一种多无人机运动规划方法
本发明属于无人机运动规划,具体涉及一种多无人机运动规划方法。
背景技术:
1、人工势场法是一种常用的无人机路径规划方法,它基于构建虚拟势场来引导机器人移动。它最初被用于无人机和移动机器人的自主导航和避障问题,利用梯度下降来引导无人机移动。传统的人工势场法有很多明显的缺点,在复杂环境复杂的规划任务中,无人机可能会陷入局部最小值,发生轨迹震荡等,导致规划失败。在去中心化的多无人机规划中,如把其他无人机也视作一个势力场源头,则势力场之间相互作用的关系则更加复杂,极难得到一个能规划出满意路径的势场。
2、基于学习的方法目前越来越多的被研究和应用在运动规划领域。但受限于现实中数据集获取困难,数据集质量难以保证,单纯的用模仿学习去学习规划策略,策略网络对于数据集中未包含的状态,可能会输出非常糟糕的动作决策。目前,有用强化学习和模仿学习相结合的方法,用强化学习在仿真环境中采集更多的数据去拟合神经网络策略。但完全的从感知端到执行器的“端到端”决策,完全的“黑盒”神经网络,在实际应用中仍然带来了很多质疑,导致实际落地困难。
技术实现思路
1、针对上述背景技术中的问题,本发明提供了一种多无人机运动规划方法,该方法采用融入了人工势场法的先验经验的强化学习算法进行前端的路径规划,后端则采用b样条进行曲线插值和优化。
2、本发明采用如下技术方案实现:
3、一种多无人机运动规划方法,包括如下步骤:
4、步骤1:设定无人机集群运动规划场景
5、设定无人机集群包含k架无人机。设定各无人机的初始位置随机。按照无人机初始位置的y坐标对无人机进行标记排序。从y坐标最大的无人机开始计数,依次排列。y轴坐标排在第i位次的无人机表示为ui。无人机的最大加速度为amax,最大速度为vmax,最大角速度为wmax。
6、将无人机,障碍物,目标位置设定为圆形,其半径分别表示为ru,rc,rt;
7、无人机的运动学方程为:
8、
9、无人机t时刻的状态量为[xt,yt,vt,ψt],控制变量为动作空间[at,wt],其中xt,yt,vt,ψt分别代表t时刻无人机的x坐标,y坐标,速度以及航向角;at,wt分别代表t时刻无人机的加速度和角速度;在控制变量的作用下,经过时间步长δt,根据无人机的运动学方程,可得无人机下一时刻的状态量[xt+1,yt+1,vt+1,ψt+1],xt+1,yt+1,vt+1,ψt+1分别代表t+1时刻无人机的x坐标,y坐标,速度以及航向角;
10、无人机需要满足如下运动约束:
11、
12、其中,vmax为无人机的最大速度;amax为无人机的最大加速度;wmax为无人机的最大角速度;
13、无人机的通信范围设为rcom;无人机在规划中,与通信组网中的其他无人机不断进行位姿信息的传递。
14、步骤2:基于matd3算法的路径规划的策略神经网络的构建
15、步骤2.1神经网络的输入
16、无人机ui的策略网络πi的输入为观测空间,观测空间具体包括如下四个部分:
17、1)无人机自身状态的观测空间
18、采用向量表示为[x,y,v,w,ru]。
19、其中,x,y分别表示无人机在二维平面上的横、纵坐标。v表示无人机移动速度。w为无人机的偏航角,ru为无人机的半径。
20、2)来自无人机间通信的观测空间
21、无人机通过通信,获取其他无人机的位姿信息。采用向量表示为[x1,y1,x2,y2,...,xi-1,yi-1,xi+1,yi+1,...,xk,yk],其长度为2(k-1)。如无人机自身脱离组网,则全部填充为0;若其他无人机脱离组网,则无人机将其他无人机对应的位置处用0进行填充。
22、3)无人机集群中心的观测空间
23、采用向量表示为[xf,yf]。pf=[xf,yf]表示无人机集群中心在二维平面上的坐标,坐标根据以下公式获取:
24、
25、
26、pf实际上是由无人机集群的k架无人机坐标的平均值加上一个服从正态分布的随机扰动α得到,随机扰动α用来模拟由通信延迟问题带来的计算偏差;
27、4)任务目标的观测空间
28、采用向量表示为[xt,yt],[xt,yt]表示无人机目标区域在二维平面上的坐标,设定为所有无人机在规划任务开始时便已获取该信息。
29、步骤2.2神经网络的输出
30、无人机ui的策略网络πi的输出即动作空间[at,wt]。
31、步骤3:奖励函数参数设定
32、设置四个奖励,ra1,ra2,rr1,rr2及对应的权重ga1,ga2,gr1,gr2,权重根据一段时间的训练情况进行调整,通过优化各个奖励的权重的大小,实现预期多无人机的规划目标。则整体奖励函数写为r=ga1×ra1+ga2×ra2+gr1×rr1+gr2×rr2。
33、步骤3.1为使无人机接近目标位置,设置ra1
34、设当前的无人机的位置距离目标位置的距离为d,上一个时间步无人机距离目标位置的距离为dt-1,则根据两次距离之差给无人机一个行进中的稠密奖励,为dt-1-dt。当无人机趋向目标时,则会获得一个正向奖励。同时,设置一个稀疏奖励,当无人机到达目标位置后,则一次性给予一个比较大的奖励tm。
35、则奖励ra1为:
36、
37、其中,d的计算表达式为:[xuav,yuav]为无人机当前的位置坐标,[xtar,ytar]为无人机的目标位置坐标。
38、步骤3.2为了实现无人机向群中心的靠拢和保持组网,设置ra2
39、期望无人机集群能够在以无人机集群中心pf为圆心,rf为半径的圆中进行规划飞行。ε为一个可调整参数,当其大于1的时候,可以保证无人机与以pf为圆心,rf为半径范围内的其他无人机保持组网通信。
40、
41、其中tf为一个正数,r为无人机位置和无人机集群中心位置pf的距离。当距离小于rf时给与奖励tf,大于时给与惩罚-tf。
42、步骤3.3为了满足无人机防止碰撞的要求,设置rr1
43、对无人机半径做一个膨胀处理,膨胀系数为br。则当无人机与障碍物的几何中心之间的距离为rmin=br×ru+rc,视为发生碰撞。设定一个基准惩罚数mc,每发生一次碰撞,则给予无人机一个1.5mc的惩罚。设定rmax=1.2rmin,当无人机与周围的障碍物的距离在(rmin,rmax]时,加入一个稠密惩罚,引导无人机和障碍物保持一定安全距离。奖励rr1的分段函数如下:
44、
45、步骤3.4为了无人机保持轨迹间的纵向间距,设置奖励函数rr2
46、rr2包括个体奖励rr21和群体奖励rr22:rr2=rr21+rr22。
47、个体奖励rr21设置为,对于无人机ui,若y轴坐标在集群中当前的排序c和初始的无人机排序i相一致即给予一个奖励tl,不一致时给予一个惩罚-tl。
48、
49、群体奖励rr22设置为,当无人机各轨迹之间的间隔都满足时给予一个奖励tg,不满足时给予全体一个惩罚-tg。
50、步骤4:基于人工势场法的无人机路径规划数据的采集
51、步骤4.1:基于人工势场法的路径规划
52、对应奖励函数中ra1,ra2,rr1,rr2分别设置四个势场ua1、ua2、ur1、ur2。
53、无人机ui的引力势场函数一,作用是使无人机ui接近目标位置;引力势场函数一表示为:
54、
55、其中,ua1为无人机指向目标点的引力势场,wa1为无人机指向目标点引力势场的权重,pi=[xi,yi]为第i架无人机的坐标;pg=[xg,yg]为规划目标点的坐标;
56、无人机ui的引力势场函数二,作用是使无人机ui实现无人机向群中心的靠拢和保持组网;引力势场二表示为:
57、
58、其中,ua2为无人机指向集群中心的引力势场,wa2为无人机指向集群中心引力势场的权重;
59、无人机ui的斥力势场函数一,作用是防止碰撞;斥力势场函数一表示为:
60、
61、其中,ur1为防止无人机相互碰撞的斥力势场,wr1为防止无人机相互碰撞的斥力势场的权重;n为感知范围内无人机数量和障碍物的数量;pj=[xj,yj]为感知范围内识别到的第j个无人机或障碍物的坐标;dr是一个常数,当无人机ui与障碍物或者其他无人机的距离大于此值时,则斥力势场作用消失;dr1为无人机ui与障碍物或其他无人机之间的距离,由pj和pi的坐标计算得出:
62、无人机ui的斥力势场函数二,作用是保持无人机按初始排序进行飞行,且使轨迹不发生交叉;斥力势场函数二表示为:
63、
64、其中,ur2为保持无人机按初始排序进行飞行,且使轨迹不发生交叉的斥力势场;wr1为保持无人机按初始排序进行飞行,且使轨迹不发生交叉的斥力势场的权重;yi为当前无人机的纵坐标,yo为其他无人机的纵坐标;dr2为无人机之间的纵坐标距离,dl是一个常数,当无人机之间纵坐标距离超过这个距离,相互之间的斥力视为0;
65、无人机的总势力场为u=ua1+ua2+ur1+ur2,无人机受到的合力为f=-grad[u]。步骤4.2基于人工势场法的数据筛选
66、基于步骤4.1所述方法,不断变动无人机的初始位置以及障碍物的位置,进行数据的采集;
67、在采集过程中,进行数据的筛选,筛选的标准同时满足如下2个条件:
68、1)消除规划失败、发生碰撞、超时到达、集群形态过于松散的数据。
69、2)设定奖励最低门栏,消除低于奖励最低门栏的数据。
70、步骤5:训练基于matd3算法的路径规划的策略神经网络
71、步骤5.1经验池的构建
72、经验池大小设置为106,从步骤4筛选的无人机路径规划数据中选取105个载入到强化学习算法的经验池,当做先验经验。
73、步骤5.2策略网络的训练
74、从经验池中提取先验经验,训练matd3的神经网络,直至当结果能够不发生碰撞,行进中保持组网,无人机行进中能够保持纵向间距时,结束训练,得到策略网络。
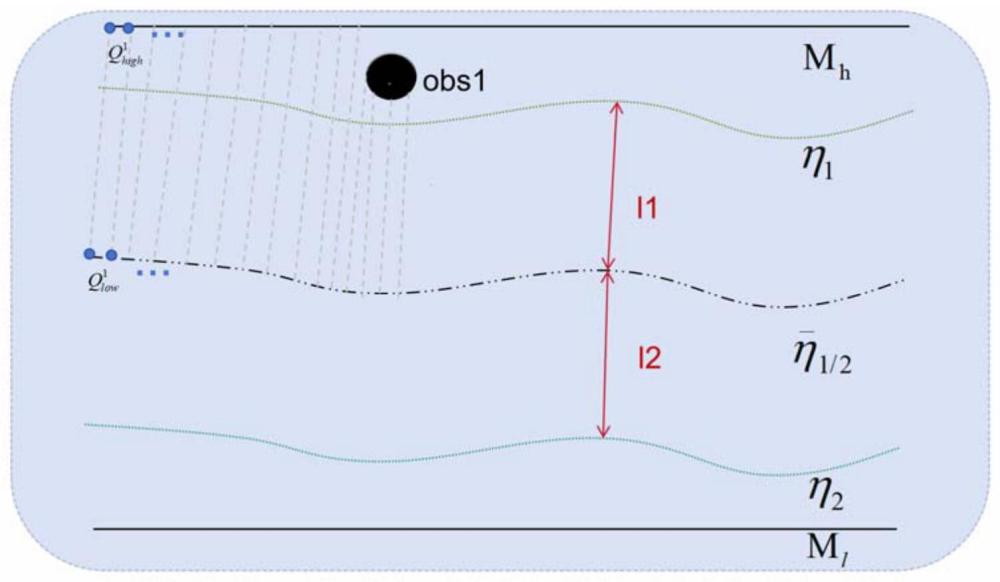
75、步骤6:轨迹优化
76、训练好的策略网络根据当前感知到的观测空间,不断输出动作,得到从起点到终点的一系列的离散轨迹点;对所得的离散轨迹进行轨迹优化即可得到无人机最终的轨迹;具体方法为:
77、设定无人机每次用路径规划的策略神经网络进行推理规划的时间为h个时间步,则每次需要对无人机进行路径规划时,将规划t=δt·h时长的路径;规划完成后,将这h个时间步中各无人机自身的轨迹信息,拼成离散的轨迹,然后再进行轨迹优化,即可得到t时长的无人机的轨迹;重复无人机的路径规划和轨迹优化步骤直至无人机运动到目标位置,即可得到多无人机的轨迹。
78、上述技术方案中,进一步地,所述步骤6中,对所得的离散轨迹进行轨迹优化,具体包括以下步骤:
79、1)划分各无人机的轨迹可行域
80、对于无人机ui,其轨迹可行域ηi包括可行域上边界和可行域下边界可行域上边界由地图的上边界mh或中线去除障碍物后形成的离散点拼成,可行域下边界由地图的下边界ml或中线去除障碍物后形成的离散点拼成。所述中线的计算方式为:对无人机ui以及与其相邻的无人机,在h时间步上分别求二者在y轴的中线。
81、2)路径信息转换为三阶b样条
82、将轨迹转换为均匀的三阶b样条来表示。具体方法为:初始的qi用ηi中的位置点表示,从而得到三阶b样条。三阶b样条表示如下:
83、
84、其中,qi为位置b样条的控制点,n(t)表示三阶b样条的基函数,c(t)为所求的轨迹;
85、同时可依次根据以下公式求解得到速度、加速度、加加速度的控制点。其中vi为速度b样条控制点,ai为加速度b样条控制点。ji为加加速度b样条控制点。
86、
87、
88、
89、3)轨迹优化
90、优化的目标设置为最小化加速度控制点ai和加加速度的控制点ji。优化变量为位置控制点qi。其中速度、加速度的限制条件为步骤1无人机需要满足的运动约束中速度的限制条件。位置控制点qi的限制条件为wa为加速度优化项的权重。wj为加加速度优化项的权重。nc为要优化的位置控制点qi的数量,对应的要优化的速度控制点数量和加加速度的控制数量为nc-1和nc-2。即可得到无人机ui的优化方程:
91、
92、
93、4)求解优化方程,得到优化后的控制点qi;基于优化后得到的控制点qi,根据步骤2)中的计算公式得到新的速度控制点,新的加速度控制点、新的加加速度控制点;将四者分别和对应的基函数进行相乘运算,可得到优化后的位置轨迹、速度轨迹、加速度轨迹以及加加速度轨迹。
94、本发明方法可有效解决以下问题:
95、1.人工势场法在多无人机路径规划中容易陷入局部最优,发生轨迹震荡,导致规划失败的缺点;以及基于人工势场法的路径规划经验和神经网络相结合的问题。
96、2.将神经网络应用到运动规划领域,完全端到端的不可解释性问题。
97、3.多无人机轨迹优化时,无人机之间轨迹发生交互,导致优化困难的问题。
98、本发明的有益效果为:
99、1.用融入先验知识的强化学习解决传统人工势场法在多无人机规划问题中存在的容易陷入局部最优,轨迹震荡,失败等缺点。先通过人工势场法得到路径规划的先验经验池,然后对这些经验数据进行筛选,选取质量高的数据对策略网络进行预训练,之后预训练的网络再用强化学习在多无人机路径规划场景中进行进一步地采集数据和学习。
100、2.采用传统的路径规划和轨迹优化相结合的方式。用神经网络进行路径规划,用数值优化进行轨迹优化。将大部分的避障及协作的规划要求放到前段的路径规划进行操作,后端主要平滑轨迹和优化能量消耗。
101、3.用一种轨迹不交互的方法进行轨迹优化。在前端路径规划部分,人工势场法的势场设置和强化学习的奖励函数相对应,除了设置有用于规划飞行的势场和奖励函数外,还设置了一个根据无人机的初始纵坐标位置来进行调整轨迹间距的力场和奖励函数。在后端的轨迹优化部分,根据前端路径规划得到的轨迹信息,计算相邻无人机的轨迹的平分分界线;在两条平分的分界线中,排除障碍物的边界,作为轨迹的可行区域,并在这个可行区域中优化b样条的控制点。前端路径规划的策略神经网络承担整个规划过程中更大的计算量,降低后端轨迹优化问题的难度。
- 还没有人留言评论。精彩留言会获得点赞!