基于细微面部动作识别的驾驶员打哈欠检测方法与流程
本发明涉及计算机视觉技术领域,具体为基于细微面部动作识别的驾驶员打哈欠检测方法。
背景技术:
智能驾驶包括提供预警信号,监控和协助车辆控制是近年来改善道路安全的热门研究话题。每年有数千人因驾驶员在车上睡着而死亡或严重受伤。道路安全受到驾驶员疲劳的严重威胁。美国国家公路交通安全管理局进行了调查,结果显示超过三分之一的受访者承认在驾驶时经历过疲劳。在疲劳驾驶事故中,10%的人承认他们在过去一个月和过去一年中发生过此类事故。研究人员发现,驾驶员疲劳导致了22%的交通事故。在没有任何警告的情况下,驾驶疲劳导致碰撞或接近碰撞的可能性是正常驾驶的六倍。因此,研究识别驾驶员疲劳的方法对于提高道路安全性非常重要。在过去的几十年中,提出了许多驾驶员疲劳检测方法,以帮助驾驶员安全驾驶并提高交通安全性。疲劳驾驶中驾驶员的行为特征包括眨眼,点头,闭眼和打哈欠。在这些行为中,打哈欠是疲劳表现的主要形式之一。因此,研究人员对打哈欠检测做了大量研究。与传统的全身动作识别相比,面部动作可以被视为细微的脸部动作。
虽然许多研究人员提出了不同的方法来检测打哈欠,但他们仍然面临着巨大的挑战。由于在真实驾驶环境中复杂的驾驶员面部动作和表情,现有方法难以准确、稳健地检测打哈欠,特别是当有一些面部动作和表情的嘴部形变和打哈欠类似,极易发生错检。因此,面对驾驶环境的新特点、新挑战,如何快速而又准确的进行驾驶员打哈欠行为检测是我们需要研究的课题。
技术实现要素:
本发明的目的为解决已存在的驾驶员打哈欠行为检测算法无法有效区分一些特殊的打哈欠和类打哈欠行为的问题,比如唱歌时打哈欠等特殊打哈欠行为,大声喊叫等类打哈欠行为,提出基于细微面部动作识别的驾驶员打哈欠检测方法。
为实现上述目的,本发明提供如下技术方案:基于细微面部动作识别的驾驶员打哈欠检测方法,包括以下步骤:
步骤1,对车载摄像机捕捉到的驾驶员驾驶视频进行预处理,进行人脸检测和分割,图像大小归一化和去噪;
步骤2,提出关键帧提取算法,通过图片直方图相似度阈值筛选以及离群相似度图片剔除相结合的方法,来提取细微动作序列中的关键帧;
步骤3,根据选择的关键帧,建立具有低时间采样率的3d深度学习网络(3d-lts)以检测各种打哈欠行为。
进一步的,所述对车载摄像机捕捉到的驾驶员驾驶视频进行预处理包括:采用viola-jones人脸检测算法进行驾驶员人脸区域的检测,分割出驾驶员面部区域,采用快速中值滤波法进行去噪处理。
进一步的,所述关键帧提取算法从一系列原始的视频帧f={fj,j=1,…,n}中提取一系列关键帧k={ki,i=1,…,m};其中m表示从原始帧中选择的关键帧的数量,n表示原始帧的数量,所述关键帧提取算法包括两个选择阶段:
在第一选择阶段,计算每个视频帧的rgb颜色直方图;然后,利用欧氏距离计算两个连续帧的颜色直方图γj和γj+1之间的相似度:
其中,1≤j≤n-1,n是图片颜色直方图的维度。
通过公式(2)计算相似度阈值ts:
ts=μs(2)
其中,μs为mean(s),s为sj的集合,当sj>ts时,认为fj和fj+1相似度较小,将fj加入候选关键帧队列。
在第二个选择阶段,剔除候选关键帧中那些具有离群特征的候选关键帧图片,来得到最终的关键帧,使用两种图像相似度度量指标:欧氏距离(ed)和均方根误差(rmse),使用中值绝对偏差(mad)来检测具有离群特征的帧,根据式(3)计算mad:
mad=median(|xi-median(x)|)(3)
将连续的两个候选关键帧记为ki,i+1,对于所有的ki,i+1,计算它们的rmse和ed值,对于计算出的每一个rmse(ki,i+1)和ed(ki,i+1),计算它们的mad值,记作α=mad(rmse),β=mad(ed),rmse(ki,i+1)的计算公式如公式(4)所示,ed(ki,i+1)的计算公式如公式(5)所示,当rmse(ki,i+1)小于α而且ed(ki,i+1)小于β时,认为ki是具有离群特征的候选关键帧,并将ki移除候选关键帧。
这里n代表ki的尺寸。
这里m代表候选关键帧的图片颜色直方图维度。
进一步的,所述3d-lts网络,用于时空特征提取和细微动作的识别,所述3d-lts网络使用8个非超帧帧作为输入,使用四个3d卷积层从连续帧中提取时空特征,所有的卷积滤波器都是3×3×3,步幅为1×1×1,所有池层都是最大池,第一和第二汇集层的内核大小为1×2×2,前四个卷积层的滤波器数量分别为32,64,128和256,第三个池内核层为2×4×4,卷积层后面是一个完全连接的层,用于映射特征,使用一个具有1024个输出的完全连接层,用于集成特征的分布。
与现有技术相比,本发明的有益效果是:
本发明提出了一种基于细微面部动作识别的驾驶员打哈欠检测方法,首先,提出了一种两阶段的关键帧提取算法,该算法具有计算速度快且可以有效地从原始帧序列中提取细微动作的关键帧的优点;其次,本发明还提出了一种基于三维卷积网络的细微动作识别网络,用于提取时空特征和检测各种面部细微动作;本发明提出的方法在识别率和整体性能方面优于现有方法,能有效区分打哈欠和其他面部细微动作,有效降低了驾驶员打哈欠行为的误检率。
附图说明
图1为本发明基于细微面部动作识别的驾驶员打哈欠检测框架图;
图2为本发明关键帧提取结果演示图;
图3为二维卷积和三维卷积的比较图;
图4为本发明提出的3d-lts网络的结构图;
图5为来自yawddr数据集的一些帧样本;
图6为yawddr数据集中两种动作的一些图像序列(a)说话(b)打呵欠;
图7为本发明高清摄像机及驾驶员位置图;
图8为本发明mfay数据集中三个面部动作的图像序列(a)打哈欠(b)唱歌(c)喊叫;
图9为本发明mfay数据集中的视频序列数图;
图10为本发明方法和四种先进的方法在mfay数据集上的检测结果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于解释本发明技术方案,并不限于本发明。
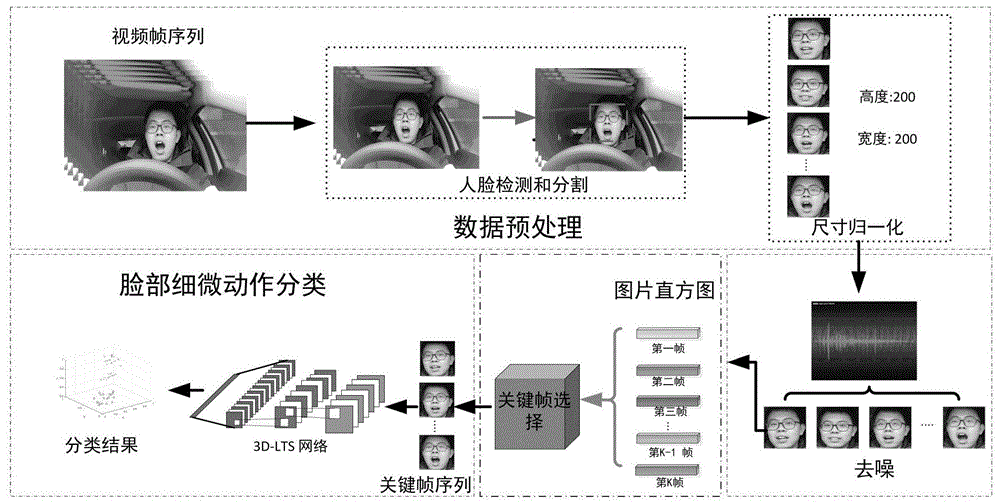
本发明提供一种技术方案:基于细微面部动作识别的驾驶员打哈欠检测方法,其整体框架如图1所示,包括以下步骤:
步骤1,对车载摄像机捕捉到的驾驶员驾驶视频进行预处理,进行人脸检测和分割,图像大小归一化和去噪;
步骤2,提出关键帧提取算法,通过图片直方图相似度阈值筛选以及离群相似度图片剔除相结合的方法,来提取细微动作序列中的关键帧;
步骤3,根据选择的关键帧,建立具有低时间采样率的3d深度学习网络(3d-lts)以检测各种打哈欠行为。
视频预处理是我们研究内容中的重要一步,由于驾驶员打哈欠检测涉及到驾驶员的疲劳驾驶,所以必须具有实时性的要求。必须采用更快更好的视频处理技术来对车载摄像头录制的视频进行处理。我们首先将视频进行分帧处理。由于分帧后的图片中包含许多背景等的冗余信息,而这些信息对于我们后续的分类没有一点用处,反而会造成很大的干扰。我们的目标是对驾驶员脸部的动作进行分类,所以我们的关注区域应该是驾驶员的脸部区域。我们用viola-jones人脸检测算法进行驾驶员人脸区域检测。viola-jones人脸检测算法具有快速、稳定、准确的特点,是一种使用最为广泛的人脸检测算法。但是它对超过一定旋转角度的人脸的检测效果并不好。在本发明中,摄像头的位置是正对驾驶员脸部的,所以可以确保有100%的人脸检出率。在检测出人脸区域之后,我们将连续帧的大小统一为200×200。
现实中的驾驶环境,由于汽车的运动,会有震动发生。这就导致了我们的车载摄像头在拍摄的过程中会因为震动而产生噪音和干扰。为了尽可能的减少这些噪声带来的干扰,我们采用快速中值滤波法进行去噪处理。快速中值滤波法是中值滤波法的gpu加速版本。中值滤波法可以有效去除散点噪声和椒盐噪声,由于震动产生的噪声大多属于这两种。所以采用快速中值滤波法可以使去噪效果达到最好,将噪声带来的干扰减至最小。
在预处理阶段,视频被分成30帧/秒的帧序列。由于原始的帧序列中相邻帧之间的信息量差别很小,存在大量冗余帧,这些冗余帧使得动作分类的精度下降,尤其是对于动作变化幅度较小的细微动作。为了解决这些问题,本发明提出一种基于图片相似度阈值筛选和离群相似度剔除的有效实时的关键帧提取算法。图2显示了由该算法选择的关键帧序列。
本发明提出的关键帧提取算法从一系列原始的视频帧f={fj,j=1,…,n}中提取一系列关键帧k={ki,i=1,…,m}。其中m表示从原始帧中选择的关键帧的数量,n表示原始帧的数量。本发明将基于阈值的直方图相似度滤波与离群值检测相结合。图片直方图具有计算成本低的优点。与局部特征相比,分类中的图像距离和直方图等全局特征可以有效地减少误报。
本发明提出的关键帧提取算法包括两个选择阶段:
在第一选择阶段,计算每个视频帧的rgb颜色直方图;然后,利用欧氏距离计算两个连续帧的颜色直方图γj和γj+1之间的相似度:
其中,1≤j≤n-1,n是图片颜色直方图的维度。经过计算,我们获得了一个包括了fj和fj+1相似度的集合s。我们需要确定一个相似度阈值ts来进行关键帧的选择。这个阈值能代表帧之间相似度的平均水平。我们考虑了两种阈值计算方法。最大和最小相似度的一半和平均相似度。我们使用这两个阈值从我们自我收集的数据集和处理过的yawdd基准数据集中选择关键帧。我们的网络在自我收集的数据集上进行训练,并在已处理的yawdd数据集上进行测试。结果显示在表1中,其中s表示相似度集,并且yt是谈话时打哈欠的缩写。从结果我们可以看出,使用平均相似度作为度量阈值允许我们的打哈欠检测方法实现最佳的整体结果。最大帧相似度和最小帧相似度的一半融合了两个极端相似度。该阈值不能代表这些面部动作的相似度的平均值。作为阈值的平均相似度可以选择最具代表性的关键帧。
表1两种阈值下的实验结果(单位:%)
通过公式(2)计算相似度阈值ts:
ts=μs(2)
其中,μs为mean(s),s为sj的集合,当sj>ts时,认为fj和fj+1相似度较小,将fj加入候选关键帧队列。
在第二个选择阶段,剔除候选关键帧中那些具有离群特征的候选关键帧图片,来得到最终的关键帧,使用两种图像相似度度量指标:欧氏距离(ed)和均方根误差(rmse),使用中值绝对偏差(mad)来检测具有离群特征的帧,根据式(3)计算mad:
mad=median(|xi-median(x)|)(3)
将连续的两个候选关键帧记为ki,i+1,对于所有的ki,i+1,计算它们的rmse和ed值,对于计算出的每一个rmse(ki,i+1)和ed(ki,i+1),计算它们的mad值,记作α=mad(rmse),β=mad(ed),rmse(ki,i+1)的计算公式如公式(4)所示,ed(ki,i+1)的计算公式如公式(5)所示,当rmse(ki,i+1)小于α而且ed(ki,i+1)小于β时,认为ki是具有离群特征的候选关键帧,并将ki移除候选关键帧。
这里n代表ki的尺寸。
这里m代表候选关键帧的图片颜色直方图维度。
在本发明中,另一个重要的贡献是将动作识别机制引入打哈欠检测。近年来,动作识别在准确性和速度方面都取得了很大进步。研究人员已提出各种网络来识别行动。广泛使用的动作识别框架是双流融合网络和3d卷积网络。
3d卷积网络在动作识别,场景和目标识别以及动作相似性分析中引起了很多关注。与其他基于双流网络的时空特征提取方法相比,三维卷积网络具有计算速度快,准确率高的优点。一些研究人员试图叠加2d卷积连续特征图来对视频动作进行分类,但在2d卷积过程中时间信息也已丢失。相比之下,3d卷积网络使用多个连续视频帧作为输入,如图3所示.3d卷积网络通过3d卷积和3d池化操作实现更好的时间信息建模。经过实验发现,3×3×3大小的3d卷积核可以提取最具代表性的时空特征。
基于三维卷积,本发明提出了一种具有低时间采样率的3d-lts网络,用于时空特征提取和细微动作的识别。该3d-lts网络使用3d卷积来提取时空特征,并采用softmax层进行分类。在数据预处理和关键帧选择之后,确定将多少帧用作3d-lts网络的输入以获得最佳识别性能非常重要。我们将3d-lts网络的结果与不同的输入帧数进行了比较。我们的网络在自我收集的数据集上进行训练,并在已处理的yawdd数据集上进行测试。实验结果如表2。从整体识别结果来看,结果表明我们的3d-lts网络对输入帧的数量不是很敏感。我们的网络使用8个非超帧帧作为输入,表现出更好的性能。3d-lts使用四个3d卷积层从连续帧中提取时空特征。3d-lts的结构如图4所示。从结构图中我们可以看到所有的卷积滤波器都是3×3×3,步幅为1×1×1。所有池层都是最大池。如果我们在时间维度上减慢浅汇集层的汇集速率,则深卷积层可以从浅卷积层提取更具代表性的时间特征。这对于认识细微的行为非常重要。基于该理论分析,我们的3d-lts中的第一和第二汇集层的内核大小为1×2×2。前四个卷积层的滤波器数量分别为32,64,128和256。第三个池内核层为2×4×4。卷积层后面是一个完全连接的层,用于映射特征。我们使用了一个具有1024个输出的完全连接层。完全连接的层用于集成特征的分布。我们发现我们的3d-lts在其后面是一个完全连接的层时获得了最佳的识别性能。
表2网络不同输入帧数的实验结果(单位:%)
本发明实验中,首先我们采用一个标准的哈欠检测数据集来测试我们的系统,yawdd数据集,yawdd是一个公共的打哈欠检测数据集。它可用于验证人脸检测,人脸特征提取,打哈欠检测和其他算法。该数据集收集了来自不同性别,年龄,国家和种族的志愿者的一系列动作视频。该数据集包含351个视频。它为每位驾驶员录制了三到四个视频,包括不同的嘴巴状况,如说话,打哈欠和打哈欠。
由于yawdd数据集中的大多数视频片段持续时间超过一分钟,并且包含多个面部动作,因此我们需要将yawdd数据集中的视频片段划分为仅包含单个动作的视频片段。通过这种方式,我们基于yawdd数据集构建了yawddr数据集。yawddr数据集中的视频长度约为8秒。此数据集中有三种操作:交谈(t),打哈欠(y)和交谈时打哈欠(yt)。在yawddr中收集了486个图像序列。数据集中的一些示例(在面部分割之前和分割之后)显示在图5和图6中。我们使用该数据集来验证我们的方法的有效性。
许多面部数据集用于身份识别,面部表情识别和面部检测。然而,没有一个公共驾驶员打呵欠检测数据集包括各种面部动作。收集此数据集的目的是验证我们的方法在各种面部动作中进行驾驶员打哈欠检测的效率。因此,通过在实际驾驶环境中使用hd相机来构建我们的mfay数据集。我们将各种面部动作分为可能在驾驶期间发生的六个等级。驾驶员在说话(t);说话时打哈欠(yt);打呵欠(y);唱歌(s);唱歌时打哈欠(ys);大喊(st)。鉴于疲劳驾驶的危险,我们的收集地点是在很少行人的宽阔道路上选择的。在不影响驾驶的情况下,在驾驶员面前安装迷你高清摄像头以捕捉他们的面部动作。在实验过程中,驾驶员在不同的照明和道路条件下驾驶汽车。在车辆的副驾驶员中,研究人员持续监视每个受试者的面部动作变化,以注释每个面部动作的基本事实。高清摄相机和驾驶员的位置如图7所示。
20名测试人员(年龄范围从20到46岁)的面部视频是在汽车运动时的不同情况下获得的。mfay数据集的样本图像如图8所示。所有视频都转换为音频-视频交错格式,视频速率为30fps。最后,如图9所示,从获得的视频中提取347个图像序列(53652个图像)。每个图像序列的长度约为5秒(150帧)。
本发明基于yawddr数据集和mfay数据集进行了以下三部分实验:
实验一:为了证明我们的关键帧提取算法能够有效地选择驱动视频帧序列中的关键帧,我们在yawddr数据集和mfay数据集上进行了以下实验。首先,图片直方图用于删除差别很小的帧并选择候选关键帧,我们将此操作记录为阶段一。为了验证我们的算法能够有效提高各种面部动作的识别率,我们还提供了识别结果,没有使用任何关键帧提取算法。我们将此案称为“不使用”。结果如表3所示。在阶段一之后,准确性得到了提高。在阶段一的基础上,我们使用mad剔除具有离群特征的候选关键帧。完成此处理后,我们将获得所需的关键帧。从表三可以看出,与阶段一和不使用关键帧选取相比,我们的两阶段关键帧提取算法实现了最佳识别性能。验证了我们的关键帧提取算法的有效性。
表3不同关键帧选择阶段的实验结果(单位:%)
实验二:在这个实验中,我们专注于我们提出的方法和一些其他现有的基于图像的方法之间的比较实验。我们将我们的方法与duy等人提出的基于核化模糊粗糙集的方法进行了比较。基于anithac等人提出的双折代理专家系统的算法。和两种基于卷积神经网络的方法。为了验证我们的方法的有效性,我们采用以下模型训练和测试策略:训练集包括随机的视频剪辑根据它们所属的类别从mfay数据集和yawddr数据集中提取。其余的视频剪辑用于测试模型。所有视频剪辑都由我们提出的关键帧提取算法处理。选定的关键帧用于训练和测试网络模型。由于基于图像的方法不能有效地检测像yt这样的动作,因此这些情况下的实验结果没有记录在我们的表格和图中。如表4和图10所示,与其他方法相比,基于细微面部动作和视频关键帧的打哈欠检测方法的识别率得到了显着提高。我们识别各种面部动作的方法优于现有方法,有效地减少了错误检测。基于视频的方法可以有效地提取足够的时空动作特征并实现动态的打哈欠检测。这进一步验证了我们提出的方法的稳健性。
表4本发明所提方法和四种先进的方法在yawddr数据集上的检测结果(单位:%)
实验三:在本实验中,我们比较了基于图像的方法和基于视频的方法。我们的方法使用连续帧作为输入,这是一种基于视频的方法。对于基于图像的方法,yawddr数据集和mafy数据集中的帧图像用于训练和测试。我们从两个数据集中均匀地提取一些帧,并根据它们所属的类为它们分配标签。这些实验的数据处理步骤和验证算法是相同的。实验结果如表5所示。结果表明,基于视频的方法比基于图像的方法具有更好的性能,因为打哈欠是连续动作而不是静态。基于视频的方法可以检测各种面部情况下的打哈欠。如果仅使用一帧进行识别,帧之间的重要时间动作信息将丢失。表示打哈欠的特征可能与指示动作唱歌或喊叫的特征相混淆。相比之下,基于视频的方法可以提供足够的时空动作信息,其可以通过动作帧序列对动作进行分类。将打哈欠视为动作而不是静止的状态去检测,可以显著改善基于静态图像检测的方法中存在的大量错检问题。
表5基于图片和基于视频的检测方法实验结果(单位:%)
实验表明,本发明提出的方法在识别率和整体性能方面优于现有方法,能有效区分打哈欠和其他面部细微动作,有效降低了驾驶员打哈欠行为的误检率。
以上所述仅表达了本发明的优选实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形、改进及替代,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!