一种高压电力设备局部放电模式识别方法和装置与流程
本申请涉及高压电领域,更具体地说,涉及一种高压电力设备局部放电特征提取方法和装置。
背景技术
高压电力设备的运行状态直接关系到整个电力系统的安全运行。在现场运行中,局部放电是导致高压电力设备绝缘劣化的重要原因之一,特别是随着电力设备容量、电压等级不断增大的情况下,这个问题更为严重。局部放电的检测和模式识别是目前电力变压器绝缘状态检测的重要手段。局部放电信号的检测和模式识别能够及时发现高压电力设备内部潜伏性故障,对保障设备的安全运行具有至关重要的意义。其中,分类器的设计是模式识别研究中的关键环节。
目前,大量的人工智能分类方法已经被应用在局部放电类型模式识别的研究中。现有的局部放电分类方法往往忽略各个特征值之间的内在联系,并且对小样本数据的识别能力较差。另外,传统的识别方法不能够识别出属于不包含在训练样本集合中的放电类型的样本。
技术实现要素:
有鉴于此,本申请提供一种高压电力设备局部放电模式识别方法和装置,以提高局部放电模式识别的精度。
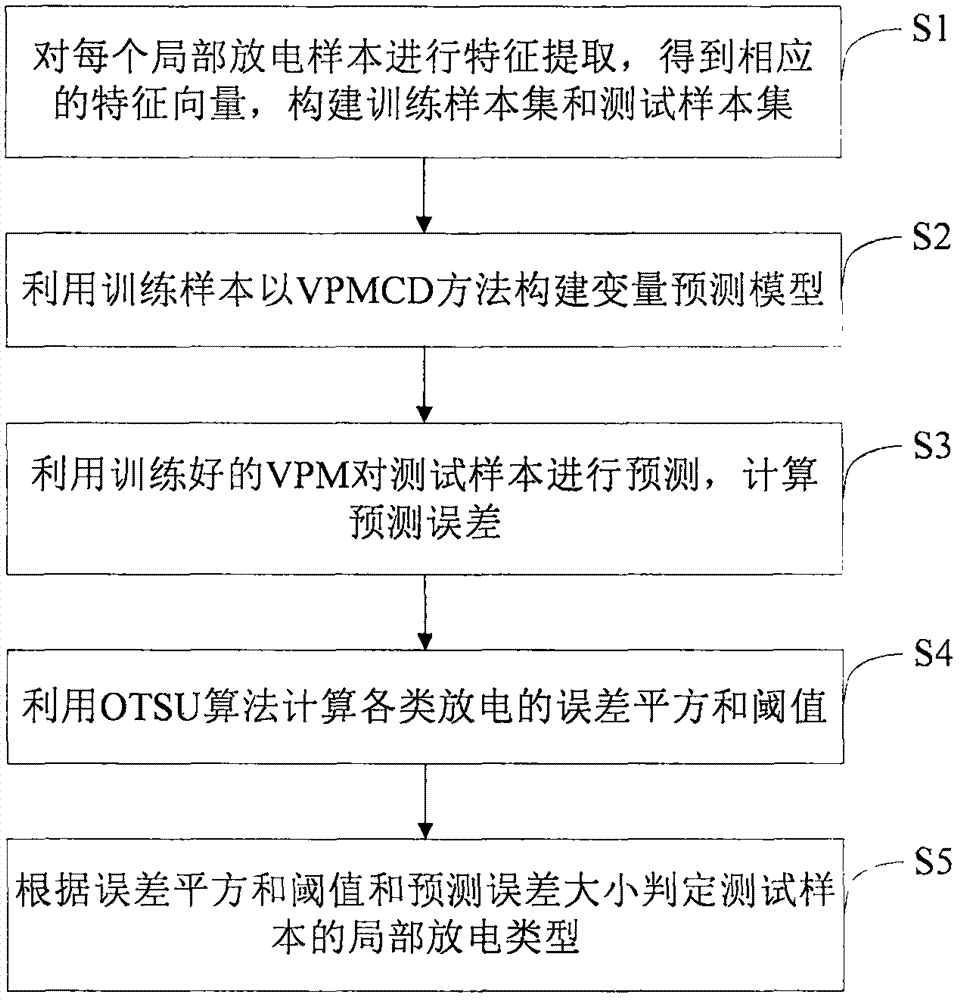
一种高压电力设备局部放电模式识别方法,包括:
获取高压电力设备局部放电的样本信号。
对所述放电样本进行特征提取,获得每个样本的特征向量。根据样本标签将所有样本划分训练样本集合和测试样本集合。同时,利用所有样本构成无标签样本集合s。
利用rvm-vpmcd方法对训练样本集合中的所有放电样本进行训练,构建各类型放电的变量预测模型vpm,训练过程包括:
设训练样本集合vtrain中共包含g类放电,共n个放电样本,其中n=n1+n2+...+ng。集合中某一样本xj=[xj1,xj2,...,xjp]。
步骤一:令k=1,i=1;
步骤二:利用nk个第k类样本进行训练,以rvm回归对第xj的i个特征值xji建立变量预测模型vpmik;
步骤三:i←i+1,循环步骤二,至i=p结束;
步骤四:k←k+1,循环步骤二~步骤三,至k=g结束;
步骤五:至此,共训练获得g×p个变量预测模型vpm。
利用构建完成的各类型放电的变量预测模型对依次对测试样本集中每一个样本进行预测,获得系列相应的预测误差,其实现过程包括:
设训练样本集合vtest中共n个放电样本。
步骤一:设测试样本集中共包含n个样本,集合中某一样本xj=[xj1,xj2,...,xjp]。
步骤二:令j=1,k=1;
步骤三:对任一测试样本xj利用vpmlk~vpmpk对xj1~xjp进行预测,获得预测值
步骤四:计算预测误差平方和
步骤五:k←k+1,循环步骤三~步骤四,至k=g结束。至此,完成所有预测模型对测试样本xj的预测,即得到预测误差slj~sgj;
步骤六:j←j+1,循环步骤三至五,至j=n结束。至此,完成对所有测试样本的预测。
设置各类型放电对应的预测误差阈值。各类型放电的误差阈值ssekt的确定过程包括:
步骤一:以所有训练样本和测试样本构成集合s,依据权利要求3中所述对训练样本进行训练,建立相应的变量预测模型vpmik;
步骤二:令k=1,利用vpmlk~vpmpk对集合s中的样本进行预测,得到相应的ssekj(j=1,2,...,n+n);
步骤三:将所有ssekj依据大小划分为1~m个等级,其中max{ssekj}对应等级m,min{ssekj}对应等级1;
步骤四:利用otsu算法对所有ssekj划分阈值t,并求得t对应的阈值ssekt;
根据预测误差平方和判定测试样本放电类型,判定过程包括:
3)以误差阈值ssekt为判定标准,ssekt表示第k类放电的误差阈值。若样本xj的预测误差skj<ssekt,则判定该样本为第k类放电样本。
4)当k=g时,测试样本集合中的剩余样本判别为放电类型不属于已知g类放电的未知放电类型的样本。
经由上述技术方案可知,本申请公开了一种高压电力设备局部放电模式识别方法和装置。该方法通过对提取特征后的局部放电样本特征向量集合,以rvm-vpmcd方法进行局部放电类型的模式识别。首先,通过rvm对已知类型的训练样本进行训练;其次,对各放电类型建立相应的变量预测模型;然后,利用这些模型对测试样本进行回归预测,得到各样本相应的预测平方和误差;最后,依据otsu算法设置误差阈值,通过阈值判定各放电样本的放电类型。vpmcd方法根据样本各特征值之间相互内在的联系,针对不同的类别对各个特征值建立vpm。利用建立好的vpm进行回归预测,以预测误差平方和构建判别函数,从而实现分类和识别。vpmcd不需要先验知识,避免了寻优过程,计算速度快。另外,为了克服vpmcd中多项式响应面法高阶计算量大、拟合效果差的缺点,本申请以rvm回归实现特征值的预测,它具有可调参数少、收敛速度快和泛化性能强等优点。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
图1示出了本发明一个实施例公开的一种高压电力设备局部放电模式识别方法的流程示意图;
图2示出了本发明公开的一种vpmcd方法的训练过程示意图;
图3示出了本发明公开的一种样本局部放电类型的判定过程示意图;
具体实施方案
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1示出了本发明一个实施例公开的一种高压电力设备局部放电模式识别方法的流程示意图。
在本实施例中,该方法包括:
s1:获取高压电力设备局部放电的样本,对所述放电样本进行特征提取,获得每个样本的特征向量。根据样本标签将所有样本划分训练样本集合和测试样本集合。同时,利用所有样本构成无标签样本集合s。
常用的局部放电特征有很多种,例如prpd特征,放电灰度图像特征等。本发明以对采集到的放电样本所提取出的特征向量为研究对象,构建样本集合并将样本划分为训练样本和测试样本。
s2:利用rvm-vpmcd方法对训练样本集合中的所有放电样本进行训练,构建各类型放电的变量预测模型vpm。
s3:依次利用各类放电的vpm对每一个测试样本进行预测,得到一系列相应的预测误差。
s4:利用otsu算法设置各类型放电对应的预测误差阈值。其实现过程为:
s41:以所有训练样本和测试样本构成集合s,依据权利要求3中所述对训练样本进行训练,建立相应的变量预测模型vpmlk;
s42:令k=1,利用vpm1k~vpmpk对集合s中的样本进行预测,得到相应的ssekj(j=1,2,...,n+n);
s43:将所有ssekj依据大小划分为1~m个等级,其中max{ssekj}对应等级m,min{ssekj}对应等级1;
s44:利用otsu算法对所有ssekj划分阈值t,并求得t对应的阈值ssekt。
s5:根据误差平方和阈值和预测误差大小判定每一个测试样本的放电类型。
参见图2示出了本发明实施例公开的vpmcd方法的训练过程(即变量预测模型vpm的建立过程)示意图。
其中vpmcd方法的识别过程包括:
设某一样本x可由p个特征值描述,其特征向量形式可表示为x=[x1,x2,....,xp]。当样本类别不同时,各特征值之间的相互关联也不相同。为了识别不同的样本类型,需要建立能够表征特征值x1~xp间关系的数学模型vpm,以便能够对测试样本的特征值进行回归预测,进一步实现对样本类别的正确划分。
对特征值xi进行预测,其对应的变量预测模型vpmi可表示为:
xi=f(xj,...,xl,bq,...,bo,r)+ε(1)
式中,1≤j≤l≤p且j,q≠i,bq,...,bo为模型参数,r为模型阶数且r≤p-1,ε为预测误差。
对于某一样本类型,若预测模型的类型、阶数以及对xi的预测变量确定,则参数bq~bo可通过多项式响应面法求解获得:
y=d·b(2)
式中,y为模型响应值,即xi的预测值;d为输入变量的多项式基函数;b为模型参数矩阵。
对于第k种样本类型,在模型类型和阶数确定的前提下,根据预测变量xj的不同组合,可得到crp-1种xi的预测模型vpmik,以拟合误差平方和最小的目标函数,寻求最优vpmik,即:
minjk(b)=min||d·b-xt||2(3)
对于g种不同样本类型,经过训练建立g×p个预测模型vpmik(k=1,2,...,g)。
vpmcd方法对测试样本利用
利用训练样本构建各类型放电的变量预测模型vpm的训练过程包括:
s21:设训练样本集合vtrain中共包含g类放电,共n个放电样本,其中n=n1+n2+...+ng。集合中某一样本xj=[xj1,xj2,...,xjp]。
s22:令k=1,i=1;
s23:利用nk个第k类样本进行训练,以rvm回归对第xj的i个特征值xji建立变量预测模型vpmik;
s24:i←i+1,循环步骤二,至i=p结束;
s25:k←k+1,循环步骤二~步骤三,至k=g结束;
s26:至此,共训练获得g×p个变量预测模型vpm。
另外,s23中rvm回归的具体过程包括:
给定训练样本集{xi,ti}mi=1,
ti=y(xi,ω)+εi(5)
式中,xi为输入向量,ti为目标值,m为训练样本数,ω为模型训练权值向量,ε为附加噪声。
由于训练样本之间相互独立分布,rvm的预测函数为
式中,ω0为偏移量。核函数k(x,xi)多选为高斯核函数。
训练集的似然函数为
式中,φ为核函数组成的结构矩阵,σ2为噪声参数。
通过式(7)将似然函数最大化,可求得参数,但会出现模型过学习。所以假设参数ω服从均值为0,方差为α的高斯分布概率分布,可得出:
式中,α为决定权值ω的先验超参数。
根据贝叶斯原则推倒后可得到关于ω和t的后验正态分布,即
令a=diag(α1,α2,...,αm),则后验协方差概率和后验均值分别为
∑=(σ-2φtφ+a)-1(11)
μ=σ-2∑φtt(12)
γi=1-αi∑ji(15)
式中,
如果给定新的输入数据x*,其相对应的输出概率分布为
可看出
y*=μtφ(x*)(18)
显然,y*为t*的预测值。至此,完成rvm的回归预测。
参见图3示出了本发明对测试样本放电类型的判定流程图。
s31:以误差阈值ssekt为判定标准,ssekt表示第k类放电的误差阈值。若样本xj的预测误差skj<ssekt,则判定该样本为第k类放电样本。
s32:当k=g时,测试样本集合中的剩余样本判别为放电类型不属于已知g类放电的未知放电类型的样本。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个......”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!