基于淀粉样蛋白实现小分子肽类高效分泌表达的方法及其应用与流程
本发明属于基因工程和生物制药技术领域,特别涉及一种基于淀粉样蛋白实现小分子肽类高效分泌表达的方法及其应用。
背景技术:
大肠杆菌具有遗传背景清楚、繁殖快、成本低、表达量高、表达产物容易纯化等优点,是外源蛋白表达技术中发展最早和目前应用最广泛的经典表达系统,也是重组蛋白表达运用最广泛的宿主之一。目前大肠杆菌体系已用于制备多种酶制剂和药用蛋白质如干扰素、胰岛素和人血清蛋白等,但很多异源蛋白在大肠杆菌中表达往往会形成不溶性的包涵体,需要通过后期繁琐的变复性操作来获得具有正确结构和功能的蛋白,并且复性率往往很低,只有百分之十左右,成为其规模化、工业化的难题。相对于胞内表达,分泌表达就显得极为有优势,无需破碎细胞、蛋白纯化、甚至蛋白变复性等复杂的实验流程。
近几年来不同物种的重组蛋白已在大肠杆菌中成功实现分泌表达,choi等使用木聚糖酶信号肽将两种不同杆菌的碱性磷酸酯酶分泌到大肠杆菌的周质空间(kanepm,yamashiroct,wolczykdfetal.proteinsplicingconvertstheyeasttfp1geneproducttothe69-kdsubunitofthevacuolarh(+)-adenosinetriphosphatase[j].science,1990,250:651-657)。jeong等将人类β-内啡肽基因和一种外膜蛋白ompf融合后能促使其分泌表达到培养基中(perlerfb.inbase,theinteindatabase[j].nucleicacidsres,2000,28:344-345)。郝春芳等利用集胞藻6803膜蛋白的分泌信号肽作为革兰氏阴性菌分泌表达的信号肽,实现了hegf在大肠杆菌中的分泌表达(郝春芳,徐虹,章军等.一种新型广谱的原核型分泌表达载体的建立及人表皮生长因子的表达[j].高技术通讯,2007,17(11):1192-1197.)。但是目前报道的分泌表达仍存在很多问题,如蛋白分泌到周质,仍需要分离、提取等步骤;蛋白分泌至培养基中,一般情况下培养基中都存在较多杂蛋白,需要进一步纯化,以上操作过程都较为繁琐、且成本昂贵。
抗菌肽天蚕素a是世界上发现最早、研究最彻底、效果最明显的一类抗菌肽,属于α螺旋类抗菌肽(bechingerb.structureandfunctionsofchannel-formingpeptides:magainins,cecropins,melittinandalamethicin.[j].thejournalofmembranebiology,1997,156(3):197-211)。其热稳定性好,无免疫原性,抗菌能力强,能有效抑制革兰氏阳性菌和革兰氏阴性菌的生长。目前,关于天蚕素a的制备主要有以下三种:从自然界中分离纯化、化学合成和以融合蛋白的形式进行表达。自然界分离纯化和化学合成的方法具有成本昂贵、得率低等缺点;以融合蛋白的形式进行表达目前使用最为广泛,但是通过该方法得到的抗菌肽均需细胞破碎、蛋白纯化等繁琐的处理流程。
技术实现要素:
本发明的首要目的在于克服现有技术的缺点与不足,提供一种基于淀粉样蛋白实现小分子肽类高效分泌表达的方法。
本发明的另一目的在于提供所述的基于淀粉样蛋白实现小分子肽类高效分泌表达的方法的应用。
本发明的目的通过下述技术方案实现:一种基于淀粉样蛋白实现小分子肽类高效分泌表达的方法,包括如下步骤:
(1)将自剪切短肽通过一个连接肽与自聚集肽进行拼接,得到融合蛋白;
(2)将信号肽连接到步骤(1)中得到的融合蛋白的n端,得到表达载体i;
(3)将小分子肽类(目的蛋白)连接到步骤(2)中得到的表达载体i上,得到分泌表达载体ii;
(4)敲除细菌基因组中的csgbac基因,构建突变株,得到表达宿主;
(5)将步骤(3)中得到的分泌表达载体ii转化到步骤(4)中得到的表达宿主中,得到工程菌;
(6)将步骤(5)中得到的工程菌通过诱导表达,离心收集菌体,再加入诱导剂,离心收集上清,得到小分子肽类。
步骤(1)中所述的自剪切短肽为具有自剪切特性的短肽,优选为mxegyra、dnab、dnae、mtureca或srtac;更优选为mxegyra,其核苷酸序列如seqidno:1所示。
步骤(1)中所述的连接肽优选为氨基酸序列如seqidno:2或seqidno:3所示的连接肽。
步骤(1)中所述的自聚集肽为具有聚集功能的聚集肽,优选为curi菌毛的主要蛋白单体csga、酵母朊蛋白sup35nm、rnq1(朊蛋白rnq1)、ure2或new1;更优选为酵母朊蛋白sup35nm,其核苷酸序列如seqidno:4所示。
步骤(1)中所述的拼接的顺序为自剪切短肽-连接肽-自聚集肽或自聚集肽-连接肽-自剪切短肽。
步骤(2)中所述的信号肽为大肠杆菌curli系统csga单体蛋白n端的42个氨基酸,其氨基酸序列如seqidno:5所示。
步骤(2)中所述的表达载体i为可在e.coli中过量表达的诱导型载体,只要其能在e.coli中具有诱导目的蛋白在菌体表达以活性聚集体的形式即可。
步骤(2)中所述的表达载体i的连接顺序为信号肽-自剪切短肽-连接肽-自聚集肽或信号肽-自聚集肽-连接肽-自剪切短肽。
步骤(3)中所述的小分子肽类为能成功表达及分泌至细胞表面的小分子肽类,优选为小分子抗菌肽类、细胞因子和小分子酶类中的一种;更优选为抗菌肽天蚕素a,其核苷酸序列如seqidno:6所示。
步骤(3)中所述的分泌表达载体ii的连接顺序为信号肽-小分子肽类-自剪切短肽-连接肽-自聚集肽或信号肽-自聚集肽-连接肽-自剪切短肽-小分子肽类。
步骤(4)中所述的细菌为能产生curli菌毛的原核细菌;优选为大肠杆菌;更优选为e.colibl21(de3),e.colimc4100,e.colidh5α,e.colijm109,e.colijm110,e.colitop10,e.colibl21,e.colibl21(de3)/plys和e.colibl21rosetta中的一种。
步骤(5)中所述的转化的方法优选为热激法、cac12方法或电转化方法。
步骤(6)中所述的工程菌通过添加诱导物进行诱导表达。
所述的诱导物优选为0.05%(w/w)的l-ala(l-阿拉伯糖),在该浓度下,目的蛋白(融合蛋白)能成功分泌到菌体表面、表达量适宜,并且不会抑制菌体的生长。
所述的诱导表达的温度优选为25℃,诱导表达的时间优选为3天。
步骤(6)中所述加入诱导剂进行诱导的温度优选为在25℃。
步骤(6)中所述的诱导剂优选为dtt(二硫苏糖醇),用于诱导短肽(自剪切短肽)发生自剪切。
所述的基于淀粉样蛋白实现小分子肽类高效分泌表达的方法,还包括将步骤(6)中得到的小分子肽类进一步浓缩纯化。
所述的浓缩纯化优选为采用超滤管进行浓缩纯化。
所述的超滤管优选为10kda的超滤管。
所述的浓缩还可以用蔗糖进一步浓缩。
所述的基于淀粉样蛋白实现小分子肽类高效分泌表达的方法在制备小分子肽类中的应用。
所述的小分子肽类为不含二硫键的抗菌肽或短肽,优选为抗菌肽天蚕素a。
本发明相对于现有技术具有如下的优点及效果:
1、本发明构建了一种可以使抗菌肽天蚕素a融合蛋白以聚集体的形式分泌在大肠杆菌的表面,无需细胞破碎,金属离子层析等复杂操作步骤,只需简单地离心收集菌体,一步短肽自剪切获得抗菌肽天蚕素a的制备方法。
2、本发明是基于大肠杆菌的csg分泌系统,构建突变株bl21(de3)δcsgbac;利用合成生物学的技术与方法构建分泌性重组表达载体,其含如下原件:信号肽序列(csgass)、天蚕素a、自剪切短肽mxegyra、淀粉样蛋白sup35nm。将该质粒导入突变株bl21(de3)δcsgbac中,低温诱导蛋白表达。目的融合蛋白分泌至菌体表面并在sup35nm淀粉样蛋白的作用下发生聚集,形成纤维状聚集体。通过离心收集菌体,然后添加dtt诱导短肽mxegyra发生自剪切,释放出天蚕素a抗菌肽单体。本发明将融合蛋白表达至菌体表面,利用自剪切短肽的自剪切特性,无需蛋白纯化等繁琐操作,简单离心即可获得高纯度抗菌肽天蚕素a,并且获得的天蚕素a与化学合成的天蚕素a具有相同的抑菌活性。
3、本发明基于大肠杆菌的csg系统,通过red同源重组的方法敲除大肠杆菌的csgbac基因,使其丧失表达鞭毛的能力。一方面利用淀粉样蛋白sup35nm的体外高效自组装特性,将目的蛋白通过一个自剪切短肽mxegyra与sup35nm连接,成功构建能在体外自剪切的高效表达载体。然后通过大肠杆菌的sec分泌系统实现重组蛋白跨过周质空间到胞外的高效分泌表达;另一方面,通过表达csgg蛋白,提高sup35nm蛋白的附着点,极大地提高目的蛋白的表达量。表达后的菌体只需离心,不需要复杂的细胞破碎、亲和标签纯化等复杂程序即可获得高纯度、高活力的目的蛋白;不但排除了亲和标签对目的蛋白结构和功能的影响;而且通过自组装短肽的自剪切特性,大大减少了目的蛋白的损失,在工业生产领域具有极大地优势和应用前景。
4、膜蛋白csgg可以成功定位到膜表面,并且在膜表面形成一个通道,该通道是目的融合蛋白的成功分泌并聚集在菌体表面的必经之路,因此,要实现目的融合蛋白的成功分泌就必须要对这个膜蛋白进行表达量及其膜定位功能进行优化及验证。本发明通过优化csgg蛋白的表达条件,选择0.05%(w/w)的l-ala作为最佳诱导浓度,使csgg蛋白表达量适宜,并且不会抑制菌体的生长。
附图说明
图1是分泌载体设计及蛋白切割示意图;其中,图a为分泌载体设计示意图,图b为各基因元件组合示意图,c为蛋白切割示意图。
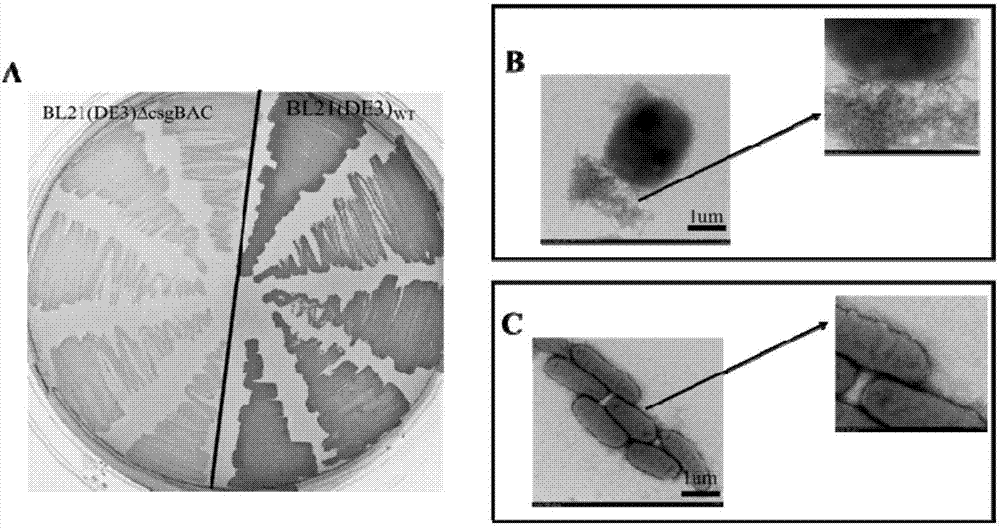
图2是突变株bl21(de3)δcsgbac的构建及鉴定结果图;其中,图a为刚果红平板验证结果图;图b为野生菌bl21(de3)的透射电子显微镜观察结果图;图c为突变株bl21(de3)δcsgbac的透射电子显微镜观察结果图。
图3是膜蛋白csgg蛋白的表达优化westernblotting结果图与添加不同l-阿拉伯糖诱导剂浓度对菌体的生长抑制曲线图;其中,图a为westernblotting结果图,泳道m:蛋白marker,泳道1~8为不同浓度的诱导剂诱导后的结果;图b为生长抑制曲线图。
图4是csgg蛋白膜定位荧光鉴定结果图;其中,图a为荧光场,图b为明场,图c为荧光场与明场的混合场,图d为荧光场的局部放大图。
图5是rfp-mxe-sup35nm融合蛋白的分泌情况鉴定结果图;其中,图a~d为透射电子显微镜观察图;图e为sdd-age检测结果图,泳道m:蛋白marker,泳道no:未诱导,泳道1~4:诱导。
图6是天蚕素a-mxe-sup35nm融合蛋白的分泌情况鉴定结果图;其中,图a~d为透射电子显微镜观察图;图e为sdd-age检测结果图,泳道m:蛋白marker,泳道no:未诱导,泳道1~4:诱导。
图7是天蚕素a切割后的sds-page结果图;其中,图a为dtt诱导的自剪切上清蛋白电泳结果图,泳道m:蛋白marker,泳道1:dtt诱导的自剪切上清蛋白;图b为经10kda超滤管浓缩后的上清蛋白电泳结果图,泳道m:蛋白marker,泳道ce:经10kda超滤管浓缩后的上清蛋白。
图8是天蚕素a对大肠杆菌的mic测定结果图;其中,a为化学合成的抗菌肽天蚕素a;b为本发明的抗菌肽天蚕素a;第1~10孔:浓度分别为280,140,70,35,17.5,8.75,4.375,2.188,1.094,0.547ng/μl的抗菌肽溶液;第11孔:不含抗菌肽的对照组;第12孔:不含指示菌的对照组。
具体实施方式
下面结合实施例对本发明作进一步详细的描述,但本发明的实施方式不限于此。
本发明中自聚集肽为具有聚集功能的聚集肽,可以为curi菌毛的主要蛋白单体csga、酵母朊蛋白sup35(seqidno:4)、rnq1(https://www.ncbi.nlm.nih.gov/gene/850329)、ure2(https://www.ncbi.nlm.nih.gov/gene/855492)或new1(https://www.ncbi.nlm.nih.gov/gene/855875)。
实施例1:突变株bl21(de3)δcsgbac的构建
(1)根据敲除靶基因序列设计同源臂序列:
(2)以pkd4质粒为模板,用上述同源臂引物进行卡那抗性基因的扩增,具体步骤如下:
a.pcr反应体系(50μl):
b.pcr扩增反应程序:
c.pcr反应结束后,1%(w/v)琼脂糖凝胶电泳鉴定,得到大小为420bp的包含酶切位点和linker序列的基因片段,对pcr产物进行纯化回收,得到含有卡那抗生素基因的同源臂片段,置于4℃保存待用。
(3)利用同源重组的原理与方法敲除bl21(de3)(购买于天根生化科技有限公司)的csgbac基因,具体敲除方法如下:
a.将上述回收得到的含有卡那抗生素基因的同源臂片段通过电转化的方法导入进大肠杆菌bl21(de3),电转化参数如下:
电转化设备:eppendorf2510;电转电压:1.8kv,4ms.
b.通过添加了终浓度为50μg/ml的卡那霉素抗性的lb平板进行筛选阳性克隆,并进行菌落pcr验证。将构建的突变株命名为bl21(de3)δcsgbac。
(4)对筛选到的突变株进行刚果红平板培养观察以及电镜观察鉴定,结果如图2所示,具体方法如下:
a.刚果红平板培养观察鉴定
挑取上述突变株单克隆划线与带有卡那抗性的刚果红lb固体平板(10μg/m刚果红+50μg/ml卡那霉素)中进行低温培养3天,培养温度为25℃。用肉眼观察菌体颜色。若菌体颜色没有变红,是乳白色,则说明该克隆是敲除成功的突变株bl21(de3)δcsgbac,结果如图2a所示,以大肠杆菌bl21(de3)为对照(平板右边),平板左边的菌体为乳白色,说明突变株构建成功。
b.电镜观察鉴定
挑取突变株单克隆划线与带有卡那抗性的lb固体平板(50μg/ml)中,低温25℃培养3天,送广州微生物研究所进行电镜观察。若菌体周边生有纤维类的菌毛类物质,则为野生型bl21(de3),见图2b;若菌体周边无任何纤维类的菌毛类物质,则为敲除成功的突变株bl21(de3)δcsgbac,见图2c。
实施例2:膜蛋白csgg的表达优化
1、构建携带csgg基因的质粒:
通过扩增大肠杆菌bl21(de3)基因组中的csgg基因,然后连接至表达载体pkje7(购自宝生物工程(大连)有限公司)中,构建成可成功表达膜蛋白csgg的重组表达质粒。具体构建方法如下:
a.设计扩增csgg基因的引物
b.pcr反应体系(50μl):
c.pcr扩增反应程序:
d.回收csgg目的基因,然后配制线性扩增反应体系,将回收的csgg目的基因插入载体pkje7中,具体反应体系如下:
pcr反应体系(50μl):
pcr扩增反应程序:
e.pcr反应完后,将步骤(d)中得到的pcr产物进行dpni酶切消化,具体操作如下:
酶切反应体系(20μl):
置于37℃恒温pcr仪中反应1h。
f.酶切反映完毕后,将酶切后的产物转化至大肠杆菌dh5α中,然后将菌液涂至含氯霉素(终浓度为25ug/ml)的lb固体平板中,置于37度培养箱培养过夜,其中,转化方法采用的是化学转化法。
g.对平板中长出的单克隆进行测序鉴定,筛选出正确携带csgg基因的质粒,命名为pkje7-csgg。
2、将上述携带csgg基因的质粒(pkje7-csgg)导入实施例1中得到的突变株bl21(de3)δcsgbac中,挑选单克隆至lb液体培养基中,进行37℃,220rpm过夜培养作为种子液。将种子液按1:100(v/v)的比例接种到新鲜的lb液体培养基中,置于37℃,220rpm进行培养,当od600=0.6~0.8时,添加诱导剂l-ala(l-阿拉伯糖)至终浓度分别为0.002%、0.005%、0.01%、0.05%、0.1%、0.15%(质量百分比),诱导3h。表达结束后,制备样品,进行westernblot验证,同时制备荧光观察样品,进行荧光显微镜的观察;其结果如图3所示:随着l-阿拉伯糖诱导剂浓度的不断提高,菌体生长的抑制现象越来越明显,一方面为了最大限度的减少菌体生长受抑制的现象,另一方面又保证csgg蛋白的表达,我们最终选择0.05%(w/w)的l-ala作为最佳诱导浓度。图4为在0.05%(w/w)的l-ala诱导浓度下的荧光显微镜观察结果,从图中可以看出,诱导过表达的csgg蛋白大部分是均匀弥散的绿光,而不是呈聚集的绿点,说明过表达的csgg膜蛋白可以成功的定位在细胞外膜上。
实施例3:rfp融合蛋白和cecropina融合蛋白的胞外分泌验证
以rfp融合蛋白的胞外分泌验证为例,天蚕素a(cecropina)融合蛋白也是同样的操作步骤:
1、(1)构建rfp融合蛋白的质粒(pet21-csgass-rfp-mxe-ptlinker-sup35nm),该质粒的构建分五步进行(rfp目的基因(seqidno:7)、mxegyra(seqidno:1)、酵母朊蛋白sup35nm(seqidno:4)、连接肽(seqidno:2)均由生工生物工程(上海)股份有限公司合成):
第一步通过扩增大肠杆菌bl21(de3)基因组中的csgass基因,然后连接至表达载体pet21中,构建重组表达质粒i,命名为pet21-csgass;
第二步将酵母朊蛋白sup35nm添加至载体pet21-csgass中,构建质粒ii,命名为pet21-csgass-sup35nm;
第三步将mxegyra基因插入载体pet21-csgass-sup35nm中,构建质粒iii,命名为pet21-csgass-mxe-sup35nm;
第四步将rfp目的基因插入载体pet21-csgass-mxe-sup35nm中,构建质粒iv,命名为pet21-csgass-rfp-mxe-sup35nm。
第五步将连接肽(seqidno:2)插入载体pet21-csgass-rfp-mxe-sup35nm中,构建质粒v,命名为pet21-csgass-rfp-mxe-ptlinker-sup35nm。
构建方法均相同,以质粒pet21-csgass的构建为例,pet21-csgass-sup35nm、pet21-csgass-mxe-sup35nm、pet21-csgass-rfp-mxe-sup35nm、pet21-csgass-rfp-mxe-ptlinker-sup35nm是同样的操作步骤。质粒pet21-csgass具体构建方法如下:
a.设计扩增csgass基因的引物
b.pcr反应体系(50μl):
c.pcr扩增反应程序:
d.回收csgass目的基因,然后配制线性扩增反应体系,将回收的csgass目的基因插入载体pet21中,具体反应体系如下:
pcr反应体系(50μl):
pcr扩增反应程序:
e.pcr反应完后,将步骤(d)中得到的pcr产物进行dpni酶切消化,具体操作如下:
酶切反应体系(20μl):
置于37℃恒温pcr仪中反应1h。
f.酶切反映完毕后,将酶切后的产物转化至大肠杆菌dh5α中,然后将菌液涂至含氨苄青霉素(终浓度为100ug/ml)的lb固体平板中,置于37度培养箱培养过夜.转化方法采用的是化学转化法。
g.对平板中长出的单克隆进行测序鉴定。筛选出正确携带csgass基因的质粒pet21-csgass。
(2)将上述含有rfp融合蛋白的质粒(pet21-csgass-rfp-mxe-ptlinker-sup35nm)通过化学转化的方法导入到突变株bl21(de3)δcsgbac中,挑选单克隆接种至lb液体培养基中进行37℃,220rpm过夜培养作为种子液。将种子液用lb液体培养基进行稀释,稀释至od600=0.01,37℃孵育30min,然后取10μl进行点板。所用的平板为带有相应抗性及诱导物的yesca固体平板(具体配方如下:10g/l酪蛋白氨基酸,1g/l酵母浸粉,20g/l琼脂粉,0.05%(w/w)的l-ala,1mmiptg,25ug/ml氯霉素,100ug/ml氨苄青霉素)。然后置于25℃下进行诱导表达,培养时间为3天。3天后,用buffer1(20mmtris-hcl,500mmnacl,1mmedta(disodiumedetate),ph8.5)将菌体从平板上洗下来,一方面制备电镜观察样品,另一方制备sdd-age电泳样品进行鉴定。图5a~d为投射电子显微镜观察结果(图5a为未诱导,图b、c和d为诱导后)。根据观察结果可以看出:进过诱导后的菌体周边有大量的纤维样物质存在,而未诱导的菌周边则没有纤维样物质;为了验证这种纤维样物质是否为rfp融合蛋白聚集体,我们采用了sdd-age的检测方法,如图5e(泳道no:未诱导,泳道1-4:诱导),可以看出诱导后的菌体产生了大量淀粉样物质。综合上述结果说明菌体经诱导后确实能产生大量rfp融合蛋白,并且该rfp融合蛋白能形成淀粉样聚集体。
2、参考上述步骤,构建含有天蚕素a-mxe-sup35nm融合蛋白(天蚕素a的基因序列(seqidno:6)是由生工生物工程(上海)股份有限公司合成)的质粒并转化到突变株bl21(de3)δcsgbac中进行培养、诱导表达;再进行sdd-age电泳检测以及用投射电子显微镜观察,结果如图6所示,图中结果显示:天蚕素a融合蛋白可以成功分泌至菌体表面,并且形成具有淀粉样特性的聚集体。
实施例4:天蚕素a抗菌肽的收集
按照实施例3的方法,大量表达天蚕素a(cecropina)融合蛋白。25℃培养3天后,用buffer1将菌体从yesca固体平板中洗下来,并且用同样的buffer对菌体洗涤2次。然后用buffer2(20mmtris-hcl,500mmnacl,1mmedtaand40mmdithiothreitol(dtt),ph8.5)诱导短肽mxe发生自剪切,释放天蚕素a抗菌肽。经过一次高速离心(4℃,11000g、30min),收集上清获得天蚕素a抗菌肽。然后将上清通过10kda超滤管进行超滤,收集离心管底的溶液,并用蔗糖进行浓缩,最终获得高纯度的天蚕素a,进行sdd-age电泳,电泳结果如图7所示:在进行dtt切割的过程中,由于dtt对细胞的毒性作用会导致部分菌体裂解,释放出包容物,因此切割后的菌体经过告诉离心后上清中不仅有目的蛋白天蚕素a,也有较多的其他蛋白杂质,如图7a;进一步对其进行10kda超滤管超滤过程,则可以得到较高纯度的天蚕素a抗菌肽,如图7b所示。
实施例5:天蚕素a抗菌肽对大肠杆菌的mic测定
以化学合成的天蚕素a(购买于生工生物工程(上海)股份有限公司)抗菌肽做对比,通过添加一系列不同弄浓度的抗菌肽溶液(280,140,70,35,17.5,8.75,4.375,2.188,1.094,0.547ng/μl)来确定天蚕素a对大肠杆菌的mic(最低抑菌浓度)。具体操作方法如下:
(1)菌悬液的制备
挑取大肠杆菌单克隆(e.coliatcc25922)于mhb固体平板(购自广东环凯微生科技有限公司)中,置于37℃培养18~24h进行活化。从活化的平板中挑取大肠杆菌菌落于装有无菌mhb液体培养基(购自广东环凯微生科技有限公司)的试管中,漩涡器混匀,使其od625为0.08~0.13,得到菌悬液。
(2)抑菌实验
首先,向96孔板的第2~11孔加入50μl灭菌的mhb液体培养基(购自广东环凯微生科技有限公司),向第12孔中加入100μl的mhb液体培养基(购自广东环凯微生科技有限公司)作为阳性对照。然后在第1孔中加入100μl280ng/μl的抗菌肽溶液(化学合成肽和本发明产生的抗菌肽),然后从第1孔中吸取50μl至第2孔、从第2孔中取50μl至第3孔,以此类推…..至第10孔,从第10孔吸取50μl弃掉,作为平衡。再向第2~11孔中加入50μl经上述稀释好的指示菌液(步骤(1)制备的菌悬液),最后置于37℃培养16~20h。
(3)观察
用肉眼观察抑菌情况,指示菌不能生长的浓度即为天蚕素a抗菌肽对大肠杆菌的mic,结果如图8所示:化学合成的天蚕素a与用本专利采用的方法获得的天蚕素a抗菌肽具有相同的抑菌活性。当抗菌肽浓度为70ng/ul时没有菌体生长,当抗菌肽浓度为35ng/ul时,菌体有明显的生长。因此,天蚕素a对大肠杆菌的mic是70ng/ul。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
sequencelisting
<110>华南理工大学
<120>基于淀粉样蛋白实现小分子肽类高效分泌表达的方法及其应用
<130>1
<160>13
<170>patentinversion3.5
<210>1
<211>594
<212>dna
<213>artificialsequence
<220>
<223>mxegyra
<400>1
tgcatcaccggcgacgccttagtggcactgccggaaggcgaaagcgtgcgtattgccgat60
atcgttccgggtgcacgccctaacagcgataatgcaatcgacctgaaagtgttagatcgc120
cacggcaatcctgttctggccgatcgcctgtttcacagtggcgaacatccggtgtacaca180
gtgcgcaccgtggaaggtctgcgcgtgaccggcacagcaaatcacccgctgctgtgttta240
gtggacgttgcaggcgtgcctacactgctgtggaagctgatcgatgaaatcaagccgggt300
gactacgcagtgattcagcgcagtgccttcagcgttgattgcgccggttttgcacgtggc360
aaaccggaatttgcaccgaccacctacaccgtgggtgtgccgggcctggttcgtttcctg420
gaagcacaccatcgtgatccggacgcacaggccattgccgatgagctgaccgacggccgc480
ttttactatgccaaagttgccagcgtgacagatgcaggtgtgcagccggtttacagttta540
cgcgtggataccgccgatcacgcattcattaccaacggcttcgttagccatgcc594
<210>2
<211>17
<212>prt
<213>artificialsequence
<220>
<223>连接肽
<400>2
prothrproprothrthrprothrproprothrthrprothrprothr
151015
pro
<210>3
<211>6
<212>prt
<213>artificialsequence
<220>
<223>连接肽
<400>3
glyserglyglysergly
15
<210>4
<211>759
<212>dna
<213>artificialsequence
<220>
<223>酵母朊蛋白sup35nm
<400>4
atgagcgacagcaaccagggtaacaaccagcagaactaccaacagtatagccagaacggc60
aaccagcagcagggcaacaaccgttaccagggctatcaggcctataacgcacaggcccag120
ccggccggtggttattaccagaactaccagggctacagcggctatcagcagggcggttac180
cagcaatacaatccggatgccggctaccagcagcaatacaaccctcagggtggctatcaa240
cagtacaatccgcaaggcggttatcagcagcagttcaatcctcagggcggccgcggtaat300
tacaagaattttaactacaataacaatctgcaaggttaccaggccggcttccagccgcag360
agccagggcatgagtctgaacgactttcagaagcagcagaaacaggccgccccgaaaccg420
aaaaagacactgaagctggtgagcagcagcggcatcaaactggccaacgcaaccaaaaag480
gtgggtaccaaacctgccgagagcgacaaaaaagaagaagagaaaagcgccgaaaccaaa540
gagccgaccaaagagcctaccaaggtggaggaaccggtgaaaaaagaagaaaagccggtt600
cagaccgaggagaagacagaagagaagagcgagttaccgaaggtggaggatctgaagatc660
agtgagagcacccacaacaccaacaacgccaacgtgaccagtgccgatgccctgatcaaa720
gaacaggaagaagaagttgacgatgaagtggtgaatgat759
<210>5
<211>42
<212>prt
<213>artificialsequence
<220>
<223>信号肽
<400>5
metlysleuleulysvalalaalailealaalailevalphesergly
151015
seralaleualaglyvalvalproglntyrglyglyglyglyasnhis
202530
glyglyglyglyasnasnserglyproasn
3540
<210>6
<211>111
<212>dna
<213>artificialsequence
<220>
<223>天蚕素a
<400>6
aagtggaaactgttcaagaagattgagaaagtgggtcagaacatccgtgacggcatcatc60
aaagccggtcctgccgtggcagttgttggccaggccacccagatcgccaag111
<210>7
<211>675
<212>dna
<213>artificialsequence
<220>
<223>rfp目的基因
<400>7
atggcttcctccgaagacgttatcaaagagttcatgcgtttcaaagttcgtatggaaggt60
tccgttaacggtcacgagttcgaaatcgaaggtgaaggtgaaggtcgtccgtacgaaggt120
acccagaccgctaaactgaaagttaccaaaggtggtccgctgccgttcgcttgggacatc180
ctgtccccgcagttccagtacggttccaaagcttacgttaaacacccggctgacatcccg240
gactacctgaaactgtccttcccggaaggtttcaaatgggaacgtgttatgaacttcgaa300
gacggtggtgttgttaccgttacccaggactcctccctgcaagacggtgagttcatctac360
aaagttaaactgcgtggtaccaacttcccgtccgacggtccggttatgcagaaaaaaacc420
atgggttgggaagcttccaccgaacgtatgtacccggaagacggtgctctgaaaggtgaa480
atcaaaatgcgtctgaaactgaaagacggtggtcactacgacgctgaagttaaaaccacc540
tacatggctaaaaaaccggttcagctgccgggtgcttacaaaaccgacatcaaactggac600
atcacctcccacaacgaagactacaccatcgttgaacagtacgaacgtgctgaaggtcgt660
cactccaccggtgct675
<210>8
<211>77
<212>dna
<213>artificialsequence
<220>
<223>pkd4-f
<400>8
caaccaagttgaaatgatttaatttcttaaatgtacgaccaggtccagggtgacaacgtg60
taggctggagctgcttc77
<210>9
<211>75
<212>dna
<213>artificialsequence
<220>
<223>pkd4-r
<400>9
gattcgcagcagaccattctctccagattcatcttatgctcgatatttcaacaaaatggg60
aattagccatggtcc75
<210>10
<211>50
<212>dna
<213>artificialsequence
<220>
<223>pkje7-csgg-f
<400>10
ggctatggattgtggagacgtttagatgcagcgcttatttcttttggttg50
<210>11
<211>50
<212>dna
<213>artificialsequence
<220>
<223>pkje7-csgg-r
<400>11
ccgtgaattattacgaaagcagaaatcaggattccggtggaaccgacata50
<210>12
<211>49
<212>dna
<213>artificialsequence
<220>
<223>csgass-f
<400>12
tgtttaactttaagaaggagatataatgaaacttttaaaagtagcagca49
<210>13
<211>49
<212>dna
<213>artificialsequence
<220>
<223>csgass-r
<400>13
tttgttagcagccggatcttattatgcggccgcatttgggccgctatta49
- 还没有人留言评论。精彩留言会获得点赞!