胶囊内窥镜图像辅助阅片系统及方法与流程
本发明涉及医用设备领域,具体地指一种胶囊内窥镜图像辅助阅片系统及方法。
背景技术:
消化道疾病如胃癌、肠癌、急慢性胃炎、溃疡病等,多为常见病、多发病,它对人类的健康有很大的威胁。2015年全国肿瘤登记中心调查数据显示,消化道癌症占全部癌症发病率的43%。传统的光纤式内窥镜需插入病人体内进行观察,极为不便,而且给患者造成了痛苦。胶囊内窥镜能够以无痛无创的方式对整个消化道进行检查,是一场革命性的技术突破。胶囊内窥镜在进行检测的过程中会采集大约50000张图像,大量的图像数据使得医生的阅片工作变得艰巨且耗时。
基于深度学习的图像识别以及图像和视频的描述方法成为了近年来国内外非常热门的领域之一。随着深度学习方法在图片分类与定位(imagenet数据集)以及图像语义理解(coco数据集)等方面取得突破性的进展,深度学习技术也越来越多的应用于辅助医学诊断领域。目前已经有将深度学习技术应用于皮肤癌、脑部肿瘤、肺癌等的辅助检测,对于将深度学习技术用于消化道图像辅助诊断方面的研究尚不多见。
专利公开号为cn103984957a的中国专利,公开了一种胶囊内窥镜图像可疑病变区域自动预警系统,该系统采用图像增强模块对图像进行自适应增强,再通过纹理特征提取模块对平坦性病变的纹理特征进行检测,最后用分类预警模块进行分类,实现了对小肠平坦性病变的检测和预警功能。
上述方案只能对可疑病变区域进行预警,并不能对病灶进行分类识别,效果单一,而且不能给出疾病的位置信息。不利于医生对病灶的准确判断。
技术实现要素:
本发明的目的就是要提供一种胶囊内窥镜图像辅助阅片系统及方法,本发明利用机器学习技术,首先对消化道图像进行位置分类,得到消化道位置分类数据,并且能够检测出包含可疑病灶的图像,进一步根据检测出的可疑病灶图像生成诊断报告,将这些可疑病灶的图像和诊断报告展现给医生,支持医生对图像中的可疑病灶(如出血、息肉、溃疡等)进行进一步诊断分析,从而大大减少医生观看消化道图像的工作量,提高医生的诊断效率。
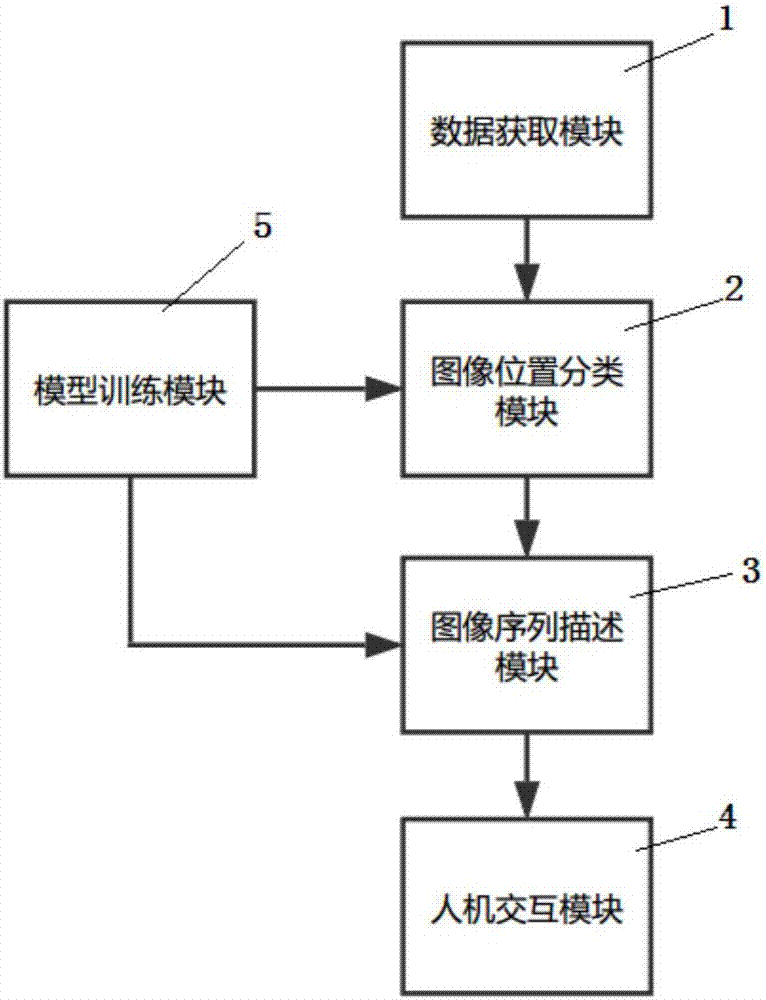
为实现此目的,本发明所设计的一种胶囊内窥镜图像辅助阅片系统,其特征在于,它包括数据获取模块、图像位置分类模块和图像序列描述模块,其中,数据获取模块的信号输出端连接图像位置分类模块的信号输入端,图像位置分类模块的信号输出端连接图像序列描述模块的信号输入端;
所述数据获取模块用于获取检查者的胶囊内窥镜图像数据;所述图像位置分类模块用于将所述的胶囊内窥镜图像数据按照拍摄的消化道部位的不同分为不同的图像序列;所述图像序列描述模块用于识别消化道不同部位的图像序列中的病灶,并生成对图像序列的描述性文字,从而形成诊断报告。
一种利用上述系统的胶囊内窥镜图像辅助阅片方法,其特征在于,它包括如下步骤:
步骤1:数据获取模块获取检查者的胶囊内窥镜图像数据;
步骤2:数据获取模块将获取的检查者的胶囊内窥镜图像数据输入到图像位置分类模块内的第一卷积神经网络cnn(convolutionalneuralnetwork,cnn)模型中按照拍摄部位的不同进行图像分类,从而得到不同消化道部位的图像序列;
步骤3:图像位置分类模块将不同消化道部位的图像序列发送给图像序列描述模块的第二卷积神经网络cnn模型中,得到不同消化道部位图像序列的特征矢量序列,不同消化道部位的图像序列中的每一张图像均对应一个特征矢量,所有的特征矢量组成特征矢量序列;
步骤4:将特征矢量序列输入到图像序列描述模块的递归神经网络rnn(recurrentneuralnetwork)模型中得到不同消化道部位的图像序列的描述性文字,图像序列描述模块根据上述不同消化道部位的图像序列的描述性文字生成辅助诊断报告。
本发明采用深度学习模型,通过模型的训练自动学习如何按照拍摄的消化道位置进行图像分类、识别图像中的病灶以及生成描述性文字,继而帮助医生处理大量的消化道图像,最终辅助医生做出正确判断和有效决策。本发明可以大大降低医生的工作量和工作压力,提高其工作效率。
附图说明
图1为本发明的结构框图;
图2为本发明中加入模型训练模块的结构框图;
图3为本发明中图像序列描述方法的网络结构图;
图4为本发明中lstm网络的结构图;
其中,1—数据获取模块、2—图像位置分类模块、3—图像序列描述模块、4—人机交互模块、5—模型训练模块。
具体实施方式
以下结合附图和具体实施例对本发明作进一步的详细说明:
如图1和2所示的胶囊内窥镜图像辅助阅片系统,它包括数据获取模块1、图像位置分类模块2和图像序列描述模块3,其中,数据获取模块1的信号输出端连接图像位置分类模块2的信号输入端,图像位置分类模块2的信号输出端连接图像序列描述模块3的信号输入端;
所述数据获取模块1用于获取检查者的胶囊内窥镜图像数据;所述图像位置分类模块2用于将所述的胶囊内窥镜图像数据按照拍摄的消化道部位的不同分为不同的图像序列;所述图像序列描述模块3用于识别消化道不同部位的图像序列中的病灶,并生成对图像序列的描述性文字,从而形成诊断报告。
上述技术方案中,所述图像位置分类模块2用于使用第一卷积神经网络cnn模型将胶囊内窥镜图像按拍摄部位的不同进行分类,分为包括食道、贲门、胃底、胃体、胃角、胃窦、幽门、十二指肠、空肠、回肠等部位的图像序列。
上述技术方案中,所述图像序列描述模块3用于利用第二卷积神经网络cnn模型对不同拍摄部位的图像序列进行图像特征提取得到不同消化道部位图像序列的特征矢量序列;所述图像序列描述模块3还用于利用递归神经网络rnn模型将特征矢量序列中的图像特征转化为描述性文字,从而形成辅助诊断报告。
上述技术方案中,它还包括人机交互模块4,所述图像序列描述模块3的信号输出端连接人机交互模块4的信号输入端;
所述人机交互模块4用于将生成的诊断报告呈现给医生,供医生根据机器识别的结果进行病情诊断分析。
上述技术方案中,它还包括模型训练模块5,所述模型训练模块5的第一数据通信端连接图像位置分类模块2的训练数据通信端,模型训练模块5的第二通信端连接图像序列描述模块3的训练数据通信端;
所述模型训练模块5用于利用随机梯度下降法训练所述图像位置分类模块2中使用的第一卷积神经网络cnn模型,训练后的分类模型能够对输入的胶囊内窥镜图像按拍摄部位的不同进行分类;
模型训练模块5还用于利用随机梯度下降法训练所述图像序列描述模块3中使用的第二卷积神经网络cnn模型,训练后的分类模型能够提取不同消化道部位图像序列的特征矢量序列,并得到特征矢量序列;
模型训练模块5还用于利用随机梯度下降法训练所述图像序列描述模块3中使用的递归神经网络rnn模型,训练后的递归神经网络rnn模型能根据特征矢量序列得到不同消化道部位的图像序列的描述性文字。
上述技术方案中,递归神经网络rnn模型使用长短时记忆lstm网络,能够学习长期依赖关系,将可变长输入映射为可变长的输出。
一种利用上述系统的胶囊内窥镜图像辅助阅片方法,其特征在于,它包括如下步骤:
步骤1:数据获取模块1获取检查者的胶囊内窥镜图像数据;
步骤2:数据获取模块1将获取的检查者的胶囊内窥镜图像数据输入到图像位置分类模块2内的第一卷积神经网络cnn模型中按照拍摄部位的不同进行图像分类,从而得到不同消化道部位的图像序列;
步骤3:图像位置分类模块2将不同消化道部位的图像序列发送给图像序列描述模块3的第二卷积神经网络cnn模型中,得到不同消化道部位图像序列的特征矢量序列(通过将传统神经网络中的最后一个全连接分类层去掉,直接获得表征图像特征的矢量),不同消化道部位的图像序列中的每一张图像均对应一个特征矢量,所有的特征矢量组成特征矢量序列;
步骤4:将特征矢量序列输入到图像序列描述模块3的递归神经网络rnn模型中得到不同消化道部位的图像序列的描述性文字(主要是图像中的病灶信息),图像序列描述模块3根据上述不同消化道部位的图像序列的描述性文字生成辅助诊断报告。
上述技术方案的步骤4中,图像序列描述模块3的递归神经网络rnn模型由两层lstm(longshort-termmemory,lstm,是一种时间递归神经网络)网络组成,将图像序列描述模块3的卷积神经网络cnn模型的输出作为第一层lstm网络的输入,将第一层lstm网络的隐藏层作为第二层lstm网络的输入,lstm网络作为特征矢量序列的解码器,生成相应的辅助诊断描述文字。
上述技术方案的步骤2中,模型训练模块5对图像位置分类模块2内的第一卷积神经网络cnn模型进行训练,训练过程包括预训练和模型优化两个阶段,在预训练阶段,使用随机梯度下降法在imagenet数据集上训练图像位置分类模块2内的第一卷积神经网络cnn模型,得到预训练后的第一卷积神经网络cnn模型;在优化阶段,用人工标记的消化道分段样本对预训练过的第一卷积神经网络cnn模型的参数进行调优(使用自己的数据再一次对网络进行训练,英文为fine-tuning)。
上述技术方案的所述步骤3中,模型训练模块5对图像序列描述模块3的第二卷积神经网络cnn模型进行训练,训练过程包括预训练和模型优化两个阶段,在预训练阶段,使用随机梯度下降法在imagenet数据集上训练图像序列描述模块3内的第二卷积神经网络cnn模型,得到预训练后的第二卷积神经网络cnn模型;在优化阶段,用人工标记的不同类型的消化道病灶(如出血、息肉、溃疡等)图像数据样本对预训练过的第二卷积神经网络cnn模型的参数进行调优。
上述技术方案的所述步骤3中,模型训练模块5将特征矢量序列和人工标记的图像特征与图像序列描述性文字的对应关系样本输入到递归神经网络rnn模型中进行训练,得到输入的图像特征序列所对应的描述性文字。
上述技术方案中,所述的递归神经网络rnn模型之所以选择lstm网络,是因为对于某个消化道部位的诊断是需要综合该部位所有的图像信息。要得出诊断报告,就需要能够处理较长历史记忆功能的模型,以便综合考虑所有的图像信息,而lstm模型能够记忆较长时间的信息,将可变长输入映射为可变长的输出,即lstm网络能够很好的处理图像序列信息,得到图像序列综合性的描述。
上述技术方案中,第一卷积神经网络cnn模型和第二卷积神经网络cnn模型可以是alexnet、vgg、googlenet、resnet等,本实施例优选为深度残差网络resnet(deepresidualnetwork),该网络模型相较于其他模型具有更深的网络层次,并且识别错误率更低,进而能够取得较好的分类识别效果。
图3是一种图像序列描述方法的网络结构图。将图像序列作为卷积神经网络cnn模型输入,由卷积神经网络cnn模型生成图像特征向量,接下来使用lstm网络作为图像特征向量的解码器,生成相应的辅助诊断描述文字。lstm模型由于可以学习较长特征序列之间的依赖关系,因此可利用lstm模型的这种特性学习图像序列的时间序列关系,并通过学习到的语言模型生成消化道图像序列的诊断信息。
图4是一种lstm网络结构图。lstm分为编码过程(encoding)和解码过程(decoding)。
上述技术方案中,所述lstm网络分为编码过程和解码过程:
lstm网络的编码过程使用图像特征xt和隐藏状态ht-1作为输入,通过lstm网络中lstm单元的计算得到记忆单元状态ct,其中下标t表示第t步递归,完整的lstm编码过程的计算公式如下:
it=σ(wxixt+whiht-1+bi)
ft=σ(wxfxt+whfht-1+bf)
ot=σ(wxoxt+whoht-1+bo)
ct=ft·ct-1+it·gt
其中,
lstm网络解码过程产生的辅助诊断信息需要通过输入图像序列的条件概率来评估,公式如下:
其中,(x1,…,xn)表示输入的不同消化道部位的图像序列,n表示图像帧数,(y1,…,ym)表示输出的文字序列,m表示文字个数;p(yt|hn+t)是由词汇表的softmax函数计算得到的概率,hn+t是通过hn+t-1,yt-1根据编码过程的公式计算得到,下标t表示第t次递归,n表示第n帧图像,p表示概率;
lstm网络的训练过程即求解码阶段p(y1,…,ym|x1,…,xn)的极大似然估计,极大似然估计的公式如下:
其中
本说明书未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!