供多重PCR的引物的设计方法与流程
本发明涉及一种供多重pcr的引物的设计方法。
背景技术:
利用近年来开发的dna测序仪等可以容易地进行基因分析。然而,基因组的总碱基长度通常庞大,另一方面测序仪的读取能力是有限的。于是,作为通过仅扩增所需的特定的基因区域、并限定于其碱基序列进行读取来有效且高精度地进行基因分析的技术,正在普及pcr法。特别将通过同时对某一个pcr反应系统供给多种类型的引物来选择性地扩增多个基因区域的方法称为多重pcr。
专利文献1中记载的是,针对同一染色体上按坐标顺序所配置的m个目标区域,设计多重pcr中使用的引物的方法。在此,m为1以上的整数。
首先,从成为扩增对象的dna的碱基序列中选出对应于第一个目标区域x1的候选引物。此时,候选引物设为根据表示引物的解链温度tm、gc含量、碱基序列的长度、碱基序列的特异性、形成发夹结构及引物二聚体的难度的评分来选出。解链温度、gc含量及碱基序列的长度处于预定的范围内的、对应于目标区域x1的n个候选引物中,将根据碱基序列的特异性、形成发夹结构及引物二聚体的难度计算出的表示候选引物的优越性的评分最高的候选引物称为p11、将评分第2高的候选引物称为p12、而且将第n个候选引物称为p1n。对应于第2个目标区域x2的n’个候选引物p21,p22,…,p2n’也与上述同样地选出。对所有目标区域重复同样的操作,选出对应于第m个目标区域xm的k个候选引物pm1,pm2,…,pmk。
接着,为了从所选出的候选引物中选出最适于反应的引物的组合,调查不同的目标区域的引物彼此之间是否在非预期的位置具有互补的碱基序列。在不同的目标区域的引物彼此之间形成引物二聚体的可能性低的引物成为能够用于多重pcr的引物。
现有技术文献
专利文献
专利文献1:日本专利第5079694号公报
技术实现要素:
发明要解决的技术课题
然而,特别是针对从单一细胞中提取的数pg至十几个pg的少量基因组dna,想要扩增数百处以上的区域而进行多重pcr时,即使是同一区域,有时也存在多个单一细胞间的扩增偏差大的区域。
在多个单一细胞间存在每个区域的扩增偏差大的区域,示意dna扩增不稳定,因此,要求减小多个单一细胞间的扩增偏差以能够进行更稳定的dna扩增。
于是,本发明课题在于,提供一种供多重pcr的引物的设计方法,其能够抑制多个单一细胞间的每个目标区域的扩增偏差。
用于解决技术课题的手段
本发明人为了解决上述课题而反复进行了专心研究,结果得知,重复进行针对少数目标区域的多重pcr试验,并划分为序列读取数的变异系数为阈值以上的目标区域组和小于阈值的目标区域组,对于各个组,制作横轴取为了对目标区域进行pcr扩增所使用的1对引物的平均tm值、纵轴取目标区域数的直方图,计算引物设计时的tm值范围的下限值及上限值,并设定所得到的tm值范围,从而设计引物,由此能够抑制多个单一细胞间的每个目标区域的扩增偏差,完成了本发明。
[1]一种供多重pcr的引物的设计方法,其是供源于单一细胞的多重pcr的引物的设计方法,包括设定引物设计时的tm值范围的tm值范围设定工序,其中,
在进行n次对n个目标区域中m个目标区域进行pcr扩增并统计每个目标区域的序列读取数的试验,并计算每个目标区域的序列读取数的变异系数的情况下,在将第i个目标区域的序列读取数的变异系数的实际值设为cvi,将为了对第i个目标区域进行pcr扩增所使用的1对引物的平均tm值设为tmi时,
在所述tm值范围设定工序中,通过下述工序来确定引物的tm值范围:
由输入装置输入序列读取数的变异系数的目标值cv0,并存储于存储装置的工序;
输入n次试验中的目标区域数m、第i个目标区域的序列读取数的变异系数的实际值cvi及为了对第i个目标区域进行pcr扩增所使用的1对引物的平均tm值tmi,并存储于存储装置的工序;
运算装置利用cvt=h(cv0)计算序列读取数的变异系数的阈值cvt作为目标值cv0的函数,并存储于存储装置的工序;
运算装置将所述m个目标区域划分为由序列读取数的变异系数cvi为cvi≥cvt的m1个目标区域组成的r1组、和由序列读取数的变异系数cvi为cvi<cvt的m2个目标区域组成的r2组,对于r1组及r2组的各个组,制作横轴取为了对目标区域进行pcr扩增所使用的1对引物的平均tm值、纵轴取目标区域数的直方图,并存储于存储装置的工序;及,
运算装置计算从r1组的直方图的左端的值、右端的值、及最频值、r2组的直方图的左端的值、及r1组的直方图和r2组的直方图的交点的tm值中预先指定的一个值,作为tm值范围的下限值存储于存储装置的工序;
运算装置计算r2组的直方图的右端的值,作为tm值范围的上限值存储于存储装置的工序;
运算装置读取存储装置所存储的下限值及上限值,显示于显示装置的工序。
其中,n为满足2≤n的整数,m为满足2≤m≤n的整数,n为满足3≤n的整数,i为满足1≤i≤m的整数,m1及m2为满足1≤m1<m、1≤m2<m、m1+m2=m的整数。
[2]上述[1]所述的供多重pcr的引物的设计方法,其中,cvt=h(cv0)=√2×cv0。
[3]上述[1]所述的供多重pcr的引物的设计方法,其中,cvt=h(cv0)=cv0。
发明效果
根据本发明,可提供一种供多重pcr的引物的设计方法,其能够抑制多个单一细胞间的每个目标区域的扩增偏差。
通过抑制多个单一细胞间的每个目标区域的扩增偏差,在多个单一细胞间pcr扩增结果变得稳定,从而能够进行高精度的染色体数定量及snp识别。
附图说明
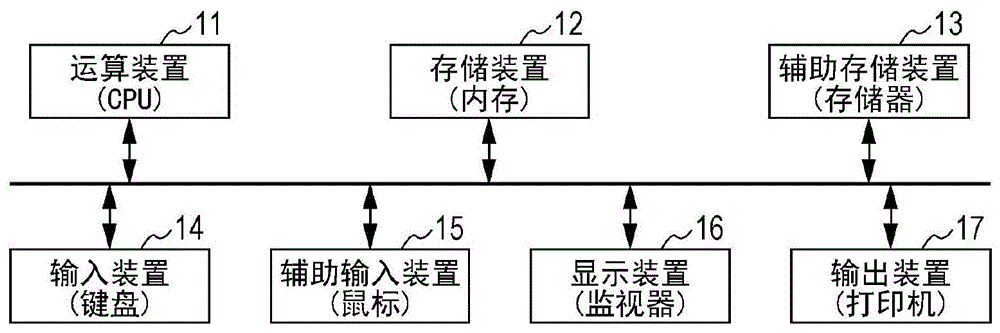
图1是表示本发明中使用的硬件的概念图。
图2是说明本发明中的设定引物设计时的tm值范围的tm值范围设定工序的流程图。
图3是如下制作的直方图,即,对于进行n次对n个目标区域中m个目标区域进行pcr扩增并统计每个目标区域的序列读取数的试验的结果所得到的r1组及r2组的各个组,横轴取为了对目标区域进行pcr扩增所使用的1对引物的平均tm值,纵轴取目标区域数。图中“a”~“e”点为引物设计时的tm值范围的下限值的选项,“f”为tm值范围的上限值。
图4是说明用于对目标区域进行pcr扩增的引物的设计方法的第1方式的图。
图5是说明用于对目标区域进行pcr扩增的引物的设计方法的第2方式的图。
图6是说明用于对目标区域进行pcr扩增的引物的设计方法的第1方式的图。
具体实施方式
本发明中用“~”所表示的范围是指该范围包括记载于“~”前后的两端的范围。例如,“a~b”表示包括a及b的范围。
本发明为供源于单一细胞的多重pcr的引物的设计方法,其包括设定引物设计时的tm值范围的tm值范围设定工序。
[tm值范围设定装置]
对于执行本发明中的tm值范围的设定工序的装置(也称为“硬件”或“执行装置”。),参照图1进行说明。
本发明中,通过具备运算装置(cpu;centralprocessingunit,中央运算处理装置)11、存储装置(内存)12、辅助存储装置(存储器)13、输入装置(键盘)14及显示装置(监视器)16的硬件(装置)来进行优先序位的设定。该装置可以进一步具备辅助输入装置(鼠标)15及输出装置(打印机)17等。
对各个装置进行说明。
输入装置(键盘)14是对装置输入指示及数据等的装置。辅助输入装置(鼠标)15可代替输入装置(键盘)14或与其一起来使用。
运算装置(cpu)11是进行运算处理的装置。
存储装置(内存)12是存储运算装置(cpu)11的运算处理的结果或存储来自输入装置(键盘)14的输入的装置。
辅助存储装置(存储器)13是保存操作系统、用于确定所需基因座数量的程序等的存储器。还能够将辅助存储装置(存储器)13的一部分用于扩展存储装置(内存)12(虚拟内存)。
下面,对tm值范围设定工序及用于对目标区域进行pcr扩增的引物的设计方法进行说明。
[tm值范围设定工序]
参照图2及图3进行说明。
在tm值范围设定工序中,以下述状况为前提,即,在进行n次对n个目标区域中m个目标区域进行pcr扩增并统计每个目标区域的序列读取数的试验,并计算每个目标区域的序列读取数的变异系数的情况下,将第i个目标区域的序列读取数的变异系数的实际值设为cvi,将为了对第i个目标区域进行pcr扩增所使用的1对引物的平均tm值设为tmi时。
在上述tm值范围设定工序中,引物的tm值范围通过如下操作来设定。
(1)由输入装置14输入序列读取数的变异系数的目标值cv0,并存储于存储12(图2的“输入变异系数目标值(cv0)”s11)。
(2)输入n次试验中的目标区域数m、第i个目标区域的序列读取数的变异系数的实际值cvi、及为了对第i个目标区域进行pcr扩增所使用的1对引物的平均tm值tmi,并存储于存储装置12(图2的“输入引物tm值(tmi)、变异系数实际值(cvi)”s12)。
(3)运算装置11利用cvt=h(cv0)计算序列读取数的变异系数的阈值cvt作为目标值cv0的函数,并存储于存储装置12(图2的“计算变异系数阈值cvt)”s13)。对cv0的函数h(cv0)没有特别限定,优选为h(cv0)=√2×cv0、或h(cv0)=cv0,更优选为h(cv0)=√2×cv0。
(4)运算装置11将上述m个目标区域划分为由序列读取数的变异系数cvi为cvi≥cvt的m1个目标区域组成的r1组、和由序列读取数的变异系数cvi为cvi<cvt的m2个目标区域组成的r2组,对于r1组及r2组的各个组,制作横轴取为了对目标区域进行pcr扩增所使用的1对引物的平均tm值、纵轴取目标区域数的直方图,并存储于存储装置12(图3)。
(5)运算装置11计算从r1组的直方图的左端的值(图3的“a”)、右端的值(图3的“c”、及最频值(图3的“b”)、r2组的直方图的左端的值(图3的“e”)、以及r1组的直方图与r2组的直方图的交点(图3的“d”)中预先选择的一个值,作为tm值范围的下限值存储于存储装置12(图2的““计算tm值下限值”s15)。
(6)运算装置11计算r2组的右端的值(图3的“f”),作为tm值范围的上限值存储于存储装置12(图2的““计算tm值上限值”s16)。
(7)运算装置11将tm值范围显示于显示装置16或输出到输出装置17(图2的““输出tm值范围”s17)。
其中,n为满足2≤n的整数,m为满足2≤m≤n的整数,n为满足3≤n的整数,i为满足1≤i≤m的整数,m1及m2为满足1≤m1<m、1≤m2<m、m1+m2=m的整数。
[用于对目标区域进行pcr扩增的引物的设计方法]
本发明的供多重pcr的引物的设计方法中的、用于对目标区域进行pcr扩增的引物的设计方法包括以下的工序。
<用于对目标区域进行pcr扩增的引物的设计方法的第1方式>
用于对目标区域进行pcr扩增的引物的设计方法的第1方式包括以下工序:(a)对象区域选择工序、(b)候选引物碱基序列制作工序、(c)局部比对工序、(d)第一阶段选拔工序、(e)全局比对工序、(f)第二阶段选拔工序、以及(g)引物采用工序。
(a)对象区域选择工序,从目标区域中选择对象区域。
(b)候选引物碱基序列制作工序,基于基因组dna上的上述对象区域的两端的各附近区域的碱基序列,分别制作至少各一个用于对上述对象区域进行pcr扩增的候选引物的碱基序列。
(c)局部比对工序,对于所有从上述候选引物碱基序列制作工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(d)第一阶段选拔工序,基于上述局部比对评分,进行用于对上述对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(e)全局比对工序,对于所有从上述第一阶段选拔工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(f)第二阶段选拔工序,基于上述全局比对评分,进行用于对上述对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(g)引物采用工序,采用在上述第一阶段选拔工序及上述第二阶段选拔工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述对象区域进行pcr扩增的引物的碱基序列。
其中,在上述(a)工序~上述(g)工序中,上述(c)工序及上述(d)工序两工序与上述(e)工序及上述(f)工序两工序可以是任意的顺序或同时进行。即,可以在进行上述(c)工序及上述(d)工序后进行上述(e)工序及上述(f)工序,也可以在进行上述(e)工序及上述(f)工序后进行上述(c)工序及上述(d)工序,也可以同时进行上述(c)工序及上述(d)工序与上述(e)工序及上述(f)工序。
在进行上述(e)工序及上述(f)工序后进行上述(c)工序及上述(d)工序的情况下,优选上述(e)工序及上述(c)工序分别设为下述(e’)工序及下述(c’)工序。
(e’)全局比对工序,对于所有从上述候选引物碱基序列制作工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(c’)局部比对工序,对于所有从上述第二阶段选拔工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
另外,在同时进行上述(c)工序及上述(d)工序与上述(e)工序及上述(f)工序的情况下,优选上述(e)工序设为下述(e’)工序。
(e’)全局比对工序,对于所有从上述候选引物碱基序列制作工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
<用于对目标区域进行pcr扩增的引物的设计方法的第2方式>
用于对目标区域进行pcr扩增的引物的设计方法的第2方式包括以下工序:(a1)对象区域选择第1工序、(b1)候选引物碱基序列制作第1工序、(c1)局部比对第1工序、(d1)第一阶段选拔第1工序、(e1)全局比对第1工序、(f1)第二阶段选拔第1工序、(g1)引物采用第1工序、(a2)对象区域选择第2工序、(b2)候选引物碱基序列制作第2工序、(c2)局部比对第2工序、(d2)第一阶段选拔第2工序、(e2)全局比对第2工序、(f2)第二阶段选拔第2工序、以及(g2)引物采用第2工序。
(a1)对象区域选择第1工序,从目标区域中选择第1对象区域。
(b1)候选引物碱基序列制作第1工序,基于基因组dna上的上述第1对象区域的两端的各附近区域的碱基序列,分别制作至少各一个用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列。
(c1)局部比对第1工序,对于所有从上述候选引物碱基序列制作第1工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比对的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(d1)第一阶段选拔第1工序,基于上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(e1)全局比对第1工序,对于所有从上述第一阶段选拔第1工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的含有2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(f1)第二阶段选拔第1工序,基于上述全局比对评分,进行用于对上述第1对象区域进行pcr扩增候选引物的碱基序列的第二阶段的选拔。
(g1)引物采用第1工序,采用在上述第一阶段选拔第1工序及上述第二阶段选拔第1工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列。
(a2)对象区域选择第2工序,从目标区域中选择与上述第1对象区域不同的第2对象区域。
(b2)候选引物碱基序列制作第2工序,基于基因组dna上的上述第2对象区域的两端的各附近区域的碱基序列,分别制作至少各一个用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列。
(c2)局部比对第2工序,对于所有从上述候选引物碱基序列制作第2工序中所制作的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(d2)第一阶段选拔第2工序,基于上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(e2)全局比对第2工序,对于所有从上述第一阶段选拔第2工序中所选拔出的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(f2)第二阶段选拔第2工序,基于上述全局比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(g2)引物采用第2工序,采用在上述第一阶段选拔第2工序及上述第二阶段选拔第2工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列。
其中,在上述(a1)工序~上述(g1)工序中,上述(c1)工序及上述(d1)工序两工序与上述(e1)工序及上述(f1)工序两工序可以是任意顺序或同时进行。即,可以在进行上述(c1)工序及上述(d1)工序后进行上述(e1)工序及上述(f1)工序,也可以在进行上述(e1)工序及上述(f1)工序后进行上述(c1)工序及上述(d1)工序,也可以同时进行上述(c1)工序及上述(d1)工序与上述(e1)工序及上述(f1)工序。
在进行上述(e1)工序及上述(f1)工序后进行上述(c1)工序及上述(d1)工序的情况下,优选上述(e1)工序及上述(c1)工序分别设为下述(e1’)工序及下述(c1’)工序。
(e1’)全局比对第1工序,对于所有从上述候选引物碱基序列制作第1工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(c1’)局部比对第1工序,对于所有从上述第二阶段选拔第1工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
另外,在同时进行上述(c1)工序及上述(d1)工序与上述(e1)工序及上述(f1)工序的情况下,优选上述(e1)工序设为下述(e1’)工序。
(e1’)全局比对第1工序,对于所有从上述候选引物碱基序列制作第1工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
其中,在上述(a2)工序~上述(g2)工序中,上述(c2)工序及上述(d2)工序两工序与上述(e2)工序及上述(f2)工序两工序可以是任意的顺序或同时进行。即,可以在进行上述(c2)工序及上述(d2)工序后进行上述(e2)工序及上述(f2)工序,也可以在进行上述(e2)工序及上述(f2)工序后进行上述(c2)工序及上述(d2)工序,也可以同时进行上述(c2)工序及上述(d2)工序与上述(e2)工序及上述(f2)工序。
在进行上述(e2)工序及上述(f2)工序后进行上述(c2)工序及上述(d2)工序的情况下,优选上述(e2)工序及上述(c2)工序分别设为下述(e2’)工序及下述(c2’)工序。
(e2’)全局比对第2工序,对于所有从上述候选引物碱基序列制作第2工序中所制作的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(c2’)局部比对第2工序,对于所有从上述第二阶段选拔第2工序中所选拔出的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
另外,在同时进行上述(c2)工序及上述(d2)工序与上述(e2)工序及上述(f2)工序的情况下,优选上述(e2)工序设为下述(e2’)工序。
(e2’)全局比对第2工序,对于所有从上述候选引物碱基序列制作第2工序中所制作的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
进而,在上述至少1个目标区域包含3个以上的目标区域的情况下,在采用用于对尚未从上述3个以上的目标区域中选择的第3以后的对象区域进行pcr扩增的引物的碱基序列时,对于上述第3以后的对象区域,重复上述(a2)工序~上述(g2)工序为止的各工序。
<用于对目标区域进行pcr扩增的引物的设计方法的第3方式>
用于对目标区域进行pcr扩增的引物的设计方法的第3方式包括以下工序:(a-0)多个对象区域选择工序、(b-0)多个候选引物碱基序列制作工序、(c-1)第1局部比对工序、(d-1)第1第一阶段选拔工序、(e-1)第1全局比对工序、(f-1)第1第二阶段选拔工序、(g-1)第1引物采用工序、(c-2)第2局部比对工序、(d-2)第2第一阶段选拔工序、(e-2)第2全局比对工序、(f-2)第2第二阶段选拔工序、以及(g-2)第2引物采用工序。
(a-0)多个对象区域选择工序,从目标区域中选择多个对象区域。
(b-0)多个候选引物碱基序列制作工序,基于基因组dna上的上述多个对象区域的各自的两端的各附近区域的碱基序列,分别制作至少各一个用于对上述多个对象区域的各个区域进行pcr扩增的候选引物的碱基序列。
(c-1)第1局部比对工序,将在上述多个对象区域选择工序中选择的多个对象区域中的1个对象区域作为第1对象区域,对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(d-1)第1第一阶段选拔工序,基于上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(e-1)第1全局比对工序,对于从上述第1第一阶段选拔工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的所有组合,针对上述组合所含的含有2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(f-1)第1第二阶段选拔工序,基于上述全局比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(g-1)第1引物采用工序,采用在上述第1第一阶段选拔工序及上述第1第二阶段选拔工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第1对象区域进行pcr扩增的引物碱基序列。
(c-2)第2局部比对工序,将在上述多个对象区域选择工序中选择的多个对象区域中除了上述第1对象区域以外的1个对象区域作为第2对象区域,对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(d-2)第2第一阶段选拔工序,基于上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(e-2)第2全局比对工序,对于所有从上述第2第一阶段选拔工序中所选拔出的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(f-2)第2第二阶段选拔工序,基于上述全局比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(g-2)第2引物采用工序,采用在上述第2第一阶段选拔工序及上述第2第二阶段选拔工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列。
其中,在上述(c-1)工序~上述(g-1)工序中,上述(c-1)工序及上述(d-1)工序两工序与上述(e-1)工序及上述(f-1)工序两工序可以是任意的顺序或同时进行。即,可以在进行上述(c-1)工序及上述(d-1)工序后进行上述(e-1)工序及上述(f-1)工序,也可以在进行上述(e-1)工序及上述(f-1)工序后进行上述(c-1)工序及上述(d-1)工序,也可以同时进行上述(c-1)工序及上述(d-1)工序与上述(e-1)工序及上述(f-1)工序。
在进行上述(e-1)工序及上述(f-1)工序后进行上述(c-1)工序及上述(d-1)工序的情况下,优选上述(e-1)工序及上述(c-1)工序分别设为下述(e’-1)工序及下述(c’-1)工序。
(e’-1)第1全局比对工序,将在上述多个对象区域选择工序中选择的多个对象区域中的1个对象区域作为第1对象区域,对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(c’-1)第1局部比对工序,对于从上述第1第二阶段选拔工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的所有组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
另外,在同时进行上述(c-1)工序及上述(d-1)工序与上述(e-1)工序及上述(f-1)工序的情况下,优选上述(e-1)工序设为下述(e’-1)工序。
(e’-1)第1全局比对工序,将在上述多个对象区域选择工序中选择的多个对象区域中的1个对象区域作为第1对象区域,对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
其中,在上述(c-2)工序~上述(g-2)工序中,上述(c-2)工序及上述(d-2)工序两工序与上述(e-2)工序及上述(f-2)工序两工序可以是任意的顺序或同时进行。即,可以在进行上述(c-2)工序及上述(d-2)工序后进行上述(e-2)工序以及上述(f-2)工序,也可以在进行上述(e-2)工序及上述(f-2)工序后进行上述(c-2)工序及上述(d-2)工序,也可以同时进行上述(c-1)工序及上述(d-1)工序与上述(e-1)工序及上述(f-1)工序。
在进行上述(e-2)工序及上述(f-2)工序后进行上述(c-2)工序及上述(d-2)工序的情况下,优选上述(e-2)工序及上述(c-2)工序分别设为下述(e’-2)工序及下述(c’-2)工序。
(e’-2)第2全局比对工序,将在上述多个对象区域选择工序中选择的多个对象区域中除了上述第1对象区域以外的1个对象区域作为第2对象区域,对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(c’-2)第2局部比对工序,对于所有从上述第2第二阶段选拔工序中所选拔出的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
另外,在同时进行上述(c-2)工序及上述(d-2)工序与上述(e-2)工序及上述(f-2)工序的情况下,优选上述(e-2)工序设为下述(e’-2)工序。
(e’-2)第2全局比对工序,将在上述多个对象区域选择工序中选择的多个对象区域中除了上述第1对象区域以外的1个对象区域作为第2对象区域,对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
进而,在上述至少1个目标区域包含3个以上的目标区域,且在上述多个对象区域选择工序中选择3个以上的对象区域,并且上述多个候选引物碱基序列制作工序中制作用于对上述3个以上对象区域的各个对象区域进行pcr扩增的候选引物的碱基序列的情况下,将在上述多个对象区域选择工序中选择的多个对象区域中除了上述第1及第2对象区域以外的1个对象区域作为第3对象区域,采用用于对上述第3以后的对象区域进行pcr扩增的引物的碱基序列时,对于上述第3以后的对象区域,重复自上述第2局部比对工序至上述第2引物采用工序为止的各工序。
<各工序的说明>
对于用于对目标区域进行pcr扩增的引物的设计方法的第1~第3方式,适当地参照图4~图6对各工序进行说明。
《对象区域选择工序》
在本说明书中,有时将对象区域选择工序s101(图4)、对象区域选择第1工序s201及对象区域选择第2工序s211(图5)、以及多个对象区域选择工序s301(图6)进行统称,简称为“对象区域选择工序”。
(第1方式:对象区域选择工序s101)
在图4中,示为“对象区域选择”。
在第1方式中,(a)对象区域选择工序是从目标区域中选择对象区域的工序。对选择方法没有特别限定,例如,在目标区域附加有引物设计的优先序位的情况下,按照其优先序位表示的顺序从目标区域中选择设计引物的对象区域。
(第2方式:对象区域选择第1工序s201及对象区域选择第2工序s211)
在图5中,示为“对象区域选择第1”及“对象区域选择第2”。
在第2方式中,(a1)对象区域选择第1工序是从目标区域中选择第1对象区域的工序,(a2)对象区域选择第2工序是从尚未作为对象区域被选择的目标区域中选择第2对象区域的工序。对选择方法没有特别限定,例如,在目标区域附加有引物设计的优先序位的情况下,按照其优先序位表示的顺序从目标区域中选择设计引物的对象区域。
(第3方式:多个对象区域选择工序s301)
在图6中,示为“多个对象区域选择”。
在第3方式中,(a-0)多个对象区域选择工序是从目标区域中选择多个对象区域的工序。对选择方法没有特别限定,例如,在目标区域附加有引物设计的优先序位的情况下,按照其优先序位表示的顺序从目标区域中选择多个设计引物的对象区域。
《候选引物碱基序列制作工序》
在本说明书中,有时将候选引物碱基序列制作工序s102(图4)、候选引物碱基序列制作第1工序s202及候选引物碱基序列制作第2工序s212(图5)、以及多个候选引物碱基序列制作工序s302(图6)进行统称,简称为“候选引物碱基序列制作工序”。
(第1方式:候选引物碱基序列制作工序s102)
在图4中,示为“候选引物碱基序列制作”。
在第1方式中,(b)候选引物碱基序列制作工序是如下工序:基于基因组dna上的上述对象区域的两端的各附近区域的碱基序列,分别制作至少各一个用于对对象区域进行pcr扩增的候选引物的碱基序列。
(第2方式:候选引物碱基序列制作第1工序s202及候选引物碱基序列制作第2工序s212)
在图5中,示为“候选引物碱基序列制作第1”及“候选引物碱基序列制作第2”。
在第2方式中,(b1)候选引物碱基序列制作第1工序是如下工序:基于基因组dna上的上述第1的对象区域的两端的各附近区域的碱基序列,分别制作至少各一个用于对第1对象区域进行pcr扩增的候选引物的碱基序列,(b2)候选引物碱基序列制作第2工序是如下工序:基于基因组dna上中的上述第2对象区域的两端的各附近区域的碱基序列,分别制作至少各一个用于对第2对象区域进行pcr扩增的候选引物的碱基序列。
在第2方式中,对于1个对象区域进行候选引物的碱基序列的制作、候选引物的选拔、及引物的采用,对于其后的1个对象区域,重复相同的工序。
(第3方式:多个候选引物碱基序列制作工序s302)
在图6中,示为“多个候选引物碱基序列制作”。
在第3方式中,(b-0)多个候选引物碱基序列制作工序是如下工序:基于基因组dna上的上述多个对象区域的各自的两端的各附近区域的碱基序列,分别制作至少各一个用于对多个对象区域的各个对象区域进行pcr扩增的候选引物的碱基序列。
在第3方式中,对于多个对象区域的所有对象区域,制作候选引物的碱基序列,通过以后的工序重复进行选拔及采用。
(附近区域)
所谓对象区域的两端的各附近区域是指对自对象区域的5’端起的外侧的区域、及自对象区域的3’端起的外侧的区域进行统称。对象区域的内侧不包括在附近区域内。
对附近区域的长度没有特别限定,优选为能通过pcr扩展的长度以下,更优选为期望扩增的dna片段长度的上限以下。特别优选为容易进行集中选择和/或序列读取的长度。可以根据pcr中使用的酶(dna聚合酶)的种类等进行适当变更。具体的附近区域的长度优选为20~500个碱基左右、更优选为20~300个碱基左右、进一步优选为20~200个碱基左右、更进一步优选为50~200个碱基左右。
(引物的设计参数)
另外,制作候选引物的碱基序列时,与通常的引物设计方法中需要注意的事项相同,如引物的长度、gc含量(指所有核酸碱基中的鸟嘌呤(g)及胞嘧啶(c)的合计摩尔百分率。)、解链温度(指双链dna的50%解离而成为单链dna的温度。另外,有时也源于meltingtemperature,称为“tm值”。单位为“℃”。)、以及序列的偏移等。
·引物的长度
对引物的长度(核苷酸数)没有特别限定,优选为15mer~45mer、更优选为20mer~45mer、进一步优选为20mer~30mer。当引物的长度为该范围内时,易于设计特异性及扩增效率优异的引物。
·引物的gc含量
对引物的gc含量没有特别限定,优选为40摩尔%~60摩尔%、更优选为45摩尔%~55摩尔%。当gc含量为该范围内时,不易产生由高级结构引起的特异性及扩增效率下降的问题。
·引物的tm值
对引物的tm值没有特别限定,优选为50℃~65℃的范围内、更优选为55℃~65℃的范围内。
对于引物的tm值之差,在引物对及引物组中,优选设为5℃以下、更优选设为3℃以下。
tm值可用oligoprimeranalysissoftware(molecularbiologyinsights公司制)或primer3(http://www-genome.wi.mit.edu/ftp/distribution/software/)等软件进行计算。
另外,也可以根据引物的碱基序列中的a、t、g及c的数量(分别设为na、nt、ng及nc),利用下述式通过计算来求得。
tm值(℃)=2(na+nt)+4(nc+ng)
tm值的计算方法并不限定于此,可以利用现有公知的各种方法来计算tm值。
其中,在本发明的供多重pcr的引物的设计方法中,在上述的“设定引物设计时的tm值范围的tm值范围设定工序”中确定tm值的范围后,使用该tm值的范围。
·引物的碱基的偏移
候选引物的碱基序列优选设为整体上碱基无偏移的序列。例如,希望避免局部富含gc的序列及局部富含at的序列。
另外,还希望避免t和/或c的连续(聚嘧啶)、以及a和/或g的连续(聚嘌呤)。
·引物的3’末端
进而,优选3’末端碱基序列避免富含gc的序列或富含at的序列。3’末端碱基优选g或c,但并不限定于此。
《特异性检查工序》
基于在“候选引物碱基序列制作工序”中制作的各候选引物的碱基序列与染色体dna的序列互补性,可以实施评价候选引物的碱基序列的特异性的特异性检查工序(未图示)。
特异性的检查进行染色体dna的碱基序列与候选引物的碱基序列的局部比对,在局部比对评分小于预先设定的值的情况下,可评价为该候选引物的碱基序列与基因组dna的互补性低、特异性高。在此,希望对染色体dna的互补链也进行局部比对。这是因为相对于引物是单链dna,染色体dna是双链。另外,也可以使用与其互补的碱基序列取代候选引物的碱基序列。
另外,可以将候选引物的碱基序列作为查询序列,对基因组dna碱基序列数据库进行同源性检索。作为同源性检索工具,例如,可举出:blast(basiclocalalignmentsearchtool:基于局部比对算法的搜索工具)(altschul,s.a.,另外4名,“basiclocalalignmentsearchtool”,journalofmolecularbiology,1990年,10月,第215卷,p.403-410)及fasta(pearson,w.r.,另外1名,“improvedtoolsforbiologicalsequencecomparison”,美国科学院纪要,美国科学院,1988年,4月,第85卷,p.2444-2448)等。作为进行同源性检索而得到的结果,可获得局部比对。
评分及局部比对评分的阈值均没有特别限定,可根据候选引物的碱基序列的长度、和/或pcr条件等适当设定。在使用同源性检索工具的情况下,可以使用该同源性检索工具的默认值。
例如,作为评分,可考虑采用匹配(互补碱基)=+1、不匹配(非互补碱基)=-1、indel(插入和/或缺失)=-3,将阈值设定为+15等。
在候选引物的碱基序列与染色体dna上非设想的位置的碱基序列具有互补性、且特异性低的情况下,使用该碱基序列的引物进行pcr时,有时不是对对象区域进行扩增而是对伪像(artifact)进行扩增,因此不包括这种情况。
《局部比对工序》
在本说明书中,有时将局部比对工序s103(图4)、局部比对第1工序s203及局部比对第2工序s213(图5)、以及第1局部比对工序s303及第2局部比对工序s313(图6)进行统称,简称为“局部比对工序”。
(第1方式:局部比对工序s103)
在图4中,示为“局部比对”。
在第1方式中,(c)局部比对工序是如下工序:对于所有从上述候选引物碱基序列制作工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(第2方式:局部比对第1工序s203及局部比对第2工序s213)
在图5中,示为“局部比对第1”及“局部比对第2”。
在第2方式中,(c1)局部比对第1工序是如下工序:对于所有从上述候选引物碱基序列制作第1工序中所制作的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对,从而求出局部比对评分,(c2)局部比对第2工序是如下工序:对于所有从上述候选引物碱基序列制作第2工序中所制作的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(第3方式:第1局部比对工序s303及第2局部比对工序s313)
在图6中,示为“第1局部比对”及“第2局部比对”。
在第3方式中,(c-1)第1局部比对工序是如下工序:对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对第1对象区域进行pcr扩增的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对,从而求出局部比对评分,(c-2)第2局部比对工序是如下工序:对于所有从上述多个候选引物碱基序列制作工序中所制作的候选引物的碱基序列中、用于对第2对象区域进行pcr扩增的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的2个碱基序列,在该进行比较的部分序列包含上述2个碱基序列的3’末端的条件下,以双序列进行局部比对而求出局部比对评分。
(局部比对的方法)
进行局部比对的碱基序列的组合可以是允许重复而选择的组合,也可以是不允许重复而选择的组合,在尚未评价同一碱基序列的引物间的引物二聚体形成性的情况下,优选允许重复而选择的组合。
对于组合的总数,将进行局部比对的碱基序列的总数设为p个,在允许重复而选择的情况下,为“ph2=p+1c2=(p+1)!/2(p-1)!”,在不允许重复而选择的情况下,为“pc2=p(p-1)/2”。
局部比对是对部分序列进行的比对,可局部检查互补性高的部分。
其中,在本发明中,与通常对碱基序列进行的局部比对不同,在“进行比较的部分序列包含碱基序列的3’末端”的条件下进行局部比对,以使进行比较的部分序列包含双方的碱基序列的3’末端。
进而,在本发明中,优选方式是,在“进行比较的部分序列包含碱基序列的3’末端”的条件、即“仅考虑进行比较的部分序列自一方的序列的3’末端开始至另一方的序列的3’末端结束的比对”的条件下进行局部比对,以使进行比较的部分序列包含双方的碱基序列的3’末端。
此外,局部比对可以插入间隙。间隙是指碱基的插入和/或缺失(indel)。
另外,局部比对将碱基序列对间碱基互补的情况设定为一致(匹配),将不互补的情况设定为不一致(不匹配)。
以分别对匹配、不匹配及插入缺失评分、使总评分成为最大的方式进行比对。评分适当设定即可。例如,可以如下述表1那样设定评分。此外,表1中“-”表示间隙(插入和/或缺失(indel))。
[表1]
表1
例如,考虑对于以下表2所示的序列编号1及2的碱基序列进行局部比对。在此,评分设定如表1所示。
[表2]
表2
根据序列编号1及2的碱基序列制作表3所示的圆点阵列(点阵)。具体而言,将序列编号1的碱基序列按自5’至3’的方向从左向右排列,将序列编号2的碱基序列按自5’至3’的方向从下向上排列,对碱基为互补性的格子记入“●”,从而获得表3所示的点阵。
[表3]
表3
根据表3所示的点阵,获得以下表4所示的部分序列的比对(双序列比对)(参照表3的斜线部分)。此外,表4中,分别用“|”表示匹配,用“:”表示不匹配。
[表4]
表4
在该(双序列)比对中,有2处匹配,有4处不匹配,没有indel(间隙)。
因此,基于该(双序列)比对的局部比对评分成为(+1)×2+(-1)×4+(-1)×0=-2。
此外,比对(双序列比对)不仅可利用在此例示的点阵法来获得,而且可利用动态规划法、单词法、或其他各种方法来获得。
《第一阶段选拔工序》
在本说明书中,有时将第一阶段选拔工序s104(图4)、第一阶段选拔第1工序s204及第一阶段选拔第2工序s214(图5)、以及第1第一阶段选拔工序s304及第2第一阶段选拔工序s314(图6)进行统称,简称为“第一阶段选拔工序”。
(第1方式:第一阶段选拔工序s104)
在图4中,示为“第一阶段选拔”。
在第1方式中,(d)第一阶段选拔工序是如下工序:基于上述局部比对评分进行用于对上述对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(第2方式:第一阶段选拔第1工序s204及第一阶段选拔第2工序s214)
在图5中,示为“第一阶段选拔第1”及“第一阶段选拔第2”。
在第2方式中,(d1)第一阶段选拔第1工序是如下工序:基于上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔,(d2)第一阶段选拔第2工序是如下工序:基于上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(第3方式:第1第一阶段选拔工序s304及第2第一阶段选拔工序s314)
在图6中,示为“第1第一阶段选拔”及“第2第一阶段选拔”。
在第3方式中,(d-1)第1第一阶段选拔工序是如下工序:基于上述局部比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔,(d-2)第2第一阶段选拔工序是如下工序:基于上述局部比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第一阶段的选拔。
(第1阶段选拔的方法)
预先设定好局部比对评分的阈值(也称为“第1阈值”。)。
如果局部比对评分小于第1阈值,则判断这些2个碱基序列的组合的二聚体形成性低,进行以后的工序。
另一方面,如果局部比对评分为第1阈值以上,则判断这些2个碱基序列的组合的引物二聚体形成性高,对于该组合而言不进行以后的工序。
对第1阈值没有特别限定,可以适当设定。例如,可以根据成为聚合酶链反应的模板的基因组dna的量等pcr条件来设定第1阈值。
在此,考虑在上述“局部比对”所示的例子中将第1阈值设定为“+3”的情况。
在上面的例子中,由于局部比对评分为“-2”,小于作为第1阈值的“+3”,因此可判断序列编号1及2的碱基序列的组合的引物二聚体形成性低。
此外,针对在局部比对工序s103、局部比对第1工序s203、局部比对第2工序s213、第1局部比对工序s303、或者第2局部比对工序s313中计算出局部比对评分的所有组合进行本工序。
《全局比对工序》
在本说明书中,有时将全局比对工序s105(图4)、全局比对第1工序s205及全局比对第2工序s215(图5)、以及第1全局比对工序s305及第2全局比对工序s315(图6)进行统称,简称为“全局比对工序”。
(第1方式:全局比对工序s105)
在图4中,示为“全局比对”。
在第1方式中,(e)全局比对工序是如下工序:对于所有从上述第一阶段选拔工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(第2方式:全局比对第1工序s205及全局比对第2工序s215)
在图5中,示为“全局比对第1”及“全局比对第2”。
在第2方式中,(e1)全局比对第1工序是如下工序:对于所有从上述第一阶段选拔第1工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对,从而求出全局比对评分,(e2)全局比对第2工序是如下工序:对于所有从上述第一阶段选拔第2工序中所选拔出的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(第3方式:第1全局比对工序s305及第2全局比对工序s315)
在图6中,示为“第1全局比对”及“第2全局比对”。
在第3方式中,(e-1)第1全局比对工序是如下工序:对于从上述第1第一阶段选拔工序中所选拔出的候选引物的碱基序列中选择2个候选引物的碱基序列的所有组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对,从而求出全局比对评分,(e-2)第2全局比对工序是如下工序:对于所有从上述第2第一阶段选拔工序中所选拔出的候选引物的碱基序列及已经采用的引物的碱基序列中选择2个候选引物的碱基序列的组合、以及选择1个候选引物的碱基序列及1个已经采用的引物的碱基序列的组合,针对上述组合所含的包含2个碱基序列的3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
(全局比对的方法)
从由“候选引物碱基序列制作工序”制作的全部候选引物(在首先进行了“局部比对工序”及“第1阶段选拔工序”的情况下,存在局部比对评分小于第1阈值的候选引物的组合时,为该组合所含的全部候选引物。)及全部已经采用的引物(限于存在已经采用的引物的情况)组成的组中取出2个引物,针对包含3’末端的预先设定的序列长度的碱基序列,以双序列进行全局比对而求出全局比对评分。
进行全局比对的碱基排列的组合可以是允许重复而选择的组合,也可以是不允许重复而选择的组合,但在尚未评价同一碱基序列的引物间的引物二聚体形成性的情况下,优选允许重复而选择的组合。
对于组合的总数,将进行全局比对的碱基序列的总数设为x个,在允许重复而选择的情况下,为“xh2=x+1c2=(x+1)!/2(x-1)!”,在不允许重复而选择的情况下,为“xc2=x(x-1)/2”。
全局比对是对“整个序列”进行的比对,可检查整个序列的互补性。
其中,在此,“整个序列”是包含候选引物的碱基序列的3’末端的预先设定的序列长度的整个碱基序列。
此外,全局比对可以插入间隙。间隙是指碱基的插入和/或缺失(indel)。
另外,全局比对将碱基序列对间碱基互补的情况设定为一致(匹配),将不互补的情况设定为不一致(不匹配)。
以分别对匹配、不匹配及indel评分、使总评分成为最大的方式进行比对。评分适当设定即可。例如,可以如上述表1那样设定评分。此外,表1中“-”表示间隙(插入和/或缺失(indel))。
例如,对于以下的表5所示的序列编号1及2的碱基序列,考虑对各自的3’末端的3碱基(大写字母处)进行全局比对。在此,评分设定如表1所示。
[表5]
表5
当以使评分成为最大的方式对于序列编号1的碱基序列的3’末端的3碱基(大写字母处)及序列编号2的3’末端的3碱基(大写字母处)的碱基序列进行全局比对时,可获得以下的表6所示的比对(双序列比对)。此外,表6中,用“:”表示不匹配。
[表6]
表6
该(双序列)比对中,有3处不匹配,匹配及插入缺失(间隙)均没有。
因此,基于该(双序列)比对的全局比对评分成为(+1)×0+(-1)×3+(-1)×0=-3。
此外,比对(双序列比对)可利用点阵法、动态规划法、单词法、或者其他各种方法来获得。
《第二阶段选拔工序》
在本说明书中,有时将第二阶段选拔工序s106(图4)、第二阶段选拔第1工序s206及第二阶段选拔第2工序s216(图5)、以及第1第二阶段选拔工序s306及第2第二阶段选拔工序s316(图6)进行统称,简称为“第二阶段选拔工序”。
(第1方式:第二阶段选拔工序s106)
在图4中,示为“第二阶段选拔”。
在第1方式中,(f)第二阶段选拔工序是如下工序:基于上述全局比对评分,进行用于对上述对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(第2方式:第二阶段选拔第1工序s206及第二阶段选拔第2工序s216)
在图5中,示为“第二阶段选拔第1”及“第二阶段选拔第2”。
在第2方式中,(f1)第二阶段选拔第1工序是如下工序:基于上述全局比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔,(f2)第二阶段选拔第2工序是如下工序:基于上述全局比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(第3方式:第1第二阶段选拔工序s306及第2第二阶段选拔工序s316)
在图6中,示为“第1第二阶段选拔”及“第2第二阶段选拔”。
在第3方式中,(f-1)第1第二阶段选拔工序是如下工序:基于上述全局比对评分,进行用于对上述第1对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔,(f-2)第2第二阶段选拔工序是如下工序:基于上述全局比对评分,进行用于对上述第2对象区域进行pcr扩增的候选引物的碱基序列的第二阶段的选拔。
(第二阶段选拔的方法)
预先设定好全局比对评分的阈值(也称为“第2阈值”。)。
如果全局比对评分小于第2阈值,则判断这些2个碱基序列的组合的二聚体形成性低,进行以后的工序。
另一方面,如果全局比对评分为第2阈值以上,则判断这些2个碱基序列的组合的二聚体形成性高,对于该组合而言不进行以后的工序。
对第2阈值没有特别限定,可以适当设定。例如,可以根据成为聚合酶链反应的模板的基因组dna的量等pcr条件来设定第2阈值。
此外,通过将引物的自3’末端起的多个碱基的碱基序列设定为同一碱基序列,可将对包含各引物的碱基序列的3’末端的预先设定的碱基数量的碱基序列以双序列进行全局比对而求出的全局比对评分设定为小于第2阈值。
在此,在上述“全局比对工序”所示的例子中,考虑将第2阈值设定为“+3”的情况。
在上面的例子中,由于全局比对评分为“-3”,小于作为第2阈值的“+3”。因此可判断序列编号1及2的碱基序列的组合的引物二聚体形成性低。
此外,针对在全局比对工序s105、全局比对第1工序s205、全局比对第2工序s215、第1全局比对工序s305、或第2全局比对工序s315中计算了全局比对评分的所有组合进行本工序。
另外,为了减少计算量,优选预先实施“全局比对工序”及“第2阶段选拔工序”两工序,针对通过了“第2阶段选拔工序”的引物的碱基序列的组合,实施“局部比对工序”及“第1阶段选拔工序”两工序。特别是,对象区域数越增加,候选引物的碱基排列数越增加,减少计算量的效果越好,从而可实现整体处理的高速化。
这是因为,由于在“全局比对工序”中对“预先设定的序列长度”的较短长度的碱基序列进行全局比对,因此,计算量少于在包含3’末端的条件下从整个碱基序列中找出互补性高的部分序列的局部比对评分,从而可快速进行处理。此外,在通常所知的算法中,已知如果是针对相同长度的序列的比对,则全局比对的速度比局部比对快。
《扩增序列长度检查工序》
针对在“第1阶段选拔工序”及“第2阶段选拔工序”中判断为引物二聚体形成性低的候选引物的碱基序列的组合,可以实施扩增序列长度检查工序,即,计算在染色体dna上的候选引物的碱基序列的端部之间的距离,判断该距离是否为预先设定的范围内(未图示)。
如果碱基序列的端部之间的距离为预先设定的范围内,则可判断该候选引物的碱基序列的组合可以对对象区域适当地进行扩增的可能性大。对候选引物的碱基序列的端部之间的距离没有特别限定,可根据酶(dna聚合酶)的种类等pcr条件适当设定。例如,可设定为100~200个碱基(对)的范围内、120~180个碱基(对)的范围内、140~180个碱基(对)的范围内、140~160个碱基(对)的范围内、160~180个碱基(对)的范围内等各种范围。
《引物采用工序》
在本说明书中,有时将引物采用工序s107(图4)、引物采用第1工序s207及引物采用第2工序s217(图5)、以及第1引物采用工序s307及第2引物采用工序s317(图6)进行统称,简称为“引物采用工序”。
(第1方式:引物采用工序s107)
在图4中,示为“引物采用”。
在第1方式中,(g)引物采用工序是如下工序:采用上述第一阶段选拔工序及上述第二阶段选拔工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述对象区域进行pcr扩增的引物的碱基序列。
(第2方式:引物采用第1工序s207及引物采用第2工序s217)
在图5中,示为“引物采用第1”及“引物采用第2”。
在第2方式中,(g1)引物采用第1工序是如下工序:采用上述第一阶段选拔第1工序及上述第二阶段选拔第1工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第1对象区域进行pcr扩增的引物的碱基序列,(g2)引物采用第2工序是如下工序:采用上述第一阶段选拔第2工序及上述第二阶段选拔第2工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列。
(第3方式:第1引物采用工序s307及第2引物采用工序s317)
在图6中,示为“第1引物采用”及“第2引物采用”。
在第3方式中,(g-1)第1引物采用工序是如下工序:采用上述第1第一阶段选拔工序及上述第1第二阶段选拔工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第1对象区域进行pcr扩增引物的碱基序列,(g-2)第2引物采用工序是如下工序:采用上述第2第一阶段选拔工序及上述第2第二阶段选拔工序的任一工序中所选拔出的候选引物的碱基序列,作为用于对上述第2对象区域进行pcr扩增的引物的碱基序列。
(引物采用的方法)
在引物采用工序中,采用如下所述的候选引物的碱基序列作为用于对对象区域进行扩增的引物的碱基序列,即,对于各候选引物的碱基序列,在进行比较的部分序列包含该碱基序列的3’末端的条件下,以双序列进行局部比对而求出的局部比对评分小于第1阈值,并且,对于包含各候选引物的碱基序列的3’末端的预先设定的碱基数量的碱基序列,以双序列进行全局比对而求出的全局比对评分小于第2阈值。
例如,考虑采用表7所示的序列编号1及2的碱基序列作为对对象区域进行扩增的引物的碱基序列。
[表7]
表7
如上所述,在序列编号1和序列编号2的组合中,由于局部比对评分为“-2”,因此小于作为第1阈值的“+3”,另外,由于全局比对评分为“-3”,因此小于作为第2阈值的“+3”。
因此,可采用序列编号1所示的候选引物的碱基序列及序列编号2所示的候选引物的碱基序列作为用于对对象区域进行扩增的引物的碱基序列。
《其他目标区域的引物设计》
在针对1个目标区域采用引物后,可以进一步对其他目标区域设计引物。
在第1方式中,在候选引物碱基序列制作工序s102中,如果制作了针对其他目标区域的候选引物的碱基序列,则自局部比对工序s103起进行。如果没有制作针对其他目标区域的候选引物的碱基序列,则由于在对象区域选择工序s101中没有选择目标区域,因此,在对象区域选择工序s101中选择其他目标区域,在候选引物碱基序列制作工序s102中,制作针对该目标区域的候选引物的碱基序列后,进行局部比对工序s103以后的工序。
在第2方式中,自对象区域选择第2工序s211中选择第1目标区域以外的目标区域处起重复。
在第3方式中,由于已经在多个候选引物碱基序列制作工序s302中制作了针对在多个对象区域选择工序s301中选择的目标区域的候选引物的碱基序列,因此自第2局部比对工序s313起重复。
《引物等的设计中的特征点》
本发明的供多重pcr的引物的设计方法中的、用于对目标区域进行pcr扩增的引物的设计方法中的特征点在于,概括地说,选择多个特定的对象区域,检索邻近的碱基序列,确认与已提取各引物组的互补性,选择互补性少的碱基序列,由此获得扩增对象包括对象区域、且相互不形成互补的引物组。
引物的碱基序列的互补性的确认中的特征点在于,以使用局部比对而使整个序列的互补性变低、且对引物的碱基序列的端部使用全局比对而使互补性变低的方式来制作引物组。
进而,作为制作候选引物的碱基序列时的tm值,通过使用根据目标值及实际值计算出的tm值范围,能够实现更稳定的目标区域的pcr扩增。
下面,利用实施例更具体地说明本发明,但本发明并不限定于这些实施例。
[实施例]
[实施例1]
1.在通常的tm值范围中的引物设计
将tm值设定为通常的60℃~80℃的范围(称为“第1tm值范围”。),设计了用于对目标区域进行pcr扩增的引物。将所设计的引物中用于对目标区域v1~v20进行pcr扩增的引物示于表8。
[表8]
表8
2.在通常的tm值范围进行引物设计时的试验结果
表9中,示出细胞no.1~no.5的目标区域no.1~no.12的序列读取数和每个目标区域的变异系数。
在第1tm值范围进行引物设计时,存在每个目标区域的变异系数超过1.0的目标区域,pcr扩增的偏差大。
[表9]
表9
3.tm值范围的计算
将序列读取数的变异系数的目标值设定为1.0,将阈值设定为目标值的√2倍,根据对各目标区域进行pcr扩增的引物的tm值及每个目标区域的变异系数,计算出新的tm值范围(称为“第2tm值范围。)。
4.在新的tm值范围的引物设计
将tm值设定为第2tm值范围,设计了用于对目标区域进行pcr扩增的引物。将所设计的引物中用于对目标区域v1、及v21~v39进行pcr扩增的引物示于表10。
[表10]
表10
5.在新的tm值范围进行引物设计时的试验结果
表11中,示出细胞no.6~no.10的目标区域no.1~no.12的序列读取数和每个目标区域的变异系数。
在第2tm值范围进行引物设计的情况下,不存在每个目标区域的变异系数超过1.0的标靶区域,pcr扩增的偏差小。
[表11]
表11
符号说明
11运算装置(cpu)
12存储装置(内存)
13辅助存储装置(存储器)
14输入装置(键盘)
15辅助输入装置(鼠标)
16显示装置(监视器)
17输出装置(打印机)
- 还没有人留言评论。精彩留言会获得点赞!