用于快速检测烟曲霉的序列、试剂盒、方法及应用与流程
本发明属于生物化学领域,具体涉及曲霉菌检测方法,特别是一种用于快速检测烟曲霉的序列、试剂盒、方法及应用。
背景技术:
侵袭性肺曲霉病(invasivepulmonaryaspergillosis,ipa)是指曲霉菌菌丝生长侵入肺实质而引起的感染性疾病,具有发病急性、进展迅速、病死率高的特点。烟曲霉是引起ipa最常见的病原菌,文献报道若ipa肺炎症状发生10天后抗真菌治疗,患者死亡率高达90%,而早期抗真菌治疗的死亡率可降低至41%。快速准确鉴定烟曲霉能指导临床选择抗真菌药、争取治疗时间。
早期诊断和及时治疗是良好预后的关键。但由于该病缺乏典型的临床表现,早期诊断尤为困难。实验室曲霉菌的鉴定方法主要有病原体分离培养、病理组织鉴定、免疫学检测、核酸检测。但是传统的病原体分离培养耗时长、阳性率低。而病理组织鉴定受到样本采集的限制、免疫学检测灵敏度不高,不能够区分不同的菌种,因此不能鉴定是否烟曲霉感染,而且常常发生假阳性或假阴性。核酸检测方法主要以近就广泛应用的聚合酶链反应(pcr)技术及一些新兴的恒温扩增技术为主。
基于pcr的检测技术近年逐渐成为临床分子诊断最成熟的核酸检测方法,具有更高的灵敏度和检测速度更快,但标本采集、运输等环节以及患者使用抗生素治疗等因素可导致标本中烟曲霉含量的减少,会影响到pcr核酸检测的敏感性。近年来开发的lamp(loop-mediatedisothermalamplification,环介导等温扩增技术)更为简单、经济,时间上比qpcr快2.5倍,当敏感度相同时,lamp的特异度优于pcr。
然而,曲霉由于种类繁多,种之间、种属之间(与其他属比如念珠菌属、隐球菌属等)的核酸序列同源性较高,同时,整个真菌基因组发生变异的几率远大于人类基因组,使得可选择做为靶基因序列进行种属检测的基因序列不多,因此,对于设计特异性检测常见曲霉(如烟曲霉)的扩增引物和crrna的难度比较大。
重组酶-聚合酶扩增(rpa)是一种快速兴起的恒温扩增技术,通过能结合单链核酸(寡核苷酸引物)的重组酶、单链dna结合蛋白(ssb)和具有链置换功能的dna聚合酶,在室温(最适反应温度为37℃~42℃)下即可获得可检测级别的扩增核酸。但是,原理上其单级扩增反应的本质并未改变,相较于目前市场上多数的qpcr检测方式,并不能有实质性的灵敏度提升。
自2017年开始,越来越多的文献报道crispr-cas基因编辑技术可应用于临床分子诊断。在crispr-cas系统中,cas蛋白在向导rna的引导下,靶向目标序列后启动其自身的“附带切割”活性,如果同时在体系中加入荧光报告分子(常用的报告分子是一段寡核苷酸序列,一端带有一个发光基团,一端带有一个淬灭基团,正常情况下由于淬灭作用,完整的报告分子不会被检测到,当寡核苷酸分子被水解后,游离的荧光信号可以被检测到),借用cas酶附带切割活性,可以实现待检序列信息向荧光信号的转化。并且通过rpa与crispr-cas的偶联,能够实现“序列扩增”(rpa完成)加上“酶促级联”(cas酶完成)的两级放大,从而超越qpcr这种单级扩增的灵敏度。此外,因为rpa扩增方式无需复杂的温度改变,从而摆脱了对qpcr仪等复杂变温扩增仪器的依赖,使得crispr-cas技术在烟曲霉的即时诊断方面具有广阔的应用前景,最快可实现40分钟检测出结果,大大缩短了检测时间,能避免更大范围的疫病传染,有着巨大的应用优势。
技术实现要素:
本发明的目的是针对以上要解决的技术问题,提供一种能够简易、快速、高特异性、灵敏地检测烟曲霉的技术方案。
为了实现以上发明目的,本发明提供了以下技术方案:
一种用于快速检测烟曲霉的序列,其包括烟曲霉-crrna序列、以及相应的带有t7启动子的rpa扩增引物序列,其中,所述烟曲霉-crrna序列的核苷酸序列如seqidno.1所示,所述rpa扩增引物序列的正向引物核苷酸序列如seqidno.2所示,所述rpa扩增引物序列的反向引物核苷酸序列如seqidno.3所示。
优选地,所述rpa扩增引物序列的终浓度为0.1~1μmol/l,所述烟曲霉-crrna的终浓度为20~200nmol/l。
另一方面,本发明还提供了一种试剂盒,其含有根据本发明所述的用于快速检测烟曲霉的序列,还含有rpa酶预混液、信号报告探针、lwcas13a蛋白、醋酸镁、t7rna聚合酶混合液、ntp缓冲液混合液。
优选地,所述rpa酶预混液中含有磷酸肌酸、肌酸激酶、dntps、atp、dtt、醋酸钾、重组酶uxsx、重组酶uxsy、单链结合蛋白和bsu聚合酶。
另一方面,本发明还提供了一种快速检测烟曲霉的方法,其包括以下步骤:
步骤一:提取待检测样本的dna;
步骤二:利用rpa和crispr一步法检测体系对烟曲霉核酸进行扩增和信号检测,其中使用根据权利要求1或2所述的用于快速检测烟曲霉的序列。
优选地,所述步骤二中,所述rpa和crispr一步法检测体系包括第一部分和第二部分;
所述第一部分含有浓度为10μm的rpa正向引物0.5-2.5μl、浓度为10μm的rpa反向引物0.5-2.5μl、rpa酶预混液21μl,其中所述rpa酶预混液含有浓度为20-80mm的磷酸肌酸、浓度为50-150mm的肌酸激酶、浓度为100-300μm的dntps、浓度为20-80mm的atp、浓度为1-10mm的dtt、浓度为50-200mm的醋酸钾、浓度为50-300ng/μl的重组酶uxsx、浓度为10-100ng/μl的重组酶uxsy、浓度为200-1000ng/μl的单链结合蛋白以及浓度为10-100ng/μl的bsu聚合酶;
所述第二部分含有浓度为1-5μm的lwcas13a蛋白1μl、浓度为1-5μm的crrna1μl、t7rna聚合酶混合液0.2-2μl、ntp缓冲液混合液1-10μl和浓度为1-10μm的信号报告探针1μl。
更优选地,将所述第一部分配制好后震荡离心把体系收集于管子底部,再加入所述第二部分,于恒温37℃反应10-30分钟后,震荡混匀后离心,读取fam荧光值。
另一方面,本发明还提供了所述用于快速检测烟曲霉的序列在用于制备烟曲霉检测试剂中的应用。
与现有技术相比,本发明的技术方案通过优选烟曲霉的特定序列,来设计cas13a对应的crrna,进行荧光检测,提高了检测的灵敏度,实现反应体系里接近单个基因组拷贝的检测,本发明的基于crispr-cas技术的优选特定序列组合缩短了烟曲霉的检测时间,最快可40min完成检测,该序列组合及试剂盒灵敏性高、特异性强、操作简便、检测速度快。
附图说明
图1是烟曲霉crrna序列验证筛选结果的
图2是烟曲霉引物筛选结果。
图3是烟曲霉体系灵敏度分析结果。
图4是烟曲霉体系特异性分析结果。
具体实施方式
以下结合具体实施例,对本发明作进一步说明。应理解,以下实施例仅用于说明本发明,而非用于限制本发明的范围。
实验材料
引物及插入了目标序列的质粒载体由艾基生物技术有限公司合成,信号报告探针由生工生物工程(上海)股份有限公司合成,向导rna(crrna)由金斯瑞生物科技有限公司合成,lwcas13a蛋白由金斯瑞生物科技有限公司表达纯化。rpa酶预混液购自杭州众测生物科技有限公司,其他生化试剂均为进口分装或国产分析纯。
实验仪器
金属浴,离心机,涡旋混合仪,abi7500荧光检测仪器等。
实施例1
烟曲霉检测相关序列的设计。
1、靶标序列选定。
选择烟曲霉基因组its区域作为目标检测序列,经过序列比对和筛选,设计出可以特异性检测烟曲霉的引物和crrna,该序列组合可以识别烟曲霉,但不与其他真菌菌种如黄曲霉、黑曲霉、土曲霉、构巢曲霉等交叉,具有高度的特异性和灵敏性。
本实施例的待检样本为插入了一段烟曲霉所选靶点序列区域的质粒(艾基生物技术有限公司合成),插入的序列(seqidno.4)如下:
5’tcaaacccggtcatttagaggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgcggaaggatcattaccgagtgagggccctctgggtccaacctcccacccgtgtctatcgtaccttgttgcttcggcgggcccgccgtttcgacggccgccggggaggccttgcgcccccgggcccgcgcccgccgaagaccccaacatgaacgctgttctgaaagtatgcagtctgagttgattatcgtaatcagttaaaactttcaacaacggatctcttggttccggcatcgatgaagaacgcagcgaaatgcgataagtaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacattgcgccccctggtattccggggggcatgcctgtccgagcgtcattgctgccctcaagcacggcttgtgtgttgggcccccgtccccctctcccgggggacgggcccgaaaggcagcggcggcaccgcgtccggtcctcgagcgtatggggctttgtcacctgctctgtaggcccggccggcgccagccgacacccaactttatttttctaaggttgacctcggatcaggtagggatacccgctgaacttaagcatatcaataagcggaggaaaagaaaccaacagggatt-3’
2、扩增引物对和crrna的设计。
rpa引物长度一般为30~38nt,引物过短会严重影响重组酶的活性,过长则容易形成二级结构。gc含量30%~70%,且引物的序列要与扩增片段严格互补。扩增产物一般低于500bp,最适长度为100~200bp,最短70~80bp。
实验中需要针对烟曲霉its区域设计多对rpa引物扩增靶标序列并进行筛选优化。所设计的引物扩增产物长度介于110~260bp,分别为its区域设计上游扩增引物4条,下游扩增引物4条,引物序列如下:
向导rna(crrna)的结构为5’-锚定序列-向导序列-3’
锚定序列根据cas13a蛋白的来源不同,分为lshcas13a,lbucas13a和lwcas13a等,本发明中的cas13a蛋白的来源为lwcas13a,其特异的锚定序列为5’-gauuuagacuaccccaaaaacgaaggggacuaaaac-3’(seqidno.5);
向导序列则与靶向rna中的片段匹配,长度为20-30个核苷酸,优选为28个(见表1)。
表1烟曲霉的crrna和扩增引物对序列
实施例2:crrna和rpa扩增引物的扩增效率筛选
1、crrna检测效率筛选
1.1方法
本实验中从靶标序列内设计2条crrna进行优化、筛选。根据2条crrna序列分别合成包含其特异性识别的带上t7启动子的两条单链序列作为模板,即包含与crrna中的向导序列同向及互补配对序列(具体序列见表2)进行退火后得到转录模板,避免由于扩增引物的差异影响crrna的信号。
表2用于验证crrna的序列
把fumigatus-crrna1-f和fumigatus-crrna1-r分别稀释到20μm后以1:1体积比混合,fumigatus-crrna2-f和fumigatus-crrna2-r分别稀释到20μm后以1:1体积比混合,分别在1×退火buffer(tris,ph7.5~8.010mm,nacl50mm,edta1mm)环境下在pcr仪上进行退火反应,退火条件为95℃2分钟;95℃~22℃0.1℃/秒;4℃保持,得到的退火产物作为模板,配合表1所列的2条特异性crrna验证并筛选最佳crrna。
具体操作如下:
反应体系:退火产物0.1μm,lwcas13a蛋白1μl(浓度1-5μm),crrna1μl(浓度1-5μm),t7rna聚合酶混合液0.2-2μl,ntpmix1-10μl,信号报告探针1μl(浓度1-10μm)。每组设置以水为模板的阴性对照。
反应条件:37℃反应10min,每1min读取fam荧光值。
1.2结果分析
使用荧光检测仪,对扩增产物进行荧光检测,实验设阴性对照。根据荧光检测仪读到的荧光值,计算目标样本的foldchange值(foldchange值=检测样本的荧光量/阳性对照的荧光量),阴性判断标准:foldchange值≦3.0。阳性判断标准:foldchange值>3.0
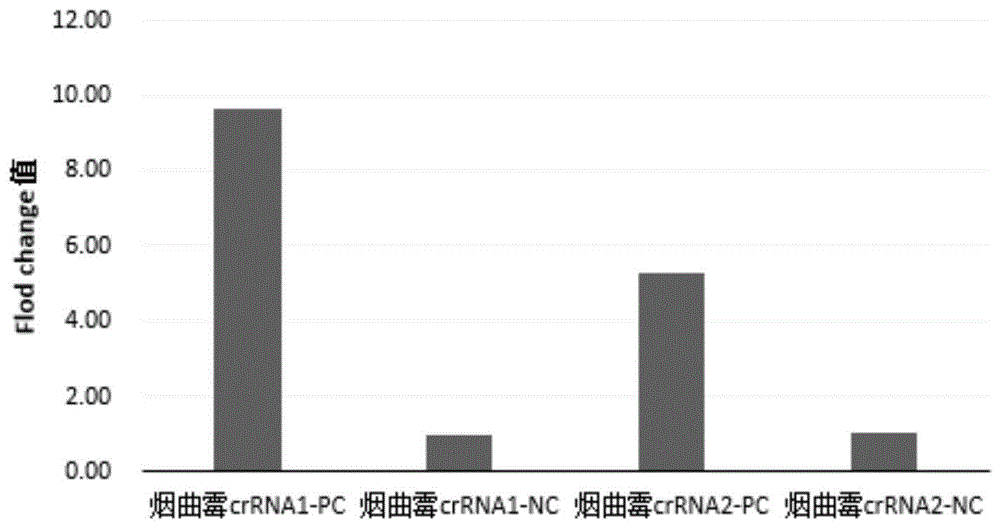
使用abi7500荧光检测仪,对上表1中烟曲霉的crrna进行检测筛选,结果如图1所示,图中纵坐标为flodchange,显示crrna-1的信号均较理想。
2、rpa引物扩增效率筛选
2.1方法
为了筛选cas13a的rpa扩增引物,首先通过rpa对靶序列进行扩增,模板为1000拷贝/μl。
反应体系部体系为30μl,主要分成两部分:
第一部分包括rpa上游引物0.5-2.5μl(浓度10μm),rpa下游引物0.5-2.5μl(浓度10μm),rpa酶预混液21μl(其中含有:磷酸肌酸(浓度20-80mm)、肌酸激酶(浓度50-150mm)、dntps(浓度100-300μm)、atp(浓度20-80mm)、dtt(浓度1-10mm)、醋酸钾(浓度50-200mm)、重组酶uxsx(50-300ng/μl)、uxsy(10-100ng/μl)、单链结合蛋白(200-1000ng/μl)、bsu聚合酶(10-100ng/μl))
第二部分包括lwcas13a蛋白1μl(浓度1-5μm),crrna1μl(浓度1-5μm),t7rnapolymerasemix0.2-2μl,ntpmix1-10μl,信号报告探针1μl(浓度1-10μm)。
其中第一部分配制好后震荡离心把体系收集于管子底部,再往管盖上加入第二部分的混合液,盖上盖子,于恒温37℃反应10-30min后,把盖子上的液体离心收集到管了底部,震荡混匀后短暂离心,使用具体fam荧光读取功能的荧光检测仪进行信号读取,可选(abi7500(thermofisher),abi7500(thermofisher),abiviia7dx(thermofisher),slan-96p(上海宏石),或酶标仪(biotek)等。反应条件和时间为37℃反应10-30min,每1min读取fam荧光值。
2.2.结果分析:
使用荧光检测仪,对扩增产物进行荧光检测,实验设阴性对照。根据荧光检测仪读到的荧光值,计算目标样本的foldchange值(foldchange值=检测样本的荧光量/阳性对照的荧光量),阴性判断标准:foldchange值≦3.0。阳性判断标准:foldchange值>3.0。
本实施例中阳性信号为来自于rna探针断裂后发出的荧光信号,rna探针的序列特点为带有荧光基团和淬灭基团的rna,当cas13a蛋白在crrna的帮助下,识别具有靶向序列的靶向rna后,被激活的cas13a酶可以降解该带有信号的rna探针,从而释放荧光信号,实现检测。
使用abi7500荧光检测仪,对烟曲霉的引物(上表1中引物所示的引物)两两组合进行了检测筛选,最终选出一组扩增效率好的引物对f4/r1,筛选结果如图2所示,图中纵坐标为flodchange值。
实施例3
本实施例基于rpa扩增、t7体外转录和cas13a进行灵敏度检测。
以分别带有烟曲霉保守序列的质粒为模板,并计算稀释为3000拷贝/μl、300拷贝/μl、30拷贝/μl、3拷贝/μl、0拷贝/μl共5个梯度作为灵敏度检测的模板。
1、方法。
参照上述实施例2中引物筛选的操作方法
对烟曲霉体系进行灵敏度分析,实验设阴性对照。
2、结果。
使用abi7500荧光检测仪,对扩增产物进行荧光检测。结果显示,烟曲霉的检测限为单个反应体系7.5拷贝,如图3所示。
实施例4:特异性试验
本实施例基于rpa扩增、t7体外转录联合cas13a,进行烟曲霉的特异性验证。
以烟曲霉基因组dna、插入了目标序列的质粒dna、黄曲霉基因组dna、黑曲霉基因组dna、土曲霉基因组dna、构巢曲霉基因组dna、溜曲霉基因组dna、红曲霉基因组dna、桔青霉基因组dna、无乳链球菌基因组dna、结核分枝杆菌基因组dna、大肠杆菌基因组dna为检测模板,基因组各样本稀释至104拷贝/μl,以hela细胞基因组dna作为阴性质控,测试烟曲霉体系的特异性。
1、方法:
参照上述实施例2中的方法
总体积为30μl,其中使用引物对f4/r1。
2、结果分析:
使用abi7500荧光检测仪,对扩增产物进行荧光检测。实验结果如图4显示,只有烟曲霉基因组dna和插入了目标序列的质粒dna能够被特异性检出,其它样本没有明显信号。
实施例5
一、制备用于检测烟曲霉的试剂盒,包括:
(1)烟曲霉特异性引物及crrna具体如下:
烟曲霉-crrna:
5’ggggauuuagacuaccccaaaaacgaaggggacuaaaacuuacgauaaucaacucagacugcauacu-3’,浓度为1μm;
烟曲霉正向引物:
5’-taatacgactcactatagggggtccaacctcccacccgtgtctatc-3’,浓度为10μm;
烟曲霉反向引物:
5’-tcgatgattcactgaattctgcaattcacattac-3’,浓度为10μm;
rpa酶预混液:磷酸肌酸(浓度20-80mm)、肌酸激酶(浓度50-150mm)、dntps(浓度100-300μm)、atp(浓度20-80mm)、dtt(浓度1-10mm)、醋酸钾(浓度50-200mm)、重组酶uxsx(50-300ng/μl)、uxsy(10-100ng/μl)、单链结合蛋白(200-1000ng/μl)、bsu聚合酶(10-100ng/μl);
醋酸镁:浓度280mm。
lwcas13a蛋白:浓度为2μm;
t7rna聚合酶混合液:市售(neb)
ntp混合液1-10μl:市售,浓度为每种ntp20mm;
信号报告探针:5’6-fam-uuuuuuuuuuuuuu-bhq1-3’,浓度为10μm。
二、采用上述试剂盒进行烟曲霉的检测
(1)检测样本的dna提取
检测样本可以是培养的病毒株,也可以是临床样本(主要包括痰液、肺泡灌洗液等)或是其它科研实验样本。
(2)rpa扩增及crispr分析
参照上述实施例2中的方法。
(3)结果分析:
上述检测过程中,由于在反应体系中加入两端分别连接荧光基团和淬灭基团的信号报告探针,当cas13a蛋白在crrna的帮助下,识别具有靶向序列的靶向rna后,被激活的cas13a酶可以降解该带有信号的rna,从而释放荧光信号,实现检测。
使用abi7500荧光检测仪,得到的累积荧光值作为信号强度,根据荧光检测仪读到的荧光值,计算目标样本的foldchange值(foldchange值=检测样本的荧光量/阳性对照的荧光量),阴性判断标准:foldchange值≦3.0。阳性判断标准:foldchange值>3.0。
其中,阴性对照组为每个实验组对应设置的以加入同时以depc处理水(生工生物工程(上海)股份有限公司)的阴性信号组。
以上述实施例5的试剂盒进行临床样品的检测。结果表明,能够快速、灵敏、高特异性地检测临床样品中的烟曲霉。
序列表
<110>广州医科大学附属第一医院
广州呼吸健康研究院
<120>用于快速检测烟曲霉的序列、试剂盒、方法及应用
<160>16
<170>siposequencelisting1.0
<210>1
<211>67
<212>rna
<213>人工序列(artificialsequence)
<400>1
ggggauuuagacuaccccaaaaacgaaggggacuaaaacuuacgauaaucaacucagacu60
gcauacu67
<210>2
<211>46
<212>dna
<213>人工序列(artificialsequence)
<400>2
taatacgactcactatagggggtccaacctcccacccgtgtctatc46
<210>3
<211>34
<212>dna
<213>人工序列(artificialsequence)
<400>3
tcgatgattcactgaattctgcaattcacattac34
<210>4
<211>659
<212>dna
<213>人工序列(artificialsequence)
<400>4
tcaaacccggtcatttagaggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgc60
ggaaggatcattaccgagtgagggccctctgggtccaacctcccacccgtgtctatcgta120
ccttgttgcttcggcgggcccgccgtttcgacggccgccggggaggccttgcgcccccgg180
gcccgcgcccgccgaagaccccaacatgaacgctgttctgaaagtatgcagtctgagttg240
attatcgtaatcagttaaaactttcaacaacggatctcttggttccggcatcgatgaaga300
acgcagcgaaatgcgataagtaatgtgaattgcagaattcagtgaatcatcgagtctttg360
aacgcacattgcgccccctggtattccggggggcatgcctgtccgagcgtcattgctgcc420
ctcaagcacggcttgtgtgttgggcccccgtccccctctcccgggggacgggcccgaaag480
gcagcggcggcaccgcgtccggtcctcgagcgtatggggctttgtcacctgctctgtagg540
cccggccggcgccagccgacacccaactttatttttctaaggttgacctcggatcaggta600
gggatacccgctgaacttaagcatatcaataagcggaggaaaagaaaccaacagggatt659
<210>5
<211>36
<212>rna
<213>人工序列(artificialsequence)
<400>5
gauuuagacuaccccaaaaacgaaggggacuaaaac36
<210>6
<211>67
<212>rna
<213>人工序列(artificialsequence)
<400>6
ggggauuuagacuaccccaaaaacgaaggggacuaaaaccucagacugcauacuuucaga60
acagcgu67
<210>7
<211>54
<212>dna
<213>人工序列(artificialsequence)
<400>7
taatacgactcactatagggtaggtgaacctgcggaaggatcattaccgagtga54
<210>8
<211>54
<212>dna
<213>人工序列(artificialsequence)
<400>8
taatacgactcactatagggtgaacctgcggaaggatcattaccgagtgagggc54
<210>9
<211>55
<212>dna
<213>人工序列(artificialsequence)
<400>9
taatacgactcactatagggcggaaggatcattaccgagtgagggccctctgggt55
<210>10
<211>36
<212>dna
<213>人工序列(artificialsequence)
<400>10
actcgatgattcactgaattctgcaattcacattac36
<210>11
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>11
atgattcactgaattctgcaattcacattac31
<210>12
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>12
ttagaaaaataaagttgggtgtcggc26
<210>13
<211>55
<212>dna
<213>人工序列(artificialsequence)
<400>13
taatacgactcactatagggtgaaagtatgcagtctgagttgattatcgtaatca55
<210>14
<211>55
<212>dna
<213>人工序列(artificialsequence)
<400>14
tgattacgataatcaactcagactgcatactttcaccctatagtgagtcgtatta55
<210>15
<211>53
<212>dna
<213>人工序列(artificialsequence)
<400>15
taatacgactcactatagggtgaacgctgttctgaaagtatgcagtctgagtt53
<210>16
<211>53
<212>dna
<213>人工序列(artificialsequence)
<400>16
aactcagactgcatactttcagaacagcgttcaccctatagtgagtcgtatta53
- 还没有人留言评论。精彩留言会获得点赞!