一种玉米种子灌浆调控基因ZmDef1及应用的制作方法
本发明属于基因工程技术领域,具体地说,涉及一种玉米种子灌浆调控基因zmdef1及应用。
背景技术:
种子灌浆是一个重要的生物学过程,玉米作为主要粮食、饲料及工业原料,在我国国民经济中占有重要的地位。尽管玉米作为我国第一大作物,种植面积全世界第一,却依旧难以满足玉米在全球范围内不断上涨的需求量。玉米的产量是受多基因调控的复杂数量性状,主要取决于粒重和穗粒数,而灌浆是影响粒重的重要因素,灌浆是指将光合作用产生的淀粉、蛋白质和积累的有机物质通过同化作用储存在籽粒中的过程,研究发现谷物干重基本与灌浆时间呈线性增长关系,表明籽粒粒重受灌浆速率和持续时间的影响,灌浆速率快、持续时间长的品种,籽粒就越饱满,百粒重也越高。种子灌浆是一个复杂的生理代谢过程,受多基因调控,具有复杂的遗传效应;同时还受光照、温度、水分、矿质元素、金属离子转运等多种因素的协同影响,表现出复杂的动态变化特征。目前玉米种子灌浆的研究主要集中在淀粉和蛋白的合成、积累,胚乳细胞的发育以及蔗糖转运等方面,但在矿质元素、金属离子转运协同调控方面的研究还很少,完整的灌浆调控机制仍需进一步深入研究。
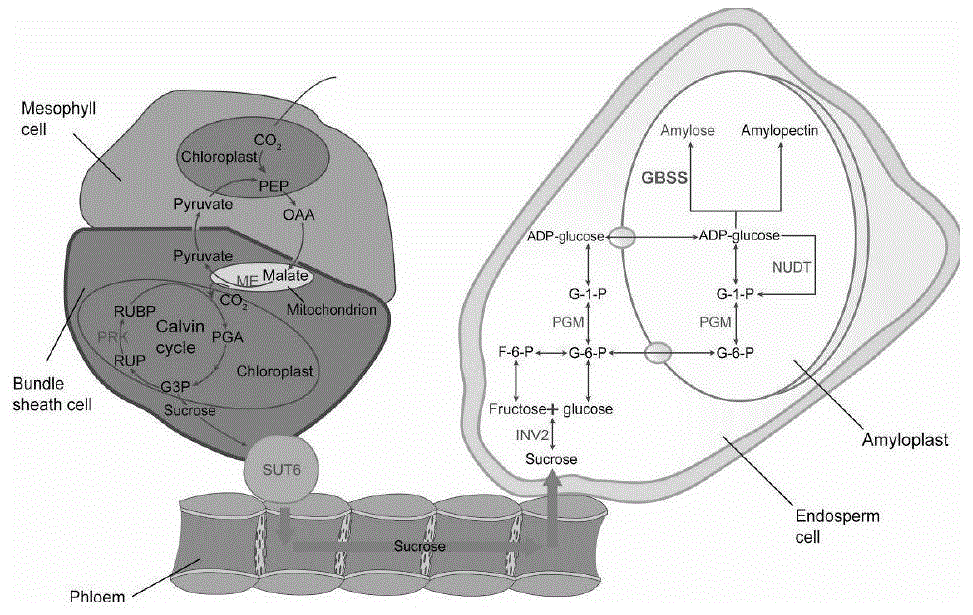
淀粉合成缺陷影响种子灌浆:玉米籽粒胚乳中含有约70%的淀粉,淀粉是种子干重的主要构成部分。淀粉作为灌浆过程中主要的同化物,也是植物中重要的碳水化合物储存介质,淀粉合成是一个复杂的过程,涉及一系列生物合成酶的共同作用(图1,2)。蔗糖合酶sus是调控种子灌浆的关键酶,sus催化蔗糖裂解成果糖和udp-葡萄糖,为淀粉合成提供原料,sus活性与灌浆速率和淀粉积累量显著相关,在灌浆早期,优质籽粒的sus活性高于的劣质籽粒,tang等研究发现谷粒中蔗糖及aba浓度的增加可增强籽粒中sus活性和sus蛋白的表达。adp-葡萄糖焦磷酸化酶agpase是催化所有高等植物淀粉生物合成途径中的一个关键酶,玉米中agpase的大亚基(lsu)突变后产生籽粒灌浆不饱满突变体shrunken2(sh2),小亚基(ssu)突变后也会造成类似表型的突变体brittle2(bt2)。颗粒结合淀粉合成酶gbss有两种类型,gbssi主要在贮藏组织如种子胚乳中发挥作用,gbssii在瞬时淀粉的积累及非贮藏植物组织中起作用,谷类作物中的gbssi由waxy(wx)基因编码,在水稻、玉米、大麦、小麦中,一旦wx突变后将导致直链淀粉含量降低甚至完全缺失。淀粉分支酶be也称为q-酶,通过切割α-1,4-葡聚糖键并通过α-1,6-葡聚糖键重新连接来形成分支点,玉米ae1突变体内be酶的缺失,使支链淀粉产量减少,导致直链淀粉积累高达50%。淀粉脱支酶dbe有两类,异淀粉酶(isa)及支链淀粉酶(pul),两类酶通过水解1,6-葡萄糖键发挥作用,isa主要去除植物糖原和支链淀粉,pul仅作用于支链淀粉。水稻isa1突变体su1支链淀粉生物合成降低,可能与dp12支链淀粉的比例下降有关。
醇溶蛋白发育异常影响灌浆:种子贮藏蛋白(ssp)主要在成熟的胚乳组织中合成并稳定积累。玉米醇溶蛋白是玉米胚乳中最丰富的贮藏蛋白,醇溶蛋白含量减少及赖氨酸含量升高都会导致胚乳向粉质转化。玉米醇溶蛋白合成或组织突变主要有两种类型:不透明(opaque)和粉质突变体(floury)。由于蛋白体合成或发育异常导致籽粒灌浆受到影响,一定程度上降低了玉米种子的产量。o1和o10影响玉米醇溶蛋白沉积和蛋白体形成;o5突变不参与玉米醇溶蛋白的代谢过程,但影响淀粉体膜的磷脂组成,产生不透光表型(图3)。fl2及fl4突变体籽粒具有柔软的粉质胚乳,蛋白质体形态结构异常;fl1突变体中玉米α-醇溶蛋白mrna和蛋白质合成的减少;而fl3是母本表达印记基因,编码与rnapiii相互作用的platz蛋白,影响trna和5srrna的转录,fl3中玉米醇溶蛋白水平明显降低,胚乳变成粉质的同时也影响了籽粒的灌浆(图4)。
玉米种子灌浆相关基因的研究进展:玉米中mn1(miniature1)编码胚乳特异性细胞壁转化酶2(incw2),incw2蛋白完全定位于基部胚乳转移细胞betl,incw2的主要生理功能是水解蔗糖,代谢释放的己糖。相对于正常发育的种子,mn1突变体中的基部胚乳的葡萄糖、果糖和山梨糖醇水平大大降低,蔗糖水平增加。另外,与mn1表型相似的rgf1(reducedgrainfilling1)也在玉米籽粒基部胚乳转移细胞中特异表达,rgf1为一种有籽粒发育缺陷的突变体,厚壁细胞层(twcl)缺失,导致粒重降低30%,rgf1籽粒具有不完整的纸质果皮的小胚乳,但胚发育不受影响,突变使花梗发育缺陷并大大降低基因在胚乳转移层的表达。虽然rgf1与mn1突变体表型十分相似,等位验证表明这两者由不同的基因调控(图5)。
种子必须高效地从成熟组织中吸收营养物质,以促进自身的发育。在玉米驯化的过程中,种子的大小是人们选育过程重点关注的性状,但糖类代谢和转运能力相关的研究却较少。研究表明可溶性糖转运到发育中种子的转运能力决定了种子细胞的大小和数目,最终影响种子的大小。sweet通过介导己糖转运调控了种子灌浆过程,zmsweet4c编码一类糖转运蛋白,负责将韧皮部运输的糖类转运至周边的库器官,原位杂交及酵母缺陷互补实验表明该基因在转移层细胞膜上特异表达,介导葡萄糖和果糖等六碳糖向籽粒内部转运,sweet基因的mu转座子插入突变体zmsweet4c-umu1表现为“空果皮”的表型,即胚乳较胚与野生型相比变得更小,但胚仍能发育成一个可育的个体,表明zmsweet4c特异地影响种子的灌浆过程(图6)。比较发现zmsweet4c启动子序列在玉米和玉蜀黍中存在较大的差异,并在种子中高丰度表达,表明该基因可能是玉米驯化过程中的一类重要的糖类代谢或转运功能位点,参与调控种子的灌浆过程。
金属耐受蛋白家族(mtp)研究进展:植物需要金属离子时,根会从土壤表面吸收,并经过维管系统转移到叶片、果穗、籽粒中。当植物面对土壤和环境中过量金属离子的胁迫时,为防止重金属中毒带来的电子传递破坏,叶绿体膜受损,活性氧(ros)增加,脂质过氧化、生物大分子退化、膜分解、离子泄漏和dna链断裂等后果,植物依靠一系列防御机制来控制这些危险元素的吸收、积累和迁移,并通过排出细胞质中的游离离子形式来解毒。锌、锰、铁等二价金属微量元素对植物的新陈代谢和发育至关重要。阳离子扩散促进剂(cationdiffusionfacilitator,cdf)家族蛋白是二价金属阳离子转运蛋白,负责金属离子的稳态,该家族在植物中称为金属耐受蛋白家族(metaltoleranceprotein,mtp),mtp蛋白可将金属离子封存到液泡或囊泡中,也可通过细胞排出到胞外区域,在植物金属离子耐受和金属解毒方面发挥着关键作用。
植物mtp家族包括12个成员,根据金属特异性可分为三个不同的系统发育亚组:zn-cdf,fe/zn-cdf和mn-cdf亚组。这三个亚组分别承担不同的金属离子转运,zn-cdf主要包括mtp1、2、3、4、5和12成员,负责zn的转运;fe/zn-cdf主要包括mtp6和mtp7成员,负责fe或者fe、zn转运;mn-cdf主要包括mtp8、9、10和11成员,负责mn、fe的转运。zn-cdf的mtp1定位在质膜或液泡膜上,mtp3定位在液泡膜上,在缺铁和锌供应过剩的情况下,可通过调节外排锌来维持金属稳态。细菌和酵母的mtp蛋白属于fe/zn-cdf;植物fe/zn-cdf家族仅有黄瓜mtp7蛋白得到验证,csmtp7是一种线粒体转运蛋白,参与线粒体中铁的增加。mn-cdf亚组的csmtp8均定位在液泡膜上,csmtp8参与了黄瓜根细胞内mn稳态的维持;osmtp11定位于高尔基体,atmtp11定位于液泡膜前质体(pvc),在减轻mn毒性方面具有重要作用。
截至目前关于mtp家族蛋白介导种子灌浆的研究还未见报道,我们通过图位克隆获得了一个玉米种子灌浆缺陷表型的基因(详见本发明具体实施方式),该基因编码mtp家族蛋白,在玉米种子中该类蛋白的转运底物是哪种金属离子,是否影响淀粉合成物质的转运,该基因在种子灌浆过程的调控作用等都未知,对其开展系统、深入的研究非常必要。因此,深入开展玉米种子灌浆基因的克隆、功能鉴定、调控机理的研究,探究其通过改变籽粒灌浆特性调控粒重,进而提高玉米产量,对籽粒性状改良及高产育种具有十分重要的意义。
技术实现要素:
有鉴于此,本发明提供了一种玉米种子灌浆调控基因zmdef1及应用,该基因突变导致玉米籽粒灌浆缺陷,使部分胚乳细胞无淀粉积累,造成籽粒缺口表型。
为了解决上述技术问题,本发明公开了一种玉米种子灌浆调控基因zmdef1,其位于2号染色体上,包括如seqidno.1所示的核苷酸序列。
可选地,编码一个叶绿体定位的mtp家族蛋白mtpc4。
可选地,所述蛋白mtpc4的氨基酸序列如seqidno.2所示。
本发明还公开了一种玉米种子灌浆调控基因zmdef1的突变体,包括突变体zmdef1,zmdef1-1,zmdef1-2,zmdef1-3,zmdef1-4,zmdef1-5,zmdef1-6,分别在3-10号外显子上存在g>a的变异。
可选地,本发明以突变体zmdef1为实例,该突变体在4号外显子上存在一个g>a的变异,编码氨基酸由甘氨酸转变为天冬氨酸。
本发明还公开了一种含有上述的玉米种子灌浆调控基因zmdef1的表达载体。
本发明还公开了一种上述的调控玉米种子灌浆调控基因zmdef1在控制植株淀粉合成中的应用。
本发明还公开了一种上述的调控玉米种子灌浆调控基因zmdef1在经济作物育种改良领域中的应用。
与现有技术相比,本发明可以获得包括以下技术效果:
1)本发明克隆了一个新的调控玉米籽粒灌浆的编码mtp蛋白的基因zmdef1,同时获得了该基因的不同突变类型的突变体zmdef1,zmdef1-1,zmdef1-2,zmdef1-3,zmdef1-4,zmdef1-5,zmdef1-6,明确了zmdef1基因的不同类型的变异都会导致籽粒特定部位灌浆缺陷,造成玉米产量降低。
2)在同化器官中,该基因主要在叶绿体及线粒体中行使功能,在发育的籽粒中,该基因主要在基部胚乳转移层细胞(betl)中行使功能,其编码的蛋白mtpc4调控fe的转运,影响营养物质运输到籽粒中,进而影响淀粉相关合成酶的表达量,该基因突变后导致籽粒特定部位灌浆缺陷,产生灌浆缺陷型籽粒。
3)本发明zmdef1的编码区序列变异将导致mtpc4蛋白质的序列及功能出现问题,从而导致籽粒发育不正常,即出现灌浆缺陷籽粒,该基因可作为标记用于育种改良。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有技术效果。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明背景技术中的同化物产生运输及淀粉合成模式图;
图2是本发明背景技术中淀粉合成详细途径;
图3是本发明背景技术中opaque(o5)突变体表型;
图4是本发明背景技术中floury3(fl3)突变体表型;
图5是本发明背景技术中mn1及rgf1突变体表型及等位验证;
图6是本发明背景技术中zmsweet4c-umu1突变体表型;
图7是本发明zmdef1突变体表型;a-c为植株(a),果穗(b)和籽粒(c)的表型比较,每张图片的左侧为野生型,右侧为突变体zmdef1,三角形表示表型变异的位置;d为15dap的野生型和突变体的胚乳细胞碘染色,染色的颜色越深,淀粉含量越高;e和f分别为15dap的野生型和突变体的石蜡切片分析,聚集的小圆点为淀粉体,包围淀粉体的不规则形状为细胞轮廓(f,g);dap表示受精后天数;g和h分别代表15dap的野生型和突变体的表型差异部位的扫描电子显微镜成像;i代表成熟籽粒百粒重比较;星号表示野生型和突变体之间呈统计学显著性差异,**p<0.01;
图8是本发明石蜡切片观察籽粒发育;其中,a-f为野生型与zmdef1的形态结构对比;a为野生型8-dap;b为zmdef18-dap,c为野生型15-dap,d为zmdef115-dap,e为野生型成熟籽粒,f为zmdef1成熟籽粒;g-l为基部转运层的局部放大图,箭头指示基部转运层的位置,en为胚乳;em为胚;a-f中的bar=1mm,g-l中的bar=80um;
图9是本发明目标基因附近多态性引物筛选结果;
图10是本发明精细定位标记部分单株电泳结果;
图11是本发明zmdef1图位克隆及该基因不同变异类型突变体,其中,a为图位克隆获得的目标基因zmdef1,b为zmdef1转录本,箭头标注了该基因不同的变异位点,c为该基因的系列等位变异突变体果穗表型;bar=4cm;
图12是本发明突变体zmdef1变异位点及其等位变异位点测序,其中,a代表zmdef1变异位点及测序结果,b代表zmdef1的等位变异zmdef1-1,zmdef1-2,zmdef1-3,zmdef1-4,zmdef1-5,zmdef1-6的测序结果;
图13是本发明zmdef1表达模式分析,其中,a为qrt-pcr检测zmdef1在不同组织中的表达;b为zmdef1在玉米原生质体亚细胞定位,zmdef1与叶绿体及线粒体存在共定位,bar=10μm;c为6dap、8dap、12dap籽粒原位杂交结果,zmdef1在籽粒betl层中特异表达,bar=200μm;
图14是本发明fe胁迫处理野生型材料(a)及zmdef1突变体(b);
图15是本发明zmdef1及其突变体中淀粉合成相关基因的表达量分析;
图16是本发明zmdef1及其突变体授粉后不同时间段籽粒的淀粉含量差异;
图17是zmdef1及其突变体授粉后不同时间段及不同部位的可溶性糖含量差异。
具体实施方式
以下将配合实施例来详细说明本发明的实施方式,藉此对本发明如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。
实施例1zmdef1突变体表型观察
在大田育种过程中,发现一个纯合的籽粒灌浆缺口材料,将其命名为defectiveendospermfilling1(zmdef1)(图7),经多代自交发现其性状稳定,与野生型材料相比,突变体株型、果穗大小及籽粒大小未发生明显变化(图7a,7b)。但突变体籽粒顶部特定部位出现由籽粒灌浆缺陷导致的缺口,由于成熟籽粒该部位种皮下缺少糊粉层细胞及淀粉胚乳细胞而变成透明状(图7c)。将表型出现(15dap)时的籽粒纵切、横切后用ki染色(淀粉遇碘呈显色反应)发现,野生型淀粉积累较多,分布在籽粒胚乳不同部位的细胞中,而突变体淀粉积累较少,主要分布在籽粒顶部,籽粒中下部几乎无淀粉积累(图7d)。
细胞学观察发现,15dap材料的石蜡切片结果表明野生型该部位胚乳细胞淀粉较多(图7e),而突变体def1该部位淀粉积累较少,部分细胞无淀粉积累(图7f)。进一步进行扫描电镜发现,与野生型相比,def1胚乳细胞内的淀粉粒形态及大小并未发生明显改变(图7g,7h)。统计发现突变体籽粒百粒重较野生型显著下降(图7i)。由此可见,zmdef1突变后导致籽粒灌浆缺陷,粒重减小,但淀粉粒形态及大小并未发生明显改变。
对8dap、15dap及成熟籽粒进行石蜡切片观察,结果表明,与正常发育的野生型相比(图8a,8c,8e),突变体胚乳细胞在切片过程中更容易破碎(图8b,8d,8f),细胞结合不紧密。在籽粒发育8dap时,突变体(图8g)比野生型(图8h)的基部胚乳转移层的细胞壁更薄,在整个生育期突变体胚乳转移层的厚度都小于野生型(图8i-8l)。在籽粒发育的成熟期,野生型胚发育成熟,胚各部分的结构分化明显,且形态正常,突变体胚乳灌浆充实,结构整齐(图8e)。而突变体的肧及胚乳结构松散,切片时易破碎,未充实淀粉的部分胚乳细胞则随着籽粒成熟而凋亡消失,在籽粒顶部种皮下形成空腔,造成籽粒缺口表型(图8f)。
实施例2zmdef1突变基因的克隆
(1)构建定位群体:本发明构建了两个初级定位群体用于基因定位,将zmdef1与b73杂交后的f1自交获得f2分离群体,经表型鉴定共确定粒569个与突变体表型一致的籽粒,正常籽粒为1623粒,经卡方检验(χ2)可知,其χ2c=1.0225<3.84χ2(0.05,1),差异不显著,符合单基因控制的孟德尔分离定律。同时将f1材料与zmdef1回交构建bc群体,经表型鉴定共确定了362个与突变体表型一致的籽粒,正常籽粒为401粒,经卡方检验(χ2)可知,其χ2c=1.8925<3.84χ2(0.05,1),差异不显著,符合单基因控制的孟德尔分离定律,该突变表型为单基因控制的隐性性状。
(2)突变体bsa混池筛选
设计合成基因组ssr引物(表1),利用b73及def1作为亲本筛选,选出亲本有差异的多态性引物。提取b73与def1定位群体单株的dna,选择20株隐性单株(突变表型)dna构建混池,同时提取b73与def1定位群体20株正常表型单株dna构建混池,利用b73、def1、隐性混池、显性混池用于筛选多态标记。选择隐性混池与def1带型一致的共显性分子标记ssr-3、ssr-4、ssr-5、ssr-6、ssr-171、ssr-172(图9),这些标记与目标基因连锁。
表1目标基因附近多态性引物序列
(3)突变体基因定位
用筛选到的bsa连锁的ssr标记检测了93个f2定位群体单株,统计f2群体交换率,将基因初步定位在ssr-5(2.68%)与ssr-6(1.07%)之间。在这两个标记之间开发新标记(表2),扩大定位群体单株数(931株),pcr扩增及电泳检测f2交换情况,部分单株电泳结果见(图10),最终将区段定位在id-8162(0.054%)至id-8225(0.107%)之间,区段大小为631.26kb(图7a)。
表2精细定位分子标记
(4)突变基因克隆
根据定位结果发现搜索区段内编码基因,发现区段内共有4个orfs,分别为zm00001d004090,zm00001d004091,zm00001d004092,zm00001d004093(图11a),设计引物扩增、测序,序列比对发现4个orfs仅zm00001d004091的4号外显子存在一个g>a的变异(图12a),该变异使编码氨基酸由甘氨酸转变为天冬氨酸,推测该基因即为导致突变体籽粒灌浆缺陷表型的基因zmdef1。zmdef1注释为mtpc4(metaltoleranceproteinc4),全长28078bp,共6个转录本,最长转录本共有1754bp(其核苷酸序列如seqidno.1所示),编码含474个氨基酸(其氨基酸序列如seqidno.2所示)的金属耐受蛋白(图11b),属于mtp家族。同时在ems库中还筛选到一系列表型类似突变体,通过遗传学验证及分子扩增发现6个zmdef1的alleles(def1-1--def1-6),其中def1-1与def1-4为无义突变。这些等位变异分布在不同的外显子上,大多位于基因的前半部分(图12b)。突变后表型与def1类似,出现灌浆缺陷导致的缺口(图11c)。
实施例3zmdef1的表达分析
利用qrt-pcr分析zmdef1基因及其突变体zmdef1在玉米不同组织的表达情况。zmdef1为组成型表达基因,根、叶及发育中的种子里,zmdef1基因都有表达,在叶、根及授粉后13dap、15dap的种子之中表达量较高,而在该基因的突变体def1中均有不同程度的降低,尤其是在叶、根及发育早期的籽粒中有显著降低(图13a)。
将该基因连接到含有gfp标签的亚细胞定位载体pm999中,转化玉米原生质体,观察其定位信号。实验证明zmdef1蛋白定位于叶绿体及线粒体上(图13b),推测其在叶绿体和线粒体中发挥功能。
取授粉后不同时间点的籽粒,设计探针进行原位杂交。结果表明,在授粉后第6-12天,zmdef1高表达且在种子的基部胚乳转移层(betl)呈特异表达(图13c)。
实施例4zmdef1突变前后对fe胁迫的反应
对苗龄5-7天的幼苗进行fe胁迫处理,对照组以不含糖的1/2ms液体培养基培养,实验组再添加500μm的铁盐,正常光周期,28℃条件下胁迫下3-4天。结果发现,在野生型材料zmdef1中,fe处理前后差异不明显,但主根长微短于对照(图14a),而在zmdef1突变体中,施用500μm的铁盐会显著抑制根系发育及主根伸长(图14b)。
实施例5zmdef1突变后对淀粉合成相关基因的影响
取授粉后9dap、11dap、13dap、15dap、18dap、20dap的籽粒每组2重复送至诺禾致源进行rna-seq分析,结果表明,9dap-20dap籽粒发育的过程中,大部分淀粉合成基因表达量随时间的增加而上升,但是所有时期中,突变体zmdef1中各主要淀粉合成相关基因的表达量均显著低于野生型。意味着在籽粒生长发育的全时期内,zmdef1突变后淀粉合成相关基因的表达均受到显著抑制(图15a),取15dap籽粒进行定量验证,发现结果与rnaseq测序一致,突变体zmdef1中淀粉合成相关基因的表达均呈显著下调表达(图15b)。
实施例6zmdef1突变后对植株不同部位糖及淀粉影响:
测量了野生型和突变体zmdef1授粉后不同时间点的籽粒的淀粉含量(图16),结果发现,在授粉后15dap及20dap时,籽粒的淀粉含量差异较大,突变体zmdef1籽粒中淀粉含量显著低于野生型。测量了野生型和突变体zmdef1授粉后不同时期的不同部位的可溶性糖含量(图17),结果发现,从15dap(灌浆期)开始,突变体zmdef1的可溶性糖在茎秆、果穗及籽粒中一直保持高于野生型的水平,30dap时,除叶片外,突变体所有部位的可溶性糖含量均高于野生型。由此可知,在野生型zmdef1的茎秆、果穗及籽粒中可溶性糖含量均呈下降趋势,说明野生型中有大量淀粉合成,造成可溶性糖被充分利用,而突变体各部位的可溶性糖呈稳定或上升趋势,表明突变体淀粉合成减少,糖需求量降低,造成各个部位糖的累积。
结合前期rna-seq结果及原位杂交结果发现,所有淀粉合成酶表达量在突变体中均下降,zmdef1在籽粒基部胚乳转移层高表达。由此可推测,野生型和突变体均能正常利用光合同化co2产生同化的糖并通过韧皮部转移到籽粒,但由于在基部胚乳转移层特异性表达的zmdef1发生变异,使糖类不能充分进入籽粒中,植物则相应做出了调节,降低了籽粒淀粉合成的各类酶的含量,造成突变体糖分的积累,由于淀粉合成相关酶含量降低,进一步加剧了糖分的累积,造成突变体各部位可溶性糖含量显著高于野生型。
综上,本发明鉴定并克隆了mtp家族基因zmdef1,并表明了其通过影响fe离子转运调控籽粒灌浆,影响籽粒粒重。zmdef1主要在籽粒基部胚乳转移层表达,参与fe的转运,突变后导致叶片产生的可溶性糖不能充分进入籽粒用于籽粒淀粉合成,导致灌浆后期各部位可溶性糖积累,进一步导致籽粒淀粉合成相关酶含量下降,表明其可能通过调控玉米的糖同化及转运、籽粒淀粉合成及积累的方式影响籽粒灌浆。
上述说明示出并描述了发明的若干优选实施例,但如前所述,应当理解发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离发明的精神和范围,则都应在发明所附权利要求的保护范围内。
序列表
<110>山东农业大学四川农业大学
<120>一种玉米种子灌浆调控基因zmdef1及应用
<130>2018
<160>30
<170>siposequencelisting1.0
<210>1
<211>1754
<212>dna
<213>玉米(corn)
<400>1
agtctcggagagtcgctccgaggaatgggagtcgtgccccaccggcggcagcagcaccgg60
tgacgccggcacgcctaaatgcgtcgtcccctcgcctctgcggccctccgcctccgcttc120
ttctcttccacctcccctgcccgccttctctcgccctgcccattccttctatcccgccgt180
gacgacgacggcggccgcgaggcctcctcgtcgccgctgcccccgctcccgccttctggc240
tcggctttctccccacgcccgctcctcttctctgcatcagctgccgcgggcctcttcagc300
ctccatggcgggtggtggaggcaggctcttcctcctgcagcgtcgcggcccctcggctcc360
gtctctgacgcagctcccgtccggctcaccatctcccgcagttattctctgcgtgtggcc420
aagggcaagaagaaagcacattttgacgatgaacacagccatcgagcggttaacatggca480
ctatggtgcaacttcctcgttttctccctaaagtttggagtgtggatttcaacttcaagt540
catgttatgctagctgagcttgtgcattctgttgcagactttgctaaccaggctcttctt600
gcttatggtttgagcagctcaagacgtgctccagatgctctacacccctatggttattct660
aaggaaagatttgtatggtctctcatatctgcagttggaatattttgcttgggttccggt720
gctacaattgtgcatggagttcaaaatttatggaattctcatcctccagagaatattcac780
tgggctgcattagtgattggtgggtccttcctaattgaaggtgcttcactgcttgttgct840
ataaaggctgttaggaaaggtgcagaagcagagggaatgagtatctgggactatatctgg900
cgtggtcatgatccaacttccgttgctgttatgactgaagatggtgctgctgttacaggc960
cttgctattgctgcagcatctttggtagctgttcaaatgacaggaaatgctatgtatgat1020
ccaattggctcaatcattgttggcaatttactggggatggttgctatttttctcattcag1080
aggaataggcatgctttaattggccgggccattgatgatcatgacatgcaacgagtcctt1140
gaatttctgaagtctgatccggttgtagatgctctttatgattgcaaaagtgaggtgatt1200
gggccaggtttttttagattcaaggctgaaattgatttcaatggagttgttctggtacaa1260
aattatttggaaaggactggacgtgggagttgggcaaaacagttccgggaagctgcaatg1320
tccaaggatgatacggaattgctaagggtcatggccaactacggggaggatgtagttgaa1380
gctctgggatatgaagtggatcggctggagtctgagatccaaaagcttgtgcctgggatt1440
aaacatgttgacatcgaggcacacaatcccgaaggacttgctcttagagcagaagttttg1500
tagattacctgtgtacattgcatttgattaacactgttgctggtcgctgccagtttgatt1560
tgggtccaccaccattcgataagattgtcttccattggcaatgtaagaatcagatggctg1620
ttgttgcgtagcgaggcggtatttttatttggaagaagacgtggtcgcgcctgacatgga1680
aggctttatgttcaaggttggcatcagtatgtatttttgccttgcgatgcagtcccataa1740
gtattactccctcc1754
<210>2
<211>474
<212>prt
<213>玉米(corn)
<400>2
metargargproleualaseralaalaleuargleuargphepheser
151015
serthrserproalaargleuleuserprocyspropheleuleuser
202530
argargaspaspaspglyglyargglualaserserserproleupro
354045
proleuproproserglyseralapheserproargproleuleuphe
505560
seralaseralaalaalaglyleupheserleuhisglyglytrptrp
65707580
argglnalaleuproproalaalaserargproleuglyservalser
859095
aspalaalaprovalargleuthrileserargsertyrserleuarg
100105110
valalalysglylyslyslysalahispheaspaspgluhisserhis
115120125
argalavalasnmetalaleutrpcysasnpheleuvalpheserleu
130135140
lyspheglyvaltrpileserthrserserhisvalmetleualaglu
145150155160
leuvalhisservalalaaspphealaasnglnalaleuleualatyr
165170175
glyleuserserserargargalaproaspalaleuhisprotyrgly
180185190
tyrserlysgluargphevaltrpserleuileseralavalglyile
195200205
phecysleuglyserglyalathrilevalhisglyvalglnasnleu
210215220
trpasnserhisproprogluasnilehistrpalaalaleuvalile
225230235240
glyglyserpheleuilegluglyalaserleuleuvalalailelys
245250255
alavalarglysglyalaglualagluglymetseriletrpasptyr
260265270
iletrpargglyhisaspprothrservalalavalmetthrgluasp
275280285
glyalaalavalthrglyleualailealaalaalaserleuvalala
290295300
valglnmetthrglyasnalamettyraspproileglyserileile
305310315320
valglyasnleuleuglymetvalalailepheleuileglnargasn
325330335
arghisalaleuileglyargalaileaspasphisaspmetglnarg
340345350
valleuglupheleulysseraspprovalvalaspalaleutyrasp
355360365
cyslyssergluvalileglyproglyphepheargphelysalaglu
370375380
ileasppheasnglyvalvalleuvalglnasntyrleugluargthr
385390395400
glyargglysertrpalalysglnpheargglualaalametserlys
405410415
aspaspthrgluleuleuargvalmetalaasntyrglygluaspval
420425430
valglualaleuglytyrgluvalaspargleuglusergluilegln
435440445
lysleuvalproglyilelyshisvalaspileglualahisasnpro
450455460
gluglyleualaleuargalagluvalleu
465470
<210>3
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>3
attggaaggatctgcgtgac20
<210>4
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>4
cagctggtggactgcatcta20
<210>5
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>5
cctagcatttacgcggaggag21
<210>6
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>6
ctggtccgaggtctcgtcttc21
<210>7
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>7
gggacaaaagaagaagcagag21
<210>8
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>8
gaaatgggacagagacagacaat23
<210>9
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>9
gagataagcttcgccctgtacctc24
<210>10
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>10
ctcatcgcgatctcccagtc20
<210>11
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>11
agttagcatcttcattccttggt23
<210>12
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>12
tgacaacagtaagggcgacg20
<210>13
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>13
gcattcaaacgcccataaaagc22
<210>14
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>14
acggtaagtgatagtgtggtgt22
<210>15
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>15
catttgggcattagcataacacag24
<210>16
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>16
agtgtcggttactgagctttct22
<210>17
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>17
ttctgcggttgactctccac20
<210>18
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>18
tagcgctaccaagagcaacc20
<210>19
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>19
aagcgacagttggtttcagttttc24
<210>20
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>20
agttgcatgaccttgtcaaccttt24
<210>21
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>21
ctgggcatacaaagctcaca20
<210>22
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>22
tgcataaaccgtttccacaa20
<210>23
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>23
atgtgacaagtttggccggg20
<210>24
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>24
acccacatgggttttcctcct21
<210>25
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>25
agcacctaacagacaacaggatt23
<210>26
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>26
tggtgggtccttcctaattgaag23
<210>27
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>27
acaacaaatcactgcagaagatct24
<210>28
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>28
acggtaacttttcccctctatcg23
<210>29
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>29
atgaattcggtaccgagctcatgcgtcgtcccctcgc37
<210>30
<211>38
<212>dna
<213>人工序列(artificialsequence)
<400>30
cccatggctctagagagctcacacatccccagtaaatt38
- 还没有人留言评论。精彩留言会获得点赞!