基于LM‑GA算法的红外光谱定性分析方法与流程
本发明涉及红外光谱定性分析领域,具体涉及一种基于LM-GA算法的红外光谱定性分析方法。
背景技术:
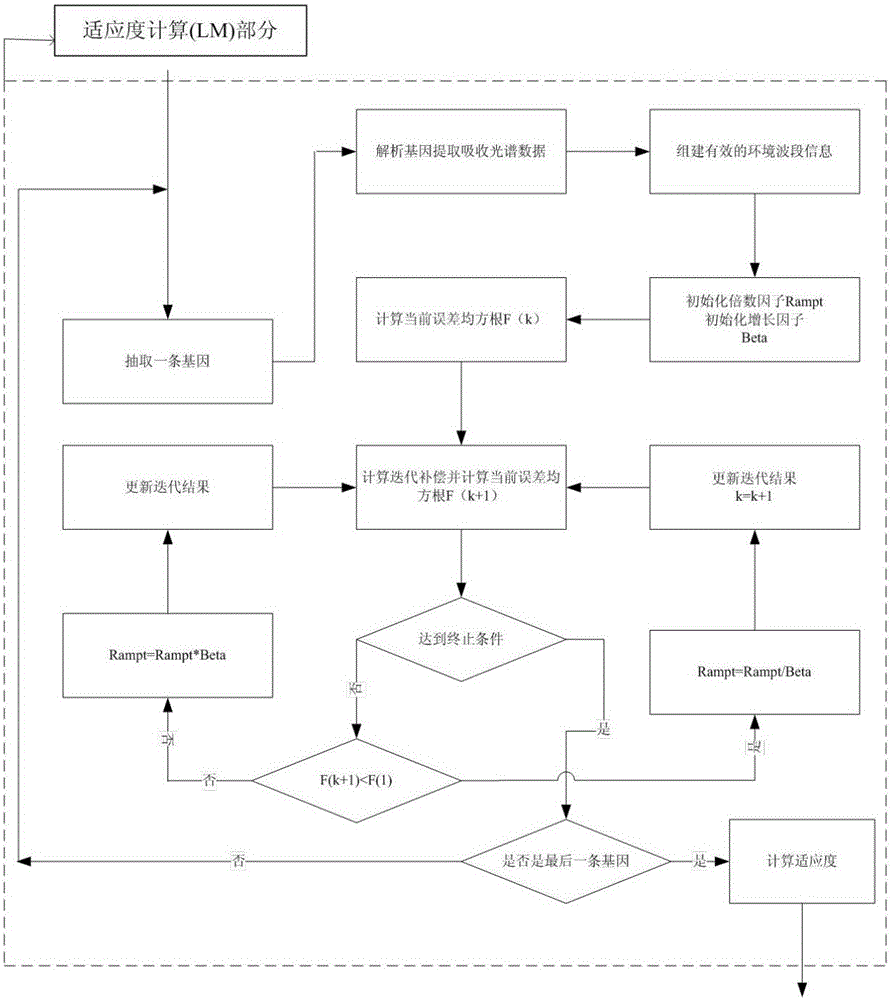
:在对傅里叶变换红外光谱进行组分定量分析时,首先需要解决的问题是清楚地知道其吸收的组分,亦即需要先对其进行定性分析。随着傅里叶变换红外光谱定性分析算法的发展,现有技术已经有多种算法可以对傅里叶变换红外光谱进行定性分析:如光谱差减法、经典最小二乘回归法(CLS)、主成分回归(PCR)、偏最小二乘法(PLS)、人工神经网络算法(ANN)、基于朗博比尔定律的遗传算法(GA)等,然后基于这些算法对红外光谱进行定性分析时都存在着一定的缺陷。比如,采用光谱差减法来实现光谱组分识别时候需要一个有经验的操作者设置有效的缩放因子,随着算法的发展,有些算法虽然可以实现缩放因子的自动设置,但是当光谱组分变得复杂时,通常自动设置缩放因子的方式得到的结果无效;又如,采用CLS来进行组分识别时,首先需要选出所考察波段所有光谱的吸光度数据,但是所有光谱数据最后都能影响到该算法的识别结果,而在采用PLS建模进行定性分析时,新组分的出现将会降低识别的准确度。近年来人工神经网络算法发展迅速,但是该算法需要复杂的训练过程,并且单一人工神经网络算法只能对单一组分进行定性识别。相比来说,基于朗博比尔定律的遗传算法可以为优化LM神经网络算法设计优秀的神经网络结构,因此遗传算法能对红外光谱数据中多组分进行同时识别,但是在仪器参数等带来的光谱漂移以及低分辨率的情况下,傅里叶变换红外光谱的吸收会偏离朗博比尔定律,从而造成识别的准确度较差。为此,对于组分复杂的样品来说,要想实现红外光谱的准确定性分析,目前来说还尚有难度。现有技术中,张长胜等人2008年的吉林大学学报上公开了一篇名称为“一种基于遗传算法和LM算法的混合学习方法”的论文,该论文公开的方法首先是通过遗传算法进行粗调得到一个全局近似解,然后以此为初值再通过遗传算法和LM算法交替进行训练,直到达到所限制的精度或最大交替步数为止,虽然该论文中公开了遗传算法和LM算法的混合算法,但是该方法中LM算法与GA算法是充当相同的功能,两者是等价的,即GA算法寻找全局最优解,LM算法寻找局部最优解,具体来说,该方法中LM算法与GA算法是并行运算用来训练ANN算法的参数,实际上,LM算法是高斯-牛顿迭代算法的改进算法,其对初值根本就不敏感,因此该论文既然是依据这点来使用GA算法进而克服高斯牛顿迭代算法对初值的依赖性的话,而实际运算过程中采用的仍是LM算法,那么GA算法在其GALM算法中也是无足轻重的。另外,申请人经试验验证表明该论文公开的算法结构并不适用于红外光谱的定性分析。因此,如何实现红外光谱的实时、准确分析,这还有待研究。技术实现要素:本发明的目的是提供一种操作简单、分析准确度高的基于LM-GA算法的红外光谱定性分析方法。为实现上述目的,本发明采用的技术方案是:一种基于LM-GA算法的红外光谱定性分析方法,一种基于LM-GA算法的红外光谱定性分析方法,其步骤如下:1)提取待测样品的红外光谱数据,建立参数文件,然后读取参数文件并对红外光谱数据的有效性进入判断,若有效,则进入步骤2),否则结束程序并输出报告;所述的参数文件包括:分子光谱数据库个数、类型及其路径信息;待处理光谱数据路径信息;分析波段信息(起始波段、终止波段、扩展波数信息);波数漂移初始值信息;切趾函数修正类型以及修正初始值信息;基线拟合阶数以及其初始值信息;环境信息(温度、压强等);GA参数;LM参数;2)通过读取分子光谱数据库中所有组分的吸收光谱数据,总数量为M。随机生成N个基因个体,每个基因个体的长度为M。基因每一位分别代表一种组分,当该位为0时,表示不存在该组分,当该位为1是表示存在该组分。同时建立起种群数据库,种群数据库包括三个部分,当前基因集合,淘汰基因集合,无效基因集合。将随机生成的N各基因个体放入到当前基因;;3)采用LM算法计算每个基因个体的适应度;4)若当前迭代次数≥最大迭代次数,则结束计算并输出报告,否则迭代次数加1并进入步骤5);5)对种群数据库中的有效基因个体进行交叉、变异运算,分析选择;6)若出现程序设定的最优解,则结束程序并输出报告,否则返回到步骤4),所谓的最优解也即是拟合误差小于参数中设定的最小误差,最小误差的设定大小直接常规定义即可,一般来说,最小误差都设定在10-6~10-10的范围内。采用上述技术方案产生的有益效果在于:本发明结合了LM算法的多参数拟合能力以及GA算法的全局最优搜索能力对傅里叶变换红外光谱进行定性分析,经实际应用表明该方法能快速准确识别傅里叶变换红外光谱中的吸收组分,与现有技术相比,采用本发明公开的方法定性分析红外光谱中的吸收组分不仅操作简单,而且事先无需建模和基线校正等繁琐的数据预处理步骤,其可以实时在线自动分析谱图,分析结果快速、准确。另外,与张长胜等人公开的LMGA算法相比,本发明所述分析方法中涉及的LM算法是为GA算法服务,LM算法参与GA算法中适应度的计算,因此本发明与现有的上述算法结构本身就完全不同。需要说明的是,本发明公开的方法对待测样品的物理性质没有限制,也即是说,对于固体、熔融状以及气体待测样品来说,本发明公开的方法均可以对其红外光谱进行定性分析。具体的方案,步骤3)中基因个体的适应度的计算步骤为:a)抽取一个基因个体的基因数据,采用二进制编码解析基因,提取数据库中对应组分在分析波段的光谱数据;b)初始化LM算法的倍数因子Rampt、增长因子Beta以及最大迭代次数B;c)拟合测量光谱,计算当前均方根误差F(k),其中k为当前迭代次数;d)计算迭代补偿,然后计算均方根误差F(k+1);e)判断是否达到终止条件:(|(F(k)-F(k+1)|)/F(k+1)是否小于最小误差,若是进入步骤f),否则进入步骤k),最小误差一般都设定为10-9左右;f)若F(k+1)<F(k),则进入步骤g),否则进入步骤i);g)更新Rampt=Rampt/Beta。h)更新迭代结果,k=k+1,并返回到步骤d);i)更新Rampt=Rampt*Beta。j)迭代结果保持不变,返回到步骤d);k)判断是否已经计算到最后一个基因个体,若是进入步骤l),否则返回到步骤a);l)计算每个基因个体的适应度:基因个体的基因型的标准差定义为:StdE(Gi)=1n-1Σj=1n(yc(vj)-ym(vj))2,]]>式中:StdE(Gi)表示第Gi个基因型的标准差;yc(vj)、ym(vj)分别表示实际测量光谱和计算光谱在第j个波数处的光强,n表示测量光谱数据中的点个数,j表示波数位置;基因个体的第Gi个基因型的适应度定义为:F(i)=1/StdE(Gi)Σ1/StdE(Gi).]]>实际上对于适应度的计算,本发明并未具体说明其拟合计算方法,但是本领域技术人员在已知测量光谱数据以及建立的基因个体的基因型的基础上均可知采用上述公式以及拟合计算光谱的数学模型实现基因个体的适应度的计算。具体来说,步骤1)中红外光谱数据的有效性判断步骤为:①、提取待测样品的红外光谱数据,剔除无效的环境信息,若存在有效的环境信息,则进入步骤②,否则结束程序并输出报告;②、组件有效的波段信息,若其波段信息有效,则进入步骤③,否则结束程序并输出报告,也就是说对提取的待测样品的红外光谱来说,先要对其相应的图谱进行初步的判定确定其是否是有效的;③、提取数据库中的吸收光谱数据并转换,若其存在有效的分子吸收光谱数据信息,则进入步骤2),否则结束程序并输出报告。也就是说,在对待测样品的红外光谱进行定性分析时需要做些参数的准备工作,即在分析前先要判定其红外检测时的温度、大气压强、光程信息等环境信息以及波段信息等是否在有效范围内,若无误,则进行接下来的分析工作,否则直接退出程序,具体可以见图1所示,这些参数准备工作实际上对红外光谱进行定性分析前的初期准备工作,只有满足了是有效的红外光谱数据,接下来对其进行定性分析才有意义。具体的,步骤4)中最大迭代次数是基因个体长度的0.5-1倍。作为进一步的优选方案,步骤5)分析选择的步骤为:第一步,将种群数据库中的有效基因个体交叉、变异运算生成的子代种群基因个体与种群数据库比对,剔除子代种群基因个体中的重复基因个体;第二步,计算子代基因个体的适应度,然后将子代基因个体和种群数据库中的有效基因个体的适应度一并按从大到小的顺序排列,只保留适应度大的前N个基因个体作为种群数据库中的当前有效基因。这样通过迭代重复运算分析即可得到最优解。另外,优选的,第一步在计算基因个体适应度过程中,将出现的奇异解或者离散解(例如某些组分光谱数据在分析波段是线性相关的时候会出现奇异解)归类为无效基因个体,第二步中剔除的适应度小的基因个体归类为非候选基因个体的淘汰基因个体,所述的无效基因个体、淘汰基因个体分别被纳入无效基因集合和淘汰基因集合中,程序控制基因个体交叉、变异运算生成的子代基因个体与无效基因集合及淘汰基因集合中的基因个体相异。这样对于种群数据库中新一代有效基因来说,可以有效避免其在运算中产生无效基因或淘汰基因,进而提高运算的效率。附图说明图1是本发明的方法分析的基本流程图;图2是基于LM算法图1中的基因个体的适应度计算流程图;图3是混合气体的红外光谱图。具体实施方式以下通过1个实施例来对本发明公开的技术方案作进一步的说明:实施例1:红外光谱的定性分析1)采用傅里叶变换红外光谱仪采集一条混合气体组分光谱图,光谱图如图3所示;2)建立参数文件:确定有效的分析波段1900cm-1-2145cm-1,扩展波数为10cm-1,拟合波数漂移并设置初始值为0,拟合函数采用诺顿比尔切趾函数,拟合基线初始值设置为1,0,0,0,设置环境信息温度、压强为当前实际环境信息;设置GA参数中的初始种群数目N为10,最大迭代次数为10,基因突变几率为0.9,设置LM参数中的最大迭代次数B为50;3)程序读取光谱,将待测样品光谱的起始波段,终止波段,以及光强信息读入。4)验证输入的环境信息,无误;5)验证参数中的波段信息,无误;6)分析数据库信息(本次实施例提取的是HITRAN高分辨率光谱数据库中的波段新新),并提取数据库中对应波段1900cm-1~2145cm-1的光谱数据,数据库中此波段所包含的光谱数据组分共19种,如表1所示;7)随机生成10个基因个体,建立初始种群数据库,基因个体中的基因数目为数据库中对应波段的组分个数,即19个,采用二进制编码将种群数据库中基因个体的19种表现型解码成二进制基因型,如表2所示,其中二进制基因型中的1表示包含该组分,0表示不包含该组分,表1中的各表现组分(按H2O,CO2,O3,……,HBr,HI,OCS,……,NO+的顺序)与表2-11中的基因型均按顺序一一对应,这样建立的初始种群数据库中的当前有效基因个体为10,另外初始种群数据库中的无效基因集合以及淘汰基因集合中的个体数目均为0;8)计算当前有效基因里面的每一条基因个体的适应度:a)抽取有效基因里面一个基因个体的基因数据,其二进制编码以及数据库中对应波段的光谱数据的分析选择已在步骤6)、7)中完成;b)初始化LM算法参数,倍数因子Rampt=0.01,增长因子Beta=10,由于程序的编排,有些参数条件的设置顺序可以适度的调整,但是不影响本发明的分析方法的具体应用,比如LM算法的最大迭代次数B在步骤2)中已直接在程度中设定为50,因此图1、2中给出的计算步骤只是为了便于理解,其与要求保护的步骤并没有冲突;c)拟合测量光谱,计算当前均方根误差F(k),其中k为当前迭代次数;d)计算迭代补偿,然后计算均方根误差F(k+1),迭代补偿的计算采用LM算法中的常规计算方法即可;e)判断是否达到终止条件,即(|(F(k)-F(k+1)|)/F(k+1)是否小于最小误差,若是进入步骤f),否则进入步骤k),其中最小误差的设定本领域技术人员根据经验值很容易确定,具体要看实际基因个体以及个体中基因型的数目,本次实施例中设定最小误差为10-6;f)若F(k+1)<F(k),则进入步骤g),否则进入步骤i);g)更新Rampt=Rampt/Beta。h)更新迭代结果,k=k+1,并返回到步骤d);i)更新Rampt=Rampt*Beta。j)迭代结果保持不变,返回到步骤d);k)判断是否已经计算到最后一个基因个体,若是进入步骤l),否则返回到步骤a);l)计算每个基因个体的适应度:基因个体的基因型的标准差定义为:StdE(Gi)=1n-1Σj=1n(yc(vj)-ym(vj))2,]]>式中:StdE(Gi)表示第Gi个基因型的标准差;yc(vj)、ym(vj)分别表示实际测量光谱和计算光谱在第j个波数处的光强,n表示混合气体分析波段的测量光谱数据中的点个数,j表示波数位置,该实施例中n=2197;i为1,2,……,19;基因个体的第Gi个基因型的适应度定义为:F(i)=1/StdE(Gi)Σ1/StdE(Gi);]]>9)若当前迭代次数≥10,则结束计算并输出报告,否则迭代次数加1并进入步骤10);10)对种群数据库中的有效基因个体进行交叉、变异运算生成的子代种群基因个体,与种群数据库比对,剔除子代种群基因个体中的重复基因个体;按照步骤8)的方法计算子代基因个体的适应度,然后将子代基因个体和种群数据库中的有效基因个体的适应度一并按从大到小的顺序排列,只保留适应度大的前10个基因个体作为种群数据库中的当前有效基因,同时将计算过程中出现的奇异解或者离散解纳入无效基因集合,将剔除的适应度小的基因个体相应地纳入种群数据库的或淘汰基因集合;11)本次实施例设定遗传算法的最小误差为10-10,其迭代计算10次,直至GA算法结束,提取种群数据库中当前有效基因里面的最优解作为识别结果。如表2-11所示的是GA算法的迭代计算过程中每一代的当前基因个体以及每个基因个体的标准差值,从迭代第10次的表11中可以看出,最优解为基因编号1,其基因型为:1100100101000111001,对该基因个体的基因型对照表1进行解码可知,采用上述方法分析出来的组分有9种(基因型中的1代表包含表1中对应的组分)H2O、CO2、CO、NH3、HBr、HCN、C2H2、PH3,NO+,而试验中可以确定混合气体中包含的组分为H2O,CO2,CO,NH3,而其它5种组分均是空气中含量较少的常见组分,并且在此分析波段并不具有强烈红外吸收,相比之下只是作为干扰组分出现,故可忽略,由此证明采用上述方法定性分析混合气体的红外光谱准确性高。表1光谱数据库中波段1900cm-1~2145cm-1所包含的光谱数据组分H2OCO2O3N2OCOCH4NONH3OHHBrHIOCSN2HCNC2H2PH3COF2H2SNO+表2迭代次数1表3迭代次数2表4迭代次数3表5迭代次数4表6迭代次数5表7迭代次数6表8迭代次数7表9迭代次数8表10迭代次数9表11迭代次数10当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 一种基于近红外定性分析的种子品种真实性鉴别方法
- 一种基于近红外提高鉴别结果的定性分析方法
- 一种应用于小分子定性定量分析检测和高通量筛选微生物培养液样品试剂盒及其制备方法
- 一种应用于小肽分子定性定量分析检测和高通量筛选增强试剂盒及其制备方法
- 一种应用于污染物小分子定性定量分析检测和高通量筛选增强试剂盒及其制备方法
- 一种应用于小分子定性定量分析检测和高通量筛选细胞培养液样品试剂盒及其制备方法
- 一种应用于小分子定性定量分析检测和高通量筛选血液样品试剂盒及其制备方法
- 一种应用于碱性小分子定性定量分析检测和高通量筛选增强电离缓冲液试剂盒及其制备方法
- 一种应用于胆碱及脂类分子定性定量分析检测和高通量筛选增强试剂盒及其制备方法
- 一种应用于三聚氰胺分子定性定量分析检测和高通量筛选增强试剂盒及其制备方法