用于根据电磁光谱信息表征物理样本中成分的方法和设备与流程
本发明涉及机器学习领域,特别是用于分析高分辨率或超分辨率光谱数据的机器学习,分析所述数据通常包括分析高度复杂的样本/物质的混合物,例如激光诱导击穿光谱技术(libs)。本文公开的方法属于可解释人工智能类别。
背景技术:
等离子体发射光谱技术(特别是激光诱导击穿光谱技术(libs))是高分辨率且高度解析的技术。等离子体发射光谱技术的全部潜力通过解译在分子击穿电离过程期间获取的发射线的动态信息结构来提供,其中每种不同的成分具有不同的等离子体发射动态。此动态'指纹'包含关于存在于物理样本中的化学元素和/或其同位素、分子和/或其构象、状态和结构的所有信息。等离子体发射(例如libs)通常用于分析自然存在的或人造的复杂样本/物质的混合物。
如果仪器具有无限的光学分辨率并且仅存在量子不确定性,那么化学元素和分子的识别将是简单的操作,因为每种元素的发射线都是得到良好表征,并且与认证数据库(例如nist原子光谱线数据库)的直接匹配将足以评估物理样本。然而,从物理样本获得的光谱信息是光物理现象的复杂叠加和卷积的结果。这对任何复杂样本的光谱中的光谱信息造成多尺度干扰。
等离子体发射光谱系统(例如libs)解析光谱信息的能力(即光学光谱分辨率)是有限的,其受在光谱系统中使用的ccd中像素的数量和布置限制。这个事实使得不可能验证光谱线不包括每种元素的假设。
在更复杂的样本中,因为不同的化学元素在非常靠近的波长处呈现光谱线,使用光学光谱分辨率的方法不能够输出准确的识别或量化结果。例如,锂(li)光谱线会被错误识别为:i)铁(fei)(610.329nm和670.74nm);或ii)钨(w)(670.8202nm);或iii)钛(ti):(610.35nm和670.76nm)。光学分辨率下的谱线匹配算法很可能无法识别元素。这对于等离子体发射光谱技术来说是非常显著的限制,因为许多元素具有显著数量的重叠带区,原因是它们具有增加数量的会干扰其他元素的线。
现有等离子体发射光谱系统(特别是libs系统)已经准备好在光谱带之间的低干扰下识别和量化物理样本中的元素。这些系统通过以下方式来最小化等离子体物理效应(诸如多普勒和斯塔克展宽):降低压力或使用气调,或操纵激光能量/脉冲以使信号强度最大化并且使潜在热力学平衡下的光谱带不确定性最小化。所有元素识别和量化都在基于像素的信号中直接进行,这在所评估样本极其复杂(例如矿物或生物样本)的情况下是显著的缺点。对libs系统实施基于像素的方法得到的成功是有限的,因为卷积光谱带的使用不允许通过光谱线确定性地识别存在于物理样本中的成分。在此过程期间,引入了不必要的干扰和不确定性,从而将基于像素的方法约束到概率性的识别、分类和量化。
ep1967846公开了一种基于匹配算法对未知化合物混合物的光谱进行分类或量化的方法。然而,ep1967846仅在分析纯化学品或纯化学品的混合物方面的表现是准确的,所述纯化学品或纯化学药品的混合物在光学分辨率内具有无干扰的连续光谱信号,从而允许与纯化学品或化学品的混合物的拉曼光谱数据库进行匹配。复杂样本(诸如生物样本)表现出如此之多的多尺度干扰,以致于光谱特征无法与组成直接相关。
此外,现有方法识别、量化和预测物理样本的组成的能力仍然取决于人类专家的先前知识(hahn和omenetto,2010年)。因此,量化模型的开发高度依赖于为光谱线识别提供正确的环境(cousin等人,2011年)。从这个意义上说,本领域已知两种主要的机器学习方法,具体地是化学计量和神经网络/深度学习。
化学计量是提供预测潜在变量的方法的标准途径。此方法无法应用于复杂样本,仅限于具有更简单组成的样本或具有低组成可变性的接近纯的化学品(诸如药品)或样本。例如,化学计量模型(诸如偏最小二乘(pls))不能够正确地量化包含锂的矿石中的锂含量,因为化学计量技术未正确地对正确的等离子体发射信息以及光谱线之间的干扰进行建模。
支持向量机器、神经网络/深度学习方法提供输入与输出之间的确定性非线性映射。
所有这些方法都不能够找到组成、光谱带及其干扰模式之间的正确的协方差。这是由于所有元素之间的叠加的且多尺度的干扰以及等离子体发射的所有物理现象。数据如此庞大且详细,以致于找到可预测组成的正确网络架构是极其低效的机器学习过程。这些是全局模型,并且随着新数据的收集,需要创建新的全局模型。
此外,这些现有方法并不提供确定给定样本是否可预测的方式;并且这些现有方法在检测异常值方面存在显著的困难。
缺少此特性是在关键领域(诸如其中必须进行故障安全操作的医药或危险工业应用)中的机器学习(ml)方法的主要障碍。
对于等离子体诱导光谱信息处理(诸如激光诱导等离子体光谱技术(libs))来说,当前的机器学习对其在以下方面的全部理论潜力呈现一系列显著的限制:i)测量和识别化学元素及其同位素;ii)测量分子结构和组成;iii)遵循等离子体加强的化学反应;iv)识别、表征和量化材料、其分子构象和化学元素组成;v)通过等离子体指纹法识别和量化生物材料;vi)分析在不同的压力或温度下处于不同状态(固体、液体或气体)的同一样本;以及vii)处理在不同的压力和温度下的测量结果。
此外,当前的机器学习技术(诸如svm和ann)通常依赖于黑箱途径。尽管取得了积极的结果,但是这些方法并未提供对结果的可解释解译以用于允许人类控制和与之交互的互操作性、解译和交互,使得要对算法的结果和内部运作两者进行调试并且要根据人类知识和推理来验证和策展预测结果。这对等离子体发射光谱技术来说是严重的限制,其中诊断发射线波长及其强度如何干扰和有助于识别、分类和量化对于正确的物理建模并准确预示新的且未知的数据以及创建在许多应用领域中都支持此水平技术的固化且得到科学验证的数据库是至关重要的。
本发明包括一种机器学习方法和系统,其实时地并且在使用点/护理点处提供高度复杂的样本中的分析准确度度性组成预测,从而克服此类已知方法。
技术实现要素:
因此,本发明的一个目的是一种用于根据物理样本的电磁光谱信息表征这种物理样本中的一种或多种成分的方法,每种成分由化学元素和/或其同位素、分子和/或其构象或状态中的一者或其组合组成,所述方法包括以下步骤:
·获得对应于所述物理样本的电磁光谱信息、优选地包括一个或多个电磁光谱的分辨率,
·在对应于所述光谱信息的所述光谱分辨率是亚光光谱分辨率的情况下,从所述电磁光谱信息提取一条或多条光谱线,
·将所述光谱线投影到确定性特征空间的样本点中,这种确定性特征空间由多维向量空间组成,所述多维向量空间包括具有预先确定的向量基的多条光谱线,这种具有预先确定的向量基的多条光谱线:
ο存储在数据库中并且已经通过亚光光谱分辨率提取获得,并且
ο对应于多种已知成分,
其中所述多维向量空间的每个维度都是所述电磁光谱信息所对应于的所述物理样本中的所述一种或多种成分的预测特征,这种预测特征提供对所述物理样本中的一种或多种成分的量的确定、分类和/或识别。
本文公开的方法使用亚光光谱数据来以提高的准确度提取光谱线,使用此信息作为特征变量来对物理样本中的一种或多种成分进行识别和/或量化。因此,与根据基于像素的技术的现有技术相比,存在两个主要优点:i)对准确限定的光谱线的访问允许将所观察到的光谱线确定性地分配到它们的期望理论波长和跃迁概率,描述于kramida等人,2018年;ii)提取动态击穿分子离子发射线(即,动态等离子体发射分析)提供关于分子结构的信息,从而允许高度准确的成分识别、分类和量化。代替提供必须使用大数据数据库进行训练的全局模型,所提出的方法在确定性特征空间中的现有数据中搜索提供足够的解译(可解释的模型)并且准确地识别、分类和量化成分的光谱线和样本。借助于通过可解释的接口提供用于识别和量化成分的光谱线的贡献,所述方法还允许人类理解模型(可解释的人工智能)。通过为量子力学数学原子和分子模型提供质量数据,这种贡献可进一步用于理解等离子体发射动态和击穿。通过提供人类可解译的信息,动态等离子体发射分析进一步为开发新的且先进的仪器提供有价值的信息。所述样本点可被描述为特征空间中的特定样本电磁光谱的坐标。
所述方法可根据现有数据或新添加的数据自学习,并且可在进行任何预测之前关于预测能力进行自诊断。通过使用自监督模型构造的理论知识,所述方法还包括自教授应使用什么光谱线进行解译的能力。在不存在等离子体诱导大数据数据库的情况下,自主不断学习和与人类解译交互的能力对于复杂可变性领域(诸如地质、医药和生物技术)中的应用是极其必要的。
因此,本发明的方法通过仅使用亚光光谱信息(即,在低于光谱仪系统的光学分辨率下提取光谱线)来改变与现有技术方法相关联的范例。这是可能的,因为像素密度高于光学分辨率,并且入射在电荷耦合装置(ccd)传感器上的光谱线通过线性ccd的连续像素而展宽。因此,根据这种光谱信息确定光谱线位置减轻与基于像素的方法相关联的不确定性。光谱线中的这种超低波长误差允许准确提供成分信息,从而允许对它或它们进行识别、分类和量化并且根据电磁光谱确定化学结构。此外,光谱线确定中的极低误差将对元素或小分子离子发射的识别转变为确定性过程,这与先前基于像素的方法中的概率性过程不同。
如权利要求1所述的方法使用所有所述化学元素和/或其同位素、分子和/或其构象或状态的多条光谱线作为变量向量基,根据所述变量向量基,等离子体发射信息数据库扩展成包含潜在热力学平衡下的所有可能光谱的矩阵形式,或扩展成包含多个样本的所有时间依赖性等离子体发射光谱的张量格式。这些矩阵或张量用于产生多维向量空间,即所述确定性特征空间,其表示所有现有光谱线的特征空间域中的一个或多个物理样本特征。所有先前已知的光谱线存储在数据库中,对应于针对多种成分提取的光谱线。
所确定的预测特征提供关于样本成分的信息,所述样本由从中获得电磁光谱信息的物理样本组成,这种所获得的信息由关于存在于物理样本中的一种或多种成分的量、分类或识别的信息组成。
如上文所指示,成分可由化学元素和/或其同位素、分子和/或其构象或原子态、壳层和构型中的一者或其组合组成,从而包括但不限于如以各种构象或状态存在的纯元素、分子或物质、金属合金及其组合的实例,此类成分存在并由此形成物理样本的整体或部分。
向量基由已知概念组成,并且可限定为产生特征空间的线性无关的标准正交向量。对分子的构象的提及表示原子在分子中的特定排列,而状态表示单独原子的电子云的特定排列。确定性特征空间表示特征,在本案例中表示光谱线,从而允许产生相同输出。光谱线可由发射线组成。
本发明的方法是一种水平技术,其适用于最需要最低程度破坏性和最低程度侵入性应用的领域,诸如:医疗保健、动物护理、生物技术、制药、食品和农业、原材料和矿物、微米和纳米技术、分子生物、内陆安全和军事、化学和纳米工程材料。它不需要在实验室中制备物理样本。本发明方法的光谱信息优选地通过能够进行等离子体诱导的技术(即激光诱导等离子体光谱技术(libs))获得。
本发明的方法提供自学习,因此提供根据数据进行的非监督学习,以及根据数据进行的内隐自动监督学习,即自教授。
本发明的又一个目的是一种用于表征物理样本中的一种或多种成分的具有自学习能力的计算设备,每种成分由化学元素和/或其同位素、分子和/或其构象或状态中的一者或其组合组成,其中所述计算设备被配置来实现所描述实施方案中的任一个中的本发明的方法,所述计算设备优选地还包括能够在物理样本中诱导等离子体状态的光谱装置,所述光谱信息从所述光谱装置获得,所述光谱装置优选地由libs装置组成。所述设备可包括等离子体诱导光谱装置,并且被配置来控制这种光谱装置。
此外,本发明的又一个目的是一种非暂时性存储介质,其包括可执行以实施所描述实施方案中的任一个中的本发明的方法的程序指令。
附图说明
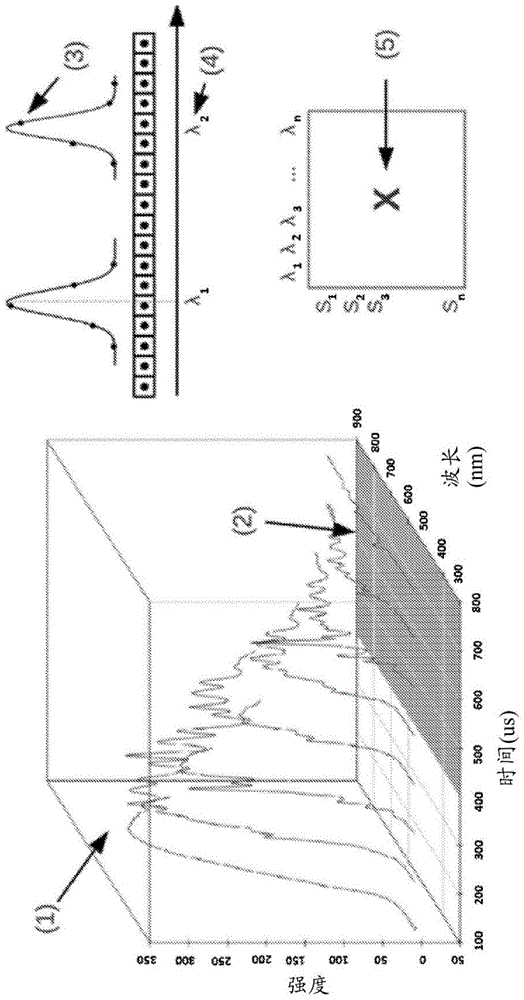
图1呈现从激光烧蚀到潜在热力学平衡下的离子发射的典型动态libs信号,以及亚光光谱线提取,其中以矩阵格式存储对应的数据。
图2介绍亚光光谱线提取中的干扰的影响,对光谱带去卷积的方式,以及对光谱线进行解析和提取的方式。它还介绍专有光谱线(9)和干扰性光谱线(11)的概念。
图3示出从确定性全局特征空间(12)构建确定性局部特征空间(15)的方式的具体实施方案,具体是其中分析由成分(13)组成的三个样本的实施方案。可确定专有光谱线(9)和干扰性光谱线(11),并将其用作局部确定性特征向量来构建确定性局部特征空间(15)。确定性全局特征空间(12)的不同区域表示多个样本的特定专有光谱线(9)和干扰性光谱线(11)的组合。由不同成分(13)组成的样本簇提供成分的光谱线指纹,所述指纹有可能与这些谱线组合成全局特征空间(即所述局部确定性特征空间(12))的子空间。
图4是成分量化过程(22)的视觉解释,其中从未知物理样本提取的光谱线被投影到确定性全局特征空间(12)的样本点(16)中。
图5是未知物理样本的分类和识别过程的视觉演示,其中从未知物理样本提取的光谱线被投影到确定性全局特征空间(12)的样本点(25)中。
图6呈现用于使用以下各项从多个libs物理样本获得确定性全局特征空间(12)的不同方法,其中对应的时间进程光谱线以张量l(28)形式存储:i)在lte下提取的光谱线(29);ii)展开的张量l的分层多块(30);iii)张量l的tucker3d分解(31);以及iv)张量l的parafac分解(32)。
图7呈现用于对未知物理样本等离子体发射光谱进行预测的主要步骤:i)确定光谱分辨率(33)、光谱线数据库(39)和去卷积参数(39);ii)去卷积(40)和专有/干扰光谱线提取(42);以及iii)确定性特征空间构造(45),以及对未知物理样本进行量化、分类和识别(48)。
图8呈现来自bejanca矿的钨锰铁矿矿石(51)的libs表征。钨锰铁矿矿物(黑矿石)(52)包封在石英(53)中。
图9呈现来自gelfa-portugal的锂矿石(54)的libs表征,其中锂矿脉(55)由石英(55)包围。
图10呈现狗血和猫血中na、k、fe和mg的量化。
图11呈现锂辉石(59)和透锂长石(60)结构中的锂矿石晶体的等离子体发射光谱。
具体实施方式
在本发明的方法的发明方面,所述还包括以下步骤:
·在所述确定性特征空间内选择对应于已知成分量的最少量的相邻样本点,使得所投影样本点使与所述对应的最少量的相邻点的协方差最大化,
·根据所述最小量的相邻点选择专有光谱线、干扰光谱线和独特光谱线,从而得到所述相邻样本点内的局部特征空间,以及
·通过考虑将要量化的所述物理样本的投影到所选择相邻样本点的协方差特征空间中的光谱线来关联来自所述局部特征空间的所述已知成分,来预测来自将要量化的所述物理样本的所述成分的量化。
因此,在将所提取的来自物理样本的光谱线投影到确定性特征空间中之后,所述计算方法确定对应的最少量的相邻点,即存在于数据库中的使对应于已知成分的协方差最大化的样本。所述方法还包括创建局部特征空间,即确定性特征空间的子空间,其仅由产生此局部多维向量空间的最少量的相邻点的专有光谱线、干扰光谱线和独特光谱线作为变量组成。所述方法包括确定:i)专有光谱线—如仅属于特定离子元素或分子的那些光谱线;ii)干扰光谱线—叠加且不能用亚光提取解析的光谱线;以及iii)独特光谱线—仅属于特定成分等离子体动态的光谱线。当与基于像素的方法相比时,对专有光谱线、干扰光谱线和独特光谱线的选择也是显著的演变,在基于像素的方法中,因为这些方法的特征空间不是确定性的,所以选择示不可行的。此后,通过确定使光谱特征与特定成分的量之间的协方差最大化的方向来执行特定成分的量化。所述所选择的相邻样本点可被描述为维持局部模型生成的协方差的在多维特征空间中的欧几里德短距离内的所选择样本。
在本发明的方法的另一个发明方面,所述方法还包括以下步骤:
·通过确定所投影样本点是否在所述确定性特征空间的预先确定的区域内,在所述确定性特征空间内选择最少量的相邻样本点,使得此类相邻样本点属于特定类别,这种区域由非线性逻辑边界界定,以及
·针对定界在所述区域内部的所述最少量的相邻样本点,选择专有光谱线、干扰光谱线和独特光谱线以得到局部特征空间,从而在所述相邻样本点和所述样本点内提供匹配。
因此,这种方法高效地使得能够对存在于物理样本中的成分进行分类和/或识别,其中如果所投影光谱线在确定性特征空间的预先确定的区域内部(由非线性逻辑边界(即限定特定成分类别的边界)界定),则所述物理样本被称为属于已知特定物理样本(指代成分)类别。进一步通过将相邻样本点和所述样本点的专有光谱线、干扰光谱线和独特光谱线进行匹配来执行成分、化学元素和/或其同位素、分子和/或其构象或状态的识别,所述独特光谱线是在其他成分中不可观察到的光谱线。
此外并且在包括如权利要求4所述的另外的特征(以便确定上文提及的非线性逻辑边界)的实施方案中,所述方法通过以下方式来在确定性特征空间中搜索两个或更多个不同类别的样本之间的边界:确定使逻辑函数的误差最小化的搜索方向,并且确定局部地限定逻辑边界的类别样本,即所述极端支持辨别样本(维持样本之间的逻辑辨别边界的样本)。通过递归地应用此方法,针对特定类别确定所述非线性逻辑边界。所述搜索方向提供在特征空间中的方向搜索。
在如权利要求5所述的本发明的方法的另一实施方案下,一旦预先确定了类别,就可更直接执行识别和量化,因为类别专有光谱线、干扰光谱线和独特光谱线是已知的。任选地并且在如权利要求6所述的另一实施方案下,还确定化学结构。非贡献等离子体效应可由散射、展宽、连续背景组成。相关线可由包含量化效应的线组成。匹配指数可被描述为相似度指标。
本发明的方法的另一个发明方面在于:其中所提及的电磁光谱信息是根据等离子体诱导光谱方法、优选地激光诱导击穿光谱技术(libs)获得的。
任选地,在上文描述的具体实施方案中,所提及的电磁光谱信息包括在特定时间流逝内随时间的光谱信息变化,所述等离子体诱导光谱方法在这种时间流逝内已经对物理样本产生影响。
因此,结合获得在时间流逝期间的整个时间内的光谱信息包包括等离子体诱导光谱方法使得能够进一步表征物理样本。等离子体诱导光谱方法(诸如激光诱导等离子体光谱技术)在等离子体相期间提供分子击穿,导致化学键在特定电离能下的特性分子结构离解,从而提供关于样本成分的化学结构的信息。
实际上,在所提及的电磁光谱信息中将包括与时间中的若干瞬间相对应的若干电磁光谱,从而使得能够更好/更深入地了解成分量、分类或识别,例如无需借助若干技术和实验室准备即可更好地确定成分的构象或状态。
在本发明的方法的实施方案中,所提及的随时间的变化是离散的,电磁光谱信息由此包括多个电磁光谱,每个光谱对应于所提及的时间流逝中的瞬间,由此针对所述多个光谱中的每个光谱提取光谱线,从而针对每个光谱产生一条或多条光谱线。
在本发明的方法的另一个方面中,所提及的确定性特征空间是通过分层多块技术或张量分解获得的,因此所述方法是用于将特征空间融合成单个超集的方法。
在本发明的方法的一个方面,在所述特征空间内选择最少量的相邻样本点还包括如权利要求11所述的步骤。
在本发明的方法的另一方面,所述方法还包括如权利要求12所述的另外的步骤。
在本发明的计算设备的优选实施方案中,所述计算设备包括光谱装置,这种光谱装置优选地由从其获得所述光谱信息的libs装置组成,所述计算设备进一步被配置来在预先确定的时间流逝期间从所述光谱装置获得光谱信息,并由此获得由对应于所述预先确定的时间流逝中的若干瞬间的多个电磁光谱组成的光谱信息,所述等离子体诱导光谱装置在这种时间流逝期间已经对所述物理样本产生影响。
实施方案
结合附图,本发明的技术内容和详细描述在下文根据优选实施方案进行描述,而不用于限制其执行范围。本发明所要求保护的权利要求涵盖根据所附权利要求做出的任何所有等效变化和修改。
本文档描述一种用于根据物理样本的电磁光谱信息表征这种物理样本中的一种或多种成分的方法。所谓成分,意图意指化学元素和/或其同位素、分子和/或其构象或状态中的一者或其组合。
在本文描述的本发明中,通过等离子体发射光谱技术来获取物理样本的电磁光谱信息。在优选实施方案中,使用libs作为等离子体发射光谱技术。针对以下一组给定数据记录对物理样本si取得的所述电磁光谱信息:激光能量和脉冲函数、波长;大气组成、压力和温度。
图1呈现典型libs信号,其涵盖以下阶段:激光烧蚀、等离子体膨胀与分子击穿和电离、等离子体冷却和电子衰变(1);以及在潜在热力学平衡(lte)下的离子原子发射(2)。
对于每个样本si,沿时间(t)在不同波长(λ)下记录光谱强度,将其以矩阵格式存储为li(λ,t)。当记录多个物理样本slibs光谱时,以三向张量格式l(s,λ,t)存储这些光谱强度。
大多数现有libs系统仅使用延迟的信息,以获得最小黑体辐射、最小多普勒和斯塔克展宽,并且仅记录在lte下的测量结果。在这种情况下,对于多个物理样本,每个样本由向量xi(即在不同波长下记录的光谱)和x(s,λ)(即在lte下记录的光谱)表示。
本发明引入亚光光谱线提取的特征,其中,在像素位置(3)处记载的光谱带拟合到足以提取强度最大值处的光谱线波长(4)的点扩散函数。因此,将结果记录为多个样本的亚光光谱线x(s,λ)(4),从而显著减小在使用基于像素的值时所观察到的复杂样本分析中的波长误差。
参考图2来解释亚光光谱线提取中的干扰的影响,以及将光谱线存储为变量的方式。在本文公开的发明中,考虑光学部件(7)(狭缝、光栅和像素大小/密度)、多普勒和斯塔克展宽的影响来对光谱带去卷积(6)。详细地,如果去卷积光谱带的概率干扰(8)低于针对原子光谱线数据库优化的给定阈值,则解析光谱线。如果解析的频带和对应的光谱线仅属于特定元素,则它们被认为是专有光谱线(9)。未解析或非专有光谱线(10)被认为是干扰性光谱线(11)。将所提取的线存储为专有的和干扰性的,并且限定x(s,λ)或l(s,λ,t)的λ尺寸。
图3演示到确定性全局特征空间(12)的不同区域中的x(s,λ)或l(s,λ,t)表征,所述不同区域表示多个样本的专有光谱线和干扰性光谱线的不同组合。由不同成分(13)组成的样本簇显示出不同的专有光谱线(9)和干扰性光谱线(11),从而产生独特光谱线(14),即成分的光谱'指纹'。
根据全局的专有光谱线、独特光谱线和干扰性光谱线,使用相邻样本点类别来构造全局特征空间(12)的子空间,即所述局部确定性特征空间(15),其中成分的光谱'指纹'。例如,由化学元素a、d、e和f组成的成分(14)将位于确定性全局特征空间(12)的特定位置处。
局部确定性特征空间(15)的创建是本发明的关键特征概念之一。局部确定性特征空间(15)的细节允许对在表征物理样本时要使用的正确的相关光谱线信息进行搜索、自学习和自监督。例如,由元素a、d、e和f组成的成分(14)将位于全局特征空间的特定位置处。a、d、e和f的主要光谱特征周围的光谱线中的变化是由于以下原因:i)这些元素可借以形成分子基础的分子重排/结构和组合;ii)由相同元素的不同分子组合组成的非均质材料;iii)将增加或减少来自纯离子元素的预期线并且在击穿期间呈现瞬态分子离子的不同分子构型和结构的等离子体分子击穿动态;iv)基体效应,其中每条光谱线的强度通过在等离子体中吸收和传播能量而受影响;以及v)压力和温度的峰展宽效应。
除了识别存在于物理样本中的成分之外,本文公开的方法还能够量化同一所述物理样本中的成分。图4中针对特征空间(12)的给定区域解释成分量化过程,所述给定区域表征具有成分元素a、d、e和f的物理样本的化学元素光谱线(14)。
由先前元素组成的任何特定分子结构提供不同的动态和lte等离子体击穿光谱线指纹,其中强度进一步受激光功率函数、基体效应、压力和温度(在本文档中,将所有这些称为‘测量环境’)影响。为了量化在给定测量环境内排列成特定分子结构的化学元素的特定组合,应使光谱线、其强度和对应的干扰与成分的浓度关联。此外,应使用特定元素的专有或干扰光谱线并且在分子或复杂成分的情况下应使用独特光谱线进行量化。
使用图4所描绘的实例,化学元素a、d、e和f的分子组合占据确定性全局特征空间(12)的特定区域。在此假设下,使用a、d、e和f的专有和干扰光谱线构造局部确定性特征空间(15),并且通过分析未知样本(16)与其样本点邻域、给定光谱线及其强度之间的关系来进行量化。
为了量化局部特征空间内部的元素a,所提出的方法搜索特征空间中使与元素a浓度关联的未知样本点(16)与最少量相邻点之间的协方差最大化的方向,以便找到统计上一致的协方差方向(17),也就是说,给定已知样本光谱带的数据库和对应元素浓度,有可能找到可维持未知样本中的a的量化的样本(最少量相邻样本点)。
如果未知样本(16)在置信区间限制(20)内部,则可进行浓度预测。可将任何未知物理样本的可预测性评估为与协方差方向(17)的误差距离(19)。当未知样本点(16)在置信区间(20)外部(18)时,所述方法输出无法预测准确的成分量化。
图4呈现本发明的另一关键原理:使量化准确性最大化的对相邻样本和光谱线信息的选择。一旦找到协方差方向,所述方法就通过进行样本选择和光谱信息的正交过滤(21)(与期望预测正交的过滤效应)两者来进一步优化与量化相关的相邻样本点和光谱线的最小数量。此类操作允许去除不对成分a进行量化的等离子体发射信息,从而允许人工解译(22)。例如,在构型a、d、e和f下,a的量化由a的两条专有线的正贡献(23)、a的一条独特的‘基于环境的’线的正贡献(23)以及干扰线af的负贡献(23)给出。本领域中受过训练的人类观察者应理解:正在使用正确的信息进行量化,因为a贡献是非负的,并且对f的干扰随着a浓度的增加而降低af线的强度。不预期a专有线的负贡献。然而,如果观察到统计上有效的关系,则人类可通过仅分析最少量相邻样本光谱信息来进一步研究等离子体击穿过程期间的原因。
图5呈现分类和识别方法的视觉演示。通过非线性分类器(即非线性逻辑边界(24))在全局确定性特征空间(12)中进行样本分类。一旦未知样本点(25)在包含于非线性逻辑边界(24)内的类别内部,则通过极端支持辨别样本(26)所支持的局部逻辑回归得到属于特定成分类别的概率。一旦属于特定类别的概率高于阈值,则通过以下方式来实现识别过程:将未知物理样本的提取光谱线与特定类别的对应相邻点进行匹配(27),从而识别成分、分子结构或状态两者。
图6呈现用于全局特征空间构造的不同方法的说明。等离子体发射是动态的,并且对于特定构型,以张量格式l(s,λ,t)存储。在一种实现方式中,在lte下的等离子体发射数据(29)中,仅使用lte下的信息x(s,λ)通过使与给定特定成分的协方差最大化的基变换(例如svd、傅里叶、小波、曲波)来构建特征空间
在另一种实现方式(30)中,通过分层多块特征空间信息融合来合并动态信息。使用一系列时间步处的不同的光谱线来使每个块x1、x2、x3…xn(s,λ.)与成分浓度或样本分类的协方差最大化,以便将每个块特征空间的信息融合到合并等离子体发射动态的单个全局确定性特征空间
在其他实现方式中,通过张量分解方法合并动态信息。在tucker3d方法(31)中,通过tucker3d技术来分解张量l(s,λ,t):
l(s,λ,t)=∑r∑q∑(p)gr,q,p·ai,p·bj,q·ck,r+es,λ,t
其中,a(s,p)、b(λ,q)和c(t,r)是正交的,并且可独立分析,并且可与g(r,q,p)组合以通过样本关系a(s,p)→g(r,q,p)→b(λ,q)、c(t,r)得到确定性全局特征空间
在第二方法中,通过parafac方法来分解张量l(s,λ,t):
l(s,λ,t)=ξr,r,r·ai,r*bj,r*ck,r+ei,j,k
其中,a(i,p)、b(j,q)和c(k,r)是非正交的,并且ζ(r,r,r)是相关联的本征值。通过使用一组相关的本征值维度ζ(r,r,r),可使用a(s,r)、b(λ,r)和c(t,r)构造全局特征空间,如在先前技术中一样。对于所有以上构造确定性特征空间构造,量化、分类和识别是等同的。
提供了本发明的基本和高级关键概念,现在参考附图为权利要求提供详细支持,现在使用算法和结果来提供详细支持。
图7呈现用于实现量化、分类和识别的主要工作流程。提供了新的未知等离子体发射光谱x(λ,t)或x(λ)(33),所述过程开始于通过确定像素强度的局部最大值来获得光谱峰(34)。对于这些峰(34),使用每个局部最大值的相邻像素进行高斯拟合。使用不重叠的峰(p<10-12)通过对应的半极大处全宽度(fwhm)确定均值光谱分辨率。
光学分辨率确定:i)可使用的光谱线数据库;以及ii)用于在亚光分辨率下从物理光谱提取光谱线的最佳去卷积参数。光谱线数据库根源在于特定光学分辨率,因为这些是使用利用提升的richardson-lucy算法微调的去卷积参数得到的。本发明与针对给定固定光谱分辨率的现有光谱线数据库协作,从而确定确定性特征空间(12,46)和构成人工智能知识库的样本点。所述数据库存储:i)多种成分在lte下的光谱线或动态等离子体发射的光谱线;ii)对应的成分浓度;iii)成分化学结构和命名;以及iv)成分分类。
因此,一旦记录了未知的物理样本等离子体发射光谱,第一步骤就是通过以下方式确定光学分辨率(33-37):
i.通过确定局部最大值来获得光谱带峰(33);
ii.对每个峰执行高斯函数拟合(34);
iii.确定独立光谱线(p<10-12)的fwhm;
iv.将均值fwhm确定为光谱分辨率(36);以及
v.鉴于所述光谱分辨率:a)确定应使用什么光谱线数据库来构建特征空间和知识库;以及b)richardson-lucy迭代和提升步骤的数量。
第二步骤包括提取光谱发射线(波长和强度)(43)。
可使用等离子体发射光谱的去卷积来最小化峰展宽的影响,以便减轻以下各项的影响:i)自然展宽;ii)热效应;iii)多普勒效应;以及iv)碰撞展宽;使得可在亚光分辨率下准确地提取光谱线。
这些效应(以高斯(g)线型和洛伦兹(l)线型为主)的卷积产生给定的特征福格特分布线型:
其中:
对于给定的数据库,高斯方差(σ)和洛伦兹比例因子(γ)是预先确定的,并且卷积进行平衡以校正峰展宽在动态等离子体发射测量结果中的影响。
去卷积之后,通过以下方式获得未知光谱线:
i.确定每个光谱带的局部最大值(34);
ii.通过对每个光谱带进行高斯拟合以提取拟合的平均波长(λ)来提取亚光光谱线;
然后,通过以下步骤确定专有和干扰光谱线(42):
1.在所记录的未知样本线之间:如果通过平均测试给出的邻近去卷积光谱带的干扰p值低于阈值(例如,p<0.05),则将光谱线的波长和强度存储为样本专有的;另一方面,如果发生干扰,则存储其平均波长和强度。针对每条所提取线,存储波长、强度和分辨率(fwhm),其中:i)lte作为波长/强度向量λ=[λ1,λ2,…λn|fwhm];以及ii)动态等离子体发射x(λ,t|fwhm);然后,
2.在所提取光谱线之间,通过在对应的fwhm区间内针对每个λi或xi寻找直接对应性来确定λ或x(λ,t|fwhm)和数据库光谱线。如果存在直接对应性,则可将向量λ=[λ1,λ2,…λn]和x(λ,t)使用λ=[λ1,λ2,…λn|λ空]和x(λ,t|λ空)直接投影到确定性特征空间中,其中λ空在不存在的光谱线处为空。如果找到新的独立光谱线,则将新的线(λ新)添加到数据库,其中先前的成分样本取空值。
参考构造确定性特征空间的过程(44-46)。此操作的第一步骤是将数据库光谱线组织到专有光谱线、干扰光谱线和独特光谱线中(44)。将成分专有光谱线直接分派为确定性特征空间变量,而通过使用例如λ1、λ2、λ3→λint的均值波长将干扰线折叠到相同的特征空间变量中。使用与未知样本相同的标准进行波长干扰折叠,并且此操作的最终结果是可使用在给定光谱分辨率下提取的光谱线的定义来构造确定性特征空间,即lte下的λ=[λ1,λ2,λ3…λn]或动态等离子体x(λ,t),其中λ=[λ1,t1,λ2t1,λ3t1,…,λ4t2,λ5t2,λ6t2…λn](45)。此操作为构造确定性特征空间和对应的自学习人工智能知识库提供预处理数据。
先前步骤(33-45)中的任一个确保数据库中光谱线数据的正确提取和组织,其中光谱线由现在可被认为是确定性变量的专有光谱线和干扰光谱线组成。这是因为专有光谱线直接提供存在于等离子体中的特定离子元素的确定性识别,并且等离子体发射动态中的专有线和序列是关于分子击穿的确定性信息,其提供关于样本成分的分子结构的信息。此外,干扰光谱线提供关于成分量化的信息,因为光谱干扰强度与等离子体中的成分的浓度有关。
确定性特征空间t(12)由使与物理样本成分y的协方差最大化的向量基限定。成分(y)是针对每个对应物理样本的成分浓度所提供的矩阵。可考虑特殊组成情况,诸如:i)纯元素;ii)纯分子;iii)元素和分子混合物;以及iv)复杂样本(例如地质和生物样本)。此外,特定成分组成组合情况提供允许其分类y→i的独特光谱指纹,其中i存储每种类别的概率。
考虑样本光谱线x(s,λ)或l(s,λ,t)及其对应组成y的数据库。两者可以基w和c分别变换(例如核、导数、傅里叶、小波、曲波)成特征空间f和k,使得f和k的局部潜在方差t和u之间的协方差最大化:
f(w,c)=argmax(ttu)
其中:f=twt;并且k=uct并且受制于:wtw=1并且ctc=1。通过应用拉格朗日乘子法来解决优化问题,将其恢复为:
ktf=wσct
这是ktf的奇异值分解,其中w=w[1,],c=c[1,],且相关联的协方差为σ[1,]。可进一步得出结论:ftkkftw=ρw并且ktfftkc=ρc。因此,w和c是cov(f,k)=cov(k,f)的特征本征向量,以潜在空间ttu表示,其中w和c产生协方差几何的特征尺寸。此类奇异值分解提供用于寻找矩阵的本征向量和本征值。
由于等离子体发射光谱线携带关于成分组成的直接信息,因此预期在x(s,λ)或l(s,λ,t)→f和y→k的理想变换之后,f和k携带相同的信息,即t=u,因此最大化f(w,c)=argmax(ttu)。这意味着光谱信息和组成共享共同的特征本征结构或几何。
为了研究ttu的几何,本征向量的标准正交基w和c是必要的,使得针对每个局部f,可得到其局部特征维度和几何。这通过f和k的降阶来实现:
fi+1=fi-tiwit
ki+1=ki-uicit
其中,ti=fiwi,ui=kici,并且wi=wi/||wi||,ci=ci/||ci||。
直到f或k的最大秩为止的循环降阶允许通过解译ti、wi及其与针对每个本征向量所捕获的协方差σ有关的对应重要性来确定协方差的几何及其复杂性,其中连续降阶组成确定性特征空间,t=[ti|t]且u=[ui|u]。如果假设f(w,c)=argmax(ttu)的最优最大化,那么:
fi+1=fi-tipit
ki+1=ki-uiqit
其中p和q由以下方程确定:pi=fitti(titti)-1以及qi=kitti(titti)-1。可建立k与f之间的最优线性关系:f=kβpls+e,其中:βpls=w(ptw)-1q,是偏最小二乘回归系数。
因此,确定性特征空间t对于k和f两者来说等同的,并且因此,通过将任何新的光谱信息投影到t中,可建立与组成的接直对应性。图6例示针对以下获得t的方式:i)lte下的等离子体发射,其中将数据库光谱信息x(s,λ)直接变换成f(29);ii)将动态l(s,λ,t)展开成x(s,λt)并将其变换成f(30);iii)使动态l(s,λ,t)经受tuker3d分解(31),并且将a(s,r)变换成f;以及iv)使动态l(s,λ,t)经受parafac分解(32),并且将a(s,r)变换成f。
这种方法解决寻找以下确定性特征空间t的问题,所述确定性特征空间t在f与k之间保持相同的本征结构或几何,其中t≈u,将x(s,λ)、a(s,r)看作输入。通过x(s,λ)或a(s,r)的标准正交基分解(例如奇异值分解、傅里叶、小波、曲波)执行初始化。也可以使用非正交分解,一旦分解后,就通过奇异值分解来强制执行基的正交化。步骤1启动f和k的n个随机群体。当不使用特定基向量时,fi=0或ki=0。步骤2确定fi和ki的每个组合之间的协方差。在步骤3中,使用提供t'u的最适值的fi和ki对来执行下一代fi和ki的交叉。重复步骤2和3允许使fi和ki的群体稳定。在步骤5中,将所有向量基级联到空间f和k中。在这些空间空间中,仅提供ttu~ttt的降阶被认为具有ttu一致性,并且被认为在光谱线与组成之间具有确定性对应性。这些分别是最终确定性特征空间f和组成空间k。
这种方法在基变换成f和k的整个过程中提高光谱(x(s,λ)或l(s,λ,t))与成分数据y之间的信息的一致性。当f=wfσfcft=tfcft并且k=wkσkckt=ukckt时,f和k具有相似的本征结构,因此通过本征结构中的相似性强制执行f(w,c)=argmax(tftuk)。处理复杂多维本征结构时的另一个重要度量是度量特征空间复杂性的方式。如果考虑具有指数衰减σ=σr+(σ1-σr)e-ki的光谱信息的本征结构的几何,其中r是秩本征值并且k是指数衰减,则数据集的复杂性(ξ)可限定为:ξ=npc/(k·r)。本发明的以下方法旨在降低全局本征结构的复杂性,使得可使用较低秩的数据来执行自学习的预测,并且提供可进行人工解译和针对现有人类知识进行认证的信息。
参考图4中的步骤(46-47)以作为进行以下操作的主要里程碑:针对给定的未知样本点进行协方差定向搜索,在确定性特征空间(12)中提供局部相邻样本点,使得找到构造局部确定性特征空间(15、45)以及对应的量化、分类和识别(48)所必需的光谱信息。
这种方法提供对未知样本光谱的协变样本点相邻样本点的搜索,所述协变样本点相邻样本点被投影到已知特征空间f的潜变量中。它开始于围绕所投影的未知tu以半径r限定搜索圆。在此圆内,所述方法限定具有搜索体积v的方向d的数量n。通过以下各项评估搜索方向适合度:已知样本点的预测误差、tu的可预测性以及降阶的数量npc。所述搜索体积是沿着搜索方向的搜索体积。
i.已知样本点的预测误差(ei):已知预测误差是已知样本点在f与k之间的协方差一致性的度量,如果是这样的话,则已知信息中存在执行预测的一致性;
ii.tu的可预测性:如果所投影的tu在协方差置信区间内,则它意指未知样本属于相同的协方差样本点群组,具有相同的f和k的本征结构和对应性t和u,因此使用过去的知识进行预测是可能的。
iii.降阶次数(npc_max):较低的降阶次数使用较少维度提供协方差信息,也就是说,关于t与u之间的已知样本点协变的信息汇集到提供局部群组一致性的特定特征中。
这种方法可分为2个不同的步骤:
步骤1.通过对每个搜索体积内部的样本点执行偏最小二乘回归并且评估预测误差(ei)、可预测性(p)和npc,找到最佳搜索方向。如果搜索方向不满足所有这些标准,则重组最佳结果(例如进化方法)以优化新的搜索方向,直到找到合适方向为止。
步骤2.通过对方向样本点进行进化搜索(例如单纯形)来最小化协方差方向上的样本的数量,直到建立匹配预测误差(ei)、可预测性(p)和npc的已知样本点的稳定群体,来最小化搜索体积。标准。
参考图7中的程序47-49。在选择最佳相邻样本点之后,仅考虑对应样本点等离子体发射光谱的专有光谱线和干扰光谱线来构建局部确定性特征空间(47)。通过以下方式获得确定性局部特征空间:将前面描述的程序应用到对应的局部x(sl,λl)或l(sl,λl,t)以将其变量变换为局部确定性的fl和kl,其秩明显低于原始确定性特征空间且其协方差结构更简单。
尽管f和k变换以及相邻样本点选择显著减少组成不相关的信息的量,但是由于散射和非线性等离子体发射效应(诸如烧蚀过程和等离子体屏蔽),仍然存在组成不相关的信息。这些仅影响线发射强度,并且在理论上难以针对这些影响得到信号校正,因此采用了正交过滤。图4(22)示出挑选最小数量的相邻样本点和变量如何允许降低原始数据的复杂性,通过组合样本和变量,原始数据集x1至x4减缩为一个优化的数据集x。
可通过去除与组成信息正交的系统变化来进一步优化光谱信息,使得:
f=tpt+topto
k=tqt+uoqto
其中t是使协方差最大化的共享f与k之间的共同信息的潜在变量。to和uo是正交信息;即,to⊥k并且uo⊥f。
在此阶段,预期正确的特征空间变换导致并且样本邻域导致topto→0并且f=tpt。
理想地,uoqto也应为零。具有分析级质量的任何量化都不应具有与其对应的光谱信息正交的任何系统变化。当uoqto显著时,这意指自学习系统不能得到适当的训练以提供准确的预测,因为原始训练信息存在系统误差或未包含在光谱中的信息。在适当条件下,topto→0且uoqto→0,并且t≈u且不需要降阶,这意味着信息在光谱与组成之间直接相关。
然而,在许多情况下,topto仍然是显著的,这意指特征变换步骤在仅隔离系统组成信息方面并不完全有效。这些情况通过以下方式来校正:对f和k中的信息进行正交过滤,诸如fcoor=f–topto并且kcoor=k-uoqto,从而产生通过可能的人类交互和解译两者执行量化的局部模型。
关于对确定性特征空间中的样本进行分类和识别的过程,请参考图5,所述过程通过以下步骤计算整个特征空间中的类别之间的非线性逻辑边界:
·确定两种类别之间的给定边界的支持辨别样本(26);
·赋予每个类别布尔值以代替组成(y);
·执行先前描述的方法以确定局部线性逻辑多变量线性模型;
·沿着边界重复所述过程(i至iii),并且将连续模型存储为非线性逻辑边界,并且通过以下方式预测未知样本的分类:
ο如果到特征空间中的投影在特定类别边界内部,则将其分类为属于对应的分类;
ο如果投影位于两个或更多个类别的边界内(即,在支持辨别样本(26)之间),则使用相邻支持样本点来构建局部逻辑模型以确定类别概率。
关于执行成分(诸如元素以及分子离子和分子结构)的识别,同样参考图5。元素离子通过匹配专有光谱线或通过特定环境的光谱线强度的秩匹配来直接识别。分子及其结构预测通过针对分子在样本分类结果的相似环境下的纯光谱进行秩匹配来执行。秩匹配有两个主要步骤:i)对于边界类别环境内部的每个分子,按光谱线的强度对其进行排名,并且如先前所描述确定对应的专有光谱线和干扰光谱线;以及ii)针对相等或相似的秩距离对未知样本进行搜索:搜索光谱中是否存在特定分子的所有光谱线,如果为真,则:a)如果发现专有光谱线,则识别所述分子和对应结构;并且如果不是这种情况,则b)确定未知样本与已知分子之间的秩距离。这种方法输出特定未知样本的所有阳性识别,以及与不完全匹配的秩距离。
所提出的方法的另一个优点是人工解译。参考图4(22),其中人类专家可解译自学习系统为何在包含a、d、e和f元素的分子的环境下选择专有光谱线、基于环境的专有光谱线和干扰光谱线来量化a元素。在某些情况下,诸如对于痕量元素,可找到共线性量化,并且应根据样本的环境仔细解译存在于量化中的专有线,因为使用元素之间的共线性信息具有假阳性/阴性量化的风险。为了正确地诊断,用户可访问局部确定性特征空间,并且验证所选择相邻样本点的可预测性以作为基于环境的共线性一致性的度量。用户可固化自学习量化和分类的另一种方式是比较模型系数相对于原子光谱发射线的相关性(kramida等人,2018年)。每种元素最强烈的发射线通常是具有较高跃迁概率的发射线,并且到基态的跃迁应存在于显著的强度下。此外,基态跃迁通常是专有发射线。用户还可使用等离子体发射模拟理论模型来使用萨哈电离平衡公式和波尔兹曼分布针对对应于已知相邻样本中的浓度的离子丰度分布对离子群体进行估计,以进一步固化并且降低假阳性和阴性的可能性。
人类用户可通过表1中呈现的指标进一步访问特征空间的分析和诊断,以用于访问:
i.由遵循这种协方差模式的样本点的数量对局部方向的统计表示;
ii.潜在可变比率,其用于诊断方向复杂性和代表性
iii.复杂性衰减率:方差或协方差本征向量沿着正交降阶衰减的速率:
iv.复杂性:通过表征维度数量、衰减率和样本点的数量给出的给定数据集的几何复杂性:
v.press:预测残留误差平方和;
vi.特征空间和组成空间的共线性;
vii.模型方差:模型预测中所使用的方差的量;
viii.预测方差:预测k方差或量化/分类信息
ix.光谱不相关信息:不对给定的组成或分类信息进行量化或分类的信息
x.组成无关信息:组成数据中未包含在光谱中的信息;以及
xi.f与k信息之间的可解释协方差。
人类还可解译以下信息:
i.潜在空间基p:直接对与k的协方差有贡献的光谱线和相对重要性,即成分及其浓度;
ii.潜在空间基q:与光谱信息直接相关的组成或分类信息,即光谱线波长和强度;
iii.潜在空间基po:与组成信息无关且因此应作进一步研究以进行识别的的光谱线;
iv.潜在空间基qo:未反映在光谱信息中且因此用户可设计进一步研究以了解产生此类影响的原因的组成;
v.潜在空间坐标to:应执行量化以使得自学习系统可提供预测的样本群组簇。
vi.潜在空间坐标uo:发现不具有光谱信息的样本群组(诸如,仅具有痕量元素的样本),以提供有关如何改进物理测量的信息。
借助于所提供的所有信息,人类可理解自动化自学习系统是否正确运行,以及解译复杂的光谱信息。
实施例
a.元素识别和量化
通过对以下真实矿石的两个案例研究呈现libs矿物和元素识别:i)来自bejanca矿(葡萄牙,vouzela-viseu)的钨锰铁矿;ii)来自gelfa(葡萄牙,gelfa)的锂。图8呈现来自bejanca矿的典型的包含钨锰铁矿的矿石(51)。钨锰铁矿矿物(黑色)封闭在石英中。钨锰铁矿由铁和钨组成。来自铁和钨的专有峰位于200nm与400nm之间(52)。两种元素在这些波长中具有显著的光谱线,因此需要高分辨率光谱仪和亚光光谱线提取来对其进行解析和识别。53中是包围钨锰铁矿的石英的libs光谱。石英主要是硅,但是它示出一些铁含量。在石英矿物中未发现钨。石英和钨锰铁矿两者均展现出显著不同的光谱指纹,这使得很容易使用libs光谱技术对其进行分类和辨别。
图9呈现来自葡萄牙gelfa的锂矿石的libs表征(54)。在此实施例中,锂矿脉由石英包围。锂矿脉的libs光谱在锂带610.20nm处展现出极高的发射(55),这是来自锂的专有光谱线。相同的峰存在于周围的石英中,但是由于在显微镜下可能观察到的流体夹杂物,其强度低得多。本文公开的发明允许成功地识别锂矿脉中的锂的存在,从而在矿脉与周围的石英之间进行辨别。
参考表2,其呈现锂矿石的锂量化基准。使libs锂量化以锂光谱线强度为基准,并且研究锂浓度。610.20nm被证明与锂浓度保持统计学上相关的关系。结果显示无法正确地预测较低锂浓度的校准模型中的高方差。使用全光谱干扰可提高准确性。开发多变量偏最小二乘模型。尽管减小了偏差和方差,但是pls模型仍然高估了低浓度锂矿物(见表1)。结果表明:libs光谱线强度与元素浓度的对应性是高度非线性且多尺度的现象,因为线性模型不能够提供libs光谱技术中的分析质量偏差对方差量化。
盲测给出明显证据:在620nm处的线强度下获得的线性模型和多变量pls模型低估矿脉中的锂含量,并过度高估周围石英中的锂含量(见表2)。本发明中所提出的方法能够正确地估计石英中的锂的量,其被示出为低于1%(表2)。
此外,表3中呈现使用本发明的方法对以下元素进行的盲测预测:al、si、li、fe、na、k和rb。可观察到,在标准化浓度(%)范围内,相关性非常显著,并且预测误差非常小。
图10所例示的另一个实施方案中呈现狗血(57)和猫血(58)(作为复杂生物样本的参考)中的na、k、fe和mg的识别和量化,重点在于等离子体诱导光谱技术在兽医和人类保健中的应用。
图11所呈现的另一个实施方案中是锂辉石(lialsi2o6)(59)和透锂长石(lialsi4o8)(60)的识别。这些锂晶体在它们的组成上具有相同的元素,因此共享li、al、si和o的主要离子光谱线。不同的晶体结构在等离子体形成期间产生每种晶体的专有光谱线,这在图11中由圆圈呈现。这些光谱线用于识别矿物或矿石样本中的晶体的类型,并且可用于对进行矿物纯度进行量化和分类。
如本领域技术人员将清楚的,本发明不应限于本文描述的实施方案,并且保持在本发明的范围内的多种改变是可能的。
当然,上文所示出的优选实施方案可以不同的可能形式进行组合,在此避免了重复所有这样的组合。
表1.对特征空间的人类交互诊断
表2.锂矿石中锂的量化。
表3.地质标准盲样中铝、硅、铁、钠、钾和铷的量化。
参考文献
kramida,a.,ralchenko,yu.,reader,j.andnistasdteam(2018).nistatomicspectradatabase(version5.5.6),[online].available:https://physics.nist.gov/asd[tuemay292018].nationalinstituteofstandardsandtechnology,gaithersburg,md.
d.w.hahnandomenetton.laser-inducedbreakdownspectroscopy(libs),parti:reviewofbasicdiagnosticsandplasma-particleinteractions:still-challengingissueswithintheanalyticalplasmacommunity.applspectrosc.,64(12):335--66,2010.
a.cousin,o.forni,s.maurice,o.gasnault,c.fabre,v.sautterd,r.c.wiense,andj.mazoyera.feasibilityofgeneratingausefullaser-inducedbreakdownspectroscopyplasmaonrocksathighpressure:preliminarystudyforavenusmission.spectrochim.actapartb,59:987-999,2011.
- 还没有人留言评论。精彩留言会获得点赞!