基于异构纹理特征的锌浮选工况状态划分方法与流程
本发明属于泡沫浮选
技术领域:
,具体涉及一种锌浮选工况状态的划分方法。
背景技术:
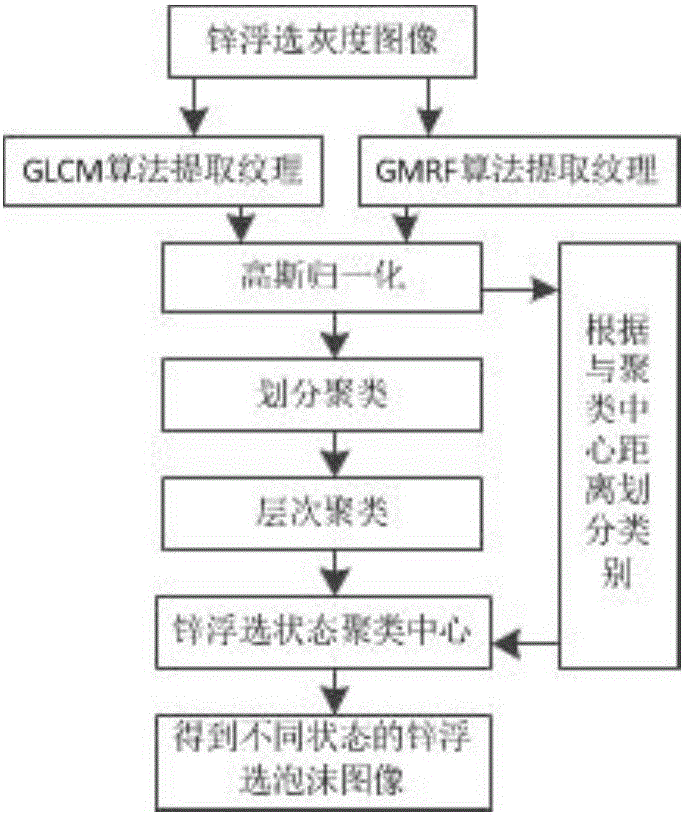
:泡沫浮选是当今锌冶炼中最主要的选矿方法之一,浮选法是一种利用矿物颗粒表面的物理化学性质不同导致亲水性不同,进而对矿物进行分选的方法,具有很强的实用价值。通过在浮选过程中不断地搅拌和充气,可以形成大量具有不同尺寸、颜色、形态以及纹理等特征的气泡,矿物颗粒黏附在气泡表面进而实现矿物分选。正确识别浮选工况是实现浮选生产优化操作的基础和关键。浮选泡沫的视觉特征包含了大量与生产操作变量和产品质量有关的信息,是判断浮选效果的重要依据。实际浮选过程中,操作人员主要通过观察浮选槽表面泡沫的视觉特征来判断当前工况,这种方式主观性和随意性强,影响了工况的准确判断随着计算机技术、数字图像处理技术的快速发展,将基于机器视觉的软测量技术应用于浮选过程给浮选指标的实时监测带来了新的突破,获得了更多与锌浮选工况相关的浮选指标。研究表明,泡沫图像的颜色、纹理、大小等特征是能较好地反映浮选工况,其中,纹理特征由于对光照变化不敏感而成为工况识别中主要的应用特征。但是泡沫纹理表现出来的微观异构性、复杂性以及其概念的不明确性给纹理提取带来了巨大的挑战,采用单一的方法对锌浮选泡沫状态鉴别存在一定的困难,为了能对浮选状态进行分类与识别,需从多个方面对纹理特征进行分析,以进一步实现浮选生产工况的自动分类与识别。同时,传统的泡沫图像聚类多采用单一聚类模型,难以同时满足聚类精度和效率上的需求,因此有必要结合多种聚类方法的优点实现更为准确地锌浮选图像聚类算法。技术实现要素:本发明所需解决的技术问题是提供一种锌浮选泡沫图像异构纹理特征提取方法,同时构造一种锌浮选纹理特征的二次聚类方法,该方法对锌浮选泡沫图形识别具有良好的模式可分性,且易于实施。一种基于异构纹理特征的锌浮选状态划分方法,包括以下步骤:S1:利用锌浮选现场所获得的泡沫视频读取RGB泡沫图像,将RGB泡沫图像进行灰度化;S2:对泡沫灰度图像Ip×q(x,y),选择灰度共生矩阵对泡沫图片进行纹理特征提取,用GLCM表示灰度共生矩阵,用来表示纹理特征,在基于GLCM的14个纹理特征中,仅有对比度、逆差矩、相关性、能量4个特征是不相关的,这4个特征既便于计算又能给出较高的分类精度;因此,分别计算四个方向(0°,45°,90°,135°)的对比度、逆差矩、相关性、能量作为泡沫图像纹理特征,设GLCM提取的特征向量为F1=[x1,x2,...,xm];其中,p×q为泡沫灰度图像分辨率,(x,y)表示泡沫灰度图像中任一像素点的坐标,x1~x4表示0°方向的四个纹理特征,x5~x8表示45°方向的四个纹理特征,x9~x12表示90°方向的四个纹理特征,x13~x16表示135°方向的四个纹理特征,m=16;由于GLCM仅对高频纹理特征具有较强的获取能力,难以适应锌浮选泡沫的各种变化可能,需要步骤S3对中低频纹理特征做出补充;S3:对泡沫灰度图像Ip×q(x,y),选择能够对不同工况泡沫图像进行区分,同时计算量相对不大的五阶高斯马尔科夫随机场算法,用GMRF表示高斯马尔科夫随机场算法,提取12维纹理特征参数,设GMRF算法提取的特征的特征向量为F2=[y1,y2,...,yn],yi表示每一维的特征参数,n=12;S4:对特征向量高斯归一化,融合了GLCM算法和GMRF算法的特征向量为F=[f1,f2,...,fm,fm+1,fm+2,...,fm+n],其中,[f1,f2,...,fm]=[x1,x2,...,xm],[fm+1,fm+2,...,fm+n]=[y1,y2,...,yn]对各参数进行内部归一化;设图像纹理的N维特征向量为F=[f1,f2,...,fN],其中,N=m+n,L幅图像分别表示为I1,I2,...,IL,则图像Ii对应的特征向量就可以记为F=[fi1,fi2,...,fiN]。按这种表示方法将样本库中的M幅图像各自的特征参数表示成1个二维L×N矩阵F={fi,j}.其中fi,j为第i幅图像的第j个特征元素;每一个特征fi的均值为μi,标准差为δi,特征归一化方程为:且将归一化后大于1的特征值定义为1,小于-1的特征值定义为-1,保证所有特征值都落在区间[-1,1]上;得到锌浮选异构纹理特征向量F'=[fi1',fi2',...,fiN'];S5:一般聚类方法难以实现精度和效率的平衡,将划分聚类高效率和层次聚类高精度的特点相结合,提出锌浮选泡沫图像的集成聚类算法;集成聚类算法的基本思想是:在原数据集的多个子集上重复进行划分聚类,对得到的聚类中心用层次聚类进行组合,集成聚类算法包括3个步骤:bootstrap重采样、划分聚类、层次聚类,集成聚类算法的计算流程如下:1)通过重采样得到原始数据集F'的B个bootstrap训练样本通过多次实验当B=10时,样本子集已基本包含样本集的信息,取B=10;2)对每个训练样本进行划分聚类,采用K-means聚类,得到B×K个聚类中心c11,c22,...,c1K,c21,...,cBK,其中K为每个样本的聚类数,ci,j为第i个训练样本的第j个聚类中心;3)将所有的聚类中心组合成一个新的数据集CB=(c11,c12,...,cBK);4)对数据集CB进行层次聚类,得到S个类簇5)对于原始数据集F'中的任一对象,若用c(x)∈CB表示与x距离最近的聚类中心,则将x划分到包含c(x)的类簇中;S6:将锌浮选测试图片依次经过灰度化,采用灰度共生矩阵算法和高斯马尔科夫随机场算法提取纹理特征,对特征高斯归一化,然后分别通过计算与S个聚类中心的距离,将原始数据集中所有对象x∈F'划分给S个类簇,聚类结束,锌浮选图像被划分为S个不同的工况状态;所述S2对S1得到的锌浮选泡沫图像采用灰度共生矩阵算法求取纹理特征,其中,P(i,j;d,θ)表示在θ方向上,相隔距离为d的一对像素分别具有灰度值i和j出现的概率,d=1,θ分别为0°,45°,90°,135°;设f(x,y)为图像像素坐标在(x,y)的点所对应的灰度值,L表示图像灰度等级,Lr,Lc分别表示图像的行、列的维数;则像素对f(x,y)=i和f(x',y')=j在四个方向上的共生矩阵分别定义如下:P(i,j;d,0°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)|x'-x=0,|y'-y|=d,f(x,y)=i,f(x',y')=j}P(i,j;d,45°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)|(x'-x=d,y'-y=d)or(x'-x=-d,y'-y=-d),f(x,y)=i,f(x',y')=j}P(i,j;d,90°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)||x'-x|=d,y'-y=0,f(x,y)=i,f(x',y')=j}P(i,j;d,135°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)|(x'-x=d,y'-y=-d)or(x'-x=-d,y'-y=d),f(x,y)=i,f(x',y')=j}其中,#表示在该集合中的元素数目;通过灰度共生矩阵提取具体的纹理特征的计算公式为:1)对比度:2)逆差分矩:3)相关性:式中:4)能量:所述S3中利用高斯马尔科夫随机场算法提取锌浮选泡沫图像纹理特征的具体步骤为:高斯马尔科夫随机场的阶数与邻域关系见图1;设S为M×M网格上的点集,其中,M为像素点个数,S={(i,j),1≤i,j≤M},假定纹理[y(s),s∈S,S={(i,j),1≤i,j≤M}]是零均值的高斯随机过程,则GMRF算法可以用一个包含多个未知参数的线性方程表示:其中,Ns为点S的邻域,r为邻域半径,θr是系数,e(s)是均值为零的高斯噪声序列,(s+r)为封闭环形区域S中的点,当s=(i,j),r=(k,l)时满足:y(s+r)=y(s+r),s+r∈Sy[(i+k-1)mod(M+1),(j+l-1)mod(M+1)],s+r∉S]]>将上式应用于区域S中的每一点,则得到M2个关于{e(s)}和{y(s)}的方程:y(1,1)=Σr∈Nsθry((1,1)+r)+e(1,1)]]>…………y(1,M)=Σr∈Nsθry((1,M)+r)+e(1,M)]]>…………y(M,1)=Σr∈Nsθry((M,1)+r)+e(M,1)]]>…………y(M,M)=Σr∈Nsθry((M,M)+r)+e(M,M)]]>写成矩阵形式为:y=QTθ+e,QT为关于全部y(s+r)的矩阵,θ为模型的待估计特征向量;以最小平方误差准则估计求解得:其中,S1=S-SB,SB={s=(i,j),s∈S且};五阶高斯马尔科夫随机场模型中:Qs=[ys+r1+ys-r1,...,ys+r12+ys-r12],]]>{r1,r2,...,r12}={(0,1),(1,0),(1,1),(1,-1),(0,2),(2,0),(1,2),(-1,2),(2,1),(-2,2),(2,2)},θ为12维参数向量,θ=(θ1,θ2,...,θ12)T为所求纹理特征向量。所述S5中集成聚类中的划分聚类部分采用K-means聚类,在集成聚类算法中,划分聚类可看作对层次聚类的数据预处理步骤;若直接对原始数据集进行层次聚类,则需要计算所有对象两两之间的欧氏距离并存储该距离矩阵,时间和空间开销很大,划分聚类效率最高,用其输出的聚类中心表征原始数据集的结构,从而大幅缩减数据规模,和随机抽样相比,聚类中心包含原始数据集更多的信息并能消除噪声点和离群点的影响,K-means聚类的具体步骤如下:A、从每一个样本子集中随机取k个元素,作为k个簇的各自的中心;B、分别计算剩下的元素到k个簇中心的欧式距离,将这些元素分别划归到相异度最低的簇;C、根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;D、将每一个样本子集中全部元素按照新的中心重新聚类;E、重复第B-D步,直到聚类结果不再变化;F、将结果输出;用数学表达式来说,共有L个数据点需要分为K个cluster,k-means要做的就是最小化:每个样本子集得到K个聚类中心,为保证用划分聚类中心表征原始数据集结构的完整性,K等于10。所述S5中在集成聚类算法中,层次聚类看作是对样本集划分聚类的输出结果进行组合;为了解决划分聚类容易陷入局部最优解和受初始聚类中心影响较大的问题,采用层次聚类算法对划分聚类输出的聚类中心进行组合,进而得到最终的聚类结果;采用AgglomerativeNesting算法,即AGNES算法,它是一种凝聚的层次聚类算法,如果簇C1中的一个对象和簇C2中的一个对象之间的距离是所有属于不同簇的对象间欧式距离中最小的,C1和C2被合并。这是一种单连接方法,其每个簇可以被簇中的所有对象代表,两个簇之间的相似度由这两个簇中距离最近的数据点对的相似度来确定;AGNES算法具体描述:输入:包含B×K个对象的数据库,终止条件簇的数目S输出:S个簇(1)将每个对象当成一个初始簇;(2)根据两个簇中最近的数据点找到最近的两个簇;(3)合并两个簇,生成新的簇的集合;(4)重复(2)-(3),直到达到定义的簇的数目,得到所需聚类结果本发明提出了一种基于异构纹理特征的锌浮选状态二次集成聚类划分方法,针对采用单一方法提取泡沫纹理特征,难以满足浮选现场工况的变化情况,纹理特征的描述方面比较片面,综合了能够对高频段纹理特征效果较好的灰度共生矩阵算法,以及对中低频纹理图像具有较好建模效果的高斯马尔科夫随机场算法提取锌浮选图像纹理特征,并对将其高斯归一化作为纹理特征向量。对于经典聚类算法各具优缺点的情况,为了将不同算法的优点相结合,提出了集成聚类算法;在集成聚类算法中,划分聚类可看作对层次聚类的数据预处理步骤。划分聚类效率相对高,用其输出的聚类中心表征原始数据集的结构,从而大幅缩减数据规模。和随机抽样相比,聚类中心包含原始数据集更多的信息并能消除噪声点和离群点的影响。层次聚类可看作是对样本集划分聚类的输出结果进行组合,为了解决划分聚类容易陷入局部最优解和受初始聚类中心影响较大的问题,采用聚类质量较好、稳定性较高的层次聚类算法对划分聚类输出的聚类中心进行组合,进而得到最终的聚类结果。实验证明,本发明所提取的纹理特征量具有良好的模式可分性,集成聚类算法可以很好地将不同状态的泡沫区分开来,且这种方法可以直接在计算机上实现,成本低,效率高,易于实施,为现场工人对工况判别具有较好的知道作用。附图说明图1高斯马尔科夫随机场的阶数与邻域关系;图2是本发明实施中锌浮选状态划分的流程图。具体实施方式下面是结合本发明附图2,对本发明中所采用的技术方案更加详细、清楚地做出了描述和解释。本发明针对传统的单一纹理特征描述方式的局限性,综合了不同纹理特征的提取方法,并采用集成聚类的方式综合传统聚类方法的优点,将锌浮选状态做出了较好的划分。显然,所描述的实施例仅是本发明实施例中的一部分,并不是实施例的全部。基于本发明中的实施例,相关领域的技术人员在没有做出创造性劳动的前提所获得所有其它的实施例都应为本发明的保护范围。如图1所示本发明所需解决的技术问题是提供一种锌浮选泡沫图像异构纹理特征提取方法,同时构造一种锌浮选纹理特征的二次聚类方法,该方法对锌浮选泡沫图形识别具有良好的模式可分性,且易于实施。一种基于异构纹理特征的锌浮选状态划分方法,包括以下步骤:S1:利用锌浮选现场所获得的泡沫视频读取RGB泡沫图像,将RGB泡沫图像进行灰度化;S2:对泡沫灰度图像Ip×q(x,y),选择灰度共生矩阵对泡沫图片进行纹理特征提取,用GLCM表示灰度共生矩阵,用来表示纹理特征,在基于GLCM的14个纹理特征中,仅有对比度、逆差矩、相关性、能量4个特征是不相关的,这4个特征既便于计算又能给出较高的分类精度;因此,分别计算四个方向(0°,45°,90°,135°)的对比度、逆差矩、相关性、能量作为泡沫图像纹理特征,设GLCM提取的特征向量为F1=[x1,x2,...,xm];其中,p×q为泡沫灰度图像分辨率,(x,y)表示泡沫灰度图像中任一像素点的坐标,x1~x4表示0°方向的四个纹理特征,x5~x8表示45°方向的四个纹理特征,x9~x12表示90°方向的四个纹理特征,x13~x16表示135°方向的四个纹理特征,m=16;具体步骤如下:对S1得到的锌浮选泡沫图像采用灰度共生矩阵算法求取纹理特征,其中,P(i,j;d,θ)表示在θ方向上,相隔距离为d的一对像素分别具有灰度值i和j出现的概率,d=1,θ分别为0°,45°,90°,135°;设f(x,y)为图像像素坐标在(x,y)的点所对应的灰度值,L表示图像灰度等级,Lr,Lc分别表示图像的行、列的维数;则像素对f(x,y)=i和f(x',y')=j在四个方向上的共生矩阵分别定义如下:P(i,j;d,0°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)|x'-x=0,|y'-y|=d,f(x,y)=i,f(x',y')=j}P(i,j;d,45°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)|(x'-x=d,y'-y=d)or(x'-x=-d,y'-y=-d),f(x,y)=i,f(x',y')=j}P(i,j;d,90°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)||x'-x|=d,y'-y=0,f(x,y)=i,f(x',y')=j}P(i,j;d,135°)=#{((x,y),(x',y'))∈(Lr,Lc)×(Lr,Lc)|(x'-x=d,y'-y=-d)or(x'-x=-d,y'-y=d),f(x,y)=i,f(x',y')=j}其中,#表示在该集合中的元素数目;通过灰度共生矩阵提取具体的纹理特征的计算公式为:5)对比度:6)逆差分矩:7)相关性:式中:8)能量:由于GLCM仅对高频纹理特征具有较强的获取能力,难以适应锌浮选泡沫的各种变化可能,需要步骤S3对中低频纹理特征做出补充;S3:对泡沫灰度图像Ip×q(x,y),选择能够对不同工况泡沫图像进行区分,同时计算量相对不大的五阶高斯马尔科夫随机场算法,用GMRF表示高斯马尔科夫随机场算法,提取12维纹理特征参数,设GMRF算法提取的特征的特征向量为F2=[y1,y2,...,yn];利用高斯马尔科夫随机场提取锌浮选泡沫图像纹理特征的具体步骤为:高斯马尔科夫随机场的阶数与邻域关系见图1;设S为M×M网格上的点集,其中,M为像素点个数,S={(i,j),1≤i,j≤M},假定纹理[y(s),s∈S,S={(i,j),1≤i,j≤M}]是零均值的高斯随机过程,则GMRF算法可以用一个包含多个未知参数的线性方程表示:其中,Ns为点S的邻域,r为邻域半径,θr是系数,e(s)是均值为零的高斯噪声序列,(s+r)为封闭环形区域S中的点,当s=(i,j),r=(k,l)时满足:y(s+r)=y(s+r),s+r∈Sy[(i+k-1)mod(M+1),(j+l-1)mod(M+1)],s+r∉S]]>将上式应用于区域S中的每一点,则得到M2个关于{e(s)}和{y(s)}的方程:y(1,1)=Σr∈Nsθry((1,1)+r)+e(1,1)]]>…………y(1,M)=Σr∈Nsθry((1,M)+r)+e(1,M)]]>…………y(M,1)=Σr∈Nsθry((M,1)+r)+e(M,1)]]>…………y(M,M)=Σr∈Nsθry((M,M)+r)+e(M,M)]]>写成矩阵形式为:y=QTθ+e,QT为关于全部y(s+r)的矩阵,θ为模型的待估计特征向量;以最小平方误差准则估计求解得:其中,S1=S-SB,SB={s=(i,j),s∈S且};五阶高斯马尔科夫随机场模型中:Qs=[ys+r1+ys-r1,...,ys+r12+ys-r12],]]>{r1,r2,...,r12}={(0,1),(1,0),(1,1),(1,-1),(0,2),(2,0),(1,2),(-1,2),(2,1),(-2,2),(2,2)},θ为12维参数向量,θ=(θ1,θ2,...,θ12)T为所求纹理特征向量。S4:对特征向量高斯归一化,融合了GLCM算法和GMRF算法的特征向量为F=[f1,f2,...,fm,fm+1,fm+2,...,fm+n],其中,[fm+1,fm+2,...,fm+n]=[y1,y2,...,yn]对各参数进行内部高斯归一化;设图像纹理的N维特征向量为F=[f1,f2,...,fN],其中,N=m+n,L幅图像分别表示为I1,I2,...,IL,则图像Ii对应的特征向量就可以记为F=[fi1,fi2,...,fiN];按这种表示方法将样本库中的M幅图像各自的特征参数表示成1个二维L×N矩阵F={fi,j},其中fi,j为第i幅图像的第j个特征元素;每一个特征fi的均值为μi,标准差为δi,特征高斯归一化方程为:且将高斯归一化后大于1的特征值定义为1,小于-1的特征值定义为-1,保证所有特征值都落在区间[-1,1]上;得到锌浮选异构纹理特征向量F'=[fi1',fi2',...,fiN'];S5:一般聚类方法难以实现精度和效率的平衡,将划分聚类高效率和层次聚类高精度的特点相结合,提出锌浮选泡沫图像的集成聚类算法;集成聚类算法的基本思想是:在原数据集的多个子集上重复进行划分聚类,对得到的聚类中心用层次聚类进行组合。集成聚类算法包括3个步骤:bootstrap重采样、划分聚类、层次聚类。集成聚类算法的计算流程如下:1)通过重采样得到原始数据集F'的B个bootstrap训练样本通过多次实验当B=10时,样本子集已基本包含样本集的信息,取B=10;2)对每个训练样本进行划分聚类,采用K-means聚类,集成聚类中的划分聚类部分采用K-means聚类,在集成聚类算法中,划分聚类可看作对层次聚类的数据预处理步骤;若直接对原始数据集进行层次聚类,则需要计算所有对象两两之间的欧氏距离并存储该距离矩阵,时间和空间开销很大;划分聚类效率最高,用其输出的聚类中心表征原始数据集的结构,从而大幅缩减数据规模;和随机抽样相比,聚类中心包含原始数据集更多的信息并能消除噪声点和离群点的影响;K-means聚类的具体步骤如下:A、从每一个样本子集中随机取k个元素,作为k个簇的各自的中心;B、分别计算剩下的元素到k个簇中心的欧式距离,将这些元素分别划归到相异度最低的簇;C、根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;D、将每一个样本子集中全部元素按照新的中心重新聚类;E、重复第B-D步,直到聚类结果不再变化;F、将结果输出;用数学表达式来说,共有L个数据点需要分为K个cluster,k-means要做的就是最小化:每个样本子集得到K个聚类中心,为保证用划分聚类中心表征原始数据集结构的完整性,K等于10。得到B×K个聚类中心c11,c22,...,c1K,c21,...,cBK,其中K为每个样本的聚类数,ci,j为第i个训练样本的第j个聚类中心。3)将所有的聚类中心组合成一个新的数据集CB=(c11,c12,...,cBK)。4)对数据集CB进行层次聚类,在集成聚类算法中,层次聚类看作是对样本集划分聚类的输出结果进行组合;为了解决划分聚类容易陷入局部最优解和受初始聚类中心影响较大的问题,采用层次聚类算法对划分聚类输出的聚类中心进行组合,进而得到最终的聚类结果;采用AGNES(AgglomerativeNesting)算法,它是一种凝聚的层次聚类算法,如果簇C1中的一个对象和簇C2中的一个对象之间的距离是所有属于不同簇的对象间欧式距离中最小的,C1和C2被合并。这是一种单连接方法,其每个簇可以被簇中的所有对象代表,两个簇之间的相似度由这两个簇中距离最近的数据点对的相似度来确定;AGNES算法具体描述:输入:包含B×K个对象的数据库,终止条件簇的数目S输出:S个簇(1)将每个对象当成一个初始簇;(2)根据两个簇中最近的数据点找到最近的两个簇;(3)合并两个簇,生成新的簇的集合;(4)重复(2)-(3),直到达到定义的簇的数目,得到所需聚类结果得到S个类簇5)对于原始数据集F'中的任一对象,若用c(x)∈CB表示与x距离最近的聚类中心,则将x划分到包含c(x)的类簇中;S6:将锌浮选测试图片依次经过灰度化,采用灰度共生矩阵算法和高斯马尔科夫随机场算法提取纹理特征,对特征高斯归一化,然后分别通过计算与S个聚类中心的距离,将原始数据集中所有对象x∈F'划分给S个类簇,聚类结束,锌浮选图像被划分为S个不同的工况状态。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1