用于单分子检测的阵列及其应用的制作方法
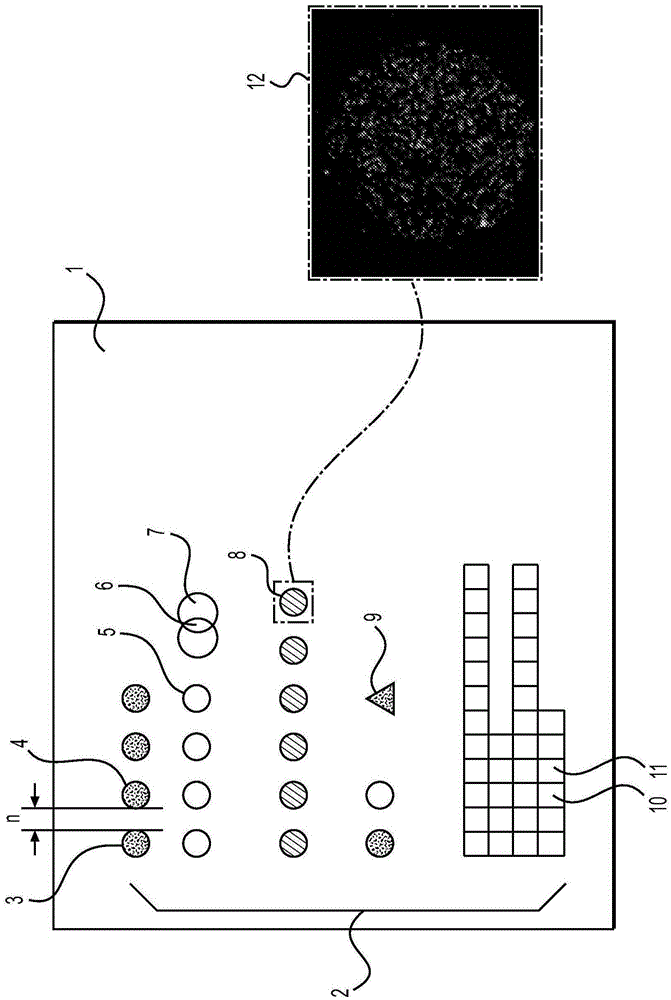
本发明涉及检测来自受试对象的遗传样品中的遗传变异的方法。检测遗传变异在人类生物学的许多方面是重要的。本发明还涉及制造和使用空间上可寻址的低密度或高密度分子阵列以及基于单分子检测技术的分析方法。人类基因组计划的进展已经带来了以下需求:(i)分析基因和基因产物的表达特征,和(ii)分析基因和基因组的变异。这引起了对大规模平行研究方法的极大兴趣。使用dna标志物在寻找单基因遗传病的基因中的成功和近来对用于剖析复杂性状的大规模关联研究的提议,已经进一步增强了对开发用于检测变异的新方法的兴趣。在制药业的寻找药物方面,也需要大规模研究和高通量筛选。对大规模研究的这种兴趣在未来也可能扩展到其它领域,例如,其中出现基于诸如聚(对亚苯基亚乙烯)(ppv)等有机分子的器件的半导体工业,并且分子电子学和纳米技术的新兴领域需要具有新型或期望特征的新分子,这进而可能需要转向大规模的搜索。在生物技术和制药领域,大规模研究优选在微量滴定板(常见的是96孔、384孔板,更高容量的板也可获得)上的均相测定中进行,或以阵列形式进行。化学或生物化学物质的空间上可寻址的阵列(其中分子的序列身份由包含该分子的组件在组件阵列中的位置确定,所述组件在本文中也称为“元件”或“阵列斑点”或“微阵列斑点”)已广泛应用在遗传学、生物学、化学和材料学中。阵列可形成于:(i)分散固相中,例如珠和束状中空纤维/光纤,(ii)微量滴定板/纳米小瓶(nanovial)的各个孔中,(iii)其上各个组件是能够在空间上可寻址的均匀介质/表面上,或(iv)具有纳米孔或其它物理结构的表面。阵列类型(iii)或(iv)可以在半透性材料和不透性载体上制造,所述半透性材料为例如凝胶、凝胶垫、多孔硅、微通道阵列(所谓的3-d生物芯片)(benoit等,anal.chem200173:2412-2420),所述不透性载体为例如硅晶片、玻璃、金涂覆的表面、陶瓷和塑料。它们也可以在微流体通道的壁内制造(gao等;nucleicacidsres.200129:4744-4750)。此外,表面或子表面可以包括诸如电极等功能层。(i)类和(iii)类阵列中的所有组件都包含在单个反应体积内,而(ii)的各成员都包含在分开的反应体积中。本发明的阵列中的所有组件都可以包含在单个反应体积内,或者它们可以在分开的反应体积中。迄今为止,方法已经涉及对分子的反应进行整体分析。尽管整体或总体方法已在过去被证明是有用的,但在许多方向上存在进展障碍。所产生的结果通常是数百万个反应的平均值,其中多个事件、多步骤事件和与平均值的误差不能解析,并且适用于高频事件的检测方法对罕见事件不灵敏。与整体分析相关的实际限制包括以下方面:1.用于检测体相(bulkphase)分析中的事件的技术对于检测罕见事件不够灵敏,这可能是由于样品量少或与探针的相互作用弱。a.检测mrna谱采集中罕见转录本的存在。该问题与批量分析的有限动态范围(其数量级为104)有关,而细胞中mrna的不同丰度水平在105范围内。因此,为了适应更常见的事件,检测方法对于检测罕见事件不够灵敏。b.在通常可用于进行遗传分析的样品的量中,在待检测的基因组dna中的各序列的拷贝数不足。因此,使用聚合酶链反应(pcr)来增加来自基因组dna的材料的量,从而可以从所需的基因座获得足够的检测信号。c.由于某些靶基因座周围的二级结构,非常少的杂交事件能够完成。而这些非常少的事件却是需要检测的。这些事件可能太少而无法通过常规整体测量来检测。d.样品中分析物分子的数量极其少。例如,在植入前分析中,必须分析单一分子。在分析古代dna时,可用的样品材料量往往也很少。2.在特定基因座处的常见事件背景下的罕见事件因为被更常见的事件掩蔽而不可能以体相检测。在很多情形下这是重要的:a.检测包含混合细胞群的肿瘤中的杂合性丧失(loh)以及肿瘤发生中的早期事件。b.通过检测野生型背景下的突变,确定癌症患者的最小残留疾病和复发的早期检测。c.直接用母体循环中的少量胎儿细胞来在产前诊断遗传病(因此用母亲血液而不是用羊膜穿刺来检测)。d.检测汇集的群体样品中的特定等位基因。3.难以解析异质事件。例如,难以从基于所测量的相互作用的真实信号中分离出来自诸如折回、误引发或自引发等错误的信号的贡献(或缺乏)。4.诸如基因组dna或mrna群等复杂样品造成困难。a.一个问题是样品中的分析物物质的交叉反应。b.在阵列上,另一个问题是高度的错误相互作用,在许多情况下这可能归因于由高有效浓度的特定物质造成的错配相互作用。这是低信噪比的一个原因。在用于碱基识别的公开阵列研究中已经使用低至1:1.2的比(cronin等,humanmutation7:244-55,1996).c.在一些情况下错误的相互作用甚至可以造成大多数信号(mir,k;d.philthesis,oxforduniversity,1995)。d.检测mrna群内的罕见mrna转录物的真实代表性信号是困难的。e.pcr用于遗传分析以减少来自基因组dna的样品的复杂性,从而使所需基因座变得富集。5.常规方法的整体性不允许获得个体分子的特定特征(特别是多于一种特征)。遗传分析中的一个实例是需要获得遗传相或单体型信息——与各染色体相关的特定等位基因。整体分析不能从杂合体样品中解析出单体型。目前可用的分子生物学技术,例如等位基因特异性或单分子pcr,难以优化和大规模应用。6.瞬时过程难以解析。这在破译过程的分子机制时是需要的。此外,瞬时分子结合事件(例如杂交事件的成核,其传播由于目标中的二级结构而被阻断)具有常规固相结合测定无法检测到的微小占据时间。当比较两个样品时,难以明确地辨别出小的浓度差异(小于2倍的差异)。使用未扩增的cdna靶标的微阵列基因表达分析通常需要106个细胞或100微克组织。对于获自单个细胞的材料,既不能直接进行表达分析,也不能直接进行遗传变异分析,而这在许多情况下是有利的(例如分析来自早期发育的细胞的mrna或者来自精子的基因组dna)。此外,如果可以避免在大多数生物学分析或遗传分析前所需要的扩增过程,则是高度期望的。使用pcr来分析数目可变的串联重复序列,其对于法医学和亲子测试而言是关键的。连锁研究一直传统地使用短串联重复序列作为pcr分析的标志物。在大规模snp分析中,避免pcr的需要特别迫切。设计引物和对大量snp位点进行pcr的需要是主要缺点。目前正在实施的最大规模的分析(例如使用orchidbioscienceandsequenom系统)仍然过于昂贵以致于不允许所有而仅允许少数大型组织(例如制药公司)进行有意义的关联研究。尽管关联研究所需的snp数量一直在热烈辩论,但由于近期有报道称基因组内存在大段的连锁不平衡,所以最高估计值正被向下修正。因此,代表基因组多样性所需的snp数量可能比先前预期的少10倍。然而,需要预先声明的是,存在一些基因组区域,其中连锁不平衡程度要低得多,并且需要更多数量的snp来代表这些区域的多样性。即使如此,如果每个位点都必须单独扩增,则任务将是巨大的。实际上,pcr可以被多重化。然而,可以这样做的程度是有限的,并且增加的错误(例如引物二聚体的形成和错配以及增加的反应粘度)对成功造成障碍且在大多数实验室中将多重化限制在约10个位点。显然,如果每个反应都需要单独进行,或者如果仅存在有限的多重化可能性,则以对群体中多态性的高通量分析所需的规模进行snp检测反应的成本是过高的。如果要实现药物基因组学、药物遗传学以及大规模遗传学的潜力,则会需要高度多重的、简单且经济的snp分析途径。dna汇集是遗传分析的一些方面的解决方案,但是必须获得准确的等位基因频率,这对于罕见的等位基因尤其困难。由于它涉及确定沿着单个染色体的一系列等位基因的关联性,所以认为单体型比单个snp的分析提供远远更多的信息。国际上正努力制作人类基因组的综合单体型图谱。通常,通过长范围等位基因特异性pcr来确定单体型。然而,单体型确定之前体细胞杂交体的构建是一种替代方法。专利(wo01/90418)中已提出了在溶液中对单分子进行单体型分型的方法,然而,在该方法中,分子未被表面捕获,未获得snp的位置信息,并且各snp必须用不同的颜色编码。数年来,已经围绕复杂疾病的常见疾病-常见变体(cd/cv)(即常见的snp)假说设定了大规模snp分析的计划(reichdeandlanderestrendsgenet17:502-502001))。snp联盟已经聚集了超过一百万个推定常见的snp。然而,该集合的实际使用因以下事实而受阻:不同的snp在不同种族人群中可能是常见的,而且许多推定的snp可能不具有真正的多态性。此外,cd/cv假说近来受到罕见等位基因可能有助于常见疾病的论断的挑战(weisskm,clarkag,trendsgenet2002jan;18(1):19-24)。如果是这样,虽然“新的”罕见等位基因会与常见snp充分地处于连锁不平衡中从而能够成功地与包含两者的区域进行关联,但是如果该等位基因是“古老的”并且罕见的,则常见snp和单体型图谱不会代表多样性。在这种情况下,需要替代策略来发现致病区域(causativeregion)。代替常见snp的全基因组扫描的可以是如下需求:对全基因组测序或对数千个病例和对照样品再测序来获取所有变体。基于公共基因组计划的信息而构建的人类基因组的商业测序在大约一年的时间耗费约3亿美元。这种成本和时间尺度作为用于发现dna序列和疾病之间关联的snp分析的替代方案而言是不可行的。显然,如果测序要取代目前的大规模遗传研究方法,则需要完全不同的方法。如果测序可以在基因组或者至少小基因组或者全基因规模上运行,则是有利的。即使读取长度增加超过300-500nt也会是有用的。当今,测序几乎完全由sanger双脱氧法完成。已经提出了许多替代性测序方法,但是目前没有应用。这些方法包括:1通过合成测序;2直接分析单分子的序列;和3通过杂交测序。通过芯片法进行再测序是重新测序的替代方法。21号染色体非重复序列的2170万个碱基最近已经由patil等通过芯片法进行了再测序(science294:1719-1722,2001)。通过在芯片分析之前制造体细胞杂交体,使得在本研究中单体型结构得以保留。然而,通过这种方法进行大规模再测序的成本仍然很高,只有65%的被探查碱基给出了具有足够的碱基识别置信度的结果。技术实现要素:本发明涉及进行测定的方法,包括检测来自受试对象的遗传样品中的遗传变异的方法。本发明还涉及使用经标记的探针并对所述探针中的标记数量进行计数来检测来自受试对象的遗传样品中的遗传变异的方法。本发明另外涉及使用经标记的探针来检测来自受试对象的遗传样品中的遗传变异的方法,所述经标记的探针靶向优先保留在来自受试对象的遗传样品中的基因组区域。本发明进一步涉及使用检测野生型序列的探针和检测包含插入或缺失的突变型序列的另一探针来检测来自受试对象的遗传样品中的遗传变异的方法。本发明也涉及制造和使用空间上可寻址的分子阵列的方法以及基于单分子检测技术的分析方法。本发明还涉及所述阵列用于进行测定的用途,所述测定包括来自受试对象的遗传样品中的遗传变异。本发明涉及在分子阵列上进行测定的方法,所述方法包括:(a)产生分子阵列,其包括至少通过(i)可选地预选择待固定的寡核苷酸、(ii)将寡核苷酸的至少一部分固定在固相上和(iii)在固定步骤之前或之后用至少两种不同标记来标记寡核苷酸的至少一部分,来在固相上产生经标记的经固定的寡核苷酸,其中,位于固相上的经标记的经固定的寡核苷酸的至少一部分与所述固相上的其它经标记的经固定的寡核苷酸是光学上能够单独解析的;和(b)进行测定,其包括对所述光学上能够单独解析的经标记的经固定的寡核苷酸的至少一部分的数量进行计数以进行测定,所述寡核苷酸在固相上是光学上能够单独解析的。本发明还涉及在分子阵列上进行测定的方法,所述方法包括:(a)产生分子阵列,其包括至少通过(i)预选择多个待固定的寡核苷酸、(ii)将多个寡核苷酸的至少一部分固定至固相和(iii)在固定步骤之前或之后用至少两种不同标记来标记多个寡核苷酸的至少一部分,来在固相上产生经标记的经固定的寡核苷酸,其中,位于固相上的经标记的经固定的寡核苷酸的至少一部分排布在两个以上空间上可寻址的分开的离散元件中,并且与所述固相上的其它经标记的经固定的寡核苷酸是光学上能够单独解析的;和(b)进行测定,其包括对固相上的光学上能够单独解析的经标记的经固定的寡核苷酸的至少一部分的数量进行计数。在一个方面,固定步骤包括将寡核苷酸的所述至少一部分固定在固相上以形成两个以上分开的离散元件,所述两个以上元件中的至少两个为空间上可寻址的,所述至少两个元件各自包含一个或多个经固定的寡核苷酸,其中,位于至少两个分开的离散元件中的经固定的寡核苷酸的至少一部分的序列身份由包含经固定的寡核苷酸的至少一部分的所述至少两个分开的离散元件中的至少一个元件的位置来指定。在另一方面,经标记的经固定的寡核苷酸包含一个或多个第一经标记的经固定的寡核苷酸和一个或多个第二经标记的经固定的寡核苷酸,二者具有不同的标记,并且所述至少两个元件各自包含所述一个或多个第一经标记的经固定的寡核苷酸和所述一个或多个第二经标记的经固定的寡核苷酸。在另一方面,所述方法还可以包括:在所述至少两个元件中的至少一个中,将所述一个或多个第一经标记的经固定的寡核苷酸的计数数量与所述至少一个或多个第二经标记的经固定的寡核苷酸的计数数量进行比较。在另一方面,产生步骤可以包括将所述寡核苷酸的至少一部分连接到靶核酸以形成探针-靶分子复合物。在一些实施方式中,探针-靶分子复合物包含环化的dna。在另一方面,产生步骤还可以包括通过滚环扩增将探针-靶分子复合物的至少一部分扩增。在另一方面,产生步骤还可以包括用经标记的引物对探针-靶分子复合物的至少一部分进行引物延伸。在另一方面,凭借选自以下组的手段将寡核苷酸的至少一部分固定至固体载体:与抗生物素蛋白、抗生蛋白链菌素或去糖基化抗生物素蛋白复合的生物素-寡核苷酸;经由二硫键与sh-表面共价连接的sh-寡核苷酸;与活化的羧基或醛基共价连接的胺-寡核苷酸;与水杨酸羟肟酸(sha)复合的苯基硼酸(pba)-寡核苷酸;以及与硫醇或硅烷表面反应过的或与丙烯酰胺单体共聚形成了聚丙烯酰胺的acrydite-寡核苷酸。在另一方面,两个以上离散元件由凸起区域或蚀刻槽分开。本发明涉及产生阵列的方法,所述方法包括:(a)分别确定第一靶探针和第二靶探针与多个捕获探针的杂交效率,其中,所述第一靶探针和第二靶探针以及所述多个捕获探针是寡核苷酸探针,所述第一靶探针包含第一标记或序列,所述第二靶探针包含与所述第一标记或序列不同的第二标记或序列;(b)基于所述杂交效率预选择所述多个捕获探针在基板上将要被固定的密度;和(c)根据所述密度将所述多个捕获探针固定至所述基板,从而在基板上产生多个元件。本发明涉及检测来自受试对象的遗传样品中的遗传变异的方法,所述方法包括:(a)使第一探针组和第二探针组的至少一部分分别与存在于所述遗传样品中的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交,其中所述第一探针组和第二探针组分别包含第一标签探针和第二标签探针;(b)产生捕获探针阵列,其包括(i)确定第一标签探针和第二标签探针与多个捕获探针的杂交效率,(ii)基于所述杂交效率预选择所述多个捕获探针在基板上将要被固定的密度;和(iii)根据所述密度将所述多个捕获探针固定到所述基板上,从而在所述基板上产生多个元件;(c)可选地扩增所述第一探针组和第二探针组以分别形成第一经扩增探针组和第二经扩增探针组;(d)用第一标记和第二标记来分别标记所述第一和第二探针组和/或第一和第二经扩增探针组的至少一部分,其中所述第一标记和第二标记是不同的;(e)通过使第一标签探针和第二标签探针的至少一部分杂交至所述多个捕获探针来进行固定,并且产生第一和第二经固定杂交产物,所述第一和第二经固定杂交产物包含(i)所述第一和第二探针组和/或第一和第二经扩增探针组和(ii)所述多个捕获探针,其中,所述第一和第二经固定杂交产物的第一标记和第二标记是光学上能够解析的;(f)对(i)所述第一经固定杂交产物的第一标记的第一数量和(ii)所述第二经固定杂交产物的第二标记的第二数量进行计数,其中,所述第一数量对应于固定至所述基板的所述第一探针组和/或所述第一经扩增探针组的数量,所述第二数量对应于固定至所述基板的所述第二探针组和/或所述第二经扩增探针组的数量;和(g)比较所述第一数量和第二数量以确定所述遗传样品中遗传变异的存在。本发明还涉及制造分子阵列的方法,所述方法包括:提供包含多个物理上离散的元件的固体载体,其中所述物理上离散的元件通过一个或多个凸起区域或槽彼此分开;将多个靶寡核苷酸分子固定到所述多个物理上离散的元件上,其中在所述固定后,所述多个物理上离散的元件中的至少两个元件包含仅单个经固定的靶寡核苷酸分子/元件。在另一方面,本发明涉及制造分子阵列的方法,所述方法包括:提供包含多个物理上离散的孔的固体载体;将多个靶寡核苷酸分子固定到所述孔中,其中在所述固定后,所述多个孔中的至少两个孔包含仅单个经固定的靶寡核苷酸分子/孔。在另一方面,本发明涉及制造分子阵列的方法,所述方法包括:提供包含多个物理上离散的、空间上可寻址的孔的固体载体,其中所述多个孔的至少一部分各自包含多个经固定的寡核苷酸;将多个靶寡核苷酸分子固定到所述多个物理上离散的、空间上可寻址的孔中,其中在所述固定后,所述多个物理上离散的、空间上可寻址的孔中的至少两个孔包含仅单个经固定的靶寡核苷酸分子/孔;在所述至少两个物理上离散的、空间上可寻址的孔中扩增所述单个经固定的靶寡核苷酸分子,以在所述至少两个物理上离散的、空间上可寻址的孔的每一个中形成多个经固定靶寡核苷酸分子,每孔的所述多个经固定的靶寡核苷酸分子由单一分子物种(species)组成;并且对于所述至少两个物理上离散的、空间上可寻址的孔中的每一个孔,用一种或多种标记来标记多个经固定的靶寡核苷酸分子的至少一部分,由此在所述至少两个孔的每一个中产生至少一个经标记的靶寡核苷酸分子。在另一方面,本发明还涉及制造分子阵列的方法,所述方法包括:提供包含多个物理上离散的元件的固体载体,其中多个物理上离散的元件的至少一部分各自包含多个经固定的寡核苷酸,并且所述物理上离散的元件通过一个或多个凸起区域或沟槽彼此分开;和将多个靶核寡苷酸分子杂交至所述经固定的寡核苷酸并由此产生经固定的杂交产物,其中在所述杂交后,所述多个物理上离散的元件中的至少两个元件包含仅单个经固定的靶核寡苷酸分子/元件。本发明涉及制造分子阵列的方法,所述方法包括:(i)可选地预选择多个待固定的寡核苷酸,(ii)用一种或多种标记来标记所述多个寡核苷酸的至少一部分,由此产生经标记的寡核苷酸,(iii)将经标记的寡核苷酸的至少一部分固定在固体载体上,固定的密度允许固体载体上的所述经标记的寡核苷酸的至少一部分的每一个能够被单独解析,由此形成两个以上分开的离散元件,所述两个以上元件中的至少两个元件是空间上可寻址的,所述至少两个元件各自包含来自所述经标记的寡核苷酸的至少一部分的多个经标记的经固定的寡核苷酸,其中所述至少两个元件中的每一个元件中的所述多个经标记的经固定的寡核苷酸的至少一部分的序列身份由包含寡核苷酸的所述至少元件中的每一个元件的位置来指定;和(iv)分析所述至少两个元件的经标记的经固定的寡核苷酸的至少一部分是否相对于另一部分经标记的经固定的寡核苷酸是光学上能够单独解析的,由此所述至少两个元件的每一个上的所述经标记的经固定的寡核苷酸的所述至少一部分相对于另一部分经标记的经固定的寡核苷酸是光学上能够单独解析的。本发明涉及产生生物传感器的方法,所述方法包括:在固体载体上沉积寡核苷酸;和在沉积之前或之后用至少两种不同的标记来标记所述寡核苷酸的至少一部分,由此所沉积的经标记的寡核苷酸的至少一部分与固体载体上的其它沉积的经标记的寡核苷酸分离,从而产生多个分离的经标记的寡核苷酸。本发明还涉及制造分子阵列的方法,所述方法包括:将多个寡核苷酸直接或间接固定至固相以形成两个以上分开的离散元件,所述两个以上分开的离散元件中的至少两个元件是空间上可寻址的并包含多个经固定的寡核苷酸;和用两种以上标记来标记多个经固定的寡核苷酸的至少一部分,其中所述至少两个元件包含多个经标记的经固定的寡核苷酸,其中所述多个经标记的经固定的寡核苷酸的至少一部分是能够单独解析的。本发明还涉及制造分子阵列的方法,所述方法包括:用两种以上标记来标记多个寡核苷酸以形成多个经标记的寡核苷酸;和将所述多个经标记寡核苷酸的至少一部分直接或间接固定至固相以形成两个以上分开的离散元件,所述两个以上分开的离散元件中的至少两个元件是空间上可寻址的,所述至少两个元件包含多个经标记的经固定的寡核苷酸,其中所述多个经标记的经固定的寡核苷酸的至少一部分是能够单独解析的。本发明还涉及进行遗传分析的方法,所述方法包括:将多个经标记的寡核苷酸沉积至微量滴定板上的一个或多个孔以形成多个经标记的沉积寡核苷酸,和进行遗传分析,所述遗传分析包括对多个经标记的沉积寡核苷酸的至少一部分的数量进行计数,其中所述多个经标记的沉积寡核苷酸的沉积密度使得所述多个经标记的沉积寡核苷酸的至少一部分能够被单独解析,并且所述多个经标记的沉积寡核苷酸的至少一部分标记有至少两种不同的标记。本发明还涉及产前诊断的方法,所述方法包括:提供与来自母体血液的样品中存在的核酸的至少一部分互补的多个探针;使所述核酸的至少一部分与所述多个探针杂交以产生杂交分子或杂交产物;和对所述杂交分子的至少一部分进行计数以确定所述核酸的频率。本发明还涉及进行单分子计数的方法,所述方法包括:在溶液中使多个探针与靶分子接触以形成探针-靶分子复合物,其中所述探针-靶分子复合物直接或间接地标记有至少两种不同的标记;在接触之前或之后将包含探针-靶分子复合物的溶液施加至固相;和通过比较来自所述至少两种不同的标记的信号的数量来确定靶分子的相对数量。本发明涉及检测怀孕的人类受试对象的胎儿中的三体性的方法,所述方法包括:使第一探针组和第二探针组与来自怀孕的人类受试对象的无细胞dna样品接触,其中第一探针组包含第一标记探针和第一标签探针,第二探针组包含第二标记探针和第二标签探针,第一标签探针和第二标签探针包含共同的标签核苷酸序列;使第一探针组和第二探针组的至少一部分分别与在无细胞dna样品中存在的位于第一染色体和第二染色体中的核苷酸分子杂交;通过将第一标记探针和第一标签探针连接而连接第一探针组的至少一部分以形成第一连接探针组;通过将第二标记探针和第二标签探针连接而连接第二探针组的至少一部分以形成第二连接探针组;扩增步骤,(i)用第一正向引物和反向引物扩增第一连接探针组,其中第一正向引物和反向引物中的至少一种包含第一标记并与第一连接探针组的第一标记探针杂交,和(ii)用第二正向引物和反向引物扩增第二连接探针组,其中第二正向引物和反向引物中的至少一种包含第二标记并与第二连接探针组的第二标记探针杂交,从而形成经扩增的第一连接探针组和第二连接探针组,所述第一连接探针组和第二连接探针组分别包含(i)第一标记和第二标记且包含(ii)从所述共同的标签核苷酸序列扩增得到的经扩增的共同标签核苷酸序列,其中第一标记与第二标记不同;通过将经扩增的共同标签核苷酸序列的至少一部分杂交至固定在基板上的亲和核苷酸标签而进行固定,固定的密度使得经扩增的第一和第二连接探针组的第一标记和第二标记在固定后是光学上能够解析的,其中亲和核苷酸标签包含所述经扩增的共同标签核苷酸序列的至少一部分的互补序列;可选地,在第一成像通道和第二成像通道中读取基板上的第一标记和第二标记,所述第一成像通道和第二成像通道分别对应于第一标记和第二标记;可选地,产生基板的一个或多个图像,其中在所述一个或多个图像中第一标记和第二标记是光学上能够解析的;可选地,区分来自单个第一标记的第一光学信号与来自背景和/或多个第一标记的剩余光学信号,这通过以下方式来进行:计算第一光学信号相对于来自单个第一标记的光学信号的强度的相对信号和/或信噪比强度,并确定所述光学信号是否来自单个标记;可选地,区分来自单个第二标记的第二光学信号与来自背景和/或多个第二标记的剩余光学信号,这通过以下方式来进行:计算第二光学信号相对于来自单个第二标记的光学信号的强度的相对信号和/或信噪比强度,并确定所述光学信号是否来自单个标记;计数步骤,(i)根据来自单个第一标记的第一光学信号对第一标记的第一数量进行计数,其中第一数量对应于固定至基板的经扩增的第一连接探针组的数量,和(ii)根据来自单个第二标记的第二光学信号对第二标记的第二数量进行计数,其中第二数量对应于固定至基板的经扩增的第二连接探针组的数量;和比较第一数量和第二数量,以确定第一染色体的拷贝数是否大于第二染色体的拷贝数,其中第一染色体的拷贝数大于第二染色体的拷贝数表示在胎儿中存在第一染色体的三体性。本发明还涉及检测怀孕的人类受试对象的胎儿中的三体性的方法,所述方法包括:使第一探针组和第二探针组与从怀孕的人类受试对象的血液样品分离出的遗传样品接触,其中第一探针组包含第一标记探针和第一标签探针,第二探针组包含第二标记探针和第二标签探针;使第一探针组和第二探针组的至少一部分分别与存在于遗传样品中的核苷酸分子杂交;至少通过将第一标记探针和第一标签探针连接而连接第一探针组的至少一部分以形成第一连接探针组;至少通过将第二标记探针和第二标签探针连接而连接第二探针组的至少一部分以形成第二连接探针组;扩增步骤,(i)用第一正向引物和反向引物扩增第一连接探针组,其中第一正向引物和反向引物中的至少一种包含第一标记,和(ii)用第二正向引物和反向引物扩增第二连接探针组,其中第二正向引物和反向引物中的至少一种包含第二标记,从而形成分别包含第一标记和第二标记的经扩增的第一连接探针组和第二连接探针组,其中第一标记与第二标记不同;将经扩增的第一连接探针组和第二连接探针组固定在基板上,其中经扩增的第一连接探针组和第二连接探针组的第一标记和第二标记在固定后是光学上能够解析的;计数步骤,(i)对固定至基板的经扩增的第一探针组中的第一探针的第一数量进行计数,和(ii)对固定至基板的经扩增的第二探针组中的第二探针的第二数量进行计数;和比较第一数量和第二数量以确定胎儿中三体性的存在。本发明涉及检测来自受试对象的遗传样品中的核酸拷贝数变异的方法,所述方法包括:使第一探针组和第二探针组与遗传样品接触,其中第一探针组包含第一标记探针和第一标签探针,第二探针组包含第二标记探针和第二标签探针;使第一探针组和第二探针组的至少一部分分别与存在于遗传样品中的核苷酸分子中的第一和第二目标核酸区杂交;可选地分别扩增第一探针组和第二探针组以形成第一经扩增的探针组和第二经扩增的探针组;分别用第一和第二标记来标记第一和第二标记探针和/或第一和第二经扩增的探针组的至少一部分;将第一和第二探针组和/或第一和第二经扩增的探针组的至少一部分固定至基板,固定的密度使得第一和第二探针组和/或第一和第二经扩增的探针组的第一和第二标记在固定后是光学上能够解析的;计数步骤,(i)对固定至基板的第一标记的第一数量进行计数,其中第一数量对应于固定至基板的第一探针组和/或第一经扩增的探针组的数量;和(ii)对固定至基板的第二标记的第二数量进行计数,其中第二数量对应于固定至基板的第二探针组和/或第二经扩增的探针组的数量;和比较第一数量和第二数量以确定第一目标核酸区的第一拷贝数是否与第二目标核酸区的第二拷贝数不同,其中第一拷贝数和第二拷贝数的不同表示在遗传样品中存在核酸拷贝数变异。本发明还涉及检测来自受试对象的遗传样品中的核酸拷贝数变异的方法,所述方法包括:通过使一个或多个第一寡核苷酸探针与存在于遗传样品中的核苷酸分子中的第一目标核酸区杂交,形成包含多个第一寡核苷酸的第一探针产物;通过使一个或多个第二寡核苷酸探针与存在于遗传样品中的核苷酸分子中的第二目标核酸区杂交,形成包含多个第二寡核苷酸的第二探针产物;将多个第一寡核苷酸中的至少两个寡核苷酸连接以形成第一连接探针产物;将多个第二寡核苷酸中的至少两个寡核苷酸连接以形成第二连接探针产物;可选地分别扩增第一连接探针产物和第二连接探针产物的至少一部分以形成第一经扩增的探针产物和第二经扩增的探针产物;分别用第一和第二标记来标记第一和第二连接探针产物和/或第一和第二经扩增的探针产物的至少一部分;将第一和第二连接探针产物和/或第一和第二经扩增的探针产物的至少一部分固定至基板,固定的密度使得第一和第二连接探针产物和/或第一和第二经扩增的探针产物的第一标记和第二标记在固定后是光学上能够解析的;计数步骤,(i)对固定至基板的第一标记的第一数量进行计数,其中第一数量对应于固定至基板的第一连接探针产物和/或第一经扩增的探针产物的数量;和(ii)对固定至基板的第二标记的第二数量进行计数,其中第二数量对应于固定至基板的第二连接探针产物和/或第二经扩增的探针产物的数量;和比较第一数量和第二数量以确定第一目标核酸区的第一拷贝数是否与第二目标核酸区的第二拷贝数不同,其中第一拷贝数和第二拷贝数的不同表示在遗传样品中存在核酸拷贝数变异。在一些实施方式中,所述计数步骤可以包括将本文所述的标记的数量归一化。例如,可以基于遗传样品中核苷酸分子的丰度或者基于样品批次将标记的数量归一化。在另一些实施方式中,本文所述的引物可以包含多个标记,包括荧光染料。在另外的实施方式中,本文所述的探针可以包含多个标记,例如,在不与来自遗传样品的核苷酸分子杂交的区域中包括一个或多个标记。附图说明图1描绘了在基板上包含本文所述的结合伴侣、标签、亲和标签、标签探针、探针组和/或经连接的探针组的示例性阵列组件。图2描绘了从单标记样品和多标记抗体测量的信号强度的归一化柱状图。图3描绘了来自各种标记的平均漂白特性(bleachingprofile)。图4~13显示了针对各种alexa488标记的随时间变化的累积标记强度图。图14描绘了当荧光团的激发是通过用与该物质的最大吸收一致的窄光谱带进行照射来实现时通过标准操作得到的激发(ex)光谱和发射(em)光谱。图15描绘了通过用与标准操作中不同的(或除其之外额外的)各种激发颜色和收集的发射带进行查询(interrogation)而得到的激发光谱和发射光谱。图16显示了当收集来自这些各种成像构造(例如各种发射滤光片)的光并将其与目标荧光团的校正值进行比较时得到的结果。图17显示了用各种参照物(包括具有单调(flat)发射谱(污染物1;三角形))或蓝色权重谱(污染物2;星形)的那些)收集的结果。图18描绘了两种荧光团的显著不同的激发带。图19描绘了示例性系统的流程图。图20描绘了包括各种数据分析方法的示例性系统流程图。图21~46描绘了本文所述的示例性探针组。图47和48显示了所得的荧光图案,其中,产物含有独特的亲和标签序列,并且下方的基板含有互补物,所述互补物与在所述基板的相同位置(例如作为相同组件)内的每种独特的亲和标签互补。图49和51显示了所得的荧光图案,其中,不同的产物含有相同的亲和标签序列,并且下方的基板含有所述亲和标签的互补物。图50和52分别显示了图49和51的放大位置。图53和54显示了所得的荧光图案,其中,产物含有独特的亲和标签序列,并且下方的基板具有:含有一种亲和标签互补物的互补物的一个位置(例如作为一个组件)和含有另一种亲和标签的互补物的另一位置(例如作为另一组件)。图55描绘了两种探针组;用于基因座1的一种探针组和用于基因座2的一种探针组——虽然如上所述,但也可以为每个基因组基因座设计多种探针组。图56描绘了将应用至探针组的集合的程序性工作流程。图57描绘了图56所示的程序性工作流程的修改版本。图58a、58b和58c提供了用于基因座1和基因座2的探针产品如何可以用不同的标记分子标记的实例。图59提供了证据证明:代表针对一个基因座的多个基因组位置的探针产品可以使用杂交-连接法以连接酶特异性方式产生。图60a和60b提供了数据表明:探针组可用于检测拷贝数状态的相对变化。图61a、61b和61c提供了证据证明:探针产品的混合物可用于产生定量微阵列数据。图62~64说明了图55~58中所述的通常步骤的变型。图65a和65b描绘了图62所述的变型步骤的另一实施方式。图66a、66b和66c描绘了图65所述的步骤的另一实施方式。图67a、67b和67c描绘了用于本文所述方法中的示例性探针组。图68a、68b和68c描绘了当测定具有已知断点的易位时用于本文所述的方法中的示例性探针组。图69a和69b描绘了当靶向位于snp处的突变时用于本文所述的方法中的示例性探针组。图70图示了本发明的一些实施方式的对单分子的编码探查。图71图示了本发明的一些实施方式的通过连接进行的互补链合成。图72图示了本发明的一些实施方式的空位填充连接。图73图示了本发明的一些实施方式的二级抗探针标记的使用。图74图示了本发明的一些实施方式的生物传感器阵列。图75图示了本发明的一些实施方式的snp检测。图76a.本发明的一些实施方式的在正常设置下的微阵列扫描图像。该阵列携带了12个数量级浓度的梯度稀释(从上至下),和一系列针对替代性cy3和cy5标记的寡核苷酸的寡核苷酸连接法(从左至右),b.同一阵列,但具有降低的γ设置,c.来自相同阵列但是用全内反射显微术(tirf)分析的微阵列印记,从而能够检测单分子(红色箭头指示来自单分子的荧光),d.针对单分子信号的强度对时间的作图,显示了闪光和一步光漂白。图77显示了本发明的一些实施方式的利用tirf对单分子进行的计数。图78图示了:a,在显微镜载玻片上展开的串联体化的λ噬菌体(fov,约250微米),和b,本发明的一些实施方式的对λ串联体(箭头)进行重复探查所得的序列。图79:本发明的一些实施方式的空间上可寻址的梳直(comb)的λdna斑点。a:高探针浓度下的λdna斑点的阵列杂交和梳直,100x物镜放大率;b:低探针浓度下的λdna斑点的阵列杂交和梳直,100x物镜放大率;c:λdna斑点的阵列杂交和梳直,100x物镜放大率;d:λdna斑点的阵列杂交和梳直,10x物镜放大率。图80显示了描述一种被配置成以单像素度量单分子事件(统计学而言,在大多数情况下)的系统的示例性方案。可以将该系统装配成例如将多个像素配置为查询单个分子。图81显示了对于来自单个图像的所观察到的推定标记的示例性信噪比分布。该分布为双峰,第一个峰为背景,第二个峰为真实标记(例如,标记有cy5的寡核苷酸)。图82显示包括示例性纯化程序的程序性工作流程。图83显示了对来自图82中所述的纯化程序的产物的分析结果。图84显示了100x100像素区域内不同密度的标记的示例性图像。图85显示了来自实施例12的标记的图像。图86描绘了基于样品批次进行归一化之前和之后的示例性数据。图87描绘了根据本公开的示例性方法对引物和探针进行标记。例如,一组t用作标记区,其中在扩增期间并入了许多荧光团,因为互补碱基附着有荧光团。在该情况下,并不是所有的互补核苷酸都被标记,因此不是所有的t上都并入了荧光团。探针的非标记部分中的其他t也可以被标记。模板可以是基因组或者探针序列。图88描绘了基于位置的示例性探针设计,用于检测已定位的遗传变异。例如,基于其在靶区域中的位置,将探针指定至标签。指定至给定标签的探针组所跨越的子区域的尺寸可以相似或不同。所述区域可以重叠或不重叠。所述区域可以覆盖整个靶标或靶标的子集。对于不同标签可以存在不同数量的探针。探针可以通过标签固定至数字阵列。对于数字阵列上的给定标签,探针可能不能彼此区分。探针可以代表靶区域的子区域并且检测靶区域的该子区域中的遗传变异。图89和90描绘了使用包含插入/缺失的可变序列的示例性探针。可以在杂交之前或之后添加标记(例如直接添加至探针上或在连接产物的扩增期间添加)。可以在任一条链上设计探针。如图90所示,错配引起探针之间的重叠或空位,因此未发生连接。具体实施方式除非另外指出,本文所述的方法可以采用分子生物学(包括重组技术)、细胞生物学、生物化学和微阵列及测序技术的常规技术和描述,其在本领域技术人员的技能内。此类常规技术包括聚合物阵列合成、寡核苷酸的杂交和连接、寡核苷酸的测序以及使用标记来检测杂交。合适技术的具体说明可以参考本文的实施例而获得。但是,当然也可以使用等效的常规程序。此类常规技术和描述可以例如在kimmel和oliver,dnamicroarrays(2006)elsevier;campbell,dnamicroarray,synthesisandsyntheticdna(2012)novascience;bowtell和sambrook,dnamicroarrays:molecularcloningmanual(2003)coldspringharborlaboratorypress中发现。在描述本文的组合物、研究工具和方法之前,应该理解的是本发明不限于所描述的具体方法、组合物、靶标和应用,因为这些当然可以变化。还应该理解的是,本文所用的术语的目的仅在于描述特定方面,并不旨在限制本发明的范围,本发明的范围仅受所附权利要求的限制。本发明涉及检测来自受试对象的遗传样品中的遗传变异的方法。本文所述的遗传变异可以包括但不限于核苷酸序列(例如dna和rna)和蛋白质(例如肽和蛋白质)中的一个或多个取代、倒位、插入、缺失或突变,一种或多种微缺失、一种或多种罕见等位基因、多态性、单核苷酸多态性(snp)、大规模遗传多态性,例如倒位和易位、一种或多种核苷酸分子(例如dna)的丰度和/或拷贝数差异(例如拷贝数变体,cnv)、三体性、单体性和基因组重排。在一些实施方式中,遗传变异可以与疾病(例如癌)的转移、存在、不存在和/或风险、药代动力学变化性、药物毒性、不良事件、复发和/或受试对象中器官移植排斥的存在、不存在或风险相关。例如,her2基因的拷贝数变化影响乳腺癌患者是否会对赫赛汀治疗产生响应。类似地,检测怀孕妇女血液中的染色体21(或18、13或性染色体)的拷贝数的增加可用作未出生婴儿的唐氏综合征(或帕韬氏综合征或爱德华综合症)的非侵入性诊断。另外的实例是检测在受体基因组中不存在的来自移植器官的等位基因——监视这些等位基因的频率或拷贝数可以鉴定潜在的器官排斥的征兆。多种方法可用于检测此类变化(例如rtpcr、测序和微阵列)。所述方法之一是对单个的经标记的分子进行计数,以检测突变的存在(例如癌中的egfr突变)或特定基因组序列或区域的过量(例如唐氏综合征中的染色体21)。对单一分子进行计数可以以许多方式完成,一种常见的读取方式是在表面上沉积分子并成像。另外,遗传变异可以是重新基因突变,例如单或多碱基突变、易位、亚染色体扩增和缺失以及非整倍性。在一些实施方式中,遗传变异可以表示在基因座处的替代性核苷酸序列,其可存在于个体群体中并且相对于该群体的其它成员包括核苷酸取代、插入和缺失。在另外的实施方式中,遗传变异可以是非整倍性。在其它实施方式中,遗传变异可以是13三体、18三体、21三体、x的非整倍性(例如xxx三体和xxy三体)或y的非整倍性(例如xyy三体)。在进一步的实施方式中,遗传变异可以位于22q11.2、1q21.1、9q34、1p36、4p、5p、7q11.23、11q24.1、17p、11p15、18q或22q13区中。在进一步的实施方式中,遗传变异可以是微缺失或微扩增。在一些实施方式中,检测、发现、确定、测量、评价、计数和评估遗传变异可以相互替换地使用,并且包括定量和/或定性的确定,包括例如鉴定遗传变异、确定遗传变异的存在和/或不存在和定量遗传变异。在进一步的实施方式中,本说明书的方法可以检测多种遗传变异。本文使用的术语“和/或”定义成表示组分的任意组合。此外,单数形式的“一种”、“一个”和“所述”可以还包括复数的指代物,除非上下文明确地指出例外。因此,例如,提到“一个核苷酸区”是指一个该区、多于一个该区或该区的混合物,提到“一种测定”可以包括提到本领域技术人员已知的等效步骤和方法,等等。“样品”是指来自生物、环境、医学或患者来源的一定量的材料,在所述材料中试图检测、测量或标记靶标核酸、肽和/或蛋白质。一方面,其是指包括试样或培养物(例如微生物培养物)。另一方面,其是指包括生物样品和环境样品。样品可以包括合成来源的试样。环境样品包括环境材料,例如表面物质、土壤、水和工业样品,以及获自食品和乳品处理仪器、设备、器械、器皿、一次性和非一次性物品的样品。“遗传样品”可以是具有在核酸的核苷酸序列中所编码的遗传性和/或非遗传性生物信息的任何液体或固体样品。样品可以获自来源,所述来源包括但不限于全血、血清、血浆、尿、唾液、汗液、粪便物、眼泪、肠液、粘膜样品、肺组织、肿瘤、移植器官、胎儿和/或其它来源。遗传样品可以来自动物(包括人)、流体、固体(例如粪便)或组织。遗传样品可以包括取自患者的材料,包括但不限于培养物、血液、唾液、脑脊髓液、胸膜液、乳、淋巴液、痰、精液和针抽吸物等。此外,遗传样品可以是来自母体血液样品的胎儿遗传材料。胎儿遗传材料可以分离自母体血液样品。遗传样品可以是胎儿和母体遗传材料的混合物。另外,遗传样品可以包括因肿瘤形成或转移而造成的异常基因序列,和/或存在于移植受体中的供体dna特征物。在另外的实施方式中,当遗传样品是血浆时,所述方法可以包括从受试对象的血液样品中分离出所述血浆。在进一步的实施方式中,当遗传样品是血清时,所述方法可以包括从受试对象的血液样品中分离出所述血清。在其它实施方式中,当遗传样品是无细胞dna(cfdna)样品时,所述方法还包括从获自本文所述的来源的样品中分离出无细胞dna样品。本文的无细胞dna样品是指在血流中在任何细胞或细胞器之外游离循环的dna分子的群体。在妊娠的情况下,来自母亲的无细胞dna携带母体dna和胎儿dna的混合物。这些实例不应解释为限制适用于本发明的样品类型。在又一实施方式中,样品是福尔马林固定且石蜡包埋的。例如,可以使用包含多种肿瘤和在正常细胞中稀释的肿瘤细胞的异质肿瘤样品。本发明允许检测罕见细胞类型、肿瘤异质性或在肿瘤核酸和正常核酸的稀混合物中来自肿瘤的核酸。在一个方面,样品可以包括无细胞dna(cfdna)、无细胞rna(cfrna)、细胞外dna和/或外来体。在另外的实施方式中,可以针对特定尺寸范围内的dna片段富集样品。例如,cfdna的长度通常为100至300bp,并且富集样品中的可能是cfdna而不是细胞dna的片段可以增加该样品的测试灵敏度或减少执行测试所需的材料量。在产前测试的情况下,与未富集的样品相比,富集cfdna可以富集胎儿组分。此外,来自胎儿的cfdna片段比来自母亲的cfdna片段短,因为一部分胎儿dna片段短于300bp,而一部分母体dna片段>300bp。因此,针对胎儿来源的片段群体富集cfdna可以对灵敏度产生额外益处。cfdna群体的尺寸选择也可以在其它临床背景下提供益处,例如在已经证实源自肿瘤的dna和源自非癌细胞的dna之间存在尺寸差异时监测癌症诊断,或在已经报道源自供体的dna和源自受体的dna之间存在尺寸差异时的移植。移植的器官包括但不限于心脏、肝、肾、肺、血液或其它组织。在另外的实施方式中,富集方法包括基于珠的方法、分子网(molecularnet)、纳米颗粒(例如,nanovison;nvigen.com/dna_sizerange.php)、基于凝胶的选择(例如凝胶电泳),固相可逆固定(spri)技术、纯化柱、按质量选择,等等。在另外的实施方式中,可以用捕获探针(可选地还用其它连接物)以单层或三维结构(例如含有捕获探针和连接物和/或间隔物的三维基质)包被珠。在一些实施方式中,这种三维结构可以被固定在基板上,例如珠。固定可以是共价或非共价的。样品可以与三维结构接触以对样品进行尺寸选择、纯化和/或富集。这些分子(例如捕获探针或部分、间隔物、桥接分子)的密度、间距和结构元件可以允许捕获样品中的某一尺寸的片段、并排除一些或全部其它片段。然后可以除去珠并洗脱样品。捕获可以基于包含或排除低于给定尺寸的核酸、包含或排除高于给定尺寸的核酸或选择在一定尺寸范围内的片段。作为替代,珠可以用羧基包被,所述羧基会基于总电荷而选择性地结合不同尺寸的dna分子。结合的分子尺寸可以通过改变包含珠和dna的溶液的组分来控制。基于珠的方法特别适用于使用标准流体学处理的微量滴定板中的自动化。使用具有不同孔径的珠或凝胶的其它方法可用来产生包装材料,其能够基于尺寸或分子量从孔中差异性排驱分子。还可以使用琼脂糖或丙烯酰胺凝胶电泳来实现尺寸富集,其中分子基于其电荷而被分离或利用分级分离制备型毛细管电泳而被分离。另一个选择是使用微加工的筛(microfabricatedsieve),通过该筛,不同尺寸的分子根据其固有扩散系数而移动。无细胞rna或任何其它核酸可以以与上述相似的方式富集。在另一方面,可以使用片段尺寸的分布来评估胎儿组分和三体性的存在。该信息可以与本发明的阵列组合使用,以提供关于胎儿材料在样品中的存在和胎儿的疾病状态的更多信息(例如,在其携带三体性的情况下)。这些富集cfdna的方法可与许多不同的技术一起使用,这些技术包括但不限于dna测序、基因分型、qpcr、单分子计数。在进行测定之前或在固定在阵列上之前,可以将样品片段化、扩增、变性或进行其他修饰。在一些实施方式中,本说明书的方法可以包括通过富集胎儿或肿瘤细胞、外来体或囊泡来富集胎儿或肿瘤遗传物质。例如,蛋白质标志物可用于选择性地捕获肿瘤细胞,但所获得的物质通常不会包含100%的肿瘤细胞,因为也会包含正常(非肿瘤)细胞。然而,该富集增加了肿瘤dna在样品中的比例。细胞可与cfdna联合使用或独立使用。富集也可以通过基于尺寸选择材料(例如,胎儿cfdna分子平均可能比母体cfdna分子小)来进行。非侵入性产前测试(nipt)对于高危妊娠而言已变得普遍。这些可能包括35岁以上的妇女、血清或其他筛查测试呈阳性的妇女、或具有儿童疾病家族史的妇女(例如以前的异常妊娠)。目前的nipt测试是基于序列的,由于其成本,这意味着它通常仅用于高危妊娠。本发明涉及制造可用于筛选所有妊娠的低成本单分子阵列。它也可用于预后性、监测性和诊断性产前测试。在一些实施方式中,本说明书的方法可以包括选择和/或分离目标基因座,并且对所存在的每种基因座的量(例如用于确定拷贝数)和/或不同基因座变体的相对量(例如给定dna序列的两种等位基因)进行定量。提到本文使用的基因组或靶多核苷酸时,区域、目标区域、基因座或目标基因座是指基因组或靶多核苷酸的连续亚区域或区段。如本文所用,核苷酸分子中的区域、目标区域、基因座或目标基因座可以指核苷酸、基因或基因组中基因的一部分(包括线粒体dna或其它非染色体dna)的位置,或者其可以指基因组序列的任何连续部分,无论其是否在基因内或者与基因相关。核苷酸分子中的区域、目标区域、基因座、基因座或目标基因座可以是单一核苷酸至长度为几百或几千个核苷酸以上的区段。在一些实施方式中,目标区域或基因座可以具有与其相关的参照序列。本文使用的“参照序列”表示与核酸中的目标基因座比较的序列。在某些实施方式中,参照序列认为是目标基因座的“野生型”序列。含有序列不同于目标基因座的参照序列的目标基因座的核酸有时被称为“多态性”或“突变的”或“遗传变异”。含有序列并非不同于目标基因座的参照序列的目标基因座的核酸有时被称为“非多态性”或“野生型”或“非遗传变异”。在某些实施方式中,目标基因座可以具有多于一种与其有关的独特参照序列(例如,当目标基因座已知具有多态性时,认为其是正常或野生型)。在一些实施方式中,本说明书的方法还可以包括选择和/或分离目标肽,并对存在的每种肽的量和/或不同肽的相对量进行定量。在另外的实施方式中,本文所述的目标区域可以包括“共有基因变体序列”,其是指这样的核酸或蛋白序列:已知其核酸或氨基酸以高频率出现在携带编码功能不正常的蛋白的基因的个体群体中,或者其中核酸自身功能不正常。另外,本文所述的目标区域可以包括“共有正常基因序列”,其是指这样的核酸序列:已知其核酸在其相应位置以高频率出现在携带编码功能不正常的蛋白的基因的个体群体中,或者其自身功能不正常。在进一步的实施方式中,本文所述的对照区域(其非目标区域)或者参照序列可以包括“共有正常序列”,其是指这样的核酸或蛋白序列:已知其核酸或氨基酸以高频率出现在携带编码功能正常的蛋白质的基因的个体群体中,或者其中核酸自身具有正常功能。本文所述方法可以产生对遗传变异的高度准确的测量。本文所述的一种变异类型包括两个以上不同的基因组基因座的相对丰度。在该情况下,基因座可以尺寸较小(例如小至约300、250、200、150、100或50个核苷酸以下)、尺寸中等(例如约1,000、10,000、100,000或1000000个核苷酸)以及大至染色体臂的一部分或整个染色体或染色体组。该方法的结果可以确定一个基因座相对于另一个的丰度。本说明书的方法的精度和准确性可以使得能够检测非常小的拷贝数变化(低至约25、10、5、4、3、2、1、0.5、0.1、0.05、0.02或0.01%以下),这使得能够鉴定非常稀的遗传变异特征。例如,胎儿非整倍性的特征物可以发现于母体血液样品中,在该样品中胎儿遗传异常被母体血液稀释,并且约2%的能够观察到的拷贝数变化表示胎儿三体性。如本文所用,术语“约”是指修饰例如核苷酸序列的长度、误差程度、维度、成分在组合物中的量、浓度、体积、处理温度、处理时间、产率、流速、压力等值及其范围,是指在数值量上的变化,该数值量可以通过以下方式产生:例如用于制造化合物、组合物、浓缩物或应用配方的常见测量和处理步骤;在这些过程中的疏忽误差;用于执行所述方法的原料或成分的制造、来源或纯度上的差异;等等。术语“约”还包括由于例如具有特定起始浓度和混合物的组合物、制剂或细胞培养物的老化而导致不同的量,以及由于对具有特定起始浓度和混合物的组合物、制剂或细胞培养物进行混合或加工而导致不同的量。无论是否用术语“约”修饰,所附权利要求包括这些量的等效量。术语“约”还可以指与所述参考值类似的值的范围。在某些实施方式中,术语“约”是指落入所述参考值的50%、25%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%以下范围内的值。在一些实施方式中,受试对象可以是怀孕受试对象、人类、具有高遗传疾病(例如癌)风险的受试对象、所有各科家畜动物以及未驯化或野生的动物。在一些实施方式中,遗传变异可以是怀孕受试对象的胎儿中的遗传变异(例如,胎儿中的拷贝数变体和非整倍性)。在一些实施方式中,受试对象可以是怀孕的受试对象,并且遗传变异是怀孕受试对象的胎儿中的变异,位于选自由下述组成的组的区域中:22q11.2、1q21.1、9q34、1p36、4p、5p、7q11.23、11q24.1、17p、11p15、18q、和22q13(例如22q11.2、1q21.1、9q34、1p36、4p、5p、7q11.23、11q24.1、17p、11p15、18q和22q13区域中任一个中的突变和/或拷贝数变化)。本文所述的胎儿是指人或其它动物的未出生的后代。在一些实施方式中,胎儿可以是受孕后超过1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20周的后代。在另外的实施方式中,胎儿可以是通过植入受精、体外受精、多胎妊娠或孪生而受孕的后代。在另外的实施方式中,胎儿可以是一对双胞胎(同卵或异卵)或者一组三胞胎(同卵或异卵)的部分。一些实施方式的发明包括至少两个主要组分:用于选择性鉴定基因组基因座的测定,和用于高准确度地定量这些基因座的技术。所述测定可以包括选择性地标记和/或分离一种或多种核酸序列的方法,其方式使得标记步骤自身足以产生含有对鉴定特定测定背景下的特定序列而言所必需的全部信息的分子(在本发明中定义为“探针产物”、“经连接的探针组”、“经缀合的探针组”、“经连接的探针”、“经缀合的探针”或“经标记的分子”)。例如,所述测定可以包括使探针与样品接触、结合和/或杂交,连接和/或缀合所述探针,可选地扩增经连接/缀合的探针,并且将所述探针固定至基板。在一些实施方式中,本文所述的测定和方法可以对单一输入样品平行地进行,作为本文所述的多重测定。在一些实施方式中,可以将探针组设计成检测基因组中任何位置的拷贝数变异。可以使用待检测的拷贝数变异的大小(例如,以千碱基计)来确定探针的数量及其平均间距。可以基于探针的位置(例如,在基因中,在没有已知snp的区域中)或以给定间距(例如,均匀间距)来选择探针。例如,可以如下选择探针:平均而言,连续探针之间的距离为约10mb、5mb、1mb或100kb以下且约50kb、1mb、2mb、3mb、4mb、5mb以上。探针组可以具有两种或更多种探针,平均间距为约1mb、5mb、10mb、25mb、50mb以上且10mb、20mb、30mb、40mb、50mb以下。探针可以簇集在特定的目标区域中。这些包括但不限于基因、功能区、启动子、外显子、内含子、端粒区、着丝粒区、已知拷贝数变化的区域、复现拷贝数变化的区域、一种或多种癌症中已知拷贝数变化的区域、一种或多种癌症中复现拷贝数变化的区域、基因组不稳定性区域、没有或几乎没有已知遗传多态性或遗传变异的区域、具有独特序列的区域或与癌症或其他感兴趣的疾病相关的区域。在一些实施方式中,焦点不是整个基因组,而是基因组的特定子集或区域。例如,编码区、外显子组或特定癌症相关区域。在另外的实施方式中,探针将靶向snp,并且每个探针组将包括设计成靶向snp的一个或多个等位基因的探针。等位基因信息可用于识别拷贝数变化或拷贝中性事件,例如杂合性缺失(loh)。在进一步的实施方式中,用于检测全基因组拷贝数变化的探针组可以包括约10、50、100、500、1000、3000、5000、10000种探针或更多且20000、10000、8000、6000、3000、1200、700、300、80、40、30种探针或更少。在进一步的实施方式中,将探针设计成查询靶标中变异位点处的一个或两个等位基因,例如snp或突变。在另外的实施方式中,本公开的方法可以包括选择、设计和/或使用靶向基因组区域的探针,所述区域在来自受试对象的遗传样品(例如血清或血浆)中是保留的或完整的。例如,cfdna可以作为核小体或染色体循环,并且靶向这些受保护区域的探针是更可用的或更完整的模板,这意味着来自基因组这些区域的dna分子多于本文所述遗传样品中的随机探针组。参见snyder等,cell-freednacomprisesaninvivonucleosomefootprintthatinformsitstissues-of-origin,cell,164,57-68(2016)。本文描述的方法可以包括检测来自遗传样品核酸分子的不同区域的dna分子的数量,并确定与其他区域相比检测到更多dna分子的区域。保留性可能由于其他原因而发生,例如,基于特定序列、分子的尺寸或长度或者dna提取或dna纯化方法。可以凭经验(例如,通过随机测序或靶向测序)来鉴定保留的或未受损的区域,并且该信息可以用于探针选择。如果探针含有许多靶分子并且存在过量的探针,那么与靶向随机序列的探针相比,平均而言会形成更多的探针产物。在一些实施方式中,通过使用靶向遗传样品中保留的或未受损的基因组区域的探针,所述方法可以减少探针的数量并产生与使用随机探针组时相同的计数值和/或检测率。在另外的实施方式中,通过使用靶向遗传样品中保留的基因组区域的探针,与使用随机探针组使相比,所述方法可以减少测定循环的数量。例如,寡核苷酸连接测定(ola)中的杂交连接步骤的数目或pcr循环的数目。在进一步的实施方式中,当探针靶向在cfdna中过量出现或在遗传样品中保留的区域时,可以缩短测定(或一些或所有测定步骤)的时间长度。在一些实施方式中,本文所述的探针可以靶向完全包含在保留区内的同源区。在另外的实施方式中,探针的同源区基本上包含在保留区中(例如大于50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%)。在另一个实施方式中,探针的同源区部分地包含在保守区中(例如,大于5%、10%、20%、30%、40%或50%)。使用靶向遗传样品中的保留的或过量丰富的dna区(例如cfdna)的探针可提供优于随机或鸟枪测序的显著优势。例如,当探针的同源区小于平均cfdna片段的尺寸时,该方法是有益的。探针可以在所靶向区域的中心设计,避免片段长度的任何不一致,因此避免cfdna片段的末端序列的不一致。当靶区域较大并且可以基于诸如基因组丰度等标准来选择探针时,这可能是特别有利的。在另一方面,本文所述的探针组可以包含:检测野生型序列的探针,和检测含有插入或缺失的突变型序列的另一探针。单核苷酸多态性可以用于提供等位基因信息或用于区分两条染色体。对于本文所述的寡核苷酸连接测定,可以存在两种探针(每个等位基因一种),其在与基因组上的第二通用探针相邻之处杂交。当它们位于正确的位置后,可以将它们连接。然而,由于在等位基因探针之间仅有单个碱基差异,它们可以交叉杂交并且可以成功连接到通用探针,以形成不代表下面的模板或靶标的测定产物。替代性方法是使用插入/缺失(indel)多态性,这可以不易形成不正确的测定产物,如图89和90所示。在这种情况下,当靶标与正确的探针匹配时,两个探针(一个针对插入或缺失,一个针对野生型序列)将仅在与通用探针相邻之处杂交。在交叉杂交的情况下,两个探针之间存在空位(在缺失的情况下)或重叠(在插入的情况下)。在任一情况下,连接可能是不可行的,或发生概率低得多。以这种方式,indel是非常特异的,因为当探针交叉杂交或与靶标错误地相互作用时,它们限制了连接的可能性。此类indel探针可用于与本文所述的其他snp探针相同的应用。例如,indel可用于测量胎儿组分,或用于检测多态性,或用于全基因组拷贝数分析,或用于检测拷贝数变化和许多其他应用。例如,它们可以用于产前测试(例如nipt),用于确定肿瘤的存在或不存在,用于确定肿瘤类型,用于对肿瘤的量(总体或特定克隆)定量,用于监测治疗或疗法的功效,用于测量癌症的进展或转移,用于测量移植排斥和用于本文所述的许多其他目的。在一些实施方式中,插入和/或缺失的长度可以是1、2、3、4、5、6、7、8、9、10个碱基对以上。在某些情况下,它们可以是约50、100、150、200、300、400、500bp以上且100、800、600、400、200、100bp以下。示例性的indel探针列于本文的表9和表10中。探针产物、经连接的探针组、经缀合的探针组、经连接的探针、经缀合的探针和经标记的分子可以是因对探针组施加的酶促作用(例如测定)而产生的单一连续分子。在探针产物或经标记的分子中,可以对来自探针组的一个或多个单个探针进行共价修饰从而使它们形成与任一探针或探针组相比不同的单一分子物质。结果,探针产物或经标记的分子可以是化学上不同的,并且因此可从探针或探针组中被鉴定出、计数、分离或进一步操作。在一个实施方式中,使用至少10、至少1,000、至少10,000个探针组来查询相同的基因座。例如,探针产物可以含有一个或多个鉴定标记,或一个或多个亲和标签以用于分离和/或固定。在一些实施方式中,不必对探针产物进行额外的修饰(例如,dna序列确定)。在一些实施方式中,不需要对dna序列进行额外的查询(interrogation)。含有标签的探针产物可以直接计数,通常在固定至固相基板上的固定步骤之后直接计数。例如,使用有机荧光团标记来标记探针产物,并且所述探针产物通过将探针产物固定至玻璃基板并随后用荧光显微镜和数码相机成像来直接计数。在其它实施方式中,根据经标记的分子是否与其互补基因组基因座相互作用,可以选择性地猝灭或移除所述标记。在另外的实施方式中,位于探针产物的相对部分的两个标记可以共同作用以根据经标记的分子是否与其互补基因组基因座相互作用来递送荧光共振能量传递(fret)信号。对于给定的基因组基因座,含有所述标记的标记探针可以设计用于在该基因座之内的任何序列区。具有相同或不同标记的一组多个标记探针也可以设计成用于单一基因组基因座。在该情况下,探针可以选择性地分离和标记特定基因座内的不同区域或者基因座内的重叠区域或相同区域。在一些实施方式中,含有亲和标签的探针产物可以经由亲和标签被固定至基板上。例如,使用亲和标签来将探针产物固定至基板上,并对含有亲和标签的探针产物直接计数。对于给定的基因组基因座,含有亲和标签的标签探针可以设计成用于在该基因座之内的任何序列区。具有相同或不同亲和标签的一组多个标签探针也可以设计成用于单一基因组基因座。在该情况下,探针可以选择性地分离和加标特定基因座内的不同区域或者基因座内的重叠区域。在一个方面,本说明书的方法可以包括使本文所述的探针组与本文所述的遗传样品接触。在一些实施方式中,本说明书的方法可以包括使多个探针组(例如第一探针组和第二探针组)与遗传样品接触。在另外的实施方式中,各探针组包含标记探针和标签探针。例如,第一探针组包含第一标记探针和第一标签探针,第二探针组包含第二标记探针和第二标签探针。使探针组与遗传样品接触可以同时进行,或在将探针杂交、连接、扩增和/或固定之后进行。另外,使探针组与遗传样品接触可以同时进行,或在将探针杂交、连接、扩增和/或固定之前进行。对于在遗传样品中核苷酸分子的给定基因组基因座或区域,该基因座内的单一核酸序列或该基因座内的多个核酸序列可以通过探针产物的形成而被查询(interrogate)和/或定量。基因组基因座内的经查询的序列可以不同和/或重叠,并且可以含有或不含有遗传多态性。探针产物通过设计一种或多种被称为“探针组”的寡核苷酸而形成。例如,探针产物可以通过连接所述探针组(通过连接所述探针组中的探针)而形成。探针组包含至少一种探针,所述探针与靶分子杂交、缀合、结合或固定至靶分子,所述靶分子包括核酸(例如dna和rna)、肽和蛋白质。在一些实施方式中,探针可以包含经分离的、纯化的、天然存在的、非天然存在的和/或人工材料,例如包括任何长度的寡核苷酸(例如3、5、10、11、12、13、14、15、16、17、18、19、20、30、40、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个核苷酸以上并且5、10、11、12、13、14、15、16、17、18、19、20、30、40、50、100、150、200、300、400或500个核苷酸以下),其中所述寡核苷酸序列的至少一部分(例如50、60、70、80、85、90、91、92、93、94、95、96、97、98、99或100%)与存在于一种或多种靶分子中的序列基序和/或杂交区域互补,从事使所述探针构造成与一种或多种靶分子或目标核酸区域部分杂交或全部杂交(或以类似的方式相互作用)。靶分子或目标核酸区域的与探针杂交的部分被称为探针的“杂交区域”,其可以是本文所述的靶分子或目标核酸区域的一部分或全部。探针可以是单链或双链的。在一些实施方式中,探针可以以经纯化的限制性消化产物制备或者以合成、重组或pcr扩增方式来产生。在另外的实施方式中,探针可以包括与特定肽序列结合的材料。本文所述的探针组可以包含一种或多种探针的组,其被设计成对应于单个基因组位置或蛋白质序列中的肽。本文所用的“核苷酸”是指脱氧核糖核苷酸或核糖核苷酸或任何核苷酸类似物(例如dna和rna)。核苷酸类似物包括在碱基、糖和/或磷酸的化学结构中具有修饰的核苷酸,包括但不限于5’-位嘧啶修饰、8-位嘌呤修饰、胞嘧啶环外胺的修饰、5-溴-尿嘧啶的取代等;和2’-位糖修饰,包括但不限于其中2’-oh被选自h、or、r、卤素、sh、sr、nh2、nhr、nr2或cn的基团置换的糖修饰型核糖核苷酸。shrna也可以包含非天然元件,例如,诸如次黄嘌呤和黄嘌呤等非天然核苷酸,诸如2’-甲氧基核糖等非天然糖,或诸如甲基膦酸酯、硫代磷酸酯和肽等非天然磷酸二酯键。在一个实施方式中,shrna还包含使shrna对核酸酶消化具有抗性的元件或修饰。“多核苷酸”或“寡核苷酸”可相互替换地使用,并且各自表示核苷酸单体的线性聚合物。构成多核苷酸和寡核苷酸的单体能够借助于单体-单体相互作用的规律性模式(例如watson-crick型碱基配对、碱基堆叠、hoogsteen型或反向hoogsteen型碱基配对等)来与天然和/或人工多核苷酸特异性地结合。此类单体和其核苷间键可以是天然存在的,或者可以是其类似物,例如天然存在或非天然存在的类似物。非天然存在的类似物可以包括pna、lna、硫代磷酸酯核苷间键、含有允许标记(例如荧光团或半抗原等)附着的连接基团的核苷酸。无论何时寡核苷酸或多核苷酸的应用需要酶促加工(例如通过聚合酶来延伸、通过连接酶来连接,等等),本领域普通技术人员都会理解这些情况下的寡核苷酸或多核苷酸在任何或一些位置不会含有核苷间键、糖部分或核苷酸的某些类似物。多核苷酸的尺寸通常为几个单体单元(此时称其为“寡核苷酸”)至数千个单体单元。无论何时多核苷酸或寡核苷酸由字母(大写或小写)序列表示(例如“atgcctg”),都应理解核苷酸是从左至右5’→3’顺序。通常多核苷酸包含由磷酸二酯键连接的四种天然核苷酸(例如对于dna而言为脱氧腺苷、脱氧胞苷、脱氧鸟苷、脱氧胸苷,或者对于rna而言为其核糖对应物);但是它们还可以包含非天然核苷酸类似物,例如包括经修饰的核苷酸、糖或核苷间键。对本领域技术人员显而易见的是,当酶的活性要求特定寡核苷酸或多核苷酸底物时,例如单链dna、rna或rna/dna双链体等时,则针对寡核苷酸或多核苷酸底物选择合适的组合物在本领域技术人员的知识内。在另一方面,本说明书的方法可以包括使第一探针组和第二探针组的至少一部分分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交。探针与目标核酸区的杂交可以同时进行,或者在使探针与遗传样品接触、连接探针、扩增探针和/或固定探针之后进行。此外,探针与目标核酸区的杂交可以同时进行,或者在连接、扩增和/或固定探针之前进行。探针的一部分或全部可以与样品中的单链或双链核苷酸分子、蛋白质或抗体中的目标区域的一部分或全部杂交。与探针杂交的目标区域可以为1~50个核苷酸、50~1000个核苷酸、100~500个核苷酸、5、10、50、100、200个核苷酸以下,或者2、5、10、50、100、200、500、1000个核苷酸以上。探针可以设计或构造成与靶区域或分子完美地杂交,或者它们可以设计成单碱基错配(例如单核苷酸多态性或snp位点)或少量此类错配不能产生探针和靶分子的杂交体。某些结构的标记可能易受臭氧降解的影响。当它们从湿状态转变到干状态时可能尤其如此。例如,alexa647被正常水平的臭氧显著降解。在单分子阵列的情况下,此类降解将导致计数的偏差,必须对其进行校正,否则可能导致错误的结果。这与臭氧降解将导致较低的信号强度的常规阵列相反。在一些情况下,部分或全部测定和阵列杂交步骤可以在无臭氧或臭氧降低的环境中进行。虽然臭氧降解是已知的现象,但其对于单分子计数是特别有害的,因为每个丢失的荧光团直接影响计数的准确性。测量特定染料的臭氧消耗的方法可以用作qc方法或用于误差校正。在另外的实施方式中,第一标记探针和/或第一标签探针与第一目标核酸区杂交,第二标记探针和/或第二标签探针与第二目标核酸区杂交。在另外的实施方式中,与目标核酸区杂交的探针组的多个或所有探针和/或其它成分(例如标记探针、标签探针和空位探针(gapprobes))彼此相邻。当与目标核酸区杂交的两种探针和/或成分是“相邻的”或“直接相邻的”时,在目标核酸区中,两个探针的杂交区域之间不存在核苷酸。在该实施方式中,探针组内的不同探针可以共价连接在一起,以形成较大的寡核苷酸分子。在另一实施方式中,探针组可以设计成与非连续但接近的目标核酸区部分杂交,从而在目标核酸区上存在未被探针占据的一个或多个核苷酸的“空位”,其位于探针组的已杂交的探针之间。在该实施方式中,可以使用dna聚合酶或其它酶来合成新多核苷酸序列,在一些情况下共价接合来自单一探针组的两个探针。在探针组内,任何探针可以携带用于基因座鉴定或分离的一个或多个标记或亲和标签。在一个方面,第一标记探针和第二标记探针分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交;第一标签探针和第二标签探针分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交;第一标记探针与和第一标签探针所杂交之处相邻的区域杂交;并且第二标记探针与和第二标签探针所杂交之处相邻的区域杂交。发生杂交的方式使得可以修饰探针组内的探针以形成新的较大的分子实体(例如探针产物)。本文的探针可以在严格条件下与目标核酸区杂交。如本文所用,术语“严格”用来指温度、离子强度和其它化合物(例如有机溶剂)的存在等条件,在该条件下进行核酸杂交。“严格”通常出现在约tm℃至低于tm约20℃~25℃的范围内。可以使用严格杂交来分离和检测相同的多核苷酸序列或者分离和检测相似或相关的多核苷酸序列。在“严格条件”下,核苷酸序列会以其全部或部分与其完全互补序列和紧密相关序列杂交。低严格条件包括与下述条件等效的条件:当使用长度为约100~约1000个核苷酸的探针时,在68℃下,在由5×sspe(43.8g/lnacl、6.9g/lnah2po4.h2o和1.85g/ledta,ph用naoh调整至7.4)、0.1%sds、5×丹哈德试剂(denhardt’sreagent)(每500ml的50×丹哈德试剂含有5gficoll(type400),5gbsa)和100μg/ml变性鲑鱼精子dna组成的溶液中进行结合或杂交,然后在包含2.0+sspe、0.1%sds的溶液中于室温下洗涤。本领域公知的是,可以使用许多等效条件来构成低严格条件;可以改变以下因素来产生与上述条件不同但是等效的低严格杂交条件:例如探针的长度和性质(dna、rna、碱基组成)和靶标的性质(dna、rna、碱基组成,存在于溶液中或经固定,等等),盐及其它成分的浓度(例如甲酰胺、硫酸右旋糖、聚乙二醇的存在或不存在),以及杂交溶液的成分。另外,促进在高严格条件(例如提高杂交和/或洗涤步骤的温度,在杂交溶液中使用甲酰胺,等等)下杂交的条件是本领域公知的。在提及核酸杂交时使用的高严格条件包括与下述条件等效的条件:当使用长度为约100~约1000个核苷酸的探针时,在68℃下,在由5+sspe、1%sds、5×丹哈德试剂和100μg/ml变性鲑鱼精子dna组成的溶液中进行结合或杂交,然后在包含0.1+sspe和0.1%sds的溶液中于68℃洗涤。在一些实施方式中,只有在探针组内的探针正确杂交时才可以形成探针产物。因此,探针产物可以以高严格度和高准确度形成。同样地,探针产物可以含有足够的信息以鉴定设计探针产物所要查询的基因组序列。因此,产生并直接定量特定的探针产物(在该情况下,通过分子计数)可以反映出起始样品中特定基因序列的丰度。在另外的实施方式中,构造探针所要杂交的目标核酸区位于不同的染色体中。例如,第一目标核酸区位于染色体21,第二目标核酸区不位于染色体21(例如,位于染色体18)。在另一方面,本说明书的方法可以包括连接第一标记探针和第一标签探针,以及连接第二标记探针和第二标签探针。探针的连接可以同时进行,或在使探针与遗传样品接触、扩增探针和/或固定探针之后进行。此外,探针的连接可以同时进行,或在使探针与遗传样品接触、扩增探针和/或固定探针之前进行。本文的连接是指将两个探针连接在一起(例如连接两个核苷酸分子)的过程。例如,本文的连接可以包括形成连接两个核苷酸的3’,5’-磷酸二酯键,作为能够引起连接的试剂的连接剂可以是酶或化学剂。在另一方面,本说明书的方法可以包括扩增经连接的探针和/或经连接的探针组。经连接的探针的扩增可以同时进行,或在使探针与遗传样品接触、连接探针、杂交探针和/或固定探针之后进行。另外,经连接的探针的扩增可以同时进行,或在固定探针之前进行。本文的扩增的定义为产生探针和/或探针产物的额外的拷贝,并且可以使用本领域公知的聚合酶链反应技术进行。如本文所用,术语“聚合酶链反应”(pcr)是指用于增加靶序列(例如在与基因组dna的混合物中)的区段的浓度而无需克隆或纯化的方法。通过两个寡核苷酸引物相对于彼此的相对位置来确定所需靶序列的扩增区段的长度,因此,该长度是可控的参数。借助于该过程的重复,将该方法称为“聚合酶链反应”(下文称为“pcr”)。由于靶序列的所需扩增区段在混合物中变为主导序列(在浓度方面),因此将它们称为“经pcr扩增的”。利用pcr,可以将基因组dna中的单个拷贝的特定靶序列扩增至用数种不同方法(例如用经标记的探针杂交)能够检测到的水平。除了基因组dna之外,可以用合适的引物分子组扩增任何寡核苷酸序列。具体而言,pcr过程自身所形成的扩增区段本身就是随后的pcr扩增的高效模板。如果可获得允许在扩增反应进行时测量反应产物的检测化学,例如leone等,nucleicacidsresearch,26:2150-2155(1998)中所述的“实时pcr”或“实时nasba”,则扩增可以是“实时”扩增。引物通常是单链的以使扩增中的效率最大化,但是作为选择可以是双链的。如果是双链的,通常在用于制备延伸产物之前先处理引物以将其链分开。该变性步骤通常受热影响,但是作为选择可以使用碱然后中和来进行。因此,“引物”与模板互补,并通过氢键或杂交与模板复合而提供用于引发聚合酶合成的引物/模板复合体,其通过在dna合成时添加与模板互补的连接在其3’末端处的共价键合的核苷酸而延伸。本文所用的“引物对”是指正向引物和相应的反向引物,具有适合于靶核酸的基于核酸的扩增的核酸序列。此类引物对通常包括序列与靶核酸的第一部分的序列相同或相似的第一引物,和序列与靶核酸的第二部分的序列互补的第二引物,从而提供靶核酸或其片段的扩增。除非另外指出,本文提到“第一”和“第二”是任意的。例如,第一引物可以设计为“正向引物”(其从靶核酸的5’-末端起引发核酸的合成)或设计为“反向引物”(其从延伸产物的5’-末端起引发核酸的合成,该延伸产物由正向引物所引发的合成产生)。同样地,第二引物可以设计为正向引物或反向引物。在一些实施方式中,本文的核苷酸分子中的目标核酸区可以通过本文所述的扩增方法进行扩增。样品中的核酸可以使用通用扩增方法(例如全基因组扩增和全基因组pcr)在分析之前进行扩增,或者不扩增。目标核酸区的扩增可以同时进行,或者在使探针与遗传样品接触、连接探针、扩增探针和/或固定探针之后进行。此外,经连接的探针的扩增可以同时进行,或在使探针与遗传样品接触、连接探针、固定探针和/或对标记进行计数之前进行。在另外的实施方式中,所述方法不包括在杂交或连接之后扩增遗传样品的核苷酸分子。在进一步的实施方式中,所述方法不包括在杂交和连接之后扩增遗传样品的核苷酸分子。在另一方面,本说明书的方法可以包括将标签探针固定至基板上的预定位置。将探针固定至基板可以同时进行,或者在使探针与遗传样品接触、使探针与目标核酸区杂交、连接探针和/或扩增探针之后进行。此外,将探针固定至基板可以同时进行,或者在使探针与遗传样品接触、使探针与目标核酸区杂交、连接探针、扩增探针和/或对探针进行计数之前进行。本文的固定是指通过物理或化学连接将标签探针直接或间接地结合至基板上的预定位置。在一些实施方式中,本文的基板可以包含结合伴侣,该结合伴侣被构造成接触并结合至本文所述的标签探针中的部分或全部标签,并且将该标签固定,并由此固定包含所述标签的标签探针。标签探针的标签可以包含本文所述的基板上的结合伴侣的相应结合伴侣。在一些实施方式中,基板可以包含一个或多个基准(fiducial)来定位基板上的位置。在其它实施方式中,基板可以包含一个或多个可用于确定背景水平的空白点。这些包括由以非特异性方式附着至表面上的经标记的分子和可能被误认为经标记的分子的其它颗粒状材料引起的颗粒背景。固定可以通过将部分或全部标签探针杂交至基板上的部分或全部结合伴侣并由此在基板上产生经固定的杂交产物来进行,所述经固定的杂交产物包含标签探针和结合伴侣。例如,固定步骤包括将标签或标签核苷酸序列的至少一部分杂交至基板上固定的相应核苷酸分子。此处,相应核苷酸分子是构造成与标签或标签核苷酸序列部分或全部杂交的标签或标签核苷酸序列的结合伴侣。在一些实施方式中,寡核苷酸或多核苷酸结合伴侣可以是单链的,并且可以通过例如5’末端或3’末端共价地附着至基板。固定还可以通过以下示例性结合伴侣和结合手段来进行:与抗生物素蛋白、抗生蛋白链菌素或中性抗生物素蛋白(neutravidin)复合的生物素-寡核苷酸;经由二硫键共价连接至sh-表面的sh-寡核苷酸;共价连接至激活的羧酸基或醛基的胺-寡核苷酸;与水杨基氧肟酸(sha)复合的苯基硼酸(pba)-寡核苷酸;与硫醇或硅烷表面反应或与丙烯酰胺单体共聚形成聚丙烯酰胺的丙烯酰胺基(acrydite)-寡核苷酸;或者用本领域已知的其它方法。对于优选使用带电表面的一些应用,表面层可以由如美国专利申请公开第2002/025529号所示的聚电解质多层(pem)结构组成。在一些实施方式中,固定可以通过公知的方法进行,所述方法包括例如使探针与附着有结合伴侣的载体接触一段时间,在探针因延伸而耗尽后,可选地将具有经固定的延伸产物的载体用合适的液体冲洗。在另外的实施方式中,将探针产物固定至基板上可以允许进行剧烈的洗涤以从生物样品和测定中除去成分,由此减少背景噪音并提高准确度。“固体载体”、“载体”、“基板”和“固相载体”可相互替换地使用,是指具有刚性或半刚性表面的材料或材料组。在一些实施方式中,基板的至少一个表面基本上是平的,但在其它实施方式中可以理想地用例如孔、纳米孔、凸起区域、钉状物或蚀刻槽等物理地分开针对不同化合物的合成区域。在另外的实施方式中,基板可以包含至少一个平面固相载体(例如显微镜载玻片、显微镜盖玻片)。例如,各元件可以由凸起区域或蚀刻槽、其它物理隔离件或者机械或物理分隔物分开。根据其它实施方式,基板可以采用珠、树脂、凝胶、微球、液滴或其它几何构型的形式。在一个方面,本说明书的一些实施方式的基板不包括珠、树脂、凝胶、液滴和/或微球。在一些实施方式中,可以理想的是,在半导体芯片、纳米小瓶、光电二极管、电极、纳米穴(nanopore)、凸起区域、钉状物、蚀刻槽或其他物理结构上物理地分开区域,例如孔、纳米孔、微孔。在另一个实施方式中,固体载体可以通过化学手段划分,例如设置排斥或吸引沉积在基板上的材料的疏水性或亲水性区域。基板可以安装在保持体、载体、盒、工作台嵌入槽(stageinsert)、微量滴定板,流动池或其它形式中,其提供稳定性、防止受环境影响的保护、更容易或更精确的处理、更容易或更精确的成像、自动化能力或其它期望的特性。在一些实施方式中,如图1所示,本文所述的结合伴侣、标签、亲和标签、标记、探针(例如标签探针和标记探针)和/或探针组可以作为阵列(2)固定在基板(1)上。本文的阵列具有多个组件(3-10),其在组件之间可以具有或不具有重叠(6)。每个组件可以具有至少一个区域不与另一组件重叠(3-5和7-10)。在另外的实施方式中,各组件可以具有不同的形状(例如圆点(3-8)、三角形(9)和方形(10))和尺寸。阵列的组件(本文也称为“元件”)的面积可以为约1~107μm2,100~107μm2,103~108μm2,104~107μm2;105~107μm2;约0.0001、0.001、0.01、0.1、1、10、100、103、104、105、106、107、108μm2以上;和/或约0.001、0.01、0.1、1、10、100、103、104、105、106、107、108μm2以下。阵列组件的尺寸可以例如是约1、5、10、20、30、40、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200微米以上;和/或约10、50、100、110、120、130、140、150、160、170、180、190、200、250、260、270、280、290、300、310、320、330、340、350、500、1000微米以下。在一些实施方式中,至少一部分阵列组件或元件在所有维度上以以下距离分隔开:约1至1000微米、5至100微米或1至300微米;约0.1、1、5、10、20、30、50、100、150、200、250或300微米以上;和/或约10、50、100、150、200、250、300、350、400、500、600、700、800、900或1000微米以下。例如,组件或元件的至少一部分、至少10%、20%、30%、40%、50%、60%、70%、80%、90%、95%、96%、97%、98或99%与相邻组件或元件的距离为:从约1、2、3、4、5、6、7、8、9、10、30、50、100、200、250或300微米至约50、100、200、300、400、500、800微米。在另外的实施方式中,本文所述的组件可以在一个或多个组件中具有至少两种不同的标签或亲和标签。标签的各种组合可以存在于单个组件中或存在于多个组件中。阵列可以包含一组相同或不同的阵列。该组的组件可以是基板、微量滴定板、阵列、微阵列、流动池或它们的混合物。在一些实施方式中,使用相同或不同的探针在该组阵列中的一个或多个上测试相同的样品。组中的每个阵列可以用于测试相同或不同的遗传变异。组中的给定阵列可以用于使用相同或不同的探针测试多个不同的样品。例如,这种类型的阵列可以包括一组微量滴定板。在板的每个孔中,可以测试不同的样品。在组的第一个微量滴定板中,可以测试所有样品的特定遗传变异。在第二个微量滴定板中,可以对相同的样品测试不同的遗传变异。本发明的一些实施方式的示例性组件(8)的图像以符号12显示。另外,包含相同类型的结合伴侣、标签、亲和标签、标记、探针(例如标签探针和标记探针)和/或探针组的两个以上组件可以具有相同的形状和尺寸。具体而言,根据本文所述的方法构造成或用于检测同一遗传变异或对照的包含结合伴侣、标签、亲和标签、标记、标签探针和/或探针组的阵列组件可以具有相同的形状和尺寸。此外,基板上的阵列的每一个组件都可以具有相同的形状和尺寸。在其它实施方式中,根据本文所述的方法构造成或用于检测不同遗传变异或对照的包含结合伴侣、标签、亲和标签、标记、探针和/或探针组的阵列组件可以具有相同的形状和尺寸。另外,每一阵列组件可以包含不同的结合伴侣、标签、亲和标签、标记、探针和/或探针组。在一些实施方式中,阵列的两个组件可以通过下述方式来分隔:(i)距离,在该距离内可以不存在或仅存在极少量的经固定的结合伴侣、标签、亲和标签、标记、探针(例如标签探针和标记探针)和/或探针组,和/或(ii)将一个组件与其它组件区分开的任何分隔物(例如增高的基板,防止结合伴侣、标签、亲和标签、探针(例如标签探针)和/或探针组与基板结合的任何材料,以及组件之间的任何非探针材料)。在另外的实施方式中,阵列的组件可以至少仅通过其位置而彼此区分开。阵列的组件可以通过下述距离分隔开:约0~104μm、0~103μm、102~104μm或102~103μm;约0、0.001、0.1、1、2、3、4、5、10、50、100、103、104、105、106、107或108μm以上;和/或约0、0.001、0.1、1、2、3、4、5、10、50、100、103、104、105、106、107或108μm以下。此处,将阵列的两个组件分隔开的距离可以通过组件边缘之间的最短距离来确定。例如,在图1中,将阵列(2)的两个组件符号3和4分隔开的距离是由符号n表示的距离。另外,例如,将基板(1)上的阵列(2)的组件分隔开的最短距离是0,例如将阵列的两个组件符号10和11分隔开的距离。在其它实施方式中,阵列的两个组件可以不分隔开,并且可以具有重叠(6)。在此类实施方式中,各组件可以至少具有与另一组件不重叠的区域(7)。在一些实施方式中,阵列组件的尺寸和本文所述的经标记的探针或经固定的杂交产物的密度可以利用沉积在基板上的材料(例如本文所述的探针)的体积和浓度来控制。例如,可以使用平均浓度为0.01nm、0.1nm、1nm、5nm、10nm、50nm、100nm、200nm、500nm、1000nm、2000nm或10000nm的经标记的探针、标签、亲和标签和/或捕获探针来形成具有所需的平均尺寸或含有所需的平均数量的分子的组件。在另外的实例中,可以使用平均浓度小于0.01nm、0.1nm、1nm、5nm、10nm、50nm、100nm、200nm、500nm、1000nm、2000nm或10000nm的经标记的探针、标签、亲和标签和/或捕获探针来形成具有所需的平均尺寸或含有所需的平均数量的分子的组件。在进一步的实例中,可以使用平均浓度大于0.01nm、0.1nm、1nm、5nm、10nm、50nm、100nm、200nm、500nm、1000nm、2000nm或10000nm的经标记的探针、标签、亲和标签和/或捕获探针来形成具有所需的平均尺寸或含有所需的平均数量的分子的组件。在另外的实施方式中,本文所述的方法可以包括使用间隔物(例如oligodt)、肌氨酸、去垢剂或其它添加剂来产生固定在基板上的经标记的探针的更均匀的分布。这些间隔物可以不具有功能,并且不以任何特定方式与经标记的寡核苷酸相互作用。例如,在间隔物寡核苷酸和经标记的寡核苷酸或经固定的寡核苷酸之间不存在序列特异性相互作用。在进一步的实施方式中,本文所述的结合伴侣、标签、亲和标签、标记、探针和/或探针组的阵列或阵列组件可以位于基板上的预定位置上,并且在固定之前,可以预先确定阵列的各组件的形状和尺寸以及组件之间的距离。本文的预定位置是指在固定之前确定或鉴定的位置。例如,阵列的各组件的形状和尺寸在固定之前确定或鉴定。在另外的实施方式中,基板可以含有结合伴侣的阵列,该阵列的各组件包含结合伴侣,例如寡核苷酸或多核苷酸,其被固定(例如通过化学键来固定,该化学键在探针与本文所述的基板的结合伴侣杂交的过程中不会断裂)至空间限定的区域或位置;即,所述区域或位置通过基板上的限定区域或位置而在空间上离散或分隔开。在进一步的实施方式中,所述基板可以包含阵列,该阵列的各组件包含与空间上限定的区域或位置结合的结合伴侣。被构造成包含结合伴侣的每个空间上限定的位置可以额外地是“可寻址的”,因为其位置和其固定的结合伴侣的身份是已知的或预定的(例如在其使用、分析或附着至标签探针和/或探针组中的其结合伴侣之前)。针对固定至基板的探针组,术语“可寻址的”是指本文所述的探针组的末端附着部分(例如基板的结合伴侣的结合伴侣、标签、亲和标签和标签探针)的核苷酸序列或其它物理和/或化学特性可以由其地址确定,即,探针组的末端附着部分的序列或其它性质与固定有探针组的基板上的空间位置或该基板的特性之间一一对应。例如,探针组的末端附着部分的地址是空间位置,例如,固定探针组的末端附着部分的拷贝的特定区域的平面坐标。但是,探针组的末端附着部分也可以以其它方式寻址,例如通过颜色或微转发器的频率等,例如chandler等,pct公开wo97/14028,本文通过援引将其全部内容并入以用于所有目的。在进一步的实施方式中,本文所述方法不包括“随机微阵列”,其是指基板的结合伴侣(例如寡核苷酸或多核苷酸)的空间离散区域和/或探针组的末端附着部分并未在空间上定址的微阵列。即,所附着的结合伴侣、标签、亲和标签、标签探针和/或探针组的身份不能从其位置(至少在开始时)辨别。在一个方面,本文所述的方法不包括作为微珠平面阵列的随机微阵列。本说明书的一些实施方式的核酸阵列可以通过本文所述的产生阵列、微阵列、流动池或生物传感器的方法或本领域公知的任何其他方法产生,包括但不限于:美国专利申请公开第2013/0172216号中所述的方法,通过援引将其全部内容并入以用于所有目的;schena,microarrays:apracticalapproach(irlpress,oxford,2000)。例如,可以使用dna捕获阵列。dna捕获阵列是表面上共价连接有经定位的寡核苷酸的固体基板(例如盖玻片)。这些寡核苷酸可以在表面上具有一种或多种类型,并且还可以在基板上地理上分开。在杂交条件下,与其它非特异性部分相比,dna捕获阵列会优先结合互补性靶标,由此用于将靶标定位至表面并将其与不期望的物质分开。在一些实施方式中,连接至经固定的标签探针的第一标记探针和第二标记探针和/或其经扩增的标记探针分别包含第一标记和第二标记。本文的标记探针是指包含标记或被构造成与标记结合的探针。标记探针自身可以包含标记,或者可以经修饰以包含标记或者与标记结合。本文的经扩增的探针的定义为在将本文所述的起始探针扩增后产生的起始探针的额外拷贝。因此,经扩增的探针可以具有作为起始探针的核苷酸序列和/或起始探针的核苷酸序列的互补序列的序列。经扩增的探针可以含有与起始探针的核苷酸序列部分或完全匹配的序列。术语“互补”或“互补性”用来指通过碱基配对法则涉及的核苷酸序列。例如,序列“5’-cagt-3’”与序列“5’-actg-3’”互补。互补性可以是“部分”或“全部”的。“部分”互补性是指探针中的一个或多个核酸核苷酸根据碱基配对法则不匹配,而其它核苷酸则匹配。核酸之间的“全部”或“完全”互补性是指探针中的每一个核酸碱基根据碱基配对法则都与另一碱基匹配。本文的经固定的探针的定义为通过物理或化学连接直接或间接结合至基板的探针。在一些实施方式中,标记探针可以通过与固定于本文所述的基板的标签探针连接而间接地固定至基板。本文的标记是指有机的、天然存在的、合成的、人工的或非天然存在的具有能够检测且可选地能够定量的性质或特性的分子、染料或部分。标记可以是能够直接检测的(例如,放射性同位素、荧光团、化学发光体、酶、胶体颗粒、荧光物质、量子点或其它纳米颗粒、纳米结构、金属化合物、有机金属标记和肽适体);或标记可以是使用特定的结合伴侣而能够间接检测的。荧光物质的实例包括荧光染料,例如荧光素、磷光体、罗丹明和聚甲炔染料衍生物等。商业上可获得的荧光物质的实例包括荧光染料,例如bodypyfl(商标,由molecularprobes,inc.制造)、fluoreprime(产品名,由amershampharmaciabiotech,inc.制造)、fluoredite(产品名,由milliporecorporation制造)、fam(由abiinc.制造)、cy3和cy5(由amershampharmacia制造)、tamra(由molecularprobes,inc.制造)、pacificblue、tamra、alexa488、alexa594、alexa647、atto488、atto590和atto647n等。“量子点”(qd)是指纳米级半导体晶体结构,通常由硒化镉制造,其吸收光然后在数纳秒后以特定颜色重新发射光。具有各种经缀合表面或反应性表面(例如氨基、羧基、抗生蛋白链菌素、蛋白质a、生物素和免疫球蛋白)的qd也包括在本说明书内。在一些实施方式中,本文所述的标记可以包含红外染料。较长波长的染料(例如,大于580nm的红移染料)比蓝移染料显示出较少的单分子污染。因此,在该范围内的染料和滤光片的组合可用于本文所述的单分子计数。可以一起使用的一对实例是atto590和atto647n。使用适当的滤光片,可以使渗出(bleed-through)最小化,使得可以通过以下描述的检测方法区分荧光团。尽管单分子污染对传统阵列几乎没有影响,它对数字单分子阵列造成虚假或错误的计数。加标记可以包括信号放大方法,这包括但不限于信号的复制、倍增或增大。该信号放大可能与标记所标记的核酸的扩增(例如经标记的pcr)有关,或者与被标记的核酸(例如分支-dna)无关。标记也可以是瞬时性质,例如染料分子的暂时猝灭。标记的检测可以是直接观察或测量,或者是通过检测所得到的性质或二次效应(例如探针和靶标之间的相互作用结果)来进行。例如,将脱氧核糖核苷酸三磷酸(dntp)并入dna链引起可以通过离子传感器(例如,离子敏感性场效应晶体管阵列)检测到的氢离子释放。与许多生物学应用不同,人眼不能看到单分子阵列的信号。这样,染料是否以可见光波长发光不如许多生物应用中重要。因此,红外(ir)或近红外染料特别良好地适用于本应用,因为它们具有低污染。在另外的实施方式中,第一标记和第二标记不同,从而使标记可以能够彼此区分。在其它实施方式中,第一标记和第二标记在其物理、光学和/或化学性质方面不同。在一些实施方式中,经固定的标记是光学上能够解析的。本文的术语“光学上能够解析的标记”或“光学上能够单独解析的标记”或“光学上分开的标记”是指(例如在本文所述的固定后)可以通过其光子发射或其它光学性质而相互区分的一组标记。在另外的实施方式中,即使标记可能具有相同的光学和/或光谱发射性质,经固定的标记也可以在空间上彼此区分开。在一些实施方式中,相同类型的标记的定义为具有相同光学性质的标记,其被固定在基板上,例如作为本文所述的阵列的组件,其密度和/或间距使得个体探针产物能够如图1的符号12所示那样得到解析。在本说明书中,“相同的标记”的定义为具有相同的化学和物理组成的标记。本文的“不同的标记”是指具有不同的化学和物理组成的标记,包括具有不同的光学性质的“不同类型的标记”。本文的“相同类型的不同标记”是指具有不同的化学和/或物理组成但具有相同的光学性质的标记。图1的符号12描述了包含经固定的标记的阵列的示例性组件的图像。在这些实施方式中,标记是空间上能够寻址的,因为分子的位置指明了其身份(并且在空间组合合成中,身份是位置的结果)。在另外的实施方式中,基板上的阵列的一个组件可以具有固定至该组件的一个或多个带标记的探针。当多个带标记的探针固定至阵列的一个组件时,固定至基板上的阵列的这一个组件上的带标记的探针中相同类型的标记可以如图1的符号12所示那样彼此在空间上区分开。在一些实施方式中,相同类型的固定标记或具有相同类型的固定标记的经固定杂交产物在所有维度上通过以下距离分隔开:约1~1000nm、5~100nm或10~100nm;约1、5、10、20、30、50、100、150、200、250、300、350或400nm以上;和/或约50、100、150、200、250、300、350、400、500、600、700、800、900或1000nm以下。例如,基板上的至少一个元件中的固定标记或包含固定标记的经固定杂交产物的至少一部分、至少10%、20%、30%、40%、50%、60%、70%、80%、90%、95%、96%、97%、98%或99%与该至少一个元件中的相邻的同类型固定标记或包含同类型固定标记的经固定杂交产物的距离为:从10、30、50、100、200、250、300或500nm至600、700、800或900nm。探针产物及其在基板上的标记的密度可以至多为每个基板上数百万(且至多为十亿以上)个待计数的探针产物。对含有标记的大量探针产物进行计数的能力允许准确地定量核酸序列。在一些实施方式中,经固定的第一标签探针和第二标签探针和/或其经扩增的标签探针分别包含第一标签和第二标签。本文的标签探针是指被构造成直接或间接与基板结合的探针。标签探针自身可以与基板结合,或者可以经修饰以与基板结合。本文的标签或亲和标签是指用于特异性分离、富集或固定探针产物的基序。标签或亲和标签的实例包括本文所述的结合伴侣、允许序列特异性捕获的独特dna序列(包括天然基因组序列和/或人工非基因组序列)、生物素-抗生蛋白链菌素、his标签、flag八肽、点击化学(例如在温和的水性条件下快速地选择性地相互反应的官能团对)和抗体(例如叠氮化物-细胞周期蛋白)。例如,固定步骤包括将标签、亲和标签或标签核苷酸序列的至少一部分杂交至固定在基板上的相应核苷酸分子。将标签或亲和标签构造成与实体结合,所述实体包括但不限于珠、磁珠、显微镜载玻片、盖玻片、微阵列或分子。在一些实施方式中,固定步骤通过将标签固定至基板的预定位置而进行。在另一方面,对固定在基板上的不同标记的数量进行计数,并因此对包含所述标记的不同的固定探针产物的数量进行计数。例如,将来自每个基因座的探针产物分组在一起,对经固定的探针产物中的标记进行计数。在一些实施方式中,基因组基因座内的多个序列可以通过创建多个探针产物类型来查询。对于该实例,针对相同基因组基因座的不同探针产物可以组合(可以通过固定至基板的相同位置,例如作为本文所述阵列组件),并且这些探针产物中的标记可以直接计数。针对相同基因组基因座的不同探针产物也可以是分离的(可以通过固定至基板的不同位置,例如作为本文所述阵列的不同组件),并且这些探针产物中的标记可以直接计数。在另外的实施方式中,基板可以在基板上的每个位置(例如作为基地上的阵列组件)中具有一个或多个特异性亲和标签。因此,用于定量核酸序列的另一方法通过以下方式来实现:将针对单一基因组基因座的探针产物(这可以是一种探针产物类型,或可以是针对特定基因组基因座的多于一种探针产物的组)固定至基板上的与对应于第二基因组基因座的探针产物相同的位置(例如作为本文所述阵列的相同组件),其可以充当或不充当参照或对照基因座。在该情况下,基于用于产生探针产物的不同的标记的存在,来自第一基因组基因座的探针产物将能够与来自第二基因组基因座的探针产物区分开。在一个实例中,为了通过检查母体血液样品来检测胎儿的21三体(非整倍性),产生对应于染色体21的探针产物组(例如用红色荧光团标记产生),并对其进行计数。还从参照或对照基因座(例如染色体18)产生第二探针产物组,并对其进行计数。该第二探针产物组可以例如用绿色荧光团标记产生。在一些实施方式中,可以制备这些探针产物从而凭借基因座(在该情况下染色体21或染色体18)将其分组在一起,并在基板上单独进行计数。即,对应于染色体21的探针产物可以被分离并单独计数,对应于染色体18的探针产物可以被分离并单独计数。在另外的实施方式中,这些探针产物也可以以下述方式制备:在基板的同一位置(例如作为本文所述阵列的同一组件)将它们分组在一起。在该情况下,在基板的相同区域上,携带红色荧光团的探针产物将对应于染色体21,携带绿色荧光团的探针产物将对应于染色体18。例如,由于所有这些探针产物是能够单独解析的,并因此可以非常准确地计数,所以,染色体21探针产物相对于染色体18探针产物的频率增加(即使小至0.01%、0.1%、1%以上或以下)将表明在胎儿中存在21三体。在该情况下,针对染色体18的探针产物可以充当对照。在另一方面,本说明书的方法可以包括对固定至基板的探针组的标记进行计数。在另一方面,所述方法可以包括对本文所述的标记、探针、探针组进行枚举、定量、检测、发现、确定、测量、评价、计算、计数和评估,例如,包括定量和/或定性确定,包括例如鉴定标记、探针、探针组,确定标记、探针、探针组的存在和/或不存在、比例、相对信号或相对计数,和对标记、探针、探针组进行定量。在一些实施方式中,所述方法还包括对(i)固定至所述基板的第一标记的第一数量和(ii)固定至所述基板的第二标记的第二数量进行枚举、定量、检测、发现、确定、测量、评价、计算、计数和评估。所述检测、发现、确定、测量、评价、计算、计数和/或评估步骤可以在将经连接的探针组固定至基板之后进行,并且可以将固定有经连接的探针组的基板保存在防止经连接的探针组降解的条件(例如在室温或在低于室温的温度)下,然后进行该步骤。在一些实施方式中,计数步骤包括基于一个或多个推定标记的强度、能量、相对信号、信噪比、焦点、锐度、尺寸或形状来确定标记、探针或探针组的数量。推定标记包括例如标记、颗粒、点状、离散或粒状的背景,和/或模仿标记或类似于标记的其它背景信号或假信号。本文所述的方法可以包括对标记、探针和探针组进行枚举、定量、检测、发现、确定、测量、评价、计算、计数和评估的步骤。该步骤不限于对标记、探针和探针组进行整数计数。例如,计数可以由来自标记的信号的强度进行加权。在一些实施方式中,与较低的强度信号相比,较高的强度信号被给予更大的权重并导致更高的计数。在两个分子非常接近的情况下(例如,当成像受衍射限制时),两个标记将不容易彼此解析。在该情况下,它们可能看上去是单个标记,但是比典型的单个标记具有更强的强度(即两个标记的累积信号)。因此,当考虑或权重标记的强度或其它度量(例如下面描述的尺寸和形状)时,计数可以比不考虑这些度量而对图像中标记的数量进行计数更准确。在一些实施方式中,考虑标记的形状,并且计数可以根据标记的形状来包括或排除一个或多个标记。在另外的实施方式中,可以考虑图像上的一个或多个标记或物体、对象或斑点的尺寸,并且计数可以根据该尺寸来包括、排除或进行调整。在另外的实施方式中,可以以任何尺度进行计数,包括但不限于整数、有理数或无理数。可以使用标记或多个标记的任何性质来定义对观察结果进行的计数在另外的实施方式中,计数步骤可以包括:通过对含有推定标记相关信息(例如,强度、能量、相对信号、信噪比、焦点、锐度、尺寸或形状)的矢量或矩阵进行求和来确定标记、探针或探针组的数量。例如,对于标记的每个离散观察,可以使用关于其尺寸、形状、能量、相对信号、信噪比、焦点、锐度、强度和其它因素的信息来对计数进行权重。该方法的价值的一些实例将是当两个荧光团重合并且显示为单个点时。在这种情况下,两个荧光团将具有比一个荧光团更高的强度,因此该信息可用于校正该计数(即计2而不是1)。在一些实施方式中,可以通过执行下述的校准来校正或调整计数。矢量或矩阵可以包含整数、有理数、无理数或其他数字类型。在一些实施方式中,加权还可以包括确定、评价、计算或评估可能性或概率,例如,观察结果是标记而不是背景颗粒的概率。这些概率可以基于先前的观察、理论预测或其它因素。在另外的实施方式中,初始计数是观察到的推定标记的数量。然后可以通过以适当的方式对每个推定标记进行加权来改进、校正或校准该数量。在一个方面,计数步骤可以包括将标记的数量或标记的比例归一化。在一些实施方式中,归一化可以包括基于本文所述的遗传样品中的分子丰度来归一化标记的数量。因为基因组的不同区域可能以不同的频率出现在cfdna中(基于不同的降解速率或选择),所以最佳的归一化方法将考虑到这一点。例如,相对丰度可用于归一化计数,其中计数可以是测序读出结果或固定的探针产物。当比较两个靶区域时(例如,为了确定一个靶区域的拷贝数是否高于另一个),如果这两个区域以不同的比例自然出现在cfdna中,则可能会出现错误结果。纠正这种内在差异对于获得拷贝数或相对拷贝数的准确测量是重要的。一种方法是为在cfdna样品中平均具有相同丰度的不同的靶标设计探针组。在单分子阵列中,如果已知探针靶分子的丰度或相对丰度,则可以控制固定在表面上的分子的密度。这可以用来在单分子阵列上提供带标记的分子的更一致的密度,这进而可以减少由计数不同密度的分子的准确度引起的偏差。在另外的实施方式中,归一化可以包括基于样品批次将标记的数量或标记的比例归一化。本文所述的遗传样品可以分批处理。例如,可以提取dna以用于一组不同的样品。其他类型的批次可以基于抽血的位置或时间、血清与细胞的分离、测定、测序或其他处理或纯化过程。这些批次可能存在程序本身带来的人为差异。在这种情况下,可以将分析限制于选定的批次,以便具有最小偏差和/或最高准确度。为了组合或比较批次,可能需要将它们相互归一化。例如,均值或中位数或其他度量可以在批次之间归一化或变得等同。这有助于去除不想要的方差,其不是样本固有的,而是各批次组中样品处理的一部分。本文所述的归一化可以通过本领域已知的方法进行。举例而言,考虑两个批次的样品,其中计算每个样品的染色体21上的标记计数与染色体18上的计数的比率的量度。这些样品来自孕妇,且正在用于测试唐氏综合征的存在,唐氏综合征是由胎儿的胎儿基因组中21号染色体的额外拷贝引起的。在这两个批次中,所有样品都是正常的,因此应该具有相同的值,但是采样过程将引入一定程度的差异。即使存在采样差异,多份样品中的比率的平均值在两个批次中也应该是相同的。如果观察到两个批次的样品具有不同的平均值,则归一化可以是有利的。如果将这些批次相对于其批次水平平均值进行归一化(例如,通过将每个样品的比例除以批次的平均比率),则将两个批次的平均值设定为1。图86显示了来自单独处理的两个批次的样品的数据。在批次a中,平均比率为0.950143,在批次b中,平均比率为0.955143。平均值的差异可能归因于偶然或归因于批次水平效应所导致的差异,例如批次处理方式中的故意或意外的差异。为了将两个批次归一化,将每个样品的比率值除以其所属批次的平均比率。图87显示了归一化后的数据,其中两个批次具有相等的平均比率。以此方式,消除了批次效应,并且可以在批次之间比较样品。在没有归一化的情况下,具有较高平均比率的批次b中的样品可能被判断为三体性妊娠,而实际上它们是正常妊娠。在一些实施方式中,本文所述的计数可以通过例如表面上的标记的密度、观察到的背景颗粒的密度(其模拟标记)或其它因素来归一化。在另一方面,可以使用标准数学函数和变换(例如对数)来转换计数。在另一方面,计数可用于产生比例。例如,如果标记1和标记2的计数为x和y,则可以使用比率x/y来组合这两个数字。这些比率可以在样品内和样品之间进行比较。在一些情况下,如果标记1表示染色体21,标记2表示染色体1,则会预期在来自胎儿具有唐氏综合征的孕妇的cfdna中的比例x/y比在来自胎儿不具有唐氏综合征的孕妇的cfdna中的该比例高。为了准确地定量不同的基因组序列的相对丰度,例如,为了定量dna拷贝数或定量等位基因频率,可以对大量探针产物进行计数。例如,可以基于测量例如经固定的探针的物理化学、电磁学、电学、光电子学或电子化学性质或特性来检测和计数标记。在一些实施方式中,标记可以通过以下方式来检测:扫描探针显微镜(spm)、扫描隧道显微镜(stm)和原子力显微镜(afm)、电子显微镜、光学查询/检测技术,包括但不限于近场扫描光学显微镜(nsom)、共聚焦显微镜和隐失波激发。这些技术的更具体的版本包括远场共焦显微镜、双光子显微镜、广视野落射光照明(wide-fieldepi-illumination)和全内反射(tir)显微镜。许多以上技术也可以以分光镜模式使用。实际检测通过电荷耦合装置(ccd)照相机和增强ccd、光二极管和/或光电倍增管进行。在一些实施方式中,计数步骤包括光学分析,以检测标记的光学性质。在另外的实施方式中,光学分析包括本文所述的图像分析。在另一方面,对于本文所述的方法,希望快速的周转时间。扫描时间测量从成像开始到对于给定方法应用而言足够数据的收集完成时的时间。本发明的一些实施方式提供了可以在小于60分钟内扫描的阵列。也就是说,可以在小于60分钟内收集足够的数据来计算具体测试的明确结果。更理想的是,可以在小于30分钟或小于15分钟内扫描。较大的阵列可以在小于120分钟、小于180分钟或小于240分钟内扫描。在一些实施方式中,扫描时间可以大于1、3、5、10、15、20或30分钟。扫描时间可以与所计数的分子数量成比例,更长的扫描时间提供更高的灵敏度和/或更低的假阳性率和/或更低的假阴性率。减少扫描时间的新步骤包括:自动聚焦发现,使用基准来定位阵列上的位置,标记和滤光片的特定组合,硬件(例如光源)的硬件优化,针对标记的性质定制的最佳基板和差分曝光时间。此外,例如,对于检测用传感器的像素尺寸,可以使用63×油浸和40×干物镜来优化标记的尺寸。在大多数情况下,具有6.5平方微米的像素尺寸的40×物镜(40x放大率)(例如hamamatsuorcaflash4.0)中,标记(例如alexa488)被9个像素(3×3的方形)包封,信噪比为3:1。这可以允许经固定的经标记的寡核苷酸被有效地包装以减少扫描时间,从而增加通量。在产前测试中,扫描时间很重要,因为需要扫描大量样品(平均每年在美国有4,000,000个怀孕,而筛选范例中,全部4,000,000个都将被测试)。这将需要每小时扫描几乎50个样品,且全年每天每小时都进行。因此,减少扫描时间的发明尤其重要。理想的是,样品被单独扫描。也就是说,他们没有汇集或混合在一起。对于基于测序的产前测试方法,样品被加条码,然后汇集并批量测序。所有当前的产前测试方法都使用样品多重化(multiplexing)。这种多重化导致潜在误差或错误报告的结果。其进一步需要扫描以适于具有最低胎儿组分的样品。如果逐个分析样品,则可以扫描每个样品以对适当数量的探针进行计数,从而具有所需的统计力。与具有高胎儿组分的样品(要求相对较低数量的计数)相比,具有低胎儿组分的样品(要求非常高数量的计数)可以具有非常不同计数数量。样品多重化还要求可获得一批样品以高效地运行仪器。因此,样品可能被延误,因为实验室等待样品达到最佳数量。在本发明中,样品可以在它们到达时运行,而不需要等待获得多个样品。每个样品可以具有唯一的基板,或多个样品可以位于同一基板的不同区域。在优选实施方式中,每个样品在唯一的基板上扫描。在另一方面,计数步骤包括在分别对应于第一标记和第二标记的第一成像通道和第二成像通道中读取基板,并且产生基板的一个或多个图像,其中第一标记探针和第二标记探针在一个或多个图像中是能够解析的。在一些实施方式中,计数步骤包括空间滤波以进行图像分割。在另外的实施方式中,计数步骤包括分水线(watershedding)分析,或用于成像分割的杂交法。单个的方法可以应用多于一次,且使用相同或不同的参数或条件。例如,分水线可以将图像划分成一组区域,然后可以在每个区域内再次应用分水线来检测由初始分水线分析定义的区域内的一个或多个标记。在另一方面,点扩散函数的锐度或独特形状可用于区分标记与其它噪声或信号类型。本文所述的方法还可以着眼于相同基因座处的不同的等位基因(例如给定单核苷酸多态性的两个等位基因)的频率。这些方法的准确度可以检测频率的非常小的变化(例如低至约10、5、4、3、2、1、0.5、0.1或0.01%以下)。作为实例,在器官移植的情况下,血液样品会含有非常稀的来自供体器官的遗传特征。该特征可以是存在不在所捐献的器官的受体的基因组中的等位基因。本文所述的方法可以检测等位基因频率的非常小的偏差(例如,低至约10、5、4、3、2、1、0.5、0.1或0.01%以下),并且可以鉴定宿主样品(例如血液样品)中供体dna的存在。不健康的移植器官可以导致宿主血液中供体dna的水平升高——增加仅几个百分点(例如,低至约10、5、4、3、2、1、0.5、0.1或0.01%以下)。本文所述的方法可以足够灵敏,从而以所需的灵敏度鉴定等位基因频率的变化,因此可以准确确定宿主血液中供体dna的存在和改变量。在另一方面,本说明书的方法可以包括比较第一数量和第二数量以确定遗传样品中的遗传变异。在一些实施方式中,比较步骤包括获得具有第一目标核酸区和第二目标核酸区的核苷酸分子的相对数量的估计值。在另一方面,本说明书的方法可以包括在接触步骤之前(例如在制造探针的过程中)用第一标记和第二标记来分别标记第一标记探针和第二标记探针。标记所述探针可以同时进行,或在使探针与遗传样品接触、杂交探针、连接探针、扩增探针和/或固定探针之后进行。另外,标记所述探针可以同时进行,或在使探针与遗传样品接触、杂交探针、连接探针、扩增探针和/或固定探针之前进行。对探针进行标记可以包括通过物理或化学连接将标记添加、固定或结合至探针。标记可以位于探针序列内的任何地方,包括在5’末端或3’末端。在另一方面,本说明书的方法还包括在接触步骤之前(例如在制造探针的过程中)用第一标签和第二标签分别对第一标签探针和第二标签探针加标签。对探针加标签可以同时进行,或在使探针与遗传样品接触、杂交探针、连接探针、扩增探针和/或标记探针之后进行。另外,对探针加标签可以同时进行,或在使探针与遗传样品接触、杂交探针、连接探针、扩增探针、固定探针和/或标记探针之前进行。对探针加标签可以包括通过物理或化学连接将标签添加、固定或结合至探针。标签可以位于探针序列内的任何地方,包括在5’末端或3’末端。在另一方面,本文的探针组可以设计成根据将要固定标签的预定位置来具有标签。在一些实施方式中,构造成检测遗传变异的所有探针组中的标签是相同的,并被构造成直接或间接地固定在基板上的相同位置。在另外的实施方式中,第一标签和第二标签是相同的,并且其余标签的每一种都与第一或第二标签不同。在进一步的实施方式中,基板上的多个预定位置的阵列的每个组件或一组组件都可以具有待固定的独特标签。在另一方面,可以扩增一些实施方式的探针组,并且可以在扩增过程中产生经标记的探针组。在另一方面,各标记探针可以包含正向或反向引发序列(primingsequence),各标签探针包含相应的反向或正向引发序列和作为标签的标签核苷酸序列。正向或反向引发序列是被构造成分别与相应的正向或反向引物杂交的序列。在一些实施方式中,扩增步骤包括扩增:(i)具有分别与正向引发序列和反向引发序列杂交的第一正向和反向引物的已连接的第一标记和标签探针,其中杂交至第一标记探针的第一正向或反向引物包含第一标签,和(ii)具有分别与反向和正向引发序列杂交的第二正向和反向引物的已连接的第二标记和标签探针,其中杂交至第二标记探针的第二正向或反向引物包含第二标签。在另外的实施方式中,将标签探针的经扩增的标签核苷酸序列固定至基板上的预定位置,其中第一标签探针和第二标签探针的经扩增的标签核苷酸序列是第一标签和第二标签。在一些实施方式中,第一标签和第二标签是相同的,且/或被构造成结合至基板上的相同位置。在另一实施方式中,第一标签和第二标签是不同的,且/或被构造成结合至基板上的不同位置。在其它实施方式中,当扩增了探针时,所述方法包括对固定至基板上的经扩增的探针和/或探针组中的标记的数量计数。例如,第一数量是固定至基板的经扩增的第一探针组中的第一标记的数量,第二数量是固定至基板的经扩增的第二探针组中的第二标记的数量。在另一方面,可以扩增一些实施方式的探针组,并且可以使用经标记的反向引物而不使用正向引物来产生经标记的探针组。在另一方面,各标记探针可以包括反向引发序列,并且各标签探针可以包含作为标签的标签核苷酸序列。在一些实施方式中,扩增步骤可以包括扩增:(i)具有与第一标记探针的第一反向引发序列杂交的第一反向引物的已连接的第一标记和标签探针,其中所述第一反向引物包含第一标记,和(ii)具有与第二标记探针的第二反向引发序列杂交的第二反向引物的已连接的第二标记和标签探针,其中所述第二反向引物包含第二标记。在另外的实施方式中,将标签探针的经扩增的标签核苷酸序列固定至基板上的预定位置,其中第一标签探针和第二标签探针的经扩增的标签核苷酸序列是第一标签和第二标签。在其它实施方式中,第一数量是在固定至基板的经扩增的第一探针组中的第一标记的数量,第二数量是在固定至基板的经扩增的第二探针组中的第二标记的数量。在一些实施方式中,如图87所示,上述引物可以包含多个本文公开的标记。例如,引物可以包含1、2、3、4、5、6、7、8、9或10个本文公开的标记。在另外的实施方式中,本文所述的方法可以包括在引物合成期间添加多个标记(例如荧光染料)。常常制造包含荧光染料分子的探针或引物,并且本文所述的方法可以包括制造引物或探针,包括在该过程中添加多个荧光染料分子,通常通过使多个核苷酸各自带一个标记。在一个实施方式中,可以将多种荧光染料分子添加到pcr引物中。在另外的实施方式中,本文所述的引物可包含加标记部分。当扩增是本文所述测定的一部分时,引物例如可以具有含有多个本文所述的标记的尾部。通过使标记移动远离引发序列(即与待扩增的靶标同源的部分),可以降低标记干扰扩增过程或引入偏差的可能性。例如,可以在制造期间将一系列本文所述的核苷酸添加到引物的一侧,并且可以标记这些核苷酸中的一些或全部。这在引发位点的上游提供了明亮的实体。在另一方面,一些实施方式的经连接的探针组可以使用连接酶链反应产生。在另一方面,本文所述的方法包括使第三探针组和第四探针组与遗传样品接触,其中第三探针组包含第三标记探针和第三标签探针,第四探针组包含第四标记探针和第四标签探针。所述方法还可以包括:使第一探针组和第二探针组分别与来自遗传样品的双链核苷酸分子的单链核苷酸分子中的第一目标正义核酸链和第二目标正义核酸链杂交;并使第三探针组和第四探针组分别与第一目标正义核酸链和第二目标正义核酸链的反义核酸链杂交。所述方法还可以包括至少通过连接以下(i)至(iv)来产生经连接的第一、第二、第三和第四探针组:(i)第一标记探针和第一标签探针,(ii)第二标记探针和第二标签探针,(iii)第三标记探针和第三标签探针,和(iv)第四标记探针和第四标签探针。所述方法可以还包括执行本领域已知的连接酶链反应来扩增经连接的探针和/或经连接的探针组。在一些实施方式中,连接酶链反应可以包括使未连接的第一探针组、第二探针组、第三探针组和第四探针组分别与经连接的第三探针组、第四探针组、第一探针组和第二探针组杂交,并且连接未连接探针组的至少(i)第一标记探针和第一标签探针、(ii)第二标记探针和第二标签探针、(iii)第三标记探针和第三标签探针和(iv)第四标记探针和第四标签探针。所述方法还可以包括将标签探针固定至基板上的预定位置,其中分别连接至经固定的第一标签探针、第二标签探针、第三标签探针和第四标签探针的第一标记探针、第二标记探针、第三标记探针和第四标记探针分别包含第一标记、第二标记、第三标记和第四标记;经固定的标记是光学上能够解析的;经固定的第一标签探针、第二标签探针、第三标签探针和第四标签探针分别包含第一标签、第二标签、第三标签和第四标签,并且固定步骤通过将所述标签固定至所述预定位置来进行。所述方法还可以包括对(i)固定至基板的第一和第三标记的第一总和和(ii)固定至基板的第二和第四标记的第二总和进行计数,并比较所述第一总和和第二总和以确定遗传样品中的遗传变异。在另外的实施方式中,所述方法还包括在接触步骤之前分别用第一标记、第二标记、第三标记和第四标记标记第一标记探针、第二标记探针、第三标记探针和第四标记探针。在其它实施方式中,第一标记和第三标记是相同的,第二标记和第四标记是相同的。在另一方面,本文所述的方法包括使第三探针组和第四探针组与遗传样品接触,其中第三探针组包含第三标记探针和第三标签探针,第四探针组包含第四标记探针和第四标签探针,第一标记探针和第三标记探针包含第一反向引发序列,第二标记探针和第四标记探针包含第二反向引发序列,并且各标签探针包含作为标签的标签核苷酸序列。所述方法还包括使第一探针组和第二探针组分别与来自遗传样品的双链核苷酸分子的单链核苷酸分子中的第一目标正义核酸链和第二目标正义核酸链杂交;并使第三探针组和第四探针组的至少一部分分别与第一目标正义核酸链和第二目标正义核酸链的反义核酸链杂交;通过连接(i)第一标记探针和第一标签探针、(ii)第二标记探针和第二标签探针、(iii)第三标记探针和第三标签探针和(iv)第四标记探针和第四标签探针来产生经连接的第一、第二、第三和第四探针组。所述方法还可以包括执行连接酶链反应。在一些实施方式中,连接酶链反应包括使未连接的第一探针组、第二探针组、第三探针组和第四探针组的至少一部分分别与经连接的第三探针组、第四探针组、第一探针组和第二探针组杂交,并连接未经连接探针组的(i)第一标记探针和第一标签探针、(ii)第二标记探针和第二标签探针、(iii)第三标记探针和第三标签探针和(iv)第四标记探针和第四标签探针。所述方法还可以包括扩增:(i)具有与第一反向引发序列杂交的第一反向引物的经连接的第一和第三探针组,其中所述第一反向引物包含第一标记,和(ii)具有与第二反向引发序列杂交的第二反向引物的经连接第二和第四探针组,其中所述第二反向引物包含第二标记,将标签探针的经扩增的标签核苷酸序列固定至基板上的预定位置,其中第一标签探针、第二标签探针、第三标签探针和第四标签探针的经扩增的标签核苷酸序列是第一标签、第二标签、第三标签和第四标签,第一数量是固定至基板的经扩增的第一和第三探针组中的第一标记的数量,第二数量是固定至基板的经扩增的第二和第四探针组中的第二标记的数量。在另一方面,经连接的第一标记探针和第二标记探针位于第一和第二连接探针组的3’末端,并且包含分别与第一和第二反向引物杂交的第一和第二反向引发序列。在一些实施方式中,第一和第二反向引物包含第一标记和第二标记。在另外的实施方式中,经连接的第一标签探针和第二标签探针位于第一和第二连接探针组的5’末端。在其它实施方式中,经连接的第一标签探针和第二标签探针位于第一和第二连接探针组的5’末端,并且包含分别与第一和第二正向引物杂交的相应的第一和第二正向引发序列。在另一方面,本文的方法包括消化样品中的双链分子以产生单链分子。在一些实施方式中,扩增步骤包括使核酸外切酶与经扩增的探针和/或探针组接触,并且从双链的经扩增的探针和/或探针组的一条链的5’末端开始消化经扩增的探针和/或探针组。例如,扩增步骤包括使核酸外切酶与探针组中的经扩增的探针接触,并且从双链的经扩增的探针组的一条链的5’末端开始消化经扩增的探针组。在另外的实施方式中,接触核酸外切酶的经扩增的探针和探针组的一条链在5’末端不具有任何标记。核酸外切酶与未标记的双链探针的接触可以从5’末端消化未标记的链,产生单链探针。在另一方面,在5’末端包含标记的经扩增的探针组的5’末端可以得到保护而免受核酸外切酶消化。在另一方面,所述方法可以检测1~100,1~50,2~40或5~10个遗传变异;2、3、4、5、6、7、8、9、10个以上遗传变异;和100、50、30、20、10个以下遗传变异。在一些实施方式中,本文所述的方法可以使用至少(x+1)数量的不同探针组来检测x数量的遗传变异。在这些实施方式中,可以将来自一种类型的探针组的标记的数量与来自其余不同类型的探针组的标记的一个或多个数量比较。在一些实施方式中,本文所述的方法可以以各种解析度(例如以300,000个碱基的解析度)以连续方式在整个基因组上检测遗传变异,从而使得可以单独查询和定量在所有染色体上分布的100个变异。在另外的实施方式中,碱基解析度为1或10~100000个核苷酸,至多至1000000、10000000或1亿个以上核苷酸。在另一方面,一些实施方式的方法可以检测至少两种遗传变异。在一些实施方式中,本文所述的方法还包括使第五探针组与遗传样品接触,其中第五探针组包含第五标记探针和第五标签探针。所述方法还可以包括使第五探针组的至少一部分与遗传样品的核苷酸分子中的第三目标核酸区杂交,其中第三目标核酸区不同于第一目标核酸区和第二目标核酸区。所述方法还可以包括至少通过连接第五标记探针和第五标签探针来连接第五探针组。所述方法还可以包括扩增经连接的探针组。所述方法还可以包括将各标签探针固定在基板上的预定位置,其中连接至经固定的标签探针的第五标记探针和/或其经扩增的标记探针包含第五标记,所述第五标记不同于第一标记和第二标记,经固定的标记是光学上能够解析的,经固定的第五标签探针和/或其经扩增的标签探针包含第五标签,并且固定步骤通过将标签固定至预定位置来进行。所述方法可以包括对固定至基板的第五标记的第三数量进行计数,并比较第三数量与第一和/或第二数量以确定遗传样品中的第二遗传变异。在一些实施方式中,受试对象可以是怀孕的受试对象,第一遗传变异是所述怀孕的受试对象的胎儿中的21三体,第二遗传变异选自由所述怀孕的受试对象的胎儿中的13三体、18三体、x非整倍性和y非整倍性组成的组。在另一方面,一些实施方式的方法可以检测至少三种遗传变异。在一些实施方式中,本文所述的方法还包括使第六探针组与遗传样品接触,其中第六探针组包含第六标记探针和第六标签探针。所述方法还可以包括使第六探针组的至少一部分与遗传样品的核苷酸分子中的第四目标核酸区杂交,其中所述第四目标核酸区不同于第一目标核酸区、第二目标核酸区和第三目标核酸区。所述方法还可以包括至少通过连接第六标记探针和第六标签探针而连接第六探针组。所述方法还可以包括扩增经连接的探针组。所述方法还可以包括将各标签探针固定在基板上的预定位置,其中连接至经固定的标签探针的第六标记探针和/或其经扩增的标记探针包含第六标记,所述第六标记不同于第一标记和第二标记,经固定的标记是光学上能够解析的,经固定的第六标签探针和/或其经扩增的标签探针包含第六标签,并且固定步骤通过将标签固定至预定位置来进行。所述方法还可以包括对固定至基板的第六标记的第四数量进行计数,并比较第四数量与第一、第二和/或第三数量以确定遗传样品中的第三遗传变异。在另一方面,一些实施方式的方法可以检测至少四种遗传变异。在一些实施方式中,本文所述的方法还包括使第七探针组与遗传样品接触,其中第七探针组包含第七标记探针和第七标签探针。所述方法还可以包括使第七探针组的至少一部分与遗传样品的核苷酸分子中的第五目标核酸区杂交,其中所述第五目标核酸区不同于第一目标核酸区、第二目标核酸区、第三目标核酸区和第四目标核酸区。所述方法还可以包括至少通过连接第七标记探针和第七标签探针而连接第七探针组。所述方法还可以包括可选地扩增经连接的探针组。所述方法还可以包括将各标签探针固定在基板上的预定位置,其中连接至经固定的标签探针的第七标记探针和/或其经扩增的标记探针包含第七标记,所述第七标记不同于第一标记和第二标记,经固定的标记是光学上能够解析的,经固定的第七标签探针和/或其经扩增的标签探针包含第七标签,并且固定步骤通过将标签固定至预定位置来进行。所述方法还可以包括对固定至基板的第七标记的第五数量进行计数,并比较第五数量与第一、第二、第三和/或第四数量以确定遗传样品中的第四遗传变异。在另一方面,一些实施方式的方法可以检测至少五种遗传变异。在一些实施方式中,本文所述的方法还包括使第八探针组与遗传样品接触,其中第八探针组包含第八标记探针和第八标签探针。所述方法还可以包括使第八探针组的至少一部分与遗传样品的核苷酸分子中的第六目标核酸区杂交,其中所述第六目标核酸区不同于第一目标核酸区、第二目标核酸区、第三目标核酸区、第四目标核酸区和第五目标核酸区。所述方法还可以包括至少通过连接第八标记探针和第八标签探针而连接第八探针组。所述方法还可以包括扩增经连接的探针组。所述方法还可以包括将各标签探针固定在基板上的预定位置,其中连接至经固定的标签探针的第八标记探针和/或其经扩增的标记探针包含第八标记,所述第八标记不同于第一标记和第二标记,经固定的标记是光学上能够解析的,经固定的第八标签探针和/或其经扩增的标签探针包含第八标签,并且固定步骤通过将标签固定至预定位置来进行。所述方法还可以包括对固定至基板的第八标记的第六数量进行计数,并比较第六数量与第一、第二、第三、第四和/或第五数量以确定遗传样品中的第五遗传变异。在一些实施方式中,受试对象是怀孕的受试对象,并且第一遗传变异、第二遗传变异、第三遗传变异、第四遗传变异和第五遗传变异是所述怀孕的受试对象的胎儿中的13三体、18三体、21三体、非整倍性x和非整倍性y。在另一方面,受试对象是怀孕的受试对象,遗传变异是所述怀孕的受试对象的胎儿中的21三体,第一目标核酸区位于染色体21中,第二目标核酸区不位于染色体21中。在另一方面,受试对象是怀孕的受试对象,遗传变异是所述怀孕的受试对象的胎儿中的21三体,第一目标核酸区位于染色体21中,第二目标核酸区位于染色体18中。在一个方面,本文的探针组可以包含2、3、4、5个以上的标记探针,和/或2、3、4、5个以上的标记。在一些实施方式中,本文所述的方法还包括:第一探针组和第二探针组还分别包含第三标记探针和第四标记探针;经固定的第一探针组和/或经扩增的第一探针组还包括在第三标记探针和/或其经扩增的产物中的第九标记;并且经固定的第二探针组和/或经扩增的第二探针组还包括在第四标记探针和/或其经扩增的产物中的第十标记。在这些实施方式中,如果第九标记和第十标记与第一标记和第二标记不同,则该方法可用于确认针对第一标记和第二标记计数的数量。如果第九标记和第十标记分别与第一标记和第二标记相同,则该方法可用于提高固定至各目标核酸区的检测标记的准确度。例如,使用多个标记会比使用一个标记更亮,因此多个标记可以比一个标记更容易检测。此外,标记的数量可以用于定量一个或多个分子。更多的标记给出更亮的信号。多个标记的优点是来自多个标记的累积信号通常比单个标记更容易检测。这允许更高通量的扫描、更厚的基板、更低的放大倍率成像、更短的曝光时间和其它性质。在一些实施方式中,本文所述的探针可以包含加标记部分。在另外的实施方式中,可以设计一系列核苷酸以在pcr反应或其他扩增过程期间在加标记部分中引入经标记的核苷酸。探针的加标记部分可以包含2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个相同的核苷酸(“a”,“c”,“t”或“g”)。例如,可以将一串相同核苷酸(例如“tttttttttttt”)添加到探针,如图87所示。当扩增发生时,将沿着“t”串长度引入经标记的互补碱基(在这种情况下为“a”)。这提供了带有许多引入的标记的分子区域。当标记(例如荧光染料)紧密地堆积在一起时,它们可能彼此猝灭。为了避免这种情况,可以改变经标记的互补碱基的相对浓度。在上述实例中,经标记的“a”的比例可以是100%或50%或10%或1%或<1%,其余部分是未标记的。这样,并非所有的“t”都具有标记,因此降低了标记紧密接近的机会,从而降低了猝灭的机会。例如,经标记的“a”也可以引入探针的其他部分,包括同源区。探针的其他部分可以设计成具有最小或减少数量的互补核苷酸,或者在极端情况下,没有互补核苷酸,以减少同源区域中的标记。这同样可以适用于任何核苷酸(“a”、“c”、“t”、“g”)或适用于可以在扩增、复制或延伸反应期间引入的其他结构或序列。可以使用更复杂的标记结构,而不仅限于单个碱基。它们可以是任何数量的核苷酸以任何顺序的混合。经标记的与未标记的核苷酸的比例也可以在不同的碱基之间变化。标记可以不同或相同。在另外的实施方式中,(i)经固定的第一探针组和/或经扩增的第一探针组还包括在标记探针中的第十一标记,和(ii)经固定第二探针组和/或经扩增的第二探针组还包括在标记探针中的与第十一标记不同的第十二标记。在其它实施方式中,其中第一标记、第二标记、第十一标记和第十二标记彼此不同,并且计数步骤还包括对固定在基板上的第十一标记和第十二标记的数量进行计数。在另一方面,本文所述的方法还可以用对照样品来进行。在一些实施方式中,所述方法还可以包括用与来自受试对象的遗传样品不同的对照样品重复所述步骤。所述方法还可以包括对固定至基板的标记的对照数量进行计数,并比较所述对照数量与第一、第二、第三、第四、第五和/或第六数量以确定遗传样品中的遗传变异。在另一方面,受试对象可以是怀孕的受试对象,且遗传变异是所述怀孕的受试对象的胎儿中的遗传变异。在此类实施方式中,所述方法可以使用单核苷酸多态性(snp)位点来确定所述胎儿材料(例如胎儿组分)的比例(例如浓度和基于样品中核苷酸分子的数量的数量百分比)是否足以使胎儿的遗传变异可以在来自怀孕受试对象的样品中以合理的统计学显著性被检测出。在另外的实施方式中,所述方法还可以包括使母体探针组和父体探针组与遗传样品接触,其中母体探针组包含母体标记探针和母体标签探针,父体探针组包含父体标记探针和父体标签探针。所述方法还可以包括使母体探针组和父体探针组各自的至少一部分与遗传样品的核苷酸分子中的目标核酸区杂交,所述目标核酸区包含预定的snp位点,其中母体探针组的至少一部分与位于所述snp位点处的第一等位基因杂交,父体探针组的至少一部分与位于所述snp位点处的第二等位基因杂交,并且所述第一和第二等位基因彼此不同。所述方法还可以包括至少通过连接(i)母体标记探针和母体标签探针和(ii)父体标记探针和父体标签探针来连接母体探针组和父体探针组。所述方法还可以包括扩增经连接的探针。所述方法还可以包括将标签探针固定在基板上的预定位置,其中连接至经固定的标签探针的母体和父体标记探针和/或其经扩增的标记探针分别包含母体标记和父体标记;所述母体标记和父体标记是不同的,并且经固定的标记是光学上能够解析的。所述方法还可以包括对母体和父体标记的数量进行计数,并确定遗传样品中的胎儿材料的比例是否足以基于所述母体和父体标记的数量来检测所述胎儿中的遗传变异。所述方法还可以包括确定遗传样品中胎儿材料的比例。在另一方面,肿瘤组分与本文所述的胎儿材料或胎儿组分类似。肿瘤组分可以是来自肿瘤的材料的比例的量度,其方式类似于用胎儿组分来度量来自胎儿和/或胎盘的材料的比例。通常,当癌症处于早期(例如ii期或更早期)时,肿瘤组分<1%。在一些实施方式中,当受试对象是怀孕的受试对象且遗传变异是所述怀孕的受试对象的胎儿中的遗传变异时,所述方法还可以包括:使具有等位基因特异性的等位基因a探针组和等位基因b探针组与遗传样品接触,其中等位基因a探针组包含等位基因a标记探针和等位基因a标签探针,等位基因b探针组包含等位基因b标记探针和等位基因b标签探针。所述方法还可以包括使等位基因a探针组和等位基因b探针组各自的至少一部分与遗传样品的核苷酸分子中的目标核酸区杂交,所述目标核酸区包含预定的单核苷酸多态性(snp)位点,在所述snp位点处母体等位基因图谱(即基因型)与胎儿等位基因图谱不同(例如,母体等位基因组成可以是aa,而胎儿等位基因组成可以是ab或bb。在另一实例中,母体等位基因组成可以是ab,而胎儿等位基因组成可以是aa或bb),其中等位基因a探针组的所述至少一部分与位于所述snp位点处的第一等位基因杂交,等位基因b探针组的所述至少一部分与位于所述snp位点处的第二等位基因杂交,并且所述第一等位基因和第二等位基因彼此不同。所述方法还可以包括至少通过连接(i)等位基因a标记探针和标签探针和(ii)等位基因b标记探针和标签探针来连接等位基因a探针组和等位基因b探针组。所述方法还可以包括扩增经连接的探针组。所述方法还可以包括将标签探针固定在基板的预定位置上,其中连接至经固定的标签探针的等位基因a和等位基因b标记探针和/或其经扩增的标记探针分别包含等位基因a标记和等位基因b标记,所述等位基因a标记和等位基因b不同,并且经固定的标记是光学上能够解析的。所述方法还可以包括对等位基因a标记和等位基因b标记的数量进行计数,并确定遗传样品中的胎儿材料的比例是否足以基于等位基因a标记和等位基因b标记的数量来检测所述胎儿中的遗传变异。所述方法还可以包括确定遗传样品中胎儿材料的比例。在一些实施方式中,当受试对象是怀孕的受试对象、遗传变异是所述怀孕的受试对象的胎儿中的遗传变异且遗传样品包含y染色体时,所述方法还可以包括使母体探针组和父体探针组与所述遗传样品接触,其中母体探针组包含母体标记探针和母体标签探针,父体探针组包含父体标记探针和父体标签探针。所述方法还可以包括使母体探针组和父体探针组的至少一部分分别与遗传样品的核苷酸分子中的母体和父体目标核酸区杂交,其中父体目标核酸区位于所述y染色体中,母体目标核酸区不位于所述y染色体中。所述方法还可以包括至少通过连接(i)母体标记探针和标签探针和(ii)父体标记探针和标签探针来连接母体探针组和父体探针组。所述方法还可以包括扩增经连接的探针组。所述方法还可以包括包含预定的单核苷酸多态性(snp)位点的目标核酸区,该位点含有多于一个snp,例如两个或三个snp。此外,snp位点可以含有具有高连锁不平衡的snp,从而将标记探针和标签探针构造成相对于仅一个snp匹配或错配具有改善的多个snp匹配或错配的能量学的优势。所述方法还可以包括将标签探针固定在基板的预定位置上,其中连接至经固定的标签探针的母体和父体标记探针和/或其经扩增的标记探针分别包含母体标记和父体标记,所述母体标记和父体标记不同,并且经固定的标记是光学上能够解析的。所述方法还可以包括对母体标记和父体标记的数量进行计数,并确定遗传样品中的胎儿材料的比例是否足以基于母体标记和父体标记的数量来检测所述胎儿中的遗传变异。所述方法还可以包括确定遗传样品中的胎儿材料的比例。在另外的实施方式中,可以使用其它遗传变异(例如单碱基缺失、微卫星和小插入)来代替本文所述的snp位点处的遗传变异。在一方面,本文所述的探针组可以包含三个以上探针,包括位于标记探针和标签探针之间的至少一个探针。在一些实施方式中,第一探针组和第二探针组还分别包含第一空位探针和第二空位探针,第一空位探针与第一标记探针和第一标签探针所杂交的区域之间的区域杂交,第二空位探针与第二标记探针和第二标签探针所杂交的区域之间的区域杂交。所述方法还可以包括连接步骤,所述连接步骤包括连接至少(i)第一标记探针、第一标签探针和第一空位探针以及(ii)第二标记探针、第二标签探针和第二空位探针。在另外的实施方式中,空位探针可以包含标记。例如,将第一和第二空位探针和/或其扩增产物用标记(例如第十三和第十四标记)标记,并且这些标记各自可以与其余的标记(例如第一标记和第二标记)不同。空位探针中的标记(例如第十三和第十四标记)可以彼此相同或不同。在另一方面,第一标记探针和第二标记探针分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交;第一标签探针和第二标签探针分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交;第一和第二空位探针分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交。在一些实施方式中,在第一标记探针和标签探针所杂交的区域之间,存在0~100个核苷酸,1~100个核苷酸,2~50个核苷酸,3~30个核苷酸,0、1、2、3、4、5、6、7、8、9、10、20、30、40、50、100、150或200个以上核苷酸,或者1、2、3、4、5、6、7、8、9、10、15、25、35、45、55、110、160或300个以下核苷酸;在第二标记探针和标签探针所杂交的区域之间,存在0~100个核苷酸,1~100个核苷酸,2~50个核苷酸,3~30个核苷酸,0、1、2、3、4、5、6、7、8、9、10、20、30、40、50、100、150或200个以上核苷酸;或者1、2、3、4、5、6、7、8、9、10、15、25、35、45、55、110、160或300个以下核苷酸。在另外的实施方式中,位于标记探针和标签探针之间的空位探针的长度可以为0~100个核苷酸,1~100个核苷酸,2~50个核苷酸,3~30个核苷酸,0、1、2、3、4、5、6、7、8、9、10、20、30、40、50、100、150或200个以上核苷酸;或者1、2、3、4、5、6、7、8、9、10、15、25、35、45、55、110、160或300个以下核苷酸。在另一方面,本文所述的探针组可以包含与标记探针和标签探针连接和/或缀合的间隔物。所述间隔物可以包含或不包含寡核苷酸。间隔物可以包含分离的、纯化的、天然存在的或非天然存在的材料,包括任何长度的寡核苷酸(例如5、10、20、30、40、50、100或150个核苷酸以下)。在一些实施方式中,探针可以是纯化的限制性消化物形式,或通过合成、重组或pcr扩增来产生。例如,第一标记探针和标签探针通过第一间隔物缀合,第二标记探针和标签探针通过第二间隔物缀合,所述第一和第二间隔物不与遗传样品的核苷酸分子杂交。在一些实施方式中,所述方法还包括用酶消化经杂交的遗传样品,并在消化之后使第一和第二间隔物中的键断裂。在另一方面,本文所述的方法不包括鉴定遗传样品的核苷酸分子中的序列和/或对目标核酸区和/或探针进行测序。在一些实施方式中,不包括对探针进行测序的方法包括不对标签探针中的条码和/或亲和标签进行测序。在另外的实施方式中,用于检测不同的遗传变异、目标核苷酸区和/或目标肽的经固定的探针组不需要单独检测或扫描,因为在此处描述的方法中不需要测序。在另外的实施方式中,固定至基板的不同标记的数量同时计数(例如通过单次扫描和/或成像),因此不同标记的数量不单独计数。在另一方面,本文所述的方法不包括整体阵列读取或模拟(analog)定量。本文所述的整体阵列读取是指测量来自单一类型的多个标记的累积合并信号的单次测量,其可选地与来自第二类型的多个标记的累积合并信号第二测量组合,而无需解析来自每个标记的信号。从一个以上此类测量(其中未解析单个的标记)的组合得出结果。在另一方面,本文所述的方法可以包括测量相同的标记、相同类型的不同标记和/或相同类型的标记的单次测量,其中未解析单个的标记。本文所述的方法可以不包括模拟定量,而是可以使用数码定量,其中仅确定标记的数量(通过测量个体标记的强度和形状来确定)而不是标记的累积或合并的光学强度。在另一方面,本文所述探针组可以包含结合剂。结合剂是与本文所述的标签或亲和标签相同的材料。在一些实施方式中,所述方法还包括在连接步骤之前或之后将结合剂固定至固相。所述方法还可以包括在连接步骤之后从未连接的探针中分离出经连接的探针组。在另外的实施方式在,结合剂包括生物素,所述固相包含磁珠。在一些实施方式中,利用相同或不同的结合机制的结合剂、标签、亲和标签或捕获探针在固相上在所有维度上至少以检测标记所用的波长分隔开,或以下述距离分隔开:约1至1000nm,5至100nm,500至5000nm,600至2000nm,700至3000nm,或10至100nm;约1、5、10、20、30、50、100、150、200、250、300、350、400、500、600、700、800、900、1000、5000、10000、20000或50000nm以上;和/或约50、100、150、200、250、300、350、400、500、600、700、800、900、1000、1500、2000、2500、3000、3500、4000、5000、10000、20000或50000nm以下。例如,基板上的至少一个元件中的结合剂、标签或亲和标签的至少一部分、至少10%、20%、30%、40%、50%、60%、70%、80%、90%、95%、96%、97%、98%或99%与所述至少一个元件中的利用相同结合机制的相邻的结合剂、标签或亲和标签相距的距离为:从约10、30、50、100、200、250、300、500、600、700、800、900或1000nm至600、700、800、1000、1500、2000、3000、4000、5000、10000、20000、50000或100000nm。在一个方面,该方法可以包括修饰来自本文所述的基因组样品的核苷酸分子以包含本文所述的结合剂,并且本文所述的方法可以进一步包括在将核苷酸分子杂交至两个以上探针或探针组之前或之后以及在连接步骤之前或之后将结合剂固定至固相,例如如图82所示。该方法可以进一步包括将未杂交的探针或探针组与杂交至核苷酸分子的探针或探针组分离。该方法还可以包括在分离之前或之后连接探针或探针组。在另一方面,本文所述的计数步骤还可以包括校正、验证和/或确认所计数的数量。此处所述的校正是指检查和/或调整所计数的数量的准确度。此处所述的验证和确认是指确定所计数的数量是否准确,和/或如果存在误差,误差是多少。在另一方面,本文的验证和确认还可以指确定所计数的数量是否是来自目标遗传样品的准确数值。如本文所述,遗传样品可以是两种不同的遗传样品的混合物。例如,遗传样品可以是母体和胎儿dna的混合物。在肿瘤学筛查中,样品可以是癌症患者的种系dna和肿瘤dna的混合物。在移植筛选中,样品可以是受体dna和移植器官dna的混合物。测试可以寻找两个样品之间的dna差异。在某些情况下,如果一份样品偶然具有模拟在另一样品中所要测试的变化的dna变化,则可能会出现假阳性或假阴性测试结果。例如,唐氏综合征的产前测试寻找21号染色体的扩增。如果母亲具有21号染色体的部分或全部的扩增,那将模糊对胎儿中的扩增的鉴定。在该情况下,母亲种系dna中21号染色体的微量扩增可能足够小,以至于母亲不会表现出被测试的表型(或任何其他特定表型),但可能导致假阳性。当母亲的dna占据样品的大部分时(即当胎儿组分较低时),例如包括超过50%、80%、90%、95%、96%、97%、98%或99%的遗传样品时,尤其如此。在这种情况下,甚至母亲21号染色体的一个小区域的扩增都可能显著改变21号染色体的计数数量,从而可能导致假阳性检测结果,其中在胎儿中错误地检测到三体性,而实际上胎儿是二倍体。检测这种效应的一种示例性方法是将探针划分成在染色体上相对靠近在一起的组,如图88所示。例如,探针可以分成组,每组代表整个染色体或目标区域中的非重叠子集。例如,染色体可以分成多个100、50、40、30、20、10、5或3mb的区域,并且在每个区域内选择探针组。然后可以将这些探针组固定到基板的不同区域,例如,单分子阵列。固定可以以本文所述的许多方式进行,例如,包括使用代表每组探针的dna标签(并且常常还代表第二对照探针组)。与可以将测序读出结果指定至染色体区域的dna测序不同,在本文所述的发明中,在使用单分子阵列进行读取时可以不区分探针,因为它们将具有相同的标记。因此,可以在分析样品之前选择探针以形成组。特别而言,使来自每个组的探针与不用于其他组的标签(用于固定)相关联是有利的。这意味着给定标签仅代表靶区域中的一个组或子集。以这种方式,标签测量靶区域的特定子区域中的遗传变体(例如,包括拷贝数变体)。在21号染色体的情况下,标签会与来自21号染色体的子区域的探针相关联,并且将报告该区域的拷贝数差异。在一个实施方式中,对照区用于针对该21号染色体子区域进行比较。为了检测胎儿三体性,可以汇集所有子区域以提供最大的统计能力。然而,分别分析每个子区域可以检测和识别假阳性,用作品质控制步骤。如果胎儿对于21号染色体是三体性的,则与对照(例如,对照染色体)相比,会预期21号染色体的每个子区域平均显示出该区域的计数数量的成比例的相同增加。如果大多数子区域报告胎儿是正常的(即不是三体性的),但子区域的子集显示出三体性的证据,这可能是由于一个或多个母体微量扩增。因此,本文所述的方法包括:在使用单分子计数方法检测遗传变异时检测假阳性。该方法可以应用于基因组中的任何区域或靶标或任何类型的遗传变异。与dna测序不同,本文所述的发明有意地将探针组与标签组相关联,使得针对给定标签的全部或大部分探针都来自预定的子区域。在另一个实施方式中,有意地将探针组与基因组的特定区域相关联。在另一方面,使用强度和/或信噪比作为鉴定单一标记的方法。当染料分子或其它光学标记紧密相邻时,它们常常不可能用基于荧光的成像区分开,这是因为光散射的固有限制。即,接近在一起的两个标记将不能区分,因为它们之间无可见的空隙。用于确定给定位置的标记数量的一个示例性方法是检查相对于已知具有单一荧光的位置的相对信号和/或信噪比。两个以上标记会通常发射比单一荧光更亮的信号(和一种能够更清楚地与背景区分的信号)。图2显示了由单一标记样品和多标记抗体(都是alexa546;通过漂白特性验证)测得的信号强度的归一化柱状图。两种群体是能够清楚地分开的,并且多个标记可以清楚地与单一标记区分开。在另一方面,使用能量、相对信号、信噪比、焦点、锐度、尺寸、形状和/或其它性质来作为将单个标记与模仿标记或与标记相似的颗粒、点状、离散或粒状背景或其它背景信号或假信号区分开的方法。这些假信号可以由颗粒物引起,例如未标记的分子、不同标记的分子、其它染料的渗出、无机或有机颗粒材料和/或随机效应,例如噪音、散粒噪音或其它因素。用于在给定位置将标记与颗粒、点状、离散或粒状背景区分开的一些示例性方法是检查基板上的推定标记的能量、相对信号、信噪比、焦点、锐度、尺寸或形状。标记通常会比颗粒、点状、离散或粒状背景发出更亮(或更暗)的信号。例如,图81显示了来自图像的经计数的推定标记的示例性信噪比(snr)分布。该实例中的标记是荧光染料(cy5)。第一个峰(左)是背景颗粒,第二个峰(右)是实际标记。snr可用于区分、确定或加权观察值,并将其分类为背景和标记。在一些实施方式中,计数步骤可以包括测量来自经固定的标记的光学信号,并通过将来自单一标记的光学信号与来自背景和/或多个标记的其余光学信号区分开来校正所计数的数量。在一些实施方式中,所述区分包括计算所述光学信号与来自单一标记的光学信号强度相比的相对信号和/或信噪比强度。所述区分还可以包括确定所述光学信号是否来自单一标记。在另外的实施方式中,如果光学信号的相对信号和/或信噪比强度与来自单一标记的光学信号强度相差预定的量以下,则所述光学信号来自单一标记。在其它实施方式中,所述预定的量为来自单一标记的光学信号强度的0%~100%,0%~150%,10%~200%,0、1、2、3、4、5、10、20、30或40%以上,和/或300、200、100、50、30、10或5%以下。在另一方面,不同的标记可以具有不同的闪光(blinking)和漂白性质。它们还可以具有不同的激发性质。为了比较用于两种不同的标记的染料分子的数量,需要确保这两种染料以相似的方式作用,并且具有相似的发射特性。例如,如果一种染料比另一种暗淡的多,在该通道中分子的数量可能少计。可以逐步增加数种因素以给出染料之间的最优等价性(equivalence)。例如,计数步骤和/或校正步骤可以包括:优化(i)用于激发标记的光源的功率、(ii)光源的类型、(iii)标记的曝光时间和/或(iv)使标记与来自标记的光学信号匹配的滤光器组,并测量来自标记的光学信号。这些因素可以单独地或组合地而变化。另外,所优化的度量可以不同。例如,其可以是整体强度、信噪比、最小背景、强度的最低方差或任何其它特征。漂白特性是标记特异性的,并且可以用于添加用于区分标记类型的信息。图3显示了来自不同标记的平均漂白特性。该图显示了每种标记类型的归一化计数作为以60秒间隔收集的连续图像的函数。符号c1是cy3荧光剂,符号c2是atto647荧光剂,符号c3是alexa488荧光剂。在另一方面,闪光行为可用作鉴定单一标记的方法。已知许多染料分子暂时地进入暗状态(例如burnette等.,proc.natl.acad.sci.usa(2011)108:21081–21086)。这产生闪光效应,其中标记会经历一个或多个亮-暗-亮步骤。这些暗周期的长度和数量可以变化。本发明使用该闪光行为来将在衍射受限的成像中可能看上去类似的一种标记与两种以上标记区分开。如果存在多种标记,在闪光期间信号完全消失是不太可能的。更可能的是强度会降低,因为一种标记变暗,但是其它不变暗。所有标记同时闪光的概率(并因此看起来像单一荧光剂)可以基于染料的特定闪光特性来计算。在一些实施方式中,来自标记的光学信号在至少两个时间点测量,并且如果光学信号的强度通过单阶梯函数(singlestepfunction)减少,则该光学信号来自单一标记。在一些实施方式中,这两个时间点可以间隔0.1分钟~30分钟,1秒~20分钟,10秒~10分钟;0.01、0.1、1、2、3、4、5、10、20、30、40、50、60秒以上;和/或1、2、3、4、5、10、20、30、40、50、60秒以下。在另外的实施方式中,来自单一标记的光学信号的强度随时间具有单阶梯降低,来自两个以上标记的光学信号的强度随时间具有多阶梯降低。在其它实施方式中,来自标记的光学信号在至少两个时间点测量,并且被归一化至标记的漂白特性。在另一方面,本文所述的方法和/或计数步骤还可以包括在至少两个时间点测量来自对照标记的光学信号,并且将来自对照标记的光学信号与来自所述标记的光学信号比较,以确定来自所述标记的光学信号的增加或减少。在另一方面,计数步骤还包括通过使用对照分子来确认所述计数。可以使用对照分子来确定分子类型的频率变化。实验目标经常在于确定两种以上类型的分子的丰度,所述丰度为绝对值或相对于彼此的。考虑用两种不同的染料标记的两种分子的实例。如果无效假设是它们为相等频率,则可以在单分子阵列上对它们进行计量,并且可以将计数比率与无效假设进行比较。本文的“单分子阵列”的定义为被构造成检测单个分子的阵列,包括例如美国专利申请公开第2013/0172216号中所述的阵列。如果比率从1:1起开始变化,这暗示了这两种分子为不同频率。但是,据推测可能并不清楚是否一个具有增加的丰度或者另一个具有减少的丰度。如果使用第三染料作为也应该处于相同频率的对照分子,其应该与其它两种染料具有1:1的比率。考虑到用染料a和b标记的两种分子的实例,目标在于查明用染料b标记的分子与用染料a标记的分子相比频率增加还是降低。在实验中包括用染料c标记的第三分子,且应当使其与其它两种分子处于相同的丰度。如果分别标记有a和b的分子之比是1:2,则第一分子具有降低的频率,或者第二分子具有增加的频率。如果标记有a和c的分子之比是1:1,并且标记有b和c的分子之比是1:2,则很可能用染料b标记的分子与用染料a标记的分子相比频率增加。这种情况的实例会出现在确定二倍体基因组中的dna拷贝数变化时。重要的是知道一条序列是否被扩增或者另一条是否缺失,且使用对照分子可实现这种确定。注意对照可以是基因组的另一区域或人工对照序列。在一些实施方式中,本文所述的方法的结果(例如标记的计数数量)可以通过使用不同的标记但使用与起始方法中所用的相同标签来确认。此类确认可以与起始方法同时进行,或者在进行起始方法之后进行。在另外的实施方式中,此处所述的确认包括使第一和第二对照探针组与遗传样品接触,其中第一对照探针组包含第一对照标记探针和第一标签探针(其与本文所述的第一探针组的标签相同),第二对照探针组包含第二对照标记探针和第二标签探针(其与本文所述的第二探针组的标签相同)。所述确认还可以包括使第一和第二对照探针组的至少一部分分别与遗传样品的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交。所述确认还可以包括至少通过连接第一对照标记探针和第一标签探针来连接第一对照探针组。所述确认还可以包括至少通过连接第二对照标记探针和第二标签探针来连接第二对照探针组。所述确认还可以包括扩增所连接的探针组。所述确认还可以包括:将各标签探针固定在基板上的预定位置,其中连接至经固定的标签探针的第一和第二对照标记探针和/或其经扩增的标记探针分别包含第一和第二对照标记,所述第一和第二对照标记是不同的,并且经固定的标记是光学上能够解析的。所述确认还可以包括:测量来自固定至基板的对照标记的光学信号。所述确认还可以包括:将来自经固定的第一对照标记和第二对照标记的光学信号与来自经固定的第一标记和第二标记的光学信号进行比较,以确定是否存在基于标记的误差。本文所用的“基于标记的误差”是指由标记引起的任何误差,如果在所述方法中使用不同标记,其可能不会出现。在一些实施方式中,第一标记和第二对照标记是相同的,第二标记和第一对照标记是相同的。漂白可以用作鉴定单一标记的方法。读取的关键因素在于个体标记是“能够解析的”,即独特的。这在表面密度低时是无关紧要的,此时紧密相邻的标记的可能性非常低。对于较高的密度,假设标记位于随机位置(即泊松分布),紧密相邻的机会增加至以下程度:显著数量的标记自身的荧光发射与其相邻标记的发射部分(或全部)重叠。此时,标记不再是“能够解析的”,并且处于过渡方案,其介于单一标记检测(即数码检测)和测量来自许多分子的平均信号的经典的多标记阵列型检测(例如模拟检测)之间。换言之,个体分子的数码计数方案切换至来自许多分子的平均荧光强度的模拟方案。增加加载范围同时保持个体解析性的一个方案是利用荧光团漂白。长期暴露至光可以引起标记漂白,即,失去其荧光性质。换言之,随着时间流逝,标记可能熄灭。这通常作为阶梯函数出现,标记看上去发生“关闭”。本发明可以使用该漂白行为来将在衍射受限的成像中可能看上去类似的一种标记与两种以上标记区分开。对于多种标记,通过信号强度的一系列的逐步降低,预期会发生消光。例如,图4~13显示了累积标记强度相对于时间(显示了随着强度变化的漂白事件)的图,其用各种alexa488标记获得。可以容易地区分单个标记物质与多个标记物质(例如根据光学信号强度是否如图中所示以单阶和多阶减少)。在另一方面,本文所述的方法可以包括通过标记对换或染料对换来校正和/或确认所计数的数量。在分别用标记1和2标记探针产物1和2的一些实施方式时,各种误差模式可以模仿探针产物的差异性频率。例如,如果观察到标记1和标记2的比例为1:2,这可能归因于频率的真实差异(探针产物2是探针产物1的2倍)、杂交效率的差异(探针产物为相同的丰度,但是探针产物2比探针产物1更高效地杂交)或标记的性质差异(例如,如果标记是荧光染料,标记1可能比标记2更快地漂白、更频繁地闪光、给出较低的信号或较低的信噪比)。如果用调换的标记重复相同的实验,所述比例应当反转,如果其是分子的不同频率的真实观察结果的话,此时标记1是标记2的2倍。但是,如果这归因于差异性的杂交效率,则所述比例会是≤2:1。如果1:2的比例归因于标记的性质,则所述比例会变成标记1:标记2为2:1,如果它们确实为相同的频率的话。该方法可以扩展到任何数量的经标记的探针组。在一些实施方式中,第一目标核酸区位于第一染色体中,第二目标核酸区位于与第一染色体不同的第二染色体中。计数步骤还可以包括确认所述计数,其中所述确认步骤包括使第一和第二对照探针组与遗传样品接触,其中第一对照探针组包含第一对照标记探针和第一对照标签探针,第二对照探针组包含第二对照标记探针和第二对照标签探针。所述确认步骤还可以包括将第一和第二对照探针组的至少一部分分别与位于第一和第二染色体中的第一和第二对照区杂交,其中第一和第二对照区与所述第一和第二目标核酸区不同。该确认步骤还可以包括至少通过连接(i)第一对照标记和标签探针和(ii)第二对照标记和标签探针来连接第一和第二对照探针组。所述确认步骤还可以包括扩增所连接的探针组。所述确认步骤还可以包括将(i)第一探针组和第二对照探针组固定至第一预定位置,和(ii)将第二探针组和第一对照探针组固定至第二预定位置。在一些实施方式中,连接至经固定的标签探针的第一和第二对照标记探针和/或其经扩增的标记探针分别包含第一和第二对照标记,所述第一标记和第二对照标记是不同的,所述第二标记和第一对照标记是不同的,经固定的标记是光学上能够解析的,经固定的第一和第二对照标签探针和/或其经扩增标签探针分别包含第一和第二对照标签,所述固定步骤通过将标签固定至预定的位置来进行。所述确认步骤还可以包括:测量来自固定至基板的对照标记的光学信号。所述确认步骤还可以包括:将来自固定的对照标记的光学信号与来自固定的第一标记和第二标记的光学信号进行比较,以确定是否存在基于目标核酸区的误差。在其它实施方式中,第一标签和第二对照标签是相同的,第二标签和第一对照标签是相同的。在另一方面,本文所述的方法的计数步骤还可以包括通过下述方式来校正和/或确认所计数的数量:(i)用被构造成与相同的目标核苷酸和/或肽区域或相同目标基因组中的不同区域结合和/或杂交的不同的探针组来重复本文所述的方法的一些或全部步骤(例如包括接触、结合、杂交、连接、扩增和/或固定的步骤),和(ii)将已结合和/或杂交于相同的目标核苷酸和/或肽区域或相同目标基因组的探针组中的标记的计数数量取平均值。在一些实施方式中,取平均值的步骤可以在比较步骤之前进行,由此比较的是与相同的目标核苷酸和/或肽区域结合和/或杂交的不同探针组的组中的标记的平均计数数量,而不是单个探针组中的标记的计数数量。在另一方面,本文所述的方法还可以包括通过下述方式来校正和/或确认对遗传变异的检测:(i)用被构造成与没有任何已知遗传变异的对照区域结合和/或杂交的不同探针组来重复本文所述的方法的一些或全部步骤(例如包括接触、结合、杂交、连接、扩增、固定和/或计数的步骤),和(ii)将已与对照区域结合和/或杂交的探针组中的标记的计数数量取平均值。在一些实施方式中,将与对照区域结合和/或杂交的探针组中的标记的平均数量与结合和/或杂交于本文所述的目标区域的探针组中的标记的数量进行比较,以确认遗传样品中的遗传变异。在另一方面,校正和/或确认的步骤可以与起始步骤同时重复,或者在进行起始步骤之后再重复。在另一方面,来自一个或多个群体的标记(例如荧光染料)可以基于其潜在的光谱特性来测量和/或鉴定。大多数荧光成像系统包括在多个光谱通道中收集图像的选项,这由光源和光谱激发/发射/二向色性滤光器的组合来控制。这能够允许用多个不同输入光色带来查询给定样品上的相同荧光物质,并捕获所需的输出光色带。在正常操作下,荧光团的激发通过用与该物质的最大吸收一致的窄光谱带(例如用宽带led或弧光灯以及激发滤光器来在光谱上将输出光定形,或者用光谱上均匀的激光)进行照射而实现,并且用匹配的发射滤光器和长通二向色性滤光器来收集来自荧光团的大多数发射,以区分激发和发射(图14)。在替代性操作中,荧光部分的独特身份可以通过用各种激发颜色进行查询并通过与标准操作情况不同(或标准操作情况以外)的所收集的发射带来确认(图15)。收集来自这些各种成像构造(例如各种发射滤光器)的光,并将其与目标荧光团的校正值比较(图16)。在实施例情况下,实验测量结果(点)与该荧光团的预期的校正/参照数据(三角形)匹配,但是与替代假设(正方形)符合不佳。在给定一个或多个通道的测试和校正数据的情况下,可以以自动化且稳健的方式针对各假设校正光谱计算出拟合优度或卡方,并选择最佳拟合。各种参照可以是可关注的,包括在系统中使用的荧光团,以及常见荧光污染物,例如具有单调发射谱(污染物1;三角形)或蓝色权重谱(污染物2;星形)的那些(图17)。针对滤光器选择的设计限制可以与标准设计不同,对于标准设计,目标仅仅是将单通道中所收集的光最大化,同时避免来自其它通道的显著贡献。在我们的发明中,目标是光谱选择性而不仅仅是光的收集。例如,考虑具有显著不同的激发带的两种荧光团,如图18所示(注意,仅显示激发区域而未显示激发光谱)。标准设计可以使对荧光剂1发射的捕获(用em1滤光器,实线)最大化,并且使对来自荧光剂2前沿的捕捉最小化,并且荧光剂2会可选地被em2(其是稍微红移的,以避免荧光剂1光的显著收集)捕获。在我们的设计中,需要用em1滤光器验证荧光剂2的存在,这使待捕获的带变宽(“em1+”,细虚线)。这产生了额外信息来验证荧光剂2的身份。类似地,em2可以变宽或者向荧光剂1移动,以捕获更多的该荧光剂的光(em2+,细虚线)。光谱信息的该增加还必须与来自给定荧光团的全部可获得的光平衡,以保持可检测性。换言之,来自给定通道中的给定荧光团的贡献只有在相应的信号大于背景噪音时是显著的,并且因此是具有信息量的,除非计划用作阴性对照。以此方式,如果物质-独特特征可以更有效地定量,荧光实体的光谱特征可以用于稳健的鉴定,并且捕获更多的光可以是次要优先的。给出的探针产物可以标记有多于一种荧光团,从而使光谱特征更复杂。例如,探针产物可以总是携带通用荧光剂(例如alexa647)和基因座特异性荧光团(例如针对基因座1的alexa555和针对基因座2的alexa594)。由于污染物会极少携带产生两种荧光剂的特征,这可以进一步增加污染排斥的可信性。实施会包括在该实例中的三个以上通道中进行成像,从而通过上述比较测试与参照的拟合优度法来确认各荧光剂的存在或不存在,从而产生基因座1、基因座2或非基因座产物的决定结果。添加额外的荧光剂会辅助荧光剂鉴定,因为更多的光可供收集,但代价是正确形成的测定产物的收率和总成像时间(可能需要额外的通道)。其它光谱修正剂也可用于增加光谱信息和独特性,包括当紧密相邻或位于其它部分中时会改变颜色的fret对。在另一方面,本文描述的阵列可以与其它测试方法结合使用以提高其准确度。例如,可以使用关于患者的表型数据(例如年龄、体重、bmi、疾病状态)来预测异常怀孕的概率或具有低量的胎儿材料(即低胎儿组分)的患者的cfdna的概率。作为另一选择,本发明的阵列可以与测定(例如,寡-连接测定,其中产物捕获在阵列上)直接一起使用,或与能够用于复制、确认或改善来自阵列的结果的独立测定一起使用。例如,可以使用dna测序、质谱、基因分型、标准微阵列、核型分析、基于pcr的方法或其它方法作为正交方法,并且可以将来自这些方法的数据与来自本发明的阵列的数据整合,以提供更准确或更不模糊的结果。本文描述的阵列可用于筛选、诊断、复制、确认、验证、排除或监测状况疾病,例如胎儿中的唐氏综合征。在一些实施方式中,本文所述的阵列可与其它遗传和基因组信息一起使用。例如,某些基因已知或被预测为具有比其母体等效物更高的甲基化(例如rassf1a、apc、casp8、rarb、scgb3a1、dab2ip、ptpn6、thy1、tmeff2和pycard)。使用差异甲基化与本文所述的阵列组合可提供关于胎儿的更多信息,包括其是否携带任何三体性。在另一方面,如本文所述,本说明书的方法可以用于检测肽或蛋白质中的遗传变异。在此类情况下,所述方法还可以包括使第一探针组和第二探针组与遗传样品接触,其中第一探针组包含第一标记探针和第一标签探针,第二探针组包含第二标记探针和第二标签探针。所述方法还可以包括通过物理或化学连接使探针组与目标肽区域结合,来代替在检测核酸分子中的遗传变异的情况下本文所述的杂交步骤。具体而言,所述方法还可以包括将第一探针组和第二探针组的至少一部分分别与遗传样品的肽或蛋白质中的第一和第二目标肽区域结合。例如,所述结合可以通过在与目标肽区域特异性结合的探针组的至少一个探针中具有结合剂来进行。在一些实施方式中,检测肽或蛋白质中的遗传变异的方法还可以包括:至少通过缀合第一标记探针和第一标签探针而利用化学键来缀合第一探针组,并至少通过缀合第二标记探针和第二标签探针来缀合第二探针组,由此代替在检测核酸分子中的遗传变异的情况下本文所述的连接步骤。所述方法还可以包括将标签探针固定至本文所述的基板上的预定位置。在另外的实施方式中,缀合至经固定的标签探针的第一标记探针和第二标记探针分别包含第一标记和第二标记;第一标记和第二标记是不同的;经固定的标记是光学上能够解析的;经固定的第一标签探针和第二标签探针和/或其经扩增的标签探针分别包含第一标记和第二标记;固定步骤通过将标签固定至预定位置来进行。如本文所述,所述方法还可以包括对(i)固定至基板的第一标记的第一数量和(ii)固定至基板的第二标记的第二数量进行计数,并比较所述第一数量和第二数量以确定遗传样品中的遗传变异。本发明还涉及制造和使用具有本文所述组件的空间上可寻址的分子阵列的方法。本发明还涉及用于检测上述遗传变异的基于单分子检测技术的分析方法。此类方法克服了与整体分析相关的上述实际局限性。这能够通过精确度、信息丰富程度、速度和通量来实现,这些可以通过在单分子水平上进行分析而获得。本发明特别解决了大规模和全基因组分析的问题。到目前为止,单分子分析仅在简单的实例中进行过,但如上所述,现代遗传学和其它领域的挑战是大规模地应用测试。用于快速分析大量分子的任何单分子检测技术的一个重要方面是用于并行地分选和追踪(或跟踪)单个分子的个体反应的系统。在具有已知序列或编码的序列的单分子的空间可寻址阵列上捕获和解析单分子可以实现这一点。在目前的整体方法中,分析是通过在测定中观察所有分子的总体信号来进行的。所获得的探针分子空间密度或测定信号的密度过高,从而不能通过通常使用的方法(例如微阵列扫描仪、平板扫描器、读板器、显微镜)解析单个分子。本发明的一些实施方式的方法与传统的整体阵列技术的区别特别在于其所要获取的信息的类型。此外,它描述了功能性分子的密度大大低于整体阵列的密度的阵列。来自这些阵列的低密度信号可能不能被通常用于分析整体阵列结果的仪器充分地读出,这特别归因于高背景。本发明的单分子阵列的制造需要如本文所述的特殊措施。在一个方面,本发明涉及一种通过控制或调节每个阵列元件中的探针密度来产生阵列的方法。在一些实施方式中,探针是捕获探针,包括本文所述的标签或亲和标签。一些实施方式的发明允许在多个靶分子的杂交或固定之后控制每个阵列元件处的材料或探针的量。在另外的实施方式中,选择捕获探针的密度以使得杂交的靶标的量对于所有阵列元件都是相等或接近相等的。当寻找小的效应时,例如本文所述的拷贝数或次要等位基因频率的偏差时,优选在标准模拟微阵列的情况下具有相似的强度或在数字单分子阵列的情况下具有相似的密度。在这两种情况下,准确度、噪声、信号、信噪比和其他因素随着给定阵列元件中固定的靶标的量而变化。在固定靶标后使各元件在强度和/或密度方面彼此更相似将使数据更一致、更具可比性、更准确、变化更少和噪声更少。然而,在杂交的情况下,如果不同的靶标与不同的捕获探针杂交,它们将很可能具有不同的杂交效率。当所有靶标在相同的杂交条件下同时杂交时,不允许提高对每种特异性靶序列的杂交效率。也就是说,如果靶标都处于相同的反应体积中,则将一套杂交条件用于所有靶标,而不管它们的序列如何。如果捕获探针都具有相同的密度,那么与杂交较低的靶标相比,与其互补捕获探针更高效杂交的靶标在杂交后将会更丰富,并且具有更高的密度或强度。因此,基于捕获探针的特征(例如其序列)来改变捕获探针密度,允许控制或去除杂交效率的偏差。本发明还涉及产生本文所述的阵列、空间可寻址阵列、分子阵列、流动池、生物传感器或单分子阵列的方法,所述方法包括确定每种不同的靶探针与一种或多种捕获探针的杂交效率,其中所述靶探针和一种或多种捕获探针是寡核苷酸探针。在一些实施方式中,产生本文所述的阵列、空间可寻址阵列、分子阵列、流动池、生物传感器或单分子阵列的方法包括分别确定第一靶探针和第二靶探针与多个相同或不同的捕获探针的杂交效率,其中所述第一靶探针和第二靶探针以及多个捕获探针是寡核苷酸探针,所述第一靶探针包含第一标记或序列,所述第二靶探针包含不同于第一标记或序列的第二标记或序列。对于第一和第二靶探针,捕获探针可以相同或不同。在另外的实施方式中,可以引入超过两种不同的靶探针,包括至少3、4、5、6、7、8、9、10、50、100、500或1000种且5、10、200、600、900或1200种以下不同的如上所述的靶探针,并且在产生本文所述的阵列、空间可寻址阵列、分子阵列、流动池、生物传感器或单分子阵列的方法中可以确定靶探针与不同的捕获探针(包括至少1、2、3、4、5、6、7、8、9、10、50、100、500或1000种且5、10、200、600、900或1200种以下不同的捕获探针)中的每一种的杂交效率。靶探针与捕获探针的杂交效率是指靶探针如何高效地与捕获探针杂交。在一些实施方式中,靶探针与捕获探针的杂交效率可以通过确定相对于施加到杂交用捕获探针上的靶探针数量的杂交的靶探针的数量来测量。例如,靶探针与捕获探针的杂交效率可以通过确定以下(a)和(b)来测量:(a)施加到固定数量的杂交用捕获探针上的溶液中的靶探针的第一数量或浓度,和(b)在杂交后已经在溶液中或在基板上与捕获探针杂交的靶探针的第二数量或浓度;和/或通过确定第一数量或浓度与第二数量或浓度的相对数量来测量。在另外的实施方式中,第一数量或浓度和第二数量或浓度可以通过对靶探针中的寡核苷酸的至少一部分的拷贝数进行计数来确定。或者,如果靶标探针带有标记,则已与捕获探针杂交的靶探针的第二数量或浓度可以被已杂交的靶探针中的标记的数量、浓度、强度或聚集强度代替。例如,标记的靶探针与捕获探针的杂交效率可以通过确定以下(a)和(b)来测量:(a)施加到固定数量的杂交用捕获探针上的溶液中的靶探针的第一数量或浓度,和(b)在杂交后已经在溶液中或在基板上与捕获探针杂交的靶探针中的标记的第二数量、浓度或总强度;和/或通过确定第一数量或浓度与第二数量、浓度或总强度的相对数量来测量。如上所述,本文的标记可以是相同类型或不同类型,并且可以包括例如荧光染料。可选的是,第一靶探针和第二靶探针分别包含第一标记和第二标记;第一标签和第二标签是不同类型的;第一标签和第二标签是荧光染料;和/或产生阵列的方法可包括用所述第一和第二标记来标记所述第一靶探针和第二靶探针。上述产生阵列、空间可寻址阵列、分子阵列、流动池、生物传感器或单分子阵列的方法还包括:基于杂交效率来预选择捕获探针的将要在基板上固定的密度;和根据所述密度,将捕获探针固定到基板上从而在基板上产生多个元件。在一些实施方式中,产生多个元件的步骤还包括在将捕获探针固定到基板之前或之后将不同的靶探针(例如第一靶探针和第二靶探针)与至少一部分捕获探针杂交,并产生不同的(即第一和第二)固定的杂交产物,所述固定的杂交产物包含(i)不同的(即第一和第二)靶探针,和(ii)捕获探针。在另外的实施方式中,不同的靶探针可以与相同或不同的捕获探针杂交,并且阵列上的每个元件可以具有相同或不同的捕获探针,如下文进一步描述的。在进一步的实施方式中,预选择捕获探针或每种不同的捕获探针的所述密度,使得当在相同杂交条件下将不同的(即第一和第二)靶探针施加到多个元件中的至少一个上时,不同的固定杂交产物的密度相同,或者相差1000%、500%、200%、100%、50%、30%、25%、20%、19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2或1%以下。例如,预选择捕获探针或每种不同的捕获探针的所述密度,使得当在相同杂交条件下将第一靶探针和第二靶探针施加到多个元件中的至少一个上时,在多个元件中的所述至少一个中,包含第一靶探针的第一经固定杂交产物的第一密度和包含第二靶探针的第二经固定杂交产物的第二密度相同,或相差20%以下。在一些实例中,可以通过比较不同的经固定杂交产物的标记的总强度、数量或密度来比较不同的经固定杂交产物的密度。例如,所述第一靶探针和第二靶探针分别包含所述第一标记和第二标记;所述第一经固定杂交产物和第二经固定杂交产物中的所述第一靶探针和第二靶探针的所述第一标记和第二标记是光学上能够解析的;并且预选择多个捕获探针的密度,使得多个捕获探针的所述密度被选择为其最大值,在该最大值下,(i)所述第一经固定杂交产物中的所述第一靶探针的第一标记中的至少两个是光学上能够解析的,和(ii)所述第二经固定杂交产物中的所述第二靶探针的第二标记中的至少两个是光学上能够解析的。在进一步的实施方式中,不同的靶探针包含不同的标记,其在固定靶探针后是光学上能够解析的,并且(a)预选择一种或多种捕获探针中的每一种的密度,使得捕获探针的所述密度被选择为其最大值,在该最大值下,经固定杂交产物中的靶探针的标记中的至少两个是光学上能够解析的,和/或(b)预选择一个或多个捕获探针中每一个的密度,使得捕获探针的所述密度被选择为其最大值,在该最大值下,经固定杂交产物中的不同靶探针的标记中的每一种中的至少10%、25%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、93%、95%、96%、97%、98%或99%是光学上能够解析的。例如,所述第一靶探针和第二靶探针分别包含所述第一和第二标记;所述第一经固定杂交产物和第二经固定杂交产物中的所述第一靶探针和第二靶探针的所述第一标记和第二标记是光学上可解析的;并且预选择多个捕获探针的所述密度,使得所述多个捕获探针的所述密度被选择为其最大值,在该最大值下,(i)所述第一经固定杂交产物中的所述第一靶探针的第一标记中的至少50%是光学上能够解析的;和(ii)所述第二经固定杂交产物中的所述第二靶探针的第二标记中的至少50%是光学上能够解析的。如上所述,阵列元件可以具有各种面积和尺寸。例如,多个元件的至少一部分具有从约50、100或150微米至200、250、300、400或500微米的尺寸,和/或多个元件的至少一部分与相邻元件相距的距离为:从约1、5、10、50或100μm至200、250、300、400或500μm。在更进一步的实施方式中,预选择捕获探针或每种不同的捕获探针的密度,使得当在相同的杂交条件下将每种靶探针施加到多个元件中的至少一个上时,包含靶探针的经固定杂交产物的密度相同,或相差1000%、100%、50%、25%、10%、9%、8%、7%、6%、5%、4%、3%、2%或1%以下。在另外的实施方式中,不同的靶探针可以与相同或不同的捕获探针杂交。而且,多个元件中的每一个可包括相同的捕获探针、相同类型的捕获探针、或不同的捕获探针。例如,预选择捕获探针或每个不同的捕获探针的密度,使得当在相同的杂交条件下将第一靶探针施加到多个元件中的一个上并且将第二靶探针施加到多个元件中的另一个上时,在所述多个元件中所述第一经固定杂交产物的第一密度和所述第二经固定杂交产物的第二密度相同,或者相差50%、25%、10%、9%、8%、7%、6%、5%、4%、3%、2%或1%以下。如上所述,例如,关于相同类型的经固定标记或具有相同类型的固定标记的经固定杂交产物之间的距离,在一些实施方式中,多个元件中的至少一个中的所述第一经固定杂交产物的至少一部分与多个元件中的所述至少一个中的相邻或最接近的第一经固定杂交产物相距的距离为:从约1、5、10、20、30、50、100、150、200、250、300、350或400nm至约50、100、150、200、250、300、350、400、500、600、700、800、900、1000、2000、5000、10000、20000或500000nm,并且多个元件中的至少一个中的所述第二经固定杂交产物的至少一部分与多个元件中的所述至少一个中的相邻或最接近的第二经固定杂交产物相距的距离为:从约1、5、10、20、30、50、100、150、200、250、300、350或400nm至约50、100、150、200、250、300、350、400、500、600、700、800、1000、2000、5000、10000、20000或500000nm。同样如上所述,例如,关于结合剂、标签和亲和标签之间的距离,在一些实施方式中,多个元件中的至少一个中的捕获探针的至少一部分与多个元件中的所述至少一个中的相邻或最接近的捕获探针相距的距离为:从约1、5、10、15、20、50、100或200nm至约500、1000、2000、5000、10000、20000或500000nm。在一些实施方式中,多个元件中的至少一个中的捕获探针的至少一部分与多个元件中的所述至少一个中的相邻捕获探针的距离至少为检测第一标记和/或第二标记所用的波长。在另一个实施方式中,选择捕获探针的密度以提供计数的准确度和精确度。也就是说,选择捕获探针密度以产生本文所述的可计数的标记探针或标记靶探针的密度。可计数密度的量度可以是预定区域中计数的标签的数量。该区域可以是基板上、阵列上、元件内的区域,或是对基板、阵列或元件拍摄的一个或多个图像上的区域。例如,可计数密度可以是在单位面积(例如,200微米×200微米)中计数的标记的平均数量或者通过数码相机或其他记录或成像装置拍摄的图像的测量单位(例如,100×100像素或1000×1000像素)。图84描绘了显示出100×100像素区域中的不同密度的示例性图像。可计数密度为0意味着在该区域中没有可检测的带标记探针。可计数密度为200和300分别意味着在区域中检测到200和300个带标记的探针。计数的数量取决于所存在的带标记探针的数量以及对带标记探针进行检测和计数的方法或算法。对于预选择的计数方法或算法,可以选择捕获探针密度来产生固定的标记或带标记探针(例如带标记的靶探针)的可计数密度。在所选区域中,该可计数密度应大于0。在一些实施方式中,在图像的100x100像素区域中,可计数密度可以大于约10、20、30、40、50、100、150、200、300或400个标记,但小于约700、600、500、400、300、200或100个标记。在一些实施方式中,在图像的100x100像素区域中,可计数密度大于约20、50、75、100、125、150、175、200、225、250、275、300、350、400、450、500或1000且小于约100000、50000或10000。在进一步的实施方式中,对于一个或多个阵列元件的一组图像,大部分(例如,大于50%、60%、70%、80%、90%、95%、96%、97%、98%或99%)数据应当在可计数密度的范围或区间中收集。也就是说,大多数(例如,大于50%、60%、70%、80%、90%、95%、96%、97%、98%或99%)图像具有规定范围或区间中的可计数密度,但一些图像可能具有较高的可计数密度,而一些图像可能具有较低的可计数密度。在一些实施方式中,对于一组图像,在图像的100×100像素区域或不同尺寸的区域中,可计数密度的范围或区间为约0至50、0至100、25至100、50至100、50至200、50至500或0至500。对于一个或多个图像的多于一个区域,可以根据可计数密度的平均值来计算范围或区间。在一些实施方式中,有利的是,在两个或更多个元件中具有不同的捕获探针密度,其中两个或更多个元件包含相同的捕获探针和/或相同类型的捕获探针,例如,通过使用下文所述的梯度稀释来实现。相同类型的捕获探针包含本文所述的相同的结合剂、标签、亲和标签或标签核苷酸序列。当阵列包含具有不同密度的相同捕获探针的不同元件时,例如,在带标记的探针与捕获探针杂交后,这些元件对于固定的标记或带标记的探针将具有不同的可计数密度。在一些实施方式中,一些元件将包含光学上能够解析的标记或标记探针,而其他一些元件将包含很少或不包含光学上能够解析的标记或标记探针。当标记探针的数量、浓度或质量最初未知或测量不佳时,这可能是有利的特征。可能不清楚应选择何种密度的捕获探针来产生如上所述的光学解析性或所需的可计数密度,即使杂交效率可能是已知的。在基板上的多种捕获探针密度中,至少一些元件可以具有光学上能够解析的标记探针或所需的可计数密度,并且不需要重复进行固定步骤来鉴定出产生本文所述的所需的光学上能够解析的标记或标记探针或所需的可计数密度的捕获探针密度。在另一个实施方式中,基板上的一个或两个元件可以设计成不具有光学上能够解析的带标记的分子或具有高密度的光学上不可解析的固定标记。这些元件,即所谓的“高密度元件”或“基准元件”,可以具有比被设计成具有光学上能够解析的标记探针(包括待固定到捕获探针上的靶探针)的元件更高的捕获探针密度。这些高密度元件可用作基准或标志物,用来定向阵列、确定其他元件的位置或帮助成像装置聚焦。在使用短的相机快门曝光时间、低放大率和/或当基板在运动时(例如,当扫描整个阵列寻找特定特征或元件时),光学上能够解析的元件可能难以检测。这是因为光学解析性与相对低密度的标记探针相关,并因此与低信号量相关,因为每单位面积的标记很少。例如,当标记是单个荧光染料分子(例如cy5、alexa647)时,具有低密度的固定标记的低密度元件将难以检测。基准元件含有密度高得多的固定标签,因此可以在用短的相机快门曝光时间、低放大率甚至当基板处于运动中时(例如,当扫描整个阵列寻找特定特征或元件时)检测。在一些实施方式中,本文描述的阵列可包括两种元件类型:高密度和低密度元件。阵列可以包括一个或多个元件,其捕获探针密度允许标记或经标记的靶探针被固定,并使得至少约10%、20%、30%、40%、50%、60%、70%、80%、90%或95%的经固定的标记是光学上可检测的;和另外一个或多个元件,其捕获探针密度允许标记或经标记的靶探针以更高的密度被固定,并使得至少约10%、20%、30%、40%、50%、60%、70%、80%、90%、95%、98%或100%的经固定的标记是光学上不可检测的。在进一步的实施方式中,控制捕获探针密度可以导致跨越一系列元件的标记探针的均匀性更大。例如,可以使用相同的捕获探针密度产生多个元件,这导致相似的标记探针密度。在某些情况下,有利的是,在一些或所有元件(例如,对于具有用相同波长的荧光染料标记的探针的所有元件)中具有相似的可计数密度。在该实施方式中,在元件中每单位面积上将计数相似数量的标记探针。在另一个实施方式中,当以相同的捕获探针密度产生元件时,这将减少以下参数的变化:可计数密度、标记探针的计数数量、光学上可解析的标记探针的比例和含有光学上可解析的分子的阵列元件的比例。在一些实施方式中,预选择步骤可以包括:通过以不同密度将多个捕获探针固定到基板上而在基板上产生具有不同密度的捕获探针的多个对照元件;在相同的杂交条件下,将靶探针施加到对照元件上(例如,(i)将所述第一靶探针施加到多个对照元件中的至少两个上,和/或(ii)将所述第二靶探针施加到多个对照元件中的至少两个上);和确定所述靶探针的标记在对照元件中是否是光学上能够解析的。在另外的实施方式中,每个靶探针包含共同的标签核苷酸序列,并且捕获探针包含与所述共同的标签核苷酸序列互补的共同的互补标签核苷酸序列。包含共同的互补标签核苷酸序列的捕获探针可以是相同的捕获探针或具有不同的组成或全序列的不同的捕获探针。在其他实施方式中,靶探针包含不同的标签核苷酸序列,并且捕获探针包含与所述不同的标签核苷酸序列互补的不同的互补标签核苷酸序列。例如,第一靶探针和第二靶探针包含彼此不同的第一标签核苷酸序列和第二标签核苷酸序列,并且多个捕获探针包含第一捕获探针和第二捕获探针,其具有分别与第一标签核苷酸序列和第二标签核苷酸序列互补的第一互补标签核苷酸序列和第二互补标签核苷酸序列。然而,包含不同的互补标签核苷酸序列的捕获探针仍然可以具有相同的结合剂以固定到基板上。多个元件可以包括第一元件和第二元件,并且所述第一元件和第二元件中的每一个可以包括所述第一捕获探针和第二捕获探针。或者,多个元件可以包括第一元件和第二元件,并且第一元件和第二元件可以分别包括所述第一捕获探针和第二捕获探针。在进一步的实施方式中,如上所述,标签核苷酸序列可以是非基因组序列。此外,本文所述的标签核苷酸序列的长度为:从至少5、10、11、12、13、14、15、20、25、30、40或50至5、10、20、30、40、50或100个核苷酸,和/或可以包含选自由以下表6中所示seqidno:370至seqidno:375组成的组的一个或多个序列。另外如上所述,本文所述的探针可以包括任意长度的寡核苷酸。例如,靶探针的长度可以为:从10、20、30、40、50、60、70、80、90、100或130至150、180、200或250个核苷酸,并且捕获探针的长度可以为:从5、8、10、11、12、13、14、15、16、17、18、19或20至15、16、17、18、19、20、21、25、30、40或50个核苷酸。在另一方面,在产生阵列或检测本文所述的遗传变异的方法中,在同一阵列组件或元件中的至少一部分不同的探针可具有相似的解链温度(例如,约15、10、9、8、7、6、5、4、3、2、1或0.5℃(含)以内),以便可以在相同温度下检测它们。例如,多个元件中的每个中的所述第一靶探针和/或第二靶探针具有至少一个解链温度与所述第一靶探针和第二靶探针的平均解链温度相差约15、10、9、8、7、6、5、4、3、2、1或0.5℃(含)以下。如本文所述,探针可以通过打印和/或点样来施加。例如,元件的产生可以包括将包含多个捕获探针的稀溶液打印和/或点样到基板上。同样如上所述,关于沉积在基板上的材料的体积和浓度,在一些实施方式中,可以使用打印和/或点样在基板上以产生元件的含有靶探针和/或捕获探针的溶液的体积来来控制元件的大小,以及/或者靶探针和/或捕获探针的密度。在一些实施方式中,在打印和/或点样基板上以产生元件的含有相同或不同靶探针和/或捕获探针的多种溶液的至少一部分的体积保持相同,或保持在体积平均值的约50%、40%、30%、20%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%之内。例如,打印和/或点样在基板上以产生多个元件中的一个的所述稀溶液的第一体积和打印和/或点样在基板上以产生多个元件中的另一个的所述稀溶液的第二体积是相同的,或与第一体积和第二体积的平均值相差约30%、20%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%以下。在另外的实施方式中,可以将在稀溶液中具有不同探针浓度的相同或不同探针的梯度稀释液施加到基板上的不同位置或元件上。例如,可以将具有不同浓度的一种或多种不同的探针(例如一种或多种靶探针和/或捕获探针)的1、2、3、4、5、6、7、8、9、10种以上且2、3、4、5、6、7、8、9、10、50、100、150、200、300、400、500、1000、5000、10000种以下稀溶液施加到基板上的不同位置,以在基板上固定一种或多种不同的探针,从而在基板上形成1、2、3、4、5、6、7、8、9、10个以上且2、3、4、5、6、7、8、9、10、50、100、150、200、300、400、500、1000、5000、10000个以下元件。在另一个实施方式中,在打印和/或点样之后对阵列进行干燥的速度、方法和温度将决定对应于已知体积的液体中的已知浓度的捕获探针的元件尺寸和它们各自的密度。如上所述,关于标签、亲和标签和捕获探针,例如,捕获探针可以包含选自以下组的第一固定手段:(i)生物素、(ii)sh基团、(iii)胺基、(iv)苯基硼酸(pba)基团和(v)acrydite基团,并且所述基板包含选自以下组的第二固定手段:(i)抗生物素蛋白、抗生蛋白链菌素或中性抗生物素蛋白、(ii)sh基团、(iii)激活的羧酸基和醛基、(iv)水杨基氧肟酸(sha)基团和(v)硫醇表面、硅烷表面和丙烯酰胺单体。在另一方面,本发明涉及检测来自受试对象的遗传样品中的遗传变异的方法,所述方法包括:(a)使第一探针组和第二探针组的至少一部分分别与遗传样品中存在的核苷酸分子中的第一目标核酸区和第二目标核酸区杂交,其中第一探针组和第二探针组分别包含第一标签探针和第二标签探针;(b)产生捕获探针阵列,其包括(i)确定第一标签探针和第二标签探针与多个捕获探针的杂交效率,(ii)基于所述杂交效率预选择多个捕获探针的将在基板上固定的密度,和(iii)根据上述密度将多个捕获探针固定到所述基板上,从而在所述基板上产生多个元件;(c)可选地扩增第一探针组和第二探针组以分别形成第一经扩增探针组和第二经扩增探针组;(d)分别用第一标记和第二标记来标记所述第一探针组和第二探针组以及/或者第一经扩增探针组和第二经扩增探针组的至少一部分,其中所述第一标记和第二标记是不同的;(e)通过将第一标签探针和第二标签探针的至少一部分杂交至所述多个捕获探针而进行固定,并且产生第一经固定杂交产物和第二经固定杂交产物,所述第一经固定杂交产物和第二经固定杂交产物包含(i)所述第一探针组和第二探针组以及/或者第一经扩增探针组和第二经扩增探针组,和(ii)所述多个捕获探针,其中第一经固定杂交产物和第二经固定杂交产物的第一标记和第二标记是光学上能够解析的;(f)对(i)所述第一经固定杂交产物的第一标记的第一数量和(ii)所述第二经固定杂交产物的第二标记的第二数量进行计数,其中所述第一数量对应于固定在基板上的第一探针组和/或第一经扩增探针组的数量,所述第二数量对应于固定在基板上的第二探针组和/或第二经扩增探针组的数量;和(g)比较第一数量和第二数量以确定所述遗传样品中遗传变异的存在。在一些实施方式中,第一探针组和第二探针组还包含第一标记探针和第二标记探针;所述方法还包括在所述杂交步骤之后但在所述扩增步骤和产生步骤之前将所述第一标记探针和第二标记探针与所述第一标签探针和第二标签探针连接,并且/或者在所述杂交步骤期间,使所述第一标记探针和第二标记探针分别与所述第一目标核酸区和第二目标核酸区杂交。在另外的实施方式中,在杂交期间,第一标签探针和第二标签探针分别与所述第一目标核酸区和第二目标核酸区杂交,并且/或者在标记期间,用所述第一标记和第二标记分别标记第一标签探针和第二标签探针。在另外的实施方式中,比较步骤包括对第一数量和第二数量进行比较以确定第一目标核酸区的第一拷贝数与第二目标核酸区的第二拷贝数是否不同,其中所述第一拷贝数与第二拷贝数不同指示在所述遗传样品中存在核酸拷贝数变异。如上所述,关于检测遗传变异的方法,在一些实施方式中,标记步骤在杂交步骤之前进行。此外,该方法可以包括扩增,和/或可以包括同时进行扩增和标记。在另外的实施方式中,用第一正向引物和第一反向引物扩增第一探针组;用第二正向引物和第二反向引物扩增第二探针组;第一正向引物和第二正向引物和/或第一反向引物和第二反向引物分别包含第一标记和第二标记。例如,第一正向引物和第二正向引物不包括标记并且具有相同的核苷酸序列,和/或(ii)第一反向引物和第二反向引物不包括标记并且具有相同的核苷酸序列。如上所述,所述遗传变异的存在指示受试对象中癌是否存在,转移性癌、癌的复发、肿瘤负荷、肿瘤异质性、药代动力学变化性、药物毒性、移植排斥、治疗功效或非整倍性是否存在;和/或所述遗传变异选自由下述组成的组:替换、倒位、插入、缺失、突变、核苷酸序列中的单核苷酸多态性(snp)和易位、以及核苷酸拷贝数变异。受试对象可以是怀孕的受试对象,并且遗传变异选自由本文所讨论的受试对象的胎儿中的13三体、18三体、21三体、x非整倍性、y非整倍性、22q11.2、1q21.1、9q34、1p36和22q13组成的组。在另外的实施方式中,遗传样品选自由来自受试对象的无细胞dna样品、全血、血清、血浆、尿、唾液、汗液、粪便和眼泪组成的组;计数步骤包括空间滤波和/或分水分析;比较步骤包括获得具有第一目标核酸区和第二目标核酸区的核苷酸分子的相对数量的估计值;和/或计数步骤包括:测量来自经固定的标记的光学信号,并通过区分来自单一标记的光学信号和来自背景和/或多个标记的其余光学信号来校正第一数量和第二数量。在另外的实施方式中,本文所述的检测遗传变异的方法可以不包括对第一探针组和第二探针组或者第一经扩增探针组和第二经扩增探针组进行测序,和/或所述计数步骤不包括对第一标记和/或第二标记的整体阵列读取。产生分子阵列的本发明方法的一些另外的实施方式包括在基板上固定多个探针,其固定密度使得单独的经固定的探针能够被单独解析,其中阵列中每个单独的探针的身份是空间上可寻址的,并且每个探针的身份在固定之前是已知的或者已确定。本发明的另外的实施方式还提供了一种产生分子阵列的方法,所述方法包括将多个确定的探针固定到基板上,其固定密度使得各个经固定的探针能够通过选择的方法被单独解析,其中在阵列中每个单独的探针是空间上可寻址的。在进一步的实施方式中,本发明提供一种产生分子阵列的方法,所述方法包括:(i)提供分子阵列,其包含固定至基板的多个探针,固定的密度使得各个经固定的探针不能被单独解析;和(ii)减少阵列中功能性的经固定的探针的密度,使得剩余的各个功能性经固定的探针能够被单独解析;其中所得阵列中的每个单独探针的身份是空间上可寻址的,并且每个探针的身份在密度减少步骤之前是已知的或已确定。本发明的另外实施方式还提供一种产生分子阵列的方法,包括:(i)提供分子阵列,其包括固定至基板上的多个确定的空间上可寻址的探针,固定的密度使得各个经固定的探针不能用光学手段或所选择的其它方法单独解析;和(ii)减少阵列中功能性的经固定的探针的密度,使得每个剩余的个体功能性经固定的探针能够被单独解析。在另一方面,在本发明的一些实施方式中,产生分子阵列的方法包括:(i)预选择多个待固定的寡核苷酸;(ii)将所述多个寡核苷酸中的至少一部分固定至固相以形成两个以上分开的离散组件,所述两个以上组件中的至少两个是空间上可寻址的,所述至少两个组件包含多个经固定的寡核苷酸;和(iii)用一种或多种标记来标记位于所述至少两个组件中的每一个处的多个经固定的寡核苷酸中的至少一部分,其中位于所述至少两个组件处的所述多个经标记的经固定的寡核苷酸中的至少一部分是能够单独解析的。另外,在本发明的其它实施方式中,产生分子阵列的方法包括:(i)预选择多个待标记的寡核苷酸;(ii)用一种或多种标记来标记所述多个寡核苷酸中的至少一部分;和(iii)将所述多个经标记寡核苷酸中的至少一部分固定至固相以形成两个以上分开的离散组件,所述两个以上组件中的至少两个是空间上可寻址的,所述至少两个组件包含多个经固定的寡核苷酸,其中位于所述至少两个组件处的多个经标记的经固定的寡核苷酸中的至少一部分是能够单独解析的。此外,在本发明的另外实施方式中,产生微阵列的方法包括:(i)预选择多个待固定的寡核苷酸;(ii)将所述多个寡核苷酸中的至少一部分固定至固体载体,固定的密度使得固体载体上的所述多个寡核苷酸中的至少一部分中的每一个在标记后都能够被单独解析,由此形成两个以上分开的离散组件,所述两个以上组件中的至少两个组件是空间上可寻址的,所述至少两个组件中的每一个包含来自所述多个寡核苷酸中的至少一部分的多个经固定的寡核苷酸,其中所述至少两个组件的每一个中的所述多个经固定的寡核苷酸中的所述至少一部分的序列身份由包含寡核苷酸的所述至少两个组件的每一个的位置来指定;(iii)用一种或多种标记来标记位于所述至少两个组件中的每一个处的多个经固定的寡核苷酸中的至少一部分,由此产生经标记的经固定的寡核苷酸;和(iv)分析所述至少两个组件中的经标记的经固定的寡核苷酸的至少一部分是否相对于另一部分经标记的经固定的寡核苷酸是光学上能够单独解析的,由此所述至少两个组件的每一个上的经标记的经固定的寡核苷酸的所述至少一部分相对于所述另一部分经标记的经固定的寡核苷酸是光学上能够单独解析的。在一些实施方式中,固定步骤包括将相同序列的多个第一寡核苷酸固定至第一分开的离散组件。在另外的实施方式中,固定步骤还包括固定相同序列的多个第二寡核苷酸,其中第二寡核苷酸与第一寡核苷酸具有不同的序列。在另外的实施方式中,多个第二寡核苷酸固定至第二分开的离散组件。在其他实施方式中,所述两个以上组件中的至少两个是空间上可寻址的,而无需对一个或多个经固定的寡核苷酸中的至少一部分进行测序。在另外的实施方式中,在产生分子阵列的方法的以上实施方式中的寡核苷酸可以包含本文所述的标签或亲和标签或由其组成。优选的是,经固定的探针存在于离散的空间上可寻址的组件内。在一个此类实施方式中,多个分子物种存在于一个或多个离散的空间上可寻址的组件内,并且组件内的每个分子物种可以凭借标记与该组件内的其它分子物种区分开。在另一实施方式中,多个探针不能凭借标记来区分,但是包含简并序列组,例如代表基因家族的成员,根据此可以将它们区分开。在一些实施方式中,阵列可以包含单个单层。在不存在离散的或制造元件(例如,通过点样(spotting)或通过使用物理结构进行划分来制备)时,可以制造覆盖一部分或全部阵列的更大单层。在一个实例中,在阵列上会存在单个单层。如果正在对样品进行多于一个的测试,会使用多于一个的阵列。例如,可以对每个测试产生一个阵列。在其它情况下,在同一单层上查询多个样品,例如,使用不同的荧光染料来将一个样品与其它样品区分开。在另一实施方式中,样品置于同一单层上的不同位置上。不同样品放在不同位置,而不是一个样品覆盖整个阵列。通过沉积进行划分可以产生与标准阵列元件相似的区域,但可以在使用阵列的过程中形成而不是在制造过程中形成。在一些实施方式中,阵列可以查询本文所述的dna条码和/或标签。在另外的实施方式中,阵列可以查询例如(i):一条或多条染色体,包括如本文所述的染色体21、18、13、x、y和/或其它染色体,(ii)本文所述的微缺失、唐氏综合征、帕韬氏综合征和爱德华综合症,(iii)本文所述的探针,而不是直接查询基因组dna,(iv)本文所述的在同一阵列上的多种不同类型的遗传变异(例如拷贝数变化和突变),和(v)本文所述的对拷贝数变化的全基因组筛选。例如,可以使用跨整个基因组间隔开的一组探针。在进一步的实施方式中,对于所有的探针对,相邻探针之间的距离可以大致相同。低密度探针:本发明在一个方面涉及产生分子阵列,其中基板上的组件中的各个探针的密度足够低从而使得各个探针能够被单独解析,即,当使用所选方法可视化时,每个探针可以与相邻探针分开可见,而无论这些相邻探针的身份如何。所需密度根据可视化方法的解析度而不同。作为指导,当阵列计划用于相对低解析度的光学检测系统(可见光的衍射极限为约300~500nm)时,探针的分隔距离优选在两个维度上均为约至少250、500、600、700或800nm。如果最接近的相邻单个探针标记有不同的荧光团,或者其功能化(参见下文)可以短暂解析,则可以通过解卷积算法和/或图像处理获得更高的解析度。作为另一选择,在使用较高解析度的检测系统(例如扫描近场光学显微镜(snom))时,可以使用降低至约50nm的分隔距离。随着检测技术的改进,可以进一步减少最小距离。诸如afm等非光学方法的使用,允许将特征物之间的距离有效地减少至0。由于例如在许多固定步骤或密度降低步骤的过程中,所有探针都至少被解析所需的最小距离分隔开的概率较低,所以一部分探针比该最小距离更近是能够接受的。然而,优选的是,至少50%,更优选至少75%、90%或95%的探针处于单独解析所需的最小间隔距离。此外,基板组件中探针的实际密度可以高于单独解析所允许的最大密度,因为这些探针中仅有一部分将是用所选择的解析方法能够检测的。因此,在例如解析涉及使用标记时,在单独经标记的探针能够被解析的前提下,更高密度的未标记的探针的存在是不重要的。因此,阵列中的各探针的密度对于整体分析而言是正常的,但是将阵列功能化以使得仅一部分探针(其中基本上所有探针都能够被单独解析)得到分析。该功能化可以在对阵列进行测定之前完成。在其它情况下,功能化由测定引起。例如,可以将测定构造成使得样品的添加量如此低以致于仅与阵列的一部分探针发生相互作用。由于检测到的标记与这些相互作用的发生特异性相关,因此低密度的探针可以从更高密度的阵列中功能化。因此,在获得其中单个探针能够被解析和分析的活性产物之前,正常密度的阵列实际上为中间状态。能够固定在阵列中的探针包括核酸,例如dna及其类似物和衍生物,例如pna。核酸可以从任何来源获得,例如基因组dna或cdna,或使用诸如逐步合成等已知技术来合成。核酸可以是单链或双链。dna纳米结构或其它超分子结构也可以被固定。其它探针包括:通过酰胺键连接的化合物,例如肽、寡肽、多肽、蛋白质或含有它们的复合物;确定的化学实体,例如有机分子;缀合的聚合物和碳水化合物,或其组合文库。在多个实施方式中,在通过本发明的方法制造阵列之前,探针的化学身份必须是已知的或编码的。例如,核酸的序列(或至少是用于结合样品分子的区域的全部或部分序列)以及其它化合物的组成和结构应当是已知的或编码的,从而使得目标分子的序列可以参照对照表来确定。因此本文所用的术语“空间上可寻址”是指探针的位置指定了其身份(并且在在空间组合合成中,身份是位置的结果)。可以使用各种方法对探针进行标记以能够进行查询。合适的标记包括:光学活性染料,例如荧光染料;纳米颗粒,例如荧光球和量子点、棒或纳米棒;和表面等离子体共振颗粒(prp)或共振光散射颗粒(rls)-散射光的银或金颗粒(prp/rls颗粒的尺寸和形状决定了散射光的波长)。参见schultz等,2000,pnas97:996-1001;yguerabide,j.andyguerabidee.,1998,analbiochem262:137-156。每个组件都是空间上可寻址的,因此存在于每个组件中的探针的身份是已知的或者能够基于之前的编码确定。所以,如果查询组件以确定给定的分子事件是否发生,则经固定的探针的身份凭借其在阵列中的位置而已知。在优选的实施方式中,每个组件内仅存在一种探针物种,为单拷贝或多拷贝。如果以多拷贝存在,则优选的是各个探针是能够单独解析的。在一个实施方式中,阵列中的组件可以包含能够单独解析的多种物种。通常,多种物种被差异化标记,以使得它们可以被单独辨别出。举例而言,组件可以包含许多种不同的探针用于检测单核苷酸多态性等位基因,每种探针具有不同的标记,例如不同的荧光染料。通过本发明方法产生的分子阵列优选包含至少10种不同的分子物种,更优选至少50或100种不同的分子物种。对于基因表达分析应用而言,阵列组件的数目可以由基因的数量最终决定。对于snp分析,组件的数量可以由充分采样基因组多样性所需的snp的数量来确定。对于测序应用而言,组件的数量可以由基因组片段化后的尺寸来确定,例如对于50,000kb的片段,可能需要20,000个组件来代表全部基因组,并且需要较少的组件来代表编码区。下面概述了制造用于本发明的低密度阵列的两种可行的方法。i.从新制造在本发明的一个实施方式中,通过将已知组成的多个探针固定至固相来产生低密度分子阵列。通常,探针固定在固体基板的离散区域之上或固定在该离散区域中。基板可以是多孔的以允许固定在基板内(例如benoit等,2001,anal.chemistry73:2412-242),或者是基本上非多孔的,在这种情况下探针通常固定在基板的表面上。本文所述的固体基板可由直接或间接结合探针的任何材料制成。合适的固体基板的实例包括平板玻璃、石英、硅晶片、云母、陶瓷和诸如塑料等有机聚合物,包括聚苯乙烯和聚甲基丙烯酸酯。表面可以被配置为充当电极或导热基板(这增强了杂交或鉴别过程)。例如,微米和亚微米电极可以使用光刻技术在合适的基板的表面上形成。更小的纳米电极可以通过电子束写入/光刻制成。电极也可以使用导电聚合物制成,导电聚合物可以通过喷墨打印装置、通过软光刻将基板图案化,或者通过湿化学均匀地施加。可利用涂覆有tno2的玻璃基板。可以设置电极,其密度使得每个经固定的探针具有其自己的电极,或为更高的密度以使得探针或组件的组与单独的电极连接。作为另一选择,一个电极可以作为在阵列表面之下形成单个电极的单层提供。在另一实施方式中,基板可以是半导体、二极管或光电二极管。固体基板可以可选地与渗透层或缓冲层相接。也可以使用广泛可用的半透膜,例如硝化纤维素或尼龙膜。半透膜可以安装在更稳固的固体表面上,例如玻璃。表面层可以包含溶胶-凝胶。表面可以可选地涂覆有金属层,例如金、铂或其它过渡金属。合适的固体基板的具体实例是商业上可获得的sprbiacoretm芯片(pharmaciabiosensors)。heaton等,2001(pnas98:3701-3704)已经将静电场施加到spr表面并且使用该电场来控制杂交。优选的是,固体基板通常是具有刚性或半刚性表面的材料。在优选实施方式中,基板的至少一个表面基本上是平坦的,但在其它实施方式中,可以理想地用例如凸起区域或蚀刻槽等将离散的组件物理分隔开。例如,固体基板可以包括纳米小瓶——例如平坦表面中的直径10μm且深度10μm的小空穴。这对于从表面切割探针并在其中进行测定或其它过程(例如扩增)而言特别有用。溶液相反应比固相反应更有效,同时使结果保持空间上可寻址,这是有利的。还优选的是,固体基板适于探针(例如核酸)在离散区域中的低密度应用。提供通道以允许毛细作用也是有利的,因为在某些实施方式中,这可以用于实现个体核酸分子的所需的拉直。通道可以为二维构造(例如quakes,andscherer.,200,science290:1536-1540)或三维流通构造(benoit等,2001,anal.chemistry73:2412-2420)。通道提供更高的表面积,因此可以固定更多数量的探针。在3-d流动通道的情况下,阵列查询可以通过共焦显微镜来进行,所述共焦显微镜对通道在z轴方向上的多个片层成像。此外,表面或子表面可以包括功能层,例如磁性或发光层或光转换层。在一些情况下,阵列组件在电极/电极阵列上凸起。在一些情况下,阵列组件是二极管或光电二极管。在另一实施方式中,二极管或光电二极管包含在孔、物理结构或纳米孔中。覆盖有透明导电层(例如氧化铟锡(ito))的载玻片可以用作显微镜的基板,显微镜包括全内反射显微镜(可购自bioelectrospec,pa,usa)。将固体基板方便地分割成多个部分。这可以通过诸如光刻等技术或通过应用疏水性墨(例如基于特氟隆的墨(cel-line,usa))来实现。各不同的探针或分子物种的组所在的离散位置可以具有任何方便的形状,例如圆形、矩形、椭圆形、楔形等。将多个探针附着到基板可以通过共价或非共价(例如静电)手段进行。多个探针可以经由该多个探针所结合的中间分子层附着到基板上。例如,多个探针可以用生物素标记,基板用抗生物素蛋白和/或抗生蛋白链菌素包被。使用生物素化分子的便捷之处在于可以容易确定与固体基板偶联的效率。由于多个探针可能对某些固体基板仅不良地结合,因此可能需要在固体基板(例如在玻璃的情况下)和多个探针之间提供化学界面。合适的化学界面的实例包括各种硅烷连接物和聚乙二醇间隔物。另一实例是使用涂覆聚赖氨酸的玻璃,然后在需要时使用标准方法对聚赖氨酸进行化学修饰以引入亲和配体。核酸可以直接固定在聚赖氨酸表面上(通过静电)。表面电荷的表面密度对于以允许在测定和检测中良好地呈现探针的方式固定探针而言是非常重要的。使用偶联剂将探针附着到固体基板的表面的其它方法是本领域已知的,参见例如wo98/49557。探针也可以通过可切割的连接物附着到表面。在一个实施方式中,通过点样(spotting)(例如通过使用机器人微量点样技术–schena等.,1995,science270:467-470)或者喷墨打印将探针施加至固体基板,该喷墨打印使用例如本领域已知的装备有喷墨(佳能专利)或压电装置的机器人装置来进行。例如,可以将溶解有预先合成的寡核苷酸的100mmnaoh或2-4xssc或50%dmso施涂至涂覆有3-糖二氧基丙基三甲氧基硅烷或乙氧基衍生物的载玻片上。然后在室温下放置12-24小时,然后置于4℃。有利的是,寡核苷酸可以是氨基封端的,但也可以点样未修饰的寡聚物(然后可以在室温温育之前将其在110-20℃下放置15分钟至20分钟)。作为另一选择,可以将氨基封端的寡核苷酸点样至50%dmso中的3-氨基丙基三甲氧基硅烷上,然后以300毫焦耳进行uv交联。可以将cdna或其它未修饰的dna点样到上述载玻片上或点样到涂覆聚l赖氨酸的载玻片上。2-4×ssc或1:1dmso:水可用于点样。用uv和琥珀酸酐处理是可选的。应在进行测定前洗涤载玻片,从而清洗掉未结合的探针。单分子阵列可通过点样稀溶液来产生。以下是制备单分子阵列的经测试的规程。制造单分子阵列需要考虑许多因素。主要的要求当然是探针的表面密度使得单个探针能够被单独解析。一般来说,获得最高品质的微阵列的一般标准应适用于此。斑点在形状和内部形态方面必须具有最高的品质,并且非特异性背景应该较低。在斑点区域内单个探针必须均匀分布,并且探针或内部斑点图案的聚束,例如由于斑点干燥过程而导致的“晕环(doughnut)”效应,应该最小。理想的是,斑点的形状和尺寸应相当相似。斑点的排布应该为规则图案,并且应避免线外斑点(已经移出记录区的斑点),这似乎在载玻片保持在高湿度下时出现。载玻片表面化学、点样方法和相关参数决定了为了获得单分子阵列而在微量滴定板孔中必须提供的寡核苷酸最佳浓度。因此,当以下各项变化时,需要根据经验确定微量滴定板孔中的寡核苷酸浓度:阵列点样系统(有许多设备制造商),点样头的类型(即喷墨、毛细管、隐形针(stealthpin)、环和针),点样参数(例如,毛细管撞击表面的强度,分配多少体积),载玻片化学,寡核苷酸化学,寡核苷酸是否包含任何末端修饰,以及点样缓冲液的类型和浓度和点样过程中的湿度。有许多供应商销售具有不同表面修饰的载玻片和适当的缓冲液,例如corning(usa),quantifoil(jena,germany),surrmodics(usa),zeiss(germany)和mosaic(boston,usa)。固定也可以通过以下手段进行:与抗生物素蛋白、抗生蛋白链菌素或中性抗生物素蛋白复合的生物素-寡核苷酸;经由二硫键共价连接至sh-表面的sh-寡核苷酸;共价连接至激活的羧酸基或醛基的胺-寡核苷酸;与水杨基氧肟酸(sha)复合的苯基硼酸(pba)-寡核苷酸;与硫醇或硅烷表面反应或与丙烯酰胺单体共聚形成聚丙烯酰胺的acrydite-寡核苷酸。或者用本领域已知的其它方法。对于优选使用带电表面的一些应用,表面层可以由聚电解质多层(pem)结构组成(us2002025529)。也可以通过将微量滴定板密封在基板表面上并离心而沉积阵列,其中微量滴定板的样品侧在该表面上。随后翻转并离心,此时基板在上。单分子阵列可以通过短的第一次离心和长的第二次离心来产生。作为另一选择,可以通过离心来沉积稀溶液。所需的低密度通常使用稀溶液来实现。已经显示铺展在1cm2面积上的1微升的10-6m溶液在表面上产生12.9nm的平均分子间间隔,该距离太小而不能用光学显微镜解析。每稀释10倍将平均分子间间隔增至3.16倍。因此10–9m的溶液产生约400nm的平均分子间间隔,10–12m产生约12.9μm的平均分子间间隔。在平均间隔为约12.9μm的情况下,如果探针和/或探针的标记聚焦成显示直径为0.5μm,并且平均距离为5μm,则两个探针和/或标记重叠的机会(即中心之间的距离为5微米以下)约为1%(基于m.ungere.kartalov,c.schiu,h.lesterands.quake,"singlemoleculefluorescenceobservedwithmercurylampillumination",biotechniques27:1008-1013(1999))。因此,用于点样或打印阵列的稀溶液的典型浓度(在使用远场光学方法进行检测的情况下)为约至少10-9m,优选至少10-10m或10-12m。在使用超解析度远场方法或spm时所用浓度更高。还应该记住,只有一部分点样在表面上的探针稳固地附着在表面上(例如0.1%至1%)。因此,取决于各种点样和载玻片参数,1-500nm的寡核苷酸可以适合于点样到环氧硅烷载玻片和增强型氨基硅烷载玻片和氨基硅烷载玻片上。取决于固定方法,只有一部分稳固附着的探针可用于杂交或酶学测定。例如,在使用氨基连接的寡核苷酸并且点样到涂覆有氨基丙基三乙氧基硅烷(aptes)的载玻片表面的情况下,约20%的寡核苷酸可用于微测序。在进行测定之前,可能需要预处理载玻片以封闭可能发生非特异性结合的位置。另外,在例如经标记的dntp或ddntp经常非特异性地粘附到表面上的引物延伸中,可能需要以化学或电子方式在表面上提供负电荷以排斥这些探针。在第二实施方式中,表面被设计成使得附着位点(即化学连接物或表面部分)是稀释的或者所述位点被选择性地保护或封闭。在这种情况下,只要附着对这些位点具有特异性,用于喷墨打印或点样的样品的浓度是无关紧要的。在原位合成探针的情况下,用于引发合成的更低数量的可用位点允许更高效的合成,从而提供获得全长产物的更高机会。聚合物(例如核酸或多肽)也可以使用光刻法和其它掩蔽技术原位合成,由此探针以逐步方式合成,其中通过掩蔽技术和光不稳定反应物控制单体在特定位置上的引入。例如,美国专利第5,837,832号公开了一种基于非常大规模的集成技术来生产固定在硅基板上的dna阵列的方法。特别而言,美国专利第5,837,832号描述了一种称为“平铺”的策略来在基板上的空间限定位置合成特定的探针组。美国专利第5,837,832号还提供了也可以使用的早期技术的参考文献。通过使用已描述的数字光微镜芯片(texasinstruments)也可以进行光引导合成(singh-gasson等,(1999)naturebiotechnology17:974-978)。利用其中例如以空间上可寻址的方式产生对dna单体选择性地脱保护的光酸的光引导方法,可以使用常规脱保护基团(例如二甲氧基三苯甲基)来代替使用用光直接处理的光脱保护基团(mcgall等,pnas199693:1355-13560;gao等,j.am.chemsoc.1998120:12698-12699)。酸的电化学生成是正在开发的另一种手段(例如combimatrixcorp.)。可以使用半导体方法和制造技术来产生阵列。阵列组件的尺寸通常为0.1×0.1微米以上,这样可以被喷墨或点打印到图案化表面上,或通过光刻或物理掩蔽来产生。通过纳米光刻术(例如扫描探针显微镜)产生的阵列组件可以更小。探针可以在单个附着点附着到固相,该点可以位于探针末端或其它位置。或者,探针可以附着在两个以上附着点。在核酸的情况下,使用使经固定的探针相对于固体基板“水平化”的技术可以是有利的。例如,dna液滴的流体固定先前已经显示出将dna延伸并固定到衍生化表面,例如硅烷衍生化表面。这可以促进经固定的探针对靶分子的可及性。在快速蒸发条件下通过羽毛笔(quill)/针/笔点样样品可在样品干燥时产生毛细作用力以拉长分子。jong-inhahm在5月17-18日华盛顿特区举办的剑桥健康技术研究所第五届年会的advancesinassays,molecularlabels,signallinganddetection中已经描述了通过通道中的毛细作用拉直分子的手段。样品可以通过通道阵列施加。在表面上伸展的分子的密度通常受到dna分子的回转半径的约束。任何物质的单分子阵列的制造方法可以包括以下步骤:(i)用宽稀释范围的探针梯度稀释液制造一系列微阵列斑点;(ii)使用所需的检测方法进行分析,以看出哪些斑点提供单探针解析度;(iii)可选地,基于来自(ii)的信息,用更集中的梯度稀释液重复(i)和(ii);和(iv)用确定的稀释液制造微阵列。空间上可寻址的自组装体:本文描述的固定化探针和/或标签还可用于结合其它分子和/或探针以完成阵列的制造。例如,固定在固体基板上的核酸可用于通过杂交捕获其它核酸或捕获多肽。类似地,多肽可以与其它化合物(例如其他多肽)一起温育。可能需要使用例如uv交联和合适的交联试剂永久地“固定”这些相互作用。二级分子和/或探针的捕获可以通过结合至单个经固定的标签或亲和标签或结合至两个以上标签或亲和标签来实现。当二级分子和/或探针结合至两个以上标签时,这可以具有水平地包含二级分子和/或探针的理想效果。通过诸如分子梳直和纤维fish等方法,也可以使本文所述的二级分子和/或探针在没有标签或第二探针的情况下变得水平和拉直。一个详细的方法在实施例中描述(参见图10)。这与junpingjingpnasvol.95,issue14,8046-8051,1998年7月7日(us6221592)的预分选分子的阵列片段是非常不同的,因为我们已经使基因组分子自组装到空间上可寻址的位点,因此它是为高度平行的单分子分析进行基因组分选的一种方式。对于代表全基因组的schwartz的阵列斑点,将需要使用传统的克隆技术来分离每个个体基因组片段以进行点样。在完成以上后,阵列的组件优选不是彼此紧邻,每个功能性阵列组件之间应该存在空位,因为预期伸展的dna纤维会从组件的边缘伸展出去(并且将突出到紧邻的组件中)。在这些情况下,阵列组件的间隔由被固定的探针的长度决定。例如,对于λdna而言,分隔组件的距离应该至少为15至30微米。该过程可以在标签或探针的空间上可寻址的阵列上自组装通常由靶分子组成的二级阵列。这是一种将复杂样品(例如基因组或mrna群体)分类并将其呈现于进一步分析(例如单倍体分型或测序)的方法。ii.高密度阵列的密度降低在替代性实施方式中,分子阵列可以通过以下方式获得:使用本领域已知的多种方法提供以正常(高)密度的探针产生的阵列,然后降低表面覆盖率。可以以许多方式来减少实际或有效的表面覆盖率。当探针通过连接物附着到基板上时,可以切割连接物。代替使切割反应完成的是,反应部分进行以达到期望的表面覆盖率密度所需的水平。在通过环氧化物和peg键附着于玻璃的探针(例如寡核苷酸)的情况下,可以在已知逐渐破坏平层(lawn)的氨中加热来实现部分去除探针。还可以通过例如使用酶或化学试剂使探针功能原位失活来获得表面覆盖率的降低。使用的酶或试剂的量应足以实现所需的降低,而不使所有探针失活。虽然该方法的最终结果常常是基板的探针本身的密度与密度降低步骤之前相同,但是由于许多原始探针已经失活,功能性探针的密度已降低。例如,通过多核苷酸激酶使3'连接的寡核苷酸的5'末端的磷酸化(这使得寡核苷酸可用于连接测定)仅有10%的效率。用于获得探针密度降低的替代方法是通过对仅一部分预先存在的经固定的探针加标记或加标签来获得有效的密度降低,从而使得只有所需密度的经标记/加标签的探针可用于相互作用和/或分析。在靶标引入标记时,这对于分析在正常密度阵列上的低靶标数量而言特别有用。这些密度降低步骤可以方便地应用于由各供应商(例如affymetrix、corning、agilent和perkinelmer)出售的现成的分子阵列。作为另一选择,可以根据需要处理专有的分子阵列。本发明还提供了一种“阵列的阵列”,其中将所述的分子阵列(1级)的阵列构造成用于多重分析的阵列(2级)。多重分析可以通过密封单独腔室中的每个分子阵列(1级)来进行,这形成了与共同基板的密封,从而可以对每个分子阵列应用单独的样品。或者,每个分子阵列(1级)可以放置在针(通常用于组合化学中)或纤维的端部,并且可以浸入诸如384孔微量滴定板等多孔板中。纤维可以是能够用于将每个阵列的信号传送到检测器的光纤。分子阵列(1级)可以在自组装到中空光纤上的珠,如walt与合作者(illuminainc.):karri等,anal.chem199870:1242-1248所描述的。此外,阵列可以具有已知和确定类型的随机固定分子的阵列,例如来自特定人样品的每个17聚物或基因组dna的完整寡核苷酸组。本发明的阵列可以提供用于不同应用的探针,例如针对某些应用所需的snp分型和str分析,例如对y染色体上的多态性进行分型。生物传感器:低密度分子阵列或低密度功能化分子阵列可用于生物传感器中,所述生物传感器可用于监测基板表面(例如芯片)上的单分子测定。该阵列可以包括例如1至100个不同的经固定的分子(例如探针)、激发源和检测器(例如ccd),全部在集成器件内。样品处理可以集成或不集成到该器件中。在一个方面,生物传感器将包括多个组件,每个组件含有不同的分子,例如探针序列。然后,每个组件可以对例如不同病原性生物体的检测具有特异性。在优选的实施方式中,经固定的分子是分子信标的形式,并且基板表面将使得可以在表面产生倏逝波。这可以通过在基板表面上形成光栅结构或者通过在例如光纤(在光纤内光完全内反射)上制造阵列而实现。ccd检测器可以放置在阵列表面下方或阵列上方,与表面以短距离分隔开以为反应体积留出空间。生物传感器构造的实例在图6中给出,其中:(a)是基于荧光能量共振转移(fret)的集成检测方案。样品施加在两个板之间,一个具有ccd,另一个具有在其表面上具有光栅结构的led。(b)是在光纤上具有分子信标的集成检测系统(tyagi等,nat.biotechnol.1998,16:49-53)。可以使用其他方法,例如全内反射荧光(tirf)。单分子可以在条状熔融二氧化硅光纤上观察,基本上如watterson等所述(sensorsandactuatorsb74:27-36(2001)。分子信标可以以同样的方式看到(liu等,(2000)analyticalbiochemistry283:56-63)。这是基于倏逝场中的单分子分析的生物传感器器件的基础。本发明还提供了通过本发明的上述第一和第二实施方式获得的分子阵列。本发明还提供分析单个探针的手段,其中可以确定物理、化学或其它性质。例如,可以对在特定测试波长下发荧光的探针直接取样。本发明还提供了用于检测样品分子与本文所述的探针之间的相互作用的多种技术。因此,本发明提供了分子阵列在鉴定与靶标相互作用的一种或多种探针的方法中的用途,该分子阵列包括固定在基板上的多个探针,其密度允许每个单个的经固定的探针能够被单独解析,其中每个单个的经固定的探针的身份根据其在空间上可寻址的阵列中的位置而已知,并且每个经固定的探针的身份是已知的或者每个单个的探针的身份被编码并且可以被解码,例如参考对照表来解码。通常,所述方法包括使该阵列与样品接触并查询一个或多个单个的经固定的探针以确定靶分子是否已经结合。优选的是,对靶分子或探针-靶分子复合物进行标记。优选的是,查询通过检测电磁辐射的方法进行,例如选自下述的方法:远场光学法、近场光学法、表面荧光光谱、共焦显微镜、双光子显微镜和全内反射显微镜,其中靶分子或探针-靶分子复合物标记有电磁辐射发射体。其它显微镜方法,例如原子力显微镜(afm)或其他扫描探针显微镜(spm)也是适用的。此处可能没有必要标记靶或探针-靶分子复合物。作为另一选择,可以使用通过spm检测的标记。在一个实施方式中,经固定的探针具有与靶分子相同的化学类别。在另一个实施方式中,经固定的探针具有与靶分子不同的化学类别。本文中总体阐述了本发明的分子阵列的具体应用和单分子检测技术的具体应用。特别优选的用途包括:在生物传感器中以及遗传方法(例如关联研究)和在基因组学和蛋白质组学中的核酸分析,例如在snp分型、测序等中的核酸分析。在另一方面,本发明涉及一种对核酸中的单核苷酸多态性(snp)和突变进行分型的方法,所述方法包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针库(repertoire),所述核酸可能具有一个或多个多态性,所述库呈现为使得探针可以被单独解析;b)将样品暴露于库,并使存在于样品中的核酸以所需的严格性与探针杂交,并且可选地进行进一步处理;c)检测结合事件或处理结果。可以通过从库中洗脱出未杂交的核酸并检测单个的经杂交的核酸探针来辅助检测结合事件。有利的是,库以阵列形式呈现,其优选为上文所述的阵列。本发明特别适用于遗传分析和低频多态性检测中的dna汇集策略。dna汇集策略包括将多个样品混合在一起并对其一起分析,以节省成本和时间。本发明也适用于野生型背景中的低频突变的检测。本发明也可用于样品材料量低的情况,例如生物传感器或化学传感器应用中。本发明还适用于单体型分型,其中使用多等位基因探针组来同时分析每个样品分子的两个以上特征。例如,可以使用第一探针来将样品核酸固定到基板,并且可选地同时鉴定一种多态性或突变;并且可以使用第二探针来与经固定的样品核酸杂交并检测第二种多态性或突变。因此,将第一探针(或双等位基因探针组)阵列化到基板上,并且在溶液中提供第二探针(或双等位基因探针组)(或者也将其阵列化;见下文)。可以根据需要使用其他探针。因此,本发明的方法可以包括将样品核酸与溶液中的一种或多种其他探针杂交的另外步骤。由第一和第二探针产生的信号可以通过例如使用可区分的信号分子(例如在不同波长发光的荧光团)来区分,如下文更详细描述。此外,信号可以基于其沿着基板上的靶分子的位置而区分。为了帮助沿着探针定位信号,可以通过本领域已知的方法来伸展探针。在又一方面,本发明涉及确定一种或多种靶dna分子的序列的方法。此类方法可以适用于例如下述的核酸样品指纹识别方法。此外,该方法可以应用于核酸分子的完全或部分序列测定。因此,本发明提供了一种确定靶核酸的完全或部分序列的方法,所述方法包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针库,所述第一库呈现为使得探针可以被单独解析;b)使包含靶核酸的样品与探针杂交;c)使一种或多种具有确定序列的其它探针与靶核酸杂交;和d)检测单个的其它探针与靶核酸的结合。有利的是,其它探针标记有可区分的标记,例如不同的荧光团。有利的是,库以阵列形式呈现,其优选为上文所述的阵列。在有利的实施方式中,靶核酸在多个点被捕获在基板表面上,这使得探针可以在表面上水平地排布,并且可选的是,多个捕获位点处于使靶分子延伸的位置。在进一步的实施方式中,探针通过单个点附着,并采取物理措施使其水平化。然后可以根据位置以及根据标记的差异来确定其它探针的杂交。在另一实施方式中,本发明提供了一种确定样品核酸中的序列重复的数量的方法,包括以下步骤:a)提供与样品中存在的一种或多种核酸互补的一种或多种探针,所述核酸可能具有一个或多个序列重复,所述探针呈现为使得探针可以被单独解析;b)使包含重复的核酸样品杂交;c)使核酸和与所述序列重复互补的经标记的探针或聚合酶和核苷酸接触;和d)通过单独评估引入到每个探针中的标记数量,例如通过测量由标记产生的信号的亮度,来确定每个样品核酸上存在的重复的数量;其中在优选实施方式中,仅处理来自还引入了标记有不同标记的第二溶液寡核苷酸的探针的信号。可以针对标记有第一颜色的重复探针与标记有第二颜色的第二探针的强度比来分析结果。有利的是,库以阵列形式呈现,其优选为上文所述的阵列。本发明还提供了一种分析样品中一种或多种基因的表达的方法,包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针库,所述库呈现为使得探针可以被单独解析;b)使包含所述核酸的样品与探针杂交;c)通过对与探针杂交的单个探针进行计数来确定样品中存在的单个的核酸物种的性质和量。在一些情况下,可以利用能够区分备选的转录物或基因家族的不同成员的序列来进一步探测单个的探针。有利的是,库以阵列形式呈现,其优选为上文所述的阵列。优选的是,探针库包含各自被赋予特异性的多个探针,从而允许捕获样品中的多于一种核酸物种。这使得通过单个探针计数能够准确定量表达水平。在另一实施方式中,含有每种物种的多个拷贝的靶样品被固定并铺展在表面上,将多个探针以网格化方式加载在该第一层上。每个网格点在其区域内含有至少一个拷贝的每种靶物种。在洗涤步骤后,确定已经结合的探针。本发明提供了一种全部或部分靶核酸分子的序列的方法,包括:(i)在两个以上点处将靶分子固定在基板上,使得该分子相对于基板表面基本上水平;(ii)在固定期间或之后拉直靶分子;(iii)使靶分子与已知序列的核酸探针接触;和(iv)确定靶分子内的与探针杂交的位置;(v)必要时重复步骤(i)至(iv);和(vi)重建靶分子的序列。优选地,使靶分子与多个探针接触,更优选每个探针都经编码,例如标记有不同的可检测标记或标签。靶分子可以与多个探针中的每一个依次接触。在一个实施方式中,在使靶分子与不同探针接触前,去除每个探针,或将其标记从靶分子中去除或光漂白。通常,通过加热、改变盐浓度或ph,或通过施加适当偏置的电场来去除探针。或者,与探针互补并且与靶链形成更强的杂交物的另一寡核苷酸可以置换靶链。在另一实施方式中,探针或其标记都不被去除,而是记录其沿分子的相互作用位置,而后再添加另一探针。经过一定数量的探针添加后,在结合更多的探针之前必须除去结合的探针。作为另一选择,使靶分子基本上同时与所有多个探针接触。在一个实施方式中,靶标基本上是双链分子,并且通过链侵入与lna或pna探针杂交。在另一实施方式中,靶双链在表面上是被梳直的(或制造纤维fish纤维),并在梳直之前或之后变性。在另一实施方式中,靶基本上是单链的,并且通过伸展/拉直而使其在随后的杂交中更易被接触,这可以利用作用在溶液中的靶标上的毛细管力来实现。在一个实施方式中,在需要确定单链分子的序列的情况下,靶核酸分子是双链分子,并且其通过合成与目标单链核酸互补的链而衍生自该目标单链核酸分子。本发明还提供了一种确定全部或部分靶单链核酸分子的序列的方法,所述方法包括:(i)在一个、两个或更多个点处将靶分子固定在基板上,使得该分子相对于基板表面基本上水平;(ii)在固定期间或之后拉直靶分子;(iii)使靶分子与已知序列的多个核酸探针接触,各探针都标记有不同的可检测标记;和(iv)连接结合的探针以形成互补链。当探针不以连续方式结合时,优选在步骤(iv)之前,通过由所述结合的探针引发的聚合来填充结合的探针之间的任何空位。本发明还提供了一种确定全部或部分靶单链核酸分子的序列的方法,该方法包括:(i)使靶分子与已知序列的多个核酸探针接触,各探针都标记有不同的可检测标记;(ii)连接结合的探针以形成互补链;(iii)在一个或多个点处将靶分子固定在基板上,使得该分子相对于基板表面基本上水平;和(iv)在固定期间或之后拉直靶分子。当探针不以连续方式结合时,优选在步骤(iii)之前,通过由结合的探针引发的聚合来填充所述结合的探针之间的任何空位。在该过程期间或之后记录每个连接探针附着的位置。本发明还提供了用上述方法中的任一种制备或可获得的阵列。本发明涉及将单分子阵列的制备与在单分子阵列上进行测定结合在一起。特别是当将二者或其中任一个与本文所述的对基板上的单个探针的检测/成像以及基于对单分子计数或者对单分子的信号进行记录和测量的测定结合在一起时。本发明还提供了用于处理来自上述方法的数据的软件和算法。用于根据本文所述方法检测遗传变异的系统包括多种元件。一些元件包括将原始生物样品转化成有用的分析物。然后检测该分析物,产生数据,稍后将数据处理成报告。图19中显示了可以包括在所述系统中的各种模块。图20中显示了用于分析数据的各种方法的更多细节(例如包括图像处理)。分析可以在计算机上进行,并且包括与产生数据的装置连接的网络以及用于储存数据和报告的数据服务器。可选地是,分析物数据之外的其它信息可以包括在最终报告中,例如母体年龄或之前的已知风险。在一些实施方式中,测试系统包括一系列模块,其中一些是可选的或者可以根据之前模块的结果而重复。测试可以包括:(1)接收请求,例如来自下指令的临床医生或医师的请求,(2)接收患者样品,(3)对该样品进行测定(包括品质控制),从而在合适的成像基板上产生测定产物(例如使探针与样品接触、结合和/和杂交,连接所述探针,可选地扩增经连接的探针,并且将探针固定至本文所述的基板),(4)在一个或多个光谱通道中将基板成像,(5)分析图像数据,(6)进行统计学计算(例如比较第一数量和第二数量以确定遗传样品中的遗传变异),(7)创建和审批临床报告,和(8)将报告返回至下指令的临床医生或医师。测试系统可以包括被构造成接收请求(例如来自下订单的临床医生或医师的请求)的模块,被构造成接收患者样品的模块,(3)被构造成执行对该样品进行测定(包括品质控制)以在合适的成像基板上产生测定产物的模块,(4)被构造成在一个或多个光谱通道中将基板成像的模块,(5)被构造成分析图像数据的模块,(6)被构造成执行统计学计算的模块,(7)被构造成创建和确认临床报告的模块,和/或(8)被构造成将报告返回至下指令的临床医生或医师的模块。在一个方面,本文所述的测定和方法可以对单个输入样品同时进行。例如,所述方法可以包括:验证处于或高于本文所述的最小阈值的胎儿基因组分子的存在,然后,如果并且只有满足该最小阈值,则进行评估靶拷贝数状态的步骤。因此,可以对输入的样品单独运行用于进行执行胎儿组分计算的等位基因特异性测定和用于计算拷贝数状态的基因组靶测定。在其它实施方式中,本文所述的测定和方法可以在相同时间以相同的流体体积对相同的样品平行地进行。还可以以相同的通用测定处理步骤平行地进行另外的品质控制测定。由于可以针对每种测定和每种测定产物来独特地设计待固定至基板的探针产物、经连接的探针组或经标记的分子中的标签、亲和标签和/或标签探针,可以在成像基板上的不同物理位置将所有平行测定产物定位、成像和定量。在另一方面,使用相同的探针和/或检测相同的遗传变异或对照的本文所述的相同测定或方法(或其步骤中的一些)可以在本文所述的相同或不同模块(例如试管)中对多个样品同时进行。在另一方面,使用不同的探针和/或检测不同的遗传变异或对照的本文所述的测定或方法(或其步骤中的一些)可以在相同或不同模块(例如试管)中对单个或多个样品同时进行。在另一方面,图像分析可以包括:图像预处理,图像区段化以鉴定标记,表征标记品质,基于品质过滤所检测的标记的群体,和根据图像数据的性质进行统计学计算。在一些情况下,例如当进行等位基因特异性测定并成像时,可以计算胎儿组分。在其它方面,例如在基因组靶标测定和成像中,计算两个靶基因组区域之间的相对拷贝数状态。图像数据的分析可以在控制图像获取的相同计算机上或在网络计算机上实时进行,从而可以以接近实时的方式将分析结果并入测试工作流决策树中。理想的是,将阵列的组件设计成使得它们足够大,以致于它们包含所收集的图像的视野或尺寸。也就是说,由相机拍摄的整个图像捕获了组件内部的区域。在某些情况下,图像的>90%、>80%、>50%、25%或>10%属于包含在组件内的区域。在该情况下,图像的尺寸是相机传感器尺寸、放大率和光路组件(例如视场光阑)的函数。以此方式,整个传感器填充有分子(与组件之外的空白区域相反),因此将数据收集和样品通量最大化。具有大于相机传感器的组件也将减少诸如用点样阵列时看到的环绕或反馈(donating)等问题。选择放大率、组件尺寸、光路和传感器尺寸的这种方法与单帧包括许多组件的传统微阵列相反。对于传统阵列而言这是可行的,因为每个组件都给出单一测量结果。相反,在单分子阵列中,每个组件给出数千、数万或数十万次的测量结果(每个测量结果是经标记分子的存在)。如果每个组件的平均荧光团数量是已知的,则可以计算出收集给定数量的计数所需的组件总数。在一个实施方式中,在单个阵列上产生2、5、10、50、100、500或1000个组件。每组件计数的荧光团数量取决于经标记的分子的密度。每个组件平均可以包含100、500、1,000、5,000、10,000.、20,000、50,000、100,000或更多经标记的分子。组件和每个组件的经标记分子的组合产生了可以计数的经标记分子的总数。分子总数可用于计算灵敏度、特异性、阳性预测值、阴性预测值和其它参数或因素。分子总数可用于计算统计力、预期假阳性率和预期假阴性率。理想的是,对于每个样品,对10,000、100,000、500,000、1,000,000、5,000,000、10,000,000、100,000,000或更多个经标记的分子进行计数。这些将包含在1个或更多个组件中。分子可以标记有一个或多个标记。在产前检测中,将对每个待测的基因组区域计数分子。可以使用标准方法计算测试的统计力,并根据具体应用定制(参见例如statisticalmethodsincancerresearch–volumesi&ii,breslow&day编写,iarcscientificpublications)。在产前检测中,优选对每个测试的基因组区域计数至少100,000个分子、理想地至少1,000,000个分子。如果存在显著的误差、污染或其它形式的噪声,那么计数的分子数量将理想地更大。从单分子阵列收集的数据量与基于测序的测试非常不同。例如,在全基因组测序中,许多测序读数会被定位(map)到未被测试的染色体。即使对于靶向测序方法,许多测序读数也不会唯一地定位到基因组,而会是引物二聚体或其他伪像。在优选的实施方式中,单分子阵列不需要测序或将序列定位到基因组。在另一方面,本文所述的方法中需要计数的探针的数量可以高到分析单个样品需要多个基板的程度。例如,如果使用盖玻片(例如22mm×22mm),则可用于计数的分子数量可能不足以达到所需的灵敏度。在该情况下,将需要多个盖玻片或更大格式的基板。对于产前测试,可以单独或组合使用平均10mm2、100mm2、1000mm2或>1000mm2的基板。在另一方面,由于在常见的单分子阵列上的荧光团密度低,所以成像过程的定向可能有问题。因此,本说明书的方法可以包括在图像采集之前或期间使用基准来确定载玻片上的位置。基准可以是组件或其他特征物。如果其是组件,它们可能含有高密度的经标记的分子,并且该标记可以与其他组件使用的标记相同或不同。基准可以包含多于一种标记或多于一种类型的经标记的分子。基准组件的尺寸可以小于、大于或等于阵列上的其他组件。也可以通过蚀刻、光刻或表面标记来产生基准。基准可以分组存在和/或遍布整个阵列。它们可以以复杂或非对称图案存在,以帮助确定图像或快照的位置。基准可用于自动化图像采集过程中,用算法从多个基准之一确定位置,然后使用已知位置开始数据收集(例如通过从阵列组件移动到阵列组件)。表面上的定向也可以通过不对称的基板或保持基板的保持器或盒进行。其还可以通过将阵列非常精确地放置在成像器上(例如,显微镜上的工作台嵌入槽中的载玻片)来进行。在另一方面,对于成像用基板的不同部分,以上测试的步骤(4)和(5)可以重复多次,从而使结果支配后续步骤。例如,本文所述的测试和方法包括:在测试基因组靶标的相对拷贝数状态之前,确认在获自受试对象的遗传样品中的胎儿样品的存在和精确水平。如本文所述,可以使用等位基因敏感性测定来定量胎儿dna相对于母体dna的水平。所得的探针产物可以被拉入基板上的胎儿组分区1,并成像。在一些实施方式中,如果并且只有所计算的胎儿组分大于最低系统要求,则可以继续测试并产生有效结果。以此方式,在进行另外的成像和分析之前,可以终止那些不能确认至少最小输入胎儿组分的样品测试。相反地,如果胎儿组分高于最小阈值,可以继续基因组靶标(例如染色体21、18或13)的进一步的成像(所述测试的步骤4),随后进行另外的分析(所述测试的步骤5)。也可以使用和测试其它标准。在另一方面,并不是等位基因特异性测定中探测的每一个snp都可以产生有用的信息。例如,对于给定的snp(例如等位基因对ab)母体基因组材料可以具有杂合性等位基因,胎儿材料也可能在该位点处是杂合性的(例如ab),因此胎儿材料是不能辨别的,且不能计算胎儿组分。但是,对于相同输入样品的另一snp位点可能依然显示母体材料是杂合性的(例如ab)而胎儿材料是纯合性的(例如aa)。在该实例中,由于胎儿dna的存在,等位基因特异性测定可以产生比b计数稍微更多的a计数,由此可以计算胎儿组分。由于对于规定的样品不能推知snp谱(即基因型),应当设计多个或许多snp位点,以使得几乎每一个可能的样品都会产生有信息的snp位点。各snp位点可以定位至成像用基板上的不同物理位置,例如通过对各snp使用不同的标签。但是,对于给定测试,胎儿组分仅可以成功地计算一次。因此,可以对用于查询snp的基板上的单个或多个位置成像并进行分析(例如在1、2、3、4、5、10、20、50以下和/或1、2、3、4、5、10、20、50以上的组中),直到检测到有信息的snp。通过交替进行成像和分析,可以避免成像所有可能的snp点,并显著地减少平均测试持续时间,同时保准确性和稳健性。在另一方面,除了终止样品中胎儿组分的比例不足的测试之外,确定样品的胎儿组分还可以辅助所述系统的其它方面。例如,如果胎儿组分较高(例如20%),则对于给定的统计功效,每个基因靶标(例如chr21)所需的计数数量会较低;如果胎儿组分较低(例如1%),则对于相同的统计功效,每个基因组靶标需要非常高的计数数量来达到相同的统计学显著性。因此,在(4-1)对胎儿组分区1进行成像之后,(5-1)对产生所需的计数通量/基因组靶标的那些数据进行分析,(4-2)以所需的通量开始进行基因组靶区2的成像,然后(5-2)对那些图像数据和输入靶标的基因组变异的测试结果进行分析。在另一方面,以上测试的步骤(4)和(5)可以出于品质控制目的而进一步重复,这些目的包括评估:成像用基板上的荧光剂的背景水平、污染性部分、阳性对照或即时测试之外的拷贝数变化的其它原因(例如母体或胎儿中的癌、胎儿嵌合性、孪生)。因为图像分析可以是实时的,并且不需要在产生结果之前完成整个成像运行(与dna测序法不同),因此中间结果可以由决策树支配后续步骤,并且定制用于获得对个体样品的理想性能的测试。品质控制还可以包括验证:样品具有可接受的品质且存在,成像用基板被正确配置,测定产物存在且/或具有正确的浓度或密度,存在可接受水平的污染,成像仪器起作用,以及分析产生正确的结果,所有都馈至最终测试报告中以供临床团队审阅。在另一方面,以上测试包括一个或多个以下步骤:(1)接收请求(例如来自下指令的临床医生或医师的请求),(2)接收患者样品,(3)对该样品进行测定(包括等位基因特异性部分、基因组靶标部分和品质控制),产生含有测定产物的成像用基板,(4-1)在一个或多个光谱通道中将基板的等位基因特异性区域成像,(5-1)分析等位基因特异性图像数据以计算胎儿组分(待定的足够的胎儿组分),(4-2)在一个或多个光谱通道中将基板的基因组靶标区域成像,(5-2)分析基因组靶标区域图像数据以计算基因组靶标的拷贝数状态,(4-3)在一个或多个光谱通道中将基板的品质控制区域成像,(5-3)分析品质控制图像数据以计算、证实和验证所述测试,(6)进行统计学计算,(7)产生和审批临床报告,和(8)将报告发送回下指令的临床医生或医师。可以使用许多手段检测阵列中的单个分子及其与靶分子的相互作用。检测可以基于测量例如经固定的分子和/或靶分子的物理化学、电磁学、电学、光电子学或电化学性质或特征。有两个因素与表面上分子的单分子检测相关。第一个是实现足够的空间解析度来解析单个分子。分子的密度使得只有一个分子位于显微镜的衍射极限点中,其为约300nm。低信号强度降低了能够确定单个分子的空间位置的准确度。第二个是实现对所需单分子相对于背景信号的特异性检测。扫描探针显微镜检(spm)包括使探针尖端与分子紧密接触,因为在附着有分子的相对平坦表面上对尖端进行扫描。该技术的两个众所周知的版本是扫描隧道显微镜(stm)和原子力显微镜(afm;参见moeller等,2000,nar28:20,e91),其中分子的存在将自身分别表现为隧道电流或探针尖端高度的偏转。使用附着到探针尖端的碳纳米管可以增强afm(wooley等,2000,naturebiotechnology18:760-763)。可以同时获取图像的spm探针阵列正在由许多小组开发,并且可以加速图像采集过程。金或其他材料的珠可用于帮助扫描探针显微镜自动找到分子。可以使用基于灵敏地检测吸收或发射的光学方法。通常,使用光激发手段来查询阵列,例如常常由激光源产生的各种波长的光。常用的技术是激光诱导的荧光。虽然一些分子对于检测而言具有足够的固有发光,但通常阵列中的分子(和/或靶分子)需要用发色团(例如染料或光学活性颗粒)来标记(参见上文)。如果需要,来自单分子测定的信号可以通过例如用负载染料的纳米颗粒或多标记的树枝状大分子或prp/spr进行标记来放大。等离子体共振颗粒(prp)是金属纳米颗粒,其由于金属中的传导电子的集体共振(即表面等离子体共振)而以显著的效率弹性地散射光。可以形成在光谱的可见光范围内的任何地方都具有散射峰的prp。与纳米颗粒相关的等离子体共振的幅度、峰值波长和光谱带宽取决于颗粒的尺寸、形状和材料组成以及局部环境。这些颗粒可用于标记目标分子。纳米颗粒上的sers(表面增强型拉曼散射)利用单分子本身的金属纳米粒子上的拉曼振动,并且可用于放大其光谱特征。此外,这些技术中的许多可以应用于检测相互作用的荧光共振能量转移(fret)法,其中例如阵列中的分子用荧光供体标记,而靶分子(或报告寡核苷酸)用荧光受体标记,当这些分子非常接近时产生荧光信号。此外,可以使用诸如分子信标等结构,其中fret供体和受体(猝灭剂)连接到相同的分子上。染料分子的使用会遇到光漂白和闪光的问题。用负载染料的纳米颗粒或表面等离子体共振(spr)颗粒进行标记减少了该问题。然而,单染料分子在暴露于光一段时间之后会漂白。已经在单分子领域有利地使用了单染料分子的光漂白特性作为区分来自多个分子或其它颗粒的信号与单分子信号的手段。光谱技术需要使用单色激光,其波长根据应用而变化。然而,显微镜成像技术可以使用更宽谱的电磁源。光学查询/检测技术包括近场扫描光学显微镜(nsom)、共焦显微镜和倏逝波激发。这些技术的更具体的版本包括远场共焦显微镜、双光子显微镜,广视野落射和全内反射(tir)显微镜。许多以上技术也可以以分光镜模式使用。实际的检测手段包括电荷耦合器件(ccd)相机和增强的ccd、光电二极管和光电倍增管。这些手段和技术在本领域是公知的。然而,下面提供了许多这些技术的简要描述。场扫描显微镜(nsom):在nsom中,通过将样品置于5-10nm的亚波长尺寸的光学孔内,可以实现约50-100nm的亚衍射空间解析度。通过在透射或收集模式中使用物镜来在远场中检测光信号(参见barer,cosslett,eds1990,advancesinopticalandelectronmicroscopy.academic;betzig,1992,science257:189-95)。nsom的优点是其改进的空间解析度和将光谱信息与地形数据关联的能力。阵列的分子需要具有固有的光学可检测的特征(例如荧光),或者用光学活性染料或颗粒(例如荧光染料)标记。已经提出通过扫描无孔显微镜可以将解析度降低到仅几纳米(scanninginterferometricaperturelessmicroscopy:opticalimagingat10angstromresolution”f.zenhausern,y.martin,h.k.wickramasinghe,science269,p.1083;t.j.yang,g.a.lessard,ands.r.quake,"anaperturelessnear-fieldmicroscopeforfluorescenceimaging",appliedphysicsletters76:378-380(2000))。在共焦显微镜下,使用油浸的高数值孔径物镜将激光束带入样品内的衍射极限焦点。从样品的50-100μm区域出现的荧光信号通过光子计数系统测量,并显示在视频系统上(进一步的背景信息参见pawleyj.b.,ed1995,handbookofbiologicalconfocalmicroscopy)。对光子计数系统的改进允许实时跟踪单分子荧光(参见nie等,1994,science266:1018-21)。远场共焦显微镜的进一步发展是双光子(或多光子)荧光显微镜,其可以允许用单个较高波长的光源激发具有不同激发波长的分子(分子进行多个较低能量的激发,例如参见mertz等,1995,opt.lett.20:253234)。该激发的空间定位性也非常高。广视野落射:该方法中使用的光学激发系统通常由激光源、散焦光学器件、高性能二向色分束器和浸油低自发荧光物镜组成。通过使用冷却的薄背电荷耦合器件(ccd)相机或增强的ccd(iccd),这种方法实现了高灵敏度检测。也可以使用大功率汞灯来提供比现有激光源所能实现的更均匀的照射。在funatsu等,1995,nature374:555-59中描述了使用表面荧光对单个肌球蛋白分子成像。在玻璃和液体/空气之间的界面处,光电磁场以指数方式衰减进入液相(或空气)。紧邻该界面的约300nm的薄层中的分子可以被快速衰减的光场(称为倏逝波)激发。贴近表面的分子所感应到的场大于约300nm远的场。使用倏逝波激发来对单分子成像描述于hirschfeld,1976,appl.opt.15:2965-66和dickson等,1996,science274:966-69。用于倏逝波激发的成像装置通常包括被构造成在玻璃/样品界面处发生全内反射的显微镜(axelrodd.methodsoncellbiology198930:245-270)。作为另一选择,周期性光学微结构或光栅可以在光栅结构的光学近场处提供倏逝波激发。这用于增加阵列信号约100倍(表面平面波导器已经由zeptosens,switzerland开发,类似的技术已经由wolfgagbudach等,novartisag,switzerland开发,在剑桥健康技术研究所第五届年会上张贴在“advancesinassays,molecularlabels,signallinganddetection”)。优选的是使用增强ccd来进行检测。超限分辨远场光学法:超限分辨远场光学法已经由weiss,2000(pnas97:8747-8749)着重描述。一种新途径是通过受激发射耗尽的点扩散函数工程(klar等,2000,pnas97:8206-8210),这可以将远场解析度提高10倍。使用远场显微镜的距离测量精度优于10nm,这可以通过使用压电扫描仪扫描具有纳米尺寸步骤的样品来实现(lacoste等,pnas200097:9461-9466)。然后通过拟合到显微镜的激发点扩散函数的已知形状,使得到的斑点精确地定位。激发光束的圆形扫描的类似测量能力是已知的。更短的距离通常可以通过使用fret的分子标记策略(ha等,chem.phys.1999247:107-118)或诸如spm等近场法来测量。这些距离测量能力可用于本发明提出的测序应用。微阵列扫描仪:基于许多上述光学方法,新兴的微阵列领域引入了大量不同的扫描仪。这些包括基于扫描共焦激光、tirf和用于照射的白光和光电倍增管、雪崩光电二极管和用于检测的ccd的扫描仪。然而,其标准形式的商业阵列扫描仪对于smd不够灵敏,并且分析软件不合适。以此方式,可以读取阵列中的许多组件或少数组件,并处理结果。可获得用于将基板移动到正确位置的x-y平台平移机构来与显微镜载玻片安装系统(一些具有100nm的解析度)一起使用。必要时通过计算机来自动地控制平台的移动。ha等(appl.phys.lett.70:782-784(1997))已经描述了一种计算机控制的光学系统,其自动且快速地对单个分子进行定位和光谱测量。可以使用检流计镜或数字微镜装置(texasinstruments,houston)来实现从静止光源扫描图像。信号可以由ccd或其他成像设备处理并以数字形式存储,以用于后续的数据处理。多色成像:不同波长的信号可以通过多次采集来获得或通过将信号分割、使用rgb检测器或分析全光谱以进行同时采集来获得(richardlevenson,cambridgehealthtechinstitutes,fifthannualmeetingonadvancesinassays,molecularlabels,signallinganddetection,may17-18thwashingtondc)。可以使用滤光轮或单色光源获得几条光谱线。可以使用电子可调谐滤波器(例如声光可调谐滤光器或液晶可调滤光器)来获得多光谱成像(例如oleghait,sergeysmirnov和chieud.tran,2001,analyticalchemistry73:732-739)。获得光谱的替代性方法是超光谱成像(schultz等,2001,cytometry43:239-247)。背景荧光的问题:显微镜和阵列扫描通常不被配置用于单分子检测。荧光采集效率必须最大化,这可以用高数值孔径(na)透镜和高灵敏度电光检测器来实现,例如达到高达0.8的检测量子产率的雪崩二极管和增强ccd(例如i-pentamaxgeniii;roperscientific,trenton,njusa)或冷却ccd(例如modelst-71(santabarbarainstrumentsgroup,ca,usa))。然而,问题并非过多地在于对来自期望的单分子的荧光(单荧光团可以发射~108个光子/秒)的检测,而是在于背景荧光的排除。这可以部分地通过仅查询最小体积来进行,就像在共焦、双光子和tirf显微镜中那样。可以应用传统的光谱滤光片(例如570df30omega滤光片)以减少周围材料的贡献(主要是由溶剂引起的激发激光束的瑞利和拉曼散射以及来自污染物的荧光)。为了将背景荧光降低到允许检测来自单分子的真实信号的水平,可以使用与时间门控低光级ccd同步的脉冲激光照射源(enderlein等,在microsystemtechnology:apowerfultoolforbiomolecularstudies中;编者:m.t.mejevaia,h.p.saluz(basel,1999)311-29))。这是基于下述现象,即在足够短脉冲的激光激发之后,分析物荧光的衰减(1-10ns)通常比光散射的衰减(~102ps)长得多。恰当选择的激光器的脉冲可以降低背景计数率,从而可以检测来自各个荧光团的单独光子。必须适当配置激光功率、光束尺寸和重复率。商业阵列扫描仪及其软件可以定制(fairfieldenterprises,usa),从而可以实现稳健的单分子灵敏度。作为另一选择,可以使用时间相关单光子计数(tcspc)来在脉冲激发之后收集所有的荧光发射,然后通过其时间特征分布来从目标发射中筛选出背景发射。可以使用合适的商业仪器(例如,lightstation,atto-tec,heidelberg,germany)。除了对抗来自样品体积内的荧光噪声的这些方法之外,仪器本身可以产生背景噪声。此类热电子噪声可以例如通过冷却检测器来降低。将spm测量与光学测量结合允许将光学检测到的信号与靶向结构关联,而不是关联其它来源产生的信号。针对靶向同一分子的两个(荧光)探针的信号的空间或时间相关性表明了所需的信号而不是外源信号(例如castro和williams,anal.chem.199769:3915-3920)。基于fret的检测方案也有利于排除背景。优选使用低荧光浸渍油作为具有低固有荧光的超清洁基板。玻璃片/盖玻片优选地具有高品质和被充分清洁(例如用诸如alconex和chromerge(vwrscientific,usa)等洗涤剂和高纯水)。优选的是,使用诸如熔融石英或纯白色玻璃等基板,其具有低固有荧光。单个荧光团可以凭借几个特征而与污染颗粒区分开:光谱依赖性、浓度依赖性、量子化发射和闪光。颗粒污染物通常具有广谱荧光,其在几个滤光器组中获得,而单个荧光团仅在特定的滤光器组中可见。也可以使用具有较高信号强度的标记(例如荧光团(molecularprobesinc.))或经多重标记的树枝状大分子(dendrimer)来改善信噪比。可以将清除剂放入介质中以防止光漂白。合适的氧清除剂包括例如甘氨酸dtt、巯基乙醇、甘油等。无标记检测:许多物理现象可以适用于检测,其依赖于经固定的分子自身或者与捕获的靶标复合时的物理性质,或者其改变一些其它元件的活性或性质。例如,太赫兹频率允许能够检测双链和单链dna之间的差异;brucherseifer等,2000,appliedphysicsletters77:4049-4051。其他手段包括干涉测量、椭圆测量、折射、来自集成到表面中的发光二极管的信号的改变、天然电子性质、光学性质(例如吸光度)、光电子性质和电化学性质、石英晶体微量天平和能够以无标记方式检测表面上的差异的各种afm模式。原始数据的处理和限制错误的手段信号的数字分析:可以通过各种亮度来定义测定分类的离散组(例如核苷酸碱基识别)。选择独特参数的组来定义几个离散组中的每一个。对每个单个分子的查询结果可以分配至离散组之一。可以分配一个组来表示未落入已知模式的信号。例如,在延伸测定中可能存在用于真实碱基添加的组,a、c、g和t。单分子解析技术不同于整体方法的基本原因之一是它们允许访问单个分子的行为。可以获得的最基本的信息是对特定组的命中发生频率。在整体分析中,信号由(任意)强度值(从中可以推断浓度)以模拟形式表示,这指示例如碱基识别方面的测定结果,或者其可以凭借其校准的相互作用曲线(或其在一个样品中与另一个样品相比的相对水平)来指示样品中的特定分子的水平。相比之下,单分子方法能够直接计数和将单个事件分类。一旦单分子已通过例如阈值化被标记,则用于单分子计数的一般算法是:循环遍历所有像素,p(x,y)从左至右,从上至下a.如果p(x,y)=0,不进行操作b.如果p(x,y)=1,加入计数器本发明的方法需要对所获得的原始图像执行基本的图像处理操作和计数、测量和分配操作。本发明包括改造和应用本领域已知的用于数字信号处理、计数、测量和从原始数据进行分配的一般方法(包括软件和算法)。这包括贝叶斯、启发式、机器学习和基于知识的方法。此外,数字数据处理有利于阵列表面处的反应的误差校正和时间解析。因此,可以使用时间解析的显微镜技术来区分探针和样品之间的真正反应和因在延长的温育时间内发生的异常相互作用而产生的“噪声”。在此类实施方式中,使用时间门控检测或时间相关的单光子计数是特别优选的。因此,本发明提供一种根据可用来处理信号的置信度对从单分子分析获得的信号进行分选的方法。信号的高置信度导致信号被添加到pass(合格)组并计数;置信度低的信号被添加到fail(不合格)组并丢弃,或用于误差评估和作为用于设计测定的资源(例如,特定引物序列产生引物延伸中的错误的倾向可用来为未来实验中的引物设计提供信息)。将满足多种标准的信号放入pass表中。该pass表是在对每种颜色的信号数量进行计数后碱基识别的基础。将fail表制成可以收集关于错误率的信息。可以将五种不同类型的错误收集到fail表中的单独区块中,以便可以记录不同类型的错误的发生。这些信息可能有助于实验方法减少错误,例如其可以揭示哪种是最常见的错误类型。作为另一选择,可以丢弃失败的信号。用于评估错误的五个标准是:1.如果强度小于p,其中p=最小阈值强度。这是高通滤波器,用来消除低荧光强度的伪像;2.如果强度小于q,其中q=最大强度阈值。这是一种低通滤波器,用来消除高荧光强度的伪像;3.如果时间小于x,其中x=早期时间点。这是为了消除由于早期可能发生的自引发而产生的信号;4.如果时间大于z,其中z=后期时间点。这是为了消除由于长时间后酶所能够并入的核苷酸的错误引发而产生的信号。例如,这可能是由于“模板上模板”所致的引发造成的,这是两步过程,包括将第一模板与阵列杂交,然后将第二模板分子杂交至第一模板分子;和5.比较最接近的相邻像素,以消除在多个相邻像素上携带信号的那些像素,这表示信号来自例如ddntp的团块或聚集体的非特异性吸附。通过调节反应成分(例如盐浓度、ddntp浓度、温度或ph值)来控制反应,以使得并入出现在所分析的时间窗内。可以包括子程序来检查荧光显示出单步光漂白特性,但忽略可能是由闪光引起的短程波动。如果将在一段时间后发生光漂白的单个染料分子与每个ddntp联结,则可以添加一个附加子过程/子程序,其在使得缺失不能归因于闪光的数量的时间点之后消除在初始突发后在同一像素中重新出现的信号。这可能是作为真实延伸的在同一焦点处的非特异性吸收。可以包括子程序以消除高于所分析的染料的预期水平的、在多个滤光器中出现的任何荧光。通过分析信号的浓度依赖性,可以将单个染料分子产生的荧光与颗粒污染区分开。这可以在将每个序列以两个以上的浓度阵列化时实现。在整个阵列稀释上保持相等浓度的信号是伪像,真信号是频率随着阵列探针浓度变化而变化的信号。如果阵列由组件组成,则可以使用一个附加过程将数据组织成表示这些阵列组件的分组。在所描述的方案中,将系统构造成以单个像素度量单个分子事件(统计学上,在大多数情况下)。可以将系统配置为例如使得几个像素被构造成查询单个分子(图80)。因此,在优选的实施方式中,本发明涉及一种对核苷酸中的单核苷酸多态性(snp)和突变进行分型的方法,包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针的库,所述核酸可以具有一种或多种多态性;b)将所述库阵列到固体表面上,以使得库中的每个探针能够被单独解析;c)使样品暴露于所述库,并使存在于样品中的核酸以所需的严格性与探针杂交/被酶处理至探针,从而使杂交的/经酶处理的核酸/探针对是可检测的;d)使阵列成像以检测单个的靶核酸/探针对;e)分析来自步骤(d)的信号并计算每个检测事件的置信度以产生高置信度结果的pass表;和f)显示来自pass表的结果以将存在于核酸样品中的多态性分型。有利的是,通过对样品核酸和/或探针分子加标记并使用合适的检测器使阵列上的所述标记成像来产生检测事件。本文描述了优选的标记和检测技术。减少错误的方法:单分子分析允许获得单个分子的特定性质和特性及其相互作用和反应。单分子的特定分子事件的行为的具体特征可能掩饰有关其起源的信息。对于酶学测定,例如,错误并入的速率可能比正确并入慢。另一个实例是,与靶标形成模板时的引发相比,自引发可能具有不同的并入速率。自引发的速率特性可能比样品引发更快。这是因为自引发是单分子反应,而样品dna的引发是双分子的。因此,如果进行时间解析显微镜检,则引发的时间依赖性可以将自引发和错误引发与正确的样品引发区分开。作为另一选择,可以预期,与错误引发和自引发相比,来自完美匹配的样品的dna引发具有在多引物的引物延伸方法中并入更多数量的荧光染料ntp的能力(dubiley等,nucleicacidsresearch199927:e19i-iv),并因此提供更高的信号水平或分子亮度。因为即使错误的碱基可能花费更长的时间来并入,其也可能在与正确并入的碱基相同的时间长度内与引物联结,所以在微型测序(多碱基法)中区分正确并入和错误并入可能是困难的。为了解决这个问题,如果在并入时使ddntp的荧光强度猝灭至一定程度,则可以使用分子亮度/荧光强度来区分错误并入(其需要更长时间来固定)和正确并入。可以将不同的减少误差的手段设计到系统中。例如,在遗传分析中,可以将fret探针整合到等位基因位点。完美匹配的构象使得荧光能量被猝灭,而错配的构象则不能。fret探针可以放置在间隔物上,其可以被构造成突出匹配和错配的碱基对组之间的fret探针距离。在某些情况下,可以通过用酶(例如核糖核酸酶a)进行切割来消除错配错误。该酶切割rna:dna异源双链体中的错配(myersrm,larinz,maniatist.science1985dec13;230(4731):1242-6)。在引物延伸中,可以采用作为酶的三磷酸腺苷双磷酸酶(其是核苷酸降解酶)来准确区分匹配和错配的引物-模板复合物。三磷酸腺苷双磷酸酶介导的等位基因特异性扩增(amase)规程允许当反应动力学快速时并入核苷酸(匹配的3'-末端引物),但当反应动力学较慢时在延伸前将核苷酸降解(错配的3'-末端引物)(ahmadian等,nucleicacidsresearch,2001,vol.29,no.24e121)。除了上述假阳性错误之外,假阴性可以是基于杂交的测定中的主要问题。当短探针和长靶标之间进行杂交时尤其如此,其中形成稳定的异源双链体所需的低严格条件同时促进靶标中二级结构的形成,这会掩蔽结合位点。该问题的影响可以通过以下方式来降低:将靶标片段化,将类似碱基并入靶标(例如并入不能相互配对但可与探针的天然dna碱基配对的靶标类似物碱基)或探针,操纵缓冲液等。酶可以通过捕捉瞬时相互作用并驱动杂交反应向前进行来帮助减少假阴性(southern,mirandshchepinov,1999,naturegenetics21:s59)。这种效果也可以通过将经补骨质素标记的探针交联到其靶分子上来实现。然而,假阴性可能会保持在一定水平。如前所述,因为能够进行不需要pcr的大规模snp分析,因此一些snp不产生数据的事实不是主要问题。对于更小规模的研究,可能需要预先选择有效的探针。在样品材料的量低的情况下,必须采取特殊措施以防止样品分子粘附在反应容器和用于处理材料的其它容器的壁上。可以将这些容器硅烷化以减少样品材料的粘附,和/或可以预先用诸如denhardt试剂或trna等封闭材料处理这些容器。管理单倍体分型错误:在进行单倍体分型研究(见d2部分)时,沿着将被查询的snp位点的经捕获的靶分子的位置是已知的(除非在snp之间存在重复或缺失)。在某些情况下,可能所有的探针已经结合到其snp位点。zhong等(pnas98:3940-3945)使用滚环扩增(rca)将fish纤维状态下的单体型可视化,其中许多纤维显示寡核苷酸探针与沿着分子的三个邻接位点的结合。然而,经常发生的是,不是每个探针都会与其互补序列结合,并且沿着该分子的位点串中可能存在空位。但是,当分子群体可用于分析时,可以根据从已经被捕获在空间上可寻址的单分子阵列上的特定种类的所有分子获得的信息,用算法重建关于每个位点处的snp等位基因的正确信息。在一个实施方式中,将获取纤维和结合的探针的图像,然后处理信息。1.拍摄每个阵列组件内和周围的图像;2.离线处理信息。存在这种应用专用的图像处理包。在另一个实施方式中,将使用机器视觉来查找和追踪单个分子,可选的是在该过程期间处理信息(“即时”)。以下列表显示了形成用于从分析中去除错误链、并将良好信息传递给序列重建程序的计算机程序的基础的步骤:1.转到特定的微阵列组件;2.下载关于snp沿着预期会被捕获在该组件中的链的预期位置排列的之前数据;3.识别纤维/链(末端标志物可以辅助该步骤);4.识别标志物(例如末端标志物);5.将探针沿分子的位置可视化;6.评估探针的分隔距离(标志物可以辅助该步骤);7.评估连续探针的分隔距离是否与预期一致;8.如果对于给定纤维,探针处于预期的分隔,则转向10;9.如果不是,那么a.如果没有探针结合,则忽略纤维,b.如果为完全异常的结合模式,则忽略纤维/添加到失败表,c.如果snp位点中有空位,则收集存在的信息,并转向10;10.确定在发生结合的每个位置处的标记的身份,转向11;和11.将标记的身份添加到重建算法中。参见digitalimageprocessing,rafaelc.gonzalez,richarde.woods,pub:addison–wesley。重建算法:重建算法叠置来自纤维的数据,并且评估是否存在一个(单体型的纯合子)或两个(单体型杂合子)单体型以及它们是什么。在汇集的dna的情况下,存在多于两种不同的单体型的可能性。阵列探针有可能捕获了错误的链。剔除这些情况将很简单,因为单体型探针不太可能与此类分子杂交,并且如果它们真杂交的话,也会杂交至沿着分子的异常位置,其可以被鉴定。当捕获了序列的非功能性副本(例如假基因)时,这将是更大的问题。这可以表示单体型中与序列的功能性拷贝不同的等位基因。虽然在罕见时可以检测到这种情况发生,但是当其与功能性序列有效竞争时会更困难。然而,利用关于基因组组织和基因组内复制的发生的现有知识,可以管理这种错误。可以避免已知重复的基因组区域,或者会考虑它们的贡献。可以计算出精确的物理距离。使用标记以外的标志物可以辅助该计算,例如在分子末端或其它位点加标志,包括具有能够与用于大多数snp的2色snp标签区分开的标志物的snp位点。在某些情况下,尽管有严格性控制,探针可能已经结合,但它可能是错配的相互作用。然而,由于其在被分析的单分子群体中的相对稀少性,可以将其忽略(或者添加到给出错误的相互作用的等位基因列表中,以供将来参考)。在汇集的dna中或当样品来自细胞的异质样品时,该测定可能必须允许较小程度的这种类型的错误。例如,获得罕见等位基因的频率的准确度可以是1000+/-1分之1。在某些情况下这里概述的错误管理方法也可能与指纹确定和再测序相关(见第d3部分)。用于检测和解码结果的替代性方法:如上所述,使用可检测的标记或其他方式,并将阵列上的标记位置与关于结合有标记的阵列化探针的性质的信息相关联,可以检测分子。可以设想进一步的检测手段,其中标记本身即提供已结合的探针的相关信息,而不需要位置信息。例如,每个探针序列可被构建成包含代表探针序列的独特荧光或其它标签(或其组)。这种编码可以通过利用分割和合并组合化学逐步共同合成探针和标签来完成。10步产生所有10聚物编码的寡核苷酸(约100万个序列)。16步产生所有16聚物编码的寡核苷酸(约40亿个序列),预期其在基因组中仅出现一次。用于编码的荧光标签可以具有不同的颜色或不同的荧光寿命。此外,独特的标签可以连接到单个的单分子探针上,并用于在抗标签阵列上分离分子。抗标签阵列可以是空间上可寻址的或经编码的。测定技术和用途:本发明的另一方面涉及基于单分子检测的测定技术。可以使用通过本发明的方法或通过任何其它合适的手段产生的分子阵列来进行这些测定。空间上可寻址的阵列是捕获和组织分子的一种方式。然后可以以多种方式测定分子,包括使用适用于单分子检测的任何测定方法,例如在wo0060114;us6210896;wattwebb,researchabstract:newopticalmethodsforsequencingindividualmoleculesofdna,doehumangenomeprogramcontractor-granteeworkshopiii(2001年2月5日)中描述的那些。通常,本发明的测定方法包括使分子阵列与样品接触,并使用上述查询/检测方法查询阵列的全部或部分。作为另一选择,分子阵列本身是样品,并且随后使用上述查询/检测方法直接查询或用其它分子或探针进行查询。许多测定方法依赖于检测阵列中的经固定分子与样品中的靶分子之间的结合。然而,可以鉴定的其它相互作用包括例如可能是瞬时的但是会导致对阵列中的经固定分子的性质改变的相互作用,例如电荷转移。一旦将样品与阵列一起温育所需的时间,就可以简单地查询阵列(在可选的洗涤步骤后)。然而,在某些实施方式中,特别是基于核酸的测定,被捕获的靶分子可以被进一步处理或与其它反应物一起温育。例如,在抗体-抗原反应的情况下,携带标记的二抗可以与含有抗原-一抗复合物的阵列一起温育。施加至阵列的样品中的目标靶分子可以包括核酸,例如dna及其类似物和衍生物,例如pna。核酸可以从任何来源获得,例如基因组dna或cdna,或使用已知技术(例如逐步合成)合成。核酸可以是单链或双链的。其它分子包括:通过酰胺键连接的化合物,例如肽、寡肽、多肽、蛋白质或含有其的复合物;确定的化学实体,例如有机分子;组合文库;缀合的聚合物、脂质和碳水化合物。由于所述方法的灵敏度高,如果需要可以消除特异性扩增步骤。因此,在分析snp的情况下,提取的基因组dna可以直接呈递至阵列(对于一些应用,可能需要几轮全基因组扩增)。在基因表达分析的情况下,可以使用正常的cdna合成法,但起始材料的量可以较低。在用于本发明的方法中之前,通常将基因组dna片段化。例如,基因组dna可以被片段化成使得基本上所有的dna分子的尺寸为1mb、100kb、50kb、10kb和/或1kb以下。可以使用标准技术来实现片段化,例如使dna通过窄规格注射器、超声处理、碱处理、自由基处理、酶处理(例如dnasei)或其组合。靶分子可以作为分子群体呈现。可以将多于一个群体同时施加至阵列。在这种情况下,不同的群体优选是经差异性标记的(例如,cdna群可以用cy5或cy3标记)。在其它情况,例如汇集dna的分析中,对每个群体可以进行或不进行差异性标记。本发明的多种测定方法是基于分析物与阵列组件的单分子的杂交。此时可以停止测定并对杂交结果进行分析。然而,杂交事件也可以构成进一步的生物化学或化学操作或杂交事件的基础,以能够进行进一步探针探测或能够检测(如在夹心测定中)。这些进一步事件包括:来自经固定的分子/被捕获的分子复合物的引物延伸;额外探针与经固定的分子/被捕获的分子复合物的杂交;和额外核酸探针与经固定的分子/被捕获的分子复合物的连接。例如,在经固定的寡核苷酸特异性地捕获(通过杂交或者杂交加酶连接或化学连接)单个靶链后,可以对靶分子进行进一步的分析。这可以对末端固定的靶标(或其拷贝-见下文)进行。或者,经固定的寡核苷酸锚定靶链,然后靶链能够与第二(或更高数量)的经固定的寡核苷酸相互作用,从而使靶链水平放置。当不同的经固定的寡核苷酸是不同基因座的不同等位基因探针时,靶链可以在多个基因座中以等位基因确定。也可以在用本领域已知的各种物理方法使经固定的寡核苷酸捕获靶链之后将靶链水平化和拉直。这可以允许以空间上可寻址的方式梳直靶核酸,并使其适合于进一步分析。在一个实施方式中,在杂交后,可以将阵列寡核苷酸用作引物以产生共价固定在适当位置并且是可寻址的已结合的靶分子的永久拷贝。在大多数单分子测定中,结果基于对每种靶分子物种的群体的分析。例如,每个阵列斑点可以捕获特定物种的大量拷贝。然而,在某些情况下,结果可能仅基于一个分子的信号,而不是基于大量分子的普查。这些测定的单分子计数甚至允许检测基本同源的群体中的罕见的多态性/突变。下面描述了一些特定的测定构造和用途。核酸阵列和获取遗传信息:为了查询序列,在大多数情况下,靶标必须是单链形式。例外包括三链体形成、蛋白质与双链dna结合等情况(taylorjr,fang,mm和s.nie,2000,anal.chem.72:1979-1986),或者通过reca(参见seong等,2000,anal.chem.72:1288-1293)或通过利用pna探针(bukanov等,1998,pnas95:5516-5520;cherny等,1998,biophysicaljournal1015-1023)而促进的序列识别。另外,已经显示了利用muts蛋白检测退火双链体中的错配(sun,hbs和hyokoto,2000,anal.chem72:3138-3141)。长rna(例如mrna)可以在线性dsdna内形成r环,这可以作为在阵列化基因组dna上定位基因的基础。当将双链dna靶标阵列化时,可能需要提供合适的条件以部分破坏双链体中的天然碱基配对,从而能够与探针发生杂交。这可以通过加热基板的表面/溶液、操纵盐浓度/ph或施加电场来解开双链体来实现。用于探测序列的一个优选方法是使用链侵入锁核酸(lna)或肽核酸(pna)探针来探测双链dna。这可以在使得双链体结构中能够出现短暂的呼吸节(breathingnode)的条件下进行,例如在50-65℃、于0-100mm一价阳离子中。用于预测lna解链点的软件工具在本领域是可获得的,例如在www.lna-tm.com。用于设计pna探针(包括pna分子信标)的工具可从www.bostonprobes.com获得。另外对于pna探针的设计,参见kuhn等,jamchemsoc.2002feb13;124(6):1097-103)。分子梳直方法:已经描述了数种伸展双链dna的方法,以使其可以沿其长度被查询。方法包括光学捕获、静电捕获、分子梳直(bensimon等,science1994265:20962098)、蒸发液滴/膜内的力(yokota等,anal.biochem1998264:158-164;jing等,pnas199895:8046-8051)、离心力和通过空气流来移动空气-水界面(li等,nucleicacidresearch(1998)6:4785-4786).涉及由移动的空气-水界面/弯月面产生的表面张力以及对基本技术的修改的分子梳直已被用于在玻璃表面上伸展数百个单倍体基因组(michalet等,science.1997277:1518-1523)。对于单链dna,已经描述的方法相对较少。woolley和kelly(nanoletters20011:345-348)通过使dna溶液液滴线性地平移跨过被覆正电荷的云母表面来实现ssdna的伸长。施加在ssdna上的力被认为来自在行进的空气-水界面处的流体流动和表面张力的组合。流体流动内的力可以足以在通道中将单链伸展。毛细管力可用于在通道内移动溶液。除了伸展dna之外,这些方法还克服了在杂交所需条件下普遍存在于ssdna中的分子间二级结构。克服表面上的核酸的二级结构形成的替代性方法是加热基板的表面或对表面施加电场。下面描述的大多数测定不需要将分子线性化,因为不需要沿着分子长度的位置信息。在需要位置信息的情况下,需要将dna线性化/水平化。附着到多于一个的表面固定的探针有助于该过程。双链靶标可以固定在具有粘性末端的探针上,例如通过限制性消化形成的那些探针。在一个实施方案中,在被经固定的寡核苷酸捕获后,靶链被拉直。这可以通过分子梳直在平坦表面上完成。在一个实施方式中,将探针放置在例如阵列组件的最左侧的窄线上,然后捕获的分子通过后退的空气-水界面而在从左侧到右侧的行中伸展。或者,捕获的靶标可以在通道或毛细管中伸展,其中捕获的探针附着至到容器的(一个或多个)壁上,并且流体内的物理力使得被捕获的靶标伸展。流体流动促进混合,并使杂交和其他过程更高效。在反应过程中反应物可以在通道内再循环。单个分子也可以在凝胶中被捕获并伸展。例如,可将凝胶层倒在载玻片上。可以用acrydite对标签、探针或靶分子进行末端修饰并使其在聚丙烯酰胺凝胶内与丙烯酰胺单体共聚。当施加电场时,如在凝胶电泳中,分子可以伸展并同时保持附着。在与标签或探针杂交后,可以有利的是,将靶标独立地固定到表面。这可以在适当的ph下进行,例如在ph6.5的10mmmes缓冲液中固定到裸露玻璃上,或在ph8.5的10mmampso缓冲液中固定到氨基硅烷载玻片上。作为另一选择,在与阵列相互作用之前,靶分子可以与某部分预反应,该部分将在合适的活化之后或在给定合适长度的反应时间后允许共价附着到表面。在纤维fish(荧光原位杂交)中,探针被定位到在表面上伸展的变性双链dna上。与dna结合的探针呈现为串珠状。已经表明,该珠状外观是缘于以下事实:使dna变性时所用的条件实际上导致了dna链断开(snap)。线性化分子:用于探测序列的一个优选方法是使用链侵入锁核酸(lna)或肽核酸(pna)探针在使得双链体结构中可出现短暂呼吸节的条件下(例如在50-65℃在0-100mm一价阳离子中)探测双链dna。作为另一选择,可以使用来自fiberfish的方法,其中使靶链在载玻片上原位部分变性或在制备纤维之前部分变性。取决于检测方法,探针可以用染料分子、多标记的树枝状大分子或纳米颗粒或微球体标记。探针将优先用大的纳米颗粒或微球体标记,以便能够通过表面荧光显微镜容易地检测,否则可能难以在背景上看到它们。再探测线性化分子:在本发明的一些实施方式中,可能需要在结合另外的探针前除去一种或多种结合的探针。这可以用许多方法完成,包括热、碱处理和电场产生。对于使用完整文库进行的系列探测,可能需要将结合的探针尽可能温和地去除。一种方法是用与探针互补的序列置换靶链(可能的机制参见yurke等,nature406:605-608,2000)。作为另一选择,当使用更苛刻的条件去除探针时,可能有利的是,不在每次后续的探针添加之前、而是仅在数次添加之后去除探针。例如,可以使具有特定tm的所有寡核苷酸同时杂交,然后去除。然后,添加和除去具有另一种tm的所有寡核苷酸,以此类推,注意每个循环后结合的位置。在一个组中的一些第一寡核苷酸不与单分子杂交(因为与该组中能够杂交的第二寡核苷酸重叠)情况下,通过观察单分子的群体,很可能存在与第一寡核苷酸结合而不与第二寡核苷酸结合的其它单分子。关于由表面上的杂交和变性循环导致的损耗的有害影响的顾虑的另一解决方案。一个问题是在表面上伸展的分子经常经受光致断裂。用落射荧光显微镜可以看到标记有yoyo的经梳直的λdna链的断开。如果发生这种情况,dna的长度缩小。虽然这是不期望的,但是仍然可以保留结合的寡核苷酸的长程位置。脉冲激光激发能够克服这种dna断裂,因为可以使用低得多的激光功率。另外,如果探针标记有多标记的树枝状大分子或大的纳米颗粒或微球体,则检测到的信号来自许多染料分子的事实意味着照射强度可以最小化。克服必须在一个载玻片上进行数百或数千次退火-变性循环的另一方式是制备其中捕获相同基因组样品的多个载玻片(为此,可能需要首先进行全基因组扩增)。然后在第一载玻片上探测会利用寡核苷酸组1、2、3,在第二载玻片上会利用寡核苷酸组4、5、6,第三载玻片利用寡核苷酸组7、8、9,如此类推。将来自与在每个这些载玻片上的相同空间上可寻址的位点杂交的信息组合,以提供用于重建序列的数据。可以使用阵列的阵列,其中每个阵列与不同的探针组杂交。例如,阵列和被捕获的链可以位于平底微型板的表面上,并且板的每个孔(例如96孔板的每个孔)可能采用不同的探针组。退火和变性步骤可以在适于能够添加和去除探针分子的热循环仪或类似装置上循环进行。下面在单独标题下讨论各个方面,但是这些方面通常广泛地适用于期望在多个位点同时查询单个分子的任何检测技术。1.单核苷酸多态性(snp)和突变的再测序和/或分型a.杂交对于snp的再测序或分型,阵列的组织化通常遵循affymetrix教导的已知技术,例如lipshutz等,naturegenetics199921:s20-24;hacia等,naturegenetics21:s42-47))。简言之,可以用最简单形式的含有确定探针的阵列组件模块(block)分析snp,其中探针指向每个已知的或可能的等位基因。这可以包括取代和简单的缺失或插入。然而,虽然affymetrix技术需要复杂的平铺路径来解决错误,但单分子方法的高级版本可以用更简单的阵列来满足,因为可以使用辨别错误的其它手段。也可以记录瞬时相互作用。通常,寡核苷酸长度为约17至25个核苷酸,但在某些情况下可以使用更长或更短的探针。较长的探针对于克服二级结构的影响特别有用。然而,长度越长,通过杂交来辨别单个碱基差异就越不容易。条件的选择对于用更长的探针实现单碱基辨别是重要的。例如,hughes等(naturebiotechnology19:342-3472001)已经示出可以辨别55聚物中的1个碱基差异。基于单分子计数的分析应该有帮助。在不同的实施方式中,将与所有等位基因互补的探针的混合物置于单个阵列组件内。包含不同等位基因的每个探针与其它探针是可区分的,例如,特定等位基因的每个单分子可以具有与其相关的特定染料。本发明的单分子测定系统允许这种节省空间的操作,并且当将预先合成的寡聚物点样到阵列上时容易进行。探针可以附加有促进其形成二级结构的序列,其有助于辨别错配(例如,探针序列位于环中的茎环结构)。类似地,探针序列可以是分子信标,使得该测定不需要非固有标记。以下是可以使用的典型反应条件:在tris缓冲液中的1mnacl或3-4.4mtmacl(四甲基氯化铵),靶标样品,在湿室中4至37℃,持续30分钟至过夜。已认识到,罕见物种的杂交与在常规的反应条件下相比可被辨别出,而富含a-t碱基对的物种不能像富含g-t的序列那样有效地杂交。某些缓冲液能够均衡罕见和富含a-t的分子的杂交,从而在杂交反应中获得更有代表性的结果。杂交缓冲液中可以包括以下组分以改善对特异性具有积极作用的杂交,和/或降低碱基组成的影响,和/或减少二级结构,和/或减少非特异性相互作用,和/或促进酶反应:1m乙酸三丙胺;n,n-二甲基庚胺;1-甲基哌啶;litca;dtb;c-tab;甜菜碱;异硫氰酸胍;甲酰胺;四甲基氯化铵(tmacl);四乙基氯化铵(teacl);十二烷基肌氨酸钠(sarkosyl);sds(十二烷基硫酸钠);dendhardt试剂;聚乙二醇;脲;海藻糖;cotdna;trna;聚d(a);n-n-二甲基异丙基胺乙酸盐。含有n-n-二甲基异丙基胺乙酸盐的缓冲液对于特异性和碱基组成非常好。也可以使用具有类似结构和电荷排布和/或疏水性基团的相关化合物。参见wo9813527。可能的话,将探针选择为具有二级结构(除非其是设计的一部分)和与非靶向序列交叉杂交的最小潜力。当靶分子为基因组dna且不使用特异性pcr来富集所选择的snp区域时,需要采取措施来减少复杂性。通过将靶标片段化并将其预杂交到c0t=1dna来减少复杂性。cantor和smith(genomics,thescienceandtechnologybehindthehumangenomeproject1999;johnwileyandsons]描述了其它方法。在分析之前进行全基因组扩增也可以是有用的。探针优先是吗啉代锁核酸(lna)或肽核酸(pna)。分子及其产物可以在诸如电极等带电表面上固定和操纵。当整体溶液处于高严格度时,对电极施加适当的偏压可以加速杂交,并有助于克服二次结构。切换极性有助于优先消除错配。b.叠置杂交在溶液中添加序列特异性探针或一个完整的探针组、使其同轴地叠置到经固定的探针上、并以靶标为模板,可以提高杂交的稳定性和特异性。存在与叠置相关的稳定性因素,并且如果在经固定的探针和溶液探针之间存在错配,则将该因素废除。因此,可以通过使用适当的温度和序列来区分错配事件。使用lna探针是有利的,因为它们可以由于其预先构造的“锁定”结构而提供更好的叠置特征。以下是可以使用的典型反应条件:tris缓冲液中的1mnacl;1~10nm(或更高浓度)的叠置寡核苷酸;靶标样品;4-37℃下30分钟至过夜。c.引物延伸这是一种改善经固定探针的游离端的特异性并用于捕捉瞬时相互作用的手段。可以用两种方式来实施。第一种是多聚物方法,而对于杂交阵列而言,存在单独的阵列组件包含针对每个等位基因的单个分子。第二种是多碱基方法,其中单个阵列包含单一种类的引物,所述引物的最后一个碱基位于多态性位点的上游。不同的等位基因通过并入各自带有差异性标记的不同的碱基来区分。该方法也被称为微型测序。可以使用以下反应混合物和条件:5x聚合酶缓冲液,ph7.5的200mmtris-hcl,100mmmgcl2,250mmnacl,2.5mmdtt;ddntp或dntp(多碱基);dntp(多引物);聚合酶稀释缓冲液中的sequenasev.2(0.5μ/μl),靶标样品,37℃下1小时。如果延伸信号与经标记的标签或探针处于相同位置,则可以有利的是对引物、标签或探针进行标记,以给予延伸信号更高的置信度。有利的是,使用浓度为10-7m的dntp,例如dctp。优选的是不加入对应于经标记的dntp的冷dntp。有利的是,使用外聚合酶,优选thermosequenase(amersham)或taquenase(promega)。可以使用上游引物将靶标捕获固定和合成引发。多个引物可以在沿着被捕获的靶标的数个点处引发合成。靶标可以被水平化或者可以不被水平化。d.连接测定(化学或酶)连接是用于改善特异性和捕捉瞬时相互作用的另一种手段。此处,靶链被经固定的寡核苷酸捕获,然后以靶标依赖性方式将第二寡核苷酸连接到第一寡核苷酸。有两种方式可以应用。在第一种测定中,在溶液中提供的“第二”寡核苷酸在被研究的已知多态性的区域内是互补性的。阵列寡核苷酸或“第二”溶液寡核苷酸的中的一个寡聚物与snp位点重叠,而另一个在其上游的一个碱基处终止。第二种测定中,溶液中的第二寡核苷酸包含完整的组,每个寡核苷酸序列具有给定长度。这允许分析靶标中的每个位置。可以优选使用给定长度的所有序列,其中一个或多个核苷酸为lna。典型的连接反应如下:5x连接缓冲液,ph8.3的100mmtris-hcl,0.5%tritonx-100,50mmmgcl,250mmkcl,5mmnad+,50mmdtt,5mmedta,溶液寡核苷酸5-10pmol,嗜热栖热菌(thermusthermophilus)dna连接酶(tthdna连接酶)1u/ul,靶标样品,在37℃和65℃之间1小时。作为另一选择,可以首先在高盐中进行叠置杂交:1mnacl,3-4.4mtmac1,5-10pmol溶液寡核苷酸,靶标样品。在保留溶液寡核苷酸的条件下从阵列中洗涤掉过量的试剂,之后,将减去溶液寡核苷酸和靶标样品的上述反应混合物加入到反应混合物中。组合不同的测定方法的效力引物延伸和连接的效力可以组合到称为空位连接的技术(将两种酶的持续合成能力和辨别力组合)中。此处设计第一和第二寡核苷酸,它们在相互非常接近的位置与靶标杂交,但具有优选单个碱基的空位。其中一个寡核苷酸的最后一个碱基在多态位点上游或下游的一个碱基处终止。在终止于下游的情况下,第一级的辨别通过杂交发生。另一级的辨别通过使第一寡核苷酸延伸一个碱基的引物延伸而发生。延伸的第一寡核苷酸现在与第二寡核苷酸相邻。当延伸的第一寡核苷酸连接到第二寡核苷酸时,发生最终级别的辨别。作为另一选择,以上c和d中描述的连接和引物延伸反应可以在同一阵列组件内同时进行,其中阵列中的一些分子由于连接而产生结果,而其它分子由于引物延伸而产生结果。这可以增加碱基识别的置信度,由两个测定/酶系统独立进行。连接产物可以带有与引物延伸产物不同的标记。引物或连接寡核苷酸可以被特意设计成在用于查询多态性位点的碱基以外的位点处具有错配碱基。这用于减少错误,因为具有两个错配碱基的双链体比仅具有一个错配的双链体的稳定性差得多。可以需要在上述酶学测定中使用完全或部分由lna(其具有改善的结合特性并与酶相容)组成的探针。本发明提供了一种snp分型方法,其使基因组snp分析能够具有在可接受的时间范围内以可承担的成本实现的潜力。通过单分子识别对snp进行分型的能力固有地减少了因质量分析技术所固有的不准确和pcr诱导的偏差而引起的错误。此外,如果出现留下一定百分比的未分型的snp的错误,假设在snp在基因组中的位置方面的错误是随机的,则剩余的snp不需要执行单独(或多重)pcr就可被分型的事实仍然具有优势。这允许以具有时间和成本效益的方式进行大规模的关联研究。因此,可以平行地测试所有可用的snp,并从中选择来自具有置信度的那些的数据以进行进一步分析。有一个问题是,基因组的重复区域可能导致错误,其中测定结果可能因来自重复区域的dna而产生偏差。通过单分子检测对基因组的直接测定不会比利用pcr的测定更容易受到该问题的影响,因为在大多数情况下,pcr扩增snp位点周围的小区段(这是实现多重pcr所必需的)。然而,在基因组序列可获时,这不是那么大的问题,因为在某些情况下,可以选择基因组的非重复区域进行分析。在其它情况下,偏差的来源是已知的,因此可以解决。如果信号获自从仅代表一个等位基因的探针或标记,则样品很可能是纯合的。如果来自2个,并且基本上1:1的比例,则样品很可能是杂合的。由于测定基于单分子计数,因此当使用dna汇集策略时,可以确定高度准确的等位基因频率。在这些情况下,分子的比例可以是1:100。类似地,可能发现在野生型等位基因背景中的罕见的突变等位基因具有1:1000的分子比例。加标签错配作为选择snp或突变的替代性手段,当将杂合子样品dna(其中一个或两个含有2'-胺取代的核苷酸)变性并重新退火以产生异源双链体时检测错配位点,可以通过2'胺酰化来加标签。优选的是,未知样品dna可以与已知序列的经修饰的测试dna杂交。这因以下事实而成为可能:酰化优选发生在dna中的柔性位置,而较不优选发生在双链约束区中(johnd和kweeks,chem.biol.2000,7:405-410)。该方法可用于将大体积标签放在已经水平化的dna上的错配位点上。然后可以通过例如afm检测这些位点。当将此应用至全基因组时,基因组可以凭借阵列探针或使用编码探针获得的片段的身份而得到分选。均相测定通过两种方法可以实现低背景荧光和消除对测定后处理以去除未反应的荧光标记的需要。第一种方法是使用分子信标(tyagi等,nat.biotechnol.1998,16:49-53)和包括染料-染料相互作用的其它分子结构,其中荧光仅在靶标结合状态下发射,并且在该结构未与靶标结合时猝灭。在实践中,分子信标的一部分发荧光,因此图像可能需要在向阵列添加靶标之前拍摄,以记录假阳性。第二种方法是染料标记的分子的荧光偏振分析(chen等,genomeres.1998,9:492-98)。例如,在微型测序测定中,游离和并入的染料标记表现出不同的旋转行为。当染料与诸如ddntp等小分子连接时,其能够快速旋转,但是当染料与较大的分子连接时,正如通过并入ddntp而将其添加至引物时,旋转受到约束。静止分子发射回到固定平面,但旋转使发射的光不同程度地消偏振。可以获得四种染料终止剂的最佳组,其中可以辨别不同的发射。这些方法可以构造在单分子检测方案中。mir和southern(annrev.genomicsandhumangenetics2000,1:329-60)描述了其它均相测定。焦磷酸测序中固有的原理(ronaghim等,science,1998,363-365)也可以适用于单分子测定。2.单倍体分型捕获能够单独解析的dna分子是通过各种手段确定靶标中的单体型的基础。这可以通过分析来自含有单个dna分子的单个焦点的信号或通过将dna线性化并分析沿着dna长度的信号空间排布来完成。可以分析同一dna链上的两个或多个多态性位点。这可以包括寡核苷酸与不同位点的杂交,但每个都用不同的荧光团标记。如所描述的,酶法可以同样地应用于被捕获的单分子上的这些另外的位点。在一个实施方式中,双等位基因探针组中的每个探针可以被差异性标记,并且这些标记不同于与第二位点的探针相关联的标记。测定读数可以是来自同时读数,通过按波长对发射光分光而进行,其获自同一焦点或获自一端固定的dna靶分子的投影的2-d半径所定义的焦点区。该半径由经固定的探针的位点与第二探针之间的距离定义。如果去除来自第一双等位基因探针组的探针或将其荧光团光漂白,则可以用第二双等位基因探针组进行第二次获取,在该情况下,其不需要与第一双等位基因探针组的标记不同的标记。在另一个实施方式中,可以对捕获在等位基因特异性微阵列上的单个分子进行单体型分型。对于最邻近的snp,单体型信息可以通过例如利用空间上可寻址的等位基因特异性探针确定第一snp而进行(参见图7a)。标记是由于第二snp的等位基因探针(其在溶液中提供)导致。根据snp内检测到哪种焦点颜色,1个等位基因特异性斑点确定第二snp的等位基因。因此,微阵列斑点的空间位置决定了第一snp的等位基因,然后微阵列斑点内的焦点颜色决定了第二个snp的等位基因。如果被捕获的分子足够长并且阵列探针相隔足够远,则可以通过将信号共定位到相同的焦点来解析各自用不同颜色标记的另外的snp等位基因特异性探针。对于三种以上snp,更广泛的单体型可以从对重叠的最邻近snp单体型的分析中重建(参见图7b),或者通过在相同分子上用带不同标记的探针进一步探测来重建。可以对样品分子进行预处理以使远端位点更靠近。例如,这可以通过对pcr或连接探针的适当的模块化设计来完成。例如,模块化连接探针具有连接到一个位点的5'序列,并且3'部分具有连接在靶标上远端位点的序列。使用这种模块化探针将两个目标远端组件并置,并切掉不感兴趣的中间区域。在靶标已经被水平化的情况下,与第一个基因座相关的标记不需要与随后的基因座相关的标记不同;位置指定了身份。一旦靶分子已经被拉直,就会加入针对所有待分析的等位基因的探针。作为另一选择,探针可以在阵列捕获之前与样品dna反应。目前正在努力建立基因组的单体型结构。在这些信息可获得时,可以使用少得多的snp探针来代表单体型多样性。例如,与使用30个探针来评估捕获/梳直的dna阵列上的单体型不同的是,仅4个探针就可以足够。一种替代性方法是使用单体型标签(johnson等,natgenet2001oct;29(2):233)来捕获特定的单体型。该标签将形成阵列上的空间上可寻址的探针组件之一。用于基因分型的dna汇集法的局限性在于,因为不分析单个的基因型,所以单倍体的估计是复杂的。然而,在本发明中所述的方法中,可以使用dna汇集策略来获得单体型频率。3.指纹识别通过利用杂交或其它手段进行进一步探测,可以进一步表征并唯一地鉴定被捕获的靶链。与靶链联结的特定寡核苷酸提供了关于靶序列的信息。这可以通过用经类似标记的探针进行多次采集来完成(例如在光漂白或去除第一组之后),或用经差异标记的探针同时完成。经差异性标记的一组寡核苷酸可以专门用于同时指纹识别。同样,可以对单个分子同时进行多次探测,如针对单倍体分型所述那样。4.str分析常规的微阵列表达分析是使用固定在固体基板上的合成寡核苷酸探针(例如40-75nt)或更长的cdna或pcr产物探针(通常为0.6kb以上)来进行。根据本发明,这些类型的阵列能够以低表面覆盖率(如a节所述)制造。杂交后,可以使用本发明的方法通过单分子计数来确定基因表达水平。这提供提高的灵敏度,并允许由噪声引起的事件与真实事件区分开。另外,由于计数的基本单位是单分子,所以即使是罕见的转录物也可以被检测出。表达分析的一种实施方式包括通过利用双色标记在同一芯片上同时进行分析来比较两个mrna群体。这也可以通过利用例如光束分割分别计数每种颜色来在单分子水平上完成。靶cdna或mrna的捕获可以允许通过寡核苷酸探针探测进行进一步分析。例如,这可以用于区分以替代方式剪接的转录物。微阵列理论表明,当样品材料为极限量时,可以获得平衡时的准确基因表达比。通过对单分子阵列上的分隔开的分子进行引物延伸,可以制备mrna群体的永久可寻址的拷贝。可以基于可获得的基因组序列或基因片段序列来设计引物。或者,可以使用二元探针来采样未知序列,所述二元探针包含可锚定所有mrna的固定元件和可以寻址/分选群体中的mrna物种库的可变元件。固定元件可以与所有mrna所共有的序列基序互补,例如polya序列或聚腺苷酰化信号aauaaa,或优选与在5'或3'端连接到所有mrna或cdna上的共有夹持序列(clampsequence)互补。该拷贝可用作进一步分析(例如测序)的基础。5.表达分析常规的微阵列表达分析是使用固定在固体基板上的合成寡核苷酸探针(例如40-75nt)或更长的cdna或pcr产物探针(通常为0.6kb以上)来进行。根据本发明,这些类型的阵列能够以低表面覆盖率(如a节所述)制造。杂交后,可以使用本发明的方法通过单分子计数来确定基因表达水平。这提供提高的灵敏度,并允许由噪声引起的事件与真实事件区分开。另外,由于计数的基本单位是单分子,所以即使是罕见的转录物也可以被检测出。表达分析的一种实施方式包括通过利用双色标记在同一芯片上同时进行分析来比较两个mrna群体。这也可以通过利用例如光束分割分别计数每种颜色来在单分子水平上完成。靶cdna或mrna的捕获可以允许通过寡核苷酸探针探测进行进一步分析。例如,这可以用于区分以替代方式剪接的转录物。微阵列理论表明,当样品材料为极限量时,可以获得平衡时的准确基因表达比。通过对单分子阵列上的分隔开的分子进行引物延伸,可以制备mrna群体的永久可寻址的拷贝。可以基于可获得的基因组序列或基因片段序列来设计引物。或者,可以使用二元探针来采样未知序列,所述二元探针包含可锚定所有mrna的固定元件和可以寻址/分选群体中的mrna物种库的可变元件。固定元件可以与所有mrna所共有的序列基序互补,例如polya序列或聚腺苷酰化信号aauaaa,或优选与在5'或3'端连接到所有mrna或cdna上的共有夹持序列互补。该拷贝可用作进一步分析(例如测序)的基础。6.比较基因组杂交(cgh).网格化的基因组dna或通过空间上可寻址的标签或探针(或互补拷贝)固定的基因组dna用来自不同来源的基因组dna探测,以检测两个样品之间具有差异性缺失和扩增的区域。含有每个物种的多个拷贝的经固定的样品可以是参照组,并且可以对来自两个不同来源的基因组dna进行差异性标记并通过杂交与参照进行比较。7.检测靶标与寡核苷酸库的结合靶标可以与配体库杂交。单分子分析是有利的;例如,它揭示了构象异构体的结合特征,并克服了靶分子与具有紧密组装的分子的阵列的结合的相关空间位阻。杂交在与任何选定配体的计划用途中出现的条件接近的条件下进行。对于与rna结合的反义寡核苷酸,杂交发生在:0.05至1mnacl或kcl,和浓度为0~10mm的mgcl2,在例如tris缓冲液中。一皮摩尔以下的靶标就足够。(参见ep-a-742837:发现配体的方法)。8.蛋白质-核酸相互作用生物分子(例如如蛋白质)和核酸之间的相互作用可以以多种方式来分析。双链dna多核苷酸(通过设计序列的折回)可以固定至其中单个分子是能够解析的表面,以形成分子阵列。然后使固定的dna与候选蛋白质/多肽接触,并通过上述方法确定任何结合。或者,可以将rna或双链体dna用本文所提及的任何方法水平化并可选地拉直。然后可以使用本文所述的方法在特定rna或dna内鉴定蛋白结合位点。候选生物分子通常包括转录因子、调控蛋白和其它分子或离子,例如钙或铁。当分析与rna的结合时,通常保留有意义的二级结构。经标记的转录因子或其它调控蛋白与用本文所述的方法固定和线性化的基因组dna的结合可用于鉴定基因组中的活性编码区或基因位点。这是通常用于发现基因组中的编码区的生物信息学方法的实验替代方法。类似地,可以使用对5-甲基胞嘧啶特异的抗体来鉴定和标记基因组的甲基化区域。差异性甲基化可以是基因组的表观遗传控制的重要手段,对其的研究正在变得越来越重要。来自标签序列探针的信息可以与关于甲基化区域和编码区的信息组合。用于确定dna的甲基化状态的替代性手段是通过使用afm的力分析或化学力分析。例如,氮化硅afm尖端与dna中的甲基胞嘧啶差异性地相互作用,其比非甲基化的dna更疏水。9.光学定位(opticalmapping)光学定位(其中直接对在表面上线性化的dna进行限制性消化)可以通过以阵列化探针空间可寻址地捕获基因组片段而以有序的全基因组方式来完成。然后可以执行限制性消化。限制性消化将是获得限制片段长度多态性(rflp)信息的方式。其它应用包括涉及dna序列标签与抗标签阵列的杂交的rna结构分析和测定。当固定在通道或鞘内时,代替水平化的是,可以使分子与通道长度平行。n聚物阵列和测定n聚物阵列(给定长度的所有可能的序列)可用于杂交测序。n聚物阵列也可以用于分选复杂的样品。当它们连接到锚定序列(例如聚腺苷酰化信号序列或polya尾)或与已经连接到靶分子上的夹持/接头序列互补的序列时,这是特别有利的。空间上可寻址的阵列的每个组件将含有一个共同的锚定序列和n聚物组的独特组件。这些探针可以用于杂交、引物延伸、连接测定等。具体而言,它们可以用于通过合成反应进行的引发测序,其中例如序列已经片段化并且片段已经连接到夹持序列上。n聚物的优点在于,在利用合成反应进行测序之前,仅通过n聚物的杂交就已经从靶标获得了一定量的序列信息。茎环探针可能是有利的构造,其中一条茎链形成粘性末端,靶夹持序列在其上与之杂交并可选地连接在其上。其它类型的测定本发明不限于分析核酸和核酸之间的相互作用的方法。例如,在本发明的一个方面,分子是蛋白质。可以使用抗体来结合蛋白质。其它探针可进一步查询蛋白质。例如,可以使抗体接触进一步的表位,或使小分子药物接触活性位点。低密度分子阵列也可用在高通量筛选与给定的目标分子相互作用的化合物的方法中。在该情况下,多个分子代表候选化合物(具有已知身份)。使目标分子与阵列接触,并且查询阵列以确定分子在何处结合。由于阵列是空间上可寻址的,因此可以容易地确定经鉴定已结合了目标分子的每个经固定的分子的身份。目标分子可以是例如多肽,并且多个经固定的分子可以是小分子有机化合物的组合文库。上述测定中的许多涉及检测阵列中的分子与施加至阵列的样品中的靶分子之间的相互作用。然而,其它测定包括确定阵列化的多个分子的性质/特性(即使它们的身份是已知的),例如确定单个分子的激光诱导的荧光特性。相对于整体分析的优点是检测到瞬时过程和功能性异构体。因此,总之,本发明的测定和本发明的低密度分子阵列可用于多种应用,包括:遗传分析,例如snp检测、单倍体分型、str分析、测序和基因表达研究;鉴定样品中存在的化合物/序列(包括环境取样、病原体检测、基因修饰的食品和毒理学);和高通量筛选具有目标性质的化合物。高通量遗传分析可用于医学诊断以及研究目的。单分子阵列方法的优点可概括如下:1.能够解析复杂样品;2.能够将正确的信号与错误的信号分开;3.精确到分析物中的单分子的检测灵敏度;4.在常见(例如野生型)分子池内检测单个变异分子的灵敏度;5.消除了对样品扩增的需要;6.允许靶样品中的单个分子被分选至离散的阵列组件中,并且调查所述靶分子的具体信息,例如分析多个多态性位点(即单倍体分型);7.能够对阵列组件内的单分子事件进行时间解析的显微镜检查,从而检测单分子过程的瞬时相互作用或时间特征;和8.由于单分子计数,能够获得对特定事件(例如等位基因频率或mrna浓度比)的非常精确的测量。在另一方面,本说明书涉及以下方法和用途。1.一种产生分子阵列的方法,所述方法包括:将多个分子固定在固相上,固定的密度允许各个经固定的分子能够被单独解析,其中阵列中的每个分子是空间上可寻址的,并且每个分子的身份在固定之前是已知的或已确定。2.如方法1所述的方法,其中,所述分子通过选自下述的方法施加至所述固相:打印、电子寻址、原位光导合成、喷墨合成或物理掩蔽。3.如方法2所述的方法,其中,所述分子通过打印稀溶液而施加至所述固相。4.一种产生分子阵列的方法,所述方法包括:(i)提供包含固定至固相上的多个分子的分子阵列,固定的密度使得各个经固定的分子不能被单独解析;和(ii)减少阵列中的功能性的经固定的分子的密度,使得剩余的各个功能性的经固定的分子能够被单独解析;其中所得阵列中每个单个的功能性分子是空间上可寻址的,并且每个分子的身份在密度减少步骤之前是已知的或已确定。5.如方法4所述的方法,其中,功能性分子的密度通过从固相上切割所有或部分分子来减少。6.如方法4所述的方法,其中,功能性分子的密度通过使所述分子原位功能性失活来减少。7.如方法4所述的方法,其中,功能性分子的密度通过下述方式来减少:标记多个分子中的一些,以使得各个经固定的经标记的分子能够被单独解析。8.如任一项前述方法所述的方法,其中,所述经固定的分子存在于离散的空间上可寻址的元件中。9.如方法8所述的方法,其中,存在于每个离散的空间上可寻址的元件中的分子的结构是已知的,并且基本上不存在非有意的结构。10.如方法8所述的方法,其中,在一个或多个元件中存在多个分子物种,并且元件中的每个分子物种能够凭借标记与元件中的其它分子物种区分开。11.如任一项前述方法所述的方法,其中,能够被单独解析的多个分子能够通过光学手段来解析。12.如任一项前述方法所述的方法,其中,能够被单独解析的多个分子能够通过扫描探针显微镜来解析。13.如方法1~12中任一项所述的方法,其中,所述分子在单个确定的点处附着至所述固相。14.如方法1~12中任一项所述的方法,其中,所述分子在两个以上点处附着至所述固相。15.如任一项前述方法中所述的方法,其中,所述分子包含可检测标记。16.如方法15所述的方法,其中,所述标记能够通过光学方法读出。17.如方法15或方法16所述的方法,其中,所述标记是单个荧光分子、纳米颗粒或纳米棒,或者多个荧光分子、纳米颗粒或纳米棒。18.如方法15所述的方法,其中,所述标记能够通过spm读出。19.如方法18所述的方法,其中,所述标记是非荧光的分子、纳米颗粒或纳米棒。20.如方法1~19中任一项所述的方法,其中,所述分子选自:确定的化学实体、寡核苷酸、多核苷酸、肽、多肽、缀合的聚合物、有机小分子或其类似物、模拟物或缀合物。21.如方法20所述的方法,其中,所述分子是cdna和/或基因组dna。22.如前述方法中任一项所述的方法,其中,所述经固定的分子存在于离散的空间上可寻址的元件中,且每个元件包含不同的空间上可寻址的微米电极或纳米电极。23.如方法22所述的方法,其中,所述电极由导电聚合物形成。24.如方法23所述的方法,其中,所述电极通过选自下述的方法产生:喷墨打印、软光刻、纳米压印光刻/光刻诱导的自组装、vlsi方法和电子束写入。25.如方法1~24中任一项所述的方法,其中,所述经固定的分子固定在单个电极上。26.如方法22~25中任一项所述的方法,其中,当靶分子与存在于与电极相同的元件中的经固定的分子结合时,所述电极转导信号。27.用前述方法中任一项所述的方法获得的分子阵列。28.分子阵列在鉴定样品中的一个或多个靶分子的方法中的用途,所述分子阵列包含固定至固相的多个分子,固定的密度允许各个经固定的分子能够被单独解析,其中阵列中的每个单独的经固定的分子是空间上可寻址的,并且每个经固定的分子的身份是已知的或已编码的。29.如方法28所述的用途,其中,所述方法包括使阵列与样品接触,并查询一个或多个单独的经固定的分子以确定靶分子是否已经结合。30.如方法29所述的用途,其中,查询基本上所有的经固定的分子。31.如方法28~30中任一项所述的用途,其中,查询通过光学方法进行。32.如方法31所述的用途,其中,所述光学方法选自:远场光学法、近场光学法、表面荧光光谱、扫描共焦显微镜、双光子显微镜、全内反射显微镜。33.如方法32所述的用途,其中,将脉冲激光激发照射与时间相关的单分子计数(tcspc)或同步时间门控结合。34.如方法28~30中任一项所述的用途,其中,查询通过扫描探针显微镜或电子显微镜进行。35.如方法28~34中任一项所述的用途,其中,确定经固定的分子的物理化学性质,例如形状、尺寸、质量、疏水性或电荷。36.如方法28~34中任一项所述的用途,其中,确定经固定的分子的电磁性质、电性质、光电性质和/或电化学性质。37.如方法29~34中任一项所述的用途,其中,确定经固定的分子与靶分子之间的复合物的特征。38.如方法28~37中任一项所述的用途,其中,经固定的分子属于与靶分子相同的化学类别。39.如方法28~37中任一项所述的用途,其中,经固定的分子属于与靶分子不同的化学类别。40.如方法28~37中任一项所述的用途,其中,靶分子是基因组dna或其复杂度降低的代表物。41.如方法40所述的用途,其中,通过将靶标片段化并使其预杂交至c0t=1dna来降低复杂性。42.如方法40或方法41所述的用途,其中,基因组dna在分析前经历全基因组扩增。2843.如方法28~37中任一项所述的用途,其中,靶分子是mrna或cdna。44.方法28中所定义的分子阵列在下述中的用途:遗传分析、基因表达研究、鉴定在阵列中与分子靶标相互作用的一个或多个分子,或者检测或分型核酸样品中的单核苷酸多态性,单倍体分型,或测序。45.方法32所定义的分子阵列的用途,其中,阵列的经固定的分子和靶分子是核酸,并且接触步骤在允许经固定的分子与靶分子杂交的条件下进行。46.如方法45所述的用途,其中,靶核酸与经固定的核酸的杂交通过从所得的复合物进行引物延伸来检测。47.如方法45所述的用途,其中,观察到连续的加标签的单体碱基添加使得能够通过合成进行测序。48.如方法46或方法47所述的用途,其中,使用三磷酸腺苷双磷酸酶来减少并入3'末端错配碱基。49.如方法45所述的用途,其中,通过核酸探针与靶核酸/经固定的核酸复合物的杂交来检测靶核酸与经固定的核酸的杂交。50.如方法49所述的用途,其中,所述探针被差异性标记。51.如方法47所述的用途,其中,通过核酸探针与靶核酸/经固定的核酸复合物的连接来检测靶核酸与经固定的核酸的杂交。52.如方法47所述的用途,其中,观察到与加标签的寡核苷酸前导的连续连接使得能够通过合成进行测序。53.如方法28~52中任一项所述的用途,其中,使阵列与两个以上靶分子群接触。54.如方法53所述的用途,其中每个靶分子群被差异性标记。55.一种对核酸中的单核苷酸多态性(snp)和突变进行分型的方法,所述方法包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针库,所述核酸可以具有一种或多种多态性,所述库呈现为使得所述库中的分子能够被单独解析;b)使样品暴露于库,并允许存在于样品中的核酸以所需的严格性与探针杂交,并且可选地用酶进行处理;c)在可选地从库中洗脱出未反应的核酸之后,检测各个经反应的核酸分子。56.如方法55所述的方法,其中,所述库在固相上阵列化。57.如方法56所述的方法,其中,所述阵列是方法27所述的阵列。58.如方法55~57中任一项所述的方法,其中,使样品暴露至第二探针库,所述探针在与第一库的探针不同的位置处与样品的一个或多个分子结合。59.如方法58所述的方法,其中,所述第一库和第二库被差异性标记。60.一种确定靶核酸的全部或部分序列的方法,所述方法包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的第一探针组,所述第一探针组呈现为使得阵列化的分子可以被单独解析;b)使包含靶核酸的样品与第一探针组杂交;c)使一个或多个确定序列的其它探针与靶核酸杂交;和d)检测各个其它探针与靶核酸的结合。e)和检测分隔开各探针的大致距离或每个探针的排序。61.如方法60所述的方法,其中,第一探针组是探针库。62.如方法61所述的方法,其中,所述库在固相上阵列化。63.如方法62所述的方法,其中,靶核酸在一个或多个点处被捕获至固相。64.如方法60~63中任一项所述的方法,其中,所述库以使得所述库中的分子能够被单独解析的密度阵列化。65.如方法64所述的方法,其中,所述阵列是方法27所述的阵列。66.如方法60~65中任一项所述的方法,其中,所述探针被差异性标记。67.一种确定核酸样品中序列重复的数量的方法,所述方法包括以下步骤:a)提供与样品中存在的一种或多种核酸互补的一种或多种探针,所述核酸可以具有一个或多个序列重复,所述探针与所述重复的一个末端的侧翼序列互补,并且所述探针呈现为使得分子可以被单独解析;b)使所述核酸与经标记的探针和经差异标记的探针接触,所述经标记的探针与所述序列重复的单元互补,所述经差异标记的探针与所靶向的重复的另一末端的侧翼序列互补;c)使b)中形成的复合物与a)中的探针接触;和d)通过对并入每个分子的标记的数量进行单独评估、并且仅计数同时联结有与侧翼序列互补的经差异标记的探针的那些分子,来确定每个样品核酸上存在的重复的数量。68.如方法67所述的方法,其中,所述库在固相上阵列化。69.如方法67或方法68所述的方法,其中,所述库以使所述库中的分子能够被单独解析的密度阵列化。70.如方法69所述的方法,其中,所述阵列是方法27所述的阵列。71.一种分析样品中一种或多种基因的表达的方法,所述方法包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针库,所述库呈现为使得分子可以被单独解析;b)使包含所述核酸的样品与探针杂交;和c)通过对与探针杂交的单个分子进行计数来确定样品中存在的各个核酸物种的性质和量。72.如方法71所述的方法,其中,所述库在固相上阵列化。73.如方法71或方法72所述的方法,其中,所述库以使得所述库中的分子能够被单独解析的密度阵列化。74.如方法73所述的方法,其中,所述阵列是方法27所述的阵列。75.如方法71~74中任一项所述的方法,其中所述库包含具有每种给定特异性的多个探针。76.一种对核酸中的单核苷酸多态性(snp)和突变进行分型的方法,所述方法包括以下步骤:a)提供与存在于样品中的一种或多种核酸互补的探针的库,所述核酸可以具有一种或多种多态性;b)将所述库阵列化成使得所述库中的每个单针都是能够单独解析的;c)使样品暴露至所述库,并允许存在于样品中的核酸以所需的严格性与探针杂交,并且可选地用酶进行处理,以使得经杂交/经处理的核酸/探针对能够被检测;d)从库中洗脱出未杂交的核酸,并检测单个的经杂交/经处理的核酸/探针对;e)分析来自步骤d)的信号并计算各检测事件的置信度,以产生具有高置信度结果的pass表;和f)显示来自pass表的结果,以指定碱基识别并将存在于核酸样品中的多态性分型。77.如方法76所述的方法,其中,步骤(e)包括分析来自步骤(d)的信号并计算出各检测事件中的具有低置信度结果的fail表,并使用该表以为引物和测定设计提供信息。78.如方法76或方法77所述的方法,其中,重复该过程以用于通过合成进行测序。79.如方法76所述的方法,其中,各检测事件中的置信度根据图80来计算。80.如方法76或方法77所述的方法,其中,检测事件通过对样品核酸和/或探针分子进行标记并且使用检测器对阵列上的所述标记成像而产生。81.如方法55或76-80中任一项所述的方法,其中,被探针探测的snp是针对单体型链段或连锁不平衡区域的标签。82.一种通过对汇集的dna进行单分子计数而获得等位基因频率的方法。83.如方法82所述的方法,其中,所获得的等位基因频率用于关联研究或其它遗传方法中。84.如方法76-83中任一项所述的方法,其中,探针和/或靶标充当引物或连接底物。85.如方法76-80中任一项所述的方法,其中,用连接酶或聚合酶或其嗜热变体或其重新设计/改组(shuffled)的变体对所述探针和/或靶标进行酶处理。86.如方法76-85中任一项所述的方法,其中,所述探针形成促进或稳定杂交或改善错配辨别的二级结构。87.一种确定全部或部分靶核酸分子的序列的方法,所述方法包括:(i)将靶分子在两个以上点处固定至固相,使得分子相对于固相表面基本上水平;(ii)在固定期间或之后拉直靶分子;(iii)使靶分子与已知序列的核酸探针接触;和(iv)确定靶分子内的与探针杂交的位置;88.如方法87所述的方法,其中,使靶分子与多个探针接触。89.如方法88所述的方法,其中,每个探针都标记有不同的可检测标记。90.如方法87或88所述的方法,其中,使靶分子与多个探针中的每一个依次接触。91.如方法90所述的方法,其中,将每个探针从靶分子上去除,再使靶分子与另一个不同的探针接触。92.如方法88或89所述的方法,其中,使靶分子基本上同时与所有多个探针接触。93.如方法91所述的方法,其中,探针通过加热、改变盐浓度或ph、或通过施加适当偏置的电场来去除。94.如方法28~93中任一项所述的方法或用途,其中,靶标基本上是双链分子,并且使用pna或lna通过链侵入来对其进行探测。95.如方法97~94中任一项所述的方法,其中,靶核酸分子是双链分子,并且通过合成与目标单链核酸互补的互补链而衍生自目标单链核酸分子。96.如方法28~94中任一项所述的方法,其中,靶分子基本上是单链的,并且通过延伸或伸展而使得其易于接触以进行杂交。97.如方法28~96中任一项所述的方法或应用,其中,同时分析多个靶分子。98.一种确定全部或部分靶单链核酸分子的序列的方法,所述方法包括:(i)将靶分子在两个以上点处固定至固相,使得分子相对于固相表面基本上水平;(ii)在固定期间或之后拉直靶分子;(iii)使靶分子与已知序列的多个核酸探针接触,每个探针都标记有不同的可检测标记;和(iv)连接已结合的探针以形成互补链。99.如方法98所述的方法,其中,在步骤(iv)之前,通过由所述已结合的探针引发的聚合来填充已结合的探针之间的任何空位。100.如方法87~99中任一项所述的方法,其中,所述固相是珠或颗粒。101.如方法87~100中任一项所述的方法,所述固相是基本上平的表面。102.一种将多个核酸分子阵列化的方法,所述方法包括:(i)使多个核酸分子与多个探针接触,每个探针用唯一指示探针身份的标签标记,使得每个分子可以通过检测与所述分子结合的探针并确定相应的标签的身份而被唯一鉴定;(ii)将多个核酸分子随机固定在固体基板上;和可选地(iii)在固定期间或之后将所述分子水平化和拉直。103.如方法102所述的方法,其中,所述多个核酸分子以使得样品中的各个经固定的分子能够被单独解析的密度固定。104.如方法102~103中任一项所述的方法,其中,所述固相是基本上平的固体基板或珠/颗粒/棒/条。105.用方法102~104中任一项所述的方法产生的阵列。106.一种鉴定和/或表征样品中存在的多个分子中的一个或多个分子的方法,所述方法包括:(i)通过包括将存在于样品中的多个分子固定至固相的方法来产生分子阵列,其中多个分子以使得样品中的各个分子能够被单独解析的密度固定;和(ii)通过包括使经固定的分子与多个编码的探针接触的方法来鉴定和/或表征固定至阵列的一个或多个分子;其中,每个探针通过用唯一指示探针身份的标签进行标记而被编码,以使得可以通过检测与分子结合的探针并确定相应标签的身份来唯一地鉴定经固定的分子。107.如方法106所述的方法,其中,加标签的探针使用组合化学产生。108.如方法106所述的方法,其中,所述标签选自纳米颗粒、纳米棒和量子点。109.如方法106~108中任一项所述的方法,其中,每个标签包含多个分子物种。110.如方法106~109中任一项所述的方法,其中,所述标签是通过光学手段可检测的。111.如方法106所述的方法,其中,所述标签是颗粒物并且包含表面基团。112.如方法106所述的方法,其中,所述标签是颗粒物并且包裹可检测实体。113.如方法106~112中任一项所述的方法,其中,标签能够通过扫描探针显微镜来检测和区分。114.如方法106~113中任一项所述的方法,其中,所述固体基板选自珠、颗粒、棒和条。115.如方法106~114中任一项所述的方法,其中,所述固相包含通道或毛细管,其中所述分子被固定在其中。116.如方法106~115中任一项所述的方法,其中,所述固相包含凝胶。117.一种生物传感器,其包含方法27或105中任一项所述的分子阵列。118.一种集成的生物传感器,其包含方法117所述的分子阵列、激发源、检测器(例如ccd)和可选的信号处理装置。119.如方法117或118所述的生物传感器,其中,所述生物传感器包括多个元件,每个元件含有不同的分子,例如探针序列。120.如方法119所述的生物传感器,其中,每个元件对于检测不同的靶标具有特异性,所述不同的靶标例如不同的致病生物体。121.如方法117~120中任一项所述的生物传感器,其中,所述分子阵列形成在光纤或波导器上。122.如方法106所述的方法,其中,所述多个探针标记有唯一指示探针身份的标签。123.如任一项前述方法所述的方法,其中,多个加标签的探针基本上同时杂交或以探针组杂交。124.如任一项前述方法所述的方法,其中,将探针根据其tm分组。125.如方法106所述的方法,其中,多个经标记的探针中的每一个依次连续与经固定的核酸杂交,并且可以使用与每个分子杂交的那些探针的记录来鉴定或重新组装经固定分子的序列。126.一种通过以空间上可寻址的方式探测固定在固相上的单分子来确定单体型的方法。127.如方法126所述的方法,为了进行单倍体分型,其中用不同的标记探测连续的snp位点。128.一种单倍体分型方法,其中,第一snp由出现结合的阵列元件的地址确定,后续的snp由不同的标记确定。129.一种在阵列上进行单倍体分型的方法,其中,第一snp由阵列上的地址确定,后续的snp通过溶液探针来鉴定。130.一种在阵列上对被捕获和水平化的和/或线性化的dna进行单倍体分型的方法,其中,第一snp由阵列上的地址确定,后续的snp通过溶液探针来鉴定。131.如方法130所述的方法,其中,使用两种不同的标记来区分双等位基因探针组的组件,并且每个连续的snp凭借其沿分子的位置来鉴定。132.如方法131所述的方法,其中,根据探针沿分子的预期结合位置来计算错误。133.一种方法,其中,对分子群体进行分析,并且根据来自单个分子的信号的共性(consensus)来计算单体型。134.如方法126-132和44、47、52和78中任一项所述的方法,其中,可以确定单体型频率。135.如132所述的方法和测序方法,其中,添加标志物以帮助定位snp位点/或定位靶标结合。136.如前述方法中任一项所述的方法,其中,对探针加标记或标志,并且在靶标结合或测定之后的信号仅在其与探针上的标记或标志一致时被认为是真信号。137.一种鉴定样品中的一个或多个靶分子的方法,所述方法包括使用分子阵列,该分子阵列包含固定至固相的多个分子,固定的密度使得各个经固定的分子能够被单独解析,其中阵列中的每个单独的经固定的分子是空间上可寻址的,并且每个经固定的分子的身份是已知的或被编码的。在以下描述中,参照附图来描述各种示例性实施方式。图21是用于定量两个基因组基因座处的基因组拷贝数的测定的实施情况。在该测定的该实施方式中,105和106是靶分子。105含有对应于查询拷贝数(例如染色体21)的第一基因组基因座“基因座1”的序列,106含有对应于查询拷贝数(例如染色体18)的第二基因组基因座“基因座2”的序列。图21包含了每个基因组基因座一个探针组的实例,但是在该测定的一些实施方式中,可以设计多个探针组以查询基因组基因座内的多个区域。例如,可以设计对应于染色体21的大于10、大于100或大于500个探针组。图21说明了针对每个基因组基因座的仅单个探针组,但是重要的是本发明的范围允许为每个基因组基因座用多个探针组。图21也说明了靶分子和探针组之间的单杂交事件。实践中,在测定样品中会存在多个靶分子。许多靶分子会含有用于杂交至探针组并且形成探针产物的必需序列。不同的靶分子可以与探针组杂交,因为一些靶分子会带有遗传多态性。另外,由基因组dna产生的靶分子可以具有随机的各种各样的分子尺寸以及各种起始和末端序列。本质上,存在可以与给定探针组杂交的多个靶分子。在单个测定中,添加多个拷贝的给定探针组。因此,在单个测定中可以形成至多数千或数十万或者数百万个特定探针产物。图21描绘了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。第一探针组含有成员探针101、102、103。符号101含有“a”型标记(100)。符号103含有亲和标签(104),其可用于分离和鉴定探针产物。102可以不含有修饰,例如标记或条形码。具有成员探针108、109、110的第二探针组携带第一探针组中的相应特征。但是,108含有“b”型标记(107),其与“a”型可区分。符号110含有亲和标签(111),其可与104相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列但具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列但具有相同的标记类型“b”。在该实施方式中,用于基因座1的许多种探针组的亲和标签可以是相同的或是独特的,用于基因座2的许多种探针组的亲和标签可以是相同的或是独特的。将一个或多个探针组添加至单个容器中的靶分子,并暴露至序列特异性杂交条件。对于各探针组,使三个探针(例如101、102、103)与靶分子(105)杂交(或经由类似的探针-靶标相互作用来连接),从而使靶分子上探针之间无空位。即,来自探针组的探针彼此相邻并且是有连接能力的。将连接酶添加至经杂交的探针并且暴露至标准连接酶条件。经连接的探针形成探针产物。来自基因座1的所有(或大多数)探针产物都具有标记类型“a”。来自基因座2的所有探针产物都具有标记类型“b”。对应于基因组基因座1和2的探针产物的定量使用标记“a”和“b”来进行。在一些实施方式中,使用探针产物的亲和标签将探针产物固定至基板上。例如,如果亲和标签是dna序列,则探针产物可以以对于随后的成像而言合适的密度杂交至dna捕获阵列的区域中。在一些实施方式中,亲和标签104和111含有允许基于表面定位至一个或多个位置的独特的正交序列,其可以在杂交产物之间共有或者不共有。图47和48显示了所得的荧光团图案,其中,产物含有独特的亲和标签序列,且下方的基板含有互补物,所述互补物与基板上相同区域(例如相同的阵列组件)内的每种独特的亲和标签互补。这些图像属于基板的相同区域,但是图47显示了cy3标记(与染色体18产物共价键和),图48显示了alexafluor647标记(与染色体21产物共价键和)。对于以下的其它测定实施方式可以产生相似的图案。在另一实施方式中,亲和标签104和111含有相同的序列,其允许基于表面定位至基板上的相同区域(例如相同的阵列组件)。即,不同的产物竞争相同的结合位点。图49和51显示了所得的荧光图案,其中,不同的产物含有相同的亲和标签序列,并且下方的基板含有所述亲和标签的互补物。这些图像属于基板上的相同位置,但是图49显示了cy3标记(与染色体18产物共价键和),图51显示了alexafluor647标记(与染色体21产物共价键和)。图50和52分别显示了图49和51的放大区域,清楚地证明了单分子解析度和可单个区分的标记。对于以下的其它测定实施方式可以产生相似的图案。在另一实施方式中,亲和标签104和111含有独特的正交序列,其允许基于表面定位至基板上的多于一个位置。图53和54显示了所得的荧光图案,其中,产物含有独特的亲和标签序列,并且下方的基板具有:含有一种亲和标签互补物的互补物的一个区域,和含有另一种亲和标签的互补物的另一单独的区域。这些图像属于基板的两个分开的区域,每个区域含有之前所述的单个亲和标签互补物。图53显示了cy3标记(与染色体21产物共价键和),图54显示了alexafluor647标记(与染色体18产物共价键和)。对于以下的其它测定实施方式可以产生相似的图案。根据一些实施方式,本发明的一个特征是通过多个相邻探针的组合而实现了特异性,所述多个相邻探针必须成功地连接在一起以成功地形成、捕获和检测探针产物。如果探针产物因任何原因未成功形成,则其不能使用亲和标签分离或富集并被检测到。例如,如果探针101未成功地连接至探针102,则所得产物不能被检测到。类似地,如果探针103未成功地连接至探针102,则所得产物不能使用亲和标签分离或富集。要求来自探针组的所有探针都成功地与靶分子杂交并且成功地连接在一起,该要求提供了高特异性,并且极大地减少了交叉杂交问题并因此减少了假阳性信号问题。在该测定中,通过序列特异性杂交和连接而实现了特异性。在优选实施方式中,形成探针产物的特异性在分离或富集探针产物之前(例如固定至表面或其它固体基板上时)在反应容器中出现。这避开了基于标准表面的杂交(例如基因组微阵列)的挑战,在所述杂交中,特异性必须通过仅用长(>40bp)寡核苷酸序列进行的杂交(例如agilentandaffymetrix阵列)来完全实现。使用亲和标签允许将探针产物固定在基板上,因此能够将过量的未结合的探针使用标准方法洗去或者使用标准方法除去。所以表面上的所有或大多数标记是固定至表面的特异性形成的探针产物的一部分。根据一些实施方式,本发明的一个特征是表面捕获不影响准确度。即,其不引入任何偏差。在一个实例中,如果将相同的亲和标签用于来自不同基因组基因座的探针组,则靶向每个基因座的探针组具有不同的标记。可以使用相同的亲和标签将来自两个基因组基因座的探针产物固定至基板上的相同位置。即,来自基因座1和基因座2的探针产物会以相同的效率被捕获,因此不会引入任何基因座特异性偏差。在一些实施方式中,在进行表面捕获之前,使用标准方法除去一些或所有的未结合的探针和/或靶分子。这降低了在表面捕获过程中未结合的探针和/或靶分子与探针产物之间的干扰。根据一些实施方式,本发明的一个特征是多个亲和标签类型可以放置在基板的相同区域(例如,阵列的相同阵列点或组件)中。这具有许多优点,包括放置对照和校正标志物。图22至46描述了本发明的其它示例性实施方式。这些图不代表所有可能的实施方式,并且将该测定的所有其它变形都作为本发明的一部分包括在内。另外,图21中描述的实施方式的所有特征都适用于本申请所述的测定的所有另外的其它实施方式。图22描述了图21中所描述的一般步骤的变型。图22描绘了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。207和214是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针202、204、206。202含有“a”型标记(201)。206含有亲和标签(205),其可用于分离和鉴定探针产物。具有成员探针209、211、231的第二探针组携带如第一探针组中那样的相应特征。但是,209含有“b”型标记(208),其与“a”型可区分。213含有亲和标签(212),其可与205相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以是相同的或是独特的,或者是相同和独特的混合,针对基因座2的许多种探针组的亲和标签可以是相同的或是独特的,或者是相同和独特的混合。在该实施方式中,探针204和211可以含有一个或多个“c“型标记(203,210)。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图23描述了图21中描述的一般步骤的变型。图23描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。307和314是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针302、303、305。302含有“a”型标记(301)。305含有亲和标签(306),其可用于分离和鉴定探针产物。具有成员探针309、310、312的第二探针组携带如第一探针组中那样的相应特征。但是,309含有“b”型标记(308),其与“a”型可区分。312含有亲和标签(313),其可与306相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针305和312含有一个或多个”c”型标记(304,311)。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图24描述了图21描述的一般步骤的变型。图24描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。407和414是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针402、405。402含有“a”型标记(401)。405含有亲和标签(406),其可用于分离和鉴定探针产物。具有成员探针409、412的第二探针组携带如第一探针组中那样的相应特征。但是,409含有“b”型标记(408),其与“a”型可区分。412含有亲和标签(413),其可与406相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针402和405与对应于基因座1的序列杂交,但是在靶分子上存在“空位”,该空位由位于已杂交的探针402和405之间的一个或多个核苷酸组成。在该实施方式中,dna聚合酶或其它酶可用于合成共价连接402和405的新多核苷酸物质(404)。即,在该实例中形成的探针产物是单一连续核酸分子,其序列对应于基因座1,并且携带以上标记和/或亲和标签。另外,404可以含有一个或多个“c”型标记,这可能归因于引入了一个或多个携带“c”型标记的核苷酸。该实例也适用于针对基因座2形成的探针产物,其含有探针409和412。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图25描述了图21描述的一般步骤的变型。图25描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。505和510是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针502、503。502含有“a”型标记(501)。503含有亲和标签(504),其可用于分离和鉴定探针产物。具有成员探针507、508的第二探针组携带如第一探针组中那样的相应特征。但是,507含有“b”型标记(506),其与“a”型可区分。508含有亲和标签(509),其可与504相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。图26描述了图21描述的一般步骤的变型。图26描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。606和612是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针602、603。602含有“a”型标记(601)。603含有亲和标签(605),其可用于分离和鉴定探针产物。具有成员探针608、609的第二探针组携带如第一探针组中那样的相应特征。但是,608含有“b”型标记(607),其与“a”型可区分。609含有亲和标签(611),其可与605相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针603和609含有一个或多个“c”型标记(604,610)。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图27描述了图21描述的一般步骤的变型。图27描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,用于区分母体和胎儿等位基因,在分离自怀孕妇女的无细胞dna的情况下,或用于区分宿主和供体等位基因,在来自器官移植受体的无细胞dna的情况下。图27描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。706和707是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针702、703、704。702含有“a”型标记(701)。704含有亲和标签(705),其可用于分离和鉴定探针产物。具有成员探针709、703、704的第二探针组携带如第一探针组中那样的相应特征。在该实施方式中,703和704对于这两个探针组是相同的。但是,709含有“b”型标记(708),其与“a”型可区分。在该实施方式中,702和709含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,被构造成与等位基因1和等位基因2的区域杂交的这两个探针的杂交区序列含有等位基因1的互补区(702)和等位基因2的互补区(709)。另外,702和709上的每个杂交区域的长度以及实验杂交条件被设计成使探针702会仅与等位基因1杂交且探针709会仅与等位基因2杂交。该测定类型的目的在于准确地定量样品中的等位基因1和等位基因2的频率。图28描述了图21描述的一般步骤的变型。图28描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,用于区分母体和胎儿等位基因,在分离自怀孕妇女的无细胞dna的情况下,或用于区分宿主和供体等位基因,在来自器官移植受体的无细胞dna的情况下。图28描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。807和810是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针802、804、805。802含有“a”型标记(801)。805含有亲和标签(806),其可用于分离和鉴定探针产物。具有成员探针809、804、805的第二探针组携带如第一探针组中那样的相应特征。在该实施方式中,804和805对于这两个探针组是相同的。但是,809含有“b”型标记(808),其与“a”型可区分。在该实施方式中,802和809含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,这两个探针的杂交区序列含有等位基因1的互补区(802)和等位基因2的互补区(809)。另外,802和809上的每个杂交区域的长度以及实验杂交条件被设计成使探针802会仅与等位基因1杂交且探针809会仅与等位基因2杂交。该测定类型的目的在于能够准确地定量样品中的等位基因1和等位基因2的频率。在该实施方式中,探针804含有一个或多个“c”型标记(803)。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。图29描述了图21描述的一般步骤的变型。图29描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,用于区分母体和胎儿等位基因,在分离自怀孕妇女的无细胞dna的情况下,或用于区分宿主和供体等位基因,在来自器官移植受体的无细胞dna的情况下。图29描述了两种探针组,用于等位基因1的一种探针组和用于等位基因2的一种探针组。907和910是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针902、905。902含有“a”型标记(901)。符号905含有亲和标签(906),其可用于分离和鉴定探针产物。具有成员探针909、905的第二探针组携带如第一探针组中那样的相应特征。在该实施方式中,905对于这两个探针组是相同的。但是,909含有“b”型标记(908),其与“a”型可区分。在该实施方式中,902和909含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,这两个探针的杂交区序列含有等位基因1的互补区(902)和等位基因2的互补区(909)。另外,902和909上的每个杂交区域的长度以及实验杂交条件被设计成使探针902会仅与等位基因1杂交且探针909会仅与等位基因2杂交。该测定类型的目的在于能够准确地定量样品中的等位基因1和等位基因2的频率。在该实施方式中,探针902和905与对应于等位基因1的序列杂交,以使在靶分子上存在“空位”,该空位由位于已杂交的探针902和905之间的一个或多个核苷酸组成。在该实施方式中,dna聚合酶或其它酶可用于合成共价连接902和905的新多核苷酸物质(904)。即,在该实例中形成的探针产物是单一连续核酸分子,其序列对应于等位基因1,并且携带以上标记和/或亲和标签。另外,904可以含有一个或多个“c”型标记,这可能归因于引入了携带“c”型标记的核苷酸。该实例也适用于针对等位基因2形成的探针产物,其含有探针909和905。图30描述了图21描述的一般步骤的变型。图30描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,用于区分母体和胎儿等位基因,在分离自怀孕妇女的无细胞dna的情况下,或用于区分宿主和供体等位基因,在来自器官移植受体的无细胞dna的情况下。图30描述了两种探针组,用于等位基因1的一种探针组和用于等位基因2的一种探针组。1006和1007是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针1001、1003、1004。1003含有“a”型标记(1002)。1004含有亲和标签(1005),其可用于分离和鉴定探针产物。具有成员探针1001、1009、1004的第二探针组携带如第一探针组中那样的相应特征。在该实施方式中,1001对于这两个探针组是相同的,且1004对于这两个探针组是相同的。但是,1009含有“b”型标记(1008),其与“a”型可区分。在该实施方式中,1003和1009含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,这两个探针的杂交区序列分别含有等位基因1的互补区(1003)和等位基因2的互补区(1009)。另外,1003和1009上的每个杂交区域的长度以及实验杂交条件被设计成使探针1003会仅与等位基因1杂交且探针1009会仅与等位基因2杂交。该测定类型的目的在于能够准确地定量样品中的等位基因1和等位基因2的频率。在该实施方式中,探针1001含有一个或多个“c”型标记(1000)。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。图31描述了图21描述的一般步骤的变型。图31描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,用于区分母体和胎儿等位基因,在分离自怀孕妇女的无细胞dna的情况下,或用于区分宿主和供体等位基因,在来自器官移植受体的无细胞dna的情况下。图31描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。1104和1105是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针1101、1102。1101含有“a”型标记(1100)。1102含有亲和标签(1103),其可用于分离和鉴定探针产物。具有成员探针1107、1102的第二探针组携带如第一探针组中那样的相应特征。在该实施方式中,1102对于这两个探针组是相同的。但是,1107含有“b”型标记(1106),其与“a”型可区分。在该实施方式中,1101和1107含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,这两个探针的杂交区序列含有等位基因1的互补区(1101)和等位基因2的互补区(1107)。另外,1101和1107上的每个杂交区域的长度以及实验杂交条件被设计成使探针1101会仅与等位基因1杂交且探针1107会仅与等位基因2杂交。该测定类型的目的在于能够准确地定量样品中的等位基因1和等位基因2的频率。图32描述了图21描述的一般步骤的变型。图32描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,用于区分母体和胎儿等位基因,在分离自怀孕妇女的无细胞dna的情况下,或用于区分宿主和供体等位基因,在来自器官移植受体的无细胞dna的情况下。图32描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。1206和1207是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针1202、1203。1202含有“a”型标记(1201)。1203含有亲和标签(1205),其可用于分离和鉴定探针产物。具有成员探针1209、1203的第二探针组携带如第一探针组中那样的相应特征。在该实施方式中,1203对于这两个探针组是相同的。但是,1209含有“b”型标记(1208),其与“a”型可区分。在该实施方式中,1202和1209含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,这两个探针的杂交区序列含有等位基因1的互补区(1202)和等位基因2的互补区(1209)。另外,1202和1209上的每个杂交区域的长度以及实验杂交条件被设计成使探针1202会仅与等位基因1杂交且探针1209会仅与等位基因2杂交。该测定类型的目的在于能够准确地定量样品中的等位基因1和等位基因2的频率。在该实施方式中,探针1203含有一个或多个“c”型标记(1204)。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。图33描述了图21描述的一般步骤的变型。图33描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1304和1305是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1301、1302。1301含有“a”型标记(1300)。1301含有亲和标签(1303),其可用于分离和鉴定探针产物。具有成员探针1307、1308的第二探针组携带如第一探针组中那样的相应特征。但是,1307含有“b”型标记(1306),其与“a”型可区分。1307含有亲和标签(1309),其可与1303相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1301和1307具有相似的结构。例如,在探针1301上存在两个不同的杂交区域,以使探针1302可以连接至1301的每一端,形成由连续的拓扑闭合的dna分子(例如环状分子)构成的探针产物。探针1301上的非杂交序列可以含有另外的特征,可以是限制性酶位点,或用于通用扩增的引物结合位点。其它相关测定可用来形成具有许多有用性质的环状分子(例如挂锁探针、分子倒置探针等)。例如,外切核酸酶可用于消化线状核酸,但不消化环状核酸,提供了一种用于清理测定、去除外源探针、引物或其它寡核苷酸从而纯化样品的方式。环状分子,例如环状测定产物或探针产物,也可以使用滚环或其它方法来扩增。通过在滚环扩增或其它扩增方法(例如乳液pcr、基于液滴的pcr、桥式扩增、线性扩增、线性重复等等)中使用经标记的引物或探针,可以以相同的方式实现信号的扩增。扩增产物可以以各种方式(例如通过杂交)压缩或浓缩,以产生比使用长分子时可实现的信号更集中的信号。其一个实例是dna纳米球。其它测定可以形成特异性的探针-靶标复合物,例如其中一个或多个探针与靶标本身连接。这可以通过使用模板来实现,所述模板允许探针和靶标二者的部分杂交并因此允许连接。该实施方式的一个特征是所有探针产物都是连续的环状分子。以此方式,可以通过对所有线性核酸分子进行酶促降解(例如使用核酸外切酶)而将探针产物与所有其它核酸分离。图34描述了图21描述的一般步骤的变型。图34描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1405和1406是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1401、1403。1401含有“a”型标记(1400)。1401含有亲和标签(1404),其可用于分离和鉴定探针产物。具有成员探针1408、1410的第二探针组携带如第一探针组中那样的相应特征。但是,1408含有“b”型标记(1407),其与“a”型可区分。1408含有亲和标签(1411),其可与1404相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1401和1408具有相似的结构。例如,在探针1401上存在两个不同的杂交区域,以使探针1403可以连接至1401的每一端,形成由连续的拓扑闭合的dna分子(例如环状分子)构成的探针产物。探针1401上的非杂交序列可以含有另外的特征,可以是限制性酶位点,或用于通用扩增的引物结合位点。该实施方式的一个特征是所有探针产物都是连续的环状分子。以此方式,可以通过对所有线性核酸分子进行酶促降解(例如使用核酸外切酶)而将探针产物与所有其它核酸分离。在该实施方式中,探针1403和1410含有一个或多个“c”型标记(1402,1409)。因此,探针产物将含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图35描述了图21描述的一般步骤的变型。图35描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1505和1506是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1501。1501含有“a”型标记(1500)。1501含有亲和标签(1504),其可用于分离和鉴定探针产物。具有成员探针1508的第二探针组携带如第一探针组中那样的相应特征。但是,1508含有“b”型标记(1507),其与“a”型可区分。1508含有亲和标签(1511),其可与1504相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1501和1508具有相似的结构。例如,在探针1501上存在两个不同的杂交区域,使得当与靶分子杂交时,在两个杂交区域之间存在空位。在该实施方式中,dna聚合酶或其它酶可用于合成共价地填充1501的杂交区域之间的空位的新多核苷酸物质(1503)。即,在该实例中形成的探针产物是单个连续的拓扑闭合的dna分子(例如环状分子),其序列对应于基因座1,并且携带以上标记和/或亲和标签。另外,1503可以含有一个或多个“c”型标记,这可以归因于引入了携带“c”型标记的核苷酸。该实例也适用于针对基因座2形成的探针产物,其含有探针1508。探针1501和探针1508的非杂交序列可以含有另外的特征,可以是限制酶位点。该实施方式的一个特征是所有探针产物都是连续的环状分子。以此方式,可以通过对所有线性核酸分子进行酶促降解(例如使用核酸外切酶)而将探针产物与所有其它核酸分离。探针产物将含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图36描述了图21描述的一般步骤的变型。图36描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1605和1606是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1602。1602含有“a”型标记(1600)。1602含有亲和标签(1601),其可用于分离和鉴定探针产物。具有成员探针1609的第二探针组携带如第一探针组中那样的相应特征。但是,1609含有“b”型标记(1608),其与“a”型可区分。1609含有亲和标签(1607),其可与1601相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“a”。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列,但是具有相同的标记类型“b”。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1602和1609分别与对应于基因座1或基因座2的序列杂交,并且可以使用dna聚合酶或其它酶来合成新的聚核苷酸序列,例如在基因座1的情况下未1603,或者在基因座2的情况下为1611。在该实施方式中,1603和1611可以含有一个或多个“c”型标记(1604),这可以归因于引入了携带“c”型标记的一个或多个核苷酸。该实例也适用于针对基因座2形成的探针产物。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。该实施方式产生分别对基因座1或基因座2中的序列具有高度特异性的探针产物。图37了描述图21描述的一般步骤的变型。图37描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1704和1705是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1702。1702含有亲和标签(1700),其可用于分离和鉴定探针产物。具有成员探针1708的第二探针组携带如第一探针组中那样的相应特征。1708含有亲和标签(1706),其可与1700相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1702和1708分别与对应于基因座1和基因座2的序列杂交。针对基因座1和基因座2的各探针的设计使得紧接杂交区域的第一个相邻核苷酸在针对基因座2和针对基因座1时含有不同的核苷酸。在该实例中,紧接1702的杂交区域的第一个相邻核苷酸是“a”,而紧接1708的杂交区域的第一个相邻核苷酸是“t”。在该实施方式中,针对基因座1的所有探针应该设计成使得与杂交区域直接相邻的第一个核苷酸会由不同于与针对基因座2的探针的杂交区域直接相邻的第一个核苷酸的核苷酸组成。即,通过设计,可以根据与杂交区域直接相邻的第一个核苷酸的身份将来自基因座1和基因座2的探针组彼此区分开。在该实施方式中,会使用dna聚合酶或其它酶来向各探针序列添加至少一个额外的核苷酸。在该实例中,用于dna聚合酶的核苷酸底物能够用于单个添加,例如,核苷酸可以是双脱氧链终止剂。即,仅一个新的核苷酸应该添加至每个探针序列。在该实例中,添加至探针1702的核苷酸会含有一个或多个“a”型标记(1703)。添加至探针1708的核苷酸会含有一个或多个“b”型标记(1709),从而使针对基因座1的探针产物可以与来自基因座2的探针产物区分开。图38描述了图21描述的一般步骤的变型。图38描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1804和1805是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1802。1802含有亲和标签(1800),其可用于分离和鉴定探针产物。具有成员探针1808的第二探针组携带如第一探针组中那样的相应特征。1808含有亲和标签(1806),其可与1800相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1802和1808分别与对应于基因座1和基因座2的序列杂交。针对基因座1和基因座2的各探针的设计使得紧接杂交区域的第一个相邻核苷酸在针对基因座2和针对基因座1时含有不同的核苷酸。在该实例中,紧接1802的杂交区域的第一个相邻核苷酸是“a”,而紧接1808的杂交区域的第一个相邻核苷酸是“t”。在该实施方式中,针对基因座1的所有探针应该设计成使得与杂交区域直接相邻的第一个核苷酸会由不同于与针对基因座2的探针的杂交区域直接相邻的第一个核苷酸的核苷酸组成。即,通过设计,可以根据与杂交区域直接相邻的第一个核苷酸的身份将来自基因座1和基因座2的探针组彼此区分开。在该实施方式中,会使用dna聚合酶或其它酶来向各探针序列添加至少一个额外的核苷酸。在该实例中,用于dna聚合酶的核苷酸底物能够用于单个添加,可能是因为添加至反应混合物的核苷酸是双脱氧核苷酸。即,仅一个新的核苷酸应该添加至每个探针序列。在该实例中,添加至探针1802的核苷酸会含有一个或多个“a”型标记(1803)。添加至探针1808的核苷酸会含有一个或多个“b”型标记(1809),从而使针对基因座1的探针产物可以与来自基因座2的探针产物区分开。在该实施方式中,探针1802和1808含有一个或多个c型标记(1801,1806)。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图39描述了图21描述的一般步骤的变型。图39描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。1906和1907是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针1902。1902含有亲和标签(1901),其可用于分离和鉴定探针产物。具有成员探针1910的第二探针组携带如第一探针组中那样的相应特征。1910含有亲和标签(1908),其可与1901相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针1902和1910分别与对应于基因座1和基因座2的序列杂交。针对基因座1和基因座2的各探针的设计使得紧接杂交区域的第一个相邻核苷酸在针对基因座2和针对基因座1时含有不同的核苷酸。在该实例中,紧接1902的杂交区域的第一个相邻核苷酸是“a”,而紧接1910的杂交区域的第一个相邻核苷酸是“t”。在该实施方式中,针对基因座1的所有探针应该设计成使得与杂交区域直接相邻的第一个核苷酸会由不同于与针对基因座2的探针的杂交区域直接相邻的第一个核苷酸的核苷酸组成。即,通过设计,可以根据与杂交区域直接相邻的第一个核苷酸的身份将来自基因座1和基因座2的探针组彼此区分开。不同的核苷酸,并非用于区分来自基因座1或基因座2的探针的核苷酸,应该充当链终止剂。在该特定实例中,使用靶分子上的“a”核苷酸来区分针对基因座1的探针,使用“t”核苷酸来区分针对基因座2的探针。在该实例中,“c”核苷酸可以充当链终止剂。在该情况下会将“c”核苷酸添加至测定中,其不能进行链延伸(例如双脱氧c)。另一个限制是:将探针序列设计成不存在以下情况:在1906上在针对基因座1的区别性核苷酸与链终止性核苷酸之间存在针对基因座2的鉴定性核苷酸。在该实例中,在1906上,在1902的杂交区域之后且在与链终止剂c配对的g之前,不会存在“t”核苷酸。在该实施方式中,会使用dna聚合酶或类似的酶来合成新的核苷酸序列,并且在针对基因座1的区别性核苷酸位置处添加的核苷酸会含有一个或多个“a”型标记(1903)。在针对基因座2的区别性核苷酸位置处添加的核苷酸会含有一个或多个“b”型标记(1911),从而使针对基因座1的探针产物可以与来自基因座2的探针产物区分开。在该实施方式中,在链终止位置处添加的核苷酸会含有一个或多个“c”型标记(1912)。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。在另一实施方式中,链终止剂可以不含有标记。在该实施方式中,可以将第四核苷酸添加至测定中,其含有一个或多个“c”型标记。该第四核苷酸不与针对等位基因1的鉴定性核苷酸(在该实例中,a)配对,不与针对等位基因2的鉴定性核苷酸(在该实例中,t)配对,不与链终止性核苷酸(在该实例中,g)配对。在该实例中,带有一个或多个“c”型标记的第四核苷酸是g,并且会与在1906和1907上的c位置配对。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图40描述了图21描述的一般步骤的变型。图40描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。2005和2006是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针2001。2001含有亲和标签(2000),其可用于分离和鉴定探针产物。具有成员探针2008的第二探针组携带如第一探针组中那样的相应特征。2008含有亲和标签(2007),其可与2000相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针2001和2008分别与对应于基因座1和基因座2的序列杂交。针对基因座1和基因座2的各探针的设计使得存在一种或多种下述情况:区别性核苷酸(在该实例中,“a”是针对基因座1的区别性核苷酸,“t”是针对基因座2的区别性核苷酸)之后是链终止性核苷酸(在该实例中,“g”),其与探针的杂交区域相邻。重要的是不会存在下述情况:在2005上的2001的杂交区域与2005上的链终止性核苷酸之间存在针对基因座2的区别性核苷酸(在该实例中,“t”)。类似地,不会存在下述情况:在2006上的2008的杂交区域与2006上的链终止性核苷酸之间存在针对基因座1的区别性核苷酸(在该实例中,“a”)。在该实施方式中,会使用dna聚合酶或类似的酶来合成新的核苷酸序列(2004,2011)直到添加了链终止性核苷酸,一个可能的实例是双脱氧c。在该实施方式中,在针对基因座1的区别性核苷酸位置处添加的核苷酸会含有一个或多个“a”型标记(2003)。在针对基因座2的区别性核苷酸位置处添加的核苷酸会含有一个或多个“b”型标记(2010),从而使针对基因座1的探针产物可以明显地与来自基因座2的探针产物区分开。图41描述了图21描述的一般步骤的变型。图41描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。2105和2106是分别对应于基因座1和基因座2的靶分子。第一探针组含有成员探针2102。2102含有亲和标签(2100),其可用于分离和鉴定探针产物。具有成员探针2109的第二探针组携带如第一探针组中那样的相应特征。2109含有亲和标签(2107),其可与2100相同或不同。可以设计靶向“基因座1”的许多种探针组,其含有独特的探针序列。类似地,可以设计靶向“基因座2”的许多种探针组,其含有独特的探针序列。在该实施方式中,针对基因座1的许多种探针组的亲和标签可以相同或是独特的,针对基因座2的许多种探针组的亲和标签可以相同或是独特的。在该实施方式中,探针2102和2109分别与对应于基因座1和基因座2的序列杂交。针对基因座1和基因座2的各探针的设计使得存在一种或多种下述情况:区别性核苷酸(在该实例中,“a”是针对基因座1的区别性核苷酸,“t”是针对基因座2的区别性核苷酸)之后是链终止性核苷酸(在该实例中,“g”),其与探针的杂交区域相邻。重要的是不会存在下述情况:在2105上的2102的杂交区域与2105上的链终止性核苷酸之间存在针对基因座2的区别性核苷酸(在该实例中,“t”)。类似地,不会存在下述情况:在2106上的2109的杂交区域与2106上的链终止性核苷酸之间存在针对基因座1的区别性核苷酸(在该实例中,“a”)。在该实施方式中,会使用dna聚合酶或类似的酶来合成新的核苷酸序列(2104,2110)直到添加了链终止性核苷酸,一个可能的实例是双脱氧c。在该实施方式中,在针对基因座1的区别性核苷酸位置处添加的核苷酸会含有一个或多个“a”型标记(2103)。在针对基因座2的区别性核苷酸位置处添加的核苷酸会含有一个或多个“b”型标记(2110),从而使针对基因座1的探针产物可以明显地与来自基因座2的探针产物区分开。在该实施方式中,探针2102和2109含有一个或多个“c”型标记(2101,2108)。因此,探针产物会含有标记的组合。对于基因座1,探针产物会含有“a”型和“c”型标记,而来自基因座2的探针产物会含有“b”型和“c”型标记。图42描述了图21描述的一般步骤的变型。图42描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,在分离自怀孕妇女的无细胞dna的情况下用于区分母体和胎儿等位基因,或在来自器官移植受体的无细胞dna的情况下用于区分宿主和供体等位基因。图42描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。2203和2204是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针2201。2201含有亲和标签(2200),其可用于分离和鉴定探针产物。在该实施方式中,用于鉴定两个不同的等位基因的探针组相同。即,针对等位基因2的探针组由成员探针2201组成。在该实施方式中,在图42中探针2201分别与对应于等位基因1和等位基因2的序列杂交。探针2201的设计使得紧接杂交区域的第一个相邻核苷酸在针对等位基因1和针对等位基因2时含有不同的核苷酸。换言之,与杂交区域相邻的第一个核苷酸可以是单核苷酸多态性或snp。在该实例中,2203上的与2201的杂交区域紧邻的第一个相邻核苷酸是“a”,2204上的与2201的杂交区域紧邻的第一个相邻核苷酸是“t”。即,来自等位基因1和等位基因2的探针产物可以基于与杂交区域直接相邻的第一个核苷酸的身份而彼此区分开。在该实施方式中,将使用dna聚合酶或其它酶来向各探针序列添加至少一个额外的核苷酸。在该实例中,用于dna聚合酶的核苷酸底物能够用于单个添加,可能是因为添加至反应混合物的核苷酸是双脱氧核苷酸。即,仅一个新的核苷酸应该添加至每个探针序列。在该实例中,添加至针对等位基因1的探针2201的核苷酸会含有一个或多个“a”型标记(2202)。添加至针对等位基因2的探针2201的核苷酸会含有一个或多个“b”型标记(2205),从而使针对等位基因1的探针产物可以与来自等位基因2的探针产物清楚地区分开。即,针对等位基因1的探针产物由探针2201加上携带一个或多个“a”型标记的一个额外的核苷酸组成,针对等位基因2的探针产物由探针2201加上携带一个或多个“b”型标记的一个额外的核苷酸组成。图43描述了图21描述的一般步骤的变型。图43描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,在分离自怀孕妇女的无细胞dna的情况下用于区分母体和胎儿等位基因,或在来自器官移植受体的无细胞dna的情况下用于区分宿主和供体等位基因。图43描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。2304和2305是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针2302。2302含有亲和标签(2300),其可用于分离和鉴定探针产物。在该实施方式中,用于鉴定两个不同的等位基因的探针组相同。即,针对等位基因2的探针组由成员探针2302组成。在该实施方式中,在图43中探针2302分别与对应于等位基因1和等位基因2的序列杂交。探针2302的设计使得紧接杂交区域的第一个相邻核苷酸在针对等位基因1和针对等位基因2时含有不同的核苷酸。换言之,与杂交区域相邻的第一个核苷酸可以是单核苷酸多态性或snp。在该实例中,2304上的与2302的杂交区域紧邻的第一个相邻核苷酸是“a”,2305上的与2302的杂交区域紧邻的第一个相邻核苷酸是“t”。即,来自等位基因1和等位基因2的探针产物可以基于与杂交区域直接相邻的第一个核苷酸的身份而彼此区分开。在该实施方式中,将使用dna聚合酶或其它酶来向各探针序列添加至少一个额外的核苷酸。在该实例中,用于dna聚合酶的核苷酸底物能够用于单个添加,可能是因为添加至反应混合物的核苷酸是双脱氧核苷酸。即,仅一个新的核苷酸应该添加至每个探针序列。在该实例中,添加至针对等位基因1的探针2302的核苷酸会含有一个或多个“a”型标记(2303)。添加至针对等位基因2的探针2302的核苷酸会含有一个或多个“b”型标记(2306),从而使针对等位基因1的探针产物可以与来自等位基因2的探针产物清楚地区分开。即,针对等位基因1的探针产物由探针2302加上携带一个或多个“a”型标记的一个额外的核苷酸组成,针对等位基因2的探针产物由探针2302加上携带一个或多个“b”型标记的一个额外的核苷酸组成。在该实施方式中,探针2302含有一个或多个“c”型标记(2301)。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。图44描述了图21描述的一般步骤的变型。图44描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,在分离自怀孕妇女的无细胞dna的情况下用于区分母体和胎儿等位基因,或在来自器官移植受体的无细胞dna的情况下用于区分宿主和供体等位基因。图44描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。2405和2406是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针2401。2401含有亲和标签(2400),其可用于分离和鉴定探针产物。在该实施方式中,用于鉴定两个不同等位基因的探针组相同。即,针对等位基因2的探针组由成员探针2401组成。在该实施方式中,在图44中探针2401分别与对应于等位基因1和等位基因2的序列杂交。探针2401的设计使得紧接杂交区域的第一个相邻核苷酸在针对等位基因1和针对等位基因2时含有不同的核苷酸。换言之,与杂交区域相邻的第一个核苷酸可以是单核苷酸多态性或snp。在该实例中,2405上的与2401的杂交区域紧邻的第一个相邻核苷酸是“a”,2406上的与2401的杂交区域紧邻的第一个相邻核苷酸是“t”。即,来自等位基因1和等位基因2的探针产物可以基于与杂交区域直接相邻的第一个核苷酸的身份而彼此区分开。在该实施方式中,会使用dna聚合酶或其它酶来向各探针序列添加至少一个的外的核苷酸。在该实例中,添加至针对等位基因1的探针2401的核苷酸会含有一个或多个“a”型标记(2402)。添加至针对等位基因2的探针2401的核苷酸会含有一个或多个“b”型标记(2407),从而使针对基因座1的探针产物可以与来自基因座2的探针产物清楚地区分开。即,针对等位基因1的探针产物含有探针2401加上携带一个或多个“a”型标记的一个额外的核苷酸,针对等位基因2的探针产物含有探针2401加上携带一个或多个“b”型标记的一个额外的核苷酸。另一种核苷酸,并非用于区分等位基因1和等位基因2的核苷酸,应该充当链终止剂。在该特定实例中,使用靶分子上的“a”核苷酸来鉴定等位基因1,使用“t”核苷酸来鉴定等位基因2。在该实例中,“c”核苷酸可以充当链终止剂。在该情况下,可以将“c”核苷酸添加至测定中,其不能进行链延伸(例如双脱氧c)。一个另外的限制是,将探针序列设计成不存在以下情况:在2405上在针对等位基因1的区别性核苷酸与链终止性核苷酸之间存在针对等位基因2的鉴定性核苷酸。在该实例中,在2405上,在2401的杂交区域之后且在与链终止剂c配对的g之前,不会存在“t”核苷酸。在该实施方式中,会使用dna聚合酶或类似的酶来合成新的核苷酸序列,并且在针对等位基因1的区别性核苷酸位置处添加的核苷酸会含有一个或多个“a”型标记(2402)。在针对等位基因2的区别性核苷酸位置处添加的核苷酸会含有一个或多个“b”型标记(2407),从而使针对等位基因1的探针产物可以清楚地与来自等位基因2的探针产物区分开。在该实施方式中,在链终止位置处添加的核苷酸会含有一个或多个“c”型标记(2403)。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。图45描述了图21描述的一般步骤的变型。图45描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,在分离自怀孕妇女的无细胞dna的情况下用于区分母体和胎儿等位基因,或在来自器官移植受体的无细胞dna的情况下用于区分宿主和供体等位基因。图45描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。2505和2506是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针2501。2501含有亲和标签(2500),其可用于分离和鉴定探针产物。在该实施方式中,用于鉴定两个不同等位基因的探针组相同。即,针对等位基因2的探针组由成员探针2501组成。在该实施方式中,在图45中探针2501分别与对应于等位基因1和等位基因2的序列杂交。探针2501的设计使得紧接杂交区域的第一个相邻核苷酸在针对等位基因1和针对等位基因2时含有不同的核苷酸。换言之,与杂交区域相邻的第一个核苷酸可以是单核苷酸多态性或snp。在该实例中,2505上的与2501的杂交区域紧邻的第一个相邻核苷酸是“a”,2506上的与2501的杂交区域紧邻的第一个相邻核苷酸是“t”。即,来自等位基因1和等位基因2的探针产物可以基于与杂交区域直接相邻的第一个碱基的身份而彼此区分开。在该实施方式中,会使用dna聚合酶或其它酶来向各探针序列添加至少一个额外的核苷酸。在该实例中,添加至针对等位基因1的探针2501的核苷酸会含有一个或多个“a”型标记(2502)。添加至针对等位基因2的探针2501的核苷酸会含有一个或多个“b”型标记(2507),从而使针对基因座1的探针产物可以与来自基因座2的探针产物清楚地区分开。即,针对等位基因1的探针产物含有探针2501加上携带一个或多个“a”型标记的一个额外的核苷酸,针对等位基因2的探针产物含有探针2501加上携带一个或多个“b”型标记的一个额外的核苷酸。另一种核苷酸,并非用于区分等位基因1和等位基因2的核苷酸,应该充当链终止剂。在该特定实例中,使用靶分子上的“a”核苷酸来鉴定等位基因1,使用“t”核苷酸来鉴定等位基因2。在该实例中,“c”核苷酸可以充当链终止剂。在该情况下,可以将“c”核苷酸添加至测定中,其不能进行链延伸(例如双脱氧c)。一个另外的限制是,将探针序列设计成不存在以下情况:在2505上在针对等位基因1的区别性核苷酸与链终止性核苷酸之间存在针对等位基因2的鉴定性核苷酸。在该实例中,在2505上,在2501的杂交区域之后且在与链终止剂c配对的g之前,不会存在“t”核苷酸。在该实施方式中,会使用dna聚合酶或类似的酶来合成新的核苷酸序列,并且在针对等位基因1的区别性核苷酸位置处添加的核苷酸会含有一个或多个“a”型标记(2502)。在针对等位基因2的区别性核苷酸位置处添加的核苷酸会含有一个或多个“b”型标记(2507),从而使针对等位基因1的探针产物可以清楚地与来自等位基因2的探针产物区分开。在该实施方式中,可以将第四核苷酸添加至测定中,其含有一个或多个“c”型标记(2508,2503)。该第四核苷酸不与针对等位基因1的鉴定性核苷酸(在该实例中,a)配对,不与针对等位基因2的鉴定性核苷酸(在该实例中,t)配对,不与链终止性核苷酸(在该实例中,g)配对。在该实例中,带有一个或多个“c”型标记的第四核苷酸是g,并且会与在2505和2506上的c位置配对。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。图46描述了图21描述的一般步骤的变型。图46描述了用于鉴定相同基因组基因座的各种等位基因的两种探针组。例如,在分离自怀孕妇女的无细胞dna的情况下用于区分母体和胎儿等位基因,或在来自器官移植受体的无细胞dna的情况下用于区分宿主和供体等位基因。图46描述了两种探针组——用于等位基因1的一种探针组和用于等位基因2的一种探针组。2605和2606是分别对应于等位基因1和等位基因2的靶分子。第一探针组含有成员探针2602。2602含有“a”型标记(2601)。2602含有亲和标签(2600),其可用于分离和鉴定探针产物。具有成员探针2609的第二探针组携带如第一探针组中那样的相应特征。但是,2609含有“b”型标记(2608),其与“a”型可区分。2609含有亲和标签(2607),其可与2600相同或不同。在该实施方式中,2602和2609含有几乎相同的序列,不同之处仅在于序列中的一个核苷酸。因此,这两个探针的杂交区序列与等位基因1互补(2605)或与等位基因2互补(2606)。另外,2602和2609上的每个杂交区域的长度以及实验杂交条件被设计成使探针2602会仅与等位基因1杂交且探针2609会仅与等位基因2杂交。该测定类型的目的在于能够准确地定量样品中的等位基因1和等位基因2的频率。在该实施方式中,可以使用dna聚合酶或其它酶来合成新的多核苷酸序列,例如在等位基因1的情况下为2604,在等位基因2的情况下为2611。在该实施方式中,2604和2611可以含有一个或多个“c”型标记(2603,2610),这可归因于引入了携带“c”型标记的一个或多个核苷酸。因此,探针产物会含有标记的组合。对于等位基因1,探针产物会含有“a”型和“c”型标记,而来自等位基因2的探针产物会含有“b”型和“c”型标记。该实施方式产生分别对等位基因1或等位基因2中的序列具有高特异性的探针产物。图55~58描述了图21~46中所描述的一般步骤的变型。图55描述了两种探针组,一种探针组用于基因座1,一种探针组用于基因座2,虽然如此,对于每个基因组基因座可以设计多种探针组。基因座1探针组的左臂由正向引发序列、亲和标签序列和基因座1序列的同源物组成。基因座1探针组的右臂由基因座1序列的同源物和用于用标记a标记基因座1探针组的反向引发序列组成。基因座2探针组的左臂由正向引发序列、亲和标签序列和基因座2序列的同源物组成。基因座2探针组的右臂由基因座2序列的同源物和用于用标记b标记基因座2探针组的反向引发序列组成。正向引发序列和亲和标签序列对于基因座1和基因座2的探针组而言是相同。同源序列对于单个基因组基因座是特异性的。每个探针组的基因座同源序列彼此直接相邻,从而使得当它们与其靶基因座杂交时,它们会彼此直接邻接并由此可以经连接而形成一个连续分子。反向引发序列对于所述标记(例如标记a或标记b)是特异性的,所述标记用于对针对特定亲和标签序列的特定基因座的探针产物进行标记。图56描述了会应用至探针组的集合(例如图55中所述的那些探针组)的工作流程。该描述基于针对一个基因组基因座的一种探针组(例如图55中所示的针对基因座1的探针组)。在步骤1中,将探针组的集合与经纯化的无细胞dna混合。在步骤2中,使每个探针组中的基因座特异性序列与无细胞dna样品中的其相应的同源序列杂交。在步骤3中,添加连接酶以催化左臂同源物上的3’碱基和右同源物的5’臂之间的磷酸二酯键的形成,以封闭两条臂之间的空位,并由此形成作为探针产物的一个连续分子。在步骤4中,添加经修饰的引物和pcr反应组分(taq聚合酶、各dntp和反应缓冲液)以扩增经连接的探针产物。将正向引物修饰以使其具有5’磷酸根基团,5’磷酸根基团使其成为用于步骤6中所用的λ核酸外切酶的优选模板,将反向引物修饰以使其含有标记(蓝色圆圈),所述标记对于针对特定亲和标签的特定基因座的探针产物是特异性的。在步骤5中,pcr扩增探针产物以产生双链pcr产物,其中正向链含有5’磷酸根基因,反向链含有5’标记。在步骤6中,添加λ核酸外切酶以在5’至3’方向消化正向链——正向链上的5’磷酸根基因使其成为用于λ核酸外切酶消化的优选模板。所得材料是具有5’标记的单链(仅反向链)。这是用于与微阵列或单层杂交的经标记的靶材料。图57描述了图56中所述的工作流程的变型版本。在该实施方式中,每个探针组的左臂含有由该图的步骤1~6中的“b”所指示的末端生物素分子。这种生物素化使得能够在杂交-连接反应完成之后和在pcr扩增之前对探针产物的集合进行纯化。对于步骤1~3,该实施方式的流程与图57所述的流程相同。在步骤4中,向杂交-连接反应中添加抗生蛋白链菌素包被的磁珠。探针产物中所含的生物素分子会使所述产物结合至抗生蛋白链菌素。在步骤5中,洗涤磁珠以除去未生物素化的dna(无细胞基因组dna和右臂寡核苷酸),以产生纯化的探针产物。步骤6~9以与图56中针对步骤4~7所描述的相同的方式进行。在探针与基因组杂交之后并且在添加连接酶之前引入洗涤步骤,可以改善杂交-连接过程的特异性。这可以消除未与来自连接反应的基因组模板形成稳定杂交体的探针,使得它们不会存在并形成可以因探针与基因组或探针彼此之间的非特异性相互作用而产生的脱靶连接产物(即不含靶分子的连接产物)。例如,该洗涤步骤可以通过以下方式进行:使用例如本文所述的生物素化或其他结合机制,修饰每个探针对的一半(即,探针对的每个左臂探针或每个右臂探针),这允许将其固定在例如珠上。具有左臂和右臂的探针混合物将与基因组dna模板合并,并且可以在防止或减少非特异性杂交的条件下使探针与其互补靶序列杂交。杂交后,可以利用一半探针上的修饰来固定杂交产物(例如左臂探针-右臂探针-基因组dna复合物),然后洗涤以除去未经修饰的所有未杂交的那一半探针。然后可以加入连接酶以封闭每个杂交的左臂-右臂对之间的切口。该连接步骤可以使用高特异性条件(例如在高温下和在诸如亚精胺等试剂的存在下)进行,以防止或减少任何未被洗涤过程消除的非杂交探针的连接。在一些实施方式中,可以修饰全部两个探针以允许固定。图82描绘了另一种程序性工作流程,其包括替代性的示例性杂交后纯化程序。修饰了基因组dna模板,而不是来自每个探针产物或探针对的一个探针。这可以使得杂交产物(例如左臂探针-右臂探针-基因组dna复合物)能够被固定和洗涤,从而去除来自每个探针组的全部两种未杂交的探针。在一些实施方式中,可以修饰基因组dna的一条或全部两条链,例如,通过向3'末端添加生物素化的核苷酸来进行修饰(例如图82中的步骤1)。可以通过对经修饰的dna进行柱纯化或乙醇沉淀来除去游离生物素。然后可以将探针组和抗生蛋白链菌素包被的珠添加到dna中,可以加热该混合物以使dna链分开,然后可以温育混合物以使探针组与其在基因组dna上的靶区域杂交,并且使生物素与珠结合(例如图82的步骤2)。然后可以将结合有与探针组杂交的基因组dna链的珠拉到磁体上,并洗涤多次以去除任何未杂交的探针(例如图82的步骤3)。然后可以将珠-基因组dna-左臂探针-右臂探针复合物重悬浮在含有连接酶的溶液中,以封闭每个杂交探针组的左臂和右臂之间的切口(例如图82的步骤4)。可以使连接酶热失活,并且可以洗涤珠以去除酶和其他反应组分。然后可以通过先将复合物拉到磁体上然后加热到将使dna链解链的温度来将连接的探针组与它们的基因组模板分离。虽然基因组模板可以保持附着在磁体上,但是可以移走含有连接的探针组的上清液(例如图82的步骤5)。然后可以进一步分析连接的探针组材料(例如连接产物)。例如,然后,在含有带标记的反向引物的pcr反应中,可以将连接产物用作模板,产生染料标记的测定产物以与微阵列杂交。图83示出了聚丙烯酰胺凝胶分析结果,其证实了使用该示例性过程产生的测定产物。将基因组固定的优点可以是它允许去除全部两种探针,而如果来自每个探针组的一个探针被固定,则在洗涤步骤中仅能去除另一种探针。此外,如果固定靶标(例如基因组)而不是探针,则可能不会出现使用固定的探针作为模板时由两个探针形成的嵌合连接产物。以这种方式,连接产物可以含有更少(或更小比例)的错配或嵌合体,以及更多(或更大比例)的正确形成的连接产物。这里,正确形成的连接产物可以是来自探针组的在与其靶标中的正确位置杂交后而连接的两个探针。图58提供了如何可以用不同的标记分子标记针对基因座1和基因座2的探针产物的实例。在图58a中,在一个pcr扩增反应中用标记a(绿色)标记基因座1探针产物并用标记b(红色)标记基因座2探针产物。针对两个基因座的探针产物都含有亲和标签序列a。在图58b中,使带不同标记的探针产物的混合物与微阵列位置杂交,在该位置中,捕获探针序列与亲和标签a序列互补。在图58c中,将所述微阵列位置成像,并且对标记a和标记b分子的数量进行计数,以提供样品中存在的基因座1和基因座2的水平的相对量度。图59提供了证据表明:代表针对一个基因座的大量基因组位置的探针产物可以使用杂交-连接过程以连接酶特异性方式生成。8个探针组各自由图55中所述的左臂和右臂组分组成,并且含有8个染色体18位置的同源物,将这8个探针组杂交至合成的寡核苷酸模板(约48个核苷酸)并使用连接酶连接,以将每个探针组的左臂和右臂连接起来。使用变性聚丙烯酰胺凝胶电泳分析反应产物。凝胶泳道1含有分子量梯度以指示dna条带的尺寸。泳道2~9含有8个染色体18探针组的杂交-连接反应产物。约100个核苷酸的dna条带存在于泳道2~9的每一个中,代表约60个核苷酸的左臂和约40个核苷酸的右臂的探针产物。泳道10和11含有未添加连接酶的阴性对照反应物。在泳道10和11中不存在约100个核苷酸的dna条带。图60提供了数据表明可以使用这些探针组来检测拷贝数状态的相对变化。使用含有8个不同染色体x位置的同源物的8个探针组的混合物来测定包含表1中所示的不同数量的染色体x的细胞系。表1:含有不同拷贝数的染色体x的细胞系coriell细胞系id染色体x的拷贝数na121381na137832na002543na014164na060615使用定量pcr来确定在图57中所述的杂交-连接和纯化过程(步骤1~5)之后对于各细胞系而言存在的探针产物的量。如图60a所示,对于各种细胞系测量的拷贝数状态遵循表1中所示的预期趋势。例如,qpcr显示na12138(其具有一个拷贝的染色体x)的拷贝数状态小于2。na00254(3个拷贝的x)的测量的拷贝数状态大于2,na01416(4个拷贝的x)大于3,na06061(5个拷贝的x)大于4。该方法在检测拷贝数状态的差异时的响应性由图60b进一步说明,在图60b中,将所测量的拷贝数状态相对于理论拷贝数状态绘图。图61提供了证据表明可以如图56和57所示使用探针产物的混合物来产生定量性微阵列数据。图61a描述了在两个正交成像通道(alexa488:绿色,alexa594;红色)中两个阵列点的代表性荧光图像。自动选择目标区域(roi)(大圆圈),将任何不需要的亮污染物从图像中遮掩(在roi内的较小的轮廓区域)。将单个经杂交的测定产物上的单个荧光团可视化为所述阵列点内的小点特征。(i)在绿色通道中成像的“平衡”点(代表以1:1的浓度比输入至所述测定的基因组靶标),和(ii)在红色通道中成像的相同点。(iii)在绿色通道中成像的“增加”点(代表以大于1:1的浓度比输入至所述测定的基因组靶标),和(iv)在红色通道中成像的相同点。图61b呈现了对于“平衡的”和“增加的”条件的各自五个点在2个通道中的所检测的荧光团的原始计数。除了荧光剂的绝对数量上的一些变化外,在“平衡的”情况下,两个通道中的数量紧密追随,但在“增加的”情况下却显示出的明显分离。图61c显示了对于来自“平衡”和“增加的”条件各自的5个点,用绿色通道中荧光剂的数量除以红色通道中荧光剂的数量所得到的计算比值。“平衡”情况集中在1.0的比值附近,“增加”情况为升高的比值。将“平衡”情况认为是比较两个平衡的基因组基因座,并将“增加”情况认为是一个基因座相对于另一个基因座增加的情况,我们可以使用独立的2组t检验来计算这两种条件的分离的置信度,产生的p值为8x10-14。图62描述了图55~58中所描述的一般步骤的变型。在该实施方式中,针对各基因组位置设计第二探针组,即探针组b,使得探针组b中的基因组同源序列与探针组a中的基因组同源序列反向互补。探针组a会与基因组dna的反向链杂交,探针组b会与基因组dna的正向链杂交。相对于图55~58所述的实施方式,该实施方式会提供增加的灵敏度,因为其会产生约2倍的探针产物数量/基因座。图63描述了图57中所描述的一般步骤的变型。在该实施方式中,对在步骤6中使用的反向引物进行额外的修饰,以使得连接寡核苷酸序列中的前5个核苷酸的4个键是硫代磷酸酯键。该修饰会使在pcr扩增(步骤7)过程中产生的所有pcr产物都在5’末端具有硫代磷酸酯修饰。该修饰会保护反向链免遭在步骤8中用λ核酸外切酶处理的过程中可能出现的任何消化。虽然正向链上的5’磷酸酯基团使得其是用于λ核酸外切酶消化的优选模板,但反向链仍然在一定程度上易受消化的损伤。反向链的5’末端的硫代磷酸酯修饰会减少其对λ核酸外切酶消化的易受损性。图64描述了图55~58中所描述的一般步骤的变型。在该实施方式中,通过向步骤6中的扩增反应中添加反向引物而不添加正向引物而将探针产物的pcr扩增替换成线性扩增。如果仅存在反向引物,扩增产物会是单链的–具有5’末端标记的反向链。由于扩增产物已经是单链的,在杂交至微阵列之前其不需要进一步的处理,即可以省略λ核酸外切酶消化。由于在该实施方式中未使用正向引物,探针组的左臂不需要含有正向引发序列。左臂会仅由亲和标签序列和基因座同源序列组成,如图64所示。图55~58中描述的一般步骤的另一个实施方式是:步骤3中的单次连接反应过程被循环连接反应过程代替。这通过将用于催化连接反应的热不稳定性连接酶(例如t4连接酶)替换成热稳定性连接酶(例如taq连接酶)而实现。当使用热稳定性连接酶时,可以将杂交-连接反应加热至会使所有dna双链体在最初的杂交和连接循环发生后都解链的温度(例如95℃)。这会使基因组模板dna完全可供另一探针组杂交和连接。随后降低温度(例如至45℃)会使接下来的杂交和连接事件能够发生。在会使dna双链体解链的温度和会使杂交和连接出现的温度之间进行的每个杂交和连接反应热循环将线性地增加该反应所产生的探针产物的量。如果使反应经历30个这样的循环,会产生使用单次连接反应的过程时至多30倍的探针产物的量。图65描述了图62中所述的变型步骤的另一实施方式。该实施方式利用了将针对各探针组的反向互补物的存在与热稳定性连接酶的使用组合起来的连接酶链反应(lcr),以能够进行使产物以指数形式扩增的循环连接反应。图65描述了两种探针组,针对一个基因座的探针组a和探针组b;其中探针组b中的基因组同源序列是探针组a中的基因组同源序列的反向互补物。各探针组的5’臂由亲和标签序列和同源物组成,而各探针组的3’臂由同源序列和所附的标记组成。在热循环反应的第一个循环中,基因组dna会是使杂交和连接能够发生以产生探针产物的唯一可用模板,如图65a所示。但是在第二个循环中,在第一个循环中产生的探针产物b会充当用于探针组a的额外模板,并且类似地,在第一个循环中产生的探针产物a会充当用于探针组b的额外模板,如图65b所示。以该相同的方式,来自每个相继循环的探针产物会在下一循环中充当用于探针组杂交和连接的模板。该过程会消除对探针产物的pcr扩增的需要,所述探针产物可以直接用作微阵列靶标。图65中所示的步骤的另一实施方式是利用lcr但是使用具有图55中所述结构的探针组的实施方式,即,左臂和右臂都侧接有引发序列,左臂含有生物素分子,右臂不含有标记。在完成lcr后,如图56和57所示,使用磁珠将探针产物纯化(可选的),然后进行pcr扩增并制备微阵列靶标。图66描述图65中所描述的步骤的又一实施方式。各探针组的5’臂由亲和标签序列和同源物组成,而各探针组的3’臂由同源序列和引发序列组成且没有标记附着,如图66a所示。在完成lcr之后,可以将探针产物纯化。然后可以通过添加附着有标记的单个引物以及反应组分(taq聚合酶、各dntp和反应缓冲液)以线性方式扩增lcr产物,如图66b所示。该扩增的产物将是单链的(仅反向链),具有5’标记,如图66c所示。因此,不需要用λ核酸外切酶对其进行处理,而其可以直接用作微阵列靶标。在另一方面,用本文所述的方法确定的遗传变异指示了受试对象中癌、药代动力学变化性、药物毒性、移植排斥或非整倍性的存在或不存在。在另一方面,经确定的遗传变异指示了癌的存在或不存在。因此,可以进行本文所述的方法来诊断癌。肿瘤学的一个重大挑战是癌的早期检测。这对于难以成像或活组织检查的癌(例如胰腺癌、肺癌)尤其正确。患者血液中的无细胞肿瘤dna(肿瘤cfdna)提供了非入侵性检测肿瘤的方法。这些可以是实体肿瘤、良性肿瘤、微肿瘤、液体肿瘤、转移物或其它体细胞生长物。检测可以在肿瘤发展的任何阶段,虽然理想地是在早期(i期或ii期)。早期检测允许进行可以延长生命或导致消退的干预(例如外科手术、化疗、药物治疗)。肿瘤学的其它问题包括监视治疗功效、治疗剂剂量的滴定、在相同器官中作为原发性肿瘤或者在远端位置处的肿瘤复发以及检测转移。本发明可用于所有这些应用。在一些实施方式中,本说明书的探针组可以被构造成靶向与肿瘤相关的已知遗传变异。这些可以包括突变、snp、拷贝数变体(例如扩增、缺失)、拷贝中性变体(例如倒位、易位)和/或这些变化的复杂组合。例如,与肿瘤相关的已知遗传变异包括在cancer.sanger.ac.uk/cancergenome/projects/cosmic;nature.com/ng/journal/v45/n10/full/ng.2760.html#supplementary-information中列出的那些以及在以下表2和3中列出的那些:bgene=在峰内来自校正至fdr的p值;k已知经常扩增的致癌基因或缺失的tsg;p推测的癌基因;e表观遗传调空因子;m线粒体相关基因;**与峰区域直接相邻;t与近端着丝粒染色体的端粒或着丝粒相邻。在一些实施方式中,本说明书的探针组可以被构造成靶向与肿瘤相关的已知遗传变异。这些可以包括突变、snp、拷贝数变体(例如扩增、缺失)、拷贝中性变体(例如倒位、易位)和/或这些变体的复合组合。在一些实施方式的诊断癌的方法中,通过设计出与一个探针臂中的断点至少部分地重叠的探针,可以容易地靶向出现在已知位置的倒位(图67a)。结合“正常”序列的第一探针靶向未倒位的基因组材料(图67b),并且携带第一标记类型。结合“倒位”的靶标的第二探针携带第二标记类型(图67c)。共同的右探针臂结合不易发生倒位的天然序列,并与前两个探针直接相邻。该右探针臂还携带共同的下拉标签,其将探针产物定位至成像用基板的相同区域。以此方式,探针对可以与基因组靶标杂交、连接并且成像,以产生两种潜在物质的相对计数。类似地,还可以测定具有已知断点的易位。图68a显示了以其天然顺序或经易位的两个基因元件。与这些易位断点至少部分重叠的探针臂允许区分基因材料的正常顺序和转座顺序。如图68b和68c中所示,通过选择两条左臂上的独特标记,可以在成像过程中区分和计数所得的经连接的探针产物。检测拷贝中性变化(例如倒位、易位)的这些方法还可用于检测癌中或其它疾病或病况中的种系变异体。突变或snp也涉及在许多癌中,并且以与在出生前诊断应用中确定胎儿组分时所查询的那些类似的方式被靶向。在图69a和69b所示的一些实施方式中,左探针臂被设计成利用由一个或多个错配snp引起的能量失衡。这使一个探针臂(1101,携带一个标记)比第二探针臂(1107,携带第二类型的标记)更有利地结合。两种设计都连接至携带通用下拉标签的相同右探针臂(1102)。可以通过一种方法或者多于一种方法的组合来探测给定的患者血液。另外,在一些情况下,定制针对患者的特异性探针可能是有价值的。这会包括表征来自原发性肿瘤的样品(例如活组织检查)中的肿瘤特征(snp,易位,倒位等),并且创建对于检测患者血液中的那些患者特异性遗传变异而优化了的一种或多种定制探针组,提供低成本的非侵入性监视方法。这在复发的情况可以具有重大价值,其中尽可能早地检测肿瘤类型(与原始肿瘤相同或相关)的低水平复发是理想的。对于常见疾病发展途径,可以设计额外的判别组来预期和监视疾病进展。例如,如果突变倾向于以给定秩序累积,可以将探针设计成监视当前状态和发展“检查点”,并且指导治疗选择。癌的早期检测:例如,alk易位已经与肺癌相关。可以使用设计成查询alk易位的探针来用血液样品检测这种类型的肿瘤。这会是特别有利的,因为检测肺肿瘤的标准方法是通过胸部x射线来进行,其是对患者健康可能有害的昂贵方法,因此不标准地进行。检测原发性肿瘤类型的复发:例如,her2+乳腺瘤通过外科手术除去,并且患者处于消退中。可以使用靶向her2基因的探针来在一个或多个时间点监视her2基因的扩增。如果检测到这些,则患者可能在原发位置或其它位置具有第二her2+肿瘤。检测非原发性肿瘤类型:例如,her2+乳腺瘤通过外科手术除去,并且患者处于消退中。可以使用靶向egfr基因的探针来监视egfr+肿瘤。如果检测到这些,则患者可能在原发位置或其它位置具有第二egfr+肿瘤。转移的检测:例如,患者具有her2+乳腺肿瘤。可以使用设计成查询alk易位的探针来用血液样品检测这种类型的肿瘤。该肿瘤可能不在乳腺中,并且更可能位于肺中。如果检测到这些,则患者可能在原发性器官的远端具有转移性肿瘤。确定肿瘤异质性:许多肿瘤具有以不同的遗传变异体为特征的多个克隆群体。例如,乳腺肿瘤可以具有her2+的一种细胞群体和egfr+的另一种细胞群体。使用设计成靶向这两种变体的探针会允许鉴定该潜在的遗传异质性。肿瘤负荷的测量:在所有以上实例中,可以测量肿瘤cfdna的量并且可以将其用于确定患者肿瘤的尺寸、生长速率、侵袭性、阶段、预后、诊断和其它属性。理想地是,在多于一个时间点进行测量,以显示肿瘤cfdna的量的变化。监视治疗:例如,用赫赛汀治疗her2+乳腺肿瘤。可以使用靶向her2基因的探针来监视肿瘤cfdna的量,其可以是肿瘤尺寸的代替指标。其可以用于确定肿瘤尺寸是否变化以及是否可以改变治疗以优化患者的后果。这可以包括改变剂量、停止治疗、改变为另一疗法、组合多种疗法。肿瘤dna的筛选:目前对于癌不存在通用筛选。本发明提供了一种途径来检测体内的一些或所有位置处的肿瘤。例如,在整个基因组上以100kb的间距开发出一组探针。该组可用作检测整个基因组上的遗传变异的途径。在一个实例中,该组检测整个基因组上的某一尺寸的拷贝数变化。这种拷贝数变化与肿瘤细胞相关,因此该测试检测肿瘤细胞的存在。不同的肿瘤类型可以产生不同量的肿瘤cfdna或者可以具有基因组的不同部分中的变异。因此,该测试可以能够鉴定哪个器官受影响。此外,肿瘤cfdna的测得量可以表示肿瘤的阶段或尺寸或者肿瘤的位置。以此方式,该测试是许多或全部肿瘤类型的全基因组筛选。对于所有以上测试,为了减少假阳性,可以使用阈值来确定肿瘤的存在或确定性。此外,所述测试可以在多个样品上或者在多个时间点重复,以增加结果的确定性。所述结果还可以与其它信息或症状组合,以提供关于肿瘤的更多信息或更确定的信息。可用于本文所述的方法来测量目标核酸区的拷贝数的示例性探针组和引物列于以下表4中。表4中的每个示例性探针组包含两种探针。第一(标签)探针具有包括正向引发位点、标签和同源物1的结构。第二(标记)探针具有包括同源物2和反向引物位点的结构,其用于进行标记。还显示了探针(标签、同源序列等)的组成序列。可用于本文所述的方法中以检测位于snp位点处的多态性的示例性探针组和引物列于以下表5中。表5中的每个示例性探针组中包含三种探针,两种等位基因特异性探针(其用于进行标记)和一种标签探针。在这些实例中,两种等位基因特异性探针具有在一个或多个核苷酸处不同的同源序列。第一等位基因探针的结构包括正向引物位点等位基因1和同源性等位基因1;第二等位基因探针的结构包括正向引物位点等位基因2和同源性等位基因2。在实践中,经标记的引物在使用时可以在这两个引物上带有不同的标记(因此标记是等位基因特异性的)。在这些实例中,还存在通用3’探针,其包括同源区(不具有任何snp)、标签核苷酸序列和反向引物位点。还显示了探针(标签、同源序列等)的组成序列。在本说明书中,描述了附图,并且以下公开了具体实施例,其形成说明书的一部分,并且其中示出了根据所描述的实施方式的具体实施方式。虽然已经足够详细地描述了这些实施方式以使本领域技术人员能够实践所述的实施方式,但是应当理解,这些实施例不是限制性的;因此可以使用其它实施方式,并且可以在不脱离所描述的实施方式的精神和范围的情况下进行改变。表6:示例性的非基因组标签核苷酸序列seqid序列seqid:370agtgacccgctcgtacatgaseqid:371caggtacccggtcgcaatagseqid:372actttattcgcaaggcccgaseqid:373attgccaaccgcccgtatagseqid:374cgctccgaacgtgtaagaggseqid:375aaacctccgcgcacttaaga实施例实施例1-清洁基板以下步骤优选在洁净室中进行。通过例如在表面活性剂溶液(2%micro-90)中超声25分钟来彻底清洁纯白色玻璃板/载玻片(knittelglazer,德国)(为了平整性可以将其抛光)或spectrosil载玻片的表面,在去离子水中洗涤,用milliq水彻底冲洗,并浸入6:4:1的milliqh2o:30%nh4oh:30%h2o2或浸入h2so4/cro3清洗液中1.5小时。清洁后,将板冲洗并储存在无尘环境中,例如在milliq水下。云母基板的顶层通过用透明胶带覆盖并迅速撕下该层而被剥离。实施例2-显微镜检1)tirftirf有两种配置可以使用:物镜法和棱镜法。物镜法得到olympusmicroscopes的支持,并且应用须知在以下网址找到:olympusmicro.com/primer/techniques/fluorescence/tirf/olympusaptirf.html。棱镜法描述于osborne等,j.phys.chem.b,105(15),3120-3126,2001中。该仪器由倒置光学显微镜(尼康te200,日本)、双色激光激发源和增强电荷耦合器件(iccd)相机(pentamax,princetoninstruments,nj)组成。将锁模倍频nd:yag激光器(76mhzantares76-s,coherent)分成两束,以提供最高100mw的532nm激光器和泵浦染料激光器(700系列,coherent),其输出功率在630nm处超过200mw(dcm,lambdaphysik)。样品室倒置在x100油浸物镜和60熔融二氧化硅分散棱镜上,其通过甘油薄膜光学耦合到载玻片的背面。用20厘米焦距透镜将激光聚焦在棱镜,以使得在玻璃/样品界面处,它面对与载玻片法线成约68°的角,并经历全内反射(tir)。玻璃/水界面的临界角为66°。tir足迹具有约300米的1/e2直径。通过用表面特异性倏逝波激发样品而产生的荧光被物镜收集,穿过二向色分束器(560drlp,omegaoptics),并在成像到iccd相机上之前被过滤。对于经tamra标记的基板,通过使用同步的532nm激发并在580nm(580df30,omega)下检测来记录图像,对于经cy5标记的探针,通过使用630nm激发并在670nm(670df40,omega)下检测来记录图像。曝光时间设置为250~500ms,iccd增益最大(1kv)。在这两个激光波长下,棱镜处的激光功率调节到40mw。2)具有脉冲激光和时间解析检测的共焦显微镜该装置可作为来自atto_tec的lightstation(heidelberg)获得3)afm可以使用带有纳秒示波器iv控制器和si悬臂尖端的multimodeiiia(veeco,santabarbara,ca)来获得图像。将其放置在主动隔离系统(mod1-m,halcyonics,gottingen,germany)上。常见的成像参数为60-90hz共振频率,0.5-1v振荡幅度,0.3-0.7v设定点电压,1.5-2hz扫描速率。4)snom可以将biolysersnom(triple-opotsdam,germnay)用于近场光学成像。可以使用以下ccd装置:i-pentamaxgeniii;roperscientific,trenton,njusa)或冷却(例如modelst-71(santabarbarainstrumentsgroup,ca,usa);由sit相机(hamamatsu)、图像增强器和(vs-1845,videoscopeinternational,usa)组成的isit相机,并存储在s-vhs录像带上。用数字图像处理器(argus-30,hamamatsuphotonics)处理录像带中的图像。根据相机和信号亮度来调节增益设置。通过将基板安装在高精度tst系列x-y平移台(newport)上,可以进行从一个视场向另一个视场的移动。当在溶液中进行单分子分析时,可以使用以下氧清除液来使光漂白最小化:过氧化氢酶(0.2mg/ml)、葡萄糖氧化酶(0.1mg/ml)、dtt(20mm)、bsa(0.5mg/ml)、葡萄糖3mg/ml。这可以添加到实验中使用的缓冲溶液中。实施例3-用于确定制造单分子阵列的最佳点样浓度的一般方案。在通过点样制造阵列的情况下,将不同序列或身份的寡核苷酸斑点置于表面上的不同的空间位置。制备单分子微阵列的程序中的第一步是制作荧光寡核苷酸的梯度稀释液。这已经用13聚物和25聚物完成,但是可以选择任何适当长度的寡核苷酸。这些寡核苷酸可以胺化并优选在5'端标记cy3。尽管这是对寡核苷酸进行例示,但是该程序也适用于蛋白质和化学点样。将10um的寡核苷酸溶液置于微量滴定板的第一孔中。为进行10倍稀释,将1ul转移到微量滴定板的下一个孔中,依次类推进行几个数量级。测试了12个数量级。将正在测试的1:1体积的2x点样缓冲液加入各个孔中。其在第一孔中产生5um的浓度,在第二孔中产生500nm,依次类推。然后使用微阵列(amershamgenerationiii)点样阵列。然后通过tirf显微镜、afm或其他相关显微镜系统分析梯度稀释液。观察斑点的形貌,确定斑点内的分子分布。选择具有所需数量的可解析单分子的斑点范围。可选的是,围绕目标稀释度进一步制作更集中的梯度稀释液。例如,可以进行500nm~50nm范围内的两个50%稀释。在第一个实验中,用4个缓冲液对跨12个数量级的梯度稀释液进行点样,以建立必要的稀释范围。随后,使用更集中的梯度稀释。发现250nm~67.5nm给出了可鉴定斑点内的可解析单分子。(如果分子太少,则很难准确地知道斑点的位置,但是当已知斑点位置和形貌是规则的并且平移台或ccd的移动是自动化的而不是手动的时候,这不会成问题)。有些斑点给出环绕外周的微弱的环,这可以帮助鉴定斑点。为了实现单分子阵列,在以下条件下测试了经修饰和未修饰的寡核苷酸的梯度稀释液:a)在数种不同的点样缓冲液中;b)在三种不同的载玻片化学成分上;c)在来自数个不同的制造商的载玻片上;d)使用两种不同的湿度;和e)使用数种不同的点样后规程。由于光漂白的影响,预曝光量也影响能够计数的经单染料标记的单分子的数量。载玻片发现来自不同供应商的载玻片的固有荧光不同。我们发现最适合于我们的低荧光需求(通过tirf显微镜检来确定)的载玻片是来自asperbiotech(tartu,爱沙尼亚)的商业载玻片,其在由knittelglaser(德国)提供的载玻片上涂覆和清洁。这些载玻片不仅具有均匀的硅烷表面涂层,而且具有非常低的固有荧光。普通玻璃载玻片是浮法玻璃,含有一定程度的固有荧光,但专用纯白色玻璃更适合。spectrosil熔融二氧化硅玻璃(tslgroup,tyneandwear,uk)也是合适的,但更昂贵。由硼硅酸盐玻璃制成的盖玻片也具有低荧光,但是一些点样器不能在这些上点样。载玻片化学成分已经测试了三种不同的载玻片化学成分:环氧硅烷、氨基硅烷和增强的氨基硅烷(3-氨基丙基三甲氧基硅烷+1,4-亚苯基二异硫氰酸酯)。用所有三种化学成分都能够获得单分子阵列。寡核苷酸化学成分测试了未修饰的dna寡核苷酸和在5'或3'末端胺化的寡核苷酸。无论寡核苷酸是否被末端修饰,形貌或附着似乎都没有显着差异。然而,仅有末端修饰的寡核苷酸在杂交或其它测定中进行了测试。测试了探测tnfα启动子的不同长度的数种不同序列。缓冲液测试了总共11种不同的缓冲液。从研究中发现,asperbiotech提供的环氧硅烷载玻片上最好的通用缓冲液是50%dmso和50%水。该缓冲液产生了比所测试的任何其它缓冲液优异得多的斑点形貌。点样湿度影响形貌。在42-43%和53-55%的湿度下测试了点样,两种条件都提供了可利用的阵列。然而,与55%湿度下几乎完美的均匀性相比,在43%的湿度下有轻微的晕环效应。qmt2(quantifoil,jenagermany)缓冲液也在asper的环氧硅烷载玻片上给出了合理的斑点。点样后,可选地将环氧硅烷载玻片放置在97℃下15分钟,然后在室温下保存12-24小时。接着在4℃下储存过夜或优选更长时间。载玻片在使用前清洗。两种洗涤方法都效果良好。第一种是在室温下用milliq水洗涤3x。第二种是在amershamslideprocessor(asp)上洗涤。使用了以下洗涤规程:asp洗涤规程:在来自asperbiotech的增强型氨基硅烷(3-氨基丙基三甲氧基硅烷+1,4-亚苯基二异硫氰酸酯)载玻片上的最佳缓冲液为50%1.5m甜菜碱/50%3xssc和10%qmt1点样缓冲液(quantifoil,jena)。此外,来自quantifoil(jena,germany)的一些其它缓冲液表现相当不错;不同浓度的这些缓冲液可以提供更好的形貌。用落射显微镜看到的详细的内部形貌并不好。dmso缓冲液(amersham)在斑点内产生强烈的“太阳黑子”,即强荧光点;可以想象,单个分子可以在斑点的其余部分中计数,并忽略黑子。在43%和55%湿度下测试了点样,两种条件都提供了可利用的阵列。对于增强型氨基硅烷载玻片,后处理包括可选的在潮湿室中在37度处理2小时。在这些条件下,更多的分子粘附,但是有可能斑点能够出线或合并。为了避免这种情况,将斑点阵列化得分隔足够远以防止合并。然后在4℃下过夜(或更长时间)。接着将载玻片浸入1%氨溶液中2-3分钟。然后将载玻片在milliq水中洗涤3次,然后在4℃下放置过夜。杂交后从斑点中出现一定程度的染料渗出。这可以通过更严格或更长的洗涤来解决。如果微量滴定孔中的缓冲液变干,则可以再次将其重悬在水中。然而,当进行此操作时,甜菜碱缓冲液表现不佳。50%dmso是氨基硅烷载玻片的最佳缓冲液。点样后,这些载玻片在stratagenecrosslinker上立即以300毫焦耳交联。将阵列在热水中振荡洗涤两次两分钟,然后在95%乙醇中浸5次,并立即用强制的空气进行干燥。与具有其它载玻片化学成分的表面相比,具有该载玻片化学成分的表面上粘附了显著更多的胺化寡核苷酸,即使当载玻片不是新鲜的时也是如此。因此,需要点样更少的寡核苷酸以获得特定的表面密度。点样针在不同的点样运行中使用了针对硫氰酸钠缓冲液优化的来自amershambiotech的毛细管针,或者针对dmso缓冲液优化的针。这两种类型的针都使得能够构建单分子阵列。其它优选的点样方法是affymetrix环和针系统以及喷墨打印。也可以使用羽毛笔。实施例4-与单分子阵列杂交测试了含有双等位基因探针组(其针对tnfα启动子的两个序列)的简单阵列。阵列探针设计成在13聚物序列的中心具有多态性碱基。使与两个双等位基因探针之一互补的在5'端具有cy3标记(或tamra标记)的两个寡核苷酸之一与单分子阵列杂交。该阵列含有双等位基因探针组的梯度稀释。发现与错配相比,来自完美匹配的信号更多。沿着梯度稀释分析斑点,并在发现给出单分子信号的均匀和可解析的分布的斑点中进行单分子计数。通过优化装置和使用去卷积软件,可以以更高的稀释度解析分子。bsa、载体dna、trna、ntp可以添加到杂交混合物中,或进行预杂交以封闭非特异性结合。寡核苷酸与阵列上的13聚物寡核苷酸杂交的杂交循环:使用来自amershampharmacia的自动化载玻片处理器进行杂交。asp杂交规程作为另一选择,可以使用本领域已知的手动杂交装置。简言之,将杂交混合物的液滴夹在阵列基板和盖玻片之间。在潮湿室中进行杂交(可选地用橡皮膏密封边缘)。盖玻片在洗涤缓冲液中滑落,优选在一些振动下进行洗涤。在增强型氨基硅烷载玻片上,qmt缓冲液1、1.5m甜菜碱3xssc给出了最好的结果。在1.5m甜菜碱3xssc中的斑点周围看到了微弱的环。250nm~67.5nm的浓度适合于在相对新鲜的载玻片上进行单分子计数。这些载玻片应储存在-70℃。在室温下,在点样后保持探针的能力在2个月时间内不良地减弱。通过tirf显微镜分析结果。使用了氧清除液。实施例5-制备单链dna/rna,与初级阵列杂交以制备二级阵列,探测二级阵列用单链dna制备二级阵列时的一种探测方法如下:■通过例如以下制备单链:不对称(长距离)pcr、磁珠法、选择性保护一个链免受外切核酸酶降解、或体外rna转录。■使单链dna杂交至阵列○单链dna可以在微阵列元件之间或微阵列元件内的两个点处杂交,以使其能够伸展(保持两个阵列探针中的一个或两个的连接物应当能够旋转)○或者,对于25聚物而言,单链dna可以在3-6xssc缓冲液中在室温下与阵列杂交,这可以通过酶促反应(例如连接)或通过同轴堆叠寡聚物或堆叠数个连续的寡聚物来促进。选择已知在低严格条件下保持对探测的可及性的位点以用于探测(这些可以在寡核苷酸阵列上选择;参见milner等,natbiotechnol.1997jun;15(6):537-41.)。○在单链杂交后,该链需要共价连接在捕获位点处,然后严格洗涤以除去二级结构。○被捕获的单链靶标然后可以按照woolley和kelly(nanoletters20011:345-348)所描述的通过使液滴移动经过带正电的表面而伸展。■需要通过涂覆1ppm聚-l-赖氨酸来控制表面上的正电荷密度。需要根据经验来确定其它表面涂层(例如氨基硅烷)的适当浓度。■需要在低离子强度下保持ssdna。使用10mmtris,1medta,ph8(te缓冲液)。■进行移动从而使液滴以约0.5mm/s(在0.2-1mm/s范围内)的速率在表面上移动通过。这可以通过以下方式来完成:将载玻片/云母固定到tst系列平移台(newport)上,将液滴放置在其上,并且通过将静止的玻璃移液管沾到液滴上而使流体相对于表面平移。玻璃移液管通过毛细作用吸引液滴,并且当载玻片/云母移动时,液滴保持静止。■溶液蒸发后,用水冲洗云母并用压缩空气干燥。○或者使用如上所述的michalet等的动态分子梳直程序。○或者使用上述asp法。○可选的是,单链dna可以用单链结合蛋白(amersham)包被。■单链dna可以用吖啶染料标记。■通过在低于寡核苷酸探针的tm5℃的温度下杂交,可以用单链dna探测伸展的单链分子。优选使用低盐浓度(50mmnacl)下的的lna寡核苷酸或在0或5mmnacl下的pna。实施例6-单分子阵列上的连接测定靶标制备基本上与snp分型/再测序部分以及靶标分析中一样·混合:5x连接缓冲液*溶液寡核苷酸5-10pmol,在3’端标记有荧光染料,在5’端磷酸化嗜热栖热菌dna连接酶(tthdna连接酶)1u/ul,靶标样品·添加至阵列中心·在阵列区域顶部加上盖玻片,并用橡皮膏密封边缘·在65℃下放置1小时。*5x连接缓冲液由下述组分组成:100mmtris-hclph8.3,0.5%tritonx-100,50mmmgcl,250mmkcl,5mmnad+,50mmdtt,5mmedta在该实施例中,用所述的点样方法将确定snp等位基因的不同序列放置在微阵列中的相邻斑点中。这些序列的最后一个碱基与靶标中的变异碱基重叠。阵列上的寡核苷酸点样时带有5'胺化。3'末端是游离的以用于与5'磷酸化溶液寡核苷酸连接。或者,阵列寡核苷酸可以是3'胺化和5'磷酸化的。溶液寡核苷酸可以在5'末端被磷酸化和标记。溶液寡核苷酸优选为所有9聚物的混合物(oswel,southampton,uk)。实施例7-图像处理、单分子计数和错误管理可以使用本发明的详细描述中的任何类型的算法来完成上述各项。另外,以下是如何使用简单的商业软件进行单分子计数的实例。目的是使用图像分析来计数和确定微阵列斑点内来自单分子的推定信号的置信度。使用图像处理包sigmascanpro来自动化单分子计数和测量。这里描述的程序或其修改版本可用于简单的单分子信号计数或更复杂的单分子信息分析、多色分析和错误管理。使用低光ccd相机(pentamaxgeniii或geniv(roperscientific))和现成的帧采集板来捕获微阵列斑点图像。单分子由tirf配置中的激光激发。使用100x物镜和直径约200微米的斑点。使用图像、校准、距离和区域菜单选项对图像进行空间校准。使用微米单位进行2点重新标度校准。单分子区域随后将以平方微米报告。增加单分子与周围区域之间的对比度将有助于利用阈值来鉴定单个分子。通过从图像-强度菜单中执行直方图拉伸来提高图像对比度。该过程测量图像中的灰度水平。然后,用户在整个255级的强度范围内大幅度“拉伸”灰度水平范围。在该情况下,使用鼠标将旧起始线移动到64的强度处将消除不明显的深灰色水平的影响并改善对比度。可以通过对强度水平取阈值以填充到最黑物体中来鉴定单个分子。这通过从图像菜单中选择阈值、强度阈值来完成。在某些点样条件下(例如在增强型氨基硅烷载玻片上的1.5m甜菜碱3xssc以及在某些条件下的50%dmso缓冲液中),斑点在边缘周围具有稀薄但可辨别的亮环。这可以用于定义要处理的区域。可以使用图像叠加层数学将单个分子信号与由环的内部组成的叠加平面相交,由此从对数据的贡献中除去该环。通过在斑点的内部填充光像素并利用阈值选择环来创建所述叠加。将级别设置为180,并将选项设定为选择比此级别亮的对象。选择填充测量模式(油漆桶图标),然后左键点击板的内部以填充它。在“测量”、“设置”,“叠加”对话框中将源叠加设置为红色。在红色叠加平面上存在未被填充的“洞”,因为它们含有来自单分子的亮像素。为了填充它们,选择“图像”、“叠加滤光器”,然后选择“填充洞”选项。让源和目标叠加都是红色的。红色圆形叠加平面包含绿色细菌菌落。使用叠加数学特征来识别红色和绿色叠加层的交集。从“图像”菜单中选择“叠加数学”,并指定红色和绿色为源层,蓝色为目标层。然后将这两层“合并”以获得交集。蓝色像素叠加了现在可以计数的单个分子。从“测量设置”对话框的“叠加”选项卡中选择蓝色叠加平面作为源叠加。从“测量设置”对话框中的“测量”选项卡中选择周长、面积、形状因子、紧凑度(compactness)和像素数。然后使用“测量”菜单中的“测量对象”来测量单分子信号。单分子信号可以任意编号,并将相应的测量量放入excel(microsoft)表格中。写入宏以对阵列中的每个斑点执行此操作。使用tst系列x-y平移台(newport)使微阵列载玻片相对于ccd平移,并以大约每100微米的间距拍摄图像。这里给出的实例是终点分析。然而,为了获得增强的错误辨别,实时分析可以是理想的,在这种情况下,可以用ccd相机在较低放大倍率下拍摄整个阵列的更宽视场图像,并且通过图像处理进行增强。然而,在大多数情况下,反应开始之后的时间窗已经确定,应当在此时间窗内获取图像以排除错误,这些错误可能发生在该过程中的早期(非特异性吸收)和晚期(错配的相互作用)。adobephotoshop软件包含一些可以使用的图像处理工具,并可获得更高级的插件。可以从quantitativeimageanalysis获得photoshops、micrografxpicturepublisher、nihimage和其他程序的插件imageprocessingtoolkit。实施例8-用聚乙烯亚胺(pei)将玻璃衍生化对于afm分析,需要将阵列点样在高度平坦的衍生化表面上。afm分析需要约1~2nm或优选更低的表面平坦度。玻璃载玻片(优选经抛光)可用聚乙烯亚胺衍生化,其与诸如aptes等试剂相比,给出适合于afm分析的相对平坦的表面涂层。用0.1n乙酸洗涤玻璃载玻片,然后用水冲洗,直到冲洗载玻片后的水的ph等于用于冲洗载玻片的水的ph。然后将载玻片干燥。向95:5乙醇:水溶液中加入足量的三甲氧基甲硅烷基丙基-聚乙烯亚胺(600mw)在2-中的50%w/w溶液,以达到2%w/w的终浓度。将该2%溶液搅拌5分钟后,将载玻片浸入该溶液中,轻轻搅拌2分钟,然后移出。将玻璃载玻片浸入乙醇中,以洗去过量多余的硅烷基化试剂。然后将玻璃载玻片风干。将胺化寡核苷酸点样于ph8.3的1m硼酸钠基缓冲液或50%dmso中。可达到原子级平坦度的云母可以以类似的方式用pei涂覆。基因组dna标记规程:为了基于微阵列的比较用基因组杂交而开发。基因组dna可以使用基于gibco/brl'sbioprimedna标记试剂盒的简单随机引发规程进行标记,但缺口平移规程也可使用。例如,bioprime标记试剂盒(gibco/brl)是随机八聚物、反应缓冲液和高浓度的klenow的便捷且廉价的来源,但其它来源的随机引物和高浓度的klenow也表现良好。1.向eppendorf管加入待标记的2ugdna样品注意:对于高复杂性dna(例如人类基因组dna),如果首先减少dna片段的尺寸,则标记反应会更高效。这可以通过限制酶消化(通常是dpnii,但其它4-切割酶也表现良好)来实现。消化后,应利用苯酚/氯仿提取/etoh沉淀(qiagenpcr纯化试剂盒也表现良好)来清洗dna。2.添加ddh20或te8.0以使总体积为21ul。然后添加20ul的2.5x随机引物/反应缓冲液混合物。煮沸分钟,然后放置在冰上。2.5x随机引物/反应缓冲液混合物:125mmtris6.812.5mmmgcl225mm2-巯基乙醇750ug/ml随机八聚物3.在冰上,添加5ul10xdntp混合物10xdntp混合物:1.2mm每种datp、dgtp和dttp0.6mmdctp10mmtris8.0,1mmedta4.添加3ulcy5-dctp或cy3-dctp(amersham,1mm原液)注意:cy-dctp和cy-dutp同样良好地起作用,如果使用cy-dutp,相应地调整10xdntp混合物。5.添加1ulklenow片段.注意:通过neb或gibco/brl(作为bioprime标记试剂盒的一部分)可获得的高浓度klenow(40-50单位/ul)产生更好的标记。6.37℃下温育1~2小时,然后加入5μl0.5medtaph8.0来停止反应7.与rna探针一样,可以使用microcon30过滤器(amicon/millipore)纯化dna探针:加入450ulte7.4来停止标记反应。铺放在microcon30过滤器上。在8000g离心约10分钟(微量离心机中为10,000rpm)。倒置和8000g离心1分钟,以将纯化的探针回收到新管(约20-40μl体积)。8.对于双色阵列杂交,将经纯化的探针(经cy5和cy3标记的探针)合并在新的eppindorf管中。然后添加:30-50ug人cot-1dna(gibco/brl;1mg/ml原液;如果在阵列上存在,则封闭与重复dna的杂交).100ug酵母trna(gibco/brl;制成5mg/ml原液;封闭非特异性dna杂交).20ug聚(da)-聚(dt)(sigma目录号p9764;制成5mg/ml原液;封闭与cdna阵列元件的聚a尾的杂交)。450ulte7.4用如上所述的microcon30过滤器进行浓缩(8000g,约15分钟,然后每1分钟检查体积,直至适当)。将探针混合物收集在12ul以下的体积中。9.探针混合物的体积用ddh20调节至12ul。然后添加2.55μl20xssc(对于最终浓度为3.4x)和0.45μl10%sds(对于终浓度为0.3%)。注意:最终杂交体积为15ul。该体积适合于在22mm2盖玻片下杂交。对于更大的阵列/盖玻片,体积应相应上调。10.使杂交混合物变性(100℃,1.5分钟),在37℃下温育30分钟(cot-1预退火步骤),然后与阵列杂交。11.使微阵列在65℃下杂交过夜(16~20小时)。注意,有关杂交的详细信息,参见人类阵列杂交规程。12.按照mrna标记规程来洗涤阵列,并扫描:第一次洗涤:2xssc,0.03%sds,5min,65℃第二次洗涤:1xssc,5minrt第三次洗涤:0.2xssc,5minrt注意:第一个洗涤步骤应在65℃进行;这看上去显著增加了特异性-非特异性杂交信号比。实施例9-通过afm沉积来制造空间上可寻址的阵列通过afm进行拾取并进行沉积来以低浓度制造单分子的空间上可寻址的阵列,这通过例如以下步骤来进行:制备松散结合的分子的图案化阵列,牵拉该阵列的单个分子并将其拾取并沉积在以及在已知坐标的基板上特定位置上。该坐标可以通过单分子荧光中的光学显微镜或afm来寻址。理想的是,afm台不在压电状态,以使漂移最小化。实施例10:固定捕获探针表面化学:在涂有环氧硅烷的盖玻片上打印阵列。盖玻片尺寸为22×22×0.170mm。环氧硅烷涂层是具有活性环氧基团的二维表面,其使得寡核苷酸(或蛋白)能够共价偶联至玻璃表面。环氧硅烷可以与寡核苷酸或蛋白上的氨基、巯基或羟基反应。将用于阵列打印的寡核苷酸在该寡核苷酸5'末端的6-碳链上被胺基修饰。活性基团的密度为每平方厘米约3.7-5.6×1012个分子。也可以使用其他表面化学剂,例如n-羟基琥珀酰亚胺酯反应性基团。原理是相同的,表面上的活性基团与寡核苷酸上的连接物结合形成共价键。阵列打印:打印用的缓冲液含有磷酸钠、寡(dt)20、洗涤剂和捕获寡核苷酸(参见下面的配方)。阵列斑点尺寸随着洗涤剂浓度的增加而增加。寡(dt)浓度保持恒定,而打印寡聚物浓度根据经验确定,并且范围为10-2500nm。平均斑点尺寸为300um。使用arrayitspotbot生成阵列。其利用针头(“stealthpins”)通过接触打印来沉积打印缓冲液。所使用的smp5针头的吸液体积为0.25微升,递送体积为1.5纳升。可以使用其他针头点样器和其他沉积或点样方法。实施例11:以下操作规程描述了通过杂交-连接、纯化、扩增、微阵列靶标制备、微阵列杂交和微阵列洗涤对至多24个无细胞dna样品进行的处理。制备或获得以下材料:在20μl体积的水中的无细胞dna(cfdna);探针混合物:各自浓度为2nm的所有标签和标记探针寡核苷酸的混合物;taq连接酶(40u/μl);磁珠:myone抗生蛋白链菌素c1dynabeads;珠结合和洗涤缓冲液,1x和2x浓度;正向扩增引物,带有5’磷酸修饰;反向扩增引物,带标记;amplitaqgold酶(5u/μl);dntp混合物;λ核酸外切酶(5u/μl);杂交缓冲液,1.25x;杂交对照寡核苷酸;微阵列洗涤缓冲液a;微阵列洗涤缓冲液b;微阵列洗涤缓冲液c杂交-连接反应:将cfdna样品(20μl)添加至96孔反应板的a3-h3孔中。向各cfdna样品添加以下试剂,总反应体积为50μl,并且通过上下吹吸5-8次而混合。成分体积h2o19.33μl探针混合物5μl10xtaq连接酶缓冲液5μltaq连接酶0.67μl将板放置在热循环仪中,并且使用以下循环策略进行连接:(i)95℃下5分钟;(ii)95℃下30秒;(iii)45℃下25分钟;(iv)重复步骤b-c4次;和(v)保持4℃。杂交-连接产物纯化:洗涤dynabeads:将一小瓶dynabeads以最高速设置涡旋混合30秒。将260μl的珠转移至1.5ml管中。将900μl的2x珠结合和洗涤缓冲液以及混合珠通过上下吹吸5-8次而混合。将管放置在磁力支架上1分钟,弃去上清液。从磁力支架取出管并通过上下吹吸5-8次将经洗涤的磁珠再悬浮在900μl的2x珠结合和洗涤缓冲液中。将管放置在磁力支架上1分钟,弃去上清液。从磁力支架取出管,添加1,230μl的2x珠结合和洗涤缓冲液。通过上下吹吸5-8次将所述珠再悬浮。固定hl产物:将50μl经洗涤的珠转移至96孔反应板中的各杂交-连接反应产物中,并通过上下吹吸8次而混合,在室温温育15分钟,在温育时间过程中在板形磁体上混合2次。将所述珠在板形磁体上分离3分钟,然后除去并弃去上清液。从板形磁体取下所述板,添加200μl1x珠结合和洗涤缓冲液,并通过上下吹吸5-8次将珠再悬浮。将所述板放置在板形磁体上1分钟,弃去上清液。从板形磁体取下所述板,添加180μl1xssc,并通过上下吹吸5-8次将所述珠再悬浮。将所述板放置在板形磁体上1分钟,弃去上清液。纯化杂交-连接产物:将50μl新制备的0.15mnaoh添加至各孔,通过上下吹吸5-8次将所述珠再悬浮,并且在室温温育10分钟。将所述板放置在板形磁体上2分钟,然后取下,弃去上清液。从板形磁体上取下所述板,添加200μl新制备的0.1mnaoh,通过上下吹吸5-8次将所述珠再悬浮。将所述板放置在板形磁体上1分钟,弃去上清液。从板形磁体上取下所述板,添加180μl0.1mnaoh,通过上下吹吸5-8次将所述珠再悬浮。将所述板放置在板形磁体上1分钟,弃去上清液。从板形磁体上取下所述板,添加200μl的1x结合和洗涤缓冲液,通过上下吹吸5-8次将所述珠再悬浮。将所述板放置在板形磁体上1分钟,弃去上清液。从板形磁体上取下所述板,添加180μlte,通过上下吹吸5-8次将所述珠再悬浮。将所述板放置在板形磁体上1分钟,弃去上清液。向各孔添加20μl水,通过上下吹吸5-8次将所述珠再悬浮。将所述板密封,并贮存在4℃直到用于随后的步骤中。扩增:向96孔反应板中的每个杂交-连接反应产物中添加以下试剂,总反应体积50μl。成分体积h2o17.25μl正向引物10μm2.5μl反向引物10μm2.5μl4mmdntp混合物(l/n052114)2.5μl10xamplitaqgold缓冲液5μlamplitaqgold酶0.25μl将板放置在热循环仪中,并且使用以下循环策略连接探针:(i)95℃下5分钟;(ii)95℃下30秒;(iii)45℃下25分钟;(iv)重复步骤b-c4次;和(v)保持4℃。杂交-连接产物纯化:通过上下吹吸5-8次使试剂混合。将板放置在热循环仪中,并且使用以下循环策略来扩增探针:(i)95℃下5分钟;(ii)95℃下30秒;(iii)54℃下30秒;(iv)72℃下60秒,(v)重复步骤b-d29次;(vi)72℃下5分钟;(vii)重复步骤b-c4次;并且(v)保持4℃。微阵列靶标制备(单链消化):向96孔反应板中的各经扩增的反应产物中添加以下试剂,总反应体积60μl。成分体积h2o3μl10xλ核酸外切酶缓冲液6μlλ核酸外切酶1μl通过上下吹吸5-8次使试剂混合。将板放置在热循环仪中,并且使用以下循环策略消化探针:(i)37℃下60分钟;(ii)80℃下30分钟;(iii)保持4℃。将板放置在speed-vac中,使用中等热设置将样品干燥约60分钟或者直到所有液体已经蒸发。将样品在黑暗中贮存在4℃,直到用于随后的步骤。微阵列杂交:向96孔反应板中的各经干燥的微阵列靶标添加以下试剂,总反应体积20μl。成分体积h2o3μl1.25x杂交缓冲液16μl杂交对照寡核苷酸1μl通过上下吹吸10-20次使试剂混合以将其再悬浮,并短暂地旋转以使内含物到达板孔的底部。将板放置在热循环仪中,并且使用以下循环策略使探针变性:(i)70℃下3分钟;(ii)保持42℃。在跟踪页(trackingsheet)中针对各样品记录待使用的微阵列条形码。制备杂交室,该杂交室含有用于待处理的每个微阵列的lifterslip。对于每个样品,向杂交室中的lifterslip的中心添加15μl微阵列靶标,然后通过将上边缘向下放在lifterslip上并使其缓慢落下变平而立即将合适的微阵列放置在靶流体上。关闭杂交室,在42℃将其温育60分钟。打开杂交室,从lifterslip取出各微阵列并放入浸没在微阵列洗涤缓冲液a中的支架中。一旦所有微阵列位于支架中,以650rpm将支架搅拌5分钟。从微阵列洗涤缓冲液a中取出微阵列的支架,在干净的擦拭布(roomwipe)上吸掉过量液体,将支架快速地置于微阵列洗涤缓冲液b中。以650rpm将支架搅拌5分钟。从微阵列洗涤缓冲液b中取出微阵列的支架,在干净的擦拭布上吸掉过量液体,将支架快速地置于微阵列洗涤缓冲液c中。以650rpm将支架搅拌5分钟。在微阵列洗涤缓冲液c中洗涤5分钟完成后,立即从该缓冲液中缓慢地取出微阵列的支架。这花费5-10秒以使洗涤缓冲液从盖玻片表面的展开最大化。在干净的擦拭布上吸掉过量液体。使用真空抽吸器除去存在于各微阵列任一表面上的任何残留的缓冲液液滴。将微阵列贮存在处于氮气下于黑暗中的载玻片支架中,直到分析所述微阵列。实施例12:调节打印浓度以在微阵列上实现相当的荧光密度测试了针对两种不同的寡核苷酸标签的打印浓度,其是待施加到基板上不同位置的稀溶液的浓度,并确定适当的打印浓度以实现相当的标记密度。将阵列设计为其中两种标签序列以交替模式打印,且具有一系列浓度的打印寡核苷酸。t005打印浓度:10、15、25、50、100和250nmt1023打印浓度:250、500、1000、1500、2000和2500nm阵列布局的示意图如下表7所示。使用标签t005的打印浓度为斜体,使用标签t1023的打印浓度为粗体。打印浓度对照斑点也显示在表中。表7:阵列上各斑点的打印浓度按照上述实施例10,通过递送1.5纳升具有上述浓度的稀溶液来制备阵列。除了捕获探针的组成外,稀溶液的其余组成是相同的。阵列的图像显示在图85中。通道1和2代表来自两种不同的荧光染料的标记的图像:alexa-647(通道1)和alexa-594(通道2)。每种标记与靶标中的特定序列相关联,所述特定序列与基板上的捕获探针之一互补。这些图像说明了从高(顶行)到低(底行)的打印浓度和靶分子关联的标记的密度之间的剂量响应。阵列顶部的元件非常密集。密度从上到下减少。还值得注意的是,两种寡核苷酸标签具有不同的密度响应曲线。下表8显示了两种标签寡核苷酸的每个通道的打印浓度和背景扣除后密度。使用背景扣除来将观察到的密度相对于不应存在标记的空白斑点归一化。通常,由于非特异性结合,这些背景元件中的密度不会为零,但会明显低于数据元件中的密度。表8:打印浓度和背景扣除后密度系列标签打印浓度c1fd_背景扣除c2fd_背景扣除48a-2-dct00510514648a-2-dct00515817648a-2-dct0052510810348a-2-dct0055012813148a-2-dct00510015415148a-2-dct00525016617648a-2-dct1023250131048a-2-dct1023500282048a-2-dct10231000503948a-2-dct10231500675248a-2-dct10232000836948a-2-dct102325008672在15nm的打印浓度下,通道1和2的t005标记密度分别为81和76。t1023在打印浓度为2000nm时具有相当的标记密度,标记密度为83和69。在图84中,以2000nm打印的标签t1023位于阵列图像的c1-c5位置处。以15nm打印的标签t005位于上述图像的f1-f5位置处。因此,为了使这两种寡核苷酸标签(捕获探针)具有大致相同的密度,将两种寡核苷酸标签以不同的浓度打印到基板上。实施例13:indel探针将探针组设计成查询已知的indel(参照其rsid)。示例性探针描述在下表9和10中。表9:使用包含插入和/或缺失的突变序列的示例性探针制造了这些探针,并对种系基因组dna或cfdna的8个样品进行了测试。在一些样品中,在样品中仅观察到一种等位基因(ref或alt)。在另一些样品中,以不同的频率观察到两种等位基因,如对具有不同胎儿组分的cfdna样品和对基因组dna样品所预期的那样。下表10显示了在种系和cfdna样品中观察到的插入/缺失和野生型序列(alt和ref)的计数。表10rsid_等位基因样品1样品2样品3样品4样品5样品6样品7样品8rs150236770_alt106261587501772917055672289388966rs150236770_ref34885672500175728762816rs5783632_alt3902730300rs5783632_ref39355933290226225615191957715512rs5785116_alt190274313681336862rs5785116_ref141440083781862014023104898427上述实验证明,我们可以凭经验确定不同的标签寡核苷酸的个体打印浓度,该打印浓度将导致杂交时相似的标记密度。序列表<110>卓异生物公司p·j·柯林斯h·b·琼斯<120>用于单分子检测的阵列及其应用<130>31753-5008wo<150>us62/342,036<151>2016-05-26<160>384<170>patentinversion3.5<210>1<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>1gccctcatcttcttccctgcgttctcaccaccctcaccaaggaagaagtgagggcttctc60<210>2<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>2gccctcatcttcttccctgcgttctcaccaccctcaccaaaaatcaaggtgaccagctcc60<210>3<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>3gccctcatcttcttccctgcgttctcaccaccctcaccaatcatctgccaagacagaagt60tc62<210>4<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>4gccctcatcttcttccctgcgttctcaccaccctcaccaagcaggagagtcaaaggtctg60<210>5<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>5gccctcatcttcttccctgcgttctcaccaccctcaccaagttgccatggagattgttgc60<210>6<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>6gccctcatcttcttccctgcgttctcaccaccctcaccaacagctcagtgatgtcattgc60<210>7<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>7gccctcatcttcttccctgcgttctcaccaccctcaccaaccttgacctctgctaatgtg60g61<210>8<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>8gccctcatcttcttccctgcgttctcaccaccctcaccaacacctgtccaacagctacag60<210>9<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>9gccctcatcttcttccctgcgttctcaccaccctcaccaaagaatgtatcttcaggcctg60c61<210>10<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>10gccctcatcttcttccctgcgttctcaccaccctcaccaaaagtaatcactctgggtggc60<210>11<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>11gccctcatcttcttccctgcgttctcaccaccctcaccaaagctcacagacaaccttgtg60<210>12<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>12gccctcatcttcttccctgcgttctcaccaccctcaccaagcaatagacacctacaggcg60<210>13<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>13gccctcatcttcttccctgcgttctcaccaccctcaccaagcacattatcaaaggccacg60<210>14<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>14gccctcatcttcttccctgcgttctcaccaccctcaccaacaacgacctaaagcatgtgc60<210>15<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>15gccctcatcttcttccctgcgttctcaccaccctcaccaagacatacatggctttggcag60<210>16<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>16gccctcatcttcttccctgcgttctcaccaccctcaccaagagatactgccacttatgca60cg62<210>17<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>17cgtgctaatagtctcagggcttcctccaccgaacgtgtct40<210>18<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>18cgacgcttcattgcttcattttcctccaccgaacgtgtct40<210>19<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>19cttgcgccaaacaattgtccttcctccaccgaacgtgtct40<210>20<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>20gctgcagagtttgcattcatttcctccaccgaacgtgtct40<210>21<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>21catacacacagaccgagagtcttcctccaccgaacgtgtct41<210>22<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>22ggatgtcagccagcataagtttcctccaccgaacgtgtct40<210>23<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>23gcaagtgccaaacagttctcttcctccaccgaacgtgtct40<210>24<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>24gattccagcacacttgagtctttcctccaccgaacgtgtct41<210>25<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>25ccgttgcaggtttaaatggcgccctattgcaagccctctt40<210>26<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>26caagagtgctttatgggcctgccctattgcaagccctctt40<210>27<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>27gcactcaaggagatcagactggccctattgcaagccctctt41<210>28<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>28ggctatcgaactacaaccacagccctattgcaagccctctt41<210>29<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>29gtagctgtctgtggtgtgatcgccctattgcaagccctctt41<210>30<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>30caagaaacttcgagccttagcagccctattgcaagccctctt42<210>31<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>31gtgaaccagtccgagtgaaagccctattgcaagccctctt40<210>32<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>32gcaaatgatgttcagcaccacgccctattgcaagccctctt41<210>33<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>33gccctcatcttcttccctgc20<210>34<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>34gttctcaccaccctcaccaa20<210>35<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>35ggaagaagtgagggcttctc20<210>36<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>36aaatcaaggtgaccagctcc20<210>37<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>37tcatctgccaagacagaagttc22<210>38<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>38gcaggagagtcaaaggtctg20<210>39<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>39gttgccatggagattgttgc20<210>40<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>40cagctcagtgatgtcattgc20<210>41<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>41ccttgacctctgctaatgtgg21<210>42<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>42cacctgtccaacagctacag20<210>43<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>43agaatgtatcttcaggcctgc21<210>44<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>44aagtaatcactctgggtggc20<210>45<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>45agctcacagacaaccttgtg20<210>46<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>46gcaatagacacctacaggcg20<210>47<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>47gcacattatcaaaggccacg20<210>48<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>48caacgacctaaagcatgtgc20<210>49<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>49gacatacatggctttggcag20<210>50<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>50gagatactgccacttatgcacg22<210>51<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>51cgtgctaatagtctcagggc20<210>52<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>52cgacgcttcattgcttcatt20<210>53<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>53cttgcgccaaacaattgtcc20<210>54<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>54gctgcagagtttgcattcat20<210>55<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>55catacacacagaccgagagtc21<210>56<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>56ggatgtcagccagcataagt20<210>57<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>57gcaagtgccaaacagttctc20<210>58<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>58gattccagcacacttgagtct21<210>59<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>59ccgttgcaggtttaaatggc20<210>60<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>60caagagtgctttatgggcct20<210>61<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>61gcactcaaggagatcagactg21<210>62<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>62ggctatcgaactacaaccaca21<210>63<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>63gtagctgtctgtggtgtgatc21<210>64<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>64caagaaacttcgagccttagca22<210>65<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>65gtgaaccagtccgagtgaaa20<210>66<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>66gcaaatgatgttcagcaccac21<210>67<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>67ttcctccaccgaacgtgtct20<210>68<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>68gccctattgcaagccctctt20<210>69<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>69ttcctccaccgaacgtgtctagaccagcacaacttactcg40<210>70<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>70ttcctccaccgaacgtgtctccaaatgcacctgcctg37<210>71<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>71ttcctccaccgaacgtgtctagtttggacaaaggcaattcg41<210>72<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>72ttcctccaccgaacgtgtcttgagcttagccaatatcaagaagg44<210>73<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>73ttcctccaccgaacgtgtctacgtgaactttccttggtacac42<210>74<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>74ttcctccaccgaacgtgtcttgaagatgttctaataccttgccg44<210>75<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>75ttcctccaccgaacgtgtctcagtgtggagactgaacg38<210>76<211>43<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>76ttcctccaccgaacgtgtctaggcagggtaatgtcatgaaatg43<210>77<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>77ttcctccaccgaacgtgtctgattgtctggagcgctg37<210>78<211>36<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>78ttcctccaccgaacgtgtctagggagcaataggccg36<210>79<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>79ttcctccaccgaacgtgtctctgcagggtacaacacg37<210>80<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>80ttcctccaccgaacgtgtctcgtatctgggaagacggc38<210>81<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>81ttcctccaccgaacgtgtctcctgtaatcccttgcaatgc40<210>82<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>82ttcctccaccgaacgtgtctggtctcagcacggttctg38<210>83<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>83ttcctccaccgaacgtgtctgcacctccctaccacac37<210>84<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>84ttcctccaccgaacgtgtctgcctctagctagagagaagtc41<210>85<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>85ttcctccaccgaacgtgtctctggcagtctagccgttac39<210>86<211>43<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>86ttcctccaccgaacgtgtcttgtcttagaatttggcaactggc43<210>87<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>87ttcctccaccgaacgtgtctgcaggaaagcctactgaac39<210>88<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>88ttcctccaccgaacgtgtctgggagccagagaaatgtcc39<210>89<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>89ttcctccaccgaacgtgtcttgtctccagttccacttcatttag44<210>90<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>90ttcctccaccgaacgtgtctcccgttaattgcctactcg39<210>91<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>91ttcctccaccgaacgtgtctctcggtcccactggaaag38<210>92<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>92ttcctccaccgaacgtgtctacacccatgattcagttactg41<210>93<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>93ttcctccaccgaacgtgtctgctagtatgaacatcacaggc41<210>94<211>43<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>94ttcctccaccgaacgtgtctacaaatgagtaagaagcgagtcg43<210>95<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>95ttcctccaccgaacgtgtctgataagggttgctctgcg38<210>96<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>96ttcctccaccgaacgtgtctccatgcaccagctaccc37<210>97<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>97ttcctccaccgaacgtgtctaactgtaccctactcccagc40<210>98<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>98ttcctccaccgaacgtgtctaggaccaagggaccagtttag41<210>99<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>99ttcctccaccgaacgtgtctagagttcctccaagaaattgcg42<210>100<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>100ttcctccaccgaacgtgtctacattatacagcatgctggctatc44<210>101<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>101ttcctccaccgaacgtgtctgaggaagaaagtgaggtttgc41<210>102<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>102ttcctccaccgaacgtgtctctgaattatgtgcttaccaagagc44<210>103<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>103ttcctccaccgaacgtgtcttgggttctgataaccttatcaagc44<210>104<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>104ttcctccaccgaacgtgtctggttagtcaaacatgctgc39<210>105<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>105ttcctccaccgaacgtgtctgacactggcagaatcaaatcac42<210>106<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>106ttcctccaccgaacgtgtctagagttacacctttagctaaccac44<210>107<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>107ttcctccaccgaacgtgtctccaggagttcaagaagcg38<210>108<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>108ttcctccaccgaacgtgtctaccactcctttctcccatctc41<210>109<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>109ttcctccaccgaacgtgtctgtcttatgggacaatggttgatag44<210>110<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>110ttcctccaccgaacgtgtctctaccctcaaccctcgtc38<210>111<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>111ttcctccaccgaacgtgtctccaagactgatcatgccg38<210>112<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>112gccctattgcaagccctcttagaccagcacaacttactta40<210>113<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>113gccctattgcaagccctcttccaaattcacctgccca37<210>114<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>114gccctattgcaagccctcttagtttggacaaaggcgattta41<210>115<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>115gccctattgcaagccctctttgagcttagccaatatcaacaaga44<210>116<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>116gccctattgcaagccctcttacgtgaactttccttggtaaat42<210>117<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>117gccctattgcaagccctctttgaagatgttctaataccttgcta44<210>118<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>118gccctattgcaagccctcttcagtgtggagaccgaaca38<210>119<211>43<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>119gccctattgcaagccctcttaggcagggtaatgtcatgaagtt43<210>120<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>120gccctattgcaagccctcttgattgtctggagggctc37<210>121<211>36<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>121gccctattgcaagccctcttagggagcaataggcta36<210>122<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>122gccctattgcaagccctcttctgcagggtacaagaca37<210>123<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>123gccctattgcaagccctcttcgtatctgggaagatggg38<210>124<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>124gccctattgcaagccctcttcctgtaatcccttgcaataa40<210>125<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>125gccctattgcaagccctcttggtctcagcacggtcctt38<210>126<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>126gccctattgcaagccctcttgcacctccctatcacat37<210>127<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>127gccctattgcaagccctcttgcctctagctagagagaagcg41<210>128<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>128gccctattgcaagccctcttctggcagtctagccattat39<210>129<211>43<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>129gccctattgcaagccctctttgtcttagaatttggcaactagt43<210>130<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>130gccctattgcaagccctcttgcaggaaagcctattgaat39<210>131<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>131gccctattgcaagccctcttgggagccagagaaatttct39<210>132<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>132gccctattgcaagccctctttgtctccagttccacttcatgtaa44<210>133<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>133gccctattgcaagccctcttcccgttaattgcctattta39<210>134<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>134gccctattgcaagccctcttctcggtcccactgggaaa38<210>135<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>135gccctattgcaagccctcttacacccatgattcagttacca41<210>136<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>136gccctattgcaagccctcttgctagtatgaacatcacaagt41<210>137<211>43<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>137gccctattgcaagccctcttacaaatgagtaagaagcgagtta43<210>138<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>138gccctattgcaagccctcttgataagggttgctctaca38<210>139<211>37<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>139gccctattgcaagccctcttccatgcaccagctacta37<210>140<211>40<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>140gccctattgcaagccctcttaactgtaccctactcccaat40<210>141<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>141gccctattgcaagccctcttaggaccaagggaccagttcac41<210>142<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>142gccctattgcaagccctcttagagttcctccaagaaattgta42<210>143<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>143gccctattgcaagccctcttacattatacagcatgctggttaga44<210>144<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>144gccctattgcaagccctcttgaggaagaaagtgagatttgt41<210>145<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>145gccctattgcaagccctcttctgaattatgtgcttaccaggagt44<210>146<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>146gccctattgcaagccctctttgggttctgataaccttatcaact44<210>147<211>39<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>147gccctattgcaagccctcttggttagtcaaacatgttgt39<210>148<211>42<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>148gccctattgcaagccctcttgacactggcagaatcaaaccaa42<210>149<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>149gccctattgcaagccctcttagagttacacctttagctaactag44<210>150<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>150gccctattgcaagccctcttccaggagttcaaggagca38<210>151<211>41<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>151gccctattgcaagccctcttaccactcctttctcccgtctt41<210>152<211>44<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>152gccctattgcaagccctcttgtcttatgggacaatggtcgatat44<210>153<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>153gccctattgcaagccctcttctaccctcaaccctcatt38<210>154<211>38<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>154gccctattgcaagccctcttccaagactgatcatgcta38<210>155<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>155cacttgacaaagttctcacgcgccgaagttctccgaaggatgccctcatcttcttccctg60c61<210>156<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>156cattagggattaacggcttgggacagactgacggagcttcagccctcatcttcttccctg60c61<210>157<211>63<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>157cacacgttaagaagactttctgctgactctgccgcacatgatcgccctcatcttcttccc60tgc63<210>158<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>158ctaagtgccctccatgagaaaggatccgatagccctctgcaggccctcatcttcttccct60gc62<210>159<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>159gcacagatttcccacactctcaacaggcctgctaaacaccgccctcatcttcttccctgc60<210>160<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>160cttacaggaggtctggcatcaggtcaacaaccgagggactcgccctcatcttcttccctg60c61<210>161<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>161ccacaatgagaaggcagagttgtcattaatgctggcggcgccctcatcttcttccctgc59<210>162<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>162gctgtggcatagctacactccggtgacggtttgcaactttgccctcatcttcttccctgc60<210>163<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>163cagggtaatttgtgggtctggtccggcagttaagggtctcgccctcatcttcttccctgc60<210>164<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>164gggctatccagaaagataagaatactcacaaacgactgcgcagccctcatcttcttccct60gc62<210>165<211>63<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>165cataactggtggagtatttcactcgtatatggccgactggagggccctcatcttcttccc60tgc63<210>166<211>64<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>166cttcaaggaagaaattcaacagggtagggtttgcggcgataagggccctcatcttcttcc60ctgc64<210>167<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>167catggattcaacacagcaaacaccaagtcaaccacccgagacgccctcatcttcttccct60gc62<210>168<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>168ctctgacctccttcactcttacacttccctggccttccttctgccctcatcttcttccct60gc62<210>169<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>169gctttcatttgtgctaaacctcgcttgggtcctctcctgaacgccctcatcttcttccct60gc62<210>170<211>58<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>170catcccagatgccctcataacgtccgaaccacaatgctgccctcatcttcttccctgc58<210>171<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>171gtagaaatcccaaggcaatcagctcctcgcatccaacagtcggccctcatcttcttccct60gc62<210>172<211>63<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>172gaacaactaactccacagaacccccaccgtagcactccttcttgccctcatcttcttccc60tgc63<210>173<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>173gtgcagaggacaggaagaacggagcgtcggtagtgtaaagccctcatcttcttccctgc59<210>174<211>63<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>174ggtgcttcaagacatacaccttaacaactcgacgaacctaccggccctcatcttcttccc60tgc63<210>175<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>175ggaacctctgtgaccttggatggcccatccttatgtgctggccctcatcttcttccctgc60<210>176<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>176cccagtggtaccttctgaaggtcgttattgctcaagcccgccctcatcttcttccctgc59<210>177<211>63<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>177cttctgttgcttatttgggtaacttgattctggccctcccatcgccctcatcttcttccc60tgc63<210>178<211>56<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>178cccactggatgcctccctcacgccggctatttaggtgccctcatcttcttccctgc56<210>179<211>58<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>179cggagagacgcatctgaaagtctgggtaggtggaggacgccctcatcttcttccctgc58<210>180<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>180caggatttccagcttacagggcgactgagccacatccaactgccctcatcttcttccctg60c61<210>181<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>181cttgcaagatgtgcctcttagagcctcagccggaattgaagccctcatcttcttccctgc60<210>182<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>182gggtggtttctctaaacacaaattgccattctgcaccaatgcgccctcatcttcttccct60gc62<210>183<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>183gcagggtattgagagaaggatctattggtgttcgcggctgatgccctcatcttcttccct60gc62<210>184<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>184gtgcacatttcttgatgaagggatgggcgtaacaggaggactgccctcatcttcttccct60gc62<210>185<211>62<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>185gagcaatgcctgtttcatgagaggaatggcctacctgcatcagccctcatcttcttccct60gc62<210>186<211>64<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>186gttaacattatacagcatggtggccccgttgttgtcatcgcatcgccctcatcttcttcc60ctgc64<210>187<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>187gcagaacatgtcctgaagcgttcgatgcgtcccatgagtgccctcatcttcttccctgc59<210>188<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>188cagcttgttcccaaacccatcaacccgcgtagatgttcctgccctcatcttcttccctgc60<210>189<211>61<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>189caaagtgtggaagttgcttccgccagctcaagagtgtagccgccctcatcttcttccctg60c61<210>190<211>58<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>190ggtcgactttgtccatccttcttgatcctgcgcgatgtgccctcatcttcttccctgc58<210>191<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>191ctctgttgcctgtggactcatcgcaggcgttccctatacgccctcatcttcttccctgc59<210>192<211>64<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>192ctaactagaattagtctgcctgcctattggacctccgaccacgagccctcatcttcttcc60ctgc64<210>193<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>193gtgagccataatcgtgtcaagccaccatttagatccgcggccctcatcttcttccctgc59<210>194<211>63<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>194gagaattaatgctccctctcctggaccagtagaagtctgcccggccctcatcttcttccc60tgc63<210>195<211>59<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>195gtggtctgctgttgaccaatttcagaatggccgagctgtgccctcatcttcttccctgc59<210>196<211>60<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>196ggttgcaactgctgatctataggtgaccttcttgtacgccgccctcatcttcttccctgc60<210>197<211>58<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>197ctttcccagtcaaggcagggcgcgtccttatttccatcgccctcatcttcttccctgc58<210>198<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>198agaccagcacaacttactcg20<210>199<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>199ccaaatgcacctgcctg17<210>200<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>200agtttggacaaaggcaattcg21<210>201<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>201tgagcttagccaatatcaagaagg24<210>202<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>202acgtgaactttccttggtacac22<210>203<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>203tgaagatgttctaataccttgccg24<210>204<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>204cagtgtggagactgaacg18<210>205<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>205aggcagggtaatgtcatgaaatg23<210>206<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>206gattgtctggagcgctg17<210>207<211>16<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>207agggagcaataggccg16<210>208<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>208ctgcagggtacaacacg17<210>209<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>209cgtatctgggaagacggc18<210>210<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>210cctgtaatcccttgcaatgc20<210>211<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>211ggtctcagcacggttctg18<210>212<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>212gcacctccctaccacac17<210>213<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>213gcctctagctagagagaagtc21<210>214<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>214ctggcagtctagccgttac19<210>215<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>215tgtcttagaatttggcaactggc23<210>216<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>216gcaggaaagcctactgaac19<210>217<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>217gggagccagagaaatgtcc19<210>218<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>218tgtctccagttccacttcatttag24<210>219<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>219cccgttaattgcctactcg19<210>220<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>220ctcggtcccactggaaag18<210>221<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>221acacccatgattcagttactg21<210>222<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>222gctagtatgaacatcacaggc21<210>223<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>223acaaatgagtaagaagcgagtcg23<210>224<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>224gataagggttgctctgcg18<210>225<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>225ccatgcaccagctaccc17<210>226<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>226aactgtaccctactcccagc20<210>227<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>227aggaccaagggaccagtttag21<210>228<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>228agagttcctccaagaaattgcg22<210>229<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>229acattatacagcatgctggctatc24<210>230<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>230gaggaagaaagtgaggtttgc21<210>231<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>231ctgaattatgtgcttaccaagagc24<210>232<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>232tgggttctgataaccttatcaagc24<210>233<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>233ggttagtcaaacatgctgc19<210>234<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>234gacactggcagaatcaaatcac22<210>235<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>235agagttacacctttagctaaccac24<210>236<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>236ccaggagttcaagaagcg18<210>237<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>237accactcctttctcccatctc21<210>238<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>238gtcttatgggacaatggttgatag24<210>239<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>239ctaccctcaaccctcgtc18<210>240<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>240ccaagactgatcatgccg18<210>241<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>241agaccagcacaacttactta20<210>242<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>242ccaaattcacctgccca17<210>243<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>243agtttggacaaaggcgattta21<210>244<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>244tgagcttagccaatatcaacaaga24<210>245<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>245acgtgaactttccttggtaaat22<210>246<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>246tgaagatgttctaataccttgcta24<210>247<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>247cagtgtggagaccgaaca18<210>248<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>248aggcagggtaatgtcatgaagtt23<210>249<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>249gattgtctggagggctc17<210>250<211>16<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>250agggagcaataggcta16<210>251<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>251ctgcagggtacaagaca17<210>252<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>252cgtatctgggaagatggg18<210>253<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>253cctgtaatcccttgcaataa20<210>254<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>254ggtctcagcacggtcctt18<210>255<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>255gcacctccctatcacat17<210>256<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>256gcctctagctagagagaagcg21<210>257<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>257ctggcagtctagccattat19<210>258<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>258tgtcttagaatttggcaactagt23<210>259<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>259gcaggaaagcctattgaat19<210>260<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>260gggagccagagaaatttct19<210>261<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>261tgtctccagttccacttcatgtaa24<210>262<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>262cccgttaattgcctattta19<210>263<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>263ctcggtcccactgggaaa18<210>264<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>264acacccatgattcagttacca21<210>265<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>265gctagtatgaacatcacaagt21<210>266<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>266acaaatgagtaagaagcgagtta23<210>267<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>267gataagggttgctctaca18<210>268<211>17<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>268ccatgcaccagctacta17<210>269<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>269aactgtaccctactcccaat20<210>270<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>270aggaccaagggaccagttcac21<210>271<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>271agagttcctccaagaaattgta22<210>272<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>272acattatacagcatgctggttaga24<210>273<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>273gaggaagaaagtgagatttgt21<210>274<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>274ctgaattatgtgcttaccaggagt24<210>275<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>275tgggttctgataaccttatcaact24<210>276<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>276ggttagtcaaacatgttgt19<210>277<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>277gacactggcagaatcaaaccaa22<210>278<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>278agagttacacctttagctaactag24<210>279<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>279ccaggagttcaaggagca18<210>280<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>280accactcctttctcccgtctt21<210>281<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>281gtcttatgggacaatggtcgatat24<210>282<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>282ctaccctcaaccctcatt18<210>283<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>283ccaagactgatcatgcta18<210>284<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>284cacttgacaaagttctcacgc21<210>285<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>285cattagggattaacggcttgg21<210>286<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>286cacacgttaagaagactttctgc23<210>287<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>287ctaagtgccctccatgagaaag22<210>288<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>288gcacagatttcccacactct20<210>289<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>289cttacaggaggtctggcatca21<210>290<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>290ccacaatgagaaggcagag19<210>291<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>291gctgtggcatagctacactc20<210>292<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>292cagggtaatttgtgggtctg20<210>293<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>293gggctatccagaaagataagaa22<210>294<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>294cataactggtggagtatttcact23<210>295<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>295cttcaaggaagaaattcaacaggg24<210>296<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>296catggattcaacacagcaaaca22<210>297<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>297ctctgacctccttcactcttac22<210>298<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>298gctttcatttgtgctaaacctc22<210>299<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>299catcccagatgccctcat18<210>300<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>300gtagaaatcccaaggcaatcag22<210>301<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>301gaacaactaactccacagaaccc23<210>302<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>302gtgcagaggacaggaagaa19<210>303<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>303ggtgcttcaagacatacacctta23<210>304<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>304ggaacctctgtgaccttgga20<210>305<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>305cccagtggtaccttctgaa19<210>306<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>306cttctgttgcttatttgggtaac23<210>307<211>16<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>307cccactggatgcctcc16<210>308<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>308cggagagacgcatctgaa18<210>309<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>309caggatttccagcttacaggg21<210>310<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>310cttgcaagatgtgcctctta20<210>311<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>311gggtggtttctctaaacacaaa22<210>312<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>312gcagggtattgagagaaggatc22<210>313<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>313gtgcacatttcttgatgaaggg22<210>314<211>22<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>314gagcaatgcctgtttcatgaga22<210>315<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>315gttaacattatacagcatggtggc24<210>316<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>316gcagaacatgtcctgaagc19<210>317<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>317cagcttgttcccaaacccat20<210>318<211>21<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>318caaagtgtggaagttgcttcc21<210>319<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>319ggtcgactttgtccatcc18<210>320<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>320ctctgttgcctgtggactc19<210>321<211>24<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>321ctaactagaattagtctgcctgcc24<210>322<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>322gtgagccataatcgtgtca19<210>323<211>23<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>323gagaattaatgctccctctcctg23<210>324<211>19<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>324gtggtctgctgttgaccaa19<210>325<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>325ggttgcaactgctgatctat20<210>326<211>18<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>326ctttcccagtcaaggcag18<210>327<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>327gccgaagttctccgaaggat20<210>328<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>328gacagactgacggagcttca20<210>329<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>329tgactctgccgcacatgatc20<210>330<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>330gatccgatagccctctgcag20<210>331<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>331caacaggcctgctaaacacc20<210>332<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>332ggtcaacaaccgagggactc20<210>333<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>333ttgtcattaatgctggcggc20<210>334<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>334cggtgacggtttgcaacttt20<210>335<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>335gtccggcagttaagggtctc20<210>336<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>336tactcacaaacgactgcgca20<210>337<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>337cgtatatggccgactggagg20<210>338<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>338tagggtttgcggcgataagg20<210>339<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>339ccaagtcaaccacccgagac20<210>340<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>340acttccctggccttccttct20<210>341<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>341gcttgggtcctctcctgaac20<210>342<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>342aacgtccgaaccacaatgct20<210>343<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>343ctcctcgcatccaacagtcg20<210>344<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>344ccaccgtagcactccttctt20<210>345<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>345cggagcgtcggtagtgtaaa20<210>346<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>346acaactcgacgaacctaccg20<210>347<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>347tggcccatccttatgtgctg20<210>348<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>348ggtcgttattgctcaagccc20<210>349<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>349ttgattctggccctcccatc20<210>350<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>350ctcacgccggctatttaggt20<210>351<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>351agtctgggtaggtggaggac20<210>352<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>352cgactgagccacatccaact20<210>353<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>353gagcctcagccggaattgaa20<210>354<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>354ttgccattctgcaccaatgc20<210>355<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>355tattggtgttcgcggctgat20<210>356<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>356atgggcgtaacaggaggact20<210>357<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>357ggaatggcctacctgcatca20<210>358<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>358cccgttgttgtcatcgcatc20<210>359<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>359gttcgatgcgtcccatgagt20<210>360<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>360caacccgcgtagatgttcct20<210>361<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>361gccagctcaagagtgtagcc20<210>362<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>362ttcttgatcctgcgcgatgt20<210>363<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>363atcgcaggcgttccctatac20<210>364<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>364tattggacctccgaccacga20<210>365<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>365agccaccatttagatccgcg20<210>366<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>366gaccagtagaagtctgcccg20<210>367<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>367tttcagaatggccgagctgt20<210>368<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>368aggtgaccttcttgtacgcc20<210>369<211>20<212>dna<213>人工序列(artificialsequence)<220><223>合成序列(syntheticsequence)<400>369ggcgcgtccttatttccatc20<210>370<211>20<212>dna<213>人工序列(artificialsequence)<220><223>non-genomictaggingnucleotidesequence<400>370agtgacccgctcgtacatga20<210>371<211>20<212>dna<213>人工序列(artificialsequence)<220><223>non-genomictaggingnucleotidesequence<400>371caggtacccggtcgcaatag20<210>372<211>20<212>dna<213>人工序列(artificialsequence)<220><223>non-genomictaggingnucleotidesequence<400>372actttattcgcaaggcccga20<210>373<211>20<212>dna<213>人工序列(artificialsequence)<220><223>non-genomictaggingnucleotidesequence<400>373attgccaaccgcccgtatag20<210>374<211>20<212>dna<213>人工序列(artificialsequence)<220><223>non-genomictaggingnucleotidesequence<400>374cgctccgaacgtgtaagagg20<210>375<211>20<212>dna<213>人工序列(artificialsequence)<220><223>non-genomictaggingnucleotidesequence<400>375aaacctccgcgcacttaaga20<210>376<211>55<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>376gctggacgtcgatataggcgcgacgtcgtccgatttggatactccagagttgcgt55<210>377<211>39<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>377atacaacaaactggtgaatatcgtactcgagacttcgcc39<210>378<211>40<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>378atacaatacaacaaactggtgtctcatccgaacgatgcct40<210>379<211>60<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>379gctggacgtcgatataggcgcgagcctaagattcgatcggtttatataaccaggttgctt60<210>380<211>42<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>380aattgcatagtaaaatttactgatcgtactcgagacttcgcc42<210>381<211>42<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>381acaattgcatagtaaaatttacgtctcatccgaacgatgcct42<210>382<211>58<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>382gctggacgtcgatataggcggcgttccggtacgagactaggaagttctacctagtggg58<210>383<211>40<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>383tactactacaggagatagtgatcgtactcgagacttcgcc40<210>384<211>40<212>dna<213>人工序列(artificialsequence)<220><223>探针(probe)<400>384tactacaggagatagtgattgtctcatccgaacgatgcct40当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1