序列,确保了断裂片段两端的接头种类不同,使得靶DNA的利用率得到最大化。
本发明进一步提供了上述环状转座子复合物在构建DNA文库中的应用。
本发明所使用的术语“标签序列”是指向它所接合的核酸片段提供寻址手段的非靶核酸组分的DNA序列。在本发明中,靶DNA经体外转座、酶解处理后得到了大量DNA片段,其两端引入了标签序列。本发明标签序列可以依实验要求的不同,标签序列的设计可以灵活多样,使得本发明环状转座子复合物的应用范围得到极大扩展,例如所述标签序列可以为PCR引物识别序列、二代测序接头序列(包括测序仪锚定序列和测序引物识别序列)等,可用于二代测序技术的基因组DNA文库构建、转录组测序文库构建、宏基因组测序文库的构建、PCR片段文库构建、大规模平行DNA测序文库构建,等等。因此,将本发明的环状转座子复合物用于二代测序技术的基因组DNA文库的构建、转录组测序文库的构建、宏基因组测序文库的构建、PCR片段文库构建、大规模平行DNA测序文库的构建等均在本发明的保护范围之内。
本发明还提供了一种高效的DNA文库构建方法,包括以下步骤:获取靶DNA;获取环状转座子复合物:所述环状转座子复合物包含Tn5转座酶和插入DNA;将靶DNA与环状转座子复合物孵育,酶解反应;即得DNA文库。
本发明所述插入DNA包含转座子末端序列、2个标签序列和含酶切位点的DNA序列;所述插入DNA两端为转座子末端序列,在转座子末端序列内侧则是2个标签序列;所述2个标签序列之间为含酶切位点的DNA序列。所述含酶切位点的DNA序列包括但不限于含U的单链或双链DNA序列、含限制性酶切位点的DNA序列或含有不互补碱基对的双链DNA序列。
本发明根据所述2个标签序列之间的带有酶切位点的DNA序列不同,用相应的酶进行酶解反应:
当所述2个标签序列之间为含限制性酶切位点的DNA序列,加入限制性内切酶进行酶解反应;
当所述2个标签序列之间的DNA序列为含U的单链或双链DNA序列,加入UDG酶进行酶解反应;
当所述2个标签序列之间的DNA序列为含有不互补碱基对的双链DNA序列,加入诸如T7endonuclease I、T4endonuclease VII或E.coli endonuclease V等核酸外切酶进行酶解反应。
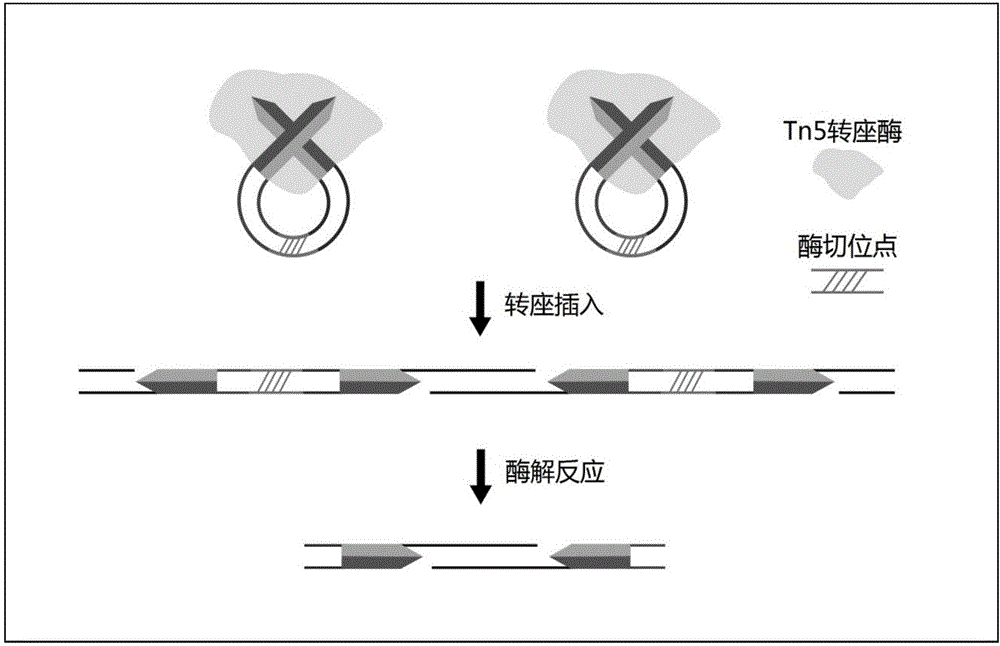
本发明使用Tn5转座酶与两端均带有转座子末端序列(MEDS)且中间带酶切位点的插入DNA组成环状的转座子复合物,并将其与靶DNA(基因组DNA)孵育,将插入DNA随机插入靶DNA中,此时靶DNA并未断裂,然后用相应的酶处理靶DNA,使其发生广泛断裂。因此,当插入DNA携带的是两个不同的标签序列时,断裂后的靶DNA片段,5’、3’两端的标签序列来自插入DNA,因而成为两端带不同标签序列的DNA片段。在插入的DNA中设计好标签序列,即可在Tn5转座酶与能断裂酶切位点的酶的共同作用下,收获两端带有不同标签序列的大量DNA片段。然后以这些片段为模板,附以诸如PCR等扩增步骤,即可完成以靶DNA为测序目标的文库构建工作。
本发明是一种利用环状转座子与酶解反应相结合,断裂靶DNA的同时在断裂形成的DNA片段末端引入标签序列的技术。通过调整反应体系中环状转座子与靶DNA的浓度、体外转座反应的具体条件,可简单地控制断裂产生的带标签DNA片段的大小分布。
在本发明优选的实施例中,在形成环状转座子复合物后,可对其进行纯化工作,去除未参与反应的Tn5转座酶与插入DNA,获得纯的环状转座子提高转座效率更高,使得实验结果更稳定。
在本发明优选的实施例中,用UDG酶断裂体外转座产物,UDG酶反应条件十分宽泛,因此既可以首先单独用UDG酶处理转座产物,也可以与DNA聚合酶(如PCR酶)在同一反应体系中共同作用,一步完成“片段化—加标签—扩增”的全过程。
进一步,本发明所述环状转座子复合物应有且仅有一个插入DNA。
本发明的有益效果如下:
传统测序文库构建方法,步骤较多,操作繁琐,耗时费力,且文库构建效率低下,完成建库需要最少4小时,且所需DNA量较大,通常需要1~5μg DNA作为建库模板。Neiman等对该方法进行步骤整合,加以改进后,在一定程度上简化了操作,但仍然需要3小时左右才能完成文库构建,所需的DNA为5~1000ng,用量依旧较高。另外,通过在Neiman方法的基础上对以上建库方法作出改进,使用具有不同末端结构的接头混合物与加A产物进行连接,通过提升接头连接效率以提升建库效率,但对于建库操作流程的简化有限。
本发明利用环状转座子复合物的文库构建方法操作简便,建库效率高,仅需80分钟即可完成文库构建全程,所需的DNA量也大幅下降,1~50ng的靶DNA即足以用于建库,且该方法成本显著低于Illumina等公司的商品化试剂盒,推动测序技术在生命科研与精准医疗产业的广泛应用,具有重大而深远的意义。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明。
图1示出传统二代测序文库构建原理示意图;
图2示出本发明的原理示意图;
图3示出利用本发明断裂片段,PCR构建文库示意图;
图4示出实施例1转座子与靶DNA反应产物经安捷伦高灵敏DNA芯片电泳图;
图5示出实施例1成功构建二代测序文库中DNA片段的结构;
图6示出实施例1PCR反应模板及产物经安捷伦高灵敏DNA芯片电泳图。
具体实施方式
为了更清楚地说明本发明,下面结合优选实施例和附图对本发明做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
实施例中所用的材料及来源:
UDG反应混合物、MagicPureTM Size Selection DNA Beads、TransNGSTM Library Amplification SuperMix(2×)(北京全式金生物技术有限公司),
安捷伦2100高灵敏DNA芯片(安捷伦公司),
高灵敏DNA测试试剂(Thermo Fisher Scientific公司),
DNA合成(Life technologies公司),
二代测序(北京诺禾致源生物信息科技有限公司)。
实施例1验证环状转座子可实现靶DNA的打断,并同时插入标签序列
1.制备插入DNA
合成两条长度为72nt的两端带有的转座子末端序列(5’磷酸化的序列如SEQ ID No.1所示,3’的序列如SEQ ID No.2所示;)、在转座子末端序列内侧则是2个不同标签序列(下划线为标签序列)、之间含2个U单链DNA,序列如下:
Insert DNA F:
5’-CTGTCTCTTATACACATCTTCCGAGCCCACGAGACUUAATCGTCGGCAGCGTCAGATGTGTATAAGAGACAG-3’(如序列表SEQ ID No.3所示)
Insert DNA R:
5’-CTGTCTCTTATACACATCTGACGCTGCCGACGAUUAAGTCTCGTGGGCTCGGAAGATGTGTATAAGAGACAG-3’(如序列表SEQ ID No.4所示)
将合成的两条单链DNA粉末分别用1×杂交缓冲液(10mM Tris-HCl pH8.0,50mM NaCl)溶解,浓度为200μM,等体积混合后进行退火反应。退火产物条件为:95℃5分钟,缓慢冷却至室温。取1μl于2.0%的琼脂糖凝胶电泳检测。
退火产物即插入DNA,为1条72bp的双链DNA,浓度100μM。其结构符合“转座子末端序列——第一标签序列——酶解序列——第二标签序列——转座子末端序列”。
2.制备环状转座子
转座酶Tn5经BCA法定量,计算摩尔浓度。
配制Tn5储存液:50mM HEPES-KOH pH 7.2,0.1M NaCl,0.1mM EDTA,1mM DTT,0.1%Triton X-100,10%glycerol。
配制反应体系如下:
Tn5 (终浓度2μM)xμl
插入DNA(100μM) (终浓度2μM)2μl
Tn5储存液 加至100μl
反应条件为:30℃,1小时。-20℃保存。
3.转座子与靶DNA反应及UDG酶解反应(如图2所示)
以50ng大肠杆菌O157:H7基因组DNA为靶DNA,转座子使用0.5μl/1μl/2μl,配制转座反应体系:
反应条件为:55℃,5分钟。之后加入30μl UDG反应混合物,55℃,5分钟。
使用1.0×MagicPureTM Size Selection DNA Beads纯化以上60μl反应混合物,使用0.5μl转座子的产物记名为“片段化DNA-0.5”,使用1μl转座子的产物记名为“片段化DNA-1”,使用2μl转座子的产物记名为“片段化DNA-2”,片段化DNA使用安捷伦2100高灵敏DNA芯片检测片段大小(如图4)。
4.反应产物验证(反应的原理如图3所示)
测序文库中成功反应产物DNA序列的结构如图5所示:
根据反应产物两端不同的标签序列设计特异引物,以片段化DNA-2为模板,通过PCR方法验证反应是否成功进行。引物序列如下:
Tn5Primer F:
5’-AATGATACGGCGACCACCGAGATCTACACTAGATCGCTCGTCGGCAGCGTC-3’(如SEQ ID No.5所示)
Tn5Primer R:
5’-CAAGCAGAAGACGGCATACGAGATTCGCCTTAGTCTCGTGGGCTCGGA-3’(如SEQ ID No.6所示)
PCR反应体系如下:
PCR反应条件为:
PCR产物使用1.0×MagicPureTM Size Selection DNA Beads纯化,产物使用安捷伦2100高灵敏DNA芯片检测片段大小(如图6)。经高灵敏DNA测试试剂测定浓度,计算PCR模板量和产量分别为:片段化DNA-2模板量共28ng,经5个PCR扩增后产量为370ng,经7个PCR扩增后产量为1200ng。由于所用引物为针对标签序列a和b设计的特异引物,由此可知转座子成功实现了靶DNA的打断,并同时插入标签序列。
另外,通过本实验可以看出:靶DNA的片段化程度可简单地通过调整转座子与靶DNA的反应比例控制。转座子与靶DNA反应以及酶解反应共需10分钟,取代传统二代测序文库构建片段化、末端修复、5’末端磷酸化、3’末端加dA和接头连接过程,明显简化二代建库流程。
实施例2验证本发明方法可作为一种高效的二代测序文库构建方法。
1.制备插入DNA
同实施例1中步骤1。
2.制备环状转座子
同实施例1中步骤2。
3.转座子与靶DNA反应及UDG酶解反应
以50ng人类血液基因组DNA为靶DNA,转座子使用2μl。步骤同实施例1中步骤3。
4.PCR扩增
同实施例1中步骤4,PCR循环数为7。
5.磁珠法分选产物片段大小
根据测序公司对二代测序文库片段大小的要求,使用MagicPureTM Size Selection DNA Beads分选片段大小,第一轮磁珠比例为0.6×,第二轮磁珠比例为0.15×,所得产物即为二代测序文库,文库记名为“Tn5_Human”。
6.使用二代测序仪验证文库质量
文库经Illumina Hiseq XTM系统测序,测序策略为PE150。测序数据质量控制如表1,测序数据与参考基因组序列比对结果如表2:
表1测序数据质量控制
表2测序数据与参考基因组序列比对结果
从表2中可以看出:对于基因组较大的人类基因组DNA,仅仅50ng的起始样品量,在测序深度约10×的情况下即可达到98.99%的覆盖率,二代测序文库构建效果可与传统文库构建方法媲美,且文库构建过程快速、操作简便,所需样品量少。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
SEQUENCE LISTING
<110> 北京全式金生物技术有限公司
<120> 一种环状转座子复合物及其应用
<130> JLC16I0775E
<160> 6
<170> PatentIn version 3.3
<210> 1
<211> 19
<212> DNA
<213> 人工合成的转座子末端序列
<400> 1
ctgtctctta tacacatct 19
<210> 2
<211> 19
<212> DNA
<213> 人工合成的转座子末端序列
<400> 2
agatgtgtat aagagacag 19
<210> 3
<211> 72
<212> DNA
<213> 人工合成的Insert DNA F
<400> 3
ctgtctctta tacacatctt ccgagcccac gagacuuaat cgtcggcagc gtcagatgtg 60
tataagagac ag 72
<210> 4
<211> 72
<212> DNA
<213> 人工合成的Insert DNA R
<400> 4
ctgtctctta tacacatctg acgctgccga cgauuaagtc tcgtgggctc ggaagatgtg 60
tataagagac ag 72
<210> 5
<211> 51
<212> DNA
<213> 人工合成的Tn5 Primer F
<400> 5
aatgatacgg cgaccaccga gatctacact agatcgctcg tcggcagcgt c 51
<210> 6
<211> 48
<212> DNA
<213> 人工合成的Tn5 Primer R
<400> 6
caagcagaag acggcatacg agattcgcct tagtctcgtg ggctcgga 48
- 还没有人留言评论。精彩留言会获得点赞!