用于手势指点翻译的方法、装置及电子设备与流程
本发明涉及电子设备技术领域,尤其是指一种用于手势指点翻译的方法、装置及电子设备。
背景技术:
无论生活还是学习,将一种语言的文字翻译为另一种语言的文字为经常会遇到的情况,例如在阅读英文说明书和外文书籍资料时或者在国外观看英文指示牌时,时常会碰到不认识的英文单词需要了解释义;甚至有时候在阅读中文资料时,有时也会有不认识的字,需要了解读音。
目前,在上述情形下碰到需要翻译、解释的文字,通常采取的方法是自行使用词典进行查询,或者使用手机等具有图像摄取装置及图像数据处理功能的智能电子设备,对需要翻译的文字区域进行图像摄取,利用ocr手段从包含文字的图像中识别出文字,并将文字的翻译结果显示在显示屏上。
然而,上述两种方式中,通过使用词典查询的方式,虽然可以保证文字查询结果的准确,但却存在需要用户手动输入文字,操作比较麻烦、费时的缺点。
通过使用手机等智能电子设备拍摄文字图像进行翻译的方式,虽然操作上简便,无需用户手动输入文字,但是目前常见的图像文字翻译方式通常是对所拍摄图像中所包含的所有文字进行翻译,一方面耗时比较长,另一方面由于用户往往仅需要翻译个别文字,一些常见高频简单词汇是不需要翻译的,因此致使翻译结果没有针对性,同时还造成了计算资源的浪费。
此外,采用上述两种方式的任何一种,都需要使用者的关注点跳出正在阅读的文字,转而利用其它工具进行翻译操作,无疑打断了自然流畅的阅读体验,存在违背人们阅读习惯的弊端。
技术实现要素:
本发明技术方案的目的是提供一种用于手势指点翻译的方法、装置及电子设备,解决现有的文字翻译方式造成阅读体验不佳的问题。
本发明提供一种用于手势指点翻译的方法,其中,包括:
获取阅读文字视野范围内的当前图像;
检测所述当前图像中是否存在指示文字信息的预定操作手势;
当确定所述当前图像中存在所述预定操作手势时,识别所述当前图像中所述预定操作手势所指示的文字;
获取所述文字关于预设语言的翻译信息;
呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
优选地,上述所述的方法,其中,在所述显示界面同时显示所述当前图像和所述翻译信息的步骤中:
使所述当前图像中所述预定操作手势所指示的文字与其他文字区分显示。
优选地,上述所述的方法,其中,在所述显示界面同时显示所述当前图像和所述翻译信息的步骤中:
在所述当前图像中,确定所述文字所在文本行与上方文本行之间的空白区域;
在所述空白区域输出显示所述翻译信息。
优选地,上述所述的方法,其中,所述在所述当前图像中,确定所述文字所在文本行与上方文本行之间的空白区域的步骤包括:
确定所述空白区域的高度和在所述当前图像上的位置;
确定所述文字在所在文本行的起始位置和终止位置;
根据所述空白区域的高度,确定所述翻译信息输出的字体大小;
根据所述空白区域在所述当前图像上的位置和所述文字在所在文本行的起始位置和终止位置,计算所述翻译信息在所述空白区域显示时的中心位置;
其中,在所述空白区域输出显示所述翻译信息的步骤包括:
使所输出的所述翻译信息以所确定的字体大小输出,且中心位于所述中心位置处。
优选地,上述所述的方法,其中,在所述空白区域输出显示所述翻译信息的步骤之前,所述方法还包括:
确定所述文字所在文本行相对于水平方向的倾斜角度a;
确定所述文字的字符相对于竖直方向的倾斜角度b;
其中,在所述空白区域输出显示所述翻译信息的步骤还包括:
使所输出的所述翻译信息所构成的每一文本行相对于水平方向的倾斜角度为a,以及使所述输出的所述翻译信息的每一字符相对于竖直方向的倾斜角度为b。
优选地,上述所述的方法,其中,在所述显示界面同时显示所述当前图像和所述翻译信息的步骤包括:
在所述显示界面的第一区域显示所述当前图像,同时在所述显示界面的第二区域显示所述翻译信息。
优选地,上述所述的方法,其中,在所述显示界面同时显示所述当前图像和所述翻译信息的步骤之前,所述方法还包括:
根据预先设定的显示区域设定信息,确定所述第一区域和所述第二区域。
优选地,上述所述的方法,其中,在所述显示界面同时显示所述当前图像和所述翻译信息的步骤中:
确定所述当前图像中所述文字的位置;
根据所述当前图像中所述文字的位置,确定气泡显示区域的弹出位置坐标;
在整个显示界面上显示所述当前图像,并在所述当前图像上叠加一位于所述文字上方、且从所述弹出位置坐标弹出的气泡显示区域,使所述翻译信息在所述气泡显示区域内显示。
优选地,上述所述的方法,其中,所述根据所述当前图像中所述文字的位置,确定气泡显示区域的弹出位置坐标的步骤包括:
根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的起始位置和终止位置;
根据所述文字在所在文本行的起始位置和终止位置,确定所述文字在水平方向的中心线坐标,将所述水平方向的中心线坐标设定为所述弹出位置坐标的水平方向坐标;
根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的上沿起始位置,将所述文字在所在文本行的上沿起始位置设定为所述弹出位置坐标的竖直方向坐标。
优选地,上述所述的方法,其中,所述使所述当前图像中所述预定操作手势所指示位置的文字与其他文字区分显示的步骤包括:
确定待翻译所述文字所在文本行的上沿起始位置和下沿终止位置;
确定待翻译所述文字在所述文本行的起始位置和终止位置;
确定待翻译所述文字所在文本行与水平线所成的夹角a;
确定待翻译所述文字的字符相对于竖直方向的倾斜角度b;
确定边界范围分别为上沿起始位置、下沿终止位置、起始位置和终止位置,相对于水平方向的倾斜角度为a、错切角度为b的平行四边形区域为待翻译所述文字的显示区域;
使所述显示区域中的文字与其他文字区分显示。
优选地,上述所述的方法,其中,所述检测所述当前图像中是否存在指示文字信息的预定操作手势的步骤包括:
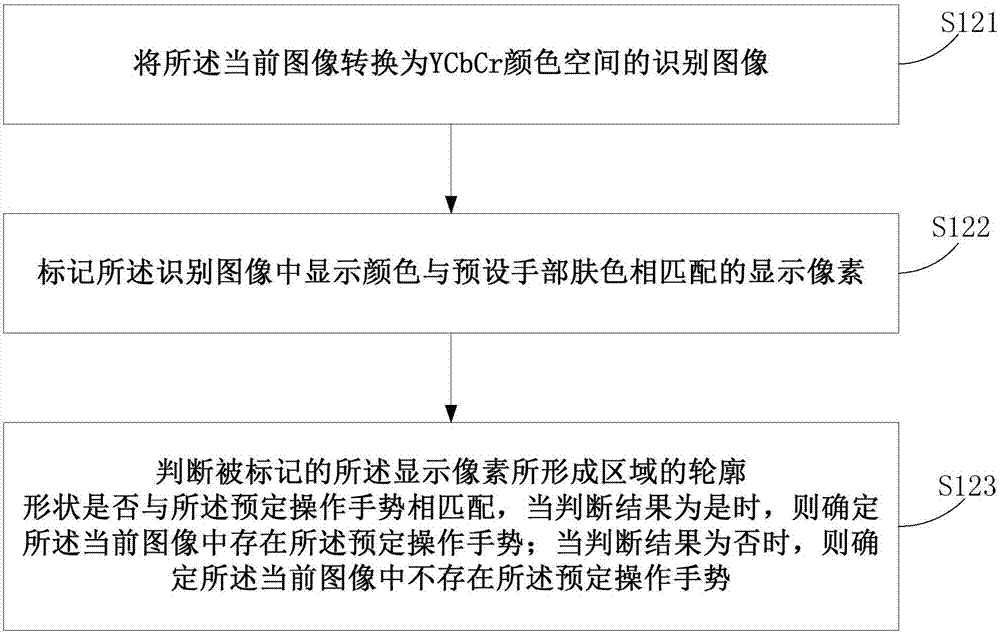
将所述当前图像转换为ycbcr颜色空间的识别图像;
标记所述识别图像中显示颜色与预设手部肤色相匹配的显示像素;
判断被标记的所述显示像素所形成区域的轮廓形状是否与所述预定操作手势相匹配,当判断结果为是时,则确定所述当前图像中存在所述预定操作手势;当判断结果为否时,则确定所述当前图像中不存在所述预定操作手势。
优选地,上述所述的方法,其中,所述识别所述当前图像中所述预定操作手势所指示的文字的步骤包括:
确定所述预定操作手势对所述文字信息的指示位置;
截取所述当前图像中所述指示位置处预定范围的图像区域,获得截取图像;
对所述截取图像进行预处理,获得所述截取图像的二值图像;
对所述二值图像进行校正处理,获得包括待翻译所述文字的待读取图像;
对所述待读取图像中的字符进行分割,提取所分割出的每一字符;
识别每一所述字符,形成为所述文字。
优选地,上述所述的方法,其中,所述对所述二值图像进行校正处理,获得包括待翻译所述文字的待读取图像的步骤包括:
对所述二值图像进行图像倾斜校正,将所述二值图像中的文本行旋转至水平,获得校正后图像;
对所述校正后图像进行文本行分割,截选仅包括待翻译所述文字的文本图像;
对所述文本图像进行错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像。
优选地,上述所述的方法,其中,所述对所述二值图像进行图像倾斜校正,将所述二值图像中的文本行旋转至水平,获得校正后图像的步骤包括:
将所述二值图像在预定角度范围内进行不同角度旋转;
将每次旋转后所述二值图像在竖直方向上进行投影;
计算每次旋转后所述二值图像在竖直方向上进行投影时,所获得投影数列的标准差;
确定所述标准差最大时所对应旋转后所述二值图像,为所述校正后图像。
优选地,上述所述的方法,其中,所述对所述文本图像进行水平方向的错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像的步骤包括:
将所述文本图像在预定正切值范围内进行水平方向、不同正切值的错切变换;
将每次进行错切变换后所述文本图像在水平方向上进行投影;
计算每次进行错切变换后所述文本图像在水平方向上进行投影时,所获得投影数列的标准差;
确定所述标准差最大时所对应错切变换后所述文本图像,为所述待读取图像。
优选地,上述所述的方法,其中,当所述待读取图像中的字符为中文时,所述对所述待读取图像中的字符进行分割的步骤包括:
将所述待读取图像在水平方向上进行投影;
根据投影结果,确定所述待读取图像中的字符区域和背景区域;
设定被确定为背景的对应区域为相邻字符的初步分割位置;
对所述初步分割位置进行筛选,使每一字符的宽度为固定值,获得最后确定分割位置。
优选地,上述所述的方法,其中,当所述待读取图像中的字符为英文时,所述对所述待读取图像中的字符进行分割的步骤包括:
确定所述待读取图像中用于表示字符设置范围的第一水平基线和第二水平基线;
将所述待读取图像中处于所述第一水平基线和所述第二水平基线之间的图像在水平方向上进行投影;
根据投影结果,确定所述待读取图像中的字符区域和背景区域;
设定被确定为背景的对应区域为相邻字符的初步分割位置;
根据所述待读取图像中每一连通域的大小和位置,对所述初步分割位置进行筛选,获得最后确定分割位置。
本发明另一方面提供一种用于手势指点翻译的装置,其中,包括:
图像获取模块,用于获取阅读文字视野范围内的当前图像;
图像检测模块,用于检测所述当前图像中是否存在指示文字信息的预定操作手势;
图像识别模块,用于当确定所述当前图像中存在所述预定操作手势时,识别所述当前图像中所述预定操作手势所指示的文字;
翻译模块,用于获取所述文字关于预设语言的翻译信息;
输出模块,用于呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
优选地,上述所述的装置,其中,所述输出模块包括:
区别显示单元,用于使所述当前图像中所述预定操作手势所指示位置的文字与其他文字区分显示。
优选地,上述所述的装置,其中,所述输出模块包括:
空白区域确定单元,用于确定在所述当前图像中,所述文字所在文本行与上方文本行之间的空白区域;
第一显示单元,用于在所述空白区域输出显示所述翻译信息。
优选地,上述所述的装置,其中,所述空白区域确定单元包括:
第一信息获取子单元,用于确定所述空白区域的高度和在所述当前图像上的位置;
第二信息获取子单元,用于确定所述文字在所在文本行的起始位置和终止位置;
第一计算子单元,用于根据所述空白区域的高度,确定所述翻译信息输出的字体大小;
第二计算子单元,用于根据所述空白区域在所述当前图像上的位置和所述文字在所在文本行的起始位置和终止位置,计算所述翻译信息在所述空白区域显示时的中心位置;
其中,所述第一显示单元具体用于:
使所输出的所述翻译信息以所确定的字体大小输出,且中心位于所述中心位置处。
优选地,上述所述的装置,其中,所述空白区域确定单元还包括:
第三信息获取子单元,用于确定所述文字所在文本行相对于水平方向的倾斜角度a;
第四信息获取子单元,用于确定所述文字的字符相对于竖直方向的倾斜角度b;
其中,所述第一显示单元还用于:
使所输出的所述翻译信息所构成每一文本行相对于水平方向的倾斜角度为a,以及使所述输出的所述翻译信息的每一字符相对于竖直方向的倾斜角度为b。
优选地,上述所述的装置,其中,所述输出模块包括:
第二显示单元,用于在所述显示界面的第一区域显示所述当前图像,同时在所述显示界面的第二区域显示所述翻译信息。
优选地,上述所述的装置,其中,所述输出模块还包括:
显示区域确定单元,用于根据预先设定的显示区域设定信息,确定所述第一区域和所述第二区域。
优选地,上述所述的装置,其中,所述输出模块包括:
文字位置计算单元,用于确定所述当前图像中所述文字的位置;
弹出位置计算单元,用于根据所述当前图像中所述文字的位置,确定一气泡显示区域的弹出位置坐标;
第三显示单元,用于在整个显示界面上显示所述当前图像,并在所述当前图像上叠加一位于所述文字上方、且从所述弹出位置坐标弹出的气泡显示区域,使所述翻译信息在所述气泡显示区域内显示。
优选地,上述所述的装置,其中,所述弹出位置计算单元包括:
第三计算子单元,用于根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的起始位置和终止位置;
第四计算子单元,用于根据所述文字在所在文本行的起始位置和终止位置,确定所述文字在水平方向的中心线坐标,将所述水平方向的中心线坐标设定为所述弹出位置坐标的水平方向坐标;
第五计算子单元,用于根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的上沿起始位置,将所述文字在所在文本行的上沿起始位置设定为所述弹出位置坐标的竖直方向坐标。
优选地,上述所述的装置,其中,所述区别显示单元包括:
第六计算子单元,用于确定待翻译所述文字所在文本行的上沿起始位置和下沿终止位置;
第七计算子单元,用于确定待翻译所述文字在所述文本行的起始位置和终止位置;
第八计算子单元,确定待翻译所述文字所在文本行与水平线所成的夹角a;
第九计算子单元,用于确定待翻译所述文字的字符相对于竖直方向的倾斜角度b;
区别范围确定子单元,用于确定边界范围分别为上沿起始位置、下沿终止位置、起始位置和终止位置,相对于水平方向的倾斜角度为a、错切角度为b的平行四边形区域为待翻译所述文字的显示区域;
输出子单元,用于使所述显示区域中的文字与其他文字区分显示。
优选地,上述所述的装置,其中,所述图像检测模块包括:
图像转换单元,用于将所述当前图像转换为ycbcr颜色空间的识别图像;
图像标记单元,用于标记所述识别图像中显示颜色与预设手部肤色相匹配的显示像素;
分析单元,用于判断被标记的所述显示像素所形成区域的轮廓形状是否与所述预定操作手势相匹配,当判断结果为是时,则确定所述当前图像中存在所述预定操作手势;当判断结果为否时,则确定所述当前图像中不存在所述预定操作手势。
优选地,上述所述的装置,其中,所述图像识别模块包括:
位置确定单元,用于确定所述预定操作手势对所述文字信息的指示位置;
图像截取单元,用于截取所述当前图像中所述指示位置处预定范围的图像区域,获得截取图像;
图像处理单元,用于对所述截取图像进行预处理,获得所述截取图像的二值图像;
图像校正单元,用于对所述二值图像进行校正处理,获得仅包括待翻译所述文字的待读取图像;
图像分割单元,用于对所述待读取图像中的字符进行分割,提取所分割出的每一字符;
字符识别单元,用于识别每一所述字符,形成为所述文字。
优选地,上述所述的装置,其中,所述图像校正单元包括:
文本行校正子单元,用对所述二值图像进行图像倾斜校正,将所述二值图像中的文本行旋转至水平,获得校正后图像;
文本行分割子单元,用于对所述校正后图像进行文本行分割,截选仅包括待翻译所述文字的文本图像;
字符校正子单元,用于对所述文本图像进行错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像。
优选地,上述所述的装置,其中,所述文本行校正子单元包括:
角度旋转结构,用于将所述二值图像在预定角度范围内进行不同角度旋转;
第一投影计算结构,用于将每次旋转后所述二值图像在竖直方向上进行投影;
第一标准差计算结构,用于计算每次旋转后所述二值图像在竖直方向上进行投影时,所获得投影数列的标准差;
第一确定结构,用于确定所述标准差最大时所对应旋转后所述二值图像,为所述校正后图像。
优选地,上述所述的装置,其中,所述字符校正子单元包括:
错切变换结构,用于将所述文本图像在预定正切值范围内进行水平方向、不同正切值的错切变换;
第二投影计算结构,用于将每次进行错切变换后所述文本图像在水平方向上进行投影;
第二标准差计算结构,用于计算每次进行错切变换后所述文本图像在水平方向上进行投影时,所获得投影数列的标准差;
第二确定结构,用于确定所述标准差最大时所对应错切变换后所述文本图像,为所述待读取图像。
优选地,上述所述的装置,其中,当所述待读取图像中的字符为中文时,所述图像分割单元包括:
第一投影子单元,用于将所述待读取图像在水平方向上进行投影;
区域确定子单元,用于根据投影结果,确定所述待读取图像中的字符区域和背景区域;
第一初步分割子单元,用于设定被确定为背景的对应区域为相邻字符的初步分割位置;
第一最后分割子单元,用于对所述初步分割位置进行筛选,使每一字符的宽度为固定值,获得最后确定分割位置。
优选地,上述所述的装置,其中,当所述待读取图像中的字符为英文时,所述图像分割单元包括:
基线确定子单元,用于确定所述待读取图像中用于表示字符设置范围的第一水平基线和第二水平基线;
第二投影子单元,用于将所述待读取图像中处于所述第一水平基线和所述第二水平基线之间的图像在水平方向上进行投影;
区域确定子单元,用于根据投影结果,确定所述待读取图像中的字符区域和背景区域;
第二初步分割子单元,用于设定被确定为背景的对应区域为相邻字符的初步分割位置;
第二最后分割子单元,用于根据所述待读取图像中每一连通域的大小和位置,对所述初步分割位置进行筛选,获得最后确定分割位置。
本发明另一方向还提供一种电子设备,其中,包括:
至少一个处理器;以及
与所述至少一个处理器连接的存储器;其中,
所述存储器存储有可被所述至少一个处理器执行的指令程序,所述指令程序被所述至少一个处理器执行,以使所述至少一个处理器用于:
获取阅读文字视野范围内的当前图像;
检测所述当前图像中是否存在指示文字信息的预定操作手势;
当确定所述当前图像中存在所述预定操作手势时,识别所述当前图像中所述预定操作手势所指示的文字;
获取所述文字关于预设语言的翻译信息;
呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
本发明具体实施例上述技术方案中的至少一个具有以下有益效果:
通过用户阅读过程中实时地拍摄获得所阅读视野范围内情景的当前图像,确定用户当前阅读时是否作出了指示所阅读文字信息的其中一文字被翻译的预定操作手势,并实时地识别当前图像中的预定操作手势所指示的文字,并对该文字进行翻译和输出,使用户在进行阅读的同时只需要作出预定操作手势,指示需要被翻译文字,即能够实时获得翻译信息,不需要跳出阅读过程,从而能够获得更好的阅读体验。
附图说明
图1表示本发明实施例所述用于手势指点翻译的方法的流程示意图;
图2表示图1中步骤s120的流程示意图;
图3表示图1中步骤s130的流程示意图;
图4表示图3中步骤s134的流程示意图;
图5表示本发明实施例所述用于手势指点翻译的装置的结构组成示意图;
图6表示本发明实施例所述装置中输出模块的结构组成示意图;
图7表示本发明实施例所述装置中图像检测模块的结构组成示意图;
图8表示本发明实施例所述装置中图像识别模块的结构组成示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参阅图1所示,本发明第一实施例所述用于手势指点翻译的方法,包括步骤:
s110,获取阅读文字视野范围内的当前图像;
具体地,该步骤中可以通过一摄像头拍摄获得用户阅读一文字信息时所阅读视野范围内情景的当前图像。该文字信息可以为一纸制文档上所显示文字,也可以为一电子设备的显示屏幕上显示的文字。此外,在用户阅读文字信息的过程中,可以实时拍摄获得所阅读视野范围内情景的当前图像。
此外,本发明实施例中所提及的“阅读文字视野范围内的当前图像”是指,用于显示用户阅读一文字信息时所阅读视野范围内情景的当前图像,所拍摄的当前图像应该能够显示用户当前正在阅读的区域以及用户在该区域内所做出的操作手势,且所拍摄获得的图像应该清晰、易于识别。
s120,检测所述当前图像中是否存在指示文字信息的预定操作手势;
通过检测当前图像中是否存在指示文字信息的预定操作手势,确定用户当前在阅读过程中是否作出了指示其中的部分文字需要被翻译的指示动作。
具体地,该预定操作手势可以由用户预先输入,且并不限于为一种,但无论为哪一种,该预定操作手势必须能够具有指示作用,能够指示出文字信息上的一个位置。例如,该预定操作手势可以为:右手食指伸出,右手的其他手指呈握拳的状态,通过伸出的右手食指的指示作用,能够定位出预定操作手势所指示文字信息上的一位置,确定该位置处的文字为用户所指示的需要被翻译的文字;又例如:该预定操作手势也可以为:右手食指和中指同时伸出,右手的其他手指呈握拳的状态,且右手食指和中指呈分离状态,通过伸出的右手食指和中指的指示作用,能够定位出该预定操作手势所指示文字信息上的两个位置,确定该两个位置处的文字为用户所指示需要被翻译的文字。
s130,当确定所述当前图像中存在所述预定操作手势时,识别所述当前图像中所述预定操作手势所指示的文字;
当通过上述的步骤s120,确定所获得的当前图像中存在预定操作手势后,通过该步骤s130,进一步确定预定操作手势所指示的位置并识别出所指示位置的文字,以确定用户需要被翻译的文字。
s140,获取所述文字关于预设语言的翻译信息;
该步骤中,通过预存的字典信息库,根据所识别出的文字,确定该文字关于预设语言的翻译信息。
具体地,该文字需要被翻译的预设语言可以在阅读之前进行预先输入,例如当前进行英文阅读,需要将英文翻译为中文时,该预设语言为中文,在阅读之前可以先输入需要被翻译成为的该预设语言的类型,以在阅读过程中,查找相应的字典信息典,对预定操作手势所指示位置的文字进行实时翻译,获得翻译信息。
s150,呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
进一步,较佳地,在所述显示界面同时显示所述当前图像和所述翻译信息的步骤中:
使所述当前图像中所述预定操作手势所指示位置的文字与其他文字区分显示。
例如,使预定操作手势所指示位置的文字以不同颜色显示、颜色加深显示、高亮显示或者外围添加边框显示等等,只要能够使所指示位置的文字与其他文字进行区分,使用户对所翻译的文字一目了然,以便于核对。
采用上述步骤的用于手势指点翻译的方法,通过用户阅读过程中实时地拍摄获得所阅读视野范围内情景的当前图像,确定用户当前阅读时是否作出了指示所阅读文字信息的其中一文字被翻译的预定操作手势,并实时地识别当前图像中的预定操作手势所指示的文字,对该文字进行翻译和输出,使用户在进行阅读的同时只需要作出预定操作手势,指示需要被翻译文字,即能够实时获得翻译信息,不需要跳出阅读过程,从而能够获得更好的阅读体验。
进一步,当输出翻译信息时,通过在所述显示界面同时显示所述当前图像和所述翻译信息的方式,使用户可以对比阅览被翻译文字和相对应的翻译信息,从而更便于查看。
以下结合附图对本发明所述用于手势指点翻译的方法中,各步骤的具体实施方式进行详细说明。
具体地,结合图2,上述步骤s120中,用于检测所述当前图像中是否存在指示文字信息的预定操作手势的步骤包括:
s121,将所述当前图像转换为ycbcr颜色空间的识别图像;
通常摄像头拍摄获得的图像为rgb图像,通过将rgb图像转换为ycbcr颜色空间,使当前图像转换为二值图像,只具有两个灰阶值的像素,以方便后续的手部区域的识别。
也即,通过该步骤s121,使当前图像转换后的识别图像形成为二值图像。
s122,标记所述识别图像中显示颜色与预设手部肤色相匹配的显示像素;
该步骤中,可以利用肤色椭圆模型检测方式或者高斯模型方式,对识别图像中的各个显示像素进行检测识别,将显示颜色与手部肤色相匹配的显示像素标记为第一值;将显示颜色与手部肤色不相匹配的显示像素标记为第二值。
本实施例中,将显示颜色与手部肤色相匹配的显示像素标记为1,将显示颜色与手部肤色不相匹配的显示像素标记为0,这也是通常图像处理中对二值图像的标记方式。
s123,判断被标记的所述显示像素所形成区域的轮廓形状是否与所述预定操作手势相匹配,当判断结果为是时,则确定所述当前图像中存在所述预定操作手势;当判断结果为否时,则确定所述当前图像中不存在所述预定操作手势。
可以理解的是,在二值图像中,属于同一部件的显示像素的颜色相同,依据上述方式,属于同一部件、多个颜色相同的显示像素在进行标记时,被标记的数值相同,且相互连接,所形成区域为连通域。
本发明实施例中,在进行操作手势匹配之前,为准确识别与预定操作手势相匹配的连通域,较佳地,需要根据当前图像的分辨率及手部区域大小等先验信息,设置合适大小的滤波模板,利用二值图像开操作滤去小的肤色区块,也即滤去小面积、显示标记为1的连通域,之后利用滤去一部分连通域之后的识别图像中、显示标记为1的连通域与预定操作手势相匹配,确定当前图像中是否存在预定操作手势。
此外,较佳地,当识别图像中存在多个显示标记为1的连通域时,则对每一连通域进行标号,并记录每一连通域的位置。
具体地,本发明实施例所述方法的步骤s123中,判断被标记所述显示像素所形成区域的轮廓形状是否与所述预定操作手势相匹配的步骤包括:
获取所述预定操作手势的图像模版;
将所述连通域的形状与所述图像模版的形状进行匹配,当匹配一致时,则确定所述当前图像中存在所述预定操作手势;当匹配不一致时,则确定所述当前图像中不存在所述预定操作手势。
采用上述的方式,通过将连通域的形状与预定操作手势的图像模版进行匹配的方式,能够确定当前图像中是否存在预定操作手势。
此外,上述步骤s123中,所述判断被标记所述显示像素所形成区域的轮廓形状是否与所述预定操作手势相匹配的步骤,也可以包括:
确定预定机器学习模型中表征所述预定操作手势的特定特征;
采用所述特定特征对所述预定机器学习模型进行训练,获得离线训练数值;
根据所述离线训练数值确定所述预定机器学习模型的影响因素;
获取所述当前图像中被标记显示像素所形成区域的轮廓形状的特定特征,将所述轮廓形状的特定特征输入到所述预定机器学习模型中,根据所述预定机器学习模型的输出,判断所述特定特征是否与所述操作手势相匹配。
更具体地,上述机器学习的方式包括:
第一步:选择合适的机器学习模型为预定机器学习模型,所述预定机器学习模型可以是神经网络、逻辑回归、支持向量机等;
第二步:获取采用多个所述预定操作手势的图像作为训练数据集,也即获取能够表征预定操作手势的特定特征,(例如预定操作手势的二值图像或灰度图像或梯度向量直方图),对所述预定机器学习模型进行训练,确定所述机器学习模型中相关系数的值,也即为机器学习模型参数;以及根据所述离线训练数值确定所述预定机器学习模型的影响因素;
第三步:获取所述当前图像中被标记显示像素所形成区域的轮廓形状的轮廓特征,将轮廓特征输入到训练好、包括所述机器学习模型参数的所述预定机器学习模型中;
第四步:根据所述预定机器学习模型的输出逻辑数值来确定所述轮廓形状是否预定操作手势相匹配,例如:当所述机器学习模型输出逻辑数值为1时,则确定所述轮廓形状与预定操作手势相匹配;当所述机器学习模型输出逻辑数值为0时,则确定所述轮廓形状不与所述预定操作手势相匹配,由此能够确定当前图像中是否存在预定操作手势。
上述的方式中,采用机器学习的方式判断所述轮廓形状是否与所述预定操作手势相匹配;
当采用机器学习的方式判断所述轮廓形状与所述预定操作手势相匹配时,则确定所述当前图像中存在所述预定操作手势;当判断所述轮廓形状与所述预定操作手势不相匹配时,则确定所述当前图像中不存在所述预定操作手势。
因此,采用上述的方式,通过离线训练的方式,也能够确定当前图像中是否存在预定操作手势。在进行上述的预定操作手势的检测步骤之后,较佳地,可以通过逻辑数值输出检测结果,例如当检测到当前图像中存在指示文字信息上至少一位置的预定操作手势时,则确定用户在当前阅读过程中需要进行文字翻译,输出逻辑数值为1;当检测到当前图像中不存在预定操作手势时,则确定用户在当前阅读过程中不需要进行文字翻译,输出逻辑数值为0。
进一步地,结合图1与图3,本发明所述方法的步骤s130中,当确定所述当前图像中存在所述预定操作手势时,所述识别所述当前图像中所述预定操作手势所指示位置的文字的步骤包括:
s131,确定所述预定操作手势对所述文字信息的指示位置;
s132,截取所述当前图像中所述指示位置处预定范围的图像区域,获得截取图像;
s133,对所述截取图像进行预处理,获得所述截取图像的二值图像;
s134,对所述二值图像进行校正处理,获得包括待翻译所述文字的待读取图像;
s135,对所述待读取图像中的字符进行分割;
s136,识别所分割出的每一所述字符,形成为所述文字。
具体地,步骤s131中,确定所述预定操作手势对所述文字信息的指示位置的步骤包括:
将所述当前图像转换为ycbcr颜色空间的识别图像;
确定所述预定操作手势在所述识别图像上的对应连通域;
判断所述对应连通域的凸出顶点位置,将所述凸出顶点位置设定为所述指示位置。
具体地,结合上述步骤s121至s123的描述,当将当前图像转换为ycbcr颜色空间的识别图像后,使当前图像所转换的识别图像形成为二值图像,通过标记识别图像中显示颜色与手部肤色相匹配的显示像素,将显示颜色与手部肤色相匹配的显示像素标记为1,显示颜色与手部肤色不相匹配的显示像素标记为0后,当前图像所转换的识别图像对应预定操作手势的区域为标记为1的连通域,通过上述的步骤s121至s123可以识别出与预定操作手势相对应的该连通域。
当在预定操作手势相对应的该连通域的边缘作包络曲线时,沿连通域的边缘形成为凹凸曲线,其中对应连通域的凸出顶点位置即为预定操作手势的指示位置,将所述凸出顶点位置设定为所述指示位置。
s132,截取所述当前图像中所述指示位置处预定范围的图像区域,获得截取图像的步骤中,根据所确定的预定操作手势的指示位置,在当前图像的指示位置处截取预定大小的图像区域,获得截取图像,使截取图像中包括预定操作手势所指示用于翻译的文字。
s133中,对所述截取图像进行预处理,获得所述截取图像的二值图像的步骤包括:
采用类间最大方差法(即otsu法)确定二值化操作的阈值,对截取图像进行二值化操作处理。也即具体地,将截取图像的显示像素划分为两部分:灰度值大于该阈值的显示像素和灰度值小于该阈值的显示像素。其中,二值化操作之后,将灰度值大于该阈值的显示像素转换为白色(或者黑色),灰度值小于该阈值的显示像素转换为黑色(或者白色)。
其中,本实施例中,在设定二值化操作的阈值时,需要考虑到截取图像中保留的手指部分,使二值图像中去除手指部分图像。
较佳地,为了获得清晰、分辨率较高的二值图像,在对截取图像进行二值化操作之前,先对截取图像依次进行图像去噪和对比度拉伸的图像预处理操作。
进一步,本发明实施例方法中,在获得截取图像的二值图像之后,所述方法还包括:
对二值图像进行标记,将二值图像中的文字区域标记为第一数值,将二值图像中的背景区域标记为第二数值。依据通常图像处理方法,二值图像中的图形区域和背景区域分别标记为1和0。本发明实施例中,将文字区域标记为1,将背景区域标记为0。
当采用上述标记方式之前,分别统计二值图像中不同颜色显示像素的面积,由于背景区域的面积大于文字区域的面积,因此当将较小面积颜色的显示像素标记为1,将较大面积颜色的显示像素标记为0时,则即将文字区域标记为1,将背景区域标记为0。
在上述处理过程的基础上,根据图4所示,其中步骤s134中,对所述二值图像进行校正处理,获得包括待翻译所述文字的待读取图像的步骤包括:
s1341,对所述二值图像进行图像倾斜校正,将所述二值图像中的文本行旋转至水平,获得校正后图像;
s1342,对所述校正后图像进行文本行分割,对包括待翻译所述文字所在行进行截选,获得包括待翻译所述文字的文本图像;
s1343,对所述文本图像进行水平方向的错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像。
由于当二值图像中的文本行不是水平时,会对后续图像处理工作造成很大困难,因此需要在提取文字之前对二值图像进行图像倾斜校正,将二值图像中的文本行校正至水平,也即具体地步骤s1341包括:
将所述二值图像在预定角度范围内进行不同角度旋转;
将每次旋转后所述二值图像在竖直方向上进行投影;
计算每次旋转后所述二值图像在竖直方向上进行投影时,所获得投影数列的标准差;
确定所述标准差最大时所对应旋转后所述二值图像,为所述校正后图像。
采用上述的处理方式,通过对二值图像进行不同角度试旋转,确定不同角度旋转时二值图像在竖直方向上进行投影时所获得投影数列的标准差最大时,所对应的旋转角度为二值图像从当前状态转动的角度,标准差最大时所对应旋转后的二值图像,为校正后图像。
上述确定标准差最大时的校正过程具体包括如下的步骤:
1)进行初始参数设置
设定所述二值图像进行角度旋转的所述预定角度范围为[θ1,θ2],其中θ1<θ2,单位为度;通常,包含有文字的图像的倾斜角度在一定范围内,因此可根据经验选定图像的可能倾斜角度范围[θ1,θ2],例如[-15,15];
确定进行角度旋转的调整步长为s1和当前旋转角度t1=θ1;
将当前最大标准差maxstd设置为0,将图像倾斜校正角度α设置为0;
2)执行图像校正过程
将初始的二值图像(此处以ibw表示)旋转t1角度,获得新的二值图像(以irot表示);
将二值图像irot向竖直方向投影,获得二值图像irot在竖直方向上的投影数列iproj;
具体地,依据上述对二值图像中各显示像素的标记,获得二值图像irot每一行显示像素在竖直方向上投影时的相加之和,获得各个投影数列iproj;也即,将二值图像irot中第一行显示像素的值相加求和,作为投影数列iproj的第一项;再将二值图像irot中第二行显示像素的值相加求和,作为投影数列iproj的第二项;……;逐行扫描二值图像irot,直到计算完二值图像irot的最后一行,得到投影数列iproj。
本发明实施例中,二值图像irot中文字部分被标记为1,背景部分被标记为0,上述方式获得的投影数列iproj,即为每一行中对应为文字部分的像素单元的个数。
记录投影数列iproj的长度为m,也即二值图像irot中显示像素的行数为m,xi为iproj的第i个元素,
之后,根据iproj的平均值
上述过程所计算获得的标准差std,也即为当前旋转后二值图像的标准差std。
之后,将当前旋转后二值图像的标准差std与当前最大标准差maxstd进行比较,若当前旋转后二值图像的标准差std大于当前最大标准差maxstd,则将当前旋转后二值图像的标准差std赋给当前最大标准差maxstd,并将当前的旋转角度t1的值赋给图像倾斜校正角度α,之后进行下一次旋转;若当前旋转后二值图像的标准差std小于等于当前最大标准差maxstd,则不作赋值操作,也即当前最大标准差maxstd保持不变,图像倾斜校正角度α保持不变。
进一步,若当前旋转角度t1小于θ2,且t1+s1≤θ2时,则以当前旋转角度t1增加所述调整步长s1所获得值,赋给当前旋转角度t1(也即将t1+s1赋给t1),重新进行下一次旋转的图像校正过程,获得新的旋转后的二值图像;
若t1+s1>θ2时,则提取当前的图像倾斜校正角度α,将初始的二值图像旋转当前的图像倾斜校正角度α,所获得旋转后二值图像,为校正后图像,在二值图像从[θ1,θ2]转动过程中,在竖直方向上投影数列的标准差最大。
通过上述的执行步骤,使二值图像中的文本行旋转至水平,获得校正后图像。在此基础上,需要对校正后图像进行截取,以获得包括待翻译文字的文本图像。
具体地,上述步骤s1342中,对所述校正后图像进行文本行分割,对待翻译所述文字所在行进行截选,获得包括待翻译所述文字的文本图像的步骤包括:
将所述校正后图像在竖直方向上进行投影;
获得所投影每一像素行的累加数值,将所述累加数值与第一预设数值进行比较;
当所述累加数值大于所述第一预设数值时,则确定所对应像素行为文本行;
当所述累加数值小于所述第一预设数值时,则确定所述对应像素行为背景行;
根据所确定的文本行,截选获得所述文本图像。
其中,根据所确定的文本行,截选获得所述文本图像的步骤中,由于一个文字字符通常由多个像素行构成,因此相邻多个被确定为文本行的对应像素行均构成为待翻译所述文字所在行,对待翻译所述文字所在每一行进行截选,获得包括待翻译所述文字的文本图像。
上述将校正后图像在竖直方向上进行投影,获得所投影每一像素行累加数值的具体方式与二值图像中文本行的校正过程对应方式相同,在此不再赘述。
通过上述的处理方式,根据预先设置的第一预设数值,将文字行和背景行区分开来,截取获得包括待翻译所述文字的文本图像。
进一步地,由于在文本图像的文本行内,很大可能存在着斜体印刷字体或投影成像导致的字符倾斜,会对后续字符分割和识别过程带来困难,因此本发明所述方法还包括将文本图像中呈倾斜状态的所述文字的字符变换为竖直,也即图4的步骤s1343。
本发明实施例中,将文本图像中呈倾斜状态的所述文字的字符变换为竖直的方式为:对文本图像进行水平方向的错切变换。
具体地,步骤s1343中,对所述文本图像进行水平方向的错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像的步骤包括:
将所述文本图像在预定正切值范围内进行水平方向、不同正切值的错切变换;
将每次进行错切变换后所述文本图像在水平方向上进行投影;
计算每次进行错切变换后所述文本图像在水平方向上进行投影时,所获得投影数列的标准差;
确定所述标准差最大时所对应错切变换后所述文本图像,为所述待读取图像。
采用上述的处理方式,通过对文本图像在预定正切值范围内进行水平方向、不同正切值的错切变换,确定在不同正切值的错切变换后文本图像在水平方向上进行投影时所获得投影数列的标准差最大时,所对应的错切变换后的图像为待读取图像。
上述进行水平方向、不同正切值的错切变换的过程具体包括如下的步骤:
1)进行初始参数设置
设定所述文本图像进行水平方向、不同正切值的错切变换的所述预定正切值范围为[k1,k2],其中-1<k1<k2<1;通常,文本行内的字符的倾斜角度在一定范围内,因此可根据经验选定字符倾斜角度的正切值范围[k1,k2],例如如[-0.3,0.3];
根据校正精度要求,确定进行正切值变化的调整步长s2和当前正切值t2为k1;
将当前最大标准差maxstd设置为0,将一字符校正确认正切值tan(β)设置为0。
2)执行错切变换过程
对初始的文本图像,也即截取包括待翻译所述文字后的图像(此处以itext表示),做水平方向上的错切变换,错切变换的显示像素坐标对应关系为:
得到错切变换后图像ishear,其中xnew,ynew分别为错切变换后图像ishear中显示像素x方向和y方向的坐标,xold,yold分别为错切变换前图像中显示像素x方向和y方向的坐标。
将错切变换后图像ishear在水平方向投影,获得错切变换后图像ishear在水平方向上的投影数列iproj;
具体地,依据对二值图像中各显示像素的标记,计算错切变换后图像ishear每一列显示像素在水平方向上投影时的相加之和,获得各个投影数列iproj;也即,将错切变换后图像ishear中第一列显示像素的值相加求和,作为投影数列iproj的第一项;将错切变换后图像ishear中第二列显示像素的值相加求和,作为投影数列iproj的第二项;……;逐列扫描错切变换后图像ishear,直到计算完错切变换后图像ishear的最后一列,得到投影数列iproj。
本发明实施例中,错切变换后图像ishear中文字部分被标记为1,背景部分被标记为0。上述方式获得的投影数列iproj,即为每一列中对应为文字部分的像素单元的个数。
记录投影数列iproj的长度为m,也即错切变换后图像ishear中显示像素的列数为m,xi为iproj的第i个元素,
之后,根据iproj的平均值
上述过程所计算获得的标准差std,也即为当前错切变换后文本图像ishear的标准差std。
之后,将当前错切变换后文本图像ishear的标准差std与当前最大标准差maxstd进行比较,若当前错切变换后文本图像的标准差std大于当前最大标准差maxstd,则将当前错切变换后文本图像ishear的标准差std赋给当前最大标准差maxstd,并将当前正切值t2的值赋给字符校正确认正切值tan(β),之后进行下一次水平方向的错切变换;若当前错切变换后文本图像ishear的标准差std小于等于当前最大标准差maxstd,则不作赋值操作,也即当前最大标准差maxstd保持不变,字符校正确认正切值tan(β)保持不变。
进一步,若当前正切值t2小于k2,且t2+s2≤k2时,则以当前正切值t2增加所述调整步长s2所获得值,赋给当前正切值t2(也即将t2+s2赋给t2),重新进行下一次旋转的错切变换过程,获得新的错切变换后图像;
若t2+s2>k2时,则提取当前的字符校正确认正切值tan(β),对初始的文本图像以当前的字符校正确认正切值tan(β)进行水平方向的错切变换,所获得错切变换后文本图像,为待读取图像。该待读取图像为原始的文本图像以[k1,k2]角度范围作水平方向错切变换时,在水平方向上投影数列的标准差最大。
具体地,初始的文本图像与待读取图像中显示像素的像素坐标对应关系为:
其中xnew,ynew分别为待读取图像也即字符已被校正到无倾斜时图像中显示像素x方向和y方向的坐标,xold,yold分别为初始的文本图像中显示像素x方向和y方向的坐标,tan()为上述错切变换过程中最后的字符校正确认正切值tan(β)。
依据上述的方式和过程,获得字符被转换到无倾斜状态的待读取图像,该待读取图像可以用于进一步的字符的分割和读取,也即根据图3,执行步骤s135,对所述待读取图像中的字符进行分割。
由于语言的不同,所显示文字字符的结构形式不同,因此对应不同语言的字符分割方式也不同。
当所述待读取图像中的字符为中文时,步骤s135中,所述对所述待读取图像中的字符进行分割的步骤包括:
将所述待读取图像在水平方向上进行投影;
根据投影结果,确定所述待读取图像中的字符区域和背景区域;
设定被确定为背景的对应区域为相邻字符的初步分割位置;
对所述初步分割位置进行筛选,使每一字符的宽度为固定值,获得最后确定分割位置。
具体地,上述步骤中,根据投影结果,确定所述待读取图像中的字符区域和背景区域的步骤包括:
获得所投影每一像素列的累加数值,将所述累加数值与第二预设数值进行比较;
当所述累加数值大于所述第二预设数值时,则确定所对应像素列的区域为字符;
当所述累加数值小于所述第二预设数值时,则确定所对应像素列的区域为背景。
上述的分割方式,利用待读取图像中对应为文字的显示像素被标记为1,对应为背景的显示像素被标记为0的标记方式,当前待读取图像在水平方向上进行投影时,获得每一列显示像素在水平方向投影时的相加之和。根据经验,设定一第二预设数值,将投影结果中大于该第二预设数值的显示像素所对应区域确定为字符区域,投影结果中小于该第二预设数值的显示像素所对应区域确定为背景区域。
采用以上的方式,将被确定为背景的对应区域,也即一或多列相邻显示像素均被确定为背景区域的区域,设定为相邻字符的初步分割位置。
较佳地,将相邻两个字符区域之间、被确定为背景区域的中间位置,设定为相邻字符的初步分割位置。
进一步地,根据中文每个字符均等宽的特性,所确定的相邻两个分割位置之间的间距应该相等,因此需要对上述所确定的初步分割位置进行筛选,对于两个相邻初步分割位置距离较小,且初步分割位置所对应背景区域的宽度较小的初步分割位置,则与左右相邻的字符进行合并,最后使得每一字符的宽度为固定值,获得最后确定分割位置。
当所述待读取图像中的字符为英文或其他西文语种时,因西文字体的衬线会形成字符间粘连,严重影响字符分割结果。
本发明所述方法该实施例中,利用西文字符通常存在水平基线,且基线位置固定,文本行二值图像在竖直方向的投影往往于基线处产生峰值的特点,采用基线确定法进行西文字符的分割。
具体地,当所述待读取图像中的字符为英文或其他西文语种时,步骤s135中,所述对所述待读取图像中的字符进行分割的步骤包括:
确定所述待读取图像中用于表示字符设置范围的第一水平基线和第二水平基线;
将所述待读取图像中处于所述第一水平基线和所述第二水平基线之间的图像在水平方向上进行投影;
根据投影结果,确定所述待读取图像中的字符区域和背景区域;
设定被确定为背景的对应区域为相邻字符的初步分割位置;
根据所述待读取图像中每一连通域的大小和位置,对所述初步分割位置进行筛选,获得最后确定分割位置。
进一步地,与中文字符分割方式中字符区域和背景区域的确定方式相同,利用待读取图像中对应为文字的显示像素被标记为1,对应为背景的显示像素被标记为0的标记方式,当前待读取图像在水平方向上进行投影时,获得每一列显示像素在水平方向投影时的相加之和。根据经验,设定一第二预设数值,将投影结果中大于该第二预设数值的显示像素所对应区域确定为字符区域,投影结果中小于该第二预设数值的显示像素所对应区域确定为背景区域。
具体地,上述步骤中,根据投影结果,确定所述待读取图像中的字符区域和背景区域的步骤包括:
获得所投影每一像素列的累加数值,将所述累加数值与第二预设数值进行比较;
当所述累加数值大于所述第二预设数值时,则确定所对应像素列的区域为字符;
当所述累加数值小于所述第二预设数值时,则确定所对应像素列的区域为背景。
另外,所述确定所述待读取图像中用于表示字符设置范围的第一水平基线和第二水平基线的步骤包括:
将所述待读取图像在竖直方向进行投影;
获得所投影每一像素行的累加数值,设定累加数值较大两个像素行分别为第一水平基线和第二水平基线的所在位置。
采用上述方式,确定所述待读取图像中在竖直方向投影时的累加数值较大两处所对应像素行分别为第一水平基线和第二水平基线的位置。之后利用第一水平基线与第二水平基线之间的图像在水平方向上的投影,初步确定待读取图像的字符区域和背景区域,根据初步确定的字符区域和背景区域,进行相邻字符的粗分割,也即获得初步分割位置。
较佳地,将相邻两个字符区域之间、被确定为背景区域的中间位置,设定为相邻字符的初步分割位置。在此基础上,根据所述待读取图像中每一连通域的大小和位置,对所述初步分割位置进行筛选,获得最后确定分割位置,具体方式为:
对于面积过小的连通域,考察该连通域周围是否有其他连通域,如有其他连通域,则将该连通域与周围相邻的连通域进行合并;如没有其他连通域,且该面积较小连通域处于第一水平基线或第二水平基线附近时,则将该面积较小的连通域视为标点符号;
对于面积过大、且水平方向上宽度过大的连通域,将该连通域所对应区域的二值化阈值提高,重新进行二值化操作,确定是否能分割为两个或多个在水平方向上无重叠的连通域;
最后结合上述的初步分割位置与各连通域的位置,检测初步分割位置是否合理,若不合理则进行撤销,此外调整初步分割位置以正确分开每个连通域,同时将水平方向上较宽的背景区域间隔视为单词间的空格,完成字符的精分割。
较佳地,在完成上述对待读取图像中的字符进行分割的步骤之后,所述方法还包括:
对待读取图像中待翻译所述文字的每一字符进行归一化处理,也即使每一字符的图像大小一致,且字符在所述待读取图像中处于居中位置。
经过上述归一化处理之后的字符,更便于后续的字符识别过程。
根据图3,步骤s136中,识别所分割出的每一所述字符,形成为所述文字的方式可以为:
将所分割出每一字符与不同字符模版进行匹配,确定与该字符匹配的字符模版,即可识别出该字符;或者采用机器学习的方式,识别所分割出每一字符。
具体地,该采用机器学习的方式,识别所分割每一字符的方式包括:
确定预定机器学习模型中表征预设语言中每一字符的特定特征;
采用所述特定特征对所述预定机器学习模型进行训练,获得离线训练数值;
根据所述离线训练数值确定所述预定机器学习模型的影响因素;
获取所分割出的每一所述字符的特定特征,将每一所述字符的特定特征输入到所述预定机器学习模型中,根据所述预定机器学习模型的输出,识别所述预设语言中与每一所述字符对应的字符。
其中,字符的特征可以是笔画数、笔画方向、笔画交叉点个数等,也可以为上述进行归一化处理后的待读取图像本身。
此外,由于字符识别的结果容易误判,为保证字符识别的准确性,所述方法还包括:将所识别出的每一字符组合构成的待翻译所述文字与字典内的单词进行对比,以修正字符识别结果。
进一步地,本发明实施例所述方法在经过上述图像处理和字符识别过程,识别出当前图像中预定操作手势所指示位置的文字之后,则进一步执行文字翻译的步骤,具体为:
根据预先输入需要翻译的语言,查找字典资料库,对所识别出文字进行翻译,如该文字有多重含义,则还需要根据当前图像中预定操作手势所指示位置文字的前后文字符进一步确定该文字的准确含义。
在完成上述对预定操作手势所指示位置的文字的翻译之后,所述方法还包括:输出该翻译信息,以使用户实时了解需要翻译文字的翻译信息。
本发明实施例中,较佳地呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
进一步,较佳地,使所述当前图像中所述预定操作手势所指示位置的文字与其他文字区分显示。
例如,使预定操作手势所指示位置的文字以不同颜色显示、颜色加深显示、高亮显示或者外围添加边框显示等等,只要能够使所指示位置的文字与其他文字进行区分,使用户对所翻译的文字一目了然,以便于核对。
本发明实施例所述方法中,在显示界面同时显示当前图像和翻译信息的具体方式可以包括如下几种,具体为:
第一种方式
确定在所述当前图像中,所述文字所在文本行与上方文本行之间的空白区域;
在所述空白区域输出显示所述翻译信息。
其中,较佳地,在所述文字所在文本行与上方文本行之间的空白区域输出显示翻译信息的步骤中,根据空白区域的面积大小,确定所输出翻译信息的字体大小,根据待翻译所述文字的倾斜状态,确定所输出翻译信息的倾斜状态,并进一步使翻译信息的中心位置位于待翻译所述文字上方空白区域的中间区域。
因此,采用上述方式时,确定在所述当前图像中,所述文字所在文本行与上方文本行之间的空白区域的步骤包括:
确定所述空白区域的高度和在所述当前图像上的位置;
确定所述文字在所在文本行的起始位置和终止位置;
根据所述空白区域的高度,确定所述翻译信息输出的字体大小;
根据所述空白区域在所述当前图像上的位置和所述文字在所在文本行的起始位置和终止位置,计算所述翻译信息在所述空白区域显示时的中心位置;
其中,在所述空白区域输出显示所述翻译信息的步骤包括:
使所输出的所述翻译信息以所确定的字体大小输出,且中心位于所述中心位置处。
另外,在所述空白区域输出显示所述翻译信息的步骤之前,所述方法还包括:
确定所述文字所在文本行相对于水平方向的倾斜角度a;
确定所述文字相对于竖直方向的倾斜角度b。
其中,在所述空白区域输出显示所述翻译信息的步骤还包括:
使所输出的所述翻译信息所构成每一文本行相对于水平方向的倾斜角度为a,以及使所述输出的所述翻译信息的每一字符相对于竖直方向的倾斜角度为b。
结合上述对二值图像进行校正处理,获得包括待翻译所述文字的待读取图像的步骤,也即步骤s134,为获得以上用于在空白区域显示翻译信息的具体参数信息,在进行图像校正处理的步骤中需要记录以下的信息:
在步骤s1341,对所述二值图像进行图像倾斜校正,将所述二值图像中的文本行旋转至水平的步骤中,记录二值图像中的文本行与水平线所成的夹角,记为a;
在步骤s1342,对所述校正后图像进行文本行分割的步骤中,获得待翻译所述文字在所在文本行的上沿起始位置(记为line_start)和下沿终止位置(记为line_end),也即分别为待翻译所述文字所在文本行的上沿直线和下沿直线的位置;
在步骤s1342,对所述校正后图像进行文本行分割的步骤中,获得待翻译所述文字所在文本行上方空白区域的上沿直线位置(记为space_start),也即为待翻译所述文字所在文本行的上一行文本行的下沿直线位置。
在步骤s1343,对所文本图像进行水平方向的错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像的步骤中,获得并记录所述文字的字符相对于竖直方向的倾斜角度b,也即为待翻译所述文字相对于竖直方向所成的夹角;
在步骤s1342,对所述校正后图像进行文本行分割的步骤中,记录所述文字在所在文本行的起始位置和终止位置,也即所述文字中最左端位置和最右端位置(分别记为word_start和word_end)。
具体地,根据上述的space_start、line_start和line_end,确定空白区域的高度和在当前图像上的位置;
根据空白区域的高度,可以确定所述翻译信息输出的字体大小;
根据空白区域在当前图像上的位置、word_start和word_end,计算翻译信息在空白区域显示时的中心位置;
具体地,根据line_start、space_start、word_start及word_end,确定翻译信息显示输出时的中心位置为middlepos={水平中心=(word_start+word_end)/2,竖直中心=(line_start+space_start)/2};
这样,当在所述空白区域输出显示所述翻译信息时:
使所输出的所述翻译信息以所确定的字体大小输出,且中心位于所述中心位置处。
进一步,根据所述文字所在文本行相对于水平方向的倾斜角度a以及所述文字的字符相对于竖直方向的倾斜角度b,使得在所述空白区域输出显示所述翻译信息时,所输出的所述翻译信息所构成每一文本行相对于水平方向的倾斜角度为a,以及使所述输出的所述翻译信息的每一字符相对于竖直方向的倾斜角度为b,与待翻译所述文字保持一致。
通过上述的显示方式,使得在阅读过程中实时地拍摄获得所阅读视野范围内情景的当前图像,根据用户所作出预定操作手势,实时显示所拍摄到的当前图像和对应的翻译信息,使得待翻译的当前图像和翻译获得的翻译信息能够完美地对应,在图像中融为一体,视觉效果较好。
第二种方式
在所述显示界面同时显示所述当前图像和所述翻译信息的步骤中:
在所述显示界面的第一区域显示所述当前图像,同时在所述显示界面的第二区域显示所述翻译信息。
也即,具体地,将所输出的显示界面划分为两个区域,如上下两个区域,上面的显示区域用于显示阅读过程中实时拍摄的当前图像,下面的显示区域用于显示当前图像中预定操作手势所指示的文字的翻译信息。
对于当前显示界面上第一区域和第二区域的划分规则,可以进行预先设定。也即,在执行本发明实施例所述方法之前,通过用户预先设定用于显示当前图像的区域和用于显示所对应翻译信息的区域,形成为预先设定的显示区域设定信息。
当在显示界面同时显示所述当前图像和所述翻译信息时,根据预先设定的显示区域设定信息,确定所述第一区域和所述第二区域。
另外,当在显示界面的第一区域显示当前图像,在显示界面的第二区域显示翻译信息时,为清楚显示翻译信息所对应的文字,使当前图像中待翻译所述文字的显示方式均与其他文字的显示方式相区别。
具体地,为了使当前图像中待翻译所述文字的显示方式均与其他文字的显示方式相区别,需要确定待翻译所述文字在当前图像上的显示位置,包括:
确定待翻译所述文字所在文本行的上沿起始位置line_start和下沿终止位置line_end;
确定待翻译所述文字在所述文本行的起始位置word_start和终止位置word_end;
确定待翻译所述文字所在文本行与水平线所成的夹角a;
确定待翻译所述文字的字符相对于竖直方向的倾斜角度b;
确定边界范围分别为上沿起始位置line_start、下沿终止位置line_end、起始位置word_start和终止位置word_end,相对于水平方向的倾斜角度为a、错切角度为b的平行四边形区域为待翻译所述文字的显示区域;
使所述显示区域中的文字与其他文字区分显示,该显示区域为需要与其他文字区别显示的区域。
上述的显示方式,相较于第一种显示方式,使翻译信息所输出的显示面积增大,不受显示器大小、分辨率的限制,能够显示翻译信息中更为丰富的翻译内容,例如音标、例句、辨析等。
第三种方式
在所述显示界面同时显示所述当前图像和所述翻译信息的步骤中:
确定所述当前图像中所述文字的位置;
根据所述当前图像中所述文字的位置,确定一气泡显示区域的弹出位置坐标;
在整个显示界面上显示所述当前图像,并在所述当前图像上叠加一位于所述文字上方、且从所述弹出位置坐标弹出的气泡显示区域,使所述翻译信息在所述气泡显示区域内显示。
其中,所述根据所述当前图像中所述文字的位置,确定一气泡显示区域的弹出位置坐标的步骤包括:
根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的起始位置和终止位置;
根据所述文字在所在文本行的起始位置和终止位置,确定所述文字在水平方向的中心线坐标,将所述水平方向的中心线坐标设定为所述弹出位置坐标的水平方向坐标;
根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的上沿起始位置,将所述文字在所在文本行的上沿起始位置设定为所述弹出位置坐标的竖直方向坐标。
具体地,确定当前图像中所述文字的位置的方式,可以参阅第一种方式,在步骤s1342,对所述校正后图像进行文本行分割的步骤中,记录所述文字在所在文本行的起始位置和终止位置,也即所述文字中最左端位置和最右端位置(分别记为word_start和word_end),根据word_start和word_end,确定当前图像中待翻译所述文字的位置。
进一步,根据步骤s1342,对所述校正后图像进行文本行分割的步骤中,获得待翻译所述文字在所在文本行的上沿起始位置(记为line_start)。
根据word_start、word_end和line_start,确定所述弹出位置坐标。具体地为,该弹出位置坐标在水平方向上的坐标为(word_start+word_end)/2,在竖直方向上的坐标为line_start。通过该种设置方式,使得气泡显示区域从待翻译所述文字的上边沿的中心位置弹出。本发明实施例中,气泡显示区域的大小依据翻译信息的内容多少确定,并保证所显示内容的字大能够被清晰辨认。
进一步地,为避免气泡显示区域内所显示翻译信息与当前图像中的文字叠加导致难以辨认,较佳地,气泡显示区域应该设置为不透明或具有较低透明度。
采用上述的显示方式,翻译信息和被翻译的所述文字能够具有较好的对应显示效果,且相较于第一种显示方式,显示内容的信息量更大,不受显示器大小、分辨率的限制,但从显示区域和能够显示翻译信息的信息量来说,又低于第二种显示方式。
本发明上述所提及翻译信息的第一种显示方式至第三种显示方式,较佳地,当前图像中待翻译所述文字的显示方式均与其他文字的显示方式相区别,具体地,采用第一种显示方式时获得的line_start、line_end、word_start和word_end信息,确定待翻译所述文字在当前图像上的显示位置,另外根据所获得的该些信息,确定出一个倾斜角度为a、错切角度为b的平行四边形区域,在此区域内所显示的文字为需要与其他文字区别显示。
具体区别显示的方式,可以为以不同颜色显示、颜色加深显示、高亮显示或者外围添加边框显示中的其中一种,但并不以此为限。
本发明实施例另一方向还提供一种用于手势指点翻译的装置,参阅图5所示,该装置包括:
图像获取模块100,用于获取阅读文字视野范围内的当前图像;
图像检测模块200,检测所述当前图像中是否存在指示文字信息的预定操作手势;
图像识别模块300,用于当确定所述当前图像中存在所述预定操作手势时,识别所述当前图像中所述预定操作手势所指示的文字;
翻译模块400,用于获取所述文字关于预设语言的翻译信息;
输出模块500,用于呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
包括上述模块的用于手势指点翻译的装置,通过用户阅读过程中实时地拍摄获得所阅读视野范围内情景的当前图像,确定用户当前阅读时是否作出了指示所阅读文字信息的其中一文字被翻译的预定操作手势,并实时地识别当前图像中的预定操作手势所指示的文字,对该文字进行翻译和输出,使用户在进行阅读的同时只需要作出预定操作手势,指示需要被翻译文字,即能够实时获得翻译信息,不需要跳出阅读过程,从而能够获得更好的阅读体验。
进一步,当输出翻译信息时,通过在所述显示界面同时显示所述当前图像和所述翻译信息的方式,使用户可以对比阅览被翻译文字和相对应的翻译信息,从而更便于查看。
较佳地,上述所述的装置中,如图6所示,当所述输出模块在所述显示界面同时显示所述当前图像和所述翻译信息时,所述输出模块包括:
区别显示单元,用于使所述当前图像中所述预定操作手势所指示位置的文字与其他文字区分显示。
较佳地,所述输出模块的其中一实施例中,所述输出模块包括:
空白区域确定单元,用于确定在所述当前图像中,所述文字所在文本行与上方文本行之间的空白区域;
第一显示单元,用于在所述空白区域输出显示所述翻译信息。
较佳地,所述空白区域确定单元包括:
第一信息获取子单元,用于确定所述空白区域的高度和在所述当前图像上的位置;
第二信息获取子单元,用于确定所述文字在所在文本行的起始位置和终止位置;
第一计算子单元,用于根据所述空白区域的高度,确定所述翻译信息输出的字体大小;
第二计算子单元,用于根据所述空白区域在所述当前图像上的位置和所述文字在所在文本行的起始位置和终止位置,计算所述翻译信息在所述空白区域显示时的中心位置;
其中,所述第一显示单元具体用于:
使所输出的所述翻译信息以所确定的字体大小输出,且中心位于所述中心位置处。
进一步,所述空白区域确定单元还包括:
第三信息获取子单元,用于确定所述文字所在文本行相对于水平方向的倾斜角度a;
第四信息获取子单元,用于确定所述文字的字符相对于竖直方向的倾斜角度b;
其中,所述第一显示单元还用于:
使所输出的所述翻译信息所构成每一文本行相对于水平方向的倾斜角度为a,以及使所述输出的所述翻译信息的每一字符相对于竖直方向的倾斜角度为b。
所述输出模块采用上述的设置结构,待翻译所述文字的翻译信息在所述文字所在文本行与上方文本行之间的空白区域显示,使得待翻译的当前图像和翻译获得的翻译信息能够一体显示,且完美地对应,在图像中融为一体。
所述输出模块的另一实施例中,所述输出模块包括:
第二显示单元,用于在所述显示界面的第一区域显示所述当前图像,同时在所述显示界面的第二区域显示所述翻译信息。该种显示方式中,将所输出的显示界面划分为两个区域,分别用于当前图像和对应翻译信息的显示。相较于第一种显示方式,使翻译信息所输出的显示面积增大,不受显示器大小、分辨率的限制,能够显示翻译信息中更为丰富的翻译内容,例如音标、例句、辨析等。
另外,所述输出模块还包括:
显示区域确定单元,用于在所述显示界面同时显示所述当前图像和所述翻译信息之前,根据预先设定的显示区域设定信息,确定所述第一区域和所述第二区域。
通过上述结构,在使用本发明实施例所述装置之前,通过用户预先设定用于显示当前图像的区域和用于显示所对应翻译信息的区域,形成为预先设定的显示区域设定信息。
所述输出模块的另一实施例中,所述输出模块包括:
文字位置计算单元,用于确定所述当前图像中所述文字的位置;
弹出位置计算单元,用于根据所述当前图像中所述文字的位置,确定一气泡显示区域的弹出位置坐标;
第三显示单元,用于在整个显示界面上显示所述当前图像,并在所述当前图像上叠加一位于所述文字上方、且从所述弹出位置坐标弹出的气泡显示区域,使所述翻译信息在所述气泡显示区域内显示。
较佳地,所述弹出位置计算单元包括:
第三计算子单元,用于根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的起始位置和终止位置;
第四计算子单元,用于根据所述文字在所在文本行的起始位置和终止位置,确定所述文字在水平方向的中心线坐标,将所述水平方向的中心线坐标设定为所述弹出位置坐标的水平方向坐标;
第五计算子单元,用于根据所述当前图像中所述文字的位置,确定所述文字在所在文本行的上沿起始位置,将所述文字在所在文本行的上沿起始位置设定为所述弹出位置坐标的竖直方向坐标。
在所述输出模块的上述实施例中,通过在待翻译所述文字上方弹出气泡显示区域的方式显示翻译信息,翻译信息和被翻译的所述文字能够具有较好的对应显示效果,且相较于第一种显示方式,显示内容的信息量更大,不受显示器大小、分辨率的限制。
进一步地,为避免气泡显示区域内所显示翻译信息与当前图像中的文字叠加导致难以辨认,较佳地,气泡显示区域应该设置为不透明或具有较低透明度。
进一步,所述区别显示单元包括:
第六计算子单元,用于确定待翻译所述文字所在文本行的上沿起始位置line_start和下沿终止位置line_end;
第七计算子单元,用于确定待翻译所述文字在所述文本行的起始位置word_start和终止位置word_end;
第八计算子单元,确定待翻译所述文字所在文本行与水平线所成的夹角a;
第九计算子单元,用于确定待翻译所述文字的字符相对于竖直方向的倾斜角度b;
区别范围确定子单元,用于确定边界范围分别为上沿起始位置line_start、下沿终止位置line_end、起始位置word_start和终止位置word_end,相对于水平方向的倾斜角度为a、错切角度为b的平行四边形区域为待翻译所述文字的显示区域;
输出子单元,用于使所述显示区域中的文字与其他文字区分显示。
通过上述区别显示单元的结构,确定在当前显示界面中使待翻译所述文字与其他文字相区别显示的显示区域。
较佳地,上述所述的装置,其中参阅图7所示,所述图像检测模块200包括:
图像转换单元,用于将所述当前图像转换为ycbcr颜色空间的识别图像;
图像标记单元,用于标记所述识别图像中显示颜色与预设手部肤色相匹配的显示像素;
分析单元,用于判断被标记的所述显示像素所形成区域的轮廓形状是否与所述预定操作手势相匹配,当判断结果为是时,则确定所述当前图像中存在所述预定操作手势;当判断结果为否时,则确定所述当前图像中不存在所述预定操作手势。
较佳地,上述所述的装置,其中,所述分析单元包括:
第一获取子单元,用于获取所述预定操作手势的图像模版;
第一分析子单元,用于将所述轮廓形状与所述图像模版的形状进行匹配,当匹配一致时,则确定所述当前图像中存在所述预定操作手势;当匹配不一致时,则确定所述当前图像中不存在所述预定操作手势。
采用上述的方式,通过将连通域的形状与预定操作手势的图像模版进行匹配的方式,能够确定当前图像中是否存在预定操作手势。
或者,上述所述的装置,其中,所述分析单元包括:
第二获取子单元,用于确定预定机器学习模型中表征所述预定操作手势的特定特征;
第三获取子单元,用于采用所述特定特征对所述预定机器学习模型进行训练,获得离线训练数值;
第二分析子单元,根据所述离线训练数值确定所述预定机器学习模型的影响因素;
判断子单元,用于获取所述当前图像中被标记显示像素所形成区域的轮廓形状的特定特征,将所述轮廓形状的特定特征输入到所述预定机器学习模型中,根据所述预定机器学习模型的输出,判断所述特定特征是否与所述操作手势相匹配。
采用上述的方式,通过离线训练的方式,也能够确定当前图像中是否存在预定操作手势。
在进行上述的预定操作手势的检测步骤之后,较佳地,可以通过逻辑数值输出检测结果,例如当检测到当前图像中存在指示文字信息上至少一位置的预定操作手势时,则确定用户在当前阅读过程中需要进行文字翻译,输出逻辑数值为1;当检测到当前图像中不存在预定操作手势时,则确定用户在当前阅读过程中不需要进行文字翻译,输出逻辑数值为0。
较佳地,上述所述的装置,参阅图8所示,其中,所述图像识别模块300包括:
位置确定单元,用于确定所述预定操作手势对所述文字信息的指示位置;
图像截取单元,用于截取所述当前图像中所述指示位置处预定范围的图像区域,获得截取图像;
图像处理单元,用于对所述截取图像进行预处理,获得所述截取图像的二值图像;
图像校正单元,用于对所述二值图像进行校正处理,获得包括待翻译所述文字的待读取图像;
图像分割单元,用于对所述待读取图像中的字符进行分割;
字符识别单元,用于识别所分割出的每一所述字符,形成为所述文字。
较佳地,上述所述的装置,其中,所述位置确定单元包括:
颜色转换子单元,用于将所述当前图像转换为ycbcr颜色空间的识别图像;
连通域确定子单元,用于确定所述预定操作手势在所述识别图像上的对应区域;
指示位置确定子单元,用于判断所述对应区域的凸出顶点位置,将所述凸出顶点位置设定为所述指示位置。
通过上述结构的位置确定单元,当将当前图像转换为ycbcr颜色空间的识别图像后,使当前图像所转换的识别图像形成为二值图像,通过标记识别图像中显示颜色与手部肤色相匹配的显示像素,将显示颜色与手部肤色相匹配的显示像素标记为1,显示颜色与手部肤色不相匹配的显示像素标记为0后,当前图像所转换的识别图像对应预定操作手势的区域为标记为1的连通域,通过上述的步骤s121至s123可以识别出与预定操作手势相对应的该连通域。
当在预定操作手势相对应的该区域的边缘作包络曲线时,沿连通域的边缘形成为凹凸曲线,其中对应区域的凸出顶点位置即为预定操作手势的指示位置,将所述凸出顶点位置设定为所述指示位置。
较佳地,上述所述的装置,其中,所述图像处理单元包括:
预处理子单元,用于依次对所述截取图像进行去噪、对比度拉伸和进行二值化操作后,获得所述截取图像的二值图像。
该预处理子单元采用类间最大方差法(即otsu法)确定二值化操作的阈值,对截取图像进行二值化操作处理。也即具体地,将截取图像的显示像素划分为两部分:灰度值大于该阈值的显示像素和灰度值小于该阈值的显示像素。其中,二值化操作之后,将灰度值大于该阈值的显示像素转换为白色(或者黑色),灰度值小于该阈值的显示像素转换为黑色(或者白色)。
其中,本实施例中,在设定二值化操作的阈值时,需要考虑到截取图像中保留的手指部分,使二值图像中去除手指部分图像。
较佳地,为了获得清晰、分辨率较高的二值图像,在对截取图像进行二值化操作之前,该预处理子单元先对截取图像依次进行图像去噪和对比度拉伸的图像预处理操作。
较佳地,上述所述的装置,其中,所述图像校正单元包括:
文本行校正子单元,用于对所述二值图像进行图像倾斜校正,将所述二值图像中的文本行旋转至水平,获得校正后图像;
文本行分割子单元,用于对所述校正后图像进行文本行分割,对待翻译所述文字所在行进行截选,获得包括待翻译所述文字的文本图像;
字符校正子单元,用于对所述文本图像进行水平方向的错切变换,将所述文本图像中呈倾斜状态的所述文字的字符变换为竖直,获得所述待读取图像。
较佳地,上述所述的装置,其中,所述文本行校正子单元包括:
角度旋转结构,用于将所述二值图像在预定角度范围内进行不同角度旋转;
第一投影计算结构,用于将每次旋转后所述二值图像在竖直方向上进行投影;
第一标准差计算结构,用于计算每次旋转后所述二值图像在竖直方向上进行投影时,所获得投影数列的标准差;
第一确定结构,用于确定所述标准差最大时所对应旋转后所述二值图像,为所述校正后图像。
较佳地,上述所述的装置,其中,所述角度旋转结构包括:
第一设定子结构,用于设定所述二值图像进行角度旋转的所述预定角度范围为[θ1,θ2],其中θ1<θ2;
第二设定子结构,用于确定进行角度旋转的调整步长为s1和当前旋转角度t1=θ1;
旋转执行子结构,用于以所述当前旋转角度t1=θ1进行初始旋转,将所述当前旋转角度t1增加所述调整步长s1所获得数值,赋值给所述当前旋转角度t1进行下一次旋转,其中t1+s1≤θ2。
较佳地,上述所述的装置,其中,所述文本行校正子单元还包括:
第一比较结构,用于将当前旋转后所述二值图像的标准差std与当前最大标准差maxstd进行比较;
第一执行结构,用于若当前旋转后所述二值图像的标准差std大于所述当前最大标准差maxstd,则将当前旋转后所述二值图像的标准差std赋给所述当前最大标准差maxstd,将当前旋转角度t1赋给一图像倾斜校正角度α,并进行下一次旋转;
第二执行结构,用于若当前旋转后所述二值图像的标准差std小于等于所述当前最大标准差maxstd,则所述当前最大标准差maxstd和所述图像倾斜校正角度α维持不变;
其中,在进行初始旋转时,所述当前最大标准差maxstd为零,所述图像倾斜校正角度α为零。
较佳地,上述所述的装置,其中,所述角度旋转结构还包括:
第一停止确定子结构,用于在将所述二值图像在预定角度范围内进行不同角度旋转的过程中,若所述当前旋转角度t1增加所述调整步长s1所获得数值大于θ2,则停止对所述二值图像进行角度旋转;
其中,所述第一确定结构包括:
校正角度提取子结构,用于提取当前的所述图像倾斜校正角度α;
第一校正图像确定子结构,用于确定所述二值图像旋转当前的所述图像倾斜校正角度α时所对应旋转后所述二值图像,为所述校正后图像。
包括上述结构的文本行校正子单元,具体进行文字行校正的过程可以参阅以上关于方法部分的描述。通过本发明所述文本行校正子单元,使二值图像中的文本行旋转至水平,获得校正后图像。
较佳地,上述所述的装置,其中,所述字符校正子单元包括:
错切变换结构,用于将所述文本图像在预定正切值范围内进行水平方向、不同正切值的错切变换;
第二投影计算结构,用于将每次进行错切变换后所述文本图像在水平方向上进行投影;
第二标准差计算结构,用于计算每次进行错切变换后所述文本图像在水平方向上进行投影时,所获得投影数列的标准差;
第二确定结构,用于确定所述标准差最大时所对应错切变换后所述文本图像,为所述待读取图像。
较佳地,上述所述的装置,其中,所述错切变换结构包括:
第三设定子结构,用于设定所述文本图像进行水平方向、不同正切值的错切变换的所述预定正切值范围为[k1,k2],其中-1<k1<k2<1;
第四设定子结构,用于确定进行错切变换的调整步长为s2和当前正切值t2为k1;
错切变换执行子结构,用于以所述当前正切值t2=k1进行初始错切变换,将所述当前正切值t2增加所述调整步长s2所获得数值,赋值给所述当前正切值t2,进行下一次错切变换,其中t2+s2≤k2。
较佳地,上述所述的装置,其中,所述字符校正子单元还包括:
第二比较结构,用于将当前错切变换后所述文本图像的标准差std与当前最大标准差maxstd进行比较;
第三执行结构,用于若当前错切变换后所述文本图像的标准差std大于所述当前最大标准差maxstd,则将当前错切变换后所述文本图像的标准差std赋给所述当前最大标准差maxstd,将当前正切值t2赋给一字符校正确认正切值tan(β),并进行下一次错切变换;
第四执行结构,用于若当前错切变换后所述文本图像的标准差std小于等于所述当前最大标准差maxstd,则所述当前最大标准差maxstd和所述字符校正确认正切值tan(β)维持不变;
其中,在进行初始错切变换时,所述当前最大标准差maxstd为零,所述字符校正确认正切值tan(β)为零。
较佳地,上述所述的装置,其中,所述错切变换结构还包括:
第二停止确定子结构,用于在将所述文本图像在预定正切值范围内进行水平方向、不同正切值的错切变换的过程中,若所述当前正切值t2增加所述调整步长s2所获得数值大于k2,则停止对所述文本图像进行错切变换;
其中,所述第二确定结构包括:
正切值提取子结构,用于提取当前的所述字符校正确认正切值tan(β);
第二校正图像确定子结构,用于确定所述文本图像以当前的所述字符校正确认正切值tan(β)进行水平方向的错切变换时,所对应错切变换后所述文本图像为所述待读取图像。
本发明实施例中,包括上述结构的字符校正子单元,通过水平方向错切变换,使字符被转换到无倾斜状态,以便用于进一步的字符的分割和读取。具体所进行水平方向错切变换的具体执行过程,可以参阅以上方法部分的描述,在此不再赘述。
较佳地,上述所述的装置,其中,所述文本行分割子单元包括:
第三投影计算结构,用于将所述校正后图像在竖直方向上进行投影;
第三比较结构,用于获得所投影每一像素行的累加数值,将所述累加数值与第一预设数值进行比较;
文本行确定结构,用于当所述累加数值大于所述第一预设数值时,则确定所对应像素行为文本行;
背景行确定结构,用于当所述累加数值小于所述第一预设数值时,则确定所述对应像素行为背景行;
截选执行结构,用于根据所确定的文本行,截选获得所述文本图像。
包括上述结构的文本行分割子单元,根据预先设置的第一预设数值,将文字行和背景行区分开来,截取获得包括待翻译所述文字的文本图像。
较佳地,上述所述的装置,其中,当所述待读取图像中的字符为中文时,所述图像分割单元包括:
第一投影子单元,用于将所述待读取图像在水平方向上进行投影;
区域确定子单元,用于根据投影结果,确定所述待读取图像中的字符区域和背景区域;
第一初步分割子单元,用于设定被确定为背景的对应区域为相邻字符的初步分割位置;
第一最后分割子单元,用于对所述初步分割位置进行筛选,使每一字符的宽度为固定值,获得最后确定分割位置。
具体地,所述区域确定子单元中,利用待读取图像中对应为文字的显示像素被标记为1,对应为背景的显示像素被标记为0的标记方式,当前待读取图像在水平方向上进行投影时,获得每一列显示像素在水平方向投影时的相加之和。根据经验获得,设定一第二预设数值,将投影结果中大于该第二预设数值的显示像素所对应区域确定为字符区域,投影结果中小于该第二预设数值的显示像素所对应区域确定为背景区域。
采用以上的方式,将被确定为背景的对应区域,也即一或多列相邻显示像素均被确定为背景区域的区域,设定为相邻字符的初步分割位置。
进一步地,利用中文每个字符均等宽的特性,所确定的相邻两个分割位置之间的间距应该相等,因此需要对上述所确定的初步分割位置进行筛选,对于两个相邻初步分割位置距离较小,且初步分割位置所对应背景区域的宽度较小的初步分割位置,则与左右相邻的字符进行合并,最后使得每一字符的宽度为固定值,获得最后确定分割位置。
较佳地,上述所述的装置,其中,当所述待读取图像中的字符为英文时,所述图像分割单元包括:
基线确定子单元,用于确定所述待读取图像中用于表示字符设置范围的第一水平基线和第二水平基线;
第二投影子单元,用于将所述待读取图像中处于所述第一水平基线和所述第二水平基线之间的图像在水平方向上进行投影;
区域确定子单元,用于根据投影结果,确定所述待读取图像中的字符区域和背景区域;
第二初步分割子单元,用于设定被确定为背景的对应区域为相邻字符的初步分割位置;
第二最后分割子单元,用于根据所述待读取图像中每一连通域的大小和位置,对所述初步分割位置进行筛选,获得最后确定分割位置。
较佳地,上述所述的装置,其中,所述区域确定子单元包括:
第四比较结构,用于获得所投影每一像素列的累加数值,将所述累加数值与第二预设数值进行比较;
字符区域确定结构,用于当所述累加数值大于所述第二预设数值时,则确定所对应像素列的区域为字符;
背景区域确定结构,用于当所述累加数值小于所述第二预设数值时,则确定所对应像素列的区域为背景。
较佳地,上述所述的装置,其中,所述基线确定子单元包括:
第四投影计算结构,用于将所述待读取图像在竖直方向进行投影;
基线位置确定结构,用于获得所投影每一像素行的累加数值,设定累加数值较大两个像素行分别为第一水平基线和第二水平基线的所在位置。
采用上述结构图像分割单元,首先需要确定所述待读取图像中在竖直方向投影时的累加数值较大两处所对应像素行分别为第一水平基线和第二水平基线的位置。之后利用第一水平基线与第二水平基线之间的图像在水平方向上的投影,初步确定待读取图像的字符区域和背景区域,根据初步确定的字符区域和背景区域,进行相邻字符的粗分割,也即获得初步分割位置。
在此基础上,根据所述待读取图像中每一连通域的大小和位置,对所述初步分割位置进行筛选,获得最后确定分割位置,具体方式为:
对于面积过小的连通域,考察该连通域周围是否有其他连通域,如有其他连通域,则将该连通域与周围相邻的连通域进行合并;如没有其他连通域,且该面积较小连通域处于第一水平基线或第二水平基线附近时,则将该面积较小的连通域视为标点符号;
对于面积过大、且水平方向上宽度过大的连通域,将该连通域所对应区域的二值化阈值提高,重新进行二值化操作,确定是否能分割为两个或多个在水平方向上无重叠的连通域;
最后结合上述的初步分割位置与各连通域的位置,检测初步分割位置是否合理,若不合理则进行撤销,此外调整初步分割位置以正确分开每个连通域,同时将水平方向上较宽的空白背景间隔视为单词间的空格,完成字符的精分割。
较佳地,上述所述的装置,其中,所述图像识别模块还包括:
字符大小调整单元,用于当对所述待读取图像中的字符进行分割之后,调整每一字符图像的大小,使每一字符图像的大小相等,且每一字符图像组合构成的待翻译所述文字在所述待读取图像中处于居中位置。
经过上述归一化处理之后的字符,更便于后续的字符识别过程。
较佳地,上述所述的装置,其中,所述字符识别单元包括:
字符模版匹配子单元,用于将所分割出每一所述字符与不同字符模版进行匹配,确定与所述字符匹配的字符模版,识别出所述字符;或者
第一训练子单元,用于确定预定机器学习模型中表征预设语言中每一字符的特定特征;
第二训练子单元,用于采用所述特定特征对所述预定机器学习模型进行训练,获得离线训练数值;
第三训练子单元,用于根据所述离线训练数值确定所述预定机器学习模型的影响因素;
训练结果识别子单元,获取所分割出的每一所述字符的特定特征,将每一所述字符的特定特征输入到所述预定机器学习模型中,根据所述预定机器学习模型的输出,识别所述预设语言中与每一所述字符对应的字符。
本发明实施例所述用于手势指点翻译的装置,通过上述功能的各结构,能够在用户阅读过程中实时地拍摄获得所阅读视野范围内情景的当前图像,当根据该当前图像确定用户作出了指示所阅读文字信息的其中一文字被翻译的预定操作手势时,实时地识别该预定操作手势所指示的文字,对该文字进行翻译和输出,使用户在进行阅读的同时只需要作出预定操作手势,指示需要被翻译文字,即能够实时获得翻译信息,不需要跳出阅读过程,从而能够获得更好的阅读体验。
本发明另一方面提供一种电子设备,其中,包括:
至少一个处理器;以及
与所述至少一个处理器连接的存储器;其中,
所述存储器存储有可被所述至少一个处理器执行的指令程序,所述指令程序被所述至少一个处理器执行,以使所述至少一个处理器用于:
获取阅读文字视野范围内的当前图像;
检测所述当前图像中是否存在指示文字信息的预定操作手势;
当确定所述当前图像中存在所述预定操作手势时,识别所述当前图像中所述预定操作手势所指示的文字;
获取所述文字关于预设语言的翻译信息;
呈现一显示界面,在所述显示界面同时显示所述当前图像和所述翻译信息。
本发明方法方案中所述的任一方案,都可通过所述电子设备的至少一个处理器来调用存储器的相关指令程序来执行完成。在描述电子设备部分,不再赘述。
上述结构的电子设备,能够实时地识别阅读过程中预定操作手势所指示的文字,对该文字进行翻译和输出,使用户在进行阅读的同时只需要作出预定操作手势,指示需要被翻译文字,即能够实时获得翻译信息,不需要跳出阅读过程,从而能够获得更好的阅读体验。
上述结构的电子设备可以为一移动终端,如手机或pad,也可以为一配戴于用户头上的眼镜,或者为配戴于用户头上的专用于实时翻译阅读信息的独立装置。
较佳地,本发明实施例所述装置中,图像获取模块可以为一后置摄像头,用于拍摄获取示用户阅读一文字信息时所阅读视野范围内情景的当前图像。较佳地,该装置还可以包括另一前置摄像头,通过分析用户的瞳孔位置以读出用户的视线,以配合后置摄像头使后置摄像头进行准确对焦,更加准确地拍摄到用户当前阅读视野范围内情景的当前图像。
为了进一步提升用户体验,该装置还可以包括另一后置摄像头,也同时拍摄获取示用户阅读一文字信息时所阅读视野范围内情景的当前图像,该装置还可以进一步通过计算两个后置摄像头所拍摄到的当前图像的视差,确定用户当前视野区域的深度,以用于后续的三维立体显示输出,使得用户观看到三维立体显示的图像和翻译信息的输出形式。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!