一种HTTP请求双层递进式异常检测方法与流程
本发明涉及网络安全
技术领域:
,特别是涉及一种面向网络应用防火墙的http请求双层递进式异常检测方法。
背景技术:
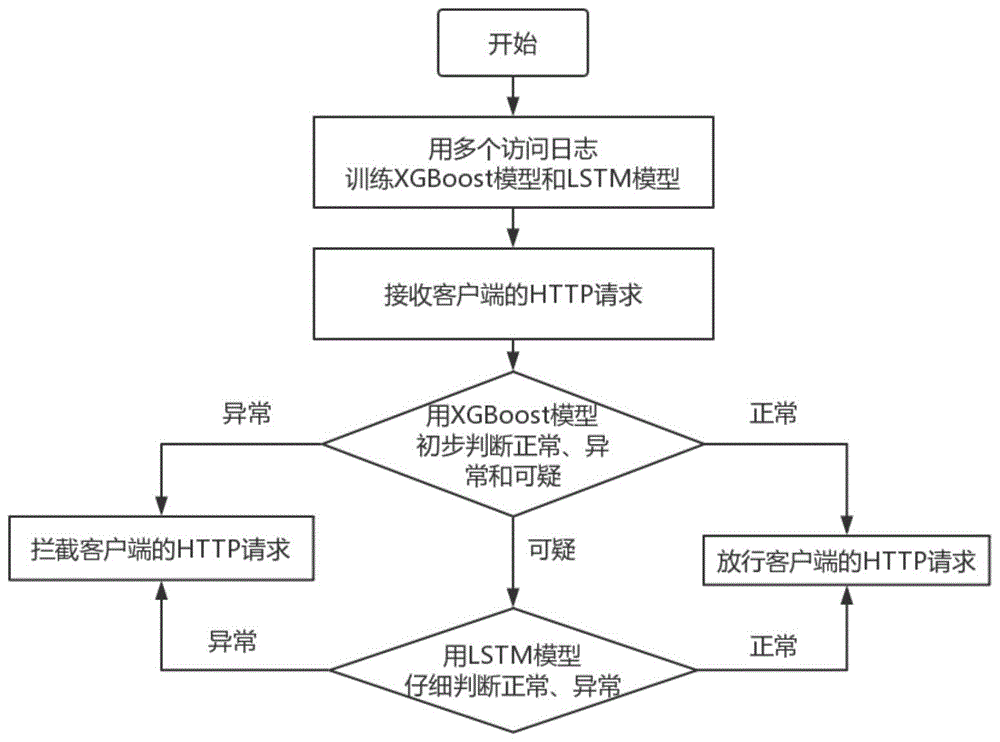
:随着云计算和大数据技术的发展,网络应用在海量数据下的安全性受到威胁。传统的网络应用防火墙使用规则匹配的方法进行http请求的异常检测,无法应对需求多变、攻击复杂、数据量大等挑战。因此,研究者开始将机器学习的方法应用到网络应用防火墙中。单一的机器学习模型普遍存在模型复杂、特征工程复杂、准确度低、假阳性高、难以长期依赖等缺点。例如,在单一的k-means聚类分析中,很难衡量两个http请求的距离并分离出远离中心点的异常数据;单一的支持向量机(svm)模型需要将输入数据映射到高维并进行高维超平面分割,存在高维数据稀疏,内存开销大,语法树重建复杂等问题。单一的隐马尔科夫模型(hmm)是在单词层面上识别http请求中的url,但其泛化能力有限,分词难度大。单一的决策树模型则过于简单,不能应对复杂多变的业务需求;而且决策树模型普遍存在假阳性高的问题,假阳性高将导致恶意http请求被误识别为正常http请求,引起很严重的网络安全问题。近年来出现了很多改进的单一机器学习模型,但都只能适用于特定的业务和数据中,灵活性不佳。因此,复合的机器学习模型开始用于入侵检测中。多种机器学习模型符合能克服彼此之间的缺点,最终的输出结果将由复合模型中的每一个模型的输出值综合后再给出,达到提高模型性能的目的。复合机器学习模型包括集成聚类、随机森林、svm-dt算法等。这些算法均在准确性和普适性上做到了进一步的提升,其特征工程的好坏直接影响了模型的准确性和扩展性。这种复合方法优点与缺点并存。优点是集成了多个弱分类器,每一个弱分类器的特征提取相对简单;缺点在于弱分类器的选取和优化较难,弱分类器的重训练很耗时间;而且,一些简单的复合机器学习算法即使经过重训练后,其长期依赖效果也不好。因此,有必要设计一种新的面向网络应用防火墙的异常检测方法,以实现对更大规模的、假阳性低的、长期依赖性更好的用户请求过滤和异常检测。技术实现要素:本发明所解决的技术问题是,针对现有技术的不足,提供一种http请求双层递进式异常检测方法,准确度高,具有一定的长期依赖性。本发明所提供的技术方案为:一种http请求双层递进式异常检测方法,包括以下步骤:步骤1、提取最近一段时间内的http请求作为样本;基于现有方法获得样本类别标签,样本类别标签包括异常和正常两种;步骤2、对各个样本分别进行特征提取;步骤3、构建双层递进式异常检测模型,其中包括xgboost(极端梯度提升)模块和lstm(长短期记忆网络)模块两个子模块,基于样本的特征和类别标签对两个子模块分别进行训练,得到训练好的双层递进式异常检测模型;双层递进式异常检测模型的使用均包含两个阶段,其一是训练阶段,将所述步骤1中的特征向量制作成数据文件,调用python语言的xgboost库和lstm库进行训练,在使用xgboost库的过程中,把目标函数设置为二分类逻辑回归函数,设置输出为相应的http请求为正常的概率p;在使用lstm库的过程中,设置lstm模块的激活函数为softmax,属于相应的http请求为正常和异常的概率;保存训练好的模型文件;其二是实际应用阶段,加载训练好的的模型文件,对待检测的http请求进行异常检测。步骤4、对待检测的http请求,提取其特征,将其特征输入双层递进式异常检测模型,判断该待检测的http请求是否异常。进一步地,所述步骤2中,采用现有的防火墙中基于规则的http请求异常检测方法,将http请求样本标记为异常或正常。进一步地,所述步骤2和步骤4中,针对xgboost模块,提取http请求的六类特征作为xgboost模块的输入数据,即http请求的分类特征(包括协议类型和请求方法特征)、与http请求的长度相关的特征、与http请求的时间相关的特征、url特殊符号个数、url中是否存在特定的敏感词、url的香农信息熵。进一步地,所述步骤2和步骤4中,针对lstm模块,提取http请求的九类特征作为lstm模块的输入数据,包括http请求解码后的内容长度(content_length)、请求长度、内容类型编码、用户代理编码、url编码、url中符号“?”的个数、url中符号“/”的个数、url中符号“&”的个数、url中符号“=”的个数。进一步地,所述步骤3中,以降低检测结果的假阳性为目的,对双层递进式异常检测模型进行训练(联合优化)。将xgboost模块的目标函数设置为二分类逻辑回归函数,其输出为输入数据对应的http请求为正常的概率p。为了降低检测结果的假阳性,根据经验设定一个可疑阈值和一个正常阈值,其中可疑阈值小于正常阈值;若xgboost模块输出的概率p大于正常阈值,则判定输入数据对应的http请求是正常的;若p小于可疑阈值,则判定输入数据对应的http请求是异常的。进一步地,设定正常阈值选为0.6,可疑阈值选为0.4。进一步地,设置lstm模块输出层的激活函数为softmax,其输出为输入数据对应的http请求为正常和异常的概率,分别记为p1和p2;若p1大于p2,则判定输入数据对应的http请求是正常的;否则判定输入数据对应的http请求是异常的。进一步地,双层递进式异常检测模型对http请求样本/待检测的http请求进行异常检测的过程为:先由xgboost模块进行初步的异常检测,计算出该http请求是正常的概率;若该概率大于正常阈值,则判定该http请求是正常的,予以放行;若概率小于可疑阈值,则判定该http请求是异常的,予以拦截;若概率处于可疑阈值和正常阈值之间,则判定该http请求是可疑的,由lstm模型进行进一步地异常检测,如果lstm模块判定该http请求是正常的,则予以放行;如果lstm模块判定该http请求是异常的,则予以拦截。进一步地,由于lstm长短期记忆网络具有一定的长期依赖能力,同时为了复合模型的优化,实际应用中一段时间后需要对双层递进式异常检测模型中的xgboost模块和lstm模块进行重训练;所述的重训练的方法为:提取最近一段时间内的http请求,构建重训练xgboost模块的样本集,基于该样本集内的样本,按照步骤2~步骤3所述的方法重新训练xgboost模块;并且,根据该段时间的http请求,选取以往部分异常http请求作为新的样本,与原样本一起构建成重训练lstm模块的样本集,按照步骤2~步骤3所述的方法重新训练lstm模块;得到新训练好的双层递进式异常检测模型,用新训练后好的模型对待检测的http请求进行异常检测。其中,选取以往部分异常http请求作为新的样本的具体方法为:随机选取该段时间内的nr条http请求,对选取的每一条http请求,分别提取出其中的url并进行url进行编码,得到的nr条http请求的url编码,其中第j条http请求的url编码记为uwjrandom,j=1,2,..,nr;将以往第i条异常http请求的url编码记为uwianomaly,分别计算它与每一个uwjrandom的皮尔逊相关系数rij,并将rij映射到[0,1]之间,记为r’ij;最后计算nr个r’ij的平均值,记为ri;若ri大于设定阈值,则选取此条异常http请求作为新的样本。进一步地,所述设定阈值为0.2。uwianomaly与uwjrandom的皮尔逊相关系数rij计算公式如下:其中,和分别为向量uwjrandom和向量uwianomaly中第k个元素。和分别为向量uwjraandom和向量uwianomaly中所有元素的平均值。将rij映射到[0,1]之间,得到r’ij。计算公式如下:r’ij=0.5×rij+0.5然后,再计算上述nr个皮尔逊相关系数的平均值,公式如下:有益效果:本发明公开了一种面向网络应用防火墙的http请求双层递进式异常检测模型。该模型由xgboost模块和lstm模块组成,通过对一定规模的http请求数据集进行训练,先用第一层xgboost模块进行快速判断,存疑的http请求再输入到第二层lstm模块进行仔细判断,达到通过正常http请求,拦截恶意http请求的目的。本发明可以适用于大规模的http请求异常检测,可以有效提高对http请求异常检测的准确度,降低异常的检测的假阳性,并使异常检测模型具有一定的长期依赖性。附图说明图1是本发明实施的流程图。具体实施方式为使本发明的目的、设计思路和优点更加清楚,以下结合具体实例,并参照附图,对本发明作进一步详细说明。本发明公开了一种http请求双层递进式异常检测方法,基于双层递进式异常检测模型进行异常检测。该模型由xgboost梯度提升树模块和lstm长短期记忆网络模块组成。在对一定规模的http请求数据集进行训练之后,该模型先用第一层xgboost梯度提升树模块进行快速判断,存疑的http请求再输入到第二层lstm模块进行仔细判断,实现http请求异常检测,达到通过正常http请求,拦截恶意http请求的目的。本发明可以有效提高对http请求异常检测的准确度,降低异常检测的假阳性,并使异常检测模型具有一定的长期依赖性。所述双层递进式异常检测模型如图1所示,其训练过程包括以下4个主要步骤:步骤1、提取一个时间段内的http请求作为样本。http请求数据来自于智为公司2018年5月天网云服务网络应用防火墙的nginx访问日志;nginx访问日志包含用户请求信息、tcp连接信息等多种信息。对每一条日志信息,按照表1中所述的属性提取属性值得到其中的一个http请求。需要提取的属性以及其说明和示例如下表所示:表1从nginx日志中提取出http请求属性属性说明属性值示例content_length内容长度161request_length请求长度849request_time请求时间0.892url统一资源标识符/index.actionapi_index=xxxx-xxxrequest_body请求体api_index=xxxx-xxxscheme协议类型httpsrequest_method请求方法postipip地址113.246.107.46content-type内容类型application/x-www-xxxcharset=utf-8user-agent用户代理mozilla/5.0(macintosh;intelmacos...接着,对所述提取的http请求做去重处理。步骤2、对步骤2所述的http请求进行类别标记和特征提取;设定一个类别标签,名为is_anomaly,其含义如下:http请求为异常时,is_anomaly=1,http请求为正常时,is_anomaly=0。是布尔型变量。根据现有的防火墙基于规则的http请求异常检测方法,将每一条http请求标记为异常或者正常。步骤1中的90000多条日志信息,其中5000多条日志信息中的http请求已经被网络应用防火墙判定为异常请求。异常原因为这些异常的http请求疑似为sql注入、跨站脚本攻击等网络应用层攻击。针对xgboost模块,特征提取工作包括如下步骤:步骤2.11、对表1中所述的属性值,进一步提取http请求的协议类型和请求方法特征,包括:协议类型(scheme),如http,https。请求方法(request_method),如post,get。步骤2.12、对表1中所述的属性值,进一步提取与http请求的长度相关的特征,包括:内容长度(content_length),是数值型变量。请求长度(request_length),是数值型变量。步骤2.13、对表1中所述的属性值,进一步提取与http请求的时间相关的特征,包括:请求时间(request_time),是数值型变量。设定时间窗口内,该ip地址是否重复访问(is_repeat_request),是布尔型变量。设定时间窗口内,该ip地址重复的次数(repeat_count)。步骤2.14、对表1中所述的属性值,进一步提取特殊符号类的特征,包括url字符串中“.”、“-”、“_”、“=”、“/”、“\”、“?”、“;”、“&”、“@”等特殊符号的个数。是数值型变量。步骤2.15、对表1中所述的属性值,进一步根据业务需求提取敏感词类的特征,包括是否存在select、.jar、.jpg、cookie等敏感词,是布尔型变量。步骤2.16、对表1中所述的属性值,进一步提取url,对url进行解码后,计算url的香农信息熵。香农信息熵的计算方法为,将一条url视为一个有n个字符的字符串,在一条url中,将每一个字符ci出现的频率视为该字符在此条url中出现的概率p(ci),则该条url的香农信息熵h的计算公式如下:上述所有的特征构成了xgboost模块的输入,即http请求的分类特征。如下表所示:表2xgboost模块的输入将所有针对xgboost模块提取的特征和http请求的类别标签制作成csv格式的文件,作为xgboost库训练时调用的样本文件;针对lstm模块,特征提取工作包括如下步骤:步骤2.21、将所有http请求中的内容类型提取出来构成一个元素不重复(元素互不相同)的集合,并对集合中的元素进行独热编码(one-hot编码,又称一位有效编码)。编码完成后,将每条http请求中的内容类型用其编码代替。步骤2.22、将所有http请求中的用户代理(useragent)提取出来构成一个元素不重复的集合,并对集合中的元素进行独热编码。编码完成后,将每条http请求中的用户代理用其编码代替。步骤2.23、将所有http请求中的url提取出来,使用编程语言,根据“/”、“&”、“=”、“?”四个符号对url进行分词,得到多个字符串。所有url的分词结果,即字符串构成一个元素不重复的集合,然后对集合中的元素按字符串长度进行从小到大排序,构成一个有序的集合,并对集合中的元素编码,编码方法为:取一个较小的阈值m,如取m=15,将有序集合中的字符串分为两个部分。前一部分的字符串长度均小于阈值m,将它们用自然数1,2,3...进行顺序编码;后一部分的字符串长度均大于阈值m,按照步骤2.6的香农信息熵的计算方法,计算其香农信息熵,并将其扩大10倍取整,作为它们的编码;将url中的各个分词结果,即字符串用其编码代替,得到url编码;将url按上述方法编码后,将会出现各个url编码的长度不一致的情况。此时,选出一个最长编码,其他比之短的编码进行补零处理直至长度与最长编码的长度n相同为止。经过此处理后,所有url编码的长度都是一致的,即都为n。步骤2.24、经步骤2.21~步骤2.23提取得到的特征,构建最终的特征,即lstm模块的输入数据x,x=[ct;ua;uw],其中x由向量ct、ua和uw拼接而成,ct、ua和uw分别为http请求经步骤2.21~步骤2.23提取得到的内容类型编码、用户代理编码和url编码。以第i条http请求为例,由其经步骤2.21~步骤2.23提取得到的特征构建的lstm模块的输入数据为xi=[cti;uai;uwi],cti为第i条http请求的内容类型编码,uai为第i条http请求的用户代理编码,uwi=[uwi1,uwi2,...,uwij,...]为第i条http请求的url编码,uwij表示第i条http请求中的url第j个分词的编码。在应用lstm模块对第i条http请求进行异常检测时,将xi中的各个元素依次输入lstm模块中。表3lstm模块的输入数据以及取值示例输入数据取值内容类型编码cti(0,0,0,..,0,1)用户代理编码uai(0,0,0,..,0,1)url编码uwi(1,2,4,...,47,50,0,0)将所有http请求针对lstm模块取的特征和http请求的类别标签制作成csv格式的文件,作为和lstm库训练时调用的样本文件;步骤4、对所述的xgboost模块和lstm模块进行训练,训练的方法为:基于样本文件,调用python语言的xgboost库和lstm库训练双层递进式异常检测模型。在使用xgboost库的过程中,需要把目标函数设置为二分类逻辑回归函数(即设置xgboost库的训练参数’objective’项为’binary:logistic’),设置输出为输入数据对应的http请求是正常的概率,并对训练完成的xgboost进行交叉认证,评估其正确率和假阳性。在使用lstm库的过程中,设置输出层的激活函数为softmax激活函数,输出为输入数据对应的异常和正常的概率。步骤5、设置正常阈值和可疑阈值。本实施例中设定正常阈值选为0.6,可疑阈值选为0.4。所述的网络应用防火墙的http请求双层递进式异常检测模型实际使用方法为:接收客户发送的http请求,首先由xgboost模块进行初步的异常检测,计算出该http请求是正常的概率。若该概率大于正常阈值,则认为该http请求是正常的;若概率小于可疑阈值,则认为该http请求是异常的,予以拦截。若概率处于可疑阈值和正常阈值之间,则认为该http请求是可疑的,传递给lstm模块进行异常检测,如果lstm模块判定为异常,则拦截该http请求,并记录该http请求的通过步骤2提取到的所有特征信息。如果lstm模块判定为正常则放行该http请求。所述的网络应用防火墙的http请求双层递进式异常检测模型重训练方法为:在一个月之后,提取最近一段时间内的http请求,构建重训练xgboost模块的样本集,基于该样本集内的样本,按上述方法重新训练xgboost模块。同时,根据该段时间的http请求,选取以往部分异常http请求作为新的样本,与原样本一起构建成重训练lstm模块的样本集,按照步骤2~步骤4所述的方法重新训练lstm模块;选取以往部分异常http请求的具体方法为:随机选取nr条该段时间内的http请求,本实施例中取nr=500;对每一条http请求,分别提取出其中的url并按照步骤2.23的方法进行url进行编码,得到的500条http请求的url编码,其中第j条http请求的url编码记为uwjrandom。将以往第i条异常http请求的url编码记为uwianomaly。对第i条异常http请求的url编码uwianomaly,分别计算它与每一个uwjrandom的皮尔逊相关系数rij,并将计算结果映射到[0,1]之间,得到r’ij。最后计算500个r’ij的平均值,记为ri;若ri大于0.2,则将此条异常http请求加入到重训练的样本集当中。uwianomaly与uwjrandom的皮尔逊相关系数rij计算公式如下:其中,和分别为向量uwjrandom和向量uwianomaly中第k个元素。和分别为向量uwjrandom和向量uwianomaly中所有元素的平均值。将rij映射到[0,1]之间,得到r’ij。计算公式如下:r’ij=0.5×rij+0.5然后,再计算上述500个皮尔逊相关系数的平均值,公式如下:对于新的样本,按照步骤2.11~步骤2.16所述的方法构建lstm模块的输入数据;然后调用python中的lstm库来重新训练lstm模块。对于新的样本,按照步骤2.21~步骤2.24所述的方法构建lstm模块的输入数据;然后调用python中的lstm库来重新训练lstm模块。模型训练完成后,对待检测的http请求,按照步骤2提取其特征,并将提取到的特征输入双层递进式异常检测模型,判断该待检测的http请求是否异常。本发明相比于传统的基于规则的网络应用防火墙,能适应需求的变化、应对更加复杂的网络攻击、处理大量的数据,并且具有更好的长期依赖性,对未知的网络应用层攻击起到了更好的防护作用。另外,对xgboost模块和lstm模块的联合优化也同时降低了http请求异常检测的假阳性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1