一种优化的基于细菌细胞表面展示系统的目标物捕获体系的制作方法
本发明属于生物工程领域,涉及目标物捕获体系,尤其涉及一种优化的基于细菌细胞表面展示系统的目标物捕获体系,目标物如病毒受体或特异性吸附配体等。
背景技术:
分析和鉴定病毒受体是探索研究病毒入侵细胞和宿主感染机制的关键步骤。目前,病毒受体分析主要依赖于免疫共沉淀方法和dna介导的转化;再以体外培养并富集的大量病毒颗粒对病毒受体进行验证;最后,获得病毒受体的组分和结构。但是,很多病毒暂无成熟的体外增殖体系,这些方法不具有实际操作性。即,缺少病毒吸附介质的分离体系是阻碍深入研究病毒与宿主互作的主要瓶颈。因此,如何大量获得易于后期试验操作的病毒替代物,成为解析不可体外培养的病毒的受体的关键。以下以人源诺如病毒(humannoroviruses,hunovs)为例展开描述。
在杆状病毒体系中,外源表达的hunovsvp1蛋白可以自动折叠并形成类病毒粒子(virus-likeparticles,vlps);在原核表达体系中,只有p结构域的外源表达产物可以折叠成24个单位的p颗粒(pparticles);vlps和p颗粒具有良好的免疫原性和与已知受体(如:组织血型抗原(histo-bloodgroupantigens,hbgas))结合的特性,常被用于研究hunovs与载体互作的替代物。但是,两者的表达系统操作繁琐且难以从复杂体系中分离获得病毒衣壳蛋白与受体(吸附介质)的复合物。为了克服上述技术瓶颈,目前的研发技术通过建立细菌细胞表面展示系统来构建约百倍放大的假hunovs。
细菌细胞表面展示系统是指通过脱氧核糖核酸重组技术,将某外源蛋白的编码基因与可锚定于受体细菌表面的编码基因进行融合,通过融合蛋白在宿主细胞中表达、分泌,最终将融合蛋白跨膜锚定在宿主细胞的表面,达到研究融合蛋白功能或对融合蛋白进行应用的目的。冰晶核蛋白(ice-nucleationprotein,inp)可通过糖基磷脂酰肌醇而锚定在细菌表面,利于大分子蛋白的表面展示。inp的n端结构域(inaqn)也具有完整inp的表面展示功能。锚定于细胞表面的外源蛋白可以克服融合蛋白在胞内无法正确折叠等弊端。研究发现:假hunovs的承载体(大肠杆菌)会严重干扰病毒受体的分析。因此,需要开发优化的假hunovs,用来构建新的细菌表面展示系统。
因此,本领域的技术人员致力于开发一种优化的基于细菌细胞表面展示系统的目标物捕获体系。
技术实现要素:
发明人前期已经通过构建重组表达质粒pet28a-inaqn-p(gii.4)建立了一种基于细菌细胞表面展示系统的病毒受体捕获体系,前期的发明内容由于应用中病毒受体(介质)分析容易受到所展示病毒衣壳蛋白承载体(大肠杆菌)的背景干扰,影响分析结果。本发明所要解决的技术问题是降低背景干扰,提高吸附效率并提供一种基于细菌细胞表面展示系统的目标物捕获体系,在原有病毒受体捕获体系的基础上,通过简单的诱导使病毒衣壳蛋白高效表达并锚定于宿主细菌的细胞表面,通过加入可被蛋白酶识别且作用的接头蛋白,降低背景干扰、提升目标物分离效率,从而应用于病毒受体的捕获、富集和分析,以及目标外源蛋白的分离纯化。
为实现上述目的,本发明的一方面提供了一种基于优化的细菌细胞表面展示系统的目标物捕获体系,该目标物捕获体系包括能锚定在宿主菌细胞表面的冰核蛋白n端结构域,与冰核蛋白n端结构域相连的接头蛋白,以及与接头蛋白相连的病毒的衣壳蛋白。
进一步地,接头蛋白能被蛋白酶处理而断裂,使得病毒的衣壳蛋白脱离宿主菌的表面。
进一步地,病毒衣壳蛋白的编码基因片段,其dna序列如seqidno:1所示。
进一步地,冰核蛋白n端结构域的编码基因片段,其dna序列如seqidno:2所示。
进一步地,接头蛋白的氨基酸序列如seqidno:3所示。
优选地,宿主菌为大肠杆菌bl21。
本发明的另一方面提供了一种优化的基于细菌细胞表面展示系统的目标物捕获体系,包括以下步骤:
(1)将病毒的衣壳蛋白编码基因片段与编码冰核蛋白n端结构域的编码基因片段之间插入接头蛋白的编码基因片段,获得融合基因片段;
(2)验证所述融合基因片段的脱氧核糖核酸序列;
(3)将融合基因片段插入诱导型原核表达质粒,获得重组诱导型表达质粒;
(4)将重组诱导型表达质粒转化入宿主菌,获得病毒的衣壳蛋白的细菌细胞表面展示系统;
(5)在诱导剂的诱导下使病毒的衣壳蛋白展示在宿主菌细胞表面,获得目标物捕获体系。
进一步地,步骤(1)中的病毒的衣壳蛋白编码基因片段,其序列如seqidno:1所示。
进一步地,步骤(1)中的编码冰核蛋白n端结构域的编码基因片段,其序列如seqidno:2所示。
进一步地步骤(1)中的接头蛋白,其氨基酸序列如seqidno:3所示。
其中,接头蛋白的编码基因片段用于优化的细菌细胞表面展示系统的构建。
进一步地,步骤(4)中的宿主菌为大肠杆菌(escherichiacoli)bl21。
进一步地,步骤(5)中诱导包括以下诱导步骤:
(a)将转化有重组诱导型表达质粒的宿主菌接种于液体培养基中,在30℃~39℃条件下震摇培养8h~16h;
(b)将步骤(a)中的细菌培养物以1.0%~20.0%接种量,转接于新鲜培养基中,在30℃~39℃条件下震摇培养;
(c)待步骤(b)中的细菌培养物od600为0.6~1.0时,无菌条件下加入诱导剂后,15℃~30℃继续震摇培养8h~24h;
(d)收集步骤(c)中细菌培养物的菌体,将菌体重悬至无菌磷酸盐缓冲液中,得到菌悬液,即获得目标物捕获体系。
进一步地,步骤(c)中的诱导剂为异丙基硫代-β-d-半乳糖苷(isopropylβ-d-1-thiogalactopyranoside,iptg),诱导终浓度为0.1mmol/l~2.0mmol/l。
进一步地,步骤(d)中无菌磷酸盐缓冲液的ph=7.2。
进一步地,步骤(d)获得的菌悬液的od600为0.6~1.0。
进一步地,步骤(d)获得的菌悬液的保存温度为1℃~6℃。
另一方面,本发明还提供了上述基于优化的细菌细胞表面展示系统的目标物捕获体系的应用,用于捕获和分离病毒受体,或用于目标外源蛋白的分离纯化。
当细菌细胞表面展示的外源蛋白与细胞外环境中的特定反应物直接接触,并捕获环境中的特定反应物,再通过蛋白酶处理接头蛋白并辅以简单的低速离心即可获得特定反应物与衣壳蛋白的复合物;在分析该特定反应物前剔除大肠杆菌,大大降低了背景干扰,为发掘hunovs新(类)受体及目标物分离纯化提供技术支撑。
本发明通过基因工程手段将病毒衣壳蛋白锚定并展示在细菌细胞的表面,免去了纯化病毒衣壳蛋白的繁杂步骤,这不仅大大降低了获取病毒衣壳蛋白的成本,大幅缩短病毒衣壳与病毒受体复合物的回收周期,并且避免了展示体系承载体对分析捕获的病毒受体(介质)时的背景干扰,更容易分离环境中相应的病毒受体,具有高效、节约、环保的效果。
相对于现有技术,本发明具有以下技术优点:
1、以细菌细胞表面展示体系将病毒衣壳蛋白锚定在大肠杆菌表面。所展示的衣壳蛋白可以与病毒(类)受体结合。通过蛋白酶消化辅以低速离心即可获得衣壳蛋白和病毒(类)受体的复合物,并进行病毒(类)受体的分析、鉴定;
2、无需特殊试剂和设备即可完成病毒(类)受体的分离;
3、以蛋白酶消化辅以低速离心即可剥离衣壳蛋白和病毒(类)受体的复合物与其承载体(大肠杆菌),大幅降低了承载体对病毒(类)受体分析的干扰;
4、该细菌细胞表面展示体系仅需普通培养和诱导过程,周期短。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
图1是本发明hunovsgii.4重组衣壳蛋白e.coli细胞表面展示重组菌sds-page检测结果示意图。
其中1:pet28a诱导菌体;2:重组菌pet28a-inaqn-p诱导菌体;3:重组菌pet28a-inaqn-tb-p诱导菌体;4:蛋白酶酶切pet28a-inaqn-tb-p菌体:5:酶切上清p结构域蛋白;6:浓缩后的p结构域蛋白;m:pagerulerprestainedproteinladder(sm0671)。
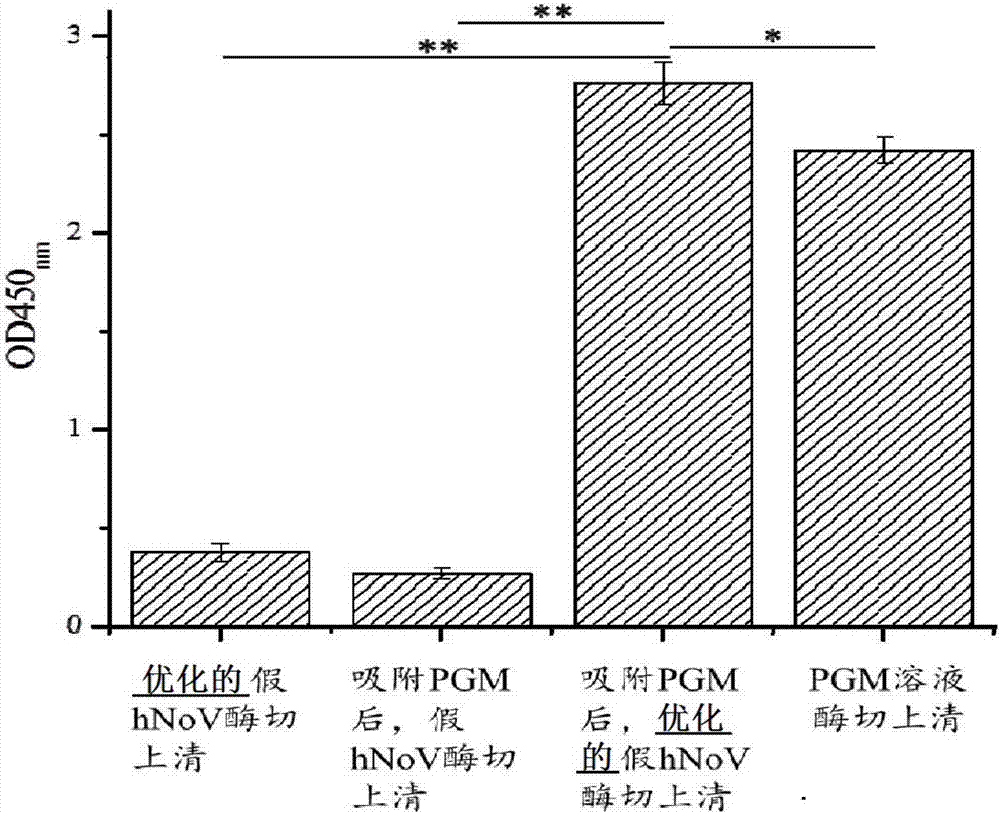
图2是本发明的一个较佳实施方式中的优化的细菌细胞表面展示体系吸附相应病毒受体的能力的示意图。
具体实施方式
以下结合附图和具体实施方式对本发明进行更详细地说明。
发明人前期已经构建了重组表达质粒pet28a-inaqn-p(gii.4),其构建方法如下:
1)序列扩增:
根据人源诺如病毒主要衣壳蛋白编码基因(orf2),其序列如seqidno:4所示,设计扩增orf2及orf2的3’端基因片段(即p基因片段)的引物对p1和p2、p5和p6,以人源诺如病毒腹泻临床样本rna进行rt-pcr扩增orf2,以orf2为模板、用引物对p5和p6进行pcr扩增获得p基因片段。根据如seqidno:2所示的基因序列设计扩增inaqn基因片段的引物对p3和p4,以丁香假单胞菌基因组dna为模板进行pcr扩增,得到inaqn基因片段。引物信息如下:
p1(5’→3’):ggaagatctatgaagatggcgtcg
p2(5’→3’):ccggaattcttataaagcacgtctg
p3(5’→3’):ccatggatggatctcgacaaggcg
p4(5’→3’):agatctggtctgcaaattctgcgg
p5(5’→3’):agatcttcaagaactaaaccattctc
p6(5’→3’):gaattcttatagtgcacgcctacgcc
引物p1、p4和p5含有bglii酶切位点,引物p2和p6含有ecori酶切位点,引物p3含有ncoi酶切位点。
orf2的rt-pcr反应条件为:42℃反转录10min;95℃变性1min;95℃预变性5min;95℃变性30s,53℃退火30s,72℃延伸2min,32个循环;72℃延伸10min;4℃保温。
inaqn的pcr反应条件为:95℃预变性5min;95℃变性30s,55℃退火30s,72℃延伸45s,32个循环;72℃延伸10min;4℃保温。
orf2的3’端(即p基因片段)pcr反应条件为:95℃预变性5min;95℃变性30s,52℃退火30s,72℃延伸1min,32个循环;72℃延伸10min;4℃保温。
经序列测定证实,获得了正确的orf2的3’端基因片段(即p基因片段)和inaqn基因片段。
2)pet28a-inaqn-p(gii.4)的构建
将上述获得的orf2的3’端基因片段(即p基因片段)和inaqn基因片段分别连接至pmd19-t载体,将连接产物以42℃热激法转入大肠杆菌dh5α,进行蓝白斑筛选后,挑取白斑单菌落,将所挑取出的单菌落进行培养后从中提取质粒,得到重组质粒pmd19-p和pmd19-inaqn。
用bglii/ecori对pmd19-p进行双酶切处理,用bglii/ncoi对pmd19-inaqn进行双酶切处理,并分别经过1.5%琼脂糖凝胶电泳分析,回收约为960bp和525bp的dna片段,并对诱导型表达质粒pet-28a进行ecori/ncoi双酶切。将上述回收的基因片段(inaqn+p+pet-28a)在t4dna连接酶的作用下进行连接,酶连接后的产物转化大肠杆菌dh5α。在含有kan的lb平板上筛选阳性克隆子,并进行培养,提取质粒。进行双酶切验证及测序正确后,即得到质粒pet28a-inaqn-p。
本具体实施方式中的病毒的衣壳蛋白3’端片段(p)、编码冰核蛋白n端结构域的编码基因片段来自于重组表达质粒pet28-inaqn-p(gii.4),这两个基因的脱氧核糖核酸(下文称为dna)序列,分别如序列表seqidno:1、seqidno:2所示,用于插入在这二者之间的接头蛋白编码基因(以下简称为tb)来源于人工合成的核酸片段,接头蛋白编码基因编码的氨基酸序列如seqidno:3所示,用于优化的细菌表面展示系统的构建。
首先,利用重组表达质粒pet28a-inaqn-p(gii.4),进行双酶切回收目的基因片段:约5.3kb的pet28载体核酸片段和960bp的p蛋白编码基因核酸片段;人工合成的543bp的tb蛋白编码基因片段(含inaqn片段)。将三种dna片段通过t4连接酶连接后得到重组诱导型表达质粒pet28-inaqn-tb-p(gii.4),通过序列测定来验证重组表达质粒的真实性和准确性。将上述重组的诱导型表达质粒转化入大肠杆菌宿主菌,携带上述重组诱导型表达质粒的大肠杆菌便成为重组病毒衣壳蛋白的细菌细胞表面展示系统。
本领域技术人员可知,上述构建方法仅是举例说明,还可以通过其他方法构建获得重组诱导型表达质粒pet28-inaqn-tb-p(gii.4)或其他病毒衣壳蛋白细菌的细胞表面展示体系。
在添加诱导剂的条件下诱导在上述细菌表面展示系统表达tb-p所编码的蛋白质。
上述细菌表面展示系统诱导表达的诱导步骤如下。
(1)将携带有重组的诱导型表达质粒的大肠杆菌单菌落接种于培养基例如luria-bertani培养基(lb培养基)中,在30℃~37℃条件下震摇培养8h~16h,获得细菌培养物。根据重组质粒所携带的抗生素标记基因,培养基中须含有相应的抗生素例如卡那霉素(kan)。
(2)从步骤(1)的细菌培养物中取菌液转接到含卡那霉素的新鲜培养基中,接种量优选为占培养基体积的1.0%~20.0%,继续在30℃~39℃条件下震摇培养。
(3)当步骤(2)的培养物的od600=0.6~1.0时,加入诱导剂例如异丙基硫代-β-d-半乳糖苷,添加后的终浓度为0.1mmol/l~2.0mmol/l,将培养温度降至15℃~30℃,继续震摇培养8h~24h,此时即可使重组病毒衣壳蛋白表达后锚定在大肠杆菌的细胞表面。
(4)通过低速离心收集菌体细胞,将菌体细胞重悬至无菌磷酸盐缓冲液(ph=7.2)中,得到菌悬液,即获得所述的优化的病毒受体捕获体系。其中,菌悬液的od600=0.6~1.0,1℃~6℃保存备用。
上述得到的菌悬液就是优化的基于细菌细胞表面展示系统的病毒受体捕获体系,可直接用于病毒受体的吸附和分离,以及目标外源蛋白的分离纯化。
实施例1
诱导型表面展示病毒衣壳蛋白原核表达质粒载体的构建:
将人工合成的inaqn-tb融合基因片段,其序列如seqidno:5所示,连接至原核克隆载体puc57中,连接产物以热激法转入大肠杆菌dh5α,在含有氨苄青霉素(amp)的lb平板上筛选阳性克隆子,将所挑取出的单菌落进行培养后从中提取质粒,得到重组质粒puc57-inaqn-tb。
用ncoi/ecori和bglii/ecori分别对pet28a-inaqn-p(gii.4)进行双酶切处理,再用ncoi/bglii对puc57-inaqn-tb进行双酶切,分别回收约5.3kb、960bp、543bp的dna片段。将上述三个片段在t4dna连接酶的作用下进行连接,酶连接后的产物转化大肠杆菌dh5α。在含有卡那霉素(kan)的lb平板上筛选阳性克隆子,培养,并抽提重组质粒。首先对重组质粒进行双酶切验证,之后,对重组质粒进行测序,测序结果表明读码框正确。即得到诱导型表面展示病毒衣壳蛋白的原核表达质粒pet28-inaqn-tb-p(gii.4)。
实施例2
诱导型表面展示病毒衣壳蛋白原核表达质粒的表达及表面展示系统的功能鉴定:
将实施例1中制备的原核表达质粒pet28-inaqn-tb-p(gii.4)转化大肠杆菌bl21,携带该诱导型表面展示病毒衣壳蛋白原核表达质粒pet28-inaqn-tb-p(gii.4)的大肠杆菌bl21命名为il-2.4p。挑取其单菌落,接种于含有100μg/ml卡那霉素的lb培养基中,37℃培养12h~14h后,以1.0%接种量接种于新鲜的培养基中,继续震摇培养至od600nm为0.6时,添加终浓度为0.4mmol/l的iptg,在26℃条件下继续震摇培养16h。4℃,5000rpm离心10min收集菌体,然后将菌体重悬于ph7.2的无菌pbs缓冲液中,od600nm调至1.0,于4℃保存备用。
如图1所示,通过重组菌sds-page检测,空载pet28a诱导菌中没有出现目标条带;重组菌pet28a-inaqn-p(gii.4)诱导菌体、重组菌pet28a-inaqn-tb-p(gii.4)诱导菌体中出现了目标蛋白。通过蛋白酶酶切后,酶切上清中出现了背景干扰小的p结构域蛋白。
以包被液(ph9.60.05mol/lna2co3-nahco3)溶解猪胃黏膜(porcinegastricmucin,以下简称:pgm;含hunovs受体hbgas)至终浓度为1.0mg/ml,将诱导菌液与等体积不同稀释度的pgm溶液于37℃孵育0.5h,离心去上清;pbs洗涤3次后,用100u/ml蛋白酶(按照切割质量比1:2000)37℃振荡水浴酶切处理3h后。然后4℃,10,000rpm离心5min,收集上清。对照组不与pgm孵育,其他处理一致;pet28a作为阴性对照。
将上述样品各取100μl加入酶标板,4℃包被过夜;弃液后pbs洗涤三次,120μl/孔1.0%bsa进行封闭,37℃孵育1h;弃液后pbs洗涤三次,100μl/孔添加一抗(hbgas单克隆抗体bg2,1:1000稀释,signetlaboratories,dedham,ma,usa),37℃孵育60min。弃液后tbst洗涤三次,100μl/孔二抗[hrp-羊抗鼠igg(h+l)购于上海翊圣生物科技有限公司]稀释液(1:3000稀释于含1.0%bsa的tbst溶液中),经37℃孵育60min。弃液后tbst洗涤三次,100μl/孔tmb[福因德科技(武汉)有限公司]混匀后避光反应10min。每孔加入50μl终止液(2mol/lh2so4),15min内于450nm处测定od值。
如图2所示,通过测定od值,结果证明优化的假hunovs酶切上清对pgm具有极其显著的吸附能力;优化的假hunovs酶切上清对pgm的吸附能力极其显著大于假hunovs酶切上清。说明本设计构建的优化的病毒受体捕获体系对对应的病毒有极其显著的吸附能力,且本设计的吸附能力显著高于已有的病毒受体捕获体系。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
序列表
<110>上海交通大学
<120>一种优化的基于细菌细胞表面展示系统的目标物捕获体系
<160>5
<170>patentinversion3.5
<210>1
<211>960
<212>dna
<213>诺如病毒衣壳蛋白3'端结构域编码基因p基因
<400>1
tcaagaactaaaccattctctgtcccagttttaactgttgaggagatgaccaattcaaga60
ttccccattcctttggaaaagttgttcacgggtcccagcagtgcctttgttgtccaacca120
caaaacggtaggtgcacgactgatggcgtgctcctaggcgccacccaactgtctcctgtc180
aacatctgcaccttcagaggagatgtcacccatatcacaggtagtcgtaactacacaatg240
aatttggcttctcaaaattggagcaattatgacccaacagaagaaatcccagcccctcta300
ggaactccagattttgtggggaagattcaaggcgtgctcacccaaaccacaaggacagat360
ggctcaacacgcggccacaaagccacagtgtacactgggagcgccgactttgctccaaaa420
ctgggtagagttcaatttgaaactgacacagaccgtgattttgaagctaaccaaaacaca480
aagttcaccccagttggtgtcatccaagatggtagcaccacccaccgaaatgaaccccaa540
cagtgggtgctcccaagttactcaggcagaaatactcctaatgtgcatctggcccccgct600
gtagcccccacttttccgggtgagcaacttctcttcttcagatccaccatgcccggatgc660
agcgggtaccccaacatggatttggactgtctgctcccccaggaatgggtgcagtacttc720
taccaagaggcagccccagcacaatctgatgtggctctgctaagatttgtgaatccagac780
acaggtagggttttgtttgagtgtaagcttcataaatcaggctatgttacagtggctcac840
actggccaacatgatttggttatcccccccaatggttattttaggtttgattcctgggtc900
aaccagttttacacgcttgcccccatgggaaatggaacggggcgtaggcgtgcactataa960
<210>2
<211>525
<212>dna
<213>冰核蛋白n端结构域编码基因inaqn
<400>2
atggatctcgacaaggcgttggtgctgcgtacctgtgcaaataacatggccgatcattgc60
ggccttatatggcccgcttctggcacggtggaatccaaatactggcagtcaaccaggcgg120
catgagaatggtctggtcggtttactgtggggcgctggaaccagcgcttttctaagcgtg180
catgccgatgcgcgatggattgtccgtgaagtcgccgttgccgacatcatcagcctggaa240
gagcccggaatggtcaagtttccgcgggccgaggtggttcatgtcggcgacaggatcagc300
gcgtcacactttatttcggcacgtcaggccgaccctgcatcaacgccaacgccaacgcca360
acgccaatgaccgcggccacgcccccacccacgcccgcgacagcaaatgtcacgttaccg420
gtggccgaacaggccagtcatgaagtgttcgatgtggcgttggtcagcgcggctgccccc480
ccggtaaataccctgccggtgacgacgccgcagaatttgcagacc525
<210>3
<211>6
<212>prt
<213>人工蛋白
<400>3
leuvalproargglyser
15
<210>4
<211>1623
<212>dna
<213>诺如病毒衣壳蛋白编码基因orf2
<400>4
atgaagatggcgtcgagtgacgccaacccatctgatgggtccgcagccaacctcgtccca60
gaggtcaataatgaggttatggctctggagcccgttgttggtgccgccattgcggcacct120
gtagcgggccaacaaaatgtaattgacccctggattagaaataattttgtaccagcccct180
ggtggagagtttacagtatcccctagaaacgctccaggtgaaatactatggagcgcgccc240
ttgggccctgatctaaatccctacctatcccatttggccagaatgtacaatggttatgca300
ggtggttttgaagtgcaggtaattctcgcggggaacgcgttcaccgccgggaaggtcata360
tttgcagcagtcccaccaaattttccaactgaaggcttgagccccagccaggtcactatg420
ttcccccatatagtagtagatgttaggcaactagaacctgtgttgattcccttacccgat480
gttaggaataatttctatcattacaatcaatcaaatgaccccaccattaagttgatagca540
atgttgtacacaccacttagggctaacaatgctggggatgatgtcttcacagtttcttgc600
cgagttctcacgagaccatcccccgattttgatttcatatttctagtgccacccacagtt660
gagtcaagaactaaaccattctctgtcccagttttaactgttgaggagatgaccaattca720
agattccccattcctttggaaaagttgttcacgggtcccagcagtgcctttgttgtccaa780
ccacaaaacggtaggtgcacgactgatggcgtgctcctaggcgccacccaactgtctcct840
gtcaacatctgcaccttcagaggagatgtcacccatatcacaggtagtcgtaactacaca900
atgaatttggcttctcaaaattggagcaattatgacccaacagaagaaatcccagcccct960
ctaggaactccagattttgtggggaagattcaaggcgtgctcacccaaaccacaaggaca1020
gatggctcaacacgcggccacaaagccacagtgtacactgggagcgccgactttgctcca1080
aaactgggtagagttcaatttgaaactgacacagaccgtgattttgaagctaaccaaaac1140
acaaagttcaccccagttggtgtcatccaagatggtagcaccacccaccgaaatgaaccc1200
caacagtgggtgctcccaagttactcaggcagaaatactcctaatgtgcatctggccccc1260
gctgtagcccccacttttccgggtgagcaacttctcttcttcagatccaccatgcccgga1320
tgcagcgggtaccccaacatggatttggactgtctgctcccccaggaatgggtgcagtac1380
ttctaccaagaggcagccccagcacaatctgatgtggctctgctaagatttgtgaatcca1440
gacacaggtagggttttgtttgagtgtaagcttcataaatcaggctatgttacagtggct1500
cacactggccaacatgatttggttatcccccccaatggttattttaggtttgattcctgg1560
gtcaaccagttttacacgcttgcccccatgggaaatggaacggggcgtaggcgtgcacta1620
taa1623
<210>5
<211>543
<212>dna
<213>inaqn-tb融合基因片段
<400>5
atggatctcgacaaggcgttggtgctgcgtacctgtgcaaataacatggccgatcattgc60
ggccttatatggcccgcttctggcacggtggaatccaaatactggcagtcaaccaggcgg120
catgagaatggtctggtcggtttactgtggggcgctggaaccagcgcttttctaagcgtg180
catgccgatgcgcgatggattgtccgtgaagtcgccgttgccgacatcatcagcctggaa240
gagcccggaatggtcaagtttccgcgggccgaggtggttcatgtcggcgacaggatcagc300
gcgtcacactttatttcggcacgtcaggccgaccctgcatcaacgccaacgccaacgcca360
acgccaatgaccgcggccacgcccccacccacgcccgcgacagcaaatgtcacgttaccg420
gtggccgaacaggccagtcatgaagtgttcgatgtggcgttggtcagcgcggctgccccc480
ccggtaaataccctgccggtgacgacgccgcagaatttgcagaccggatccacgcggaac540
cag543
- 还没有人留言评论。精彩留言会获得点赞!