一种智能语音识别机器人及控制系统的制作方法
本发明涉及机器人领域,特别涉及一种智能语音识别机器人及控制系统。
背景技术:
随着生活水平的不断提高,卡拉OK练歌房在我国已经非常普遍。卡拉OK机的自动评分功能往往会引起一些人的兴趣,觉得机器能够自动评分是件挺神奇的事。但同时也会发现它有一个很大的缺点--评分不太准。本项目立足于近几年出现的一些数据处理和控制集成芯片,将一些语音信号处理的专用算法应用到评分系统中来,以改进现行系统,增强评分的准确性。
当这个想法被一个叫唐骏的中国留学生提出并付诸实践后,立即在日本引起了巨大的轰动。人们普遍都感到非常的新奇,都想尝试尝试这种有趣的机器,这就造就了第一个买下这项专利的三星公司的卡拉OK设备的销售量的飞涨,甚至有人评价说是这项发明挽救了当时处在市场危机中的三星公司。不过,过了一段时间人们发现这种机器有一种问题——评分不准。后来这项专利的发明者唐骏也公开表示,该系统的评分效果不是很准确,演唱时只要尽力模仿唐骏的声音就一定能得到高分。
所以研发一种具备高识别能力和识别准确性的智能语音识别机器人及控制系统就显得尤为重要。
技术实现要素:
鉴于此,本发明提供了一种智能语音识别机器人及控制系统,本发明具有识别准确、实时更新和结构简单等优点。
本发明采用的技术方案如下:
一种智能语音识别机器人,其特征在于,所述机器人包括:声音采集装置、闪存、硬盘存储器、数字信号处理控制中心、显示装置和数据更新装置;所述声音采集装置信号连接于数字信号处理控制中心;所述数字信号处理控制中心分别信号连接于显示装置、闪存和硬盘存储器;所述硬盘存储器信号连接于数据更新装置;所述数据更新装置信号连接于云端数据库。
采用上述技术方案,本发明的智能语音识别机器人能够实时采集到使用者的歌声,并对该歌声进行处理,针对处理后的结果和硬盘存储器中的样本声音进行比较和判断,最终对歌唱者的声音进行打分。
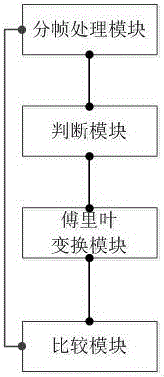
所述数字信号处理控制中心包括:分帧处理模块、判断模块、傅里叶变换模块和比较模块;所述分帧处理模块信号分别信号连接于声音采集装置、比较模块和判断模块;所述判断模块分别信号连接于傅里叶变换模块、闪存和硬盘存储器;所述傅里叶变换模块信号连接于比较模块;所述比较模块分别信号连接于显示装置分帧处理装置。
采用上述技术方案,数字信号处理控制中心对声音信号进行分帧处理后,将对分帧后的声音信号进行判断、傅里叶变换和比较处理。并根据判断模块的判断结果和比较模块的比较结果对声音信号进行打分,将打分结果发送至显示装置进行显示。
所述分帧处理模块,用于对采集到的声音信号进行分帧;所述判断模块,用于判断分帧处理后的声音信号是否协调;所述傅里叶变换模块,用于对判断模块处理后的信号进行傅里叶变换;所述比较模块,用于对傅里叶变换后的声音信号进行频域的比较。
所述分帧处理模块包括:分帧模块和判断模块;所述分帧模块分别信号连接于声音采集装置和判断模块,用于将声音信号进行分帧处理;所述判断模块信号连接于分帧模块,用于对分帧后的声音信号进行判断,判断其是否位于声音信号的最后一帧。
采用上述技术方案,分帧处理模块将对声音信号进行分帧处理。然后再针对每一帧的声音信号进行后续处理。可以对声音信号进行更高精度的识别和处理。
所述傅里叶变换模块包括:变换模块和幅度求取模块;所述变换模块分别信号连接于判断模块和幅度求取模块,用于对判断模块处理后的信号进行傅里叶变换处理;所述幅度求取模块分别信号连接于变换模块和比较模块,用于对傅里叶变换后的信号进行处理,求取该信号的短时平均幅度;所述比较模块,用于根据信号的短时平均幅度进行判断,判断其频域的幅度是否协调。
采用上述技术方案,傅里叶变换模块将对判断模块处理后的信号进行傅里叶变换,将时域的信号转换为频域的信号。再求取频域信号的幅度。
一种智能语音识别机器人的控制系统,其特征在于,所述系统运行包括以下步骤:
步骤1:机器人进行初始化;
步骤2:机器人中的声音采集装置开始采集声音信号;将采集到的声音信号发送给数字信号处理控制中心;
步骤3:数字信号处理控制中心接收到采集到的声音信号后,对声音信号进行处理,然后将处理后的声音信号存入闪存中;首先从硬盘存储器中获取声音样本;并对采集到的声音信号进行处理后和声音样本进行比较;将比较后的结果发送至显示装置进行显示;
步骤4:机器人在运行过程中从云端数据库中实时更新声音样本,将声音样本下载到硬盘存储器中。
采用上述技术方案,数字信号处理控制中心将对采集到的声音信号进行一系列的处理和操作,然后将处理后的声音信号存储进闪存中,再从硬盘存储器中调取样本,并将样本和处理后的声音信号进行对比,根据对比的结果得出分数,将分数发送给显示装置进行显示。
所述数字信号处理控制中心对采集到的声音信号进行处理的方法包括以下步骤:
步骤1:数字信号处理控制中心接收到声音采集装置采集到的声音信号后,分帧处理模块对声音信号进行分帧处理;将分帧处理后的每一帧声音信号发送至判断模块;
步骤2:判断模块对每一帧处理后的声音信号进行协调性判断;将判断结果进行保存后发送至傅里叶变换模块;
步骤3:傅里叶变换模块开始对声音信号进行傅里叶变换,将变换后的声音信号发送至比较模块;
步骤4:比较模块对傅里叶变换后的声音信号进行频域比较,将比较结果发送至闪存中进行暂存;
步骤5:分帧处理模块在处理声音信号时,会实时判断处理的是否是声音信号的最后一帧,如果是则调取闪存中的存储结果发送至显示装置进行显示;如果不是则继续执行步骤1。
采用上述技术方案,数字信号处理中心将采集到的声音信号进行分帧处理后,不仅要在时域进行能量求取,还要在频域对采集到的声音信号进行幅度求取。
所述判断模块对分帧处理后的声音信号进行协调性判断的方法包括以下步骤:
步骤1:求取分帧处理后的信号的短时能量,所述短时能量的求取方法采用如下公式:
,其中是声音信号在某一点的采样信号;
步骤2:根据求取出的短时能量区分出清音还是浊音信号;
步骤3:若分辨出是浊音信号,则从硬盘存储器中获取样本,同样提取声音信号在该点的采样,求取出短时能量;
步骤4:将浊音信号在该店的短时能量和样本在该点的短时能量进行对比,判断两者的差异,进而判断采集到的声音信号是否协调。
采用上述技术方案,因为语音一般由三部分组成:无音段、清音段和浊音段。无音段不存在语音信号,在背景噪声较低的情况下,幅度近似为零。清音信号的幅度很小,没有规律,类似于随机噪声。浊音信号幅度较大,波形的上下起伏近似呈现周期性,称之为准周期性。所以我们可以根据声音信号的短时能量判断出信号属于清音信号、浊音信号还是无音信号。
采用以上技术方案,本发明产生了以下有益效果:
1、识别准确:本发明的智能语音识别机器人,除了在时域对信号求取能量,针对该能量进行判断以外,还在频域针对信号的幅度进行求取和判断。根据两者的判断结果进行综合评判,将大大提高声音信号的识别准确性和评价的准确性。
2、实时更新:本发明的智能语音识别机器人,能够从云端实时获取最新的声音文件的样本,更新到本地的硬盘存储器中。保证了能够获取最新的声音样本,更加准确的评判使用者的歌声。
3、结构简单:本发明的智能语音识别机器人,整体结构简单。将核心处理部分都封装在数字信号处理控制中心中,外部的闪存、硬盘存储器、显示装置和声音采集装置的连接关系都一目了然。使得后期的维护和检修非常的方便,同时采用这种部件分离的方式,可以实现不同的厂商生产不同的组件,然后合并组装,降低了生产的成本。
附图说明
图1是本发明的一种智能语音识别机器人的系统结构示意图。
图2是本发明的一种智能语音识别机器人的数字信号处理控制中心的结构示意图。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
本说明书(包括任何附加权利要求、摘要)中公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
本发明实施例1中提供了一种智能语音识别机器人,系统结构如图1所示:
声音采集装置、闪存、硬盘存储器、数字信号处理控制中心、显示装置和数据更新装置;所述声音采集装置信号连接于数字信号处理控制中心;所述数字信号处理控制中心分别信号连接于显示装置、闪存和硬盘存储器;所述硬盘存储器信号连接于数据更新装置;所述数据更新装置信号连接于云端数据库。
采用上述技术方案,本发明的智能语音识别机器人能够实时采集到使用者的歌声,并对该歌声进行处理,针对处理后的结果和硬盘存储器中的样本声音进行比较和判断,最终对歌唱者的声音进行打分。
所述数字信号处理控制中心包括:分帧处理模块、判断模块、傅里叶变换模块和比较模块;所述分帧处理模块信号分别信号连接于声音采集装置、比较模块和判断模块;所述判断模块分别信号连接于傅里叶变换模块、闪存和硬盘存储器;所述傅里叶变换模块信号连接于比较模块;所述比较模块分别信号连接于显示装置分帧处理装置。
采用上述技术方案,数字信号处理控制中心对声音信号进行分帧处理后,将对分帧后的声音信号进行判断、傅里叶变换和比较处理。并根据判断模块的判断结果和比较模块的比较结果对声音信号进行打分,将打分结果发送至显示装置进行显示。
所述分帧处理模块,用于对采集到的声音信号进行分帧;所述判断模块,用于判断分帧处理后的声音信号是否协调;所述傅里叶变换模块,用于对判断模块处理后的信号进行傅里叶变换;所述比较模块,用于对傅里叶变换后的声音信号进行频域的比较。
所述分帧处理模块包括:分帧模块和判断模块;所述分帧模块分别信号连接于声音采集装置和判断模块,用于将声音信号进行分帧处理;所述判断模块信号连接于分帧模块,用于对分帧后的声音信号进行判断,判断其是否位于声音信号的最后一帧。
采用上述技术方案,分帧处理模块将对声音信号进行分帧处理。然后再针对每一帧的声音信号进行后续处理。可以对声音信号进行更高精度的识别和处理。
所述傅里叶变换模块包括:变换模块和幅度求取模块;所述变换模块分别信号连接于判断模块和幅度求取模块,用于对判断模块处理后的信号进行傅里叶变换处理;所述幅度求取模块分别信号连接于变换模块和比较模块,用于对傅里叶变换后的信号进行处理,求取该信号的短时平均幅度;所述比较模块,用于根据信号的短时平均幅度进行判断,判断其频域的幅度是否协调。
采用上述技术方案,傅里叶变换模块将对判断模块处理后的信号进行傅里叶变换,将时域的信号转换为频域的信号。再求取频域信号的幅度。
本发明实施例2中提供了一种智能语音识别机器人的控制系统:
一种智能语音识别机器人的控制系统,其特征在于,所述方法包括以下步骤:
步骤1:机器人进行初始化;
步骤2:机器人中的声音采集装置开始采集声音信号;将采集到的声音信号发送给数字信号处理控制中心;
步骤3:数字信号处理控制中心接收到采集到的声音信号后,对声音信号进行处理,然后将处理后的声音信号存入闪存中;首先从硬盘存储器中获取声音样本;并对采集到的声音信号进行处理后和声音样本进行比较;将比较后的结果发送至显示装置进行显示;
步骤4:机器人在运行过程中从云端数据库中实时更新声音样本,将声音样本下载到硬盘存储器中。
采用上述技术方案,数字信号处理控制中心将对采集到的声音信号进行一系列的处理和操作,然后将处理后的声音信号存储进闪存中,再从硬盘存储器中调取样本,并将样本和处理后的声音信号进行对比,根据对比的结果得出分数,将分数发送给显示装置进行显示。
所述数字信号处理控制中心对采集到的声音信号进行处理的方法包括以下步骤:
步骤1:数字信号处理控制中心接收到声音采集装置采集到的声音信号后,分帧处理模块对声音信号进行分帧处理;将分帧处理后的每一帧声音信号发送至判断模块;
步骤2:判断模块对每一帧处理后的声音信号进行协调性判断;将判断结果进行保存后发送至傅里叶变换模块;
步骤3:傅里叶变换模块开始对声音信号进行傅里叶变换,将变换后的声音信号发送至比较模块;
步骤4:比较模块对傅里叶变换后的声音信号进行频域比较,将比较结果发送至闪存中进行暂存;
步骤5:分帧处理模块在处理声音信号时,会实时判断处理的是否是声音信号的最后一帧,如果是则调取闪存中的存储结果发送至显示装置进行显示;如果不是则继续执行步骤1。
采用上述技术方案,数字信号处理中心将采集到的声音信号进行分帧处理后,不仅要在时域进行能量求取,还要在频域对采集到的声音信号进行幅度求取。
所述判断模块对分帧处理后的声音信号进行协调性判断的方法包括以下步骤:
,其中是声音信号在某一点的采样信号;
步骤2:根据求取出的短时能量区分出清音还是浊音信号;
步骤3:若分辨出是浊音信号,则从硬盘存储器中获取样本,同样提取声音信号在该点的采样,求取出短时能量;
步骤4:将浊音信号在该店的短时能量和样本在该点的短时能量进行对比,判断两者的差异,进而判断采集到的声音信号是否协调。
采用上述技术方案,因为语音一般由三部分组成:无音段、清音段和浊音段。无音段不存在语音信号,在背景噪声较低的情况下,幅度近似为零。清音信号的幅度很小,没有规律,类似于随机噪声。浊音信号幅度较大,波形的上下起伏近似呈现周期性,称之为准周期性。所以我们可以根据声音信号的短时能量判断出信号属于清音信号、浊音信号还是无音信号。
本发明实施例3中提供了一种智能语音识别机器人及控制系统,系统结构图如图1所示:
声音采集装置、闪存、硬盘存储器、数字信号处理控制中心、显示装置和数据更新装置;所述声音采集装置信号连接于数字信号处理控制中心;所述数字信号处理控制中心分别信号连接于显示装置、闪存和硬盘存储器;所述硬盘存储器信号连接于数据更新装置;所述数据更新装置信号连接于云端数据库。
采用上述技术方案,本发明的智能语音识别机器人能够实时采集到使用者的歌声,并对该歌声进行处理,针对处理后的结果和硬盘存储器中的样本声音进行比较和判断,最终对歌唱者的声音进行打分。
所述数字信号处理控制中心包括:分帧处理模块、判断模块、傅里叶变换模块和比较模块;所述分帧处理模块信号分别信号连接于声音采集装置、比较模块和判断模块;所述判断模块分别信号连接于傅里叶变换模块、闪存和硬盘存储器;所述傅里叶变换模块信号连接于比较模块;所述比较模块分别信号连接于显示装置分帧处理装置。
采用上述技术方案,数字信号处理控制中心对声音信号进行分帧处理后,将对分帧后的声音信号进行判断、傅里叶变换和比较处理。并根据判断模块的判断结果和比较模块的比较结果对声音信号进行打分,将打分结果发送至显示装置进行显示。
所述分帧处理模块,用于对采集到的声音信号进行分帧;所述判断模块,用于判断分帧处理后的声音信号是否协调;所述傅里叶变换模块,用于对判断模块处理后的信号进行傅里叶变换;所述比较模块,用于对傅里叶变换后的声音信号进行频域的比较。
所述分帧处理模块包括:分帧模块和判断模块;所述分帧模块分别信号连接于声音采集装置和判断模块,用于将声音信号进行分帧处理;所述判断模块信号连接于分帧模块,用于对分帧后的声音信号进行判断,判断其是否位于声音信号的最后一帧。
采用上述技术方案,分帧处理模块将对声音信号进行分帧处理。然后再针对每一帧的声音信号进行后续处理。可以对声音信号进行更高精度的识别和处理。
所述傅里叶变换模块包括:变换模块和幅度求取模块;所述变换模块分别信号连接于判断模块和幅度求取模块,用于对判断模块处理后的信号进行傅里叶变换处理;所述幅度求取模块分别信号连接于变换模块和比较模块,用于对傅里叶变换后的信号进行处理,求取该信号的短时平均幅度;所述比较模块,用于根据信号的短时平均幅度进行判断,判断其频域的幅度是否协调。
采用上述技术方案,傅里叶变换模块将对判断模块处理后的信号进行傅里叶变换,将时域的信号转换为频域的信号。再求取频域信号的幅度。
一种智能语音识别机器人的控制系统,其特征在于,所述方法包括以下步骤:
步骤1:机器人进行初始化;
步骤2:机器人中的声音采集装置开始采集声音信号;将采集到的声音信号发送给数字信号处理控制中心;
步骤3:数字信号处理控制中心接收到采集到的声音信号后,对声音信号进行处理,然后将处理后的声音信号存入闪存中;首先从硬盘存储器中获取声音样本;并对采集到的声音信号进行处理后和声音样本进行比较;将比较后的结果发送至显示装置进行显示;
步骤4:机器人在运行过程中从云端数据库中实时更新声音样本,将声音样本下载到硬盘存储器中。
采用上述技术方案,数字信号处理控制中心将对采集到的声音信号进行一系列的处理和操作,然后将处理后的声音信号存储进闪存中,再从硬盘存储器中调取样本,并将样本和处理后的声音信号进行对比,根据对比的结果得出分数,将分数发送给显示装置进行显示。
所述数字信号处理控制中心对采集到的声音信号进行处理的方法包括以下步骤:
步骤1:数字信号处理控制中心接收到声音采集装置采集到的声音信号后,分帧处理模块对声音信号进行分帧处理;将分帧处理后的每一帧声音信号发送至判断模块;
步骤2:判断模块对每一帧处理后的声音信号进行协调性判断;将判断结果进行保存后发送至傅里叶变换模块;
步骤3:傅里叶变换模块开始对声音信号进行傅里叶变换,将变换后的声音信号发送至比较模块;
步骤4:比较模块对傅里叶变换后的声音信号进行频域比较,将比较结果发送至闪存中进行暂存;
步骤5:分帧处理模块在处理声音信号时,会实时判断处理的是否是声音信号的最后一帧,如果是则调取闪存中的存储结果发送至显示装置进行显示;如果不是则继续执行步骤1。
采用上述技术方案,数字信号处理中心将采集到的声音信号进行分帧处理后,不仅要在时域进行能量求取,还要在频域对采集到的声音信号进行幅度求取。
所述判断模块对分帧处理后的声音信号进行协调性判断的方法包括以下步骤:
步骤1:求取分帧处理后的信号的短时能量,所述短时能量的求取方法采用如下公式:
,其中是声音信号在某一点的采样信号;
步骤2:根据求取出的短时能量区分出清音还是浊音信号;
步骤3:若分辨出是浊音信号,则从硬盘存储器中获取样本,同样提取声音信号在该点的采样,求取出短时能量;
步骤4:将浊音信号在该店的短时能量和样本在该点的短时能量进行对比,判断两者的差异,进而判断采集到的声音信号是否协调。
采用上述技术方案,因为语音一般由三部分组成:无音段、清音段和浊音段。无音段不存在语音信号,在背景噪声较低的情况下,幅度近似为零。清音信号的幅度很小,没有规律,类似于随机噪声。浊音信号幅度较大,波形的上下起伏近似呈现周期性,称之为准周期性。所以我们可以根据声音信号的短时能量判断出信号属于清音信号、浊音信号还是无音信号。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
- 还没有人留言评论。精彩留言会获得点赞!