综合式消费者基因组服务的制作方法
本申请要求提交于2014年2月13日的标题为“综合式消费者基因组服务(INTEGRATED CONSUMER GENOMIC SERVICES)”的美国临时申请No.61/939,695和提交于2014年7月31日的标题为“消费者生物数据系统和方法(CONSUMER BIOLOGICAL DATA SYSTEM AND METHOD)”的美国临时申请No.62/031,556的权益,这两个申请的公开内容出于所有目的以引用方式被并入本文。
背景技术:
本公开一般涉及购买、分布、共享、显示和消费基因组信息,并且更具体地,涉及在客户端服务器环境中购买、分布、共享、显示和消费基因组信息。
传统上,个人DNA或基因组测序在一般公众中尚属遥不可及。执行测序所需的机器是昂贵的,并且通常由较大实体购买,诸如研究机构或公司。此外,一旦获得样本,这些机器一般耗费长时间段来对DNA进行测序。
近年来,测序的成本和用于执行测序所需的时间已降低。先前需要数月进行测序的样本现在可在数天或数周内进行测序。全基因组测序或部分基因组测序现在可以低得多的成本来执行,这消除了对大多数消费者而言的成本壁垒。
若干公司已利用较低成本和较短测序时间来直接向个人消费者提供基因组产品或服务。例如,一些公司提供允许个人消费者基于DNA样本追溯他或她的祖先的服务。其他服务包括基于DNA样本提供统计值,诸如个人消费者在他或她生命中会感染具体疾病的可能性。
然而,在利用这些公司的服务之后,如果个人消费者或用户想利用另一家公司的服务,那么该用户将必须提供另一份DNA样本并且等待对该样本进行测序。例如,如果用户已通过一家仅追溯祖先的公司测序其DNA,那么在他想要关于在他生命中可能感染的疾病的报告的情况下,该用户将必须通过另一家公司对其DNA进行测序。这可能导致多家公司执行重复工作。这也可能导致该用户DNA的多个副本被储存于各个位置,这对于该用户而言可能难以保持追踪,并且对于大量消费者而言还可能引发隐私问题。
另外,此类直面消费者的服务可提供不同格式的信息,这些格式难以与其他类型的可用信息协调,诸如基于网络的搜索信息。例如,在没有另外的上下文或工具的情况下,某些消费者可能难以理解序列数据或统计数据。其他消费者(诸如医疗专业人员)可能很少使用基本上下文信息,而是反而可能希望直接访问原始基因组数据以用于进一步分析。因此,存在对各种类型的序列数据(例如,基因组信息)的消费者驱动交互工具和对更有效的购买、分布、共享、显示和消费基因组信息的需求。
技术实现要素:
本文提供用于与测序数据、基因组数据或其他类型的生物数据进行用户交互的技术,这些数据可经由中央中枢来介导,该中央集线器储存并控制测序数据的拥有者或系统的次级用户对与测序数据的各种交互的访问。例如,交互可包括与社交媒体、数据工具、消费者产品供应、保健信息等的交互。这些交互可有助于用户从用户界面推送或拖出关于测序数据的信息。在一个示例中,搜索引擎可被提供成基于基因组信息以及患者的许可返回结果,其可被视为用于患者与系统进行交互的“基因组头像(genome avatar)”或“基因组cookie”。例如,如果特定患者关注于临床试验而非营销信息,那么结果可朝向授权许可偏斜。消费者中枢系统解决患者对于由测序设施所提供的基因组数据中的可实践性和功能性的关注。
此外,测序或其他生物数据为存储器密集的。因此,终端用户可能不希望将此类数据储存于移动装置或平板电脑上。然而,因为消费者越来越频繁地使用移动装置来访问互联网,所以具有有利于数据访问的远程中枢允许消费者与其数据进行交互,而无需将数据储存于其自己的装置上。例如,用户可能希望使用将其基因组与名人基因组相比较的新型应用程序。在这样的实施例中,用户可将应用程序下载至其移动装置并且许可该应用程序从中枢访问其基因组数据。虽然基因组比较工具可能需要超出通常的移动装置能够达到的处理功率,但是分析可远程地执行(例如,经由中枢或通信地联接至中枢的处理器),并且应用程序可仅用作图形输出或其他应用程序显示的终端接收者。这样,基因组数据未被传送至移动装置并由该移动装置处理,这(如所提及的)释放了处理和内存。
本技术还提供对生物数据的粒度和动态许可和/或访问控制。例如,测序数据可包括某些序列,这些序列与外部状态相关联,包括眼睛颜色、头发颜色、种族等。此外,某些类型的序列分析(例如,表观遗传数据)可提供关于测序个人的年龄的信息。因此,作为消费者,在个人测序数据与中枢进行交互的情况下,个人可能希望不仅为匿名的,而且阻止访问可能包括识别信息的那些序列和/或数据。为了有利于粒度和动态许可控制,本技术可包括用户界面工具,这些用户界面工具通过许可等级引导序列拥有者。
在某些实施例中,本公开提供一种用于测序数据交互的系统。该系统包括至少一个服务器,该服务器包括储存与拥有者相关联的测序数据的一个或更多个存储器装置。服务器被联接至处理器,该处理器被配置成执行指令,该指令包括:从第一个基于处理器的装置接收访问测序数据的第一请求;访问测序数据的许可信息;当许可信息指示第一个基于处理器的装置与测序数据的拥有者相关联时,向服务器提供指令以容许第一个基于处理器的装置访问测序数据;从第二个基于处理器的装置接收访问测序数据的第二请求;以及当许可信息指示第二个基于处理器的装置与授权用户相关联以用于有限基因组访问时,向服务器提供指令以容许第二个基于处理器的装置仅访问测序数据的一部分。在另一个实施例中,处理器被配置成执行指令,该指令包括:从第三个基于处理器的装置接收访问测序数据的第三请求;以及当许可信息指示第三个基于处理器的装置不与授权用户相关联时,向服务器提供指令以容许第三个基于处理器的装置仅访问关于测序数据的默认信息。在另一个实施例中,来自第一个基于处理器的装置的访问测序数据的第一请求包括如下指令:在服务器或远离第一个基于处理器的装置的其他装置上执行基因组分析,以及将基因组分析的输出传送至第一个基于处理器的装置。在另一个实施例中,第一请求不包括将测序数据发送至第一个基于处理器的装置的请求。在另一实施例中,处理器被配置成执行指令,该指令包括:从与外部用户相关联的第三个基于处理器的装置接收访问测序数据的第三请求;以及将外部用户的访问测序数据的请求已被接收的通知传送至第一个基于处理器的。
在另一个实施例中,本公开还提供一种用于与序列数据进行交互的计算机实现的方法。该方法包括以下步骤:将搜索请求传送至相关于序列数据的服务器,该序列数据与个人相关联,其中序列数据没有被储存于移动装置上;传送与搜索请求相关联的许可或识别信息;在与搜索请求相关联的用户已基于许可或识别信息而许可访问序列数据的情况下,基于搜索请求接收搜索输出,该搜索输出包括相关于序列数据的搜索引擎结果;以及显示搜索输出。在另一个实施例中,处理器被配置成执行指令,该指令包括:从第一个基于处理器的装置接收对许可信息的更新。该更新可包括如下指令:允许第三个基于处理器的装置对基因组信息的全部或部分访问,或响应于其他外部用户的未来请求允许对基因组信息的全部或部分访问,该外部用户具有类似于与第三个基于处理器的装置相关联的外部用户(例如,临床试验管理者)的简档,并且其中该更新包括接受对其他临床试验管理者进行测序数据访问的请求的指令。当外部用户为零售卖方时,该更新可包括用于拒绝第三个基于处理器的装置访问基因组信息的的指令。更新可包括用于拒绝响应于其他外部用户的未来请求而访问基因组信息的指令,该外部用户具有类似于与第三个基于处理器的装置相关联的外部用户的简档。在某些实施例中,搜索输出可包括包含针对临床状况的搜索引擎结果,并且其中搜索输出基于对序列数据的分析。搜索引擎结果可基于对序列数据的分析进行分级或过滤。对序列数据的分析可包括对一个更多个突变的识别或与临床状况相关联的多态性。搜索输出可包括对基因标记或药物化合物的搜索引擎结果(例如,基于序列数据是否包括与药物化合物的可变药物遗传响应相关联的序列)。在一个实施例中,如果与搜索请求相关联的用户基于许可或识别信息不许可访问序列数据,那么该方法可包括接收不相关于序列数据的默认搜索输出。
在另一个实施例中,本公开提供一种用于储存序列信息的系统。该系统包括至少一个联网计算机系统。联网计算机系统被配置成储存与相应序列拥有者相关联的多个序列,其中各个相应序列包括一个或更多个许可;从次级用户接收访问信息的请求,该信息相关于来自多个序列中的与特定共同特征相关联的序列;确定多个序列中的哪些序列与特定共同特征相关联;并且允许次级用户仅访问相关于与特定共同特征相关联的序列的信息和容许次级用户访问该信息的许可。在一个实施例中,至少一个联网计算机系统被配置成将相关于与特定共同特征相关联的序列的信息和容许次级用户访问该信息的许可传送至次级用户。该信息可包括联系或识别信息、社交媒体简档信息或序列数据。在一个实施例中,至少一个联网计算机系统被配置成接收与新序列拥有者相关联的新序列;确定该序列是否与特定共同特征相关联;并且通知新序列拥有者由于特定共同特征而存在对于新序列数据的未解决的访问请求。
在另一个实施例中,本公开还提供一种用于测序数据的计算机实现的消费者系统。该系统包括至少一个处理器,该处理器被配置成:接收序列数据和与序列拥有者相关联的简档数据;分析序列数据;从序列拥有者接收与序列数据进行交互的请求;基于对序列数据和简档数据的分析,确定用于序列拥有者与序列数据进行交互的用户界面配置;并且将相关于用户界面配置的信息传送至与序列拥有者相关联的远程装置。相关于用户界面配置的信息可包括以下建议:基于序列数据加入一个或更多个社交媒体群组或安装相关于序列数据的一个或更多个应用程序。
在另一个实施例中,本公开还提供一种用于分析测序数据的系统。该系统包括至少一个处理器,该处理器被配置成:接收与序列拥有者相关联的序列数据;接收与序列数据相关联的隐私数据;接收与序列拥有者相关联的简档数据;从次级用户接收与序列数据进行交互的请求;基于隐私数据确定次级用户对序列数据的容许访问等级;并且基于容许访问等级将相关于序列数据或简档数据的信息传送至次级用户。容许访问等级可基于次级用户的类型或可特定于仅一部分的序列数据。
在另一个实施例中,本公开还提供一种用于处理基因组信息的方法,该方法包括:由用户在图形用户界面将基因组表示拖动至卖方表示;根据基因组表示与卖方表示重叠的预定百分比,确定卖方定义数据集,其中卖方定义数据集由卖方定义;将卖方定义数据子集与用户定义数据集相比较;基于所述比较,确定卖方定义数据集是否为用户定义数据集的子集;如果卖方定义数据集是用户定义数据集的子集:在图形用户界面显示来自卖方的基因组出售物;如果卖方定义数据集不是用户定义数据集的子集:识别卖方定义数据集中不是用户定义数据集的子集的部分;并且在图形用户界面显示不是用户定义数据集的子集的卖方定义数据集。
在另一个实施例中,本公开还提供一种用于处理基因组信息的系统,该系统包括处理器,该处理器被配置成:在图形用户界面将基因组表示拖动至卖方表示;根据基因组表示与卖方表示重叠的预定百分比,确定卖方定义数据集,其中卖方定义数据集由卖方定义;将卖方定义数据子集与用户定义数据集相比较;基于所述比较,确定卖方定义数据集是否为用户定义数据集的子集;如果卖方定义数据集是用户定义数据集的子集:在图形用户界面显示来自卖方的基因组出售物;如果卖方定义数据集不是用户定义数据集的子集:识别卖方定义数据集中不是用户定义数据集的子集的部分;并且在图形用户界面显示不是用户定义数据集的子集的卖方定义数据集。
在另一个实施例中,本公开还提供一种用于处理基因组信息的方法,该方法包括:将第一用户交易数据储存于中央储存库中,其中第一用户交易数据随着第一用户完成第一用户交易而被创建,其中第一用户交易包括来自下述事项中的至少一者:查看卖方、查看卖方出售物和购买卖方出售物;将第二用户交易数据储存于中央储存库中,其中第二用户交易数据随着第二用户完成第二用户交易而被创建,其中第二用户交易包括来自下述事项中的至少一者:查看卖方、查看卖方出售物和购买卖方出售物;将第一用户交易数据与第二用户交易数据相比较;基于所述比较,在图形用户界面向第二用户推送有关卖方出售物的通知。
在另一个实施例中,本公开还提供一种用于处理基因组信息的系统,该系统包括处理器,该处理器被配置成:将第一用户交易数据储存于中央储存库中,其中第一用户交易数据随着第一用户完成第一用户交易而被创建,其中第一用户交易包括来自下述事项中的至少一者:查看卖方、查看卖方出售物和购买卖方出售物;将第二用户交易数据储存于中央储存库中,其中第二用户交易数据随着第二用户完成第二用户交易而被创建,其中第一用户交易包括下述事项中的至少一者:查看卖方、查看卖方出售物和购买卖方出售物;将第一用户交易数据与第二用户交易数据相比较;基于所述比较,在图形用户界面向第二用户推送有关卖方出售物的通知。
在另一个实施例中,本公开还提供一种用于处理基因组信息的方法,该方法包括:通过图形用户界面提示用户选择用户基因组信息的至少一部分;在接收对用户基因组信息的至少一部分的选择后,通过图形用户界面提示用户指示关于对用户基因组信息的至少一部分的选择的共享等级;以及基于对用户基因组信息的至少一部分的选择和所指示的共享等级,允许第二用户查看用户的基因组信息。
在另一个实施例中,本公开还提供一种用于处理基因组信息的方法,该方法包括:接收用户的DNA序列;接收用户的表型信息;使用户的DNA序列与用户的表型信息相关联;将用户的DNA序列和用户的表型信息储存于中央储存库中;在图形用户界面通过客户端装置上的应用程序生成图标;以及从图标创建针对所储存的用户的DNA序列的指针。
在另一个实施例中,本公开还提供计算机程序产品,该计算机程序产品包括机器可读指令以用于:由用户在图形用户界面将基因组表示拖动至卖方表示;根据基因组表示与卖方表示重叠的预定百分比,确定卖方定义数据集,其中卖方定义数据集由卖方定义;将卖方定义数据子集与用户定义数据集相比较;基于所述比较,确定卖方定义数据集是否为用户定义数据集的子集;如果卖方定义数据集是用户定义数据集的子集:在图形用户界面显示来自卖方的基因组出售物;如果卖方定义数据集不是用户定义数据集的子集:识别卖方定义数据集中不是用户定义数据集的子集的部分;并且在图形用户界面显示不是用户定义数据集的子集的卖方定义数据集。
附图简要说明
在参考附图阅读下述具体实施方式时,本公开的这些和其他特征、方面和优点将变得更好理解,其中同样的符号在所有图中表示同样的部分,其中:
图1为根据本发明的并入生物数据消费者中枢的系统的图解概略图;
图2为根据本发明的并入作为联网计算环境的一部分的中枢的系统的图解概略图;
图3为参考图2所讨论的类型的中枢的控制模块的图解概略图;
图4为在测序数据的初级用户或消费者、生物数据消费者中枢和一个或更多个次级用户之间进行交互作用的方法的流程图,该方法可结合参考图1所讨论的系统来执行;
图5为经由参考图1所讨论的类型的中枢向次级用户提供访问特定测序数据的方法的流程图;
图6为根据图5的流程图的用于次级用户访问测序数据的用户界面的显示屏的示例;
图7为经由参考图1所讨论类型的中枢基于测序数据提供搜索结果的方法的流程图;
图8为用于经由参考图1所讨论类型的中枢与自己的测序数据进行交互的用户界面的显示屏的示例;
图9为用于经由参考图1所讨论类型的中枢设置与自己的测序数据进行交互的用户界面的用户界面显示屏的示例;
图10为用于经由参考图1所讨论类型的中枢设置与自己的测序数据进行交互的用户界面的用户界面显示屏的示例;
图11为显示屏的示例,该显示屏示出用于经由参考图1所讨论类型的中枢与测序数据进行交互的基因组隐私设定选择器;
图12示出根据一些实施例的图形用户界面;
图13示出根据一些实施例的图形用户界面;
图14示出根据一些实施例的图形用户界面;以及
图15示出根据一些实施例的图形用户界面。
具体实施方式
如本文所用,除非上下文中明确指示其他含义,否则单数形式“一个”(“a”、“an”)和“所述(the)”包括多个指代物。因此,例如,对“序列(a sequence)”的提及可包括多个此类序列,等等。除非另有明确指示,本文所用的所有技术和科学术语具有与本发明所属领域的普通技术人员通常所理解相同的含义。
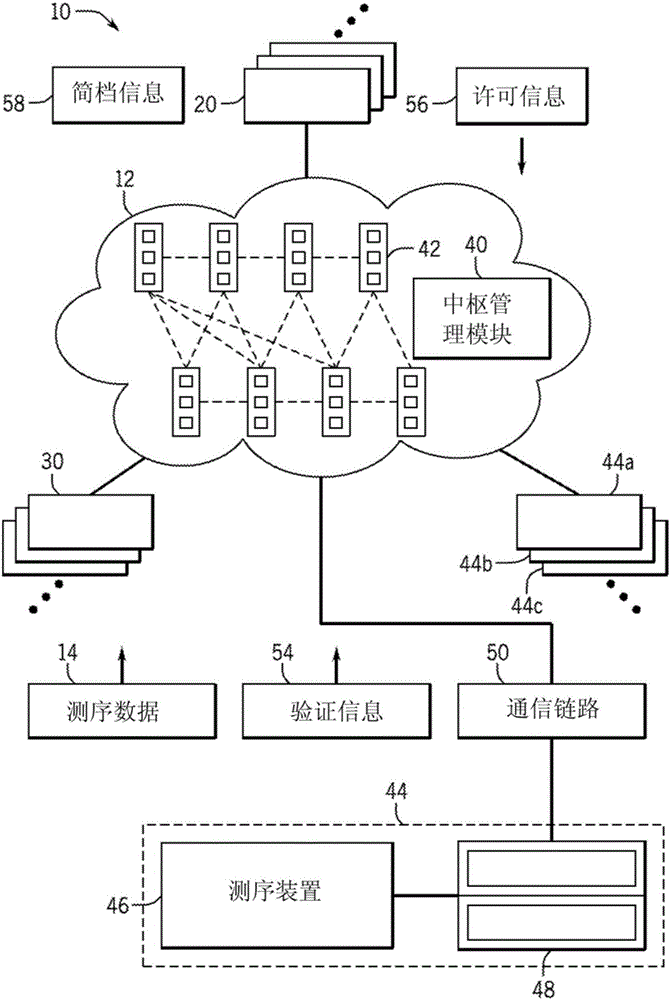
现转向附图,并且首先参考图1,图解地示出生物数据消费者中枢系统10。系统10包括生物数据消费者中枢12,其作为信息交流中心(clearinghouse)用于互连各种用户、服务、功能和数据。例如,在一个实施例中,中枢12用作来自多个个人拥有者的测序数据14的中央储存器。在一些实施例中,测序数据14由系统10中的消费者20生成或拥有。即,测序数据14是个人测序数据。在其他实施例中,测序数据14由研究机构或公司实体而非个人拥有,并且这些机构在这些实施例中也可被视为消费者14。
例如,应当理解,测序数据14可由来自消费者自己的生物样本生成,并且因此,可代表消费者自己的基因组的全部或部分。因此,消费者20也可为测序数据14的拥有者。在某些实施例中,消费者20可拥有或控制访问来自不是他们自己的生物样本的测序数据14,例如家庭成员或非人类数据。例如,测序数据14可由来自陪伴型动物(例如,猫、狗、鸟)、农业动物、植物、食品培养物、实验室样品、取自受试者的培养物(例如,喉咙或伤口拭子)等的非人类生物样本生成。另外,测序数据14可代表基因组序列的全部或仅部分,并且另外,可包括基因组DNA、cDNA、hnRNA、mRNA、rRNA、tRNA、cRNA、另选剪切mRNA、核仁小RNA(snoRNA)、微小RNA(miRNA)、小干扰RNA(siRNA)、piwi RNA(piRNA)、任何形式的合成或修饰RNA、片段核酸、得自亚细胞细胞器(诸如线粒体或叶绿体)的核酸,以及得自微生物或DNA或RNA病毒(可存在于生物样本之上或之中)的核酸。如本文所用,“基因组DNA”可指全部或部分基因组,并且基因组序列可指全部或部分基因组序列。测序数据14可包括种系序列、体细胞序列、基因表达和转录组序列、表观遗传分析(例如,甲基化、乙酰化、组蛋白折叠、结构变异,诸如染色质映射或蛋白质-DNA交互作用映射)、组织序列(例如,肿瘤组织与正常组织)。此外,虽然本公开的实施例可在测序数据的语境下讨论,但是应当理解,中枢12可有利于访问其他类型的生物数据,诸如蛋白质序列数据、微阵列数据等。因此,中枢12可被配置成储存包括可代表蛋白质序列、核酸序列、多糖简档等的数据。
在某些实施例中,测序数据14可以不是任何个人拥有的。例如,来自未要求保护(例如,历史的)或无主生物样本的测序数据14可具有研究兴趣。在这些情况下,测序数据14可公布于众或可由采集样本并且安排进行测序的研究机构或其他实体拥有。另外,据设想,中枢12还可有利于与非人类测序数据14的交互,包括合成数据、哺乳动物有机体数据(例如,陪伴型动物)、真核生物数据、原核生物数据、病毒数据等。在某些实施例中,测序数据14可包括微生物基因组数据(诸如来自环境样本的数据),以及得自感染有机体的微生物基因组数据(微生物组数据)或人微生物组数据。
除了有利于消费者20访问测序数据14之外,中枢12还可有利于次级用户30访问消费者的测序数据14。此类次级用户30可包括医学提供者、医院、保险公司和制药公司。这些次级用户30可对某些测序数据14具有研究或商业兴趣。另外,消费者20在访问非他所有的数据14时也可为次级用户30。例如,消费者20出于宗谱的目的可能希望访问来自可能的亲戚的测序数据。在此类实施例中,消费者20可为初级用户和次级用户30两者。
访问数据还可由第三方应用程序提出请求,诸如社交媒体应用程序32、搜索引擎34、可包括各种数据分析工具的软件应用程序(例如,"应用(apps)")36,以及卖方38(包括消费者产品卖方(例如,购物应用程序))。例如,如果消费者是特殊疾病的社交媒体群组的成员(例如,所有成员共享常见的序列变异),那么在消费者所选许可条件下操作的中枢12可允许访问该特定社群的测序数据14。在其他实施例中,社交媒体应用程序可请求访问测序数据14以协助亲生父母搜索。在此类实施例中,对中枢12的请求可涉及释放测序数据14的可有助于该搜索的相关部分。其他社交媒体应用程序32或软件应用程序36可包括约会或行为群组。例如,约会应用程序可包括评估两个用户的基因组的匹配百分比、其基因组之间的估计“距离”或两人的估计共同祖先(例如,4代、5代)的工具或功能,此类工具可执行匹配而无需向任一用户提供测序数据14。也就是说,应用程序36基于数据提供输出,而非数据本身。
在搜索引擎34的语境下,测序数据14可被提供为对相关搜索的输入,如本文所提供的。另外,测序数据还可用作对数据分析工具36的输入,该数据分析工具36可为消费者20可能希望下载的附加应用程序的一部分。此类应用程序可着重于提供医学上相关的分析,而其他类型的应用程序可为消费者可经由应用程序商店购买的新型应用程序。在此类实施例中,应用程序可以类似于次级用户30的方式与测序数据进行交互。例如,在一个实施例中,应用程序请求许可以访问消费者20的测序数据14。根据应用程序的类型,可以定制许可用于分析。例如,某些数据分析工具36可请求位置信息以及有限的测序数据14。这样,特定工具36还可与当地社交媒体、消费者零售产品或服务应用程序32链接在一起。
中枢12可被配置成接收并储存测序数据14,例如,中枢12可接收来自测序设施22的测序数据14。另选地或除此之外,中枢12可有利于访问远程储存的,例如储存于一个或更多个测序设施22或专用服务器设施的测序数据14。另外,中枢12可与作为云计算环境的一部分的一个或更多个服务器通信以访问测序数据14。
图2为可结合图1的中枢12使用的中枢管理模块40和系统的示例。在所描述的实施例中,中枢12的某些特征可被实施为云计算环境的一部分,该云计算环境包括多个分布式节点42。节点42的计算资源被合并以服务多个消费者,其中不同的物理和虚拟资源根据消费者的需求动态地分配和重新分配。资源的示例包括储存、处理、存储器、网络带宽和虚拟机器。节点42可彼此通信以分布资源,并且资源分布的此类通信和管理可由驻留于一个或更多个节点42的云管理模块40控制。节点42可经由任何合适布置和协议进行通信。另外,节点14可包括与一个或更多个提供者相关联的服务器。例如,某些程序或软件平台可经由一组节点42来访问,该组节点42由程序的拥有者提供,而其他节点42由数据储存公司提供。某些节点42还可为在较高负荷时间期间使用的溢出节点。
在一个实施例中,中枢管理模块40负责处理与系统10中的参与者通信的数据。中枢12被配置成与各用户进行通信,包括用于生成生物数据的装置的用户。此类数据可包括经由测序装置44生成的序列数据,该测序装置44在特定实施例中可包括装置18和相关联的计算机20,该装置18包括用于接纳生物样本并生成序列数据的模块,该相关联的计算机20包括用于分析序列数据并且将其通信至中枢12的可执行指令。应当理解,在某些实施例中,测序装置44也可被实施为一体化装置。测序装置44被配置成经由合适的通信链路50与中枢12通信。与测序装置44的中枢12以及其他中枢用户(例如,消费者20、次级用户30)的通信可包括通过通信链路50经由局域网(LAN)、一般广域网(WAN)和/或公共网络(例如,互联网)的通信。特别地,通信链路50将测序数据26(并且在某些实施例中,将验证信息54)发送至中枢12。验证信息可确认测序装置44为中枢12的客户端。
如所提及的,中枢12可以用相关联的装置(例如,装置44a、44b和44c)服务多个用户或客户端。另外,中枢12还可由其他类型的客户端访问,诸如次级用户30或第三方软件持有人(参见图1;例如,搜索引擎34、卖方38等)。因此,中枢12可根据特定客户端的访问等级提供不同类型的服务。测序客户端可访问储存和数据分析服务器,而次级用户30仅可访问共享或公共序列。第三方软件持有人34可与测序客户端协商以确定适当的访问权限。例如,开放源软件可免费或在有限许可的基础上供应,而其他类型的软件可根据各种费用或订阅基础供应。
一旦测序数据14已被通信至中枢12,与测序数据14的进一步交互和对其的访问可能不一定被联接至测序装置44。此类实施例在其中生物样本和/或序列数据的拥有者已例如向核心测序设施39签订合约以测序的实施例中可为有益的。在此类实施例中,初级用户可为拥有者(例如,消费者20),而与测序装置44相关联的核心实验设施在测序数据14已被通信至中枢12之后至多为次级用户30。因此,消费者20还可提供许可信息56以用于次级用户20进一步访问测序数据14,许可信息56可被预设并同时与测序数据14通信(经由测序装置44)。另选地或除此之外,消费者20还可直接提供许可信息56。消费者20还可提供与测序数据14相关联的简档信息58(例如,健康信息、个人特征)。
在某些实施例中,序列数据可通过安全参数来访问,诸如中枢12中的密码保护的客户端账户或与特定机构或IP地址相关联。通过从中枢12下载一个或更多个文件或通过登录基于网络的界面或软件程序(其提供其中序列数据被描述为文本、图像和/或超链接的图形用户显示),测序数据14可访问。在该实施例中,测序数据14可以数据包的形式被提供至消费者20或次级用户30,该数据包经由通信链路或网络传送。
如本文所用,测序数据14可指在测序运行期间获得的数据,该测序运行指物理或化学步骤的重复过程,该重复过程被执行以获得指示单体在聚合物中的次序的信号。该信号可指示单体在单个单体分辨率或较低分辨率下的次序。在特定实施例中,步骤可起始于核酸靶,并且可被执行以获得指示碱基在核酸靶中的次序的信号。该过程可被执行至其典型完成,该完成通常由这样的点定义:来自该过程的信号不能再以合水平的确定性来区分靶中的碱基。如果需要,完成可更早发生,例如,在已经获得期望量的序列信息时。在一些实施例中,测序运行由数个循环构成,其中每个循环包括一系列的两个或更多个步骤,并且这些系列的步骤在每个循环重复。例如,合成法测序运行的10个循环可被执行以识别具有10个核苷酸的序列。10个循环中的每个循环可包括以下步骤:聚合酶催化的引物延伸以添加具有阻断部分和标记部分的核苷酸类似物;检测延伸引物上的标记部分;以及从延伸引物移除标记部分和阻断部分。
测序运行可根据任何测序技术经由测序装置44来实施,诸如包含描述于美国专利公开No.2007/0166705、No.2006/0188901、No.2006/0240439、No.2006/0281109、No.2005/0100900;美国专利No.7,057,026、WO 05/065814、WO 06/064199、WO 07/010,251的合成法测序方法的那些测序技术,这些专利的公开内容通过引用以其全部被并入本文。另选地,连接法测序技术可用于测序装置44中。此类技术使用DNA连接酶来并入寡核苷酸并识别此类寡核苷酸的并入,并且描述于美国专利No.6,969,488、美国专利No.6,172,218和美国专利No.6,306,597中,这些专利的公开内容通过引用以其全部被并入本文。一些实施例可利用纳米孔测序,由此靶核酸链或从靶核酸以核酸外切方式移除的核苷酸穿过纳米孔。随着靶核酸或核苷酸穿过纳米孔,各种类型的碱基可通过测量该孔的电传导的波动来识别(美国专利No.7,001,792;Soni&Meller,Clin.Chem.(《临床化学》)53,1996-2001(2007);Healy,Nanomed.(《纳米医学》)2,459-481(2007);和Cockroft等人,J.Am.Chem.Soc.(《美国化学会志》)130,818-820(2008),这些文献的公开内容通过引用以其全部被并入本文)。再其他实施例包括检测在将核苷酸并入延伸产物中时释放的质子。例如,基于检测释放质子的测序可使用电检测器和相关技术(可商购自Ion Torrent公司(Guilford,CT,Life Technologies的子公司))或测序方法和系统(描述于US 2009/0026082Al、US 2009/0127589 Al、US 2010/0137143 Al或US 2010/0282617 Al,这些专利中的每篇通过引用以其全部被并入本文)。特定实施例可利用涉及实时监测DNA聚合酶活性的方法。核苷酸结合可通过带有荧光团的聚合酶和γ-磷酸根标记的核苷酸之间的荧光共振能量转移(FRET)相互作用来检测,或以零模波导来检测,如例如描述于Levene等人,Science(《科学》)299,682-686(2003);Lundquist等人,Opt.Lett.(《光学快报》)33,1026-1028(2008);Korlach等人,Proc.Natl Acad.Sci.USA(《美国国家科学院院刊》)105,1176-1181(2008),所述文献的公开内容通过引用以其全部被并入本文。其他合适的另选技术包括例如荧光原位测序(FISSEQ)和大量平行标记测序(MPSS)。在特定实施例中,测序装置44可为来自Illumina公司(加利福尼亚州拉霍亚)的HiSeq、MiSeq或HiScanSQ。
测序装置44可生成作为基础调用文件的测序数据14。测序装置44和中枢12两者均能够处理基础调用文件以执行扩增子、重新组装、文库QC、宏基因组学、重新测序和小RNA发现。其他类型的数据分析可包括临床分析,诸如基因研究(GeneInsight)。在特定实施例中,数据分析可根据行业或监管机构标准(诸如CLIA)来执行。由各种分析生成的文件可采取FASTQ文件、二进制比对文件(bam)*.bcl、*.vcf和/或*.csv文件的形式。输出文件格式上可与可用序列数据查看、修改、注释和操作软件兼容。因此,如本文所提供的可访问测序数据14可为原始数据、部分处理的或处理的数据,和/或与特定软件程序兼容的数据文件的形式。另外,输出文件可与其他数据共享平台或第三方软件兼容。
图3为中枢节点42的框图。中枢节点42可被实施为个人计算机系统、服务器计算机系统、瘦客户端、胖客户端、手持式或膝上型装置、多处理器系统、基于微处理器的系统、机顶盒、可编程的消费者电子设备、网络PC、小型计算机系统、大型计算机系统或云计算环境等中的一者或更多者,该云计算环境包括上述系统或装置中的任一者。另外,虽然所描述的实施例在节点42的语境中讨论,但是应当理解,类似的部件可在消费者20或次级用户30所使用的与中枢12和/或节点42进行交互的装置中实施。节点42可包括一个或更多个处理器或处理单元60、存储器架构62,该存储器架构62可包括RAM 64和非易失性存储器66。存储器架构62还可包括可移除/不可移除的易失性/非易失性计算机系统储存介质。另外,存储器架构62可包括一个或更多个读取器以用于从不可移除的非易失性磁介质读取和对其写入,诸如硬盘驱动器、磁盘驱动器(用于从可移除的非易失性磁盘(例如,“软磁盘”)读取和对其写入),和/或光盘驱动器(用于从可移除的非易失性光盘(诸如CD-ROM、DVD-ROM)读取或对其写入)。节点42还可包括各种计算机系统可读介质。此类介质可为云计算环境可访问的任何可用介质,诸如易失性和非易失性介质以及可移除和不可移除介质。
存储器架构62可包括至少一个程序产品,该程序产品具有一组(例如,至少一个)程序模块,该程序模块被实施为可执行指令,该可执行指令被配置成执行本技术的功能。例如,可执行指令68可包括操作系统、一个或更多个应用程序、其他程序模块和程序数据。一般来讲,程序模块可包括执行特定任务或实施特定抽象数据类型的例程、程序、对象、部件、逻辑、数据结构等。程序模块可执行如本文所描述的技术的功能和/或方法,包括但不限于初级序列数据分析和次级序列分析。
节点42的部件可由内总线70联接,内总线70可被实施为若干类型的总线结构中的一者或更多者,包括存储器总线或存储器控制器、外围总线、加速图形端口,以及利用各种总线架构中的任一种的处理器或局部总线。通过示例而非限制的方式,此类架构包括工业标准架构(ISA)总线、微通道架构(MCA)总线、增强型ISA(EISA)总线、视频电子标准协会(VESA)局部总线和外围部件互连(PCI)总线。
节点42还可与一个或更多个外部装置通信,诸如键盘、指向装置、显示器72等,该外部装置允许操作者与中枢12进行交互;和/或与允许节点42与一个或更多个其他计算装置通信的任何装置(例如,网卡、调制解调器等)通信。此类通信可经由I/O接口74发生。此外,中枢12的节点42可经由合适的网络适配器与一个或更多个网络通信,诸如局域网(LAN)、一般广域网(WAN)和/或公共网络(例如,互联网)。
中枢12可执行用户交互软件(例如,经由基于网络的接口或应用程序平台),该用户交互软件为用户(例如,消费者20和次级用户30)提供图形用户界面并且有利于访问测序数据14、研究者社群或群组、数据共享或分析程序、可用第三方软件,以及用于负荷平衡和仪器设置的用户选择。例如,在特定实施例中,测序装置44上用于测序运行的设置可经由中枢12来设定。因此,中枢12和个人测序装置44(或消费者装置/次级用户装置)能够双向通信。该实施例可以对于控制远程测序运行的参数是特别有用的。
如所提及的,中枢12可以用相关联的装置(例如,装置44a、44b和44c)服务多个用户或客户端。另外,中枢12还可由其他类型的客户端访问,诸如次级用户30或第三方软件持有人(参见图1;例如,搜索引擎34、卖方38等)。因此,中枢12可根据特定客户端的访问等级和许可56提供不同类型的服务。测序客户端可访问储存和数据分析服务器,而次级用户30仅可访问共享或公共序列。第三方软件持有人可与消费者20协商以确定对测序数据14的适当的访问权限。
如本文所提供的,系统10有利于消费者20和/或测序数据14的拥有者与中枢12和协作者或次级用户(例如,次级用户30)的交互。为此,图4为一些示例性交互的路径的流程图。方法100可涵盖所描述的步骤或交互的任何可行子集或组合。在一个实施例中,方法100可开始于在框102处提供生物样本。例如,样本可被提供至测序装置44,该测序装置44继而获取测序数据14。当获取测序数据14时,测序装置44将测序数据14通信至中枢12,在框104处该中枢12接收序列数据。另选地,在框106处消费者20可直接提供数据14。
中枢12中的序列数据14可被储存和/或进一步处理。例如,中枢12能够分析测序数据14(框108)或将指令提供至联网装置以执行该分析。用户可为中枢12所接收的数据设定参数。例如,用户可指出该分析例如经由中枢12远程地执行。在一个实施例中,参数可被设定成使得初级分析(例如,碱基识别)在本地执行,而次级分析(例如,基因组组装)在中枢12中执行。另选地,次级用户30可被指示或允许执行数据分析(框110)。数据分析的结果可被储存用于消费者20和/或次级用户30之后的访问。
系统10还提供用于授权次级用户的技术,该技术包括可由用户设定(框114)并且在测序装置44处接收(框116)的访问和/或许可指令。如果指令指示测序数据14要与一个或更多个次级用户30共享,那么该指令可通过中枢12通信以通知一个或更多个次级用户30(框118)。然后,根据指令实施访问。例如,如果指令包括通知供应,那么将通知发送(框118)至次级用户,该通知在云计算账户中可以例如邮件或消息的形式接收(框119)。消费者20所提供的信息还可包括健康和/或简档信息(框120)。该信息继而被接收于中枢12处(框122)并且可连同所提供的测序数据14一起被通信至次级用户。
对消费者的测序数据14的访问可经由消费者20的请求通过中枢12来促进(框130)。在收到消费者20的访问请求(框142)后,中枢12在传送数据14(框146)之前验证该请求(框144),该数据14由适当的消费者相关联的装置接收(框150)。在其他实施例中,序列数据访问指令还可对次级用户30的至少部分访问设定许可,该次级用户30发送访问序列数据的请求(框140),该请求被中枢12接收(框142)。该请求基于框114处的指令进行验证(框144),并且序列数据14根据框146处的指令进行通信。次级用户30可访问或以下载文件的形式接收序列数据(框148),或可经由基于网络的接口或软件包访问该序列数据。当次级用户30没有访问测序数据14的许可时,提供拒绝通告或提供某些默认简档信息。例如,拒绝可包括“您没有访问客户Joe P.的序列的许可。Joe P.,男性,29岁,来自威斯康星州。”的消息。另外,中枢12可通知消费者20(框152),消费者20继而接收该通知(框154):次级用户已请求/访问测序数据14。
除了介导个人消费者20和次级用户30之间的互相通信之外,中枢12还可充当用于采集有关消费者群组的信息和/或数据及其测序数据14的中介机构。例如,图5为采集在其间具有特定共同特征的一组基因组数据(例如,测序数据14)的方法200的流程图。在框102处,中枢12接收次级用户对具有所关注的共同特征的任何基因组数据的访问请求。所关注的特征可为所关注的特定序列存在或不存在,诸如所关注的基因或基因变异体、基因突变、SNP或微卫星序列。在其他实施例中,所关注的特定共同特征可相关于消费者简档信息(例如,简档信息58)。例如,次级用户30可为临床试验管理者,其正在寻找特定年龄段、种族等的参与者。另外,临床试验管理者可能正在寻找具有或不具有某些临床简档的参与者。在一个实施例中,简档可为已病情得到控制达3年以上的癌症幸存者。在该实施例中,临床试验可涉及对来自这些个人的测序数据14进行的数据挖掘以查找DNA中的有益序列或有益表观遗传变化。在一个实施例中,搜索可为对任何开放访问序列的搜索。即,搜索请求可仅包括作为搜索参数的特定许可设定。中枢12可将所储存的基因组信息和(如果适当)简档信息与请求相比较(框204)以确定是否存在任何匹配的基因组序列。
虽然中枢12可储存匹配期望简档的与消费者20相关联的一组基因组序列数据14,但是基于序列拥有者的个人许可设置,不是所有的所储存序列都是对次级用户30可访问的。在框206处,中枢12可确定哪些个人序列已允许由所讨论的次级用户进行访问。另外,许可可为粒度的。即,某些序列可对所有次级用户开放,其他序列可对所有研究开放但不可用于商业用途。在其他实施例中,某些序列可以仅对一个机构是可访问的,但对相同类型的其他机构为不可访问的。因此,匹配搜索请求并且具有允许次级用户访问的许可(在框208处生成)的序列组可以小于总匹配序列组,而不论许可如何。在框210处,中枢12可允许次级用户30访问相关的基因组数据。另外,中枢12可开始与较大组中的不可访问成员联系以通知他们访问请求并且指出该请求已被拒绝。在该实施例中,如果消费者20改变其隐私以允许访问,中枢12还可接收更新的隐私设置。
在另一个实施例中,次级用户可能希望访问的不是序列数据,而是消费者的联系信息。即,基于序列谱,次级用户30可能希望将消费者产品销售给特定用户。例如,如果消费者产品公司已确定序列变异体与头皮屑相关联,那么次级用户30可能希望将头皮屑产品销售给具有该变异体的消费者。在其他实施例中,中枢12可便于联系消费者20以维护消费者隐私。
请求可被构造为持续搜索,使得随着新基因组序列被中枢12接收,它们被自动地评估以确定它们是否包括所关注的特征和适当的许可设置。如果是,那么该数据被转发至次级用户。如果否,消费者20可被通知存在对于其数据的未解决的请求。此外,当消费者20针对基因组信息的设置与中枢12进行交互时,设置过程可包括对符合其数据和/或简档的序列数据的任何未解决的请求的自动评估。在一个实施例中,请求被“推送”至设置屏幕上,并且消费者20可根据需要接受或否决。
对于作为中枢系统10的成员的一部分请求基因组或测序数据14的次级用户30而言,中枢12可提供用户界面以用于数据交互。取决于次级用户的类型,此类服务可免费或基于订阅。图6为用于与可用序列数据14进行交互的图形显示屏250的一个示例。图形显示屏250可包括可选菜单选项以用于选择特定基因组和/或从中枢12访问相关于所选基因组的数据。此外,所显示的信息可包括相关的数据分析应用程序的链接或可链接图标254或相关于序列数据的所描述部分的其他信息。可链接图标254可被链接至相关应用或应用程序。点击链接可将用户带至来自第三方卖方的有关数据分析或其他工具的应用程序商店。因为用户会在云端储存有多种多样的数据集(在其内容的大小和性质方面均不同),所以不同应用程序可能适合于不同类型的数据集。显示屏250还可显示用于管理通知260和共享262的链接。
除了介导消费者20和次级用户30之间的互相通信之外,中枢12还可充当通常可以独立于序列的方式起作用的软件应用程序或其他工具的中介机构。然而,在某些实施例中,将测序数据14作为输入提供至此类工具可增强或靶向特定输出。例如,图7为序列依赖型搜索的流程图,该序列依赖型搜索可由中枢12介导。消费者20或次级用户30可以常规的方式输入搜索请求,该搜索请求继而被中枢12接收(框302)。如果请求与任何可访问序列数据14相关联,那么访问序列数据和任何相关的分析数据(例如,特定突变或变异体的存在)(框304)。搜索结果基于所访问数据被提供至请求者(框306)。在某些实施例中,搜索结果基于可用序列数据进行排序(框308)和/或过滤(框310)。
在一个实施例中,搜索引擎输出可根据序列数据14进行排序。如果序列数据指示消费者20具有与乳腺癌相关联的特定变异体,诸如BRCA1,那么可针对词语“乳腺癌”的搜索结果进行排名以包括BRCA1或将BRCA1加权为在其他乳腺癌结果之上的词语。该加权在没有来自消费者20的任何额外输入的情况下执行。这样,为了接收靶向搜索结果,消费者20无需是医学经验丰富的。中枢12可包括它自己的搜索引擎,或方法300可使中介机构服务于常规搜索引擎结果。例如,对于“乳腺癌”的谷歌搜索结果可被提交至中枢12,并且然后由中枢12根据序列数据14进行排序和/或过滤。
在另一个实施例中,搜索引擎输出可被过滤以包括或排除某些结果。例如,如果序列数据14指示消费者20在CYP2D6基因中具有指示可待因代谢作用降低的特征突变,那么其针对“止痛药物”的搜索结果可被过滤以排除可待因。在另一个实施例中,中枢12基于序列数据14可提出特定搜索词语。例如,如果序列数据14是祖先型分析的一部分,那么搜索词语可包括针对消费者20所预测的起源地区。其他搜索类型可基于所预测的出现临床状况的风险进行分级或过滤,如通过对序列数据14的分析所指示的。另外,搜索引擎可用于查找专门研究治疗与序列突变相关联的疾病的医生或专业人员。在另一个实施例中,基于如根据序列数据14所确定的种族起源,例如,基于广泛地或非广泛地体现在特定族群中的变异体,可过滤具体搜索结果。例如,某些种族可具有出现特定临床状况的不同可能性。因此,相对于一般人群或其他族群,某些搜索结果(即,较高可能的临床状况)可能比其他搜索结果(即,较低可能的临床状况)受到更高关注。
出于消费者自身以及对此有所关注的第三方的利益,中枢12用作来自多个消费者20的序列数据14的信息交流中心。消费者20可以是医学经验丰富的或缺乏经验的,并且中枢12可被配置成为多种不同类型的序列数据消费者创建定制用户界面。图8至图10为所显示的图形用户界面的示例,该图形用户界面通过与序列数据14和中枢12的交互引导消费者20。
图8为所显示的介绍屏幕400的一个示例。该屏幕包括基因组表示。例如,人的全部或部分基因组序列(或其他类型的序列数据14)可在应用程序窗口中由图标402表示,该应用程序窗口在客户机(诸如移动电话)中由应用程序生成。该图标402或基因组表示可用于向卖方识别个人消费者或用户,该卖方提供基因组服务,诸如族谱。在一些实施例中,基因组表示自身保持个人消费者的基因组信息。在一些实施例中,基因组表示可为指向数据的图标,该数据被储存于远程位置(诸如服务器),或被本地储存于客户机上,其中该数据包括基因组信息。在一些实施例中,该图标402包括基因型信息、表型信息,或基因型信息和表型信息的组合。因为基因组表示和其包括的基因组信息可包括隐私信息,所以无论基因组表示或该基因组表示指向的基因组信息被储存在哪里,都应该使用安全措施(诸如加密),有关基因组表示或基因组信息的通信也应如此。介绍屏幕400可包括简化软键或链接404以进入更复杂的设置屏幕,如图9所示。
图9为所显示的设置屏幕410的一个示例,该设置屏幕410允许用户根据最适合其需求的简档412遵从默认或自动设置。通过示例的方式,简档可包括相对地经验不丰富示例用户“Joe”,其不具有任何特定疾病简档或关注区域。选择一个简档通向下一相关联的设置屏幕,而选择另一个简档通向不同的相关联的设置屏幕。其他简档示例包括医学研究者、癌症患者或系谱学者。每个简档通向所定制的建议设置,如图10所示。设置包括以下针对消费者20的选项:下载建议的应用422,加入社交媒体群组424,以及点击有关特定疾病的信息426。在其他实施例中,加入特定群组的建议可基于序列分析和特定序列变异体的存在。在可以适合于至少具有基础的基因学知识的消费者20的另一个实施例中,消费者20可例如经由滚动和/或点击来导航基因组的染色体视图。如果特定区域与分析应用程序、共享特征、社交媒体群组、新闻,和/或保健专员相关联,那么此类选项可被提供为基因组区域上的可点击链接。
除了设置用户界面之外,消费者20可与中枢12就设定数据和简档许可方面进行交互。图11为粒度和动态许可图标450的一个示例。在所描述实施例中,粒度可被设定为次级用户等级。例如,图标450可为圆盘或轮,其包括针对具体次级用户30的可选区域。通过点击特定区域,诸如“保健提供者”452,显示出可用许可和限制的列表。这些可根据消费者20的喜好来改变或定制。消费者20可能希望具有针对某些保健提供者的开放序列访问、针对保险公司454的有限序列访问(例如,充分访问所关注区域以针对检验或手术提供保险范围的文档),以及针对消费者产品公司460的更有限访问。为了引导用户通过各种隐私设定,中枢12可包括针对示例用户所储存的隐私简档,该隐私简档类似于图10中的用户配置简档。
另选地或除此之外,图标450还可被配置成有利于用户选择访问或许可的序列块。在全基因组的情况下,图标450可为染色体的表示,并且消费者20可在染色体中进行导航以选择区域来与次级用户30共享。因此,仅可共享序列数据14的某些部分。在一个实施例中,消费者20可共享仅某些染色体、仅某些基因序列、仅基因组的与转录基因相关联的区域、仅垃圾DNA等。此类共享还可为粒度的,并且可被定制用于个人次级用户30,如图11中。另外,图标450可被整合入图标402中,使得选择或拖动图标402还选择了相关许可。这样,消费者20可经由包括数据、简档信息和隐私设定的基因组头像或cookie与中枢12进行交互。另外,应当理解,隐私设定为动态的,并且可在任何时间授权或抑制对序列数据14的访问。
本公开提供一种用以呈现或显示图形用户界面的方法,该图形用户界面适合于购买、分布、共享、显示和消费基因组信息。图形用户界面可在客户机上被显示或呈现给用户或个人消费者。客户机可为移动装置,诸如智能电话、平板电脑或膝上型电脑等。客户机可为非移动装置,诸如个人台式计算机等。在一些实施例中,图形用户界面通过在客户机上运行的应用程序或程序而被显示或呈现于客户机上。例如,移动装置上的应用程序可用于向用户显示图形用户界面。
图形用户界面可用于在客户端-服务器环境(诸如,通过网络连接通信至服务器的客户端)预览或购买基因组产品或服务。网络连接可包括互联网或本地网络等。
图形用户界面特别可用于客户端-服务器环境,该客户端-服务器环境有利于基因组信息的购买、分布、显示、共享和消费。基因组信息为高度个人化的和机密的,所以基因组信息在客户端和服务器之间或在客户端和其他客户端之间的任何传送都应该是安全的并且由个人消费者控制。基因组信息的该受控传送或分布可利用加密或其他已知安全技术来防止第三方(诸如黑客)的未授权访问。用户账户可由个人用户创建以有利于限制对个人用户的基因组信息的未授权访问,以及限制或划定授权用户的权利。安全技术,诸如加密和用户账户,在传送或下载期间以及在储存于客户机或服务器期间限制对基因组信息的访问。图形用户界面还可由个人用户使用以识别待从基因组卖方购买的基因组产品或服务,以及定位储存于客户机、基因组卖方的服务器或其他服务器上的基因组信息。
本公开可以若干方式来实现,诸如方法、系统、设备、图形用户界面或计算机程序产品。计算机程序产品可包括被储存于计算机可读储存介质(诸如硬盘驱动器、DVD-ROM、CD-ROM、固态驱动器,或能够储存数字信息的任何其他介质)上的机器可读代码。这些计算机可读储存装置无需为物理装置。这些计算机可读储存装置也可为虚拟化储存装置,其中逻辑驱动器物理地跨多个机器驻留。计算机程序产品还可横跨地理上的不同位置。例如,计算机程序产品可包括客户机界面,以及通过客户机界面访问的远程服务器数据库。
可结合基因组信息使用的某些图形用户界面示于图12至图15中。在图形用户界面,基因组信息可由基因组表示来表示。例如,人的全基因组序列可在应用程序窗口中由图标表示,该应用程序窗口在客户机(诸如移动电话)中由应用程序生成。该图标或基因组表示可用于向卖方识别个人消费者或用户,该卖方提供基因组服务,诸如族谱。在一些实施例中,基因组表示自身保持个人消费者的基因组信息。在一些实施例中,基因组表示可以是指向数据的图标,该数据被储存于远程位置(诸如服务器),或被本地储存于客户机上,其中该数据包括基因组信息。在一些实施例中,该图标可包括基因型信息、表型信息,或基因型信息和表型信息的组合。因为基因组表示和其包括的基因组信息可包括隐私信息,所以无论基因组表示或该基因组表示指向的基因组信息被储存在哪里,都应该使用安全措施(诸如加密),有关基因组表示或基因组信息的通信也应如此。
在一些实施例中,用于处理基因组信息的方法包括:接收用户的DNA序列;接收用户的表型信息;使用户的DNA序列与用户的表型信息相关联;将用户的DNA序列和用户的表型信息储存于中央储存库中;在图形用户界面通过客户端装置上的应用程序生成图标;以及从图标创建针对所储存的用户的DNA序列的指针。
不同的卖方可提供不同的基因组服务。一个卖方可提供族谱服务,而另一个卖方可提供健康和保健服务。这些不同的服务可能需要不同的基因组信息以便执行其相应的基因组服务。例如,卖方A可能需要基因X和基因Y来提供服务L,而卖方B可能需要基因Z来提供服务M。在这种情况下,如果基因组信息包括个人用户的整个基因组序列,那么他或她可能不想共享其基因组信息。在一些实施例中,图形用户界面将包括允许用户修改共享等级和共享的其基因组信息的子集的控制或设定。
在上述示例之后,假设用户的基因组信息包括该用户的整个基因组序列,或该用户的完整的DNA序列。用户不愿意共享基因Y和Z,因为这些基因指示用户在其一生中可能会感染衰竭性疾病。通过在图形用户界面设定适当的隐私设定,第三方将不能够查看用户的基因Y和Z。实际上,作为默认设定,可期望的是,用户的整个基因组序列和/或识别信息被设定为隐私的,意为第三方在不首先获得该用户的许可的情况下将不能够查看该用户的整个基因组序列或识别信息。
因为用户尚未与第三方共享基因Y和Z,并且因为卖方A需要基因Y并且卖方B需要基因Z,所以用户将不能够利用卖方A或B的服务。然而,在一些实施例中,即使在所需的基因组信息的子集未被共享时,用户仍能够浏览由卖方提供的服务选择。例如,图形用户界面可包括由应用程序在客户机上产生的第一应用程序窗口和由应用程序在客户机上产生的第二应用程序窗口,该第一应用程序窗口允许用户浏览提供基因组服务的多个卖方,该第二应用程序窗口允许用户当在第一应用程序窗口从多个卖方中选择一个卖方时查看由该卖方提供的多个卖方服务。第一应用程序窗口的内容(其可包括卖方列表)包括可被储存于远程服务器上的数据。例如,应用程序可经由无线网络连接与远程服务器通信,以确定卖方列表并在图形用户界面的第一应用程序窗口中显示这些卖方。类似地,第二应用程序窗口的内容(其可包括由具体卖方所提供的卖方服务或基因组出售物的列表)可被储存于远程服务器上。例如,应用程序可经由无线连接与远程服务器通信,以确定基因组出售物列表并在图形用户界面的第二应用程序窗口中显示这些基因组出售物。
在一些实施例中,用于处理基因组信息的方法包括:通过图形用户界面提示用户选择用户基因组信息的至少一部分;在接收对用户基因组信息的至少一部分的选择后,通过图形用户界面提示用户指示关于对用户基因组信息的至少一部分的选择的共享等级;以及基于对用户基因组信息的至少一部分的选择和所指示的共享等级,允许第二用户查看用户的基因组信息。
用户可预览、浏览或读取呈现于由应用程序所生成的第二应用程序窗口中的对卖方服务的简要描述。在一些实施例中,对卖方服务的预览或简要描述可指示在可利用卖方服务之前需要共享的基因组信息或基因。此类服务可包括用于数据分析的应用程序以及新型或娱乐应用程序,以及购物或卖方应用程序。例如,这些应用程序可包括用于健康分析的应用程序。在另一个示例中,这些应用程序可包括用于购买基于序列数据14被个性化的消费者货物的应用程序,该消费者货物。例如,消费者可选择购买绣着其自己的个人DNA的具体序列或具体表型的衣物,在这种情况下,中枢将向消费者货物制造商释放要被并入个性化产品中的那些序列。此类产品的示例可包括DNA袜子、衬衫、帽子、包等,此外,这些应用程序可包括节食或健身应用程序。例如,基于序列数据14和对过敏存在或不存在的分析,应用程序可产生膳食个性化和限制建议。
卖方或卖方服务可由卖方图标或卖方表示来表示。在上述示例之后,卖方A可被显示为图形用户界面中的图标。卖方表示或卖方图标可包括卖方的图形表示,诸如卖方的商标或识别卖方的其他可识别图形。卖方表示还可包括卖方服务的图形表示,诸如产品的缩略图或者产品或服务的商标。
在一些实施例中,用户可在卖方表示上拖动或投放基因组表示或图标以确定卖方是否可向用户提供卖方服务。例如,用户可将用户的图形表示拖动至卖方表示,而卖方表示可变灰,从而指示卖方服务在当前共享等级下不可用,并且图形用户界面中的提示可向用户指示为了利用卖方服务所需的基因组信息的子集。提示还可指示基因组信息的哪个子集已被共享以及还剩下哪些基因组信息需要被共享。在上述示例之后,如果卖方为卖方A,那么提示可向用户指示基因X已被共享,但是基因Y将也需要被共享以便利用服务L。在消费者货物的个性化的示例中,提示可指示被共享且因此可用于个性化的基因。
特别是在小触摸屏的客户机中,诸如缺少硬件键盘的移动装置,将基因组表示整个地拖动或投放至卖方表示上可以是麻烦的。在这些情况下,可期望的是使用预定的重叠百分比来推断用户想要将基因组表示拖动至卖方表示上。例如,如果预定重叠百分比为70%,那么在用户的基因组信息覆盖70%或更多的卖方表示时,应用程序然后可在图形用户界面提示用户由卖方提供的哪些卖方服务或基因组服务是可用的,或者在能够利用卖方的卖方服务之前哪些额外的基因组信息是需要的。
在一些实施例中,用于处理基因组信息的方法包括:由用户在图形用户界面将基因组表示拖动至卖方表示;根据基因组表示与卖方表示重叠的预定百分比,确定卖方定义数据集,其中卖方定义数据集由卖方定义;将卖方定义数据子集与用户定义数据集相比较;基于所述比较,确定卖方定义数据集是否为用户定义数据集的子集;如果卖方定义数据集是用户定义数据集的子集:在图形用户界面显示来自卖方的基因组出售物;如果卖方定义数据集不是用户定义数据集的子集:识别卖方定义数据集中不是用户定义数据集的子集的部分;在图形用户界面显示不是用户定义数据集的子集的卖方定义数据集。
在一些实施例中,可能有利的是中央服务器储存用户的基因组信息。该中央服务器或集中式数据库可散布于不同的地理区域,使得多个服务器可承载数据灾难情形的冗余数据或维持较高的正常运行时间百分比。被储存于中央服务器上的数据可由个人用户或卖方访问。例如,如果卖方需要查看用户的基因组信息以便完成基因组出售物或使该基因组出售物更加个人化,那么卖方将与中央服务器通信以访问用户的基因组信息(假定用户允许卖方查看该用户的基因组信息)。
类似于个人用户如何具有用户账户,卖方可具有卖方账户。具有卖方账户将允许中央服务器对卖方进行验证,并且如果具体用户与服务器通信使得卖方账户被允许查看用户的基因组信息或其子集,那么将允许卖方访问该具体用户的基因组信息。当卖方想对卖方账户添加新的基因组出售物或卖方服务时,卖方账户还可用于对卖方进行验证。
个人用户可与其他个人用户共享他或她的基因组信息。例如,个人用户可与他的兄弟、父母或亲密朋友——他们具有个人用户账户以在其相应的客户机上访问应用程序的实例——共享他的基因组信息。在这种意义上,可存在关联网络,其中每个关联体可被赋予访问不同等级或不同子集的个人用户的基因组信息。例如,个人用户可与他的父母和兄弟共享他的整个DNA序列,但与他的亲密朋友仅共享基因X、Y和Z。另外,个人用户可授权或增大共享等级,使得关联体可被允许与其他第三方共享该个人用户的基因组信息。例如,个人用户可授权其父母与卖方共享该个人用户的基因组信息,该卖方专门从事比较多个基因组和发布有关比较结果的报告。取决于共享的基因组信息的量,个人可识别信息可从共享基因组信息编辑,使得卖方将不能够将个人用户的基因组信息反向追溯至个人用户。例如,个人用户的父亲可提交具有该个人用户的基因组信息的父亲本人的DNA序列,但在提交该个人用户的基因组信息时没有标明该个人用户。此外,个人用户的基因组信息自身不足以识别该个人用户。换句话讲,个人用户的基因组信息为该个人用户的完整的DNA序列的子集。
各种共享等级也可应用于卖方。例如,个人用户可允许卖方在提供卖方服务的基因组出售物的过程中访问和查看个人用户的基因组信息。个人用户还可允许卖方向其他卖方指示该个人用户利用了该卖方的基因组出售物。基于该指示,其他卖方可通过图形用户界面提示用户,该用户是否会有兴趣预览或利用其他卖方的基因组出售物或其卖方服务。
所有该交易数据,即包括个人用户利用或预览过的所有基因组出售物的数据,可被储存于中央服务器中。中央服务器无需是物理上的一个机器,而是可在地理上多样化的,在不同位置具有多个机器。中央服务器还可包括个人用户的基因组信息,其中用户通过由在客户机上运行的应用程序所生成的图形用户界面访问并控制其相应的基因组信息。在大量的个人用户在中央服务器上储存其交易数据和基因组信息的情况下,中央服务器可充当一种文库。基因组库可由各种组织出于多种多样的理由来访问。
例如,在得到个人用户充分许可的情况下,关注使用人群基因组的研究机构可能想访问基因组库以获得具体大都市区域中的基因组的足够的样本量。基因组库中的数据可编辑,使得个人可识别信息不被公开。基因组库可包括用户位置和用户年龄等有关该用户的其他类型的元数据,并使之与用户的基因组信息相关联。代替以各个个人用户的基因组信息与其对应的姓名、位置和年龄逐行地生成报告,该报告可使数据匿名,使得不能从该报告反向追溯个人。例如,报告可包括诸如“年龄在1-18岁的所有城市居民”的部分,并且显示不具有其他相关元数据(诸如姓名、地址或出生日期)的基因组信息或DNA序列的列表。
基因组库还可用于确定个人用户可能对哪些基因组出售物或卖方服务感兴趣。因为基因组库包括交易数据,所以应用程序可将一个用户的交易数据与第二个用户的交易数据相比较。例如,假设用户A通过用户A的客户机上由应用程序产生的图形用户界面浏览了卖方1的基因组出售物,并且随后查看了卖方2的基因组出售物并从卖方2购买服务L。如果用户B通过用户B的客户机上由应用程序产生的图形用户界面浏览了卖方1的基因组出售物,并且随后关闭了显示卖方1的基因组出售物的窗口,那么在用户B下一次登录应用程序时,该应用程序可向用户B推送通知,指示用户B可能对来自卖方2的服务L感兴趣。
在一些实施例中,用于处理基因组信息的方法可包括:将第一用户交易数据储存于中央储存库中,其中第一用户交易数据随着第一用户完成第一用户交易而被创建,其中第一用户交易包括来自下述事项中的至少一者:查看卖方、查看卖方出售物和购买卖方出售物;将第二用户交易数据储存于中央储存库中,其中第二用户交易数据随着第二用户完成第二用户交易而被创建,其中第一用户交易包括来自下述事项中的至少一者:查看卖方、查看卖方出售物和购买卖方出售物;将第一用户交易数据与第二用户交易数据相比较;基于所述比较,在图形用户界面向第二用户推送有关卖方出售物的通知。
在一些实施例中,基因组库和用于访问该基因组库的图形用户界面可为基因组环境(Genomics Environment)的一部分。基因组环境为允许第三方公布应用程序的平台,该应用程序利用图形用户界面以及基因组库中所包括的信息。例如,公司A可收藏基因组库,并且允许个人用户通过图形用户界面访问该基因组库和基因组环境。公司A还可公布用于基因组环境的API套件或应用程序编程界面套件,该套件允许公司B将公司B所创建的应用程序公布于该基因组环境。在允许将公司B的应用程序公布于该基因组环境之前,公司A可对公司B的应用程序施加一些限制条件,诸如安全要求、内容要求和隐私要求等。在公布于该基因组环境之后,个人用户将能够通过基因组环境和图形用户界面下载、安装或以其他方式利用公司B的应用程序。然而,如果公司B的应用程序请求被储存于基因组库中的个人用户的敏感性或以其他方式未共享的基因组信息,那么该应用程序可能不能正常工作,或基因组出售物可能不能被充分利用。个人用户可决定与公司B的应用程序共享他或她的相应的基因组信息(如果该个人用户决定这样做的话)。如果否,那么个人用户可删除程序,或以其他方式不利用公司B的应用程序。理想地,在个人用户下载、安装和利用之前,公司B的应用程序应指出要充分利用公司B的应用程序需要哪些基因组信息。
当个人用户首次连接基因组环境时,个人用户可以没有个人用户基因组信息。在一些实施例中,参与基因组环境的卖方可供应包括全基因组测序的基因组出售物。然后,个人用户可利用卖方的基因组出售物,诸如订购试剂盒以返回DNA样本。在一些实施例中,托管基因组环境的公司可提供基因组测序服务。在一些实施例中,开设新用户账户以加入基因组环境的过程可包括将DNA样本发送至负责基因组环境的公司。
附图以示例的方式示出了本公开的原理,根据结合附图的该具体实施方式,本公开的其他方面和优点将变得显而易见。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种新型的15种人乳头瘤病毒亚型分型试剂盒和方法与流程
- 一种与水稻稻瘟病抗性基因紧密连锁的分子标记、引物及其应用的制造方法与工艺
- 一种无创高通量甲基化结肠癌诊断、研究和治疗方法与流程
- 用于检测CDKN2B基因变异的试剂盒及CDKN2B基因变异率的定量检测方法与流程
- 用于基因甲基化检测的引物和探针、采样方法、试剂盒与流程
- 一种癌症相关基因突变高灵敏度检测方法和试剂盒与流程
- 基于高通量测序法的人类多基因突变检测试剂盒的制造方法与工艺
- 一种用于检测德尔卑沙门氏菌的靶基因、特异性引物对及检测方法和试剂盒与流程
- 一种检测测序平台索引序列污染的方法及引物与流程
- 无物种限制的真核生物同时进行基因敲除和基因过表达的制造方法与工艺