一种流行性感冒预测方法及装置与流程
本发明涉及医学统计与数据处理技术领域,特别是涉及一种流行性感冒预测方法及装置。
背景技术:
流行性感冒是一种常见疾病,普通流行性感冒表现为畏寒高热,体温最高可达39℃~40℃,并伴随心率加快、血压偏高等症状。
一般人在感到身体不适时会到医院进行就诊,但此时患者已具有明显症状,也就是说此时患者已确认患感冒,医务人员只能根据患者具体病况给出相应的治疗手段,如吃药、打针等,因此病人还是会经历疼痛的患病过程和治疗过程,还是会影响到人的正常生活,或者耽搁工作。
基于此,提供一种有效的流行性感冒预测方法,具有重要的价值和意义。
技术实现要素:
本发明的目的是提供一种流行性感冒预测方法及装置,根据人体心率、体温、收缩压、舒张压及性别等对人体患流行性感冒做出预测,使人们能对感冒及时预防。
为实现上述目的,本发明提供如下技术方案:
一种流行性感冒预测方法,包括:
以人体的健康数据建立流行性感冒预测模型,所述健康数据包括心率、体温、收缩压、舒张压和性别,所述流行性感冒预测模型采用如下公式描述:
其中,P为患流行性感冒的概率,β0为常数,β1为心率影响系数,β2为体温影响系数,β3为收缩压影响系数,β4为舒张压影响系数,β5为性别影响系数,变量x1为心率值,变量x2为体温值,变量x3为收缩压值,变量x4为舒张压值,变量x5为性别;
随机采集m组人体数据,所述数据以(x1,x2,x3,x4,x5,y)描述,基于所述m组数据求解获得所述预测模型中的各影响系数,其中y表示被采集者的患病状态;
将待测人员的健康数据代入所述预测模型中,计算获得待测人员的预测结果。
可选地,采用混沌自适应粒子群算法求解获得所述预测模型中的各影响系数。
可选地,所述随机采集m组人体数据,所述数据以(x1,x2,x3,x4,x5,y)描述,基于所述m组数据求解获得所述预测模型中的各影响系数,包括:
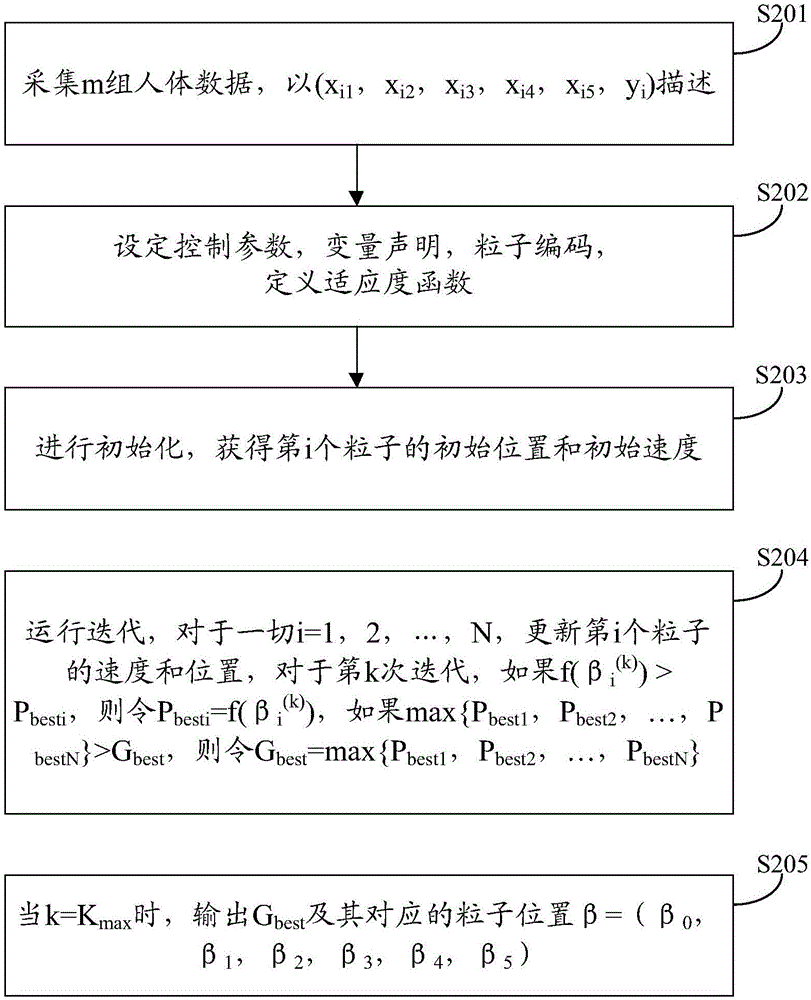
S201:采集m组人体数据,以(xi1,xi2,xi3,xi4,xi5,yi)描述,i=1,2,…,m;
S202:设定控制参数,包括设定群体规模N、最大迭代次数Kmax,其中N、Kmax均为大于零的正整数;
变量声明,包括:当前迭代次数k,第i个粒子的当前最优值Pbesti,当前全局最优值Gbest,惯性权重ω,学习因子c1和c2,随机数ξ、η,其中k为大于零的正整数;
粒子编码,对各影响系数β0、β1、β2、β3、β4、β5进行编码,第i个粒子的编码包括位置编码和速度编码,位置编码为βi=(βi0,βi1,βi2,βi3,βi4,βi5),速度编码为vi=(vi0,vi1,vi2,vi3,vi4,vi5);
定义适应度函数f(β),其中β=(β0,β1,β2,β3,β4,β5)为粒子位置;
S203:进行初始化,具体包括:令k=0,获得第i个粒子的初始位置βi(0)=(βi0(0),βi1(0),βi2(0),βi3(0),βi4(0),βi5(0)),初始速度vi=(vi0(0),vi1(0),vi2(0),vi3(0),vi4(0),vi5(0)),其中βij(0)、vij(0)是[-1000,1000]的随机数,j=1,2,3,4,5;
S204:运行迭代,对于一切i=1,2,…,N,更新第i个粒子的速度和位置,对于第k次迭代,如果f(βi(k))>Pbesti,则令Pbesti=f(βi(k)),如果max{Pbest1,Pbest2,…,PbestN}>Gbest,则令Gbest=max{Pbest1,Pbest2,…,PbestN};
S205:当k=Kmax时,输出Gbest及其对应的粒子位置β=(β0,β1,β2,β3,β4,β5)。
可选地,所述步骤S204还包括:对于第k次迭代,计算种群适应度:
f(βi(k))表示第i个粒子在迭代次数k时的适应度,f是适应度评价值,具体描述为:
判断是否σ2<σ2min,若否则运行第k+1次迭代,σ2min为预设的最小种群适应度,为正数。
可选地,若σ2<σ2min,则判定粒子群进入早熟收敛状态,对适应度最高的粒子进行随机扰动,具体包括:
S300:随机生成一个初始混沌向量,描述为z0=(z00,z01,z02,z03,z04,z05),其中z00、z01、z02、z03、z04、z05的取值范围均为[0,1];
S301:混沌迭代生成Q个混沌向量,第l个向量描述为zl=(zl0,zl1,zl2,zl3,zl4,zl5),l=1,2,,…,Q,0<Q<N,Q为正整数;
S302:产生Q个粒子,第l个粒子描述为βl=(βl0,βl1,βl2,βl3,βl4,βl5);
S303:对适应度最高的粒子进行随机扰动,描述为:
其中,zl′为施加随机扰动后(β0,β1,β2,β3,β4,β5)相对应的混沌向量,z*为最优值β*=(β0*,β1*,β2*,β3*,β4*,β5*)映射到[0,1]后形成的相应向量,zl为迭代l次后的混沌向量,l为混沌迭代次数,Q为最大混沌迭代次数,z*具体描述为:
βmax为粒子编码的最大值,βmin为粒子编码的最小值。
一种流行性感冒预测装置,包括:
信息采集模块,包括:
心率传感器,用于采集待测人员的心率信息;
血压传感器,用于采集待测人员的收缩压和舒张压;
体温传感器,用于采集待测人员的体温;
用户操作模块,用于接收用户输入的待测人员的性别信息;
数据分析模块,用于根据所采集的待测人员的健康数据,健康数据包括心率、体温、收缩压、舒张压和性别,通过所建立的流行性感冒预测模型计算获得待测人员患流行性感冒的概率,所述流行性感冒预测模型以如下公式描述:
其中,P为患流行性感冒的概率,β0为常数,β1为心率影响系数,β2为体温影响系数,β3为收缩压影响系数,β4为舒张压影响系数,β5为性别影响系数,变量x1为心率值,变量x2为体温值,变量x3为收缩压值,变量x4为舒张压值,变量x5为性别。
可选地,所述用户操作模块还用于输出和显示预测结果。
可选地,所述用户操作模块还用于接收和记录用户输入的待测人员的个人信息,包括姓名、性别、年龄及检测记录。
由上述技术方案可以看出,本发明所提供的一种流行性感冒预测方法,以人体的健康数据建立流行性感冒预测模型,所基于的健康数据包括心率、体温、收缩压、舒张压和性别,然后采集一定数量的样本数据,即随机采集一定数量的个体健康数据,每组数据包括被采集者的心率、体温、收缩压、舒张压、性别及患病状态,基于样本数据求解出模型中的各影响系数,确定预测模型的表达式。在预测流行性感冒时将待测人员的健康数据代入所述预测模型中,进而可计算获得待测人员患流行性感冒的概率,对其患流行性感冒做出预测。
本发明流行性感冒预测方法,根据人体心率、体温、收缩压、舒张压及性别等对人体患流行性感冒做出预测,得到患病概率,使人们能够对流行性感冒做出及时预防。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种流行性感冒预测方法的流程图;
图2为本发明实施例提供的求解预测模型中的各影响系数的方法流程图;
图3为本发明实施例提供的一种流行性感冒预测装置的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
本发明实施例提供的一种流行性感冒预测方法,包括:
以人体的健康数据建立流行性感冒预测模型,所述健康数据包括心率、体温、收缩压、舒张压和性别,所述流行性感冒预测模型采用如下公式描述:
其中,P为患流行性感冒的概率,β0为常数,β1为心率影响系数,β2为体温影响系数,β3为收缩压影响系数,β4为舒张压影响系数,β5为性别影响系数,变量x1为心率值,变量x2为体温值,变量x3为收缩压值,变量x4为舒张压值,变量x5为性别;
随机采集m组人体数据,所述数据以(x1,x2,x3,x4,x5,y)描述,基于所述m组数据求解获得所述预测模型中的各影响系数,其中y表示被采集者的患病状态;
将待测人员的健康数据代入所述预测模型中,计算获得待测人员的预测结果。
由上述内容可以看出,本发明实施例提供的流行性感冒预测方法,以人体的健康数据建立流行性感冒预测模型,所基于的健康数据包括心率、体温、收缩压、舒张压和性别,然后采集一定数量的样本数据,即随机采集一定数量的个体健康数据,每组数据包括被采集者的心率、体温、收缩压、舒张压、性别及患病状态,基于样本数据求解出模型中的各影响系数,确定预测模型的表达式。在预测流行性感冒时将待测人员的健康数据代入所述预测模型中,进而可计算获得待测人员患流行性感冒的概率,对其患流行性感冒做出预测。
本发明流行性感冒预测方法,根据人体心率、体温、收缩压、舒张压及性别等对人体患流行性感冒做出预测,得到患病概率,使人们能够对流行性感冒做出及时预防。
下面对本发明流行性感冒预测方法进行详细说明。
请参考图1,为本发明实施例提供的一种流行性感冒预测方法的流程图,该预测方法包括:
S1:以人体的健康数据建立流行性感冒预测模型,所述健康数据包括心率、体温、收缩压、舒张压和性别,所述流行性感冒预测模型采用如下公式描述:
其中,P为患流行性感冒的概率,β0为常数,β1为心率影响系数,β2为体温影响系数,β3为收缩压影响系数,β4为舒张压影响系数,β5为性别影响系数,变量x1为心率值,变量x2为体温值,变量x3为收缩压值,变量x4为舒张压值,变量x5为性别。
本实施例中,β0、β1、β2、β3、β4、β5的取值范围均为[-1000,1000]。其中,变量x1单位:次/分,取值范围:x1∈[0,200],变量x2单位:℃,取值范围:x2∈[0,50],变量x3单位:mmHg,取值范围:x3∈[0,200],变量x4单位:mmHg,取值范围:x4∈[0,200],对于变量x5,x5=0表示男性,x5=1表示女性。
S2:随机采集m组人体数据,所述数据以(x1,x2,x3,x4,x5,y)描述,基于所述m组数据求解获得所述预测模型中的各影响系数,其中y表示被采集者的患病状态。
本实施例中在求解预测模型中的各影响系数时采用混沌自适应粒子群算法求解,请参考图2,为本实施例提供的求解预测模型中的各影响系数的方法流程图,该求解方法包括以下步骤:
S201:采集m组人体数据,以(xi1,xi2,xi3,xi4,xi5,yi)描述,i=1,2,…,m;
所采集样本数据的数量要满足一定条件,以保证求解获得的模型影响系数的准确度。本实施例中m≥5000,m为正整数。
心率值xi1单位为次/分,取值范围[0,200],体温值xi2单位为℃,取值范围[0,50],收缩压值xi3单位为mmHg,取值范围[0,200],舒张压值xi4单位为mmHg,取值范围[0,200],xi5=0表示男性,xi5=1表示女性;yi表示被采集者的患病状态,当被采集者患病概率P≥50%时,yi=1,否则yi=0。
S202:设定控制参数,定义适应度函数,具体包括步骤:
S2020:设定控制参数,包括设定群体规模N、最大迭代次数Kmax,其中N、Kmax均为大于零的正整数;
S2021:变量声明,包括:当前迭代次数k,第i个粒子的当前最优值Pbesti,当前全局最优值Gbest,惯性权重ω,学习因子c1和c2,随机数ξ、η,其中k为大于零的正整数;
S2022:粒子编码,对各影响系数β0、β1、β2、β3、β4、β5进行编码,第i个粒子的编码包括位置编码和速度编码,位置编码为βi=(βi0,βi1,βi2,βi3,βi4,βi5),速度编码为vi=(vi0,vi1,vi2,vi3,vi4,vi5);
S2023:定义适应度函数f(β),其中β=(β0,β1,β2,β3,β4,β5)为粒子位置。
在进行粒子编码后,计算惯性权重ω、学习因子c1和c2,以及随机数ξ、η,然后定义适应度函数f(β)。
S203:进行初始化,具体包括:令k=0,获得第i个粒子的初始位置βi(0)=(βi0(0),βi1(0),βi2(0),βi3(0),βi4(0),βi5(0)),初始速度vi=(vi0(0),vi1(0),vi2(0),vi3(0),vi4(0),vi5(0)),其中βij(0)、vij(0)是[-1000,1000]的随机数,j=1,2,3,4,5。
S204:运行迭代,对于一切i=1,2,…,N,更新第i个粒子的速度和位置,对于第k次迭代,如果f(βi(k))>Pbesti,则令Pbesti=f(βi(k)),如果max{Pbest1,Pbest2,…,PbestN}>Gbest,则令Gbest=max{Pbest1,Pbest2,…,PbestN};
S205:当k=Kmax时,输出Gbest及其对应的粒子位置β=(β0,β1,β2,β3,β4,β5)。
在迭代次数达到最大迭代次数时,输出得到的Gbest以及对应的粒子位置β=(β0,β1,β2,β3,β4,β5),则求解得到预测模型中的各影响系数。
S3:将待测人员的健康数据代入所述预测模型中,计算获得待测人员的预测结果。
在基于采集的人体健康数据求解获得预测模型中的影响系数β0、β1、β2、β3、β4、β5后,将影响系数代入预测模型中,则该预测模型的表达式确定,在进行预测时,将待测人员的健康数据,包括心率、体温、收缩压、舒张压、性别等信息数据代入预测模型表达式中,则可计算获得待测人员患流行性感冒的预测结果。
因此,本实施例所述流行性感冒预测方法,以人体的健康数据,包括心率、体温、收缩压、舒张压及性别建立流行性感冒预测模型,然后采集一定数量个体的数据,基于采集的样本数据采用混沌自适应粒子群算法求解获得预测模型中的各影响系数,得到预测模型的表达式,进而通过该预测模型对待测人员患流行性感冒作出预测。本实施例流行性感冒预测方法,根据人体心率、体温、收缩压、舒张压及性别等对人体患流行性感冒做出预测,得到患病概率,使人们能够对流行性感冒做出及时预防。
进一步优选的,本实施例中在采用混沌自适应粒子群算法求解模型的影响系数时,在上述步骤S204中,当一个粒子搜索到一个局部最优解时,所有粒子受到这个最优解的吸引,容易快速聚集到这个局部最优解的附近,从而出现早熟状态,那么就会很难出现更好的适应度值,难以搜索到全局最优。鉴于此,在本实施例求解方法中,所述步骤S204还包括:
对于第k次迭代,计算种群适应度:
f(βi(k))表示第i个粒子在迭代次数k时的适应度,f是适应度评价值,具体描述为:
判断是否σ2<σ2min,若否则运行第k+1次迭代,σ2min为预设的最小种群适应度,为正数。
当σ2<σ2min,判定粒子群进入早熟收敛状态;当σ2≥σ2min,表明粒子群没有进入早熟收敛状态,此时可进行k+1次迭代。设定标准判断粒子群是否进入早熟收敛状态,便于搜索到全局最优解,以提高求解结果的准确度。
当判断粒子群进入早熟收敛状态,为了增强全局最优解的搜索性能,经过较少的迭代次数找到最优解,可以在运行迭代中选取适应性较高的优良粒子进行微小混沌扰动操作,并对适应度最高的粒子进行随机扰动,以增加粒子搜索全局最优解的能力。
具体为,在上述步骤中当判断σ2<σ2min,则判定粒子群进入早熟收敛状态,对适应度最高的粒子进行随机扰动,具体方法包括以下步骤:
S300:随机生成一个初始混沌向量,描述为z0=(z00,z01,z02,z03,z04,z05),其中z00、z01、z02、z03、z04、z05的取值范围均为[0,1];
S301:混沌迭代生成Q个混沌向量,第l个向量描述为zl=(z10,zl1,zl2,zl3,zl4,zl5),l=1,2,,…,Q,0<Q<N,Q为正整数;
S302:产生Q个粒子,第l个粒子描述为βl=(βl0,βl1,βl2,βl3,βl4,βl5);
S303:对适应度最高的粒子进行随机扰动,描述为:
其中,zl′为施加随机扰动后(β0,β1,β2,β3,β4,β5)相对应的混沌向量,z*为最优值β*=(β0*,β1*,β2*,β3*,β4*,β5*)映射到[0,1]后形成的相应向量,zl为迭代l次后的混沌向量,l为混沌迭代次数,Q为最大混沌迭代次数,z*具体描述为:
βmax为粒子编码的最大值,这里取值为1000;βmin为粒子编码的最小值,这里取值为-1000。
对适应度最高的粒子进行随机扰动后进行下一次迭代。
因此,本实施例求解方法中,通过设定标准判断粒子群是否进入早熟收敛状态,在判断粒子群进入早熟收敛状态时,选取适应性较高的优良粒子进行微小混沌扰动操作,并对适应度最高的粒子进行随机扰动,以增加粒子搜索全局最优解的能力,使获得的求解结果更准确。
相应的,本发明实施例还提供一种流行性感冒预测装置,请参考图3,装置包括:
信息采集模块400,包括:
心率传感器401,用于采集待测人员的心率信息;
血压传感器402,用于采集待测人员的收缩压和舒张压;
体温传感器403,用于采集待测人员的体温;
用户操作模块410,用于接收用户输入的待测人员的性别信息;
数据分析模块420,用于根据所采集的待测人员的健康数据,健康数据包括心率、体温、收缩压、舒张压和性别,通过所建立的流行性感冒预测模型计算获得待测人员患流行性感冒的概率,所述流行性感冒预测模型以如下公式描述:
其中,P为患流行性感冒的概率,β0为常数,β1为心率影响系数,β2为体温影响系数,β3为收缩压影响系数,β4为舒张压影响系数,β5为性别影响系数,变量x1为心率值,变量x2为体温值,变量x3为收缩压值,变量x4为舒张压值,变量x5为性别。
本发明实施例提供的流行性感冒预测装置,包括信息采集模块、用户操作模块和数据分析模块,其中信息采集模块包括心率传感器、血压传感器和体温传感器,通过用户操作模块可输入待测人员的信息数据。本实施例流行性感冒预测装置,以人体的健康数据建立流行性感冒预测模型,所基于的健康数据包括心率、体温、收缩压、舒张压和性别,在对待测人员检测时,通过信息采集模块获得待测人员的心率、收缩压、舒张压、体温等信息,并输入性别,数据分析模块基于建立的预测模型计算给出待测人员患流行性感冒的概率。
因此,本发明流行性感冒预测装置,根据人体心率、体温、收缩压、舒张压及性别等对人体患流行性感冒做出预测,得到患病概率,使人们能够对流行性感冒做出及时预防。
本实施例中,所述用户操作模块还用于输出和显示预测结果。
所述用户操作模块还用于接收和记录用户输入的待测人员的个人信息,包括姓名、性别、年龄及检测记录。当用户需要查询相关人员的检测信号时,可以通过用户操作模块相应查找。
以上对本发明所提供的一种流行性感冒预测方法及装置进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!