一组特异性识别精胺的寡核苷酸适配体的制作方法
本发明属于食品安全生物技术领域,具体涉及一组特异性识别精胺的寡核苷酸适配体。
背景技术:
精胺是含有两个氨基和两个亚氨基的多胺。它由生物体中的多种酶通过腐胺(丁二胺)和s-腺苷甲硫氨酸产生。适量的精胺是生物活性细胞必不可少的成分之一,可以调节人体的生理活动。然而,当体内积聚达到高水平时会有毒,导致人体中毒。虽然精胺的毒性不是很强,但它可以抑制组胺和酪胺相关代谢酶的活性,间接增加组胺和酪胺的浓度,引起人体中毒。此外,大量的精胺具有腐蚀性。因此,研究食品中精胺的含量,控制食品中精胺的形成有助于提高食品的质量和安全性。目前用于测定食品中生物胺的方法主要包括液相色谱(lc),气相色谱(gc),高效液相色谱(hplc)和质谱(ms)。尽管能够获得相对准确的实验结果,但大多数这些技术由于缺乏发色团而需要化学衍生化。而化学衍生化需要专业知识来操作昂贵的系统,并且耗时的操作程序限制了它们用于临床诊断的用途。
技术实现要素:
本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
鉴于上述的技术缺陷,提出了本发明。
因此,作为本发明其中一个方面,本发明克服现有技术中存在的不足,提供一组特异性识别精胺的寡核苷酸适配体,其包括,适配体apj-4和apj-6,所述apj-4的核苷酸序列如seqidno:1所示,所述apj-6的核苷酸序列如seqidno:2所示。
作为本发明所述特异性识别精胺的寡核苷酸适配体的优选方案,其中:所述适配体的5’端和/或3’端进行碱基延长和/或剪切。
作为本发明所述特异性识别精胺的寡核苷酸适配体的优选方案,其中:所述适配体的5’端和/或3’端标记fam、巯基基团、fitc、生物素的一种或多种。
作为本发明另一个方面,本发明提供一组特异性识别精胺的寡核苷酸适配体的应用,其特征在于:用于精胺的分析检测。
作为本发明另一个方面,本发明提供一组特异性识别精胺的寡核苷酸适配体的应用,其特征在于:用于小分子精胺的分析检测。
本发明的有益效果:
(1)本发明筛选出能特异性识别精胺的寡核苷酸适配体,该组序列的亲和力和特异性均较强,且可在体外筛选,筛选周期短,合成方便,易标记,性质稳定,可长期保存使用。
(2)该组序列可通过无标记或者标记各种功能基团的方法进行快速检测,操作简单且无需对靶标精胺进行化学衍生化,从而能够更灵敏地检测出环境中、食品中存在的精胺。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
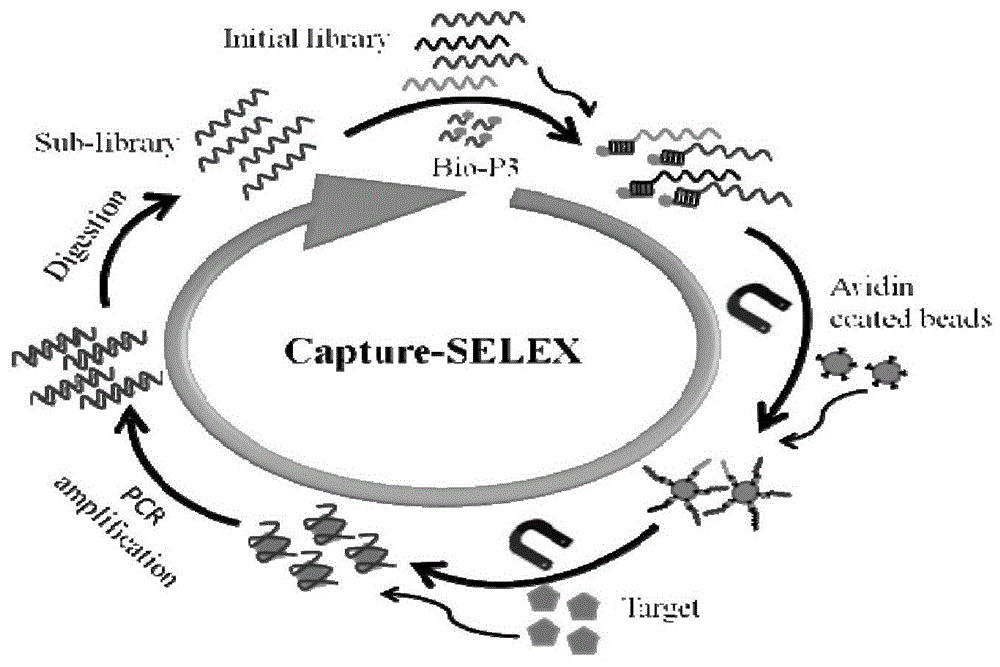
图1为本发明筛选精胺核酸适配体的原理图。
图2为筛选的2条适配体二级结构图谱,其中图2a为适配体apj-4二级结构图谱,图2b为适配体apj-6二级结构图谱。
图3为2条适配体结合精胺的亲和力饱和结合曲线,其中图3a为apj-4的亲和力饱和结合曲线,图3b为apj-6的亲和力饱和结合曲线。
图4为适配体apj-1、apj-3、apj-4、apj-6结合精胺及结构类似物的特异性图。
图5为筛选的2条适配体识别精胺的线性检测图,其中图5a为apj-4的线性检测图,图5b为apj-6的线性检测图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合具体实施例对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
合成随机单链dna文库和引物
随机ssdna文库(由美国工integrateddnatechnologies公司完成):
5’-agcagcacagaggtcagatg-n40-cctatgcgtgctaccgtgaa-3’
上游引物p1:5’-agcagcacagaggtcagatg-3’
5’磷酸化下游引物p2:5’-p-ttcacggtagcacgcatagg-3’
5’生物素化的dna文库的互补短链bio-p3:5’-biotin-cctctgtgctgct-3’
候选适配体的互补短链cdna:5’-catctgacctctg-3’
5’修饰fam发光基团,3’修饰bhq1淬灭基团的rna探针:5’-fam-ggucagaug-bhq1-3’
将随机ssdna文库和其他序列均用1×te缓冲液配制成100um贮存液存于-20℃备用。
适配体的筛选
固定随机ssdna文库
为了确保随机ssdna文库成功地固定在抗生物素蛋白包被的磁珠表面上,设计了生物素标记的互补序列(bio-p3)。首先,将bio-p3与随机ssdna文库以1.5:1的摩尔比在结合缓冲液(bindingbuffer,bb(50mmtris-hcl,5mmkcl,100mmnacl,1mmmgcl2,ph7.4))中混合,然后将混合物在95℃加热10min,随后在37℃温育2h并轻轻摇动。然后将适量的亲和素包被的磁珠加入上述杂交文库溶液中,并在37℃,130rpm温育2h以固定化。将洗涤的固定化文库重悬于bb中以与靶标孵育。
基于capture-selex的体外选择
对于第一轮capture-selex,将0.1mm精胺与1nmol固定的ssdna文库在1mlbb中于37℃、130rpm条件下孵育2小时。然后通过磁力分离获得上清液,收集上清液用于pcr扩增。50μlpcr扩增由1μlssdna模板、1μl正向引物(5μm)、1μl反向引物(5μm)、0.5μltaqdna聚合酶(5u/ml),1μldntp(2.5nm),5μl10×pcr缓冲液和40.5μl超纯水。pcr反应如下进行:在94℃变性5min,然后优化循环,在94℃变性30s,在60℃退火30s,在72℃延伸30s,然后在72℃下延伸2min,冷却至4℃。8%聚丙烯酰胺凝胶电泳用于鉴定pcr产物。用gelred染色后,在uv光下拍摄凝胶以确认80bp大小的pcr产物。用pcr纯化试剂盒纯化pcr产物。通过λ外切核酸酶消化方法产生ssdna文库。通过nanodrop2000分光光度计定量纯化的pcr产物的浓度,以计算λ核酸外切酶和核酸外切酶反应缓冲液的量。消化在37℃下进行40min,在75℃下进行10min,然后通过8%变性聚丙烯酰胺凝胶电泳进行鉴定。用苯酚/氯仿法纯化产生的ssdna,并将其溶于1×te缓冲液中,用于下一轮selex选择。
为了提高适配体选择的亲和力和特异性,在第4、6、8、10、12、13和14轮中用精胺(l-精氨酸,尸胺,亚精胺和腐胺)的结构类似物进行反向筛选。将ssdna文库固定的磁珠与靶标结构类似物在37℃下在300μl结合缓冲液中孵育,磁珠清洗后再与靶标进行孵育。所有结构类似物均使用与靶标相同的浓度。
克隆和测序
经过15轮capture-selex选择后,富集与精胺结合的适配体,并由上海生工生物技术有限公司克隆并测序pcr产物,获得41条适配体序列。使用mfold软件,通过自由能最小化算法对所得序列的二级结构进行分析(附图2所示)。基于同源性和二级结构分析将其分成8个家族。从每个家族中选出1条富集多,结构稳定,自由能级较低(△g)的候选适配体共8条(分别命名为apj-1,apj-2,apj-3,apj-4,apj-5,apj-6,apj-7和apj-8)。将候选适配体由苏州金维智生物科技有限公司合成序列,用于亲和性和特异性分析。
候选适配体的亲和力验证
使用基于敏感适配体的荧光测定来评估适配体候选物对精胺的亲和力。适配体在95℃下变性10min,并在孵育前在0℃冷却10min。用结合缓冲液将适配体分别稀释至10、25、50、100、150和200nm的浓度,然后将不同浓度的适配体分别与互补短链(cdna)混合,并在37℃下孵育30min。然后加入10μl精胺溶液(100μm)并在37℃下孵育30min。最后,在37℃下加入50nmrna探针和0.1μlrnaseh(60u/μl)并使其反应20min。所有实验均在100μl的最终反应体积下进行。使用分别使用480nm和520nm的激发和发射波长将该混合物用于荧光分析。结合缓冲液用作对照。通过graphpadprism5.0软件获得相对荧光强度相对于孵育的适配体浓度的饱和曲线(附图3所示),并通过非线性回归分析估计kd值。
由结果可知,8条候选适配体中,apj-4和apj-6对靶标精胺具有亲和力,其中apj-4的解离常数kd为13.68±2.004nm,apj-6的解离常数kd为9.648±0.896nm。
特异性的验证
为了验证候选适配体的特异性,使用精胺(l-精氨酸、尸胺、亚精胺和腐胺)的结构类似物进行比较。通过荧光方法对亲和力验证的结果,对适配体apj-1,apj-3,apj-4和apj-6进行特异性分析。将50nm适配体和12.5nmcdna混合并在37℃下孵育30min。然后加入10μl精胺溶液(100μm)或精胺(l-精氨酸、尸胺,亚精胺和腐胺)的结构类似物,并在37℃下孵育30min。最后,在37℃下加入300nmrna探针和0.1μlrnaseh并使其反应20min。每个实验进行三次。然后,如上所述测量荧光。结果显示(附图4所示)适配体apj-1和apj-3对结构类似物交叉结合率较高,其中apj-3对尸胺的交叉结合率达66.67%。apj-4和apj-6对精胺具有高特异性。apj-4的解离常数为13.68±2.004nm,apj-6的解离常数为9.648±0.896nm,由于apj-6和apj-4的亲和力强度相当,因此选择适配体apj-4和apj-6作为高特异性识别精胺的适配体进行下一步的检测实验。
适配体在精胺测定中的应用
为了证明适体apj-4和apj-6在精胺定量测定中的潜在用途,基于优化条件下0.01-150nm的不同浓度精胺的荧光强度构建校准曲线。将50nm适配体和12.5nm互补序列混合并在37℃下孵育30min。然后加入不同浓度的精胺溶液并在37℃下孵育30min。最后,在37℃下加入300nmrna探针和0.2μlrnaseh(60u/μl)并使其反应20min。使用480nm和520nm的激发和发射波长将该混合物用于荧光分析。结合缓冲液用作对照。通过synergyh1多检测酶标仪记录荧光强度。结果显示(附图5所示),对于适配体apj-4,相对荧光强度与精胺浓度呈现良好的线性关系(r2=0.9944),线性方程为y=3001.96+606.56×x,线性范围为0.01-40nm,检测限(lod)为0.025nm;对于适配体apj-6,相对荧光强度与精胺浓度呈现良好的线性关系(r2=0.9875),线性方程为y=2373.68+631.54×x,线性范围为0.1-20nm,检测限(lod)为0.052nm。检测限由方程式lod=3sd/斜率估算,其中sd表示空白样品的标准偏差,斜率从校准曲线获得。
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
序列表
<110>江南大学
<120>一组特异性识别精胺的寡核苷酸适配体
<160>2
<170>siposequencelisting1.0
<210>1
<211>80
<212>dna/rna
<213>人工序列(artificialsequence)
<400>1
agcagcacagaggtcagatgatccatcattaccttaaacttcatgtttacagagggtccc60
cctatgcgtgctaccgtgaa80
<210>2
<211>80
<212>dna/rna
<213>人工序列(artificialsequence)
<400>2
agcagcacagaggtcagatgtatgaacgatttactcgtacagacgacacttatcatttgc60
cctatgcgtgctaccgtgaa80
- 还没有人留言评论。精彩留言会获得点赞!