基于故障特征提取的脊柱四足机器人容错步态控制方法
本发明涉及四足机器人控制,具体涉及一种基于故障特征提取的脊柱四足机器人容错步态控制方法。
背景技术:
1、四足机器人在各种应用中发挥着重要作用,包括工业自动化、搜索与救援任务以及极端环境下的探测任务。它们之所以备受青睐,是因为它们具备卓越的机动性和足够的稳定性,能够在复杂的地形和环境中移动,执行多种任务。
2、然而,传统的四足机器人在面临电机失效、关节锁死或电机扭矩下降等故障情况时,容易失去平衡或无法继续执行任务,这些故障情况可能来自机械磨损、电子元件故障或不可预测的外部干扰。在传统的步态控制方法中,通常使用预先定义的开环控制策略,或者基于规则的反馈控制方法。这些方法的问题在于它们通常无法适应不同的故障情况或环境变化,因此需要一种更为灵活和自适应的控制策略。
3、本发明提供了一种基于故障特征提取的脊柱四足机器人容错步态控制方法,适用于具有多自由度脊柱关节的脊柱四足机器人,通过故障特征提取器和故障发生器结合深度强化学习算法对中枢模式控制器(cpg)进行训练优化,使机器人在故障情况下仍能保持稳定行走,并能够自适应调整步态以应对不同的故障情况。
技术实现思路
1、本发明为了解决现有技术中四足机器人无法自适应应对不同故障情况的问题,提出一种基于故障特征提取的脊柱四足机器人容错步态控制方法。
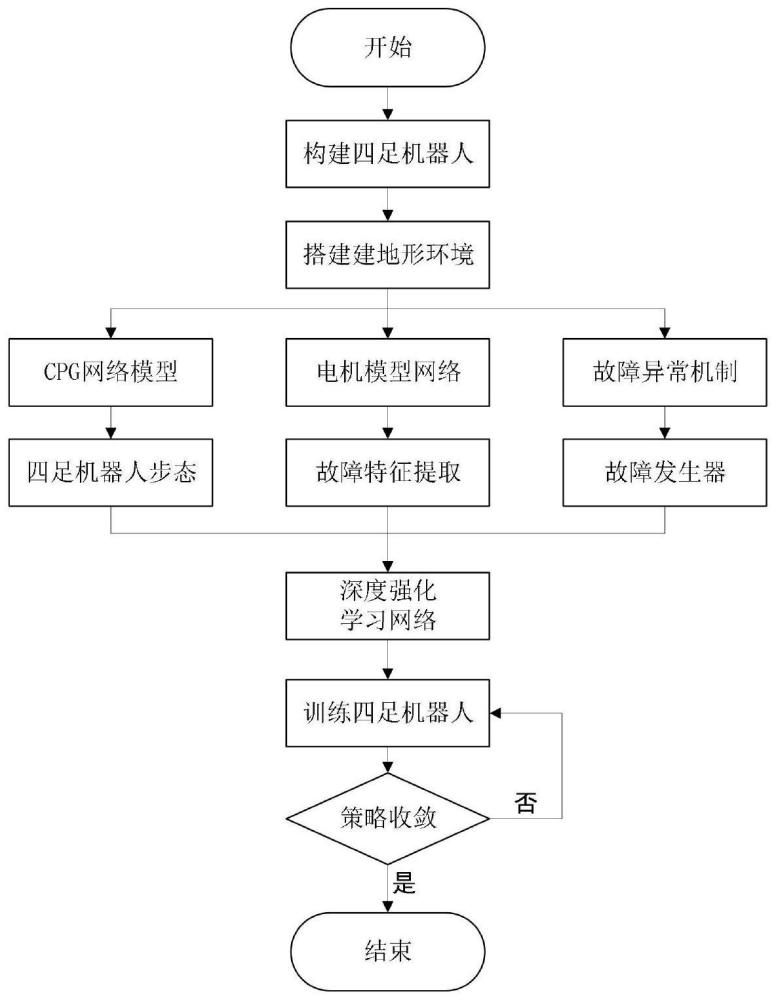
2、一种基于故障特征提取的脊柱四足机器人容错步态控制方法,包括了如下步骤:
3、步骤1:在仿真平台中搭建脊柱四足机器人整体模型,包括可控的脊柱关节,并设置多种地形环境;
4、步骤2:使用中枢模式发生器(cpg)生成周期性节律信号,用来规划四足机器人的步态,用于控制步骤1中的脊柱四足机器人运动;
5、步骤3:设计电机故障特征提取器。训练一个电机模型网络,可根据当前关节位置误差和关节速度预测脊柱四足机器人关节的扭矩输出,与机器人实际的关节扭矩值进行比较,偏差信号可指示出电机的故障特征;
6、步骤4:根据电机故障失效、关节锁死和电机扭矩不足故障情况,设计机器人的故障机制,融入机器人训练中以便脊柱四足机器人能够学到具有容错的策略;
7、步骤5:设计深度强化学习算法,构建演员网络和评论家网络,设计奖励函数,使用置信域策略优化算法(trpo)对策略网络进行更新策略;其中演员网络可包括步骤1中脊柱四足机器人的脊柱关节运动控制,评论家网络预估机器人当前状态可获得的奖励基值。
8、步骤6:训练脊柱四足机器人,直到策略收敛。由步骤2中的cpg生成四足机器人的基本步态,深度强化学习网络以脊柱四足机器人的传感器信息和步骤3中的故障特征信息作为输出,输出应对故障情况的关节信号增量,在仿真环境中根据步骤4中的故障机制对脊柱四足机器人进行训练。
9、进一步地,步骤1中包括以下步骤:
10、步骤1.1:构建脊柱四足机器人整体模型。根据脊柱四足机器人的结构特性(关节位置和数量)、各关节大小和质量、转动惯量和弹簧阻尼系数等属性建立脊柱四足机器人的躯体模型;脊柱四足机器人机身传感器有位于足端的力传感器、位于前后躯干的惯性和gps传感器和位于躯干头尾的测距传感器等。
11、步骤1.2:搭建地形环境模型。搭建平地、碎石地、凹凸地形和上下坡地形等单一地形,并组合拼接这几种地形丰富地形环境。
12、进一步地,步骤2中包括以下步骤:
13、步骤2.1:采用hopf振荡器搭建四足机器人的cpg控制器。hopf振荡器的数学模型可用于描述周期性的振荡行为,产生的周期性波形,可模拟机器人单腿的摆动和四足步态,协调四条腿的运动需要对四个cpg振荡单元进行相位变换,完整的cpg网络数学模型如下:
14、
15、ri2=(xi-u1)2+(yi-u2)2
16、
17、
18、
19、θhi=xi
20、
21、其中,xi和yi为振荡器的输出信号,α为振荡器收敛到极限环的速度,μ为振荡器的幅值,ωi为振荡器的频率,u1和u2为外部反馈,θij为振荡器i和振荡器j之间的相对相位差,ωst和ωsw分别为摆动相频率和支撑相频率,a决定了ωi在ωst和ωsw之间的变化速度,β为负载因子,为关节形式标志,ak和ah分别为髋、膝关节幅值,θhi和θki分别为髋、膝关节角度。
22、步骤2.2:设计和调整cpg控制器的参数。设计和调整cpg控制器的振荡频率、相位差和耦合强度等参数,可以实现脊柱四足机器人不同类型的步态,如步行、小跑、奔跑和跳跃等,以使机器人按照所需的步态行走。
23、进一步地,步骤3中包括以下步骤:
24、步骤3.1:收集数据集:收集脊柱四足机器人在现实中行走的关节信息数据集,其输入量为关节位置误差和关节速度,输出量为机器人关节电机扭矩值。进一步地,为了获得丰富的数据集,改变足端轨迹的幅度和频率,并在数据收集过程中手动干扰机器人。
25、步骤3.2:构建并训练电机模型网络:电机模型网络采用了多层感知器的结构,其中包括三个隐藏层,使用步骤3.1中收集到的数据集,划分为训练集和测试集。训练集用于训练电机模型网络,测试集用于评估模型的准确性。
26、步骤3.3:进行故障特征提取:由训练好的电机模型网络,输入关节位置误差和关节速度,可输出脊柱四足机器人关节扭矩的预测值。将预测扭矩输出与实际机器人关节扭矩值进行比较,偏差信号可指示出电机的故障特征,如电机故障失效、电机扭矩不足和电机扭矩过大等。故障特征提取的公式如下:
27、δτi=τi'-τi
28、
29、式中i=1,2…,12,13,为故障特征信号,threshold为故障阈值,δτi为脊柱四足机器人关节电机扭矩的偏差信号;τi'为电机模型网络的预测值,τi为电机的实际扭矩值。
30、进一步地,步骤4中包括以下步骤:
31、步骤4.1:设定故障机制。
32、脊柱四足机器人的这种故障机制设定如下:
33、jf=u{1,2,…,12}
34、tf=u(0.5,1.0)×tmax
35、
36、式中u表示集合,jf为正态分布采样得到的要锁定的关节号,tmax为每个回合最长的仿真时间,tf为发生锁定故障或扭矩不足故障的时间;为中心位置,θt为对称公差,θa表示机器人关节被锁定的范围;τmax为关机电机所能提供的最大力矩,τ为电机失效后所能提供的力矩。
37、容错策略包括了广义容错和狭义容错:广义容错指的是机器人能应对由于机械结构问题或者地形环境问题导致的关节卡住无法按规划好的步态行走的情况,机器人在步骤1.2搭建的地形环境中重复行走,通过试错学习到容错策略应对故障情况;狭义容错指的是机器人在由关节电机出现故障导致关节电机锁定、关节电机失效驱动力不足和关机位置突变的情况下仍然能稳定行走并完成任务,在每个机器人行走的回合中引入故障机制,随机触发机器人关节电机故障,以便机器人能够通过试错学习到容错策略应对故障情况。
38、进一步地,步骤5中包括以下步骤:
39、步骤5.1:构建演员网络:演员网络由四层神经网络组成分别是输入层、两个隐藏层和输出层。输入层为脊柱四足机器人的状态空间s,由机身的传感器数据获得:
40、
41、式中fτ∈r13为故障特征向量,θt∈r13为各关节当前角度,为各关节当前角速度,ft∈r4为足端触地信号,it∈r8为机身前后躯干姿态的四元数,rn为n维向量;。
42、两个隐藏层包括多个感知机,使用均匀分布方法对网络权重和偏置参数做初始化,是一个有深度且密集的神经网络架构,可处理输入的故障特征和传感器数据。
43、输出层为脊柱四足机器人的动作空间a,是机器人关节电机的期望转动角度增量:
44、δqi=[δθ3i-2,δθ3i-1,δθ3i],i=1,2,3,4
45、a=[δq1,δq2,δq3,δq4,δθ13]
46、式中δθ3i-2、δθ3i-1、δθ3i分别对应脊柱四足机器人每条腿的侧摆髋关节、髋关节、膝关节为应对故障情况的策略调节量,δθ13为脊柱四足机器人脊柱关节为应对故障情况的策略调节量。
47、步骤5.2:构建评论家网络:由输入层、隐藏层和输出层组成。输入层接收两个部分的信息,分别为步骤3.1中的状态空间s和动作空间a,隐藏层1,2分别包括多个感知机,s经过隐藏层1,2,a经过隐藏层2,之后它们的输出相加,即将状态和动作的信息结合起来以更准确地估计策略的效果,输出层为其相加的结果。
48、步骤5.3:设计奖励函数:为了激励脊柱四足机器人以合理的速度和稳定的姿态行走,并能够应对各种故障情况,需设计如下的奖励函数:
49、r=k1rt+k2rv+k3ryaw+k4rbody+k5rg+k6rq
50、
51、
52、
53、rbody=||ωr||2+||ωp||2
54、rq=||θt-θt-1||2
55、式中ki=1,2,3,4,5,6为各奖励部分的权重系数;rt为时间的正向奖励项,ts为仿真步长,tf为仿真训练最大时长;rv为速度的正向奖励项,vx为脊柱四足机器人沿机身方向的移动速度;ryaw为偏航的负向奖励项,ωy为机器人的偏航角;rbody为机身不平稳的负向奖励项,ωr为机器人机身的横滚角速度,ωp为机器人机身的俯仰角速度;rq为关节突变的负向奖励项,θt为当前时刻的关节角度,θt-1为上一时刻的关节角度。
56、步骤5.4:使用trpo算法对神经网络进行更新。策略梯度估计:
57、
58、
59、
60、其中,j(θ)是目标函数,目标是最大化预期奖励,πθ(st|at)为当前策略网络的动作概率,是旧策略网络的动作概率,是优势函数,表示动作的优势值,gt为在给定状态st时采取动作at的累积奖励值,γ为折扣因子,rk为k时刻的奖励值,t为一个回合的步长,v(st)为步骤5.2中评论家网络的值函数,表示在给定状态st下累积奖励的期望值。
61、进一步地,引入kl散度的约束项,限制新策略网络和旧策略网络的差异度,kl散度约束如下:
62、
63、其中,δ为kl散度参数,πθ为新策略网络,为旧策略网络。
64、进一步地,步骤6中包括以下步骤:
65、步骤6.1:设置终止条件。前期机器人的训练效果并不好会出现偏离轨迹和摔倒的情况,需要停止该回合并开启下回合的训练,设置的终止条件:
66、
67、其中,z是机器人躯干离地高度,x是机器人侧向偏移位移,roll,yaw,pitch分别是机器人躯干的横滚角、偏航角和俯仰角。
68、步骤6.2:训练过程。使用步骤5中的深度强化学习算法和adam优化器训练优化策略网络。
69、进一步地,对脊柱四足机器人进行仿真训练,在每个训练周期中,策略神经网络输出的是脊柱四足机器人为应对环境变化和故障情况的关节角度变化量,中枢模式发生器(cpg)输出的控制信号是脊柱四足机器人行走的关节角度,二者相加得到最终机器人的关节控制信号:
70、θsi'=θsi+δθ3i-2
71、θhi'=θhi+δθ3i-1
72、θki'=θki+δθ3i
73、θb'=δθ13
74、其中,i=1,2,3,4,θsi'为最终调整的侧摆髋关节角度,θhi'为最终调整的髋关节角度,θki'为最终调整的膝关节角度,θb'为深度强化学习网络输出的脊柱关节角度,θsi为cpg输出的侧摆髋关节角度,θhi为cpg输出的髋关节角度,θki为cpg输出的膝关节角度。
75、进一步地,控制信号发送给机器人的关节电机,用于控制机器人在仿真环境中的运动。通过机器人与仿真环境交互,根据生成的动作执行运动,获得机器人的机身状态的反馈信息,由反馈信息按机器人的性能和任务要求计算奖励值。策略神经网络根据奖励值和强化学习算法进行更新,调整策略神经网络的权重和偏差。如此循环往复,机器人与仿真环境不断交互、计算奖励、更新策略,以逐渐改进机器人的控制策略。最终,策略收敛可使机器人在未知地形中稳定行走,并且在面对故障情况时能够采取容错策略。
76、本发明的有益效果为:
77、1)本发明设计的故障特征提取器,可对比实际的关节电机扭矩和电机网络模型的预测关节电机扭矩锁定脊柱四足机器人的故障特征,进而经过强化学习策略网络,自适应输出应对不同故障情况的控制策略。与传统控制方式对相同故障但由于是不同故障腿仍需要重新规划反馈控制相比,本发明的无需多次建模,省时省力,可拓展至多种故障情况。
78、2)本发明提出的一种基于故障特征提取的脊柱四足机器人容错步态控制方法,强化学习策略网络的输出包括了脊柱关节的控制信号,无需针对脊柱关节建立运动学或动力学模型,为含多自由度脊柱关节的脊柱四足机器人的运动控制提供了一种方法。
79、3)本发明提出的一种基于故障特征提取的脊柱四足机器人容错步态控制方法,通过深度强化学习算法优化脊柱四足机器人控制器策略,提高了机器人中枢模式控制器对环境的适应能力,使其具备抗干扰能力;采取直接关节增量的方式对调节机器人的关节角度,避免了电机控制命令的突变,提升了实时的调节性能。
- 还没有人留言评论。精彩留言会获得点赞!