源自鲎属的重组蛋白及编码该重组蛋白的DNA的制作方法
源自鲎属的重组蛋白及编码该重组蛋白的dna
1.本技术是基于申请号201780055566.6、申请日2017年10月18日、发明名称为“源自鲎属的重组蛋白及编码该重组蛋白的dna”的发明专利申请的分案申请。
技术领域
2.本发明涉及源自鲎属的重组蛋白、编码该重组蛋白的dna及这些的利用方法。本发明还涉及内毒素检测剂的制造方法。
背景技术:
3.鲎被称为“活化石”,在地球上仅存在2属4种。作为属,仅有仅栖息于北美大陆东海岸的“鲎(limulus)属”、和仅栖息于亚洲东南海域的“鲎(tachypleus)属”。一个生物群在彼此远离的地域分开分布的现象被称为不连续分布,如鲎那样被分在地球上的2个地域的生物非常珍贵。
4.属于鲎(limulus)属的生物仅有美洲鲎(limulus polyphemus)1种,属于鲎(tachypleus)属的生物仅有中国鲎(tachypleus tridentatus)、巨鲎(tachypleus gigas)、东南亚鲎(tachypleus rotundicauda。也被称为圆尾鲎(carcinoscorpius rotundicauda))这3种。
5.已知存在于该生物的血中的变形细胞(amoebocyte)的提取物(阿米巴细胞溶解产物。amoebocyte lysate)在与内毒素接触时会凝固。利用该性质,阿米巴细胞溶解产物作为以高灵敏度检测内毒素的试剂被广泛用于医药品的品质管理等。
6.该试剂被称为“lysate试剂”。另外,由于内毒素而产生凝固的性质最初在美洲鲎中被发现,因此,该试剂有时被称为“鲎试剂”或“lal(limulus amoebocyte lysate)试剂”。即使使用有鲎(tachypleus)属的阿米巴细胞溶解产物的试剂,也习惯性称为“鲎试剂”或“lal试剂”。
7.目前,日欧美的医药品厂商所使用的lysate试剂(鲎试剂、lal试剂)以美洲鲎为原料。也报道有因担心灭绝而严格地限制美洲鲎捕获数,但个体数依然在减少。
8.为了保护鲎,有利用重组技术人工地制造阿米巴细胞溶解产物中的蛋白质、制作试剂的思想(专利文献1~8)。而且,实际上,利用重组蛋白的pyrogene(商标)(lonza)、endozyme(商标)(hyglos)、pyrosmart(商标)(生物化学工业)这样的制品已经上市。
9.但是,这些均使用了源自鲎(tachypleus)属生物的重组蛋白,没有报道使用源自作为lysate试剂广泛普及的美洲鲎的重组蛋白的试剂。
10.其理由是因为,美洲鲎中与由于内毒素而产生凝固的机制有关的蛋白质及其基因在结构上和功能上均没有完全得到鉴定。
11.在鲎(tachypleus)属中,例如关于与凝固机制有关的蛋白质之一的c因子,1991年报道了源自中国鲎的完整的基因序列及氨基酸序列(非专利文献1)、1995年报道了源自东南亚鲎(圆尾鲎)的完整的基因序列及氨基酸序列(非专利文献2)。
12.但是,在美洲鲎中,即使距离所述鲎(tachypleus)属的报道已经有20年以上,这些
蛋白质及基因的结构及功能这两方面的完整的鉴定上也没有获得成功。这是因为,起因于鲎的属或种的差异导致的生物体分子的各种差异或多样性等,用一般的方法不能进行这些蛋白质及基因的全长序列结构的准确的确定、表达、及功能阐明。
13.目前,作为使用有新一代测序仪的无脊椎动物基因组计划的一环,正在进行美洲鲎的基因的网络的分析(http://genome.wustl.edu/genomes/detail/limulus-polyphemus/),但没有实现与美洲鲎的凝固机制有关的全部的蛋白质及基因的全长序列的阐明。该事实也证明美洲鲎中的这些蛋白质及基因的全长序列结构的准确确定的困难性。现有技术文献专利文献
14.专利文献1:美国专利第5,712,144号说明书专利文献2:美国专利第5,716,834号说明书专利文献3:美国专利第5,858,706号说明书专利文献4:美国专利第5,985,590号说明书专利文献5:美国专利第6,645,724号说明书专利文献6:国际公开第2008/004674号专利文献7:日本特表2014-510898号公报专利文献8:国际公开第2014/092079号非专利文献
15.非专利文献1:muta t et al.,journal of biological chemistry,266,6554-6561(1991)非专利文献2:ding jl et al.,molecular marine biology and biotechnology,4(1),90-103(1995)
技术实现要素:
发明所要解决的技术问题
16.本发明的课题在于,提供与美洲鲎的凝固机制有关的全部的全长重组蛋白、编码这些重组蛋白的cdna、这些重组蛋白的用途。用于解决问题的技术方案
17.本发明人在一直无人成功的编码与美洲鲎的凝固机制有关的全部的蛋白质因子的全长cdna的取得、及其全部的重组蛋白的表达上获得成功,进而发现这些可以利用于各种用途,从而完成了本发明。
18.即,本发明包含以下的方式。[1]一种重组蛋白等重组第1蛋白质,其为以下的任一种。(a)含有序列号2或4所示的氨基酸序列的重组蛋白。(b)含有相对于序列号2或4所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有c因子活性的重组蛋白。(c)由含有相对于序列号1或3所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有c因子活性的重组蛋白。(d)由以下dna编码且具有c因子活性的重组蛋白,所述dna与包含序列号1或3所示
的碱基序列的互补序列的dna在严格的条件下进行杂交。[2]一种重组蛋白等重组第2蛋白质,其为以下的任一种。(a)含有序列号6、8、10、或12所示的氨基酸序列的重组蛋白。(b)含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有b因子活性的重组蛋白。(c)由含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有b因子活性的重组蛋白。(d)由以下dna编码且具有b因子活性的重组蛋白,所述dna与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交。[3]一种重组蛋白等重组第3蛋白质,其为以下的任一种。(a)含有序列号14、16、18、20、或22所示的氨基酸序列的重组蛋白。(b)含有相对于序列号14、16、18、20、或22所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有凝固酶原活性的重组蛋白。(c)由含有相对于序列号13、15、17、19、或21所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有凝固酶原活性的重组蛋白。(d)由以下dna编码且具有凝固酶原活性的重组蛋白,所述dna与包含序列号13、15、17、19、或21所示的碱基序列的互补序列的dna在严格的条件下进行杂交。[1-1]一种重组第1蛋白质的、用于活化具有b因子活性的蛋白质(例如以下的蛋白质等第2蛋白质)的应用。(a)含有序列号6、8、10、或12所示的氨基酸序列的蛋白质。(b)含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有b因子活性的蛋白质。(c)由含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有b因子活性的蛋白质。(d)由以下dna编码且具有b因子活性的蛋白,所述dna与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交。[1-1-1]一种[1-1]所述的应用,其中,第2蛋白质为重组第2蛋白质。[2-1]一种重组第2蛋白质的、用于活化具有凝固酶原活性的蛋白质(例如以下的蛋白质等第3蛋白质)的应用。(a)含有序列号14、16、18、20、或22所示的氨基酸序列的蛋白质。(b)含有相对于序列号14、16、18、20、或22所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有凝固酶原活性的蛋白质。(c)由含有相对于序列号13、15、17、19、或21所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有凝固酶原活性的蛋白质。(d)由以下dna编码且具有凝固酶原活性的蛋白质,所述dna与包含序列号13、15、17、19、或21所示的碱基序列的互补序列的dna在严格的条件下进行杂交。[2-1-1]根据[2-1]所述的应用,其中,第3蛋白质为重组第3蛋白质。
[3-1]一种重组第3蛋白质应用,用于将底物切断。[3-1-1]根据[3-1]所述的应用,其中,底物为合成底物。[1-2]一种被检体中的内毒素的检测方法,其包含使重组第1蛋白质与被检体接触的步骤。[1-2-1]根据[1-2]所述的方法,其还包含:使与被检体接触后的重组第1蛋白质与第2蛋白质等具有b因子活性的蛋白质接触的步骤。[1-2-1-1]根据[1-2-1]所述的方法,其中,第2蛋白质为重组第2蛋白质。[1-2-2]根据[1-2-1]或[1-2-1-1]所述的方法,其还包含如下步骤:使与“与被检体接触后的重组第1蛋白质”接触后的具有b因子活性的蛋白质与第3蛋白质等具有凝固酶原活性的蛋白质接触。[1-2-2-1]根据[1-2-2]所述的方法,其中,第3蛋白质为重组第3蛋白质。[1-2-3]根据[1-2-2]或[1-2-2-1]所述的方法,其还包含如下步骤:使与“与被检体接触后的重组第1蛋白质接触后的具有b因子活性的蛋白质”接触后的具有凝固酶原活性的蛋白质与检测用底物接触。[1-3]一种内毒素检测剂,其含有重组第1蛋白质。[1-3-1]根据[1-3]所述的试剂,其还包含第2蛋白质等具有b因子活性的蛋白质。[1-3-1-1]根据[1-3-1]所述的试剂,其中,第2蛋白质为重组第2蛋白质。[1-3-2]根据[1-3-1]或[1-3-1-1]所述的试剂,其还包含第3蛋白质等具有凝固酶原活性的蛋白质。[1-3-2-1]根据[1-3-2]所述的试剂,其中,第3蛋白质为重组第3蛋白质。[1-4]一种cdna(以下,也称为“第1cdna”),其为以下的任一种。(a)含有序列号1或3所示的碱基序列的cdna。(b)含有相对于序列号1或3所示的碱基序列具有95%以上的同源性的碱基序列、且编码具有c因子活性的蛋白质的cdna。(c)与包含序列号1或3所示的碱基序列的互补序列的dna在严格的条件下进行杂交,且编码具有c因子活性的蛋白质的cdna。(d)编码含有序列号2或4所示的氨基酸序列的蛋白质的cdna。(e)编码含有相对于序列号2或4所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有c因子活性的蛋白质的cdna。[1-4-1]一种dna构建物,其含有第1cdna。[1-4-2]一种细胞,其被[1-4-1]所述的dna构建物转化而表达重组第1蛋白质。[1-4-3]一种重组第1蛋白质的生产方法,其包含将[1-4-2]所述的细胞进行培养的步骤。
[2-4]一种cdna(以下,也称为“第2cdna”),其为以下的任一种。(a)含有序列号5、7、9、或11所示的碱基序列的cdna。(b)含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列、且编码具有b因子活性的蛋白质的cdna。(c)与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交、且编码具有b因子活性的蛋白质的cdna。(d)编码含有序列号6、8、10、或12所示的氨基酸序列的蛋白质的cdna。(e)编码含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有b因子活性的蛋白质的cdna。[2-4-1]一种dna构建物,其含有第2cdna。[2-4-2]一种细胞,其被[2-4-1]所述的dna构建物转化而表达重组第2蛋白质。[2-4-3]一种重组第2蛋白质的生产方法,其包含将[2-4-2]所述的细胞进行培养的步骤。[3-4]一种cdna(以下,也称为“第3cdna”),其为以下的任一种。(a)含有序列号13、15、17、19、或21所示的碱基序列的cdna。(b)含有相对于序列号13、15、17、19、或21所示的碱基序列具有95%以上的同源性的碱基序列、且编码具有凝固酶原活性的蛋白质的cdna。(c)与包含序列号13、15、17、19、或21所示的碱基序列的互补序列的dna在严格的条件下进行杂交、且编码具有凝固酶原活性的蛋白质的cdna。(d)编码含有序列号14、16、18、20、或22所示的氨基酸序列的蛋白质的cdna。(e)编码含有相对于序列号14、16、18、20、或22所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有凝固酶原活性的蛋白质的cdna。[3-4-1]一种dna构建物,其含有第3cdna。[3-4-2]一种细胞,其被[3-4-1]所述的dna构建物转化而表达重组第3蛋白质。[3-4-3]一种重组第3蛋白质的生产方法,其包含将[3-4-2]所述的细胞进行培养的步骤。[1-5]一种内毒素检测剂的制造方法,其包含使用第1cdna人工地使蛋白质表达的步骤。[1-5-1]根据[1-5]所述的制造方法,其还包含使用第2cdna人工地使蛋白质表达的步骤。[1-5-2]根据[1-5-1]所述的制造方法,其还包含使用第3cdna人工地使蛋白质表达的步骤。
附图说明
[0019]
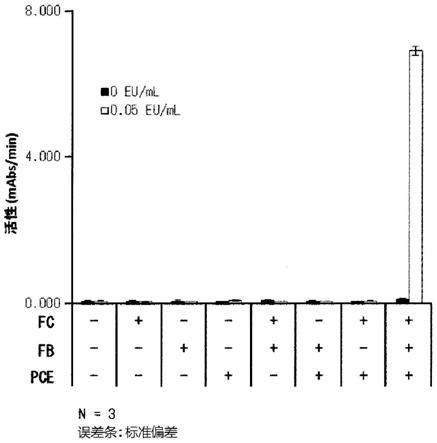
图1是美洲鲎的具有c因子活性的蛋白质的cdna取得过程中的pcr产物的电泳照片。图2是美洲鲎的具有c因子活性的蛋白质的cdna取得过程中的pcr产物的电泳照片。图3是表示各重组蛋白的单品或各种混合物与内毒素的接触所引起的合成底物的
切断活性的图。图4是表示使用3种的重组蛋白的混合物的内毒素的标准曲线的图。
具体实施方式
[0020]
<1>重组第1蛋白质及其制造方法(1)重组第1蛋白质重组第1蛋白质为具有c因子活性的重组蛋白。
[0021]
重组第1蛋白质具体而言为以下的任一种重组蛋白。(i)含有美洲鲎的具有c因子活性的蛋白质的氨基酸序列的重组蛋白。(ⅱ)为上述(i)的变体、且具有c因子活性的重组蛋白。
[0022]
作为美洲鲎的具有c因子活性的蛋白质的氨基酸序列,可举出序列号2或4所示的氨基酸序列。另外,作为编码这种氨基酸序列的碱基序列,可举出序列号1或3所示的碱基序列。
[0023]
重组第1蛋白质更具体而言可以为以下的任一种重组蛋白。(a)含有序列号2或4所示的氨基酸序列的重组蛋白。(b)含有相对于序列号2或4所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有c因子活性的重组蛋白。(c)由含有相对于序列号1或3所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有c因子活性的重组蛋白。(d)由以下dna编码且具有c因子活性的重组蛋白,所述dna与包含序列号1或3所示的碱基序列的互补序列的dna在严格的条件下进行杂交。
[0024]
需要说明的是,“含有氨基酸序列”或“含有碱基序列”这样的表现也包含该“由氨基酸序列构成的”情况或该“由碱基序列构成的”情况。
[0025]
该蛋白质通过本说明书的实施例中所公开的方法在世界上首次取得,其全长的序列结构及功能也首次明确。其功能为如下功能:在内毒素的存在下成为活性型,使后述的第2蛋白质等具有b因子活性的蛋白质变化为活性型(本技术文件中称为“c因子活性”)。重组第1蛋白质可以是至少在与重组第2蛋白质等第2蛋白质的组合中显示c因子活性的蛋白质。
[0026]
具有c因子活性这一点可以如下确认:在将成为对象的重组蛋白与第2蛋白质(没有成为活性型的蛋白质。以下称为“非活性型”)等具有b因子活性的蛋白质(非活性型)、第3蛋白质(非活性型)等具有凝固酶原活性的蛋白质(非活性型)、及检测用底物组合时,检测在内毒素存在下的级联反应的进行。
[0027]“级联反应”是指:具有c因子活性的蛋白质(非活性型)被内毒素活化、具有b因子活性的蛋白质(非活性型)被具有c因子活性的蛋白质(活性型)活化、具有凝固酶原活性的蛋白质(非活性型)被具有b因子活性的蛋白质(活性型)活化的一系列的反应。级联反应的进行可以通过检测用底物的切断而检测。
[0028]
重组第1蛋白质中,最优选的是上述(a)的重组蛋白等上述(i)的重组蛋白,但只要具有c因子活性,则可以为这些重组蛋白的变体。
[0029]
变体例如可以为包含在如上所述的重组第1蛋白质的氨基酸序列(例如序列号2或4所示的氨基酸序列)中含有1个或数个位置上的1个或数个氨基酸的置换、缺失、插入和/或
添加的氨基酸序列、且具有c因子活性的重组蛋白。上述“1个或数个”例如可以为1~20个、1~10个、1~5个、或1~3个。上述的1个或数个氨基酸的置换、缺失、插入、和/或添加为蛋白质的功能维持正常的保守变异。保守变异的代表的例子为保守置换。就保守置换而言,例如在置换部位为芳香族氨基酸的情况下,为在phe、trp、tyr间相互置换的变异,在置换部位为疏水性氨基酸的情况下,为在leu、ile、val间相互置换的变异,在置换部位为极性氨基酸的情况下,为在gln、asn间相互置换的变异,在置换部位为碱基性氨基酸的情况下,为在lys、arg、his间相互置换的变异,在置换部位为酸性氨基酸的情况下,为在asp、glu间相互置换的变异,在置换部位为具有羟基的氨基酸的情况下,为在ser、thr间相互置换的变异。作为被看作保守置换的置换,具体而言,可举出:从ala向ser或thr的置换;从arg向gln、his或lys的置换;从asn向glu、gln、lys、his或asp的置换;从asp向asn、glu或gln的置换;从cys向ser或ala的置换;从gln向asn、glu、lys、his、asp或arg的置换;从glu向gly、asn、gln、lys或asp的置换;从gly向pro的置换;从his向asn、lys、gln、arg或tyr的置换;从ile向leu、met、val或phe的置换;从leu向ile、met、val或phe的置换;从lys向asn、glu、gln、his或arg的置换;从met向ile、leu、val或phe的置换;从phe向trp、tyr、met、ile或leu的置换;从ser向thr或ala的置换;从thr向ser或ala的置换;从trp向phe或tyr的置换;从tyr向his、phe或trp的置换;及从val向met、ile或leu的置换。
[0030]
另外,变体例如可以为含有相对于如上所述的重组第1蛋白质的氨基酸序列(例如序列号2或4所示的氨基酸序列)具有80%以上、90%以上、95%以上、96%以上、97%以上、98%以上、99%以上的同源性的氨基酸序列、且具有c因子活性的重组蛋白。
[0031]
另外,变体例如可以为由以下dna编码且具有c因子活性的重组蛋白,所述dna含有相对于编码如上所述的重组第1蛋白质的氨基酸序列的碱基序列(例如序列号1或3所示的碱基序列)具有80%以上、90%以上、95%以上、96%以上、97%以上、98%以上、99%以上的同源性的碱基序列。
[0032]
另外,变体例如可以为由以下dna编码且具有c因子活性的重组蛋白,所述dna与包含编码如上所述的重组第1蛋白质的氨基酸序列的碱基序列(例如序列号1或3所示的碱基序列)的互补序列的dna在严格的条件下进行杂交。“严格的条件”是指:通过t.maniatis等编、molecular cloning:a laboratory manual 2nd ed.(1989)cold spring harbor laboratory等中记载的通常的杂交操作而形成所谓的特异性的杂合体、不形成非特异性的杂合体的条件。“严格的条件”具体而言是指:钠盐浓度为15~750mm、优选50~750mm、更优选300~750mm、温度为25~70℃、优选50~70℃、更优选55~65℃、甲酰胺浓度为0~50%、优选20~50%、更优选35~45%下的条件。进而,在严格的条件下,杂交后的过滤器的清洗条件通常钠盐浓度为15~600mm、优选50~600mm、更优选300~600mm、温度为50~70℃、优选55~70℃、更优选60~65℃。
[0033]
作为变体,具体而言,优选上述(b)~(d)的重组蛋白。上述(b)及(c)中的“95%以上”为优选96%以上、更优选97%以上、更优选98%以上、更优选99%以上。
[0034]
另外,重组第1蛋白质只要具有c因子活性,则可以添加his标签、v标签等任意的肽等。
[0035]
另外,本技术文件中,“重组蛋白”是指:通过将编码蛋白质的基因人工地导入于鲎以外的宿主细胞并使其表达而得到的蛋白质。因此,从天然的鲎中所取得的蛋白质本身不
属于本技术文件中的“重组蛋白”。
[0036]
(2)重组第1蛋白质的制法就重组第1蛋白质而言,由于本发明首次公开了其完整的氨基酸序列,因此,例如可以使用编码该序列的dna、利用基因工程的方法来制造。利用基因工程的方法制造重组第1蛋白质的方法没有特别限制,例如可以采用利用基因工程的方法制造蛋白质的通常的方法。重组第1蛋白质例如可以利用异源表达系统或无细胞蛋白质合成系统而制造。
[0037]
例如,可以通过将后述的第1cdna人工地导入于鲎以外的宿主细胞、由该cdna表达蛋白质而制造重组第1蛋白质。本发明也提供这种重组第1蛋白质的制造方法。
[0038]
在宿主细胞中人工地导入dna时,可以使用人工地重组有该dna的dna构建物(载体等)。作为这种人工的dna构建物,可以例示例如重组有第1cdna的dna构建物。关于这种人工的dna构建物,容后说明。
[0039]
就鲎以外的宿主细胞而言,只要可以由第1cdna使蛋白质有功能地(functionally)进行表达,就没有特别限定。作为鲎以外的宿主细胞,可举出例如哺乳类细胞或昆虫细胞。作为哺乳类,可举出啮齿类或灵长类。作为啮齿类,可举出中国仓鼠、仓鼠、小鼠、大鼠、天竺鼠。作为中国仓鼠的细胞,可举出例如源自中国仓鼠卵巢的细胞株(cho)。作为cho,可举出cho dg44、cho s或cho k1。作为灵长类,没有特别限制,可举出人、猴子、黑猩猩。作为人的细胞,可举出源自人胎儿肾细胞的细胞株(hek)。作为hek,可举出hek293。
[0040]“有功能地进行表达”是指所表达的重组第1蛋白质显示c因子活性。显示c因子活性可以通过后述的实施例中记载的方法来确认。另外,所表达的蛋白质是否含有上述(a)~(d)的任一种结构等目标氨基酸序列,可以通过对所表达的蛋白质的氨基酸序列进行分析、将其与目标氨基酸序列进行比较来确认。
[0041]
将第1cdna人工地导入于宿主细胞的方法也只要该cdna在宿主细胞内以可表达的方式保持的状态,就没有特别限制。通过人工地使导入有第1cdna的宿主细胞生长,可以使重组第1蛋白质表达。
[0042]
转化后的宿主细胞的生长例如可以通过将该细胞进行培养而进行。此时的培养条件也只要该细胞可以生长或増殖,就没有特别限定,可以根据需要适当修正通常用于该细胞的培养的条件而使用。例如,在宿主细胞为哺乳类细胞的情况下,可以使用通常用于哺乳类细胞的培养的培养基。作为这种培养基,可以使用例如rpmi1640培养基(sigma社)、dmem培养基(sigma社)或expi cho
tm expression medium(thermo fisher scientific)等。例如可以在36℃~38℃、5%~8%co2供给下通过静置培养或悬浮培养等而进行培养。可以使用蛋白质表达专用的试剂盒。
[0043]
表达的重组第1蛋白质作为含有其的溶液组分进行回收,可以利用于后述的各种用途。
[0044]
含有重组第1蛋白质的溶液组分例如可以为培养液、培养上清液、细胞破碎提取物、或它们的混合物等。重组第1蛋白质可以纯化成所期望的程度而使用,也可以不进行纯化而直接使用。
[0045]
可以通过用于蛋白质的纯化的公知的方法而进行纯化。作为这种方法,可举出:硫酸铵沉淀、凝胶过滤色谱法、离子交换色谱法、疏水相互作用色谱法、羟基磷灰石色谱法等。
[0046]
根据本发明,首次可以进行重组第1蛋白质的人工的、且有功能的表达。这样制造
的重组第1蛋白质例如可以用于后述的用途。
[0047]
<2>重组第2蛋白质及其制造方法重组第2蛋白质为具有b因子活性的重组蛋白。
[0048]
重组第2蛋白质具体而言为以下的任一种重组蛋白。(i)含有美洲鲎的具有b因子活性的蛋白质的氨基酸序列的重组蛋白。(ⅱ)为上述(i)的变体、且具有b因子活性的重组蛋白。
[0049]
作为美洲鲎的具有b因子活性的蛋白质的氨基酸序列,可举出序列号6、8、10、或12所示的氨基酸序列。另外,作为编码这种氨基酸序列的碱基序列,可举出序列号5、7、9、或11所示的碱基序列。
[0050]
重组第2蛋白质更具体而言可以为以下的任一种重组蛋白。(a)含有序列号6、8、10、或12所示的氨基酸序列的重组蛋白。(b)含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有b因子活性的重组蛋白。(c)由含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有b因子活性的重组蛋白。(d)由以下dna编码且具有b因子活性的重组蛋白,所述dna与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交。
[0051]
该蛋白质的功能为如下功能:在已成为活性型的第1蛋白质等具有c因子活性的蛋白质(活性型)左右下成为活性型,使后述的第3蛋白质等具有凝固酶原活性的蛋白质变为活性型(本技术文件中称为“b因子活性”)。重组第2蛋白质可以是至少在与重组第1蛋白质等第1蛋白质及重组第3蛋白质等第3蛋白质的组合中显示b因子活性的蛋白质。
[0052]
具有b因子活性这一点可以如下确认:在将成为对象的重组蛋白与第1蛋白质(活性型)等具有c因子活性的蛋白质(活性型)、第3蛋白质(非活性型)等具有凝固酶原活性的蛋白质(非活性型)、及检测用底物组合时检测级联反应的进行。在该系统中,可以进一步存在用于使具有c因子活性的蛋白质(非活性型)变化为活性型的内毒素。
[0053]
其它的说明可以引用上述<1>的说明。即,例如将上述<1>中的“序列号1或3”替换为“序列号5、7、9、或11”,将“序列号2或4”替换为“序列号6、8、10、或12”,将“(重组)第1蛋白质”替换为“(重组)第2蛋白质”,将“第1cdna”替换为“第2cdna”,将“c因子”替换为“b因子”等即可。
[0054]
<3>重组第3蛋白质及其制造方法重组第3蛋白质为具有凝固酶原活性的重组蛋白。
[0055]
重组第3蛋白质具体而言为以下的任一种重组蛋白。(i)含有美洲鲎的具有凝固酶原活性的蛋白质的氨基酸序列的重组蛋白。(ⅱ)为上述(i)的变体、且具有凝固酶原活性的重组蛋白。
[0056]
作为美洲鲎的具有凝固酶原活性的蛋白质的氨基酸序列,可举出序列号14、16、18、20、或22所示的氨基酸序列。另外,作为编码这种氨基酸序列的碱基序列,可举出序列号13、15、17、19、或21所示的碱基序列。
[0057]
重组第3蛋白质更具体而言可以为以下的任一种重组蛋白。(a)含有序列号14、16、18、20、或22所示的氨基酸序列的重组蛋白。
(b)含有相对于序列号14、16、18、20、或22所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有凝固酶原活性的重组蛋白。(c)由含有相对于序列号13、15、17、19、或21所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有凝固酶原活性的重组蛋白。(d)由以下dna编码且具有凝固酶原活性的重组蛋白,所述dna与包含序列号13、15、17、19、或21所示的碱基序列的互补序列的dna在严格的条件下进行杂交。
[0058]
该蛋白质的功能为如下功能:在已成为活性型的第2蛋白质等具有b因子活性的蛋白质(活性型)作用下成为活性型、切断后述的底物(蛋白质或肽)(本技术文件中称为“凝固酶原活性”)。重组第3蛋白质可以是至少在与重组第2蛋白质等第2蛋白质的组合中显示凝固酶原活性的蛋白质。
[0059]
具有凝固酶原活性这一点可以如下确认:在将成为对象的重组蛋白与第2蛋白质(活性型)等具有b因子活性的蛋白质(活性型)及检测用底物组合时检测级联反应的进行。在该系统中,可以进一步存在用于使具有b因子活性的蛋白质(非活性型)变化为活性型的具有c因子活性的蛋白质(活性型)。另外,在该系统中,可以进一步存在用于使具有c因子活性的蛋白质(非活性型)变化为活性型的内毒素。
[0060]
其它的说明可以引用上述<1>的说明。即,例如将上述<1>中的“序列号1或3”替换为“序列号13、15、17、19、或21”,将“序列号2或4”替换为“序列号14、16、18、20、或22”,将“(重组)第1蛋白质”替换为“(重组)第3蛋白质”,将“第1cdna”替换为“第3cdna”,将“c因子”替换为“凝固酶原”等即可。
[0061]
<4>重组第1蛋白质的应用重组第1蛋白质可以用于活化第2蛋白质等具有b因子活性的蛋白质。换句话说,本发明包含具有b因子活性的蛋白质的活化方法,该方法包含使重组第1蛋白质与具有b因子活性的蛋白质接触的步骤。
[0062]
作为具有b因子活性的蛋白质,可举出第2蛋白质。
[0063]
第2蛋白质具体而言为以下的任一种蛋白质。(i)含有美洲鲎的具有b因子活性的蛋白质的氨基酸序列的蛋白质。(ⅱ)为上述(i)的变体、且具有b因子活性的蛋白质。
[0064]
第2蛋白质更具体而言可以为以下的任一种蛋白质。(a)含有序列号6、8、10、或12所示的氨基酸序列的蛋白质。(b)含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有b因子活性的蛋白质。(c)由含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有b因子活性的蛋白质。(d)由以下dna编码且具有b因子活性的蛋白质,所述dna与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交。
[0065]
另外,作为具有b因子活性的蛋白质,也可举出以下的蛋白质。(ⅲ)含有美洲鲎以外的鲎的具有b因子活性的蛋白质的氨基酸序列的蛋白质。(ⅳ)为上述(ⅲ)的变体、且具有b因子活性的蛋白质。
[0066]
具有b因子活性的蛋白质的说明可以引用上述<2>的说明。
[0067]
根据本发明,初次明确重组第1蛋白质的(a)的蛋白质保持c因子活性。将具有这种有功能的(a)的蛋白质及其变体应用于具有b因子活性的蛋白质的活化。
[0068]
在此使用的具有b因子活性的蛋白质只要具有上述的结构及功能,则可以为从天然物中取得的蛋白质,也可以为人工地制造的蛋白质(例如重组第2蛋白质)。根据本发明,首次可以进行重组第2蛋白质的人工的且有功能的表达,可以不从天然的美洲鲎中取得第2蛋白质而以一定的品质稳定地制造,因此,具有b因子活性的蛋白质优选为重组第2蛋白质。
[0069]
使用有重组第1蛋白质的具有b因子活性的蛋白质的活化可以通过使重组第1蛋白质(活性型)分子和具有b因子活性的蛋白质(非活性型)分子接触而进行。需要说明的是,为了使重组第1蛋白质变化为活性型,可以在内毒素存在下使重组第1蛋白质(非活性型)和具有b因子活性的蛋白质(非活性型)进行接触。
[0070]
该接触时的条件只要是重组第1蛋白质(活性型)发挥c因子活性而可以将具有b因子活性的蛋白质活化的条件(在内毒素存在下进行的情况下,进而内毒素可以将重组第1蛋白质活化的条件),就没有特别限定。例如,可以采用公知的lysate试剂的反应条件。
[0071]
具有b因子活性的蛋白质被活化可以用后述的实施例中记载的方法来确认。
[0072]
<5>重组第2蛋白质的应用重组第2蛋白质可以用于活化第3蛋白质等具有凝固酶原活性的蛋白质。换句话说,本发明包含具有凝固酶原活性的蛋白质的活化方法,该方法包含使重组第2蛋白质与具有凝固酶原活性的蛋白质接触的步骤。
[0073]
作为具有凝固酶原活性的蛋白质,可举出第3蛋白质。
[0074]
第3蛋白质具体而言为以下的任一种蛋白质。(i)含有美洲鲎的具有凝固酶原活性的蛋白质的氨基酸序列的蛋白质。(ⅱ)为上述(i)的变体、且具有凝固酶原活性的蛋白质。
[0075]
第3蛋白质更具体而言可以为以下的任一种蛋白质。(a)含有序列号14、16、18、20、或22所示的氨基酸序列的蛋白质。(b)含有相对于序列号14、16、18、20、或22所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有凝固酶原活性的蛋白质。(c)由含有相对于序列号13、15、17、19、或21所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有凝固酶原活性的蛋白质。(d)由以下dna编码且具有凝固酶原活性的蛋白质,所述dna与包含序列号13、15、17、19、或21所示的碱基序列的互补序列的dna在严格的条件下进行杂交。
[0076]
另外,作为具有凝固酶原活性的蛋白质,也可举出以下的蛋白质。(ⅲ)含有美洲鲎以外的鲎的具有凝固酶原活性的蛋白质的氨基酸序列的蛋白质。(ⅳ)为上述(ⅲ)的变体、且具有凝固酶原活性的蛋白质。
[0077]
具有凝固酶原活性的蛋白质的说明可以引用上述<3>的说明。
[0078]
在此使用的具有凝固酶原活性的蛋白质只要具有上述的结构及功能,则可以为从天然物中取得的蛋白质,也可以为人工地制造的蛋白质(例如重组第3蛋白质)。
[0079]
使用有重组第2蛋白质的具有凝固酶原活性的蛋白质的活化可以通过使重组第2蛋白质(活性型)分子和具有凝固酶原活性的蛋白质(非活性型)分子接触而进行。需要说明的是,为了使重组第2蛋白质变化为活性型,可以在具有c因子活性的蛋白质(活性型)的存
在下使重组第2蛋白质(非活性型)和具有凝固酶原活性的蛋白质(非活性型)接触。进而,为了将该具有c因子活性的蛋白质活化,可以在内毒素存在下使具有c因子活性的蛋白质(非活性型)、重组第2蛋白质(非活性型)、及具有凝固酶原活性的蛋白质(非活性型)接触。
[0080]
该接触时的条件只要是重组第2蛋白质(活性型)发挥b因子活性而可以将具有凝固酶原活性的蛋白质活化的条件(在具有c因子活性的蛋白质(活性型)的存在下进行的情况下,进一步具有c因子活性的蛋白质(活性型)发挥c因子活性而可以将重组第2蛋白质活化的条件。在内毒素存在下进行的情况下,进而内毒素可以将具有c因子活性的蛋白质活化的条件),就没有特别限定。例如,可以采用公知的lysate试剂的反应条件。
[0081]
第3蛋白质被活化可以通过后述的实施例中记载的方法来确认。
[0082]
作为具有c因子活性的蛋白质,可举出第1蛋白质。
[0083]
第1蛋白质具体而言为以下的任一种蛋白质。(i)含有美洲鲎的具有c因子活性的蛋白质的氨基酸序列的蛋白质。(ii)为上述(i)的变体、且具有c因子活性的蛋白质。
[0084]
第1蛋白质更具体而言可以为以下的任一种蛋白质。(a)含有序列号2或4所示的氨基酸序列的蛋白质。(b)含有相对于序列号2或4所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有c因子活性的蛋白质。(c)由含有相对于序列号1或3所示的碱基序列具有95%以上的同源性的碱基序列的dna编码,且具有c因子活性的蛋白质。(d)由以下dna编码且具有c因子活性的蛋白质,所述dna与包含序列号1或3所示的碱基序列的互补序列的dna在严格的条件下进行杂交。
[0085]
另外,作为具有c因子活性的蛋白质,也可举出以下的蛋白质。(ⅲ)含有美洲鲎以外的鲎的具有c因子活性的蛋白质的氨基酸序列的蛋白质。(ⅳ)为上述(ⅲ)的变体、且具有c因子活性的蛋白质。
[0086]
具有c因子活性的蛋白质的说明可以引用上述<1>的说明。
[0087]
在此使用的具有c因子活性的蛋白质只要具有上述的结构及功能,则可以为从天然物中取得的蛋白质,也可以为人工地制造的蛋白质(例如重组第1蛋白质)。
[0088]
其它的说明可以引用上述<4>的说明。
[0089]
<6>重组第3蛋白质的应用重组第3蛋白质可以用于将底物切断。换句话说,本发明包含底物的切断方法,该方法包含使重组第3蛋白质与底物接触的步骤。
[0090]
该底物也可以用作所述的“检测用底物”,可以为源自天然的底物,也可以为合成底物。这种底物只要因第3蛋白质(活性型)等具有凝固酶原活性的蛋白质(活性型)具有的凝固酶原活性而被切断,就没有特别限定。
[0091]
作为因凝固酶原活性而被切断的蛋白质,可举出例如凝固蛋白原等蛋白质、或通式x-y-z(式中,x-为与y形成共价键的保护基,y为肽残基,-z为与y形成酰胺键的信号物质)所示的合成底物。
[0092]
保护基x没有特别限定,可以使用肽的公知的保护基。作为这种保护基,可举出例如叔丁氧基羰基或苯甲酰基。
[0093]
肽残基y也没有特别限定,可举出例如leu-gly-arg(lgr)或ile-glu-gly-arg(iegr)(序列号23)。
[0094]
信号物质z也没有特别限定,可举出例如在可见光下进行检测的色素或荧光色素。作为这种色素,可举出例如:pna(对硝基苯胺)、mca(7-甲氧基香豆素-4-醋酸)、dnp(2,4-二硝基苯胺)、dansyl(丹磺酰)系色素。
[0095]
这些物质中,优选boc-leu-gly-arg-pna(叔丁氧基羰基-亮氨酰-甘氨酰-精氨酰基-对硝基苯胺。boc-lgr-pna)。
[0096]
关于底物因凝固酶原活性而被切断这一点,例如在使用凝固蛋白原作为底物的情况下,可以通过探测“凝胶化”而检测。凝胶化可以例如通过目视等探测流动性降低而进行检测。
[0097]
另外,关于底物因凝固酶原活性而被切断这一点,例如在使用有如上所述的合成底物的情况下,通过y-z间的酰胺键被切断而信号z游离并发出显色或荧光等的信号,因此,可以通过探测该信号而进行检测。信号的探测通过与该信号的种类相应的方法进行即可。例如,pna的信号可以利用吸光度(405nm)进行探测。
[0098]
使用有重组第3蛋白质的底物的切断可以通过使重组第3蛋白质(活性型)分子和底物分子接触而进行。需要说明的是,为了使重组第3蛋白质变化为活性型,可以在具有b因子活性的蛋白质(活性型)的存在下使重组第3蛋白质(非活性型)和底物接触。进而,为了使该具有b因子活性的蛋白质变化为活性型,可以在具有c因子活性的蛋白质(活性型)的存在下使具有b因子活性的蛋白质(非活性型)、重组第3蛋白质(非活性型)、及底物接触。进而,为了使该具有c因子活性的蛋白质变化为活性型,可以在内毒素存在下使具有c因子活性的蛋白质(非活性型)、具有b因子活性的蛋白质(非活性型)、重组第3蛋白质(非活性型)、及底物接触。
[0099]
该接触时的条件只要是重组第3蛋白质(活性型)发挥凝固酶原活性而可以切断底物的条件(在具有b因子活性的蛋白质(活性型)的存在下进行的情况下,进而具有b因子活性的蛋白质(活性型)发挥b因子活性而可以将重组第3蛋白质活化的条件。在具有c因子活性的蛋白质(活性型)的存在下进行的情况下,进而具有c因子活性的蛋白质(活性型)发挥c因子活性而可以将第2蛋白质活化的条件。在内毒素存在下进行的情况下,进而内毒素可以将具有c因子活性的蛋白质活化的条件),就没有特别限定。例如,可以采用公知的lysate试剂的反应条件。
[0100]
其它的说明可以引用上述<4>的说明。
[0101]
<7>内毒素的检测方法本发明的内毒素的检测方法为一种被检体中的内毒素的检测方法,其包含使重组第1蛋白质与被检体接触的步骤。
[0102]
该方法可以还包含使与被检体接触后的重组第1蛋白质与第2蛋白质等具有b因子活性的蛋白质接触的步骤。该具有b因子活性的蛋白质可以为重组第2蛋白质。
[0103]
另外,该方法可以还包含使与“与被检体接触后的重组第1蛋白质”接触后的具有b因子活性的蛋白质与第3蛋白质等具有凝固酶原活性的蛋白质接触的步骤。该具有凝固酶原活性的蛋白质可以为重组第3蛋白质。
[0104]
被检体中的内毒素的检测可以通过探测与被检体接触后的重组第1蛋白质的活化
而进行。重组第1蛋白质被活化可以通过后述的实施例中记载的方法来确认。另外,重组第1蛋白质的活化也可以利用底物(检测用底物)直接探测。即,通过利用因被活化的重组第1蛋白质的c因子活性而被切断并发出信号的物质作为检测用底物,可以直接探测重组第1蛋白质的活化。因此,该方法可以还包含使“与被检体接触后的重组第1蛋白质”与检测用底物接触的步骤。
[0105]
在进一步包含与具有b因子活性的蛋白质接触的步骤的情况下,可以通过用上述<4>中记载的方法探测具有b因子活性的蛋白质的活化而进行。另外,具有b因子活性的蛋白质的活化也可以利用底物(检测用底物)直接探测。即,通过利用因被活化的具有b因子活性的蛋白质的b因子活性而被切断并发出信号的物质作为检测用底物,可以直接探测具有b因子活性的蛋白质的活化。因此,该方法可以还包含使“与重组第1蛋白质接触后的具有b因子活性的蛋白质”与检测用底物接触的步骤。
[0106]
在进一步包含与具有凝固酶原活性的蛋白质接触的步骤的情况下,可以通过用上述<5>中记载的方法探测具有凝固酶原活性的蛋白质的活化(利用上述<6>中记载的方法的底物的切断)而进行。因此,该方法可以还包含使“与具有b因子活性的蛋白质接触后的具有凝固酶原活性的蛋白质”与底物(检测用底物)接触的步骤。作为可以探测具有凝固酶原活性的蛋白质的活化的检测用底物,可举出上述<6>中例示的物质。
[0107]
这些步骤可以依次进行,也可以同时进行。例如,在同时进行这些步骤的情况下,可以使被检体、重组第1蛋白质(非活性型)、具有b因子活性的蛋白质(非活性型)、具有凝固酶原活性的蛋白质(非活性型)、检测用底物同时在同一体系中接触。
[0108]
这些接触的条件与上述<4>~<6>所述的条件同样。例如,就重组第1蛋白质与被检体的接触而言,只要是被检体中的内毒素可以将重组第1蛋白质活化的条件,就没有特别限定。接触的条件可以采用例如公知的lysate试剂的反应条件。例如,作为反应液的ph,可以采用ph5~10、优选7~8.5。作为反应温度,可以采用10℃~80℃、优选20℃~50℃、进一步优选30℃~40℃。作为反应温度,可例示例如37℃。反应时间也没有特别限定,根据各种条件适当设定即可。反应时间例如可以为5分钟~2小时、优选15分钟~90分钟、更优选30分钟~40分钟。
[0109]
被检体也只要是需要检测内毒素的试样,就没有特别限定。作为被检体,可举出例如:医疗用水、医药品、输液、血液制剂、医疗设备、医疗器具、化妆品、饮食品、环境试样、生物体成分、天然的蛋白质、重组蛋白、核酸、糖质。就被检体而言,可以将其自身或其提取物或清洗液在反应体系中进行混合、分散、或溶解,供于内毒素的检测。
[0110]
内毒素的检测可以为定性的检测,也可以为定量的检测。定量的检测例如可以如下进行:使用内毒素量(浓度)不同的多个标准品,将其量(浓度)和与底物的种类相应的检测水平(例如,在使用凝固蛋白原作为底物的情况下,为“凝胶化”的程度,在使用有合成底物的情况下,为信号的程度)的关系使用例如标准曲线或关系式预先建立关联,由使用有实际的被检体的情况的检测水平换算内毒素量(浓度)而进行。
[0111]
<8>内毒素检测剂本发明的内毒素检测剂为含有重组第1蛋白质的内毒素检测剂。
[0112]
该检测剂可以还包含第2蛋白质等具有b因子活性的蛋白质。该具有b因子活性的蛋白质可以为重组第2蛋白质。
[0113]
该检测剂可以还包含第3蛋白质等具有凝固酶原活性的蛋白质。该具有凝固酶原活性的蛋白质可以为重组第3蛋白质。
[0114]
这些蛋白质如上述<1>~<3>中说明的那样,例如可以为存在于培养液、培养上清液、细胞破碎提取物、或它们的混合物等中的形态。这些蛋白质可以纯化成所期望的程度而使用,也可以不进行纯化而直接使用。例如,在培养上清液中含有这些蛋白质的情况下,可以以含有其培养基成分的状态使用。
[0115]
该检测剂中的重组第1蛋白质、具有b因子活性的蛋白质、具有凝固酶原活性的蛋白质的各量可以根据各蛋白质的活性等而适当设定,例如,作为与被检体混合的状态的反应液中的各蛋白质的终浓度,可以例示15~30μg/ml。
[0116]
该检测剂可以进一步含有底物(检测用底物)。
[0117]
该检测剂可以通过含有这些物质作为构成成分而制造。该检测剂除此之外可以还包含赋形剂、稳定化剂、缓冲剂等的添加剂。另外,该检测剂的形状也没有特别限定,可以以固体状(例如冷冻干燥形态)、液体状等任意的形态制剂化。
[0118]
在该检测剂中,这些物质可以汇总作为构成成分被贮藏在一体的容器内,也可以被贮藏在各自的容器内。
[0119]
另外,该检测剂可以还包含溶解用的缓冲液、内毒素标准品、反应用容器(例如管或微孔板)等。该检测剂也包含试剂盒的形态。
[0120]
该检测剂例如可以在上述<7>中说明的方法中使用。
[0121]
<9>第1cdna及其利用(1)第1cdna第1cdna为以下的任一种cdna。(a)含有序列号1或3所示的碱基序列的cdna。(b)含有相对于序列号1或3所示的碱基序列具有95%以上的同源性的碱基序列、且编码具有c因子活性的蛋白质的cdna。(c)与包含序列号1或3所示的碱基序列的互补序列的dna在严格的条件下进行杂交、且编码具有c因子活性的蛋白质的cdna。(d)编码含有序列号2或4所示的氨基酸序列的蛋白质的cdna。(e)编码含有相对于序列号2或4所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有c因子活性的蛋白质的cdna。
[0122]
该cdna通过本说明书的实施例中所公开的方法在世界上首次取得,初次明确其全长的序列结构及由此所编码的蛋白质的功能。该功能为“c因子活性”。
[0123]
第1cdna中,最优选的是上述(a)的cdna,但由此所编码的蛋白质只要具有c因子活性,则可以为这些cdna的变体。
[0124]
作为变体,具体而言,优选上述(b)~(e)的cdna。上述(b)、(c)、及(e)中的“95%以上”为优选96%以上、更优选97%以上、更优选98%以上、更优选99%以上。
[0125]
另外,“严格的条件”的意义及其它的说明可以引用上述<1>的说明。
[0126]
另外,第1cdna可以为将任意的密码子置换为与其等价的密码子的cdna。例如,在上述(a)的cdna中将任意的密码子置换为与其等价的密码子而成的cdna包含在上述(d)中。
[0127]
就第1cdna而言,由于本发明公开了其完整的碱基序列,因此,可以使用该序列信
息,通过公知的dna合成方法或基因工程的方法来制造。第1cdna通过后述的实施例中记载的方法首次取得,但其碱基序列已经公开在本发明中,因此也可以利用实施例记载的方法以外的方法来制造。
[0128]
(2)含有第1cdna的dna构建物、转化细胞、使用其的重组第1蛋白质的生产方法本发明提供一种含有第1cdna的dna构建物。作为这种人工的dna构建物,例如可以例示载体。作为载体,可以根据重组dna的扩增、维持、导入、文库制作、克隆、蛋白质翻译(蛋白质表达)等的目的,适当选择质粒、病毒、其它的公知的载体。通过在这种载体等中导入第1cdna,可以制造含有第1cdna的dna构建物。
[0129]
另外,本发明提供一种含有第1cdna的细胞。这种细胞例如可以是被这种dna构建物转化而表达重组第1蛋白质的细胞。另外,本发明提供一种重组第1蛋白质的生产方法,其包含将这种细胞进行培养的步骤。
[0130]
用dna构建物转化细胞(宿主细胞)的方法、将其进行培养而生产重组第1蛋白质的方法可以引用上述<1>(2)中的说明。
[0131]
<10>第2cdna(1)第2cdna第2cdna为以下的任一种cdna。(a)含有序列号5、7、9、或11所示的碱基序列的cdna。(b)含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列、且编码具有b因子活性的蛋白质的cdna。(c)与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交、且编码具有b因子活性的蛋白质的cdna。(d)编码含有序列号6、8、10、或12所示的氨基酸序列的蛋白质的cdna。(e)编码含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有b因子活性的蛋白质的cdna。
[0132]
其它的说明可以引用上述的<9>(1)的说明。即,例如将上述<9>(1)的“c因子”替换为“b因子”,将“第1cdna”替换为“第2cdna”等即可。
[0133]
(2)含有第2cdna的dna构建物、转化细胞、使用其的重组第2蛋白质的生产方法本发明提供一种含有第2cdna的dna构建物。另外,本发明提供一种被这种dna构建物转化而表达重组第2蛋白质的细胞等含有第2cdna的细胞。另外,本发明提供一种重组第2蛋白质的生产方法,其包含将这种细胞进行培养的步骤。
[0134]
其它的说明可以引用上述<9>(2)的说明。
[0135]
<11>第3cdna(1)第3cdna第3cdna为以下的任一种第3cdna。(a)含有序列号13、15、17、19、或21所示的碱基序列的cdna。(b)含有相对于序列号13、15、17、19、或21所示的碱基序列具有95%以上的同源性的碱基序列、且编码具有凝固酶原活性的蛋白质的cdna。(c)与包含序列号13、15、17、19、或21所示的碱基序列的互补序列的dna在严格的条件下进行杂交、且编码具有凝固酶原活性的蛋白质的cdna。
(d)编码含有序列号14、16、18、20、或22所示的氨基酸序列的蛋白质的cdna。(e)编码含有相对于序列号14、16、18、20、或22所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有凝固酶原活性的蛋白质的cdna。
[0136]
其它的说明可以引用上述的<9>(1)的说明。即,例如将上述<9>(1)的“c因子”替换为“凝固酶原”,将“第1cdna”替换为“第3cdna”等即可。
[0137]
(2)含有第3cdna的dna构建物、转化细胞、使用其的重组第3蛋白质的生产方法本发明提供一种含有第3cdna的dna构建物。另外,本发明提供一种被这种dna构建物转化而表达重组第3蛋白质的细胞等含有第3cdna的细胞。另外,本发明提供一种重组第3蛋白质的生产方法,其包含将这种细胞进行培养的步骤。
[0138]
其它的说明可以引用上述<9>(2)的说明。
[0139]
<12>内毒素检测剂的制造方法本发明还提供一种内毒素检测剂的制造方法,其包含使用第1cdna人工地使蛋白质表达的步骤。
[0140]
该方法可以还包含使用第2cdna人工地使蛋白质表达的步骤。另外,可以还包含使用第3cdna人工地使蛋白质表达的步骤。
[0141]
使用这些cdna人工地表达蛋白质的方法也没有特别限定,例如可以使用上述<9>(2)、<10>(2)、<11>(2)中记载的方法。
[0142]
通过用这种方法、使用第1cdna人工地进行表达,重组第1蛋白质被表达。同样地,通过进一步使用第2cdna人工地进行表达,重组第2蛋白质被表达,通过使用第3cdna人工地进行表达,重组第3蛋白质被表达。
[0143]
被表达的蛋白质如上述<1>~<3>中说明的那样,例如可以为存在于培养液、培养上清液、细胞破碎提取物、或它们的混合物等中的形态。这些蛋白质可以纯化成所期望的程度而使用,也可以不进行纯化而直接使用。例如,在培养上清液中含有这些蛋白质的情况下,可以以含有其培养基成分的状态使用。
[0144]
其它的说明可以引用上述<8>的说明。因此,本发明的内毒素检测剂的制造方法也包含试剂盒的制造方法。
[0145]
需要说明的是,在本发明中,可以将第2蛋白质(重组第2蛋白质等)及第3蛋白质(重组第3蛋白质等)的任一种或两者分别置换为源自美洲鲎以外的鲎的它们的对应物。对第2cdna及第3cdna也同样。作为美洲鲎以外的鲎,可举出:中国鲎(tachypleus tridentatus)、巨鲎(tachypleus gigas)、东南亚鲎(tachypleus rotundicauda)等属于鲎属的生物。
[0146]
即,可以使用源自美洲鲎以外的鲎(中国鲎等)的b因子(重组b因子等)取代第2蛋白质(重组第2蛋白质等),使用源自上述生物的凝固酶原(重组凝固酶原等)取代第3蛋白质(重组第3蛋白质等),使用源自上述生物的b因子基因(cdna等)取代第2cdna,使用源自上述生物的凝固酶原基因(cdna等)取代第3cdna。
[0147]
这些蛋白质或基因均可以含有在美洲鲎以外的鲎中实际发现的氨基酸序列或碱基序列,也可以为这些的变体。关于变体,可以引用上述<1>~<11>中的变体的说明。另外,这些蛋白质或基因可以源自美洲鲎以外的相同的鲎,也可以不是如此。
[0148]
而且,由所述的说明也可知:本发明的内毒素检测剂的制造方法也包含以下方式:
分别将第1cdna、第2cdna、及第3cdna(关于第2cdna及第3cdna,可以将其任一种或两者置换为源自美洲鲎以外的鲎(中国鲎等)的基因)人工地导入于鲎以外的宿主细胞,由这些各自的cdna表达各自的重组蛋白(总计3种),接着,如上述<8>那样,含有这些被表达的各自的重组蛋白作为构成成分。实施例
[0149]
以下,通过实施例具体地说明本发明,但这些实施例为本发明的例示,本发明的范围并不限定于这些实施例。
[0150]
(1)引物的合成为了尝试美洲鲎中的具有c因子活性的蛋白质的克隆,合成了下述的各引物。
[0151]
<用于具有c因子活性的蛋白质的克隆的引物>sk15-dt20:ctgcaggaattcgattttttttttttttttttttt(序列号24)sk15-fc-s:atcgataagcttgatgatctgggcttgtgtgatga(序列号25)sk15-as:ctgcaggaattcgat(序列号26)lfc-5race:ctacaccaagttcca(序列号27)lfc-1st-s:gtaaaccatgtgacaaactggaggc(序列号28)lfc-1st-as:aataaggcctccatcgatagaagta(序列号29)lfc-ecori-kozak-s:ggggaattcaagcttgccaccatggtactagcgtcgttc(序列号30)lfc-xhoi-stop-as:gggctcgagtcaaatgaactgccgaatccacgata(序列号31)
[0152]
另外,为了尝试具有b因子活性的蛋白质及具有凝固酶原活性的蛋白质的各克隆,合成了下述的各引物。
[0153]
<用于具有b因子活性的蛋白质及具有凝固酶原活性的蛋白质的克隆的引物>sk15-fb-s:atcgataagcttgatcacatgcaaggaaaagttct(序列号32)sk15-fb-as:ctgcaggaattcgatcactgtttaaacaaactgaa(序列号33)sk15-pce-s:atcgataagcttgatagaccagagtggtctttctg(序列号34)sk15-as:ctgcaggaattcgat(序列号26)
[0154]
(2)由美洲鲎的血细胞制备总rna总rna的制备使用purelink(注册商标)rna mini kit和purelink(注册商标)dnase kit(thermo fisher scientific),基本的操作按照添附的说明书。在美洲鲎的血细胞池2.23g中添加trizol溶液,将细胞破碎。其后,向其中添加氯仿而进行离心分离,得到水层。在得到的水层中添加乙醇后,将其通入试剂盒中添附的二氧化硅膜盒,由此使核酸成分键合于二氧化硅膜。在该二氧化硅膜中加入试剂盒添附的dnasei而将dna分解,清洗盒之后,添加洗脱缓冲剂,回收总rna(1.3mg)。
[0155]
(3)美洲鲎的具有c因子活性的蛋白质的cdna(第1cdna)的取得(3-1)第1步骤以上述(2)中回收的总rna为模板,进行将sk15-d20(序列号24)用作引物的逆转录反应,得到cdna。本引物以选择性地键合于mrna的聚a序列的方式设计,进一步在其外侧具有可利用于聚合酶链反应(pcr)的添加序列。在本反应中,使用superscript iii reverse transcriptase(thermo fisher scientific)作为逆转录酶,反应条件按照添附的说明书。
[0156]
(3-2)第2步骤
以得到的cdna为模板,使用sk15-fc-s(序列号25)作为正义链引物,使用sk15-as(序列号26)作为反义链引物,使用tks gflex dna polymerase(takara bio)作为聚合酶,进行pcr。
[0157]
将pcr产物用琼脂糖凝胶电泳进行确认,结果,目标dna(lpfc1)几乎不能探测,非特异性的dna扩增被探测(图1a)。因此,尝试了以下的步骤。需要说明的是,图1a中的“1”的条带为尺寸标记物,“2”的条带为pcr产物。另外,三角符号为预料存在lpfc1的部分。
[0158]
(3-3)第3步骤从凝胶上切出预料存在lpfc1的部分,提取dna并进行纯化。将其作为模板,使用sk15-fc-s(序列号25)作为正义链引物,使用sk15-as(序列号26)作为反义链引物,使用tks gflex dna polymerase(takara bio)作为聚合酶,进行pcr。
[0159]
将pcr产物进行琼脂糖凝胶电泳的结果,令人吃惊地,目标dna(lpfc1)显著地扩增(图1b)。从凝胶上切出该lpfc1并进行提取、纯化。由此,在有编码美洲鲎的具有c因子活性的蛋白质的可能性的dna的部分片段(lpfc1)的取得上获得成功。需要说明的是,图1b中的“1”的条带为尺寸标记物,“2”的条带为pcr产物。另外,三角符号为lpfc1的位置。
[0160]
(3-4)第4步骤将lpfc1与进行了ecorv酶处理的pbluescript ii sk(+)进行混合,使用in-fusion hd enzyme premix(takara bio),通过重组反应进行向载体的导入。将反应物转化到e.coli dh5α感受态细胞,涂布于含有x-gal、iptg的氨苄青霉素lb培养基板,进行利用蓝白筛选的菌落的选定。
[0161]
其后,用相对于候补的菌落的菌落pcr进行dna扩增。此时,使用m13-20 primer作为正义链引物、使用m13 reverse primer作为反义链引物、使用tks gflex dna polymerase(takara bio)作为聚合酶。将得到的pcr产物进行琼脂糖凝胶电泳后,从凝胶上切出并提取,以纯化的dna(lpfc1)为模板,通过测序pcr确认序列。由此判明lpfc1的dna序列。
[0162]
(3-5)第5步骤将以lpfc1的序列信息为参考制作的合成dna lfc-5race(序列号27)的5’末端在atp存在下利用t4 polynucleotide kinase(takara bio)进行磷酸化。以所述的总rna为模板,通过使用有得到的磷酸化引物和逆转录酶superscript iii reverse transcriptase(thermo fisher scientific)的逆转录反应,得到目标dna(lpfc2)。由此,得到有编码含有美洲鲎的具有c因子活性的蛋白质的一部分的氨基酸序列的可能性的dna的部分片段(lpfc2)。
[0163]
将lpfc2在rnase a存在下进行高温处理(95℃、2分钟)后,进行乙醇沉淀。其后,用t4 rna ligase(new england biolabs)进行处理,结果,可得到连续地键合有lpfc2的多联体化dna(lpfc3)。由此,得到有编码含有美洲鲎的具有c因子活性的蛋白质的一部分的氨基酸序列的可能性的dna的部分片段(lpfc3)。
[0164]
以lpfc3为模板,使用lfc-1st-s(序列号28)正义链引物、使用lfc-1st-as(序列号29)作为反义链引物、且使用tks gflex dna polymerase(takara bio)的pcr来扩增目标dna(lpfc4)。
[0165]
用琼脂糖凝胶电泳确认pcr产物,结果,几乎不能探测目标dna(lpfc4),探测到非
特异性的dna扩增(图2a)。因此,尝试以下的步骤。需要说明的是,图2a中的“1”的条带为尺寸标记物,“2”的条带为pcr产物。另外,三角符号为lpfc4的位置。
[0166]
(3-6)第6步骤从凝胶上切出预料存在lpfc4的部分,提取dna并进行纯化。将其作为模板,使用lfc-1st-s(序列号28)作为正义链引物、使用lfc-1st-as(序列号29)作为反义链引物、使用tks gflex dna polymerase(takara bio)作为聚合酶,进行pcr。
[0167]
将pcr产物进行琼脂糖凝胶电泳,结果,令人吃惊地,目标dna(lpfc4)显著地扩增,以非常高浓度被检测出(图2b)。从凝胶上切出该lpfc4并提取、纯化。由此,在有编码含有美洲鲎的具有c因子活性的蛋白质的一部分的氨基酸序列的可能性的dna的部分片段(lpfc4)的取得方面获得成功。需要说明的是,图2b中的“1”的条带为尺寸标记物,“2”的条带为pcr产物。另外,三角符号为预料存在lpfc4的部分。
[0168]
以lpfc4为模板,通过测序pcr分析了lpfc4的序列。由此,判明目标蛋白质的5’侧的dna序列。
[0169]
(3-7)第7步骤以上述(3-1)中得到的cdna为模板,使用lfc-ecori-kozak-s(序列号30)作为正义链引物、使用lfc-xhoi-stop-as(序列号31)作为反义链引物、使用tks gflex dna polymerase(takara bio)作为聚合酶,进行pcr。
[0170]
苯酚氯仿提取pcr产物,通过乙醇沉淀而纯化后,用ecori酶和xhoi酶进行处理。将限制酶处理产物进行琼脂糖凝胶电泳而从凝胶上切出,提取dna并进行纯化,得到目标dna(lpfc5)。
[0171]
与将lpfc5用ecori酶和xhoi酶进行了处理的表达载体pca7(takeda et al.,2005,j virol 79:14346-14354)进行混合,使用ligation mix(takara bio)进行连接反应。将反应物转化到e.coli dh5α感受态细胞,涂布于含氨苄青霉素的lb培养基板。从得到的菌落进行通过菌落pcr的选定之后,接种于含氨苄青霉素的lb培养基。
[0172]
培养后,进行利用nucleospin(注册商标)plasmid easy pure(
マッハライ
·
ナーゲル
)的质粒纯化。以得到的2种克隆的质粒为模板,通过测序pcr分析各自的碱基序列。
[0173]
由此,在编码有美洲鲎的具有c因子活性的可能性的蛋白质的cdna的全长序列(序列号1、序列号3)和其蛋白质的氨基酸的全长序列(序列号2、序列号4)的阐明上首次获得成功。序列号1和3(序列号2和4)存在变体的关系,认为基于个体间的多态性。关于该蛋白质的表达及活性分析,容后说明。
[0174]
(4)美洲鲎的具有b因子活性的蛋白质的cdna(第2cdna)的取得以上述(3-1)中得到的cdna为模板,使用sk15-fb-s(序列号32)作为正义链引物、使用sk15-fb-as(序列号33)作为反义链引物、使用tks gflex dna polymerase(takara bio)作为聚合酶进行pcr。将扩增的片段用与上述(3-4)相同的步骤进行克隆,对得到的4种克隆分析各自的碱基序列。
[0175]
由此,阐明了编码有美洲鲎的具有b因子活性的可能性的蛋白质的cdna的全长序列(序列号5、序列号7、序列号9、序列号11)和其蛋白质的氨基酸的全长序列(序列号6、序列号8、序列号10、序列号12)。序列号5、7、9及11(序列号6、8、10及12)存在变体的关系,认为基于个体间的多态性。关于该蛋白质的表达及活性分析,容后说明。
[0176]
(5)美洲鲎的具有凝固酶原活性的蛋白质的cdna(第3cdna)的取得以上述(3-1)中得到的cdna为模板,使用sk15-pce-s(序列号34)作为正义链引物、使用sk15-as(序列号26)作为反义链引物、使用tks gflex dna polymerase(takara bio)作为聚合酶进行pcr。将扩增的片段用与上述(3-4)相同的步骤进行克隆,对得到的5种克隆分析各自的碱基序列。
[0177]
由此,阐明了编码有美洲鲎的具有凝固酶原活性的可能性的蛋白质的cdna的全长序列(序列号13、序列号15、序列号17、序列号19、序列号21)和其蛋白质的氨基酸的全长序列(序列号14、序列号16、序列号18、序列号20、序列号22)。序列号13、15、17、19及21(序列号14、16、18、20及22)存在变体的关系,认为基于个体间的多态性。关于该蛋白质的表达及活性分析,容后说明。
[0178]
(6)重组蛋白的表达将上述(5)中得到的cdna(序列号13)连接于哺乳类细胞中的蛋白质表达用载体pca7,得到表达质粒。上述(4)中得到的cdna(序列号5)按照文献(kobayashi et al.,2015,j biol chem,290:19379-19386),连接于蛋白质表达用载体pca7,得到表达质粒。使用这些表达质粒及上述(3-7)中得到的表达质粒(重组有序列号1的cdna的质粒)和expicho
tm expression system(thermo fisher scientific),以培养上清液组分的形态得到各重组蛋白。
[0179]
对细胞的表达质粒的转染和重组蛋白的回收按照添附的说明书。
[0180]
由此,在美洲鲎的有具有c因子活性的可能性的蛋白质(序列号2)、有具有b因子活性的可能性的蛋白质(序列号6)、有具有凝固酶原活性的可能性的蛋白质(序列号14)的表达及取得上首次获得成功。关于这些蛋白质的活性分析,容后说明。
[0181]
(7)活性测定在50mm tris缓冲液(ph8.0)、合成底物(boc-lgr-pna)的存在下,对上述(6)中得到的3种重组蛋白的各种组合,以美国药典标准内毒素(usp-rse。生化学工业株式会社)(0eu/ml、0.05eu/ml。eu为内毒素单位)为被检体,研究了依赖于内毒素的3种重组蛋白的活化。该反应在37℃下进行30分钟。
[0182]
如果在该分析系统中进行级联反应,则在内毒素作用下,具有c因子活性的蛋白质被活化,利用该被活化的具有c因子活性的蛋白质,具有b因子活性的蛋白质被活化,利用该被活化的具有b因子活性的蛋白质,具有凝固酶原活性的蛋白质被活化,利用该被活化的具有凝固酶原活性的蛋白质,合成底物boc-lgr-pna被切断,由此pna游离。pna的游离通过测定吸光度(a405nm)的变化而探测。其结果,在3种重组蛋白齐备的情况下,可看到合成底物的切断(图3)。需要说明的是,图3中,fc为由上述(3-7)中得到的cdna所表达的蛋白质,fb为由上述(4)中得到的cdna所表达的蛋白质,pce为由上述(5)中得到的cdna所表达的蛋白质。就与内毒素被检体混合的状态的反应液(100μl)中的蛋白质终浓度而言,fc为22.8μg/ml,fb为20.0μg/ml,pce为23.5μg/ml。各分析以n=3进行,将标准偏差作为误差条,同时记载于图中。
[0183]
该图首次显示:所表达的有具有c因子活性的可能性的蛋白质、有具有b因子活性的可能性的蛋白质、有具有凝固酶原活性的可能性的蛋白质分别具有c因子活性、b因子活性、凝固酶原活性,通过与内毒素接触而产生级联反应。另外,首次显示利用这些重组蛋白
可以检测内毒素。
[0184]
进而,在该条件下研究内毒素的浓度依赖性,制作标准曲线,结果,在0.001~0.1eu/ml的浓度范围内显示良好的直线性(图4)。各内毒素浓度中的分析以n=3进行,将标准偏差作为误差条,同时记载于图中。
[0185]
由以上的结果首次显示:通过使用所述的3种各重组蛋白,也可以进行内毒素的定量的高灵敏度且高精度的检测。
[0186]
(8)与源自鲎属的重组c因子的活性比较将源自美洲鲎的重组c因子(以下,“lfc”)和源自鲎(tachypleus)属的重组c因子(以下,“tfc”)的活性进行了比较。
[0187]
使序列号1的cdna与上述(6)同样地表达,以培养上清液组分形态得到lfc。使中国鲎的c因子基因(wo2014/092079的序列号1)利用该文献的实施例1.(2)中记载的方法与上述(6)同样地表达,以培养上清液组分形态得到tfc。在此,作为蛋白质表达用载体,均使用pci-neo(promega)。
[0188]
对供于试验的lfc和tfc,进行使用有c因子特异性的单克隆抗体(2c12;yoshiki miura,et al.,j.biochem.112:476-481(1992))的蛋白免疫印迹。将等体积的样品(各3μl)进样,就带强度的光学测定结果而言,lfc为18036,tfc为24516。即,等体积的样品中的重组c因子的相对量(tfc/lfc)为1.4。
[0189]
接着,将级联反应体系(含有c因子、b因子、及凝固酶原的体系)中的各重组c因子的活性进行比较。b因子及凝固酶原均使用源自鲎属的重组蛋白。前者使用将中国鲎的b因子基因(wo2014/092079的序列号5)用该文献中记载的方法(实施例2.重组因子b和重组凝固酶原的制备)进行表达,以培养上清液组分形态得到,后者使用将该生物的凝固酶原基因(同文献的序列号7)用该文献中记载的方法(实施例2.重组因子b和重组凝固酶原的制备)进行表达,以培养上清液组分形态得到。
[0190]
使用重组c因子(lfc或tfc)的各样品(均为等体积)、以及所述的源自中国鲎的重组b因子(tfb)及源自中国鲎的重组凝固酶原(tpce),用上述(7)中记载的方法测定活性。使用的重组c因子以外的条件设为相同。
[0191]
各级联反应体系中的0eu/ml(空白)及0.05eu/ml的各内毒素浓度中的吸光度的变化(mabs/min)在lfc的系统中为0.53及14.27,在tfc的系统中为0.51、9.15。即,在该系统中,lfc显示tfc的约1.6倍(如果考虑所述的蛋白量的差异,则为约2.2倍)的活性。
[0192]
本发明包括以下的方面:1、一种重组蛋白,其为以下的任一种:(a)含有序列号2或4所示的氨基酸序列的重组蛋白;(b)含有相对于序列号2或4所示的氨基酸序列具有95%以上的同源性的氨基酸序列、且具有c因子活性的重组蛋白;(c)由含有相对于序列号1或3所示的碱基序列具有95%以上的同源性的碱基序列的dna编码、且具有c因子活性的重组蛋白;(d)由以下dna编码且具有c因子活性的重组蛋白,所述dna为与包含序列号1或3所示的碱基序列的互补序列的dna在严格的条件下进行杂交的dna。2、一种项1所述的重组蛋白的、用于活化以下的蛋白质的用途,
(a)含有序列号6、8、10、或12所示的氨基酸序列的蛋白质;(b)含有相对于序列号6、8、10、或12所示的氨基酸序列具有95%以上的同源性的氨基酸序列,且具有b因子活性的蛋白质;(c)由含有相对于序列号5、7、9、或11所示的碱基序列具有95%以上的同源性的碱基序列的dna编码、且具有b因子活性的蛋白质;(d)由以下dna编码且具有b因子活性的蛋白质,所述dna为与包含序列号5、7、9、或11所示的碱基序列的互补序列的dna在严格的条件下进行杂交的dna。3、一种被检体中的内毒素的检测方法,其包含使项1所述的重组蛋白与被检体接触的步骤。4、一种内毒素检测剂,其含有项1所述的重组蛋白。
[0193]
日本专利申请第2016-204729号(申请日:2016年10月18日)的公开其整体通过参照而被引入于本说明书。
[0194]
本说明书中所记载的全部的文献、专利申请、及技术标准通过参照而引入各个文献、专利申请、及技术标准与具体且各个记载的情况同程度地,通过参照而被引入于本说明书中。工业上的可利用性
[0195]
根据本发明,可以提供与美洲鲎的凝固机制有关的全部的全长重组蛋白、编码这些重组蛋白的cdna、这些重组蛋白的用途。本发明特别是对内毒素的检测是有用的。
[0196]
[序列表的说明]序列号1:第1cdna的碱基序列序列号2:第1蛋白质的氨基酸序列序列号3:第1cdna-变体1的碱基序列序列号4:第1蛋白质-变体1的氨基酸序列序列号5:第2cdna的碱基序列序列号6:第2蛋白质的氨基酸序列序列号7:第2cdna-变体1的碱基序列序列号8:第2蛋白质-变体1的氨基酸序列序列号9:第2cdna-变体2的碱基序列序列号10:第2蛋白质-变体2的氨基酸序列序列号11:第2cdna-变体3的碱基序列序列号12:第2蛋白质-变体3的氨基酸序列序列号13:第3cdna的碱基序列序列号14:第3蛋白质的氨基酸序列序列号15:第3cdna-变体1的碱基序列序列号16:第3蛋白质-变体1的氨基酸序列序列号17:第3cdna-变体2的碱基序列序列号18:第3蛋白质-变体2的氨基酸序列序列号19:第3cdna-变体3的碱基序列序列号20:第3蛋白质-变体3的氨基酸序列
序列号21:第3cdna-变体4的碱基序列序列号22:第3蛋白质-变体4的氨基酸序列序列号23:合成底物肽iegr序列号24~34:引物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1