并行译码方法及装置、存储介质、电子装置与流程
本发明主要涉及通信领域,具体而言,涉及一种并行译码方法及装置、存储介质、电子装置。
背景技术:
1、低密度奇偶校验(low density parity check code,简称为ldpc)码,即,由gallager博士在1962年首先提出,是一种校验矩阵密度非常低的线性分组码。ldpc码几乎适用于所有的信道,它具有特大的灵活性,较强的纠错能力。利用它的基础简单性可以产生出性能与turbo码相差不大或者超过turbo码的系统,而且ldpc码较turbo码更易实现。
2、ldpc码具有以下特点:(1)ldpc码译码的复杂度很低,运算量不会因为码长的增加而急剧增加;(2)ldpc码采用迭代译码算法,可以实现并行操作,具有高速的译码能力;(3)由于ldpc码的奇偶校验矩阵的稀疏性,译码复杂度与码长成线性关系,克服了分组码在长码时所面临的巨大译码计算复杂度的问题,这种特性是turbo码所不能比拟的,而且,由于校验矩阵的稀疏特性,在长的编码分组时,相距很远的信息比特参与统一校验,这使得连续的突发差错对译码的影响不大。因此,ldpc码在现代通信领域中得到了广泛的应用。
3、目前已有的ldpc译码器分为全串行译码器和全并行译码器。全串行译码就是每次更新一个校验节点和变量节点,因此吞吐率比较低,但结构简单,资源较少。如图1所示,图1是全并行ldpc译码器实施框图;全并行译码在每次迭代时,所有的变量节点同时更新,所有的校验节点也同时更新,因此译码速率比较快,但资源消耗较多。
4、针对相关技术中,全串行译码吞吐率比较低,全并行译码资源消耗较多等问题,尚未提出有效的技术方案。
技术实现思路
1、本发明实施例提供了一种并行译码方法及装置、存储介质、电子装置,以至少解决相关技术中,全串行译码吞吐率比较低,全并行译码资源消耗较多等问题。
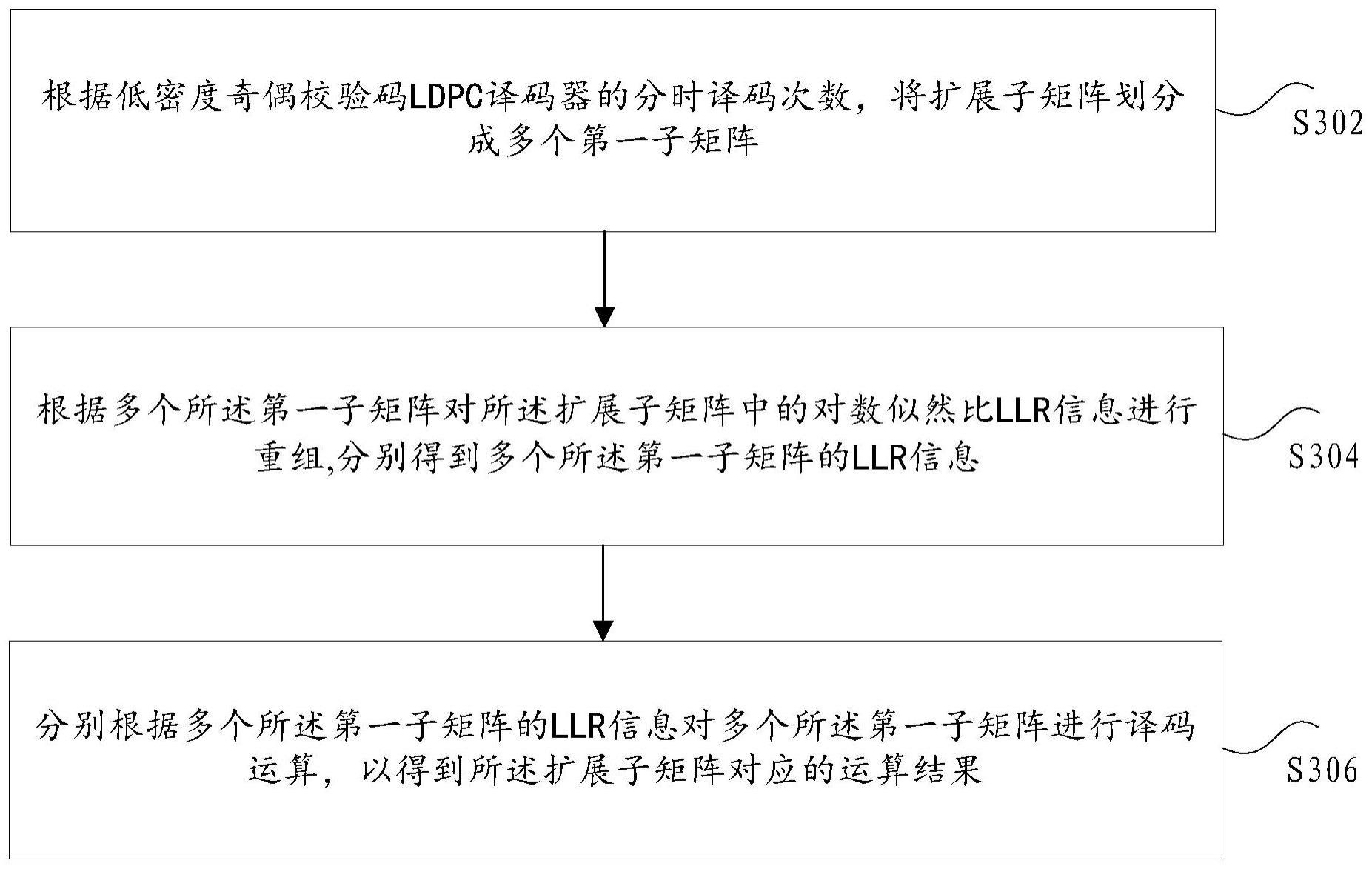
2、本发明实施例提供了一种并行译码方法,包括:根据低密度奇偶校验码ldpc译码器的分时译码次数,将扩展子矩阵划分成多个第一子矩阵;根据多个所述第一子矩阵对所述扩展子矩阵中的对数似然比llr信息进行重组,分别得到多个所述第一子矩阵的llr信息;分别根据多个所述第一子矩阵的llr信息对多个所述第一子矩阵进行译码运算,以得到所述扩展子矩阵对应的运算结果。
3、在一个示例性实施例中,所述根据所述第一子矩阵的llr信息对所述第一子矩阵进行译码运算,得到所述第一子矩阵对应的运算结果,包括:获取z×z的扩展子矩阵,其中,上述z×z的扩展子矩阵中的每行每列只有一个有效信息,z为大于或等于2的自然数,上述z×z的扩展子矩阵是低密度奇偶校验码ldpc译码器中待处理的矩阵;根据上述ldpc译码器的分时译码次数,将上述z×z扩展子矩阵划分成t个p×p的第一子矩阵,并根据t个p×p的第一子矩阵对所述z×z扩展子矩阵中的对数似然比llr信息进行重组,分别得到t个p×p的第一子矩阵的llr信息,其中,p=z/t,t表示上述分时译码次数,上述p×p的第一子矩阵中的每行每列只有一个上述有效信息,t为大于或等于2的自然数;在t次译码中,分别根据t个p×p的第一子矩阵的llr信息对t个p×p的第一子矩阵进行译码运算,得到t×p个运算结果,其中,在每次译码中,根据t个p×p的第一子矩阵的llr信息中对应的一个p×p的第一子矩阵的llr信息对所述t个p×p的第一子矩阵中的一个p×p的第一子矩阵进行译码运算,得到p个运算结果。
4、在一个示例性实施例中,上述根据上述ldpc译码器的分时译码次数,将上述z×z扩展子矩阵划分成t个p×p的第一子矩阵,包括:根据上述ldpc译码器的分时译码次数,将上述z×z扩展子矩阵划分成t个p×z的第二子矩阵,其中,上述t个p×z的第二子矩阵中的每个p×z的第二子矩阵中包括p个有效信息,上述p个有效信息中的任意两个有效信息分别位于上述每个p×z的第二子矩阵中的不同行和不同列;在上述t个p×z的第二子矩阵中的每个p×z的第二子矩阵中提取上述p个有效信息所在的列,得到上述t个p×p的第一子矩阵。
5、在一个示例性实施例中,上述根据上述ldpc译码器的分时译码次数,将上述z×z扩展子矩阵划分成t个p×z的第二子矩阵,包括:执行以下步骤,得到第i个p×z的第二子矩阵,其中,0≤i≤t-1:在上述z×z扩展子矩阵中提取第(i+t×n)行,得到上述第i个p×z的第二子矩阵,其中,n=0,1,2,…,p-1。
6、在一个示例性实施例中,上述根据t个p×p的第一子矩阵对所述z×z扩展子矩阵中的对数似然比llr信息进行重组,分别得到t个p×p的第一子矩阵的llr信息,包括:执行以下步骤,得到第i个p×p的第一子矩阵的llr信息,其中,0≤i≤t-1:在上述z×z扩展子矩阵中的llr信息中提取第(i+t×n)个llr信息,得到上述第i个p×p的第一子矩阵的llr信息,其中,n=0,1,2,…,p-1。
7、在一个示例性实施例中,将上述t个p×p的第一子矩阵的llr信息中的每个p×p的第一子矩阵的llr信息分别存储在不同的偏移地址对应的一组存储地址上。
8、在一个示例性实施例中,分别根据多个所述第一子矩阵的llr信息对多个所述第一子矩阵进行译码运算,以得到所述扩展子矩阵对应的运算结果,包括:在第i次译码中执行以下步骤,得到第i个运算结果,其中,0≤i≤t-1,所述第i个运算结果包括:p个运算结果:获取上述t个p×p的第一子矩阵的llr信息中的第i个p×p的第一子矩阵的llr信息;根据所述第i个p×p的第一子矩阵的llr信息对上述t个p×p的第一子矩阵中的第i个p×p的第一子矩阵进行译码运算,得到上述第i个运算结果。
9、在一个示例性实施例中,上述获取所述t个p×p的第一子矩阵的llr信息中的第i个p×p的第一子矩阵的llr信息,包括:获取上述第i个p×p的第一子矩阵的llr信息对应的第i个偏移地址;从上述第i个偏移地址对应的一组存储地址上获取上述第i个p×p的第一子矩阵的llr信息。
10、本发明实施例还提供了一种并行译码装置,包括:划分模块,用于根据低密度奇偶校验码ldpc译码器的分时译码次数,将扩展子矩阵划分成多个第一子矩阵;重组模块,用于根据多个所述第一子矩阵对所述扩展子矩阵中的对数似然比llr信息进行重组,分别得到多个所述第一子矩阵的llr信息;译码模块,用于分别根据多个所述第一子矩阵的llr信息对多个所述第一子矩阵进行译码运算,以得到所述扩展子矩阵对应的运算结果。
11、根据本发明的又一个实施例,还提供了一种计算机可读的存储介质,上述存储介质中存储有计算机程序,其中,上述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
12、根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,上述存储器中存储有计算机程序,上述处理器被设置为运行上述计算机程序以执行上述任一项方法实施例中的步骤。
13、通过上述技术方案,根据低密度奇偶校验码ldpc译码器的分时译码次数,将扩展子矩阵划分成多个第一子矩阵;根据多个所述第一子矩阵对所述扩展子矩阵中的对数似然比llr信息进行重组,分别得到多个所述第一子矩阵的llr信息;分别根据多个所述第一子矩阵的llr信息对多个所述第一子矩阵进行译码运算,以得到所述扩展子矩阵对应的运算结果,即将扩展子矩阵划分成第一子矩阵,根据ldpc译码器的分时译码次数分次对第一子矩阵进行译码运算,得到扩展子矩阵的运算结果,采用上述技术方案,解决了相关技术中全串行译码吞吐率比较低,全并行译码资源消耗较多等问题,进而降低处理时延、降低实现复杂度、降低面积和功耗开销,提高了硬件的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!