距离感应方法、设备及存储介质与流程
本发明涉及人机交互领域,尤其涉及一种距离感应方法、设备及存储介质。
背景技术:
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部的一系列相关技术,通常也叫做人像识别、面部识别。当前人脸识别主要运用在相机拍照定位人脸位置从而加大这个位置的清晰度,使照片在脸部的画面更漂亮,并没有计算出设备与人距离。另外市面上的麦克风录音设备都是单纯的作为声音输入,没有去计算音源与设备的距离。人机交互的界面在一百年间已经走过了旋钮、按键到触摸屏的演化,而一些厂商推出的智能音箱则代表着又一次交互的变革,它完全无需用户动手或是穿戴配件,仅仅通过语音关键词唤醒音箱进行语音交互,但是当前市面上的智能语音音箱人机互动主要通过麦克风阵列来实现的,需要通过特定关键词唤醒后才能进行语音交互,如果忘记或者说错特定关键词则无法唤醒设备,在一定程度上还是无法提供良好的人机交互体验,给用户的日常使用造成不便。
技术实现要素:
本发明的主要目的在于一种距离感应方法、设备及存储介质,旨在解决现有技术中需要特定关键词唤醒设备造成用户使用不便的技术问题。
为实现上述目的,本发明提供一种距离感应方法,所述距离感应方法包括以下步骤:
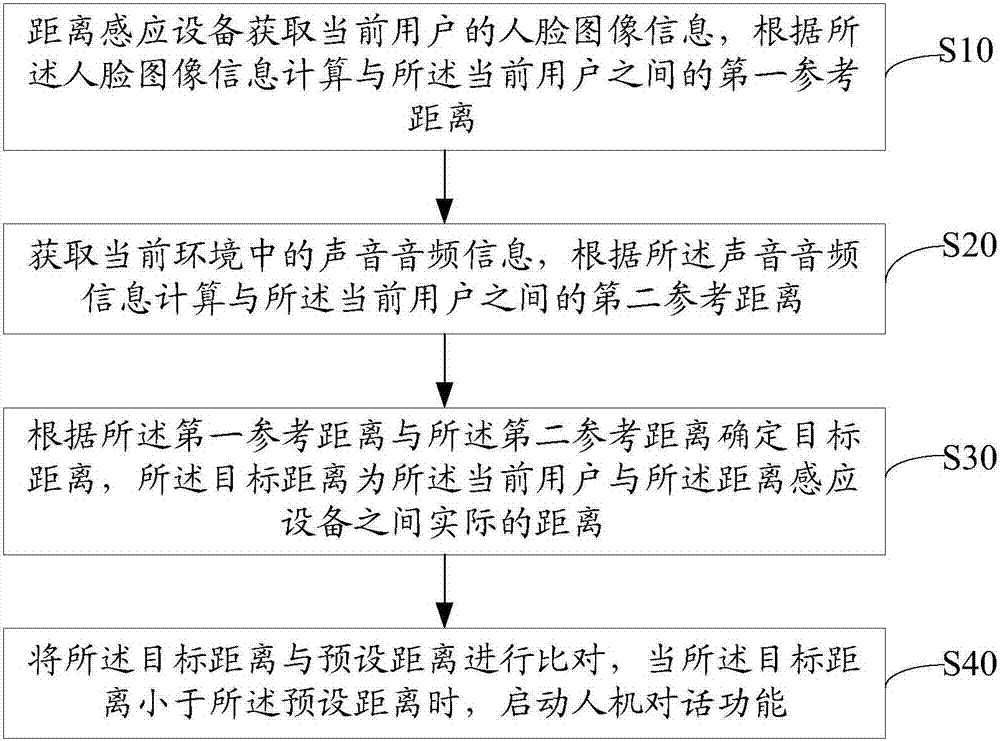
距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离;
获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离;
根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离;
将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能。
优选地,所述距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,具体包括:
采集所述当前用户的人脸图像,对所述人脸图像进行动态比对分析,并生成第一分析结果;
将所述第一分析结果作为所述人脸图像信息,利用预设人脸识别算法根据所述人脸图像信息计算与所述当前用户之间的所述第一参考距离。
优选地,所述采集所述当前用户的人脸图像,对所述人脸图像进行动态比对分析,并生成第一分析结果,具体包括:
采集所述当前用户不同角度的人脸图像,提取所述人脸图像中的多个人脸特征点,将各人脸特征点与预设人脸特征点数据库中的预设人脸特征点进行比对分析,生成所述第一分析结果。
优选地,所述获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,具体包括:
采集所述当前用户在所述当前环境中产生的声音,对所述声音进行声纹分析,并生成第二分析结果;
将所述第二分析结果作为所述声音音频信息,利用预设声纹识别算法根据所述声音音频信息计算与所述当前用户之间的所述第二参考距离。
优选地,所述采集所述当前用户在所述当前环境中产生的声音,对所述声音进行声纹分析,并生成第二分析结果,具体包括:
采集所述当前用户在所述当前环境中产生的声音,提取所述声音中的多个声纹特征,将各声纹特征与预设声纹特征数据库中的预设声纹特征进行比对分析,生成所述第二分析结果。
优选地,所述根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,具体包括:
根据预设权重比例对所述第一参考距离与所述第二参考距离进行加权平均计算,根据计算结果获取所述目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离。
优选地,所述将所述目标距离与预设距离进行比对,当所述目标距离小于预设距离时,启动人机对话功能之前,所述距离感应方法还包括:
获取所述当前用户的人体红外信息,根据所述人体红外信息计算与所述当前用户之间的第三参考距离;
根据所述第三参考距离对所述目标距离进行校正,将校正后的距离作为新的目标距离。
优选地,所述距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离之前,所述距离感应方法还包括:
获取当前运行模式,当所述当前运行模式为预设私人模式时,获取所述当前用户的人脸图像信息,将所述人脸图像信息与预设人脸图像信息库中的预设人脸图像信息进行匹配;
当所述人脸图像信息与所述预设人脸图像信息不匹配时,生成提示信息发送至预设信息接收终端。
此外,为实现上述目的,本发明还提出一种距离感应设备,所述距离感应设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的距离感应程序,所述距离感应程序配置为实现如上文所述的距离感应方法的步骤。
此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有距离感应程序,所述距离感应程序被处理器执行时实现如上文所述的距离感应方法的步骤。
本发明提出的距离感应方法,本发明通过距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能,能够通过人脸识别和声波感应获得的距离与预设距离比较,从而让设备做出不同响应,不用依赖特定关键词进行设备唤醒,缩短了设备响应的时间,让设备更加智能化和人性化,提升了用户体验。
附图说明
图1为本发明实施例方案涉及的硬件运行环境的距离感应设备结构示意图;
图2为本发明距离感应方法第一实施例的流程示意图;
图3为本发明距离感应方法第二实施例的流程示意图;
图4为本发明距离感应方法第三实施例的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例的解决方案主要是:本发明通过距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能,能够通过人脸识别和声波感应获得的距离与预设距离比较,从而让设备做出不同响应,不用依赖特定关键词进行设备唤醒,缩短了设备响应的时间,让设备更加智能化和人性化,提升了用户体验,解决了现有技术中需要特定关键词唤醒设备造成用户使用不便的问题。
参照图1,图1为本发明实施例方案涉及的硬件运行环境的距离感应设备结构示意图。
如图1所示,该距离感应设备可以包括:处理器1001,例如cpu,通信总线1002、用户端接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户端接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户端接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的距离感应设备结构并不构成对该距离感应设备的限定,可以包括比图示更多或更少的部件例如摄像头、红外传感器、麦克风阵列和喇叭等,或者组合某些部件例如智能音响,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户端接口模块以及距离感应程序。
本发明距离感应设备通过处理器1001调用存储器1005中存储的距离感应程序,并执行以下操作:
距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离;
获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离;
根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离;
将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
采集所述当前用户的人脸图像,对所述人脸图像进行动态比对分析,并生成第一分析结果;
将所述第一分析结果作为所述人脸图像信息,利用预设人脸识别算法根据所述人脸图像信息计算与所述当前用户之间的所述第一参考距离。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
采集所述当前用户不同角度的人脸图像,提取所述人脸图像中的多个人脸特征点,将各人脸特征点与预设人脸特征点数据库中的预设人脸特征点进行比对分析,生成所述第一分析结果。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
采集所述当前用户在所述当前环境中产生的声音,对所述声音进行声纹分析,并生成第二分析结果;
将所述第二分析结果作为所述声音音频信息,利用预设声纹识别算法根据所述声音音频信息计算与所述当前用户之间的所述第二参考距离。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
采集所述当前用户在所述当前环境中产生的声音,提取所述声音中的多个声纹特征,将各声纹特征与预设声纹特征数据库中的预设声纹特征进行比对分析,生成所述第二分析结果。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
根据预设权重比例对所述第一参考距离与所述第二参考距离进行加权平均计算,根据计算结果获取所述目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
获取所述当前用户的人体红外信息,根据所述人体红外信息计算与所述当前用户之间的第三参考距离;
根据所述第三参考距离对所述目标距离进行校正,将校正后的距离作为新的目标距离。
进一步地,处理器1001可以调用存储器1005中存储的距离感应程序,还执行以下操作:
获取当前运行模式,当所述当前运行模式为预设私人模式时,获取所述当前用户的人脸图像信息,将所述人脸图像信息与预设人脸图像信息库中的预设人脸图像信息进行匹配;
当所述人脸图像信息与所述预设人脸图像信息不匹配时,生成提示信息发送至预设信息接收终端。
本实施例通过上述方案,通过距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能,能够通过人脸识别和声波感应获得的距离与预设距离比较,从而让设备做出不同响应,不用依赖特定关键词进行设备唤醒,缩短了设备响应的时间,让设备更加智能化和人性化,提升了用户体验。
基于上述硬件结构,提出本发明距离感应方法实施例。
参照图2,图2为本发明距离感应方法第一实施例的流程示意图。
在第一实施例中,所述距离感应方法包括以下步骤:
步骤s10、距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离;
需要说明的是,距离感应设备可以是具有采集人脸图像及声音信息的设备,可以是例如智能音响、电视机和平板电脑等,当然也可以是智能家居控制终端等,当然还可以是其他终端设备等,本实施例对此不加以限制,所述当前用户为正在直接或间接使用所述距离感应设备的用户,可以是存储在数据库中拟定的设备使用人员,也可以是在所述距离感应设备应用的预设范围内的人员,本实施例对此不加以限制。
可以理解的是,通过所述距离感应设备获取当前用户的所述人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,通过对所述人脸图像信息可以根据人脸大小以及其他参数计算所述当前用户与所述距离感应设备的距离,所述第一参考距离可以是一个大概距离即带有误差值的距离范围,当然所述第一参考距离也可以是一个唯一的值,通过大量运算和比对获取的一个相对精确的距离参考值,本实施例对此不加以限制。
应当理解的是,通过所述人脸图像信息计算与所述当前用户之间的第一参考距离,计算所述第一参考距离的算法可以是基于深度学习的算法,例如深度神经网络算法,还可以是图像压缩识别小波算法,也可以是逻辑回归算法,当然还可以是基于无监督学习的算法等其他人脸识别算法计算所述第一参考距离,本实施例对此不加以限制。
步骤s20、获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离;
需要说明的是,所述当前环境可以是所述距离感应设备所处的环境,也可以是预先设定的所述距离感应设备的使用区域,还可以是其他条件确定的所述距离感应设备所在的环境,本实施例对此不加以限制,所述当前用户在所述当前环境中产生的声音音频信息可以是通过采集所述当前用户的脚步声、呼吸声和讲话声等声音处理后获得的声音音频信息,也可以是采集所述当前环境中的所有声音进行类似过滤、回声消除和高保真等处理后获得声音音频信息,当然还可以是通过其他方式获取的声音音频信息,本实施例对此不加以限制。
可以理解的是,通过所述距离感应设备获取所述当前用户在当前环境中产生的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,通过对所述声音音频信息可以根据声波大小以及其他参数计算所述当前用户与所述距离感应设备的距离,所述第二参考距离可以是一个大概距离即带有误差值的距离范围,当然所述第二参考距离也可以是一个唯一的值,通过大量运算和比对获取的一个相对精确的距离参考值,本实施例对此不加以限制。
应当理解的是,通过所述声音音频信息计算与所述当前用户之间的第二参考距离,计算所述第二参考距离的算法可以是基于深度学习的算法,例如深层特征算法(deepfeature)、深层矢量算法(deepvector),还可以是mel频率倒谱系数(melfrequencycepstrumcoefficient,mfcc)算法,也可以是感知线性预测系数(perceptuallinearpredictive,plp)算法,当然还可以是滤波器组(filterbank,fb)特征算法等其他声纹识别算法计算所述第二参考距离,本实施例对此不加以限制。
步骤s30、根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离;
需要说明的是,根据所述第一参考距离与所述第二参考距离确定所述目标距离可以是通过将所述第一参考距离与所述第二参考距离进行预设算法进行运算,获取运算结果,根据运算结果确定所述目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,即将所述目标距离作为所述当前用户在当前时刻与所述距离设备之间的唯一距离。
进一步地,所述步骤s30,具体包括:
根据预设权重比例对所述第一参考距离与所述第二参考距离进行加权平均计算,根据计算结果获取所述目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离。
应当理解的是,所述预设权重比例为预先设定的所述第一参考距离与所述第二参考距离进行计算时对应的权重比例,可以是技术人员通过大量训练和学习获取的比较合适的权重比例,还可以是用户自行设定的权重比例,还可以是所述距离感应设备默认的权重比例,也可以是所述距离感应设备根据用户使用习惯结合大数据分析设定的适合用户的权重比例,当然还可以是通过其他方式确定的权重比例,本实施例对此不加以限制。
可以理解的是,通过所述预设权重比例对所述第一参考距离与所述第二参考距离进行加权平均计算,根据计算结果获取所述目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,通过预设权重比例计算所述当前用户与所述距离感应设备的距离能够更加精确,更加接近所述距离感应设备与所述当前用户的实际距离,能够提高识别所述当前用户的距离的精准度,为后续操作提供准确的数据。
步骤s40、将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能。
需要说明的是,所述预设距离为预先设定的触发所述距离感应设备开启人机对话功能的距离,所述预设距离可以是技术人员通过大量训练和学习获取的比较合适的距离,还可以是用户自行设定的距离,还可以是所述距离感应设备默认的距离,也可以是所述距离感应设备根据用户使用习惯结合大数据分析设定的适合用户的距离,当然还可以是通过其他方式确定的距离,本实施例对此不加以限制。
可以理解的是,所述距离感应设备可以通过无线通信连接的方式与其他的智能家用电器或智能家居连接,获取用户的语音信息之后生成相应的控制指令,进而达到语音控制智能家用电器或智能家居的目的,将所述目标距离与所述预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能,例如所述距离感应设备可以发出提示音“欢迎您回到家!是否现在为您打开电视机?”或者“欢迎您回到家!是否现在为您打开窗帘?”等,收到用户反馈的语音信息后,生成相应的控制指令发送至对应的智能家用电器或智能家居,以达到语音控制智能家用电器或智能家居的目的。
本实施例通过距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能,能够通过人脸识别和声波感应获得的距离与预设距离比较,从而让设备做出不同响应,不用依赖特定关键词进行设备唤醒,缩短了设备响应的时间,让设备更加智能化和人性化,提升了用户体验。
进一步地,如图3所示,基于第一实施例提出本发明距离感应方法第二实施例,在本实施例中,所述步骤s10具体包括步骤:
步骤s11、采集所述当前用户的人脸图像,对所述人脸图像进行动态比对分析,并生成第一分析结果;
需要说明的是,采集所述当前用户的人脸图像可以是通所述距离感应设备的摄像头进行采集,可以是获取可见光人脸图像,还可以是获取近红外人脸图像,也可以是获取中红外、远红外和热红外的多波段的人脸图像,当然还可以是获取其他类型的人脸图像,本实施例对此不加以限制。
可以理解的是,采集所述当前用户的人脸图像后,可见将所述人脸图像与数据库中的人脸图像进行比对分析,可以是将所述人脸图像与本地数据库中的人脸图像进行比对分析,也可以是将所述人脸图像与云端数据库中的人脸图像进行比对分析,确定出人脸图像分析结果即所述第一分析结果。
进一步地,所述步骤s11,具体包括:
采集所述当前用户不同角度的人脸图像,提取所述人脸图像中的多个人脸特征点,将各人脸特征点与预设人脸特征点数据库中的预设人脸特征点进行比对分析,生成所述第一分析结果。
应当理解的是,所述预设人脸特征点数据库可以是本地数据库也可以是云端数据库,所述预设人脸特征点数据库需要预先存储有大量的人脸特征点数据,通过所述距离感应设备的摄像头可以多角度采集所述当前用户的人脸图像,提取所述人脸图像中的多个人脸特征点,将各人脸特征点与预设人脸特征点数据库中预设人脸特征点进行对比,筛选剔除一些干扰特征点,对比分析后生成所述第一分析结果。
步骤s12、将所述第一分析结果作为所述人脸图像信息,利用预设人脸识别算法根据所述人脸图像信息计算与所述当前用户之间的所述第一参考距离;
需要说明的是,所述预设人脸识别算法为预先设定的利用所述人脸图像信息计算与所述当前用户之间的距离的算法,所述预设人脸识别算法可以是基于人脸特征点识别和整幅人脸图像识别的算法,所述预设人脸识别算法也可以是基于人脸模板识别的算法,所述预设人脸识别算法还可以是基于神经网络进行识别的算法,当然所述预设人脸识别算法还可以是基于其他识别方式预先设置的算法,本实施例对此不加以限制。
可以理解的是,通过所述预设人脸识别算法可以将所述人脸图像信息代入进算法中计算与所述当前用户之间的距离,将该距离作为所述第一参考距离。
相应地,所述步骤s20具体包括步骤:
步骤s21、采集所述当前用户在所述当前环境中产生的声音,对所述声音进行声纹分析,并生成第二分析结果;
需要说明的是,所述当前用户在所述当前环境中产生的声音为所述当前用户在所述当前环境中产生的任何声音,所述当前用户在所述当前环境中产生的声音可以是通过所述距离感应设备的麦克风阵列采集的所述当前用户的脚步声、呼吸声和讲话声等声音处理后获得的声音音频信息,也可以是采集所述当前环境中的所有声音进行类似过滤、回声消除和高保真等处理后获得声音,当然还可以是通过其他方式获取的声音,本实施例对此不加以限制。
可以理解的是,采集到所述当前用户在所述当前环境中产生的声音后,可见将所述声音与数据库中的声音进行比对分析,可以是将所述声音与本地数据库中的声音进行比对分析,也可以是将所述声音与云端数据库中的声音进行比对分析,确定出声音分析结果即所述第二分析结果。
进一步地,所述步骤s21具体包括:
采集所述当前用户在所述当前环境中产生的声音,提取所述声音中的多个声纹特征,将各声纹特征与预设声纹特征数据库中的预设声纹特征进行比对分析,生成所述第二分析结果。
应当理解的是,所述预设声纹特征数据库可以是本地数据库也可以是云端数据库,所述预设声纹特征数据库需要预先存储有大量的声纹特征数据,通过所述距离感应设备的麦克风阵列可以全方位采集所述当前用户在所述当前环境中产生的声音,提取所述声音中的多个声纹特征,将各声纹特征与预设声纹特征数据库中的预设声纹特征进行比对,筛选剔除一些干扰噪声和回声,对比分析后生成所述第二分析结果。
步骤s22、将所述第二分析结果作为所述声音音频信息,利用预设声纹识别算法根据所述声音音频信息计算与所述当前用户之间的所述第二参考距离。
需要说明的是,所述预设声纹识别算法为预先设定的利用所述声音音频信息计算与所述当前用户之间的距离的算法,所述预设声纹识别算法可以是基于深度学习的算法,例如深层特征算法、深层矢量算法,还可以是mel频率倒谱系数算法,也可以是感知线性预测系数算法,当然还可以是滤波器组特征算法等其他声纹识别算法将所述声音音频信息代入计算所述第二参考距离,本实施例对此不加以限制。
可以理解的是,通过所述预设声纹识别算法可以将所述声音音频信息代入进算法中计算与所述当前用户之间的距离,将该距离作为所述第二参考距离。
本实施例通过采集所述当前用户的人脸图像,对所述人脸图像进行动态比对分析,并生成第一分析结果,将所述第一分析结果作为所述人脸图像信息,利用预设人脸识别算法根据所述人脸图像信息计算与所述当前用户之间的所述第一参考距离,采集所述当前用户在所述当前环境中产生的声音,对所述声音进行声纹分析,并生成第二分析结果,将所述第二分析结果作为所述声音音频信息,利用预设声纹识别算法根据所述声音音频信息计算与所述当前用户之间的所述第二参考距离,通过预设人脸识别算法和预设声纹识别算法能快速计算与所述当前用户之间的距离,进而加快计算距离的时间,进一步缩短了设备响应的时间,使设备更加智能化和人性化,提升了用户体验。
进一步地,如图4所示,基于第二实施例提出本发明距离感应方法第三实施例,在本实施例中,所述步骤s30之后,所述距离感应方法还包括以下步骤:
步骤s301、获取所述当前用户的人体红外信息,根据所述人体红外信息计算与所述当前用户之间的第三参考距离;
需要说明的是,所述当前用户的人体红外信息可以是通过红外传感器通过采集所述当前用户的人体红外图谱获取,也可以是通过近红外光摄像头采集所述当前用户的人体红外图谱获取,还可以是通中红外、远红外和热红外摄像头采集所述当前用户的人体红外图谱获取,当然还可以是通过其他方式获取所述当前用户的人体红外信息,本实施例对此不加以限制。
可以理解的是,获取所述当前用户的人体红外信息后,可以是利用预设红外距离算法根据所述人体红外信息计算与所述当前用户之间的距离,将该距离作为所述第三参考距离。
应当理解的是,可以是通过利用所述预设红外距离算法将所述人体红外信息代入计算与所述当前用户之间的距离,也可以是通过所述距离感应设备中的红外测距单元计算与所述当前用户之间的距离,当然还可以是通过其他方式根据所述人体红外信息计算与所述当前用户之间的第三参考距离,本实施例对此不加以限制。
步骤s302、根据所述第三参考距离对所述目标距离进行校正,将校正后的距离作为新的目标距离。
可以理解的是,根据所述第三参考距离对所述目标距离进行校正可以是根据所述第三参考距离设置误差补偿值,再将所述误差补偿值对所述目标距离进行校正补偿,也可以是将所述第三参考距离与所述目标距离再进行一次加权平均,将加权平均后的值作为新的目标距离,当然还可以是通过其他方式利用所述第三参考距离对所述目标距离进行校正,本实施例对此不加以限制。
相应地,所述步骤s10之前,所述距离感应方法还包括以下步骤:
步骤s01、获取当前运行模式,当所述当前运行模式为预设私人模式时,获取所述当前用户的人脸图像信息,将所述人脸图像信息与预设人脸图像信息库中的预设人脸图像信息进行匹配;
需要说明的是,所述当前运行模式为所述距离感应设备当前处于的运行模式,所述运行模式可以包括预设私人模式和预设公开模式,所述预设私人模式类似于安全保护模式,即为除了预设人脸图像信息库中的预设人脸图像对应的使用者外,其他使用者想要使用所述距离感应设备时,是不被允许的,所述预设公开模式即为任何人都能够使用所述距离感应设备,当然还可以是其他预设模式作为所述距离感应设备的运行模式,本实施例对此不加以限制。
可以理解的是,当所述距离感应设备的当前运行模式为所述预设私人模式时,可以起到监控所述当前环境的作用,通过获取所述当前用户的人脸图像信息,将所述人脸图像信息与所述预设人脸图像信息库中的预设人脸图像信息进行匹配可以得知当前使用者是否是被允许使用的使用者。
步骤s02、当所述人脸图像信息与所述预设人脸图像信息不匹配时,生成提示信息发送至预设信息接收终端。
需要说明的是,所述当所述人脸图像信息与所述预设人脸图像信息不匹配时,即可表明当前人脸图像信息对应的使用者并不是被允许使用的使用者,很有可能是陌生人,甚至小偷等不明身份者,所述距离感应设备可以根据采集到的所述人脸图像信息和声音音频信息生成提示信息发送至预设信息接收终端,预设信息接收终端即为预先设定的,当所述距离感应设备在预设私人模式下发现异常时,接收相应提示信息的终端,所述预设信息接收终端可以是移动终端,也可以是计算机等具有接收信息功能的终端设备,本实施例对此不加以限制。
可以理解的是,除了通过所述人脸图像信息和声音音频信息生成所述提示信息之外,还可以是生成简单的通知短信,例如提示所述距离感应设备使用异常的信息,当然还可以是通过其他方式生成所述提示信息,本实施例对此不加以限制;发送所述提示信息的方式处理可以是通过短信方式发送,还可以是通过微信等即时通信方式进行通知,也可以是通过电话和邮件等其他方式进行通知,当然还可以是通过其他方式进行对所述预设信息接收终端通知,本实施例对此不加以限制。
应当理解的是,所述预设信息接收终端通过接收到所述提示信息后显示给所述预设信息接收终端的使用者,所述预设信息接收终端的使用者根据所述提示信息可以采取相应的措施,例如报警或授权允许使用等操作,通过所述距离感应设备可以对所述距离感应设备对应的当前环境进行实时监控,若发生一些意外情况,例如火灾和偷盗等情况,可以及时生成提示信息发送预设信息接收终端以达到保护用户的财产安全的作用。
本实施例通过获取所述当前用户的人体红外信息,根据所述人体红外信息计算与所述当前用户之间的第三参考距离,根据所述第三参考距离对所述目标距离进行校正,将校正后的距离作为新的目标距离,能够提供更加精确的所述当前用户与所述距离感应设备之间的距离,进而加快计算距离的时间,进一步缩短了设备响应的时间,使设备更加智能化和人性化,提升了用户体验,通过获取当前运行模式,当所述当前运行模式为预设私人模式时,获取所述当前用户的人脸图像信息,将所述人脸图像信息与预设人脸图像信息库中的预设人脸图像信息进行匹配,当所述人脸图像信息与所述预设人脸图像信息不匹配时,生成提示信息发送至预设信息接收终端,能够使所述距离感应设备更加智能化和人性化,保障用户的财产安全,进一步提升用户体验。
此外,本发明实施例还提出一种存储介质,所述存储介质上存储有距离感应程序,所述距离感应程序被处理器执行时实现如下操作:
距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离;
获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离;
根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离;
将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
采集所述当前用户的人脸图像,对所述人脸图像进行动态比对分析,并生成第一分析结果;
将所述第一分析结果作为所述人脸图像信息,利用预设人脸识别算法根据所述人脸图像信息计算与所述当前用户之间的所述第一参考距离。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
采集所述当前用户不同角度的人脸图像,提取所述人脸图像中的多个人脸特征点,将各人脸特征点与预设人脸特征点数据库中的预设人脸特征点进行比对分析,生成所述第一分析结果。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
采集所述当前用户在所述当前环境中产生的声音,对所述声音进行声纹分析,并生成第二分析结果;
将所述第二分析结果作为所述声音音频信息,利用预设声纹识别算法根据所述声音音频信息计算与所述当前用户之间的所述第二参考距离。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
采集所述当前用户在所述当前环境中产生的声音,提取所述声音中的多个声纹特征,将各声纹特征与预设声纹特征数据库中的预设声纹特征进行比对分析,生成所述第二分析结果。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
根据预设权重比例对所述第一参考距离与所述第二参考距离进行加权平均计算,根据计算结果获取所述目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
获取所述当前用户的人体红外信息,根据所述人体红外信息计算与所述当前用户之间的第三参考距离;
根据所述第三参考距离对所述目标距离进行校正,将校正后的距离作为新的目标距离。
进一步地,所述距离感应程序被处理器执行时还实现如下操作:
获取当前运行模式,当所述当前运行模式为预设私人模式时,获取所述当前用户的人脸图像信息,将所述人脸图像信息与预设人脸图像信息库中的预设人脸图像信息进行匹配;
当所述人脸图像信息与所述预设人脸图像信息不匹配时,生成提示信息发送至预设信息接收终端。
本实施例通过上述方案,通过距离感应设备获取当前用户的人脸图像信息,根据所述人脸图像信息计算与所述当前用户之间的第一参考距离,获取当前环境中的声音音频信息,根据所述声音音频信息计算与所述当前用户之间的第二参考距离,根据所述第一参考距离与所述第二参考距离确定目标距离,所述目标距离为所述当前用户与所述距离感应设备之间实际的距离,将所述目标距离与预设距离进行比对,当所述目标距离小于所述预设距离时,启动人机对话功能,能够通过人脸识别和声波感应获得的距离与预设距离比较,从而让设备做出不同响应,不用依赖特定关键词进行设备唤醒,缩短了设备响应的时间,让设备更加智能化和人性化,提升了用户体验。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!