基于养老机器人的室内场景实时重建跟踪服务方法与流程
本发明主要涉及图像重建技术,特别是涉及实时三维场景重建的技术,更具体的说,是涉及一种基于养老机器人的室内场景实时重建跟踪服务方法。
背景技术:
伴随着当今社会人口老龄化的不断发展,我国即将成为深度人口老龄化国家,养老问题同样存在着巨大的缺口,由于子女的工作繁忙,老人不能在家中得到及时的照顾,容易患上孤独症,社会方面我们养老机构的养老功能不完善,不能满足现在老年人的养老需求。近年来人工智能的飞速发展,养老机器人也被许多老年人所喜爱,功能齐全的服务机器人能够解决一系列的养老问题,不仅让老年人享受到了高品质的生活,也大大减轻了年轻人的社会压力。
但是目前市场上的养老机器人绝大部分机器人所能服务的功能都很有限,尤其在服务的时候需要场景内的三维信息的时候,许多的养老机器人没有办法做到精确的分析三维物体,在室内三维重建方面做的也并不是很突出,因此这也是目前养老机器人的一些缺陷导致所预设的服务功能单一,没有三维信息,而不能进行多样化服务。
微软在几年前发布的kinect深度相机,这款相机与传统的相机相比较,不仅价格低廉,方便操作,而且还能实时地同步采集物体的深度信息和彩色信息,同时kinect相机具有红外线发射功能,因此采集到的信息不容易受到光照以及纹理变化的影响,采集的图像质量比较高。目前kinect已经应用在vr/ar等相关领域中。
最近,推出了一款kinectv2深度相机,这个深度相机比之前的v1版本的追踪准确度提高了20%,并且kinectv2深度相机能够进行人体跟踪,最远距离达到了4米,此外,v2版本在近距离有比v1高出2倍的精度,非常适合对室内的信息采集以及人体跟踪。
针对目前养老机器人发展现状以及kinectv2深度相机的优点,越来越多的人将深度相机应用到三维场景中间中,并且与机器人等现代科技设备相结合来提高产品的服务质量。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提出一种新颖的基于养老机器人的室内场景实时重建跟踪服务方法,来完善目前养老机器人的服务质量,提高服务功能的指令执行准确率,更进一步的进行开展机器人养老陪护工作。在此系统下,用户首先将自身的信息数据录取到所配备的手持设备(如手机)中,在手持设备中进行初步的数据分析后,通过无线传输方式传送到机器人本体中,机器人本体通过存储数据,并且开始对室内进行初始化实时重建后,执行相关服务功能。此系统能够实时的进行场景三维重建,并且将成本低廉,产生的三维模型精度较好,满足养老机器人设备上的相关功能,如智能识物,表情分析,地图导航等。
本发明的目的是通过以下技术方案实现的。
本发明基于养老机器人的室内场景实时重建跟踪服务方法,包括以下过程:
s1、手持设备的用户信息导入,并且将导入的数据信息进行去噪滤波,进行初步分析处理;
s2、通过无线传输模块将初步分析处理后的数据传输到机器人本体中的数据交互模块中的数据存储区;
s3、图像采集模块利用机器人本体中内置的kinectv2深度相机对室内进行图像采集,包括采集深度信息和颜色信息,使用前需要编译与深度相机相兼容的函数库,并且设置好环境变量;
s4、进行重建作业,将步骤s3采集到的图像信息进行测量,得到多帧的深度信息,并且利用图像去噪算法进行噪声的处理;
s5、将处理过的图像信息进行坐标轴变换,变换到一个统一的世界坐标中,从而获得点云信息;
s6、开始计算六个方向自由度的刚体变换矩阵,将目前的点云信息与已有的参考点云信息进行对齐,并且输出连续的两帧图像之间的相对变换矩阵参数,随后进行初始化为下一帧对齐时的相机姿态,此处采用icp算法;
s7、icp算法配准完成后,将图像帧之间重复的区域进行融合处理,并且提取出关键的点云信息,简化点云,并将颜色信息加入;
s8、实时进行场景的渲染并且指导用户规划深度相机的运动轨迹;
s9、利用表面重建算法对点云信息进行三角网格化,生成可视化的三维模型;
s10、将产生的三维模型放入数据交互模块的信息存储区,以备服务模块各个功能的使用调用;
s11、确定当前用户,并且利用kinectv2相机对用户进行跟踪服务,监听用户发出的指令,从而完成相应的服务功能。
s1的具体操作步骤包括:
s11、利用手持设备app导入用户当前的基本信息,例如姓名、年龄、身高、体重健康状况指标;
s12、采集用户的面部表情信息、姿势信息;
s13、进行信息预处理,对面部表情信息、姿态信息进行滤波;
s14、对采集的信息进行综合分析,通过网络参考数据,评判目前老人的健康状况,记录表情信息、姿势信息,将这些数据打包成固定的文件格式。
s2的具体操作步骤包括:
s21、通过wifi无线传输将数据传输到机器人本体的数据交互模块中;
s22、将打包好的文件存储到数据交互模块中的数据存储区。
s3的具体操作步骤包括:
s31、首先将kinectv2的相机驱动程序安装好,并且在这个图像采集模块中搭建深度相机和openni;
s32、找到opencv和vtk源码,使用cmake进行编译,并且配置kinectv2所需要的环境变量;
s33、安装cuda及其驱动程序,安装开源代码eigen库,并配置所需要的环境变量。
s4的具体操作步骤包括:
s41、将kinectv2在机器人身上安装好,并且将usb接口连接到机器人本体的内部计算机中;
s42、所有都准备妥当后,机器人开始初始化程序,将机器人放到房间的中心位置,并且开始进行图像采集;
s43、保证机器人匀速稳定的进行采集扫描场景信息,并且获得图像数据;
s44、对采集到的图像数据使用双边滤波算法进行数据的平滑去噪处理。
s5的具体操作步骤包括:
s51、将处理过的每帧图像上的像素点μ投影到相机空间中得到顶点v(μ);
s52、计算每一帧图像的世界坐标点vl,k(x,y),l为深度信息,k属于相机index;
s53、获得每一帧深度图的世界坐标后,开始计算每个顶点的法向量n;
法向量n计算过程如下:
s531、根据获得的kinectv2点云数据特征vk(x,y)得到4个邻近点,vk(x-1,y)、vk(x+1,y)、vk(x,y+1)、vk(x,y-1);
s532、计算vk(x,y)的领域质心v0;
s533、计算三阶协方差矩阵c:
s534、对c进行特征分解:
s535、λ1所对应的特征向量v1为点v1的法向量。
s6的具体操作步骤包括:
s61、经过步骤s5进行的坐标变换后,将采集的帧图像信息统一到世界坐标中,将满足深度差阈值和向量夹角阈值的点,确定为匹配点;
s62、利用icp算法最小化目标函数,从而解的最优变换参数;
s63、根据变换参数和参考点云信息确定当前对应相机的位置和朝向。
s7的具体操作步骤包括:
s71、利用gpu在内存中开辟两个分辨率为10243的体空间,用来存储空间几何信息和颜色信息;
s72、通过投影方程求出体素中心点所对应的像素点μ;
s73、通过坐标变换求出像素点μ在世界坐标中的三维位置点p,计算点云体空间的体素v与三维位置点p的距离dvpk;
s74、找出dvpk=0的交叉点,并且在点云颜色体空间中纪录颜色信息。
s10的具体操作步骤包括:
s101、将最后生成的三维模型数据存储为ply格式放入数据相互模块的数据存储区;
s102、机器人开始定位目标用户的位置,开始对用户进行跟踪服务,安全距离1.5米,监听用户指令进程开启,等待命令输入。
s11的具体操作步骤包括:
s111、当用户输入指令时候,监听程序受到用户语音信息,将语音信息转化为文本信息;
s112、从文本信息中提取关键字,例如寻找杯子,智能寻物模式开启;
s113、服务模块调用数据存储区域ply文件,并且在三维信息数据中寻找到杯子的特征数据;
s114、将杯子的位置返回到服务模块中,机器人确定其位置信息。
本发明通过对养老机器人进行了进一步的改进,提出了一种基于养老机器人的室内场景实时重建跟踪服务方法,利用手持设备和kinect的相机,使得养老机器人在进行养老陪护服务时,可以利用环境内的三维信息,增加了养老机器人的服务质量并且能够利用三维信息进行更多服务功能的开发,同时在进行实时重建的过程中,所采用的icp算法配准准确率高,成本低,能够达到所需要的三维信息要求,预期的有效效果包括:
1)本发明能够根据用户录入的信息情况能够在手持设备中进行初步的信息分析,准确对用户的健康状况,身体素质,表情信息等加以分析并且将得到的数据应用于机器人中,提高机器人的服务质量。
2)本发明利用kinect深度相机能够对所处的室内场景进行实时重建,重建前会对采集到的三维信息进行预处理,保证三维信息的质量。采用icp算法能够精确的将图像帧之间的最邻近点云配准起来,对重建完成后重建的质量能够满足机器人相关功能所需要的精度水平。
3)传统的养老机器人所带的服务功能在拥有三维信息的情况下,相关服务功能的质量都有所提升,例如三维信息在物体识别、室内导航、表情分析、避障等方面效果都有所提升。
4)本发明重建成本低廉,效率提高;优化了kinectv2深度相机采集的数据的质量;优化了顶点向量和法向量的计算;使用了icp配准,并且为每一对配准点都设定置信区间,提高了配准的鲁棒性。
附图说明
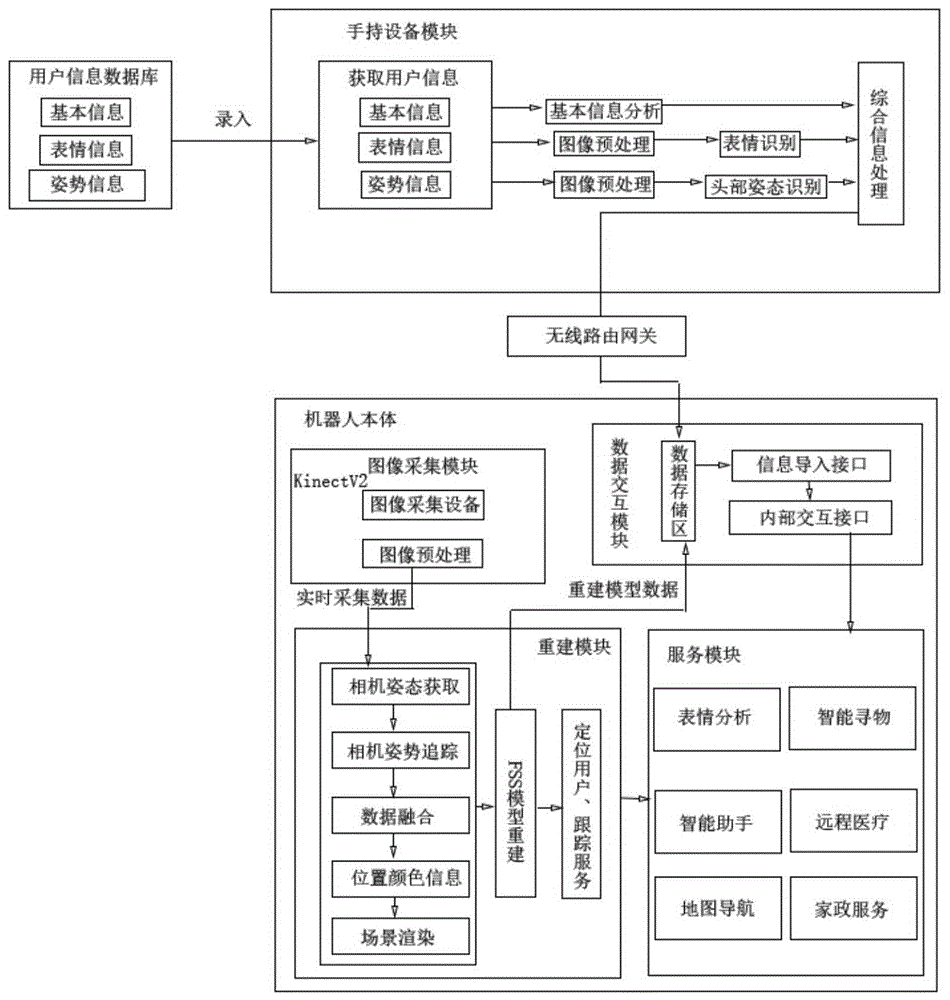
图1为本发明的整体系统框架图;
图2为本发明的手持设备模块;
图3为本发明的无线传输模块结构;
图4为本发明的kinectv2相机结构;
图5为本发明的实时重建流程图;
图6为本发明的具体实时重建步骤;
图7为本发明的部分kinectv2功能;(引用至具体实施方式中)
图8为本发明的部分机器人系统软件模块图。(引用至具体实施方式中)
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明的实施方式作进一步地详细描述。图1展示了本发明的整体方法框架。我们在此提供一个使用本发明来实现的基于养老机器人的室内场景实时重建跟踪服务方法实施过程以供参考。
本发明提出了一种基于养老机器人的室内场景实时重建跟踪服务系统,通过给老人配备一个手持设备让其控制机器人,并且将自身信息传输到养老机器人本体中,并且机器人利用kinect深度相机完成对场景的实时重建工作,将重建后的数据信息应用在服务功能模块中。
本发明基于养老机器人的室内场景实时重建跟踪服务方法,具体实现过程如下:
s1、手持设备的用户信息导入,并且将导入的数据信息进行去噪滤波,进行初步分析处理。如图2所示,具体操作步骤包括:
s11、利用手持设备app(可以与手机对接)导入用户当前的基本信息,例如姓名、年龄、身高、体重等一些健康状况指标;
s12、采集用户的面部表情信息、姿势信息等;
s13、进行信息预处理,对面部表情信息、姿态信息进行滤波;
s14、对采集的信息进行综合分析,通过网络参考数据,评判目前老人的健康状况,记录表情信息、姿势信息等,将这些数据打包成固定的文件格式。
s2、通过无线传输模块将初步分析处理后的数据传输到机器人本体中的数据交互模块中的数据存储区。如图3所示,具体操作步骤包括:
s21、通过wifi无线传输将数据传输到机器人本体的数据交互模块中;
s22、将打包好的文件存储到数据交互模块中的数据存储区。
s3、图像采集模块利用机器人本体中内置的kinectv2深度相机对室内进行图像采集,包括采集深度信息和颜色信息,使用前需要编译与深度相机相兼容的函数库,并且设置好环境变量。图4为kinectv2结构图,具体操作步骤包括:
s31、首先将kinectv2的相机驱动程序安装好,并且在这个图像采集模块中搭建深度相机和openni;
s32、找到opencv和vtk源码,使用cmake进行编译,并且配置kinectv2所需要的环境变量;
s33、安装cuda及其驱动程序,安装开源代码eigen库,并配置所需要的环境变量。
s4、进行重建作业,将步骤s3采集到的图像信息进行测量,得到多帧的深度信息(也就是视频序列的深度信息),并且利用图像去噪算法进行噪声的处理。如图5、6所示,具体操作步骤包括:
s41、将kinectv2在机器人身上安装好,并且将usb接口连接到机器人本体的内部计算机中;
s42、所有都准备妥当后,机器人开始初始化程序,将机器人放到房间的中心位置,并且开始进行图像采集;
s43、保证机器人匀速稳定的进行采集扫描场景信息,并且获得图像数据;
s44、对采集到的图像数据使用双边滤波算法进行数据的平滑去噪处理。
s5、将处理过的图像信息进行坐标轴变换,变换到一个统一的世界坐标中,从而获得点云信息。具体操作步骤包括:
s51、将处理过的每帧图像上的像素点μ投影到相机空间中得到顶点v(μ);
s52、计算每一帧图像的世界坐标点vl,k(x,y),l为深度信息,k属于相机index;
s53、获得每一帧深度图的世界坐标后,开始计算每个顶点的法向量n;
法向量n计算过程如下:
s531、根据获得的kinectv2点云数据特征vk(x,y)得到4个邻近点,vk(x-1,y)、vk(x+1,y)、vk(x,y+1)、vk(x,y-1);
s532、计算vk(x,y)的领域质心v0;
s533、计算三阶协方差矩阵c:
s534、对c进行特征分解:
s535、λ1所对应的特征向量v1为点v1的法向量。
s6、开始计算六个方向自由度的刚体变换矩阵,将目前的点云信息与已有的参考点云信息进行对齐,并且输出连续的两帧图像之间的相对变换矩阵参数,随后进行初始化为下一帧对齐时的相机姿态,此处采用icp算法。具体操作步骤包括:
s61、经过步骤s5进行的坐标变换后,将采集的帧图像信息统一到世界坐标中,将满足深度差阈值和向量夹角阈值的点,,确定为匹配点;
s62、利用icp算法最小化目标函数,从而解的最优变换参数;
s63、根据变换参数和参考点云信息确定当前对应相机的位置和朝向。
设置深度差阈值为0.2,向量夹角阈值为15°。
s7、icp算法配准完成后,将图像帧之间重复的区域进行融合处理,并且提取出关键的点云信息,简化点云,并将颜色信息加入。具体操作步骤包括:
s71、利用gpu在内存中开辟两个分辨率为10243的体空间,用来存储空间几何信息和颜色信息;
s72、通过投影方程求出体素中心点所对应的像素点μ;
s73、通过坐标变换求出像素点μ在世界坐标中的三维位置点p,计算点云体空间的体素v与三维位置点p的距离dvpk;
s74、找出dvpk=0的交叉点,并且在点云颜色体空间中纪录颜色信息。
s8、实时进行场景的渲染并且指导用户规划深度相机的运动轨迹。
利用从gpu内存中获得的空间几何信息和颜色信息,对场景进行渲染,并且确定好相机的运动轨迹。
s9、利用表面重建算法对点云信息进行三角网格化,生成可视化的三维模型
利用fss表面重建对场景进行重建,fss表面可以使得重建出来的三角网格带有颜色信息。
s10、将产生的三维模型放入数据交互模块的信息存储区,以备服务模块各个功能的使用调用。具体操作步骤包括:
s101、将最后生成的三维模型数据存储为ply格式放入数据相互模块的数据存储区;
s102、机器人开始定位目标用户的位置,开始对用户进行跟踪服务,安全距离1.5米,监听用户指令进程开启,等待命令输入。
s11、确定当前用户,并且利用kinectv2相机对用户进行跟踪服务,监听用户发出的指令,从而完成相应的服务功能,如图7,8所示。具体操作步骤包括:
s111、当用户输入指令时候,监听程序受到用户语音信息,将语音信息转化为文本信息;
s112、从文本信息中提取关键字,例如寻找杯子,智能寻物模式开启;
s113、服务模块调用数据存储区域ply文件,并且在三维信息数据中寻找到杯子的特征数据;
s114、将杯子的位置返回到服务模块中,机器人确定其位置信息,如图8所示流程。
尽管上面结合附图对本发明的功能及工作过程进行了描述,但本发明并不局限于上述的具体功能和工作过程,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可以做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!