用以分析细菌菌种的测序数据的系统及其方法与流程
本发明涉及一种用以分析细菌菌种的测序数据的系统及其方法,且特别是涉及一种针对单一检体及跨检体重复序列进行检测的用以分析细菌菌种的测序数据的系统及其方法。
背景技术:
随着生物科技的日益发展,基因测序的工作越来越完整,对于人体共生菌的研究变得非常重要。目前已知人体身上约100兆的共生菌所组成,这些共生菌的数量比人体全部的细胞整整多了十倍。此外,人体的肠胃道、皮肤、口腔、呼吸道、生殖道等等地方也有共生菌的存在,统称为菌相,这些菌相与免疫、代谢、发育,神经系统等等皆息息相关。
其中,科学家们已知利用16S核糖体RNA(16S rRNA)序列的测序,解构出人类肠道菌的种类分布,因此可利用将16S rRNA基因标定并扩增复制序列后,经过测序及根据测序的质量做前处理,再将序列与16S rRNA数据库做组序、贴序的步骤,以区分出物种。而相似性高的物种将会归类到同一个可操作性的分类单位体(operational taxonomic unit,OTU),最后统计分析不同检体的菌向差异。
然而,在传统上,若要分析多组检体数据,则需要耗费的时程及运算量是相当可观的,因此如何减少系统的运算量,以提升分析检体数据的速度,已成为本领域需要解决的问题之一。
技术实现要素:
为解决上述的问题,本发明的一个方面提供一种用以分析细菌菌种的测 序数据的系统。用以分析细菌菌种的测序数据的系统包含:单一检体去重复序列模块、跨检体重复序列判断模块、重复序列记录模块以及运算贴序模块。单一检体去重复序列模块用以搜索第一基因样本序列中的第一保守区域及特定变异区域,并将第一保守区域移除。跨检体重复序列判断模块用以判断特定变异区域是否存在与第二基因序列中的另一特定变异区域相同的跨检体子序列。重复序列记录模块用以当特定变异区域存在与第二菌体样本中的另一特定变异区域相同的跨检体子序列时,储存跨检体子序列至记录表中。运算贴序模块用以当存在跨检体子序列时,将跨检体子序列与数据库模块中的多个已知菌种基因序列进行比对,以分析第一基因样本序列与第二基因样本序列中对应跨检体子序列的菌种。
本发明的另一方面提供一种用以分析细菌菌种的测序方法。分析细菌菌种的测序方法包含:搜索第一基因样本序列中的特定变异区域以及搜索第二基因样本序列中的另一特定变异区域;判断特定变异区域与另一特定变异区域是否存在相同的跨检体子序列;当特定变异区域与另一特定变异区域存在相同的跨检体子序列时,储存跨检体子序列至记录表中;当存在跨检体子序列时,将跨检体子序列与数据库模块中的多个已知菌种基因序列进行比对,以分析该第一基因样本序列与第二基因样本序列中对应跨检体子序列的菌种。
综上所述,本发明的技术方案与现有技术相比具有明显的优点和有益效果。通过上述技术方案,可达到相当的技术进步,并具有产业上的广泛利用价值,本公开内容可减少用以分析细菌菌种的测序数据的系统的运算量,以达到提升分析检体数据速度的功效。
附图说明
为了使本发明的上述和其他目的、特征、优点与实施例能更明显易懂,提供附图如下:
图1是根据本发明一实施例绘示的一种用以分析细菌菌种的测序数据的系统的方块图;
图2是根据本发明一实施例绘示的一种用以分析细菌菌种的测序数据的方法的流程图;
图3是根据本发明一实施例绘示的一种基因样本序列的示意图;
图4A-4C是根据本发明一实施例绘示的一种基因片段的示意图。
具体实施方式
参照第1图,图1是根据本发明一实施例绘示的一种用以分析细菌菌种的测序数据的系统100的方块图。
用以分析细菌菌种的测序数据的系统100包含:单一检体去重复序列模块110、跨检体重复序列判断模块120、重复序列记录模块130以及运算贴序模块140。单一检体去重复序列模块110用以搜索第一基因样本序列中的第一保守区域及特定变异区域,并将第一保守区域移除。跨检体重复序列判断模块120用以判断特定变异区域是否存在与第二基因序列中的另一特定变异区域相同的一跨检体子序列。重复序列记录模块130用以当特定变异区域存在与第二菌体样本中的另一特定变异区域相同的跨检体子序列时,储存跨检体子序列至一记录表135中。运算贴序模块140用以当存在跨检体子序列时,将跨检体子序列与一数据库模块150中的多个已知菌种基因序列进行比对,以分析第一基因样本序列与第二基因样本序列中对应跨检体子序列的菌种。
其中,如图1所示,数据库模块150可被实作为只读存储器、闪存、软盘、硬盘、光盘、随身碟、磁带、可由网络存取的数据库或本领域技术人员可轻易思及具有相同功能的储存介质,记录表135可以为一档案,被储存于 具有储存功能的任何电子装置中。此外,单一检体去重复序列模块110、跨检体重复序列判断模块120、重复序列记录模块130以及运算贴序模块140可分别或合并被实施为例如微控制单元(microcontroller)、微处理器(microprocessor)、数字信号处理器(digital signal processor)、特殊应用集成电路(application specific integrated circuit,ASIC)或逻辑电路。
由上述可知,用以分析细菌菌种的测序数据的系统100可排除单一检体中相同或重复的基因区段,并通过跨检体地找出相同或重复的跨检体子序列,将跨检体子序列及其与菌体样本之间的关系储存至记录表135中,利用记录表135可将大量具有重复性质的跨检体子序列建立精简化的数据结构。通过此些方法可避免运算贴序模块140重复地将单一检体或跨检体中相同或重复的大量基因区段与数据库模块150中的已知数据进行比对,更可减少用以分析细菌菌种的测序数据的系统100的运算量,以提升分析检体数据的速度。
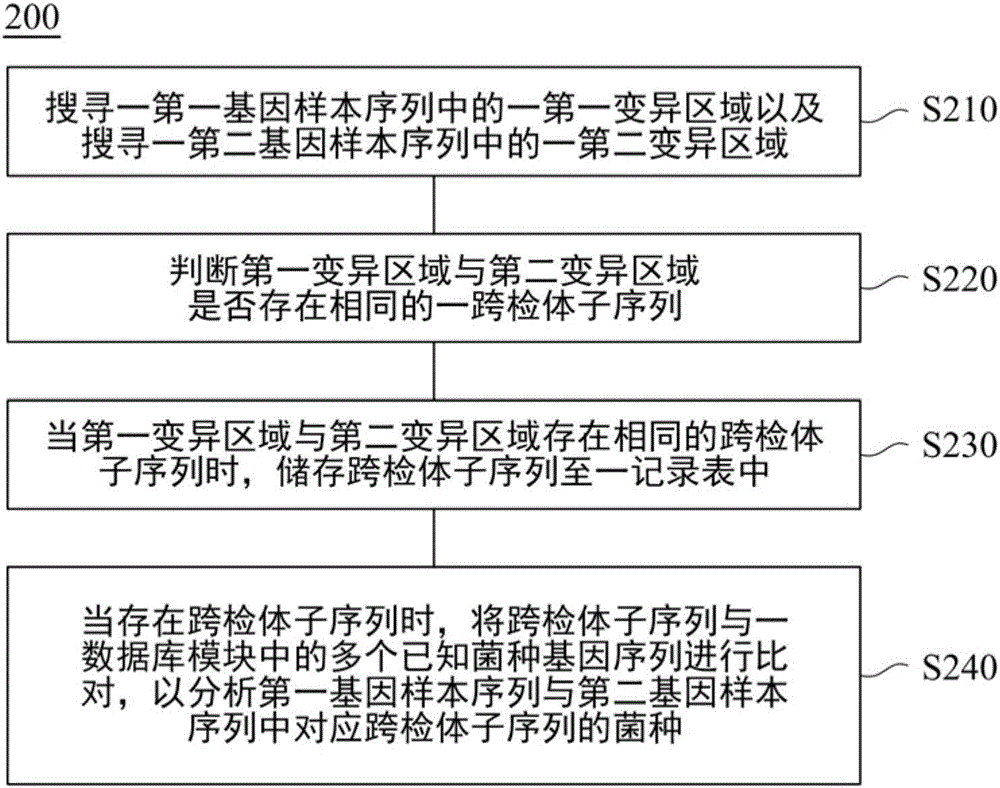
以下进一步说明分析细菌菌种的测序数据的方法200。一并参照图1-3,图2是根据本发明一实施例绘示的一种用以分析细菌菌种的测序数据的方法200的流程图。图3是根据本发明的一实施例绘示的一种基因样本序列300的示意图。为了方便说明,图1所示的用以分析细菌菌种的测序数据的系统100的操作会与用以分析细菌菌种的测序数据的方法200及基因样本序列300一并举例说明。
在步骤S210中,单一检体去重复序列模块110用以搜索第一基因样本序列中的特定变异区域以及搜索第二基因样本序列中的另一特定变异区域。于一实施例中,第一基因样本序列中的特定变异区域以及第二基因样本序列中的另一特定变异区域可以分别指第一基因样本序列和第二基因样本序列中的任一段变异区域。
于一实施例中,用以分析细菌菌种的测序数据的系统还包含检体采样模 块(未绘示)及基因测序模块(未绘示)。检体采样模块用以采样多个菌体样本,此些菌体样本包含第一菌体样本及第二菌体样本。基因测序模块用以将此些菌体样本分别进行基因测序,以取得对应第一菌体样本的第一基因样本序列,及对应第二菌体样本的第二基因样本序列。
举例而言,于某一使用者进行大肠镜检查时,可能会发现其大肠长有息肉,则检体采样模块可将息肉部份进行采样,并在息肉的附近看起来正常的地方也进行采样,以取得多个菌体样本。其中,每一份菌体样本可能具有30万笔基因数据,此些数据中通常混杂了多种对人体有害或有益的多种细菌,因此可通过将此些基因样本序列分别与数据库模块150中的已知数据进行比对,当比对出两者相同时(例如第一基因样本序列与数据库模块150中的某一已知菌种基因序列相同时),则可确认出对应此基因样本序列的菌种。例如,一共采样30份菌体样本后,利用基因测序模块进行基因测序,此基因测序模块例如为测序仪,可将每一份菌体样本的脱氧核醣核酸(DNA)提取出来,并对应每一份菌体样本各自取得至少一笔基因样本序列。
此外,于另一实施例中,当基因测序需要测序出基因序列长度为500bp的变异区域,但测序仪只能测序至100bp的基因序列长度时,测序仪可被设置成大量复制基因序列后,随机打碎此被大量复制的基因序列,再取得打碎后的各小片段的100bp的基因序列长度以进行测序,最后再将测序后各小片段组合起来,通过此方法可以测序出长度较长的基因序列。
于一实施例中,单一检体去重复序列模块110可接收多个基因样本序列。于一实施例中,单一检体去重复序列模块110可接收已完成基因测序的第一基因样本序列及第二基因样本序列,且此第一基因样本序列及第二基因样本序列来对应至同一份或不同份的检体样本。
于一实施例中,第一基因样本序列可以例如为图3所示的基因样本序列300。于图3中,基因样本序列300为一条16s rRNA,长度为1600bp(碱基 对)。本领域技术人员可理解图3中的基因样本序列300是一基因样本示意图。单一检体去重复序列模块110可应用既有的基因序列搜索方法,以搜索出此基因样本序列300所包含的保守区域C1-C10与变异区域V1-V10。其中,保守区域C1-C10是指每个细菌的16s rRNA中相同或类似的基因区段,变异区域V1-V10是指每个细菌的16s rRNA中相异的基因区段。于一实施例中,第一基因样本序列中可具有第一变异区域V1、第二变异区域V2、第三变异区域V3、第四变异区域V4…等。于一实施例中,变异区域V1-V10可各自具有不同的长度。
此外,第二基因样本序列亦可以例如为图3所示的基因样本序列300。于一实施例中,第二基因样本序列与第一基因样本序列中的基因排序方式不同。于一实施例中,第二基因样本序列与第一基因样本序列中的基因排序方式及基因样本长度均不同。本领域技术人员可理解第二基因样本序列中的另一特定变异区域的搜索方式与前述第一基因样本序列中的特定变异区域的搜索方式相同,故此处不再赘述。
通过搜索第一基因样本序列中的特定变异区域以及搜索第二基因样本序列中的另一特定变异区域,可对样本检体序列做前置处理以减低需要查询贴序的数量。
另一方面,于一实施例中,由于每一只细菌的16s rRNA都大同小异,可能仅有部分变异区域不同。因此,数据库模块150于建立已知菌种基因序列的过程中,可基于既有的次世代测序16s rRNA识别法,摘取出某一已知细菌的部分变异区域,并将此摘取出的部分变异区域储存于数据库模块150中,以供后续运算贴序模块140将此摘取出的部分变异区域与检体样本的基因序列进行比对。
由此,数据库模块150可对16S rRNA的已知菌种基因序列建构检索,意即仅摘取出各个已知细菌的部分变异区域,作为对应各个已知细菌的基因序 列代表,以精简被搜索或被用来比对的基因序列。
举例而言,若数据库模块150于建立已知菌种基因序列时,摘取出图3所示的第三变异区域V3-第四变异区域V4的基因区段,并将此摘取出的部分变异区域储存于数据库模块150中,以供后续运算贴序模块140将此摘取出的部分第三变异区域V3-第四变异区域V4与检体样本的基因序列进行比对。此外,关于比对方法的细节技术特征将于步骤S240中详述。
于一实施例中,部分第三变异区域V3-第四变异区域V4的长度例如为500bp,基因样本序列300全序列长度为1600bp,故于此实施例中,此部分第三变异区域V3-第四变异区域V4仅占基因样本序列300全序列长度的30%。
由此可知,通过此方法可将目前已知的20.3万种细菌的16s rRNA摘要出差异区域,并将其储存于数据库模块150中,运算贴序模块140后续只需将第一基因样本序列中的特定变异区域(例如为第一基因样本序列中的第三变异区域V3-第四变异区域V4)及/或第二基因样本序列中的另一特定变异区域(例如为第二基因样本序列中的第三变异区域V3-第四变异区域V4)与数据库模块150中所储存的已知细菌的部分变异区域进行比对,当比对出两者相同时,则可确认出对应此基因样本序列的菌种。
换言之,通过上述技术特征,于进行基因序列分析或贴序时,只需比对基因样本序列与数据库模块150中具代表性的基因序列区段或基因序列的变异区域,无需将整个基因样本序列或整个第二基因样本序列与数据库模块150中完整的所有数据进行比对,由此可降低运算贴序模块140于贴序过程中所需耗用的运算量,以提升分析检体数据的速度。
于步骤S220中,跨检体重复序列判断模块120用以判断特定变异区域与另一特定变异区域是否存在相同的一跨检体子序列。
于一实施例中,当经由单一检体去重复序列模块110搜索第一基因样本序列中的特定变异区域以及搜索第二基因样本序列中的另一特定变异区域 后,若第一基因样本序列与第二基因样本序列位于不同的菌体样本中,则可通过跨检体重复序列判断模块120判断特定变异区域与另一特定变异区域是否存在相同的一跨检体子序列。
例如,于特定变异区域包含于第一基因样本序列中,第一基因样本序列包含于第一菌体样本,且另一特定变异区域包含于第二基因样本序列中,第二基因样本序列包含于第二菌体样本的情况下,若特定变异区域与另一特定变异区域具有某一相同的基因子序列(substring),则将此部分基因子序列视为跨检体子序列。
于一实施例中,若检体重复序列判断模块120判断特定变异区域与另一特定变异区域存在相同的一跨检体子序列,则进入步骤S230。
反之,若检体重复序列判断模块120判断特定变异区域与另一特定变异区域未存在相同的一跨检体子序列,则运算贴序模块140直接将第一基因样本序列中的特定变异区域与数据库模块150中的多个已知菌种基因序列进行比对,以分析第一基因样本序列中对应特定变异区域的菌种。换句话说,当某个变异区域只有在某一菌体样本中出现,没有出现在其他菌体样本时,例如前述的特定变异区域与另一特定变异区域未存在相同的一跨检体子序列时,则此变异区域不会被移除,且运算贴序模块140一定会将此变异区域与数据库模块150中的数据进行比对。
在步骤S230中,重复序列记录模块130用以当特定变异区域与另一特定变异区域存在相同的跨检体子序列时,储存跨检体子序列至一记录表135中。
于一实施例中,重复序列记录模块130更用以记录跨检体子序列所对应的特定变异区域、跨检体子序列所对应的特定变异区域的所属的第一菌体样本、另一特定变异区域、跨检体子序列所对应的另一特定变异区域的所属的第二菌体样本。藉由记录此些数据,可利于减少后续贴序时及/或分析可操 作性的分类单位体时所需要的运算量,例如,于分析可操作性的分类单位体时,可透过记录表13追溯出对应某一跨检体子序列的某一变异区域及其所属的菌体样本,无须再次重新比对所有基因样本序列。
在步骤S240中,运算贴序模块140用以当存在跨检体子序列时,将跨检体子序列与数据库模块150中的多个已知菌种基因序列进行比对,以分析第一基因样本序列与第二基因样本序列中对应跨检体子序列的菌种。
由此,当存在跨检体子序列时,运算贴序模块140会将此跨检体子序列摘取出来,再将此垮检体子序列与数据库模块150中的全部数据或已知菌种的部分变异区域进行比对一次,并将比对结果记录于记录表135中。因此,当多个菌体样本中都具有相同的基因子序列(即跨检体子序列)时,运算贴序模块140仍只需要将此相同的基因子序列时与已知数据比对一次,即可得知基因子序列对应到某一特定的已知菌体,亦可推得此些菌体样本中都包含此特定的已知菌体,而无须将每一个菌体样本中所有相关于跨检体子序列的基因序列都一一进行比对。
此外,于后续计算环境基因体比对分析时,运算贴序模块140可回查记录表135,以得知此变异区域在哪些菌种上面,且此些菌种存在于哪几个菌体样本中(步骤S230),藉此可减少运算贴序的次数。
接着,参阅图4A-4C,图4A-4C是根据本发明一实施例绘示的一种基因片段的示意图。以下进一步说明于步骤S220及S240中相关于单一检体去重复的细部方法及其基因序列的比对方法。
于一实施例中,参照图4A,第一基因样本序列包含第一基因片段D1及第二基因片段D2。于步骤S210中还包含判断第一基因片段D1与第二基因片段D2是否完全相同,当第一基因片段与第二基因片段完全相同时,特定变异区域排除第二基因片段D2。
举例而言,当第一基因片段D1与第二基因片段D2完全相同时,单一检 体去重复序列模块110将第二基因片段D2视为至少第一保守区域的其中之一,故可将特定变异区域视为排除(或不包含)第二基因片段D2。此外,运算贴序模块140将第一基因片段D1与数据库模块150中的已知菌种基因序列进行比对,以分析对应第一基因片段D1的所属菌种。
于一实施例中,参照图4B,第一基因样本序列包含第一基因片段D1及第二基因片段D2,且当第一基因片段D1长于第二基因片段D2时,于步骤S210中,还包含判断第二基因片段D2是否完全相同于第一基因片段D1的一部分;当第二基因片段D2完全相同于第一基因片段D1的一部分时,特定变异区域排除第二基因片段D2。
举例而言,当第一基因片段D1长于第二基因片段D2,且第二基因片段D2完全相同于第一基因片段D1的一部分时,可将特定变异区域视为排除(或不包含)第二基因片段D2。此外,运算贴序模块140将第一基因片段D1与数据库模块150中的已知菌种基因序列进行比对,以分析对应第一基因片段D1的所属菌种。
于一实施例中,参照图4C,其中第一基因样本序列包含第一基因片段D1及第二基因片段D2,当第一基因片段D1长于第二基因片段D2,且第二基因片段D2完全相同于第一基因片段D1的一部分时,运算贴序模块140将第二基因片段D2储存至记录表135中。
此外,于一实施例中,在确认某一基因序列对应至何种菌种及其所属菌体样本后,可进一步进行环境基因体比对分析,以判断此些分析出来的菌种及所属菌体样本中的益菌或坏菌所占的比例;于一实施例中,亦可基于分析结果进一步进行群集分析,以分析细菌分布的情况,例如,癌症患者的细菌群集中的某些特定菌数量会较多,由此可分析病患的健康程度;于一实施例中,可基于分析结果进一步进行菌落功能分析,以判断此些菌种是否具有益生菌或是与某些特定疾病相关的已知菌种,由此以得知病患的健康状况。
综上所述,本发明所示的用以分析细菌菌种的测序数据的系统及其方法,可对样本检体序列做前置处理,减低需要查询贴序的数量,以精简需要进行比对的基因序列,可减少用以分析细菌菌种的测序数据的系统的运算量,以提升分析检体数据的速度。
虽然本发明已以实施方式揭露如上,然而其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,可作各种修改与改变,因此本发明的保护范围以所附权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!