人工纤维小体、利用其分解纤维素及生产酒精的方法与流程
本发明是涉及纤维素的分解方法,特别是关于利用具有噬菌体支架的纤维小体分解纤维素的方法及利用其生产酒精的方法。
背景技术:
已知的生物质酒精制程中,联合生物转化制程(consolidatedbioprocessing,cbp)是为目前最优秀的制程,通过整合生产过程中的所有反应于同一菌株(例:酿酒酵母)中,可大幅降低生产成本及需求。其中,在厌氧热纤梭菌(c.thermocellum)中发现的纤维小体被视为cbp程序发展中的关键技术之一。
纤维小体(cellulosome)主要以蛋白支架结构为主体,并于支架结构结合多种纤维素分解酶,以使整体形成具有多种分解功能的复合体,不仅克服了以往透过转基因技术将分解酶表达于细胞表面却受限制的困境,更被证实复合体相较于同样数量的分解酶具有更高的酶活性。然而,纤维小体的构造十分复杂,自然界中又仅于发酵产能不足的厌氧菌中发现其存在,故人工合成纤维小体并通过细胞表面表达技术使其表达于具有高发酵产能的酿酒酵母表面是目前最重要的发展趋势。
自然界中所发现的纤维小体,单一小体可连结约96个纤维素分解酶,而现有文献所记载的人工合成纤维小体可连结约达63个纤维素分解酶,相比天然的纤维小体仍有产能上的差距。
技术实现要素:
鉴于以上不足,本发明提供一种以重组噬菌体作为蛋白支架的纤维小体,通过自组装方式可于单一噬菌体表面连结上百至上千个纤维素分解酶,并锚定于酿酒酵母表面,不仅克服目前分解产能的问题,更可通过噬菌体本身极短的复制周期,得到可高速生产的人工纤维小体,提供高效率的纤维素分解平台。
根据上述理由,本发明提供一种纤维素的分解方法,包含:建立重组噬菌体,其中重组噬菌体是通过修改噬菌体的基因组,使该噬菌体的表面表达:与分解酶具有亲和性的接合肽,及与细胞表面的锚定位具有亲和性的锚定肽;使分解酶接触重组噬菌体;以及使纤维素接触该分解酶。
优选地,接合肽与1至3000个酶连接。
优选地,分解酶是内切型纤维素分解酶、外切型纤维素分解酶、纤维双糖分解酶或其组合。
优选地,分解酶表达seqidno:5、seqidno:6、seqidno:7、seqidno:8或其组合。
优选地,锚定位是表达seqidno:5、seqidno:6、seqidno:7、seqidno:8或其组合,且与前述分解酶表达的序列不重复。
优选地,噬菌体是选自λ噬菌体及丝状噬菌体。
优选地,细胞是选自酵母菌。
通过上述提供的纤维素分解方法,本发明还提供将其用于生产生物质酒精的方法,用以包含:建立重组噬菌体,其中该噬菌体包含接合肽及锚定肽;将分解酶接合至接合肽;将锚定肽锚定于酵母菌的表面的锚定位;使分解酶分解纤维素以得到糖类;以及使酵母菌发酵糖类以得到生物质酒精。
此外,本发明更提供一种用于上述纤维素分解方法及生物质酒精的生产方法的人工纤维小体,包含:重组噬菌体,其表面表达与分解酶具有亲和性的接合肽;以及与酵母菌的表面的锚定位具有亲和性的锚定肽;以及接合于重组噬菌体表面的接合肽的纤维素分解酶。
综上所述,本发明提供具有噬菌体支架并接合酶的人工纤维小体,其相较于未接合的酶,具有更高的纤维素分解活性。因此,本发明还提供利用该人工纤维小体有效率地分解纤维素的方法,以及利用该方法有效率地生产生物质酒精的用途。
附图说明
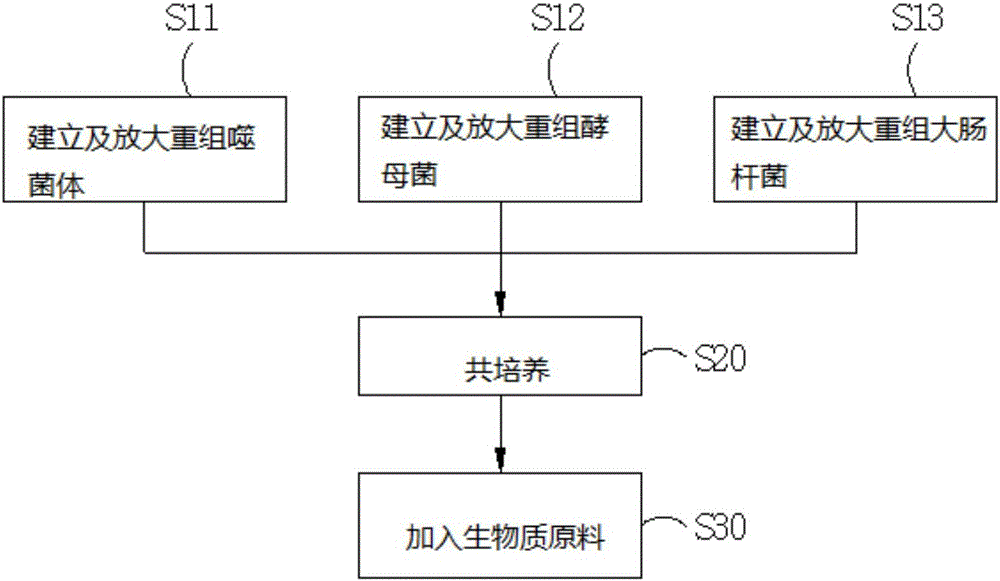
图1为本发明中一实施例的流程图。
图2为本发明中一实施例的重组噬菌体的结构示意图。
图3为本发明中一实施例的重组噬菌体锚定于酵母菌表面的型态示意图。
图4为本发明中一实施例的生物反应系统的示意图。
图5及图6为本发明中一实施例的荧光显微镜照片。
图7a至7c为本发明中一实施例的酵素活性比较图。
【符号说明】
s11、s12、s13、s20、s30:步骤
rp-bgl-sh3:接合于重组噬菌体表面且具有sh3结构域的纤维双糖分解酶
bgl-sh3:具有sh3结构域的纤维双糖分解酶
rp-cela-sh3:接合于重组噬菌体表面且具有sh3结构域的内切型纤维素分解酶
cela-sh3:具有sh3结构域的内切型纤维素分解酶
rp-ec-sh3:接合于重组噬菌体表面且具有sh3结构域的外切型纤维素分解酶
ec-sh3:具有sh3结构域的外切型纤维素分解酶
具体实施方式
现有技术中,人工制造的纤维小体通常是将分解酶直接接合于蛋白支架,以模仿天然纤维小体的结构,然而,可接合的酶数量皆无法达到与天然的纤维小体相当的数量,导致分解能力不如预期。在本发明中,蛋白支架上接合分子量较小的肽,再使肽与分解酶连接,克服了立体障碍及其他不利因素,使单一蛋白支架上可接合大量的分解酶。此外,发明人更选用噬菌体为主干作为人工纤维小体的蛋白支架,通过基因重组技术使噬菌体表面表达大量的肽,进而增进分解酶的接合量。
在本发明中,人工纤维小体的建立可使用重组酵母菌及重组噬菌体。其建立方式包含使重组酵母菌表达锚定结构域;以及使重组噬菌体的蛋白质外膜表面表达与纤维素酶具有亲和性的接合肽,并于重组噬菌体的尾端表面表达对应重组酵母菌表达的锚定结构域的锚定肽;且通过大肠杆菌制造大量纤维素酶。将重组噬菌体、重组酵母菌、以及纤维素酶共培养,即可使纤维素酶与表达在重组噬菌体表面的接合肽接合,形成人工纤维小体,同时重组噬菌体可通过锚定肽和重组酵母菌的锚定结构域的亲和性固定于重组酵母菌表面。如此一来,当生物质原料中的纤维素接触到人工纤维小体,人工纤维小体可通过其高密度的纤维素酶进行高效率的纤维素分解,并且,分解产生的六碳糖可直接被所锚定的重组酵母菌利用于发酵反应,以生产生物质酒精。
为使上述目的、技术特征以及实际实施后的增益性更为明显易懂,在下文中将以优选的实施范例辅佐对应相关的附图来进行更详细的说明。
在本发明的一实施例中,流程如图1所示。
在步骤s11中,建立重组噬菌体,并通过大肠杆菌(e.coli)快速且大量地生产。重组噬菌体rp的建立是通过修改噬菌体的基因组,使该噬菌体的表面表达与特定酶具有亲和性的接合肽、以及与特定细胞表面的锚定位具有亲和性的锚定肽。具体而言,噬菌体可为λ噬菌体及丝状噬菌体,优选地为丝状噬菌体,如m13、f1、fd噬菌体或其他适用于已知的噬菌体展示(phagedisplay)技术的种类,接合肽可选用任何与所选用的纤维素分解酶具有亲和性的配体,而锚定肽可选用任何与重组酵母菌表达的锚定位具有亲和性的配体。
在步骤s12中,建立重组酵母菌,并通过大肠杆菌快速且大量地生产。重组酵母菌的建立是通过修改酵母菌的基因组,使该酵母菌的表面表达锚定位。具体而言,酵母菌可为任何常用于酒精发酵的酵母菌,例如:schizosaccharomyces属、saccharomycodes属、hanseniaspora属酵母菌等;而锚定位可为任何对应于本发明的重组噬菌体的锚定肽具有亲和性的锚定结构域。另外,重组酵母菌也可因应需求同时使其表达五碳糖的分解酶,使其具有五碳糖的分解能力。
在步骤s13中,建立重组大肠杆菌,并通过大肠杆菌分泌表达大量的欲复制的酶,例如:纤维素分解酶。以复制纤维素分解酶为例,重组大肠杆菌的建立是通过修改大肠杆菌的基因组,使该大肠杆菌可合成纤维素分解酶并分泌至胞外,并使合成的纤维素分解酶表达与重组噬菌体表达的接合肽具有亲和性的对应域,使其与接合肽具有亲和性。大肠杆菌本身因具有快速分裂的特性,可在短时间内大量制造纤维素分解酶。在本发明生产生物质酒精的方法中,纤维素分解酶可为内切型纤维素分解酶、外切型纤维素分解酶或纤维双糖分解酶,优选地可为内切型纤维素葡萄糖分解酶(cela)、纤维双糖分解酶(bgl)、外切型纤维素分解酶(ec)或其他具有类似功能的酶。此外,可建立单一组重组大肠杆菌,使该单一组重组大肠杆菌同时分泌表达内切型纤维素分解酶、外切型纤维素分解酶或纤维双糖分解酶,或者可建立三组重组大肠杆菌,使其分别表达内切型纤维素分解酶、外切型纤维素分解酶或纤维双糖分解酶。优选地,纤维素分解酶与本发明的重组噬菌体表达的接合肽具有亲和性。
在步骤s20中,将重组噬菌体、重组酵母菌及重组大肠杆菌共培养以形成生物反应系统。生物反应系统可为任何能使重组噬菌体、重组酵母菌及重组大肠杆菌共存并持续生长的环境,加入生物质原料至生物反应系统中后,生产生物质酒精并提取。
在步骤s30中,加入生物质原料至生物反应系统中。具体而言,生物质原料可为任何具有纤维素的原料,例如:大麦、小麦、燕麦、稻米、甜菜、甜高粱、木薯、以及甘藷等粮食原料;或者非粮食原料,例如:麦秆、稻秆、玉米秆等;或者农业、都市和建筑废弃物,如厨余、报纸、木屑、废木材等;或者成长快速的纤维质作物,如芒草、狼尾草、柳枝稷;或者易于采集的原料,如海藻等。
以下将以一示例性实施例搭配上述步骤s11~s13、s20及s30以描述本发明。
对应步骤s11,建立表面表达接合肽及锚定肽的重组m13噬菌体。为便于描述,以下步骤皆以接合肽选用sh3配体,而锚定肽选用pdz配体为示例进行描述,但实际实施并不限于此。在m13噬菌体的基因中,将sh3配体的基因(seqidno:2)插入在pviii蛋白的基因序列中,以及将pdz配体(seqidno:1)的基因插入在piii蛋白的基因序列中。在设计重组质体时,piii蛋白必须保留完整的结构而使m13噬菌体保留感染性,使其能通过感染大肠杆菌进而快速复制。重组噬菌体最终结构如图2所示,具有pdz配体的piii蛋白位于重组噬菌体的尾端,而具有sh3配体的pviii蛋白位于长杆状的部分。此外,重组噬菌体依照本身piii及pviii蛋白的数量产生对应数量的sh3配体及pdz配体,正常的m13噬菌体可具有约3~5个piii蛋白及约2700个pviii蛋白,故优选地重组噬菌体可具有约3~5个sh3配体及约2700个pviii配体。重组噬菌体放大后供后续使用。上述接合肽及锚定肽的选择可互换,或可选用其他不同的配体或其组合,例如:gbd配体(seqidno:3)、sh2配体(seqidno:4)等,但接合肽及锚定生态不使用重复的配体。
对应步骤s12,建立表面表达锚定位的重组酵母菌。举例而言,承上述步骤s11的例子,酵母菌选用saccharomyces属的s.cerevisiae酵母菌,在选用pdz配体为锚定肽的情况,锚定位选用与重组噬菌体的piii结构域表达的pdz配体具有亲和性的pdz结构域。通过将pdz结构域的基因(seqidno:5)插入s.cerevisiae酵母菌的基因中,使s.cerevisiae酵母菌的表面表达pdz结构域,得到重组酵母菌。重组噬菌体,并经由培养放大后供后续使用。应被理解的是,在选用其他锚定肽时,可搭配不同的结构域锚定位,例如:gbd配体搭配gbd结构域(seqidno:7)、sh2配体搭配sh2结构域(seqidno:8)等。
对应步骤s13,建立具有分泌表达纤维素分解酶能力的重组大肠杆菌。通过将内切型纤维素分解酶的基因(seqidno:9)、外切型纤维素分解酶的基因(seqidno:10)及纤维双糖分解酶的基因(seqidno:11)分别与sh3结构域的基因(seqidno:6)插入大肠杆菌的基因中,使大肠杆菌具有分泌表达与sh3配体具有亲和性,即具有sh3结构域的内切型纤维素分解酶、外切型纤维素分解酶以及纤维双糖分解酶的能力,得到重组大肠杆菌。重组大肠杆菌经由培养放大后供后续使用。同前述,在选用其他锚定肽时,可搭配不同的结构域锚定位。
对应步骤s20,将重组噬菌体、重组酵母菌及重组大肠杆菌混合于同一培养系统中,以作为生产生物质酒精的生物反应系统。培养过程中,重组大肠杆菌可分泌大量的内切型纤维素分解酶、外切型纤维素分解酶以及纤维双糖分解酶,使其分散于生物反应系统中。重组噬菌体通过其表面表达的sh3配体与上述纤维素分解酶的亲和性,在相互接触时使纤维素分解酶接合至重组噬菌体的表面上。理论上,重组噬菌体具有约2700个sh3配体,应可接合约2700个纤维素分解酶至其表面上。然而,根据各重组噬菌体实际表达的sh3配体数量差异,实际接合的位置、角度及立体空间的分配、以及生物反应系统中两者的数量及浓度关系,接合的纤维素分解酶的数量可能因此而变动。重组噬菌体接合的纤维素分解酶可为1~3000个,优选地为100~2000个。另一方面,重组噬菌体还通过其表面表达的pdz配体与重组酵母菌表面表达的pdz结构域的亲和性,于相互接触时使重组噬菌体锚定至重组酵母菌的表面上。理论上,每个重组酵母菌表面可锚定对应于其表面表达的pdz结构域的数量的重组噬菌体。然而同样地,根据实际锚定的位置、角度及立体空间的分配、以及生物反应系统中两者的数量及浓度关系,锚定的重组噬菌体的数量可能因此而变动。上述接合及锚定的过程皆为生物反应系统中在培养过程中自发性发生的流程,最终,重组噬菌体、重组酵母菌及重组大肠杆菌所生产的纤维素分解酶可自组装而成为一个整体,如图3所示,其结构可视为重组酵母菌表面具有以重组噬菌体为蛋白支架,并与纤维素分解酶组合而成的人工纤维小体,拟似自然界中天然表面表达纤维小体的厌氧嗜热菌t.saccharolyticum,通过表面的纤维小体分解纤维素后,再将分解的产物转由纤维小体所锚定的细菌本体以续行发酵反应以生产酒精。然而,相较于天然的t.saccharolyticum,本发明的人工纤维小体上接合更大量的纤维素分解酶,因而具有更高效的纤维素分解能力。
对应步骤s30,加入生物质原料至生物反应系统中,以生产生物质酒精。生物反应系统内的物质转化及供应流程如图4所示,加入艾维素
整体而言,上述所记载的生物反应系统同时具有纤维素分解能力及六碳糖发酵能力,也能因应需求而修改使其同时具有五碳糖的分解能力。此外,生物反应系统中的重组大肠杆菌可自产纤维素分解酶,且其所需的能量可由纤维素分解后产生的六碳糖供给,以致于整个生物反应系统中无需提供外加能量,仅需持续供应足量的生物质原料,即可永续运作。
以下,将测试上述实施例中重组噬菌体表面接合的纤维素分解酶的活性数据,证明本发明的纤维素分解方法可达到足量的纤维素分解效果,达到有效生产生物质酒精的目的。
如图5所示,当插入pdz结构域的序列至重组酵母菌的基因时,以alexafluor488荧光染料进行标记。图5a部分显示未重组的酵母菌在显微镜亮视野下的照片;而c部分显示重组酵母菌在显微镜亮视野下的照片。图5b部分显示与a部分相同视野下激发alexafluor488荧光染料的波长观察的结果,并未见到任何荧光讯号,表示并无pdz结构域;然而图5d部分,即显示与c部分相同视野下激发alexafluor488荧光染料的观察结果,明显观察到绿色荧光,显示pdz结构域确实表达于重组酵母菌的表面。
如图6所示,以syto9荧光染料标记重组噬菌体。图6a部分显示重组噬菌体rp与未重组酵母菌混合,并移除未锚定的重组噬菌体后在显微镜亮视野下的照片;而c部分显示重组噬菌体与重组酵母菌混合,并移除未锚定的重组噬菌体后在显微镜亮视野下的照片。图6b部分显示与a部分相同视野下激发syto9荧光染料的波长观察的结果,并无绿色荧光讯号,表示重组噬菌体并未锚定于未重组酵母菌上;而d部分显示与部分相同视野下激发syto9荧光染料的观察结果,明显观察到绿色荧光,显示由重组噬菌体确实锚定于重组酵母菌上。
表1显示具有sh3结构域的纤维双糖分解酶(bgl-sh3)及接合于重组噬菌体表面且具有sh3结构域的纤维双糖分解酶(rp-bgl-sh3)的活性比较。表1中et为酶浓度;vmax为最大反应速率;kcat为反应常数;km为米氏常数。rp-bgl-sh3及bgl-sh3两者活性是通过比较kcat/km的数据,即催化效率而得。根据表1及第7a图的结果,通过初始速率对观察4-硝基苯-β-d-吡喃葡萄糖苷(4-nitrophenylβ-d-glucopyranoside,pnpg)的浓度变化得知rp-bgl-sh3的催化效率约为bgl-sh3的2.33倍,显示即便存在相同浓度的bgl-sh3,有无接合于噬菌体表面上可造成纤维素分解的催化效率差异达到约2.33倍。
表1
表2显示具有sh3结构域的内切型纤维素分解酶(cela-sh3)及接合于重组噬菌体表面且具有sh3结构域的内切型纤维素分解酶(rp-cela-sh3)的活性比较,其中各参数代号与表1相同。根据表2及第7b图的结果,通过观察初始速率对羧甲基纤维素(carboxymethylcellulose,cmc)的浓度变化得知rp-cela-sh3的催化效率约为cela-sh3的1.81倍,显示即便存在相同浓度的cela-sh3,有无接合于噬菌体表面上可造成纤维素分解的催化效率差异达到约1.81倍。
表2
表3显示具有sh3结构域的外切型纤维素分解酶(ec-sh3)及接合于重组噬菌体表面且具有sh3结构域的外切型纤维素分解酶(rp-ec-sh3)的活性比较,其中测量方法与各参数代号与表1相同。根据表3及第7c图的结果,通过观察初始速率对磷酸溶胀纤维素(phosphoricacidswollencellulose,pasc)的浓度变化得知rp-ec-sh3的催化效率约为cela-sh3的1.57倍,显示即便存在相同浓度的ec-sh3,有无接合于噬菌体表面上可造成纤维素分解的催化效率差异达到约1.57倍。
表3
综上所述,所得的结果都证实本发明的具有噬菌体支架的人工纤维小体即便于相同酶浓度下仍可使纤维素的分解效率大幅提升。再者,利用本发明的人工纤维小体分解纤维素,并用于生产生物质酒精,理应在相同酶浓度下使纤维素的分解效率大幅提升。况且,本发明的人工纤维小体更通过锚定至重组酵母菌表面并与重组大肠杆菌共培养,形成完整的联合生物转化制程,是以本发明能确实突破现有联合生物转化制程的产能限制。
虽然本发明已以上述实施例具体描述本发明的纤维素分解方法、生物质酒精生产方法及用于其的纤维小体,然而具本发明所属技术领域的普通技术人员应理解,可在不违背本发明的技术原理及精神下,对实施例作修改与变化。因此本发明的权利保护范围应如后述的权利要求所述。
序列表
<110>朱一民
长春人造树脂厂股份有限公司
长春石油化学股份有限公司
<120>人工纤维小体、利用其分解纤维素及生产酒精之方法(artificialcellulosomehavingbacteriophagescaffold,methodofdecomposingcelluloseandmanufacturingalcoholusingthesame)
<160>11
<170>patentinversion3.5
<210>1
<211>21
<212>dna
<213>小鼠α-互养蛋白(mouseα-syntrophin(syn))
<400>1
ggcgtgaaggagtcgctggtg21
<210>2
<211>33
<212>dna
<213>小鼠crk(mousecrk)
<400>2
ccgccgccggccctgccgccgaaacgtcgtcgt33
<210>3
<211>96
<212>dna
<213>大鼠n-wasp(ratn-wasp)
<400>3
ctggtgggcgccctgatgcacgtgatgcagaagcgcagccgcgccatccacagcagcgac60
gagggcgaggaccaggccggcgacgaggacgaggac96
<210>4
<211>10
<212>prt
<213>美洲钩虫(necatoramericanus)
<400>4
tyrglugluileglualalyslyslyscys
1510
<210>5
<211>285
<212>dna
<213>小鼠α-互养蛋白(mouseα-syntrophin(syn))
<400>5
ctccagcggcgccgcgtgacggtgcgcaaggccgacgcgggcgggctgggcatcagcatc60
aaagggggccgggagaacaagatgcctattctcatttccaagatcttcaagggcctggca120
gctgaccagacagaggccctcttcgtgggggatgccatcctgtctgtgaacggagaagac180
ttgtcctccgccactcatgacgaggcagtgcaggctctcaagaagacaggcaaagaggtg240
gtgctggaggtcaagtacatgaaggaggtctcaccgtatttcaag285
<210>6
<211>171
<212>dna
<213>小鼠crk(mousecrk)
<400>6
gctgaatatgtgcgagctctctttgactttaatggaaacgatgaagaagatcttccattt60
aagaaaggagacatactgagaatccgggataaacctgaagagcaatggtggaatgcagaa120
gacagcgaaggaaagaggggaatgatacctgttccttacgtcgagaagtat171
<210>7
<211>237
<212>dna
<213>大鼠n-wasp(ratn-wasp)
<400>7
accaaggcagatataggaacaccaagcaatttccagcacattggacatgttggttgggat60
ccaaatacaggctttgatctgaataatttggatccagaattgaagaatcttttcgatatg120
tgtggaatctcagaggcacaacttaaagacagagaaacatcaaaagttatatatgacttt180
attgaaaaaacaggaggtgttgaagctgttaaaaatgaactgcggaggcaagcacca237
<210>8
<211>76
<212>prt
<213>美洲钩虫(necatoramericanus)
<400>8
trptyrhisglylysvalserargsergluserglutyrileleugly
151015
serglyileasnglyserpheleuvalargglusergluthrserile
202530
glyglntyrserileservalargasnaspglyargvaltyrhistyr
354045
argileasnvalaspalaasnaspargleutyrilethrglnaspala
505560
lysphelysthrleuglygluleuvalhishishis
657075
<210>9
<211>1335
<212>dna
<213>人工序列
<220>
<223>内切型纤维素分解酶(cela)
<400>9
gcaggtgtgccttttaacacaaaatacccctatggtcctacttctattgccgataatcag60
tcggaagtaactgcaatgctcaaagcagaatgggaagactggaagagcaagagaattacc120
tcgaacggtgcaggaggatacaagagagtacagcgtgatgcttccaccaattatgatacg180
gtatccgaaggtatgggatacggacttcttttggcggtttgctttaacgaacaggctttg240
tttgacgatttataccgttacgtaaaatctcatttcaatggaaacggacttatgcactgg300
cacattgatgccaacaacaatgttacaagtcatgacggcggcgacggtgcggcaaccgat360
gctgatgaggatattgcacttgcgctcatatttgcggacaagttatggggttcttccggt420
gcaataaactacgggcaggaagcaaggacattgataaacaatctttacaaccattgtgta480
gagcatggatcctatgtattaaagcccggtgacagatggggaggttcatcagtaacaaac540
ccgtcatattttgcgcctgcatggtacaaagtgtatgctcaatatacaggagacacaaga600
tggaatcaagtggcggacaagtgttaccaaattgttgaagaagttaagaaatacaacaac660
ggaaccggccttgttcctgactggtgtactgcaagcggaactccggcaagcggtcagagt720
tacgactacaaatatgatgctacacgttacggctggagaactgccgtggactattcatgg780
tttggtgaccagagagcaaaggcaaactgcgatatgctgaccaaattctttgccagagac840
ggggcaaaaggaatcgttgacggatacacaattcaaggttcaaaaattagcaacaatcac900
aacgcatcatttataggacctgttgcggcagcaagtatgacaggttacgatttgaacttt960
gcaaaggaactttatagggagactgttgctgtaaaggacagtgaatattacggatattac1020
ggaaacagcttgagactgctcactttgttgtacataacaggaaacttcccgaatcctttg1080
agtgacctttccggccaaccgacaccaccgtcgaatccgacaccttcattgcctcctcag1140
gttgtttacggtgatgtaaatggcgacggtaatgttaactccactgatttgactatgtta1200
aaaagatatctgctgaagagtgttaccaatataaacagagaggctgcagacgttaatcgt1260
gacggtgcgattaactcctctgacatgactatattaaagagatatctgataaagagcata1320
ccccacctaccttat1335
<210>10
<211>2574
<212>dna
<213>人工序列
<220>
<223>外切型纤维素分解酶(ec)
<400>10
cttgttggggcaggagatttgattcgaaaccatacctttgacaacagagtaggtcttcca60
tggcacgtggttgaatcataccctgcaaaggcaagttttgaaattacatctgatggtaag120
tacaagataactgctcaaaagatcggtgaggcaggaaaaggtgaaagatgggatatacaa180
ttccgtcacagaggactcgcattgcaacaaggtcatacttatacagtaaagtttactgtt240
actgctagcagagcttgtaaaatttatcctaaaataggtgaccagggtgatccatatgat300
gaatactggaatatgaatcaacaatggaatttcctggaattacaggctaatactccaaaa360
actgtaactcagacatttacacagactaagggagataagaagaacgttgaatttgctttt420
caccttgctcccgataaaactacatctgaggcacagaatccagcaagtttccaacctata480
acatatacttttgatgaaatttatattcaggaccctcaatttgcaggatatactgaagat540
ccacctgaacctactaatgttgtacgtttgaatcaggtaggtttctatcctaatgctgat600
aagattgcaacagtagcaacaagttcaacaactccaattaactggcagttggttaatagt660
actggagcagctgttttaacaggtaaatcaactgttaaaggtgccgaccgtgcatcaggt720
gataatgtccatatcattgatttctctagttacacaacacctggtaccgactataagata780
gtaacagatgtatcagtaacaaaagccggagacaatgaaagtatgaagttcaatattgga840
gatgacctttttactcaaatgaaatacgattcaatgaagtatttctatcacaacagaagt900
gctattccaatacaaatgccatactgtgatcaatcacaatgggcacgtcctgcaggacac960
acaactgatatacttgctccagatccaacaaaggattacaaggctaactacacacttgac1020
gttacaggtggttggtatgatgccggtgaccatggtaagtatgttgttaatggtggtatt1080
gcaacctggaccgtaatgaatgcatatgagcgtgcactacacatgggtggagacacttca1140
gttgctccatttaaagacggttctttagcaataccagaagcggaagtctatcctgacata1200
ctggacgaagctcgttaccagctcattaacatgaaaacattattaaatagtcaggttcca1260
gcaggaaagtatgcgggtatggctcaccacaaagctcatgacgaacgttggacagctctt1320
gctgtacgtcccgaccaggatacaatgaaacgttggttgcagcctccaagtacagcagct1380
acattaaatctggctgctattgctgcacaaagttcacgtctttggaaacagtttgattct1440
gctttcgcaactaagtgtttaactgcagcagaaactgctagggatgcagctgtagctcat1500
ccagaaatatatgcaactatggaacagggtgccggtggtggagcatacggagacaactat1560
gttcttgatgatttctactgggcagcatgtgaattgtatgcaactacaggcagtgacaag1620
tatttgaactacataaagagctcaaagcattatctcgaaatgcctacagaattaacaggc1680
ggtgagaatactggaattacaggggcttttgactggggttgtacagcaggtatgggaaca1740
ataacacttgcacttgtacctacaaagcttccggcagcagatgttgctacagctaaagct1800
aatattcaagctgcagctgataagttcatatcaatttcaaaagcacaaggctatggtgta1860
ccactagaagaaaaagtaatttcatctccttttgatgcatctgttgttaaaggtttccaa1920
tggggatcaaactcattcgttattaatgaagcaatagttatgtcatatgcttatgaattc1980
agcgatgttaatggcacaaagaataataaatatattaatggtgctttaacagcaatggat2040
tacctcctcggacgtaacccaaatattcaaagctatataactggttatggtgacaaccca2100
cttgaaaatcctcatcaccgtttctgggcataccaggcagacaacacattcccaaaacca2160
cctccgggatgtctgtcaggaggacctaactccggcttgcaggatccttgggttaagggt2220
tcaggctggcagccaggtgaaagacctgctgaaaaatgcttcatggacaatattgaatct2280
tggtcaacaaacgaaataaccatcaactggaatgctcctcttgtatggatatcagcttac2340
cttgatgaaaaggggccagagattggtgggtcagtgactcctccaactaatttaggagat2400
gttaacggcgatggaaacaaggatgcattggacttcgctgcattgaagaaagccttgtta2460
agccaggatacttctactataaatgttgctaatgctgatataaacaaagatggttctatt2520
gatgcagttgactttgcattactcaaatcattcttgttaggaaaaatcacacag2574
<210>11
<211>1341
<212>dna
<213>人工序列
<220>
<223>纤维双糖分解酶(bgl)
<400>11
tcaaagataactttcccaaaagatttcatatggggttctgcaacagcagcatatcagatt60
gaaggtgcatacaacgaagacggcaaaggtgaatctatatgggaccgtttttcccacacg120
ccaggaaatatagcagacggacataccggcgatgttgcatgcgaccactatcatcgttat180
gaagaagatatcaaaataatgaaagaaatcggtattaaatcatacaggttttccatctca240
tggcccagaatctttcctgaaggaacaggtaaattaaatcaaaagggactggatttttac300
aaaaggctcacaaatctgcttctggaaaacggaattatgcctgcaatcactctttatcac360
tgggaccttccccaaaagcttcaggataaaggcggatggaaaaaccgggacaccaccgat420
tattttacagaatactctgaagtaatatttaaaaatctcggagatatcgttccaatatgg480
tttactcacaatgaacccggtgttgtttctttgcttggccactttttaggaattcatgcc540
cctgggataaaagacctccgcacttcattggaagtctcgcacaatcttcttttgtcccac600
ggcaaggccgtgaaactgtttagagaaatgaatattgacgcccaaattggaatagctctc660
aatttatcttaccattatcccgcatccgaaaaagctgaggatattgaagcagcggaattg720
tcattttctctggcgggaaggtggtatctggatcctgtgctaaaaggccggtatcctgaa780
aacgcattgaaactttataaaaagaagggtattgagctttctttccctgaagatgacctg840
aaacttatcagtcagccaatagacttcatagcattcaacaattattcttcggaatttata900
aaatatgatccgtccagtgagtcaggtttttcacctgcaaactccatattagaaaagttc960
gaaaaaacagatatgggctggatcatatatcctgaaggcttgtatgatctgcttatgctc1020
cttgacagggattatggaaagccaaacattgttatcagcgaaaacggagccgccttcaaa1080
gatgaaataggtagcaacggaaagatagaagacacaaagagaatccaatatcttaaagat1140
tatctgacccaggctcacagggcaattcaggacggtgtaaacttaaaagcatactacttg1200
tggtcgcttttggacaactttgaatgggcttacgggtacaacaagagattcggaatcgtt1260
cacgtaaattttgatacgttggaaagaaaaataaaggatagcggctactggtacaaagaa1320
gtaatcaaaaacaacggtttt1341
- 还没有人留言评论。精彩留言会获得点赞!