I/O设备、可编程逻辑控制器以及运算方法与流程
本发明涉及一种用于可编程逻辑控制器的I/O设备。
背景技术:
图1是CPU设备10与多个(3台)I/O设备通过I/O总线99连接而成的PLC1000(可编程逻辑控制器)。3台I/O设备100-1~100-3与CPU设备10连接,3台I/O设备的结构相同。对于在如图1所示连接而成的PLC1000中的I/O设备之间的现有的输入输出处理,首先,CPU设备10收集(输入)各I/O设备的“输入端子信息”。在这里,“输入端子信息”是向各I/O设备的输入端子170-1输入的信息。CPU设备10使用收集到的“输入端子信息”而进行运算处理,将该运算结果向I/O设备递送(输出)。所递送的运算结果例如表示出了用于哪个I/O设备的运算结果。而且,被递送了自身的运算结果的I/O设备将运算结果向输出端子180-1输出。CPU设备10对所有的I/O设备进行该输入输出处理,另外,重复该输入输出处理。由于CPU设备10对所有的I/O设备的输入输出处理进行集中处理,因此,存在I/O之间的处理响应变慢的课题。对于该课题,在日本特开平07-244506(专利文献1)中记载了减轻CPU设备10的处理负担的方式。另外,在日本特开2000-259208(专利文献2)中记载了在不经由CPU设备10的状态下在I/O设备中进行输入输出处理的处理方法。在专利文献1中,在各I/O设备中设置“通用存储器”,在不经由CPU设备10的状态下将各I/O设备的输入端子信息在通用存储器之间进行移动,减轻CPU设备10的处理负担。但是,由于是将输入端子信息暂时存储在通用存储器中的结构,因此,在进行多个I/O设备之间的输入输出处理的情况下,无法从存储器中一次性读出多个数据。因此,无法对输入输出处理进行并行处理,处理较为花费时间。另外,由于将各I/O设备的输入端子信息全部存储在通用存储器中,因此,有时也会存储不用于I/O设备之间的输入输出处理的数据,随着I/O设备的数量的增加,导致过多地安装存储器。在专利文献2中,设置连接数据库和MPU,将各I/O设备的输入端子信息在各I/O设备之间进行发送接收,在不经由CPU设备10的状态下在I/O设备中进行输入输出处理,其中,连接数据库存储将其他I/O设备与本I/O设备的信息进行关联的映射表,MPU基于该存储的映射表而进行数据处理。但是,针对每个接收到输入端子信息的连接数据,MPU都参阅在连接数据库中存储的映射表,因此,无法一次参阅多个数据,无法对输入输出处理进行并行处理。并且,在对输入端子信息进行运算处理时,由于是将作业数据存储在存储器中并通过MPU进行处理的结构,因此,无法对多个数据进行并行处理,处理较为花费时间。另外,在进行I/O设备之间的输入输出处理时需要MPU、存储器,因此,使成本变高。另外,对于PLC的I/O设备的输出,有时希望附加延迟而使输出定时(timing)推迟,有时希望保持输出值并持续输出。作为附加延迟的使用方法例举下述情况,即,在基于输入的运算成立时,在某个处理(例如退避处理)完成之前不希望向外部进行通知。作为值保持的使用方法例举下述情况,即,在运算成立时,希望向外部持续进行通知而直到某个处理(例如退避处理)完成为止。在专利文献3中公开了下述技术,即,为了数据的传递的高速化和高效化,在I/O设备中,将与传感器等之间的输入输出保存在数据库中,在由表格定义的定时下进行输出。但没有记载下述情况,即:附加延迟、保持输出值;在机器的紧急错误信号的输入之后,对运算结果附加延迟而依次执行按照多个机器的紧急停止顺序而进行停止处理这样的连续动作。而且,专利文献3是使用了数据库的系统。由此,专利文献3的处理是顺序处理,即,对于各个输出,通过反复测量时间、参阅对应表、参阅数据库,而确认是否是与输出定时的条件相符的输出。因此,在专利文献3中,存在无法实现准确的输出定时的课题。另外,由于是使用了数据库的系统,因此,存在电路规模变大的课题。专利文献1:日本特开平07-244506号公报专利文献2:日本特开2000-259208号公报专利文献3:日本特开2010-231407号公报
技术实现要素:
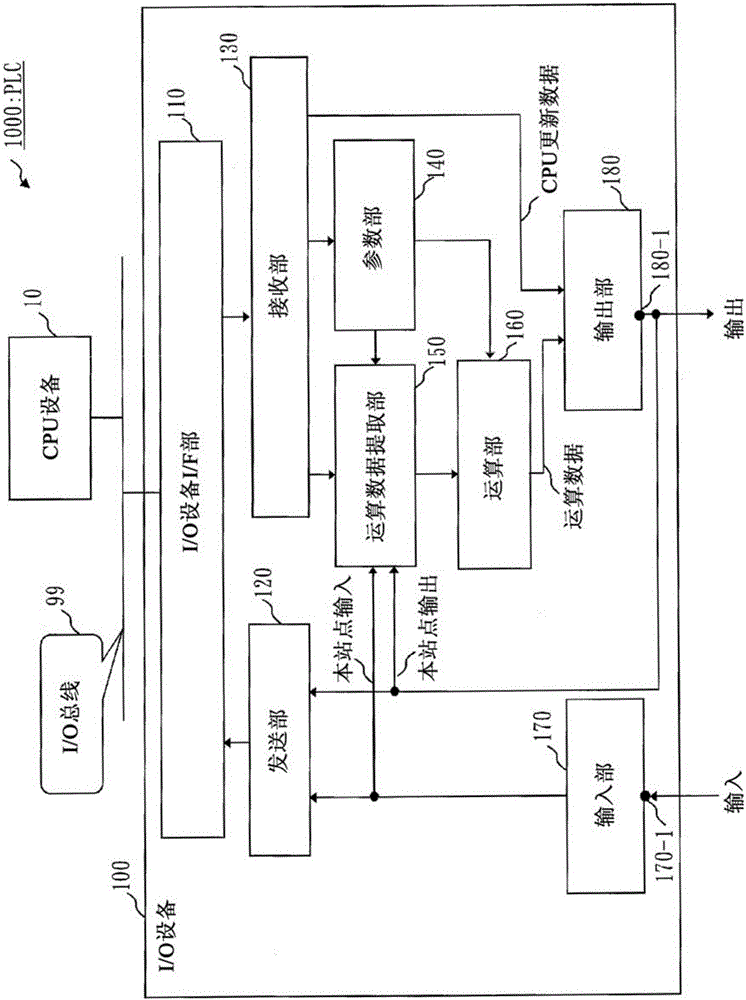
对于在不经由CPU设备10的状态下进行I/O设备之间的输入输出处理的现有方法,在将各I/O设备的输入端子信息在各I/O设备之间进行发送接收时,将各I/O设备的输入端子信息暂时存储在存储器中(专利文献1),或者针对每个接收到输入端子信息的连接数据,MPU都参阅在连接数据库中存储的映射表(专利文献2)。因此,存在无法对多个数据并行地执行输入输出处理,处理较为花费时间的课题。另外,对于过多地安装存储器的结构,存在由于需要MPU等而导致成本较高的课题。本发明的目的在于,不在I/O设备内设置用于存储输入端子信息的存储器、MPU,能够对多个数据并行地执行输入输出处理,由此以低成本实现I/O设备之间的输入输出处理的高速化。本发明的I/O设备用于具有CPU设备和多个I/O设备的可编程逻辑控制器,CPU是指中央处理单元,I/O是指输入/输出,该I/O设备的特征在于,具有:接口部,其与所述CPU设备进行通信并且与其他所述I/O设备进行通信,从其他I/O设备接收朝向所述其他I/O设备的输入信息和来自其他I/O设备的输出信息;参数部,其存储多个运算处理的方式,以及示出用于对在所述运算处理中使用的运算数据进行提取的提取条件的参数;运算数据提取部,其输入所述接口部接收到的其他所述I/O设备的输入信息和输出信息,并且,输入朝向本I/O设备的输入信息和来自本I/O设备的输出信息,将已输入的其他所述I/O设备的输入信息和输出信息、以及已输入的本I/O设备的输入信息和输出信息各自作为对象,根据在所述参数部中存储的所述参数,提取所述运算数据,将提取出的所述运算数据输出;以及运算部,其通过使用由所述运算数据提取部输出的所述运算数据,从而根据在所述参数部中存储的所述多个运算处理的方式,并行执行所述多个运算处理。发明的效果在PLC的I/O设备中,能够对多个数据并行地执行输入输出处理,以低成本实现I/O设备之间的输入输出处理的高速化。附图说明图1是实施方式1的PLC的结构图。图2是实施方式1的I/O设备100的结构图。图3是实施方式1的运算数据提取部150的框图。图4是表示实施方式1的运算部160的结构例的框图。图5是表示实施方式1的I/O设备100-1的参数设定的图。图6是表示实施方式1的I/O设备100-2的参数设定的图。图7是表示实施方式1的I/O设备100-3的参数设定的图。图8是实施方式2的运算数据提取部150-2的框图。图9是表示实施方式2的运算数据提取部150-2的动作的时序图。图10是实施方式3的I/O设备100的结构图。图11是实施方式3的延迟附加·保持部190、参数部140的框图。图12是表示实施方式3的AND0、延迟附加部1、保持部1的系列的图。图13是表示实施方式3的延迟动作的时序图。图14是表示实施方式3的保持动作的其他时序图。图15是表示实施方式3的延迟以及保持动作的时序图。图16是表示实施方式3的延迟以及保持动作的效果的时序图。图17是实施方式4的I/O设备100的结构图。图18是实施方式5的延迟附加·保持部190-5、参数部140的框图。图19是表示实施方式5的延迟以及保持动作的时序图。图20是实施方式6的I/O设备100的结构图。具体实施方式实施方式1(现有的输入处理)在背景技术中说明的现有的输入输出处理中,“输入处理”、“输出处理”的含义如下。输入处理是CPU设备10从各I/O设备收集输入端子信息并实施运算的处理。输出处理是CPU设备10向I/O设备递送运算结果,被递送了自身的运算结果的I/O设备从输出端子输出运算结果的处理。(实施方式1、2的输入处理)另外,在通过下面的实施方式1、2说明的“在I/O设备之间特别高速地进行输入输出处理的情况下”的输入输出处理中,“输入处理”、“输出处理”的含义如下。关于输入处理,在着眼于图1所示的一个I/O设备100-1的情况下,是I/O设备100-1从其他I/O设备100-2、100-3收集输入端子信息以及输出端子信息,并且,进一步使用I/O设备100-1自身的输入端子信息以及输出端子信息实施运算的处理。另外,输出处理是I/O设备100-1将运算结果从自身的输出端子180-1输出的处理。I/O设备100-2、100-3也与I/O设备100-1相同,进行同样的“输入输出处理”。下面,说明实施方式1的PLC(可编程逻辑控制器)。实施方式1的PLC的结构与图1的结构相同。即,在实施方式1的PLC中,各I/O设备以及CPU设备10的连接关系与图1相同。但各I/O设备以及CPU设备10的动作不同。图2是实施方式1的PLC1000中的I/O设备100的结构图。此外,在图1中,I/O设备100是3台,将它们作为I/O设备100-1~100-3而进行区分。各I/O设备的结构相同。另外,在不需要进行区分的情况下,记载为I/O设备100或者I/O设备。(1)I/O总线I/F部110是与I/O总线99的接口。I/O总线I/F部110进行与CPU设备10的数据的接收发送、I/O设备之间的数据的接收发送的控制。下面,将I/O总线I/F部110简称为I/F部110。(2)发送部120将I/O设备的输入信号(从输入端子170-1输入)、输出信号(从输出端子180-1输出)经由I/F部110,向I/O总线99发送。另外,当接收部130经由I/F部110从CPU设备10接收到读出请求时,发送部120向CPU设备10发送响应于请求的数据。另外,各I/O设备不分优劣,都定期或者在能够发送的定时下向所有其他I/O设备发送自身的“输入信号、输出信号”。(3)接收部130经由I/F部110从I/O总线99接收数据。接收部130在具有与I/O设备的输出信号相对的写入(图2的CPU更新数据)请求时,或者在向I/O设备内设定参数(后面进行说明)时,从CPU设备10接收数据。另外,接收部130接收从各I/O设备发送的输入信号、输出信号。(4)参数部140用于存储参数。参数是选择信息,该选择信息的用途是,为了进行I/O设备之间的输入输出处理,针对从其他I/O设备接收到的“输入信号、输出信号”、后面所述的图2所示的“本站点输入、本站点输出”,从它们中仅提取在运算部160的运算中使用的数据。另外,参数部140还存储用于选择运算种类的参数(运算处理的设定信息)。(5)运算数据提取部150根据参数部140中设定的选择信息(参数),针对从其他I/O设备接收到的“输入信号、输出信号”(接收数据)、或者“本站点输入、本站点输出”,从它们中仅提取在运算部160的运算中使用的数据,并将其保存在寄存器(会通过图3在后面进行说明)中。从其他I/O设备接收到的“输入信号、输出信号”、或者“本站点输入、本站点输出”都是由多位构成的位信息。(6)运算部160对由运算数据提取部150提取出的数据进行运算。关于本实施方式1的运算部160,以安装有多个2输入或者1输入的逻辑运算电路的结构进行说明,但只是一个例子。在图4中,作为运算部160的例子,表示了安装有32个2输入的AND电路的结构。运算部160也可以由以相对于固定的输入而输出特定的值的方式进行了编程的EPROM、可读写的非易失性存储器等构成。此外,假定为针对非易失性存储器的读写是通过CPU设备10,经由参数部140进行的。(7)输入部170将外部的数据作为输入信号进行输入。(8)输出部180将来自运算部160的运算结果数据和来自接收部130的CPU设备10的写入数据(CPU更新数据)作为输出信号向外部进行输出。输出部180在存在来自运算部160以及接收部130的更新请求时,将进行输出的值更新为来自各部的数据。图3是将运算数据提取部150和与运算数据提取部150相关的参数部140的内部示出的结构图。(运算数据提取部150)(1)“寄存器1~寄存器N”存储针对从其他I/O设备接收到的输入信号、输出信号,从它们中仅提取在运算中使用的数据而获得的数据。(2)“写入控制部1~写入控制部N”在从其他I/O设备接收到“输入信号、输出信号”(接收数据)时,对寄存器1~寄存器N进行提取出的数据的写入控制。当从其他I/O设备接收到接收数据时,“接收写入信号”变为启用状态(enable)。当对作为发送源的I/O设备进行识别的接收站点编号与参数部140中设定的选择站点编号(提取源)一致时,写入控制部将提取出的数据写入寄存器。另外,写入控制部在设定于参数部140中的选择站点编号与表示本I/O设备的本站点编号一致的情况下,无论接收写入信号的值如何,都将提取出的数据写入寄存器中。(3)第1选择部151(1)~151(N)、第2选择部152(1)~152(N)分别根据选择种类1~N、数据位置1~N的参数,而对数据进行选择。第1选择部、第2选择部例如通过多路复用器实现。(参数部140)(1)“选择种类1~选择种类N”用于存储如下参数,该参数表示作为运算数据使用的提取数据是本站点的输入信号(本站点输入A)、输出信号(本站点输出B),还是来自其他I/O设备的输入信号(其他站点输入C)、输出信号(其他站点输出D)。(2)“数据位置1~数据位置N”用于存储如下参数,该参数表示在输入信号、输出信号是多位的情况下,将哪位的位置处的数据作为运算数据进行使用。(3)“选择站点编号1~选择站点编号N”用于存储如下参数,该参数表示将哪个站点编号的I/O设备的输入信号、输出信号作为运算数据进行使用。(4)“本站点编号”用于存储表示本I/O设备的站点编号的参数。(5)“运算处理141”用于设定图5~图7所示的运算处理(运算输出0、运算输出1等)。(子提取部)在图3中,第1选择部151(1)、第2选择部152(1)、寄存器1构成子提取部(1)。第1选择部151(2)、第2选择部152(2)、寄存器2构成子提取部(2)。同样,第1选择部151(N)、第2选择部152(N)、寄存器N构成子提取部(N)。由此,运算数据提取部150具有分别提取运算数据的多个子提取部。参数部140如图3所示,针对每个子提取部存储有与子提取部相对应的提取条件。各个子提取根据相对应的参数,对运算输入数据进行提取。(运算部160的结构)图4是表示运算部160的结构例的框图。在图4中,R(1)等是寄存器。图4的运算部160是安装有32个2输入的AND电路的结构(N=32)。各I/O设备具有最大32条输入信号线(输入端子170-1)和最大32条输出信号线(输出端子180-1)。与这种情况相对应,在图4中,运算部160安装32个2输入、1输出的AND电路。AND电路0~31的总计32个输出与32条输出信号线相对应。如图4所示,运算数据提取部150中的寄存器的个数是64个。其原因在于,AND电路的2个输入中的每个输入均与一个寄存器相对应。即,寄存器的个数N是“AND电路的个数×AND电路的输入数=32×2=64”与64个(N=64)寄存器相对应,第1选择部151(N)、第2选择部152(N)、写入控制部N当然也是64个(N=64)。此外,这是用于说明运算部160的结构的一个例子。运算部160也可以由AND电路和OR电路这两种电路构成,也可以使用任意的逻辑电路。另外,在图4的例子中,一个寄存器的值仅对应一个AND电路,但也可以是一个寄存器的值用于多个逻辑电路。下面,说明动作。在通常的“输入输出处理”中,与背景技术所述的处理相同地,CPU设备10收集各I/O设备的输入端子信息而进行运算处理(输入处理),将该运算结果向作为输出目标的I/O设备递送(输出处理)。被递送了运算结果的I/O设备将运算结果向输出端子180-1输出。(参数的设定)在I/O设备之间特别高速地进行输入输出处理的情况下,在进行输入输出处理之前,CPU设备10预先向各I/O设备100的参数部140设定用于进行I/O设备之间的输入输出处理的参数。CPU设备10将在I/O设备之间的输入输出处理中使用的运算数据的选择信息、运算处理(图5的运算输出0、运算输出1等)作为参数设定至参数部140的运算处理141。此外,在后述的图5~图7中示出了运算输出0、运算输出1这两种情况,但如图4所示,在使用32个AND电路的情况下,对各AND电路进行运算输出的设定。即,将运算输出0~运算输出31这32个运算输出设定至参数部140的运算处理141。运算输出0~运算输出31这32个运算输出与32条输出信号线相对应。图5~图7表示在I/O设备100-1~I/O设备100-3中设定的参数的例子。此外,如图4的说明所述,各I/O设备具有最大32条输入信号线(输入端子170-1)和最大32条输出信号线(输出端子180-1)。在进行参数设定之后,在PLC1000中,转换为通常的PLC的输入输出处理。(1)在CPU设备10进行的“通常的输入输出处理”中,CPU设备10经由I/O设备的I/F部110收集I/O设备的输入信号的信息。(2)CPU设备10根据收集到的数据(输入信号)进行运算处理,将该运算结果经由该I/O设备的I/F部110以及接收部130,向作为输出目标的I/O设备输出。当I/O设备的接收部130接受到CPU设备10的输出更新时,即当接收部130从CPU设备10接收到运算结果时,输出部180将从CPU设备10接收到的数据(运算结果)向输出端子180-1输出。在I/O设备之间高速地进行的输入输出处理中,各I/O设备不分优劣,都定期或者在能够发送的定时下获得I/O总线99的总线权,向其他所有I/O设备发送本站点的“输入信号和输出信号”的数据。此外,在与CPU设备10的I/O总线访问发生冲突的情况下,优先向CPU设备10赋予总线权。(I/O设备100-1)I/O设备100-1从I/O设备100-2和I/O设备100-3依次接收各自的输入信号以及输出信号。关于输入信号(输入信息),例如在着眼于I/O设备100-2的情况下,是I/O设备100-1经由I/O总线99,接收与I/O设备100-1的本站点输入(图2)相当的I/O设备100-2的本站点输入的情况。同样,关于输出信号(输出信息),在以I/O设备100-2来看的情况下,是I/O设备100-1经由I/O总线99,接收与I/O设备100-1的本站点输出(图2)相当的I/O设备100-2的本站点输出的情况。I/O设备100-3的情况也一样。I/O设备100-1在从I/O设备100-2接收到输入信号时,向图3的“接收数据”即“其他站点输入C”输入I/O设备100-2的“输入信号”。另外,在这种情况下,向“接收站点编号”输入“2”,接收写入信号变为启用状态。(运算输入数据1)与成为寄存器1的输出的运算输入数据1(运算数据)相对应的参数设定(选择种类、选择站点编号、数据位置)如图5所示,设定为选择种类=其他站点输入,选择站点编号=2,数据位置=3,因此,第1选择部151(1)选择来自I/O设备100-2的“输入信号”,第2选择部152(1)选择输入信号的第3位。接收站点编号=选择站点编号=2,因此,接收写入也为启用状态。因此,写入控制部1将提取出的第3位的数据写入寄存器1中。由此,运算输入数据1成为来自I/O设备100-2的输入信号的第3位的值。同样,运算输入数据3以及运算输入数据4在图5中,也是选择种类=其他站点输入、选择站点编号=2,因此,分别成为来自I/O设备100-2的输入信号的第5位、第6位的值。通过运算输入数据得到更新,运算部160输出与进行参数设定后的“运算处理141”相符的运算结果。I/O设备100-1的运算输出0如图5所示,形成“运算输入数据1AND运算输入数据2”的运算结果。另外,运算输出1形成“运算输入数据3OR运算输入数据4”的运算结果。此外,在图4的结构图中,运算输出1是“运算输入数据3AND运算输入数据4”,但在图5中示出了“OR”的情况。I/O设备100-1的输出部180在从运算部160接受了运算结果的输出更新时,将该运算结果输出。在现有的技术中,即使接收多位的输入信号,也无法并行地执行I/O设备之间的输入输出处理,较为花费时间。但如上所述,能够对多个数据(从寄存器1~N输出的数据)并行地执行I/O设备之间的输入输出处理。即,如图4的例子所示,能够对多个数据(从寄存器1~N输出的数据)进行由32个AND电路实现的并行处理。由此,实现处理高速化的效果。另外,不需要在I/O设备内设置存储不用于运算的数据的存储器(专利文献1)、MPU(专利文献2)。因此,能够以低成本实现I/O设备之间的输入输出处理。(I/O设备100-2)下面,I/O设备100-2从I/O设备100-1和I/O设备100-3依次接收各自的“输入信号和输出信号”。I/O设备100-2在从I/O设备100-3接收到输出信号的情况下,该输出信号被输入至其他站点输出D(图3)。另外,向接收站点编号输入“3”,接收写入变为启用状态。与运算输入数据3相对应的参数设定(选择种类、选择站点编号、数据位置)如图6所示进行设定。因此,运算输入数据3的第1选择部151(3)3通过“选择种类”,选择其他站点输出即来自I/O设备100-3的输出信号。“数据位置”是0,因此,第2选择部152(3)选择输出信号的第0位。“接收站点编号”是“3”,选择站点编号也是3,所以两者一致,接收写入也是启用状态。因此,写入控制部3将提取出的第0位的数据写入寄存器3中。由此,运算输入数据3成为来自I/O设备100-3的输入信号的第0位的值。通过图6,I/O设备100-2的运算输出1成为运算输入数据3的值,运算部160将运算结果输出。如上所述,对于其他I/O设备的输出信号,也能够与输入信号相同地并行地执行I/O设备之间的输入输出处理。(I/O设备100-3)下面,I/O设备100-3从I/O设备100-2接收“输入信号”,从本站点(I/O设备100-3自身)接收“输入信号和输出信号”。I/O设备100-3从本站点接收到的输入信号向“本站点输入A”(图3)输入,输出信号向“本站点输出B”输入。(运算输入数据1)与运算输入数据1相对应的参数设定如图7所示,设定为选择种类=本站点输入,选择站点编号=3,数据位置=1。因此,第1选择部151(1)选择本站点输入即来自I/O设备100-3的输入信号,第2选择部152(1)选择输入信号的第1位。本站点编号是3,选择站点编号也是3,两者一致,因此,写入控制部1将提取出的第1位的数据写入寄存器1中。由此,运算输入数据1成为来自I/O设备100-3的输入信号的第1位的值。(运算输入数据2)同样,对于运算输入数据2,提取来自I/O设备100-3的输出信号的第1位。本站点编号是3,选择站点编号也是3,两者一致。因此,写入控制部2将提取出的第1位的数据写入寄存器2中。I/O设备100-3的运算输出0输出“运算输入数据1OR运算输入数据2”的运算结果。(运算输入数据3、4)在从I/O设备100-2接收到“输入信号”(其他站点输入)时,运算输入数据3成为从“其他站点输入”输入的输入信号的第4位的值。另外,对于运算输入数据4,从I/O设备100-3自身接收到的输入信号从“本站点输入A”输入,成为输入信号的第0位的值。I/O设备100-3的运算输出1输出“运算输入数据3AND运算输入数据4”的运算结果。如上所述,对于本I/O设备的输入信号、输出信号,也能够与来自其他I/O设备的输入信号相同地并行地执行输入输出处理。另外,I/O设备100-3的输入信号的第0位由I/O设备100-1~3所有I/O设备作为运算输入数据。能够通过将该I/O设备100-3的输入信号的第0位这种位指定为运算输入数据,使各I/O设备进行输入输出处理,从而,高速地控制各I/O设备的停止、启动等动作。实施方式2参照图8、图9说明实施方式2。在上面的实施方式1中,运算数据提取部150将从其他I/O设备、本I/O设备输入的输入信号、输出信号的数据立即传给运算部160。但是,对于以不同I/O设备的数据作为输入的运算处理,随着I/O设备的不同,接收数据的定时不同,因此,各运算输入数据的更新不同步。在I/O设备之间非同步地进行控制的输入输出处理的情况下,对于实施方式1没有问题,但在I/O设备之间同步地进行控制的输入输出处理中,会输出意料外的运算结果。因此,示出对在I/O设备之间的输入数据取得同步的实施方式。图8是将对提取的数据施加同步控制的运算数据提取部150-2和与运算数据提取部150-2相关的参数部140的内部示出的结构图。图8与图3相比,运算数据提取部150-2的结构不同。运算数据提取部150-2相对于图3的运算数据提取部150,追加有同步信号S、发送信号T以及寄存器1a~Na。寄存器1a~寄存器Na在来自I/F部110的同步信号S变为启用状态时,对在寄存器1~寄存器N中存储的数据进行存储。写入控制部1~写入控制部N在从其他I/O设备接收到输入信号、输出信号(接收数据)时,对寄存器1~寄存器N进行提取出的数据的写入控制。当从其他I/O设备接收到数据时,接收写入信号变为启用状态,当用于识别发送源I/O设备的接收站点编号与参数部140中设定的选择站点编号一致时,将提取出的数据写入寄存器中。另外,在设定于参数部140的选择站点编号与表示本I/O设备的本站点编号一致的情况下,当来自I/F部110的发送信号T变为启用状态时,将提取出的数据写入寄存器中。在图2的I/O设备的结构图中,当实施方式2的I/F部110向其他I/O设备发送了“输入信号和输出信号”的数据时,将发送信号T置为启用状态。另外,当从本站点向其他I/O设备发送,并且,从所有I/O设备接收到一遍数据时,将同步信号S置为启用状态。各I/O设备均等地获得I/O总线99的总线权,向其他所有I/O设备进行发送。因此,I/F部110能够对在固定的期间内从所有I/O设备进行了一遍数据转发这一情况进行确认。下面说明动作。图9表示各I/O设备向其他I/O设备发送输入信号和输出信号的数据、其他I/O设备接收数据的时序图。另外,图9表示与同步信号S、运算输入数据的更新相对的时序图。如图9所示,从I/O设备100-1至I/O设备100-2、I/O设备100-3,依次进行各I/O设备的数据的发送接收。当I/O设备100-1发送了数据1b时,在I/O设备100-1中发送信号T变为启用状态,在选择站点编号被设定为I/O设备100-1的寄存器中更新为所发送出的数据。在I/O设备100-2、I/O设备100-3中,在接收到数据1b时,接收写入变为启用状态,在选择站点编号被设定为I/O设备100-1的寄存器中更新为接收到的数据。在I/O设备100-2、I/O设备100-3分别发送了数据2b、数据3b时,同样,在进行了发送的I/O设备中发送信号T变为启用状态,在选择站点编号被设定为本站点编号的寄存器中更新为所发送出的数据。另外,在进行了接收的I/O设备中,接收写入变为启用状态,在选择站点编号一致的寄存器中更新为接收到的数据。当与I/O设备100-3相对应的数据的发送接收结束时,从所有I/O设备完成一遍数据转送。因此,在该定时下同步信号S变为启用状态。即,在该定时,各I/O设备的I/F部110将同步信号S置为启用状态。通过同步信号S变为启用状态,由此运算输入数据从运算输入数据1a~运算输入数据Na更新为新的运算输入数据1b~运算输入数据Nb的数据。如上所述,能够通过同步信号S,对I/O设备之间的输入数据取得同步,因此,能够在I/O设备之间同步地进行输入输出处理。另外,能够对多个数据并行地执行I/O设备之间的输入输出处理,因此,能够高速地进行处理。在上面的实施方式中,在具有CPU设备和多个I/O设备的可编程逻辑控制器中,所述各I/O设备具有:I/O设备之间的通信部件;存储在输入输出处理中使用的数据、运算的设定信息即参数的存储部件;仅提取在输入输出处理中所需的数据的提取部件;以及进行输入输出处理运算的运算部件。各I/O设备能够对从接收到的数据中仅提取在输入输出处理中所需的数据而得到的多个数据,并行地执行输入输出处理。在上面的实施方式中,说明了下面的I/O设备。I/O设备具有控制部件,该控制部件针对接收到的I/O设备之间的数据,同步地输入数据并进行输入输出处理。I/O设备能够对从接收到的数据中仅提取在输入输出处理中所需的数据而得到的多个数据,取得同步而并行地执行输入输出处理。实施方式3图10是表示实施方式3的I/O设备100的结构图。图10的I/O设备100构成为,在实施方式1的运算部160(图2~图4)的后级或者实施方式2(图8)的运算部160的后级进一步具有延迟附加·保持部190。(延迟附加·保持部190)图11是表示图10的I/O设备100的延迟附加·保持部190与参数部140、运算部160的关系的图。图11以图4为前提。如图11所示,延迟附加·保持部190(输出期间决定部)输入由运算部160并行执行处理而获得的运算结果(M1)、(M2)…(M32)。延迟附加·保持部190决定输入的运算结果(M1)、(M2)…(M32)的输出定时(也称为后面所说的延迟期间或者延迟时间)和输出持续时间(也称为后面所说的保持期间或者保持时间),根据决定将已输入的各个运算结果(M1)、(M2)…(M32)输出。(参数部140)参数部140将由延迟附加·保持部190决定的延迟时间和保持时间作为参数(输出期间信息),事先进行存储。如图11所示,参数部140将延迟值1~32作为各自的运算结果(M1)等的延迟时间进行存储。另外,参数部140将保持期间1~32作为各自的运算结果(M1)等的保持时间(保持期间)进行存储。例如,对于“AND0”的运算结果(M1),延迟附加·保持部190以如下方式进行处理。(1)如果输入了运算结果(M1),则延迟附加部1根据参数部140存储的延迟值1,从输入了运算结果(M1)的时刻经过延迟值1表示的延迟时间之后,输出运算结果(M1)。延迟值1可以是0(无延迟)。(2)如果输入了延迟附加部1的输出即运算结果(M1),则保持部1根据参数部140存储的保持期间1,在保持期间1所示的时间期间中,持续进行运算结果(M1)的输出。(3)对于从运算部160输入的运算数据(M2)~(M32),延迟附加·保持部190也同样处理。即,对于运算数据(Mi)(i=2~32),通过延迟附加部(i)和保持部(i)执行延迟以及输出持续。在实施方式3中,作为一个例子,对延迟附加部的延迟以及保持部的保持设定下面的条件1~3。通过设定这些条件,从而无需将输出信号(运算结果)大量地保持,能够以较小电路规模实现具有实施方式3的效果的I/O设备100。<条件1:与延迟附加部的延迟相关的条件>在运算结果的延迟期间(后面所述的延迟期间301)中,不将运算结果的变化反映至输出中。<条件2:与保持部的保持相关的条件>在保持期间(后面所述的保持期间302)中,保持部在运算结果发生了变化的时刻,不进行延迟,而是立即开始变化之后的运算结果的输出,将变化之后的运算结果在保持期间持续输出。<条件3:与延迟以及保持相关的条件>实施方式3的方式的延迟设定受到下述的公式(1)的限制。延迟期间(输出延迟)≤保持期间(1)通过图13~图15,说明延迟附加部、保持部的延迟以及保持的具体例子。此外,在图13~图15中,延迟附加部、保持部分别设定有下面的设定11~13、设定21~22。<延迟附加部>(设定11)延迟附加部以向自身的输入的变化为契机,开始延迟处理。(设定12)延迟附加部在延迟期间中不接受输入(上述条件1)。(设定13)延迟附加部在经过了延迟期间的时刻,在与延迟期间开始时的输入值相比没有发生值的变化时,持续无变化的输入值的输出直至输入发生变化。在经过了延迟期间的时刻存在输入变化时,延迟附加部按照设定11,以输入的变化为契机,开始延迟处理。<保持部>(设定21)保持部以向自身的输入的变化为契机,立即开始保持处理(上面的条件2)。(设定22)保持部在保持期间不接受输入。(设定23)保持部在经过了保持期间的时刻,在输入无变化时,持续无变化的输入值的输出直至输入发生变化。在存在输入变化时,按照设定21,保持部以输入的变化为契机,开始保持处理。图12是表示图11所示的AND0、延迟附加部1、保持部1的系列的图。图12以及下面的说明是关于AND0的系列的说明,但其他AND2~AND31的系列也适用AND0的说明。图13表示在对图12的AND运算进行了20ms的延迟设定(输出延迟20ms)、0ms的保持设定的情况下的时序图。“保持期间=0ms”与图12中不存在保持部1,将输出(Y10)直接作为输出(Y20)进行输出的情况相同。如图13所示,将AND运算结果的X3=1延迟20ms,作为Y10=1进行输出。在这种情况下,AND运算结果(X3)即使在10ms之后变为0,在20ms的期间中,输出Y10也依然输出1。下面,更详细地说明图13。(1)时间(t0)在时间(t0)处,延迟附加部1的输入即运算结果(X3)从0变化为1。由此,延迟附加部1开始输出延迟=20ms的倒计时,在延迟期间301即20ms的倒计时结束前不输出“X3=1”。另外,延迟附加部1在倒计时结束前的延迟期间301即时间(t0)~时间(t20)的期间,不接受输入。(2)时间(t20)(Y10=1的输出开始)在倒计时结束的时刻(t20),延迟附加部1将输入即“X3=1”作为“Y10=1”,开始输出。此时,延迟附加部1在时间(t0)~(t20)的延迟期间301中不接受输入。(3)时间(t20)(接受X3=0的输入)另外,在时间(t20)处倒计时结束。此时,输入(X3)从上一次(时间(t0))的X3=1变为X3=0。由此,在倒计时结束的时刻存在输入变化,因此,延迟附加部1开始倒计时,在倒计时结束前不输出“X3=0”。(4)时间(t40)(Y10=0的输出开始)在倒计时结束的时刻(t40),延迟附加部1将输入即“X3=0”作为“Y10=0”,开始输出。此时,延迟附加部1在时间(t20)~(t40)的延迟期间301中不接受输入。(5)时间(t40)(X3的输入处理)另外,在时间(t40)处,倒计时结束。此时,输入(X3)与上一次(时间(t20))相同,为X3=0。由此,在倒计时结束的时刻没有发生输入变化,因此,延迟附加部1不开始信号变化延迟处理,持续进行Y10=0的输出直到发生下一次输入信号(X3)的变化。图14表示在对AND运算进行了0ms的延迟设定、20ms的保持设定(保持期间302=20ms)的情况下的时序图。0ms的延迟设定与图12中不存在延迟附加部1,X3直接作为Y10进行输出的情况相同。保存部1以在参数部140中存储的保持期间1(图11),持续进行输入(Y10)的输出。保持期间1(图11)在图14中与保持期间302相对应。此外,由于是0ms的延迟设定,因此在图14中,X3与Y10相同。(1)时间(t0)在时间(t0)处,保持部1的输入即运算结果(Y10)从0变化为1。由此,保持部1在保持期间302的20ms期间中,持续进行“1”的输出。保持部1在保持期间302期间中不接受输入。由此,在时间(t10)处,即使输入(Y10)变为0,也不接受该输入,保持部1在保持期间302即20ms(t0~t20)期间中,保持输出1。由此,在保持期间302中将运算结果(输入(Y10))持续输出,在经过保持期间302之后,接受运算结果0,将该值输出。(2)时间(t20)在经过了保持期间302的时间(t20)处,保持部1接受输入(Y10)。在时间(t20)处,输入(Y10)从1变化为0。由此,保持部1在保持期间302的20ms(t20~t40)期间中,持续进行“0”的输出。(3)时间(t40)在经过了保持期间302的时间(t40)处,保持部1接受输入(Y10)。在时间(t40)处,输入(Y10)从时间(t20)处开始持续为0没有发生变化。由此,保持部1在时间(t40)以后的期间402中,持续进行现在的输入即Y10=0的输出直到发生输入(Y10)的变化。图15表示在图12的基础上对AND运算进行了输出延迟20ms、保持期间30ms的设定的情况下的时序图。由于是输出延迟20ms,因此,图15中直至Y10为止均与图13相同,仅Y20不同。对于延迟设定,根据条件(3),满足所说的下面的公式(1)延迟期间301(输出延迟)≤保持期间302(1)在不满足公式(1)的条件的情况下,形成与保持期间0ms的情况相同的动作。在图15中,输出延迟(延迟值)是20ms,保持期间是30ms,因此,满足上面的公式(1)。简单说明图15的Y20。X1、X2、X3、Y10与图13相同,因此省略说明。(1)时间(t20)在时间(t20)处,保存部1的输入即运算结果(Y10)从0变化为1。由此,保持部1在保持期间302的30ms期间中,持续进行“1”的输出(t20~t50)。保持部1在保持期间302中不接受输入。由此,在时间(t40)处,即使输入(Y10)变为0,也不接受该输入,保持部1在保持期间302即30ms(t20~t50)期间中,保持输出1。(2)时间(t50)在经过了保持期间302的时间(t50)处,保持部1接受输入(Y10)。在时间(t50)处,输入(Y10)从1变化为0。由此,保持部1在保持期间302的30ms(t50~t80)期间中,持续进行“0”的输出。(3)时间(t80)在经过了保持期间302的时间(t80)处,保持部1接受输入(Y10)。在时间(t80)处,输入(Y10)从时间(t50)处保持0未发生变化。由此,保持部1在时间(t80)以后的期间402中,持续进行现在的输入即Y10=0的输出直到输入(Y10)发生变化。在实施方式3中,I/O设备100对将“本站点输入、本站点输出”以及“其他站点输入、其他站点输出”作为对象的运算结果进行延迟附加以及值保持而进行输出。此时,延迟时间以及保持时间分别由在参数部140中存储的参数(延迟值、保持期间)决定。在输入输出是同一个I/O设备的情况下,不与其他I/O设备进行通信,在本I/O设备内进行运算之后,进行延迟附加以及保持,将运算结果输出。在输入与输出的I/O设备不同的情况下,在I/O设备之间进行通信,在输出侧的I/O设备进行运算之后,进行延迟附加以及保持,并进行输出。图16是说明延迟附加部的延迟附加和保持部的保持的效果的图。在图16中,将“延迟附加以及保持”记载为“附加延迟”。上侧的3个图形501~503表示没有实施方式3的“延迟附加以及保持”的情况。下侧的3个图形602~604表示具有实施方式3的“延迟附加以及保持”的情况。图形501表示向I/O设备100的输入。图形502表示I/O设备100的“无延迟”的输出。图形502与图形501相比,输出晚1ms。这是设备之间通信所需要的时间。如图16所示,设备之间通信的周期是1ms。图形503表示因经由CPU设备10而导致的“附加延迟”的输出。在经由CPU设备10的“附加延迟”情况下,无法比与CPU设备10进行通信的通信周期5ms更早地进行输出,因此,I/O设备100的运算结果的输出定时成为与CPU设备10进行通信的通信周期5ms的粒度。即,在经由CPU设备10的“附加延迟”的情况下,相对于“无延迟”的输出701,“附加延迟”的输出702位于与CPU设备10进行通信的通信周期5ms之后。另一方面,表示实施方式3的图形602~604如下所示。图形602表示与图形502相同的内容,因此省略说明。图形603表示设定了第1延迟设定量801的情况下的输出。图形604表示设定了第2延迟设定量802的情况下的输出。如图形603所示,I/O设备100能够早于与CPU设备10通信的通信周期5ms进行输出。即,输出定时不受通信周期的粒度限定。另外,如图形604所示,能够相对于延迟设定量801而设定具有不同的延迟设定的延迟设定量802,从而,以短时间依次进行连续的动作。即,如图16所示,能够自由设定延迟设定量801下的输出803与延迟设定量802下的输出804的间隔。如上所述,实施方式3的I/O设备100无需进行与CPU设备10之间的通信,可以通过延迟附加·保持部190进行延迟附加以及延迟。因此,具有下述效果。(1)能够实现短时间的延迟附加以及运算值的保持。(2)在输出侧的I/O设备100进行延迟附加以及保持,因此,输出定时不受通信周期的粒度限定。(3)另外,延迟附加以及保持的设定值寄存器的值通过CPU设备10向参数部140作为参数进行设定,因此,能够经由I/O总线99进行变更。其结果,能够应对例如下述要求,即,当机器的紧急错误信号从输入端子170-1向I/O设备100输入之后,将I/O设备的多个输出信号(在图12中,作为Y10输出的运算结果X3)以规定的顺序进行变更,根据多个机器的紧急停止顺序,以尽可能短的时间进行停止处理。实施方式3的延迟附加·保持部190如图11所示,针对每个I/O设备100的输出信号(运算结果),具有用于延迟、保持的延迟附加部、保持部,该延迟附加部、保持部具有计数器。该计数器对延迟期间、保持期间进行倒计时。延迟附加部1~32以及保持部1~32进行延迟以及保持直至在参数部140中存储的相对应的延迟值1~32、相对应的保持期间1~32的倒计时结束。根据这种结构,不需要用于数据库等的存储器,而使结构变简单。实施方式4图17是实施方式4的I/O设备100的结构图。实施方式4的I/O设备100构成为,在实施方式3的I/O设备100的基础上,在延迟附加·保持部190的后级添加有复合运算部195(第2运算部)。如图17所示,实施方式4的I/O设备100具有由运算数据提取部150A、运算部160A、延迟附加·保持部190A构成的第1系列101和由运算数据提取部150B、运算部160B、延迟附加·保持部190B构成的第2系列102。接收部130向运算数据提取部150A、150B输出其他站点输入和其他站点输出。输入部170向运算数据提取部150A、150B输出本站点输入。输出部180向运算数据提取部150A、150B输出本站点输出。延迟附加·保持部190A、190B向复合运算部195输出运算结果(图12所示的进行了延迟、保持的Y20)。复合运算部195使用从延迟附加·保持部190A、190B输出的运算结果执行运算处理。参数部140向运算数据提取部150A、150B等提供参数。在这种情况下,参数部140中作为参数而存储有运算定义信息,该运算定义信息用于定义使用从延迟附加·保持部190A、190B输出的各运算结果而进行的运算处理的方式,复合运算部195根据参数部140的运算定义信息执行运算。复合运算部195能够进行“或”(OR)等逻辑运算,能够如上所述,在运算部160进行运算处理,延迟附加·保持部190A、190B进行延迟附加、保持之后,由复合运算部195进行运算。因此,可以以较小的电路规模得到复杂的输出。此外,在图17中,存在第1系列101、第2系列102这2个系列,但也可以构成为仅具有第1系列101。在这种情况下,从延迟附加·保持部190A如图11所示输出M(1)~M(32)的运算结果,因此,复合运算部195也可以通过使用这32个运算结果,根据参数部140的运算定义信息进行运算。另外,在实施方式3中如图11所示,示出了“延迟附加部1以及保持部1”~“延迟附加部32以及保持部32”的32个系列的情况,但这仅是例示。系列既可以是1个,也可以是大于或等于33个。实施方式5参照图18、图19说明实施方式5的I/O设备100的结构。实施方式5的I/O设备100构成为,将实施方式3中的I/O设备100的延迟附加·保持部190(图11)替换为图18所示的延迟附加·保持部190-5。图18与图11相对应。在实施方式3的延迟附加·保持部190中,如图11所示,是延迟附加部与保持部独立地分别具有计数器的结构。与此相对,在实施方式5的延迟附加·保持部190-5中,如图18所示,延迟附加和保持通过1个计数器实现。例如,图18的子延迟附加·保持部1-5兼具图11的延迟附加部1和保持部1的功能。其他子延迟附加·保持部2-5~32-5也相同。在仅进行延迟、仅进行保持的情况下,是与实施方式3相同的动作,但在进行延迟以及保持这两者的情况下,形成下述动作。图19是在对图12的AND运算进行了输出延迟20ms、保持期间30ms的延迟设定的情况下的时序图。该延迟设定与图15相同。以图18的子延迟附加·保持部1-5为例进行说明。在这种情况下,图12的延迟附加部1和保持部1成为子延迟附加·保持部1-5。子延迟附加·保持部1-5如图19所示,将AND0的运算结果“1”(时间t0)延迟20ms进行输出(时间t20),即使AND运算结果在10ms之后(时间t10)变为“0”,在30ms(时间t20~t50)的期间仍输出“1”。由此,子延迟附加·保持部1-5不接受使运算结果延迟的期间(延迟期间551的t0~t20)的运算结果的变化,不在输出中进行反映。即,对于子延迟附加·保持部1-5,即使在延迟期间551(t0~t10)中输入X2发生变化,也将时间t0处的运算结果“1”作为延迟期间551(t0~t10)的输入X2。另外,子延迟附加·保持部1-5在延迟期间551之后,在从保持期间552的30ms中减去延迟期间551的20ms而得到的时间ΔT=10ms的期间中,不接受输入X2即运算结果。这里,ΔT=保持期间552-延迟期间551即,如图19所示,延迟附加·保持部1-5在“延迟期间551+ΔT”的期间(t0~t30)中,维持时间t0处的输入“1”,但该维持的输入“1”在经过了延迟期间551之后(t20)进行输出,该期间是“延迟期间551+ΔT”=延迟期间551+保持期间552-延迟期间551=保持期间552。子延迟附加·保持部1-5在经过了延迟期间551之后,在经过了进行相减得到的时间ΔT(在这个例子中是10ms)后的时刻即时间t30(保持期间552结束的20ms之前)处,接受AND运算结果即“0”,以20ms(保持期间552-ΔT=延迟期间551)进行延迟,在时间t50处进行输出。对于延迟设定,需要满足下面的条件。延迟期间(输出延迟)≤保持期间为了消除该条件,需要对多个通过输出延迟的设定而延迟的值暂时进行保持,因此,造成电路规模明显变大。实施方式6图20是表示实施方式6的I/O设备100的结构的图。图20与表示实施方式4的I/O设备100的结构的图17相当。图20是在实施方式4的图17的基础上,将延迟附加·保持部190替换成实施方式5的延迟附加·保持部190-5的结构。在图20中,延迟附加·保持部190A-5、190B-5均具有图18的延迟附加·保持部190-5的结构。通过形成图20的结构,可以与图17的情况相同地以较小的电路规模得到复杂的输出。此外,在图20中,存在第1系列101-5、第2系列102-5这2个系列,但也可以构成为仅具有第1系列101-5。在这种情况下,从延迟附加·保持部190A-5如图4所示输出M(1)~M(32)的运算结果,这一点与图17的情况相同。另外,与图18的情况相同,在实施方式6中,“子延迟附加·保持部1-5”~“子延迟附加·保持部32-5”的32个系列也只是例示。系列既可以是1个,也可以是大于或等于33个。标号的说明10CPU设备,100-1、100-2、100-3I/O设备,110I/F部,120发送部,130接收部,140参数部,141运算处理,150、150-2运算数据提取部,151第1选择部,152第2选择部,160运算部,170输入部,180输出部,170-1输入端子,180-1输出端子,190、190-5延迟附加·保持部,195复合运算部,1000PLC,99I/O总线。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1