用于增强痘病毒中转基因的稳定性的组合物和方法与流程
本发明涉及包含经修饰的粘蛋白1、细胞表面相关(muc1)转基因、人癌胚抗原(cea)转基因和/或一种或多种共刺激分子的重组痘病毒及其组合物。在至少一个方面,经修饰的muc1、cea和/或共刺激分子转基因通过重组痘病毒的连续传代改善痘病毒的稳定性。在另外的方面,本发明涉及用作疫苗和医药组合物的重组痘病毒及其组合物。
背景技术:
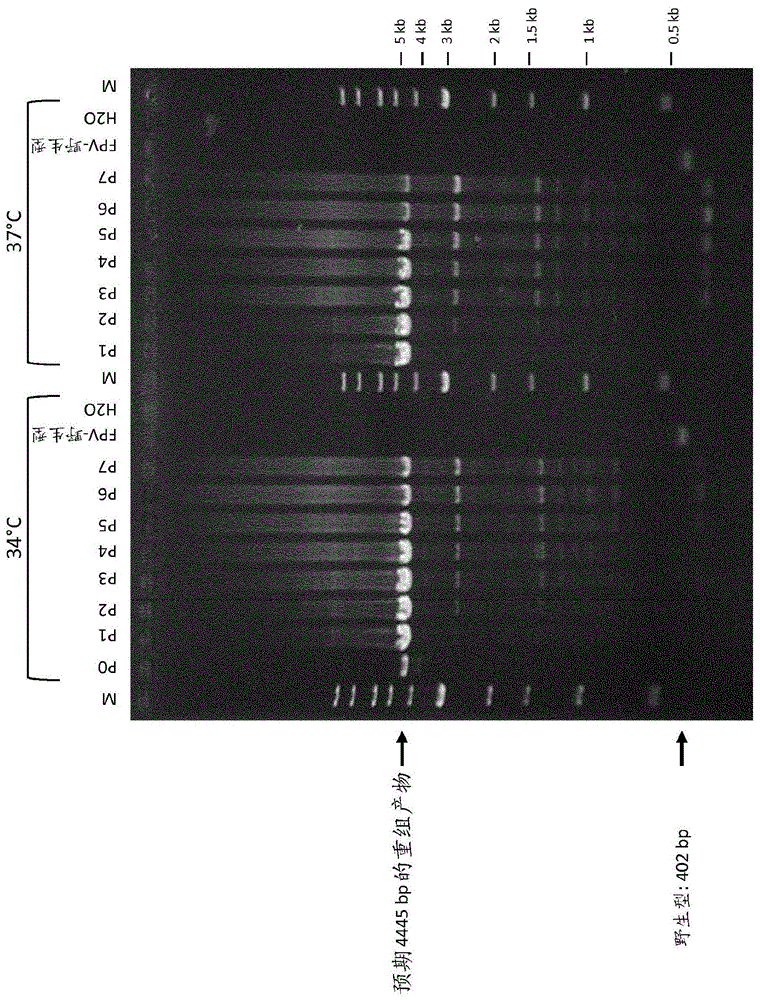
:重组痘病毒已用作针对传染性生物体的免疫治疗疫苗,并且最近用作针对肿瘤的免疫治疗疫苗。mastrangelo等人,jclininvest.2000;105(8):1031–1034。这些痘病毒组中的两个即禽痘病毒和正痘病毒已显示出在抗击肿瘤方面是有效的,并且已涉及到潜在的癌症治疗。同上。一个示例性禽痘病毒物种即鸡痘已被证明是供人类施用的安全媒介物,因为鸡痘病毒进入哺乳动物细胞并表达蛋白质,但是复制失败。skinner等人,expertrevvaccines.2005年2月;4(1):63-76。另外,在针对癌症、疟疾、结核和aids的疫苗的许多临床试验中评估了使用鸡痘病毒作为表达媒介物。同上。最为熟知的正痘病毒牛痘在世界范围内被用于根除天花,并且已显示出作为载体和/或疫苗的有用性。重组牛痘载体已被工程改造为表达许多不同的插入基因,包括若干肿瘤相关基因,诸如p97、her-2/neu、p53和eta(paoletti等人,1993)。已证明可用作针对传染病和癌症的免疫治疗疫苗的一种痘病毒毒株是经修饰的安卡拉牛痘(mva)病毒。mva通过牛痘病毒的安卡拉毒株(cva)在鸡胚成纤维细胞上的516次连续传代来产生(有关综述,参见mayr,a.等人,infection3,6-14(1975))。由于这些长期传代,所得的mva病毒的基因组的约31千碱基的基因组序列缺失,并因此被称为对于禽类细胞的复制高度受限的宿主细胞(meyer,h.等人,j.gen.virol.72,1031-1038(1991))。已在许多动物模型中显示所得的mva是明显无毒的(mayr,a.&danner,k.,dev.biol.stand.41:225-34(1978))。具有用于研发更安全的产品(诸如疫苗或药物)的增强的安全特征的mva毒株已有所描述。参见国际pct公开wo2002042480(另见例如美国专利no.6,761,893和6,913,752),它们均以引用的方式并入本文。此类变体能够在非人类细胞和细胞系(尤其是鸡胚成纤维细胞(cef))中繁殖性复制,但在人类细胞系(尤其包括hela、hacat和143b细胞系)中是复制缺陷的。此类毒株也不能体内例如在某些小鼠品系(诸如转基因小鼠模型agr129,该模型是免疫功能严重受损并且对复制型病毒高度敏感的)中繁殖性复制。参见美国专利no.6,761,893。此类mva变体及其衍生物(包括重组子,称为“mva-bn”)已有所描述。参见国际pct公开wo2002042480(另见例如美国专利no.6,761,893和6,913,752)。在癌症免疫治疗疫苗的开发中,当肿瘤抗原muc1被重组痘病毒表达时,显示出诱导和加强患者对多种癌症的免疫应答。参见例如mehebtash等人,clincancerres.2011年11月15日;17(22):7164-73。muc1(muc-1、粘蛋白1、细胞表面相关)(也称为cd227)是排列在肺、胃、肠、眼和若干其他器官中的上皮细胞的顶端表面上以及一小部分非上皮细胞(诸如造血细胞和活化的t细胞)中的糖蛋白。它在健康上皮中的主要功能是提供润滑以及对化学和微生物剂的物理屏障。hollingsworthma,swansonbj(2004年1月).“mucinsincancer:protectionandcontrolofthecellsurface”.naturereviewscancer4(1):45–60。muc1通过跨膜域锚定至顶端表面。hattrupcl,gendler,sj(2008).“structureandfunctionofthecellsurface(tethered)mucins”.annu.rev.physiol.70:431–457。muc1的胞外域包括20个氨基酸的可变数目串联重复(vntr)域,它通常是高度糖基化的,重复数目在不同个体中在20至120之间变化。braymanm,thathiaha,carsondd(2004年1月).“muc1:amultifunctionalcellsurfacecomponentofreproductivetissueepithelia”.reprodbiolendocrinol2:4。已经证明,许多人类癌症(诸如卵巢癌、乳腺癌、胰腺癌、结直肠癌和前列腺癌)和恶性血液疾病(多发性骨髓瘤和一些b细胞非霍奇金淋巴瘤)异常地过表达muc1。pecher等人,anticancerres.2001年7-8月.21:2591-2596。与在正常组织中的聚集表达相比,muc1均匀地分布在肿瘤细胞的整个表面上。correa等人,immunology.2003年1月;108(1):32–41。此外,muc1在肿瘤中通常是低糖基化的,使蛋白质核心的新型和潜在抗原表位暴露于免疫系统。reis等人,intjcancer.1998年8月21;79(4):402-10。鉴于muc1与人类癌症的相关性,现有技术已尝试修饰muc1以增强蛋白质的免疫原性。例如,hamblin等人的us2006/0147458利用“密码子使用系数”来设计与天然muc1相比具有降低的同源性并且具有7xvntr区段的muc1序列。hamblin等人的us2006/0147458在增强免疫原性的尝试中制备了hsp-70-muc1融合蛋白。颁发给finn等人的美国专利no.5,744,144通过添加两个20个氨基酸串联重复来修饰muc1蛋白。人癌胚抗原(cea)是在大多数结肠肿瘤、直肠肿瘤、胃肿瘤和胰腺肿瘤(1),约50%的乳腺癌(2)以及70%的肺癌(3)上表达的180kd糖蛋白。cea也在胎儿肠组织中表达,并且以较低程度在正常结肠上皮上表达。cea的免疫原性一直不明确,一些研究报告了患者中存在抗cea抗体(4-7),而其他研究则不然(8-10)。cea在1965年首次被描述为人类消化道腺癌中的癌症特异性胎儿抗原(gold,p.和freeman,s.o.(1965)exp.med.121:439-462)。从那时起,cea被表征为在几乎所有人类胃肠道实体瘤中过量产生的细胞表面抗原。已经克隆了人类cea蛋白的基因。(oikawa等人(1987)biochim.biophys.res.142:511-518;欧洲专利申请no.ep0346710)。对于改善癌症治疗,存在大量未满足的医疗需求。鉴于muc1和cea抗原在诱导针对癌症的免疫应答中的有效性,需要能够将抗原有效地引入癌症患者的改进的疫苗。此外,越来越需要提供能够成功地克服寻求监管批准的障碍的癌症治疗。具体地讲,大规模生产、杂质等困难可能是治疗获得监管批准以及将这些治疗转化为使患者受益的重大障碍。至少在一个方面,通过开发本发明的各种实施方案,已经成功地克服了涉及大规模生产、杂质和其他问题的困难。技术实现要素:在本发明中确定,在一个或多个重复核苷酸区中对编码muc1、cea和/或tricom的核酸的各种取代增强muc1、cea和/或tricom转基因在重组痘病毒中的稳定性。因此,在一个实施方案中,本发明涉及在重组痘病毒的连续传代中稳定的重组痘病毒。所述重组痘病毒包含编码具有至少两个可变n-末端重复(vntr)域的muc1肽的第一核酸,其中a)对所述至少两个vntr域的排列进行改组,以及b)对所述至少两个vntr域进行密码子优化,其中所述重组痘病毒在连续传代中是稳定的。在一个或多个优选的实施方案中,所述重组痘病毒包含与seqidno:2(336muc)至少95%同源的、与seqidno:3(373muc)至少95%同源的、与seqidno:4(399/400muc1)至少95%同源的或与seqidno:5(420muc1)至少95%同源的第一核酸。在一个更优选的实施方案中,所述重组痘病毒包含与seqidno:2(336muc1)至少95%同源的核酸。在另一个更优选的实施方案中,所述重组痘病毒包含与seqidno:3(373muc)至少95%同源的核酸。在又一个优选的实施方案中,所述重组痘病毒还包含与seqidno:13或14(cea)至少99%同源的核酸。在一个优选的实施方案中,所述重组痘病毒包含seqidno:13或14。据设想,所述重组痘病毒可以是任何类型的痘病毒。在某些实施方案中,痘病毒是正痘病毒或禽痘病毒。在优选的实施方案中,正痘病毒选自牛痘病毒、mva病毒、mva-bn和mva-bn的衍生物。在其他更优选的实施方案中,正痘病毒是mva、mva-bn或mva-bn的衍生物。在其他优选的实施方案中,禽痘病毒是鸡痘病毒。在其他实施方案中,除本文所述的muc1和/或cea核酸之外,本发明的重组痘病毒还包括一种或多种编码tricom(共刺激分子的三联体)的核酸。在某些实施方案中,本发明的重组痘病毒和/或核酸可用于异源初免-加强给药方案。在优选的实施方案中,所述方案包括:a)mva病毒的一个或多个初免剂量,所述mva病毒包含本公开的muc1、cea和/或tricom核酸中的一者或多者;以及b)鸡痘病毒的一个或多个加强剂量,所述鸡痘病毒包含本公开的muc1、cea和/或tricom核酸中的一者或多者。据设想,本文所述的重组痘病毒、核酸、方法、疫苗和组合物可以试剂盒体现。因此,在一个优选的实施方案中,本发明涉及包含重组正痘病毒(诸如但不限于mva)和重组禽痘病毒(诸如但不限于鸡痘)的组合物、疫苗、试剂盒或其用途,所述重组正痘病毒包含本公开的muc1、cea和/或tricom核酸中的一者或多者;所述重组禽痘病毒包含本公开的muc1、cea和/或tricom核酸中的一者或多者。在其他实施方案中,本发明涉及一种或多种用于产生编码本公开的一种或多种转基因的重组痘病毒的方法,所述重组痘病毒在重组痘病毒的连续传代中稳定。在一个实施方案中,存在一种用于产生具有在重组痘病毒的连续传代中稳定的muc1转基因的重组痘病毒的方法,所述方法包括:a)提供本公开的核酸或表达盒中的任一者;以及b)将所述核酸或表达盒插入重组痘病毒。在另一个实施方案中,存在一种用于产生在连续传代中稳定的重组痘病毒的方法,包括:a)提供编码具有至少两个可变n-末端重复(vntr)域的muc1肽的第一核酸序列,其中对所述至少两个vntr域的排列进行改组,并且对所述至少两个vntr域进行密码子优化;以及b)提供编码cea肽的第二核酸,其中所述第二核酸包含在第二核酸的至少一个重复核苷酸区中的至少一个核苷酸取代,其中所述至少一个重复核苷酸区被定义为a)三个更多个连续重复的g或c核苷酸和/或b)三个或更多个连续重复的t核苷酸;其中所述重组痘病毒在连续传代中是稳定的。本发明的另外目的和优点将在接下来的描述中部分地阐明,并且部分地将从该描述中显而易见或可通过本发明的实践来了解。通过所附权利要求中特别指出的要素和组合,将会实现和获得本发明的目的和优点。并入本说明书并构成本说明书的一部分的附图展示了本发明的一个或多个实施方案,并与描述一起用来解释本发明的原理。附图说明图1是展示panvac(muc1和cea)的转基因的不稳定性的pcr分析。图中示出了将muc1和cea整合到tbc-fpv基因组内(igr61/62)的所用位点的pcr扩增子的结果。突出显示的是预期的pcr片段和可能的野生型(wt)片段的高度。可以检测到若干较小的缺失片段,并在34℃或37℃下重复传代期间富集这些片段。示出了panva-f的第0至第7代的结果。图2a和图2b描绘了根据本发明的各种实施方案的muc1的氨基酸序列和vntr域重复的改组。a)panvac中存在的muc1氨基酸(seqidno:6)。图中展示了panvacmuc1中存在的6个vntr。b)mbn336、mbn373和mbn420中存在的muc1氨基酸(seqidno:30)。图中展示了mbn336、mbn373和mbn420muc1中存在的3个vntr。加下划线的氨基酸代表被修饰为形成wo2013/103658的激动剂表位的氨基酸。图3a-3c描绘了根据本发明的各种实施方案的双序列比对和muc1vntr域重复的示例性密码子优化。a)panvacvntr#2(seqidno:7)和mbn336、mbn373、mbn420vntr#1(seqidno:8)的比对,b)panvacvntr#1(seqidno:9)和mbn336、mbn373、mbn420vntr#2(seqidno:10)的比对,c)panvacvntr#3(seqidno:11)和mbn336、mbn373、mbn420vntr#3(seqidno:12)的比对。加下划线的核苷酸代表被修饰为形成wo2013/103658的激动剂表位的核苷酸区。图4a-4c描绘了根据本发明的基于重组痘病毒的构建体中所用的muc1编码序列与panvac相比的双序列比对。a)muc1panvac(seqidno:1)与muc1mbn336(seqidno:2);b)muc1panvac(seqidno:1)与muc1mbn373(seqidno:3);c)muc1panvac(seqidno:1)与muc1mbn420(seqidno:5);包含一个或多个取代的示例性重复区加有下划线。图5描绘了根据本发明的基于重组痘病毒的构建体中所用的mbn373和mbn420的cea编码序列(seqidno:14)与panvac的cea(seqidno:13)相比的双序列比对。包含一个或多个取代的示例性重复区加有下划线。图6描绘了根据本发明的基于重组痘病毒的构建体中所用的mbn373和mbn420的b7-1编码序列(seqidno:15)与panvac相比与panvac的b7-1(seqidno:16)相比的双序列比对。示例性重复区由所示取代(比对的非*区)来展示。图7描绘了根据本发明的基于重组痘病毒的构建体中所用的mbn373和mbn420的icam-1编码序列(seqidno:18)与panvac相比与panvac(seqidno:19)相比的双序列比对。示例性重复区由所示取代(比对的非*区)来展示。图8描绘了根据本发明的基于重组痘病毒的构建体中所用的mbn373和mbn420的lfa-3编码序列(seqidno:21)与panvac相比与panvac(seqidno:22)相比的双序列比对。示例性重复区由所示取代(比对的非*区)来展示。图9a和图9b展示了分析mbn336中muc1转基因的稳定性的实验。a)cea在七次传代中的稳定性的pcr结果,这些传代代表了临床试验材料(ctm)/gmp材料的生产期间和之外的传代。b)muc1在七次传代中的稳定性的pcr结果,这些传代代表了ctm/gmp材料的生产期间和之外的传代。c)tricom在7次传代中的稳定性的pcr结果,这些传代代表了ctm/gmp材料的生产期间和之外的传代。用于产生mva-mbn336b的重组质粒用作阳性对照,mva-用作阴性对照(空载体骨架),h2o用作pcr反应的对照。图10a和图10b展示了mbn336的第5次传代、第6次传代和第7代的分析。a)第7代样品的pcr扩增产物送去测序分析。对每个单独的转基因进行单独的pcr扩增:cea、muc1和tricom。b)muc1核苷酸序列的电泳图,该图描绘了含有导致在第5次传代中产生移码的检测到的点突变的基因座。图11a和图11b展示了分析mbn373中muc1转基因的稳定性的实验。a)每次传代的对插入的转基因的pcr分析。用于产生fpv-mbn373b的重组质粒用作阳性对照,fpv(毒株tbc-fpv)用作阴性对照。b)在第七次传代产生预期的5566bp(pcr1)和5264bp(pcr2)条带大小(涵盖插入的转基因和每个插入的侧翼区)的fpv-mbn373b的pcr分析。序列分析确认7次传代后重组子的遗传稳定性,这些传代代表了ctm/gmp材料的生产期间和之外的传代。图12是分析mbn420中muc1、cea和tricom转基因的稳定性的pcr分析。图中示出了将全部五个转基因整合到mva-bn基因组内(igr88/89)的所用位点的pcr扩增子的结果。突出显示的是预期的pcr片段和可能的野生型(wt)片段的高度。可以检测到若干较小的缺失片段,并在30℃下重复传代期间富集这些片段。示出了mbn420的第0至第7代的结果。使用clustalomega序列比对工具(可得自http://www.ebi.ac.uk/tools/msa/clustalo/)进行图中展示的所有双序列比对。具体实施方式应当理解,上文的
发明内容和下文的具体实施方式都只是示例性和说明性的,并不是对受权利要求保护的本发明进行限制。panvac采用使用牛痘(panvac-v)和鸡痘(panvac-f)的重组痘病毒的异源初免-加强策略,这些痘病毒各自表达转基因muc1、cea和tricom。panvac已显示出对治疗癌症有效,目前正处于各种癌症(包括结直肠癌、卵巢癌、乳腺癌和膀胱癌)的临床试验阶段。mva-cv301是另一种正在进行临床试验的异源疫苗组合(参见例如gulley等人,clincancerres2008;第14卷:10,tsang等人,clincancerres2005;第11卷)。mva-cv301采用使用mva和鸡痘的异源初免-加强策略,这些痘病毒各自表达转基因muc1、cea和tricom。虽然panvac和mva-cv301对治疗癌症有效,但是panvac重组痘病毒的转基因在连续传代和病毒生产中变得不太稳定。如表1和表2所示,在panvac-v和panvac-f的连续传代之后,表达muc1和cea的病毒的百分比逐步降低。表1panvac-vmvb1、mvb2和传代中表达斑块的百分比*每个数字代表从三个独立的传代实验获得的平均值。表2panvac-fmvb1、mvb2和传代中表达斑块的百分比*每个数字代表从三个独立的传代实验获得的平均值。在至少一个方面,muc1和/或cea表达的减少似乎是muc1和/或cea转基因的至少部分丧失的结果。图1展示了panvac的muc和cea转基因序列的丧失。在图1中,预期重组panvac-f产物为4445bp。然而,如图所示,实验显示存在多个较小的片段,它们被证实是muc1和cea的片段化序列(数据未示出)。muc1转基因和前述重组痘病毒中表达的丧失和不稳定性阻碍了cv301重组痘病毒的生产和纯度。在产生本发明的各种核酸和重组痘病毒之前,为了稳定转基因,本发明人进行了多次尝试来定制和/或修饰panvac的重组牛痘、重组mva和重组鸡痘病毒,以及mva-cv301。如表3和表4所示,对转基因和/或重组牛痘、重组mva和重组鸡痘病毒的修饰包括:(i)交替或修饰转基因插入到的基因间区(igr),(ii)优化一个或多个转基因的密码子,(iii)改变转基因启动子,以及(iv)修饰muc1转基因中vntr区的数目和排列。如表中所述,由于导致转基因表达丧失的功能丧失突变或片段缺失,许多构建体不能稳定产生。表3表4在这些多次尝试后,构建了mva-mbn336。如本文所述,mva-mbn336是包含经修饰的muc1、cea和经修饰的tricom转基因的mva-cv301重组痘病毒。如图9和图10所示,与panvac相比,mva-mbn336展示出转基因稳定性(参见图1和表1)。如图10所示,到第4代,mva-mbn336显示出所有转基因(muc1、cea和tricom)的稳定性。从第5次传代开始,在少数分析的材料中检测到移码突变。到第4代所展示的稳定性证实了mva-mbn336能够克服与panvac和产生包含muc1的稳定痘病毒的其他尝试相关联的稳定性问题。mva-mbn336的稳定性在其他方面是有利的,因为基于mva的疫苗的制造和大规模生产典型地由mva在第3代或第4代获得。因此,由于mva-mbn336能稳定到第4代,因此可以开始大规模产生,并且可以克服关于稳定性的重大监管障碍。为了解决和纠正不稳定性问题,合成了本发明的核酸并提供了编码muc1转基因、cea转基因和tricom转基因的一种或多种核酸。如本公开所示,本发明的muc1、cea和tricom核酸导致重组痘病毒及其中所含的转基因在重组痘病毒的连续传代中的遗传稳定性得到改善。因此,在各种实施方案中,本发明提供了具有一种或多种编码muc1、cea和/或tricom抗原的新型核酸的重组痘病毒。如本文更详细地提供,在至少一个方面,当作为重组痘病毒的一部分并入时,所述一种或多种经修饰的编码muc1、cea和/或tricom的核酸序列改善了转基因在重组痘病毒中的稳定性和存在。定义如本文所用,除非上下文另外明确指明,否则单数形式“一个/种”和“该/所述”包括复数指代物。因此,例如,提及“一种核酸”包括一种或多种核酸,并且提及“所述方法”包括提及本领域的普通技术人员已知的可以为本文所述的方法而修改或替代的等同步骤和方法。除非另外指明,否则在一系列要素之前的术语“至少”应理解为是指该系列中的每个要素。本领域的技术人员将会认识到,或仅仅使用常规实验就能够确定本文所述的本发明的具体实施方案的许多等同物。此类等同物旨在被本发明所涵盖。在整个说明书和随后的权利要求中,除非上下文另有要求,否则词语“包括”以及诸如“包含”和“含有”的变化形式将被理解为意指包括所述整数或步骤或者整数或步骤的组,但不排除任何其他整数或步骤或者整数或步骤的组。当在本文中使用时,术语“包含”可以被术语“含有”或“包括”代替,或者有时在本文中使用时,可以被术语“具有”代替。任何上述术语(包含、含有、包括、具有),尽管不太优选,但是在本文中在本发明的一个方面或实施方案的上下文中使用时,可被术语“由......组成”代替。当在本文中使用时,“由......组成”排除所主张要素中未规定的任何要素、步骤或成分。当在本文中使用时,“基本上由......组成”不排除对权利要求的基本和新颖特征无实质性影响的材料或步骤。如本文所用,多个引用要素之间的连接术语“和/或”被理解为涵盖单独和组合选项两者。例如,在两个要素由“和/或”连接的情况下,第一选项是指第一要素在不存在第二要素的情况下的适用性。第二选项是指第二要素在不存在第一要素的情况下的适用性。第三选项是指第一要素和第二要素同时存在的适用性。这些选项中的任一个都被理解为落在该含义的范围内,并因此满足本文所用的术语“和/或”的要求。多于一个选项的同时适用性也被理解为落在该含义的范围内,并因此满足术语“和/或”的要求。如本文所定义,本文所述的“突变”是对核酸的任何修饰,诸如缺失、添加、插入和/或取代。如本文所用,“共刺激分子”是当结合至其配体时递送第二信号以使得t细胞可以被激活的分子。t细胞上最为熟知的共刺激分子是cd28,它结合至b7-1(也称为b7.1或cd80)或b7-2(也称为cd86)。另外的共刺激分子是b7-3。也提供用于激活t细胞的第二信号的辅助分子包括细胞内粘附分子(icam-1和icam-2)、白细胞功能相关抗原(lfa-1、lfa-2和lfa-3)。整联蛋白和肿瘤坏死因子(tnf)超家族成员也可以作为共刺激分子。当在本文中结合重组痘病毒、muc1、cea、tricom和其他转基因使用时,重组痘病毒的“遗传稳定性”、“稳定性”、“表达的稳定性”、“在连续传代中是稳定的”、“在连续传代中的稳定性”或“在连续传代中表达的稳定性”被理解为意指重组痘病毒的转基因核苷酸序列在重组痘病毒连续传代直到至少第3代或第4代时保持实质上完整和/或实质上不变。至少到第3代或第4代具有稳定性的重组痘病毒是特别重要的,因为通过痘病毒的大规模制造和生产所产生的最终产物典型地为第3代或第4代。“实质上完整和/或实质上不变”意指不存在单个或片段突变(例如,包括取代、缺失等),所述突变随着传代次数的增加而导致转基因表达的恒定降低。例如,如表1和表2所示,panvac的各种转基因的表达水平随着传代次数的增加而降低。存在多种本领域已知的可以分析转基因的遗传稳定性或稳定性的方式,包括但不限于本专利申请的实施例2至4中所述的测定法。本领域已知的测量稳定性的另外方式包括但不限于pcr、facs、通过facs测量转基因共表达等等。如本文所用,“宿主细胞”是为了开发和/或产生外源分子、病毒或微生物而引入外源分子、病毒或微生物的细胞。在一个非限制性实例中,如本文所述,合适的细胞培养物的细胞(例如,cef细胞)可以用痘病毒感染,或者在其他替代性实施方案中,用包含外源或异源基因的质粒载体感染。因此,合适的细胞培养物作为痘病毒和/或外源或异源基因的宿主。关于本文所述的核酸序列的“序列同源性或同一性百分比(%)”被定义为在对齐序列和引入空位(如果需要)以实现最大序列同一性百分比之后,并且不考虑将任何保守取代作为序列同一性的一部分,候选序列中与参考序列(即,衍生出所述候选序列的核酸序列)中的核苷酸相同的核苷酸的百分比。为了测定核苷酸序列同一性或同源性百分比而进行的比对可以以本领域技术范围内的各种方式实现,例如使用公开可用的计算机软件,诸如blast、align或megalign(dnastar)软件。本领域的技术人员可以确定用于测量比对的适当参数,包括在进行比较的序列的全长上实现最大比对所需的任何算法。例如,smith和waterman,(1981),advancesinappliedmathematics2:482-489的局部同源性算法提供了核酸序列的适当比对。该算法可以通过使用由dayhoff,atlasofproteinsequencesandstructure,m.o.dayhoff编,5增刊3:353-358,nationalbiomedicalresearchfoundation,washington,d.c.,usa开发的评分矩阵而应用于氨基酸序列,并通过gribskov(1986),nucl.acidsres.14(6):6745-6763归一化。geneticscomputergroup(madison,wis.)在“bestfit”实用应用程序中提供了确定序列的同一性百分比的该算法的示例性具体实施。该方法的默认参数在wisconsin序列分析软件包程序手册(wisconsinsequenceanalysispackageprogrammanual),第8版(1995)(可得自geneticscomputergroup,madison,wis.)中有所描述。在本发明的上下文中确立同一性百分比的优选方法是使用版权归爱丁堡大学(universityofedinburgh)所有、由johnf.collins和shanes.sturrok开发并由intelligenetics,inc.(mountainview,calif)分销的mpsrch程序包。可以采用这套软件包中的smith-waterman算法,其中将默认参数用于评分表(例如,空位开放罚分为12,空位延伸罚分为一,空位为六)。从生成的数据中,“匹配”值反映“序列同一性”。用于计算序列之间的同一性百分比或相似性的其他合适的程序通常是本领域已知的,例如另一个比对程序是blast,其使用默认参数。例如,blastn和blastp可以使用以下默认参数运行:遗传密码=标准;过滤器=无;链=两条;截止值=60;期望值=10;矩阵=blosum62;描述=50个序列;排序方式=高分;数据库=非冗余,genbank+embl+ddbj+pdb+genbankcds翻译+swiss蛋白质+spupdate+pir。这些程序的详细信息可见于以下网址:http://http://blast.ncbi.nlm.nih.gov/。术语“初免-加强疫苗接种”或“初免-加强方案”是指使用靶向特定抗原的疫苗进行首次初免注射,然后不时使用相同的疫苗进行一次或多次加强注射的疫苗接种策略或方案。初免-加强疫苗接种可以是同源的或异源的。同源初免-加强疫苗接种使用包含用于初免注射和一次或多次加强注射两者的相同抗原和载体的疫苗。异源初免-加强疫苗接种使用包含用于初免注射和一次或多次加强注射两者的相同抗原,但用于初免注射和一次或多次加强注射的不同载体的疫苗。例如,同源初免-加强疫苗接种可以将包含表达一种或多种抗原的核酸的重组痘病毒用于初免注射并将表达一种或多种抗原的相同重组痘病毒用于一次或多次加强注射。相比之下,异源初免-加强疫苗接种可以将包含表达一种或多种抗原的核酸的重组痘病毒用于初免注射并将表达一种或多种抗原的不同重组痘病毒用于一次或多次加强注射。术语“重组”意指在自然界中不存在或以自然界中不存在的排列连接至另一种多核苷酸的半合成或合成来源的多核苷酸。如本文所用,“连续传代”涉及通过使用细胞传代来产生重组病毒。仅举例来说,在初始传代中用病毒或重组病毒感染宿主细胞。病毒复制并在初始传代中产生。在感染和培养宿主细胞之后,从宿主细胞收获病毒并收集在细胞/病毒悬液中。该过程典型地在后续细胞传代中重复多次,每次传代产生和复制更多的重组病毒。如本文所用,“转基因”或“异源”基因应理解为野生型痘病毒基因组(例如,牛痘、鸡痘或mva)中不存在的核酸或氨基酸序列。技术人员理解,当存在于痘病毒(诸如牛痘病毒)中时,“转基因”或“异源基因”将以这样的方式并入痘病毒基因组:在将重组痘病毒施用于宿主细胞之后,它以对应的异源基因产物,即以“异源抗原”和\或“异源蛋白质”表达。表达通常通过将异源基因可操作地连接至允许在痘病毒感染的细胞中表达的调控元件来实现。优选地,调控元件包括天然的或合成的痘病毒启动子。“tricom.”共刺激分子的三联体(也称为tricom)包括b7-1(也称为b7.1或cd80)、细胞内粘附分子-1(icam-1,也称为cd54)和淋巴细胞功能相关抗原-3(lfa-3,也称为cd58),并且通常包含在表达特定抗原的重组病毒载体(例如,痘病毒载体)中,以增加抗原特异性免疫应答。tricom的各个组分可以处于相同的或不同的启动子的控制下,并且可以与特定抗原提供在相同的载体上,或提供在单独的载体上。示例性载体例如在hodge等人,“atriadofcostimulatorymoleculessynergizetoamplifyt-cellactivation,”cancerres.59:5800-5807(1999)和美国专利no.7,211,432b2中有所公开,这两篇文献以引用的方式并入本文。“载体”是指可以包含异源多核苷酸的dna或rna质粒或病毒。出于预防或治疗的目的,异源多核苷酸可以包含所关注的序列,并且可以任选地呈表达盒的形式。如本文所用,载体不需要能够在最终靶细胞或受试者中复制。该术语包括克隆载体和病毒载体。新型muc1核酸序列通过本发明的开发,本发明人确定在重组痘病毒尤其是正痘病毒(例如,牛痘病毒、mva、mva-bn)和禽痘病毒(例如,鸡痘病毒)传代的过程中,编码muc1、cea和/或tricom的核酸的一个或多个区发生突变(例如,缺失、取代等),从而导致重组痘病毒和其中的转基因不稳定。vntr区的修饰如前所述,vntr区是包含20个氨基酸的可变数目串联重复(vntr)域的muc1的胞外域,重复的数目在不同个体中在20至120之间变化。参见brayman等人。虽然vntr域的氨基酸序列典型地是相同的(参见例如图2a),但是vntr的核苷酸序列可以变化。如图2a所示,作为panvac的一部分,muc1被合成为具有6个vntr。在一个方面,在本发明的开发过程中,确定对编码muc1vntr区的核酸的一个或多个修饰改善了muc1转基因在重组痘病毒中的稳定性。更具体地讲,本发明人确定,与panvacmuc1相比,对编码vntr的核酸进行改组进一步增强了muc1转基因的稳定性。如本文所用,对vntr进行“改组”被定义为重排编码vntr域重复的核酸的顺序。图2a和图2b展示了对vntr进行改组的非限制性实例。在图2a中,panvacvntr域的顺序显示为vntr#1-6。参见图2b,编码mbn336、mbn373、mbn420的vntr#1的核酸对应于panvac中的vntr#。mbn336、mbn373、mbn420的vntr#2对应于panvac中的vntr#1。因此,在合成mbn336、mbn373、mbn420的muc1时,panvacvntr#1和2的顺序被改组。通过本发明应理解,图2a和图2b所示的vntr域仅仅代表muc1vntr域,并且vntr域的数目和vntr被改组的排列可以变化。除了对vntr进行改组之外,还确定,优化vntr域的密码子进一步增强了muc1转基因的稳定性。如本文所用,“优化密码子”被定义为替换vntr的一个或多个核苷酸,以使由于重复核苷酸序列的同源性而产生的vntr的核苷酸序列的突变和/或缺失的机会最小化。在一个更具体的实施方案中,如图3a-3b的比对所描绘,本发明的一种或多种核酸包含vntr域中的各种取代。如图3a所示,除了所展示的密码子优化取代之外,mbn373和mbn420(下文中称为mbn373/420)的vntr1还包含编码来自wo2013/103658的激动剂表位的一个或多个核苷酸序列(由下划线指示的区)。如图3b和图3c所示,mbn373/420修饰的vntr2和3包含所展示的密码子优化取代。通过本发明应理解,如图3a-3c所示,所展示的对vntr域的密码子优化修饰仅仅代表muc1vntr域密码子优化。仅举例来说,本发明设想了替代性核苷酸可以在vntr域中的特定修饰点处被取代。还设想了vntr域中的特定修饰点可以变化,使得修饰为沉默修饰。如本文所用,沉默修饰意指该修饰不影响muc1抗原的氨基酸序列。因此,在一个实施方案中,本发明的muc1核酸包含一个或多个1)改组的以及2)密码子优化的vntr域区。muc1的非vntr区的修饰在本发明的另一个方面,对vntr域外部的那些区进行一个多个修饰。在一个更具体的方面,在本发明的开发过程中,确定了muc1vntr区外部的那些核苷酸区(非vntr区)中的一个或多个修饰改善了muc1转基因的稳定性。那些区(加下划线的核苷酸)的代表性样例如下所示。vntr区以灰色阴影表示。为了产生在病毒的连续传代中稳定的重组痘病毒,合成了本发明的一种或多种核酸。更具体地讲,如图2a至图2c所示,对panvacmuc1(seqidno:1)的vntr区外部的一个或多个加下划线区域进行一个或多个取代,如图所示。因此,在本发明的一个实施方案中,存在包含对muc1核酸的vntr区外部的至少一个重复核苷酸区的取代的新型muc1核酸。在至少一个方面,一个或多个重复区被定义为:(i)三个或更多个连续重复的核苷酸,(ii)三个或更多个连续的g或c核苷酸,和/或(iii)三个或更多个连续的t或c核苷酸。在更具体的方面,一个或多个重复核苷酸区还被定义为(i)四个或更多个连续重复的核苷酸,(ii)四个或更多个连续的g或c核苷酸,和/或(iii)四个或更多个连续的t或c核苷酸。在某些其他更具体的方面,连续重复的核苷酸被定义为(i)连续的g核苷酸,(ii)连续的c核苷酸和/或(iii)连续的t核苷酸。如图2a至图2c所示,新型muc1核酸可以包含muc1核酸的vntr区外部的至少2、3、4或5个重复核苷酸区中的取代。在另外的方面,新型muc1核酸可以包含vntr区外部的至少10个、15个、20个或25个重复核苷酸区中的取代。在另外其他方面,新型muc1核酸可以包含vntr区外部的那些区中的至少一个取代,这些区在重组痘病毒的连续传代中更易于突变。在一个示例性方面,新型muc1核酸可以包含vntr区外部的那些muc1核苷酸重复区(选自表5所示的panvacmuc1(seqidno:1)的核苷酸区和/或它们的组合)中的一者或多者中的至少一个取代。表57-1619-3240-4565-68122-128136-138194-200207-213222-224240-253296-299705-714731-734761-765770-773791-795847-864880-883895-922933-9531004-10061009-11131030-10501075-10811085-10901097-11021153-11561166-11711201-12121237-12461264-12801294-13001328-13321335-13461353-13571375-13811407-14101418-14231426-14311437-14421449-14541459-14641471-14791494-1500更优选地,新型muc1核酸可以包含vntr区外部的那些muc1核苷酸重复区(选自表6所示的panvacmuc1(seqidno:1)的核苷酸区和/或它们的组合)中的至少一个取代。表67-1619-3240-4565-68122-128136-138194-200207-213222-224240-253296-299705-708710-714731-734761-765770-773791-795847-855857-864880-883895-898899-914916-922933-937940-943945-9531004-10061009-11131030-10501075-10811085-10901097-11021153-11561166-11711201-12121237-12401243-12461264-12801294-13001328-13321335-13371338-13431344-13461353-13571375-13811407-14101418-14231426-14311437-14421449-14541459-14641471-14791494-1500通过本发明应理解,表5和表6中列出的核苷酸位置仅仅代表muc1的非vntr区中存在的muc1核酸重复区。因此,虽然本文所述的重复区具有seqidno:1中的指定核苷酸位置(例如,240-253),但是该特定区可以对应于另一个muc1核酸中的另一个核苷酸位置。在另外的实施方案中,对vntr外部的重复区的修饰,和/或vntr区中的修饰是沉默修饰,这意味着该修饰不影响muc1抗原的氨基酸序列。在至少一个方面,通过修饰一个或多个重复区来增强muc1转基因的稳定性是具有挑战性的,因为只有某些核苷酸和/或重复区可以被修饰而不影响muc1的氨基酸序列。鉴于前述内容,在一个或多个实施方案中,本发明包括一种或多种muc1核酸,所述muc1核酸包含1)对vntr域重复的一个或多个修饰,所述修饰选自a)改组和b)密码子优化;以及2)对vntr外部的重复区的一个或修饰。在另一个方面,本发明的muc1核酸可以包含被构造为增强muc1转基因在受试者中的免疫原性的一个或多个修饰。在一个非限制性实例中,muc1核酸可以被修饰为包含wo2013/103658中所述的一个或多个激动剂表位,该专利以引用的方式并入本文。在一个更具体的实施方案中,本发明的muc1核酸包含选自以下的激动剂表位:ylappahgv[seqidno:24]、yldtrpapv[seqidno:25]、ylaivylial[seqidno:26]、ylialavcqv[seqidno:27]、ylsytnpav[seqidno:28]和slfrspyek[seqidno:29](加下划线部分是被取代的氨基酸)。在优选的实施方案中,muc1核酸包含与seqidno:2(336muc)、seqidno:3(373muc)、seqidno:4(399/400muc1)或seqidno:5(420muc1)至少95%同源的核苷酸序列。在另外其他优选的实施方案中,muc1核酸包含与seqidno:2(336muc)、seqidno:3(373muc)、seqidno:4(399/400muc1)或seqidno:5(420muc1)至少96%、97%或98%同源的核苷酸序列。在一个更优选的实施方案中,muc1核酸包含选自seqidno:2(336muc)、seqidno:3(373muc)、seqidno:4(399/400muc1)或seqidno:5(420muc1)的核苷酸序列。在另外其他优选的实施方案中,muc1核酸包含与seqidno:31、seqidno:32、seqidno:33或seqidno:34至少95%同源的核苷酸序列。在另外其他优选的实施方案中,muc1核酸包含与seqidno:31、seqidno:32、seqidno:33或seqidno:34至少96%、97%或98%同源的核苷酸序列。在一个更优选的实施方案中,muc1核酸包含选自seqidno:31、seqidno:32、seqidno:33或seqidno:34的核苷酸序列。新型cea核酸序列在本发明的另一个方面,确定了cea核酸的重复区中的一个或多个修饰改善了cea转基因的稳定性。那些区的代表性样例如图5的双序列比对所展示。那些示例性重复区由所示的取代(比对的非*区)来展示。在至少一个方面,取代还增强了重组痘病毒的稳定性。这至少部分地通过图9和图10所示的mbn336的稳定性数据展示。如前所述,mbn336包括muc1、cea和tricom。虽然mbn336包括经修饰的muc1核酸,但是mbn336不包括对cea的任何另外修饰,并且仅包括对tricom共刺激分子的中间修饰。因此,虽然对本文公开的muc1的修饰改善了重组痘病毒的稳定性,但是从第5次传代开始仍然不稳定。一旦将经修饰的cea作为鸡痘病毒的一部分包括在mbn373中,即证实了转基因和鸡痘病毒的稳定性超过第5次传代进入第7代。(参见例如图11)。因此,在各种实施方案中,本发明包括编码cea肽的核酸(cea核酸),所述核酸包含cea核酸的至少一个重复核苷酸区中的至少一个核苷酸取代,其中所述至少一个重复核苷酸区被定义为a)三个更多个连续重复的g或c核苷酸和/或b)三个或更多个连续重复的t核苷酸。在另外的实施方案中,重复核苷酸区还被定义为a)三个或更多个连续重复的g核苷酸和/或b)三个或更多个连续重复的c核苷酸。在优选的实施方案中,cea核酸的重复核苷酸区被定义为(i)四个或更多个连续重复的核苷酸,(ii)四个或更多个连续的g或c核苷酸,和/或(iii)四个或更多个连续的t核苷酸。在另外优选的实施方案中,重复核苷酸区还被定义为(i)四个或更多个连续的g核苷酸,(ii)四个或更多个连续的c核苷酸,和/或(iii)四个或更多个连续的t核苷酸。在一个或多个实施方案中,cea核酸包含对第二核酸的至少2个、3个、4个、5个或10个重复核苷酸区的至少一个取代。在一个优选的实施方案中,cea核酸包含至少10个、至少12个、至少15个和/或至少19个重复核苷酸区中的至少一个核苷酸取代。在一个更优选的实施方案中,cea核酸包含第二核酸的19个区中的至少一个核苷酸取代。在更优选的实施方案中,cea核酸包含seqidno:14(mbn373/420cea)。新型tricom核酸序列在本发明的另一个方面,对编码tricom共刺激分子的一种或多种核酸进行一个多个修饰。在一个更具体的方面,在本发明的开发过程中,确定了tricom核酸的重复区中的一个或多个修饰改善了tricom转基因的稳定性。那些区的代表性样例如图6-8的双序列比对所展示。那些示例性重复区由所示的取代(比对的非*区)来展示。在至少一个方面,所述一个或多个取代还增强了重组痘病毒的稳定性。这至少部分地通过图9和图10所示的mbn336的稳定性数据展示。如前所述,mbn336包括经修饰的muc1。然而,mbn336不包括对cea的任何另外修饰,并且仅包括对tricom共刺激分子的中间修饰。因此,虽然对本文公开的muc1的修饰改善了mbn336的稳定性,但是在第5次传代之后仍然不稳定。一旦将经修饰的转基因作为鸡痘病毒的一部分包括在内,即证实了转基因和痘病毒的稳定性超过第5次传代进入第7代。(参见例如图11)。在一个实施方案中,新型tricom共刺激分子包含与seqidno:15或17(对于b7-1)至少80%同源的核苷酸序列、与seqidno:18或20(对于icam-1)至少80%同源的核苷酸序列和与seqidno:21或23(对于lfa-3)至少80%同源的核苷酸序列。在另外其他优选的实施方案中,tricom核酸包含与seqidno:15或17(对于b7-1)、seqidno:18或20(对于icam-1)、和/或seqidno:21或23(对于lfa-3)至少85%、90%或95%同源的核苷酸序列。在另外更优选的实施方案中,tricom核酸包含与seqidno:17(对于b7-1)、seqidno:20(对于icam-1)、和/或seqidno:23(对于lfa-3)至少85%、90%或95%同源的核苷酸序列。在另一个实施方案中,tricom共刺激分子包含seqidno:15或17(对于b7-1)、seqidno:18或20(对于icam-1)、和/或seqidno:21或23(对于lfa-3)。在又一个实施方案中,tricom共刺激分子包含seqidno:17(对于b7-1)、seqidno:20(对于icam-1)、和/或seqidno:23(对于lfa-3)。在一个优选的实施方案中,新型tricom共刺激分子包含与seqidno:15(对于b7-1)至少80%同源的核苷酸序列、与seqidno:18(对于icam-1)至少80%同源的核苷酸序列和与seqidno:21(对于lfa-3)至少80%同源的核苷酸序列。在另外其他优选的实施方案中,tricom核酸包含与seqidno:15(对于b7-1)、seqidno:18(对于icam-1)、和/或seqidno:21(对于lfa-3)至少85%、90%或95%同源的核苷酸序列。在另一个优选的实施方案中,新型tricom共刺激分子包含与seqidno:17(对于b7-1)至少80%、90%或95%同源的核苷酸序列、与seqidno:20(对于icam-1)至少80%、90%或95%同源的核苷酸序列和与seqidno:23(对于lfa-3)至少80%、90%或95%同源的核苷酸序列。在另一个实施方案中,tricom共刺激分子包含seqidno:15(对于b7-1)、seqidno:18(对于icam-1)、和/或seqidno:21(对于lfa-3)。在另一个实施方案中,tricom共刺激分子包含seqidno:17(对于b7-1)、seqidno:20(对于icam-1)、和/或seqidno:23(对于lfa-3)。据设想,本公开具体实施与本文提供的新型核酸序列互补的那些核酸序列。重组痘病毒在一个或多个实施方案中,本发明包括包含一种或多种本文所述的muc1核酸的重组痘病毒。在更优选的实施方案中,重组痘病毒包含本文所述的muc1核酸序列和cea核酸序列。在优选的实施方案中,muc1核酸包含与seqidno:2、seqidno:3(373muc)、seqidno:5(420muc1)或seqidno:4(399/400muc1)至少95%同源的核苷酸序列,并且cea核酸序列包含seqidno:13或14的。在另外其他实施方案中,本公开的重组痘病毒包括一种或多种共刺激分子,诸如但不限于本文所述的那些。在一个优选的实施方案中,共刺激分子包括tricom(b7-1、icam-1和lfa-3)。在一个更优选的实施方案中,b7-1共刺激分子选自包含seqidno:15、seqidno:16和seqidno:17的核酸序列。在一个更优选的实施方案中,icam-1共刺激分子选自包含seqidno:18、seqidno:19和seqidno:20的核酸序列。在一个更优选的实施方案中,lfa-3共刺激分子选自包含seqidno:21、seqidno:22和seqidno:23的核酸序列。在一个更优选的实施方案中,b7-1、icam-1和lfa-3分别选自包含seqidno:15、seqidno:18和seqidno:21的核酸序列。在另一个更优选的实施方案中,b7-1、icam-1和lfa-3分别选自包含seqidno:17、seqidno:20和seqidno:23的核酸序列。在本公开的各种实施方案中,重组痘病毒优选地是正痘病毒,诸如但不限于牛痘病毒、经修饰的安卡拉牛痘(mva)病毒、mva-bn或mva-bn的衍生物。牛痘病毒毒株的实例是templeofheaven(天坛)、copenhagen(哥本哈根)、paris(巴黎)、budapest(布达佩斯)、dairen(达连)、gam、mrivp、per、tashkent(塔什干)、tbk、tom、bern(伯尔尼)、patwadangar、biem、b-15、lister(利斯特)、em-63、newyorkcityboardofhealth(纽约市卫生局)、elstree(埃尔斯特里)、ikeda(池田)和wr毒株。优选的牛痘病毒(vv)毒株是wyeth(dryvax)毒株(美国专利7,410,644)。另一个优选的vv毒株是经修饰的安卡拉牛痘病毒(mva)(sutter,g.等人,[1994],vaccine12:1032-40)。在本发明的实践中有用并且已经按照布达佩斯条约(budapesttreaty)的要求保藏的mva病毒毒株的实例是1994年1月27日保藏在europeancollectionofanimalcellcultures(ecacc),vaccineresearchandproductionlaboratory,publichealthlaboratoryservice,centreforappliedmicrobiologyandresearch,portondown,salisbury,wiltshiresp40jg,unitedkingdom(英国威尔特郡索尔兹伯里波登当的应用微生物学和研究中心公共卫生实验室服务疫苗研究和制备实验室的欧洲动物细胞培养物保藏中心)的毒株mva572(保藏号为ecacc94012707),以及2000年12月7日以保藏号ecacc00120707保藏在europeancollectionofcellcultures(ecacc)(欧洲细胞培养物保藏中心)的mva575、2000年8月30日以保藏号v00083008保藏在europeancollectionofcellcultures(ecacc)的mva-bn,并且mva-bn的衍生物是另外的示例性毒株。mva-bn的“衍生物”是指表现出如本文所述的与mva-bn基本上相同的复制特征,但是在其基因组的一个或多个部分中表现出差异的病毒。mva-bn及其衍生物是复制缺陷的,意味着不能在体内和体外繁殖性复制。更具体地讲,在体外,mva-bn或其衍生物已被描述为能够在鸡胚成纤维细胞(cef)中繁殖性复制,但是不能在人类角质形成细胞系hacat(boukamp等人(1988),j.cellbiol.106:761-771)、人类骨肉瘤细胞系143b(ecacc保藏号91112502)、人类胚胎肾细胞系293(ecacc保藏号85120602)和人类宫颈腺癌细胞系hela(atcc保藏号ccl-2)中繁殖性复制。另外,mva-bn或其衍生物的病毒扩增比率在hela细胞和hacat细胞系中是mva-575的至少两分之一,更优选地三分之一。对mva-bn及其衍生物的这些性质的测试和分析在wo02/42480(美国专利申请no.2003/0206926)和wo03/048184(美国专利申请no.2006/0159699)中有所描述。前述段落中描述的术语在体外人类细胞系中“不能繁殖性复制”或“无繁殖性复制的能力”例如在wo02/42480中有所描述,该专利还教导了如何获得具有上述所需性质的mva。该术语适用于使用wo02/42480中或美国专利no.6,761,893中所述的测定法在感染后4天体外病毒扩增比率小于1的病毒。术语“不能繁殖性复制”是指如前述段落所述在感染后4天在体外人类细胞系中的病毒扩增比率小于1的病毒。wo02/42480中或美国专利no.6,761,893中所述的测定法适用于测定病毒扩增比率。如前述段落所述的病毒在体外人类细胞系中的扩增或复制通常以从感染的细胞产生的病毒(输出)与首先最初用于感染细胞的量(输入)的比率(称为“扩增比率”)来表示。扩增比率为“1”定义了从感染的细胞产生的病毒量与最初用于感染细胞的量相同的扩增状态,这意味着感染的细胞允许病毒感染和繁殖。相比之下,扩增比率小于1,即输出与输入水平相比降低,表示缺乏繁殖性复制,并因而减弱病毒。在另一个实施方案中,包含本文公开的muc1和/或其他核酸的重组痘病毒是禽痘病毒,诸如但不限于鸡痘病毒。术语“禽痘病毒”是指任何禽痘病毒,诸如鸡痘病毒、金丝雀痘病毒、暗眼灯草鹀痘病毒(uncopoxvirus)、八哥痘病毒、鸽痘病毒、鹦鹉痘病毒、鹌鹑痘病毒、孔雀痘病毒、企鹅痘病毒、麻雀痘病毒、椋鸟痘病毒和火鸡痘病毒。优选的禽痘病毒是金丝雀痘病毒和鸡痘病毒。鸡痘病毒的实例是毒株fp-1、fp-5、trovac(美国专利no.5,766,598)、poxvac-tc(美国专利7,410,644)、tbc-fpv(therionbiologics-fpv),fp-1是被修饰以用作一日龄小鸡的疫苗的duvette毒株。该毒株是命名为odcep25/cep67/2309(1980年10月)的商业鸡痘病毒疫苗毒株并且可得自institutemerieux,inc.。fp-5是鸡胚来源的商业鸡痘病毒疫苗毒株,它可得自americanscientificlaboratories(scheringcorp.的分公司)madison,wis.(美国兽医许可证号165,序列号30321)。在某些优选的实施方案中,存在包含选自seqidno:5(420muc1)、seqidno:4(399/400muc1)、seqidno:3(373muc1)或seqidno:2(336muc1)的muc1核酸序列的重组正痘病毒,诸如牛痘、mva、mva-bn或mva-bn的衍生物。在某些更优选的实施方案中,重组正痘病毒是包含选自seqidno:2(420muc1)的muc1核酸序列、选自seqidno:13或14的cea核酸、和tricom的mva病毒。在最优选的实施方案中,存在包括包含seqidno:2(336muc1)的muc1核酸序列、包含seqidno:13的cea核酸、和tricom的重组mva。在另一个最优选的中,tricom包括包含seqidno:17(b7-1)、seqidno:20(icam-1)和seqidno:23(lfa-3)的一种或多种核酸。在某些其他优选的实施方案中,存在包括包含seqidno:3(373muc1)的muc1核酸序列的重组禽痘病毒,诸如鸡痘病毒。在某些更优选的实施方案中,重组禽痘病毒是包括包含seqidno:3(373)的muc1核酸、选自seqidno:13或14的cea核酸、和tricom的鸡痘病毒。在最优选的实施方案中,存在包括包含seqidno:3(373muc1)的muc1核酸序列、包含seqidno:14的cea核酸、和tricom的重组鸡痘病毒。在另一个最优选的实施方案中,tricom包括包含seqidno:15(b7-1)、seqino:18(icam-1)和seqidno:21(lfa-3)的一种或多种核酸。表达盒/控制序列在各个方面,本文所述的一种或多种核酸包含在一种或多种核酸可操作地连接至表达控制序列的一个或多个表达盒中。“可操作地连接的”意指所描述的组分处于允许它们以其预期方式发挥功能的关系中,例如启动子转录待表达的核酸。将可操作地连接至编码序列的表达控制序列进行连接,以使得在与表达控制序列相容的条件下实现编码序列的表达。表达控制序列包括但不限于适当的启动子、增强子、转录终止子、在编码蛋白质的开放阅读框开始处的起始密码子、内含子的剪接信号、和框内终止密码子。合适的启动子包括但不限于sv40早期启动子、rsv启动子、逆转录病毒ltr、腺病毒主要晚期启动子、人类cmv立即早期i启动子和各种痘病毒启动子,包括但不限于以下牛痘病毒或mva来源和fpv来源的启动子:30k启动子、i3启动子、prs启动子、prs5e启动子、pr7.5k、pr13.5长启动子、40k启动子、mva-40k启动子、fpv40k启动子、30k启动子、prsyniim启动子和prle1启动子。另外的启动子在wo2010/060632、wo2010/102822、wo2013/189611和wo2014/063832中进一步描述,这些专利以引用的方式整体并入本文。另外的表达控制序列包括但不限于前导序列、终止密码子、多聚腺苷酸化信号以及编码所需重组蛋白质(例如,muc1、cea和/或tricom)的核酸序列在所需宿主系统中的适当转录和后续翻译所需的任何其他序列。痘病毒载体也可以包含含有核酸序列的表达载体在所需宿主系统中的转移和后续复制所需的其他元件。本领域的技术人员还将理解,此类载体可使用常规的方法容易地构建(ausubel等人,(1987),载于“currentprotocolsinmolecularbiology”,johnwileyandsons,newyork,n.y.)并且是可商购获得的。在某些实施方案中,本公开的重组正痘病毒和/或禽痘病毒包含一种或多种细胞因子(诸如il-2、il-6、il-12、rantes、gm-csf、tnf-α或ifn-γ)、一种或多种生长因子(诸如gm-csf或g-csf)、一种或多种共刺激分子(诸如icam-1、lfa-3、cd72、b7-1、b7-2或其他b7相关分子);一种或多种诸如ox-40l或41bbl的分子,或这些分子的组合,可用作生物佐剂(参见例如salgaller等人,1998,j.surg.oncol.68(2):122-38;lotze等人,2000,cancerj.sci.am.6(增刊1):s61-6;cao等人,1998,stemcells16(增刊1):251-60;kuiper等人,2000,adv.exp.med.biol.465:381-90)。这些分子可以系统性(或局部)施用于宿主。在若干实例中,施用il-2、rantes、gm-csf、tnf-α、ifn-γ、g-csf、lfa-3、cd72、b7-1、b7-2、b7-1b7-2、ox-40l、41bbl和icam-1。包含转基因的重组痘病毒的产生本文提供的重组痘病毒可以通过本领域已知的常规方法产生。获得重组痘病毒或将外源编码序列插入痘病毒基因组的方法是本领域的技术人员熟知的。例如,用于标准分子生物学技术(诸如dna的克隆、dna和rna分离、western印迹分析、rt-pcr和pcr扩增技术)的方法在molecularcloning,alaboratorymanual(第2版)[j.sambrook等人,coldspringharborlaboratorypress(1989)]中有所描述,用于病毒的处理和操纵的技术在virologymethodsmanual[b.w.j.mahy等人(编),academicpress(1996)]中有所描述。类似地,用于mva的处理、操纵和遗传工程的技术和专门技能在molecularvirology:apracticalapproach[a.j.davison&r.m.elliott(编),thepracticalapproachseries,irlpressatoxforduniversitypress,oxford,uk(1993)(参见例如第9章:expressionofgenesbyvacciniavirusvectors)]和currentprotocolsinmolecularbiology[johnwiley&son,inc.(1998)(参见例如第16章,第iv部分:expressionofproteinsinmammaliancellsusingvacciniaviralvector)]中有所描述。对于本文公开的各种重组痘病毒的产生,可应用不同的方法。待插入病毒的dna序列可以置于大肠杆菌(e.coli)质粒构建体中,与痘病毒的dna部分同源的dna已插入所述构建体中。单独地,可将待插入的dna序列连接至启动子。启动子-基因连接可以定位于质粒构建体中,以使得启动子-基因连接在两端上被与侧接痘病毒dna的含有非必需基因座的区的dna序列同源的dna侧接。所得的质粒构建体可以通过在大肠杆菌内繁殖来扩增并分离。含有待插入的dna基因序列的分离质粒可以转染进例如鸡胚成纤维细胞(cef)的细胞培养物,同时用痘病毒感染培养物。质粒和病毒基因组各自中的同源痘病毒dna之间的重组可以产生因外源dna序列的存在而修饰的痘病毒。根据一个优选的实施方案,可以用痘病毒感染合适的细胞培养物的细胞(例如,cef细胞)。随后可以用本公开提供的包含一个或多个外源或异源基因(诸如muc1、cea和/或tricom核酸中的一者或多者)的第一质粒转染经感染的细胞;优选地在痘病毒表达控制元件的转录控制下。如上所解释,质粒还包含能够指导外源序列插入痘病毒基因组的选定部分的序列。任选地,质粒载体还含有包含可操纵地连接至痘病毒启动子的标记和/或选择基因的盒。合适的标记或选择基因是例如编码绿色荧光蛋白、β-半乳糖苷酶、新霉素-磷酸核糖基转移酶或其他标记的基因。选择或标记盒的使用简化了所产生的重组痘病毒的鉴定和分离。然而,还可以通过pcr技术来鉴定重组痘病毒。随后,可以用如上所述获得的重组痘病毒感染另一细胞,并用包含一个或多个第二外源或异源基因的第二载体转染。在这种情况下,该基因应被引入痘病毒基因组的不同插入位点,第二载体的不同之处还在于指导所述一个或多个第二外源基因整合进痘病毒的基因组的痘病毒同源序列。在同源重组发生后,可以分离包含两个或更多个外源或异源基因的重组病毒。对于将另外的外源基因引入重组病毒,可以通过使用前述步骤中分离的重组病毒进行感染,并通过使用包含一个或多个另外的外源基因的另外载体进行转染来重复感染和转染步骤。替代性地,如上所述的感染和转染步骤是可互换的,即合适的细胞可以首先使用包含外源基因的质粒转染,然后使用痘病毒感染。作为另外的替代方案,还可以将每个外源基因引入不同的病毒,用所有获得的重组病毒共感染细胞,并筛选包含所有外源基因的重组子。第三种替代方案是体外连接dna基因组和外源序列并且使用辅助病毒来重建重组的牛痘病毒dna基因组。第四种替代方案是在大肠杆菌或另一细菌菌种中痘病毒基因组(以细菌人工染色体(bac)克隆)与侧接有dna序列(与侧接牛痘病毒基因组中的所需整合位点的序列同源)的线性外源序列之间的同源重组。本公开的一种或多种核酸可以插入痘病毒的任何合适部分。在一个优选的方面,用于本发明的痘病毒包括mva和/或鸡痘病毒。mva和鸡痘病毒的合适部分是mva和鸡痘基因组的非必需部分。对于mva,mva基因组的非必需部分可以是mva基因组的基因间区或已知缺失位点1-6。替代性地或除此之外,重组mva的非必需部分可以是mva基因组的对病毒生长是非必需的编码区。然而,插入位点不限于mva基因组中的这些优选的插入位点,因为本发明的范围包括:本发明的核酸(例如,muc1、cea和tricom)和如本文所述的任何伴随启动子可以插入病毒基因组中的任何位置,只要能够获得可以在至少一种细胞培养系统(诸如鸡胚成纤维细胞(cef细胞))中扩增和增殖的重组子即可。优选地,本发明的核酸可以插入mva和/或鸡痘病毒的一个或多个基因间区(igr)。术语“基因间区”优选地是指位于mva和/或鸡痘病毒基因组的两个相邻的开放阅读框(orf)之间,优选地mva和/或鸡痘病毒基因组的两个必需orf之间的那些病毒基因组部分。对于mva,在某些实施方案中,igr选自igr07/08、igr44/45、igr64/65、igr88/89、igr136/137和igr148/149。对于鸡痘病毒,igr选自bamh1,除此之外或替代性地,对于mva病毒,核苷酸序列可以插入mva基因组的一个或多个已知缺失位点,即缺失位点i、ii、iii、iv、v或vi。术语“已知缺失位点”是指在cef细胞上连续传代中缺失的那些mva基因组部分,所述部分就mva来源的亲代病毒(尤其是亲代绒膜尿囊安卡拉牛痘病毒(cva))的基因组而言在20第516次传代时表征,例如如meisinger-henschel等人,(2007),journalofgeneralvirology88:3249-3259所述。疫苗在某些实施方案中,本公开的重组痘病毒可以配制为疫苗的一部分。对于疫苗的制备,可以将痘病毒转化为生理上可接受的形式。在某些实施方案中,这种制备基于用于针对天花的疫苗接种的痘病毒疫苗制备经验,如例如stickl,h.等人,dtsch.med.wschr.99,2386-2392(1974)所述。示例性制备如下。将在10mmtris、140mmnacl(ph7.4)中以5x108tcid50/ml的滴度配制的纯化病毒储存在-80℃下。对于疫苗注射剂的制备,例如可以将102-108个病毒颗粒在安瓿瓶(优选地玻璃安瓿瓶)中在存在2%蛋白胨和1%人白蛋白的情况下在磷酸盐缓冲盐水(pbs)中冻干。替代性地,疫苗注射剂可以通过将病毒在制剂中逐步冷冻干燥而制备。在某些实施方案中,制剂含有另外的添加剂,诸如甘露糖醇、葡聚糖、糖类、甘氨酸、乳糖、聚乙烯吡咯烷酮或适合于体内施用的其他添加剂(诸如包括但不限于抗氧化剂或惰性气体、稳定剂或重组蛋白质(例如人血清白蛋白))。然后将安瓿瓶密封,并且可将其在合适的温度下(例如,在4℃与室温之间)储存数月。然而,只要不存在需求,可将安瓿瓶优选地储存在低于-20℃的温度下。在涉及疫苗接种或疗法的各种实施方案中,将冻干物溶于0.1至0.5ml水溶液(优选地生理盐水或tris缓冲液)中,并系统性或局部施用,即通过肠胃外、皮下、静脉内、肌内、鼻内、皮内或专业技术人员已知的任何其他施用途径来施用。施用模式、剂量和施用次数的优化在本领域技术人员的技能和知识范围内。在某些实施方案中,减毒牛痘病毒毒株可用于诱导免疫功能受损的动物(例如,siv感染的猴(cd4<400/μl血液))或免疫功能受损的人中的免疫应答。术语“免疫功能受损的”描述个体的免疫系统的状态,所述个体仅表现出不完整的免疫应答或抵御病原体的能力降低。试剂盒、组合物和使用方法在一个不同的实施方案中,本发明涵盖包含含有本文所述的核酸的重组痘病毒的试剂盒和/或组合物。优选地,组合物是药物或免疫原性组合物。在一个实施方案中,存在包含两种或更多种重组痘病毒的组合的试剂盒和/或组合物,每种重组痘病毒包含本公开的muc1、cea和/或tricom核酸。该组合包含a)正痘病毒,诸如牛痘、mva、mva-bn或mva-bn的衍生物,其包括本公开的muc1、cea和/或tricom核酸,和b)禽痘病毒,诸如鸡痘,其包括本公开的muc1、cea和/或tricom核酸。据设想,正痘病毒和鸡痘病毒组合可以作为同源或异源初免-加强方案施用。在另一个实施方案中,包含两种或更多种重组痘病毒的组合的试剂盒和/或组合物包含a)mva病毒,其包括本公开的muc1、cea和/或tricom核酸,和b)禽痘病毒,诸如鸡痘,其包括本公开的muc1、cea和/或tricom核酸。据设想,mva病毒和鸡痘病毒组合可以作为同源或异源初免-加强方案施用。在另外的实施方案中,所述一种或多种重组痘病毒中的每一种还包含本公开的共刺激分子中的一种或多种。在一个优选的实施方案中,一种或多种共刺激分子是本公开的tricom分子中的一种或多种。据设想,试剂盒和/或组合物可包括本公开的重组痘病毒的一个或多个容器或小瓶,以及重组痘病毒的施用说明。本文提供的试剂盒和/或组合物通常可以包含一种或多种药学上可接受的和/或批准的载剂、添加剂、抗生素、防腐剂、佐剂、稀释剂和/或稳定剂。此类辅助物质可以是水、盐水、甘油、乙醇、润湿剂或乳化剂、ph缓冲物质等等。合适的载剂典型地为大型、缓慢代谢的分子,诸如蛋白质、多糖、聚乳酸、聚乙醇酸、聚合氨基酸、氨基酸共聚物、脂质聚集体等等。对于组合物(例如,药物和/或免疫原性组合物)的制备,可以将本文提供的重组痘病毒转化为生理上可接受的形式。这可以基于用于针对天花的疫苗接种的痘病毒疫苗制备经验来进行,如h.stickl等人,dtsch.med.wschr.99:2386-2392(1974)所述。例如,可将在约10mmtris、140mmnacl(ph7.4)中以5x108tcid50/ml的滴度配制的纯化病毒储存在-80℃下。对于疫苗注射剂的制备,例如可以将102-108或102-109个病毒颗粒在安瓿瓶(优选地玻璃安瓿瓶)中在存在2%蛋白胨和1%人白蛋白的情况下在100ml磷酸盐缓冲盐水(pbs)中冻干。替代性地,疫苗注射剂可以通过将病毒在制剂中逐步冷冻干燥而产生。该制剂可以含有另外的添加剂,诸如甘露糖醇、葡聚糖、糖类、甘氨酸、乳糖或聚乙烯吡咯烷酮或适合于体内施用的其他助剂(诸如抗氧化剂或惰性气体、稳定剂或重组蛋白质(例如,人血清白蛋白))。典型的适于冷冻干燥的含病毒制剂包含10mmtris缓冲剂、140mmnacl、18.9g/l葡聚糖(mw36,000-40,000)、45g/l蔗糖、0.108g/ll-谷氨酸单钾盐一水合物ph7.4。然后将玻璃安瓿瓶密封,并且可将其在4℃与室温之间储存数月。然而,只要不存在需求,可将安瓿瓶优选地储存在等于或低于-20℃的温度下。对于疫苗接种或疗法,可将冻干物溶于水溶液(例如,0.1至0.5ml),优选地注射用水、生理盐水或tris缓冲液中,并系统性或局部施用,即通过肠胃外、皮下、静脉内、肌内、鼻内或专业技术人员已知的任何其他施用途径来施用。施用模式、剂量和施用次数可以由本领域的技术人员以已知方式优化。在各种其他实施方案中,存在与产生重组痘病毒和/或改善重组痘病毒和/或其中的转基因在重组痘病毒连续传代中的稳定性的一种或多种方法。在一个更具体的实施方案中,重组痘病毒在至少3次或4次传代中稳定。重组痘病毒在多次传代中稳定出于许多原因是特别重要的,其中一些原因包括重组病毒的大规模生产及其作为药物的用途,以及政府关于疫苗在多次传代中的稳定性的政策。对于本发明的重组痘病毒,在至少3次或4次传代中产生稳定的重组痘病毒是重要的,因为panvac-v和panvac-f在大约第1次传代开始展示出转基因存活力的不稳定和/或丧失(参见例如表1和表2;和图1a和表1b)。在一个实施方案中,存在一种用于产生具有在重组痘病毒的连续传代中稳定的muc1转基因的痘病毒的方法,所述方法包括:a)提供本公开的核酸或表达盒中的任一者;以及b)将所述核酸或表达盒插入重组痘病毒,其中重组痘病毒在连续传代中是稳定的。根据本公开的示例性方法1.在另一个实施方案中,存在一种用于产生重组痘病毒的方法,所述重组痘病毒在重组痘病毒的连续传代中是稳定的,所述方法包括:a)提供编码具有至少两个可变n-末端重复(vntr)域的muc1肽的第一核酸,其中a)对所述至少两个vntr域的排列进行改组,以及b)对所述至少两个vntr域进行密码子优化,其中所述重组痘病毒在重组痘病毒的连续传代中是稳定的。2.在另一个实施方案中,存在一种用于产生稳定的重组痘病毒的方法,所述重组痘病毒在重组痘病毒的连续传代中是稳定的,所述方法包括:提供编码muc1蛋白的第一核酸,所述muc1蛋白包含至少两个vntr域;改组或重排所述至少两个vntr域重复的顺序;优化所述至少两个vntr域重复的密码子;将所述第一核酸序列插入所述痘病毒,以产生在重组痘病毒的连续传代中稳定的重组痘病毒。3.如1和2中任一项所述的方法,其中所述第一核酸与seqidno:2至少95%同源、与seqidno:4至少95%同源、与seqidno:3至少95%同源或与seqidno:5至少95%同源。4.如1至3中任一项所述的方法,其中所述核酸与seqidno:2至少95%同源。5.如1至4中任一项所述的方法,其中所述核酸与seqidno:3至少95%同源。6.如1至5中任一项所述的方法,其中所述核酸包含seqidno:2。7.如1至6中任一项所述的方法,其中所述核酸包含seqidno:5。8.如1至7中任一项所述的方法,其中所述方法还包括取代编码cea肽的第二核酸的重复核苷酸区中的至少一个核苷酸,其中所述重复核苷酸区被定义为:(i)三个或更多个连续重复的核苷酸,(ii)三个或更多个连续的g或c核苷酸,和/或(iii)三个或更多个连续的t或c核苷酸;以及将所述第二核酸插入所述重组痘病毒中。9.如8所述的方法,其中所述第二核酸的所述重复区还被定义为(i)三个或更多个连续的g核苷酸,(ii)三个或更多个连续的c核苷酸,和/或(iii)三个或更多个连续的t核苷酸。10.如8和9中任一项所述的方法,其中所述第二核酸的所述重复核苷酸区还被定义为(i)四个或更多个连续重复的核苷酸,(ii)四个或更多个连续的g或c核苷酸,和/或(iii)四个或更多个连续的t或c核苷酸。11.在1-10的方法的一个方面,cea核苷酸区还被定义为(i)四个或更多个连续重复的核苷酸,(ii)四个或更多个连续的g或c核苷酸,和/或(iii)四个或更多个连续的t或c核苷酸。12.在1-11的方法的一个方面,cea重复区还被定义为(i)四个或更多个连续的g核苷酸,(ii)四个或更多个连续的c核苷酸,和/或(iii)四个或更多个连续的t核苷酸。13.在1-12的方法的一个方面,所述取代针对所述cea核酸的至少2个、3个、4个、5个或10个重复核苷酸区。14.在1-13的方法的一个方面,所述cea核酸包含seqidno:14。15.在1-14的方法的一个方面,所述方法还包括取代编码选自b7-1、icam-1和/或lfa-3,cea的共刺激分子的核酸的重复核苷酸区中的至少一个核苷酸,其中所述重复核苷酸区被定义为:(i)三个或更多个连续重复的核苷酸,(ii)三个或更多个连续的g或c核苷酸,和/或(iii)三个或更多个连续的t或c核苷酸;以及将编码共刺激分子的核酸插入所述重组痘病毒中。16.在1-15的方法的一个方面,所述共刺激分子重复区还被定义为(i)三个或更多个连续的g核苷酸,(ii)三个或更多个连续的c核苷酸,和/或(iii)三个或更多个连续的t核苷酸。17.在1-16的方法的一个方面,所述共刺激分子重复核苷酸区还被定义为(i)四个或更多个连续重复的核苷酸,(ii)四个或更多个连续的g或c核苷酸,和/或(iii)四个或更多个连续的t或c核苷酸。18.在1-17的方法的一个方面,所述共刺激分子重复区还被定义为(i)四个或更多个连续的g核苷酸,(ii)四个或更多个连续的c核苷酸,和/或(iii)四个或更多个连续的t核苷酸。19.在1-18的方法的一个方面,所述取代针对所述共刺激分子核酸的至少2个、3个、4个、5个或10个重复核苷酸区。20.在1-19的方法的一个方面,所述编码共刺激分子的核酸选自b7-1(seqidno:15-17)、icam-1(seqidno:18-20)和lfa-3(seqidno:21-23)。21.在1-20的方法的一个方面,所述编码共刺激分子的核酸与b7-1(seqidno:15)、icam-1(seqidno:18)和lfa-3(seqidno:21)中的至少一者至少80%、85%、90%或95%同源。22.在1-21的方法的一个方面,所述编码共刺激分子的核酸与b7-1(seqidno:17)、icam-1(seqidno:20)和lfa-3(seqidno:23)中的至少一者至少80%、85%、90%或95%同源。23.在1-22的方法的一个方面,所述编码共刺激分子的核酸包含b7-1(seqidno:17)、icam-1(seqidno:20)和lfa-3(seqidno:23)中的至少一者。24.在1-23的方法的一个方面,所述编码共刺激分子的核酸包含:b7-1(seqidno:15)、icam-1(seqidno:18)和lfa-3(seqidno:21)。25.在1-24的方法的一个方面,所述编码muc1的第一核酸选自seqidno:31、32、33和34。26.如本公开所提供,1-26的方法的重组痘病毒可以选自正痘病毒或禽痘病毒。在优选的实施方案中,正痘病毒选自牛痘病毒、mva、mva-bn和mva-bn的衍生物。在一个更优选的实施方案中,所述正痘病毒是mva、mva-bn或衍生物或mva-bn。在其他另外更优选的实施方案中,所述禽痘病毒是鸡痘病毒。在其他实施方案中,存在将根据本公开的a)核酸、b)表达盒、c)组合物、d)宿主细胞或e)载体用于产生在痘病毒的连续传代中稳定的重组痘病毒的方法的用途。在另外其他实施方案中,存在将根据本公开的a)重组痘病毒、b)核酸、c)表达盒、d)组合物、d)宿主细胞或e)载体用于制备药物(优选疫苗)的用途。在另外其他实施方案中,存在用作药物(优选疫苗)的根据本公开的重组痘病毒、b)核酸、b)表达盒、c)组合物、d)宿主细胞或e)载体。在其他另外的实施方案中,存在用在将编码序列引入靶细胞的方法中的根据本公开的重组痘病毒、b)核酸、b)表达盒、c)组合物、d)宿主细胞或e)载体。实施例以下实施例展示了本发明,但是毫无疑问不应解释为以任何方式限制权利要求的范围。实施例1:重组痘病毒的构建编码muc1(例如,mbn399、mbn400、mbn336、mbn373和mbn420)的痘病毒的产生通过以下步骤来进行:经由cef培养物的同时感染和转染而将指定的muc1和cea核酸序列及其启动子插入,然后允许病毒基因组与重组质粒pbn146之间的同源重组。分离携带插入物的病毒、进行表征,并制备病毒原种。对于mbn398和mbn400的构建,使用含有同源序列的mva重组质粒,所述同源序列也存在于牛痘病毒的igr88/89处)。将muc1和cea核苷酸序列插入牛痘病毒序列的igr88/89之间,以允许重组到牛痘病毒基因组中。因此,构建在痘病毒启动子的下游含有muc1和cea核苷酸序列的质粒。对于mbn398和mbn400,使用seqidno:1(muc1)和seqidno:13(cea)。mbn398中muc1和cea的启动子分别是prs启动子(muc1)和40k-mva1启动子(cea)。mbn400中muc1和cea的启动子分别是pr13.5长启动子(muc1)和prs5e启动子(cea)。tricom的共刺激分子作为mbn398和mbn400的一部分被包括在内。这些序列包括:b7-1、icam-1和lfa-3,并且分别包含seqidno:16、19和21。对于mbn336的构建,将三种重组质粒用于三种转基因pbn374(对于tricom)、pbn515(对于ceaseqidno:13)、pbn525(对于muc1seqidno:2),插入序列也存在于mva(igr88/89(muc1)、igr44/45(cea)、igr148/149(tricom)中。将muc1和cea核苷酸序列插入mva病毒序列之间,以允许重组到mva病毒基因组中。因此,构建在痘病毒启动子的下游含有muc1和cea核苷酸序列的质粒。对于mbn336,使用seqidno:2(muc1)和seqidno:13(cea)。启动子是prs启动子(对于muc1)和40k启动子(对于cea)。tricom的共刺激分子作为mbn336的一部分被包括在内。这些序列包括:b7-1、icam-1和lfa-3,并且分别包含seqidno:17、20和23。pbn632含有也存在于mva中(igr88/89内)的序列。将muc1和cea核苷酸序列插入mva病毒序列之间,以允许重组到mva病毒基因组中。因此,构建在痘病毒启动子的下游含有muc1和cea核苷酸序列的质粒。对于mbn420,使用seqidno:5(muc1)和seqidno:14(cea)。muc1和cea的启动子分别是pr13.5启动子(参见美国专利公开2015/0299267)(muc1)和40kmva1启动子(cea)。tricom的共刺激分子作为mbn420的一部分被包括在内,并整合进igr88/89内。这些序列包括:b7-1、icam-1和lfa-3,并且分别包含seqidno:15、18和21。对于mbn373的构建,重组质粒pbn563含有也存在于鸡痘病毒中的序列。将muc1和cea核苷酸序列插入bamh1区中的鸡痘病毒序列之间,以允许重组到鸡痘病毒基因组中。因此,构建在痘病毒启动子的下游含有muc1和cea核苷酸序列的质粒。对于mbn373,使用seqidno:3(muc1)和seqidno:14(cea)。muc1和cea的启动子分别是40kfpv-1prs启动子(muc1)和40k-mva1启动子(cea)。tricom的共刺激分子作为mbn373的一部分被包括在内。这些序列包括:b7-1、icam-1和lfa-3,并且分别包含seqidno:15、18和21。上述重组质粒还含有选择盒,该选择盒包含合成牛痘病毒启动子(ps)、抗药基因gpt、内部核糖体进入位点(ires)和增强型绿色荧光蛋白(egfp),以及抗药基因鸟嘌呤-黄嘌呤磷酸核糖基转移酶(ecogpt)与单体红色荧光蛋白的组合。所有选择基因(gfp、nptii和mrfp1)均由单个双顺反子转录物编码。用牛痘病毒(对于mbn399/400)、mva-bn(对于mbn336、mbn420)或fpv(对于mbn373)接种cef培养物,并且每种cef培养物也用质粒dna转染。继而,将来自这些细胞培养物的样品接种于含有选择药物的培养基中的cef培养物中,并通过斑块纯化来分离表达egfp的病毒克隆。在存在选择药物的情况下生长并表达egfp的病毒原种被指定为以下之一:mbn399、mbn400(牛痘病毒)、mbn336、mbn420(mva病毒)和mbn373(鸡痘)。重组病毒的产生和病毒原种的制备涉及5-12次连续传代,包括一(1)次至五(5)次斑块纯化。在不存在选择药物的情况下使重组痘病毒在cef细胞培养物中传代。不存在选择药物允许编码选择基因、gpt和egfp以及相关启动子的区(选择盒)从插入的序列中丢失。导致选择盒丢失的重组由在每个构建体的质粒中侧接选择盒的f1i4l区和该区的子段(即f1重复(f1rpt))介导。包括这些重复序列以介导导致选择盒丢失的重组,从而仅留下插入本文所述的构建体的所述基因间区中的muc1和cea序列制备了从斑块纯化的缺少选择盒的病毒。这种制备涉及十五(15)次传代,这些传代包括五(5)次斑块纯化。通过pcr分析确认了mbn336、mbn420和mbn373原种中存在muc1和cea序列而不存在亲代mva-bn病毒,并且使用巢式pcr验证了不存在选择盒(gpt和egfp基因/nptii和mrfp1)。在体外在接种mva-bn-muc1-cea-tricom的细胞中展示了muc1和cea蛋白的表达。实施例2:mva-mbn336第1-7次传代的pcr分析通过七次传代培养评估了mva-mbn336b的遗传稳定性。mva-mbn336b编码5个人转基因,其中人粘蛋白1(muc-1)和人癌胚抗原(cea)是该疫苗候选物的靶抗原,以及以下3个编码人类免疫共刺激分子的基因(称为共刺激分子的三联体或tricom)(作为诱导强烈和定向免疫应答的支持):白细胞功能相关抗原-3(lfa-3)、细胞内粘附分子1(icam-1)和b7-1。将转基因插入mva-的三个基因间区(igr):含有cea的igr44/45、含有hmuc1的igr88/89和含有tricom基因的igr148/149。转基因表达由痘病毒启动子40k-mva1、30k、i3l和prs驱动。制备原代鸡胚成纤维细胞(cef),接种于滚瓶(rb)(7x107个细胞)的vp-sfm培养基中,并在37℃下温育4天。将vp-sfm培养基更换为100mlrpmi培养基,并参考1x108个细胞/rb的细胞数以大约.3-00.1的moi感染细胞,然后在30℃下培养3天。在温育后,通过以下步骤来收获病毒样品:将rb在-20℃下冷冻至少16h,然后解冻rb以收集细胞病毒悬液。测定细胞悬浮液的准确体积,对病毒样品进行超声处理,随后等分并储存在80℃下。重复该过程六次,导致七次传代。在30℃下培养后,对每次传代进行所插入的转基因的pcr分析。图9a示出了cea在七次传代中的稳定性的pcr结果。图9b示出了muc1在七次传代中的稳定性的pcr结果。图9c示出了tricom在7次传代中的稳定性的pcr结果。用于产生mva-mbn336b的重组质粒用作阳性对照,mva-用作阴性对照(空载体骨架),h2o用作pcr反应的对照。图10a和图10b展示了第7代样品的分析。图10a是第7代样品的pcr扩增,其送样以进行测序分析。对每个单独的转基因进行单独的pcr扩增:cea、muc1和tricom。b)muc1核苷酸序列的电泳图,其描绘了含有导致移码的检测到的点突变的基因座。在第5次传代由pcr扩增首次检测到点突变,muc1核苷酸序列的电泳图描绘了含有导致移码的检测到的点突变的基因座。在分析于第5次传代、第6次传代和第7代出现的突变的电泳图中,在第5次传代中首次检测到点突变。如图9和图10所示,与panvac-v和panvac-f中的muc1、cea和tricom转基因相比,mbn336中的muc1、cea和tricom组合展示出改善和增加的稳定性(比较例如图1和表1及表2与图3和图4)。从第5次传代开始,在少数分析的材料中检测到移码突变。到第4代所展示的稳定性证实了mva-mbn336能够克服与panvac和产生包含muc1的稳定痘病毒的其他尝试相关联的稳定性问题。mva-mbn336的稳定性在其他方面是有利的,因为基于mva的疫苗的制造和大规模生产典型地由mva在第3代或第4代获得。因此,由于mva-mbn336能稳定到第4代,因此可以开始大规模产生,并且可以克服关于稳定性的重大监管障碍。实施例3:fpv-mbn373的改善的稳定性评估了七次传代中fpv-mbn373b的遗传稳定性。在用于制造临床试验材料的大规模生产期间应用的滚瓶(rb)中进行培养。通过流式细胞术测定法分析每次传代的病毒滴度,并通过pcr分析转基因插入物的正确大小。此外,通过转基因测序来分析最后一次传代(p7)。制备了原代鸡胚成纤维细胞(cef),接种于rb(7x107个细胞/rb)的vp-sfm培养基中,并在37℃下温育3天。将vp-sfm培养基更换为100mlrpmi培养基,并参考1x108个/rb的细胞数以0.1的moi感染细胞,然后在37℃下培养4天。在温育后,通过以下步骤来收获病毒样品:将rb在-20℃下冷冻至少16h,然后解冻rb以收集细胞病毒悬液。测定细胞悬浮液的准确体积,对病毒样品进行超声处理,随后等分并储存在80℃下。在每次传代后测定感染性病毒滴度,以监测病毒滴度并使得可以用限定的moi进行下一次传代感染。重复该过程六次,导致七次传代。如图11a所示,在37℃下培养后,对每次传代进行插入的转基因的pcr分析。用于产生fpv-mbn373b的重组质粒用作阳性对照,fpv用作阴性对照(空载体骨架),h2o用作pcr反应的对照。如图11b所示,在bamhij位点(含有转基因和至少600bp的每个邻接区)的扩增后进行第七次传代的测序。在第七次传代分析的fpv-mbn373b的pcr扩增子(37℃)产生预期5566bp(pcr1)和5264bp(pcr2)的条带大小,涵盖了插入的转基因和至少600bp的每个邻接区。结果显示组装序列与理论序列相比具有100%同一性,从而确认了fpv-mbn373b在37℃下的7次传代中具有遗传稳定性。在至少一个方面,muc1转基因(seqidno:3)在mbn373中的所得稳定性是令人惊讶的,因为mbn373和mbn336均包括seqidno:3。因此,虽然seqidno:3的muc1在mbn336(mva病毒)中在第5次传代开始显示出不稳定性,但是相同的seqidno:3在mbn373(鸡痘病毒)中稳定至少直到第7代。实施例4:mva-mbn420的稳定性评估了七次传代中mva-mbn420的遗传稳定性。在用于制造临床试验材料的大规模生产期间应用的滚瓶(rb)中进行培养。该研究使用大约0.05至0.1的moi和4天的病毒温育期在30℃和34℃下进行,因为这些条件代表了用于制造临床试验材料的典型大规模生产。通过流式细胞术测定法分析每次传代的病毒滴度,并通过pcr分析转基因插入物的正确大小。制备了原代鸡胚成纤维细胞(cef),接种于rb(7x107个细胞/rb)的vp-sfm培养基中,并在37℃下温育3天。将vp-sfm培养基更换为100mlrpmi培养基,并参考1x108个/rb的细胞数以0.05至0.1的moi感染细胞,然后在30℃和34℃下培养4天。在温育后,通过以下步骤来收获病毒样品:将rb在-20℃下冷冻至少16h,然后解冻rb以收集细胞病毒悬液。对病毒样品进行超声处理,随后等分并储存在80℃下。在每次传代后测定感染性病毒滴度,以监测病毒滴度并使得可以用限定的moi进行下一次传代感染。重复该过程六次,导致七次传代。在30℃下培养4后,对每次传代进行插入的转基因的pcr分析。在30℃下进行的传代结果如图12所示。用于产生mbn420的重组质粒用作阳性对照,mva-bn用作阴性对照(空载体骨架),h2o用作pcr反应的对照。如图12所示,与mbn336中的mva和mbn373中的鸡痘病毒相比,mbn420中mva的稳定性降低。实施例5:编码muc1和cea的另外的重组mva和重组鸡痘病毒的稳定性提高如实施例1所述产生了本发明的另外的重组mva和重组鸡痘病毒。如实施例1所述将包含seqidno:31、32、33或34(对于muc1)和seqidno:13或14(对于cea)的编码muc1、cea和tricom转基因的核酸插入mva-bn中。另外,如实施例1所述,将tricom插入mva中,将包含seqidno:15或17(对于b7.1)、seqidno:18或20(对于icam-1)和seqidno:21或23(对于lfa-3)的tricom序列插入mva中。另外,如实施例1所述,将包含seqidno:31、32、33或34(对于muc1)和seqidno:13或14(对于cea)的编码muc1和cea转基因的核酸插入mva-bn中。另外,如实施例1所述,将tricom插入鸡痘病毒中,将包含seqidno:15或17(对于b7.1)、seqidno:18或20(对于icam-1)和seqidno:21或23(对于lfa-3)的tricom序列插入鸡痘中。seqidno:31、32、33或34各自编码包含seqidno:35的muc1肽。seqidno:31、32、33和34的新型muc1核酸各自编码不含来自wo2013/103658的激动剂表位的本发明的核酸的变型。在若干方面,取代和/或移除激动剂表位不影响本发明的重组痘病毒的稳定性,因为激动剂表位的存在起到增强muc1的免疫原性而非稳定性或不稳定性的作用。如实施例1所述,在体外在接种mva-bn-muc1-cea-tricom的细胞中展示了muc1、cea和tricom蛋白的表达。在七次传代中评估了mva和/或鸡痘病毒中转基因的改善的遗传稳定性。在用于制造临床试验材料的大规模生产期间应用的滚瓶(rb)中进行培养。该研究使用大约00.05-00.1的moi和2、3、4、5、6或7天的病毒温育期在30℃、34℃或37℃(取决于所用的载体系统)下进行,因为这些条件代表了用于制造临床试验材料的典型大规模生产。通过流式细胞术测定法分析每次传代的病毒滴度,并通过pcr分析转基因插入物的正确大小。此外,通过转基因测序来分析最后一次传代(p7)。制备原代鸡胚成纤维细胞(cef),接种于rb(7x107个细胞/rb)的vp-sfm培养基中,并在37℃下温育3天。将vp-sfm培养基更换为100mlrpmi培养基,并以0.005至0.1的moi感染细胞,然后在30℃、34℃或37℃(取决于所用的载体系统)下培养4天。在温育后,通过以下步骤来收获病毒样品:将rb在-20℃下冷冻至少16h,然后解冻rb以收集细胞病毒悬液。对病毒样品进行超声处理,随后等分并储存在80℃下。在每次传代后测定感染性病毒滴度,以监测病毒滴度并使得可以用限定的moi进行下一次传代感染。重复该过程六次,导致七次传代。在30℃、34℃或37℃(取决于载体系统)下培养后,对每次传代进行插入的转基因的pcr分析。用于产生每种对应的痘病毒(例如,mva-bn或鸡痘病毒)的重组质粒用作阳性对照,mva-bn或鸡痘病毒用作阴性对照(空载体骨架),h2o用作pcr反应的对照。在igr位点(含有转基因和至少600bp的每个邻接区)的扩增后进行第七次传代的测序。在第七次传代分析每个构建体的pcr扩增子。进行muc1、cea和/或tricom核酸的测序结果以验证在这些转基因之中mva和/或鸡痘病毒是稳定的。将显而易见的是,本文所述的方法或组合物的精确细节可在不脱离所述发明的精神的情况下加以改变或修改。我们要求保护在所附权利要求的范围和精神内的所有此类修改和变化。序列表<110>巴法里安诺迪克有限公司(bavariannordica/s)<120>用于增强痘病毒中转基因的稳定性的组合物和方法<130>bnit0011pct<140><141><160>35<170>patentin3.5版<210>1<211>1548<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的muc1编码序列<400>1atgacaccgggcacccagtctcctttcttcctgctgctgctcctcacagtgcttacagtt60gttacgggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagagaagttcagtgcccagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagccccggttcaggctcctccaccactcagggacaggatgtcactctg240gccccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacctcg300gtaccagttactagaccagctttaggtagcacagcacctcctgctcatggagtaactagt360gctcctgatactcgtccagctcctggcagtactgcaccaccggcacatggcgtaacatca420gcacctgatacaagacctgcacctggatctacagcgccgcctgcgcacggagtgacatcg480gcgcccgatacgcgccccgctcccggtagcaccgcaccgcccgcccacggtgttacaagt540gcacccgatacccggccggcacccggaagtaccgctccacctgcacacggggtcacaagc600gcgccagacactcgacctgcgccagggtcgactgcccctccggcgcatggtgtgacctca660gctcctgacacaaggccagccccagctagcactctggtgcacaacggcacctctgccagg720gctaccacaaccccagccagcaagagcactccattctcaattcccagccaccactctgat780actcctaccacccttgccagccatagcaccaagactgatgccagtagcactcaccatagc840acggtacctcctctcacctcctccaatcacagcacttctccccagttgtctactggggtc900tctttctttttcctgtcttttcacatttcaaacctccagtttaattcctctctggaagat960cccagcaccgactactaccaagagctgcagagagacatttctgaaatgtttttgcagatt1020tataaacaagggggttttctgggcctctccaatattaagttcaggccaggatctgtggtg1080gtacaattgactctggccttccgagaaggtaccatcaatgtccacgacgtggagacacag1140ttcaatcagtataaaacggaagcagcctctcgatataacctgacgatctcagacgtcagc1200gtgagtgatgtgccatttcctttctctgcccagtctggggctggggtgccaggctggggc1260atcgcgctgctggtgctggtctgtgttctggttgcgctggccattgtctatctcattgcc1320ttggctgtctgtcagtgccgccgaaagaactacgggcagctggacatctttccagcccgg1380gatacctaccatcctatgagcgagtaccccacctaccacacccatgggcgctatgtgccc1440cctagcagtaccgatcgtagcccctatgagaaggtttctgcaggtaatggtggcagcagc1500ctctcttacacaaacccagcagtggcagccacttctgccaacttgtag1548<210>2<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn336的muc1编码序列<400>2atgacaccgggcacccagtctcctttcttcctgctgctgctcctcacagtgcttacagtt60gttacgggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagagaagttcagtgcccagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctcctccaccactcagggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacctcg300gtaccagttactagaccagctttaggctacctggcgccaccggctcatggcgttacatcg360tatttggacactcgaccggcaccagttagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaacggcacctctgccagg540gctaccacaaccccagccagcaagagcactccattctcaattcccagccaccactctgat600actcctaccacccttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctcctctcacctcctccaatcacagcacttctccccagttgtctactggggtc720tctttctttttcctgtcttttcacatttcaaacctccagtttaattcctctctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgaaatgtttttgcagatt840tataaacaagggggttttctgggcctctccaatattaagttcaggccaggatctgtggtg900gtacagttgactctggccttccgagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataaaacggaagcagcctctcgatataacctgacgatctcagacgtcagc1020gtgagtgatgtgccatttcctttctctgcccagtctggggctggggtgccaggctggggc1080atcgcgctgctggtgctggtctgtgttctggtttacctggccattgtctatctcattgcc1140ttggctgtctgtcaggtccgccgaaagaactacgggcagctggacatctttccagcccgg1200gatacctaccatcctatgagcgagtaccccacctaccacacccatgggcgctatgtgccc1260cctagcagtctgttccgtagcccctatgagaaggtttctgcaggtaatggtggcagctac1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>3<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn373的muc1编码序列<400>3atgacaccgggcacccagtctcctttcttcctgctgctgctcctcacagtgcttacagtt60gttacgggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagagaagttcagtgcccagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctcctccaccactcagggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacctcg300gtaccagttactagaccagctttaggctacctggcgccaccggctcatggcgttacatcg360tatttggacactcgaccggcaccagttagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaacggcacctctgccagg540gctaccacaaccccagccagcaagagcactccattctcaattcccagccaccactctgat600actcctaccacccttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctcctctcacctcctccaatcacagcacttctccccagttgtctactggggtc720tctttctttttcctgtcttttcacatttcaaacctccagtttaattcctctctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgaaatgtttttgcagatt840tataaacaagggggttttctgggcctctccaatattaagttcaggccaggatctgtggtg900gtacagttgactctggccttccgagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataaaacggaagcagcctctcgatataacctgacgatctcagacgtcagc1020gtgagtgatgtgccatttcctttctctgcccagtctggggctggggtgccaggctggggc1080atcgcgctgctggtgctggtctgtgttctggtttacctggccattgtctatctcattgcc1140ttggctgtctgtcaggtccgccgaaagaactacgggcagctggacatctttccagcccgg1200gatacctaccatcctatgagcgagtaccccacctaccacacccatgggcgctatgtgccc1260cctagcagtctgttccgtagcccctatgagaaggtttctgcaggtaatggtggcagctac1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>4<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn398和mbn400的muc1编码序列<400>4atgacacctggcactcagtcaccattcttcctgctgttactcttgacagtgcttacagtt60gttacaggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagcggagttcagtgcctagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctccagcaccactcaaggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacatcg300gtaccagttactagaccagctttaggcagtactgcgccaccggctcatggcgttacatcg360gcacctgacactcgaccggcaccaggtagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaatggcacatctgccagg540gctaccacaactccagccagcaagagcactccattctcaattccaagccatcactctgat600actcctaccacacttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctccactcacctcatccaatcacagcacttctcctcagttgtctactggagtc720tccttctttttcctgtcctttcacatttcaaacttgcagttcaattcttccctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgagatgttcttgcagatt840tataaacaaggtggattccttggcctctctaatattaagttcaggccaggatctgtggtc900gtacagttgactctggccttcagagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataagacggaagcagcctcacgatataacctgacgatctcagacgtcagc1020gttagtgatgtgccatttcctttctctgcccagtctggagctggtgtgccaggctggggc1080atcgcgctgctcgtgttggtctgtgttctggttgcgctggccattgtctatctcattgcc1140ttggctgtttgtcagtgcagacgcaagaactacggacagctggacatctttccagctcgg1200gatacctaccatcctatgagcgagtaccctacctaccacacacatggtcgctatgtgcca1260cctagcagtaccgatcgtagtccctatgagaaagtttctgcaggtaatggtggcagcagc1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>5<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn420的muc1核酸序列<400>5atgacacctggcactcagtcaccattcttcctgctgttactcttgacagtgcttacagtt60gttacaggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagcggagttcagtgcctagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctccagcaccactcaaggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacatcg300gtaccagttactagaccagctttaggctacctggcgccaccggctcatggcgttacatcg360tatttggacactcgaccggcaccagttagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaatggcacatctgccagg540gctaccacaactccagccagcaagagcactccattctcaattccaagccatcactctgat600actcctaccacacttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctccactcacctcatccaatcacagcacttctcctcagttgtctactggagtc720tccttctttttcctgtcctttcacatttcaaacttgcagttcaattcttccctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgagatgttcttgcagatt840tataaacaaggtggattccttggcctctctaatattaagttcaggccaggatctgtggtc900gtacagttgactctggccttcagagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataagacggaagcagcctcacgatataacctgacgatctcagacgtcagc1020gttagtgatgtgccatttcctttctctgcccagtctggagctggtgtgccaggctggggc1080atcgcgctgctcgtgttggtctgtgttctggtttacctggccattgtctatctcattgcc1140ttggctgtttgtcaggtcagacgcaagaactacggacagctggacatctttccagctcgg1200gatacctaccatcctatgagcgagtaccctacctaccacacacatggtcgctatgtgcca1260cctagcagtctgttccgtagtccctatgagaaagtttctgcaggtaatggtggcagctac1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>6<211>515<212>prt<213>人工序列(artificialsequence)<220><221><222><223>存在于panvac中的muc1氨基酸序列<400>6metthrproglythrglnserprophepheleuleuleuleuleuthr151015valleuthrvalvalthrglyserglyhisalaserserthrprogly202530glyglulysgluthrseralathrglnargserservalproserser354045thrglulysasnalavalsermetthrserservalleuserserhis505560serproglyserglyserserthrthrglnglyglnaspvalthrleu65707580alaproalathrgluproalaserglyseralaalaleutrpglygln859095aspvalthrservalprovalthrargproalaleuglyserthrala100105110proproalahisglyvalthrseralaproaspthrargproalapro115120125glyserthralaproproalahisglyvalthrseralaproaspthr130135140argproalaproglyserthralaproproalahisglyvalthrser145150155160alaproaspthrargproalaproglyserthralaproproalahis165170175glyvalthrseralaproaspthrargproalaproglyserthrala180185190proproalahisglyvalthrseralaproaspthrargproalapro195200205glyserthralaproproalahisglyvalthrseralaproaspthr210215220argproalaproalaserthrleuvalhisasnglythrseralaarg225230235240alathrthrthrproalaserlysserthrpropheserileproser245250255hishisseraspthrprothrthrleualaserhisserthrlysthr260265270aspalaserserthrhishisserthrvalproproleuthrserser275280285asnhisserthrserproglnleuserthrglyvalserphephephe290295300leuserphehisileserasnleuglnpheasnserserleugluasp305310315320proserthrasptyrtyrglngluleuglnargaspileserglumet325330335pheleuglniletyrlysglnglyglypheleuglyleuserasnile340345350lyspheargproglyservalvalvalglnleuthrleualaphearg355360365gluglythrileasnvalhisaspvalgluthrglnpheasnglntyr370375380lysthrglualaalaserargtyrasnleuthrileseraspvalser385390395400valseraspvalprophepropheseralaglnserglyalaglyval405410415proglytrpglyilealaleuleuvalleuvalcysvalleuvalala420425430leualailevaltyrleuilealaleualavalcysglncysargarg435440445lysasntyrglyglnleuaspilepheproalaargaspthrtyrhis450455460prometserglutyrprothrtyrhisthrhisglyargtyrvalpro465470475480proserserthraspargserprotyrglulysvalseralaglyasn485490495glyglyserserleusertyrthrasnproalavalalaalathrser500505510alaasnleu515<210>7<211>60<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的vntr#2编码序列<400>7ggcagtactgcaccaccggcacatggcgtaacatcagcacctgatacaagacctgcacct60<210>8<211>60<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn420和mbn336的vntr#1编码序列<400>8ggctacctggcgccaccggctcatggcgttacatcgtatttggacactcgaccggcacca60<210>9<211>60<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的vntr#1编码序列<400>9ggtagcacagcacctcctgctcatggagtaactagtgctcctgatactcgtccagctcct60<210>10<211>60<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn420和mbn336的vntr#2编码序列<400>10gttagcacagcacctcccgcacacggtgtaactagcgcgcctgatacacgtcccgctccc60<210>11<211>60<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的vntr#3编码序列<400>11ggatctacagcgccgcctgcgcacggagtgacatcggcgcccgatacgcgccccgctccc60<210>12<211>60<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn420和mbn336的vntr#3编码序列<400>12ggatctaccgctccgccagcgcacggagtgacgtcagcaccagatacgaggccagcgcct60<210>13<211>2103<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的cea编码序列<400>13atggagtctccctcggcccctccccacagatggtgcatcccctggcagaggctcctgctc60acagcctcacttctaaccttctggaacccgcccaccactgccaagctcactattgaatcc120acgccgttcaatgtcgcagaggggaaggaggtgcttctacttgtccacaatctgccccag180catctttttggctacagctggtacaaaggtgaaagagtggatggcaaccgtcaaattata240ggatatgtaataggaactcaacaagctaccccagggcccgcatacagtggtcgagagata300atataccccaatgcatccctgctgatccagaacatcatccagaatgacacaggattctac360accctacacgtcataaagtcagatcttgtgaatgaagaagcaactggccagttccgggta420tacccggaactccctaagccttctattagctccaataatagtaagcctgtcgaagacaaa480gatgccgtcgcttttacatgcgagcccgaaactcaagacgcaacatatctctggtgggtg540aacaaccagtccctgcctgtgtcccctagactccaactcagcaacggaaatagaactctg600accctgtttaacgtgaccaggaacgacacagcaagctacaaatgcgaaacccaaaatcca660gtcagcgccaggaggtctgattcagtgattctcaacgtgctttacggacccgatgctcct720acaatcagccctctaaacacaagctatagatcaggggaaaatctgaatctgagctgtcat780gccgctagcaatcctcccgcccaatacagctggtttgtcaatggcactttccaacagtcc840acccaggaactgttcattcccaatattaccgtgaacaatagtggatcctacacgtgccaa900gctcacaatagcgacaccggactcaaccgcacaaccgtgacgacgattaccgtgtatgag960ccaccaaaaccattcataactagtaacaattctaacccagttgaggatgaggacgcagtt1020gcattaacttgtgagccagagattcaaaataccacttatttatggtgggtcaataaccaa1080agtttgccggttagcccacgcttgcagttgtctaatgataaccgcacattgacactcctg1140tccgttactcgcaatgatgtaggaccttatgagtgtggcattcagaatgaattatccgtt1200gatcactccgaccctgttatccttaatgttttgtatggcccagacgacccaactatatct1260ccatcatacacctactaccgtcccggcgtgaacttgagcctttcttgccatgcagcatcc1320aacccccctgcacagtactcctggctgattgatggaaacattcagcagcatactcaagag1380ttatttataagcaacataactgagaagaacagcggactctatacttgccaggccaataac1440tcagccagtggtcacagcaggactacagttaaaacaataactgtttccgcggagctgccc1500aagccctccatctccagcaacaactccaaacccgtggaggacaaggatgctgtggccttc1560acctgtgaacctgaggctcagaacacaacctacctgtggtgggtaaatggtcagagcctc1620ccagtcagtcccaggctgcagctgtccaatggcaacaggaccctcactctattcaatgtc1680acaagaaatgacgcaagagcctatgtatgtggaatccagaactcagtgagtgcaaaccgc1740agtgacccagtcaccctggatgtcctctatgggccggacacccccatcatttccccccca1800gactcgtcttacctttcgggagcggacctcaacctctcctgccactcggcctctaaccca1860tccccgcagtattcttggcgtatcaatgggataccgcagcaacacacacaagttctcttt1920atcgccaaaatcacgccaaataataacgggacctatgcctgttttgtctctaacttggct1980actggccgcaataattccatagtcaagagcatcacagtctctgcatctggaacttctcct2040ggtctctcagctggggccactgtcggcatcatgattggagtgctggttggggttgctctg2100ata2103<210>14<211>2103<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn373和mbn420的cea编码序列<400>14atggagtctccctcggctcctccacacagatggtgcatcccttggcagaggctcctgctc60acagcctcacttctaaccttctggaacccgcccaccactgccaagctcactattgaatcc120acgccgttcaatgtcgcagaggggaaggaggtgcttctacttgtccacaatctgcctcag180catctctttggctacagctggtacaaaggtgaaagagtggatggcaaccgtcaaattata240ggatatgtaataggaactcaacaagctactccagggcccgcatacagtggtcgagagata300atataccctaatgcatccctgctgatccagaacatcatccagaatgacacaggattctac360accctacacgtcataaagtcagatcttgtgaatgaagaagcaactggccagttccgggta420taccctgaactccctaagccttctattagctccaataatagtaagcctgtcgaagacaaa480gatgccgtcgctttcacatgcgagcccgaaactcaagacgcaacatatctctggtgggtg540aacaaccagtccctgcctgtgtctcctagactccaactcagcaacggaaatagaactctg600accctgtttaacgtgaccaggaacgacacagcaagctacaaatgcgaaacccaaaatcca660gtcagcgccaggaggtctgattcagtgattctcaacgtgctttacggacccgatgctcct720acaatcagccctctaaacacaagctatagatcaggagaaaatctgaatctgagctgtcat780gccgctagcaatcctccagctcaatacagctggtttgtcaatggcactttccaacagtcc840acccaggaactgttcattcccaatattaccgtgaacaatagtggatcctacacgtgccaa900gctcacaatagcgacaccggactcaaccgcacaaccgtgacgacgattaccgtgtatgag960ccaccaaaaccattcataactagtaacaattctaacccagttgaggatgaggacgcagtt1020gcattaacttgtgagccagagattcaaaataccacttatttatggtgggtcaataaccaa1080agtttgccggttagcccacgcttgcagttgtctaatgataaccgcacattgacactcctg1140tccgttactcgcaatgatgtaggaccttatgagtgtggcattcagaatgaattatccgtt1200gatcactccgaccctgttatccttaatgttttgtatggcccagacgacccaactatatct1260ccatcatacacctactaccgtcccggcgtgaacttgagcctttcttgccatgcagcatct1320aatccacctgcacagtactcctggctgattgatggaaacattcagcagcatactcaagag1380ttatttataagcaacataactgagaagaacagcggactctatacttgccaggccaataac1440tcagccagtggtcacagcaggactacagttaaaacaataactgtttccgcggagctgccc1500aagccctccatctccagcaacaactccaaacccgtggaggacaaggatgctgtggccttc1560acctgtgaacctgaggctcagaacacaacctacctgtggtgggtaaatggtcagagcctc1620ccagtcagtcccaggctgcagctgtccaatggcaacaggaccctcactctattcaatgtc1680acaagaaatgacgcaagagcctatgtatgtggaatccagaactcagtgagtgcaaaccgc1740agtgacccagtcaccctggatgtcctctatggaccggacacacccatcatttcacctcca1800gactcgtcttacctttcgggagcggacctcaacctctcctgccactcggcctctaaccca1860tctccgcagtattcttggcgtatcaatgggataccgcagcaacacacacaagttctcttt1920atcgccaaaatcacgccaaataataacgggacctatgcctgttttgtctctaacttggct1980actggccgcaataattccatagtcaagagcatcacagtctctgcatctggaacttctcct2040ggtctctcagctggagccactgtcggcatcatgattggagtgctggttggggttgctctg2100ata2103<210>15<211>864<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn373和mbn420的优化的b7.1编码序列<400>15atgggacacaccagaaggcagggcacaagcccatccaagtgtccctacctgaacttcttt60cagctcctggtgctggctggcctgtcccacttctgctccggagtgatccacgtgaccaag120gaggtcaaagaagtcgccacactgagctgcgggcacaatgtgtccgtggaggaactggct180cagacacggatctactggcagaaagagaagaaaatggtgctgaccatgatgtccggcgac240atgaacatctggcctgagtacaagaaccgcaccatcttcgacatcaccaacaatctgagc300atcgtgatcctcgctctgaggccctccgacgagggaacatacgagtgcgtggtgctgaag360tacgagaaggacgccttcaaacgcgagcacctggccgaggtcaccctgtccgtgaaggca420gacttcccaacacccagcatcagcgacttcgagatccctaccagcaacatccggcggatt480atctgcagcacctccggaggcttcccagagcctcacctgagctggctcgagaacggcgaa540gagctcaacgccatcaacactaccgtgtcccaggaccctgagacagagctgtacgctgtg600agcagcaagctggacttcaacatgaccacaaatcacagctttatgtgcctcatcaagtac660ggccacctgagagtgaatcagaccttcaactggaatacaaccaagcaggaacacttccca720gacaatctcctgccctcctgggctatcacactgattagcgtgaatggcatcttcgtgatc780tgctgtctgacctactgcttcgctcccagatgccgggagcgcaggagaaacgagaggctg840agacgggaatccgtgaggcccgtg864<210>16<211>864<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的b7.1编码序列<400>16atgggccacacacggaggcagggaacatcaccatccaagtgtccatacctcaatttcttt60cagctcttggtgctggctggtctttctcacttctgttcaggtgttatccacgtgaccaag120gaagtgaaagaagtggcaacgctgtcctgtggtcacaatgtttctgttgaagagctggca180caaactcgcatctactggcaaaaggagaagaaaatggtgctgactatgatgtctggagac240atgaatatatggcccgagtacaagaaccggaccatctttgatatcactaataacctctcc300attgtgatcctggctctgcgcccatctgacgagggcacatacgagtgtgttgttctgaag360tatgaaaaagacgctttcaagcgggaacacctggctgaagtgacgttatcagtcaaagct420gacttccctacacctagtatatctgactttgaaattccaacttctaatattagaaggata480atttgctcaacctctggaggttttccagagcctcacctctcctggttggaaaatggagaa540gaattaaatgccatcaacacaacagtttcccaagatcctgaaactgagctctatgctgtt600agcagcaaactggatttcaatatgacaaccaaccacagcttcatgtgtctcatcaagtat660ggacatttaagagtgaatcagaccttcaactggaatacaaccaagcaagagcattttcct720gataacctgctcccatcctgggccattaccttaatctcagtaaatggaattttcgtgata780tgctgcctgacctactgctttgccccacgctgcagagagagaaggaggaatgagagattg840agaagggaaagtgtacgccctgta864<210>17<211>864<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn336的优化的b7.1编码序列<400>17atgggccacaccagaaggcagggcaccagcccctccaagtgcccctacctgaacttcttc60cagctcctggtgctggccggcctgtcccacttctgctccggcgtgatccacgtgaccaaa120gaggtcaaagaagtcgccacactgagctgcggccacaatgtgtccgtggaggaactggct180cagacccggatctactggcagaaagaaaagaaaatggtgctgaccatgatgtccggcgac240atgaacatctggcctgagtacaagaaccgcaccatcttcgacatcaccaacaacctgagc300atcgtgatcctcgccctgaggccctccgacgagggcacctacgagtgcgtggtgctgaag360tacgagaaggacgccttcaagcgcgagcacctggccgaggtcaccctgtccgtgaaggcc420gacttcccaacccccagcatcagcgacttcgagatcccaaccagcaacatccggcggatc480atctgcagcacctccggcggcttccccgagcctcacctgagctggctcgagaacggcgaa540gaactcaacgccatcaacactaccgtgtcccaggaccccgagacagagctgtacgccgtg600agcagcaagctggacttcaacatgaccacaaaccacagctttatgtgcctcatcaagtac660ggccacctgagagtgaatcagaccttcaactggaacaccaccaagcaggaacacttcccc720gacaatctgctgccctcctgggctatcaccctgattagcgtgaatggcatcttcgtgatc780tgctgtctgacctactgcttcgcccccagatgccgggagcggcggagaaacgagcggctg840cggcgggaatccgtgaggcccgtg864<210>18<211>1596<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn373和mbn420的优化的icam-1编码序列<400>18atggctcctagctcacctagaccagctctgcctgccctgctcgtgctgctcggagctctg60ttccctggaccaggcaacgcccagaccagcgtgtcacctagcaaagtgattctgcccaga120ggaggctccgtgctggtcacatgtagcaccagctgcgaccagcccaagctcctcgggatc180gagacacctctgcccaagaaagagctgctcctgccaggcaacaatcggaaagtgtacgag240ctgtccaatgtgcaggaagatagccagcccatgtgctactccaactgtcccgacggccag300agcaccgccaagacctttctgaccgtgtactggacacctgagcgggtggaactggctcca360ctgcccagctggcagccagtgggcaagaatctgaccctgcggtgccaggtggaaggcgga420gctcccagagccaacctgacagtggtgctcctgagaggcgagaaagagctgaagcgggaa480cctgccgtgggcgagccagccgaagtgaccacaaccgtgctcgtgcggagggaccaccac540ggagccaacttcagctgcagaaccgagctggacctcaggccacagggcctggaactgttc600gagaacaccagcgctccctaccagctccagaccttcgtgctcccagcaacaccacctcag660ctggtgtcacctcgggtgctggaagtggacacccagggcacagtcgtgtgcagcctggac720ggcctgtttcccgtgtccgaagctcaggtccacctggctctcggagaccagagactgaac780cctaccgtgacctacggcaatgacagcttcagcgccaaggcctccgtgtccgtgaccgcc840gaggatgaaggcacccagaggctgacatgcgccgtgattctgggcaaccagagccaggaa900accctgcagaccgtcaccatctatagcttccctgcacctaatgtgatcctgacaaagccc960gaggtgtccgagggcactgaagtgaccgtgaaatgcgaggcccaccctagagccaaagtg1020accctgaacggcgtgccagcccagccactcggaccaagagcacagctcctgctgaaagcc1080acacccgaggataacggccggtccttctcctgcagcgctaccctcgaagtggccggacag1140ctgatccacaagaaccagaccagagagctgagagtgctgtacggccctagactggacgag1200agagactgcccaggcaactggacctggcccgagaactcccagcagacacccatgtgccag1260gcttggggcaacccactgccagagctgaagtgcctgaaggacggcaccttccctctgccc1320atcggcgagtccgtgacagtgaccagggacctggaaggcacctacctgtgcagagccaga1380tccacacagggcgaagtgacacgggaggtcaccgtgaatgtgctgtcacctcgctacgag1440atcgtgatcatcaccgtggtcgctgcagctgtgatcatgggcacagccggactgagcaca1500tacctgtacaaccggcagcggaagatcaagaagtacaggctgcagcaggcccagaaaggc1560acacccatgaagcccaacacccaggccactcctccc1596<210>19<211>1596<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的icam-1编码序列<400>19atggctcccagcagcccccggcccgcgctgcccgcactcctggtcctgctcggggctctg60ttcccaggacctggcaatgcccagacatctgtgtccccctcaaaagtcatcctgccccgg120ggaggctccgtgctggtgacatgcagcacctcctgtgaccagcccaagttgttgggcata180gagaccccgttgcctaaaaaggagttgctcctgcctgggaacaaccggaaggtgtatgaa240ctgagcaatgtgcaagaagatagccaaccaatgtgctattcaaactgccctgatgggcag300tcaacagctaaaaccttcctcaccgtgtactggactccagaacgggtggaactggcaccc360ctcccctcttggcagccagtgggcaagaaccttaccctacgctgccaggtggagggtggg420gcaccccgggccaacctcaccgtggtgctgctccgtggggagaaggagctgaaacgggag480ccagctgtgggggagcccgctgaggtcacgaccacggtgctggtgaggagagatcaccat540ggagccaatttctcgtgccgcactgaactggacctgcggccccaagggctggagctgttt600gagaacacctcggccccctaccagctccagacctttgtcctgccagcgactcccccacaa660cttgtcagcccccgggtcctagaggtggacacgcaggggaccgtggtctgttccctggac720gggctgttcccagtctcggaggcccaggtccacctggcactgggggaccagaggttgaac780cccacagtcacctatggcaacgactccttctcggccaaggcctcagtcagtgtgaccgca840gaggacgagggcacccagcggctgacgtgtgcagtaatactggggaaccagagccaggag900acactgcagacagtgaccatctacagctttccggcgcccaacgtgattctgacgaagcca960gaggtctcagaagggaccgaggtgacagtgaagtgtgaggcccaccctagagccaaggtg1020acgctgaatggggttccagcccagccactgggcccgagggcccagctcctgctgaaggcc1080accccagaggacaacgggcgcagcttctcctgctctgcaaccctggaggtggccggccag1140cttatacacaagaaccagacccgggagcttcgtgtcctgtatggcccccgactggacgag1200agggattgtccgggaaactggacgtggccagaaaattcccagcagactccaatgtgccag1260gcttgggggaacccattgcccgagctcaagtgtctaaaggatggcactttcccactgccc1320atcggggaatcagtgactgtcactcgagatcttgagggcacctacctctgtcgggccagg1380agcactcaaggggaggtcacccgcgaggtgaccgtgaatgtgctctccccccggtatgag1440attgtcatcatcactgtggtagcagccgcagtcataatgggcactgcaggcctcagcacg1500tacctctataaccgccagcggaagatcaagaaatacagactacaacaggcccaaaaaggg1560acccccatgaaaccgaacacacaagccacgcctccc1596<210>20<211>1596<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn336的优化的icam-1编码序列<400>20atggcccctagcagccctagaccagccctgcctgccctgctggtgctgctgggcgctctg60ttccccggacccggcaacgcccagaccagcgtgtcccccagcaaagtgattctgcccaga120ggcggctccgtgctggtcacatgtagcaccagctgcgaccagcccaagctcctcgggatc180gagacacccctgcccaagaaagagctgctgctgcccggcaacaaccggaaagtgtacgag240ctgtccaatgtgcaggaagatagccagcccatgtgctactccaactgccccgacggccag300agcaccgccaagacctttctgaccgtgtactggacccccgagcgggtggaactggcccca360ctgcccagctggcagcccgtgggcaagaatctgaccctgcggtgccaggtggaaggcgga420gcccccagagccaacctgacagtggtgctcctgcggggcgaaaaagagctgaagcgggag480cctgccgtgggcgagccagccgaagtgaccacaaccgtgctcgtgcggagggaccaccac540ggcgccaacttcagctgcagaaccgagctggacctcaggccacagggcctggaactgttc600gagaacaccagcgccccctaccagctccagaccttcgtgctcccagcaaccccccctcag660ctggtgtcccctcgggtgctggaagtggacacccagggcacagtcgtgtgcagcctggac720ggcctgtttcccgtgtccgaagctcaggtccacctggctctcggggaccagagactgaac780cctaccgtgacctacggcaatgacagcttcagcgccaaggcctccgtgtccgtgaccgcc840gaggatgagggcacccagaggctgacatgcgccgtgattctgggcaaccagagccaggaa900accctgcagaccgtcaccatctatagcttccctgcccccaatgtgatcctgacaaagccc960gaggtgtccgagggcactgaagtgaccgtgaaatgcgaggcccaccccagggccaaagtg1020accctgaacggcgtgccagcccagccactcggaccaagagcacagctcctgctgaaagcc1080acccccgaggataacggccggtccttctcctgcagcgctaccctcgaagtggccgggcag1140ctgatccacaagaaccagacccgggagctgagagtgctgtacggccccagactggacgag1200agagactgccccggcaactggacctggcccgagaactcccagcagacccccatgtgccag1260gcttggggcaacccactgccagagctgaagtgcctgaaggacggcaccttccctctgccc1320atcggcgagtccgtgacagtgacccgggacctggaaggcacctacctgtgccgggccaga1380tccacacagggcgaagtgacacgggaggtcaccgtgaatgtgctgtccccccgctacgag1440atcgtgatcatcaccgtggtcgctgcagctgtgatcatgggcacagccggcctgagcaca1500tacctgtacaaccggcagcggaagatcaagaagtacaggctgcagcaggcccagaaaggc1560acccccatgaagcccaacacccaggccacccctccc1596<210>21<211>750<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn373和mbn420的优化的lfa-3编码序列<400>21atggtggctggctctgatgcagggagagccctgggagtgctgtctgtcgtgtgcctgctg60cactgcttcggcttcatcagctgcttcagccagcagatctacggagtggtctacggcaac120gtgaccttccacgtgcccagcaacgtgcctctgaaagaggtgctctggaagaaacagaag180gacaaggtcgcagagctggagaacagcgagttccgggccttcagcagcttcaagaaccgg240gtgtacctggacaccgtgtccggcagcctgaccatctacaacctgaccagcagcgacgag300gacgagtacgagatggaaagccctaacatcaccgacaccatgaagttctttctgtacgtg360ctggaaagcctgcccagcccaacactgacctgtgccctgaccaacggctccatcgaggtg420cagtgcatgattcccgagcactacaactcccacagaggcctgatcatgtactcttgggac480tgccctatggaacagtgcaagcgcaacagcaccagcatctacttcaagatggagaacgac540ctccctcagaagatccagtgcacactgagcaatccactgttcaacaccacatccagcatc600atcctgacaacctgtattcccagcagtggccacagcagacacagatacgccctgatccct660attccactggccgtgatcaccacatgcatcgtgctgtacatgaacggcatcctgaagtgc720gaccggaagcccgaccggaccaacagcaac750<210>22<211>750<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自panvac的lfa-3编码序列<400>22atggttgctgggagcgacgcggggcgggccctgggggtcctcagcgtggtctgcctgctg60cactgctttggtttcatcagctgtttttcccaacaaatatatggtgttgtgtatgggaat120gtaactttccatgtaccaagcaatgtgcctttaaaagaggtcctatggaaaaaacaaaag180gataaagttgcagaactggaaaattctgaattcagagctttctcatcttttaaaaatagg240gtttatttagacactgtgtcaggtagcctcactatctacaacttaacatcatcagatgaa300gatgagtatgaaatggaatcgccaaatattactgataccatgaagttctttctttatgtg360cttgagtctcttccatctcccacactaacttgtgcattgactaatggaagcattgaagtc420caatgcatgataccagagcattacaacagccatcgaggacttataatgtactcatgggat480tgtcctatggagcaatgtaaacgtaactcaaccagtatatattttaagatggaaaatgat540cttccacaaaaaatacagtgtactcttagcaatccattatttaatacaacatcatcaatc600attttgacaacctgtatcccaagcagcggtcattcaagacacagatatgcacttataccc660ataccattagcagtaattacaacatgtattgtgctgtatatgaatggtattctgaaatgt720gacagaaaaccagacagaaccaactccaat750<210>23<211>750<212>dna<213>人工序列(artificialsequence)<220><221><222><223>来自mbn336的优化的lfa-3编码序列<400>23atggtggctggctctgatgcaggcagagccctgggcgtgctgtctgtcgtgtgcctgctg60cactgcttcggcttcatcagctgcttcagccagcagatctacggcgtggtgtacggcaac120gtgaccttccacgtgcccagcaacgtgcctctgaaagaggtgctctggaagaagcagaag180gacaaggtcgcagagctggaaaacagcgagttccgggccttcagcagcttcaagaaccgg240gtgtacctggacaccgtgtccggcagcctgaccatctacaacctgaccagcagcgacgag300gacgagtacgagatggaaagccccaacatcaccgacaccatgaagttctttctgtacgtg360ctggaaagcctgcccagccccaccctgacctgtgccctgaccaacggctccatcgaggtg420cagtgcatgatccccgagcactacaactcccaccggggcctgatcatgtactcttgggac480tgccctatggaaacgtgcaagcgcaacagcaccagcatctacttcaagatggaaaacgac540ctcccccagaaaatccagtgcaccctgagcaaccccctgttcaacaccacctccagcatc600atcctgaccacctgtatccccagcagcggccacagcagacacagatacgccctgatcccc660atccccctggccgtgatcaccacatgcatcgtgctgtacatgaacggcatcctgaagtgc720gaccggaagcccgaccggaccaacagcaac750<210>24<211>9<212>prt<213>人工序列(artificialsequence)<220><221><222><223>muc1激动剂表位<400>24tyrleualaproproalahisglyval15<210>25<211>9<212>prt<213>人工序列(artificialsequence)<220><221><222><223>muc1激动剂表位<400>25tyrleuaspthrargproalaproval15<210>26<211>10<212>prt<213>人工序列(artificialsequence)<220><221><222><223>muc1激动剂表位<400>26tyrleualailevaltyrleuilealaleu1510<210>27<211>10<212>prt<213>人工序列(artificialsequence)<220><221><222><223>muc1激动剂表位<400>27tyrleuilealaleualavalcysglnval1510<210>28<211>9<212>prt<213>人工序列(artificialsequence)<220><221><222><223>muc1激动剂表位<400>28tyrleusertyrthrasnproalaval15<210>29<211>9<212>prt<213>人工序列(artificialsequence)<220><221><222><223>muc1激动剂表位<400>29serleupheargserprotyrglulys15<210>30<211>455<212>prt<213>人工序列(artificialsequence)<220><221><222><223>存在于mbn336、mbn373和mbn420中的muc1氨基酸序列<400>30metthrproglythrglnserprophepheleuleuleuleuleuthr151015valleuthrvalvalthrglyserglyhisalaserserthrprogly202530glyglulysgluthrseralathrglnargserservalproserser354045thrglulysasnalavalsermetthrserservalleuserserhis505560serproglyserglyserserthrthrglnglyglnaspvalthrleu65707580alaproalathrgluproalaserglyseralaalaleutrpglygln859095aspvalthrservalprovalthrargproalaleuglytyrleuala100105110proproalahisglyvalthrsertyrleuaspthrargproalapro115120125valserthralaproproalahisglyvalthrseralaproaspthr130135140argproalaproglyserthralaproproalahisglyvalthrser145150155160alaproaspthrargproalaproalaserthrleuvalhisasngly165170175thrseralaargalathrthrthrproalaserlysserthrprophe180185190serileproserhishisseraspthrprothrthrleualaserhis195200205serthrlysthraspalaserserthrhishisserthrvalpropro210215220leuthrserserasnhisserthrserproglnleuserthrglyval225230235240serphephepheleuserphehisileserasnleuglnpheasnser245250255serleugluaspproserthrasptyrtyrglngluleuglnargasp260265270ileserglumetpheleuglniletyrlysglnglyglypheleugly275280285leuserasnilelyspheargproglyservalvalvalglnleuthr290295300leualaphearggluglythrileasnvalhisaspvalgluthrgln305310315320pheasnglntyrlysthrglualaalaserargtyrasnleuthrile325330335seraspvalservalseraspvalprophepropheseralaglnser340345350glyalaglyvalproglytrpglyilealaleuleuvalleuvalcys355360365valleuvaltyrleualailevaltyrleuilealaleualavalcys370375380glnvalargarglysasntyrglyglnleuaspilepheproalaarg385390395400aspthrtyrhisprometserglutyrprothrtyrhisthrhisgly405410415argtyrvalproproserserleupheargserprotyrglulysval420425430seralaglyasnglyglysertyrleusertyrthrasnproalaval435440445alaalathrseralaasnleu450455<210>31<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>不含来自wo2013/103658的激动剂表位的mbn336的muc1编码序列<400>31atgacaccgggcacccagtctcctttcttcctgctgctgctcctcacagtgcttacagtt60gttacgggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagagaagttcagtgcccagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctcctccaccactcagggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacctcg300gtaccagttactagaccagctttaggcagcacagcgccaccggctcatggcgttacatcg360gctcctgacactcgaccggcaccaggcagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaacggcacctctgccagg540gctaccacaaccccagccagcaagagcactccattctcaattcccagccaccactctgat600actcctaccacccttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctcctctcacctcctccaatcacagcacttctccccagttgtctactggggtc720tctttctttttcctgtcttttcacatttcaaacctccagtttaattcctctctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgaaatgtttttgcagatt840tataaacaagggggttttctgggcctctccaatattaagttcaggccaggatctgtggtg900gtacagttgactctggccttccgagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataaaacggaagcagcctctcgatataacctgacgatctcagacgtcagc1020gtgagtgatgtgccatttcctttctctgcccagtctggggctggggtgccaggctggggc1080atcgcgctgctggtgctggtctgtgttctggttgcactggccattgtctatctcattgcc1140ttggctgtctgtcagtgccgccgaaagaactacgggcagctggacatctttccagcccgg1200gatacctaccatcctatgagcgagtaccccacctaccacacccatgggcgctatgtgccc1260cctagcagtaccgatcgtagcccctatgagaaggtttctgcaggtaatggtggcagcagt1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>32<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>不含来自wo2013/103658的激动剂表位的mbn373的muc1编码序列<400>32atgacaccgggcacccagtctcctttcttcctgctgctgctcctcacagtgcttacagtt60gttacgggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagagaagttcagtgcccagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctcctccaccactcagggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacctcg300gtaccagttactagaccagctttaggcagcacagcgccaccggctcatggcgttacatcg360gctcctgacactcgaccggcaccaggcagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaacggcacctctgccagg540gctaccacaaccccagccagcaagagcactccattctcaattcccagccaccactctgat600actcctaccacccttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctcctctcacctcctccaatcacagcacttctccccagttgtctactggggtc720tctttctttttcctgtcttttcacatttcaaacctccagtttaattcctctctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgaaatgtttttgcagatt840tataaacaagggggttttctgggcctctccaatattaagttcaggccaggatctgtggtg900gtacagttgactctggccttccgagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataaaacggaagcagcctctcgatataacctgacgatctcagacgtcagc1020gtgagtgatgtgccatttcctttctctgcccagtctggggctggggtgccaggctggggc1080atcgcgctgctggtgctggtctgtgttctggttgcactggccattgtctatctcattgcc1140ttggctgtctgtcagtgccgccgaaagaactacgggcagctggacatctttccagcccgg1200gatacctaccatcctatgagcgagtaccccacctaccacacccatgggcgctatgtgccc1260cctagcagtaccgatcgtagcccctatgagaaggtttctgcaggtaatggtggcagcagt1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>33<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>不含来自wo2013/103658的激动剂表位的mbn420的muc1编码序列<400>33atgacacctggcactcagtcaccattcttcctgctgttactcttgacagtgcttacagtt60gttacaggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagcggagttcagtgcctagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctccagcaccactcaaggacaggatgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtcacatcg300gtaccagttactagaccagctttaggcagcacagcgccaccggctcatggcgttacatcg360gctcctgacactcgaccggcaccaggcagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaatggcacatctgccagg540gctaccacaactccagccagcaagagcactccattctcaattccaagccatcactctgat600actcctaccacacttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctccactcacctcatccaatcacagcacttctcctcagttgtctactggagtc720tccttctttttcctgtcctttcacatttcaaacttgcagttcaattcttccctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgagatgttcttgcagatt840tataaacaaggtggattccttggcctctctaatattaagttcaggccaggatctgtggtc900gtacagttgactctggccttcagagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataagacggaagcagcctcacgatataacctgacgatctcagacgtcagc1020gttagtgatgtgccatttcctttctctgcccagtctggagctggtgtgccaggctggggc1080atcgcgctgctcgtgttggtctgtgttctggttgcactggccattgtctatctcattgcc1140ttggctgtttgtcagtgcagacgcaagaactacggacagctggacatctttccagctcgg1200gatacctaccatcctatgagcgagtaccctacctaccacacacatggtcgctatgtgcca1260cctagcagtaccgatcgtagtccctatgagaaagtttctgcaggtaatggtggcagcagt1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>34<211>1365<212>dna<213>人工序列(artificialsequence)<220><221><222><223>不含来自wo2013/103658的激动剂表位的优化的mbn的muc1编码序列<400>34atgacacctggcactcagtcaccattcttcctgctgttactcttgacagtgcttacagtt60gttacaggttctggtcatgcaagctctaccccaggtggagaaaaggagacttcggctacc120cagcggagttcagtgcctagctctactgagaagaatgctgtgagtatgacaagctccgta180ctctccagccacagcccaggttcaggctccagcaccactcaaggacaggacgtcactctg240gcaccggccacggaaccagcttcaggttcagctgccttgtggggacaggatgtgacatcg300gtaccagttactagaccagctttaggcagcacagcgccaccggctcatggcgttacatcg360gctcctgacactcgaccggcaccaggcagcacagcacctcccgcacacggtgtaactagc420gcgcctgatacacgtcccgctcccggatctaccgctccgccagcgcacggagtgacgtca480gcaccagatacgaggccagcgcctgctagcactctggtgcacaatggcacatctgccagg540gctaccacaactccagccagcaagagcactccattctcaattccaagccatcactctgat600actcctaccacacttgccagccatagcaccaagactgatgccagtagcactcaccatagc660acggtacctccactcacctcatccaatcacagcacttctcctcagttgtctactggagtc720tccttctttttcctgtcctttcacatttcaaacttgcagttcaattcttccctggaagat780cccagcaccgactactaccaagagctgcagagagacatttctgagatgttcttgcagatt840tataaacaaggtggattccttggcctctctaatattaagttcaggccaggatctgtggtc900gtacagttgactctggccttcagagaaggtaccatcaatgtccacgacgtggagacacag960ttcaatcagtataagacggaagcagcctcacgatataacctgacgatctcagacgtcagc1020gttagtgatgtgccatttcctttctctgcccagtctggagctggtgtgccaggctggggc1080atcgcgctgctcgtgttggtctgtgttctggttgcactggccattgtctatctcattgcc1140ttggctgtttgtcagtgcagacgcaagaactacggacagctggacatctttccagctcgg1200gatacctaccatcctatgagcgagtaccctacctaccacacacatggtcgctatgtgcca1260cctagcagtaccgatcgtagtccctatgagaaagtttctgcaggtaatggtggcagcagt1320ctctcttacacaaacccagcagtggcagccacttctgccaacttg1365<210>35<211>455<212>prt<213>人工序列(artificialsequence)<220><221><222><223>不含来自wo2013/103658的激动剂表位的mbn336/mbn373/mbn420的muc1氨基酸<400>35metthrproglythrglnserprophepheleuleuleuleuleuthr151015valleuthrvalvalthrglyserglyhisalaserserthrprogly202530glyglulysgluthrseralathrglnargserservalproserser354045thrglulysasnalavalsermetthrserservalleuserserhis505560serproglyserglyserserthrthrglnglyglnaspvalthrleu65707580alaproalathrgluproalaserglyseralaalaleutrpglygln859095aspvalthrservalprovalthrargproalaleuglyserthrala100105110proproalahisglyvalthrseralaproaspthrargproalapro115120125glyserthralaproproalahisglyvalthrseralaproaspthr130135140argproalaproglyserthralaproproalahisglyvalthrser145150155160alaproaspthrargproalaproalaserthrleuvalhisasngly165170175thrseralaargalathrthrthrproalaserlysserthrprophe180185190serileproserhishisseraspthrprothrthrleualaserhis195200205serthrlysthraspalaserserthrhishisserthrvalpropro210215220leuthrserserasnhisserthrserproglnleuserthrglyval225230235240serphephepheleuserphehisileserasnleuglnpheasnser245250255serleugluaspproserthrasptyrtyrglngluleuglnargasp260265270ileserglumetpheleuglniletyrlysglnglyglypheleugly275280285leuserasnilelyspheargproglyservalvalvalglnleuthr290295300leualaphearggluglythrileasnvalhisaspvalgluthrgln305310315320pheasnglntyrlysthrglualaalaserargtyrasnleuthrile325330335seraspvalservalseraspvalprophepropheseralaglnser340345350glyalaglyvalproglytrpglyilealaleuleuvalleuvalcys355360365valleuvalalaleualailevaltyrleuilealaleualavalcys370375380glncysargarglysasntyrglyglnleuaspilepheproalaarg385390395400aspthrtyrhisprometserglutyrprothrtyrhisthrhisgly405410415argtyrvalproproserserthraspargserprotyrglulysval420425430seralaglyasnglyglyserserleusertyrthrasnproalaval435440445alaalathrseralaasnleu450455当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1