混合存储系统中SSD管理方法及装置与流程
本发明涉及数据存储领域,特别是指一种混合存储系统中ssd管理方法及装置。
背景技术:
目前存储系统的发展趋向于大容量,低成本和高性能,而任何单一的存储器件如非易失性随机存储器(nonvolatilerandomaccessmemory,nvram)、固态硬盘(solidstatedrives,ssd)、磁盘等由于其物理特性的限制,并不能满足以上需求。混合存储充分利用不同存储器件的特性组成高效的存储系统,既能支持存储系统容量的大幅扩展,又能在保持系统低成本的前提下,显著提高存储系统的性能。
现有的混合存储系统仅仅将ssd作为一个数据热点cachememory(高速缓冲存储器)使用,将热点数据置于ssd中来加快读数据的访问。对数据的组织方式和应用并没有改变,只是简单地做了一层缓存到磁盘的映射的查询。在随机写时,存在写放大,系统随机写的性能低。
技术实现要素:
本发明提供一种混合存储系统中ssd管理方法及装置,本发明能够将所有应用层的随机io都转换成顺序写,并避免写放大,有效地提高了随机写的性能,减少了写入延迟,有效地发挥了混合存储系统的优势。
为解决上述技术问题,本发明提供技术方案如下:
一方面,本发明提供一种混合存储系统中ssd管理方法,该方法包括:
将ssd按照一定大小划分成多个bucket,并使用b-tree管理bucket;
当需要将缓存数据写入ssd时,执行如下操作:
聚合连续io和/或同一用户的缓存数据;
选择合适的bucket,作为可用bucket;
从可用bucket的数据偏移位置开始顺序写入缓存数据,所述数据偏移位置记录bucket的已使用缓存空间的位置;
更新可用bucket的数据偏移位置,以便下次写入缓存数据。
进一步的,所述选择合适的bucket,作为可用bucket包括:
判断是否有空闲bucket,若是,选择一个空闲bucket作为可用bucket,否则,执行下列步骤;
判断是否有后备bucket,若是,选择一个后备bucket作为可用bucket。
进一步的,如果没有后备bucket,则执行如下步骤:
将所有bucket按照优先级从小到大排序,所述优先级表示bucket的使用频率;
将优先级小的若干个bucket中的热点数据转存到其中一个bucket中,释放其他bucket,释放后的bucket作为后备bucket。
进一步的,所述方法还包括:
以bkey为单位将缓存数据写回磁盘,并向b-tree更新节点。
进一步的,所述方法还包括:
使用日志按照插入时间排序记录b-tree叶子节点上bkey的更新。
进一步的,所述方法还包括:
判断要读取的数据是否已经作为缓存数据全部写入ssd中,若是,直接从ssd读出数据,否则,从磁盘读取数据至ssd中,并向b-tree更新节点。
另一方面,本发明提供一种混合存储系统中ssd管理装置,该装置包括:
bucket划分模块,用于将ssd按照一定大小划分成多个bucket,并使用b-tree管理bucket;
当需要将缓存数据写入ssd时,执行bucket管理模块,所述bucket管理模块包括:
聚合单元,用于聚合连续io和/或同一用户的缓存数据;
bucket选择单元,用于选择合适的bucket,作为可用bucket;
写入单元,用于从可用bucket的数据偏移位置开始顺序写入缓存数据,所述数据偏移位置记录bucket的已使用缓存空间的位置;
更新单元,用于更新可用bucket的数据偏移位置,以便下次写入缓存数据。
进一步的,所述bucket选择单元包括:
空闲bucket选择单元,用于判断是否有空闲bucket,若是,选择一个空闲bucket作为可用bucket,否则,执行后备bucket选择单元;
后备bucket选择单元,用于判断是否有后备bucket,若是,选择一个后备bucket作为可用bucket。
进一步的,如果没有后备bucket,则bucket选择单元还包括:
bucket排序单元,用于将所有bucket按照优先级从小到大排序,所述优先级表示bucket的使用频率;
bucket释放单元,用于将优先级小的若干个bucket中的热点数据转存到其中一个bucket中,释放其他bucket,释放后的bucket作为后备bucket。
进一步的,所述装置还包括:
日志模块,用于使用日志按照插入时间排序记录b-tree叶子节点上bkey的更新。
本发明具有以下有益效果:
本发明中,bucket内空间是追加分配的,只记录当前分配到哪个偏移了,下一次分配的时候从当前记录位置往后分配。在向bucket写入缓存数据时,有两个优先原则:1)优先考虑io连续性,即使io可能来自于不同的生产者;2)其次考虑相关性,同一个用户(进程)产生的数据尽量缓存到相同的bucket里。我们将上述缓存数据合并,一次写入bucket,这样所有应用层的随机io都转换成顺序写,并避免写放大,有效地提高了随机写的性能,减少了写入延迟,有效地发挥了混合存储系统的优势。
附图说明
图1为本发明的混合存储系统中ssd管理方法流程图;
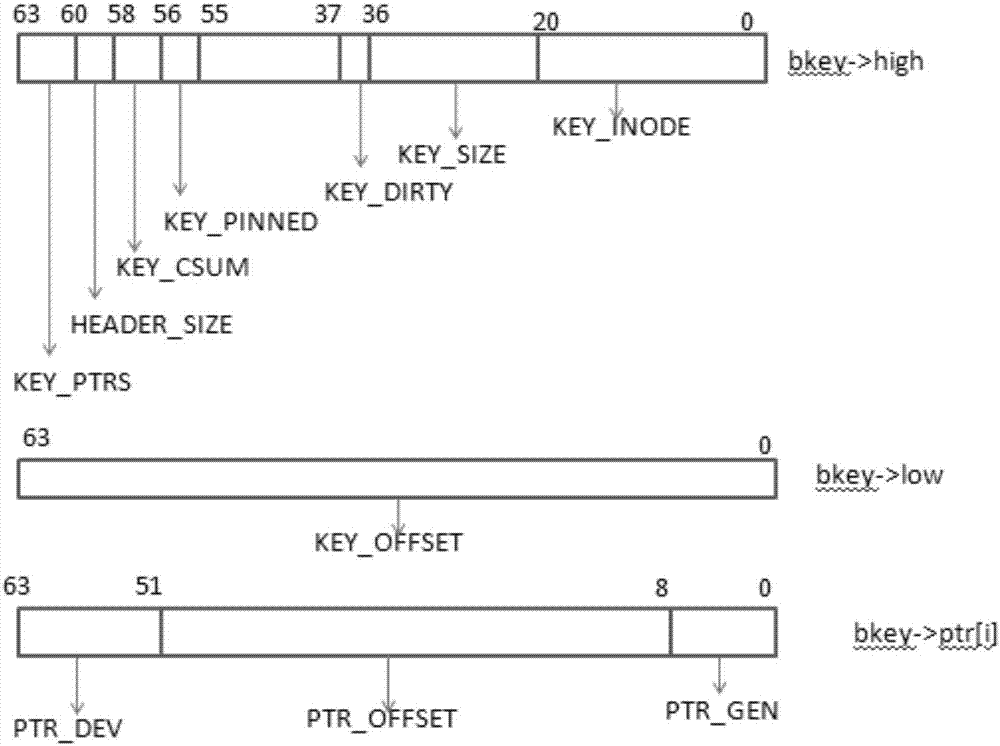
图2为为本发明中bkey的示意图;
图3为本发明的混合存储系统中ssd管理装置示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
一方面,本发明提供一种混合存储系统中ssd管理方法,如图1所示,包括:
步骤100:将ssd按照一定大小划分成多个bucket,并使用b-tree管理bucket。
缓存设备(ssd)会按照bucket大小划分成很多bucket(存储桶),bucket的大小最好是设置成与缓存设备ssd的擦除大小一致,建议128k~2m+,默认是512k。
bucket的管理是使用b+树(b-tree,b+tree,btree)索引,而b+树节点中的关键结构就是bkey,bkey就是记录缓存设备缓存数据和后端设备数据的映射关系的,其结构图2。
当需要将缓存数据写入ssd时,执行如下操作:
步骤210:聚合连续io和/或同一用户的缓存数据。
步骤220:选择合适的bucket,作为可用bucket。
步骤230:从可用bucket的数据偏移位置开始顺序写入缓存数据,数据偏移位置记录bucket的已使用缓存空间的位置。
步骤240:更新可用bucket的数据偏移位置,以便下次写入缓存数据。
本发明中,bucket内空间是追加分配的,只记录当前分配到哪个偏移了,下一次分配的时候从当前记录位置往后分配。在向bucket写入缓存数据时,有两个优先原则:1)优先考虑io连续性,即使io可能来自于不同的生产者;2)其次考虑相关性,同一个用户(进程)产生的数据尽量缓存到相同的bucket里。我们将上述缓存数据合并,一次写入bucket,这样所有应用层的随机io都转换成顺序写,并避免写放大,有效地提高了随机写的性能,减少了写入延迟,有效地发挥了混合存储系统的优势。
本发明中,bucket的分配和管理有多种方法,优选的,选择合适的bucket,作为可用bucket(步骤220)包括:
步骤221:判断是否有空闲bucket,若是,选择一个空闲bucket作为可用bucket,否则,执行下列步骤。
步骤222:判断是否有后备bucket,若是,选择一个后备bucket作为可用bucket。
如果没有后备bucket,则执行如下步骤:
步骤223:将所有bucket按照优先级从小到大排序,优先级表示bucket的使用频率。
步骤224:将优先级小的若干个bucket中的热点数据转存到其中一个bucket中,释放其他bucket,释放后的bucket作为后备bucket。
步骤221-224的一个具体实施方式如下:
每个bucket有个优先级编号(16bit的priority),每次hit(命中)都会增加,然后所有的bucket的优先级编号都会周期性地减少,不常用的会被回收,这个优先级编号主要是用来实现lru替换的。bucket还有8bit的generation,用来invalidatebucket用的。
bucket的分配如下:
a.先查看当前是否有空闲的bucket,可用下列函数查看:
fifo_pop(&ca->free[reserve_none],r)||fifo_pop(&ca->free[reserve],r));
b.若无空闲的bucket可用,则当前线程进入等待,直到有可用的bucket;
c.唤醒分配线程;
d.更新bucket信息,若该bucket分配给元数据使用,设置bucket标识为gc_mark_metadata不能随意回收标识,设置bucket目前不需要垃圾收集器处理标识。否则设置bucket为可回收标识。
分配线程如下:
a.如果后备free_inc不为空,fifo_pop(&ca->free_inc,bucket)一个后备bucket,将其加入ca->free中,这样保证分配函数有可用的bucket.然后唤醒等待分配桶的线程。若ca->free已满,则分配线程阻塞。
b.如果free_inc已经空了,则需要invalidate当前正在使用的bucket;
遍历ssd的每个bucket{
若不能回收则continue;
将bucket加入到heap中,比较函数为bucket_max_cmp,用来比较桶的优先级大小;
}
按优先级从小到大排序heap(bucket_min_cmps);
一次从堆中取出bucket,做sarw_invalidate_one_bucket;直到ca->free_inc满;
若ca->free_inc未满,则唤醒垃圾回收线程。
c.更新存储在磁盘中的bucket的gen信息sarw_prio_write。
垃圾回收线程如下:
其主要思路是:合并包含较少key的btreenode,来释放bucket,移动叶节点对应bucket(bucket->gen<=key->gen)数据区未用满的bucket来节省bucket;
它会扫描整个btree,判断哪些bkey是可以gc(回收)的,把能够gc的bkey加到moving_gc_keys链表中,然后就根据这个可以gc的key先从ssd中读出数据,然后同样根据key中记录的hdd上的偏移写到hdd中,成功后把该key从moving_gc_keys中移除。
bucket分配器在inc_free未满的情况下会唤醒垃圾回收线程线程,其流程如下:
a.sarw_gc_start设置软件标记表明gc开始工作。
b.sarw_root工作调用sarw_btree_gc_root来遍历btree,分析哪些bucket可被gc回收。
c.sarw_btree_gc_finish标记不能gc的bucket为meta,并统计能gc的bucket数目。
d.唤醒分配器线程。
e.完成实际垃圾回收工作。
它遍历b+tree的每个node,对每个node执行btree_gc_coalesce。该函数判断若一个到多个node的keys所占用的空间较小,则通过合并btreenode的方式来减少bucket的使用量。
本发明还包括写回过程,包括:
步骤300:以bkey为单位将缓存数据写回磁盘,并向b-tree更新节点。
一个bucket里面缓存的数据可能对应hdd(磁盘)上的不同位置,甚至有可能在不同的hdd。它是以bkey为单位来写回,而不是以bucket为单位。它有一个writeback_keys链表,记录需要写回的bkeys。当满足刷脏数据(写回)的条件时(脏数据比例),就会遍历整个b+树,查找dirty的bkey,放到writeback_keys链表中(writeback_keys有个大小限制),然后按照磁盘偏移排序,再进行刷脏数据的动作,数据写到hdd后,会把对应的bkey从writeback_keys链表中移除,并去掉该bkey的dirty标记。这样的好处在于刷脏数据的时候可以尽量考虑hdd上的连续性,减少磁头的移动,而如果以bucket为单位刷,一个bucket可能缓存hdd上不同位置的数据,比较随机,刷脏数据的效率不高。
写回过程的一个具体实施方式包括
a.查看是否和已有要writeback的区域有重合,若有,取消当前区域的bypass。
b.若bio为req_discard,则采用bypass。
c.向b+tree更新节点。
具体的实现过程为;
对于叶节点执行:
a.若node未dirty则延迟调用后台刷写.
b.已dirty,如果bset的大小已经很大则sarw_btree_node_write(b,null);注意对于多数情况并不会立即更新node以提高性能。这时就靠前面的sarw_journal,来记录更新的日志来保证更改不会丢失了。
对于非页节点执行:
将分三种情况实际更新b+tree
case1:要插入key<btree->key,则直接调用btree_insert_key插入。
case2:和btree已有key部分重合,计算不重合部分插入;
bkey_copy(&temp.key,insert_keys->keys);
sarw_cut_back(&b->key,&temp.key);
sarw_cut_front(&b->key,insert_keys->keys);
ret|=btree_insert_key(b,&temp.key,replace_key)。
case3:完全包含与btree->key则不插入。
本发明使用b+tree和日志(journal)混合方法来跟踪缓存数据,此时,本发明的方法还包括:
步骤400:使用日志按照插入时间排序记录b-tree叶子节点上bkey的更新。
journal不是为了一致性恢复用的,而是为了提高性能。在写回提到没有journal之前每次写操作都会更新元数据(一个bset),为了减少这个开销,引入journal,journal就是插入的keys的log,按照插入时间排序,只用记录叶子节点上bkey的更新,非叶子节点在分裂的时候就已经持久化了。这样每次写操作在数据写入后就只用记录一下log,在崩溃恢复的时候就可以根据这个log重新插入key。
日志就是插入的keys的log,按照插入时间排序,只用记录叶子节点上bkey的更新,非叶子节点在分裂的时候就已经持久化了。这样每次写操作在数据写入后就只用记录一下log,在崩溃恢复的时候就可以根据这个log重新插入key。
本发明还包括读取过程,包括:
步骤500:判断要读取的数据是否已经作为缓存数据全部写入ssd中,若是,直接从ssd读出数据,否则,从磁盘读取数据至ssd中,并向b-tree更新节点。
读取过程的一个实施方式为:
a.如果device没有对应的缓存设备,则直接将向主设备提交bio,并返回。
b.如果有cachedevice根据要传输的bio,用search_alloc建立structsearchs。
c.调用check_should_bypasscheck是否应该bypass这个bio。
d.根据读写分别调用cached_dev_read或cached_dev_write。
具体如下:
遍历b+tree叶子节点,来查找bkey:key(inode,bi_sector,0);当遍历到页节点时lookup_fn函数会被调用。
a.若带搜索的key比当前key小,则返回map_continue让上层搜索下一个key。
b.若key不在b+tree或key中的数据只有部分在b+tree则调用cache_miss(b,s,bio,sectors)。
c.如果数据已在缓存中(bkey在b+tree中,且key中的数据范围也完全在缓存中)了,则直接从缓存disk读取,命中后需将bucket的prio重新设为32768。
d.从主设备读取数据,并将bio记录到iop.bio中以便上层。
e.当iop.bio不为0时,表明有新的数据要添加到管理缓存的b+tree中,所以首先bio_copy_data(s->cache_miss,s->iop.bio)将数据拷贝到cache_missbio中,然后调用sarw_data_insert将数据更新到cache设备中。
另一发面,本发明提供一种混合存储系统中ssd管理装置,如图3所示,包括:
bucket划分模块1,用于将ssd按照一定大小划分成多个bucket,并使用b-tree管理bucket。
当需要将缓存数据写入ssd时,执行bucket管理模块2,bucket管理模块2包括:
聚合单元21,用于聚合连续io和/或同一用户的缓存数据。
bucket选择单元22,用于选择合适的bucket,作为可用bucket。
写入单元23,用于从可用bucket的数据偏移位置开始顺序写入缓存数据,数据偏移位置记录bucket的已使用缓存空间的位置。
更新单元24,用于更新可用bucket的数据偏移位置,以便下次写入缓存数据。
本发明中,bucket内空间是追加分配的,只记录当前分配到哪个偏移了,下一次分配的时候从当前记录位置往后分配。在向bucket写入缓存数据时,有两个优先原则:1)优先考虑io连续性,即使io可能来自于不同的生产者;2)其次考虑相关性,同一个用户(进程)产生的数据尽量缓存到相同的bucket里。我们将上述缓存数据合并,一次写入bucket,这样所有应用层的随机io都转换成顺序写,并避免写放大,有效地提高了随机写的性能,减少了写入延迟,有效地发挥了混合存储系统的优势。
本发明中,bucket的分配和管理有多种方法,优选的,bucket选择单元包括:
空闲bucket选择单元,用于判断是否有空闲bucket,若是,选择一个空闲bucket作为可用bucket,否则,执行后备bucket选择单元。
后备bucket选择单元,用于判断是否有后备bucket,若是,选择一个后备bucket作为可用bucket。
如果没有后备bucket,则bucket选择单元还包括:
bucket排序单元,用于将所有bucket按照优先级从小到大排序,优先级表示bucket的使用频率。
bucket释放单元,用于将优先级小的若干个bucket中的热点数据转存到其中一个bucket中,释放其他bucket,释放后的bucket作为后备bucket。
本发明使用b+tree和日志(journal)混合方法来跟踪缓存数据,此时,本发明的装置还包括:
日志模块,用于使用日志按照插入时间排序记录b-tree叶子节点上bkey的更新。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!