无色素低分子量威兰胶生产菌株及其构建方法与应用与流程
本发明涉及微生物基因工程菌领域,具体涉及无色素低分子量威兰胶生产菌株及其构建方法与应用。
背景技术:
微生物多糖是一类环保绿色的可通过生物发酵制得的产物,对人类生活和工农业生产应用具有重要的作用。微生物多糖能在科学研究和工业化生产上取得成功主要基于以下几点:(1)多糖的性质及其具有的应用价值;(2)可以通过选合适的菌种在受控条件下进行生产;(3)提取工艺的可行性;(4)不含毒素;(5)不同微生物能够合成很多非常特殊的离子型和中性多糖,这些微生物多糖在工业生产与生活的许多领域具有广泛的应用价值,可以替代很多价格不菲的化学合成品,具有良好的环境友好性和商业开发潜力。目前全世界微生物多糖需求量约为15~20万吨/年,年产值可达150-200亿美元,产量和年增长量均在10%以上,而一些新型多糖年增长量在30%以上。
上世纪80年代继黄原胶之后,美国kelco公司陆续发现了一组新型的微生物多糖即由鞘氨醇单胞菌产生的结冷胶类多糖,引起了科学界和工业界的浓厚兴趣。该类多糖主链结构均为葡萄糖、葡萄糖醛酸、甘露糖或鼠李糖,它们具有许多优良而独特的理化特性,可以作为增稠剂、悬浮剂、稳定剂等广泛用于石油、混凝土、涂料行业,也可用于油墨、食品、纺织印染、农药、化妆品、医药等行业。
目前,微生物多糖中除了黄原胶生产规模较大,结冷胶、威兰胶、鼠李糖胶生产规模均不大,而国内直到近几年才开始威兰胶生产,但仍存在许多问题亟待解决,如威兰胶生物合成伴随着类胡萝卜素的产生,后期分离过程中大量乙醇的使用进一步提高生产成本,造成下游污染;威兰胶会附着在细胞表面上,形成包囊状结构,降低传质效率,阻碍菌胶分离等,同时研究者对不同分子量威兰胶生物合成机制及应用等方面的研究较少。因此构建解除包囊结构的色度缺陷型生产菌株不仅利于提高工业生产效率,降低成本,更能获得多元分子量的威兰胶产品,有助于拓宽威兰胶的下游应用领域。
技术实现要素:
发明目的:为了解决现有威兰胶生产过程中乙醇用量大及菌胶分离困难的问题,本发明提供了一种解除包囊结构且色素缺陷的鞘氨醇单胞菌基因工程菌作为无色素低分子量威兰胶的生产菌株。
本发明进一步的目的是提供上述解除包囊结构且色素缺陷的鞘氨醇单胞菌基因工程菌的构建方法。
本发明更进一步的目的是提供鞘氨醇单胞菌基因工程菌在制备生产无色素低分子量威兰胶中的应用。
目前为止,鞘氨醇单胞菌中类胡萝卜素合成途径的研究较少。
技术方案:为解决上述技术问题,本发明采用如下技术方案:
一种鞘氨醇单胞菌基因工程菌,所述鞘氨醇单胞菌基因工程菌中八氢番茄红素合成酶基因crtb失活;
或者,八氢番茄红素合成酶基因crtb和分选酶基因srtw同时失活;
或者,八氢番茄红素合成酶基因crtb和降解酶基因gelr同时失活;
或者,八氢番茄红素合成酶基因crtb、分选酶基因srtw和降解酶基因gelr同时失活。
所述八氢番茄红素合成酶基因crtb是细菌体内类胡萝卜素合成过程中,催化牻牛儿基牻牛儿基焦磷酸(ggpp)缩合形成第一个类胡萝卜素——八氢番茄红素的关键酶。
所述分选酶基因srtw是存在于革兰氏阴性菌必须的膜蛋白组分,与胞外多糖以及其他胞外聚合体的生物合成有很大相关性,最早发现于金黄色葡萄球菌中,催化和引导细胞表面蛋白共价结合到细胞壁肽聚糖上。
所述降解酶基因gelr是类似于编码细菌和真菌多糖裂解酶的蛋白质。
所述八氢番茄红素合成酶基因crtb失活是指八氢番茄红素合成酶基因crtb丧失编码八氢番茄红素合成酶的能力,或者编码的八氢番茄红素合成酶没有活性;
所述分选酶基因srtw失活是指分选酶基因srtw丧失编码分选酶的能力,或者编码的分选酶没有活性;
所述降解酶基因gelr失活是指降解酶基因gelr丧失编码降解酶的能力,或者编码的降解酶没有活性。
其中,所述的鞘氨醇单胞菌基因工程菌的出发菌为sphingomonassp.ht-1,该菌株已保藏于中国典型培养物保藏中心,保藏号cctccno:m2012062,该菌株的详细信息已经在申请号为201210086289.4的中国专利中详细公开。
其中,所述八氢番茄红素合成酶基因crtb失活是指八氢番茄红素合成酶基因crtb被完全敲除;
所述分选酶基因srtw失活是指分选酶基因srtw被完全敲除;
降解酶基因gelr失活是指分降解酶基因gelr被完全敲除。
其中,所述八氢番茄红素合成酶基因crtb的核苷酸序列如seqidno.1所示;
所述选酶基因srtw的核苷酸序列如seqidno.2所示;
所述降解酶基因gelr的核苷酸序列如seqidno.3所示。
上述无色素低分子量威兰胶生产菌株的构建方法,其特征在于,包括如下步骤:
(1)分别构建八氢番茄红素合成酶基因crtb基因敲除片段、分选酶基因srtw基因敲除片段、降解酶基因gelr基因敲除片段,将上述三种基因敲除片段分别导入敲除质粒中,得到八氢番茄红素合成酶基因crtb基因敲除质粒、分选酶基因srtw基因敲除质粒、降解酶基因gelr基因敲除质粒;
(2)将八氢番茄红素合成酶基因crtb基因敲除质粒转化出发菌,经筛选得到八氢番茄红素合成酶基因crtb失活的基因工程菌;
将分选酶基因srtw基因敲除质粒转化出发菌,经筛选得到分选酶基因srtw失活的基因工程菌;
将降解酶基因gelr基因除质粒转化出发菌,经筛选得到降解酶基因gelr失活的基因工程菌。
通过两步同源重组构建八氢番茄红素合成酶基因(crtb)与分选酶基因(srtw)的敲除菌株wg-1,构建八氢番茄红素合成酶基因(crtb)与降解酶基因(gelr)的敲除菌株wg-2,构建八氢番茄红素合成酶基因(crtb)与分选酶基因(srtw)与降解酶基因(gelr)的敲除菌株wg-3。
以敲除编码八氢番茄红素合成酶crtb基因为例,具体的敲除方法如下:
(1a)以s.sp.ht-1基因组为模板,pcr扩增crtb上下游同源片段,以自杀型载体pjq200sk为出发质粒,构建crtb敲除载体pjq-△crtb;
(2a)将pjq-△crtb转化至大肠杆菌s17-1感受态细胞中,涂布于含50μg/ml庆大霉素的lb固体培养基上。倒置于37℃培养箱中过夜培养。挑取克隆子进行验证,所得阳性菌株命名为e.colis17-pjq-△crtb
(3a)同源重组获得crtb基因敲除重组子:
同源重组分两步进行:
第一次同源重组:利用接合转移的手段,在辅助菌e.colihb101(prk2013)的作用下,将携带crtb上下游基因片段的敲除质粒pjq-△crtb转化至s.sp.ht-1中,挑取单交换克隆子扩大培养;
第二次同源重组:利用pjq200sk中sacb基因做反向筛选,获得双交换菌株。最终构建得到色素缺陷型鞘氨醇单胞菌基因工程菌s.sp.ht-1(△crtb)。
在敲除多个基因时,可以将之前已经敲除一个基因或两个基因的菌株作为出发菌。
步骤(1)中,所述八氢番茄红素合成酶基因crtb基因敲除片段的构建方法如下:
以sphingomonassp.ht-1基因组为模板,seqidno.14和seqidno.15、seqidno.16和seqidno.17为引物分别扩增八氢番茄红素合成酶基因crtb基因上游同源臂crtb-l和下游同源臂crtb-r;以上游同源臂crtb-l和下游同源臂crtb-r为模板、seqidno.14和seqidno.14为引物,通过重叠pcr扩增,得到八氢番茄红素合成酶基因crtb基因敲除片段;
分选酶基因srtw基因敲除片段的构建方法如下:
以sphingomonassp.ht-1基因组为模板,seqidno.22和seqidno.23、seqidno.24和seqidno.25为引物分别扩增分选酶基因srtw基因上游同源臂srtw-l和下游同源臂srtw-r,再以上游同源臂srtw-l和下游同源臂srtw–r为模板,seqidno.23和seqidno.25为引物,通过重叠pcr扩增,得到分选酶基因srtw基因敲除片段;
降解酶基因gelr基因敲除片段的构建方法如下:
以sphingomonassp.ht-1基因组为模板,seqidno.28和seqidno.29、seqidno.30和seqidno.31为引物分别扩增降解酶基因gelr基因上游同源臂gelr-l和下游同源臂gelr–r,以上游同源臂gelr-l和下游同源臂gelr–r为模板,seqidno.28和seqidno.31为引物,通过重叠pcr扩增,得到降解酶基因gelr基因敲除片段。
其中,所述敲除质粒为pjq200sk,具有蔗糖致死性,是广泛用于革兰氏阴性菌中基因置换和修饰的自杀型质粒,保存于atcc(美国模式培养物集存库)商标号为77483。
上述无色素低分子量威兰胶生产菌株在制备威兰胶中的应用。
当受体菌为sphingomonassp.cctccno:m2012062时,用于发酵制备威兰胶;所述发酵阶段发酵温度为30~42℃,发酵ph为4.0~10.0,发酵过程不添加外源物调控ph。发酵培养基配方如下:碳源为葡萄糖、蔗糖、果糖、可溶性淀粉、糖蜜和淀粉水解液中的任意一种或几种的混合物,浓度为20~70g/l;所述氮源为蛋白胨、酵母膏、玉米浆、豆粕粉、棉籽饼粉、尿素、(nh4)2so4和nh4cl中的任意一种或几种的混合物,浓度为1~10g/l;所述无机盐为钾盐、镁盐、磷酸盐和硫酸盐中的任意一种或几种混合物,浓度为0.1~10g/l,溶剂为水。
上述无色素低分子量威兰胶生产菌株制备得到的威兰胶。本发明得到的威兰胶如鞘氨醇单胞菌基因工程菌wg-1、wg-3所产低分子量威兰胶具有无色素、易与细胞分离、提取有机溶剂用量少等特性。
有益效果:
本发明的鞘氨醇单胞菌基因工程菌可应用于结冷胶类多糖的生产中,去除了产物色素,解除包囊结构并生产低分子量威兰胶(分子量范围:700-1000kda),提高了鞘氨醇单胞菌的多糖产量,色素和降解酶基因缺陷型的鞘氨醇单胞菌wg-1菌株多糖产量较出发菌株提高10%~30%,达到40~45g/l,且分子量无明显变化;色素和降解酶基因缺陷型并解除包囊结构的鞘氨醇单胞菌wg-3菌株能够生产低分子量威兰胶,产量达到20~30g/l。本发明所构建菌株,显著提升了威兰胶的发酵水平,获得了不同分子量范围的威兰胶产品,在农业、医药领域方面具有较好的应用价值。
附图说明
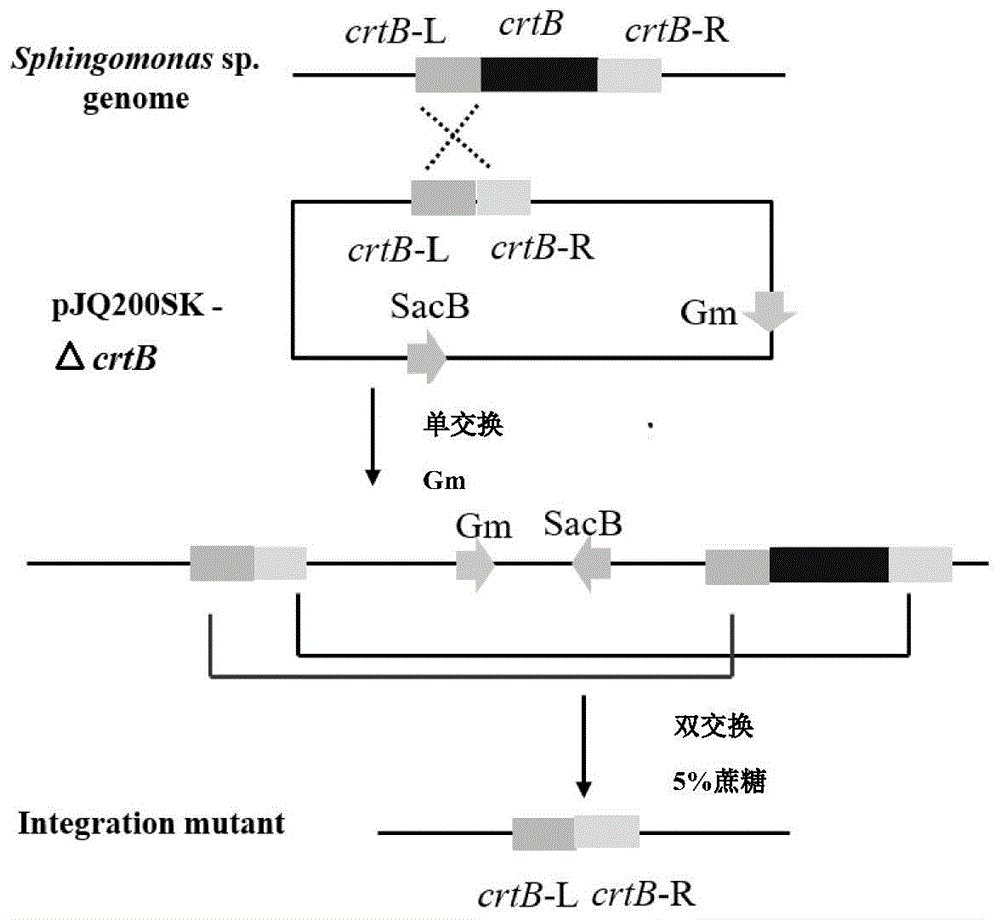
图1为基于自杀型质粒pjq200sk的两步同源重组基因敲除示意图;
图2色素缺陷型重组鞘氨醇单胞基因工程菌与原始菌株对比图,a图中左边为s.spht-1,右边为s.sp-△crtb;b图中左边为s.spht-1,右边为s.sp-△crtb。
图3包囊结构解除重组鞘氨醇单胞基因工程菌与原始菌株电镜图,a图为原始菌株,b图为包囊结构解除重组鞘氨醇单胞基因工程菌;
图4离心实验对比,a分选酶基因没有被敲除的对照组中胶体仍包裹在细胞表面,菌体不能被离心下来,b分选酶敲除菌株胶与菌体脱离,菌体被离心下来;
图5包囊结构解除重组鞘氨醇单胞基因工程菌产低分子量威兰胶gpc(凝胶渗透色谱)结果图;
图6为色素缺陷型威兰胶生产鞘氨醇单胞菌(重组鞘氨醇单胞菌)在37℃、自然ph条件下发酵过程曲线;
具体实施方式
实施例1色素缺陷型重组鞘氨醇单胞基因工程菌构建。
步骤一、s.sp.ht-1中类胡萝卜素合成途径关键酶基因鉴定
(1)简并引物设计
根据同源性较高的两株菌sphingomonassp.atcc31555(生产威兰胶)和sphingomonaselodeaatcc31461(生产结冷胶)的全基因组序列。在genbank中搜索这两株菌的类胡萝卜素合成途径关键酶相关基因序列,通过vectornti11.5.1软件设计简并引物(表1)。
表1类胡萝卜素合成途径关键酶相关基因的pcr扩增简并引物
(2)关键酶基因克隆与鉴定
s.sp.ht-1基因组提取选用takara公司的基因组提取试剂盒,具体方法参见说明书。以s.sp.ht-1基因组为模板,利用简并引物扩增类胡萝卜素合成途径关键酶基因,pcr体系、条件参见表2。所得片段经纯化后送至金斯瑞生物科技有限公司测序。利用ncbi数据库对测序所得序列进行blast,确定所得基因的功能。
表2pcr反应体系
表3pcr反应条件
步骤二、类胡萝卜素合成途径关键酶基因crtb敲除菌株构建
将八氢番茄红素合成酶crtb基因上/下游基因序列进行重叠pcr后构建至自杀型载体pjq200sk上,转化至e.colis17-1感受态细胞中。利用接合转移的手段,在辅助菌e.colihb101(prk2013)的作用下,将携带crtb上下游基因片段的自杀型质粒pjq-△crtb转化至威兰胶生产菌s.sp.ht-1中。通过两次同源重组,获得crtb敲除菌株。
(1)crtb上下游基因片段扩增
根据上一步中s.sp.ht-1中crtb基因测序结果,利用vectornti11.5.1软件设计引物扩增crtb上、下游基因序列,引物序列参见表4。pcr体系、条件参见表5。所得片段经纯化后送至金斯瑞生物科技有限公司测序。
表4构建crtb敲除菌株所需引物
(2)重叠pcr
以纯化的crtb-l/crtb-r片段为模板,以crtb-l-f/crtb-r-r为引物,进行重叠pcr。重叠pcr产物经纯化后送至金斯瑞生物科技有限公司测序。
表5重叠pcr体系
表6重叠pcr条件
(3)crtb基因敲除载体构建
以自杀型载体pjq200sk为出发质粒,利用bamhi/xbai双切得到线性化载体。利用诺唯赞clonexpressonestepmultiscloningkit连接重叠pcr纯化后片段和载体,具体方法参见试剂盒说明书。
(4)连接产物转化至大肠杆菌s17-1感受态细胞
将连接体系转化至大肠杆菌s17-1感受态细胞,涂布于含50μg/ml庆大霉素的lb固体培养基上。倒置于37℃培养箱中过夜培养。挑取克隆子进行验证,所得阳性菌株命名为e.colis17-pjq-△crtb。
(5)同源重组获得crtb基因敲除重组子
同源重组分两步进行。第一次同源重组通过庆大霉素和链霉素双抗筛选获得单交换的突变株,第二次同源重组质粒pjq200sk中sacb基因做反向筛选,获得双交换菌株。在该转化系统中,pjq200sk含有庆大霉素抗性基因,sacb反向筛选基因,orit-rp4转移起点以及p15a-origin复制起点。该质粒可以在大肠杆菌宿主中复制,但不能在鞘氨醇单胞菌中复制。因此,pjq200sk进入到鞘氨醇单胞菌中,只有整合在染色体上,才能正常复制,表现出庆大霉素抗性以及蔗糖致死特性。
第一次同源重组:利用接合转移的手段,在辅助菌e.colihb101(prk2013)的作用下,将携带crtb上下游基因片段的自杀型质粒pjq-△crtb转化至威兰胶生产菌s.sp.ht-1中。挑取单交换克隆子扩大培养。
第二次同源重组:将单交换克隆子接种到含有5%(w/v)蔗糖的威兰胶种子培养基中过夜培养。将培养液稀释涂布到有5%(w/v)蔗糖的威兰胶固体培养基上,于30℃静置培养72h。挑取白色单菌落扩增crtb基因验证。将crtb敲除的菌株命名为s.sp.-△crtb。
实施例2色素缺陷且包囊结构解除型重组鞘氨醇单胞基因工程菌构建
构建方法同实施例1,不同的是受体菌株是实施例1中的s.sp.-△crtb,敲除基因为srtw基因,核苷酸序列如seqidno:2所示,引物序列见表7、表8,将分选酶srtw基因上/下游基因序列进行重叠pcr后构建至自杀型载体pjq200sk上,转化至e.colis17-1感受态细胞中。利用接合转移的手段,在辅助菌e.colihb101(prk2013)的作用下,将携带srtw上下游基因片段的自杀型质粒pjq-△srtw转化至威兰胶生产菌s.sp.-△crtb中。挑取单交换克隆子扩大培养。第二步将单交换克隆子接种到含有5%(w/v)蔗糖的威兰胶种子培养基中过夜培养。将培养液稀释涂布到有5%(w/v)蔗糖的威兰胶固体培养基上,于30℃静置培养72h。挑取单菌落扩增庆大霉素基因(gm)以及srtw基因验证。将srtw敲除的菌株s.sp.-△crtb-△srtw命名为s.spwg-1。
表7分选酶基因的pcr扩增简并引物
表8构建srtw敲除菌株所需引物
实施例3色素缺陷且降解酶基因敲除型重组鞘氨醇单胞基因工程菌构建。
构建方法同实施例1,不同的是受体菌株是实施例1中的s.sp.-△crtb,敲除基因为gelr基因,核苷酸序列如seqidno:3所示,引物序列表见表9,得到s.sp.-△crtb-△gelr菌株命名为s.sp.wg-2。
表9构建gelr敲除菌株所需引物
实施例4色素缺陷解除包囊结构且降解酶基因敲除型重组鞘氨醇单胞基因工程菌构建。
构建方法同实施例1,不同的是受体菌株是实施例2中的s.sp.wg-2,敲除基因为gelr基因,核苷酸序列如seqidno:3所示,引物序列表见表9,得到s.sp.-△crtb-△srtw-△gelr菌株命名为s.sp.wg-3。
实施例5重组鞘氨醇单胞基因工程菌用于威兰胶发酵生产。
分别将重组鞘氨醇单胞菌(受体菌为sphingomonassp.cctccno:m2012062),s.sp.wg-1,s.sp.wg-2,s.sp.wg-3和对照组s.sp.-△crtb接种于鞘氨醇单胞菌平板/斜面培养基,30℃培养24h。接一环菌于装有135ml种子培养基的1000ml三角瓶中,转速200r/min,30℃培养16h。将培养好的种子液按体积百分比为3%的l发酵培养基的7.5l发酵罐中,于37℃、自然ph下培养66h。通过最适温度、自然ph条件下威兰胶合成能力考察发现,色素和分选酶基因敲除的重组鞘氨醇单胞菌s.sp.wg-1产小分子量(mn:700-900kda)威兰胶产量较对照组菌s.sp.-△crtb产量下降;而色素降解酶基因敲除的重组鞘氨醇单胞菌s.sp.wg-2较对照组菌s.sp.-△crtb威兰胶产量提升10%~25%,达到40.5±0.8g/l,分子量没有明显变化,mn在10000-15000kda;而色素分选酶降解酶基因同时敲除的重组鞘氨醇单胞菌s.sp.wg-3产小分子量威兰胶产量较s.sp.wg-1菌株产量提升20%~30%,达到22.5±0.20g/l。在相同培养条件下,出发菌sphingomonassp.cctccno:m2012062培养72h产生高分子量(mn:12000-15000kda)威兰胶的产量为36.5g/l。提高实际工业发酵过程中的产胶量,并解决了后期分离乙醇用量大、成本高的问题,同时开发了低分子量威兰胶的生产方法,拓宽了微生物多糖在工业领域的应用。
sphingomonassp.wg-1/wg-2/wg-3菌落平板上形态没有明显变化,但颜色变为乳白色(附图2a),解除包囊结构的s.sp.wg-1发酵液通过扫描电镜下观察,srtw基因敲除后,威兰胶的包裹结构明显减少(附图3),呈现菌胶分离状(图4),为下游分离奠定良好基础。
鞘氨醇单胞菌种子培养基:葡萄糖20g/l,酵母膏1g/l,蛋白胨3g/l,k2hpo4·3h2o2g/l,mgso40.1g/l,ph7.2~7.4。
鞘氨醇单胞菌发酵培养基配方如下:葡萄糖50g/l,酵母提取物8g/l,k2hpo4·3h2o3g/l,mgso40.4g/l。
序列表
<110>南京工业大学
<120>无色素低分子量威兰胶生产菌株及其构建方法与应用
<160>21
<170>siposequencelisting1.0
<210>1
<211>930
<212>dna
<213>人工序列(artificialsequence)
<400>1
atgagccaaccgccgctgcttgaccacgccacgcagaccatggccaacggctcgaaaagt60
tttgccaccgctgcgaagctgttcgacccggccacccgccgtagcgtgctgatgctctac120
acctggtgccgccactgcgatgacgtcattgacgaccagacccacggcttcgccagcgag180
gccgcggcggaggaggaggccacccagcgcctggcccggctgcgcacgctgaccctggcg240
gcgtttgaaggggccgagatgcaggatccggccttcgctgcctttcaggaggtggcgctg300
acccacggtattacgccccgcatggcgctcgatcacctcgacggctttgcgatggacgtg360
gctcagacccgctatgtcacctttgaggatacgctgcgctactgctatcacgtggcgggc420
gtggtgggtctgatgatggccagggtgatgggcgtgcgggatgagcgggtgctggatcgc480
gcctgcgatctggggctggccttccagctgacgaatatcgcccgggatattattgacgat540
gcggctattgaccgctgctatctgcccgccgagtggctgcaggatgccgggctgaccccg600
gagaactatgccgcgcgggagaatcgggccgcgctggcgcgggtggcggagcggcttatt660
gatgccgcagagccgtactacatctcctcccaggccgggctacacgatctgccgccgcgc720
tgcgcctgggcgatcgccaccgcccgcagcgtctaccgggagatcggtattaaggtaaaa780
gcggcgggaggcagcgcctgggatcgccgccagcacaccagcaaaggtgaaaaaattgcc840
atgctgatggcggcaccggggcaggttattcgggcgaagacgacgagggtgacgccgcgt900
ccggccggtctttggcagcgtcccgtttag930
<210>2
<211>711
<212>dna
<213>人工序列(artificialsequence)
<400>2
atgttcaaccggcgtgaccttatgatcggcgcgggctgcttcgcggccgccggcgcctcg60
ctcgccctgaagccgcgcaagcggatggacctgctgggcaatgcaaagctcgattcgctg120
ctgccgcatgcgttcggcccctggcgcgcggaagataccggtgcgctgatcgcgccgccg180
cgcgaaggcagcttggaagacaagctctataaccagaccgtcagccgcgtgttctcgcgc240
gaagacggcgcggtggtgatgatgctgatcgcctatggcaacgcccagaccgatctgctg300
cagctgcaccggcccgaagtctgctatccctttttcggcttcaccgtcgaacgcagcgaa360
gcgcagaccattcccgtcgccaacggcattgcggtgccgggccgagcgcttaccgcgtcc420
agcttcaaccgcaccgagcagatcctctactggacgcgtgtcggcgattatcttccgcag480
gacggcaatcagcagctgatggcgcggctgaagagccagatggccgggtggatcgtcgat540
ggcgtgttggtccgcatttccagcatcaccgcggacgttgcagagggtaccgcgatcaac600
ctcgatttcgcccgccagctgatcgccaccctgccgggcgcggcgctgccgccgctgctc660
ggaaccagcttcgccaaggcgttcgaagcgcagcacccgccccgtagctga711
<210>3
<211>2013
<212>dna
<213>人工序列(artificialsequence)
<400>3
tttcgcagccttgatggcggcgtccagttcgctctgattcctcacgatgatgtccggcat60
cgtggtgtgcacggtgatggacgtataggtccccgccgcaagcttgatcgtctcgccccc120
cgtcacattcaccggcttgctcgcatcgagcgaggtgatcgtgacgggcgtggtgaaggt180
gttttgtgcggccgtgacgttcttcaccaccaggttgctgctgttgatgatctgcagggt240
cacgacattgctggagccgatgatccggttcgcgtaattatagtcctgtgccggctggaa300
cccccagcccatcgacttcgtcacatcgcccgtacccccgctcagggtcacgccgtcgat360
ggcgaaatgatcgaccgaggaattcttgatcgtcacccccttgctttctcgcagcagaag420
gtcgtggaagttgttgccctgcagggtgacaccgtcgacggtgaggacgttcatccccag480
catgttgttgtcgatgacgacgttcgacgcttcggcgaaattggtgtgatcgcggcgatt540
gttcgtcatgaactggatggcgtcgggatgctcaccattcaccggatagaggttggtgaa600
gtccccctgcatcatcacgttattggtgatcgtgatgttcgtgttgcccttggtcttgcc660
gatgttttcgtagggaatgctggattcattgcccatgaatacgccctggaaggccaggcc720
cagaacgacattgatgccgtgcgtgaaaccattctggtacacgagattgtttttgatcgt780
atcggcgatcgcatccatcttcgagatgatggtattggagtccacggtgacgttcttgcc840
aacctggtccacgacattgttggtgaccttgccgccggtcacgccgtccaggcggatcca900
gtccgttgcaagcacggcgttgttcgattgagtaatgccgctcgacgttgcggtgatgac960
gttcgccagttgcgccttcgatccggccatgagatcgccgatcttgcgaagagtgaccgc1020
gacctgcgcggcaaacgcgctgcctgcaggcggctgatacccgacaccactgacgatcag1080
ctgcagatccagcagcaggttggcgccggtcgaggtctgtgctgccgcctgctccttggc1140
cgccttcgtggtctcgtccgtgctccagcgcgtctggtccacgattccggtcgcagtgaa1200
ctcgaagccggtgccggtcttcacctggaacatgccgttgctgatggcggtgagatccag1260
gtcgaagttgagcgtgaaggcgggcagcgcgaagagttgacgtgaattgtcccgcgtaag1320
ccagctctggttgacgcccatgatctggccgaccgcgcccgtcgcggtggcacgcttcat1380
ctgcccggcggcattcttgacggtgaagaccagttcgccgtccgcccggagcgagattcc1440
cgcgatcttgtgggtggccgtgtcggtcatcttggcgccgctcgtcgcgacggtatagct1500
tcccttcaccacgccatcgacatagatgatcgccttgcccttcgcgctgtcataggtcag1560
gctgccgatgtacagtccggcatattcgaccgcccgcgtgctgccgacgatcgttcccga1620
gagggcagcgtcgcgcatctcgatctcgcccacgctgccgctgaagacagcgttgaacgg1680
ggtggtcggctggctggcggcggtcgccgcggcattcagcgcaaggatctgggacgcact1740
ggtgccgagaatggttacggcgctggcggccaagctgctggtgaggctgggcttcacggt1800
cgatccccccagcgtcagcgtgccggtggtcgccgccggcagcgccgtcgacgtgaccgg1860
ggccgcattcatggcgatcgcctgggcgagcgacacttgcgcgacggacgccgtcgatgc1920
ggtggcgaacaggctattcgccacggacaggctgcccgtcgccgagacggccgcagtgcc1980
tcagacgtgatagaagtcctgcaccaacttctt2013
<210>4
<211>41
<212>dna
<213>人工序列(artificialsequence)
<400>4
ttcctgcagcccgggggatcccactatgcgcccaccgactt41
<210>5
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>5
gcgtccacagtcctgccgtgaccgtcggcgatatcgt37
<210>6
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>6
acgatatcgccgacggtcacggcaggactgtggacgc37
<210>7
<211>41
<212>dna
<213>人工序列(artificialsequence)
<400>7
accgcggtggcggccgctctagagctggtgagcggcgctaa41
<210>8
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>8
atgttacgcagcagcaac18
<210>9
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>9
cgaattgttaggtggcgg18
<210>10
<211>52
<212>dna
<213>人工序列(artificialsequence)
<400>10
ttcctgcagcccgggggatcccaggatcctggtaaaggcgcaggaagaggcg52
<210>11
<211>41
<212>dna
<213>人工序列(artificialsequence)
<400>11
cttatgatcggcgcgggcccgccccgtagctgaacgaaaaa41
<210>12
<211>48
<212>dna
<213>人工序列(artificialsequence)
<400>12
gttcagctacggggcgggcccgcgccgatcataaggtcacgccggttg48
<210>13
<211>51
<212>dna
<213>人工序列(artificialsequence)
<400>13
cgcggtggcggccgctctagatggatggtcgaccgagtcacggcgccgctg51
<210>14
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>14
atgttacgcagcagcaac18
<210>15
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>15
cgaattgttaggtggcgg18
<210>16
<211>41
<212>dna
<213>人工序列(artificialsequence)
<400>16
ttcctgcagcccgggggatcccttgccccacaggagatccc41
<210>17
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>17
gatgaagccacccacaagatcgcg24
<210>18
<211>32
<212>dna
<213>人工序列(artificialsequence)
<400>18
atcttgtgggtggcttcatccccagggcgaaa32
<210>19
<211>40
<212>dna
<213>人工序列(artificialsequence)
<400>19
cgcggtggcggccgctctagagcgtcgagagtgttgcccg40
<210>20
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>20
atgttacgcagcagcaac18
<210>21
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>21
cgaattgttaggtggcgg18
- 还没有人留言评论。精彩留言会获得点赞!