一种化工材料加工熔融指数预报方法与流程
本发明属于化工材料加工生产过程优化领域,更具体地涉及一种基于模糊支持向量回归模型预报熔融指数的方法。
背景技术:
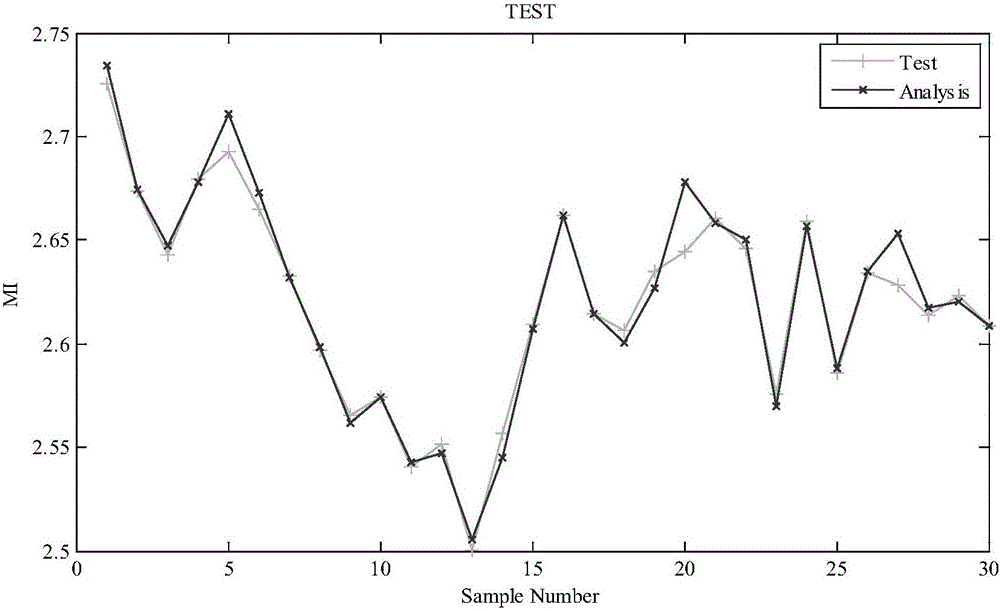
:熔融指数是一种表示塑胶材料加工时的流动性的数值。它是美国量测标准协会(ASTM)根据美国杜邦公司惯用的鉴定塑料特性的方法制定而成,其测试方法是先让塑料粒在一定时间内、一定温度及压力下,融化成塑料流体,然后通过一定直径圆管所流出的克数。其值越大,表示该塑胶材料的加工流动性越佳,反之则越差。熔融指数通常是在实验室经过特定步骤通过离线分析获得。由于该分析过程费时费力,在分析过程中实时的产品质量将无法获知,这种情况会导致产品牌号不可控以及由此带来的巨额损失。另一种选择是基于其他可实时获得的过程信息进行在线产品质量预报,这样即可对整个生产过程进行监控,从而避免在产品牌号切换过程中的质量失配。由于化工聚合过程设备操作与过程动力学分析的高度复杂性,通过机理建模方法预报熔融指数通常面临着很多问题,因此对熔融指数进行实时准确的预报相当困难。目前随着计算机技术的发展,工业过程实时数据库系统中包含了大量的过程数据,很多生产过程在此数据的基础上采用机器学习的方法来进行过程设计,监控与控制。目前很多研究已经采用各种建模方法对熔融指数进行预报。刘兴高等人采用在线矫正策略的模糊神经网络与粒子群优化算法相结合来预报熔融指数。Han等人比较研究了支持向量机,偏最小二乘和人工神经网络在预报熔融指数时的性能表现,并指出支持向量机的效果在三者之中最好。然而,关于支持向量机在这一领域的进一步研究并没有展开。本发明提出了一种模糊支持向量回归模型用于化工材料加工过程建模,可以根据其他实时测得的过程变量,对熔融指数进行预报。考虑到方法一致性的问题,采用了基于支持向量数据描述的模糊隶属度函数来进行建模,并用于获取熔融指数的鲁棒预报。技术实现要素:1、本发明的目的。本发明为了解决现有技术中熔融指数进行实时准确的预报困难的问题,而提出了一种基于模糊支持向量回归模型预报熔融指数的方法。2、本发明所采用的技术方案。本发明提出的化工材料加工熔融指数预报方法,按照如下步骤进行:步骤1、从实际化工材料加工装置的历史记录数据库中选定训练样本,并进行滤波去除异常,以提高预报质量;步骤2、预报熔融指数问题转化为模糊支持向量回归的优化命题;步骤3、步骤2所述的优化命题采用拉格朗日方法后得到对偶优化命题;步骤4、建立模糊支持向量回归模型,通过特征空间中的支持向量数据描述模糊隶属度函数:(1)假设一个中心为a半径为R的超球体,代价函数定义如下:minR2+CΣi=1lξi]]>约束为其中ξi为松弛变量,参数C为惩罚因子,用于折中球体积大小与样本点的违反程度,xi是输入数据,非线性映射将输入数据映射到高维特征空间,即转化为线性回归问题;(2)超球体的最优分界面可通过拉格朗日法转换为对偶问题进行求解:maxΣi=1lαiK(xi,xi)-Σi=1lΣj=1lαiαjK(xi,xj)]]>约束为其中αi不为0所对应的训练样本称为支持向量,用于构成超球体的边界,K为满足Mercer条件的核函数,即(3)样本到特征空间中心距离记a为特征空间中样本的中心,根据K-T条件a=∑αixi半径定义为样本到特征空间中心距离的平方为di2=K(xi,xi)-2ΣjαjK(xj,xi)+ΣiΣjαiαjK(xi,xj)]]>根据定义,半径r为超球体中心到球边界任意支持向量的距离r=dsv(4)得到每一输入样本的模糊隶属度每一输入样本的模糊隶属度为si=1-di2/(r2+δ)]]>其中δ>0是一足够小的常数,用于避免si=0的情形;步骤5、从实际化工材料加工装置的历史记录数据库中选定测试样本、推广样本,并测试基于模糊支持向量回归模型预报熔融指数的精度及稳定性。更进一步具体实施例中,所述的步骤1从实际化工材料加工装置的历史记录数据库中选定训练样本,步骤5从实际化工材料加工装置的历史记录数据库中选定测试样本、推广样本,具体方法如下:给定训练样本集及其模糊隶属度其中M表示训练样本的规模,xi是输入数据,yi是输出数据,每个训练样本均有一个对应的模糊隶属度si,该隶属度满足σ≤si≤1,其中σ是一大于0的足够小的常数。更进一步具体实施例中,所述的步骤2预报熔融指数问题转化为模糊支持向量回归的优化命题,采用方法如下:模糊隶属度si是相应样本对于回归贡献程度的度量,参数ξi是误差的度量,siξi是带权重的误差,则模糊支持向量回归优化命题转化为minw,b,ξ*,ξR(w,ξ*,ξ)=12wTw+γ{Σi=1Msiξi*+Σi=1Msiξi}]]>约束为其中wTw/2为平滑项,γ是用于折中训练误差与模型平滑度的正则化常数,ξ,ξ*是松弛变量。更进一步具体实施例中,所述的步骤3中采用拉格朗日方法后得到对偶优化命题为maxαi,αi*W=-12Σi=1MΣj=1M(αi-αi*)(αj-αj*)K(xi,xj)-ϵΣi=1M(αi+αi*)+Σi=1Myi(αi-αi*)]]>约束为其中α*,α为拉格朗日乘子,对该二次规划命题进行求解可得最终可得回归函数更进一步具体实施例中,所述的模糊支持向量回归模型的训练样本及测试样本均选自某化工材料加工装置的同一批次产品生产过程,推广样本选自另一批次产品生产过程。更进一步具体实施例中,所述的化工材料为聚丙烯,选取9个过程变量(t,p,l,a,f1,f2,f3,f4,f5),t为过程温度,p为压力,l为液位,a是气相氢气百分含量,f1,f2,f3为三股丙烯进料流量,f4为催化剂进料流量,f5为辅助催化剂进料流量。3、本发明的有益效果。本发明提出了一种模糊支持向量回归模型,用于根据化工材料尤其是丙烯聚合过程中其他过程变量来预报熔融指数。与标准支持向量回归模型相比,本发明采用了模糊支持向量数据描述建立模糊隶属度函数,可以减少噪声和异常点的影响,从而大大提高预报的精度。在合理训练之后,本发明预报熔融指数的平均相对误差仅为0.03%,相比于标准支持向量回归模型的0.22%有了较大的提高。结果表明所提出的模型具有较高的预报精度和预报稳定性,因此在实际化工材料加工场合具有很好的应用前景。附图说明图1本发明基于模糊支持向量回归模型的聚丙烯测试样本集熔融指数预报。图2基于标准支持向量回归模型的聚丙烯测试样本集熔融指数预报。图3本发明基于模糊支持向量回归模型的聚丙烯推广样本集熔融指数预报。图4基于标准支持向量回归模型的聚丙烯推广样本集熔融指数预报。具体实施方式实施例本发明对标准支持向量回归模型进行改进,通过模糊支持向量数据描述建立模糊隶属度函数模型,减少噪声和异常点的影响。1、标准支持向量回归支持向量机是用于解决分类问题的有力工具,在引入代价函数后支持向量机可以转换为支持向量回归。考虑如下函数描述的回归问题训练样本为其中M表示训练样本的规模,xi是输入数据,yi是输出数据。非线性映射将输入数据映射到高维特征空间,即可转化为线性回归问题并进行求解。支持向量回归的目标函数为规则化最小风险R(w,b)=γ1MΣi=1MLϵ(yi,f(xi)+12wTw---(2)]]>其中Lϵ(yi,f(xi)=0,|yi-f(xi)|≤ϵ|yi-f(xi)|-ϵotherwise---(3)]]>Lε称为ε不敏感损失函数,即不对小于ε的误差进行惩罚,wTw/2为平滑项,γ是用于折中训练误差与模型平滑度的正则化常数。该问题可转化为如下优化命题minw,b,ξ*,ξR(w,ξ*,ξ)=12wTw+γ{Σi=1Mξi*+Σi=1Mξi}---(4)]]>约束为其中ξ,ξ*是松弛变量。通过在上述约束中引入拉格朗日乘子α*,α对该二次规划命题进行求解可得最终可得回归函数如下f(x)=Σi=1M(αi*-αi)K(x,xi)+b---(7)]]>其中K为满足Mercer条件的核函数2、模糊支持向量回归在很多实际应用场合,各训练样本的作用程度是不一样的。在回归问题中,某些训练样本要比其他样本更为重要。因此某些有意义的训练样本值得关注,而其他样本如噪声等即使可以严格拟合也无需关注。给定训练集及其模糊隶属度每个训练样本均有一个对应的模糊隶属度,该隶属度满足σ≤si≤1,其中σ是一大于0的足够小的常数。模糊隶属度是相应样本对于回归贡献程度的度量,参数ξi是误差的度量,siξi是带权重的误差,则优化命题转化为minw,b,ξ*,ξR(w,ξ*,ξ)=12wTw+γ{Σi=1Msiξi*+Σi=1Msiξi}---(9)]]>约束为再次应用拉格朗日法,可得对偶优化命题并进行求解maxαi,αi*W=-12Σi=1MΣj=1M(αi-αi*)(αj-αj*)K(xi,xj)-ϵΣi=1M(αi+αi*)+Σi=1Myi(αi-αi*)---(11)]]>约束为针对特定问题选择合适的模糊隶属度是模糊支持向量机建模的关键。尽管有很多方法可用于定义模糊隶属度函数,但目前还没有形成通用的规则。通常,模糊隶属度是根据各数据点到其所属类别的中心之间的距离来定义的。在线性可分问题中,这样定义模糊隶属度相当简单,但在处理线性不可分问题时,过程就不尽相同了。给定训练样本xi∈Q(i=1,2,…,l),Φ(xi)是输入空间到特征空间的映射。定义Φcen为类Q的中心Φcen=1lΣxi∈QΦ(xi)---(12)]]>可得某点到中心距离的平方为di2=||Φ(xi)-Φcen||2=Φ(xi)TΦ(xi)-2Φ(xi)TΦcen+ΦcenTΦcen=K(xi,xi)-2lΣxj∈QK(xi,xj)+1l2Σxi∈QΣxj∈QK(xi,xj)]]>而该类各点之间最大距离的平方为由此,可定义每个数据点xi对应的模糊隶属度为si=1-di2/(dr2+δ)---(15)]]>其中δ>0是一足够小的常数,用于避免si=0的情形。然而上述dr的定义在整个数据集分布相对不规则的情况下并不合理。方法一致性在建模过程中是提升模型可理解性的重要设计准则。支持向量数据描述起源于支持向量分类器,通过建立类的球形包络面可用来检测奇异点和噪声。本发明提出了特征空间中的支持向量数据描述模糊隶属度函数用于建立模糊支持向量机,以获得更好的效果。假设一个中心为a半径为R的超球体,代价函数定义如下:minR2+CΣi=1lξi---(16)]]>约束为其中ξi为松弛变量,参数C为惩罚因子,用于折中球体积大小与样本点的违反程度。超球体的最优分界面可通过拉格朗日法转换为对偶问题进行求解maxΣi=1lαiK(xi,xi)-Σi=1lΣj=1lαiαjK(xi,xj)---(17)]]>约束为其中αi不为0所对应的训练样本称为支持向量,用于构成超球体的边界。记a为特征空间中样本的中心,根据K-T条件a=∑αixi(18)半径定义为样本到特征空间中心距离的平方为di2=K(xi,xi)-2ΣjαjK(xj,xi)+ΣiΣjαiαjK(xi,xj)---(20)]]>根据定义,半径r为超球体中心到球边界任意支持向量的距离r=dsv(21)则每一输入样本的模糊隶属度为si=1-di2/(r2+δ)---(22)]]>其中δ>0是一足够小的常数,用于避免si=0的情形。3、模糊支持向量回归和标准支持向量回归对比实验训练样本与测试样本均来自于某实际丙烯聚合装置的历史记录数据库。数据首先进行滤波来去除异常情形以提高预报的质量。总共选取9个过程变量(t,p,l,a,f1,f2,f3,f4,f5)建立熔融指数预报模型。其中各变量分别是t为过程温度,p为压力,l为液位,a是气相氢气百分含量,f1,f2,f3为三股丙烯进料流量,f4为催化剂进料流量,f5为辅助催化剂进料流量。本实施例共收集了170组输入输出数据,其中训练样本集和测试样本集来自于同一批次聚丙烯产品生产过程,而推广样本集来自于另一批次。模型输出预报值与期望输出测量值之差称为误差,误差可通过多种不同的方式进行度量。本发明采用平均绝对误差(MAE),平均相对误差(MRE),均方根误差(RMSE),标准差(STD),Theil不等因数(TIC)作为误差的度量,分别定义如下:MAE=1NΣi=1N|yi-y^i|---(23)]]>MRE=1NΣi=1N|yi-y^i|yi---(24)]]>RMSE=1NΣi=1N(yi-y^i)2---(25)]]>TIC=Σi=1N(yi-y^i)2Σi=1Nyi2+Σi=1Ny^i2---(26)]]>其中yi和分别表示测量值与预报值。为了证明本发明提出方法的预报精度,表1列出了本发明模糊支持向量回归方法(SVDD-FSVR)与标准支持向量回归方法(SVR)的性能比较,数据表明模糊支持向量回归模型表现要优于标准支持向量回归模型。相比于后者的平均绝对误差0.0057,前者的平均绝对误差仅为0.0008,两者的均方根误差RMSE也证实了这一点。表1测试样本集误差图1和图2给出了测试样本集条件下,熔融指数测量值(Test)与模型输出预报值(Analysis)的比较,显然图1中基于模糊支持向量回归模型的聚丙烯融融指数预报值更为接近测量值,图2中基于标准支持向量回归模型熔融指数预报值与测量值的偏差较大。为了证明本发明提出方法的预报稳定性,表2列出了两种方法在推广集上的性能比较,可见推广集上的结果与测试集的比较结果一致。SVDD-FSVR的平均绝对误差为0.0011,相比于SVR的0.0049,下降了接近80%。在MRE,RMSE,TIC等度量指标的比较中也可以看到类似的结果。表2推广样本集误差图3和图4给出了推广样本集条件下,熔融指数推广值(Generalization)与模型输出预报值(Analysis)的比较,显然图3中基于模糊支持向量回归模型的聚丙烯融融指数预报值更为接近推广值,图4中基于标准支持向量回归模型熔融指数预报值与推广值的偏差较大。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1