获取来源于脊椎动物的单细胞的碱基序列信息的方法与流程
本发明涉及一种获取来源于脊椎动物的单细胞的碱基序列信息的方法。
背景技术:
人类的血液中,在正常的个体的情况下不存在,但在孕妇或癌患者等的血液中,以非常低的几率存在被称为稀有细胞的细胞。作为其中之一,已知胎儿细胞转移到妊娠中的母亲的血液中,该胎儿细胞与血液一同在母体中循环。关于血液中的存在几率,认为以在数ml中存在数个的比例存在。如果能够再现性良好且可靠地分析这种胎儿细胞中的基因组dna,则能够实现无流产可能性的安全而且直接分析来源于胎儿的dna的基因诊断。
并且,作为其他稀有细胞,有称为血中循环肿瘤细胞(ctc:circulatingtumorcell,循环性肿瘤细胞)的癌细胞。关于该癌细胞在血液中的存在数量,认为在血液10ml中为数个至数十个左右。关于ctc,已知具有肿瘤或癌的人类个体的已进行的癌细胞会随着血液的流动而循环,在远离的脏器也引起转移,乳腺癌或前列腺癌、大肠癌等转移性癌症病例中,作为治疗效果的判定和预后预测因子的有用性得到了认可。
ctc的临床上的有用性在于,能够远比以往的诊断方法更早地进行癌化疗的治疗效果的评价。并且,期待能够根据在ctc显现的生物学标志物或基因变异、扩增、融合等信息选择每个患者的最佳治疗。
近年来,通过下一代测序(ngs:nextgenerationsequencing)技术的普及,碱基序列数据的质及量的担保变得容易,因此可轻松进行基因分析。通过ngs技术的导入,消除了全基因组分析的大部分技术性困难。但是,关于基因组的总碱基长度,在人类基因组的情况下为30亿碱基对以上,通常庞大,即使具有ngs技术,进行全基因组分析时也需要相当的费用及时间。
另一方面,作为用于实现检测基因异常的目的的方法,无法说全基因组分析是最佳方法。这是因为仅分析与基因异常相关的基因组dna上的区域(不仅包含编码区域,还包含非编码区域)即可。因此,作为通过仅对基因组dna上的所需的特定区域进行扩增,并限定在该碱基序列进行读段,由此有效且精度良好地进行基因分析的技术,普及有pcr(polymerasechainreaction;聚合酶链反应)法。尤其,将通过对某1个pcr反应系统同时供给多种引物来对多个区域选择性地进行扩增的方法称为多重pcr(多重聚合酶链反应)。
通常,以多重pcr同时进行扩增的区域的数量无法设为较多。作为其主要原因之一,已知有如下现象,即,通过引物彼此发生反应,生成称为引物二聚体的多余的扩增产物,无法有效地对基因组dna上的目标区域进行扩增。
作为抑制形成引物二聚体的方法,例如,专利文献1中,记载有如下方法,即,将引物的碱基序列分割为稳态区域和可变区域,在稳态区域中配设相同的碱基列,在可变区域中,仅限定为胞嘧啶(c)、胸腺嘧啶核苷(t)、鸟嘌呤(g)及腺嘌呤(a)中不会相互互补的2种碱基,由此对数量庞大的区域施加聚合酶反应。
并且,专利文献2中,记载有如下内容,即,针对引物的所有组合,计算表示引物之间的3’末端中的互补性的评分(3’末端的局部比对评分),选出引物彼此的互补性低的引物的组合,由此降低多重pcr中不同目标的引物彼此形成引物二聚体的可能性。
以往技术文献
专利文献
专利文献1:国际公开第2004/081225号
专利文献2:国际公开第2008/004691号
技术实现要素:
发明要解决的技术课题
这些改良技术在对从多细胞提取的丰富的dna进行扩增的情况下是有用的技术,但例如在单细胞(single-cell)分析等,成为pcr(polymerasechainreaction;聚合酶链反应)的模板的基因组dna(deoxyribonucleicacid;核糖核酸)的量极少的情况下,引物二聚体的抑制并不充分。
因此,要求获取来源于脊椎动物的单细胞的碱基序列信息的方法,该方法能够将从来源于脊椎动物的单细胞提取的基因组dna作为模板,均匀且精度良好地进行目标区域的pcr扩增。
因此,本发明的课题在于提供一种获取来源于脊椎动物的单细胞的碱基序列信息的方法,该方法能够均匀且精度良好地进行目标区域的pcr扩增。
用于解决技术课题的手段
本发明人等为了解决上述课题而反复进行了深入研究,其结果发现如下内容并完成了本发明:若利用以使引物之间的互补性降低的方式设计的引物进行目标区域的pcr扩增,则能够均匀且精度良好地进行目标区域的pcr扩增。
即,本发明提供以下[1]至[8]。
[1]一种获取来源于脊椎动物的单细胞的碱基序列信息的方法,其包含:
目标区域选择工序,从脊椎动物的基因组dna上的区域选择用于获取碱基序列信息的至少1个目标区域;
单细胞分离工序,从来源于上述脊椎动物的生物试样分离单细胞;
基因组dna提取工序,从上述单细胞提取基因组dna;
pcr扩增工序,将在上述基因组dna提取工序中提取的基因组dna作为模板,利用以对上述至少1个目标区域进行pcr扩增的方式设计的引物组合,通过pcr对上述至少1个目标区域进行扩增;及
dna测序工序,解读在上述pcr扩增工序中获得的pcr扩增产物的dna碱基序列,获取上述至少1个目标区域的碱基序列信息,
上述目标区域选择工序和从上述单细胞分离工序至上述基因组dna提取工序的工序为任意顺序,
上述获取来源于脊椎动物的单细胞的碱基序列信息的方法中,
以对上述至少1个目标区域进行pcr扩增的方式设计的引物组合通过用于聚合酶链反应的引物组合的设计方法设计,该设计方法包含:
a)对象区域选择工序,从上述至少1个目标区域选择对象区域;
b)引物候选碱基序列制作工序,根据上述脊椎动物的基因组dna上的上述对象区域两端的各个附近区域的碱基序列,分别各制作至少1个用于对上述对象区域进行pcr扩增的引物候选的碱基序列;
c)局部比对工序,针对从在上述引物候选碱基序列制作工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端这样的条件下,进行成对局部比对,从而求出局部比对评分;
d)第1阶段选拔工序,根据上述局部比对评分,进行用于对上述对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔;
e)总体比对工序,针对从在上述第1阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分;
f)第2阶段选拔工序,根据上述总体比对评分,进行用于对上述对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔;
g)引物采用工序,采用在上述第1阶段选拔工序及上述第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述对象区域进行pcr扩增的引物的碱基序列,
上述局部比对工序及上述第1阶段选拔工序这两个工序和上述总体比对工序及上述第2阶段选拔工序这两个工序为任意顺序或同时进行。
[2]一种获取来源于脊椎动物的单细胞的碱基序列信息的方法,其包含:
目标区域选择工序,从脊椎动物的基因组dna上的区域选择用于获取碱基序列信息的至少1个目标区域;
单细胞分离工序,从来源于上述脊椎动物的生物试样分离单细胞;
基因组dna提取工序,从上述单细胞提取基因组dna;
pcr扩增工序,将在上述基因组dna提取工序中提取的基因组dna作为模板,利用以对上述至少1个目标区域进行pcr扩增的方式设计的引物组合,通过pcr对上述至少1个目标区域进行扩增;及
dna测序工序,解读在上述pcr扩增工序中获得的pcr扩增产物的dna碱基序列,获取上述至少1个目标区域的碱基序列信息,
上述目标区域选择工序和从上述单细胞分离工序至上述基因组dna提取工序的工序为任意顺序,
上述获取来源于脊椎动物的单细胞的碱基序列信息的方法中,
以对上述至少1个目标区域进行pcr扩增的方式设计的引物组合通过用于聚合酶链反应的引物组合的设计方法设计,该设计方法包含:
a1)对象区域选择第1工序,从上述至少1个目标区域选择第1对象区域;
b1)引物候选碱基序列制作第1工序,根据上述脊椎动物的基因组dna上的上述第1对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列;
c1)局部比对第1工序,针对从在上述引物候选碱基序列制作第1工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,针对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分;
d1)第1阶段选拔第1工序,根据上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔;
e1)总体比对第1工序,针对从在上述第1阶段选拔第1工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分;
f1)第2阶段选拔第1工序,根据上述总体比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔;
g1)引物采用第1工序,采用在上述第1阶段选拔第1工序及上述第2阶段选拔第1工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列;
a2)对象区域选择第2工序,从上述至少1个目标区域中还未被选择的目标区域选择第2对象区域;
b2)引物候选碱基序列制作第2工序,根据上述脊椎动物的基因组dna上的上述第2对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列;
c2)局部比对第2工序,针对从在上述引物候选碱基序列制作第2工序中制作的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分;
d2)第1阶段选拔第2工序,根据上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔;
e2)总体比对第2工序,针对从在上述第1阶段选拔第2工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分;
f2)第2阶段选拔第2工序,根据上述总体比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔;及
g2)引物采用第2工序,采用在上述第1阶段选拔第2工序及上述第2阶段选拔第2工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列,
上述局部比对第1工序及上述第1阶段选拔第1工序这两个工序和上述总体比对第1工序及上述第2阶段选拔第1工序这两个工序为任意顺序或同时进行,
上述局部比对第2工序及上述第1阶段选拔第2工序这两个工序和上述总体比对第2工序及上述第2阶段选拔第2工序这两个工序为任意顺序或同时进行,
在上述至少1个目标区域包含3个以上的目标区域的情况下,且采用用于对还未从上述3个以上的目标区域选择的第3及其后的对象区域进行pcr扩增的引物的碱基序列时,针对上述第3及其后的对象区域,反复进行上述第2局部比对工序至上述第2引物采用工序的各工序。
[3]一种获取来源于脊椎动物的单细胞的碱基序列信息的方法,其包含:
目标区域选择工序,从脊椎动物的基因组dna上的区域选择用于获取碱基序列信息的至少1个目标区域;
单细胞分离工序,从来源于上述脊椎动物的生物试样分离单细胞;
基因组dna提取工序,从上述单细胞提取基因组dna;
pcr扩增工序,将在上述基因组dna提取工序中提取的基因组dna作为模板,利用以对上述至少1个目标区域进行pcr扩增的方式设计的引物组合,通过pcr对上述至少1个目标区域进行扩增;及
dna测序工序,解读在上述pcr扩增工序中获得的pcr扩增产物的dna碱基序列,获取上述至少1个目标区域的碱基序列信息,
上述目标区域选择工序和从上述单细胞分离工序至上述基因组dna提取工序的工序为任意顺序,
上述获取来源于脊椎动物的单细胞的碱基序列信息的方法中,
以对上述至少1个目标区域进行pcr扩增的方式设计的引物组合通过用于聚合酶链反应的引物组合的设计方法设计,该设计方法包含:
a-0)对象区域多个选择工序,从上述至少1个目标区域选择多个对象区域;
b-0)引物候选碱基序列多个制作工序,根据上述脊椎动物的基因组dna上的上述多个对象区域的各两端的各个附近区域的碱基序列,分别各制作至少1个用于分别对上述多个对象区域进行pcr扩增的引物候选的碱基序列;
c-1)第1局部比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第1对象区域进行pcr扩增的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分;
d-1)第一第1阶段选拔工序,根据上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔;
e-1)第1总体比对工序,针对从在上述第一第1阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分;
f-1)第一第2阶段选拔工序,根据上述总体比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔;
g-1)第1引物采用工序,采用在上述第一第1阶段选拔工序及上述第一第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列;
c-2)第2局部比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第2对象区域进行pcr扩增的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分;
d-2)第二第1阶段选拔工序,根据上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔;
e-2)第2总体比对工序,针对从在上述第二第1阶段选拔工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分;
f-2)第二第2阶段选拔工序,根据上述总体比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔;及
g-2)第2引物采用工序,采用在上述第二第1阶段选拔工序及上述第二第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列,
上述第1局部比对工序及上述第一第1阶段选拔工序这两个工序和上述第1总体比对工序及上述第一第2阶段选拔工序这两个工序为任意顺序或同时进行,
上述第2局部比对工序及上述第二第1阶段选拔工序这两个工序和上述第2总体比对工序及上述第二第2阶段选拔工序这两个工序为任意顺序或同时进行,
在上述至少1个目标区域包含3个以上的目标区域,在上述对象区域多个选择工序中选择3个以上的对象区域,且在上述引物候选碱基序列多个制作工序中制作用于分别对上述3个以上的对象区域进行pcr扩增的引物候选的碱基序列的情况下,采用用于对第3及其后的对象区域进行pcr扩增的引物的碱基序列时,针对上述第3及其后的对象区域,反复进行上述第2局部比对工序至上述第2引物采用工序的各工序。
[4]根据上述[1]至[3]中任一项所述的获取来源于脊椎动物的单细胞的碱基序列信息的方法,其中,上述单细胞为稀有细胞。
[5]根据上述[4]所述的获取来源于脊椎动物的单细胞的碱基序列信息的方法,其中,上述稀有细胞为来源于胎儿的有核红细胞。
[6]上述[4]所述的获取来源于脊椎动物的单细胞的碱基序列信息的方法,其中,上述稀有细胞为癌细胞。
[7]根据上述[6]所述的获取来源于脊椎动物的单细胞的碱基序列信息的方法,其中,上述癌细胞为血中循环癌细胞。
[8]根据上述[1]至[3]中任一项所述的获取来源于脊椎动物的单细胞的碱基序列信息的方法,其中,上述单细胞为来源于脏器的实体癌的癌细胞。
发明效果
根据本发明,能够提供一种获取来源于脊椎动物的单细胞的碱基序列信息的方法,该方法能够均匀且精度良好地进行目标区域的pcr扩增。
而且,根据本发明,无需经wga(全基因组扩增)工序就能够从单细胞获取碱基序列信息。
附图说明
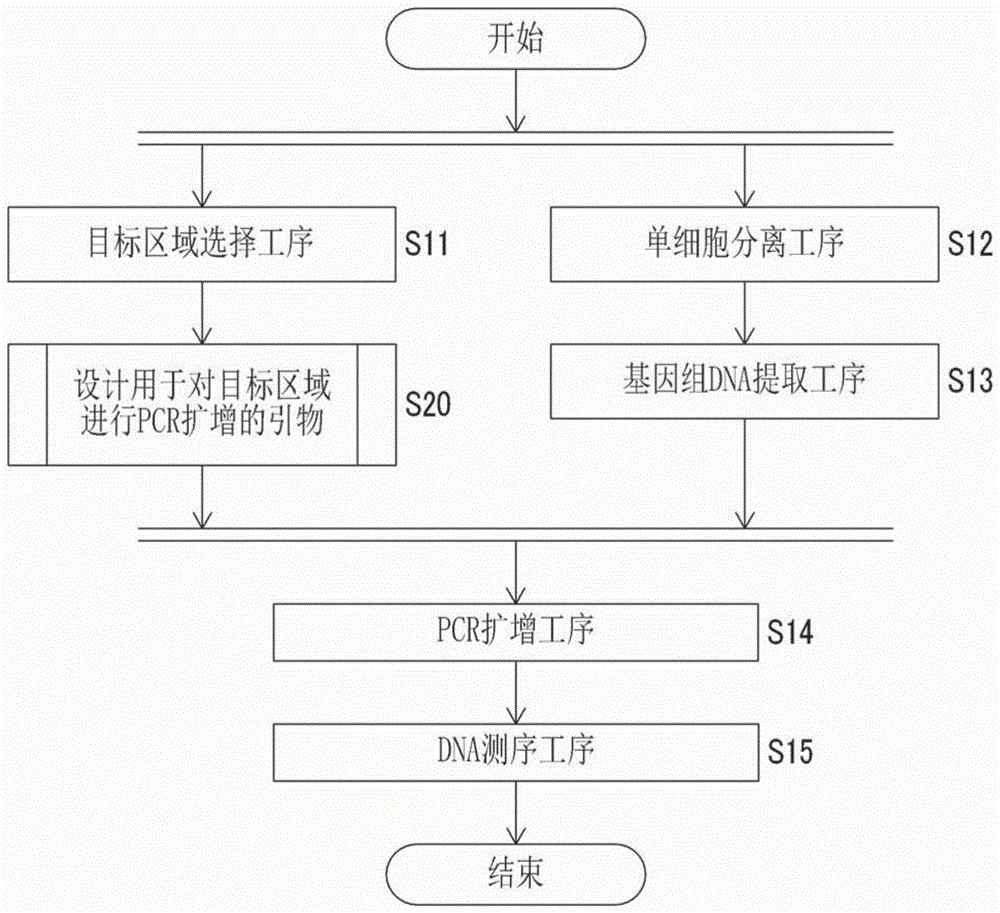
图1是表示本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法的概略的流程图。
图2是说明在本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法中使用的用于聚合酶链反应的引物组合的设计方法的第1方式的流程图。
图3是说明在本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法中使用的用于聚合酶链反应的引物组合的设计方法的第2方式的流程图。
图4是说明在本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法中使用的用于聚合酶链反应的引物组合的设计方法的第3方式的流程图。
图5是表示实施例1的结果的曲线图。细胞3、细胞8、细胞18及细胞20的4个细胞示出与标样基因组不同的图案,且这些所示出的图案相互相似,由此推断为是来源于胎儿的细胞。
图6是表示实施例1的结果的曲线图。来源于胎儿的4个细胞中,18号染色体相对于13号染色体及21号染色体中的任一染色体均存在约1.5倍的根数,示出18号染色体三体性。
具体实施方式
[获取来源于脊椎动物的单细胞的碱基序列信息的方法]
关于本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法,大致来讲是如下方法,即,从自血液中分离存在于孕妇的外周血中的来源于胎儿的有核红细胞或者血中循环癌细胞等稀有细胞的单细胞、或属于来源于实体癌的肿瘤的多个各肿瘤部分的细胞群的单细胞获取基因组dna,进行目标区域的pcr扩增,从而获取目标区域的碱基序列信息。
本发明中的特征点在于,通过聚合酶链反应对基因组dna上的目标区域进行扩增时,通过利用以使引物之间的互补性降低的方式设计的引物,即使是从单细胞提取的少量的模板dna,也能够均匀且精度良好地进行pcr扩增。
另外,本发明中,利用“~”标记数值范围时,设为该数值范围包含“~”的两侧的数值。例如,“0.1~0.5”在其范围内包含“0.1”及“0.5”,其含义与“0.1以上且0.5以下”相同。并且,对于“0.5~0.1”也相同。而且,具有大小关系或前后关系时也相同。
以下中,对本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法(以下,有时简称为“本发明的碱基序列信息获取方法”。)进行详细说明。
本发明的碱基序列信息获取方法包含以下的(1)~(5)的各工序及设计用于对目标区域进行pcr扩增的引物的工序(图1)。
(1)目标区域选择工序,从脊椎动物的基因组dna上的区域选择用于获取碱基序列信息的至少1个目标区域。
(2)单细胞分离工序,从来源于脊椎动物的生物试样分离单细胞。
(3)基因组dna提取工序,从单细胞提取基因组dna。
(4)pcr扩增工序,将在基因组dna提取工序中提取的基因组dna作为模板,利用以对至少1个目标区域进行pcr扩增的方式设计的引物组合,通过pcr对至少1个目标区域进行扩增。
(5)dna测序工序,解读在pcr扩增工序中pcr扩增的至少1个目标区域的pcr扩增产物的dna碱基序列,获取至少1个目标区域的碱基序列信息。
其中,(1)目标区域选择工序和(2)单细胞分离工序至(3)基因组dna提取工序的工序可以变更顺序。
并且,关于设计用于对目标区域进行pcr扩增的引物的工序,在选择目标区域之后且进行pcr扩增之前,事先设计引物,并制作所使用的引物即可。
关于设计用于对目标区域进行pcr扩增的引物的工序中的用于聚合酶链反应的引物组合的设计方法,另外在“用于聚合酶链反应的引物组合的设计方法”中进行详细说明。
<目标区域选择工序>
目标区域选择工序是从脊椎动物的基因组dna上的区域选择用于获取碱基序列信息的至少1个目标区域的工序。
在脊椎动物的基因组dna上,存在多个能够获取碱基序列信息的区域,但只要符合目的地选择目标区域即可。
《脊椎动物》
脊椎动物是具有脊椎的动物,包含哺乳类、鸟类、爬虫类、两栖类及鱼类。作为脊椎动物,优选为哺乳类,哺乳类中尤其优选为人类。
《基因组dna上的区域》
本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法中,“基因组dna上的区域”是指,存在具有基因多态性、单基因疾病、多因子疾病的可能性的基因区域的基因组dna上的区域。其中,区域的长度并无特别限定,1个碱基以上即可。选择目标区域的基因组dna上的区域可存在于基因区域及非基因区域中的任一区域。其中,基因区域包含存在对蛋白质进行编码的基因、核糖体rna(ribonucleicacid:核糖核酸)基因及转移rna基因等的编码区域、以及存在断开基因的内含子、转印调节区域、5’-前导序列及3’-尾随序列等的非编码区域。并且,非基因区域包含假基因、间隔物、响应元件及复制起点等非重复序列、以及串联重复序列及分散重复序列等重复序列。
基因多态性例如为snp(singlenucleotidepolymorphism:单核苷酸多态性)、snv(singlenucleotidevariant:单核苷酸变异)、strp(shorttandemrepeatpolymorphism:短串联重复序列多态性)、变异、以及插入和/或缺失(indel)等。单基因疾病是单基因的异常成为原因而发病的疾病。作为异常,可举出基因本身的缺失或者重复、和/或基因内的碱基的取代、插入和/或缺失等。将成为单基因疾病的原因的单基因称为“致病基因”。多因子疾病是多个基因参与发病的疾病,有时涉及snp的特定组合等。在对疾病具有敏感性的含义上,将这些基因称为“敏感性基因”。癌是由于基因变异而产生的疾病。与其他疾病相同,癌也存在遗传性(家族性)癌,称为基因肿瘤(家族性肿瘤)等。
基因组dna上的区域的数量并无特别限定。这是因为基因组dna上的区域是选择目标区域时的候选列表,即使有数量庞大的列表,也不需要对其全部进行分析。
《目标区域》
目标区域是从上述基因组dna上的区域作为获取碱基序列信息的对象而选择的区域。其中,选择的目标并不限定于检测与各区域相关的基因多态性、疾病或癌等,也可以以检测染色体的非整倍性等为目标。并且,选择的目标并不限定于1个,也可以具有2个以上的目标。
作为目标区域选择的基因组dna上的区域的数量根据获取碱基序列信息的目标而不同,虽并无特别限定,但优选为3处以上,更优选为5处以上,进一步优选为10处以上。
获取碱基序列信息的目标并无特别限定,例如,从胎儿有核红细胞获取碱基序列信息时,作为其目标可举出胎儿的基因状态的获取、胎儿的染色体非整倍性的检查、胎儿与疑似父亲之间的亲子(父子)鉴定或胎儿与亲属之间的血缘鉴定等,从血中循环癌细胞获取碱基序列信息时,可举出当前的癌的进行状态的评价、抗癌剂的选择或抗癌剂效果的判定等,从自实体癌分离的单癌细胞获取碱基序列信息时,可举出基因异常的检测、治疗方法的选择、抗癌剂的选择或进行状态的评价等。
例如,将胎儿的基因状态的判定作为目标时,针对单基因的异常成为疾病原因的孟德尔遗传性疾病,从omim(onlinemendelianinheritanceinman:人类孟德尔遗传)数据库选择希望检测的原因基因,设计欲检查的变异部位的数量的引物。利用所设计的引物组合,对从胎儿有核红细胞提取的基因组dna的目的基因区域进行扩增,通过测序仪求出扩增产物的碱基序列。对所解读的碱基序列与健康的参考基因组进行比较时,观察到基因的缺失、重复、倒位和/或易位时,可预想为胎儿具有基因疾病。
<单细胞分离工序>
单细胞分离工序是从来源于上述脊椎动物的生物试样分离单细胞的工序。
《生物试样》
生物试样只要是包含能够提取基因组dna的细胞的生物试样,则并无特别限定,例如,可举出血液、实体组织或培养细胞等。
《单细胞》
作为单细胞,例如,可举出血液中包含的、相对于血液中的其他细胞的存在比极低且数ml的血液中仅存在1个左右的稀有细胞。
作为人类血液中包含的稀有细胞,例如,可举出从妊娠母体采集的血液中包含的来源于胎儿的有核红细胞或从癌症患者采集的血液中包含的血中循环肿瘤细胞等。
(来源于胎儿的有核红细胞)
来源于胎儿的有核红细胞是通过胎盘而存在于母体血中的红细胞前体,是以在母体血中的约106个细胞中1个的比例存在的稀有细胞。母体在妊娠期间,胎儿的红细胞有可能是有核。有核红细胞中存在核,因此通过分离来源于胎儿的有核红细胞,能够获得胎儿基因组dna。
作为以分离来源于胎儿的有核红细胞为目的而从妊娠母体采集的血液,只要是母体血、脐带血等已知存在来源于胎儿的有核红细胞的血液即可,从最大限度抑制向妊娠母体的侵入性的观点考虑,优选为母体外周血。
妊娠母体的外周血中包含来源于母亲的嗜酸性粒细胞、嗜中性粒细胞、嗜碱性粒细胞、单核细胞、淋巴细胞等白细胞、来源于母亲的无核且已成熟的红细胞、来源于母亲的有核红细胞及来源于胎儿的有核红细胞等血液细胞。认为来源于胎儿的有核红细胞从妊娠后6周左右开始存在于母体血中。因此,将来源于胎儿的有核红细胞的分离作为目的时,用于本发明的血液优选为从妊娠后6周左右以后的妊娠母体采集的外周血或利用从妊娠后6周左右以后的妊娠母体采集的外周血制备的血液试样。
(来源于胎儿的有核红细胞的分离)
来源于胎儿的有核红细胞可通过使用光学设备的分析(还称为“光学分析”。),与存在于血液中的其他细胞区别并分离。光学分析优选为图像分析和/或光谱分析。为了容易进行光学分析,优选在光学分析之前浓缩稀有细胞。
例如,关于有核红细胞,已知有通过密度梯度离心分离来浓缩血液的方法。
以下,对有核红细胞的密度梯度离心分离进行详细说明。
((有核红细胞的基于密度梯度离心分离的浓缩))
有核红细胞可通过密度梯度离心分离,与存在于血液中的血浆成分或其他血液细胞分离。用于分离有核红细胞的密度梯度离心分离可适用公知的方法。例如,在将不同密度(比重)的2种介质重叠在离心管的不连续密度梯度的基础上,重叠用生理盐水稀释的血液并进行离心,由此能够分级并浓缩有核红细胞。
国际公开第2012/023298号中,记载有包含来源于胎儿的有核红细胞在内的母体的血细胞的密度。根据该记载,所设想的来源于胎儿的有核红细胞的密度为1.065~1.095g/ml左右,关于母亲的血细胞的密度,红细胞为1.070~1.120g/ml左右,嗜酸性粒细胞为1.090~1.110g/ml左右,嗜中性粒细胞为1.075~1.100g/ml左右,嗜碱性粒细胞为1.070~1.080g/ml左右,淋巴细胞为1.060~1.080g/ml左右,单核细胞为1.060~1.070g/ml左右。
为了分离密度1.065~1.095g/ml左右的来源于胎儿的有核红细胞与其他血液细胞,设定所层叠的介质的密度(比重)。来源于胎儿的有核红细胞的中心的密度为1.080g/ml左右,因此通过相邻层叠夹着该密度的2个不同密度的介质,能够使具有来源于胎儿的有核红细胞的组分集中在其界面。下层介质的密度设为1.08g/ml以上且大于上层介质的密度,但优选设为1.08g/ml~1.10g/ml,更优选为1.08g/ml~1.09g/ml。并且,上层介质的密度设为1.08g/ml以下且小于下层介质的密度,但优选为1.06g/ml~1.08g/ml,更优选为1.065g/ml~1.08g/ml。
作为一例,优选将下层介质的密度设为1.085g/ml,并将上层介质的密度设为1.075g/ml,从所回收的所希望的组分分离血浆成分、嗜酸性粒细胞及单核细胞。并且,通过如此设定,还能够分离红细胞、嗜中性粒细胞及淋巴细胞的一部分。
本发明中,下层介质和上层介质可使用相同种类的介质,也可以使用不同种类的介质,但优选使用相同种类的介质。
作为介质,可举出用聚乙烯基吡咯烷酮涂布的直径15nm~30nm的硅酸胶体粒子分散液即percoll(gehealthcare公司制造)、由蔗糖制作的富含于侧链的中性的亲水性聚合物即ficoll-paque(gehealthcare公司制造)、包含多聚蔗糖和泛影酸钠的histopaque(sigma-aldrich公司制造)等。本发明中,优选使用percoll和/或histopaque。percoll市售有密度1.130的产品,能够通过用水稀释来制备密度梯度。histopaque能够利用市售的密度1.077的介质及密度1.119的介质和水来制备密度梯度。
2层的不连续密度梯度例如如下形成于离心管。
首先,将处于凝固点以上且14℃以下、优选为8℃以下的温度状态的下层介质容纳于离心管的底部,或将下层介质容纳于离心管的底部之后在14℃以下、优选为8℃以下的温度下保存来冷却。
接着,在下层介质上重叠上层介质。
((基于流式细胞仪的分离))
本发明中,优选在通过密度梯度离心分离来浓缩有核红细胞之后,通过流式细胞仪法分离有核红细胞。
关于流式细胞仪中的分取,通过流式细胞仪法获取试样液的来源于细胞的信息,根据所获取的信息,将靶细胞分取至排列有具有开口的孔的容器,拍摄分取至容器的细胞,并根据该图像确定有核红细胞候选细胞来进行。
在流式细胞仪中的分取之前进行染色。首先,准备包含靶细胞的分析对象试样。向分析对象试样例如混合溶血剂及用于免疫染色的被荧光标记的抗体,通过温育,对细胞进行免疫染色。通过对细胞进行免疫染色来制备试样液s。从光源向血液细胞照射激光束等。通过激光束的照射,基于血液细胞的免疫染色的荧光标记被激励,血液细胞通过基于免疫染色的荧光标记发出荧光。通过检测器检测该荧光强度。根据检测出的信息,在流动池被施加超声波的细胞带电为正或负。细胞通过偏转电极板时,通过使带电的液滴靠近任一偏转电极板,基本上在容器的1个孔分取1个细胞。
仅通过基于流式细胞仪的分离,有时无法确定所分离的有核红细胞是来源于胎儿还是来源于母体(孕妇)。但是,本发明中,通过基于snp(单核苷酸多态性)和/或str(短串联重复序列)等的多态性分析、以及y染色体的存在的确认等基因分型分析,能够判别所分离的有核红细胞的来源。
(血中循环肿瘤细胞)
已知有在实体癌患者的血液中循环的肿瘤细胞,被成为血中循环肿瘤细胞(circulatingtumorcell;ctc)。ctc是以在108~109个血细胞成分中存在约1个的比例存在的稀有细胞。
认为ctc包含具有从原发病灶向其他部位转移的能力的细胞。认为从肿瘤细胞的块向血管内渗透的癌细胞中,穿过自身免疫系统的极少数的细胞作为ctc在血液内循环,形成转移灶。认为很难预测该转移性癌的经过,获取ctc的信息来获得针对癌症病理的准确的信息在治疗的进行上有益。关于癌症病理的经过,进行图像诊断或基于肿瘤标志物的诊断,但实际情况是很难及时判断肿瘤的活动情况,即,是休眠状态还是活跃地增殖。因此,若能够通过外周血中的ctc检查实现癌症病理预测,则会成为非常有效的方法。
肿瘤内不均匀性是在肿瘤中存在不同基因组的多个克隆的现象,成为癌症的治疗抵抗性的原因之一。由于肿瘤内不均匀性,即使治疗敏感性的克隆缩小,残留有治疗抵抗性的少数克隆时,有时该克隆增殖而导致复发。认为肿瘤内不均匀性由于在癌症的进化过程中克隆分支而产生,在肿瘤内也产生耐药性克隆的可能性高。因此,进行癌症治疗时,在掌握肿瘤内不均匀性的基础上及时研究治疗方法是非常重要的。
(血中循环肿瘤细胞的分离)
作为获取血中循环肿瘤细胞(ctc)的方法,例如已知有如下方法,即,利用与血液细胞的大小及形态的不同,利用过滤器分离血液细胞并进行浓缩(例如,日本特开2011-163830号公报、日本特开2013-042689号公报)。
并且,作为获取血中循环肿瘤细胞(ctc)的方法,市售有细胞搜索系统(cellsearch系统;veridex公司制造)。当前,利用该细胞搜索系统的乳腺癌、前列腺癌及大肠癌的病例的ctc检查获得了美国食品和药物管理局(fda;usfoodanddrugadministration)的批准。ctc能够通过利用该细胞搜索系统来获取。
作为使用细胞搜索系统获取ctc的方法,首先,通过用作为上皮细胞粘附因子的抗epcam(epithelialcelladhesionmolecule;上皮细胞粘附分子)抗体进行标记的磁性粒子,从血液中分离、提取ctc细胞候选。对该分离的细胞,进一步使已荧光标记的抗细胞角蛋白单克隆抗体发生反应,并且同时利用作为dna染色物质的dapi(4’,6-diamidino-2-phenylindole(4’,6-二脒基-2-苯基吲哚))对核进行染色。其中,为了识别白细胞,与已荧光标记的抗cd45抗体进行反应。ctc反应液转移至固定有磁铁的卡盘上,分析被磁铁捕获的ctc的荧光显色情况。能够通过确认被dapi染色的核、被抗细胞角蛋白单克隆抗体荧光染色的细胞的形态、对cd45抗体未反应,鉴定ctc。
并且,作为获取ctc的方法,作为组合微小流路和流体力学的方法,还已知有clearcellfx系统(clearbridgebiomedics公司制造)。该装置中,能够不使用抗体而通过免标记(labelfree)对ctc进行浓缩回收,还能够回收不依赖于epcam抗原的发现量的ctc。
具体而言,从约7ml的患者血液,用rbclysisbuffer(takarabioinc.制造)溶解红细胞,离心之后,利用缓冲器对颗粒进行悬浮之后,填充于clearcellfx芯片(clearbridgebiomedics公司制造),从而能够将ctc回收至软管中。
(来源于实体癌的癌细胞的分离)
用于确认肿瘤内不均匀性的细胞分离中,将原发病灶的部位划分为多个部位,并从其部位获取单细胞。
作为获取的方法,例如,可举出利用胰蛋白酶或胰蛋白酶·edta(乙二胺四乙酸)对癌细胞的块进行处理等。
并且,还可以举出如下方法等,即,利用肿瘤切片,如lcm(lasercapturemicrodissection;激光捕获显微切割技术)那样在显微镜连接有激光照射装置的设备,在显微镜下观察肿瘤切片的同时通过激光选择性地采集、回收靶细胞。作为所利用的肿瘤切片,也能够利用福尔马林或者酒精固定之后的石蜡块,但优选为用液氮保存的来源于冷冻肿瘤的肿瘤切片。
<基因组dna提取工序>
基因组dna提取工序是从上述单细胞提取基因组dna的工序。
自单细胞的基因组dna提取并无特别限定,能够通过以往公知的方法进行。
例如,可使用市售的基因组dna提取试剂盒。
并且,提取dna时,优选进行蛋白质分解处理。细胞中除了dna及rna等核酸以外,还包含蛋白质及其他物质,并且,染色体的最基本的构成要素是基因组dna和组蛋白,因此通过分解并去除蛋白质,能够提高pcr扩增工序的成功率。
分解并去除蛋白质的方法并无特别限定,但优选使用蛋白酶k等蛋白质分解酶。还能够使用市售的蛋白质分解酶试剂盒等。
<pcr扩增工序>
pcr扩增工序是将在上述基因组dna提取工序中提取的基因组dna作为模板,利用以对上述至少1个目标区域进行扩增的方式设计的引物组合,通过聚合酶链反应对上述至少1个目标区域进行扩增的工序。
以对上述至少1个目标区域进行扩增的方式设计的引物组合在后述的“为了用于聚合酶链反应的引物的设计方法”中进行说明。
(聚合酶链反应)
聚合酶链反应使用dna聚合酶反复复制模板dna。在使其扩增的dna碱基序列的开始与结束的部分加以与模板dna进行杂交的较短的dna引物,并通过聚合酶开始复制。每次重复进行复制时,模板双链dna的2条链解离并分别被复制。
多重pcr能够使用通常的pcr中使用的耐热性dna聚合酶、反应缓冲液,各引物对与模板dna进行退火的温度不同,因此有时需要研究反应条件。因此,优选使用最适合于多重pcr的耐热性dna聚合酶、反应缓冲液,本发明中,更优选使用多重pcr检测试剂盒(takarabioinc.制造)进行反应。
关于引物及引物组合的设计方法的详细内容将在后面进行叙述,因此在此作为例示,叙述检测13号、18号和/或21号染色体的非整倍性的情况的概要。
关于目标区域的数量,检测13号、18号和/或21号染色体的非整倍性时,从上述染色体中特异性的dna序列区域,选择根据检查而所需的部位的靶区域,制作用于对各靶区域进行扩增的引物候选的碱基序列,并选拔引物碱基序列之间的互补性低的区域,由此对如单细胞那样的微量的基因组dna,目标区域的扩增性也得到显著改善。
下一代测序仪技术虽然获得了飞跃性的进步,但用于序列分析的样品的制备需要非常复杂的工序。关于样品的预处理,在最广泛应用的基因组分析的情况下,在从样品提取核酸之后,需要(1)dna的片段化、(2)dna尺寸选择、(3)dna末端的平滑化处理、(4)向dna末端附加接头序列、(5)dna的纯化及(6)dna的扩增等工艺。
复杂的样品调整工序需要时间及劳力,必需确认工序是否适当进行。并且,各工序中逐渐产生偏差,在用作尤其以高水准要求结果的精度及准确度的医疗现场中的诊断工具时,需要减少该偏差。
为了解决这些问题,本发明中,利用使用后述的特定方法设计的引物来进行多重pcr,由此能够实现为了判别基因状态而选择的目标区域的更均匀的扩增。而且,通过磁珠对pcr产物进行纯化,由此能够进行更有效的扩增产物的回收。pcr反应溶液中残留有剩余引物、dntps(deoxynucleotides;脱氧核苷酸)及酶等掺杂物,因此有时会成为获得高精度的序列数据时的障碍。但是,通过利用磁珠对pcr扩增产物进行纯化,能够在显著抑制pcr扩增产物的损失的同时进行充分的纯化。此时,优选使用如下方法,即,从单细胞的非常少的dna,仅通过(1)dna的扩增及(2)dna的纯化这样的简单的样品调整工序,也均匀且高精度地扩增各种基因区域,可靠地检测胎儿的基因异常的有无。
被扩增的dna的量的测定例如能够利用测定260nm的波长的吸收度的超微量分光光度计nanodrop(thermofisherscientific制造)、利用激光荧光检测法的agilent2100bioanalyzer(agilenttechnologiesjapan,ltd.制造)或通过荧光法对双链dna进行定量的quantus荧光计(promegacorporation制造)等来进行。
pcr即invitro的dna合成中,关于细胞内的dna复制即invivo的dna合成,在pcr中为了合成双链dna,需要2种以上的称为引物的寡核苷酸。有时将在1个pcr反应系统中同时使用的引物的组合称为引物组合。
pcr能够从利用1对引物(还称为“引物对”。)对1个区域进行扩增的简单的系统轻松地扩充至利用由多个引物对构成的引物组合对多个区域同时进行扩增的复杂的系统(多重pcr)。
pcr的优点在于,从如人类的基因组dna(30亿碱基对)那样的非常长且大的dna分子中,能够仅对所希望的区域选择性地进行扩增。而且,能够将极微量的基因组dna用作模板来获得充分量的所希望的区域的扩增产物。
并且,作为pcr的优点,虽然还根据程序而不同,但还可举出如下优点,即,扩增所需的时间较短,大致为2小时左右。
而且,作为pcr的优点,还可举出工艺简单,且能够利用全自动的台式装置进行扩增。
(pcr产物的纯化)
包含pcr扩增产物的反应液中混有酶、核苷酸、盐类及其他杂质,因此优选去除它们。作为核酸的纯化方法,例如,已知有利用苯酚/氯仿/乙醇的方法、在离液盐的存在下选择性地吸附于硅滤膜等硅载体的方法及利用在peg(polyethyleneglycol:聚乙二醇)存在下核酸选择性地与通过羧基修饰的磁珠结合的现象的方法等。
作为本发明的优选实施方式,pcr扩增产物能够选择利用磁珠的纯化法。
对pcr扩增产物进行利用了作为顺磁微珠的磁珠的纯化,由此能够更有效地仅进行目标区域的分析。
对pcr扩增产物的利用磁珠的纯化法进行说明。
利用磁珠的pcr扩增产物的纯化方法中,使作为pcr扩增产物的dna片段可逆性地结合于磁珠的粒子表面,用磁铁吸附磁珠,分离已扩增的dna片段与液体,由此能够有效地去除酶、dntps、pcr引物、引物二聚体及盐等掺杂物。利用磁珠的方法与其他纯化方法相比,样品损失较少且掺杂物的去除效率较高。作为其结果,dna序列工序中,能够有效地仅进行目标区域的分析。市售有磁珠,例如,能够使用ampurexp试剂盒(beckmancoulter,inc.制造)、nucleomag(takarabioinc.制造)或epinextdnapurificationhtsystem(epigentekgroupinc.制造)等。其中,优选利用ampurexp试剂盒(beckmancoulter,inc.制造)进行纯化。
<dna测序工序>
dna测序工序是解读在上述pcr扩增工序中扩增的上述至少1个目标区域的扩增产物的dna碱基序列,获取上述至少1个目标区域的碱基序列信息的工序。
pcr扩增产物的序列分析中优选利用下一代测序仪,尤其miseq(illumina,inc.制造)。利用下一代测序仪“miseq”对多个多重pcr产物进行测序时,需要对各多重pcr产物附加由6~8个碱基构成的样品识别序列(索引序列)以及用于与miseq流动池上的寡核苷酸序列杂交的p5序列及p7序列。通过这些序列的附加,能够一次测定最多96种多重pcr产物。
作为对多重pcr产物的两个末端附加索引序列、p5序列及p7序列的方法,能够利用接头连接法(adapterligation)或pcr法等。
并且,混合多个多重pcr产物来通过miseq进行测定时,优选准确地定量各pcr产物。作为pcr产物的定量方法,还能够利用agilent2100bioanalyzer(agilenttechnologiesjapan,ltd.制造)或quantus荧光计(promegacorporation),但进一步优选通过定量pcr法测定多重pcr产物的方法。作为本发明中的定量方法,优选利用kapalibraryquantification试剂盒(nippongeneticsco.,ltd.制造)进行定量。
作为分析通过miseq获得的序列数据的方法,优选利用bwa(burrows-wheeleraligner;伯罗斯惠勒比对工具:li,h.、外1名、“fastandaccurateshortreadalignmentwithburrows-wheelertransform”、bioinformatics、2009年、第25卷、第14号、p.1754-1760.;li,h.、外1名、“fastandaccuratelong-readalignmentwithburrows-wheelertransform”、bioinformatics、2010年、第26卷、第5号、p.589-595),对已知的人类基因组序列进行映射,作为分析基因异常的方法,优选通过利用samtools(li,heng、外、“thesequencealignment/mapformatandsamtools”、bioinformatics、2009年、第25卷、第16号、p.2078-2079;sam来源于“sequencealignment/map”。)和/或bedtools(quinlan,a.r.、外1名、“bedtools:aflexiblesuiteofutilitiesforcomparinggenomicfeatures”、bioinformatics、2010年、第26卷、第6号、p.841-842),分析基因变异或染色体数量的定量。
(序列读段数的确定)
dna测序工序中,优选还测定序列读段数。
例如,针对鉴定胎儿有核红细胞的细胞,对靶区域进行pcr扩增来获得的dna片段,能够通过测序仪求出具有预先确定的140bp以上且180bp以下的区域的序列的扩增产物的扩增量(序列读段数)。作为基准(或者参考),通过测序仪求出鉴定为来源于母亲的有核红细胞的细胞的细胞中具有预先确定的140bp以上且180bp以下的区域的序列的扩增产物的扩增量(序列读段数)。若胎儿为正常的状态,则预测来源于胎儿的扩增产物的扩增量(序列读段数)与来源于母亲的扩增产物的扩增量(序列读段数)大致成为1∶1的量比。胎儿具有作为来源于所扩增的染色体的三体性的疾病时,预测该比会成为1∶1.5(或2∶3)。
本发明中,预先求出多个从多个妊娠母体采集的、相对于妊娠有正常的胎儿时的来源于母亲的pcr扩增产物的量(序列读段数)的来源于胎儿的pcr扩增产物的量(序列读段数)之比,并求出其分布。并且,求出多个相对于妊娠有三体性胎儿时的来源于母亲的扩增产物的量(序列读段数)的来源于胎儿的扩增产物的量(序列读段数)之比,并求出其分布。还能够在该2个分布不重叠的区域设定截止值。还能够对该预先确定的截止值与求出扩增产物之比的结果进行比较,如下解释检查结果,若该比为截止值以下,则胎儿为正常,若为截止值以上,则为三体性。无法获得结果时,可以从单细胞的分离重新进行。
该例中,可以进行所分离的有核红细胞是否来源于胎儿的确认,从而确定已进行来源于胎儿的单细胞的基因状态的判定。已知在从妊娠母体采集的外周血的有核红细胞中,混合有来源于母亲的有核红细胞和来源于胎儿的有核红细胞,本发明的方法能够判定胎儿的基因状态的同时鉴定来源于胎儿的有核红细胞。作为识别基因序列的个人差异的方法,通常通过检测等位基因中存在的基因多态性的方法进行。作为一例,父子辨别中,作为基因多态性的一种,还能够使用str。并且,作为识别个人差异的方法,还能够使用基因组碱基序列中的一个碱基变异并以1%以上的频率被观察的snps。本发明中,还能够利用下一代测序仪,通过在有核红细胞中有无具有不同str或snps的细胞,识别胎儿细胞与母亲细胞。并且,为了另外在基因状态的判定中使用辅助性信息来判定是否为来源于胎儿的有核红细胞,例如,能够获取来源于母亲的白细胞,并同样分析str或snps来进行判定。
并且,若是在采集有核红细胞之前通过超声波检查确认胎儿为男婴的情况,则能够通过检测所采集的有核红细胞的y染色体的有无来判定有核红细胞是否来源于胎儿。通常,作为检测所采集的细胞的y染色体的有无的方法,已知有利用y染色体特异性荧光探针的fish(fluorescentinsituhybridization:荧光原位杂交)法。作为一例,使用cepx/ydna探针试剂盒(abbottjapanco.,ltd.制造)。本发明中,优选制作具有对y染色体特异性的碱基序列的引物并利用pcr确认其有无扩增,由此鉴定是来源于男婴的有核红细胞。
认为血中循环肿瘤细胞(ctc)包含具有从原发病灶向其他部位转移的能力的细胞。
并且,认为还包含具备对抗癌剂具有耐性的耐药性能力的细胞。作为例子,非小细胞性肺癌患者中,已知有iressa(r)(astrazenecak.k.制造;通用名吉非替尼(gefitinib))及tarceva(r)(chugaipharmaceuticalco.,ltd.制造;通用名厄洛替尼盐酸盐)等egfr(epidermalgrowthfactorreceptor;表皮生长因子受体)酪氨酸激酶抑制剂,但已知在多数患者中,在用药开始后1年以内复发。作为其原因,已知在复发肿瘤中,egfr蛋白质的第790位获得了从苏氨酸取代(t790m)为蛋氨酸的耐药性变异。该变异妨碍药剂结合,因此认为在用药开始或用药之后检测有无耐药性变异是非常重要的。
随着分子靶向药物的开发,熟知的事例为egfr基因的耐药性变异,但同样地,通过事先从自患者获取的ctc同时检测kras基因变异或braf基因变异,能够选择有效的抗癌剂治疗,能够避免不必要的治疗、诊断。
作为检测基因变异的方法,已知有通过实时pcr法检测的方法。作为一例,使用therascreenegfr变异检测试剂盒rgq(qiagen公司制造)。
并且,作为利用下一代测序仪检测多个部位的基因变异的方法,已知有ionampliseqcancerhotspotpanelv2(lifetechnologyinc.制造),但未使用于来自单细胞的直接的基因变异的检测中。而且,作为利用下一代测序仪从患者的实体癌等检测多个部位的基因变异的方法,已知有trusightcancer(illuminak.k..制造),由于并非多重pcr而是利用使用寡dna的捕获方法,因此所需的dna量为50ng,从而并未使用于来自单细胞的直接的基因变异的检测中。
[用于聚合酶链反应的引物组合的设计方法]
对本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法中实施的用于聚合酶链反应的引物组合的设计方法进行说明。
<用于聚合酶链反应的引物组合的设计方法的第1方式>
本发明中,用于聚合酶链反应的引物组合的设计方法的第1方式包含以下工序。另外,以下说明中,适当参考图2。
(a)对象区域选择工序,从至少1个目标区域选择对象区域(图2的s101)。
(b)引物候选碱基序列制作工序,根据上述脊椎动物的基因组dna上的上述对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对上述对象区域进行pcr扩增的引物候选的碱基序列(图2的s102)。
(c)局部比对工序,针对从在上述引物候选碱基序列制作工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分(图2的s103)。
(d)第1阶段选拔工序,根据上述局部比对评分,进行用于对上述对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔(图2的s104)。
(e)总体比对工序,针对从在上述第1阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分(图2的s105)。
(f)第2阶段选拔工序,根据上述总体比对评分,进行用于对上述对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔(图2的s106)。
(g)引物采用工序,采用在上述第1阶段选拔工序及上述第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述对象区域进行pcr扩增的引物的碱基序列(图2的s107)。
但是,上述(a)工序~上述(g)工序中,上述(c)工序及上述(d)工序这两个工序和上述(e)工序及上述(f)工序这两个工序可以为任意顺序或同时进行。即,可以在进行上述(c)工序及上述(d)工序之后进行上述(e)工序及上述(f)工序,也可以在进行上述(e)工序及上述(f)工序之后进行上述(c)工序及上述(d)工序,还可以同时进行上述(c)工序及上述(d)工序和上述(e)工序及上述(f)工序。
在进行上述(e)工序及上述(f)工序之后进行上述(c)工序及上述(d)工序时,上述(e)工序及上述(c)工序优选分别设为下述(e’)工序及下述(c’)工序。
(e’)总体比对工序,针对从在上述引物候选碱基序列制作工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(c’)局部比对工序,针对从在上述第2阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分。
并且,同时进行上述(c)工序及上述(d)工序和上述(e)工序及上述(f)工序时,上述(e)工序优选设为下述(e’)工序。
(e’)总体比对工序,针对从在上述引物候选碱基序列制作工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
进一步设计引物时,若已制作引物候选的碱基序列,则从c)局部比对工序(图2的s103)设计引物,若未制作引物候选的碱基序列,则从b)引物候选碱基序列制作工序(图2的s102)或a)对象区域选择工序(图2的s101)设计引物(图2的s108、s109及s110)。
<用于聚合酶链反应的引物组合的设计方法的第2方式>
本发明中,作为至少1个目标区域包含2个以上的目标区域时的用于聚合酶链反应的引物组合的设计方法的派生方式之一的第2方式包含以下工序。另外,以下说明中,适当参考图3。
(a1)对象区域选择第1工序,从至少1个目标区域选择第1对象区域(图3的s201)。
(b1)引物候选碱基序列制作第1工序,根据上述脊椎动物的基因组dna上的上述第1对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列(图2的s202)。
(c1)局部比对第1工序,针对从在上述引物候选碱基序列制作第1工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分(图3的s203)。
(d1)第1阶段选拔第1工序,根据上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔(图3的s204)。
(e1)总体比对第1工序,针对从在上述第1阶段选拔第1工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分(图3的s205)。
(f1)第2阶段选拔第1工序,根据上述总体比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔(图3的s206)。
(g1)引物采用第1工序,采用在上述第1阶段选拔第1工序及上述第2阶段选拔第1工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列(图3的s207)。
但是,上述(a1)工序~上述(g1)工序中,上述(c1)工序及上述(d1)工序这两个工序和上述(e1)工序及上述(f1)工序这两个工序可以为任意顺序或同时进行。即,可以在进行上述(c1)工序及上述(d1)工序之后进行上述(e1)工序及上述(f1)工序,也可以在进行上述(e1)工序及上述(f1)工序之后进行上述(c1)工序及上述(d1)工序,还可以同时进行上述(c1)工序及上述(d1)工序和上述(e1)工序及上述(f1)工序。
在进行上述(e1)工序及上述(f1)工序之后进行上述(c1)工序及上述(d1)工序时,上述(e1)工序及上述(c1)工序分别优选设为下述(e1’)工序及下述(c1’)工序。
(e1’)总体比对第1工序,针对从在上述引物候选碱基序列制作第1工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(c1’)局部比对第1工序,针对从在上述第2阶段选拔第1工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分。
并且,同时进行上述(c1)工序及上述(d1)工序和上述(e1)工序及上述(f1)工序时,上述(e1)工序优选设为下述(e1’)工序。
(e1’)总体比对第1工序,针对从在上述引物候选碱基序列制作第1工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(a2)对象区域选择第2工序,从上述至少1个目标区域中还未被选择的目标区域选择第2对象区域(图3的s211)。
(b2)引物候选碱基序列制作第2工序,根据上述脊椎动物的基因组dna上的上述第2对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列(图3的s212)。
(c2)局部比对第2工序,针对从在上述引物候选碱基序列制作第2工序中制作的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分(图3的s213)。
(d2)第1阶段选拔第2工序,根据上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔(图3的s214)。
(e2)总体比对第2工序,针对从在上述第1阶段选拔第2工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分(图3的s215)。
(f2)第2阶段选拔第2工序,根据上述总体比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔(图3的s216)。
(g2)引物采用第2工序,采用在上述第1阶段选拔第2工序及上述第2阶段选拔第2工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列(图3的s217)。
但是,上述(a2)工序~上述(g2)工序中,上述(c2)工序及上述(d2)工序这两个工序和上述(e2)工序及上述(f2)工序这两个工序可以为任意顺序或同时进行。即,可以在进行上述(c2)工序及上述(d2)工序之后进行上述(e2)工序及上述(f2)工序,也可以在进行上述(e2)工序及上述(f2)工序之后进行上述(c2)工序及上述(d2)工序,还可以同时进行上述(c2)工序及上述(d2)工序和上述(e2)工序及上述(f2)工序。
在进行上述(e2)工序及上述(f2)工序之后进行上述(c2)工序及上述(d2)工序时,上述(e2)工序及上述(c2)工序分别优选设为下述(e2’)工序及下述(c2’)工序。
(e2’)总体比对第2工序,针对从在上述引物候选碱基序列制作第2工序中制作的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(c2’)局部比对第2工序,针对从在上述第2阶段选拔第2工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分。
并且,同时进行上述(c2)工序及上述(d2)工序和上述(e2)工序及上述(f2)工序时,上述(e2)工序优选设为下述(e2’)工序。
(e2’)总体比对第2工序,针对从在上述引物候选碱基序列制作第2工序中制作的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
进一步设计引物时,反复进行a2)对象区域选择第2工序(图3的s211)至g2)引物采用第2工序(图3的s217)(图3的s208)。即,上述至少1个目标区域包含3个以上的目标区域的情况下,采用用于对还未从上述3个以上的目标区域选择的第3及其后的对象区域进行pcr扩增的引物的碱基序列时,针对上述第3及其后的对象区域,反复进行上述(a2)工序~上述(g2)工序的各工序。
<用于聚合酶链反应的引物组合的设计方法的第3方式>
本发明中,作为至少1个目标区域包含2个以上的目标区域时的用于聚合酶链反应的引物组合的设计方法的派生方式之一的第3方式包含以下工序。另外,以下说明中,适当参考图4。
(a-0)对象区域多个选择工序,从上述至少1个目标区域选择多个对象区域(图4的s301)。
(b-0)引物候选碱基序列多个制作工序,根据上述脊椎动物的基因组dna上的上述多个对象区域的各两端的各个附近区域的碱基序列,分别各制作至少1个用于分别对上述多个对象区域进行pcr扩增的引物候选的碱基序列(图4的s302)。
(c-1)第1局部比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第1对象区域进行pcr扩增的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分(图4的s303)。
(d-1)第一第1阶段选拔工序,根据上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔(图4的s304)。
(e-1)第1总体比对工序,针对从在上述第一第1阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分(图4的s305)。
(f-1)第一第2阶段选拔工序,根据上述总体比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔(图4的s306)。
(g-1)第1引物采用工序,采用在上述第一第1阶段选拔工序及上述第一第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列(图4的s307)。
但是,上述(c-1)工序~上述(g-1)工序中,上述(c-1)工序及上述(d-1)工序这两个工序和上述(e-1)工序及上述(f-1)工序这两个工序可以为任意顺序或同时进行。即,可以在进行上述(c-1)工序及上述(d-1)工序之后进行上述(e-1)工序及上述(f-1)工序,也可以在进行上述(e-1)工序及上述(f-1)工序之后进行上述(c-1)工序及上述(d-1)工序,还可以同时进行上述(c-1)工序及上述(d-1)工序和上述(e-1)工序及上述(f-1)工序。
在进行上述(e-1)工序及上述(f-1)工序之后进行上述(c-1)工序及上述(d-1)工序时,上述(e-1)工序及上述(c-1)工序分别优选设为下述(e’-1)工序及下述(c’-1)工序。
(e’-1)第1总体比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第1对象区域进行pcr扩增的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(c’-1)第1局部比对工序,针对在从上述第一第2阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分。
并且,同时进行上述(c-1)工序及上述(d-1)工序和上述(e-1)工序及上述(f-1)工序时,上述(e-1)工序优选设为下述(e’-1)工序。
(e’-1)第1总体比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第1对象区域进行pcr扩增的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(c-2)第2局部比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第2对象区域进行pcr扩增的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分(图4的s313)。
(d-2)第二第1阶段选拔工序,根据上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔(图4的s314)。
(e-2)第2总体比对工序,针对从在上述第二第1阶段选拔工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分(图4的s315)。
(f-2)第二第2阶段选拔工序,根据上述总体比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔(图4的s316)。
(g-2)第2引物采用工序,采用上述第二第1阶段选拔工序及上述第二第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列(图4的s317)。
但是,上述(c-2)工序~上述(g-2)工序中,上述(c-2)工序及上述(d-2)工序这两个工序和上述(e-2)工序及上述(f-2)工序这两个工序可以为任意顺序或同时进行。即,可以在进行上述(c-2)工序及上述(d-2)工序之后进行上述(e-2)工序及上述(f-2)工序,也可以在进行上述(e-2)工序及上述(f-2)工序之后进行上述(c-2)工序及上述(d-2)工序,还可以同时进行上述(c-1)工序及上述(d-1)工序和上述(e-1)工序及上述(f-1)工序。
在进行上述(e-2)工序及上述(f-2)工序之后进行上述(c-2)工序及上述(d-2)工序时,上述(e-2)工序及上述(c-2)工序分别优选设为下述(e’-2)工序及下述(c’-2)工序。
(e’-2)第2总体比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第2对象区域进行pcr扩增的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
(c’-2)第2局部比对工序,针对从在上述第二第2阶段选拔工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分。
并且,同时进行上述(c-2)工序及上述(d-2)工序和上述(e-2)工序及上述(f-2)工序时,上述(e-2)工序优选设为下述(e’-2)工序。
(e’-2)第2总体比对工序,针对从在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列中用于对第2对象区域进行pcr扩增的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分。
进一步设计引物时,反复进行c-2)第2局部比对工序(图4的s313)至g-2)第2引物采用工序(图4的s317)(图3的s308)。即,上述至少1个目标区域包含3个以上的目标区域,在上述对象区域多个选择工序中选择3个以上的对象区域,且在上述引物候选碱基序列多个制作工序中制作用于分别对上述3个以上的对象区域进行pcr扩增的引物候选的碱基序列的情况下,采用用于对第3及其后的对象区域进行pcr扩增的引物的碱基序列时,针对上述第3及其后的对象区域,反复进行上述第2局部比对工序至上述第2引物采用工序的各工序。
<各工序的说明>
以下,对在本发明的获取来源于脊椎动物的单细胞的碱基序列信息的方法中实施的用于聚合酶链反应的引物组合的设计方法中包含的各工序进行详细说明。
《对象区域选择工序》
本说明书中,有时将对象区域选择工序s101(图2)、对象区域选择第1工序s201及对象区域选择第2工序s211(图3)以及对象区域多个选择工序s301(图4)简单地总称为“对象区域选择工序”。
(第1方式:对象区域选择工序s101)
图2中,示为“对象区域选择”(s101)。
第1方式中,(a)对象区域选择工序是从目标区域选择对象区域的工序。
(第2方式:对象区域选择第1工序s201及对象区域选择第2工序s211)
图3中,示为“对象区域选择第1”(s201)及“对象区域选择第2”(s211)。
第2方式中,(a1)对象区域选择第1工序是从目标区域选择第1对象区域的工序,(a2)对象区域选择第2工序是从还未被选择的目标区域选择第2对象区域的工序。
第2方式中,各选择1个目标区域。
(第3方式:对象区域多个选择工序s301)
图4中,示为“对象区域多个选择”(s301)。
第3方式中,(a-0)对象区域多个选择工序是从目标区域选择多个对象区域的工序。
第3方式中,选择多个目标区域。优选为选择所有目标区域作为对象区域。
《引物候选碱基序列制作工序》
本说明书中,有时将引物候选碱基序列制作工序s102(图2)、引物候选碱基序列制作第1工序s202及引物候选碱基序列制作第2工序s212(图3)以及引物候选碱基序列多个制作工序s302(图4)简单地总称为“引物候选碱基序列制作工序”。
(第1方式:引物候选碱基序列制作工序s102)
图2中,示为“引物候选碱基序列制作”(s102)。
第1方式中,(b)引物候选碱基序列制作工序是根据基因组dna上的上述对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对对象区域进行pcr扩增的引物候选的碱基序列的工序。
(第2方式:引物候选碱基序列制作第1工序s202及引物候选碱基序列制作第2工序s212)
图3中,示为“引物候选碱基序列制作第1”(s202)及“引物候选碱基序列制作第2”(s212)。
第2方式中,(b1)引物候选碱基序列制作第1工序是根据基因组dna上的上述第1对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对第1对象区域进行pcr扩增的引物候选的碱基序列的工序,(b2)引物候选碱基序列制作第2工序是根据基因组dna上的上述第2对象区域的两端的各个附近区域的碱基序列,分别各制作至少1个用于对第2对象区域进行pcr扩增的引物候选的碱基序列的工序。
第2方式中,针对1个对象区域进行引物候选的碱基序列的制作、引物候选的选拔及引物的采用,针对接下来的1个对象区域,反复进行相同的工序。
(第3方式:引物候选碱基序列多个制作工序s302)
图4中,示为“引物候选碱基序列多个制作”(s302)。
第3方式中,(b-0)引物候选碱基序列多个制作工序是根据基因组dna上的上述多个对象区域的各两端的各个附近区域的碱基序列,分别各制作至少1个用于分别对多个对象区域进行pcr扩增的引物候选的碱基序列的工序。
第3方式中,针对多个对象区域的所有区域制作引物候选的碱基序列,在之后的工序中反复进行选拔及采用。
(附近区域)
对象区域的两端的各个附近区域是指从对象区域的5’端靠外侧的区域及从对象区域的3’端靠外侧的区域的总称。对象区域的内侧不包含在附近区域。
附近区域的长度并无特别限定,但优选为能够通过pcr扩展的长度以下,更优选为希望扩增的dna片段长度的上限以下。尤其,优选为易实施集中选择和/或序列读段的长度。可根据pcr中使用的酶(dna聚合酶)的种类等适当变更。具体的附近区域的长度优选为20~500个碱基左右,更优选为20~300个碱基左右,进一步优选为20~200个碱基左右,更进一步优选为50~200个碱基左右。
(引物的设计参数)
并且,制作引物候选的碱基序列时,注意点与通常的引物的设计方法中的注意点相同,如引物的长度、gc含量(指所有核酸碱基中的鸟嘌呤(g)及胞嘧啶(c)的合计摩尔百分比。)、解链温度(指双链dna的50%解离而成为单链dna的温度。并且,有时来源于meltingtemperature而称为“tm值”。单位为“℃”。)及序列的偏移等。
·引物的长度
引物的长度(核苷酸数量)并无特别限定,但优选为15mer~45mer,更优选为20mer~45mer,进一步优选为20mer~30mer。若引物的长度在该范围内,则易设计特异性及扩增效率优异的引物。另外,“mer”为以核苷酸的个数表示多核苷酸的长度时的单位,1mer表示1个核苷酸。因此,例如15mer表示由15个核苷酸构成的多核苷酸。
·引物的gc含量
引物的gc含量并无特别限定,但优选为40摩尔%~60摩尔%,更优选为45摩尔%~55摩尔%。若gc含量在该范围内,则不易产生由高级结构引起的特异性及扩增效率的下降的问题。
·引物的tm值
引物的tm值并无特别限定,但优选在50℃~65℃的范围内,更优选在55℃~65℃的范围内。
引物的tm值的差在引物对及引物组合中,优选设为5℃以下,更优选设为3℃以下。
tm值能够利用oligoprimeranalysissoftware(molecularbiologyinsights公司制造)或primer3(http://www-genome.wi.mit.edu/ftp/distribution/software/)等软件计算。
并且,还能够由引物的碱基序列中的a、t、g及c的数量(分别设为na、nt、ng及nc),根据下述式通过计算来求出。
tm值(℃)=2(na+nt)+4(nc+ng)
tm值的计算方法并不限定于这些,能够通过以往公知的各种方法计算tm值。
·引物的碱基的偏移
引物候选的碱基序列优选设为整体上碱基无偏移的序列。例如,优选避免局部富gc的序列及局部富at的序列。
并且,优选还避免t和/或c的连续(聚嘧啶)以及a和/或g的连续(聚嘌呤)。
·引物的3’末端
而且,优选3’末端碱基序列避免富gc的序列或富at的序列。优选3’末端碱基为g或c,但并不限定于这些。
《特异性检查工序》
可根据在“引物候选碱基序列制作工序”中制作的各引物候选的碱基序列相对于染色体dna的序列互补性,实施评价引物候选的碱基序列的特异性的特异性检查工序。
特异性的检查中,进行染色体dna的碱基序列与引物候选的碱基序列的局部比对,局部比对评分小于预先设定的值时,能够评价为该引物候选的碱基序列相对于基因组dna的互补性低,特异性高。其中,优选对染色体dna的互补链也进行局部比对。这是因为引物为单链dna,而染色体dna为双链。并且,可代替引物候选的碱基序列,利用与此互补的碱基序列。
并且,也可将引物候选的碱基序列作为查询序列,对基因组dna碱基序列数据库进行同源性搜索。作为同源性搜索工具,例如可举出blast(basiclocalalignmentsearchtool:基本局部比对搜索工具)(altschul,s.a.、外4名、“basiclocalalignmentsearchtool”、journalofmolecularbiology、1990年、10月、第215卷、p.403-410)及fasta(pearson,w.r.、外1名、“improvedtoolsforbiologicalsequencecomparison”、美国科学院纪要、美国科学院、1988年、4月、第85卷、p.2444-2448)等。作为进行同源性搜索而得的结果,能够获得局部比对。
评分及局部比对评分的阈值均无特别限定,能够根据引物候选的碱基序列的长度和/或pcr条件等适当设定。使用同源性搜索工具时,可使用该同源性搜索工具的默认值。
例如,可考虑作为评分,采用匹配(互补碱基)=+1、不匹配(非互补碱基)=-1、indel(插入和/或缺失)=-3,将阈值设定为+15等。
引物候选的碱基序列与染色体dna上的预想外的位置的碱基序列具有互补性,且特异性低的情况下,利用该碱基序列的引物进行pcr时,有时对伪影进行扩增而非对象区域,因此排除。
《局部比对工序》
本说明书中,有时将局部比对工序s103(图2)、局部比对第1工序s203及局部比对第2工序s213(图3)以及第1局部比对工序s303及第2局部比对工序s313(图4)简单地总称为“局部比对工序”。
(第1方式:局部比对工序s103)
图2中,示为“局部比对”(s103)。
第1方式中,(c)局部比对工序是针对从在上述引物候选碱基序列制作工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分的工序。
(第2方式:局部比对第1工序s203及局部比对第2工序s213)
图3中,示为“局部比对第1”(s203)及“局部比对第2”(s213)。
第2方式中,(c1)局部比对第1工序是针对从在上述引物候选碱基序列制作第1工序中制作的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分的工序,(c2)局部比对第2工序是针对从在上述引物候选碱基序列制作第2工序中制作的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分的工序。
(第3方式:第1局部比对工序s303及第2局部比对工序s313)
图4中,示为“第1局部比对”(s303)及“第2局部比对”(s313)。
第3方式中,(c-1)第1局部比对工序是针对从选自在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列选择的用于对第1对象区域进行pcr扩增的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分的工序,(c-2)第2局部比对工序是针对从选自在上述引物候选碱基序列多个制作工序中制作的引物候选的碱基序列的用于对第2对象区域进行pcr扩增的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对上述组合中包含的2个碱基序列,在该比较的一部分序列包含上述2个碱基序列的3’末端的条件下,进行成对局部比对,从而求出局部比对评分的工序。
(局部比对的方法)
进行局部比对的碱基序列的组合可以是允许重复而选择的组合,也可以是不允许重复而选择的组合,但还未评价同一碱基序列的引物之间的引物二聚体形成性时,优选为允许重复而选择的组合。
关于组合的总数量,将进行局部比对的碱基序列的总数量设为p个,允许重复而选择时,为“ph2=p+1c2=(p+1)!/2(p-1)!”,不允许重复而选择时,为“pc2=p(p-1)/2”。
局部比对为对一部分序列进行的比对,能够局部性地检查互补性高的部分。
但是,本发明中,与通常对碱基序列进行的局部比对不同,在“所比较的一部分序列包含碱基序列的3’末端”这样的条件下,进行局部比对,以使所比较的一部分序列包含双方的碱基序列的3’末端。
而且,本发明中优选如下方式:在“所比较的一部分序列包含碱基序列的3’末端”这样的条件即“仅考虑所比较的一部分序列从其中一个序列的3’末端开始并在另一个序列的3’末端结束的比对”这样的条件下,进行局部比对,以使所比较的一部分序列包含双方的碱基序列的3’末端。
另外,局部比对可插入间隙。间隙表示碱基的插入和/或缺失(indel)。
并且,局部比对中,将在碱基序列对之间碱基为互补性的情况作为一致(匹配),将非互补性的情况作为不一致(不匹配)。
比对以对匹配、不匹配及插入和/或缺失分别赋予评分,并使合计评分成为最大的方式进行。评分适当设定即可。例如,可如下述表1那样设定评分系统。另外,表1中“-”表示间隙(插入和/或缺失(indel))。
[表1]
表1
例如,考虑对以下的表2所示的序列编号1及2的碱基序列进行局部比对。其中,评分如表1所示。
[表2]
表2
根据序列编号1及2的碱基序列制作表3所示的点阵(dotmatrix)。具体而言,将序列编号1的碱基序列从左至右以从5’至3’的方向排列,将序列编号2的碱基序列从下至上以从5’至3’的方向排列,对碱基为互补性的栅格记入“·”,由此获得表3所示的点阵。
[表3]
表3
根据表3所示的点阵获得以下的表4所示的一部分序列的比对(成对比对)(参考表3的斜线部分)。另外,表4中,以“”表示匹配,以“:”表示不匹配。
[表4]
表4
该(成对)比对中,有9处匹配,有8处不匹配,没有插入和/或缺失(间隙)。
因此,基于该(成对)比对的局部比对评分成为(+1)×9+(-1)×8+(-1)×0=+1。
另外,比对(成对比对)并不仅限于在此例示的点阵法,能够通过动态规划法、词法或其他各种方法获得。
《第1阶段选拔工序》
本说明书中,有时将第1阶段选拔工序s104(图2)、第1阶段选拔第1工序s204及第1阶段选拔第2工序s214(图3)以及第一第1阶段选拔工序s304及第二第1阶段选拔工序s314(图4)简单地总称为“第1阶段选拔工序”。
(第1方式:第1阶段选拔工序s104)
图2中,示为“第1阶段选拔”(s104)。
第1方式中,(d)第1阶段选拔工序是根据上述局部比对评分,进行用于对上述对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔的工序。
(第2方式:第1阶段选拔第1工序s204及第1阶段选拔第2工序s214)
图3中,示为“第1阶段选拔第1”(s204)及“第1阶段选拔第2”(s214)。
第2方式中,(d1)第1阶段选拔第1工序是根据上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔的工序,(d2)第1阶段选拔第2工序是根据上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔的工序。
(第3方式:第一第1阶段选拔工序s304及第二第1阶段选拔工序s314)
图4中,示为“第一第1阶段选拔”(s304)及“第二第1阶段选拔”(s314)。
第3方式中,(d-1)第一第1阶段选拔工序是根据上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔的工序,(d-2)第二第1阶段选拔工序是根据上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第1阶段的选拔的工序。
(第1阶段选拔的方法)
预先设定局部比对评分的阈值(还称为“第1阈值”。)。
若局部比对评分小于第1阈值,则判断为这2个碱基序列的组合的二聚体形成性低,进行之后的工序。
另一方面,若局部比对评分为第1阈值以上,则判断为这2个碱基序列的组合的引物二聚体形成性高,对该组合不进行之后的工序。
第1阈值并无特别限定,能够适当设定。例如,可根据成为聚合酶链反应的模板的基因组dna的量等pcr条件设定第1阈值。
其中,上述“局部比对工序”中示出的例子中,考虑将第1阈值设定为“+3”的情况。
上面的例子中,局部比对评分为“±1”,小于作为第1阈值的“+3”,因此能够判断为序列编号1及2的碱基序列的组合的引物二聚体形成性低。
另外,对在局部比对工序s103、局部比对第1工序s203、局部比对第2工序s213、第1局部比对工序s303或第2局部比对工序s313中计算出局部比对评分的所有组合进行本工序。
《总体比对工序》
本说明书中,有时将总体比对工序s105(图2)、总体比对第1工序s205及总体比对第2工序s215(图3)以及第1总体比对工序s305及第2总体比对工序s315(图4)简单地总称为“总体比对工序”。
(第1方式:总体比对工序s105)
图2中,示为“总体比对”(s105)。
第1方式中,(e)总体比对工序是针对从在上述第1阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分的工序。
(第2方式:总体比对第1工序s205及总体比对第2工序s215)
图3中,示为“总体比对第1”(s205)及“总体比对第2”(s215)。
第2方式中,(e1)总体比对第1工序是针对从在上述第1阶段选拔第1工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分的工序,(e2)总体比对第2工序是针对从在上述第1阶段选拔第2工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分的工序。
(第3方式:第1总体比对工序s305及第2总体比对工序s315)
图4中,示为“第1总体比对”(s305)及“第2总体比对”(s315)。
第3方式中,(e-1)第1总体比对工序是针对从在上述第一第1阶段选拔工序中选拔的引物候选的碱基序列选择2个引物候选的碱基序列的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分的工序,(e-2)第2总体比对工序是针对从在上述第二第1阶段选拔工序中选拔的引物候选的碱基序列及已被采用的引物的碱基序列选择2个引物候选的碱基序列的组合和选择1个引物候选的碱基序列及1个已被采用的引物的碱基序列的组合的所有组合,对包含上述组合中包含的2个碱基序列的3’末端和预先设定的序列长度的碱基序列,进行成对总体比对,从而求出总体比对评分的工序。
(总体比对的方法)
关于总体比对评分,从由在“引物候选碱基序列制作工序”中制作的所有引物候选(已先进行“局部比对工序”及“第1阶段选拔工序”的情况下,存在局部比对评分小于第1阈值的引物候选的组合时,该组合中包含的所有引物候选。)及已采用的所有引物(仅限于存在已经采用的引物的情况。)构成的组提取2个引物,对包含3’末端和预先设定的序列长度的碱基序列,进行成对总体比对来求出。
进行总体比对的碱基序列的组合可以是允许重复而选择的组合,也可以是不允许重复而选择的组合,但还未评价同一碱基序列的引物之间的引物二聚体形成性时,优选为允许重复而选择的组合。
关于组合的总数量,将进行总体比对的碱基序列的总数量设为x个,允许重复而选择时,为“xh2=x+1c2=(x+1)!/2(x-1)!”,不允许重复而选择时,为“xc2=x(x-1)/2”。
总体比对为对“整个序列”进行的比对,能够检查整个序列的互补性。
但是,其中,“整个序列”为包含引物候选的碱基序列的3’末端和预先设定的序列长度的整个碱基序列。
另外,总体比对也可以插入间隙。间隙表示碱基的插入和/或缺失(inde1)。
并且,总体比对中,将在碱基序列对之间碱基为互补性的情况作为一致(匹配),将非互补性的情况作为不一致(不匹配)。
比对以对匹配、不匹配及插入和/或缺失分别赋予评分,并使合计评分成为最大的方式进行。评分适当设定即可。例如,可如上述表1那样设定评分。另外,表1中“-”表示间隙(插入和/或缺失(indel))。
例如,考虑针对以下的表5所示的序列编号1及2的碱基序列,对各3’末端的3个碱基(大写字母部分。)进行总体比对。其中,评分如表1所示。
[表5]
表5
如以评分成为最大的方式,针对序列编号1的碱基序列的3’末端的3个碱基(大写字母部分)及序列编号2的3’末端的3个碱基(大写字母部分)的碱基序列进行总体比对,则能够获得以下的表6所示的比对(成对比对)。另外,表6中,以“:”表示不匹配。
[表6]
表6
该(成对)比对中,不匹配有3处,匹配及插入和/或缺失(间隙)均无。
因此,基于该(成对)比对的总体比对评分成为(+1)×0+(-1)×3+(-1)×0=-3。
另外,比对(成对比对)能够通过点阵法、动态规划法、词法或其他各种方法获得。
《第2阶段选拔工序》
本说明书中,有时将第2阶段选拔工序s106(图2)、第2阶段选拔第1工序s206及第2阶段选拔第2工序s216(图3)以及第一第2阶段选拔工序s306及第二第2阶段选拔工序s316简单地总称为“第2阶段选拔工序”。
(第1方式:第2阶段选拔工序s106)
图2中,示为“第2阶段选拔”(s106)。
第1方式中,(f)第2阶段选拔工序是根据上述总体比对评分,进行用于对上述对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔的工序。
(第2方式:第2阶段选拔第1工序s206及第2阶段选拔第2工序s216)
图3中,示为“第2阶段选拔第1”(s206)及“第2阶段选拔第2”(s216)。
第2方式中,(f1)第2阶段选拔第1工序是根据上述总体比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔的工序,(f2)第2阶段选拔第2工序是根据上述总体比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔的工序。
(第3方式:第一第2阶段选拔工序s306及第二第2阶段选拔工序s316)
图4中,示为“第一第2阶段选拔”(s306)及“第二第2阶段选拔”(s316)。
第3方式中,(f-1)第一第2阶段选拔工序是根据上述总体比对评分,进行用于对上述第1对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔的工序,(f-2)第二第2阶段选拔工序是根据上述总体比对评分,进行用于对上述第2对象区域进行pcr扩增的引物候选的碱基序列的第2阶段的选拔的工序。
(第2阶段选拔的方法)
预先设定总体比对评分的阈值(还称为“第2阈值”。)。
若总体比对评分小于第2阈值,则判断为这2个碱基序列的组合的二聚体形成性低,进行之后的工序。
另一方面,若总体比对评分为第2阈值以上,则判断为这2个碱基序列的组合的二聚体形成性高,对该组合不进行之后的工序。
第2阈值并无特别限定,能够适当设定。例如,可根据成为聚合酶链反应的模板的基因组dna的量等pcr条件设定第2阈值。
另外,能够通过将引物的3’末端至数个碱基的碱基序列设为同一碱基序列,使对包含各引物的碱基序列的3’末端和预先设定的碱基数的碱基序列,进行成对总体比对来求出的总体比对评分小于第2阈值。
在此,考虑在上述“总体比对工序”中示出的例子中将第2阈值设定为“+3”的情况。
上面的例子中,总体比对评分为“-3”,小于作为第2阈值的“+3”,因此能够判断为序列编号1及2的碱基序列的组合的引物二聚体形成性低。
另外,对在总体比对工序s105、总体比对第1工序s205、总体比对第2工序s215、第1总体比对工序s305或第2总体比对工序s315中计算出总体比对评分的所有组合进行本工序。
并且,为了减少计算量,优选先实施“总体比对工序”及“第2阶段选拔工序”这两个工序,对通过“第2阶段选拔工序”的引物的碱基序列的组合实施“局部比对工序”及“第1阶段选拔工序”这两个工序。尤其,对象区域的数量越增加,引物候选的碱基序列数量越增加,减少计算量的效果越大,能够实现整个处理的快速化。
这是因为,在“总体比对工序”中对“预先设定的序列长度”这样的短长度的碱基序列进行总体比对,因此计算量少于在包含3’末端这样的条件下从整个碱基序列发现互补性高的一部分序列的局部比对评分,能够快速进行处理。另外,通常已知的算法中,已知若为针对相同长度的序列的比对,则总体比对的速度比局部比对快。
《扩增序列长度检查工序》
可实施扩增序列长度检查工序,其对在“第1阶段选拔工序”及“第2阶段选拔工序”中判断为引物二聚体形成性低的引物候选的碱基序列的组合,计算染色体dna上的引物候选的碱基序列的端部之间的距离,并判断该距离是否在预先设定的范围内。
若碱基序列的端部之间的距离在预先设定的范围内,则能够判断为该引物候选的碱基序列的组合能够对对象区域适当进行扩增的可能性高。引物候选的碱基序列的端部之间的距离并无特别限定,能够根据酶(dna聚合酶)的种类等pcr条件适当设定。例如,能够设定为100~200个碱基(对)的范围内、120~180个碱基(对)的范围内、140~180个碱基(对)的范围内、140~160个碱基(对)的范围内、160~180个碱基(对)的范围内等各种范围。
《引物采用工序》
本说明书中,有时将引物采用工序s107(图2)、引物采用第1工序s207及引物采用第2工序s217(图3)以及第1引物采用工序s307及第2引物采用工序s317(图4)简单地总称为“引物采用工序”。
(第1方式:引物采用工序s107)
图2中,示为“引物采用”(s107)。
第1方式中,(g)引物采用工序是采用在上述第1阶段选拔工序及上述第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述对象区域进行pcr扩增的引物的碱基序列的工序。
(第2方式:引物采用第1工序s207及引物采用第2工序s217)
图3中,示为“引物采用第1”(s207)及“引物采用第2”(s217)。
第2方式中,(g1)引物采用第1工序是采用在上述第1阶段选拔第1工序及上述第2阶段选拔第1工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列的工序,(g2)引物采用第2工序是采用上述第1阶段选拔第2工序及上述第2阶段选拔第2工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列的工序。
(第3方式:第1引物采用工序s307及第2引物采用工序s317)
图4中,示为“第1引物采用”(s307)及“第2引物采用”(s317)。
第3方式中,(g-1)第1引物采用工序是采用在上述第一第1阶段选拔工序及上述第一第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列的工序,(g-2)第2引物采用工序是采用在上述第二第1阶段选拔工序及上述第二第2阶段选拔工序的二者中均被选拔的引物候选的碱基序列作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列的工序。
(引物采用的方法)
引物采用工序中,采用如下引物候选的碱基序列作为用于对对象区域进行扩增的引物的碱基序列,即,针对各引物候选的碱基序列,在所比较的一部分序列包含该碱基序列的3’末端这样的条件下,进行成对局部比对来求出的局部比对评分小于第1阈值,且针对包含各引物候选的碱基序列的3’末端和预先设定的碱基数的碱基序列,进行成对总体比对来求出的总体比对评分小于第2阈值。
例如,考虑采用表7所示的序列编号1及2的碱基序列作为用于对对象区域进行扩增的引物的碱基序列。
[表7]
表7
如已记载,局部比对评分为“±1”,因此小于作为第1阈值的“3”,并且,总体比对评分为“-3”,因此小于作为第2阈值的“+3”。
因此,能够采用以序列编号1表示的引物候选的碱基序列及以序列编号2表示的引物候选的碱基序列作为用于对对象区域进行扩增的引物的碱基序列。
《其他目标区域的引物设计》
可在对1个目标区域采用引物之后,进一步对其他目标区域设计引物。
第1方式中,若在引物候选碱基序列制作工序s102中制作了针对欲设计引物的目标区域的引物候选的碱基序列,则从局部比对工序s103开始进行。若未制作针对下一目标区域的引物候选的碱基序列,则由于在对象区域选择工序s101中未选择下一目标区域,因此在对象区域选择工序s101中选择下一目标区域,并在引物候选碱基序列制作工序s102中制作针对该目标区域的引物候选的碱基序列之后,进行局部比对工序s103之后的工序。
第2方式中,从对象区域选择第2工序s211开始反复进行。
第3方式中,由于已在引物候选碱基序列多个制作工序s302中制作了针对在对象区域多个选择工序s301中选择的目标区域的引物候选的碱基序列,因此从第2局部比对工序s313开始反复进行。
《引物等的设计中的特征点》
总的来说,选择目标区域之后的引物等的设计中的特征点在于,选择多个特定的对象区域,搜索附近的碱基序列,确认与已提取的各个引物组合的互补性,选择互补性少的碱基序列,由此获得扩增对象中包含对象区域且不会相互互补的引物组。
引物的碱基序列的互补性确认中的特征点在于,以如下方式制作引物组,即,利用局部比对降低整个序列的互补性,且对引物的碱基序列的端部,利用总体比对降低互补性。
以下,通过实施例对本发明进行更具体的说明,但本发明并不限定于这些实施例。
实施例
[实施例1]
<来源于胎儿的有核红细胞的单细胞(single-cell)的碱基序列信息的获取>
《目标区域的选择为
选择表8所示的13号染色体、18号染色体、21号染色体及x染色体的snp、以及y染色体上的特异性区域作为用pcr进行扩增的目标区域。
[表8]
表8
《单细胞的分离》
(外周血液试样的获取)
在7ml采血管中,作为抗凝血剂,添加10.5mg的edta(乙二胺四乙酸)的钠盐之后,在进行知情同意之后,从孕妇志愿者,作为志愿者血,在采血管内获得了外周血7ml。之后,利用生理盐水稀释了血液。
(有核红细胞的浓缩)
使用percoll液(注册商标;sigma-aldrich公司制造),制备密度1.070的液及密度1.095的液,对离心管,向离心管的底部添加密度1.095的液2ml,并在冰箱中在4℃下冷却了30分钟。之后,从冰箱取出离心管,在密度1.095的液上,以不干扰界面的方式缓慢地重叠了密度1.070的液2ml。之后,在密度1.070的介质上,向离心管缓慢添加了在上述中采集的血液的稀释液11ml。之后,以2000rpm进行了20分钟的离心分离。取出离心管,利用吸液管采集了沉积在密度1.070与密度1.095的液之间的组分。对如此采集的血液的组分,用清洗液(2mmedta(乙二胺四乙酸)、0.1%bsa(牛血清白蛋白)-pbs(磷酸缓冲生理盐水))清洗2次之后,获得了有核红细胞组分。
(有核红细胞的检测及分离)
用细胞计数器计算有核红细胞组分的细胞数,以细胞浓度成为1×107个/ml的方式,用facs(荧光激活细胞分选术)缓冲液(0.1%bsa(牛血清白蛋白)-pbs(磷酸缓冲生理盐水))进行了调整。之后,为了分别染色有核红细胞,作为白细胞标志物,添加了10μl的bv421标记抗cd45抗体(bdbiosciences公司制造),作为红细胞的幼年性标志物,添加15μl的fitc(异硫氰酸荧光素))标记抗cd71抗体(bdbiosciences公司制造),作为核染色,添加1μl的draq5(cellsignalingtechnologyjapan,k.k制造),在4℃下温育了30分钟以上。
将染色后的细胞悬浮液供给至流式细胞仪(sonycorporation制造sh800zp),将cd45阴性、cd71阳性、draq5阳性组分作为有核红细胞组分进行gate设定,用产量模式实施了单细胞排序。为了确认所排序的细胞种类和数量,在能够进行图像摄影和细胞捉取的96孔板(gravitytrap公司制造),按每一个细胞排序有核红细胞组分,仅将在摄像后的图像中包含1个有核红细胞的孔分离至pcr软管。
《基因组dna的提取》
(细胞溶解)
对所分离的单细胞,在pcr软管内进行了细胞溶解。作为反应条件,对各细胞添加了5μl的细胞溶解缓冲液(10mmtris(三)-hclph7.5,0.5mmedta,20mmkcl,0.007%(w/v)sds(十二烷基硫酸钠),13.3μg/ml蛋白酶k)。
将各pcr软管在50℃下加热60分钟,通过蛋白酶k溶解了蛋白质。接着,在95℃下加热5分钟,从而使蛋白酶k失活。
由此制备了基因组dna。
《引物的制作》
以分析胎儿细胞、分析染色体的数量异常为目的,从表8所示的扩增对象区域附近的碱基序列制作了用于多重pcr的引物组合。
关于引物,以tm值为56~64℃,且作为pcr扩增碱基长度成为140~180碱基对的方式,选择各引物之间的3’末端固定的局部比对评分小于“+3”且各引物的3’末端3个碱基的总体比对评分小于“0”的引物,制作了27对引物对。
(基于单重pcr的扩增确认)
为了确认所制作的引物对对扩增对象区域进行扩增的情况,利用multiplexpcrassaykit(takarabioinc.制造)进行了反应。
a)反应液的制备
制备了以下的反应液。
另外,基因组dna为从人类培养细胞提取的基因组dna,multiplexpcrmixl及multiplexpcrmix2为takaramultiplexpcrassaykit(takarabioinc.制造)中包含的试剂。
b)单重pcr的反应条件
单重pcr的反应条件设为如下,即,初始热变性(94℃,60秒)之后,[热变性(94℃,30秒)-退火(60℃,90秒)-延伸(72℃,30秒)]的热循环×30循环。
c)pcr扩增产物的确认
将反应结束之后的反应液的一部分进行琼脂糖凝胶电泳,确认了pcr扩增产物的有无及尺寸。
对表9所示的25对引物对能够确认到基于单重pcr的特异性扩增。
[表9]
表9
《目标区域的扩增》
(基于多重pcr的扩增)
a)反应液的制备
制备了以下的反应液。
另外,模板dna为从单细胞提取的基因组dna,引物混合物为以各引物的最终浓度成为50nm的方式混合已确认到单重中的扩增的25对引物对的混合物,multiplexpcrmix1及multiplexpcrmix2为takaramultiplexpcrassaykit(takarabioinc.制造)中包含的试剂。
b)多重pcr的反应条件
多重pcr的反应条件设为如下,即,在初始热变性(94℃,60秒)之后,[热变性(94℃,30秒)-退火(56.7℃,600秒)-延伸(72℃,30秒)]的热循环×32循环。
c)pcr反应产物的纯化
利用agencourtampurexp(beckmancoulter,inc.制造),根据附带的手册(instructionsforuse),对通过多重pcr获得的pcr反应产物进行了纯化。
具体而言,向25μl的pcr反应液添加45μl的ampurexp试剂,充分混合,并在室温下静置5分钟,使pcr反应产物结合于磁珠。
接着,利用磁性表架(magnastand,nippongeneticsco.,ltd.制造)的磁力分离结合有pcr反应产物的磁珠,去除了掺杂物。
用70%(v/v)乙醇将结合有pcr反应产物的磁珠清洗2次之后,用40μl的te(三-edta)缓冲液溶出了结合于磁珠的dna。
《dna的测序》
(序列库混合物的制备)
为了利用下一代测序仪(miseq,illumina,inc.制造)进行双索引、测序,将包含流动池结合用序列(p5序列或p7序列)、样品识别用索引序列及测序引物结合用序列的2种接头分别附加于通过多重pcr获得的dna片段的两端。
具体而言,使用各1.25μm的引物d501-f及d701-r~d706-r(表10中示出),利用multiplexpcrassaykit进行pcr,由此进行了序列向两个末端的附加。pcr条件设为如下,即,在初始热变性(94℃,3分钟)之后,[热变性(94℃,45秒)-退火(50℃,60秒)-延伸(72℃,30秒)]的热循环×5循环,接着,[热变性(94℃,45秒)-退火(55℃,60秒)-延伸(72℃,30秒)]的热循环×11循环。
[表10]
表10
利用agencourtampurexp(beckmancoulter,inc.制造)对所获得的pcr产物进行纯化之后,利用kapalibraryquantificationkits(nippongeneticsco.,ltd.制造)定量了dna。
以索引序列不同的各样品的dna浓度分别成为1.5pm的方式进行混合来设为序列库混合物。
(扩增产物的序列分析)
利用miseqreagentkitv2300cycle(illumina,inc.制造),对所制备的序列库混合物进行测序,获取了fastq文件。
利用bwa(burrows-wheeleraligner),从所获得的fastq数据对人类基因组序列(hg19)映射之后,通过samtools提取基因多态性信息,根据bedtools计算了各检测区域的序列读段数。
(细胞信息的确定)
通过对从各细胞扩增的pcr扩增产物的13号染色体、18号染色体及21号染色体的snp进行比较,在24个细胞中,确认到4个细胞具有与其他不同的snp信息。
另外,为了获取母亲的snp信息,用qiaampdnaminikit(baseconnectinc.制造),从percoll浓缩后的有核细胞组分提取了基因组dna。将10ng的基因组dna作为模板,同样地对dna进行扩增,并检测了snp,其结果,确认到与20个细胞的snp一致。通过以上,确定4个细胞为来源于胎儿的有核红细胞,确认到20个细胞为来源于母亲的有核细胞。
将结果示于图5。细胞3、细胞8、细胞18及细胞20以外的20个细胞示出与标样基因组(从来源于母亲的有核细胞提取的基因组)相同的snp图案,提示这些20个细胞来源于母亲。推断细胞3、细胞8、细胞18及细胞20来源于胎儿。
(扩增产物的量的检测)
利用下一代测序仪miseq(注册商标;illuminak.k..制造),对通过pcr扩增产物的序列分析来判别的鉴定为来源于胎儿的有核红细胞的18号染色体的检测区域的扩增产物的量,进行扩增产物的测序来进行了确定。
另外,利用miseq,对鉴定为来源于母亲的有核细胞的18号染色体的检测区域的扩增产物的量(序列读段数),进行扩增产物的测序来进行了确定。
对这些扩增产物的量进行了比较,其结果,细胞之间的偏差小,且计算了该2个的量比,其结果成为接近1∶1.5的值,推断胎儿为三体性。
对于13号染色体及21号染色体,也同样地计算了与鉴定为母亲细胞的有核细胞之间的扩增产物的量比,其结果,对于13号染色体及21号染色体的任一个,均成为接近1∶1的值。
将这些结果示于图6。细胞3、细胞8、细胞18及细胞20的18号染色体的个数为13号染色体及21号染色体各自的个数的约1.5倍,推断出胎儿的18号染色体三体性。
[比较例1]
多重pcr扩增工序中,代替在实施例1中使用的、以引物之间的互补性变低的方式设计的引物对,作为用于确认计算互补性的效果的比较,设计了不考虑引物之间的互补性的引物对。关于引物的设计,相对于与实施例1相同的染色体位置以及基因,使用primer3,分别制作了tm值为56-64,且作为pcr扩增碱基长度成为140~180碱基对的20bp的引物。
使用这些引物对进行了多重pcr,除此以外,与实施例1同样地进行了扩增产物的序列确定。其结果,映射率显著下降,且细胞之间的扩增产物量的分散大,偏差大到无法明确判断数量异常。
[实施例2]
<癌细胞的单细胞(single-cell)的碱基序列信息的获取>
《目标区域的选择》
选择了癌症相关基因变异部位。
《单细胞的分离》
利用来源于非小细胞肺癌的细胞系h1581,通过细胞计数器计算细胞数,以细胞浓度成为1×106个/ml的方式,用pbs(-)(不包含镁及钙的磷酸缓冲生理盐水)溶液进行了调整。之后,为了辨别死细胞等杂质,添加细胞膜渗透性近红外荧光dna染色试剂draq5(abcamplc制造),对核进行了染色。
核染色后的细胞悬浮液供给至流式细胞仪(facs_ariaiii,becton,dickinsonandcompany.制造),将draq5阳性组分作为癌细胞组分进行gate设定,实施单细胞排序,并回收至pcr软管。
《基因组dna的提取》
(细胞溶解)
对所分离的单细胞,在pcr软管内进行了细胞溶解。并且,同样地通过流式细胞仪在10个细胞、100个细胞中回收的样品中,也在pcr软管内进行了细胞溶解。作为反应条件,对各细胞添加了5μl的细胞溶解缓冲液(10mmtris(三)-hclph7.5,0.5mmedta,20mmkcl,0.007%(w/v)sds(十二烷基硫酸钠),13.3μg/ml蛋白酶k)。
将各pcr软管在50℃下加热60分钟,通过蛋白酶k溶解了蛋白质。接着,在95℃下加热5分钟,从而使蛋白酶k失活。
由此制备了基因组dna。
《引物的制作》
以分析癌细胞中的癌症相关基因变异为目的,从27处癌症相关基因区域制作了用于多重pcr的引物。
关于引物,以tm值为56~64℃且作为pcr扩增碱基长度成为138~300碱基对的方式,选择各引物之间的3’末端固定的局部比对评分小于“+3”且各引物的3’末端3个碱基的总体比对评分成为“小于0”的引物,从而制作了20对引物对。
(基于单重pcr的扩增确认)
为了确认所制作的引物对对扩增对象区域进行扩增的情况,利用multiplexpcrassaykit(takarabioinc.制造)进行了反应。
a)反应液的制备
制备了以下的反应液。
另外,基因组dna为从人类培养细胞提取的基因组dna,multiplexpcrmix1及multiplexpcrmix2为takaramultiplexpcrassaykit(takarabioinc.制造)中包含的试剂。
b)单重pcr的反应条件
单重pcr的反应条件设为如下,即,在初始热变性(94℃,60秒)之后,[热变性(94℃,30秒)-退火(60℃,90秒)-延伸(72℃,30秒)]的热循环×30循环。
c)pcr扩增产物的确认
将反应结束之后的反应液的一部分进行琼脂糖凝胶电泳,确认了pcr扩增产物的有无及尺寸。
对表11所示的20对引物对,能够确认到基于单重pcr的特异性扩增。
[表11]
表11
《目标区域的扩增》
(基于多重pcr的扩增)
a)反应液的制备
制备了以下的反应液。
另外,模板dna为从自癌细胞分离的单细胞提取的基因组dna,引物混合物为以各引物的最终浓度成为50nm的方式混合已确认到单重中的扩增的20对引物对的混合物,multiplexpcrmixl及multiplexpcrmix2为takaramultiplexpcrassaykit(takarabioinc.制造)中包含的试剂。
b)多重pcr的反应条件
多重pcr的反应条件设为如下,即,在初始热变性(94℃,60秒)之后,[热变性(94℃,30秒)-退火(56.7℃,600秒)-延伸(72℃,30秒)]的热循环×32循环。
c)pcr反应产物的纯化
利用agencourtampurexp(beckmancoulter,inc.制造),根据附带的手册(instructionsforuse),对通过多重pcr获得的pcr反应产物进行了纯化。
具体而言,向25μl的pcr反应液添加45μl的ampurexp试剂,充分混合,并在室温下静置5分钟,使pcr反应产物结合于磁珠。
接着,利用磁性表架(magnastand,nippongeneticsco.,ltd.制造)的磁力分离结合有pcr反应产物的磁珠,去除了掺杂物。
用70%(v/v)乙醇将结合有pcr反应产物的磁珠清洗2次之后,用40μl的te(三-edta)缓冲液溶出了结合于磁珠的dna。
《dna的测序》
(1)序列库混合物的制备
为了利用下一代测序仪(miseq,illumina,inc.制造)进行双索引、测序,将包含流动池结合用序列(p5序列或p7序列)、样品识别用索引序列及测序引物结合用序列的2种接头分别附加于通过多重pcr获得的dna片段的两端。
具体而言,使用各1.25μm的引物d501-f及d701-r~d706-r(表12中示出),利用multiplexpcrassaykit进行pcr,由此进行了序列向两个末端的附加。pcr条件设为如下,即,在初始热变性(94℃,3分)之后,[热变性(94℃,45秒)-退火(50℃,60秒)-延伸(72℃,30秒)]的热循环×5循环,接着,[热变性(94℃,45秒)-退火(55℃,60秒)-延伸(72℃,30秒)]的热循环×11循环。
[表12]
表12
利用agencourtampurexp(beckmancoulter,inc.制造)对所获得的pcr产物进行纯化之后,利用kapalibraryquantificationkits(nippongeneticsco.,ltd.制造)定量了dna。
(扩增产物的序列分析)
利用miseqreagentkitv2300cycle(illumina,inc.制造),对所制备的序列库混合物进行测序,获取了fastq文件。
利用bwa(burrows-wheeleraligner),从所获得的fastq数据对人类基因组序列(hg19)映射之后,通过samtools提取基因多态性信息,根据bedtools计算了各检测区域的序列读段数。
(细胞信息的确定)
将测序分析的结果示于表13。
[表13]
表13
单细胞中,能够在20处基因区域的所有区域中检测读段数。因此,明确到通过本方法,能够从单细胞准确地进行20处基因区域的扩增。
并且,10个细胞、100个细胞中,也能够在20处基因区域的所有区域中检测读段数。
并且,表14中示出变异编号中的检测出的碱基信息。
[表14]
表14
确认到从单细胞检测出的碱基与从10个细胞、100个细胞检测出的碱基在所有变异部位中相同。
根据该结果,明确到能够从单细胞准确地检测存在于多处基因区域的变异部位。
[比较例2]
作为用于确认在实施例2中使用的、以使引物之间的互补性降低的方式设计的引物对中计算互补性的效果的比较,设计了不考虑引物之间的互补性的引物对。关于引物的设计,以能够检测与实施例2相同的变异以及基因区域的方式,使用primer3,分别制作了tm值为56℃~64℃,且作为pcr扩增碱基长度成为140~180碱基对的20bp的引物。
使用这些引物对进行了多重pcr,除此以外,与实施例2同样地进行了扩增产物的序列确定。其结果,检测不到下一代测序数据的各基因区域的读段数的区域增加,确认到无法对各基因区域的所有区域进行扩增。
- 还没有人留言评论。精彩留言会获得点赞!