一种2-甲基丁酸侧链水解酶及其表达菌株和应用的制作方法
本发明属于蛋白质工程和医药生产领域,涉及一种2-甲基丁酸侧链水解酶以及能够生产莫纳可林j的菌株。
背景技术:
心脑血管疾病严重威胁人类健康,其发病率和死亡率在许多国家和地区排名第一。高脂血症(高胆固醇血症)是心脑血管疾病的一个重要诱因,因此预防高脂血症、调节血脂和降低血脂成为防治心脑血管疾病的关键。基于上述原因,降胆固醇药物具有很大的市场前景,多年来一直位于全球畅销药物的前列。
辛伐他汀(simvastatin)即舒降之(zocor),是merck公司研发的一种重要的降血脂药物,能有效地抑制胆固醇的体内合成,是治疗高脂血症的首选药物之一。辛伐他汀的合成是以土曲霉的发酵产物洛伐他汀(lovastatin)为原料,通过化学合成的。在辛伐他汀的合成过程中,需要先去除洛伐他汀c8位的2-甲基丁酸侧链,获得莫纳可林j(monacolinj),然后再通过后续工艺将2,2-二甲基丁酸侧链添加到莫纳可林j的c8位上,从而获得辛伐他汀。由此可见,莫纳可林j是辛伐他汀合成的重要前体物。目前,辛伐他汀的合成路线中,采用化学方法水解洛伐他汀制备莫纳可林j,整个制备过程中会使用到大量的酸、碱和有机试剂,工艺复杂、耗时长、收率低、污染压力大。
2-甲基丁酸侧链水解酶可以水解洛伐他汀的侧链酯键断裂,生成莫纳可林j和2-甲基丁酸。komagata等人于1986年在真菌emericellaunguis的菌丝体中纯化出了一种2-甲基丁酸侧链水解酶,该酶的转化效率约为86%。在接下来的几十年中,研究人员又陆续发现了多个2-甲基丁酸侧链水解酶,然而这些酶的催化效率较低,存在明显的底物抑制现象,并且关于酶的蛋白序列和相关编码基因信息都未被鉴定,因此无法直接对其进行利用和改造,这些问题都大大地限制了该酶在大规模工业生产中的应用。
本申请发明人于2017年报道了一种2-甲基丁酸侧链水解酶pcest(seqidno:1),它能够有效水解洛伐他汀的2-甲基丁酰侧链生成莫纳可林j和2-甲基丁酸,其催化效率显著高于之前报道的洛伐他汀侧链水解酯酶(wo2005040107a2)。此外,通过在高产洛伐他汀土曲霉菌株中过表达pcest,使得洛伐他汀在体内合成后即被水解成莫纳可林j,从而获得了能够直接发酵生产莫纳可林j的曲霉工程菌株,可以建立一步发酵直接生产莫纳可林j的新工艺(huangxn,liangyj,yangy,luxf.single-stepproductionofthesimvastatinprecursormonacolinjbyengineeringofanindustrialstrainofaspergillusterreus.metab.eng.,2017,42,109-114)。但是该工程菌株中洛伐他汀水解率约为95%,仍然有约5%的洛伐他汀残留,这会增加后续分离纯化的成本。因此,构建一个能高效合成莫纳可林j而又没有洛伐他汀残留的工程菌株非常有必要,可以进一步简化辛伐他汀生产工艺,降低生产成本。
技术实现要素:
本发明的目的是提供一种新的2-甲基丁酸侧链水解酶,它改善了pcest可溶性表达的效果和热稳定性,同时进一步提高其催化活性,使其能够更好地应用于工业生产,解决上述现有技术问题。
在第一个方面,本发明提供一种2-甲基丁酸侧链水解酶,是通过定点突变野生型pcest(seqidno:1)得到的突变体,突变位点是第140位,突变形式为q140l,即,所述2-甲基丁酸侧链水解酶的序列如seqidno:2所示。
在本申请文件中,如无具体说明,pcest/q140l缩写为q140l,表示蛋白突变体。本领域技术人员根据上下文内容,可以清楚地区分q140l表示的是突变形式还是突变体。
本申请文件中,氨基酸、核苷酸的缩写有本领域通用的含义。
第二个方面,提供与本发明的2-甲基丁酸侧链水解酶相关的生物材料,为:
(1)核酸分子,所述核酸分子编码本发明的2-甲基丁酸侧链水解酶;优选地,所述核酸分子为pcest/q140l,其序列如seqidno:3所示;或者
(2)包含(1)所述核酸分子的表达盒、重组载体、重组细胞或重组微生物;
优选地,所述微生物为曲霉菌株,其能够生产莫纳可林j。
关于上述生物材料,本领域技术人员根据提供的2-甲基丁酸侧链水解酶的氨基酸序列可以知晓编码该酶的核酸分子的序列,并能够容易地选择、制备和使用包含所述核酸分子从而表达蛋白的表达盒、重组载体、重组细胞和重组微生物。
第三个方面,提供本发明的2-甲基丁酸侧链水解酶在水解含有2-甲基丁酸侧链的他汀类物质中的应用;优选地,所述含有2-甲基丁酸侧链的他汀类物质为洛伐他汀、美伐他汀或普伐他汀;进一步优选地,所述他汀类物质为酸式、内酯式或盐式。
第四个方面,提供构建上述产莫纳可林j的曲霉菌株的方法,包括将出发曲霉菌株原生质体与包含编码本发明的2-甲基丁酸侧链水解酶的核酸分子的dna片段共转化,经筛选后得到。优选地,所述出发曲霉菌株为曲霉菌(aspergillussp.)hz01,其保藏编号为cgmccno.12970。
本发明中使用的出发曲霉菌(aspergillussp.)hz01于2016年10月17日保藏于中国微生物菌种保藏管理委员会普通微生物中心(cgmcc),保藏编号为cgmccno.12970,保藏中心地址为北京市朝阳区北辰西路1号院3号。
曲霉菌株原生质体的制备、原生质体与dna片段的共培养、阳性曲霉菌的筛选等都是本领域的常规技术。
优选地,所述编码本发明的2-甲基丁酸侧链水解酶的核酸分子的序列如seqidno:3所示。
第五个方面,提供本发明的核酸分子或包含所述核酸分子的表达盒、重组载体、重组细胞或重组微生物在制备产莫纳可林j的曲霉菌株中的应用。
第六个方面,提供一种制备莫纳可林j的方法,包括发酵培养本发明提供的曲霉菌株,或者用本发明提供的2-甲基丁酸侧链水解酶水解洛伐他汀。
第七个方面,提供上述本发明的生物材料或曲霉菌株或其菌悬液或其发酵液或其代谢产物在制备莫纳可林j中的应用。
第八个方面,提供上述本发明的生物材料或曲霉菌株或其菌悬液或其发酵液或其代谢产物在生产降血脂药物中的应用,其中所述降血脂药物是辛伐他汀。
本发明提供的2-甲基丁酸侧链水解酶与野生型酶相比,酶活提高,高出约2倍,对温度的稳定性提高,简化了辛伐他汀的生产工艺,减少生产成本,更有利于工业化应用。
附图说明
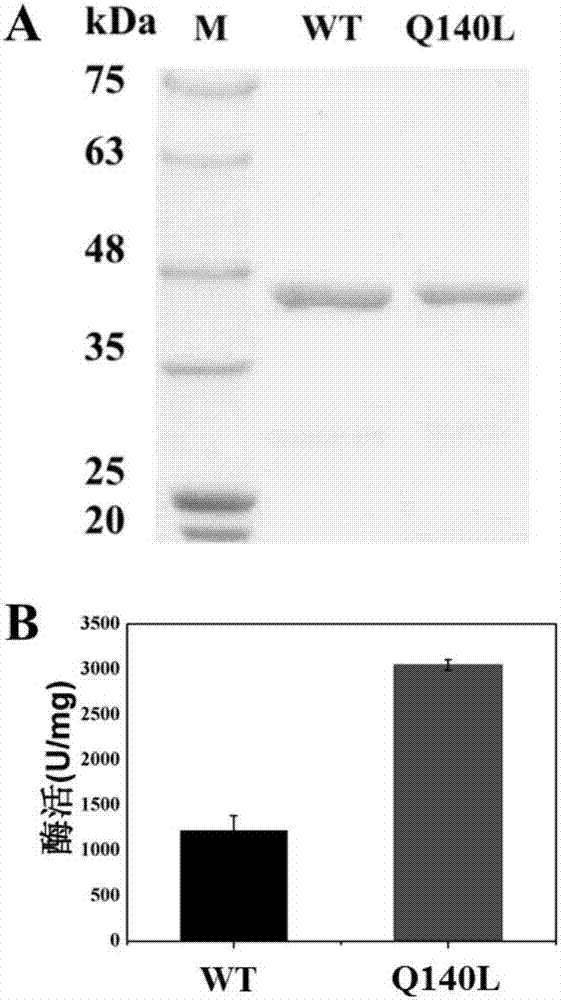
图1:a是野生型和突变体蛋白纯化结果的电泳分析图;b是酶活测定结果图,酶活力单位定义为每分钟催化产生1微摩尔莫纳可林j所需的酶量为一个活力单位(u)。图中的纵坐标表示的是每毫克酶蛋白所含有的酶活力单位数。wt:野生型pcest;q140l:pcest/q140l突变体。
图2:野生型和突变体蛋白可溶性表达的电泳分析图,wt:野生型pcest;q140l:pcest/q140l突变体。s:可溶性蛋白部分;i:不可溶性蛋白部分。
图3:野生型和突变体蛋白的热稳定性分析图,wt:野生型pcest;q140l:pcest/q140l突变体。
图4:pg3h的质粒图谱示意图。
图5:过表达pcest/q140l的曲霉转化子的基因组pcr验证结果;其中,1#、2#、7#、8#、9#、10#、11#、13#为阳性转化子,c为质粒pg3h-pcest/q140l,wt为对照菌株hz01菌株。
图6:过表达野生型pcest的曲霉转化子的基因组pcr验证结果;其中,1#、4#、5#为阳性转化子,c为质粒pg3h-pcest,wt为对照菌株hz01菌株。
图7:各菌株第8天样品的hplc分析;其中,hz01为野生型菌株,hz-pcest为过表达野生型pcest的对照菌株,hz-pcest/q140l是过表达pcest/q140l突变体的曲霉工程菌株,其中图b是图a的局部放大示意图。
图8:各菌株第8天发酵样品中洛伐他汀和莫纳可林j的含量;其中,hz01为野生型菌株,hz-pcest系列为过表达野生型pcest的对照菌株,q140l系列是过表达pcest/q140l突变体的曲霉工程菌株。
具体实施方式
下面将结合具体实施例来描述本发明内容。如无明确说明,以下实施例中使用的试剂、仪器均是本领域常规试剂、仪器,可以通过商购途径获得;所使用的方法也是常规方法,本领域技术人员根据说明书内容,可以明确地知道如何完成所述实验,获得相应的结果。
本发明中质粒提取采用omega公司plasmidminikiti试剂盒(d6942-01),dna片段回收是采用omega公司cycle-purekit试剂盒(d6492-01),凝胶回收是采用omega公司gelextractionkit试剂盒(d2500-01)。
cd培养基组成为:3g/lnano3,2g/lkcl,1g/lkh2po4,0.5g/lmgso4·7h2o,0.02g/lfeso4·7h2o,10g/l葡萄糖。
cd平板培养基组成为:3g/lnano3,2g/lkcl,1g/lkh2po4,0.5g/lmgso4·7h2o,0.02g/lfeso4·7h2o,10g/l葡萄糖,1.5g/l琼脂。
ipm液体培养基:60gl-1葡萄糖,2gl-1nh4no3,20mgl-1(nh4)2hpo4,20mgl-1feso4,0.4gl-1mgso4,4.4mgl-1znso4,0.5g/l玉米浆,ph3.5。
洛伐他汀发酵种子培养基:9gl-1葡萄糖,10gl-1蔗糖,1gl-1酵母抽提物,1gl-1蛋白胨,1gl-1乙酸钠,0.04gl-1kh2po4,0.1gl-1mgso4,5gl-1豆粕,1.5gl-1碳酸钙,ph6.8。
洛伐他汀发酵培养基:70gl-1葡萄糖,20gl-1蔗糖,1.5gl-1酵母抽提物,20gl-1蛋白胨,7gl-1乙酸钠,0.5gl-1kh2po4,0.5gl-1mgso4,5gl-1豆粕,5gl-1碳酸钙,泡敌(烟台恒鑫化工科技有限公司,型号thix-298)0.1mll-1,ph6.5。
实施例1:2-甲基丁酸侧链水解酶突变体的获得
1.2-甲基丁酸侧链水解酶突变体q140l的构建
(1)突变pcr:采用quikchange方法进行定点突变。以peasy-e2-pcest质粒(huangxn,liangyj,yangy,luxf.(2017).single-stepproductionofthesimvastatinprecursormonacolinjbyengineeringofanindustrialstrainofaspergillusterreus.metab.eng.,42,109-114)为模板,根据突变位点设计并合成引物,进行pcr扩增,得到编码2-甲基丁酸侧链水解酶突变体的基因。
pcr反应体系为:无菌水32.5μl,模板dna1μl,5×primestarhs缓冲液(mg2+plus)10μl,dntp混合液(各2.5mmol/l)4μl,突变引物对q140l-f(5’-caaaatggcgcgcactatacgcgaatccgg-3’)和q140l-r(5’-ccggattcgcgtatagtgcgcgccattttg-3’)各1μl(20pmol/μl),takaraprimestarhsdna聚合酶0.5μl。反应条件为:95℃预变性5min;94℃10s、60℃15s、72℃7.5min,18个循环;最后72℃延伸10min。
(2)酶切:将反应完成的pcr产物取出,按1:50(dpni酶:pcr产物,v:v)的比例加入dpni酶,37℃酶切1个小时。
(3)取出,转化至大肠杆菌bl21(de3)感受态细胞,在含有卡那霉素(终浓度50μg/ml)的lb平板上涂布,37℃过夜培养。
转化子长出后,挑取单克隆送去测序,按照突变体的核苷酸序列seqidno:3所示突变形式筛选正确突变的菌株及其包含的对应载体peasy-e2-pcest/q140l。
2.野生型2-甲基丁酸侧链水解酶表达载体的构建:
通过常规pcr用引物1:5’ggaattccatatggataccacctttcaggcg3’和引物2:5’ccgctcgagtcactgctgacctttccaggc3’分别从质粒peasy-e2-pcest和peasy-e2-pcest/q140l上扩增到野生型pcest基因pcest和pcest/q140l突变体基因pcest/q140l,pcr产物纯化后用限制性内切酶ndei和xhoi酶切,与经相同酶切的pet28a-smt3载体连接,得到的载体分别命名为pet-pcest和pet-pcest/q140l,质粒分别转化大肠杆菌bl21(de3)感受态细胞,挑取转化子,测序鉴定其基因序列。pcest/q140l突变体序列如seqidno:3所示,野生型pcest如seqidno:4所示。
3.蛋白质的纯化
培养表达野生型酶和突变体酶的大肠杆菌bl21(de3),37℃培养至对数生长期,加入诱导剂异丙基-β-d-硫代半乳糖苷(iptg,终浓度是0.2mm),16℃过夜诱导表达后,收集菌体,重悬于40mltris–hcl缓冲液(20mm,ph8.0)中,超声破碎菌体,得到粗酶液,经过ni-nta进行纯化。收集蛋白,用ulp1(ulp1:pcest质量比为1:50)过夜酶切,通过反挂ni柱的方式继续纯化蛋白,绝大多数目标蛋白穿出ni柱,而his-sumo与ni柱结合较紧密,需要高浓度(250mm)的咪唑才能洗脱下来,因此可以获得纯蛋白质(图1a)。
经测序,突变体酶的序列与预期的一致。
实施例2:测定酶活性
取实施例1制备的蛋白质进行酶活性测定。酶蛋白的浓度是0.05μm,底物洛伐他汀的浓度是400μm,37℃反应10分钟,利用hplc测定生成的莫纳可林j。hplc反应使用的色谱柱是agilentzorbaxxdb-c18(4.6×150mm,5μm),流动相是乙腈:0.1%磷酸(50:50,v:v)流速是1ml/min,进样10μl。结果如图1b所示,突变体q140l的2-甲基丁酸侧链水解酶的酶活为野生酶的2.51倍。
实施例3:2-甲基丁酸侧链水解酶突变体酶性质测定
1、2-甲基丁酸侧链水解酶野生型和突变体蛋白可溶性表达测定
培养编码野生型和突变体2-甲基丁酸侧链水解酶的大肠杆菌bl21(de3)100ml,37℃培养至对数生长期,加入诱导剂异丙基-β-d-硫代半乳糖苷(iptg,终浓度是0.2mm),在25℃条件下进行蛋白的诱导表达,过夜后收集菌液,超声破碎后离心,分开上清液和沉淀,沉淀部分加入相同体积的tris–hcl缓冲液(50mm,ph8.0)悬浮。取相同量的上清液和沉淀蛋白液进行sds-page蛋白电泳分析,结果如图2所示。绝大部分的野生型蛋白在沉淀部分,上清液部分只有很少量的pcest蛋白,而突变体q140l的上清液部分中pcest的蛋白量明显增多,说明q140l突变体蛋白的可溶性表达量相对于野生型有所提高。
2、2-甲基丁酸侧链水解酶野生型和突变体蛋白的温度稳定性测定
对pcr仪的反应槽温度条件进行设定,取出等量的野生型和突变体蛋白,放置在具有不同温度(20℃、22℃、25℃、28℃、30℃、32℃、35℃、37℃、40℃、42℃、45℃和50℃)的反应槽中,孵育10分钟,立即放置冰上冷却10分钟,然后从中取出蛋白进行酶活性测定,测定条件是:酶的浓度是0.05μm,底物洛伐他汀的浓度是400μm,37℃反应10分钟,利用hplc测定生成的莫纳可林j。以不做温度处理的蛋白的活性为100%,计算蛋白经过不同温度处理后酶活性的相对值,绘制曲线。如图3所示,突变体q140l的t50值比野生型提高了3℃。
实施例4:产莫纳可林j的曲霉菌株的构建
分别以peasy-e2-pcest和实施例1构建的peasy-e2-pcest/q140l两种质粒为模板,用引物pcest-f1(5’-gatccatggataccacctttcaggc-3’)和pcest-r1(5’-gatgcggccgcgttagcagccggatctcagtg-3’)扩增野生型pcest和突变体pcest/q140l基因片段,分别用限制性内切酶ncoi(thermo,fd0573)和noti(thermo,fd0593)进行酶切并回收目的片段(1.2kb)。用限制性内切酶pcii(thermo,er1871)和noti对载体pg3h(图4,xuenianhuang,xuefenglv,jianjunli*,cloningandfunctionalcharacterizationofanativeglyceraldehyde-3-phosphatedehydrogenasepromoterforaspergillusterreus,journalofindustrialmicrobiologyandbiotechnology,2014,41(3):585-592)进行酶切,回收大小约为7.3kb的片段。将酶切回收后的pcest和pcest/q140l片段分别和pg3h载体用t4连接酶进行连接,并转化大肠杆菌dh5a,pcr及测序验证正确的质粒分别记为pg3h-pcest和pg3h-pcest/q140l。分别以pg3h-pcest和pg3h-pcest/q140l为模板,用引物pgpdat-f630(5’-catcatcgcattctccctctcg-3’)和ttrpc-r2(5’-ttactattgtatacccatcttag-3’)进行pcr扩增,获得pcest的表达元件pgpdat-pcest-ttrpc和pgpdat-pcest/q140l-ttrpc,该表达元件包括启动子pgpdat、pcest(或pcest/q140l)编码序列pcest(或pcest/q140l)、终止子ttrpc,大小为2490bp,通过pcr产物回收试剂盒进行回收纯化。以质粒pptrii(takara,catalogno.:3621)为模板,以ptra-f(5’-gggcaattgattacgggatc-3’)和ptra-r(5’-atggggtgacgatgagccgc-3’)作为引物扩增获得大小约为2.0kb的筛选标记吡啶硫胺抗性基因ptra片段,经pcr产物回收试剂盒回收纯化。
将曲霉菌株hz01(保藏于中国微生物菌种保藏管理委员会普通微生物中心(cgmcc),保藏编号为cgmccno.12970,保藏中心地址为北京市朝阳区北辰西路1号院3号)。接种于pda固体平板(bd,difcotmpotatodextroseagar,213400)上,30℃培养7天,获得孢子。将hz01菌株的孢子接种至50ml液体培养基ipm(60gl-1葡萄糖,2gl-1nh4no3,20mgl-1(nh4)2hpo4,20mgl-1feso4,0.4gl-1mgso4,4.4mgl-1znso4,0.5g/l玉米浆粉(sigma,c8160-500g),ph3.5)中,使孢子浓度约为107个/ml,在200rmp、32℃培养12-18h。用无菌单层500目尼龙布过滤收集长出的菌丝,并用灭菌的0.6mmgso4溶液冲洗三次,压干后置于无菌的50ml三角瓶中;称取1g菌丝,加入10ml酶解液,在30℃、60rpm处理1-3h。酶解液成分为:0.8%(质量体积比)纤维素酶(sigma,catalogno.:c1184)、0.8%(质量体积比)裂解酶(sigma,catalogno.:l1412)、0.4%(质量体积比)蜗牛酶(上海生工,catalogno.:sb0870)、0.6mmgso4,经由0.22μm的无菌过滤器过滤除菌。将上述酶解后的混合液先用8层擦镜纸过滤,收集滤液。4℃离心收集原生质体,用预冷1.0m山梨醇溶液洗涤一次,再用预冷的stc(stc为1.0m山梨醇,50mmtris·hcl-ph8.0,50mmcacl2)洗涤一次,最后把原生质体重悬于预冷的stc中,并用stc将原生质体浓度调整为2×108个/ml,得到原生质体悬液。
向150μl上述原生质体悬液中同时加入dna片段pgpdat-pcest/q140l-ttrpc(或pgpdat-pcest/q140l-ttrpc)(约3μg)和ptra(约0.5μg),总体积为15μl,表达元件和ptra的摩尔比约为1:5。再加入50μl冰浴的pstc(pstc为40%peg4000,1.2m山梨醇,50mmtris-hcl-ph8.0,50mmcacl2),轻轻混匀,冰浴30min。加入1ml常温的pstc,混匀后室温放置20min;然后与30ml上层琼脂(cd+1.2m山梨醇+4g/l琼脂糖,灭菌后48℃保温)混合后倾注于10块cd-sp再生筛选培养基平板(cd平板+1.2m山梨醇+0.1mg/l吡啶硫胺(sigma,p0256))上,在30℃、黑暗条件下培养5-7天。
从转化筛选平板上挑取具有吡啶硫胺抗性转化子转接至筛选平板cd-p上(cd平板+0.1mg/l吡啶硫胺),在32℃培养5天进行传代纯化,连续传代4次。选取稳定传代的4个转化子(2#、3#、4#、5#)进行单孢分离纯化,选择得到的单菌落孢子接种于ipm液体培养基中,30℃,200rpm,培养48小时,收集菌丝提取基因组。用引物pgpdat-f630/ttrpc-r2进行pcr验证,能扩增出大小约为2.6kb的条带(pcest/q140l或野生型pcest表达元件)者为阳性。由图5可知1#、2#、7#、8#、9#、10#、11#、13#转化子为阳性,基因组上整合有pcest/q140l表达元件pgpdat-pcest/q140l-ttrpc,将这8株hz-pcest/q140l工程菌株分别记为q140l-1、q140l-2、q140l-7、q140l-8、q140l-9、q140l-10、q140l-11、q140l-13。由图6可知1#、4#、5#转化子为整合有pcest表达元件pgpdat-pcest-ttrpc的阳性转化子,分别记为hz-pcest-1、hz-pcest-4、hz-pcest-5。
实施例5:产莫纳可林j的曲霉菌株的发酵验证
将需要进行发酵培养的曲霉菌株接种于pda固体平板,30℃培养7天获得孢子,包括:8株过表达pcest/q140l突变体的工程菌株q140l-1、q140l-2、q140l-7、q140l-8、q140l-9、q140l-10、q140l-11、q140l-13,3株过表达野生型pcest的工程菌株hz-pcest-1、hz-pcest-4、hz-pcest-5,和出发菌株hz01。将孢子接种于35ml洛伐他汀发酵种子培养基(250ml三角瓶),28℃、220rpm震荡培养48小时,对照菌株hz01菌株接种4瓶。将3.5ml种子液接种于30ml洛伐他汀发酵培养基(250ml三角瓶),28℃,220rpm震荡培养8天。取0.8ml发酵液(用剪头的枪头)加入至15ml离心管中,加入0.8ml的0.2mnaoh溶液,再加入8ml无水甲醇,置于混匀仪上翻转震荡4小时。用0.22μm有机相滤器过滤处理样品,送hplc分析。hplc分析方法为:液相色谱柱为agilentzorbaxsb-c18液相色谱柱883975-902(4.6×150mm,5μm),流动相为乙腈/0.1%h3po4=0.7/0.3,流速为0.5ml/min,紫外检测器(237nm),25℃。结果如图7、8所示,在出发菌株hz01菌株中产物主要是洛伐他汀,莫纳可林j含量很少。过表达野生型pcest的工程菌株中主要产物是莫纳可林j,洛伐他汀残留很少,约5%-8%。过表达pcest/q140l突变体的曲霉工程菌株中,主要产物中含有大量的莫纳可林j,而洛伐他汀在部分菌株中检测不到,在部分菌株中含量极少,低于0.5%,后续不再需要进行分离纯化,进一步简化了辛伐他汀生产工艺,降低生产成本。这说明过表达酶性能提高了的pcest突变体,可以提高洛伐他汀的胞内水解效率,从而提高洛伐他汀水解率,降低洛伐他汀残留,获得性状更优的产莫纳可林j曲霉工程菌株。
序列表
<110>中国科学院青岛生物能源与过程研究所
浙江海正药业股份有限公司
<120>一种2-甲基丁酸侧链水解酶及其表达菌株和应用
<130>dp1f171503zx
<160>4
<170>siposequencelisting1.0
<210>1
<211>399
<212>prt
<213>产黄青霉(penicilliumchrysogenum)
<400>1
metaspthrthrpheglnalaalaileaspthrglylysileasngly
151015
alavalvalcysalathraspalaglnglyhisphevaltyrasnlys
202530
alathrglygluargthrleuleuserglyglulysglnproglngln
354045
leuaspaspvalleutyrleualaseralathrlysleuilethrthr
505560
ilealaalaleuglncysvalgluaspglyleuleuserleuaspgly
65707580
aspleuserserilealaprogluleualaalalystyrvalleuthr
859095
glyphethraspaspgluserproleuaspaspproproalaargpro
100105110
ilethrleulysmetleuleuthrhisserserglythrsertyrhis
115120125
pheleuaspproserilealalystrpargalaglntyralaasnpro
130135140
gluasnglulysproargleuvalgluglumetphethrtyrproleu
145150155160
serpheglnproglythrglytrpmettyrglyproglyleuasptrp
165170175
alaglyargvalvalgluargvalthrglyglythrleumetgluphe
180185190
metglnlysargilepheaspproleuglyilethraspserglnphe
195200205
tyrprovalthrarggluaspleuargalaargleuvalaspleuasn
210215220
proseraspproglyalaleuglyseralavalileglyglyglygly
225230235240
glumetasnleuargglyargglyalapheglyglyhisglyleuphe
245250255
leuthrglyleuaspphevallysileleuargserleuleualaasn
260265270
aspglymetleuleulysproalaalavalaspasnmetpheglngln
275280285
hisleuglyproglualaalaalaserhisargalaalaleualaser
290295300
proleuglyprophepheargvalglythraspprogluthrlysval
305310315320
glytyrglyleuglyglyleuleuthrleugluaspvalaspglytrp
325330335
tyrglygluargthrleuthrtrpglyglyglyleuthrleuthrtrp
340345350
pheileasparglysasnasnleucysglyvalglyalaileglnala
355360365
valleuprovalaspglyaspleumetalaaspleulysglnthrphe
370375380
arghisaspiletyrarglystyrseralatrplysglyglngln
385390395
<210>2
<211>399
<212>prt
<213>人工序列(artificialsequence)
<400>2
metaspthrthrpheglnalaalaileaspthrglylysileasngly
151015
alavalvalcysalathraspalaglnglyhisphevaltyrasnlys
202530
alathrglygluargthrleuleuserglyglulysglnproglngln
354045
leuaspaspvalleutyrleualaseralathrlysleuilethrthr
505560
ilealaalaleuglncysvalgluaspglyleuleuserleuaspgly
65707580
aspleuserserilealaprogluleualaalalystyrvalleuthr
859095
glyphethraspaspgluserproleuaspaspproproalaargpro
100105110
ilethrleulysmetleuleuthrhisserserglythrsertyrhis
115120125
pheleuaspproserilealalystrpargalaleutyralaasnpro
130135140
gluasnglulysproargleuvalgluglumetphethrtyrproleu
145150155160
serpheglnproglythrglytrpmettyrglyproglyleuasptrp
165170175
alaglyargvalvalgluargvalthrglyglythrleumetgluphe
180185190
metglnlysargilepheaspproleuglyilethraspserglnphe
195200205
tyrprovalthrarggluaspleuargalaargleuvalaspleuasn
210215220
proseraspproglyalaleuglyseralavalileglyglyglygly
225230235240
glumetasnleuargglyargglyalapheglyglyhisglyleuphe
245250255
leuthrglyleuaspphevallysileleuargserleuleualaasn
260265270
aspglymetleuleulysproalaalavalaspasnmetpheglngln
275280285
hisleuglyproglualaalaalaserhisargalaalaleualaser
290295300
proleuglyprophepheargvalglythraspprogluthrlysval
305310315320
glytyrglyleuglyglyleuleuthrleugluaspvalaspglytrp
325330335
tyrglygluargthrleuthrtrpglyglyglyleuthrleuthrtrp
340345350
pheileasparglysasnasnleucysglyvalglyalaileglnala
355360365
valleuprovalaspglyaspleumetalaaspleulysglnthrphe
370375380
arghisaspiletyrarglystyrseralatrplysglyglngln
385390395
<210>3
<211>1200
<212>dna
<213>人工序列(artificialsequence)
<400>3
atggataccacctttcaggcggcgattgataccggcaaaattaacggcgcagttgtttgc60
gcaaccgacgcacagggccattttgtttataacaaagcaaccggcgaacgtaccctgctg120
tctggcgaaaaacaaccgcaacagctggatgatgttctgtatctggcaagcgcgaccaaa180
ctgattaccaccattgctgctctgcaatgcgttgaagacggtctgctgagtctggacggc240
gatctgagtagtattgcaccggaactggcagcgaaatacgttctgaccggttttaccgac300
gacgaaagtccgctggacgatccgccggcacgtccgattaccctgaaaatgctgctgacc360
catagcagcggtaccagctatcatttcctggatccgtctatcgcaaaatggcgcgcacta420
tacgcgaatccggaaaacgaaaaaccgcgtctggtcgaagagatgttcacctatccgctg480
agttttcaaccgggtaccggctggatgtacggtccgggtctggattgggcaggtcgcgtt540
gttgaacgtgttacgggcggtaccctgatggaattcatgcagaaacgcatcttcgatccg600
ctgggtatcaccgatagccagttttatccggttacccgcgaagatctgcgcgcacgtctg660
gttgatctgaatccgtctgatccgggcgcactgggttctgcagttattggcggcggcggt720
gaaatgaatctgcgcggtcgcggcgcatttggcggtcacggtctgtttctgaccggtctg780
gatttcgtcaaaatcctgcgtagcctgctggctaacgacggtatgctgctgaaaccggct840
gctgtcgataacatgttccagcagcatctgggtccggaagcagcagcaagtcatcgcgca900
gcactggcaagtccgctgggtccgtttttccgcgttggtaccgatccggaaaccaaagtt960
ggttacggtctgggcggtctgctgaccctggaagacgttgacggttggtacggcgaacgt1020
accctgacctggggcggtggtctgaccctgacctggtttatcgaccgcaaaaacaacctg1080
tgtggtgttggcgcaattcaagcagttctgccggttgacggcgatctgatggcagatctg1140
aaacagaccttccgccacgatatctaccgcaaatacagcgcctggaaaggtcagcagtga1200
<210>4
<211>1200
<212>dna
<213>人工序列(artificialsequence)
<400>4
atggataccacctttcaggcggcgattgataccggcaaaattaacggcgcagttgtttgc60
gcaaccgacgcacagggccattttgtttataacaaagcaaccggcgaacgtaccctgctg120
tctggcgaaaaacaaccgcaacagctggatgatgttctgtatctggcaagcgcgaccaaa180
ctgattaccaccattgctgctctgcaatgcgttgaagacggtctgctgagtctggacggc240
gatctgagtagtattgcaccggaactggcagcgaaatacgttctgaccggttttaccgac300
gacgaaagtccgctggacgatccgccggcacgtccgattaccctgaaaatgctgctgacc360
catagcagcggtaccagctatcatttcctggatccgtctatcgcaaaatggcgcgcacaa420
tacgcgaatccggaaaacgaaaaaccgcgtctggtcgaagagatgttcacctatccgctg480
agttttcaaccgggtaccggctggatgtacggtccgggtctggattgggcaggtcgcgtt540
gttgaacgtgttacgggcggtaccctgatggaattcatgcagaaacgcatcttcgatccg600
ctgggtatcaccgatagccagttttatccggttacccgcgaagatctgcgcgcacgtctg660
gttgatctgaatccgtctgatccgggcgcactgggttctgcagttattggcggcggcggt720
gaaatgaatctgcgcggtcgcggcgcatttggcggtcacggtctgtttctgaccggtctg780
gatttcgtcaaaatcctgcgtagcctgctggctaacgacggtatgctgctgaaaccggct840
gctgtcgataacatgttccagcagcatctgggtccggaagcagcagcaagtcatcgcgca900
gcactggcaagtccgctgggtccgtttttccgcgttggtaccgatccggaaaccaaagtt960
ggttacggtctgggcggtctgctgaccctggaagacgttgacggttggtacggcgaacgt1020
accctgacctggggcggtggtctgaccctgacctggtttatcgaccgcaaaaacaacctg1080
tgtggtgttggcgcaattcaagcagttctgccggttgacggcgatctgatggcagatctg1140
aaacagaccttccgccacgatatctaccgcaaatacagcgcctggaaaggtcagcagtga1200
- 还没有人留言评论。精彩留言会获得点赞!