基于3D立体感知技术的自主导航机器人系统的制作方法
本发明涉及一种基于3D立体感知技术的自主导航机器人系统,可使机器人在陌生环境中完成三维自主感知、三维目标识别以及自主导航,属于机器人技术领域。
背景技术:
近年来,国家在特殊环境下作业的机器人方面取得了一系列瞩目的成果,国内一些高校和研究机构研制出了诸多危险环境作业机器人。上海交通大学等单位研制了国内首台ZXPJ01型消防机器人;北京航空航天大学开发了RT3-EOD、RAPTOR 排爆机器人;北京金吾高科技有限公司研制出JW901B型排爆机器人;中科院沈阳自动化所研制出“灵蜥”危险作业机器人;哈尔滨工业大学面向未来战场需求和反恐作战需要,研制了模块化、多功能的地面无人作战平台;中科院沈阳自动化所研制了轮、腿和履带复合型自主式移动机器人Climber等等。中科院沈阳自动化所研制出“灵蜥”危险作业机器人系列可以代替人进行一定的工作,在大多数非结构环境或危险、恶劣环境(环境状况复杂多变,地面高低不平,存在坡、沟和障碍物)条件下实施反恐防暴作业。同时,该作业型机器人使用便捷的机械手(含工具)也是拓展其应用范围的重要因素。JW-901B排爆机器人可广泛应用于搜索、排爆、放射性物质的排除,代替人去完成有危险的工作。JW-901B机器人的主要功能为抓取,优于国内外同类的各种机器人。
国外的危险环境作业机器人的发展较迅速,美国华盛顿州南部原子能研究中心根据核应急环境的需求,设计了具有攀爬、去污、搬运功能的机器人组。该组机器人既可单独工作,也可组网配合、协同工作。这套机器人具有磁性吸盘、高压水枪、运动履带等配套部件,有效地扩展了辐射中心区的施工作业范围。另外,美国还设计了一种机器人,可配合各种扳手部件,拧螺纹元件,倒推进剂,清理不能自由倒入的推进剂,最终完成强辐射环境中的自动拆卸任务。
未来世界智能机器人的发展趋势将是着力解决小型机器人系统创新设计、无损检测与故障诊断技术、多传感器信息融合与智能预警策略、恶劣环境下的高稳定遥操作或自动智能化技术、作业路径自主导航及路径优化等关键技术难题,此外,从成本低、运动灵活、操作方便等角度考虑,将继续向小型化、智能化、实用化方向发展。
目前,世界上已有60个国家装备了军用机器人,其中包括各种地面侦察机器人、空中侦察机器人、各种作战机器人等,而军用机器人的重难点技术也是机器人3D环境感知、目标识别、自主导航。
技术实现要素:
为了解决上述问题,本发明提供一种基于3D立体感知技术的自主导航机器人系统,包括场景深度信息采集系统、移动机器人实时姿态估计系统、移动机器人三维场景重构系统、复杂环境下三维目标识别系统、移动机器人自主导航系统。通过场景深度信息采集系统获取机器人所在环境中的场景深度信息,通过移动机器人实时姿态估计系统评估机器人实时姿态,通过三维场景重构系统进行实时三维重建,以获得当前环境三维信息,用以机器人进行实时三维环境感知,通过三维目标识别系统,识别复杂环境中的各目标,以便机器人更好地感知环境、规划路径及完成相关作业,通过自主导航系统,使机器人可在陌生环境中进行自主性路径规划。
本发明的技术方案如下:一种基于3D立体感知技术的自主导航机器人系统,主要工作流程包含以下步骤:
(1)场景深度信息采集:融合TOF摄像机与普通CCD阵列两种摄像机优势,TOF摄像机提供的低分辨率深度图, 研究低分辨率深度图与立体视觉的匹配融合算法,通过立体视觉以及数据融合优化的方法,在可见光摄像机视野下获取高分辨率的深度图。实现TOF摄像机与阵列立体视觉系统在相同的覆盖空间上,在空间上达到严格一致;
(2)三维场景自主感知:场景感知可以表述为在场景数据获取与表示的基础上,结合视觉分析与模式识别等技术手段,从计算统计、结构分析和语义表达等不同角度挖掘视觉数据中的特征与模式,从而实现对场景有效感知。所以,这里的“感知”不仅意味着对场景从局部到全局、从外观到几何形态的鲁棒获取,更是从低层数据到有含义实体的抽象模式的解释,主要包含机器人对场景几何结构感知、机器人位姿感知以及机器人目标物体感知。
场景几何结构感知是指三维场景重构,就是重构机器人所处的三维场景,并表示成机器人能够的理解的结构,即使机器人智能感知自己所处的环境;三维场景重构技术是移动机器人三维环境感知的基础,同时也是机器视觉领域长期以来非常活跃的研究点。
机器人位姿感知就是计算移动机器人在场景中的位置及姿态,使机器人感知到自己在场景中位姿;本项目将采用在线深度图序列实现移动机器人6DoF姿态估计及实时三维模型重构,使移动机器人不仅能够感知自身的姿态,而且可以感知到场景的三维几何结构。
场景目标物体感知就是利用目标物体的先验知识,比如目标物体模型等,采用模式识别算法训练目标识别系统,从而使机器人能在场景中识别出目标物体,即使机器人感知到场景中由哪些目标组成。复杂环境下的目标识别是机器视觉一个基础而活跃的研究领域。目标识别有着非常广泛的应用领域,比如机器人,智能监控,自动化工业组装及生物特征识别。在过去的几十年,二维目标识别得到了广泛地研究并且在某些领域已经得到相对成熟的应用,比如人脸识别和行人检测。与二维图像对比,使用距离图像(Range Images)在目标识别方面能克服很多二维图像目标识别中存在的问题:
①距离图像比相对于二维图像不仅提供了足够的纹理(Texture)信息,还额外包含了深度(Depth)信息;
从距离图像提取得到的特征受尺度,旋转及光照等因素的影响较小;
通过距离图像计算而来的目标三维姿态信息比二维图像计算的结果更为精确。
(3)机器人自主导航:移动机器人自主导航,主要使用A线算法,A线算法是一种静态路网中求解最短路径最有效的直接搜索方法,也是解决许多搜索问题的有效算法。算法中的距离估算值与实际值越接近,最终搜索速度越快。对于机器人于未知环境中进行三维环境感知及目标识别,其庞大的信息量及其处理让CPU吃力,故适用的算法要求在低的系统资源下,稳定有效的完成路径规划,并在不断运行中予以优化。
本发明的技术方案如下:一种基于3D立体感知技术的自主导航机器人系统,该系统主要包括:
(1)场景深度信息采集系统:包括TOF相机与普通CCD阵列两种摄像机,TOF相机提供低分辨率深度图,CCD阵列提供立体视觉信息,通过立体视觉与低分辨率深度图融合算法,获取到高分辨率的深度图;
(2)移动机器人实时姿态估计系统:通过上述场景深度信息采集系统获取到机器人所在环境的三维场景信息,通过场景表面点云计算出表面法线图,用以估计机器人实时姿态;
(3)移动机器人三维场景重构系统:三维场景重构主要指在机器人所处环境中进行实时三维重建,以便于机器人进行实时三维环境感知、目标识别及自主导航;
(4)复杂环境下三维目标识别系统:三维目标识别主要指在复杂背景下,对机器人所在环境中特定目标进行识别,如作业目标,障碍物等,便于机器人定位作业目标及路径规划;
(5)移动机器人自主导航系统:移动机器人自主导航是基于三维场景感知及三维目标识别基础之上,完成机器人自主规划作业路径、自主避障及在作业过程中遇见动态障碍物时自主重优化过程。
附图说明
图1为本发明基于3D立体感知技术的自主导航机器人系统的场景深度采集系统示意图;
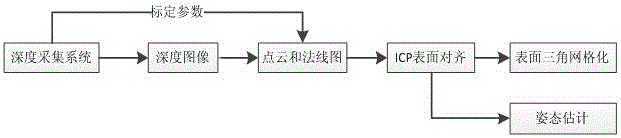
图2为本发明基于3D立体感知技术的自主导航机器人系统的移动机器人姿态估计及三维场景重构流程图;
图3为本发明基于3D立体感知技术的自主导航机器人系统的三维目标识别系统框图。
具体实施方式
下面结合附图和具体实施方式对本发明的技术方案作进一步详细地说明。
参照图1、图2及图3所示,一种基于3D立体感知技术的自主导航机器人系统,该系统主要包括场景深度信息采集系统、移动机器人实时姿态估计系统、移动机器人三维场景重构系统、复杂环境下三维目标识别系统、移动机器人自主导航系统。
TOF摄像机获得低分辨率和高精度的深度数据用来指导同等或高分辨率的阵列立体视觉处理,获取可靠的深度数据。TOF摄像机与普通CCD阵列融合的立体视觉系统、Manifold嵌入式计算机和千兆以太网交换机都安装在移动机器人上,Manifold作为机器人平台上的嵌入式计算机主要负责CCD阵列相机的深度图计算及获取TOF数据,并把它们的RGB图像和深度图像通过交换机传输到后台图像工作站。
机器人位姿感知如图2所示,利用系统输入深度采集系统得到场景的深度图序列;结合相机标定参数及三角测量原理,将深度图映射为场景表面点云并计算表面法线图;运用连续的表面点云图和法线图拼接成一个全局的场景表面模型,得到当前机器人相对全局模型姿态变化信息;在线深度图序列可以实现移动机器人6DoF姿态估计及实时三维模型重构,使移动机器人不仅能够感知自身的姿态,而且可以感知到场景的三维几何结构。
在姿态估计的同时,将全局场景模型转化为三角形网格的方式表示。针对表面拼接过程中ICP算法迭代效率低的问题,使用了一种在多个尺度表面下从粗到细地优化迭代拼接过程的方法;为了解决ICP非线性优化计算时间效率低下的问题,提出利用两个连续表面之间相对运动较小的特性,将拼接过程中的非线性优化问题近似转变成线性优化问题,从而提高优化阶段计算时间效率。最后,结合GPU并行计算能力,将以上步骤进一步加速,实现了实时的移动机器人姿态估计及三维场景重构。
机器人三维目标识别及感知如图3所示,这里所提到的三维场景表面是通过上一个模块三维场景重建得到的场景表面,通常用伪灰度、点云或者多边形网格等方式表示。多边形网格表示是由一个的三维顶点坐标矩阵和一个的三角面片顶点索引矩阵组成,即包含了顶点信息也包含了表面切片信息,较前两种方式具有更强的表达能力,并且由于信息被压缩的缘故易于在计算机上存储。其中,n为顶点数,m为面片数。多边形网格将离散的点云数据重新组织成多边形而得到的场景表示,包含了大量直观的表面信息。
在实际场景下,受被遮挡或者自遮挡的影响,一个视点下获得的场景并无法包含三维目标的全部形状信息。法向量、曲率、主曲率、平均曲率、高斯曲率和形状索引等微分几何属性作为局部表面的固有特性,构成局部特征提取的理论基础。首先利用曲面的平均曲率特性和高斯曲率特性计算曲面的形状索引图(Shape Index Map),然后计算形状索引图SIFT表面特征描述,最后匹配模型库和场景特征描述从而完成三维目标识别。
流程图中的三维扫面具体是指待识别的实际物体的模型用三维多边形网格表示,实际场景使用深度相机来获取,目的是识别出深度相机中的三维目标。在训练样本阶段,把三维网格表示的物体模型均匀地分割成点云,每个点云都表示物体的一个局部表面,用于模拟了深度相机的输入,因为深度相机一次只能重建物体的一个局部表面。
具体做法是,虚拟一种深度相机,将它们均匀地布置在一个足够包含整个模型的球体表面上,每个相机只获得模型的一个局部点云视图。实际过程中,为了得到这个球体,算法先从正二十面体的一个面开始,用4个等边三角形分割这个三角形面。针对每一个面,重复前面的做法,直到达到想要的分割的到三角形数量。分割完三角形的数量代表了使用多少三角形来逼近球体。在得到的每一个三角形重心布置一个虚拟相机,通过采样显示卡中深度缓存数据来得到模型三维多边形网格一个局部视图。这个过程包含了两个重要参数:一是模型球形的三角形数量;二是每个深度缓存的分辨率。参数1代表采样的数量,参数2代表采样的细节程度。当每个模型的局部视图都获取完成对每个视图计算它们的特征,产生模型库特征描述集。同时,还可以保存每个采样视图的坐标相对整体模型的刚体转换矩阵,以便用于几何连续性检测。
当获得当前场景与模型库中每一个模型的特征描述之后,采用FLANN算法来快速计算场景特征与模型中的特征的最近邻匹配并对应分组。由于存在一个场景中包含多个目标的情况,采用场景的特征描述与模型库中的每一个目标的特征匹配,这样如果场景中包含了多个目标也会被匹配出来。通过设置阈值剔除那些远离特征空间的对应组。最后,对于每个对应分组都将通过强制检测它们之间的几何连续性(geometric consistency)来剔除不符合要求的对应组。通过假设模型中目标与场景中的目标之间的转换是刚体的,模型库中的每一个目标的对应集分成不同的子集组,每个子集保持场景中模型的一个特定的旋转及平移矩阵。
以上所述,仅为本发明较佳的具体实施方式,本发明的应用适用范围不限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可显而易见地得到的技术方案的简单变化或等效替换均落入本发明的应用适用范围内。
- 还没有人留言评论。精彩留言会获得点赞!