一种可视化标记基因组位点的方法与流程
本发明属于生物技术领域,具体涉及一种可视化标记基因组位点的方法。
背景技术:
在人类细胞的细胞核中,大约32亿对碱基组合成庞大的人类基因组,并且进一步凝缩形成不同大小的23对染色体。尽管人类基因组计划的完成帮助我们获得了人类基因组的全部序列信息,但是这仅仅是我们认识人类基因组的结构,以及了解由基因组组成的染色质三维结构与人类发育、衰老和疾病等重要生物学过程之间关系的第一步。事实上,已有多项研究证明基因组结构失序是导致衰老和若干严重疾病的重要因素(Zhang,W.,etal.,Aging stem cells.A Werner syndrome stem cell model unveils heterochromatin alterations as a driver of human aging.Science,2015.348(6239):p.1160-3.2.Liu,G.H.,et al.,Progressive degeneration of human neural stem cells caused by pathogenic LRRK2.Nature,2012.491(7425):p.603-7.3.Misteli,T.,Higher-order genome organization in human disease.Cold Spring Harb Perspect Biol,2010.2(8):p.a000794.)。因此,明确人类基因组和由其构成的染色质的空间结构,及其与蛋白质和RNA调节子直接的相互作用,将非常有助于我们理解导致衰老和人类疾病的细胞生物学进程(Lopez-Otin,C.,etal.,The hallmarks of aging.Cell,2013.153(6):p.1194-217.2.Misteli,T.,Beyond the sequence:cellular organization of genome function.Cell,2007.128(4):p.787-800.3.Misteli,T.,The cell biology of genomes:bringing the double helix to life.Cell,2013.152(6):p.1209-12.)。
可视化的基因组标记技术可以大大提升对于基因组和染色质结构和功能研究的效率。尽管目前已有多种基因组可视化标记技术应用于科研,但是荧光标记Lac或Tet系统需要将约10kb的外源大片段整合进入基因组目的位点,因此存在低标记效率和潜在的基因组损伤等问题(Robinett,C.C.,etal.,In vivo localization of DNA sequences and visualization of large-scale chromatin organization using lac operator/repressor recognition.J Cell Biol,1996.135(6Pt 2):p.1685-700.2.Heun,P.,etal.,Chromosome dynamics in the yeast interphase nucleus.Science,2001.294(5549):p.2181-6.);荧光原位杂交(FISH)是目前研究特定序列在基因组中定位的金标准,但是该方法需要在化学固定的细胞中进行操作,因此无法实现活细胞中的基因组可视化标记(Levsky,J.M.and R.H.Singer,Fluorescence in situ hybridization:past,present and future.J Cell Sci,2003.116(Pt 14):p.2833-8.);尽管近年来兴起的CRISPR/Cas9技术可以实现端粒等基因组特殊位点的活细胞精确标记,但是细胞核内的高背景导致的低信噪比以及复杂的系统等缺点导致其无法在肿瘤细胞系之外的其它人类细胞(如多能干细胞和终末分化细胞等)中实现基因组位点的精确标记(Levsky,J.M.and R.H.Singer,Fluorescence in situ hybridization:past,present and future.J Cell Sci,2003.116(Pt 14):p.2833-8.);另一种被用做基因编辑技术的转录激活因子样效应元件(TALE)同样可以被用于基因组位点的可视化标记,然而现有的报道中既没有用FISH金标准验证TALE介导的基因组标记的正确性,同时显示其在不同细胞类型中标记的强异质性(Ma,H.,P.Reyes-Gutierrez,and T.Pederson,Visualization of repetitive DNA sequences in human chromosomes with transcription activator-like effectors.Proc Natl Acad Sci USA,2013.110(52):p.21048-53.)。
综上所述,现有的基因组可视化标记技术都存在缺陷,无法满足精确标记人类细胞基因组元件和特殊位点的需要。因此,目前无论是科研还是临床市场,都急需具备精确性、简便性和长效性的活细胞基因组可视化标记技术来弥补空白,从而推动人类衰老和重要疾病的基础研究和临床诊疗技术的发展。
技术实现要素:
本发明的一个目的是提供一种用于可视化标记基因组位点的试剂盒。
本发明提供的用于可视化标记基因组位点的试剂盒为如下1)-8)中任一种:
1)包括融合蛋白,所述融合蛋白包括用于识别或结合基因组靶序列的转录激活样效应元件蛋白TALE和硫氧还蛋白TRX;
2)包括融合蛋白,所述融合蛋白包括用于识别或结合基因组靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX;
3)包括蛋白组合物,所述蛋白组合物包括用于识别或结合基因组靶序列的转录激活样效应元件蛋白TALE和硫氧还蛋白TRX;
4)包括蛋白组合物,所述蛋白组合物包括用于识别或结合基因组靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX;
5)编码所述融合蛋白的DNA分子;
6)编码所述蛋白组合物的DNA分子;
7)包括表达1)或2)所述融合蛋白的载体;
8)包括表达3)或4)所述蛋白组合物的载体。
上述试剂盒中,所述靶序列为端粒DNA、着丝粒DNA、核仁组织区核糖体RNA编码基因或MUC4蛋白编码基因。
上述试剂盒中,所述靶序列可以根据本领域公知常识,选择它们的部分序列作为靶序列。优选的,本发明选择了如下序列作为靶序列:
所述端粒DNA的靶序列为序列14;
所述着丝粒DNA的靶序列为序列15;
所述核仁组织区核糖体RNA编码基因的靶序列为序列16;
所述MUC4蛋白编码基因的靶序列为序列17。
上述试剂盒中,
用于识别或结合基因组中所述端粒DNA的靶序列的融合蛋白为a1)或a2);
a1)由核定位序列、用于识别或结合基因组中端粒DNA的靶序列的转录激活样效应元件蛋白TALE和硫氧还蛋白TRX融合得到的蛋白质;所述融合蛋白自N端至C端依次包括核定位序列、用于识别或结合基因组中端粒DNA的靶序列的转录激活样效应元件蛋白TALE和硫氧还蛋白TRX;
a2)由核定位序列、用于识别或结合基因组中端粒DNA的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX融合得到的蛋白质;所述融合蛋白自N端至C端依次包括核定位序列、用于识别或结合基因组中端粒DNA的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX;
或用于识别或结合基因组中所述着丝粒DNA的靶序列的融合蛋白为a3)或a4);
a3)由核定位序列、用于识别或结合基因组中着丝粒DNA的靶序列的转录激活样效应元件蛋白TALE和硫氧还蛋白TRX融合得到的蛋白质;所述融合蛋白自N端至C端依次包括核定位序列、用于识别或结合基因组中着丝粒DNA的靶序列的转录激活样效应元件蛋白TALE和硫氧还蛋白TRX;
a4)由核定位序列、用于识别或结合基因组中着丝粒DNA的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX融合得到的蛋白质;所述融合蛋白自N端至C端依次包括核定位序列、用于识别或结合基因组中着丝粒DNA的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX;
或用于识别或结合基因组中所述核仁组织区核糖体RNA编码基因的靶序列的融合蛋白由核定位序列、用于识别或结合基因组中核仁组织区核糖体RNA编码基因的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX融合得到的蛋白质;所述融合蛋白自N端至C端依次包括核定位序列、用于识别或结合基因组中核仁组织区核糖体RNA编码基因的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX;
或用于识别或结合基因组中MUC4蛋白编码基因的靶序列的融合蛋白由核定位序列、用于识别或结合基因组中MUC4蛋白编码基因的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX融合得到的蛋白质;所述融合蛋白自N端至C端依次包括核定位序列、用于识别或结合基因组中MUC4蛋白编码基因的靶序列的转录激活样效应元件蛋白TALE、荧光蛋白和硫氧还蛋白TRX。
上述试剂盒中,
所述荧光蛋白为EGFP蛋白或mCherry蛋白;
a1)中所述融合蛋白的氨基酸序列为序列4;
a2)中所述融合蛋白的氨基酸序列为序列7;
a3)中所述融合蛋白的氨基酸序列为序列5;
a4)中所述融合蛋白的氨基酸序列为序列8;
用于识别或结合基因组中所述核仁组织区核糖体RNA编码基因的靶序列的融合蛋白的氨基酸序列为序列10;
用于识别或结合基因组中所述MUC4蛋白编码基因的靶序列的融合蛋白的氨基酸序列为序列12。
上述试剂盒中,
所述融合蛋白的N端还带有Flag标签序列;所述FLAG标签序列具体为3xFlag标签序列。在实际应用中,本领域技术人员还可以利用N端的Flag标签序列通过免疫荧光染色实验的方法实现细胞基因组位点的可视化检测。
上述试剂盒中,
所述EGFP蛋白的编码基因为序列13第7382-8098位所示的DNA分子;
所述mCherry蛋白的编码基因为序列6所示的DNA分子;
所述硫氧还蛋白TRX的编码基因为序列3所示的DNA分子;
所述3xFlag标签序列的编码基因为序列1第2113-2181位所示的DNA分子;
所述核定位序列的编码基因为序列1第2182-2232位所示的DNA分子;
所述用于识别或结合基因组中端粒DNA的靶序列的转录激活样效应元件蛋白TALE的编码基因为序列1第2233-4725位所示的DNA分子;
所述用于识别或结合基因组中着丝粒DNA的靶序列的转录激活样效应元件蛋白TALE的编码基因为序列2第121-2613位所示的DNA分子;
所述用于识别或结合基因组中核仁组织区核糖体RNA编码基因的靶序列的转录激活样效应元件蛋白TALE的编码基因为序列9第121-2613位所示的DNA分子;
所述用于识别或结合基因组中MUC4蛋白编码基因的靶序列的转录激活样效应元件蛋白TALE的编码基因为序列11第121-2613位所示的DNA分子。
上述试剂盒中,
表达a1)中所述融合蛋白的载体是以用于识别或结合端粒DNA的靶序列的TALE载体为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的KpnI和XhoI位点间得到的载体;其中,所述用于识别或结合端粒DNA的靶序列的TALE载体的核苷酸序列为序列1;
表达a2)中所述融合蛋白的载体是以用于识别或结合端粒DNA的靶序列的TTALE载体为骨架载体,将序列6所示的mCherry编码基因序列插入骨架载体的HpaI和KpnI位点间得到的载体;其中,所述用于识别或结合端粒DNA的靶序列的TTALE载体是以所述用于识别或结合端粒DNA的靶序列的TALE载体为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的KpnI和XhoI位点间得到的载体;
表达a3)中所述融合蛋白的载体是以用于识别或结合着丝粒DNA的靶序列的TALE载体为骨架载体,将序列3所示的人硫氧还蛋白的编码基因序列插入骨架载体的KpnI和XhoI位点间得到载体;其中,所述用于识别或结合着丝粒DNA的靶序列的TALE载体的核苷酸序列为将序列1中第2113-4725位所示的DNA片段替换为序列2所示的DNA片段后得到的序列;
表达a4)中所述融合蛋白的载体是以用于识别或结合着丝粒DNA的靶序列的TTALE载体为骨架载体,将序列13第7382-8098位所示的EGFP编码基因序列插入骨架载体的HpaI和KpnI位点间得到的载体;其中,所述用于识别或结合着丝粒DNA的靶序列的TTALE载体是以所述用于识别或结合着丝粒DNA的靶序列的TALE载体为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的KpnI和XhoI位点间得到的载体;
表达用于识别或结合基因组中所述核仁组织区核糖体RNA编码基因的靶序列的融合蛋白的载体是以用于识别或结合核仁组织区核糖体RNA编码基因的靶序列的TALE载体为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的AscI和XhoI位点间得到的载体;其中,所述用于识别或结合核仁组织区核糖体RNA编码基因的靶序列的TALE载体的核苷酸序列为将序列1第2113-4725位所示的DNA片段替换为序列9所示的DNA片段,且将序列13第7382-8098位所示的EGFP编码基因序列插入序列1的HpaI和KpnI位点间后得到的序列;
表达用于识别或结合基因组中MUC4蛋白编码基因的靶序列的融合蛋白的载体是以用于识别或结合MUC4蛋白编码基因的靶序列的TALE载体为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的AscI和XhoI位点间得到的载体;其中,所述用于识别或结合MUC4蛋白编码基因的靶序列的TALE载体的核苷酸序列为将序列1第2113-4725位所示的DNA片段替换为序列11所示的DNA片段,且将序列13第7382-8098位所示的EGFP编码基因序列插入序列1的HpaI和KpnI位点间后得到的序列。
本发明的第二个目的是提供上述试剂盒或上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物的新用途。
本发明提供了上述试剂盒或上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物在基因组可视化中的应用。
本发明还提供了上述试剂盒或上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物在制备基因组可视化的产品中的应用。
本发明还提供了上述试剂盒或上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物在如下b1)-b14)中任一种中的应用:
b1)可视化标记基因组位点;
b2)制备可视化标记基因组位点的产品;
b3)可视化标记细胞基因组中的端粒;
b4)制备可视化标记细胞基因组中的端粒的产品;
b5)可视化标记细胞基因组中的着丝粒;
b6)制备可视化标记细胞基因组中的着丝粒的产品;
b7)可视化标记细胞基因组中的核仁组织区核糖体RNA;
b8)制备可视化标记细胞基因组中的核仁组织区核糖体RNA的产品;
b9)可视化标记细胞基因组中的MUC4编码基因位点;
b10)制备可视化标记细胞基因组中的MUC4编码基因位点的产品;
b11)可视化检测端粒或着丝粒在细胞分裂不同时期的动态变化;
b12)制备可视化检测端粒或着丝粒在细胞分裂不同时期的动态变化的产品;
b13)可视化检测端粒在不同细胞衰老模型的动态变化;
b14)制备可视化检测端粒在不同细胞衰老模型的动态变化的产品。
本发明还有一个目的是提供上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物的新用途。
本发明提供了上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物在作为基因组可视化工具中的应用。
编码上述试剂盒中的融合蛋白或上述试剂盒中的蛋白组合物的DNA分子在制备基因组可视化工具中的应用也属于本发明的保护范围。
本发明的最后一个目的是提供一种可视化标记基因组位点的方法。
本发明提供的可视化标记基因组位点的方法包括将上述试剂盒中的融合蛋白或表达所述融合蛋白的载体导入细胞中,实现细胞基因组位点的可视化。
上述应用或上述方法中,
所述细胞为人或动物细胞;所述人或动物细胞为人肿瘤细胞、人胚胎肾细胞、人多能干细胞、人成体干细胞、人终末分化细胞或小鼠OP9细胞;所述人或动物细胞具体为人肿瘤细胞系(U2OS、HeLa、MCF7和HepG2)、人胚胎肾细胞系(HEK293)、人多能干细胞(胚胎干细胞hESC)、人多能干细胞(诱导多能干细胞iPSC)、成体干细胞(间充质干细胞)、成体干细胞(神经干细胞hNSC)、终末分化细胞(血管平滑肌细胞hVSMC)或小鼠OP9细胞。
本发明通过在传统的转录激活样效应元件(TALE)蛋白的C端融合硫氧还蛋白TRX,创建了新型的基因组可视化标记工具TTALE。通过实验证明:TTALE可用于在肿瘤细胞系、胚胎干细胞、成体干细胞、终末分化细胞等不同类型的人类细胞中精确标记端粒、着丝粒和核糖体RNA编码序列(Ribosomal DNA,rDNA)等基因组重复序列,以及编码基因座(MUC4)。TTALE技术能够弥补目前科研和临床市场缺乏精确性、简便性和长效性的活细胞基因组可视化标记技术的空白,从而推动人类衰老和重要疾病的基础研究和临床诊疗技术的发展。
附图说明
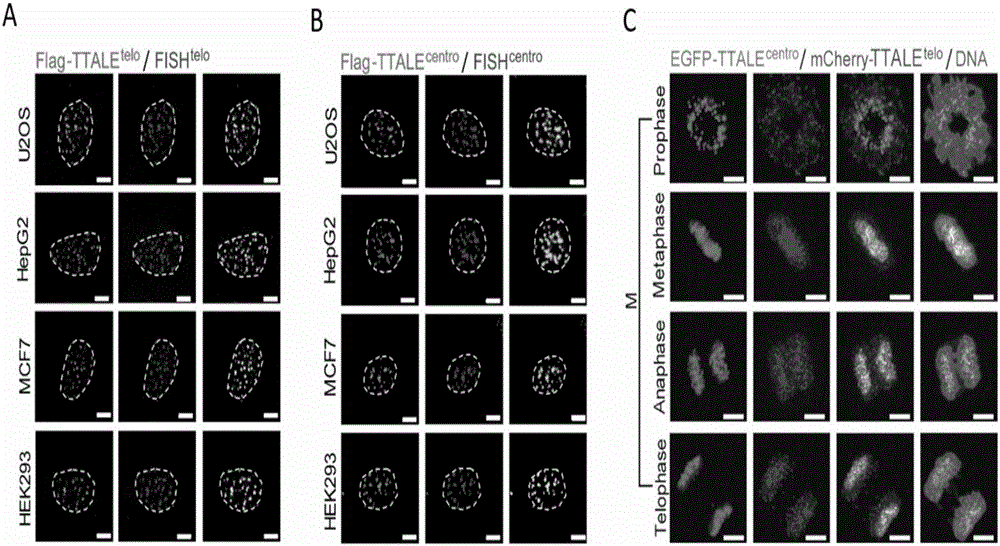
图1为本发明通过将硫氧还蛋白TRX融合在TALE的C端建立了能够精确标记细胞基因组中的端粒(Telomere)和着丝粒(Centromere)的基因组可视化标记技术(TTALE)。其中,A为TTALE标记基因组位点的模式图;B为识别端粒(Telomere)的TTALE在细胞核内的标记结果,从左到右依次为:FLAG标签标记TTALE标记端粒的结果;FISH探针标记端粒的结果;前两张图片叠加的结果,说明TTALE与FISH信号很好的共定位效果;叠加图片的局部放大结果;C为识别端粒(Telomere)的TTALE在细胞核内标记出的荧光点的分布图;D为特异性标记端粒(Telomere)的FISH探针在细胞核内标记出的荧光点的分布图;E为识别着丝粒(Centromere)的TTALE在细胞核内的标记结果;F为识别着丝粒(Centromere)的TTALE在细胞核内标记出的荧光点的分布图;G为特异性标记着丝粒(Centromere)的FISH探针在细胞核内标记出的荧光点的分布图。
图2为利用TTALE精确标记人肿瘤细胞系中的端粒(Telomere)和着丝粒(Centromere)。其中,A为识别端粒(Telomere)的TTALE在处于细胞间期的人肿瘤细胞系中的标记结果;B为识别着丝粒(Centromere)的TTALE在处于细胞间期的人肿瘤细胞系中的标记结果;C为用荧光蛋白(EGFP或mCherry)融合表达的识别端粒(Telomere)或着丝粒(Centromere)的TTALE同时标记处于细胞分裂周期不同时期的HeLa细胞基因组的结果。
图3为利用TTALE精确标记人多能干细胞(胚胎干细胞hESC或诱导多能干细胞iPSC)及其衍生的成体干细胞(间充质干细胞hMSC和神经干细胞hNSC)和终末分化细胞(神经细胞hNeuron和血管平滑肌细胞hVSMC)中的端粒(Telomere)和着丝粒(Centromere)。其中,A为识别着丝粒(Centromere)的TTALE的标记结果;B为识别端粒(Telomere)的TTALE的标记结果。
图4为利用TTALE精确标记人类细胞中的核仁组织区核糖体RNA编码序列(NOR-rDNA)。其中,A为识别核仁组织区核糖体RNA编码序列的TALE载体的标记结果;B为在hMSC中证明识别NOR-rDNA的TTALE的标记结果能够与NOR-rDNA的FISH杂交信号共定位,并且其标记信号围绕核仁组织区的分子标志物Nucleolin和Fibrillarin;C为利用TTALE精确标记人肿瘤细胞(HeLa和U2OS)以及人多能干细胞(hESC,hMSC和hNSC)中的NOR-rDNA。
图5为利用TTALE精确标记人类细胞中的基因编码序列(MUC4)。A为与识别编码基因位点(MUC4)的TALE载体的标记结果;B为利用TTALE精确标记人肿瘤细胞(HeLa)以及人多能干细胞(hMSC)中的MUC4基因位点;C为用荧光蛋白(mCherry)融合表达的识别MUC4基因位点的TTALE标记处于细胞分裂周期不同时期的HeLa细胞基因组的结果。
图6为利用识别端粒(Telomere)的TTALE在不同的细胞衰老模型中可视化标记基因组中端粒(Telomere)随细胞衰老进程的动态变化。A为不同细胞衰老模型的模式图;B为利用识别端粒(Telomere)的TTALE在不同的细胞衰老模型中可视化标记基因组中端粒(Telomere)的结果;C为WRN基因缺失的间充质干细胞的验证结果(WRN基因缺失验证实验);D为HGPS患者来源的间充质干细胞的验证结果(Progerin表达验证实验);E为三种细胞衰老模型中端粒缩短的qPCR验证;F为利用识别端粒(Telomere)的TTALE在不同的细胞衰老模型中可视化标记基因组中端粒(Telomere)的荧光强度统计结果。
图7为利用识别端粒(Telomere)的TTALE在动物体内可视化标记基因组中端粒(Telomere)的结果。A为构建表达EGFP融合的TTALE的慢病毒载体(Lentivirus)的模式图;B为利用表达EGFP融合的TTALE的慢病毒载体感染人肿瘤细胞U2OS的结果;C为利用表达EGFP融合的TTALE的慢病毒载体感染小鼠细胞OP9的结果;D为利用表达EGFP融合的TTALE的慢病毒载体(Lentivirus)在小鼠体内可视化标记基因组中端粒(Telomere)的模式图;E为利用表达EGFP融合的TTALE的慢病毒载体(Lentivirus)在小鼠肌肉、肝脏和脑组织中可视化标记基因组中端粒(Telomere)的结果。
具体实施方式
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
下述实施例中的定量试验,均设置三次重复实验,结果取平均值。
下述实施例中的HGPS病人来源的iPSC(简称HGPS-iPSCs):记载于“Liu,G.H.,Barkho,B.Z.,Ruiz,S.,Diep,D.,Qu,J.,Yang,S.L.,Panopoulos,A.D.,Suzuki,K.,Kurian,L.,Walsh,C.,et al.(2011a).Recapitulation of premature ageing with iPSCs from Hutchinson-Gilford progeria syndrome.Nature 472,221-225.”一文,公众可从申请人处获得,仅用于重复本发明实验使用。HGPS病人来源的iPSC(HGPS-iPSCs)中的LMNA基因发生了突变(LMNA基因组序列为GenBank:NG_008692.2;cDNA序列为GenBank:NM_170707.3),突变类型为C1824T(GGCGG突变为GGTGG),该位点参比序列为LMNAcDNA序列GenBank:NM_170707.3中的CDS区域。
下述实施例中的HGPS-GC-iPSCs为与HGPS-iPSC具有相同遗传背景的经过基因矫正的对照细胞系,记载于“Liu,G.H.,Suzuki,K.,Qu,J.,Sancho-Martinez,I.,Yi,F.,Li,M.,Kumar,S.,Nivet,E.,Kim,J.,Soligalla,R.D.,et al.(2011).Targeted gene correction of laminopathy-associated LMNA mutations in patient-specific iPSCs.Cell Stem Cell 8,688-694.”一文,公众可从申请人处获得,仅用于重复本发明实验使用。
下述实施例中的WRN基因缺失的人胚胎干细胞系(WS-ESC)由第一发明人创建,记载于“Zhang,W.et al.Aging stem cells.A Werner syndrome stem cell model unveils heterochromatin alterations as a driver of human aging.Science 348,1160-1163”一文,公众可从申请人处获得,仅用于重复本发明实验使用。WRN蛋白对于细胞核内组成型异染色质的结构维持至关重要,与细胞衰老密切相关,其功能缺失是成年早衰症发生的直接原因,可引起多组织器官衰老和衰老相关疾病。
下述实施例中的pLE4载体记载于“Huize Pan,Di Guan,Xiaomeng Liu,Jingyi Li,Lixia Wang,Jun Wu,Junzhi Zhou,Weizhou Zhang,Ruotong Ren,Weiqi Zhang,Ying Li,Jiping Yang,Ying Hao,Tingting Yuan,Guohong Yuan,Hu Wang,Zhenyu Ju,Zhiyong Mao,Jian Li,Jing Qu,Fuchou Tang,Guang-Hui Liu(2016).SIRT6 safeguards human mesenchymal stem cells from oxidative stress by coactivating NRF2.Cell Research 26,190-205.”一文,公众可从申请人处获得,仅用于重复本发明实验使用。
下述实施例中的人胚胎干细胞H9细胞系(WT-ESC)是WiCell公司的产品,货号:WA09(H9)-DL-7。
实施例1、精确标记细胞基因组中的端粒(Telomere)和着丝粒(Centromere)的基因组可视化标记技术(TTALE)的建立
一、融合表达TALE和TRX的表达载体TTALE的构建
1、识别端粒和着丝粒的TALE载体
参照文献“Zhang,F.,et al.,Efficient construction of sequence-specific TAL effector for modulating mammalian transcription.Nat Biotechnology,2011.29(2):p.149-53,通过Golden Gate Assembly”中的方法利用TALE Toolbox Kit(美国Addgene,货号为1000000019)分别构建识别端粒的TALE载体和识别着丝粒的TALE载体。
(1)识别端粒的TALE载体
识别端粒的TALE载体的核苷酸序列如序列1所示。识别端粒的TALE载体表达融合蛋白TALEtelo,融合蛋白TALEtel识别的端粒区DNA序列的靶序列如下:5’-AACCCTAACCCTAACCCT-3’(序列14)。
(2)识别着丝粒的TALE载体
识别着丝粒的TALE载体的核苷酸序列为将序列1中第2113-4725位所示的DNA片段替换为序列2所示的DNA片段后得到的序列。识别着丝粒的TALE载体表达融合蛋白TALEcentro,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TALEcentro识别的着丝粒区DNA序列的靶序列如下:5’-CCATTCCATTCCATTCCA-3’(序列15)。
2、识别端粒和着丝粒的TTALE载体
(1)识别端粒的TTALE载体
以步骤1中的识别端粒的TALE为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的KpnI和XhoI位点间,得到重组载体,将其记为识别端粒的TTALE载体(图1A)。识别端粒的TTALE载体表达融合蛋白TALEtelo-TRX,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TALEtelo-TRX的氨基酸序列如序列4所示。
(2)识别着丝粒的TTALE载体
以步骤1中的识别着丝粒的TALE为骨架载体,将序列3所示的人硫氧还蛋白的编码基因序列插入骨架载体的KpnI和XhoI位点间,得到重组载体,将其记为识别着丝粒的TTALE载体(图1A)。识别着丝粒的TTALE载体表达融合蛋白TALEcentro-TRX,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TALEcentro-TRX的氨基酸序列如序列5所示。
二、细胞基因组中的端粒和着丝粒分布位点检测
1、转染
将步骤一中制备的识别端粒的TTALE载体和识别着丝粒的TTALE载体分别转染U2OS细胞(美国ATCC,货号:HTB-96),同时以识别端粒的TALE载体和识别着丝粒的TALE载体为对照载体(NoTRX),转染24-48小时后,分别得到转染后细胞。
2、免疫荧光染色实验检测细胞基因组中的端粒和着丝粒分布位点
利用识别端粒的TTALE载体、识别着丝粒的TTALE载体和对照载体N端的FLAG标签序列进行免疫荧光染色实验,检测转染后细胞基因组中的端粒和着丝粒分布位点。具体步骤如下:用4%多聚甲醛(北京鼎国昌盛生物技术有限责任公司,货号:AR-0211)固定转染后细胞,然后用含0.4%TritonX100(美国Sigma公司,货号为T9284)的PBS室通透15分钟,用一抗稀释液(含有10%驴血清的PBS)室温封闭30分钟,用一抗稀释液配制的小鼠抗FLAG抗体4度孵育过夜,用PBS室温清洗3次,每次10分钟,用ALEXA-488标记的驴抗小鼠IgG室温孵育1小时,用PBS室温清洗3次,每次10分钟,用1:2000的Hoechst标记细胞核,最后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。如需与FISH探针进行共定位分析,则在孵育小鼠抗FLAG抗体之后,进行FISH探针孵育,再用Biotin标记的抗小鼠IgG室温孵育1小时,最后用ALEXA-488标记的Streptavidin(Vectorlabs,货号为SA-5488)孵育1小时。
3、荧光原位杂交实验检测细胞基因组中的端粒和着丝粒分布位点
利用特异性识别端粒和着丝粒的FISH探针完成荧光原位杂交实验。具体步骤为:用4%多聚甲醛固定转染后细胞,然后用含0.4%TritonX100(美国Sigma公司,货号为T9284)的PBS室通透15分钟,再用100微克/毫升的RNAase A(美国Sigma公司,货号为83831)于37度孵育30分钟,用90度5分钟变性过的浓度为50nM FISH探针(韩国PANAGENE公司,端粒FISH探针货号为F1002;着丝粒FISH探针货号为F3003)85度孵育10分钟,之后于室温避光孵育过夜,用PBS室温清洗3次,每次10分钟,用1:2000的Hoechst标记细胞核,最后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。
结果如图1所示。从图1中可以看出:与识别端粒或着丝粒的TALE(图1B中的No TRX,图1E中的No TRX)相比,识别端粒或着丝粒的TTALE在细胞核中标记的荧光点与FISH探针标记的荧光点几乎完全重合(图1B和图1E),并且其荧光点分布与FISH探针标记的荧光点的分布非常相似(图1C,1D,1F,1G),说明本发明的TTALE能够精确标记人类细胞基因组中的端粒或着丝粒位点。
实施例2、TTALE在精确标记不同类型人类细胞中的端粒、着丝粒、核仁组织区核糖体RNA编码序列(NOR-rDNA)以及编码基因位点(MUC4)中的应用
一、TTALE在精确标记不同类型人类细胞中的端粒和着丝粒中的应用
将实施例1中的U2OS细胞分别替换为如下细胞:人肿瘤细胞系(MCF7和HepG2,美国ATCC公司,货号分别为HTB-22和HB-8065)、人胚胎肾细胞系(HEK293,美国ATCC公司,货号为CRL-1573)、人多能干细胞(胚胎干细胞hESC,Wicell公司,货号为WA-09)、人多能干细胞(诱导多能干细胞iPSC,Wicell公司,货号为IISH6i-CML17)、成体干细胞(间充质干细胞,Lonza公司,货号为PT-2501)、成体干细胞(神经干细胞hNSC,Wicell公司,货号为NSC-H9)、终末分化细胞(血管平滑肌细胞hVSMC,Lonza公司,货号为CC-2571),且保持其他步骤不变,然后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。
结果表明:TTALE可精确标记不同类型人类细胞基因组中的端粒和着丝粒,实现上述各个细胞中端粒和着丝粒的可视化(图2A-B,图3)。
二、荧光蛋白融合表达的识别端粒或着丝粒的TTALE在精确标记人类细胞中的端粒和着丝粒中的应用
1、mCherry荧光蛋白融合表达的识别端粒的TTALE的制备
以实施例1中的识别端粒的TTALE为骨架载体,将序列6所示的mCherry编码基因序列插入骨架载体的HpaI和KpnI位点间,得到重组载体,将其记作mCherry融合表达的识别端粒的TTALE载体。mCherry融合表达的识别端粒的TTALE载体(mCherry-TTALEtelo)表达融合蛋白TTALEtelo-mCherry-TRX,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TTALEtelo-mCherry-TRX的氨基酸序列如序列7所示。
2、EGFP荧光蛋白融合表达的识别着丝粒的TTALE的制备
以识别着丝粒的TTALE为骨架载体,将序列13第7382-8098位所示的EGFP编码基因序列插入骨架载体的HpaI和KpnI位点间,得到EGFP融合表达的识别着丝粒的TTALE。EGFP融合表达的识别着丝粒的TTALE(EGFP-TTALEcentro)表达融合蛋白TTALEcentro-EGFP-TRX,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TTALEcentro-EGFP-TRX的氨基酸序列如序列8所示。
3、荧光蛋白融合表达的识别端粒或着丝粒的TTALE标记HeLa细胞
分别将mCherry融合表达的识别端粒的TTALE(mCherry-TTALEtelo)和EGFP融合表达的识别着丝粒的TTALE(EGFP-TTALEcentro)转染处于细胞分裂周期不同时期的HeLa细胞中,转染24-48小时后,用4%多聚甲醛固定细胞,然后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。
结果表明:荧光蛋白融合表达的识别端粒或着丝粒的TTALE可精确标记人类细胞中的端粒和着丝粒,实现处于细胞分裂周期不同时期的细胞中端粒和着丝粒的可视化(图2C)。
三、TTALE在精确标记不同类型人类细胞中的核仁组织区核糖体RNA编码序列(NOR-rDNA)中的应用
1、EGFP融合表达的识别核仁组织区核糖体RNA编码基因的TALE的制备
参照文献“Zhang,F.,et al.,Efficient construction of sequence-specific TAL effector for modulating mammalian transcription.Nat Biotechnology,2011.29(2):p.149-53,通过Golden Gate Assembly”中的方法利用TALE Toolbox Kit(美国Addgene,货号为1000000019)构建识别核仁组织区核糖体RNA编码序列的TALE载体。
识别核仁组织区核糖体RNA编码基因的TALE载体的核苷酸序列为将序列1第2113-4725位所示的DNA片段替换为序列9所示的DNA片段,且将序列13第7382-8098位所示的EGFP编码基因序列插入序列1的HpaI和KpnI位点间后得到的序列。识别核仁组织区核糖体RNA编码基因的TALE载体表达融合蛋白TALErDNA-EGFP,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TALErDNA-EGFP识别的核仁组织区核糖体RNA编码基因的靶序列如下:5’-ACCCTACTGATGATGTGT-3’(序列16)。
2、荧光蛋白融合表达的识别核仁组织区核糖体RNA编码基因的TTALE的制备
以步骤1中的识别核仁组织区核糖体RNA编码基因的TALE为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的AscI和XhoI位点间,得到重组载体,将其记为识别核仁组织区核糖体RNA编码基因的TTALE载体(EGFP-TTALErDNA)。识别核仁组织区核糖体RNA编码基因的TTALE载体(EGFP-TTALErDNA)表达融合蛋白TALErDNA-EGFP-TRX。融合蛋白TALErDNA-EGFP-TRX的氨基酸序列如序列10所示。
将识别核仁组织区核糖体RNA编码序列的TTALE载体(EGFP-TTALErDNA)中的EGFP编码基因替换为序列6所示的mCherry编码基因,得到识别核仁组织区核糖体RNA编码基因的TTALE载体(mCherry-TTALErDNA)。识别核仁组织区核糖体RNA编码基因的TTALE载体(mCherry-TTALErDNA)表达融合蛋白TALErDNA-mCherry-TRX。
3、识别核仁组织区核糖体RNA编码基因的TTALE标记细胞
分别将识别核仁组织区核糖体RNA编码基因的TALE载体和识别核仁组织区核糖体RNA编码基因的TTALE转染人肿瘤细胞(HeLa和U2OS)以及人多能干细胞(hESC,hMSC和hNSC)中,转染24-48小时后,用4%多聚甲醛固定细胞,然后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析,分别检测不同细胞中的核仁组织区核糖体RNA编码基因的荧光分布情况。
结果表明:与识别核仁组织区核糖体RNA编码基因的TALE载体相比(图4A),识别核仁组织区核糖体RNA编码基因的TTALE可精确标记人肿瘤细胞(HeLa和U2OS)以及人多能干细胞(hESC,hMSC和hNSC)中的核糖体RNA,实现核仁组织区核糖体RNA编码基因的可视化(图4B,4C)。
四、TTALE在精确标记不同类型人类细胞中的编码基因位点(MUC4)中的应用
1、EGFP融合表达的识别编码基因位点(MUC4)的TALE的制备
参照文献“Zhang,F.,et al.,Efficient construction of sequence-specific TAL effector for modulating mammalian transcription.Nat Biotechnology,2011.29(2):p.149-53,通过Golden Gate Assembly”中的方法利用TALE Toolbox Kit(美国Addgene,货号为1000000019)构建识别编码基因位点(MUC4)的TALE载体。
识别编码基因位点(MUC4)的TALE载体的核苷酸序列为将序列1第2113-4725位所示的DNA片段替换为序列11所示的DNA片段,且将序列13第7382-8098位所示的EGFP编码基因序列插入序列1的HpaI和KpnI位点间后得到的序列。识别编码基因位点(MUC4)TALE载体表达融合蛋白TALEMUC4-EGFP,该融合蛋白N端带有FLAG标签序列和核定位序列NLS。融合蛋白TALEMUC4-EGFP识别的编码基因位点(MUC4)的靶序列如下:5’-CCTGTCACCGACACTTCC-3’(序列17)。
2、荧光蛋白融合表达的识别编码基因位点(MUC4)的TTALE的制备
以步骤1中的识别编码基因位点(MUC4)的TALE为骨架载体,将序列3所示的人硫氧还蛋白TRX的编码基因序列插入骨架载体的AscI和XhoI位点间,得到重组载体,将其记为识别编码基因位点(MUC4)的TTALE载体(EGFP-TTALEMUC4)。识别编码基因位点(MUC4)的TTALE载体表达融合蛋白TTALEMUC4-EGFP-TRX。融合蛋白TTALEMUC4-EGFP-TRX的氨基酸序列如序列12所示。
将识别编码基因位点(MUC4)的TTALE载体(EGFP-TTALEMUC4)中的EGFP编码基因替换为序列6所示的mCherry编码基因,得到识别核仁组织区核糖体RNA编码序列的TTALE载体(mCherry-TTALEMUC4)。识别核仁组织区核糖体RNA编码序列的TTALE载体(mCherry-TTALE MUC4)表达融合蛋白TALEMUC4-mCherry-TRX。
3、识别编码基因位点(MUC4)的TTALE标记细胞
分别将识别编码基因位点(MUC4)的TALE和识别编码基因位点(MUC4)的TTALE分别转染处于细胞间期和细胞分裂周期的hMSC和HeLa细胞中,转染24-48小时后,用4%多聚甲醛固定细胞,然后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。
结果表明:与识别编码基因位点(MUC4)的TALE载体相比(图5A),识别编码基因位点(MUC4)的TTALE可精确标记细胞间期和细胞分裂周期的hMSC和HeLa细胞中的编码基因位点(MUC4),实现编码基因位点(MUC4)的可视化(图5B-C)。
实施例3、TTALE标记不同细胞衰老模型中端粒在可视化细胞衰老进程的动态变化中的应用
1、EGFP融合表达的识别端粒的TTALE载体的制备
将序列13第7382-8098位所示的EGFP编码基因序列替换实施例2步骤二的1中mCherry荧光蛋白融合表达的识别端粒的TTALE载体(mCherry-TTALEtelo)中的mCherry编码基因序列,得到EGFP融合表达的识别端粒的TTALE载体(EGFP-TTALEtelo),该融合蛋白N端带有FLAG标签序列和核定位序列NLS。
2、EGFP融合表达的识别端粒的TTALE载体标记不同衰老模型的人类间充质干细胞
(1)不同衰老模型的人类间充质干细胞的建立
1)野生型人间充质干细胞(WT-MSC)和WRN基因缺失的人间充质干细胞(WS-MSC)的制备
本发明将野生型人胚胎干细胞H9细胞系(WT-ESC)和WRN基因缺失的人胚胎干细胞系(WS-ESC),进一步体外定向分化为间充质干细胞(WT-MSC)和WRN基因缺失的人间充质干细胞(WS-MSC),具体方法如下:
A、将野生型人胚胎干细胞H9细胞系(WT-ESC)和WRN基因缺失的人胚胎干细胞系(WS-ESC)分别进行拟胚体(EB)分化,获得拟胚体(EB)。拟胚体(EB)分化具体步骤如下:准备含有300-500个细胞、大小均一的ESC克隆,用室温PBS(Gibco,10010023)清洗一次,用Dispase(Invitrogen公司,货号为17105041)37℃消化20-30min。待ESC克隆形成球体后,用CDF12培养基重悬后,加到低粘附培养板(Corning公司,货号3471)中,37℃,5%CO2条件培养1-3天后即形成拟胚体。
B、将步骤A获得的拟胚体(EB)接种于基质胶(matrigel)包被的6孔板中进行培养,继续培养2周至纤维状细胞出现。再经过一次传代后,利用流式细胞术分选其中的CD73、CD90和CD105均为阳性的细胞类群(图1),即为野生型间充质干细胞(记为WT-MSC)和WRN基因缺失的人间充质干细胞系(记为WS-MSC)。
2)HGPS病人来源的(HGPS-MSC)和经过基因矫正的人间充质干细胞(HGPS-GC-MSC)的制备
本实施例将HGPS-iPSCs和HGPS-GC-iPSCs进一步体外定向分化为间充质干细胞HGPS-MSC和HGPS-GC-MSC。具体方法如下:
分别将HGPS-iPSCs和HGPS-GC-iPSCs进行拟胚体(EB)分化,分化14天,将EB接种于基质胶(matrigel)包被的6孔板中进行培养,继续培养2周至纤维状细胞出现。再经过一次传代后,利用流式细胞术分选其中CD73、CD90和CD105均为阳性的细胞类群,即为HGPS病人来源的间充质干细胞(记为HGPS-MSC)和经过基因矫正的人间充质干细胞(记为HGPS-GC-MSC)。
3)野生型间充质干细胞的早代细胞(EP-WT-MSC)与晚代细胞(LP-WT-MSC)的制备
将步骤(1)中的野生型间充质干细胞(WT-MSC)连续传代培养至12代(记为P12代),将P1-P6代细胞记为早代间充质干细胞(记为EP-WT-MSC),将P10-P12代细胞记晚代间充质干细胞(记为LP-WT-MSC)。选取P6和P12代WT-MSC细胞作为EP-WT-MSC和LP-WT-MSC的代表进行下述相关实验。
(2)EGFP融合表达的识别端粒的TTALE载体标记不同衰老模型的人类间充质干细胞
将EGFP融合表达的识别端粒的TTALE载体利用化学转染方法导入不同衰老模型的人类间充质干细胞中(图6A,6C和6D),转染24-48小时后,用4%多聚甲醛固定细胞,然后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。
3、qPCR方法检测不同衰老模型的人类间充质干细胞中端粒长度
以步骤2中不同衰老模型的人类间充质干细胞为供试细胞。分别从供试细胞中提取基因组DNA,通过实时定量PCR的方法检测供试细胞中端粒长度。其中,以36B4为端粒长度检测的对照基因。引物序列如下:
Tel-F:5’-GGTTTTTGAGGGTGAGGGTGAGGGTGAGGGTGAGGGT-3’;
Tel-R:5’-TCCCGACTATCCCTATCCCTATCCCTATCCCTATCCCTA-3’;
36B4u:5’-CAGCAAGTGGGAAGGTGTAATCC-3’;
36B4d:5’-CCCATTCTATCATCAACGGGTACAA-3’。
结果表明,利用识别端粒的TTALE能够在不同的细胞衰老模型中可视化标记基因组中端粒,并能够反映出衰老细胞中标记的端粒的荧光强度显著降低(图6B,6F),该结果与利用qPCR方法检测的衰老细胞中端粒长度缩短的结果一致(图6E),说明TTALE技术能够精确地可视化标记基因组中端粒随细胞衰老进程的动态变化。
实施例4、识别端粒的TTALE在体外和动物体内可视化标记基因组中端粒中的应用
一、识别端粒的TTALE在体外可视化标记基因组中端粒中的应用
1、EGFP融合表达的识别端粒的TTALE慢病毒载体质粒的制备及包装
将EGFP融合表达的识别端粒的TTALE的编码基因序列插入pLE4载体的限制性内切酶酶切位点MluI和SalI之间,且保持pLE4载体的其他序列不变,得到慢病毒载体质粒pLE4-EGFP-TTALE(其核苷酸序列如序列13所示)。然后将慢病毒载体质粒pLE4-EGFP-TTALE在HEK293T(美国ATCC,货号:CRL-3216)细胞中进行慢病毒的病毒包装,慢病毒包装质粒购自Addgene,货号如下:psPAX(12260),pMD2.G(12259)。
将慢病毒载体质粒pLE4-EGFP-TTALE与包装质粒psPAX和pMD.2G共转染至HEK293T细胞中,与转染后48小时收集培养上清,并通过超高速离心纯化慢病毒颗粒。
2、EGFP融合表达的识别端粒的慢病毒载体质粒标记人或小鼠细胞
利用产生表达EGFP融合的识别端粒的TTALE的慢病毒感染人U2OS细胞(美国ATCC,货号:HTB-96)和小鼠OP9细胞(美国ATCC,货号:CRL-2749),感染24-72小时后,用4%多聚甲醛固定细胞,然后利用荧光显微镜进行观察。
结果表明,利用表达EGFP融合的识别端粒的TTALE的慢病毒载体能够在体外可视化标记人和小鼠细胞基因组中端粒(图7B,7C)。
二、EGFP融合表达的识别端粒的TTALE在动物体内可视化标记基因组中端粒中的应用
用Opti-MEM(ThermoFisher公司,货号:51985042)将步骤一中制备的表达EGFP融合的识别端粒的TTALE的慢病毒载体稀释为108病毒/微升剂量,分别在小鼠的胫骨前肌、肝脏和大脑海马区注射5微升病毒液(图7D),注射7-10天后,分离上述小鼠组织,用4%多聚甲醛固定后进行冰冻切片,分别用WGA抗体(肌肉)(ThermoFisher公司,货号:W32464)、ALB抗体(肝脏)(Abcam公司,货号:ab8940)和NeuN抗体(大脑海马区)(Abcam公司,货号:ab177487)进行免疫荧光染色,最后用荧光显微镜观察。免疫荧光染色的具体步骤如下:用4%多聚甲醛(北京鼎国昌盛生物技术有限责任公司,货号:AR-0211)室温固定切片10分钟,然后用含0.4%TritonX100(美国Sigma公司,货号为T9284)的PBS室通透30分钟,用一抗稀释液(含有10%驴血清的PBS)室温封闭45分钟,用一抗稀释液配制的WGA抗体(肌肉)(ThermoFisher公司,货号:W32464)、ALB抗体(肝脏)(Abcam公司,货号:ab8940)和NeuN抗体(大脑海马区)(Abcam公司,货号:ab177487)分别4度孵育过夜,用PBS室温清洗3次,每次10分钟,分别用ALEXA-488标记的IgG室温孵育1小时,用PBS室温清洗3次,每次10分钟,用1:2000的Hoechst标记细胞核,最后利用荧光显微镜进行观察,并利用ImageJ软件进行荧光强度计算和统计分析。
结果表明:利用表达EGFP融合的识别端粒的TTALE的慢病毒载体能够在小鼠不同组织内实现可视化标记基因组中端粒(图7E)。
序列表
<110>中国科学院生物物理研究所
<120>一种可视化标记基因组位点的方法
<160>17
<210>1
<211>7746bp
<212>DNA
<213>人工序列
<220>
<223>
<400>1
ctcatgacca aaatccctta acgtgagtta cgcgcgcgtc gttccactga gcgtcagacc 60
ccgtagaaaa gatcaaagga tcttcttgag atcctttttt tctgcgcgta atctgctgct 120
tgcaaacaaa aaaaccaccg ctaccagcgg tggtttgttt gccggatcaa gagctaccaa 180
ctctttttcc gaaggtaact ggcttcagca gagcgcagat accaaatact gttcttctag 240
tgtagccgta gttagcccac cacttcaaga actctgtagc accgcctaca tacctcgctc 300
tgctaatcct gttaccagtg gctgctgcca gtggcgataa gtcgtgtctt accgggttgg 360
actcaagacg atagttaccg gataaggcgc agcggtcggg ctgaacgggg ggttcgtgca 420
cacagcccag cttggagcga acgacctaca ccgaactgag atacctacag cgtgagctat 480
gagaaagcgc cacgcttccc gaagggagaa aggcggacag gtatccggta agcggcaggg 540
tcggaacagg agagcgcacg agggagcttc cagggggaaa cgcctggtat ctttatagtc 600
ctgtcgggtt tcgccacctc tgacttgagc gtcgattttt gtgatgctcg tcaggggggc 660
ggagcctatg gaaaaacgcc agcaacgcgg cctttttacg gttcctggcc ttttgctggc 720
cttttgctca catgttcttt cctgcgttat cccctgattc tgtggataac cgtattaccg 780
cctttgagtg agctgatacc gctcgccgca gccgaacgac cgagcgcagc gagtcagtga 840
gcgaggaagc ggaaggcgag agtagggaac tgccaggcat caaactaagc agaaggcccc 900
tgacggatgg cctttttgcg tttctacaaa ctctttctgt gttgtaaaac gacggccagt 960
cttaagctcg ggccccctgg gcggttctga taacgagtaa tcgttaatcc gcaaataacg 1020
taaaaacccg cttcggcggg tttttttatg gggggagttt agggaaagag catttgtcag 1080
aatatttaag ggcgcctgtc actttgcttg atatatgaga attatttaac cttataaatg 1140
agaaaaaagc aacgcacttt aaataagata cgttgctttt tcgattgatg aacacctata 1200
attaaactat tcatctatta tttatgattt tttgtatata caatatttct agtttgttaa 1260
agagaattaa gaaaataaat ctcgaaaata ataaagggaa aatcagtttt tgatatcaaa 1320
attatacatg tcaacgataa tacaaaatat aatacaaact ataagatgtt atcagtattt 1380
attatcattt agaataaatt ttgtgtcgcc cttaattgtg agcggataac aattacgagc 1440
ttcatgcaca gtggcgttga cattgattat tgactagtta ttaatagtaa tcaattacgg 1500
ggtcattagt tcatagccca tatatggagt tccgcgttac ataacttacg gtaaatggcc 1560
cgcctggctg accgcccaac gacccccgcc cattgacgtc aataatgacg tatgttccca 1620
tagtaacgcc aatagggact ttccattgac gtcaatgggt ggagtattta cggtaaactg 1680
cccacttggc agtacatcaa gtgtatcata tgccaagtac gccccctatt gacgtcaatg 1740
acggtaaatg gcccgcctgg cattatgccc agtacatgac cttatgggac tttcctactt 1800
ggcagtacat ctacgtatta gtcatcgcta ttaccatggt gatgcggttt tggcagtaca 1860
tcaatgggcg tggatagcgg tttgactcac ggggatttcc aagtctccac cccattgacg 1920
tcaatgggag tttgttttgg caccaaaatc aacgggactt tccaaaatgt cgtaacaact 1980
ccgccccatt gacgcaaatg ggcggtaggc gtgtacggtg ggaggtctat ataagcagag 2040
ctctctggct aactagagaa cccactgctt actggcttat cgaaattaat acgactcact 2100
ataggggcca ccatggacta taaggaccac gacggagact acaaggatca tgatattgat 2160
tacaaagacg atgacgataa gatggcccca aagaagaagc ggaaggtcgg tatccacgga 2220
gtcccagcag ccgtagattt gagaactttg ggatattcac agcagcagca ggaaaagatc 2280
aagcccaaag tgaggtcgac agtcgcgcag catcacgaag cgctggtggg tcatgggttt 2340
acacatgccc acatcgtagc cttgtcgcag caccctgcag cccttggcac ggtcgccgtc 2400
aagtaccagg acatgattgc ggcgttgccg gaagccacac atgaggcgat cgtcggtgtg 2460
gggaaacagt ggagcggagc ccgagcgctt gaggccctgt tgacggtcgc gggagagctg 2520
agagggcctc cccttcagct ggacacgggc cagttgctga agatcgcgaa gcggggagga 2580
gtcacggcgg tcgaggcggt gcacgcgtgg cgcaatgcgc tcacgggagc acccctcaac 2640
ctgaccccag agcaggtcgt ggcaattgcg agcaacatcg ggggaaagca ggcactcgaa 2700
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gacttacgcc agagcaggtc 2760
gtggcaattg cgagcaacat cgggggaaag caggcactcg aaaccgtcca gaggttgctg 2820
cctgtgctgt gccaagcgca cggactaacc ccagagcagg tcgtggcaat tgcgagccat 2880
gacgggggaa agcaggcact cgaaaccgtc cagaggttgc tgcctgtgct gtgccaagcg 2940
cacgggttga ccccagagca ggtcgtggca attgcgagcc atgacggggg aaagcaggca 3000
ctcgaaaccg tccagaggtt gctgcctgtg ctgtgccaag cgcacggcct gaccccagag 3060
caggtcgtgg caattgcgag ccatgacggg ggaaagcagg cactcgaaac cgtccagagg 3120
ttgctgcctg tgctgtgcca agcgcacgga ctgacaccag agcaggtcgt ggcaattgcg 3180
agcaacggag ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 3240
caagcgcacg gacttacacc cgaacaagtc gtggcaattg cgagcaacat cgggggaaag 3300
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cggacttacg 3360
ccagagcagg tcgtggcaat tgcgagcaac atcgggggaa agcaggcact cgaaaccgtc 3420
cagaggttgc tgcctgtgct gtgccaagcg cacggactaa ccccagagca ggtcgtggca 3480
attgcgagcc atgacggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 3540
ctgtgccaag cgcacgggtt gaccccagag caggtcgtgg caattgcgag ccatgacggg 3600
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacggc 3660
ctgaccccag agcaggtcgt ggcaattgcg agccatgacg ggggaaagca ggcactcgaa 3720
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gactgacacc agagcaggtc 3780
gtggcaattg cgagcaacgg agggggaaag caggcactcg aaaccgtcca gaggttgctg 3840
cctgtgctgt gccaagcgca cggcctcacc ccagagcagg tcgtggcaat tgcgagcaac 3900
atcgggggaa agcaggcact cgaaaccgtc cagaggttgc tgcctgtgct gtgccaagcg 3960
cacggactta cgccagagca ggtcgtggca attgcgagca acatcggggg aaagcaggca 4020
ctcgaaaccg tccagaggtt gctgcctgtg ctgtgccaag cgcacggact aaccccagag 4080
caggtcgtgg caattgcgag ccatgacggg ggaaagcagg cactcgaaac cgtccagagg 4140
ttgctgcctg tgctgtgcca agcgcacggg ttgaccccag agcaggtcgt ggcaattgcg 4200
agccatgacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 4260
caagcgcacg gcctgacccc agagcaggtc gtggcaattg cgagccatga cgggggaaag 4320
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cggactgaca 4380
ccagagcagg tcgtggcaat tgcgagcaac ggagggggaa agcaggcact cgaaaccgtc 4440
cagaggttgc tgcctgtgct gtgccaagcg cacggactca cgcctgagca ggtagtggct 4500
attgcatcca acatcggggg cagacccgca ctggagtcaa tcgtggccca gctttcgagg 4560
ccggaccccg cgctggccgc actcactaat gatcatcttg tagcgctggc ctgcctcggc 4620
ggacgacccg ccttggatgc ggtgaagaag gggctcccgc acgcgcctgc attgattaag 4680
cggaccaaca gaaggattcc cgagaggaca tcacatcgag tggcaagtta acggcgcgcc 4740
ggtaccctcg agaaaatcag cctcgactgt gccttctagt tgccagccat ctgttgtttg 4800
cccctccccc gtgccttcct tgaccctgga aggtgccact cccactgtcc tttcctaata 4860
aaatgaggaa attgcatcac aacactcaac cctatctcgg tctattcttt tgatttataa 4920
gggattttgc cgatttcggc ctattggtta aaaaatgagc tgatttaaca aaaatttaac 4980
gcgaattaat tctgtggaat gtgtgtcagt tagggtgtgg aaagtcccca ggctccccag 5040
caggcagaag tatgcaaagc atgcatctca attagtcagc aaccaggtgt ggaaagtccc 5100
caggctcccc agcaggcaga agtatgcaaa gcatgcatct caattagtca gcaaccatag 5160
tcccgcccct aactccgccc atcccgcccc taactccgcc cagttccgcc cattctccgc 5220
cccatggctg actaattttt tttatttatg cagaggccga ggccgcctct gcctctgagc 5280
tattccagaa gtagtgagga ggcttttttg gaggcctagg cttttgcaaa aagctcccgg 5340
gagcttgtat atccattttc ggatctgatc agcacgtgat gaaaaagcct gaactcaccg 5400
cgacgtctgt cgagaagttt ctgatcgaaa agttcgacag cgtctccgac ctgatgcagc 5460
tctcggaggg cgaagaatct cgtgctttca gcttcgatgt aggagggcgt ggatatgtcc 5520
tgcgggtaaa tagctgcgcc gatggtttct acaaagatcg ttatgtttat cggcactttg 5580
catcggccgc gctcccgatt ccggaagtgc ttgacattgg ggaattcagc gagagcctga 5640
cctattgcat ctcccgccgt gcacagggtg tcacgttgca agacctgcct gaaaccgaac 5700
tgcccgctgt tctgcagccg gtcgcggagg ccatggatgc gatcgctgcg gccgatctta 5760
gccagacgag cgggttcggc ccattcggac cgcaaggaat cggtcaatac actacatggc 5820
gtgatttcat atgcgcgatt gctgatcccc atgtgtatca ctggcaaact gtgatggacg 5880
acaccgtcag tgcgtccgtc gcgcaggctc tcgatgagct gatgctttgg gccgaggact 5940
gccccgaagt ccggcacctc gtgcacgcgg atttcggctc caacaatgtc ctgacggaca 6000
atggccgcat aacagcggtc attgactgga gcgaggcgat gttcggggat tcccaatacg 6060
aggtcgccaa catcttcttc tggaggccgt ggttggcttg tatggagcag cagacgcgct 6120
acttcgagcg gaggcatccg gagcttgcag gatcgccgcg gctccgggcg tatatgctcc 6180
gcattggtct tgaccaactc tatcagagct tggttgacgg caatttcgat gatgcagctt 6240
gggcgcaggg tcgatgcgac gcaatcgtcc gatccggagc cgggactgtc gggcgtacac 6300
aaatcgcccg cagaagcgcg gccgtctgga ccgatggctg tgtagaagta ctcgccgata 6360
gtggaaaccg acgccccagc actcgtccga gggcaaagga atagcacgtg ctacgagatt 6420
tcgattccac cgccgccttc tatgaaaggt tgggcttcgg aatcgttttc cgggacgccg 6480
gctggatgat cctccagcgc ggggatctca tgctggagtt cttcgcccac cccaacttgt 6540
ttattgcagc ttataatggt tacaaataaa gcaatagcat cacaaatttc acaaataaag 6600
catttttttc actgcattct agttgtggtt tgtccaaact catcaatgta tcttatcatg 6660
tctgtatacc gtcgacctct agctagagct tggcgtaatc atggtcatta ccaatgctta 6720
atcagtgagg cacctatctc agcgatctgt ctatttcgtt catccatagt tgcctgactc 6780
cccgtcgtgt agataactac gatacgggag ggcttaccat ctggccccag cgctgcgatg 6840
ataccgcgag aaccacgctc accggctccg gatttatcag caataaacca gccagccgga 6900
agggccgagc gcagaagtgg tcctgcaact ttatccgcct ccatccagtc tattaattgt 6960
tgccgggaag ctagagtaag tagttcgcca gttaatagtt tgcgcaacgt tgttgccatc 7020
gctacaggca tcgtggtgtc acgctcgtcg tttggtatgg cttcattcag ctccggttcc 7080
caacgatcaa ggcgagttac atgatccccc atgttgtgca aaaaagcggt tagctccttc 7140
ggtcctccga tcgttgtcag aagtaagttg gccgcagtgt tatcactcat ggttatggca 7200
gcactgcata attctcttac tgtcatgcca tccgtaagat gcttttctgt gactggtgag 7260
tactcaacca agtcattctg agaatagtgt atgcggcgac cgagttgctc ttgcccggcg 7320
tcaatacggg ataataccgc gccacatagc agaactttaa aagtgctcat cattggaaaa 7380
cgttcttcgg ggcgaaaact ctcaaggatc ttaccgctgt tgagatccag ttcgatgtaa 7440
cccactcgtg cacccaactg atcttcagca tcttttactt tcaccagcgt ttctgggtga 7500
gcaaaaacag gaaggcaaaa tgccgcaaaa aagggaataa gggcgacacg gaaatgttga 7560
atactcatat tcttcctttt tcaatattat tgaagcattt atcagggtta ttgtctcatg 7620
agcggataca tatttgaatg tatttagaaa aataaacaaa taggggtcag tgttacaacc 7680
aattaaccaa ttctgaacat tatcgcgagc ccatttatac ctgaatatgg ctcataacac 7740
cccttg 7746
<210>2
<211>2613bp
<212>DNA
<213>人工序列
<220>
<223>
<400>2
atggactata aggaccacga cggagactac aaggatcatg atattgatta caaagacgat 60
gacgataaga tggccccaaa gaagaagcgg aaggtcggta tccacggagt cccagcagcc 120
gtagatttga gaactttggg atattcacag cagcagcagg aaaagatcaa gcccaaagtg 180
aggtcgacag tcgcgcagca tcacgaagcg ctggtgggtc atgggtttac acatgcccac 240
atcgtagcct tgtcgcagca ccctgcagcc cttggcacgg tcgccgtcaa gtaccaggac 300
atgattgcgg cgttgccgga agccacacat gaggcgatcg tcggtgtggg gaaacagtgg 360
agcggagccc gagcgcttga ggccctgttg acggtcgcgg gagagctgag agggcctccc 420
cttcagctgg acacgggcca gttgctgaag atcgcgaagc ggggaggagt cacggcggtc 480
gaggcggtgc acgcgtggcg caatgcgctc acgggagcac ccctcaacct gaccccagag 540
caggtcgtgg caattgcgag ccatgacggg ggaaagcagg cactcgaaac cgtccagagg 600
ttgctgcctg tgctgtgcca agcgcacgga cttacgccag agcaggtcgt ggcaattgcg 660
agccatgacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 720
caagcgcacg gactaacccc agagcaggtc gtggcaattg cgagcaacat cgggggaaag 780
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cgggttgacc 840
ccagagcagg tcgtggcaat tgcgagcaac ggagggggaa agcaggcact cgaaaccgtc 900
cagaggttgc tgcctgtgct gtgccaagcg cacggcctga ccccagagca ggtcgtggca 960
attgcgagca acggaggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 1020
ctgtgccaag cgcacggact gacaccagag caggtcgtgg caattgcgag ccatgacggg 1080
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacgga 1140
cttacacccg aacaagtcgt ggcaattgcg agccatgacg ggggaaagca ggcactcgaa 1200
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gacttacgcc agagcaggtc 1260
gtggcaattg cgagcaacat cgggggaaag caggcactcg aaaccgtcca gaggttgctg 1320
cctgtgctgt gccaagcgca cggactaacc ccagagcagg tcgtggcaat tgcgagcaac 1380
ggagggggaa agcaggcact cgaaaccgtc cagaggttgc tgcctgtgct gtgccaagcg 1440
cacgggttga ccccagagca ggtcgtggca attgcgagca acggaggggg aaagcaggca 1500
ctcgaaaccg tccagaggtt gctgcctgtg ctgtgccaag cgcacggcct gaccccagag 1560
caggtcgtgg caattgcgag ccatgacggg ggaaagcagg cactcgaaac cgtccagagg 1620
ttgctgcctg tgctgtgcca agcgcacgga ctgacaccag agcaggtcgt ggcaattgcg 1680
agccatgacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 1740
caagcgcacg gcctcacccc agagcaggtc gtggcaattg cgagcaacat cgggggaaag 1800
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cggacttacg 1860
ccagagcagg tcgtggcaat tgcgagcaac ggagggggaa agcaggcact cgaaaccgtc 1920
cagaggttgc tgcctgtgct gtgccaagcg cacggactaa ccccagagca ggtcgtggca 1980
attgcgagca acggaggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 2040
ctgtgccaag cgcacgggtt gaccccagag caggtcgtgg caattgcgag ccatggaggg 2100
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacggc 2160
ctgaccccag agcaggtcgt ggcaattgcg agccatggag ggggaaagca ggcactcgaa 2220
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gactgacacc agagcaggtc 2280
gtggcaattg cgagcaacat cgggggaaag caggcactcg aaaccgtcca gaggttgctg 2340
cctgtgctgt gccaagcgca cggactcacg cctgagcagg tagtggctat tgcatccaac 2400
ggagggggca gacccgcact ggagtcaatc gtggcccagc tttcgaggcc ggaccccgcg 2460
ctggccgcac tcactaatga tcatcttgta gcgctggcct gcctcggcgg acgacccgcc 2520
ttggatgcgg tgaagaaggg gctcccgcac gcgcctgcat tgattaagcg gaccaacaga 2580
aggattcccg agaggacatc acatcgagtg gca 2613
<210>3
<211>318bp
<212>DNA
<213>人工序列
<220>
<223>
<400>3
atggtgaagc agatcgagag caagactgct tttcaggaag ccttggacgc tgcaggtgat 60
aaacttgtag tagttgactt ctcagccacg tggtgtgggc cttgcaaaat gatcaagcct 120
ttctttcatt ccctctctga aaagtattcc aacgtgatat tccttgaagt agatgtggat 180
gactgtcagg atgttgcttc agagtgtgaa gtcaaatgca tgccaacatt ccagtttttt 240
aagaagggac aaaaggtggg tgaattttct ggagccaata aggaaaagct tgaagccacc 300
attaatgaat tagtctaa 318
<210>4
<211>979
<212>PRT
<213>人工序列
<220>
<223>
<400>4
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Val Asp Leu Arg Thr Leu Gly Tyr
35 40 45
Ser Gln Gln Gln Gln Glu Lys Ile Lys Pro Lys Val Arg Ser Thr Val
50 55 60
Ala Gln His His Glu Ala Leu Val Gly His Gly Phe Thr His Ala His
65 70 75 80
Ile Val Ala Leu Ser Gln His Pro Ala Ala Leu Gly Thr Val Ala Val
85 90 95
Lys Tyr Gln Asp Met Ile Ala Ala Leu Pro Glu Ala Thr His Glu Ala
100 105 110
Ile Val Gly Val Gly Lys Gln Trp Ser Gly Ala Arg Ala Leu Glu Ala
115 120 125
Leu Leu Thr Val Ala Gly Glu Leu Arg Gly Pro Pro Leu Gln Leu Asp
130 135 140
Thr Gly Gln Leu Leu Lys Ile Ala Lys Arg Gly Gly Val Thr Ala Val
145 150 155 160
Glu Ala Val His Ala Trp Arg Asn Ala Leu Thr Gly Ala Pro Leu Asn
165 170 175
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys
180 185 190
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
195 200 205
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly
210 215 220
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
225 230 235 240
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
245 250 255
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
260 265 270
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
275 280 285
Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
290 295 300
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
305 310 315 320
Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
325 330 335
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
340 345 350
Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val
355 360 365
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
370 375 380
Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu
385 390 395 400
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
405 410 415
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala
420 425 430
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
435 440 445
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
450 455 460
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
465 470 475 480
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
485 490 495
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
500 505 510
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
515 520 525
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
530 535 540
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
545 550 555 560
Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
565 570 575
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
580 585 590
Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
595 600 605
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
610 615 620
Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val
625 630 635 640
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
645 650 655
Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu
660 665 670
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
675 680 685
Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala
690 695 700
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
705 710 715 720
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
725 730 735
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
740 745 750
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly
755 760 765
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
770 775 780
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
785 790 795 800
Ile Gly Gly Arg Pro Ala Leu Glu Ser Ile Val Ala Gln Leu Ser Arg
805 810 815
Pro Asp Pro Ala Leu Ala Ala Leu Thr Asn Asp His Leu Val Ala Leu
820 825 830
Ala Cys Leu Gly Gly Arg Pro Ala Leu Asp Ala Val Lys Lys Gly Leu
835 840 845
Pro His Ala Pro Ala Leu Ile Lys Arg Thr Asn Arg Arg Ile Pro Glu
850 855 860
Arg Thr Ser His Arg Val Ala Ser Tyr Gln Gly Met Val Lys Gln Ile
865 870 875 880
Glu Ser Lys Thr Ala Phe Gln Glu Ala Leu Asp Ala Ala Gly Asp Lys
885 890 895
Leu Val Val Val Asp Phe Ser Ala Thr Trp Cys Gly Pro Cys Lys Met
900 905 910
Ile Lys Pro Phe Phe His Ser Leu Ser Glu Lys Tyr Ser Asn Val Ile
915 920 925
Phe Leu Glu Val Asp Val Asp Asp Cys Gln Asp Val Ala Ser Glu Cys
930 935 940
Glu Val Lys Cys Met Pro Thr Phe Gln Phe Phe Lys Lys Gly Gln Lys
945 950 955 960
Val Gly Glu Phe Ser Gly Ala Asn Lys Glu Lys Leu Glu Ala Thr Ile
965 970 975
Asn Glu Leu
<210>5
<211>972
<212>PRT
<213>人工序列
<220>
<223>
<400>5
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Val Asp Leu Arg Thr Leu Gly Tyr
35 40 45
Ser Gln Gln Gln Gln Glu Lys Ile Lys Pro Lys Val Arg Ser Thr Val
50 55 60
Ala Gln His His Glu Ala Leu Val Gly His Gly Phe Thr His Ala His
65 70 75 80
Ile Val Ala Leu Ser Gln His Pro Ala Ala Leu Gly Thr Val Ala Val
85 90 95
Lys Tyr Gln Asp Met Ile Ala Ala Leu Pro Glu Ala Thr His Glu Ala
100 105 110
Ile Val Gly Val Gly Lys Gln Trp Ser Gly Ala Arg Ala Leu Glu Ala
115 120 125
Leu Leu Thr Val Ala Gly Glu Leu Arg Gly Pro Pro Leu Gln Leu Asp
130 135 140
Thr Gly Gln Leu Leu Lys Ile Ala Lys Arg Gly Gly Val Thr Ala Val
145 150 155 160
Glu Ala Val His Ala Trp Arg Asn Ala Leu Thr Gly Ala Pro Leu Asn
165 170 175
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
180 185 190
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
195 200 205
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
210 215 220
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
225 230 235 240
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
245 250 255
Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
260 265 270
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
275 280 285
Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
290 295 300
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
305 310 315 320
Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
325 330 335
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
340 345 350
Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val
355 360 365
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
370 375 380
Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu
385 390 395 400
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
405 410 415
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala
420 425 430
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
435 440 445
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys
450 455 460
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
465 470 475 480
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly
485 490 495
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
500 505 510
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
515 520 525
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
530 535 540
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
545 550 555 560
Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
565 570 575
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
580 585 590
Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
595 600 605
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
610 615 620
Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val
625 630 635 640
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
645 650 655
Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu
660 665 670
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
675 680 685
Pro Glu Gln Val Val Ala Ile Ala Ser His Gly Gly Gly Lys Gln Ala
690 695 700
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
705 710 715 720
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Gly Gly Gly Lys
725 730 735
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
740 745 750
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly
755 760 765
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
770 775 780
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
785 790 795 800
Gly Gly Gly Arg Pro Ala Leu Glu Ser Ile Val Ala Gln Leu Ser Arg
805 810 815
Pro Asp Pro Ala Leu Ala Ala Leu Thr Asn Asp His Leu Val Ala Leu
820 825 830
Ala Cys Leu Gly Gly Arg Pro Ala Leu Asp Ala Val Lys Lys Gly Leu
835 840 845
Pro His Ala Pro Ala Leu Ile Lys Arg Thr Asn Arg Arg Ile Pro Glu
850 855 860
Arg Thr Ser His Arg Val Ala Val Ile Arg Glu Trp Ser Arg Ser Arg
865 870 875 880
Ala Arg Leu Leu Phe Arg Lys Pro Trp Thr Leu Gln Val Ile Asn Leu
885 890 895
Leu Thr Ser Gln Pro Arg Gly Val Gly Leu Ala Lys Ser Ser Leu Ser
900 905 910
Phe Ile Pro Ser Leu Lys Ser Ile Pro Thr Tyr Ser Leu Lys Met Trp
915 920 925
Met Thr Val Arg Met Leu Leu Gln Ser Val Lys Ser Asn Ala Cys Gln
930 935 940
His Ser Ser Phe Leu Arg Arg Asp Lys Arg Trp Val Asn Phe Leu Glu
945 950 955 960
Pro Ile Arg Lys Ser Leu Lys Pro Pro Leu Met Asn
965 970
<210>6
<211>711bp
<212>DNA
<213>人工序列
<220>
<223>
<400>6
atggtgagca agggcgagga ggataacatg gccatcatca aggagttcat gcgcttcaag 60
gtgcacatgg agggctccgt gaacggccac gagttcgaga tcgagggcga gggcgagggc 120
cgcccctacg agggcaccca gaccgccaag ctgaaggtga ccaagggtgg ccccctgccc 180
ttcgcctggg acatcctgtc ccctcagttc atgtacggct ccaaggccta cgtgaagcac 240
cccgccgaca tccccgacta cttgaagctg tccttccccg agggcttcaa gtgggagcgc 300
gtgatgaact tcgaggacgg cggcgtggtg accgtgaccc aggactcctc cctgcaggac 360
ggcgagttca tctacaaggt gaagctgcgc ggcaccaact tcccctccga cggccccgta 420
atgcagaaga agaccatggg ctgggaggcc tcctccgagc ggatgtaccc cgaggacggc 480
gccctgaagg gcgagatcaa gcagaggctg aagctgaagg acggcggcca ctacgacgct 540
gaggtcaaga ccacctacaa ggccaagaag cccgtgcagc tgcccggcgc ctacaacgtc 600
aacatcaagt tggacatcac ctcccacaac gaggactaca ccatcgtgga acagtacgaa 660
cgcgccgagg gccgccactc caccggcggc atggacgagc tgtacaagta a 711
<210>7
<211>1229
<212>PRT
<213>人工序列
<220>
<223>
<400>7
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Val Asp Leu Arg Thr Leu Gly Tyr
35 40 45
Ser Gln Gln Gln Gln Glu Lys Ile Lys Pro Lys Val Arg Ser Thr Val
50 55 60
Ala Gln His His Glu Ala Leu Val Gly His Gly Phe Thr His Ala His
65 70 75 80
Ile Val Ala Leu Ser Gln His Pro Ala Ala Leu Gly Thr Val Ala Val
85 90 95
Lys Tyr Gln Asp Met Ile Ala Ala Leu Pro Glu Ala Thr His Glu Ala
100 105 110
Ile Val Gly Val Gly Lys Gln Trp Ser Gly Ala Arg Ala Leu Glu Ala
115 120 125
Leu Leu Thr Val Ala Gly Glu Leu Arg Gly Pro Pro Leu Gln Leu Asp
130 135 140
Thr Gly Gln Leu Leu Lys Ile Ala Lys Arg Gly Gly Val Thr Ala Val
145 150 155 160
Glu Ala Val His Ala Trp Arg Asn Ala Leu Thr Gly Ala Pro Leu Asn
165 170 175
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys
180 185 190
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
195 200 205
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly
210 215 220
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
225 230 235 240
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
245 250 255
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
260 265 270
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
275 280 285
Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
290 295 300
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
305 310 315 320
Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
325 330 335
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
340 345 350
Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val
355 360 365
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
370 375 380
Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu
385 390 395 400
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
405 410 415
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala
420 425 430
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
435 440 445
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
450 455 460
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
465 470 475 480
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
485 490 495
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
500 505 510
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
515 520 525
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
530 535 540
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
545 550 555 560
Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
565 570 575
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
580 585 590
Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
595 600 605
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
610 615 620
Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val
625 630 635 640
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
645 650 655
Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu
660 665 670
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
675 680 685
Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala
690 695 700
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
705 710 715 720
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
725 730 735
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
740 745 750
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly
755 760 765
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
770 775 780
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
785 790 795 800
Ile Gly Gly Arg Pro Ala Leu Glu Ser Ile Val Ala Gln Leu Ser Arg
805 810 815
Pro Asp Pro Ala Leu Ala Ala Leu Thr Asn Asp His Leu Val Ala Leu
820 825 830
Ala Cys Leu Gly Gly Arg Pro Ala Leu Asp Ala Val Lys Lys Gly Leu
835 840 845
Pro His Ala Pro Ala Leu Ile Lys Arg Thr Asn Arg Arg Ile Pro Glu
850 855 860
Arg Thr Ser His Arg Val Ala Ser Tyr Gln Gly Met Val Ser Lys Gly
865 870 875 880
Glu Glu Asp Asn Met Ala Ile Ile Lys Glu Phe Met Arg Phe Lys Val
885 890 895
His Met Glu Gly Ser Val Asn Gly His Glu Phe Glu Ile Glu Gly Glu
900 905 910
Gly Glu Gly Arg Pro Tyr Glu Gly Thr Gln Thr Ala Lys Leu Lys Val
915 920 925
Thr Lys Gly Gly Pro Leu Pro Phe Ala Trp Asp Ile Leu Ser Pro Gln
930 935 940
Phe Met Tyr Gly Ser Lys Ala Tyr Val Lys His Pro Ala Asp Ile Pro
945 950 955 960
Asp Tyr Leu Lys Leu Ser Phe Pro Glu Gly Phe Lys Trp Glu Arg Val
965 970 975
Met Asn Phe Glu Asp Gly Gly Val Val Thr Val Thr Gln Asp Ser Ser
980 985 990
Leu Gln Asp Gly Glu Phe Ile Tyr Lys Val Lys Leu Arg Gly Thr Asn
995 1000 1005
Phe Pro Ser Asp Gly Pro Val Met Gln Lys Lys Thr Met Gly Trp
1010 1015 1020
Glu Ala Ser Ser Glu Arg Met Tyr Pro Glu Asp Gly Ala Leu Lys
1025 1030 1035
Gly Glu Ile Lys Gln Arg Leu Lys Leu Lys Asp Gly Gly His Tyr
1040 1045 1050
Asp Ala Glu Val Lys Thr Thr Tyr Lys Ala Lys Lys Pro Val Gln
1055 1060 1065
Leu Pro Gly Ala Tyr Asn Val Asn Ile Lys Leu Asp Ile Thr Ser
1070 1075 1080
His Asn Glu Asp Tyr Thr Ile Val Glu Gln Tyr Glu Arg Ala Glu
1085 1090 1095
Gly Arg His Ser Thr Gly Gly Met Asp Glu Leu Tyr Lys Gly Thr
1100 1105 1110
Ser Gly Leu Arg Ser Arg Ala Gln Ala Ser Asn Ser Met Val Lys
1115 1120 1125
Gln Ile Glu Ser Lys Thr Ala Phe Gln Glu Ala Leu Asp Ala Ala
1130 1135 1140
Gly Asp Lys Leu Val Val Val Asp Phe Ser Ala Thr Trp Cys Gly
1145 1150 1155
Pro Cys Lys Met Ile Lys Pro Phe Phe His Ser Leu Ser Glu Lys
1160 1165 1170
Tyr Ser Asn Val Ile Phe Leu Glu Val Asp Val Asp Asp Cys Gln
1175 1180 1185
Asp Val Ala Ser Glu Cys Glu Val Lys Cys Met Pro Thr Phe Gln
1190 1195 1200
Phe Phe Lys Lys Gly Gln Lys Val Gly Glu Phe Ser Gly Ala Asn
1205 1210 1215
Lys Glu Lys Leu Glu Ala Thr Ile Asn Glu Leu
1220 1225
<210>8
<211>1212
<212>PRT
<213>人工序列
<220>
<223>
<400>8
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Val Asp Leu Arg Thr Leu Gly Tyr
35 40 45
Ser Gln Gln Gln Gln Glu Lys Ile Lys Pro Lys Val Arg Ser Thr Val
50 55 60
Ala Gln His His Glu Ala Leu Val Gly His Gly Phe Thr His Ala His
65 70 75 80
Ile Val Ala Leu Ser Gln His Pro Ala Ala Leu Gly Thr Val Ala Val
85 90 95
Lys Tyr Gln Asp Met Ile Ala Ala Leu Pro Glu Ala Thr His Glu Ala
100 105 110
Ile Val Gly Val Gly Lys Gln Trp Ser Gly Ala Arg Ala Leu Glu Ala
115 120 125
Leu Leu Thr Val Ala Gly Glu Leu Arg Gly Pro Pro Leu Gln Leu Asp
130 135 140
Thr Gly Gln Leu Leu Lys Ile Ala Lys Arg Gly Gly Val Thr Ala Val
145 150 155 160
Glu Ala Val His Ala Trp Arg Asn Ala Leu Thr Gly Ala Pro Leu Asn
165 170 175
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
180 185 190
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
195 200 205
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
210 215 220
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
225 230 235 240
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
245 250 255
Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
260 265 270
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
275 280 285
Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
290 295 300
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
305 310 315 320
Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
325 330 335
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
340 345 350
Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val
355 360 365
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
370 375 380
Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu
385 390 395 400
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
405 410 415
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala
420 425 430
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
435 440 445
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys
450 455 460
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
465 470 475 480
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly
485 490 495
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
500 505 510
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
515 520 525
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
530 535 540
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
545 550 555 560
Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
565 570 575
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
580 585 590
Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
595 600 605
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
610 615 620
Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val
625 630 635 640
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
645 650 655
Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu
660 665 670
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
675 680 685
Pro Glu Gln Val Val Ala Ile Ala Ser His Gly Gly Gly Lys Gln Ala
690 695 700
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
705 710 715 720
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Gly Gly Gly Lys
725 730 735
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
740 745 750
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly
755 760 765
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
770 775 780
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
785 790 795 800
Gly Gly Gly Arg Pro Ala Leu Glu Ser Ile Val Ala Gln Leu Ser Arg
805 810 815
Pro Asp Pro Ala Leu Ala Ala Leu Thr Asn Asp His Leu Val Ala Leu
820 825 830
Ala Cys Leu Gly Gly Arg Pro Ala Leu Asp Ala Val Lys Lys Gly Leu
835 840 845
Pro His Ala Pro Ala Leu Ile Lys Arg Thr Asn Arg Arg Ile Pro Glu
850 855 860
Arg Thr Ser His Arg Val Ala Val Ile Arg Glu Trp Ala Arg Ala Arg
865 870 875 880
Ser Cys Ser Pro Gly Trp Cys Pro Ser Trp Ser Ser Trp Thr Ala Thr
885 890 895
Thr Ala Thr Ser Ser Ala Cys Pro Ala Arg Ala Arg Ala Met Pro Pro
900 905 910
Thr Ala Ser Pro Ser Ser Ser Ala Pro Pro Ala Ser Cys Pro Cys Pro
915 920 925
Gly Pro Pro Ser Pro Pro Pro Thr Ala Cys Ser Ala Ser Ala Ala Thr
930 935 940
Pro Thr Thr Ser Ser Thr Thr Ser Ser Ser Pro Pro Cys Pro Lys Ala
945 950 955 960
Thr Ser Arg Ser Ala Pro Ser Ser Ser Arg Thr Thr Ala Thr Thr Arg
965 970 975
Pro Ala Pro Arg Ser Ser Arg Ala Thr Pro Trp Thr Ala Ser Ser Arg
980 985 990
Ala Ser Thr Ser Arg Arg Thr Ala Thr Ser Trp Gly Thr Ser Trp Ser
995 1000 1005
Thr Thr Thr Thr Ala Thr Thr Ser Ile Ser Trp Pro Thr Ser Arg
1010 1015 1020
Arg Thr Ala Ser Arg Thr Ser Arg Ser Ala Thr Thr Ser Arg Thr
1025 1030 1035
Ala Ala Cys Ser Ser Pro Thr Thr Thr Ser Arg Thr Pro Pro Ser
1040 1045 1050
Ala Thr Ala Pro Cys Cys Cys Pro Thr Thr Thr Thr Ala Pro Ser
1055 1060 1065
Pro Pro Ala Lys Thr Pro Thr Arg Ser Ala Ile Thr Trp Ser Cys
1070 1075 1080
Trp Ser Ser Pro Pro Pro Gly Ser Leu Ser Ala Trp Thr Ser Cys
1085 1090 1095
Thr Arg Val Pro Pro Asp Ser Asp Leu Glu Leu Lys Leu Arg Ile
1100 1105 1110
Pro Trp Ser Arg Ser Arg Ala Arg Leu Leu Phe Arg Lys Pro Trp
1115 1120 1125
Thr Leu Gln Val Ile Asn Leu Leu Thr Ser Gln Pro Arg Gly Val
1130 1135 1140
Gly Leu Ala Lys Ser Ser Leu Ser Phe Ile Pro Ser Leu Lys Ser
1145 1150 1155
Ile Pro Thr Tyr Ser Leu Lys Met Trp Met Thr Val Arg Met Leu
1160 1165 1170
Leu Gln Ser Val Lys Ser Asn Ala Cys Gln His Ser Ser Phe Leu
1175 1180 1185
Arg Arg Asp Lys Arg Trp Val Asn Phe Leu Glu Pro Ile Arg Lys
1190 1195 1200
Ser Leu Lys Pro Pro Leu Met Asn Ser
1205 1210
<210>9
<211>2613bp
<212>DNA
<213>人工序列
<220>
<223>
<400>9
atggactata aggaccacga cggagactac aaggatcatg atattgatta caaagacgat 60
gacgataaga tggccccaaa gaagaagcgg aaggtcggta tccacggagt cccagcagcc 120
gtagatttga gaactttggg atattcacag cagcagcagg aaaagatcaa gcccaaagtg 180
aggtcgacag tcgcgcagca tcacgaagcg ctggtgggtc atgggtttac acatgcccac 240
atcgtagcct tgtcgcagca ccctgcagcc cttggcacgg tcgccgtcaa gtaccaggac 300
atgattgcgg cgttgccgga agccacacat gaggcgatcg tcggtgtggg gaaacagtgg 360
agcggagccc gagcgcttga ggccctgttg acggtcgcgg gagagctgag agggcctccc 420
cttcagctgg acacgggcca gttgctgaag atcgcgaagc ggggaggagt cacggcggtc 480
gaggcggtgc acgcgtggcg caatgcgctc acgggagcac ccctcaacct gaccccagag 540
caggtcgtgg caattgcgag caacatcggg ggaaagcagg cactcgaaac cgtccagagg 600
ttgctgcctg tgctgtgcca agcgcacgga cttacgccag agcaggtcgt ggcaattgcg 660
agccatgacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 720
caagcgcacg gactaacccc agagcaggtc gtggcaattg cgagccatga cgggggaaag 780
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cgggttgacc 840
ccagagcagg tcgtggcaat tgcgagccat gacgggggaa agcaggcact cgaaaccgtc 900
cagaggttgc tgcctgtgct gtgccaagcg cacggcctga ccccagagca ggtcgtggca 960
attgcgagca acggaggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 1020
ctgtgccaag cgcacggact gacaccagag caggtcgtgg caattgcgag caacatcggg 1080
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacgga 1140
cttacacccg aacaagtcgt ggcaattgcg agccatgacg ggggaaagca ggcactcgaa 1200
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gacttacgcc agagcaggtc 1260
gtggcaattg cgagcaacgg agggggaaag caggcactcg aaaccgtcca gaggttgctg 1320
cctgtgctgt gccaagcgca cggactaacc ccagagcagg tcgtggcaat tgcgagcaac 1380
aacgggggaa agcaggcact cgaaaccgtc cagaggttgc tgcctgtgct gtgccaagcg 1440
cacgggttga ccccagagca ggtcgtggca attgcgagca acatcggggg aaagcaggca 1500
ctcgaaaccg tccagaggtt gctgcctgtg ctgtgccaag cgcacggcct gaccccagag 1560
caggtcgtgg caattgcgag caacggaggg ggaaagcagg cactcgaaac cgtccagagg 1620
ttgctgcctg tgctgtgcca agcgcacgga ctgacaccag agcaggtcgt ggcaattgcg 1680
agcaacaacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 1740
caagcgcacg gcctcacccc agagcaggtc gtggcaattg cgagcaacat cgggggaaag 1800
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cggacttacg 1860
ccagagcagg tcgtggcaat tgcgagcaac ggagggggaa agcaggcact cgaaaccgtc 1920
cagaggttgc tgcctgtgct gtgccaagcg cacggactaa ccccagagca ggtcgtggca 1980
attgcgagca acaacggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 2040
ctgtgccaag cgcacgggtt gaccccagag caggtcgtgg caattgcgag caacggaggg 2100
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacggc 2160
ctgaccccag agcaggtcgt ggcaattgcg agcaacaacg ggggaaagca ggcactcgaa 2220
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gactgacacc agagcaggtc 2280
gtggcaattg cgagcaacgg agggggaaag caggcactcg aaaccgtcca gaggttgctg 2340
cctgtgctgt gccaagcgca cggactcacg cctgagcagg tagtggctat tgcatccaac 2400
ggagggggca gacccgcact ggagtcaatc gtggcccagc tttcgaggcc ggaccccgcg 2460
ctggccgcac tcactaatga tcatcttgta gcgctggcct gcctcggcgg acgacccgcc 2520
ttggatgcgg tgaagaaggg gctcccgcac gcgcctgcat tgattaagcg gaccaacaga 2580
aggattcccg agaggacatc acatcgagtg gca 2613
<210>10
<211>871bp
<212>DNA
<213>人工序列
<220>
<223>
<400>10
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Val Asp Leu Arg Thr Leu Gly Tyr
35 40 45
Ser Gln Gln Gln Gln Glu Lys Ile Lys Pro Lys Val Arg Ser Thr Val
50 55 60
Ala Gln His His Glu Ala Leu Val Gly His Gly Phe Thr His Ala His
65 70 75 80
Ile Val Ala Leu Ser Gln His Pro Ala Ala Leu Gly Thr Val Ala Val
85 90 95
Lys Tyr Gln Asp Met Ile Ala Ala Leu Pro Glu Ala Thr His Glu Ala
100 105 110
Ile Val Gly Val Gly Lys Gln Trp Ser Gly Ala Arg Ala Leu Glu Ala
115 120 125
Leu Leu Thr Val Ala Gly Glu Leu Arg Gly Pro Pro Leu Gln Leu Asp
130 135 140
Thr Gly Gln Leu Leu Lys Ile Ala Lys Arg Gly Gly Val Thr Ala Val
145 150 155 160
Glu Ala Val His Ala Trp Arg Asn Ala Leu Thr Gly Ala Pro Leu Asn
165 170 175
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys
180 185 190
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
195 200 205
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
210 215 220
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
225 230 235 240
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His
245 250 255
Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
260 265 270
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
275 280 285
Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
290 295 300
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
305 310 315 320
Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
325 330 335
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
340 345 350
Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val
355 360 365
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
370 375 380
Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu
385 390 395 400
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
405 410 415
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala
420 425 430
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
435 440 445
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Asn Gly Gly Lys
450 455 460
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
465 470 475 480
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Ile Gly
485 490 495
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
500 505 510
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
515 520 525
Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
530 535 540
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
545 550 555 560
Ser Asn Asn Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
565 570 575
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
580 585 590
Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
595 600 605
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
610 615 620
Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val
625 630 635 640
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
645 650 655
Gln Val Val Ala Ile Ala Ser Asn Asn Gly Gly Lys Gln Ala Leu Glu
660 665 670
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
675 680 685
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala
690 695 700
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
705 710 715 720
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Asn Gly Gly Lys
725 730 735
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
740 745 750
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly
755 760 765
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
770 775 780
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
785 790 795 800
Gly Gly Gly Arg Pro Ala Leu Glu Ser Ile Val Ala Gln Leu Ser Arg
805 810 815
Pro Asp Pro Ala Leu Ala Ala Leu Thr Asn Asp His Leu Val Ala Leu
820 825 830
Ala Cys Leu Gly Gly Arg Pro Ala Leu Asp Ala Val Lys Lys Gly Leu
835 840 845
Pro His Ala Pro Ala Leu Ile Lys Arg Thr Asn Arg Arg Ile Pro Glu
850 855 860
Arg Thr Ser His Arg Val Ala
865 870
<210>11
<211>2613bp
<212>DNA
<213>人工序列
<220>
<223>
<400>11
atggactata aggaccacga cggagactac aaggatcatg atattgatta caaagacgat 60
gacgataaga tggccccaaa gaagaagcgg aaggtcggta tccacggagt cccagcagcc 120
gtagatttga gaactttggg atattcacag cagcagcagg aaaagatcaa gcccaaagtg 180
aggtcgacag tcgcgcagca tcacgaagcg ctggtgggtc atgggtttac acatgcccac 240
atcgtagcct tgtcgcagca ccctgcagcc cttggcacgg tcgccgtcaa gtaccaggac 300
atgattgcgg cgttgccgga agccacacat gaggcgatcg tcggtgtggg gaaacagtgg 360
agcggagccc gagcgcttga ggccctgttg acggtcgcgg gagagctgag agggcctccc 420
cttcagctgg acacgggcca gttgctgaag atcgcgaagc ggggaggagt cacggcggtc 480
gaggcggtgc acgcgtggcg caatgcgctc acgggagcac ccctcaacct gaccccagag 540
caggtcgtgg caattgcgag ccatgacggg ggaaagcagg cactcgaaac cgtccagagg 600
ttgctgcctg tgctgtgcca agcgcacgga cttacgccag agcaggtcgt ggcaattgcg 660
agccatgacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 720
caagcgcacg gactaacccc agagcaggtc gtggcaattg cgagcaacgg agggggaaag 780
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cgggttgacc 840
ccagagcagg tcgtggcaat tgcgagcaac aacgggggaa agcaggcact cgaaaccgtc 900
cagaggttgc tgcctgtgct gtgccaagcg cacggcctga ccccagagca ggtcgtggca 960
attgcgagca acggaggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 1020
ctgtgccaag cgcacggact gacaccagag caggtcgtgg caattgcgag ccatgacggg 1080
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacgga 1140
cttacacccg aacaagtcgt ggcaattgcg agcaacatcg ggggaaagca ggcactcgaa 1200
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gacttacgcc agagcaggtc 1260
gtggcaattg cgagccatga cgggggaaag caggcactcg aaaccgtcca gaggttgctg 1320
cctgtgctgt gccaagcgca cggactaacc ccagagcagg tcgtggcaat tgcgagccat 1380
gacgggggaa agcaggcact cgaaaccgtc cagaggttgc tgcctgtgct gtgccaagcg 1440
cacgggttga ccccagagca ggtcgtggca attgcgagca acaacggggg aaagcaggca 1500
ctcgaaaccg tccagaggtt gctgcctgtg ctgtgccaag cgcacggcct gaccccagag 1560
caggtcgtgg caattgcgag caacatcggg ggaaagcagg cactcgaaac cgtccagagg 1620
ttgctgcctg tgctgtgcca agcgcacgga ctgacaccag agcaggtcgt ggcaattgcg 1680
agccatgacg ggggaaagca ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc 1740
caagcgcacg gcctcacccc agagcaggtc gtggcaattg cgagcaacat cgggggaaag 1800
caggcactcg aaaccgtcca gaggttgctg cctgtgctgt gccaagcgca cggacttacg 1860
ccagagcagg tcgtggcaat tgcgagccat gacgggggaa agcaggcact cgaaaccgtc 1920
cagaggttgc tgcctgtgct gtgccaagcg cacggactaa ccccagagca ggtcgtggca 1980
attgcgagca acggaggggg aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg 2040
ctgtgccaag cgcacgggtt gaccccagag caggtcgtgg caattgcgag caacggaggg 2100
ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca agcgcacggc 2160
ctgaccccag agcaggtcgt ggcaattgcg agccatgacg ggggaaagca ggcactcgaa 2220
accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gactgacacc agagcaggtc 2280
gtggcaattg cgagccatga cgggggaaag caggcactcg aaaccgtcca gaggttgctg 2340
cctgtgctgt gccaagcgca cggactcacg cctgagcagg tagtggctat tgcatccaac 2400
ggagggggca gacccgcact ggagtcaatc gtggcccagc tttcgaggcc ggaccccgcg 2460
ctggccgcac tcactaatga tcatcttgta gcgctggcct gcctcggcgg acgacccgcc 2520
ttggatgcgg tgaagaaggg gctcccgcac gcgcctgcat tgattaagcg gaccaacaga 2580
aggattcccg agaggacatc acatcgagtg gca 2613
<210>12
<211>871
<212>DNA
<213>人工序列
<220>
<223>
<400>12
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Val Asp Leu Arg Thr Leu Gly Tyr
35 40 45
Ser Gln Gln Gln Gln Glu Lys Ile Lys Pro Lys Val Arg Ser Thr Val
50 55 60
Ala Gln His His Glu Ala Leu Val Gly His Gly Phe Thr His Ala His
65 70 75 80
Ile Val Ala Leu Ser Gln His Pro Ala Ala Leu Gly Thr Val Ala Val
85 90 95
Lys Tyr Gln Asp Met Ile Ala Ala Leu Pro Glu Ala Thr His Glu Ala
100 105 110
Ile Val Gly Val Gly Lys Gln Trp Ser Gly Ala Arg Ala Leu Glu Ala
115 120 125
Leu Leu Thr Val Ala Gly Glu Leu Arg Gly Pro Pro Leu Gln Leu Asp
130 135 140
Thr Gly Gln Leu Leu Lys Ile Ala Lys Arg Gly Gly Val Thr Ala Val
145 150 155 160
Glu Ala Val His Ala Trp Arg Asn Ala Leu Thr Gly Ala Pro Leu Asn
165 170 175
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
180 185 190
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
195 200 205
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
210 215 220
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
225 230 235 240
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
245 250 255
Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
260 265 270
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
275 280 285
Ser Asn Asn Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
290 295 300
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
305 310 315 320
Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
325 330 335
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
340 345 350
Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val
355 360 365
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
370 375 380
Gln Val Val Ala Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu
385 390 395 400
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
405 410 415
Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala
420 425 430
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
435 440 445
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
450 455 460
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
465 470 475 480
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn Asn Gly
485 490 495
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
500 505 510
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
515 520 525
Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val
530 535 540
Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala
545 550 555 560
Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu
565 570 575
Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala
580 585 590
Ile Ala Ser Asn Ile Gly Gly Lys Gln Ala Leu Glu Thr Val Gln Arg
595 600 605
Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu Gln Val
610 615 620
Val Ala Ile Ala Ser His Asp Gly Gly Lys Gln Ala Leu Glu Thr Val
625 630 635 640
Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr Pro Glu
645 650 655
Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala Leu Glu
660 665 670
Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly Leu Thr
675 680 685
Pro Glu Gln Val Val Ala Ile Ala Ser Asn Gly Gly Gly Lys Gln Ala
690 695 700
Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala His Gly
705 710 715 720
Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly Gly Lys
725 730 735
Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys Gln Ala
740 745 750
His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser His Asp Gly
755 760 765
Gly Lys Gln Ala Leu Glu Thr Val Gln Arg Leu Leu Pro Val Leu Cys
770 775 780
Gln Ala His Gly Leu Thr Pro Glu Gln Val Val Ala Ile Ala Ser Asn
785 790 795 800
Gly Gly Gly Arg Pro Ala Leu Glu Ser Ile Val Ala Gln Leu Ser Arg
805 810 815
Pro Asp Pro Ala Leu Ala Ala Leu Thr Asn Asp His Leu Val Ala Leu
820 825 830
Ala Cys Leu Gly Gly Arg Pro Ala Leu Asp Ala Val Lys Lys Gly Leu
835 840 845
Pro His Ala Pro Ala Leu Ile Lys Arg Thr Asn Arg Arg Ile Pro Glu
850 855 860
Arg Thr Ser His Arg Val Ala
865 870
<210>13
<211>10415bp
<212>DNA
<213>人工序列
<220>
<223>
<400>13
caggtggcac ttttcgggga aatgtgcgcg gaacccctat ttgtttattt ttctaaatac 60
attcaaatat gtatccgctc atgagacaat aaccctgata aatgcttcaa taatattgaa 120
aaaggaagag tatgagtatt caacatttcc gtgtcgccct tattcccttt tttgcggcat 180
tttgccttcc tgtttttgct cacccagaaa cgctggtgaa agtaaaagat gctgaagatc 240
agttgggtgc acgagtgggt tacatcgaac tggatctcaa cagcggtaag atccttgaga 300
gttttcgccc cgaagaacgt tttccaatga tgagcacttt taaagttctg ctatgtggcg 360
cggtattatc ccgtattgac gccgggcaag agcaactcgg tcgccgcata cactattctc 420
agaatgactt ggttgagtac tcaccagtca cagaaaagca tcttacggat ggcatgacag 480
taagagaatt atgcagtgct gccataacca tgagtgataa cactgcggcc aacttacttc 540
tgacaacgat cggaggaccg aaggagctaa ccgctttttt gcacaacatg ggggatcatg 600
taactcgcct tgatcgttgg gaaccggagc tgaatgaagc cataccaaac gacgagcgtg 660
acaccacgat gcctgtagca atggcaacaa cgttgcgcaa actattaact ggcgaactac 720
ttactctagc ttcccggcaa caattaatag actggatgga ggcggataaa gttgcaggac 780
cacttctgcg ctcggccctt ccggctggct ggtttattgc tgataaatct ggagccggtg 840
agcgtgggtc tcgcggtatc attgcagcac tggggccaga tggtaagccc tcccgtatcg 900
tagttatcta cacgacgggg agtcaggcaa ctatggatga acgaaataga cagatcgctg 960
agataggtgc ctcactgatt aagcattggt aactgtcaga ccaagtttac tcatatatac 1020
tttagattga tttaaaactt catttttaat ttaaaaggat ctaggtgaag atcctttttg 1080
ataatctcat gaccaaaatc ccttaacgtg agttttcgtt ccactgagcg tcagaccccg 1140
tagaaaagat caaaggatct tcttgagatc ctttttttct gcgcgtaatc tgctgcttgc 1200
aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc ggatcaagag ctaccaactc 1260
tttttccgaa ggtaactggc ttcagcagag cgcagatacc aaatactgtc cttctagtgt 1320
agccgtagtt aggccaccac ttcaagaact ctgtagcacc gcctacatac ctcgctctgc 1380
taatcctgtt accagtggct gctgccagtg gcgataagtc gtgtcttacc gggttggact 1440
caagacgata gttaccggat aaggcgcagc ggtcgggctg aacggggggt tcgtgcacac 1500
agcccagctt ggagcgaacg acctacaccg aactgagata cctacagcgt gagctatgag 1560
aaagcgccac gcttcccgaa gggagaaagg cggacaggta tccggtaagc ggcagggtcg 1620
gaacaggaga gcgcacgagg gagcttccag ggggaaacgc ctggtatctt tatagtcctg 1680
tcgggtttcg ccacctctga cttgagcgtc gatttttgtg atgctcgtca ggggggcgga 1740
gcctatggaa aaacgccagc aacgcggcct ttttacggtt cctggccttt tgctggcctt 1800
ttgctcacat gttctttcct gcgttatccc ctgattctgt ggataaccgt attaccgcct 1860
ttgagtgagc tgataccgct cgccgcagcc gaacgaccga gcgcagcgag tcagtgagcg 1920
aggaagcgga agagcgccca atacgcaaac cgcctctccc cgcgcgttgg ccgattcatt 1980
aatgcagctg gcacgacagg tttcccgact ggaaagcggg cagtgagcgc aacgcaatta 2040
atgtgagtta gctcactcat taggcacccc aggctttaca ctttatgctt ccggctcgta 2100
tgttgtgtgg aattgtgagc ggataacaat ttcacacagg aaacagctat gaccatgatt 2160
acgccaagcg cgcaattaac cctcactaaa gggaacaaaa gctggagctg caagcttaat 2220
gtagtcttat gcaatactct tgtagtcttg caacatggta acgatgagtt agcaacatgc 2280
cttacaagga gagaaaaagc accgtgcatg ccgattggtg gaagtaaggt ggtacgatcg 2340
tgccttatta ggaaggcaac agacgggtct gacatggatt ggacgaacca ctgaattgcc 2400
gcattgcaga gatattgtat ttaagtgcct agctcgatac aataaacggg tctctctggt 2460
tagaccagat ctgagcctgg gagctctctg gctaactagg gaacccactg cttaagcctc 2520
aataaagctt gccttgagtg cttcaagtag tgtgtgcccg tctgttgtgt gactctggta 2580
actagagatc cctcagaccc ttttagtcag tgtggaaaat ctctagcagt ggcgcccgaa 2640
cagggacctg aaagcgaaag ggaaaccaga gctctctcga cgcaggactc ggcttgctga 2700
agcgcgcacg gcaagaggcg aggggcggcg actggtgagt acgccaaaaa ttttgactag 2760
cggaggctag aaggagagag atgggtgcga gagcgtcagt attaagcggg ggagaattag 2820
atcgcgatgg gaaaaaattc ggttaaggcc agggggaaag aaaaaatata aattaaaaca 2880
tatagtatgg gcaagcaggg agctagaacg attcgcagtt aatcctggcc tgttagaaac 2940
atcagaaggc tgtagacaaa tactgggaca gctacaacca tcccttcaga caggatcaga 3000
agaacttaga tcattatata atacagtagc aaccctctat tgtgtgcatc aaaggataga 3060
gataaaagac accaaggaag ctttagacaa gatagaggaa gagcaaaaca aaagtaagac 3120
caccgcacag caagcggccg ctgatcttca gacctggagg aggagatatg agggacaatt 3180
ggagaagtga attatataaa tataaagtag taaaaattga accattagga gtagcaccca 3240
ccaaggcaaa gagaagagtg gtgcagagag aaaaaagagc agtgggaata ggagctttgt 3300
tccttgggtt cttgggagca gcaggaagca ctatgggcgc agcctcaatg acgctgacgg 3360
tacaggccag acaattattg tctggtatag tgcagcagca gaacaatttg ctgagggcta 3420
ttgaggcgca acagcatctg ttgcaactca cagtctgggg catcaagcag ctccaggcaa 3480
gaatcctggc tgtggaaaga tacctaaagg atcaacagct cctggggatt tggggttgct 3540
ctggaaaact catttgcacc actgctgtgc cttggaatgc tagttggagt aataaatctc 3600
tggaacagat tggaatcaca cgacctggat ggagtgggac agagaaatta acaattacac 3660
aagcttaata cactccttaa ttgaagaatc gcaaaaccag caagaaaaga atgaacaaga 3720
attattggaa ttagataaat gggcaagttt gtggaattgg tttaacataa caaattggct 3780
gtggtatata aaattattca taatgatagt aggaggcttg gtaggtttaa gaatagtttt 3840
tgctgtactt tctatagtga atagagttag gcagggatat tcaccattat cgtttcagac 3900
ccacctccca accccgaggg gacccgacag gcccgaagga atagaagaag aaggtggaga 3960
gagagacaga gacagatcca ttcgattagt gaacggatct cgacggttaa cttttaaaag 4020
aaaagggggg attggggggt acagtgcagg ggaaagaata gtagacataa tagcaacaga 4080
catacaaact aaagaattac aaaaacaaat tacaaaaatt caaaatttta tcgatggtac 4140
ctaccgggta ggggaggcgc ttttcccaag gcagtctgga gcatgcgctt tagcagcccc 4200
gctgggcact tggcgctaca caagtggcct ctggctcgca cacattccac atccaccggt 4260
aggcgccaac cggctccgtt ctttggtggc cccttcgcgc caccttctac tcctccccta 4320
gtcaggaagt tcccccccgc cccgcagctc gcgtcgtgca ggacgtgaca aatggaagta 4380
gcacgtctca ctagtctcgt gcagatggac agcaccgctg agcaatggaa gcdggtaggc 4440
ctttggggca gcggccaata gcagctttgc tccttcgctt tctgggctca gaggctggga 4500
aggggtgggt ccgggggcgg gctcaggggc gggctcaggg gcggggcggg cgcccgaagt 4560
cctccggagg cccggcattc tgcacgcttc aaaagcgcac gtctgccgcg ctgttctcct 4620
cttcctcatc tccgggcctt tcgacctgca ctctagagga tccctcgaga ccggtcgcca 4680
ccgagctctc tggctaacta gagaacccac tgcttactgg cttatcgaaa ttaatacgac 4740
tcactatagg ggccaccatg gactataagg accacgacgg agactacaag gatcatgata 4800
ttgattacaa agacgatgac gataagatgg ccccaaagaa gaagcggaag gtcggtatcc 4860
acggagtccc agcagccgta gatttgagaa ctttgggata ttcacagcag cagcaggaaa 4920
agatcaagcc caaagtgagg tcgacagtcg cgcagcatca cgaagcgctg gtgggtcatg 4980
ggtttacaca tgcccacatc gtagccttgt cgcagcaccc tgcagccctt ggcacggtcg 5040
ccgtcaagta ccaggacatg attgcggcgt tgccggaagc cacacatgag gcgatcgtcg 5100
gtgtggggaa acagtggagc ggagcccgag cgcttgaggc cctgttgacg gtcgcgggag 5160
agctgagagg gcctcccctt cagctggaca cgggccagtt gctgaagatc gcgaagcggg 5220
gaggagtcac ggcggtcgag gcggtgcacg cgtggcgcaa tgcgctcacg ggagcacccc 5280
tcaacctgac cccagagcag gtcgtggcaa ttgcgagcaa catcggggga aagcaggcac 5340
tcgaaaccgt ccagaggttg ctgcctgtgc tgtgccaagc gcacggactt acgccagagc 5400
aggtcgtggc aattgcgagc aacatcgggg gaaagcaggc actcgaaacc gtccagaggt 5460
tgctgcctgt gctgtgccaa gcgcacggac taaccccaga gcaggtcgtg gcaattgcga 5520
gccatgacgg gggaaagcag gcactcgaaa ccgtccagag gttgctgcct gtgctgtgcc 5580
aagcgcacgg gttgacccca gagcaggtcg tggcaattgc gagccatgac gggggaaagc 5640
aggcactcga aaccgtccag aggttgctgc ctgtgctgtg ccaagcgcac ggcctgaccc 5700
cagagcaggt cgtggcaatt gcgagccatg acgggggaaa gcaggcactc gaaaccgtcc 5760
agaggttgct gcctgtgctg tgccaagcgc acggactgac accagagcag gtcgtggcaa 5820
ttgcgagcaa cggaggggga aagcaggcac tcgaaaccgt ccagaggttg ctgcctgtgc 5880
tgtgccaagc gcacggactt acacccgaac aagtcgtggc aattgcgagc aacatcgggg 5940
gaaagcaggc actcgaaacc gtccagaggt tgctgcctgt gctgtgccaa gcgcacggac 6000
ttacgccaga gcaggtcgtg gcaattgcga gcaacatcgg gggaaagcag gcactcgaaa 6060
ccgtccagag gttgctgcct gtgctgtgcc aagcgcacgg actaacccca gagcaggtcg 6120
tggcaattgc gagccatgac gggggaaagc aggcactcga aaccgtccag aggttgctgc 6180
ctgtgctgtg ccaagcgcac gggttgaccc cagagcaggt cgtggcaatt gcgagccatg 6240
acgggggaaa gcaggcactc gaaaccgtcc agaggttgct gcctgtgctg tgccaagcgc 6300
acggcctgac cccagagcag gtcgtggcaa ttgcgagcca tgacggggga aagcaggcac 6360
tcgaaccgtc cagaggttgc tgcctgtgct gtgccaagcg cacggactga caccagagca 6420
ggtcgtggca attgcgagca acggaggggg aaagcaggca ctcgaaaccg tccagaggtt 6480
gctgcctgtg ctgtgccaag cgcacggcct caccccagag caggtcgtgg caattgcgag 6540
caacatcggg ggaaagcagg cactcgaaac cgtccagagg ttgctgcctg tgctgtgcca 6600
agcgcacgga cttacgccag agcaggtcgt ggcaattgcg agcaacatcg ggggaaagca 6660
ggcactcgaa accgtccaga ggttgctgcc tgtgctgtgc caagcgcacg gactaacccc 6720
agagcaggtc gtggcaattg cgagccatga cgggggaaag caggcactcg aaaccgtcca 6780
gaggttgctg cctgtgctgt gccaagcgca cgggttgacc ccagagcagg tcgtggcaat 6840
tgcgagccat gacgggggaa agcaggcact cgaaaccgtc cagaggttgc tgcctgtgct 6900
gtgccaagcg cacggcctga ccccagagca ggtcgtggca attgcgagcc atgacggggg 6960
aaagcaggca ctcgaaaccg tccagaggtt gctgcctgtg ctgtgccaag cgcacggact 7020
gacaccagag caggtcgtgg caattgcgag caacggaggg ggaaagcagg cactcgaaac 7080
cgtccagagg ttgctgcctg tgctgtgcca agcgcacgga ctcacgcctg agcaggtagt 7140
ggctattgca tccaacatcg ggggcagacc cgcactggag tcaatcgtgg cccagctttc 7200
gaggccggac cccgcgctgg ccgcactcac taatgatcat cttgtagcgc tggcctgcct 7260
cggcggacga cccgccttgg atgcggtgaa gaaggggctc ccgcacgcgc ctgcattgat 7320
taagcggacc aacagaagga ttcccgagag gacatcacat cgagtggcaa gttatcaggg 7380
aatggtgagc aagggcgagg agctgttcac cggggtggtg cccatcctgg tcgagctgga 7440
cggcgacgta aacggccaca agttcagcgt gtccggcgag ggcgagggcg atgccaccta 7500
cggcaagctg accctgaagt tcatctgcac caccggcaag ctgcccgtgc cctggcccac 7560
cctcgtgacc accctgacct acggcgtgca gtgcttcagc cgctaccccg accacatgaa 7620
gcagcacgac ttcttcaagt ccgccatgcc cgaaggctac gtccaggagc gcaccatctt 7680
cttcaaggac gacggcaact acaagacccg cgccgaggtg aagttcgagg gcgacaccct 7740
ggtgaaccgc atcgagctga agggcatcga cttcaaggag gacggcaaca tcctggggca 7800
caagctggag tacaactaca acagccacaa cgtctatatc atggccgaca agcagaagaa 7860
cggcatcaag gtgaacttca agatccgcca caacatcgag gacggcagcg tgcagctcgc 7920
cgaccactac cagcagaaca cccccatcgg cgacggcccc gtgctgctgc ccgacaacca 7980
ctacctgagc acccagtccg ccctgagcaa agaccccaac gagaagcgcg atcacatggt 8040
cctgctggag ttcgtgaccg ccgccgggat cactctcggc atggacgagc tgtacaagtc 8100
cggactcaga tctcgagctc aagcttcgaa ttccatggtg aagcagatcg agagcaagac 8160
tgcttttcag gaagccttgg acgctgcagg tgataaactt gtagtagttg acttctcagc 8220
cacgtggtgt gggccttgca aaatgatcaa gcctttcttt cattccctct ctgaaaagta 8280
ttccaacgtg atattccttg aagtagatgt ggatgactgt caggatgttg cttcagagtg 8340
tgaagtcaaa tgcatgccaa cattccagtt ttttaagaag ggacaaaagg tgggtgaatt 8400
ttctggagcc aataaggaaa agcttgaagc caccattaat gaattagtct aactcgagag 8460
cggccgcgac gcgtgtcgac aatcaacctc tggattacaa aatttgtgaa agattgactg 8520
gtattcttaa ctatgttgct ccttttacgc tatgtggata cgctgcttta atgcctttgt 8580
atcatgctat tgcttcccgt atggctttca ttttctcctc cttgtataaa tcctggttgc 8640
tgtctcttta tgaggagttg tggcccgttg tcaggcaacg tggcgtggtg tgcactgtgt 8700
ttgctgacgc aacccccact ggttggggca ttgccaccac ctgtcagctc ctttccggga 8760
ctttcgcttt ccccctccct attgccacgg cggaactcat cgccgcctgc cttgcccgct 8820
gctggacagg ggctcggctg ttgggcactg acaattccgt ggtgttgtcg gggaagctga 8880
cgtcctttcc atggctgctc gcctgtgttg ccacctggat tctgcgcggg acgtccttct 8940
gctacgtccc ttcggccctc aatccagcgg accttccttc ccgcggcctg ctgccggctc 9000
tgcggcctct tccgcgtctt cgccttcgcc ctcagacgag tcggatctcc ctttgggccg 9060
cctccccgcc tggaattcga gctcggtacc tttaagacca atgacttaca aggcagctgt 9120
agatcttagc cactttttaa aagaaaaggg gggactggaa gggctaattc actcccaacg 9180
aagacaagat ctgctttttg cttgtactgg gtctctctgg ttagaccaga tctgagcctg 9240
ggagctctct ggctaactag ggaacccact gcttaagcct caataaagct tgccttgagt 9300
gcttcaagta gtgtgtgccc gtctgttgtg tgactctggt aactagagat ccctcagacc 9360
cttttagtca gtgtggaaaa tctctagcag tagtagttca tgtcatctta ttattcagta 9420
tttataactt gcaaagaaat gaatatcaga gagtgagagg aacttgttta ttgcagctta 9480
taatggttac aaataaagca atagcatcac aaatttcaca aataaagcat ttttttcact 9540
gcattctagt tgtggtttgt ccaaactcat caatgtatct tatcatgtct ggctctagct 9600
atcccgcccc taactccgcc cagttccgcc cattctccgc cccatggctg actaattttt 9660
tttatttatg cagaggccga ggccgcctcg gcctctgagc tattccagaa gtagtgagga 9720
ggcttttttg gaggcctagg cttttgcgtc gagacgtacc caattcgccc tatagtgagt 9780
cgtattacgc gcgctcactg gccgtcgttt tacaacgtcg tgactgggaa aaccctggcg 9840
ttacccaact taatcgcctt gcagcacatc cccctttcgc cagctggcgt aatagcgaag 9900
aggcccgcac cgatcgccct tcccaacagt tgcgcagcct gaatggcgaa tggcgcgacg 9960
cgccctgtag cggcgcatta agcgcggcgg gtgtggtggt tacgcgcagc gtgaccgcta 10020
cacttgccag cgccctagcg cccgctcctt tcgctttctt cccttccttt ctcgccacgt 10080
tcgccggctt tccccgtcaa gctctaaatc gggggctccc tttagggttc cgatttagtg 10140
ctttacggca cctcgacccc aaaaaacttg attagggtga tggttcacgt agtgggccat 10200
cgccctgata gacggttttt cgccctttga cgttggagtc cacgttcttt aatagtggac 10260
tcttgttcca aactggaaca acactcaacc ctatctcggt ctattctttt gatttataag 10320
ggattttgcc gatttcggcc tattggttaa aaaatgagct gatttaacaa aaatttaacg 10380
cgaattttaa caaaatatta acgtttacaa tttcc 10415
<210>14
<211>18bp
<212>DNA
<213>人工序列
<220>
<223>
<400>14
aaccctaacc ctaaccct 18
<210>15
<211>18bp
<212>DNA
<213>人工序列
<220>
<223>
<400>15
aaccctaacc ctaaccct 18
<210>16
<211>18bp
<212>DNA
<213>人工序列
<220>
<223>
<400>16
accctactga tgatgtgt 18
<210>17
<211>18bp
<212>DNA
<213>人工序列
<220>
<223>
<400>17
cctgtcaccg acacttcc 18
- 还没有人留言评论。精彩留言会获得点赞!