医疗信息处理方法和医疗信息处理装置与流程
本发明涉及信息处理技术领域,具体而言,涉及一种医疗信息处理方法和医疗信息处理装置。
背景技术:
目前,医疗服务信息化是国际发展趋势,随着信息技术的快速发展,国内越来越多的医院正加速实施基于信息化平台、HIS(Hospital Information System,医院信息系统)的整体建设,以提高医院的服务水平与核心竞争力,医疗信息化不仅提升了医生的工作效率,使医生有更多的时间为患者服务,更提高了患者满意度和信任度,无形之中树立起了医院的科技形象。因此,医疗业务应用与基础网络平台的逐步融合正成为国内医院,尤其是大中型医院信息化发展的新方向。
在医疗信息化过程中,医疗词库的构建是一个非常重要且基础的工作,医疗词库的构建有助于实现病历电子化,有助于对互联网上大量的非结构化的医疗文本进行解析,也有助于实现病人病案的智能化分析。虽然国外有成熟的医学词库系统,但并不适合用于以中文为母语的国内医疗词库。国内也构建了英汉平行语料库、中医药学词库等,然而,国内医疗词库中的词并不全面,而且也缺乏一定的正确性。
因此,如何构建出更加准确、全面的医疗词库成为亟待解决的问题。
技术实现要素:
本发明正是基于上述问题,提出了一种新的技术方案,可以比较准确、全面地挖掘出医疗文本中存在关联关系的词,从而根据存在关联关系的词构建出的医疗词库更加准确和全面。
有鉴于此,本发明的一方面提出了一种医疗信息处理方法,包括:对 多个医疗文本进行切词,以及对所述多个医疗文本进行聚类;根据同一类别的医疗文本中每两个医疗文本的词,确定所述每两个医疗文本的关联度;根据所述每两个医疗文本的关联度,判断所述同一类别的医疗文本中任两个医疗文本的词是否存在关联关系;在判断结果为是时,将存在关联关系的词进行关联存储。
在该技术方案中,根据同一类别的医疗文本中每两个医疗文本中的词确定每两个医疗文本的关联度,以根据每两个医疗文本的关联度判断该同一类别的任两个医疗文本的词之间是否存在关联关系,并将存在关联关系的词进行关联存储,例如,存储在医疗词库中,以构建较为完善的医疗词库。例如,A医疗文本中的词有:感冒和发烧,B医疗文本中的词有:发热和咳嗽,C医疗文本中的词有:咳嗽和着凉,可见,A与B中具有相近的词:发烧和发热,A与B之间的关联度为30%,B与C中具有相同的词:咳嗽,B与C之间的关联度为50%,A与C中虽然没有相同或相近的词,但是,由于A与B之间有关联,B与C之间有关联,则可以确定A与C之间有关联,也就确定A与C的词之间存在关联关系。因此,本方案可以进一步地挖掘出存在隐含关联关系的词,从而可以更加准确、全面地挖掘出医疗文本中存在关联关系的词。进一步地,可以根据存在关联关系的词构建出医疗医疗信息的搜索引擎,或者实现医疗文本信息的自动化分析等,为门诊医生及患者查询疾病与症状提供便利。
优选地,多个医疗文本可以是医院的医疗系统中的电子病历,还可以是利用爬虫程序从医学专业网站上获取到的。由于多个医疗文本的规模比较大,因此,可以对多个医疗文本进行分布式文件系统进行存储。
在上述技术方案中,优选地,所述将存在关联关系的词进行关联存储的步骤,还包括:根据所述任两个医疗文本的关联度,确定所述任两个医疗文本中词的关联度;将所述任两个医疗文本中词的关联度进行存储。
在该技术方案中,根据任两个医疗文本的关联度,确定任两个医疗文本中词的关联度,具体地,可以将任两个医疗文本的关联度作为任两个医疗文本中词的关联度,当然还可以根据预设算法计算任两个医疗文本中词的关联度,从而根据词之间的关联度更加准确、直观地反映词之间的关联 程度。例如,A医疗文本中的词有:感冒和发烧,C医疗文本中的词有:咳嗽和着凉,A与C之间的关联度为10%,则感冒和咳嗽之间的关联度为10%。
在上述任一技术方案中,优选地,所述对多个医疗文本进行切词的步骤,具体包括:根据词典和所述多个医疗文本中词的词性,对所述多个医疗文本进行切词。
在该技术方案中,可以根据词典(优选医疗词典)中的词和词性对多个医疗文本进行切词,具体地,根据词典中的词对多个医疗文本进行切词,若词典中不存在多个医疗文本中的词语,根据该词语的词性判断其与前后词语是否存在关联,是否需要组合成新的词,从而有效地避免出现误切词和漏切词的情况,进而保证切词的准确性和全面性。
在上述任一技术方案中,优选地,所述对所述多个医疗文本进行聚类的步骤,具体包括:根据国际疾病分类和K-means算法,对所述多个医疗文本进行聚类。
在该技术方案中,可以根据国际疾病分类(International Classification of Disease,ICD)和K-means算法,对所述多个医疗文本进行聚类,由于聚类得到的同一类别的医疗文本的患病相同,因此,聚类得到的同一类别的医疗文本的词之间存在关联的可能性比较大,然后对该同一类别的医疗文本进行进一步地处理,以保证处理速度。
在上述任一技术方案中,优选地,所述将存在关联关系的词进行关联存储的步骤,具体包括:根据所述存在关联关系的词的属性,对所述存在关联关系的词进行存储。
在该技术方案中,根据存在关联关系的词的属性对该词进行存储,例如,词的属性为:身体部位(如“头”、“四肢”等)、谓词(如“疼痛”、“劳损”等)、疾病(如“发热”、“心脏病”等)、药物(如“格华止片”,“葡萄糖注射液”等)、治疗手段(如“点滴”、“麻醉”等)、忽略词(如“本院”、“患者”等对信息抽取没有贡献的词),从而保证关联关系的词的存储更加有条理。
本发明的另一方面提出了一种医疗信息处理装置,包括:处理单元, 用于对多个医疗文本进行切词,以及对所述多个医疗文本进行聚类;第一确定单元,用于根据同一类别的医疗文本中每两个医疗文本的词,确定所述每两个医疗文本的关联度;判断单元,用于根据所述每两个医疗文本的关联度,判断所述同一类别的医疗文本中任两个医疗文本的词是否存在关联关系;存储单元,用于在判断结果为是时,将存在关联关系的词进行关联存储。
在该技术方案中,根据同一类别的医疗文本中每两个医疗文本中的词确定每两个医疗文本的关联度,以根据每两个医疗文本的关联度判断该同一类别的任两个医疗文本的词之间是否存在关联关系,并将存在关联关系的词进行关联存储,例如,存储在医疗词库中,以构建较为完善的医疗词库。例如,A医疗文本中的词有:感冒和发烧,B医疗文本中的词有:发热和咳嗽,C医疗文本中的词有:咳嗽和着凉,可见,A与B中具有相近的词:发烧和发热,A与B之间的关联度为30%,B与C中具有相同的词:咳嗽,B与C之间的关联度为50%,A与C中虽然没有相同或相近的词,但是,由于A与B之间有关联,B与C之间有关联,则可以确定A与C之间有关联,也就确定A与C的词之间存在关联关系。因此,本方案可以进一步地挖掘出存在隐含关联关系的词,从而可以更加准确、全面地挖掘出医疗文本中存在关联关系的词。进一步地,可以根据存在关联关系的词构建出医疗医疗信息的搜索引擎,或者实现医疗文本信息的自动化分析等,为门诊医生及患者查询疾病与症状提供便利。
优选地,多个医疗文本可以是医院的医疗系统中的电子病历,还可以是利用爬虫程序从医学专业网站上获取到的。由于多个医疗文本的规模比较大,因此,可以对多个医疗文本进行分布式文件系统进行存储。
在上述技术方案中,优选地,所述存储单元包括:第二确定单元,用于根据所述任两个医疗文本的关联度,确定所述任两个医疗文本中词的关联度;所述存储单元具体用于,将所述任两个医疗文本中词的关联度进行存储。
在该技术方案中,根据任两个医疗文本的关联度,确定任两个医疗文本中词的关联度,具体地,可以将任两个医疗文本的关联度作为任两个医 疗文本中词的关联度,当然还可以根据预设算法计算任两个医疗文本中词的关联度,从而根据词之间的关联度更加准确、直观地反映词之间的关联程度。例如,A医疗文本中的词有:感冒和发烧,C医疗文本中的词有:咳嗽和着凉,A与C之间的关联度为10%,则感冒和咳嗽之间的关联度为10%。
在上述任一技术方案中,优选地,所述处理单元包括:切词单元,用于根据词典和所述多个医疗文本中词的词性,对所述多个医疗文本进行切词。
在该技术方案中,可以根据词典(优选医疗词典)中的词和词性对多个医疗文本进行切词,具体地,根据词典中的词对多个医疗文本进行切词,若词典中不存在多个医疗文本中的词语,根据该词语的词性判断其与前后词语是否存在关联,是否需要组合成新的词,从而有效地避免出现误切词和漏切词的情况,进而保证切词的准确性和全面性。
在上述任一技术方案中,优选地,所述处理单元包括:聚类单元,用于根据国际疾病分类和K-means算法,对所述多个医疗文本进行聚类。
在该技术方案中,可以根据国际疾病分类(International Classification of Disease,ICD)和K-means算法,对所述多个医疗文本进行聚类,由于聚类得到的同一类别的医疗文本的患病相同,因此,聚类得到的同一类别的医疗文本的词之间存在关联的可能性比较大,然后对该同一类别的医疗文本进行进一步地处理,以保证处理速度。
在上述任一技术方案中,优选地,所述存储单元具体用于,根据所述存在关联关系的词的属性,对所述存在关联关系的词进行存储。
在该技术方案中,根据存在关联关系的词的属性对该词进行存储,例如,词的属性为:身体部位(如“头”、“四肢”等)、谓词(如“疼痛”、“劳损”等)、疾病(如“发热”、“心脏病”等)、药物(如“格华止片”,“葡萄糖注射液”等)、治疗手段(如“点滴”、“麻醉”等)、忽略词(如“本院”、“患者”等对信息抽取没有贡献的词),从而保证关联关系的词的存储更加有条理。
通过本发明的技术方案,可以比较准确、全面地挖掘出医疗文本中存 在关联关系的词,从而根据存在关联关系的词构建出的医疗词库更加准确和全面。
附图说明
图1示出了根据本发明的一个实施例的医疗信息处理方法的流程示意图;
图2示出了根据本发明的一个实施例的医疗信息处理装置的结构示意图;
图3示出了根据本发明的一个实施例的医疗信息处理装置的原理示意图。
具体实施方式
为了可以更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
图1示出了根据本发明的一个实施例的医疗信息处理方法的流程示意图。
如图1所示,根据本发明的一个实施例的医疗信息处理方法,包括:
步骤102,对多个医疗文本进行切词,以及对所述多个医疗文本进行聚类;
步骤104,根据同一类别的医疗文本中每两个医疗文本的词,确定所述每两个医疗文本的关联度;
步骤106,根据所述每两个医疗文本的关联度,判断所述同一类别的医疗文本中任两个医疗文本的词是否存在关联关系,在判断结果为是时,进入步骤108,否则结束本次流程;
步骤108,将存在关联关系的词进行关联存储。
在该技术方案中,根据同一类别的医疗文本中每两个医疗文本中的词确定每两个医疗文本的关联度,以根据每两个医疗文本的关联度判断该同一类别的任两个医疗文本的词之间是否存在关联关系,并将存在关联关系的词进行关联存储,例如,存储在医疗词库中,以构建较为完善的医疗词库。例如,A医疗文本中的词有:感冒和发烧,B医疗文本中的词有:发热和咳嗽,C医疗文本中的词有:咳嗽和着凉,可见,A与B中具有相近的词:发烧和发热,A与B之间的关联度为30%,B与C中具有相同的词:咳嗽,B与C之间的关联度为50%,A与C中虽然没有相同或相近的词,但是,由于A与B之间有关联,B与C之间有关联,则可以确定A与C之间有关联,也就确定A与C的词之间存在关联关系。因此,本方案可以进一步地挖掘出存在隐含关联关系的词,从而可以更加准确、全面地挖掘出医疗文本中存在关联关系的词。进一步地,可以根据存在关联关系的词构建出医疗医疗信息的搜索引擎,或者实现医疗文本信息的自动化分析等,为门诊医生及患者查询疾病与症状提供便利。
优选地,多个医疗文本可以是医院的医疗系统中的电子病历,还可以是利用爬虫程序从医学专业网站上获取到的。由于多个医疗文本的规模比较大,因此,可以对多个医疗文本进行分布式文件系统进行存储。
在上述技术方案中,优选地,步骤108还包括:根据所述任两个医疗文本的关联度,确定所述任两个医疗文本中词的关联度;将所述任两个医疗文本中词的关联度进行存储。
在该技术方案中,根据任两个医疗文本的关联度,确定任两个医疗文本中词的关联度,具体地,可以将任两个医疗文本的关联度作为任两个医疗文本中词的关联度,当然还可以根据预设算法计算任两个医疗文本中词的关联度,从而根据词之间的关联度更加准确、直观地反映词之间的关联程度。例如,A医疗文本中的词有:感冒和发烧,C医疗文本中的词有:咳嗽和着凉,A与C之间的关联度为10%,则感冒和咳嗽之间的关联度为10%。
在上述任一技术方案中,优选地,所述对多个医疗文本进行切词的步骤,具体包括:根据词典和所述多个医疗文本中词的词性,对所述多个医 疗文本进行切词。
在该技术方案中,可以根据词典(优选医疗词典)中的词和词性对多个医疗文本进行切词,具体地,根据词典中的词对多个医疗文本进行切词,若词典中不存在多个医疗文本中的词语,根据该词语的词性判断其与前后词语是否存在关联,是否需要组合成新的词,从而有效地避免出现误切词和漏切词的情况,进而保证切词的准确性和全面性。优选地,对医疗文本进行切词得到的词为医疗词语,从而避免无关词汇(例如,每天、患者、本院)对确定医疗文本关联度时的干扰。
在上述任一技术方案中,优选地,所述对所述多个医疗文本进行聚类的步骤,具体包括:根据国际疾病分类和K-means算法,对所述多个医疗文本进行聚类。
在该技术方案中,可以根据国际疾病分类(International Classification of Disease,ICD)和K-means算法,对所述多个医疗文本进行聚类,由于聚类得到的同一类别的医疗文本的患病相同,因此,聚类得到的同一类别的医疗文本的词之间存在关联的可能性比较大,然后对该同一类别的医疗文本进行进一步地处理,以保证处理速度。
在上述任一技术方案中,优选地,步骤108具体包括:根据所述存在关联关系的词的属性,对所述存在关联关系的词进行存储。
在该技术方案中,根据存在关联关系的词的属性对该词进行存储,例如,词的属性为:身体部位(如“头”、“四肢”等)、谓词(如“疼痛”、“劳损”等)、疾病(如“发热”、“心脏病”等)、药物(如“格华止片”,“葡萄糖注射液”等)、治疗手段(如“点滴”、“麻醉”等)、忽略词(如“本院”、“患者”等对信息抽取没有贡献的词),从而保证关联关系的词的存储更加有条理。
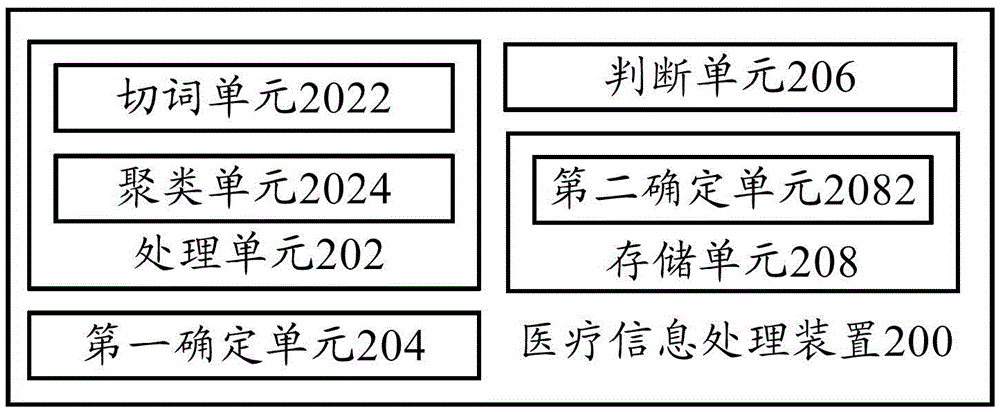
图2示出了根据本发明的一个实施例的医疗信息处理装置的结构示意图。
如图2所示,根据本发明的一个实施例的医疗信息处理装置200,包括:处理单元202,用于对多个医疗文本进行切词,以及对所述多个医疗文本进行聚类;第一确定单元204,用于根据同一类别的医疗文本中每两 个医疗文本的词,确定所述每两个医疗文本的关联度;判断单元206,用于根据所述每两个医疗文本的关联度,判断所述同一类别的医疗文本中任两个医疗文本的词是否存在关联关系;存储单元208,用于在判断结果为是时,将存在关联关系的词进行关联存储。
在该技术方案中,根据同一类别的医疗文本中每两个医疗文本中的词确定每两个医疗文本的关联度,以根据每两个医疗文本的关联度判断该同一类别的任两个医疗文本的词之间是否存在关联关系,并将存在关联关系的词关联存储,例如,存储在医疗词库中,以构建较为完善的医疗词库。例如,A医疗文本中的词有:感冒和发烧,B医疗文本中的词有:发热和咳嗽,C医疗文本中的词有:咳嗽和着凉,可见,A与B中具有相近的词:发烧和发热,A与B之间的关联度为30%,B与C中具有相同的词:咳嗽,B与C之间的关联度为50%,A与C中虽然没有相同或相近的词,但是,由于A与B之间有关联,B与C之间有关联,则可以确定A与C之间有关联,也就确定A与C的词之间存在关联关系。因此,本方案可以进一步地挖掘出存在隐含关联关系的词,从而可以更加准确、全面地挖掘出医疗文本中存在关联关系的词。进一步地,可以根据存在关联关系的词构建出医疗医疗信息的搜索引擎,或者实现医疗文本信息的自动化分析等,为门诊医生及患者查询疾病与症状提供便利。
优选地,多个医疗文本可以是医院的医疗系统中的电子病历,还可以是利用爬虫程序从医学专业网站上获取到的。由于多个医疗文本的规模比较大,因此,可以对多个医疗文本进行分布式文件系统进行存储。
在上述技术方案中,优选地,所述存储单元208包括:第二确定单元2082,用于根据所述任两个医疗文本的关联度,确定所述任两个医疗文本中词的关联度;所述存储单元208具体用于,将所述任两个医疗文本中词的关联度进行存储。
在该技术方案中,根据任两个医疗文本的关联度,确定任两个医疗文本中词的关联度,具体地,可以将任两个医疗文本的关联度作为任两个医疗文本中词的关联度,当然还可以根据预设算法计算任两个医疗文本中词的关联度,从而根据词之间的关联度更加准确、直观地反映词之间的关联 程度。例如,A医疗文本中的词有:感冒和发烧,C医疗文本中的词有:咳嗽和着凉,A与C之间的关联度为10%,则感冒和咳嗽之间的关联度为10%。
在上述任一技术方案中,优选地,所述处理单元202包括:切词单元2022,用于根据词典和所述多个医疗文本中词的词性,对所述多个医疗文本进行切词。
在该技术方案中,可以根据词典(优选医疗词典)中的词和词性对多个医疗文本进行切词,具体地,根据词典中的词对多个医疗文本进行切词,若词典中不存在多个医疗文本中的词语,根据该词语的词性判断其与前后词语是否存在关联,是否需要组合成新的词,从而有效地避免出现误切词和漏切词的情况,进而保证切词的准确性和全面性。优选地,对医疗文本进行切词得到的词为医疗词语,从而避免无关词汇(例如,每天、患者、本院)对确定医疗文本关联度时的干扰。
在上述任一技术方案中,优选地,所述处理单元202包括:聚类单元2024,用于根据国际疾病分类和K-means算法,对所述多个医疗文本进行聚类。
在该技术方案中,可以根据国际疾病分类(International Classification of Disease,国际疾病分类)和K-means算法,对所述多个医疗文本进行聚类,由于聚类得到的同一类别的医疗文本的患病相同,因此,聚类得到的同一类别的医疗文本的词之间存在关联的可能性比较大,然后对该同一类别的医疗文本进行进一步地处理,以保证处理速度。
在上述任一技术方案中,优选地,所述存储单元208具体用于,根据所述存在关联关系的词的属性,对所述存在关联关系的词进行存储。
在该技术方案中,根据存在关联关系的词的属性对该词进行存储,例如,词的属性为:身体部位(如“头”、“四肢”等)、谓词(如“疼痛”、“劳损”等)、疾病(如“发热”、“心脏病”等)、药物(如“格华止片”,“葡萄糖注射液”等)、治疗手段(如“点滴”、“麻醉”等)、忽略词(如“本院”、“患者”等对信息抽取没有贡献的词),从而保证关联关系的词的存储更加有条理。
图3示出了根据本发明的一个实施例的医疗信息处理装置的原理示意图。
如图3所示,医疗信息处理装置300首先通过爬虫技术从医学专业网站中获取医学文本,以及在医院的医疗系统中获取电子病历,由于在医学专业网站和医疗系统中获取的信息量很大,因此,将在医学专业网站中获取的医学文本和电子病历作为多个医疗文本存储在分布式文件系统中,对多个医疗文本进行切词和聚类,然后根据同一类别的医疗文本中每两个医疗文本中的词,采用Jacard方法计算每两个医疗文本的关联度,例如对于两个医疗文本A和B,A医疗文本进行切词之后的词有:“患者”、“咽痛咽痒”、“无痰”、“胃胀”、“腰痛”,B医疗文本进行切词之后的词有:“干咳”、“咽痛咽痒”、“无痰”、“胃痛”、“腰酸”、“怕冷”,通过计算可以得出完全相同的分词对:“咽痛咽痒”和“咽痛咽痒”,“无痰”和“无痰”;以及相似度较高的分词对“胃胀”和“胃痛”,“腰痛”和“腰酸”。然后再采用向量余弦方法确定同一类别的医疗文本中任两个医疗文本是否存在关联关系,从而得到一些词的关联关系,这种关联关系可能在采用Jacard方法计算相似度时中无法计算得出。例如上述两个医疗文本A和B,以及另一个医疗文本C,C医疗文本进行切词之后的词有:“发热”、“咽痛咽痒”、“咳嗽”、“扁桃体发炎”,通过计算可知病历A与C具有关联关系,因此,A与C中的词存在着关联关系,如“咽痛咽痒”和“扁桃体发炎”存在关联关系,然后将关联关系的词存储在医学词库中,从而构建出一个面向医疗实际场景的医学词库。
以上结合附图详细说明了本发明的技术方案,通过对医院的医疗系统中的真实数据(即病历)以及医学专业网站中的医疗文本进行分析,可以比较准确、全面地挖掘出医疗文本中存在关联关系的词,从而构建出一个面向医疗实际场景的医学词库。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!