提高植物耐盐耐旱性的蛋白质激酶及其用途的制作方法
本发明涉及植物基因工程领域,具体涉及一种提高植物耐盐耐旱性的蛋白质激酶及其用途。
背景技术:
干旱和土壤盐碱化是当今世界面临的两大环境问题,也是影响农作物生长,造成农作物减产的两大环境因素。干旱通常指淡水总量少,不足以满足人的生存和经济发展的气候现象,是人类面临的主要自然灾害。土壤盐渍是指易溶性盐分在土壤表层积累的现象或过程,也称盐碱化。尤其值得注意的是,随着人类的经济发展和人口膨胀,水资源短缺现象日趋严重,这也直接导致了干旱地区的扩大与干旱化程度的加重,干旱化趋势已成为全球关注的问题。而土壤盐碱化主要发生在干旱、半干旱和半湿润地区,因此干旱又加重了土壤盐碱化。虽然现今科学技术不断进步和发展,但是干旱和土壤盐碱化对人类的生产和生活带来的影响却愈发严重。随着全球气候变暖,人口急速膨胀和生态环境的不断破坏,高温、干旱及病虫害等不良环境条件对农作物生产的影响越来越严重,干旱和土壤盐碱化问题不断突出。所以,发现和寻找能够增强植物对高盐和干旱耐受性的基因和蛋白,并通过生物技术提高农作物对干旱和盐渍环境的耐受能力,对于提高农作物产量,解决粮食危机和饥饿贫穷等全球性问题具有重要意义。近年来,钙依赖蛋白激酶(Calcium-dependent protein kinase,CDPK),在植物抗逆反应中的功能研究逐渐成为生物学家们研究热点之一。
钙不仅是植物必需的大量元素之一,而且游离于植物细胞质中的钙离子是植物细胞信号转导中最基本的第二信使,几乎介导了植物生长发育和对逆境响应的所有反应。植物中有4类钙传感蛋白,包括钙调素(CaM)、钙调素类似蛋白(CaML)、钙依赖蛋白激酶(CDPKs)和钙调磷酸酶B类蛋白(CBL)。其中,钙依赖蛋白激酶研究得最为广泛。CDPKs具有4个典型的结构域,从N端到C端依次为N末端的可变区、催化区(激酶区)、连接区(自抑制区)和调控区(类钙调素区/CaM-LD)。催化区具有典型的Ser/Thr蛋白激酶的催化保守序列;连接区由20-30个氨基酸残基组成,紧靠催化区以拟底物的方式与催化区结合起自抑制作用,所以该区又称自抑制区;调控区是Ca2+结合区,一般有4个与Ca2+结合的EF手性结构。
当植物受到外界环境刺激的时候,例如受到高盐和干旱胁迫,就会引起细胞内Ca2+含量的变化。CDPKs能敏锐地感知Ca2+水平,并通过蛋白的四个结构域精细地调控其激酶活性,从而磷酸化下游底物,介导植物一系列的对逆境的响应过程。
使用基因工程技术对植物进行改良是近年来的热点。使用基因工程技术以期提高植物的抗逆性,培育出耐逆性系也是一个可行之道。但是,目前还鲜见有能综合提高植物多种抗逆性的单个基因的报道。
技术实现要素:
针对上述植物对干旱和盐碱化耐受性能差,容易受到恶劣气候影响的问题,本发明提供了一种提高植物耐盐和耐旱性的蛋白质激酶及其编码基因和用途。
本发明提供了一种提高植物耐盐耐旱性的蛋白质激酶,其氨基酸序列如SEQ ID NO:2所示。
SEQ ID NO:2蛋白质激酶的氨基酸序列
MGNTCVGPSRNGFLQSVSAAMWRPRDGDDSASMSNGDIASEAVSGELRSR LSDEVQNKPPEQVTMPKPGT DVETKDREIRTESKPETLEEISLESKPETKQETKSETKPESKPDPPAKPKKPKHMKRVSSAGLRTESVLQRKTENFKEFYSLGRKLGQGQFGTTFLCVEKTTGKEFACKSIAKRKLLTDEDVEDVRREIQIMHHLAGHPNVISIKGAYEDVVAVHLVMECCAGGELFDRIIQRGHYTERKAAELTRTIVGVVEACHSLGVMHRDLKPENFLFVSKHEDSLLKTIDFGLSMFFKPDDVFTD VVGSPYYVAP EVLRKRYGPEADVWSAGVIVYILLSGVPPFWAETEQGIFEQVLHGDLDFSSDPWPSISESAKDLVRKMLVRDPKKRLTAHQVLCHPWVQVDGVAPDKPLDSAVLSRMKQFSAMNKFKKMA LRVIAESLSEEEIAGLKEMFNMIDADKSGQITFEELKAGLKRVGANLKES EILDLMQAADVDNSGTIDYKEFIAATLHLNKIEREDHLFAAFTYFDKDGSGYITPDELQQACEEFGVEDVRIEELMRDVD QDNDGRIDYNEFVAMMQKGSITGGPVKMGLEKSFSIALKL。
本发明还提供了一种编码上述蛋白质激酶的基因。其中,上述编码提高植物耐盐耐旱性的蛋白质激酶的基因,来源于拟南芥的基因组。该基因的核苷酸序列如SEQ ID NO:1所示。
SEQ ID NO:1编码上述蛋白质激酶基因的核苷酸序列
atgggtaatacttgtgttggaccaagcagaaatggcttcttgcaatctgtttcagctgcaatgtggcggccaagagatggagatgattcggcttccatgagtaatggagatattgcaagtgaagctgtttcgggagagcttcgatctcgattatctgatgaagtccagaataaacctcctgaacaggtcacaatgccgaagccagggactgacgtcgagaccaaggacagagagattcgaactgaaagcaagcctgaaacgctagaggagataagccttgagtccaaaccagagactaagcaggagaccaagtcagagaccaagccggagtcaaaacctgatcctccagctaaacctaagaagcctaaacacatgaagagagtgtcaagtgcagggcttaggactgagtcagtgttgcagaggaagactgaaaacttcaaggaattctattccttgggaaggaaactcggacaagggcaatttgggacgacttttttatgtgtcgagaagactacggggaaggagtttgcctgcaagtcgattgctaagaggaagctattgactgatgaggacgttgaggatgtgagaagagaaattcagataatgcatcacttggctggtcaccctaatgtcatctccatcaaaggagcttatgaggatgttgtggcagtgcaccttgtaatggagtgttgtgcaggcggcgagctttttgacaggatcattcaacgcggtcactacacagagaggaaagcggctgagctcactagaaccattgttggggttgtagaggcttgccattctcttggtgttatgcatcgagacctcaagcccgagaattttctgtttgtcagtaaacacgaagattccctcttgaagacgattgattttggactctccatgttctttaaaccagacgatgtttttacagatgttgttggtagcccatattatgttgccccagaagttcttcgaaagcgttatggccctgaagctgatgtctggagtgctggagtgattgtgtacattttattaagcggagttcctccattctgggctgaaaccgaacaaggtattttcgaacaggtcctccacggtgatcttgacttttcgtccgatccatggccaagtatatctgaaagtgcaaaggatttagtgaggaaaatgcttgtcagggatcccaagaaaaggttaactgcccaccaagtattatgtcatccatgggttcaagtcgacggtgtggctccagacaagcctttggattctgctgttctgagccgtatgaagcagttttctgcaatgaacaagttcaagaaaatggctcttagagtcattgctgagagcttatctgaagaagaaatcgccggcttgaaagaaatgtttaatatgatagatgcggacaagagtggtcagataactttcgaagaactgaaagcaggactaaaacgagtaggggcgaatctcaaagagtctgaaattctcgacttgatgcaagctgctgatgtggacaacagcggaacaatagattacaaagagttcatagctgcaacattacatctaaacaaaatagagagagaggaccatttgtttgcagcctttacatactttgacaaagatgggagcggctatatcaccccagacgagcttcaacaagcttgtgaggagtttggtgttgaggatgtccgcatagaagaactgatgcgcgatgttgatcaagacaatgacgggcgaatagactacaacgagtttgtggcgatgatgcagaaaggaagcatcacaggaggacctgtgaaaatgggtctagagaaaagctttagcattgctcttaaactctag。
进一步的,所述的编码提高植物耐盐耐旱性的蛋白质激酶的基因由花椰菜花叶病毒CaMV的35S启动子(CaMV35S)启动表达。进一步的,所述的35S启动子的核苷酸序列为SEQ ID NO:24所示。
SEQ ID NO:24 35S启动子的核苷酸序列
tgagacttttcaacaaagggtaatatccggaaacctcctcggattccattgcccagctatctgtcactttattgtgaagatagtggaaaaggaaggtggctcctacaaatgccatcattgcgataaaggaaaggccatcgttgaagatgcctctgccgacagtggtcccaaagatggacccccacccacgaggagcatcgtggaaaaagaagacgttccaaccacgtcttcaaagcaagtggattgatgtgatatctccactgacgtaagggatgacgcacaatcccactatccttcgcaagacccttcctctatataaggaagttcatttcatttggagagaaca。
本发明还提供了一种含有上述基因的重组载体。
进一步的,所述载体为表达载体。优选为真核表达载体。更优选为pBI121或pCAMBIA1302。
本发明还提供了一种含有上述重组载体的宿主细胞。
本发明还提供了一种上述蛋白质激酶、编码基因、重组载体、宿主细胞在提高植物耐盐耐旱性上的用途。
进一步的,本发明提供了一种提高植物耐盐耐旱性的方法,包括以下步骤:
a、构建含有SEQ ID NO:1所示的核苷酸序列的重组载体;
b、将步骤a中的重组载体转入植物细胞;
c、筛选获得转化细胞,将转化细胞培育成高耐盐耐旱的转基因植株。
进一步的,所述的植物为十字花科植物,优选为拟南芥或油菜。
本发明的有益效果为:
本发明采用上述重组载体转化宿主植物细胞,筛选获得转化细胞,然后使用干旱和高盐的逆境条件进行筛选,得到耐盐和耐旱性的植株。本发明在耐盐耐旱基因的基因编码序列前面加上一个强启动子,使耐盐耐旱基因的表达量增加,从而使植物体内耐盐耐旱蛋白含量上升,增强植物对高盐和干旱环境的抵抗能力,获得耐盐耐旱性的植株,从生物学性能上改善植株的抗逆性,经济效益明显。
附图说明
图1所示为突变体和转基因过表达株系的鉴定;A表示拟南AtCPK1基因结构图和突变体T-DNA插入位点;B表示纯合突变体PCR鉴定图;C表示突变体AtCPK1基因表达半定量图;D突变体和转基因过表达株系AtCPK1基因表达定量图;D图中,OE2和OE7分别表示构建的两个过表达株系over-expression 2与over-expression 7的缩写;
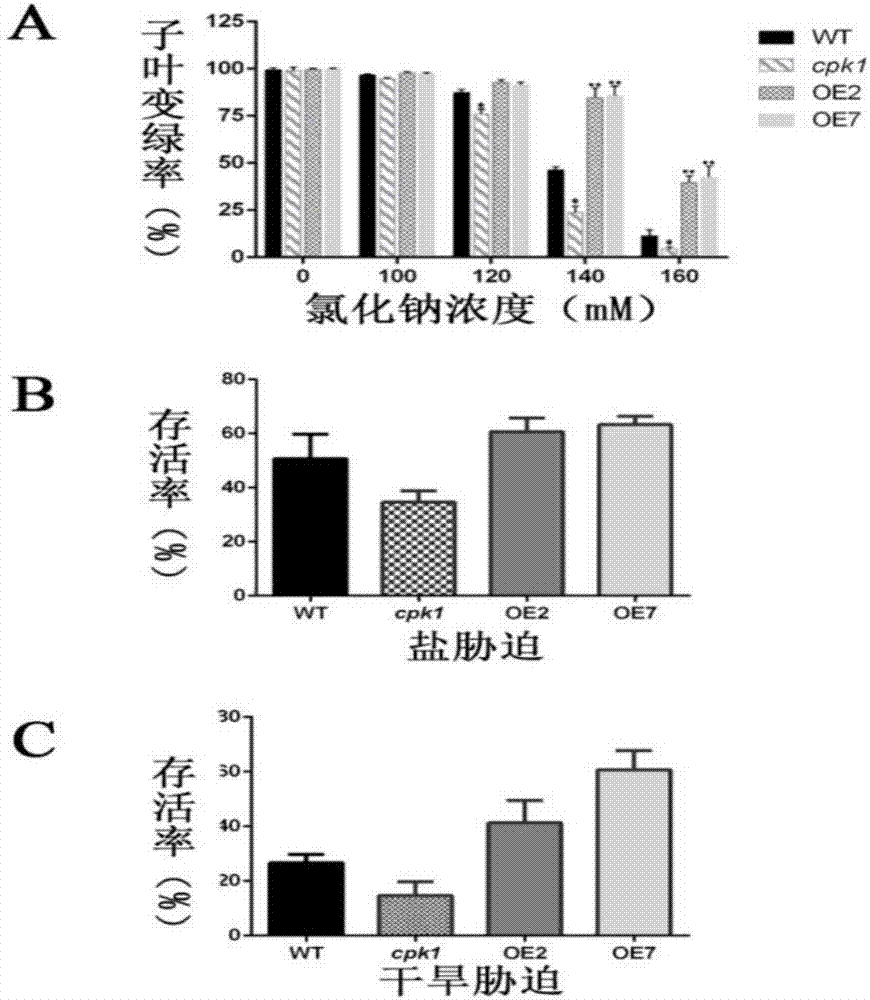
图2所示为野生型(WT)、突变体(cpk1)和转基因过表达植株(OE2和OE7)在盐和干旱胁迫下的存活率统计;A表示野生型突、突变体和转基因过表达株系在盐胁迫条件下子叶变绿率统计;B野生型突、突变体和转基因过表达株系在盐胁迫条件下存活率统计;C野生型突、突变体和转基因过表达株系在干旱条件下的存活率统计。
图3所示为突变体(cpk1),野生型(WT)和转基因过表达植株(OE2和OE7)在盐和干旱胁迫下过氧化氢,丙二醛和过脯氨酸含量的变化;A野生型、突变体和转基因过表达植株在盐和干旱胁迫下过氧化氢含量。B野生型、突变体和转基因过表达植株在盐和干旱胁迫下丙二醛含量;C野生型、突变体和转基因过表达植株在盐和干旱胁迫下脯氨酸含量。
图4所示为突变体(cpk1),野生型(WT)和转基因过表达植株(OE2和OE7)在盐和干旱胁迫下逆境响应基因的表达量变化。
具体实施方式
本发明的发明人从拟南芥中克隆到的一个可提高植物对高盐和干旱胁迫耐受性(耐盐和耐旱性)的基因AtCPK1。研究发现,所述基因AtCPK1表达的蛋白具有钙依赖蛋白激酶活性;通过将AtCPK1基因转化拟南芥,实验结果发现转基因生物的耐盐和耐旱性均有所提高。该基因可用于提高植物对高盐和干旱的耐受程度,降低盐渍和干旱引起的减产损失,同时降低成本,具有重要的经济意义和应用前景。
为了探寻AtCPK1基因的作用机理,发明人构建和筛选了AtCPK1基因的突变和过表达植株。从生理方面,测量了盐和干旱胁迫下各基因型植株的脯氨酸,丙二醛和过氧化氢的含量(见图3)。从分子层面,检测了各株系在盐和干旱胁迫下逆境胁迫应答基因在转录水平的变化情况(见图4)。
下面将通过实施例对本发明的具体实施方式做进一步的解释说明,但不表示将本发明的保护范围限制在实施例所述范围内。
下述实施例中,凡未注明具体实验条件的,均为按照本领域技术人员熟知的常规条件,下述实施例中,所用载体pET28,pCAMBIA1302购自于Qiagen公司,菌株大肠杆菌DH5α购自于Qiagen公司,载体pBI121购自于Clontech公司。
实施例1拟南芥中耐热基因AtCPK1的克隆及过量表达重组载体的构建
1、从拟南芥中筛选获得一段基因AtCPK1,其核苷酸序列如序列表中SEQ ID NO:1所示。根据SEQ ID NO:1所示核苷酸序列设计引物,
上游引物(SEQ ID NO:3):5’-ATGGGTAATACTTGTGTTGGA-3’,
下游引物(SEQ ID NO:4):5’-GAGTTTAAGAGCAATGCTAAAG-3’。
然后经PCR从拟南芥cDNA中扩增SEQ ID NO:1所示的核苷酸序列。对PCR产物纯化(纯化操作的具体过程见Qiagen公司所公开的PCR产物纯化资料),经测序验证,得到序列SEQ ID NO:1的基因片段。
2、根据SEQ ID NO:1所示核苷酸序列设计引物
上游引物(SEQ ID NO:5):5’-CGGGGGACTCTTGACATGGGTAATACTTGTGTTGGA-3’,
下游引物(SEQ ID NO:6):5’-ACTAGTCAGATCTACGAGTTTAAGAGCAATGCTAAAG-3’。
经PCR,将从拟南芥cDNA中扩增完整的SEQ ID NO:1所示的核苷酸序列扩增出同源重组臂。对PCR产物纯化(纯化操作的具体过程见Qiagen公司所公开的资料),然后与载体pCAMBIA1302进行同源重组(同源重组位点为NcoI),获得含有SEQ ID NO:1序列的过量表达重组质粒,并转入大肠杆菌DH5α中进行克隆。
实施例2转基因AtCPK1及其突变体拟南芥植株及其耐盐和耐旱性能鉴定
1、花序浸染的方法转化拟南芥
1-1、转化农杆菌
首先取出农杆菌(GV3101)感受态于冰上融化,加入2μL实施例1构建的过量表达重组质粒,液氮冻2min,然后37℃水浴5min。加入1mlLB培养基,28℃振荡培养2-3h,离心收集菌体,将其涂在LB+利福平(Rif)(25μg/ml)+卡那霉素(Kan)(50μg/ml)平板上,28℃继续培养2~3d。
1-2、阳性农杆菌转化子的鉴定
随机挑取重组平板上的农杆菌单菌落接种于LB+Rif+Kan液体培养基中进行振荡培养,培养一定时间后,用菌液作模板进行PCR扩增。
根据SEQ ID NO:1所示核苷酸序列设计的引物进行扩增:
上游引物(SEQ ID NO:5):5’-CGGGGGACTCTTGACATGGGTAATACTTGTGTTGGA-3’,
下游引物(SEQ ID NO:6):5’-ACTAGTCAGATCTACGAGTTTAAGAGCAATGCTAAAG-3’。
然后采用琼脂糖电泳检测是否有目标条带出现(条带大小约为1800bp),若有则代表目的基因已转入。
1-3、花絮浸染法介导的拟南芥稳定遗传转化
将带有目标质粒的农杆菌按1:1000体积比加入到200mL LB+Kan+Rif的培养基中,220rpm震荡培养18-20h。6000g,室温离心10min,弃上清收集菌体。将菌体溶于MS+3%蔗糖溶液中,调整OD至0.6-0.8。加入0.02%的表面活性剂Silwet L-77,混匀。选取生长状况良好、花瓣完全开放、没有角果(约5周生长时间)的拟南芥幼苗,将花絮浸入溶解有菌体的MS溶液中约1min,取出花絮。套袋在幼苗上,黑暗处理24h后揭开袋子。5天后重复浸染一次。
1-4、转基因T1代阳性苗的筛选
收取花絮浸染后的T0代种子10000-20000颗,将其播于MS+Hyg固体培养基中,pCAMBIA1302载体中带潮霉素抗性,因此阳性苗能够在含有潮霉素的培养基中正常生长。选取长出两片以上真叶,根较长的幼苗移栽入泥炭土中,温室培养。待幼苗长到六片子叶后,粗提DNA,通过PCR鉴定,去除假阳性植株。
1-5、转基因T1代阳性苗的鉴定及获得稳定转基因株系
收取T1代种子,取50-100颗种子播于1/2MS+Hyg平板中,观察潮霉素抗性分离比,符合3:1的株系为单拷贝,移栽绿色幼苗入土中温室培养。T2代再发1/2MS+Hyg平板,全部长出真叶和根为纯合子。获得稳定转基因植株T3代。
1-6、野生型、突变体以及转基因株系AtCPK1基因表达量的鉴定
利用半定量和定量PCR检测各株系中AtCPK1基因的表达量(见图1中的C,D)。
2、AtCPK1基因突变拟南芥植株的鉴定
根据SEQ ID NO:1所示核苷酸序列设计引物AtCPK1基因突变体鉴定引物,
上游引物(SEQ ID NO:7):5’-CTGAACTCGATTCCCTTCCTC-3’,
中间引物(SEQ ID NO:8):5’-ATTTTGCCGATTTCGGAAC-3’,
下游引物(SEQ ID NO:9):5’-CTTTGAGATTCGCCCCTACTC-3’。
以植株的基因组DNA为模板,分别用上游、中间引物与下游引物配对进行PCR扩增,然后琼脂糖电泳检测条带大小和数量,若全为大条带(900bp左右),为野生型;一条大带,一条小带,则为杂合突变体;两条小带(500bp左右),为纯合突变体(见图1中的B)。测序比对检测AtCPK1基因突变体T-DNA的插入位点(见图1中的A)。
3、转基因AtCPK1和突变植株耐盐和耐旱性能鉴定
3-1、盐胁迫下子叶变率
将不同的拟南芥种子在4℃温度下春化3天(打破种子的休眠期),用次氯酸钠消毒,播种在含有0、100、120、140、160mM NaCl的MS培养基上,在正常情况下培养10天,统计各个株系的子叶变绿率(见图2中的A)。
3-2、植株在盐胁迫下的存活率
将在土里正常生长3周天的苗用200Mm NaCl溶液处理,10天后观察和统计各株系植株的坏死情况(见图2中的B)。同时测量各株系植株的脯氨酸,丙二醛和过氧化氢含量(见图3)。
3-3、植株在干旱胁迫下的存活率
将在土里正常生长3周天的苗干旱处理14天,待植株萎蔫了以后复水,2天后观察和统计各株系植株的存活率(见图2中的C)。同时测量各株系植株的脯氨酸,丙二醛和过氧化氢含量(见图3)。
实施例3转基因AtCPK1和突变植株在盐和干旱胁迫下游逆境响应基因定量分析
选取在MS上正常生长14天的拟南芥幼苗,分别用150mM NaCl和12%聚乙二醇6000(PEG6000)处理6h,然后提取其RNA。
1、拟南芥转基因植物总RNA的提取及cDNA的合成
1)选取在MS培养基上生长良好12d左右的拟南芥幼苗,放入研钵中用液氮将其完全磨碎,称取0.08-0.1g放入EP管中。
2)EP管中加入1mL ambion TRIzol提取液,涡旋振荡1min后室温静置5min。
3)加入0.2mL氯仿,涡旋振荡15s,室温静置2-3min。
4)4℃,12000g离心10min,吸取水相至干净的EP管中。
5)加入等体积的异丙醇,轻轻混匀,-20℃,静置10min。
6)4℃,12000g离心10min,弃上清。
7)将沉淀用1mL 75%乙醇轻轻洗涤,4℃,12000g离心30s,弃上清。
8)室温干燥沉淀5min,加入30μL RNase free ddH2O溶解沉淀。
2、单链cDNA的合成(使用PrimeScript RT reagent Kit with gDNA Eraser试剂盒,购自Takara公司)
a.基因组DNA的除去反应
10μL反应体系中加入:
5×gDNA Eraser Buffer 2μL
gDNA Eraser 1μL
Total RNA 1μg
RNase free ddH2O至10μL
室温静置5分钟。
b.反转录反应
RNase free ddH2O至20μL
37℃15min,85℃5s。
-20℃保存。
2,根据各个基因的核苷酸序列设计AtCPK1,RD29A,COR15A,ZAT10,ZAT12,APX2基因的定量检测引物。
检测AtCPK1引物:
上游引物(SEQ ID NO:10):5’-CGAACAAGGTATTTTCGAACAG-3’;
下游引物(SEQ ID NO:11):5’-TCTTGAACTTGTTCATTGCAG-3’;
检测ACTIN2引物:
上游引物(SEQ ID NO:12):5’-ACATCCCACCTACTGGTCTGAAG-3’;
下游引物(SEQ ID NO:13):5’-GCATCTTGGTATTGCTGGTACTCT-3’;
检测RD29A引物:
上游引物(SEQ ID NO:14):5’-CCAGAAGAAGTTGAACAT-3’;
下游引物(SEQ ID NO:15):5’-CTCGTCATCATCATCATC-3’;
检测COR15A引物:
上游引物(SEQ ID NO:16):5’-AAGAGGCATTAGCAGATG-3’;
下游引物(SEQ ID NO:17):5’-GCTTCTTTACCCAATGTATC-3’;
检测ZAT10引物:
上游引物(SEQ ID NO:18):5’-GATTCTTCAGTCTTCCAT-3’;
下游引物(SEQ ID NO:19):5’-TAGATACTCTTCCTCAGT-3’;
检测ZAT12引物:
上游引物(SEQ ID NO:20):5’-TGTCCCATATGTGGAGTGGA-3’;
下游引物(SEQ ID NO:21):5’-ATTGTCCACCATCCCTAGACT-3’;
检测APX2引物:
上游引物(SEQ ID NO:22):5’-GGCTGGGACATTTGATGTG-3’;
下游引物(SEQ ID NO:23):5’-AGGGAACAGCTCCTTGATAGG-3’;
3、将反转得到的cDNA以及Q-PCR引物稀释5倍,按照下表1所示进行实时定量分析:
表1实时定量分析条件
由上述实施例能够得出以下结论:
1、AtCPK1突变体表现出对盐和干旱的敏感性,而过量表达AtCPK1能增强植物对盐和干旱的耐受性。
2、过量表达AtCPK1能够减弱盐和干旱对植株的损害,例如丙二醛和过氧化氢含量降低。
3、过量表达AtCPK1能够够增强植株应对渗透胁迫的能力,例如脯氨酸含量的增加。
4、过量表达AtCPK1能够够上调表达某些逆境响应因子基因,从而增强植株的耐盐和耐旱能力。
本发明提供的AtCPK1基因具有提高植物对高盐和干旱的耐受力的作用,通过转基因等生物技术提高作物对盐渍和干旱环境的耐受能力,增加农作物产量方面具有很好的应用前景。
序列表
<110> 四川大学
<120> 提高植物耐盐耐旱性的蛋白质激酶及其用途
<130> A180151K(序)
<141> 2018-03-09
<160> 24
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1833
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
atgggtaata cttgtgttgg accaagcaga aatggcttct tgcaatctgt ttcagctgca 60
atgtggcggc caagagatgg agatgattcg gcttccatga gtaatggaga tattgcaagt 120
gaagctgttt cgggagagct tcgatctcga ttatctgatg aagtccagaa taaacctcct 180
gaacaggtca caatgccgaa gccagggact gacgtcgaga ccaaggacag agagattcga 240
actgaaagca agcctgaaac gctagaggag ataagccttg agtccaaacc agagactaag 300
caggagacca agtcagagac caagccggag tcaaaacctg atcctccagc taaacctaag 360
aagcctaaac acatgaagag agtgtcaagt gcagggctta ggactgagtc agtgttgcag 420
aggaagactg aaaacttcaa ggaattctat tccttgggaa ggaaactcgg acaagggcaa 480
tttgggacga cttttttatg tgtcgagaag actacgggga aggagtttgc ctgcaagtcg 540
attgctaaga ggaagctatt gactgatgag gacgttgagg atgtgagaag agaaattcag 600
ataatgcatc acttggctgg tcaccctaat gtcatctcca tcaaaggagc ttatgaggat 660
gttgtggcag tgcaccttgt aatggagtgt tgtgcaggcg gcgagctttt tgacaggatc 720
attcaacgcg gtcactacac agagaggaaa gcggctgagc tcactagaac cattgttggg 780
gttgtagagg cttgccattc tcttggtgtt atgcatcgag acctcaagcc cgagaatttt 840
ctgtttgtca gtaaacacga agattccctc ttgaagacga ttgattttgg actctccatg 900
ttctttaaac cagacgatgt ttttacagat gttgttggta gcccatatta tgttgcccca 960
gaagttcttc gaaagcgtta tggccctgaa gctgatgtct ggagtgctgg agtgattgtg 1020
tacattttat taagcggagt tcctccattc tgggctgaaa ccgaacaagg tattttcgaa 1080
caggtcctcc acggtgatct tgacttttcg tccgatccat ggccaagtat atctgaaagt 1140
gcaaaggatt tagtgaggaa aatgcttgtc agggatccca agaaaaggtt aactgcccac 1200
caagtattat gtcatccatg ggttcaagtc gacggtgtgg ctccagacaa gcctttggat 1260
tctgctgttc tgagccgtat gaagcagttt tctgcaatga acaagttcaa gaaaatggct 1320
cttagagtca ttgctgagag cttatctgaa gaagaaatcg ccggcttgaa agaaatgttt 1380
aatatgatag atgcggacaa gagtggtcag ataactttcg aagaactgaa agcaggacta 1440
aaacgagtag gggcgaatct caaagagtct gaaattctcg acttgatgca agctgctgat 1500
gtggacaaca gcggaacaat agattacaaa gagttcatag ctgcaacatt acatctaaac 1560
aaaatagaga gagaggacca tttgtttgca gcctttacat actttgacaa agatgggagc 1620
ggctatatca ccccagacga gcttcaacaa gcttgtgagg agtttggtgt tgaggatgtc 1680
cgcatagaag aactgatgcg cgatgttgat caagacaatg acgggcgaat agactacaac 1740
gagtttgtgg cgatgatgca gaaaggaagc atcacaggag gacctgtgaa aatgggtcta 1800
gagaaaagct ttagcattgc tcttaaactc tag 1833
<210> 2
<211> 610
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 2
Met Gly Asn Thr Cys Val Gly Pro Ser Arg Asn Gly Phe Leu Gln Ser
1 5 10 15
Val Ser Ala Ala Met Trp Arg Pro Arg Asp Gly Asp Asp Ser Ala Ser
20 25 30
Met Ser Asn Gly Asp Ile Ala Ser Glu Ala Val Ser Gly Glu Leu Arg
35 40 45
Ser Arg Leu Ser Asp Glu Val Gln Asn Lys Pro Pro Glu Gln Val Thr
50 55 60
Met Pro Lys Pro Gly Thr Asp Val Glu Thr Lys Asp Arg Glu Ile Arg
65 70 75 80
Thr Glu Ser Lys Pro Glu Thr Leu Glu Glu Ile Ser Leu Glu Ser Lys
85 90 95
Pro Glu Thr Lys Gln Glu Thr Lys Ser Glu Thr Lys Pro Glu Ser Lys
100 105 110
Pro Asp Pro Pro Ala Lys Pro Lys Lys Pro Lys His Met Lys Arg Val
115 120 125
Ser Ser Ala Gly Leu Arg Thr Glu Ser Val Leu Gln Arg Lys Thr Glu
130 135 140
Asn Phe Lys Glu Phe Tyr Ser Leu Gly Arg Lys Leu Gly Gln Gly Gln
145 150 155 160
Phe Gly Thr Thr Phe Leu Cys Val Glu Lys Thr Thr Gly Lys Glu Phe
165 170 175
Ala Cys Lys Ser Ile Ala Lys Arg Lys Leu Leu Thr Asp Glu Asp Val
180 185 190
Glu Asp Val Arg Arg Glu Ile Gln Ile Met His His Leu Ala Gly His
195 200 205
Pro Asn Val Ile Ser Ile Lys Gly Ala Tyr Glu Asp Val Val Ala Val
210 215 220
His Leu Val Met Glu Cys Cys Ala Gly Gly Glu Leu Phe Asp Arg Ile
225 230 235 240
Ile Gln Arg Gly His Tyr Thr Glu Arg Lys Ala Ala Glu Leu Thr Arg
245 250 255
Thr Ile Val Gly Val Val Glu Ala Cys His Ser Leu Gly Val Met His
260 265 270
Arg Asp Leu Lys Pro Glu Asn Phe Leu Phe Val Ser Lys His Glu Asp
275 280 285
Ser Leu Leu Lys Thr Ile Asp Phe Gly Leu Ser Met Phe Phe Lys Pro
290 295 300
Asp Asp Val Phe Thr Asp Val Val Gly Ser Pro Tyr Tyr Val Ala Pro
305 310 315 320
Glu Val Leu Arg Lys Arg Tyr Gly Pro Glu Ala Asp Val Trp Ser Ala
325 330 335
Gly Val Ile Val Tyr Ile Leu Leu Ser Gly Val Pro Pro Phe Trp Ala
340 345 350
Glu Thr Glu Gln Gly Ile Phe Glu Gln Val Leu His Gly Asp Leu Asp
355 360 365
Phe Ser Ser Asp Pro Trp Pro Ser Ile Ser Glu Ser Ala Lys Asp Leu
370 375 380
Val Arg Lys Met Leu Val Arg Asp Pro Lys Lys Arg Leu Thr Ala His
385 390 395 400
Gln Val Leu Cys His Pro Trp Val Gln Val Asp Gly Val Ala Pro Asp
405 410 415
Lys Pro Leu Asp Ser Ala Val Leu Ser Arg Met Lys Gln Phe Ser Ala
420 425 430
Met Asn Lys Phe Lys Lys Met Ala Leu Arg Val Ile Ala Glu Ser Leu
435 440 445
Ser Glu Glu Glu Ile Ala Gly Leu Lys Glu Met Phe Asn Met Ile Asp
450 455 460
Ala Asp Lys Ser Gly Gln Ile Thr Phe Glu Glu Leu Lys Ala Gly Leu
465 470 475 480
Lys Arg Val Gly Ala Asn Leu Lys Glu Ser Glu Ile Leu Asp Leu Met
485 490 495
Gln Ala Ala Asp Val Asp Asn Ser Gly Thr Ile Asp Tyr Lys Glu Phe
500 505 510
Ile Ala Ala Thr Leu His Leu Asn Lys Ile Glu Arg Glu Asp His Leu
515 520 525
Phe Ala Ala Phe Thr Tyr Phe Asp Lys Asp Gly Ser Gly Tyr Ile Thr
530 535 540
Pro Asp Glu Leu Gln Gln Ala Cys Glu Glu Phe Gly Val Glu Asp Val
545 550 555 560
Arg Ile Glu Glu Leu Met Arg Asp Val Asp Gln Asp Asn Asp Gly Arg
565 570 575
Ile Asp Tyr Asn Glu Phe Val Ala Met Met Gln Lys Gly Ser Ile Thr
580 585 590
Gly Gly Pro Val Lys Met Gly Leu Glu Lys Ser Phe Ser Ile Ala Leu
595 600 605
Lys Leu
610
<210> 3
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
atgggtaata cttgtgttgg a 21
<210> 4
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
gagtttaaga gcaatgctaa ag 22
<210> 5
<211> 36
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 5
cgggggactc ttgacatggg taatacttgt gttgga 36
<210> 6
<211> 37
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 6
actagtcaga tctacgagtt taagagcaat gctaaag 37
<210> 7
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 7
ctgaactcga ttcccttcct c 21
<210> 8
<211> 19
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 8
attttgccga tttcggaac 19
<210> 9
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 9
ctttgagatt cgcccctact c 21
<210> 10
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 10
cgaacaaggt attttcgaac ag 22
<210> 11
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 11
tcttgaactt gttcattgca g 21
<210> 12
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 12
acatcccacc tactggtctg aag 23
<210> 13
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 13
gcatcttggt attgctggta ctct 24
<210> 14
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 14
ccagaagaag ttgaacat 18
<210> 15
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 15
ctcgtcatca tcatcatc 18
<210> 16
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 16
aagaggcatt agcagatg 18
<210> 17
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 17
gcttctttac ccaatgtatc 20
<210> 18
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 18
gattcttcag tcttccat 18
<210> 19
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 19
tagatactct tcctcagt 18
<210> 20
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 20
tgtcccatat gtggagtgga 20
<210> 21
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 21
attgtccacc atccctagac t 21
<210> 22
<211> 19
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 22
ggctgggaca tttgatgtg 19
<210> 23
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 23
agggaacagc tccttgatag g 21
<210> 24
<211> 346
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 24
tgagactttt caacaaaggg taatatccgg aaacctcctc ggattccatt gcccagctat 60
ctgtcacttt attgtgaaga tagtggaaaa ggaaggtggc tcctacaaat gccatcattg 120
cgataaagga aaggccatcg ttgaagatgc ctctgccgac agtggtccca aagatggacc 180
cccacccacg aggagcatcg tggaaaaaga agacgttcca accacgtctt caaagcaagt 240
ggattgatgt gatatctcca ctgacgtaag ggatgacgca caatcccact atccttcgca 300
agacccttcc tctatataag gaagttcatt tcatttggag agaaca 346
- 还没有人留言评论。精彩留言会获得点赞!