一种密码子优化的Chi3L1基因及其应用的制作方法
本发明属于基因工程技术领域,具体涉及一种密码子优化的Chi3L1(几丁质酶3样物1)基因及应用。
背景技术:
几丁质是一种无臭无味的白色无定形物质,广泛存在于自然界,如甲壳类动物虫下、蟹的外壳,昆虫的甲壳以及细菌、真菌的细胞壁中。几丁质是高分子物质,分子量可达1×106以上,不溶于水、稀酸、碱、乙醇或其它有机溶剂。几丁质酶及几丁质酶样蛋白属于糖基水解蛋白家族18,他们广泛分布在原核及真核生物中,两者都能结合几丁质,前者具有剪切活性,而后者则无。
几丁质酶样蛋白的重要成员几丁质酶3样物1(Chi3L1)是重要的固有免疫和获得性免疫的调节剂,主要由中性粒细胞、巨噬细胞和内皮细胞等分泌表达,在组织损伤、凋亡、Th2介导免疫反应、TGF-β1信号通路以及实质结疤过程中起重要作用。CHI3L1能够表达于各种细胞,尤其高表达于巨噬细胞晚期诱导分化阶段,故有学者认为CHI3L1是巨噬细胞分化成熟的标志。目前研究表明CHI3L1的生物学功能主要表现为:(1)细胞生长因子样作用:CHI3L1可以磷酸化ERK1/2,通过这条信号转导通路,CHI3L1可以促进相应细胞有丝分裂及生长。另外CHI3L1还可以磷酸化AKT,从而激活PI3K,通过这条信号转导途径,CHI3L1也可以促进相应细胞有丝分裂及生长。(2)调节ECM重构:CHI3L1可以减轻IL-1与TNF-a介导的炎症反应,从而减弱调亡信号介导的转导通路,限制ECM降解和调节ECM重构,促进结缔组织增生,在一些疾病发生发雇过程中发挥重要作用。(3)拮抗凋亡:CHI3L1抗细胞凋亡的具体作用机制还不清楚,可能是通过调节ERK1/2及AKT的磷酸化起作用。
肝脏疾病的研究发现,Chi3L1不仅在酒精性肝病中表达升高,而且在肝纤维化及肝硬化中的表达也异常增高,并被认为是肝纤维化潜在的标志物。前期研究发现,经过Chi3L1处理的小鼠骨髓来源巨噬细胞,其白细胞介素-1β和肿瘤坏死因子-α的表达会降低,与野生型的小鼠骨髓来源巨噬细胞相比,Chi3L1缺失的小鼠骨髓来源巨噬细胞在脂多糖LPS的刺激下,表达更高的IL-1β,TNF-α,单核细胞趋化因子-1和化学因子(C-X-C基序)配体1;在四氯化碳诱导的小鼠肝纤维化模型的预实验中,我们发现Chi3L1基因敲除小鼠比野生型小鼠存在更严重的肝纤维化,而且肝脏巨噬细胞的功能之间也有差异,这些结果提示Chi3L1在肝纤维化过程中的炎症反应调控以及巨噬细胞的功能发挥中起着巨大作用。
目前研究已经证实Chi3L1蛋白在多种恶性肿瘤中呈现高表达,并且其蛋白表达水平和肿瘤的发展、预后密切相关。因此针对Chi3L1蛋白研发抑制药物是一条新的治疗肿瘤的途径,但由于目前的Chi3L1蛋白主要通过在人源性细胞中表达获得,其表达量很低,难以满足科研和临床需求,而由于人和大肠杆菌有不同的密码子系统,因此人源的基因并不适合直接在大肠杆菌中表达,综合以上因素,我们在本发明中采用针对大肠杆菌进行密码子优化的Chi3L1基因,通过发酵获得Chi3L1蛋白,结果发现能够获得高浓度和纯度的蛋白,可以满足科研和临床的需求。
技术实现要素:
本发明所要解决的技术问题是提供密码子优化的Chi3L1基因,实现Chi3L1蛋白异源表达,以解决现有技术中Chi3L1表达量少,生物活性低的问题。
本发明还要解决的技术问题是提供一株包含Chi3L1基因的重组细胞及其构建方法。
本发明最后要解决的技术问题是提供上述Chi3L1重组蛋白在研发治疗胃癌药物中的应用。
为解决上述技术问题,本发明提供如下技术方案:
一种密码子优化的Chi3L1基因,该基因的核苷酸序列如SEQ ID NO.1所示。
包含权利要求1所述Chi3L1基因的重组载体在本发明的保护范围中。
包含权利要求1所述Chi3L1基因的重组细胞在本发明的保护范围中。
上述密码子优化的Chi3L1基因在发酵产Chi3L1蛋白中的应用在本发明的保护范围中。
一种Chi3L1蛋白的表达和纯化方法,包括如下步骤:
(1)将权利要求1所述的SEQ ID NO.1所示基因克隆至表达载体中,得到重组质粒;
(2)将重组质粒转化E.coli BL21(DE3)plysS细胞,得到重组菌;
(3)利用步骤(2)得到的重组菌发酵产种Chi3L1蛋白;
(5)采用Ni-NTA树脂层析纯化Chi3L1蛋白。
步骤(1)中,所述的表达质粒为pRSET-A。
上述Chi3L1蛋白的表达和纯化方法制备得到的Chi3L1重组蛋白在本发明的保护范围中。
上述Chi3L1重组蛋白在制备治疗胃癌药物中的应用在本发明的保护范围中。
有益效果:
本发明提供了一种成本低、简便易行的获取Chi3L1重组蛋白的方法,本发明所述的Chi3L1重组蛋白具有很强的免疫活性和促肿瘤生长的作用,可以作为免疫研究的活性药物以及作为药物靶点开发抗肿瘤药物,具有良好的基础及临床应用前景。
附图说明
图1:本发明中重组Chi3L1蛋白的诱导表达图,其中1、2、3分别为经IPTG诱导0、2、4小时后Chi3L1蛋白表达量变化情况。
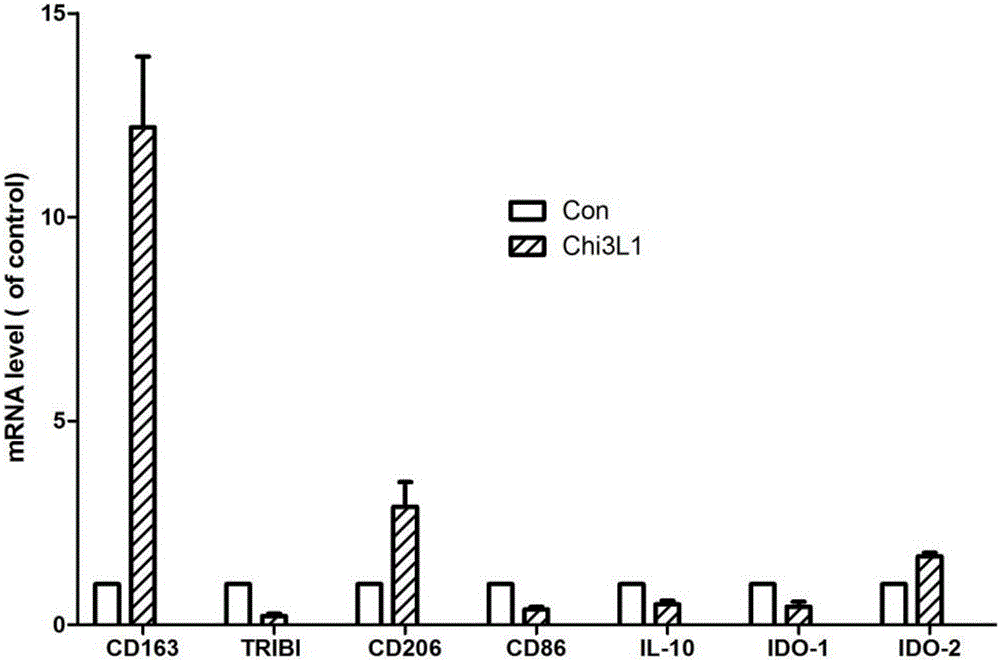
图2:重组Chi3L1蛋白体外促进巨噬细胞M2分化。
图3:重组Chi3L1蛋白对胃癌细胞生长的促进作用。
具体实施方式
根据下述实施例,可以更好地理解本发明。然而,本领域的技术人员容易理解,实施例所描述的内容仅用于说明本发明,而不应当也不会限制权利要求书中所详细描述的本发明。
实施例1:重组Chi3L1蛋白表达质粒的构建。
先合成Chi3L1(如ESQ ID No.:1所示)基因,接着通过采用NdeⅠ和HindⅢ酶切位点酶切位点亚克隆至pRSET-A质粒,得到pRSET-A-Chi3L1表达质粒,具体构建过程如下:
(1).酶切:将合成的Chi3L1的DNA片段用限制性内切酶NheI和HindⅢ进行酶切,同时用对应的内切酶对pRSET-A空载穿梭质粒进行酶切。
表1酶切反应体系
反应条件:37℃水浴2h。上述酶切产物用1%琼脂糖凝胶电泳分离回收目的片段,使用Agarose Gel DNA Extraction Kit获得纯化的目的DNA片段。
(2).连接:将酶切后的Chi3L1表达片段与pRSET-A载体连接。
表3连接反应体系
37℃4h后,转化TOP10感受态细菌,筛选阳性克隆进行后续实验。
实施例2:本实施例描述了重组Chi3L1蛋白的表达及纯化方法
表达质粒pRSET-A在插入子上游有一连续编码6个组氨酸(His6)的碱基序列,因此,所表达的多肽在氨基端有His6标识,便于表达蛋白的纯化和鉴定。表达质粒转化BL21感受态细菌,过夜培养后以1:50在100ml SOB培养基中37℃振荡培养,当OD450为0.5左右时加入终浓度为0.5mM的IPTG,继续培养4h;其中在0h、2h、4h分别取样1ml,6000r/min离心5min,沉淀加入30μl Laemmli缓冲液,95℃加热5min,取8μl经SDS-PAGE,考马斯亮蓝染色分析显示随着诱导时间的延长,在相对分子质量42kD位置附近的蛋白条带逐渐增强,且4h时蛋白表达量最高(如图1所示)。其余细菌离心沉淀,用于Chi3L1蛋白纯化。
细菌沉淀加入裂解液(6M盐酸胍,100mM NaH2PO4,10mM Tris-Cl,pH 8.0)后超声破碎,用Ni-NTA树脂(Qiagen公司)层析纯化,最后采用洗脱液(8M urea,100mMNaH2PO4,10mM Tris-Cl,pH 3.5)洗脱,采用BCA法检测蛋白浓度,达到1.2mg/ml。
实施例3:重组Chi3L1蛋白促进巨噬细胞M2分化
采用1000μg/ml是纯化后的Chi3L1蛋白处理巨噬细胞4小时,收集细胞,提取RNA,逆转录后RT-PCR检测巨噬细胞分化相关基因的表达水平,结果显示CD163,CD206等巨噬细胞M2分化相关基因表达明显增高,提示该Chi3L1重组蛋白能够有效的促进巨噬细胞的M2分化(图2)。
实施例4:重组Chi3L1蛋白对胃癌细胞生长的促进作用
采用不同浓度的Chi3L1 0、100、250、500、1000μg/ml浓度分别处理AGS胃癌细胞,48小时后WST实验检测结果显示AGS细胞的增殖率分别上升了了7.3%,6.0%,13.9%和25.1%,此结果提示Chi3L1对AGS胃癌细胞的生长具有明显的促进作用,并且该促进作用具有浓度依赖性(图3)。
SEQUENCE LISTING
<110> 一种密码子优化的Chi3L1基因及其应用
<120> 南京医科大学第二附属医院
<130> SG20161108001
<160> 2
<170> PatentIn version 3.5
<210> 1
<211> 1152
<212> DNA
<213> 密码子优化的Chi3L1基因核苷酸序列
<400> 1
atgggcgtaa aggcctcaca aacaggattt gtggtccttg tcttactaca atgctgtagt 60
gcttataagc ttgtatgtta ttatacgagc tggagtcaat atagagaggg agacggcagt 120
tgcttccctg atgccttaga tagatttttg tgtactcata taatatattc gttcgctaat 180
ataagtaacg accacataga tacatgggag tggaatgatg tcacgcttta tgggatgttg 240
aatacactta agaaccgaaa tcccaattta aagacgctcc ttagtgtagg gggctggaac 300
tttggcagtc aacgattttc aaagatagcc agcaacactc aaagtaggag gacatttata 360
aagagcgtac ctccctttct acgaacacac ggattcgacg gccttgatct cgcgtggttg 420
tatcccggac gacgagacaa gcagcatttt acgactctta taaaggaaat gaaggccgag 480
tttataaaag aggcacaacc tggaaagaag caactattgc tatcagccgc gttgtcggcc 540
gggaaggtca caatagactc gagttacgac attgctaaga ttagccaaca tttagatttt 600
atatccataa tgacttatga cttccacgga gcctggagag ggacaacagg gcatcattcg 660
ccactttttc gggggcaaga ggacgccagt cccgataggt tctcgaacac agattacgca 720
gtcggatata tgttacgcct tggggctcca gctagcaagc tcgtcatggg aataccaacg 780
tttggacgct cgtttacatt ggcgagttca gagactggag tgggagcccc tatatcaggc 840
ccaggaatac ctggccgatt tacaaaggag gctggaactt tagcgtatta cgaaatttgt 900
gattttctca gaggggcgac cgtacaccgg atacttgggc aacaagtacc gtacgctacg 960
aagggaaatc aatgggtcgg atatgacgat caagagtccg tcaagagtaa ggtgcaatat 1020
ttgaaggacc gccagttggc aggggcgatg gtgtgggcgc ttgatttgga cgattttcaa 1080
gggagttttt gcggacaaga ccttcgattt ccccttacaa atgccattaa ggatgctctt 1140
gctgctactt ag 1152
<210> 2
<211> 382
<212> PRT
<213> Chi3L1蛋白氨基酸序列
<400> 2
Gly Val Lys Ala Ser Gln Thr Gly Phe Val Val Leu Val Leu Leu Gln
1 5 10 15
Cys Cys Ser Ala Tyr Lys Leu Val Cys Tyr Tyr Thr Ser Trp Ser Gln
20 25 30
Tyr Arg Glu Gly Asp Gly Ser Cys Phe Pro Asp Ala Leu Asp Arg Phe
35 40 45
Leu Cys Thr His Ile Ile Tyr Ser Phe Ala Asn Ile Ser Asn Asp His
50 55 60
Ile Asp Thr Trp Glu Trp Asn Asp Val Thr Leu Tyr Gly Met Leu Asn
65 70 75 80
Thr Leu Lys Asn Arg Asn Pro Asn Leu Lys Thr Leu Leu Ser Val Gly
85 90 95
Gly Trp Asn Phe Gly Ser Gln Arg Phe Ser Lys Ile Ala Ser Asn Thr
100 105 110
Gln Ser Arg Arg Thr Phe Ile Lys Ser Val Pro Pro Phe Leu Arg Thr
115 120 125
His Gly Phe Asp Gly Leu Asp Leu Ala Trp Leu Tyr Pro Gly Arg Arg
130 135 140
Asp Lys Gln His Phe Thr Thr Leu Ile Lys Glu Met Lys Ala Glu Phe
145 150 155 160
Ile Lys Glu Ala Gln Pro Gly Lys Lys Gln Leu Leu Leu Ser Ala Ala
165 170 175
Leu Ser Ala Gly Lys Val Thr Ile Asp Ser Ser Tyr Asp Ile Ala Lys
180 185 190
Ile Ser Gln His Leu Asp Phe Ile Ser Ile Met Thr Tyr Asp Phe His
195 200 205
Gly Ala Trp Arg Gly Thr Thr Gly His His Ser Pro Leu Phe Arg Gly
210 215 220
Gln Glu Asp Ala Ser Pro Asp Arg Phe Ser Asn Thr Asp Tyr Ala Val
225 230 235 240
Gly Tyr Met Leu Arg Leu Gly Ala Pro Ala Ser Lys Leu Val Met Gly
245 250 255
Ile Pro Thr Phe Gly Arg Ser Phe Thr Leu Ala Ser Ser Glu Thr Gly
260 265 270
Val Gly Ala Pro Ile Ser Gly Pro Gly Ile Pro Gly Arg Phe Thr Lys
275 280 285
Glu Ala Gly Thr Leu Ala Tyr Tyr Glu Ile Cys Asp Phe Leu Arg Gly
290 295 300
Ala Thr Val His Arg Ile Leu Gly Gln Gln Val Pro Tyr Ala Thr Lys
305 310 315 320
Gly Asn Gln Trp Val Gly Tyr Asp Asp Gln Glu Ser Val Lys Ser Lys
325 330 335
Val Gln Tyr Leu Lys Asp Arg Gln Leu Ala Gly Ala Met Val Trp Ala
340 345 350
Leu Asp Leu Asp Asp Phe Gln Gly Ser Phe Cys Gly Gln Asp Leu Arg
355 360 365
Phe Pro Leu Thr Asn Ala Ile Lys Asp Ala Leu Ala Ala Thr
370 375 380
- 还没有人留言评论。精彩留言会获得点赞!