多重基因编辑的制作方法
本申请是申请日为2015年4月28日,发明名称为“多重基因编辑”,申请号为201580030358.1的中国发明专利申请的分案申请。
对相关申请的交叉引用
本申请要求于2014年4月28日提交的美国临时申请no.61/985,327的优先权,将其在此通过引用并入本文。
技术领域涉及多个位点处的基因编辑,脊椎动物细胞中的多种基因编辑及其用途。
背景技术:
对细胞以及由此类细胞制成的动物的遗传修饰可用于改变基因的表达。基因工程领域非常活跃。
技术实现要素:
制备大型脊椎动物将是非常有用的,所述大型脊椎动物在单一世代中对其遗传密码具有多种变化。如本文所公开的,可以通过在细胞或胚胎中同时编辑多个基因来实现。在脊椎动物细胞或胚胎中使用靶向性核酸酶和同源性指导修复(hdr)模板可以靶向多个基因进行编辑。这些细胞或胚胎可用于研究或制备整个动物。可以在单一世代中进行多种编辑,其在其它情况下不能进行,例如通过逐一进行的育种或遗传工程改变。
附图说明
图1a描述了用于使用单一编辑制备在两个敲除方面纯合的动物的方法。
图1b描绘了通过一次进行单个编辑制备具有多个编辑的动物的假设方法。
图2描述了用于在世代f0建立建立者的多重基因编辑。
图3猪rag2和il2rγ的多重基因编辑。小图a)surveyor和rflp分析以测定在转染后3天对细胞群体的非同源末端连接(nhej)和同源性依赖性修复hdr的效率。小图b)转染后11天对细胞群体的同源依赖性修复的rflp分析。小图c)il2rγ,rag2或两者处hdr阳性集落的百分比。从小图a中以“c”指示的群体中铺板细胞。小图d)来自用2和1μg(对于il2rγ和rag2)的talenmrna量和各1μmhdr模板转染的细胞的集落分析。集落基因型的分布在下文所示。
图4猪apc和p53的多重基因编辑。小图a)surveyor和rflp分析以测定转染后3天对细胞群体的非同源末端连接(nhej)和同源性依赖性修复hdr的效率。小图b)转染后11天对细胞群体的同源依赖性修复的rflp分析。小图c和d)源自apc,p53或两者处的hdr的指定细胞群体(在小图a,“c”和“d”中指示)的阳性集落的百分比。具有3个或更多个hdr等位基因的集落在下面列出。
图5。寡核苷酸hdr模板浓度对五基因多重hdr效率的影响。将指示量的针对猪rag2,il2rg,p53,apc和ldlr的talenmrna与2um(图a)或1um(图b)每种关联(cognate)hdr模板一起共转染到猪成纤维细胞中。通过surveyor和rflp测定法测量百分比nhej和hdr。
图6是五基因多重数据集,其显示了寡核苷酸hdr模板浓度对5-基因多重hdr效率的影响的实验数据图。将指示量的针对猪rag2,il2rg,p53,apc和ldlr的talenmrna与2um(图a)或1um(图b)的每种关联hdr模板一起共转染到猪成纤维细胞中。通过surveyor和rflp测定法测量百分比nhej和hdr。来自5-基因多重hdr的集落基因型:通过rflp分析评估集落基因型。小图a)每条线代表在每个指定的基因座处的一个集落的基因型。可以鉴定三种基因型;具有杂合或纯合的hdr的预期rflp基因型的那些以及具有rflp阳性片段的那些,加上具有指示插入或缺失(indel)等位基因的大小的可见变化(shift)的第二等位基因。在每列下面指示在规定基因座处具有编辑的集落的百分比。小图b)在0-5个基因座处编辑的集落数的计数。
图7是另一个五基因多重数据集,其显示了涉及寡核苷酸hdr模板浓度对五基因多重hdr效率的影响的第二实验的实验数据的图。第二个5基因多重试验的集落基因型。小图a)每条线代表在每个指定的基因座处的一个集落的基因型。可以鉴定三种基因型;具有杂合或纯合的hdr的预期rflp基因型的那些以及具有rflp阳性片段的那些,加上具有指示插入或缺失(indel)等位基因的大小的可见变化的第二个等位基因。在每列下面指示在规定基因座处具有编辑的集落的百分比。小图b)在0-5个基因座处编辑的集落数的计数。
图8是另一个显示集落基因型的五基因多重试验数据集。小图a)每条线代表在每个指定基因座处的一个集落的基因型。可以鉴定三种基因型;具有杂合或纯合的hdr的预期rflp基因型的那些以及具有rflp阳性片段的那些,加上具有指示插入或缺失(indel)等位基因的大小的可见变化的第二等位基因。在每列下面指示在规定基因座处具有编辑的集落的百分比。小图b)在0-5个基因座处编辑的集落数的计数。
图9描述了制备具有产生期望的基因敲除或等位基因选择的靶向性核酸酶的f0世代嵌合体的方法。
图10描述了具有正常表型的f0世代动物和具有长势不能(ftt)表型和基因型的后代的建立。
图11描述了制备具有供体胚胎遗传学的配子的嵌合动物的方法。
图12描绘了nkx-2,gata4和mesp1的三个靶基因座处的多重编辑。小图a)是实验的示意图,小图b)显示了基因的靶向,其中分别将nkx2-5,gata4和mesp1列为seqidno:1-3。小图c)描述了实验的测定结果。每个靶基因的寡聚物序列。新的核苷酸由大写字母表示。ptc由框中的浅色字母表示,并且新的hindiiirflp位点是加下划线的。
图13描述了使用talen和rgen的组合的多重基因编辑;通过rflp评估的转染细胞的测定法揭示了在这两个位点处的hdr。
具体实施方式
描述了多重基因编辑的方法。可在可用于研究或制备完整动物的细胞或胚胎中修饰多种基因。其它实施方案涉及通过选择性消灭(depopulation)宿主小生境(hostniches)来补充细胞或器官损失。这些发明提供了快速创建动物以充当模型,食品,以及作为用于工业和医学的细胞和无细胞产品的来源。
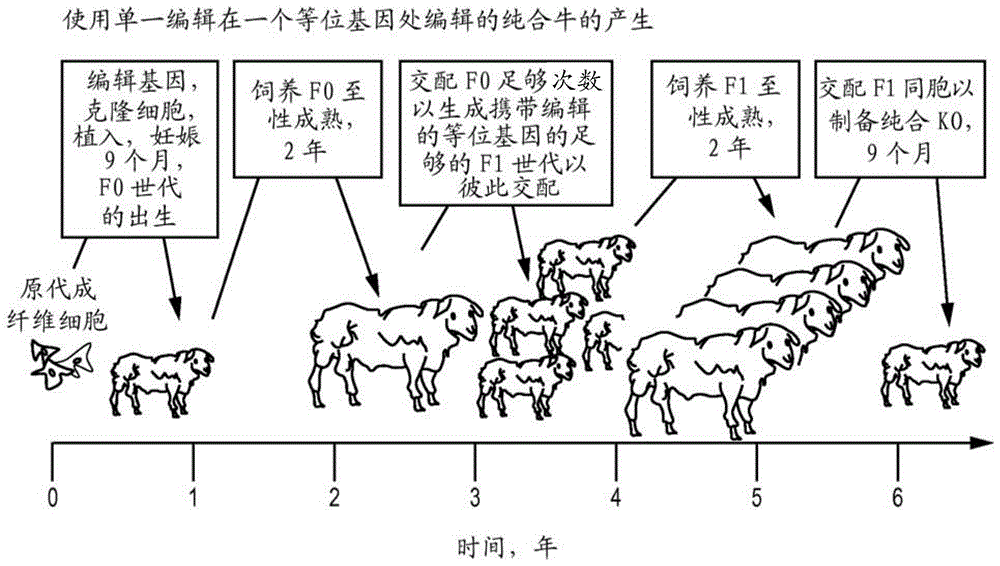
图1a具有时间线,其例示了为何使用单个编辑制备仅具有两个编辑的等位基因的家畜花费几年,对于牛来说时间为大约六年。在本上下文中,编辑是指选择基因并改变它。首先,感兴趣的基因必须在培养的体细胞中编辑(例如敲除(ko)),所述培养的体细胞经克隆以创建具有靶向性ko的杂合小牛。将杂合子养育至成熟用于育种,对于牛为约2年龄,以产生第一代(f1)雄性和雌性杂合小牛,其将彼此育种以产生纯合敲除小牛(f2)。在牛中使用常规方法产生关于多个靶向突变的纯合子将是不切实际的。根据所使用的具体方案,进行进一步编辑需要的年数和需要动物的数量以近似指数的方式增加,如图1b所示。在脊椎动物中,即使那些每世代具有较大数目的后代并且具有比牛短的妊娠时间的动物,也需要过长的时间来实现多次编辑。例如,猪每次交配有较大数量的后代,妊娠时间大约是牛的一半,但是进行多重编辑的时间可需要许多年。此外,通过激进的近亲繁殖最小化时间的方案对于多次编辑可以不是合理可能的。此外,从过程和结果观点来看,连续克隆是不期望的,特别是如果动物用作家畜或实验室模型。
图2中示出了本发明呈现的机会,其显示了在第一代动物(f0)中进行的多重编辑。胚胎是直接制备的或通过用独立选择为杂合子或纯合子的两个或多个编辑进行克隆并置于替代雌性(surrogatefemale)中妊娠。所得动物是f0代的建立者。可以制备多个胚胎并置于一个或多个替代者中以产生两种性别的后代,或者可以使用熟知的胚胎分裂技术来制备多个克隆胚胎。可以杂交和繁殖通常产生具有两种性别的幼崽(litter)的家畜(如猪)。
可以使用靶向内切核酸酶和同源性指导修复(hdr)在细胞或胚胎中破坏或以其它方式编辑多个等位基因,如本文中描述的。一个实施方案是在脊椎动物细胞或胚胎中在多个靶染色体dna位点处进行遗传修饰的方法,包括向脊椎动物细胞或胚胎中导入:针对第一靶染色体dna位点的第一靶向内切核酸酶和与所述第一靶位点序列同源的第一同源性指导修复(hdr)模板;和针对第二靶染色体dna位点的第二靶向内切核酸酶和与第二靶位点序列同源的第二hdr模板,其中第一hdr模板序列替换第一靶位点处的天然染色体dna序列,并且第二hdr模板序列替换在第二靶位点序列处的天然染色体dna序列。
出于意料且令人惊讶并且不可预测的结果是获悉,可以获得多个编辑,如敲除或替换。一种理论化的机制是存在少数可接受多次编辑的细胞,因为它们处于细胞周期中的特定阶段。当暴露于内切核酸酶和hdr模板时,它们容易响应。相关的操作理论是hdr模板化(templating)过程自身导致多个取代,因为对于一个靶向位点的细胞修复机制的激活也有利于在其它位点的修复或hdr模板化。hdr在历史上一直是低效率处理,因此显然不尝试,观察或认可多个hdr编辑。
本文中的结果表明,太多或太少的核酸内切酶和/或hdr模板可以具有负面效果,这可能混淆了该领域的先前研究。事实上,本发明人已经观察到,靶向内切核酸酶可以被设计和正确制备,但是由于它们太有效而失败。此外,成功修饰的细胞群体通常不随时间改善。修饰细胞的技术人员通常寻找细胞的寿命和修饰作为用于成功克隆或其它用途的稳定性和健康的指标。但是,这种期望在本文的多路复用(multiplexing)过程中通常不是有帮助的。此外,本发明人已经观察到,与单基因座渐渗相比,同源重组(hr)渐渗效率在多重方法中是可变的。一些基因座非常敏感,但其它基因座在效率上大幅下降。在内切核酸酶之间明显存在干扰,但是净效应不能简单解释,例如通过假定内切核酸酶竞争共同资源。
存在各种众所周知的技术以将许多基因随机或不精确地插入染色体dna中的多个位置,或进行许多破坏多个基因的随机编辑。显而易见,随机或不精确的过程不会帮助需要编辑多个特异性靶向基因以实现效果的科学家。因此,本文中所教导的hdr方法通过仅在预期的靶位点处制备的编辑和所得到的生物体而可以容易地区分。一个不同之处在于发明性的hdr编辑实施方案可以在不插入额外的基因拷贝和/或不破坏除由内切核酸酶靶向的基因以外的基因的情况下实施。并且在一个位置处进行特定编辑,因为hdr模板序列不被复制到没有合适同源性的位点中。实施方案包括其中外源等位基因仅在其关联等位基因的位点处复制到染色体dna中的生物体和方法。
基于hdr的编辑的优点是可以选择编辑。相比之下,通过非同源末端连接(nhej)过程的其它尝试可以在多个位置处产生插入缺失,使得插入缺失彼此取消而不进行移码。当涉及多路复用时,这个问题变得重要。但是hdr的成功使用提供了可以进行编辑以确保在想要时靶基因具有预期的移码。此外,等位基因替换需要hdr并且不能通过nhej,载体驱动的核酸插入,转座子插入等完成。此外,选择生物体,其没有不需要的编辑的进一步增加了难度。
然而,一般认为,先前在与家畜或大型脊椎动物相关的细胞或动物中的靶向位点处尚未实现如本文中所述的多重修饰。众所周知,自高传代细胞克隆动物创建具有如此多遗传损伤的动物,使得它们不能用作实验室模型或家畜的f0创建者。
并且,基因编辑是一个随机过程;因此,该领域传统上强调了各种筛选技术来鉴定较少百分比的已经成功编辑的细胞。由于它是随机过程,技术人员可以预期进行多个编辑的难度随着意图编辑的数量增加而以指数方式增加。
本发明的一个实施方案提供了在单个细胞或胚胎中创建多个靶向基因敲除或其它编辑的方法,本文中称为多重基因敲除或编辑的方法。术语靶向基因是指通过设计内切核酸酶系统(例如talen或crispr)选择用于内切核酸酶攻击的染色体dna的位点。术语敲除,灭活和破坏在本文中可互换使用,是指改变靶定位点,使得基因表达产物被消除或大大降低,使得基因的表达不再对整个动物具有显著影响。这些术语有时在别处用于指以可观察方式降低基因的作用而不实质上消除其作用。
基因编辑在本文中使用该术语时是指选择基因并改变它。随机插入,基因捕获等不是基因编辑。基因编辑的实例是在靶定位点处的基因敲除,添加核酸,除去核酸,消除所有功能,等位基因渐渗,多态性改变,亚等位基因改变(hypomorphicalternation)和一个或多个等位基因的替换。
等位基因的替换是指将外源等位基因复制在内源等位基因上的非减数分裂过程。术语等位基因的替换是指从天然等位基因改变为外源等位基因而没有插入缺失或其它变化,除了在一些情况下简并取代外。术语简并取代是指密码子中的碱基改变为另一个碱基,而不改变编码的氨基酸。简并取代可以选择为在外显子或内含子中。简并取代的一个用途是创建用于容易测试渐渗序列存在的限制性位点。内源等位基因在本文中也称为天然等位基因。术语基因是宽泛的,并且是指表达以产生功能性产物的染色体dna。基因具有等位基因。如果在特定基因座处有两个相同的等位基因,则基因型是纯合的,如果两个等位基因不同,则是杂合的。等位基因是位于特定染色体上特定位置处的基因的备选形式(一对中的一个成员)。等位基因决定不同的性状。等位基因在它们的dna序列(区别位置或bp)中的特定位置处具有产生不同性状并将它们彼此区分的碱基对(bp)差异,这些区别的位置充当等位基因标志物。如果它们在区别位置处具有相同的碱基,等位基因通常描述并且在本文中描述为相同;动物在其它位置中的其它bp处自然具有某些变异。当比较等位基因时,技术人员常规地调节自然变异。术语完全相同在本文中用于指在dna比对中绝对没有bp差异或插入缺失。
等位基因同一性的类似测试是将改变的生物体中的染色体dna与外源等位基因的染色体dna进行比对,因为其在自然界中被识别。外源等位基因将具有一个或多个等位标志物。标志物上游和下游的dna比对将相同一定距离。根据期望的测试,该距离可以是例如10至4000bp。虽然hdr模板可以预期创建具有完全相同的序列,但是模板区域的任一侧上的碱基当然将具有一些自然变异。技术人员常规地区分等位基因,尽管存在自然变异。技术人员将立即认识到,明确指出的界限之间的所有范围和值都是预期的,任何以下距离可用作上限或下限:15,25,50,100,200,300,400,500,600,800,1000,1200,1400,1600,1800,2000,4000。
技术人员还能够将基因编辑与基因编辑而非有性生殖的结果的等位基因区分开。当等位基因来自不能有性繁殖以混合等位基因的另一物种时,这是微不足道的。并且,许多编辑在自然界中完全找不到。即使当进行完全重复在另一种品种中天然发现的等位基因的替换时,在等位基因从一个品种迁移到下一个品种时编辑也可以容易地区分。等位基因在大多数时间上稳定地位于dna上。但是在配子形成过程中减数分裂导致雄性和雌性dna偶尔交换等位基因,称为交叉(crossover)的事件。交叉频率和遗传图谱已得到广泛研究和开发。在家畜的情况下,动物的谱系可以非常详细地追踪许多代。在遗传学中,厘摩(cm,也称为图距单位(m.u.))是测量遗传连锁的单位。它被定义为染色体位置(基因座或基因座标志物)之间的距离,对于该位置,单个世代中的居间染色体交叉的预期平均数为0.01。彼此接近的基因与在染色体上彼此远离的基因相比具有较低的交叉机会。当两个基因在染色体上彼此相邻时,交叉是非常罕见的事件。单个等位基因相对于其两个相邻等位基因的交叉是不可能的,使得此类事件必须是基因工程的产物。即使在涉及相同品种的动物的情况下,当已知亲本时,可以容易地确定天然相对工程化改造的等位基因替换。并且,通过对潜在的亲本进行基因型分型,可以高度准确地确定亲本。亲本测定是畜群和人类中常规的。
实施方案包括同时的多重基因编辑方法。术语同时是与多次处理细胞以实现多重编辑的假设过程相反,如在动物育种的连续敲除或连续克隆或居间循环(inverveningcycles)中一样。同时意味着同时以有用浓度存在,例如存在多种靶向内切核酸酶。该方法可以应用于合子和胚胎以制备其中所有细胞或基本上所有细胞具有编辑的等位基因或敲除的生物体。基本上所有细胞在例如敲除的上下文中是指将基因从这么多细胞中敲除,由于其基因产物对于生物体的功能无效,实践上不存在所述基因。该方法通过最小数目的细胞分裂,优选约0至约2个分裂来修饰细胞和胚胎中的细胞。实施方案包括涵盖在不同时间或数量的细胞分裂中发生的快速过程或过程,例如:0至20次复制(细胞分裂)。技术人员将立即理解,涵盖在明确规定的限制内的所有值和范围,例如约0至约2个复制,约0至约3个复制,不超过约4个复制,约0至约10个复制,10-17;小于约7天,小于约1,约2,约3,约4,约5或约6天,约0.5至约18天等。术语低传代是指已经历不超过约20次复制的原代细胞。
在其它地方,发明人已经显示,在牛和猪胚胎中,可以在单个胚胎中编辑母本等位基因,父本等位基因或这两个等位基因,并且因此可以使用胚胎中的hdr进行两个等位基因的模板编辑。这些编辑是在同一基因座处进行的。特别检出从姐妹染色单体的渐渗。carlson等人,pnas43(109):17382-17387,2012。
实施例1,参见图3描述了成功试图使用hdr编辑一次性敲除两个基因,并且进一步能够选择对于两个敲除而言纯合的或者对于每个敲除而言是杂合的细胞的实验。术语选择用于指鉴定和分离细胞用于进一步使用的能力;在该过程中的任何地方都没有可表达的报告基因,这是将该过程与许多其它方法区分开的非常显著的优点。处理细胞以分别导入针对第一基因(重组激活基因2,rag2)和第二基因靶标(白介素受体2,γ,il2rg或ilr2γ)的第一和第二靶向内切核酸酶(各自是talen对)。talen必须设计成靶向意图的位点并且以足够的量制备。细胞的处理花费不到5分钟。使用电穿孔,但是存在本文中所述的许多其它合适的蛋白质或dna导入方法。然后培养细胞,使得它们形成各自从单个处理的细胞传代的细胞的单个集落。在3天或11天后测试来自各种集落的细胞。rag2的敲除比率(rate)比il2rg的敲除比率高约6倍;显然一些基因比其它基因更难以敲除。敲除两个基因的效率是较高的,并且成功鉴定了两种敲除方面杂合或纯合的细胞。重要的是,talenmrna和hdr模板的剂量具有特异性和非特异性效应。il2rg的talenmrna的增加导致il2rg的nhej和hdr二者的增加,而rag2的nhej水平不变。il2rghdr模板的增加降低rag2基因座处的hdr,表明通过升高寡核苷酸浓度的同源性指导修复的非特异性抑制。这种剂量敏感性,特别是在这些低剂量下,可能导致其它人远离多重过程的追求。已经克隆了来自实施例1的细胞,并且在提交时,两只动物怀有源自所述细胞的胚胎。
实施例2,参见图4,描述了具有多重hdr编辑的相同目标但是针对不同基因的实验。第一个基因靶标是腺瘤性结肠息肉病(apc)。第二基因靶标是p53(tp53基因)。检测和分离对于两个敲除纯合的细胞和对于两个敲除杂合的细胞。
实施例3,参见图5-8,描述了敲除2-5基因的多重hdr编辑。有三个实验,对于每个实验,测试基因型的细胞集落数目范围为72-192。处理细胞以进行基因apc,p53,rag2,低密度脂蛋白受体(ldlr),il2rg,kisspeptin受体(kissr或gpr54)和真核翻译起始因子4gi(eif4gi)的各种组合的多重敲除。基因ldlr一致地比其它基因更不易修饰。从结果显而易见,可以使用talen指定的同源性指导修复(hdr)同时破坏多个等位基因。以三种组合同时共转染五个talen对(每个导致超过20%的hdr/位点)和它们的关联hdr模板(表a)。来自每个重复的一定比例的克隆在至少四个基因中的hdr事件上是阳性的,并且来自重复-a的两个克隆在所有五个基因中具有hdr事件。尽管在小鼠es细胞中通过cas9/crispr-刺激的nhej证明了在五种基因中同时的插入缺失形成,但是通过靶向核酸酶刺激的hdr对5种基因(多达7个等位基因)的精确修饰是意想不到的,令人惊讶的和无法比拟的。当重复的talen替换为cas9/crispr(将载体导入细胞中进行表达)时,修饰水平低于检测(数据未显示);然而,其它数据指向rgen多重,例如,下面的实施例9。发现在所有实验中编辑四个基因,在一个实验中编辑五个基因。
该过程的速度和效率自身导致放大,使得多于5个基因的多重敲除是可实现的,而不改变过程的性质。参考表a,测试约72-192个细胞;现在已经建立了该过程,将测试的数目增加到非常大的数目的细胞,使得可以预期更大数目的基因/等位基因的多重化并非是不合理的。许多多重基因或等位基因可以是2-25;技术人员将立即认识到,涵盖明确指出的界限之间的所有范围和值,其中任何任一项可作为彼此组合的上限或下限:2,4,5,6,7,8,9,10,11,12,14,16,18,20,25。
显然,具有多重敲除的细胞和胚胎是本发明的实施方案,以及由此产生的动物。
实施例4描述了用于制备各种动物的一些详细过程,并且通过举例的方式涉及某些基因。实施例5描述了crispr/cas9设计和生成的实施例。
实施例6提供了使用靶向核酸酶驱动的hdr过程的多重基因编辑的其它实例。用talen和hdr模板同时靶向gata结合蛋白4(gata4);同源盒蛋白nkx2-5(nkx2-5)和中胚层后部蛋白1(mesp1),以将移码突变和提前终止密码子(prematurestopcodon)导入每个基因。目的是为每个基因创建双等位敲除,用于互补研究。该过程约0.5%有效,因为2个克隆在每个基因处具有意图的双等位hdr。给定的基因单独或组合敲除的基因在没有互补的情况下将导致长势不能基因型和早期胚胎致死率。技术人员将理解,为了ftt和互补研究,单独地敲除这些基因和杂合体的杂交以获得三重敲除(约1/66的机会)在家畜中是不可行的。
实施例7提供了可以混合talen和cas9/crispr以进行基因的多重编辑的数据。一些基因/等位基因更容易被talen或cas9/crispr靶向,并且可能出现多路复用必须用这些工具的组合进行的情况。在该实施例中,真核翻译起始因子4gi(eif4gi)由talen靶向,并且p65(rela)基因由cas9/crispr靶向。通过rflp测定法分析细胞,指示hdr事件,并且在两个位点处的hdr是明显的。因此,talen和rgen可以一起或分开用于多路复用组合,包括例如1,2,3,4,5,6,7,8,9或10种talen与1,2,3,4,5,6,7,8,9或10种rgen试剂,以任何组合。
嵌合体
嵌合体可以通过制备宿主胚泡并添加来自供体动物的供体细胞来制备。所得动物将是具有源自宿主和供体二者的细胞的嵌合体。胚胎需要一些基因来创建某些种类的细胞和细胞谱系。当此类基因在宿主细胞中敲除时,引入具有缺失的基因的供体细胞可导致那些细胞和细胞谱系恢复到宿主胚胎;恢复的细胞具有供体基因型。此类过程被称为互补过程。
matsunari等人,pnas110:4557-4562,2013描述了用于制备供体衍生的猪胰腺的互补过程。他们制备改变以防止形成功能性胰腺的宿主猪胚泡。他们通过体细胞克隆制备了宿主胚泡。体细胞已经被修饰以在pdx1(胰腺和十二指肠同源盒1)的启动子下过表达hes1,其已知抑制胰腺发育。将添加的供体细胞添加到不具有这种修饰的宿主胚泡;供体细胞提供了制备胰腺所需的细胞谱系。他们已经在别处证明,可以在器官发生不能(organogenesis-disabled)的小鼠胚胎中通过胚泡互补在体内从多能干细胞(psc)产生功能性器官。他们提出了使用异种多能干细胞(psc)的未来研究,包括人诱导的psc。事实上,异种移植已被认为是对器官/组织短缺的潜在解决方案,长达大于40年。不存在敲除基因而使得胰腺不能形成的事实是重大的。
在大型脊椎动物中敲除即使一个基因是使用常规方法的资源的重要投资。相反,使用本领域的现有技术容易地实现基因产物在细胞中的过表达,例如使用将多个基因盒拷贝置于基因组中的质粒或载体。添加基因的表达比靶向基因和敲除基因更容易。通过基因产物的过表达防止器官发生的能力在这时被认为是不寻常的。事实上,工程化改造大型动物基因组的能力的限制可以是显著的。尽管如此,由于其在大小和生理上与人类的相似性以及其高繁殖力和生长速率,猪是异种移植的优选供体动物。
图9描述了在本文中用于进行如在嵌合体的上下文中应用的基因敲除或其它基因编辑的多重过程。低传代原代体细胞由基因敲除制备。分离具有精确期望的敲除分子杂合性和纯合性的细胞。这些细胞用于克隆以制备允许作为宿主胚泡发育的胚胎。术语胚泡在本文中广泛用于指从两个细胞到约三周的胚胎。术语胚胎广泛用于指从受精卵到活产的动物。建立供体胚胎并用作供体细胞的来源,其提供基因以增殖由敲除创建的小生境。将供体细胞导入宿主胚泡中并与宿主细胞一起繁殖以形成具有宿主细胞和供体细胞的嵌合体。将胚胎转移到替代雌性并且妊娠。当宿主细胞形成配子时,嵌合体的后代具有宿主基因型。嵌合体的性别由其宿主胚泡决定。
图10示出了长势不能表型(ftt)互补过程。ftt是指预期不会活到性成熟年龄的动物。给宿主胚胎提供ftt基因型和表型。多重过程是理想的,因为通过敲除仅一个基因可获得的ftt是有限的,并且对于一些器官和组织是未知的。供体细胞提供在ftt中缺少的基因并提供缺少的细胞类型。胚胎可以是大型脊椎动物,并且敲除可以是多重的,例如2-25个基因。此外,可以使用靶向内切核酸酶来实现敲除。在免疫缺陷实施方案中,il2rg-/yrag2-/-敲除是ftt,因为宿主基本上缺少免疫功能。但是供体细胞没有那些基因缺少,并且所得到的嵌合体具有基本上正常的表型,以便能够饲养和维持动物。但是,后代具有ftt表型。因此可以维持动物并方便地生成ftt动物。嵌合体可以是敲除的杂合和纯合的任何组合。因此描述了用于制备嵌合体的方法,所述嵌合体是当其它过程需要额外世代或更多时,产生长势不能(ftt)表型的f0世代动物。
嵌合体通常传递宿主细胞的遗传学。然而,本文公开的是将供体细胞遗传学传递给它们的后代而不是宿主细胞遗传学的替代合体。证明了转换遗传继承(geneticinheritance)可以创造一些有用的机会。参照图11,描述了标记为g-宿主的胚胎。胚胎已经用非功能性配子制备。制备供体胚泡并用作供体细胞的来源。供体细胞提供制备供体所需的基因和细胞谱系。所得的嵌合体具有供体细胞的配子并产生具有供体细胞遗传学的后代。在例示中,宿主胚胎是雄性brahman公牛。供体细胞来自双重肌肉公牛(double-muscledbull)。嵌合体具有brahman公牛表型,但其后代是双重肌肉的。宿主和供体可以来自相同或不同的品种或相同或不同的物种。宿主已经制备为不育的,意味着它不能有性繁殖。一些不育动物可用于制备非功能性配子,例如不能游动的精子,或者根本不产生配子,例如早期配子发生被破坏。供体细胞可以是例如野生型细胞,来自具有期望的性状的动物品种的细胞,或经遗传修饰的细胞。
本发明的实施方案包括嵌合的不育动物,例如嵌合家畜,其具有防止配子形成或精子发生的对染色体的遗传修饰。染色体可以是x染色体,y染色体或常染色体。修饰可以包括破坏现有基因。可以通过改变现有的染色体基因使得其不能表达,或通过遗传表达将抑制基因的转录或翻译的因子来创建破坏。术语配子发生是指各携带来自每个亲本的生殖细胞系的亲本的遗传补充物的一半的单倍体性细胞(卵和精子)的产生。精子的产生是精子发生。受精期间精子和卵的融合导致具有二倍体基因组的合子细胞。术语配子发生细胞是指卵子或精子的祖先,通常是生殖细胞或精原细胞。一个实施方案是宿主中精原干细胞(ssc)的敲除。可以用具有期望的遗传学的供体细胞,并提供制备具有供体基因型的配子的ssc细胞来制备动物。一些基因被组合破坏以产生引起不育的一种或多种效应,例如,acr/h1.1/smcp,acr/tnp2/smcp,tnp2/h1.1/smcp,acr/h1t/smcp,tnp2/h1t/smcp(nayerniak;drabentb;meinhardta;adhamim;schwandti;mullerc;sanckenu;kleenekc;engelwtripleknockoutsrevealgeneinteractionsaffectingfertilityofmalemice.mol.reprod.dev70(4):406-16,2005)。实施方案包括具有第一基因的敲除的第一批动物和具有第二基因敲除的第二批动物,使得品系的雄性后代是不育的。
使用遗传工程创造遗传修饰的大型脊椎动物将加速具有理想性状的动物的创造。传统的家畜育种是一个昂贵和耗时的过程,其涉及仔细选择遗传性状和冗长的等待世代繁殖。即使仔细的性状选择,有性繁殖的变异在培育和传递所需性状组合中呈现相当大的挑战。但是创造传递供体性状的嵌合体创建动物繁殖的方法,其允许快速传播所需的遗传性状,以及保护性状的专有控制。实施方案包括产生可充当供体的遗传物质的宿主的遗传和基因组不育动物。宿主的有性性交将导致供体遗传物质的繁殖。一组遗传不育的动物可用于通过有性生殖从单个供体传播相同的基因,使得可以快速产生许多供体后代。实施方案包括经修饰以产生仅一种动物性别的动物,使得接受动物的使用者将不能容易地繁殖具有性状的动物。
实施方案包括对细胞或胚胎进行遗传修饰以灭活对配子发生或精子活性具有选择性的一个或多个基因。遗传修饰的一个过程包括导入特异性结合该基因的靶向性核酸酶,例如cas9/crispr或talen对的mrna。从细胞克隆动物,或者在替代母本中直接培养修饰的胚胎。动物可以是家畜动物或其它动物。可以在早期阶段阻止配子发生。或者,可以破坏精子活性,这对于生育力是必需的,但是对动物来说不是必需的。动物因此是不育的,因为它不能有性繁殖:然而,art可以用于从经修饰的精子创建后代。选择具有期望的遗传性状(作为育种和/或遗传工程的结果)的供体动物。
快速建立具有两个或更多个敲除的f0世代建立者动物系
凭借多重化,可以同时敲除两个,三个或更多个基因(2-25)以产生具有期望的等位基因组合的f0代。如果所有敲除物的纯合性创建ftt,则一个选择是使建立者在所有敲除(除了一个之外)方面是纯合的-或无论如何最小杂合性应该用于该情况。所述一个杂合子基因可以允许非ftt表型。或者,多重敲除可以与互补组合使用以制备具有ftt后代的茁壮生长的嵌合体。此过程可以消除在多敲除动物的创建中的世代。
在任一情况下,优点是较大的,并且将许多过程移动到实际可实现的领域。通过常规育种产生具有两个基因座敲除的动物是成本高昂的,因为在f2代中仅约6%的后代将具有期望的表型(表b)。相比之下,多重方法使得能够在f0代中产生期望的基因型,这是相对于常规敲除和育种的大优点。应该强调的是,节省时间和动物不是理论上的:进步的是,使得某些种类的修饰成为可能,因为预期成功而不是失败。此外,为了继续该实例,在一个或两个嵌合rg-ko亲本之间的育种将显著地将rg-ko后代的生产率分别提高至25和100%(表b)。
免疫缺陷动物
一组实施方案涉及免疫缺陷猪或其它家畜及其制备方法。这些实施方案是利用管理纯合和杂合敲除基因型的选择的机会的多重编辑,例如敲除的实例。这些证明了多重化能够快速建立建立者系的能力。它们还包括涉及制备嵌合体的本发明的另外方面。
猪是最相关的,非灵长类动物模型,其模仿人的大小和生理机能。不幸的是,完全免疫缺陷的猪不能广泛获得,因为(1)需要多个基因敲除(ko),(2)交配以创建多基因座无效(null)动物是非常昂贵的,并且取决于可以可能的kos的数目,和(3)只有小规模的无微生物(germ-free)设施可用于猪。本文中,实施方案包括具有敲除rag2和il2rg(即rg-ko)的大型脊椎动物。术语大型脊椎动物是指猿类,家畜,犬和猫。术语家畜是指通常为了食物而饲养的动物,例如牛,绵羊,山羊,禽(鸡,火鸡),猪,水牛和鱼。可以从体细胞中敲除基因,然后将其用于克隆以产生完整的动物。或者,可以处理胚胎以敲除基因,其中动物直接源自胚胎。多重基因靶向平台可以同时破坏猪中的t,b和nk细胞发育。因此,可以使用本文的方法直接制备为没有此类细胞的动物作为f0创建者制备,但是表型是ftt。
用于多重编辑的农业靶标
可以通过同时编辑许多基因座而大大加速食品动物基因组的编辑,从而节省了将等位基因聚集在一起所需的动物品种世代(其代替一次一个产生)。此外,一些农业性状是复杂的,这意味着它们由于在多于一个基因(2至数百)处的等位基因的影响而表现。例如,dgat,abcg2处的多态性和18号染色体上的多态性一起占奶牛中的净乳制品优点变异的大部分。家畜细胞或胚胎可以进行多种基因的多重编辑,包括各种农业靶标:acan,amely,blg,bmp1b(fecb),dazl,dgat,eif4gi,gdf8,horn-poll基因座,igf2,cwc15,kissr/grp54,ofd1y,p65,prlr,prmd14,prnp,rosa,socs2,sry,zfy,β-乳球蛋白,clpg中的一种或多种。
用于多路复用的疾病建模靶标:
一些性状,如癌症,是基于多个基因处的突变引起的(参见apc/p53)。此外,许多疾病性状是所谓的复杂性状,其由于多于一个基因处的等位基因的影响而表现。例如,糖尿病,代谢,心脏病和神经疾病被认为是复杂性状。实施方案包括在单个等位基因方面,或在不同组合中与其它基因处的等位基因组合方面杂合和纯合的动物模型。例如,年轻人成年型糖尿病(matureonsetdiabetesoftheyoung)(mody)基因座个别和累加引起糖尿病,包括mody1(hnf4α),mody2(gck),mody3(hnf1α),mody4(pdx1),mody5(hnf-1β),mody6(eurogenic分化1),mody7(klf11),mody8(cel),mody9(pax4),mody10(ins),mody11(blk)。家畜细胞或胚胎可以进行用于动物建模的多种基因的多重编辑,包括各种疾病建模靶标:apc,apoe,dmd,ghrhr,hr,hsd11b2,ldlr,nf1,nppa,nr3c2,p53,pkd1,rbm20,scnn1g,tp53,dazl,fah,hbb,il2rg,pdx1,pitx3,runx1,rag2,ggta。实施方案包括具有经编辑的(例如ko)的一个或多个上述靶标的细胞,胚胎和动物。
一个物种中的基因在其它物种中一致具有直向同源物(ortholog)。人类和小鼠基因在家畜中,特别是在牛,猪,绵羊,山羊,鸡和兔中一致具有直向同源物。这些物种和鱼之间的遗传直向同源物通常是一致的,这取决于基因的功能。生物学家熟悉用于发现基因直向同源物的过程,因此本文中可以根据物种之一描述基因,而不列出其它物种的直向同源物。描述基因破坏的实施方案因此包括破坏在其它物种中具有相同或不同名称的直向同源物。有一般遗传数据库以及专门用于鉴定遗传直向同源物的数据库。此外,技术人员熟悉基因的常用缩写,并且在一种基因具有超过一种缩写,或者两个基因用相同的缩写提及的情况下使用上下文来鉴定提及哪种基因。
精原干细胞提供了家畜的第二种遗传修饰方法。遗传修饰或基因编辑可以在体外在从供体睾丸分离的精原干细胞中进行。将修饰的细胞移植到受体的生殖细胞消减(depleted)的睾丸中。植入的精原细胞干细胞产生携带遗传修饰的精子,其可用于通过人工授精或体外受精(ivf)进行育种以衍生建立者动物。
通过选择性灭绝宿主小生境的无形态细胞(nullomorphiccell)或器官损失的互补。
多重编辑可以用于自特定胚胎或动物小生境有目的地消融细胞或器官,创造有利于更好的供体细胞整合,增殖和分化的环境,增强其通过在胚胎,胎儿或动物中的互补直向同源细胞,组织或器官的贡献。具有空小生境的动物是一种缺陷载体,因为它已被创造为具有可以被供体细胞和基因填充的缺陷。具体实例包括配子发生细胞谱系(dazl,vasa,miwi,piwi等)的受体-消除和供体-拯救。
在另一个实施方案中,多重基因编辑可用于诱导先天性脱发,为供体来源的细胞参与毛滤泡生成(hairfolliculogenesis)提供机会。考虑用于多重基因编辑以引起脱发的基因包括在omim和humanphenotypeontology数据库中鉴定的那些基因;dcaf17,vdr,pnpla1,hras,端粒末端转移酶-vert,dsp,snrpe,rpl21,lama3,urod,edar,ofd1,pex7,col3a1,alox12b,hlcs,nipal4,cers3,antxr1,b3galt6,dsg4,ubr1,ctc1,mbtps2,uros,abhd5,nop10,alms1,lamb3,eogt,sat1,rbpj,arhgap31,acvr1,ikbkg,lpar6,hr,atr,htra1,aire,bcs1l,mccc2,dkc1,porcn,ebp,slitrk1,btk,dock6,apcdd1,zip4,casr,tert,edaradd,atp6v0a2,pvrl1,mgp,krt85,rag2,rag-1,ror2,claudin1,abca12,sla-dra1,b4galt7,col7a1,nhp2,gna11,wnt5a,usb1,lmna,eps8l3,nsdhl,trpv3,kras,tinf2,tgm1,dclre1c,pkp1,wrap53,kdm5c,ecm1,tp63,krt14,pipk4。用具有滤泡生成潜能的供体细胞的嵌合可用于生长人毛囊。猪或其它脊椎动物中的器官或组织的消融和来自人类起源的器官或组织的生长特别可用作医学器官或组织的来源。
用于多路复用的其它互补靶标是prkdc,bcl11a,bmi1,ccr5,cxcr4,dkk1,etv2,fli1,flk1,gata2,gata4,hhex,kit,lmx1a,myf5,myod1,myog,nkx2-5,nr4a2,pax3,pdx1,pitx3,runx1,rag2,ggta,hr,handii,tbx5。
实施方案包括以多重方法或通过其它方法靶向一个,两个或更多个(2-25个)上述靶标。
编辑的基因
本文中关于特定靶标和靶向内切核酸酶描述的方法和发明是广泛适用的。本发明人已经制备了适合于在用所有以下基因编辑的情况下克隆的原代家畜细胞。
经遗传修饰的动物
可以制备在染色体修饰方面单等位或双等位的动物,其使用在适当位置留下可遗传表达的标志物,允许其从动物中育种出来的方法,或通过不在动物中放置此类标志物的方法进行。例如,本发明人已经使用同源依赖性重组(hdr)方法来对动物染色体做出改变或插入外源基因。诸如talen和重组酶融合蛋白的工具以及常规方法在本文其它地方讨论。本文公开的支持遗传修饰的一些实验数据总结如下。本发明人先前已经证明了当从修饰细胞的多遗传群体克隆时特别的克隆效率,并且主张该方法通过用于分离的集落的体细胞核转移(scnt)避免克隆效率的变化(carlson等人,2011)。另外,然而,talen介导的基因组修饰以及通过重组酶融合分子的修饰提供了在单一世代中完成的双等位改变。例如,敲除基因纯合的动物可以通过scnt并且在没有近交以产生纯合子的情况下制备。家畜(例、如猪和牛)的妊娠长度和成熟至繁殖年龄是研究和生产的重要障碍。例如,通过克隆和育种从杂合突变体细胞(两种性别)产生纯合敲除对于猪和牛分别需要16和30个月。一些人据称通过遗传修饰和scnt的连续循环减少了这种负担(kuroiwa等人,2004),然而,这既是技术上的挑战性的又是成本高昂的,此外,存在许多原因避免用于制备f0动物的连续克隆,其实际上对大型脊椎动物实验室模型或牲畜有用。在scnt之前常规产生双等位ko细胞的能力是大型动物遗传工程中的显著进步。使用其它方法,如zfn和稀释克隆在永生细胞系中实现了双等位敲除(liu等人,2010)。另一个小组最近使用商业zfn试剂(hauschild等人,2011)证明了猪ggta1的双等位ko,其中可以通过facs在ggta1依赖性表面表位方面富集双等位无效细胞。虽然这些研究证明了某些有用的概念,但它们没有显示动物或家畜可以被修饰,因为简单的克隆稀释通常对于原代成纤维细胞隔离群是不可行的(成纤维细胞在低密度下生长不良),并且对于无效细胞的生物富集不可用于大多数基因。
可以使用靶向核酸酶诱导的同源重组,以消除对连接的选择标志物的需要。talen可以用于通过同源依赖性修复(hdr)将特异性等位基因精确转移到家畜基因组中。在初步研究中,将特定11bp缺失(belgianblue等位基因)(grobet等人,1997;kambadur等人,1997)引入牛gdf8基因座(参见us2012/0222143)。当单独转染时,btgdf8.1talen对在靶基因座处切割高达16%的染色体。与含有11bp缺失的超螺旋同源dna修复模板的共转染导致在第3天达到5%的基因转化频率(hdr),而不选择所需的事件。在筛选的分离的集落的1.4%中鉴定出基因转化。这些结果表明,talen可以用于在没有连接的选择标志物的帮助下有效地诱导hdr。
同源性指导修复(hdr)
同源性指导修复(hdr)是细胞中修复ssdna和双链dna(dsdna)损伤的机制。当存在具有与损伤部位具有显著同源性的序列的hdr模板时,该修复机制可以由细胞使用。特异性结合,如该术语在生物领域中通常使用的,是指与非靶组织相比,以相对高亲和力结合靶标的分子,并且通常涉及多种非共价相互作用,如静电相互作用,范德华相互作用,氢键合等。特异性杂交是具有互补序列的核酸之间的特异性结合形式。蛋白质还可以特异性结合dna,例如在talen或crispr/cas9系统中或通过gal4基序。等位基因的渐渗是指用模板引导过程将外源等位基因复制在内源等位基因上的过程。在一些情况下,内源等位基因可能实际上被切除并被外源核酸等位基因取代,但是现有理论是该过程是复制机制。由于等位基因是基因对,它们之间存在显著的同源性。等位基因可以是编码蛋白质的基因,或者其可以具有其它功能,如编码生物活性rna链或提供用于接受调节蛋白或rna的位点。
hdr模板是包含渐渗的等位基因的核酸。模板可以是dsdna或单链dna(ssdna)。ssdna模板优选为约20至约5000个残基,尽管可以使用其它长度。技术人员将立即理解,涵盖在明确指定的范围内的所有范围和值;例如500至1500个残基,20至100个残基,等等。模板可以进一步包括提供与内源等位基因相邻的dna或待替换的dna的同源性的侧翼序列。模板还可以包含结合到靶向核酸酶系统的序列,并且因此是系统的dna结合成员的关联结合位点。术语关联(cognate)是指通常与例如受体及其配体相互作用的两种生物分子。在hdr方法的上下文中,可以将生物分子之一设计为具有与预期的,即关联的dna位点或蛋白质位点结合的序列。
靶向内切核酸酶系统
基因组编辑工具如转录激活剂样效应器核酸酶(talen)和锌指核酸酶(zfn)已经影响了许多生物体中的生物技术,基因治疗和功能基因组研究领域。最近,rna-引导的内切核酸酶(rgen)通过互补的rna分子导向到其靶位点。cas9/crispr系统是regen。tracrrna是另一种此类工具。这些是靶向核酸酶系统的实例:这些系统具有将核酸酶定位到靶位点的dna结合成员。然后该位点被核酸酶切割。talen和zfn具有与dna结合成员融合的核酸酶。cas9/crispr是在靶dna上发现彼此的关联物。dna结合成员在染色体dna中具有关联序列。通常根据预期的关联序列设计dna结合成员,以便在预期位点处或其附近获得核溶解作用。某些实施方案适用于所有此类系统而没有限制;包括使核酸酶重新切割最小化的实施方案,用于在预期残基处精确做出snp的实施方案,以及在dna结合位点处渐渗的等位基因的放置。
talen
如本文使用的术语talen是宽泛的,并且包括可以在没有来自另一talen的辅助下切割双链dna的单体talen。术语talen还用于指被工程化设计为一起起作用以在相同位点处切割dna的一对talen的一个或两个成员。一起起作用的talen可以称为左talen和右talen,其参考dna的手性或talen对。
已经报道了tal的密码(pct公开wo2011/072246),其中每个dna结合重复负责识别靶dna序列中的一个碱基对。可以组装残基以靶向dna序列。简而言之,测定talen结合的靶位点,并创建包含核酸酶和识别靶位点的一系列rvd的融合分子。结合后,核酸酶切割dna,使得细胞修复机器可以操作以在切割端进行遗传修饰。术语talen是指包含转录激活子样(tal)效应器结合域和核酸酶域的蛋白质,并且包括本身功能性的单体talen以及需要与另一种单体talen二聚化的其它talen。当两个单体talen都相同时,二聚化可以导致同二聚体talen,或者当单体talen不同时,可以导致异二聚体talen。已显示了talen依靠两个主要的真核dna修复途径,非同源末端连接(nhej)和同源性指导修复在永生化人细胞中诱导基因修饰。talen通常成对使用,但单体talen是已知的。用于通过talen(和其它遗传工具)处理的细胞包括培养的细胞,永生化细胞,原代细胞,原代体细胞,合子,生殖细胞,原生殖细胞,胚泡或干细胞。在一些实施方案中,tal效应器可用于将其它蛋白域(例如,非核酸酶蛋白域)靶向特定核苷酸序列。例如,tal效应器可以与来自但不限于dna20相互作用酶(例如甲基化酶,拓扑异构酶,整合酶,转座酶或连接酶),转录激活物或阻遏物的蛋白质域,或与其它蛋白质如组蛋白相互作用或修饰其它蛋白质如组蛋白的蛋白质连接。此类tal效应器融合物的应用包括例如创建或修饰表遗传调节元件,在dna中进行位点特异性插入,缺失或修复,控制基因表达和修饰染色质结构。
术语核酸酶包括外切核酸酶和内切核酸酶。术语内切核酸酶是指能够催化dna或rna分子(优选dna分子)内的核酸之间的键的水解(切割)的任何野生型或变体酶。内切核酸酶的非限制性实例包括ii型限制性内切核酸酶,如foki,hhai,hindiii,notl,bbvci,ecori,bglii和alwl。当典型地具有长度为约12-45碱基对(bp),更优选地为14-45bp的多核苷酸识别位点时,内切核酸酶还包括罕见切割内切核酸酶。罕见切割的内切核酸酶在确定的基因座处诱导dna双链断裂(dsb)。罕见切割的内切核酸酶可以是例如靶向内切核酸酶,嵌合锌指核酸酶(zfn),其是由工程化的锌指域与限制性酶,如foki或化学内切核酸酶的催化域融合产生的。在化学内切核酸酶中,化学或肽切割子与核酸的聚合物或识别特定靶序列的另一dna缀合,从而将切割活性靶向特定序列。化学内切核酸酶还包括已知结合特定dna序列的合成核酸酶如邻二氮杂菲的偶联物,dna切割分子和三链体形成寡核苷酸(tfo)。此类化学内切核酸酶包括在根据本发明的术语“内切核酸酶”中。这种内切核酸酶的实例包括i-seei,i-chuli-crei,i-csmi,pi-seelpi-ttilpi-mtui,i-ceui,i-seeil1-seeiii,ho,pi-civi,pi-ctrlpi-aaei,pi-bsui,pi-dhai,pi-dralpi-mavlpi-mehi,pi-mfulpi-mfli,pi-mgalpi-mgoi,pi-minlpi-mkalpi-mlei,pi-mmai,pi-30mshlpi-msmi,pi-mthi,pi-mtui,pi-mxei,pi-npui,pi-pfulpi-rmai,pl-spbi,pi-ssplpi-faelpi-mjai,pi-pholpi-taglpi-thyi,pi-tkoi,pi-tspi,i-msol。
由talen或其它工具进行的遗传修饰可以例如选自下组:插入,缺失,外源核酸片段的插入,和取代。术语插入广泛用于意指字面上的插入染色体或使用外源序列作为修复的模板。通常,鉴定靶dna位点,并创建将特异性结合该位点的talen对。将talen递送至细胞或胚胎,例如作为蛋白质,mrna或通过编码talen的载体。talen切割dna以产生双链断裂,然后修复,通常导致插入缺失(indel)的创建,或掺入伴随的外源核酸中包含的序列或多态性,所述外源核酸插入染色体或充当模板用于使用修饰的序列修复断裂。此模板驱动的修复是改变染色体的有用过程,并且提供对细胞染色体的有效改变。
术语外源核酸是指添加到细胞或胚胎中的核酸,而不管核酸是否与天然在细胞中的核酸序列相同或不同。术语核酸片段是宽的并且包括染色体,表达盒,基因,dna,rna,mrna或其部分。细胞或胚胎可以例如选自下组:非人脊椎动物,非人灵长类,牛,马,猪,绵羊,鸡,禽,兔,山羊,犬,猫,实验室动物和鱼。
一些实施方案涉及制备遗传修饰的家畜和/或偶蹄动物的组合物或方法,包括将talen对引入家畜和/或偶蹄动物细胞或胚胎中,其在被talen对特异性结合的位点处对细胞或胚胎的dna做出遗传修饰,并从细胞产生家畜动物/偶蹄动物。直接注射可以用于细胞或胚胎,例如,合子,胚泡或胚胎。或者,可以使用用于导入蛋白质,rna,mrna,dna或载体的许多已知技术中的任何一种将talen和/或其它因子导入细胞中。遗传修饰的动物可以根据已知的方法从胚胎或细胞制备,例如将胚胎植入妊娠宿主中,或各种克隆方法。短语“在由talen特异性结合的位点处对细胞的dna的遗传修饰”等是指当talen特异性结合其靶位点时,在由talen上的核酸酶切割的位点处做出遗传修饰。核酸酶不能精确地切割talen对结合的位置,而是在两个结合位点之间的限定位点。
一些实施方案涉及用于克隆动物的组合物或细胞的处理。细胞可以是家畜和/或偶蹄动物细胞,培养的细胞,原代细胞,原代体细胞,合子,生殖细胞,原生殖细胞或干细胞。例如,一个实施方案是创建遗传修饰的组合物或方法,包括将培养物中的多个原代细胞暴露于talen蛋白或编码一个或多个talen的核酸。talen可以作为蛋白质或作为核酸片段导入,例如由mrna或载体中的dna序列编码。
锌指核酸酶
锌指核酸酶(zfn)是通过将锌指dna结合域与dna切割域融合而产生的人工限制酶。锌指域可以被工程化以靶向期望的dna序列,这使得锌指核酸酶靶向复杂基因组内的独特序列。通过利用内源dna修复机器,这些试剂可以用于改变高等生物的基因组。zfn可用于灭活基因的方法。
锌指dna结合域具有约30个氨基酸并折叠成稳定的结构。每个指主要结合dna底物内的三联体。关键位置的氨基酸残基有助于与dna位点的大多数序列特异性相互作用。这些氨基酸可以改变,同时保留剩余的氨基酸以保持必要的结构。通过串联连接几个域实现与较长dna序列的结合。其它功能如非特异性foki切割域(n),转录激活剂域(a),转录阻抑物域(r)和甲基化酶(m)可以与zfp融合以分别形成zfn,锌指转录激活物(zfa),锌指转录阻遏物(zfr)和锌指甲基化酶(zfm)。使用锌指和锌指核酸酶制备基因修饰动物的材料和方法公开于例如us8,106,255;us2012/0192298;us2011/0023159;和us2011/0281306。
载体和核酸
可以将多种核酸导入细胞中,用于敲除目的,用于基因的失活,以获得基因的表达,或用于其它目的。如本文所用,术语核酸包括dna,rna和核酸类似物,以及是双链或单链(即有义或反义单链)的核酸。核酸类似物可以在碱基部分,糖部分或磷酸骨架上被修饰,以改善例如核酸的稳定性,杂交或溶解性。可以修饰脱氧核糖磷酸骨架以产生吗啉核酸,其中每个碱基部分连接到六元吗啉环,或肽核酸,其中脱氧磷酸骨架被假肽骨架替换,并且保留四种碱基。
靶核酸序列可以可操作地连接到调节区,如启动子。调节区可以是猪调节区或可以来自其它物种。如本文所用,可操作地连接是指调节区相对于核酸序列以允许或促进靶核酸转录的方式定位。
通常,启动子的类型可以可操作地连接到靶核酸序列。启动子的实例包括但不限于组织特异性启动子,组成型启动子,诱导型启动子和对特定刺激响应或无响应的启动子。在一些实施方案中,可以使用没有显著组织或时间特异性促进核酸分子表达的启动子(即组成型启动子)。例如,可以使用β-肌动蛋白启动子如鸡β-肌动蛋白基因启动子,泛素启动子,minicag启动子,甘油醛-3-磷酸脱氢酶(gapdh)启动子或3-磷酸甘油酸激酶(pgk)启动子,以及病毒启动子如单纯疱疹病毒胸苷激酶(hsv-tk)启动子,sv40启动子或巨细胞病毒(cmv)启动子。在一些实施方案中,将鸡β肌动蛋白基因启动子和cmv增强子的融合物用作启动子。参见例如,xu等人,hum.genether.12:563,2001;和kiwaki等人,hum.genether.7:821,1996。
可用于核酸构建体的其它调节区包括但不限于聚腺苷酸化序列,翻译控制序列(例如内部核糖体进入区段,ires),增强子,诱导型元件或内含子。此类调节区可能不是必需的,尽管它们可以通过影响转录,mrna的稳定性,翻译效率等来增加表达。此类调节区可以根据需要包括在核酸构建体中,以获得核酸在细胞中的最佳表达。然而,有时可以在没有此类附加元件的情况下获得足够的表达。
可以使用编码信号肽或选择性表达标志物的核酸构建体。可以使用信号肽,使得编码的多肽针对特定的细胞位置(例如,细胞表面)。选择标志物的非限制性实例包括嘌呤霉素,更昔洛韦,腺苷脱氨酶(ada),氨基糖苷磷酸转移酶(neo,g418,aph),二氢叶酸还原酶(dhfr),潮霉素-b-磷酸转移酶,胸苷激酶(tk)和叶黄素-鸟嘌呤磷酸核糖基转移酶(xgprt)。此类标志物可用于选择培养中的稳定转化体。其它选择标志物包括荧光多肽,如绿色荧光蛋白或黄色荧光蛋白。
在一些实施方案中,编码选择性标志物的序列侧翼可以有用于重组酶(如例如cre或flp)的识别序列。例如,可选择标志物侧翼可以有loxp识别位点(由cre重组酶识别的34-bp识别位点)或frt识别位点,使得可从构建体中切除选择性标志物。参见orban等人,proc.natl.acad.sci.,89:6861,1992(关于cre/lox技术的综述),以及brand和dymecki,dev.cell,6:7,2004。含有由选择标志物基因中断的cre或flp可活化转基因的转座子也可用于获得具有转基因的条件表达的转基因动物。例如,驱动标志物/转基因表达的启动子可以是普遍存在的或组织特异性的,这将导致标志物在f0动物(例如,猪)中的遍在或组织特异性表达。转基因的组织特异性激活可以例如通过使普遍表达标志物中断的转基因的猪与以组织特异性方式表达cre或flp的猪杂交,或通过使以组织特异性方式表达标志物中断的猪与遍在表达cre或flp重组酶的猪杂交实现。转基因的受控表达或标志物的受控切除允许转基因的表达。
在一些实施方案中,外源核酸编码多肽。编码多肽的核酸序列可以包括的编码“标签”的标签序列,所述标签设计为便于随后操纵编码的多肽(例如,以便于定位或检测)。标签序列可以插入编码多肽的核酸序列中,使得编码的标签位于多肽的羧基或氨基末端。编码标签的非限制性实例包括谷胱甘肽s-转移酶(gst)和flagtm标签(kodak,newhaven,ct)。
可以使用多种技术将核酸构建体导入任何类型的胚胎,胎儿或成体偶蹄动物/家畜细胞,包括例如生殖细胞如卵母细胞或卵,祖细胞,成体或胚胎干细胞,原生殖细胞,肾细胞诸如pk-15细胞,胰岛细胞,β细胞,肝细胞或成纤维细胞如真皮成纤维细胞。技术的非限制性实例包括使用能够将核酸递送至细胞的转座子系统,可感染细胞的重组病毒或脂质体或其它非病毒方法,如电穿孔,显微注射或磷酸钙沉淀。
在转座子系统中,核酸构建体的转录单元,即与外源核酸序列可操作地连接的调节区,侧翼有转座子的反向重复。几个转座子系统,包括例如sleepingbeauty(参见美国专利6,613,752和美国2005/0003542);frogprince(miskey等人,nucleicacidsres.,31:6873,2003);tol2(kawakami,genomebiology,8(suppl.1):s7,2007);minos(pavlopoulos等人,genomebiology,8(suppl.1):s2,2007);hsmarl(miskey等人,molcellbiol.,27:4589,2007);和passport已经被开发以将核酸导入细胞,包括小鼠,人和猪细胞中。sleepingbeauty转座子特别有用。转座酶可以作为蛋白质递送,在与外源核酸相同的核酸构建体上编码,可以在单独的核酸构建体上导入,或提供为mrna(例如,体内转录和加帽的mrna)。
核酸可以掺入载体中。载体是广义术语,其包括设计成从载体移动到靶dna中的任何特定dna区段。载体可以称为表达载体或载体系统,其是将dna插入基因组或其它靶定dna序列所需的一组组件,如附加体,质粒或甚至病毒/噬菌体dna区段。用于动物中基因递送的载体系统,如病毒载体(例如逆转录病毒,腺伴随病毒和整合噬菌体病毒)和非病毒载体(例如转座子)具有两个基本组分:1)由dna(或反转录成cdna的rna)构成的载体和2)转座酶,重组酶或其它整合酶,其识别载体和dna靶序列两者,并将载体插入靶dna序列。载体最常包含一个或多个包含一个或多个表达控制序列的表达盒,其中表达控制序列是分别控制和调节另一个dna序列或mrna的转录和/或翻译的dna序列。
许多不同类型的载体是已知的。例如,质粒和病毒载体,例如逆转录病毒载体是已知的。哺乳动物表达质粒通常具有复制起点,合适的启动子和任选的增强子,以及还有任何必需的核糖体结合位点,多腺苷酸化位点,剪接供体和受体位点,转录终止序列和5’侧翼非转录序列。载体的实例包括:质粒(其也可以是另一类型载体的载体),腺病毒,腺伴随病毒(aav),慢病毒(例如,经修饰的hiv-1,siv或fiv),逆转录病毒(例如asv,alv或momlv)和转座子(例如,sleepingbeauty,p元件,tol-2,frogprince,piggybac)。
如本文所用,术语核酸是指rna和dna两者,包括例如cdna,基因组dna,合成的(例如化学合成的)dna以及天然存在的和化学修饰的核酸,例如合成的碱基或替代骨架。核酸分子可以是双链或单链(即,有义或反义单链)。术语转基因在本文中广泛使用,并且是指遗传修饰的生物体或遗传工程化的生物体,其遗传物质已经使用遗传工程技术改变。因此,敲除的偶蹄动物是转基因的,不管外源基因或核酸是否在动物或其后代中表达。
遗传修饰的动物
可以使用talen或其它遗传工程工具修饰动物,包括重组酶融合蛋白或已知的各种载体。由此类工具进行的遗传修饰可以包括基因的破坏。术语基因的破坏是指防止功能性基因产物的形成。基因产物仅在其满足其正常(野生型)功能时才具有功能。基因的破坏阻止由基因编码的功能因子的表达,并且包括由基因编码的序列和/或表达所必需的启动子和/或操纵基因中的一个或多个碱基的插入,缺失或取代。破坏的基因可以通过例如从动物基因组中去除至少基因的一部分,改变基因以阻止由基因编码的功能因子的表达,干扰rna或表达外源基因的显性负性因子。在u.s.8,518,701;u.s.2010/0251395;和u.s.2012/0222143(其在此出于所有目的通过引用并入本文)中进一步详述了遗传修饰动物的材料和方法;在冲突的情况下,以本说明书为准。术语反式作用是指作用于来自不同分子(即,分子间)的靶基因的过程。反式作用元件通常是含有基因的dna序列。该基因编码用于调节靶基因的蛋白质(或微小rna或其它可扩散分子)。反式作用基因可以在与靶基因相同的染色体上,但是活性是通过其编码的中间蛋白或rna实现。反式作用基因的实施方案是例如编码靶向内切核酸酶的基因。使用显性负性的基因失活通常涉及反式作用元件。术语顺式调节或顺式作用意指不编码蛋白质或rna的作用;在基因失活的上下文中,这通常意味着基因的编码部分或表达功能基因所必需的启动子和/或操纵子的失活。
本领域已知的各种技术可用于灭活基因以制备敲除动物和/或将核酸构建体导入动物中以产生建立者动物并制备动物品系,其中敲除或核酸构建体整合入基因组中。此类技术包括但不限于原核显微注射(us4,873,191),逆转录病毒介导的基因转移到种系中(vanderputten等人,proc.natl.acad.sci.usa,82:6148-6152,1985),基因靶向到胚胎干细胞中(thompson等人,cell,56:313-321,1989),胚胎电穿孔(lo,mol.cell.biol.,3:1803-1814,1983),精子介导的基因转移(lavitrano等人,proc.natl.acad.sci.usa,99:14230-14235,2002;lavitrano等人,reprod.fert.develop.,18:19-23,2006),以及体细胞的体外转化,如卵丘或乳房细胞或成体,胎儿或胚胎干细胞,然后进行核移植(wilmut等人,nature,385:810-813,1997;和wakayama等人,nature,394:369-374,1998)。原核显微注射,精子介导的基因转移和体细胞核转移是特别有用的技术。基因组修饰的动物是其所有细胞都具有遗传修饰的动物,包括其种系细胞。当使用产生在其遗传修饰中为嵌合的动物的方法时,动物可以是近交的,并且可以选择经基因组修饰的后代。例如,如果其细胞在胚泡状态被修饰,则克隆可以用于制备嵌合体动物,或者当单细胞被修饰时可以发生基因组修饰。被修饰使得它们不性成熟的动物对于修饰可以是纯合的或杂合的,这取决于所使用的具体方法。如果特定基因通过敲除修饰失活,通常需要纯合子。如果特定基因被rna干扰或显性失活策略灭活,则杂合性通常是足够的。
通常,在原核显微注射中,将核酸构建体导入受精卵中;1或2个细胞受精卵用作含有来自精子头的遗传物质的原核,并且在原生质中可见所述卵。原核分期受精卵可以在体外或体内(即,从供体动物的输卵管中手术回收)获得。体外受精卵可以如下产生。例如,猪卵巢可以在屠宰场收集,并在运输过程中保持在22-28℃。可以洗涤和分离卵巢以进行滤泡抽吸,并且可以使用18号针头并在真空下将范围为4-8mm的滤泡吸入50ml锥形离心管中。可以用商业tl-hepes(minitube,verona,wi)通过预过滤器漂洗滤泡液和抽吸的卵母细胞。可选择由密集丘块包围的卵母细胞,并置于补充有0.1mg/ml半胱氨酸,10ng/ml表皮生长因子,10%猪卵泡液,50μm2-巯基乙醇,0.5mg/mlcamp,10iu/ml每种孕马血清促性腺激素(pmsg)和人绒毛膜促性腺激素(hcg)在38.7℃和5%co2的湿润空气中约22小时。随后,可将卵母细胞移至新鲜的不含有camp,pmsg或hcg的tcm-199成熟培养基中,并再温育22小时。通过在0.1%透明质酸酶中涡旋1分钟,可以剥离成熟的卵母细胞的卵丘细胞。
对于猪,可以在500μlminitubeporcproivfmediumsystem(minitube,verona,wi)中在minitube5孔受精皿中对成熟卵母细胞进行受精。在体外受精(ivf)的准备中,可以洗涤新鲜收集或冷冻的公猪精液,并在porcproivf培养基中重悬于4x105个精子。可以通过计算机辅助精液分析(spermvision,minitube,verona,wi)分析精子浓度。最终体外授精可以以10μl体积进行,终浓度为约40个活动精子/卵母细胞,取决于公猪。温育所有受精卵细胞在38.7℃在5.0%co2气氛中6小时。授精后6小时,推测的合子可以在ncsu-23中洗涤两次并移至0.5ml的相同培养基中。此系统可以常规在大多数公猪中以10-30%的多精授精率产生20-30%的胚泡。
可以将线性化核酸构建体注射到原核之一中。然后,可以将注射的卵转移到受体磁性(例如,接受雌性的输卵管中),并允许在受体雌性中发育以产生转基因动物。特别地,体外受精的胚胎可以在15,000xg离心5分钟以沉淀脂质,允许原核的可视化。胚胎可以使用eppendorffemtojet注射器注射,并且可以培养直到形成胚泡。可以记录胚胎裂解的速率和胚泡形成和质量。
胚胎可以手术转移到异步接受者的子宫中。通常,使用5.5英寸
在体细胞核转移中,可以将包含上述核酸构建体的转基因偶蹄动物细胞(例如转基因猪细胞或牛细胞)如胚胎卵裂球,胎儿成纤维细胞,成体耳成纤维细胞或颗粒细胞引入去核的卵母细胞以建立组合细胞。卵母细胞可以通过在极体附近的部分带剥离,然后在解剖区域挤出细胞质使细胞去核。通常,具有尖锐斜面尖端的注射移液管用于将转基因细胞注射到在减数分裂2时阻滞的去核卵母细胞中。在一些惯例中,在减数分裂-2时阻滞的卵母细胞被称为卵。在产生猪或牛胚胎(例如通过融合和活化卵母细胞)后,胚胎在活化后约20至24小时转移到受体雌性的输卵管中。参见,例如,cibelli等人,science,280:1256-1258,1998;和us6,548,741。对于猪,可以在转移胚胎后约20-21天检查接受者雌性的妊娠。
标准育种技术可用于创建对于来自初始杂合建立者动物的外源核酸方面纯合的动物。然而,可能不需要纯合性。本文所述的转基因猪可与其它感兴趣的猪育种。
在一些实施方案中,可以在单独的转座子上提供感兴趣的核酸和选择标志物,并将其提供给不等量的胚胎或细胞,其中含有选择标志物的转座子的量远超过(5-10倍过量)含有感兴趣的核酸的转座子。可以基于选择标志物的存在和表达来分离表达目的核酸的转基因细胞或动物。因为转座子将以精确和非连锁方式(独立转座事件)整合到基因组中,所以目的核酸和选择标志物不是遗传连锁的,并且可以通过标准育种通过遗传分离容易地分离。因此,可以产生不限于在后续世代保留可选择标志物的转基因动物,这是从公共安全角度来看的略有忧虑的问题。
一旦产生了转基因动物,可以使用标准技术评估外源核酸的表达。初始筛选可以通过southern印迹分析来完成,以确定构建体是否发生整合。对于southern分析的描述,参见sambrook等人,molecularcloning,alaboratorymanual,第二版,coldspringharborpress,plainview;ny.,1989的第9.37-9.52节。聚合酶链反应(pcr)技术也可用于初始筛选。pcr指扩增靶核酸的方法或技术。通常,使用来自目标区域的末端或以外的序列信息来设计与待扩增模板的相对链序列相同或相似的寡核苷酸引物。pcr可用于从dna和rna扩增特定序列,包括来自总基因组dna或总细胞rna的序列。引物通常长度为14至40个核苷酸,但长度范围可以为10个核苷酸至几百个核苷酸。pcr描述于例如pcrprimer:alaboratorymanual编dieffenbach和dveksler,coldspringharborlaboratorypress,1995。核酸也可以通过连接酶链式反应,链替换扩增,自我维持序列复制或基于核酸序列的扩增来扩增。参见例如lewis,geneticengineeringnews,12:1,1992;guatelli等,proc.natl.acad.sci.usa,87:1874,1990;和weiss,science,254:1292,1991。在胚泡阶段,可以通过pcr,southern杂交和splinkerettepcr(参见例如dupuy等人,procnatlacadsciusa,99:4495,2002)单独处理胚胎。
编码多肽的核酸序列在转基因猪组织中的表达可以使用技术评估,所述技术包括例如从动物获得的组织样品的northern印迹分析,原位杂交分析,western分析,免疫测定法如酶联免疫吸附测定法,和逆转录酶pcr(rt-pcr)。
干扰rna
已知多种干扰rna(rnai)。双链rna(dsrna)诱导同源基因转录物的序列特异性降解。rna诱导的沉默复合物(risc)将dsrna代谢为小的21-23核苷酸小干扰rna(sirna)。risc含有双链rna酶(dsrna酶,例如dicer)和ssrna酶(例如argonaut2或ago2)。risc利用反义链作为指导来找到可切割的靶标。sirna和微小rna(mirna)都是已知的。破坏遗传修饰的动物中的基因的方法包括诱导针对靶基因和/或核酸的rna干扰,使得靶基因和/或核酸的表达降低。
例如,外源核酸序列可以诱导针对编码多肽的核酸的rna干扰。例如,可以使用与靶dna同源的双链小干扰rna(sirna)或小发夹rna(shrna)来降低该dna的表达。可以生成sirna的构建体,如例如fire等,nature,391:806,1998;romano和masino,mol.microbiol.,6:3343,1992;cogoni等,emboj.,15:3153,1996;cogoni和masino,nature,399:166,1999;misquitta和patersonproc.natl.acad.sci.96:1451,1999;和kennerdell和carthew,cell,95:1017,1998中描述的。可以如mclntyre和fanning(2006)bmcbiotechnology6:1所述产生shrna的构建体。通常,shrna转录为含有互补区的单链rna分子,其可以退火并形成短发夹。
找到针对特定基因的单个,个别功能性sirna或mirna的概率是较高的。例如,sirna的特定序列的可预测性为约50%,但是可以以良好的置信度制备许多干扰rna,使得它们中的至少一个会是有效的。
实施方案包括体外细胞,体内细胞和经遗传修饰的动物例如家畜动物,其表达针对基因的rnai,例如对发育阶段具有选择性的基因。rnai可以是例如选自下组:sirna,shrna,dsrna,risc和mirna。
诱导型系统
诱导型系统可以用于控制基因的表达。已知各种诱导型系统,其允许基因表达的时空控制。已经证明几种在转基因动物中在体内是功能性的。术语诱导型系统包括传统启动子和诱导型基因表达元件。
诱导型系统的实例是四环素(tet)开启启动子系统,其可用于调节核酸的转录。在此系统中,突变tet阻遏物(tetr)融合到单纯疱疹病毒vp16反式激活蛋白的激活域,以创建由tet或多西环素(dox)调节的四环素控制的转录激活物(tta)。在没有抗生素的情况下,转录是最小的,而在tet或dox的存在下,诱导转录。可选的诱导型系统包括蜕皮激素或雷帕霉素系统。蜕皮激素是一种昆虫蜕皮激素,其产生受蜕皮激素受体和超气门(ultraspiracle)基因(usp)的产物的异源二聚体控制。通过用蜕皮激素或蜕皮激素类似物例如幕黎甾酮(muristerone)a处理诱导表达。给动物施用以触发诱导型系统的试剂称为诱导剂。
四环素诱导型系统和cre/loxp重组酶系统(组成型或诱导型)是更常用的诱导型系统之一。四环素诱导系统涉及四环素控制的反式激活物(tta)/反向tta(rtta)。在体内使用这些系统的方法牵涉产生遗传修饰的动物的两种品系。一个动物品系表达在所选启动子控制下的激活剂(tta,rtta或cre重组酶)。另一组转基因动物表达受体,其中感兴趣基因(或待修饰的基因)的表达在tta/rtta反式激活物的靶序列的控制下(或侧翼为loxp序列)。交配两个小鼠品系提供了对基因表达的控制。
四环素依赖性调节系统(tet系统)依赖于两个组分,即四环素控制的反式激活物(tta或rtta)和以四环素依赖性方式控制下游cdna表达的tta/rtta依赖性启动子。在不存在四环素或其衍生物(如多西环素)的情况下,tta结合teto序列,允许tta依赖性启动子的转录激活。然而,在多西环素的存在下,tta不能与其靶标相互作用,并且不发生转录。使用tta的tet系统被称为tet关闭,因为四环素或多西环素允许转录下调。施用四环素或其衍生物允许体内转基因表达的时间控制。rtta是tta的变体,其在不存在多西环素的情况下没有功能,但需要存在配体用于反式激活。因此,该tet系统称为tet开启。tet系统已经在体内用于诱导型表达几种转基因,编码例如报告基因,癌基因或涉及信号级联的蛋白质。
cre/lox系统使用cre重组酶,其通过两个远的cre识别序列(即loxp位点)之间的交换来催化位点特异性重组。在两个loxp序列(称为floxeddna)之间引入的dna序列通过cre介导的重组切除。使用空间对照(具有组织或细胞特异性启动子)或时间控制(具有诱导型系统)控制转基因动物中的cre表达,导致控制两个loxp位点之间的dna切除。一个应用是用于条件基因失活(条件敲除)。另一种方法是用于蛋白质过表达,其中floxed终止密码子插入在启动子序列和感兴趣的dna之间。遗传修饰的动物不表达转基因,直到cre表达,导致floxed终止密码子的切除。该系统已经应用于b淋巴细胞中的组织特异性肿瘤生成和受控的抗原受体表达。也已经开发了诱导型cre重组酶。诱导型cre重组酶仅通过施用外源配体来激活。诱导型cre重组酶是含有初始cre重组酶和特异性配体结合域的融合蛋白。cre重组酶的功能活性依赖于能够结合融合蛋白中的该特定域的外部配体。
实施方案包括体外细胞,体内细胞和遗传修饰的动物,如家畜,其包含在诱导型系统控制下的基因。动物的遗传修饰可以是基因组或嵌合的。诱导型系统可以是例如选自下组:tet开启,tet关闭,cre-lox和hif1α。一个实施方案是本文中列出的基因。
显性阴性
因此,基因可以不仅通过去除或rnai抑制,而且还通过创建/表达对该基因产物的正常功能具有抑制作用的蛋白质的显性阴性变体而被破坏。显性负性(dn)基因的表达可以导致改变的表型,通过如下施加:a)滴定效应;dnpassively与内源基因产物竞争协作因子或内源基因的正常靶标,而没有加工相同的活性,b)毒丸(poisonpill)(或活动板钳(monkeywrench))效应,其中显性负性基因产物活性干扰正常基因功能所需的过程,c)反馈效应,其中dn活性刺激基因功能的负调节物。
建立者动物,动物品系,性状和繁殖
可通过本文所述的克隆和其它方法产生建立者动物(f0代)。建立者对于遗传修饰可以是纯合的,如在合子或原代细胞经历纯合修饰的情况下。类似地,也可以制备杂合的创建者。建立者可以是基因组修饰的,意味着细胞在其基因组中已经经过修饰。建立者在用于修饰方面可以是嵌合的,如可以当将载体导入胚胎中的多个细胞之一(通常在胚泡阶段)时发生。可以测试嵌合动物的后代以鉴定经基因组修饰的后代。当已经创建可以通过有性或通过辅助生殖技术繁殖的动物合并时建立动物品系,其中杂合或纯合后代一致地表达修饰。
在家畜中,已知许多等位基因与各种性状,如生产性状,类型性状,可加工性性状和其它功能性性状连锁。技术人员习惯于监测和量化这些性状,例如visscher等人,livestockproductionscience,40:123-137,1994;u.s.7,709,206;u.s.2001/0016315;us2011/0023140;和u.s.2005/0153317。动物品系可以包括选自下组的性状:生产性状,类型性状,可加工性性状,能育性性状,母性性状和疾病抗性性状。其它性状包括重组基因产物的表达。
重组酶
本发明的实施方案包括施用具有重组酶(例如reca蛋白,rad51)或与dna重组相关的其它dna结合蛋白的靶向核酸酶系统。重组酶与核酸片段形成细丝,实际上,搜索细胞dna以发现与该序列基本上同源的dna序列。例如,重组酶可以与充当hdr模板的核酸序列组合。然后将重组酶与hdr模板组合以形成细丝并置于细胞中。与重组酶组合的重组酶和/或hdr模板可以作为蛋白质,mrna或用编码重组酶的载体置于细胞或胚胎中。为了所有目的,将us2011/0059160(美国专利申请号12/869,232)的公开内容在此通过引用并入本文;在冲突的情况下,以说明书为准。术语重组酶是指在细胞中酶促催化在两条相对较长的dna链之间连接相对短的dna段的遗传重组酶。重组酶包括cre重组酶,hin重组酶,reca,rad51,cre和flp。cre重组酶是来自p1噬菌体的i型拓扑异构酶,其催化loxp位点之间的dna的位点特异性重组。hin重组酶是由在细菌沙门氏菌(salmonella)中发现的198个氨基酸组成的21kd蛋白。hin属于dna转化酶的丝氨酸重组酶家族,其中它依赖于活性位点丝氨酸启动dna切割和重组。rad51是人类基因。由该基因编码的蛋白是rad51蛋白家族的成员,其帮助修复dna双链断裂。rad51家族成员与细菌reca和酵母rad51同源。cre重组酶是在实验中用于缺失侧接有loxp位点的特异性序列的酶。flp是指来自面包酵母酿酒酵母(saccharomycescerevisiae)的2μ质粒的flippase重组酶(flp或flp)。
本文中,“reca”或“reca蛋白”是指具有基本上全部或大部分相同功能的reca样重组蛋白家族,特别是:(i)将寡核苷酸或多核苷酸适当定位在其同源靶标上用于随后通过dna聚合酶延伸的能力;(ii)拓扑学上制备用于dna合成的双链体核酸的能力;和(iii)reca/寡核苷酸或reca/多核苷酸复合物有效发现并结合互补序列的能力。最佳表征的reca蛋白来自大肠杆菌(e.coli);除了蛋白质的原始等位形式外,已经鉴定了许多突变体reca样蛋白,例如reca803。此外,许多生物体具有reca样链转移蛋白,包括例如酵母,果蝇,包括人的哺乳动物和植物。这些蛋白质包括例如reel,rec2,rad51,rad51b,rad51c,rad51d,rad51e,xrcc2和dmc1。重组蛋白的实施方案是大肠杆菌的reca蛋白。或者,reca蛋白可以是大肠杆菌的突变体reca-803蛋白,来自另一细菌来源的reca蛋白或来自另一生物体的同源重组蛋白。
组合物和试剂盒
本发明还提供了组合物和试剂盒,其含有例如编码位点特异性内切核酸酶,crispr,cas9,znf,talen,reca-gal4融合体的核酸分子,其多肽,含有此类核酸分子或多肽的组合物,或工程化细胞系。还可以提供对指定的等位基因的渐渗有效的hdr。此类物品可以用作例如研究工具或治疗性使用。
实施例
方法如下,除非另有说明。
组织培养和转染。
在37℃在5%co2在补充有10%胎牛血清,100i.u./ml青霉素和链霉素和2mml-谷氨酰胺的dmem中保持猪。对于转染,使用neon转染系统(lifetechnologies)通过转染递送所有talen和hdr模板。简言之,将达到100%汇合的低传代ossabaw,landrace以1:2分开,并次日在70-80%汇合时收获。每次转染由悬浮于与talenmrna和寡核苷酸混合的缓冲液“r”中的500,000-600,000个细胞组成,并使用100μl尖端进行电穿孔,所述尖端通过以下参数提供100μl工作体积:输入电压;1800v;脉冲宽度;20ms;和脉冲数;1。通常,在每次转染中包括1-2μgtalenmrna和1-4μm特异于感兴趣基因的hdr模板(单链寡核苷酸)。在图和图例中指出了与那些量的偏差。转染后,将细胞接种在6孔皿的孔中三天,并在30℃下培养。三天后,将细胞群体铺板用于集落分析和/或扩增,并在37℃,直至至少第10天以评估编辑的稳定性。surveyor突变检测和rflp分析。
使用具有1μl细胞裂解物的platinumtaqdna聚合酶hifi(lifetechnologies)根据制造商的推荐进行位于预期位点侧翼的pcr。使用surveyor突变检测试剂盒(transgenomic)根据制造商的推荐使用10μl如上所述的pcr产物分析群体中的突变频率。使用所示的限制酶对10μl的上述pcr反应进行rflp分析。surveyor和rflp反应在10%tbe聚丙烯酰胺凝胶上解析并通过溴化乙啶染色显现。使用imagej进行条带的光密度测定法测量;并如guschin等,2010(1)中所述计算surveyor反应的突变率。通过将rflp片段的总强度除以亲本带+rflp片段的总强度来计算同源性指导修复(hdr)百分比。类似地处理集落的rflp分析,除了pcr产物通过1xmytaqredmix(bioline)扩增并在2.5%琼脂糖凝胶上解析。
稀释克隆。
转染后三天,将50至250个细胞接种在10cm皿上并培养直到个体集落直径达到约5mm。此时,加入用pbs稀释的6mltryple(lifetechnologies)1:5(vol/vol),抽吸集落,转移到24孔皿的孔中并在相同条件下培养。收集到达汇合的集落并分开用于冷冻保存和基因型分型。
样品制备。
从6孔皿的孔中收集第3和10天的转染细胞群体,并将10-30%重悬于50μl1xpcr相容性裂解缓冲液:10mmtris-clph8.0,2mmedta,0.45%trytonx-100(vol/vol),0.45%tween-20(vol/vol),新鲜补充有200μg/ml蛋白酶k。使用以下程序在热循环仪中处理裂解物:55℃60分钟,95℃15分钟。如上使用20-30μl裂解缓冲液处理来自稀释克隆的集落样品。
实施例1:多重基因编辑
将针对猪rag2和il2rγ的talenmrna和hdr模板的六种条件共转染到猪成纤维细胞中。每个转染使用固定量的rag2mrna和模板,而对于每种条件如指定的改变il2rgtalenmrna和hdr模板的量。talenmrna和hdr模板的剂量具有中靶和脱靶效应两者。il2rγ的talenmrna的增加导致il2rγ的nhej和hdr两者的增加,而rag2的nhej水平不变。il2rγhdr模板的增加降低rag2基因座处的hdr,表明通过升高寡核苷酸浓度对同源性指导修复的非特异性抑制。从两种条件以4%和2%获得了在rag2和il2rγ处具有双等位hdr的集落(图3小图c,小图d),其处于和高于预期的2%的频率。预期频率通过将每个hdr等位基因作为独立事件处理的第3天hdr水平的乘法计算。参照图3,猪rag2和il2rγ的多重基因编辑。a)surveyor和rflp分析以在转染后3天对细胞群体测定非同源末端连接(nhej)和同源性依赖性修复hdr的效率。b)转染后11天对细胞群体的同源性依赖性修复的rflp分析。c)il2rγ,rag2或两者上hdr阳性集落的百分比。从小图a中以“c”所示的群体中铺板细胞。集落基因型的分布如下所示。d)来自用对于il2rγ和rag2为2和1μgtalenmrna量和每种为1μm的hdr模板转染的细胞的集落分析。集落基因型的分布如下所示。
实施例2:多重基因编辑
将针对猪apc和p53的talenmrna和hdr模板的四种条件共转染到猪成纤维细胞中。apcmrna的量从左到右序贯减少(图4小图b);剩余的量如所示保持恒定。百分比hdr以线性方式随apcmrna减少而减少。apctalen的改变的剂量对p53hdr几乎没有影响。集落的基因型分型揭示了相对于第11天值,在apc和p53两者中具有hdr等位基因的克隆的高于预期的联合;对于图4小图c和图4小图d分别为18和20%对13.7和7.1%。参照图4,猪apc和p53的多重基因编辑。小图a)surveyor和rflp分析以在转染后3天对细胞群体测定非同源末端连接(nhej)和同源性依赖性修复hdr的效率。小图b)转染后11天对细胞群体的同源依赖性修复的rflp分析。小图c)和d)源自指定细胞群体(在小图a,“c”和“d”中指示)的apc,p53或两者处hdr的阳性集落的百分比。具有3个或更多个hdr等位基因的集落在下面列出。
实施例3:具有至少三种基因的多重
在实施例1中,在hdr寡聚物的高浓度下观察到hdr的非特异性降低,因此不知道2+hdr寡聚物在没有hdr的非特异性抑制的情况下是否可以有效。测试两种浓度,对于每种靶位点为1μm和2μm。尽管talen活性在两种条件之间没有显著改变,但是对于每种模板,hdr在2μm浓度显著钝化。源自1um条件的克隆具有多种基因型,那些中的一些在每个基因中具有编辑并且具有多达7种等位基因(图6)。如果作为独立事件处理,以“a”表示的基因型的预期频率(编辑7种等位基因)为0.001%。二项分布预测在72个样本大小中鉴定此类基因型的2+集落的可能性(如本文中完成)小于0.000026%。此高成功率是无法预测的,并且是意想不到的且令人惊讶的。该结果用talen/hdr模板的两种添加组合重复(图7和8)。与第一次试验的结果一样,用直至7种等位基因和直至四种基因中的hdr编辑获得了集落(表a)。以远远大于偶然预期的频率回收几种基因型。虽然关于在几个基因座处的同时双链断裂的关注是非预期的染色体重排的诱导,从试验3细胞测试的50个核型中的50个是正常的(数据未显示)。
参照图5:寡核苷酸hdr模板浓度对5基因多重hdr效率的影响。将指示量的针对猪rag2,il2rg,p53,apc和ldlr的talenmrna与2um(图a)或1um(图b)每种关联hdr模板一起共转染到猪成纤维细胞中。通过surveyor和rflp测定法测量百分比nhej和hdr。参照图6:来自5-基因多重hdr的集落基因型。通过rflp分析评价集落基因型。小图a)每条线代表一个集落在每个规定的基因座处的基因型。可以鉴定三种基因型;具有杂合或纯合的hdr的预期rflp基因型的那些以及具有rflp阳性片段的那些,加上具有指示插入或缺失(indel)等位基因的大小的可见变化的第二等位基因。在每列下面指示在规定基因座处具有编辑的集落的百分比。小图b)在0-5个基因座处编辑的集落数的计数。参照图7:第二个5-基因多重试验的集落基因型。小图a)每条线代表在每个规定基因座处的一个集落的基因型。可以鉴定三种基因型;具有杂合或纯合的hdr的预期rflp基因型的那些以及具有rflp阳性片段的那些,加上具有指示插入或缺失(indel)等位基因的大小的可见变化的第二等位基因。在每列下面指示在规定基因座处具有编辑的集落的百分比。小图b)在0-5个基因座处编辑的集落数的计数。参照图8:集落基因型第三次5-基因多重试验。小图a)每条线代表在每个规定基因座处的一个集落的基因型。可以鉴定三种基因型;具有杂合或纯合的hdr的预期rflp基因型的那些以及具有rflp阳性片段的那些,加上具有指示插入或缺失(indel)等位基因的大小的可见变化的第二等位基因。在每列下面指示在规定基因座处具有编辑的集落的百分比。小图b)在0-5个基因座处编辑的集落数的计数。
实施例4a-4dd
实施例4a:通过多重基因编辑形成rag2/il2rg无效(rg-ko)猪成纤维细胞。
使用本发明人先前确定的方法(tan,w.等人,efficientnonmeioticalleleintrogressioninlivestockusingcustomendonucleases.pnas,110(41):16526-16531,2013.),用talen和寡核苷酸模板转染雄性猪胎儿成纤维细胞以破坏rag2和il2rg。通过例如限制性长度多态性(rflp)来鉴定rg-ko候选物,如通过测序确认。将至少约5个经验证的rg-ko集落作为克隆和嵌合体生产的资源汇集。
实施例4b:使用rg-ko宿主胚泡产生嵌合胚胎。
使用染色质转移技术,随后体外培养至胚泡期产生宿主rg-ko胚胎和雌性egfp标记的供体细胞。可以使用来自实施例1的rg-ko细胞。将来自egfp胚泡的第7天细胞团块(inercellmassclump)注入到第6天rg-ko胚胎中,之后胚胎转移到同步的母猪。使用此种方法,nagashima和同事在>50%的活产仔猪中观察到嵌合现象(nagashima,h.等人,sexdifferentiationandgermcellproductioninchimericpigsproducedbyinternalcellmassinjectionintoblastocysts.biolreprod,70(3):702-707,2004)。雄性表型在小鼠和猪两者的注射嵌合体中是显性的。因此,注射有雌性供体细胞的xyrg-ko宿主将仅传递雄性宿主遗传学。妊娠检查将在适当的时间进行,例如第25,50和100天。每天监测妊娠约100天的妊娠母猪4次,之后到第114天,进行仔猪的剖腹产导出。
实施例4c:测定非嵌合后代是否是t,b和nk细胞缺陷的。
测试非嵌合后代以确定它们是否是t,b和nk细胞缺陷的。以下处理是用于其的一种技术。将对每只携带推定嵌合体的母猪和一只携带野生型仔猪的育种母猪进行剖腹产导出。在剖腹产导出后立即从每只仔猪中分离脐带血。通过荧光激活细胞分选(facs)对脐带血白细胞评估t,b和nk细胞群体以及供体来源的egfp表达。此外,通过pcr从脐带血,耳和尾活检中进行评估嵌合现象。此初始分析将在出生的6小时内完成,使得非嵌合仔猪可以用感染体征密切监测和人道地实施安乐死。对非嵌合动物的一部分,或缺乏免疫细胞的动物实施安乐死以进行尸体剖检。
实施例4d:鉴定嵌合猪并且测定t,b和nk细胞的起源。
测试嵌合猪以测定t,b和nk细胞的起源。以下处理是用于其的一种技术。使用上述方法鉴定嵌合仔猪。在2个月时段内,将在嵌合,非嵌合和野生型仔猪之间比较循环淋巴细胞和血清免疫球蛋白的每周评价。将评估分选的t,b和nk细胞群体的egfp表达和微卫星分析以确认供体起源。rci支持来自嵌合猪的样品和精液收集的维持,直到第二阶段资金可用。
实施例a-d的样品程序:
脐带和外周血facs
如前(2)所述,在适应猪标本的情况下进行猪淋巴细胞和egfp嵌合现象的评价。在剖腹产分娩后立即从每只仔猪收集脐带血。脐带血的一部分将被处理和冷冻保存用于潜在的同种异体移植物处理,而其余部分将用于淋巴细胞的facs分析。通过标准方法在2,4,6和8周龄收集外周血样品。取出rbc,并且将约1-2e+5个细胞分配到管中。用抗猪抗体标记等分试样以鉴定t细胞(cd4和cd8),b细胞(cd45ra和cd3),nk细胞(cd16和cd3)和髓样细胞(cd3)。抗原表达将在lsrii流式细胞仪(bdbiosciences)上定量。将仔细选择荧光团以能够与表面抗原一起多重评估供体衍生的egfp细胞。通过相同的方法分析来自脾的单细胞悬浮液。
检查
对所有主要器官和组织肉眼(grossly)检查适当的解剖学形成,并且收集来自所有主要器官和组织的合适的样品,包括胰腺,肝,心脏,肾,肺,胃肠,免疫系统(外周和粘膜淋巴结和脾),和cns的适当样品,用于dna分离。将从脾制备单细胞悬浮液用于facs分析。将制备组织用于组织学检查以进一步评估嵌合现象以及可能与嵌合状态相关的任何改变和任何潜在疾病的存在。
嵌合现象的评估。
使用egfp转基因特异性的引物在脐带血,耳和尾活检上进行定量pcr,并与具有egfp与野生型细胞的已知比率的标准曲线进行比较。还通过先前所述的rflp测定来评价样品的rg-ko等位基因。在尸体剖检期间对整个动物和器官宏观评估egfp+细胞的植入。将来自主要器官的组织切片用于egfp免疫组织化学,并用dapi(4’,6-二脒基-2-苯基吲哚)复染以测定供体与宿主细胞的比率。
微卫星分析。
从我们实验室常规使用的那些中,对动物筛选宿主和供体遗传学的信息性微卫星。评价来自组织和血液的样品(分选的淋巴细胞或髓样谱系,egfp阳性和阴性)。通过miseq仪器(illumina)上的多重化扩增子测序来评估供体对宿主细胞的相对量。
动物。
制备非嵌合猪,其在脊髓和外周血中不存在t,b和nk细胞。嵌合猪具有的水平基本上类似于几乎野生型的水平。此外,t,b和nk细胞阳性嵌合体将具有基本正常的免疫功能,并且在标准条件下饲养时保持健康。
实施例5crispr/cas9设计和产生。
将基因特异性grna序列根据其方法克隆入church实验室grna载体(addgeneid:41824)。通过共转染hcas9质粒(addgeneid:41815)或从rciscript-hcas9合成的mrna提供cas9核酸酶。通过将来自hcas9质粒(涵盖hcas9cdna)的xbai-agei片段亚克隆到rciscript质粒中构建该rciscript-hcas9。如上所述进行mrna的合成,除了使用kpni进行线性化外。
实施例6用靶向内切核酸酶和hdr的多重基因编辑。小图(a)是多重实验中的每个基因的示意图(描述为由交替阴影表示的cdna-外显子),并且指示talen靶向的位点。编码每个基因的dna结合域的序列如下所示。用1μg每种talenmrna和0.1nmol每种hdr寡聚物(图12小图b)(靶向每个基因,设计用于插入提前终止密码子以及新的hindiiirflp位点,用于基因型分型)共转染猪成纤维细胞。分离总共384个集落用于基因型分型。进行gata4和nkx2-5rflp测定法(图12小图c),并通过测序评价mesp1(未显示)。两个集落(2/384,0.52%)是所有三种基因的纯合hdr敲除。用星号标记三重敲除(图12小图c)。在小图c中可以观察到另外的基因型,实例为没有hdr编辑的集落49;具有对nkx2-5的杂合编辑的集落52和63;对nkx2-5和gata4两者具有杂合编辑的集落59,等等。
实施例7使用talen和rgen的组合的多重基因编辑。参见图13。对于每个基因,用talens(1μgeif4g14.1mrna)+cas9/crispr组分(2μgcas9mrna+2μgp65gls引导rna)和02nmolhdr寡聚物共转染猪成纤维细胞。通过rflp测定评价转染的细胞,揭示了两个位点处的hdr。将来自该群体的细胞铺板用于集落分离,并鉴定在两种基因中具有编辑的隔离群。
进一步公开
本文中提及的专利,专利申请,出版物和文章通过引用并入本文;在冲突的情况下,以本说明书为准。实施方案具有各种特征;这些特征可以根据需要产生功能实施方案的引导而混合和匹配。标题和副标题是为了方便而提供的,但不是实质性的并且不限制所描述的范围。以下编号的陈述呈现本发明的实施例:
1a.在脊椎动物细胞或胚胎中在多个靶染色体dna位点处进行遗传编辑的方法,其包括:
对脊椎动物细胞或胚胎中导入:
针对第一靶染色体dna位点的第一靶向内切核酸酶和与所述第一靶位点序列同源的第一同源性指导修复(hdr)模板;和
针对第二靶染色体dna位点的第二靶向内切核酸酶和与所述第二靶位点序列同源的第二hdr模板,
其中所述第一hdr模板序列替换所述第一靶位点处的天然染色体dna序列,并且所述第二hdr模板序列替换所述第二靶位点序列处的天然染色体dna序列。
1b.编辑动物的多种等位基因的方法,其包括
对原代家畜细胞或家畜胚胎中导入多种各自靶向不同等位基因基因座的靶向核酸酶和每种靶向的等位基因基因座的同源性指导修复模板,
其中所述靶向内切核酸酶在与所述多种靶向内切核酸酶之每种关联的等位基因基因座中进行双链断裂,并且其中所述细胞将同源性指导的修复(hdr)模板核酸序列复制到与每种hdr模板关联的基因座中,从而编辑所述等位基因。
2.1中任一项的方法,其进一步包括:
对所述细胞或胚胎中导入下列一项或多项:
分别针对第三,第四,第五,第六和第七靶染色体dna位点的第三,第四,第五,第六和第七靶向内切核酸酶,和
分别与所述第三,第四,第五,第六和第七靶染色体dna位点同源的第三,第四,第五,第六和第七hdr模板。
3.1-2中任一项的方法,其中所述靶向内切核酸酶包含talen。
4.1-3中任一项的方法,其中所述靶向内切核酸酶包含锌指核酸酶或cas9。
5.1-4中任一项的方法,其中至少所述第一靶染色体dna位点是等位基因的基因座。
6.5的方法,其中至少一种所述hdr模板编码与所述模板关联的dna靶位点的敲除。
7.5的方法,其中至少一个所述hdr模板编码用于替换与所述模板关联的dna靶位点处的等位基因的外源等位基因。
8.1的方法,其中所述细胞或胚胎是家畜的第一物种或第一品种,并且多个所述编辑包括用来自动物的第二物种或第二品种的外源等位基因替换天然等位基因。
9.1的方法,其中所述动物是至少三个天然等位基因被第二品种或另一物种的相应外源等位基因替换的动物的第一品种,所述外源等位基因是在没有减数分裂重组的情况下相应的天然等位基因的替换,其中所述动物不含外源标志物基因。
10.2的方法,其中至少三个,四个,五个,六个或七个靶染色体dna位点各自是不同等位基因的基因座。
11.10的方法,其中hdr模板中的一个或多个编码与模板关联的dna靶位点的敲除。
12.10的方法,其中所述hdr模板中的至少一个编码用于替换与模板关联的dna靶位点处的等位基因的外源等位基因。
13.1-12中任一项的方法,其中所述细胞或胚胎在靶dna位点处的多个基因编辑方面是纯合的,所述编辑由与所述靶dna位点关联的hdr模板编码。
14.1-12中任一项的方法,其中所述细胞或胚胎在靶dna位点处的多个基因编辑方面是杂合的,所述编辑由与所述靶dna位点相关的hdr模板编码。
15.11-14中任一项的方法,其中所述基因编辑包括敲除或来自动物的另一种品种或动物的另一种物种的等位基因的渐渗。
16.11-14中任一项的方法,其中所述细胞或胚胎是家畜的第一物种或第一品种,并且多个编辑包括用来自动物的第二物种或第二品种的外源等位基因替换天然等位基因。
17.16的方法,其中所述外源等位基因和天然等位基因的dna序列在一个或多个位置处不同,其中用外源等位基因替换天然等位基因使得细胞或胚胎的染色体dna序列在任何所述位置的每侧的至少200个碱基对(bp)的距离方面与动物的第二品种或第二物种相同,如通过所述位置间的比对测量。
18.17的方法,其中所述距离是200和2000bp之间的数目。
19.1-17中任一项的方法,其中所述细胞或胚胎在靶dna位点处的多个基因编辑方面是纯合的,所述编辑由与所述靶dna位点关联的hdr模板编码。
20.1-17中任一项的方法,其中所述细胞或胚胎在靶dna位点处的多个基因编辑方面是杂合的,所述编辑由与所述靶dna位点关联的hdr模板编码。
21.1-20任一项的方法,其中所述细胞或胚胎选自大型脊椎动物,家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,绵羊和偶蹄动物。
22.1-21中任一项的方法,所述细胞选自下组:合子,干细胞,成体干细胞,多能细胞,祖细胞和原代细胞。
23.1-21中任一项的方法,其中所述胚胎是合子,胚泡,桑椹胚或具有1-200个细胞数。
24.1-23中任一项的方法,其包括导入编码一种或多种内切核酸酶的mrna和/或一种或多种hdr模板。
25.1-24中任一项的方法,其中将一种或多种内切核酸酶作为蛋白质导入细胞或胚胎中。
26.1-25中任一项的方法,其中
将一种或多种(例如,每种)内切核酸酶作为mrna提供并从浓度为0.1ng/ml至100ng/ml的溶液导入细胞或胚胎中;技术人员将立即认识到,在明确规定的限度内的所有值和范围是预期的,例如约20,约1至约20,约0.5至约50;等等;和/或
将一个或多个(例如,每个)hdr模板作为mrna提供并从具有约0.2μm至约20μm的浓度的溶液导入细胞或胚胎中。
27.1-26中任一项的方法,其包括用于导入内切核酸酶和/或hdr模板的电穿孔。
28.1-27中任一项的方法,其中所述内切核酸酶和/或hdr通过选自基于化学的方法,非化学方法,基于颗粒的方法和病毒方法的方法导入。
29.13-28中任一项的方法,其包括将一种或多种载体导入所述细胞或胚胎中以表达所述内切核酸酶和/或所述hdr模板。
30.1-29中任一项的方法,其中所述靶向内切核酸酶是talen或crispr,或talen和crispr的组合。
31.30的方法,其中所述编辑是基因敲除。
32.1-31中任一项的方法,其中一种或多种靶位点序列选自下组,或者其中一种或多种外源等位基因或天然等位基因选自下组:il2rgy/-,rag2-/-,il2rg-/-;rag2-/-,il2rgy/-,rag2-/-,il2rg+/-,rag2+/-,il2rgy/+,rag2+/-,il2rg+/-,rag2+/-;dgat(甘油二酯酰基转移酶),abcg2(atp结合盒亚家族g成员2),acan(聚集蛋白聚糖),amely(牙釉蛋白,y-连锁),blg(孕激素相关子宫内膜蛋白),bmp1b(fecb)(骨形态发生蛋白受体,1b型),dazl(无精子症样中的缺失),eif4gi(真核翻译起始因子4γ,1),gdf8(生长/分化因子8),horn-poll基因座,igf2(胰岛素样生长因子2),cwc15(cwc15剪接体相关蛋白),kissr/grp54(kisspeptin),ofd1y(y-连锁口-面-趾综合征1假基因),p65(v-rel网状内皮组织增生病毒癌基因同源物a),prlr(催乳素受体),prmd14(pr域containtin14),prnp(朊病毒蛋白),rosa,socs2(细胞因子信号传导抑制物2),sry(chry的性别决定区),zfy(锌指蛋白,y-连锁),β-乳球蛋白,callipyg(clpg),mody1(hnf4α)(肝细胞核因子4,α),mody2(gck)(葡萄糖激酶),mody3(hnf1α)(肝细胞核因子4,α),mody4(pdx1)(胰腺和十二指肠同源盒1),mody5(hnf-1β)(hnf1同源框b),mody6(eurogenic分化1),mody7(klf11)(kruppel样因子11),mody8(cel)(羧基酯脂肪酶),mody9(pax4)(配对框4),mody10(ins)(胰岛素),mody11(blk)(blk原癌基因,src家族酪氨酸激酶),apc(腺瘤性结肠息肉病),apoe(载脂蛋白e),dmd(肌营养不良蛋白肌营养不良),ghrhr生长激素释放激素受体),hr(毛发生长相关),hsd11b2(羟基类固醇(11-β)脱氢酶2),ldlr(低密度脂蛋白受体),nf1(神经纤维瘤蛋白1),nppa(利尿钠肽a),nr3c2(核受体亚家族3,c组,组成2),p53(细胞肿瘤抗原p53样),pkd1(多囊肾疾病1),rbm20(rna结合基序蛋白20),scnn1g(钠通道,非电压门控1γ亚基),tp53(肿瘤蛋白p53),fah(延胡索酰乙酰乙酸水解酶),hbb(血红蛋白β),il2rg(白介素2受体,γ链),pdx1(胰腺和十二指肠同源框1),pitx3(成对样同源结构域转录因子3),runx1(runt相关转录因子1),ggta(双功能性头孢菌素酰酶/γ-谷氨酰转肽酶),vasa(导管蛋白),miwi(piwi样rna介导的基因沉默1),piwi(来自转录物cg6122-ra的cg6122基因产物),dcaf17(ddb1和cul4相关因子17),vdr(维生素d受体),pnpla1(含有patatin样磷脂酶结构域1),hras(harvey大鼠肉瘤病毒癌基因同源物),端粒末端转移酶-vert,dsp(桥粒斑蛋白(desmoplakin)),snrpe(小核核糖核蛋白多肽e),rpl21(核糖体蛋白),lama3(层粘连蛋白,α3),urod(尿卟啉原脱羧酶),edar(外胚层a受体),ofd1(口-面-指综合征1),pex7(过氧化物酶体生物合成因子7),col3a1(胶原,iii型,α1),alox12b(花生四烯酸盐120脂氧合酶12r型),hlcs(羧化全酶合成酶(生物素-(丙酰-coa-羧化酶)atp水解))连接酶)),nipal4(含有nipa样结构域4),cers3(神经酰胺合酶3),antxr1(炭疽毒素受体1),b3galt6(udp-gal:βga1β1,3-半乳糖基转移酶多肽6),dsg4(桥粒芯糖蛋白4),ubr1(泛素蛋白连接酶e3组分n-识别蛋白1),ctc1(cts端粒维持复合物组分1),mbtps2(膜结合转录因子肽酶,位点2),uros(尿卟啉原iii合酶),abhd5(含有abhydrolase域5),nop10(nop10核糖核蛋白),alms1(alstrom综合征蛋白1),lamb3(层粘连蛋白,β3),eogt(egf结构域特异性o-连接的n-乙酰葡糖胺(glcnac)),sat1(精胺/精胺n1乙酰转移酶1),rbpj(免疫球蛋白κj区的重组信号结合蛋白),arhgap31(rhogtp酶活化蛋白31),acvr1(活化素a受体,i型),ikbkg(b细胞中的κ轻链多肽基因增强子抑制剂,激酶γ),lpar6(溶血磷脂酸受体6),hr(毛发生长相关),atr(atr丝氨酸/苏氨酸激酶),htra1(htra丝氨酸肽酶1),aire(自身免疫调节剂),bcs1l(bc1(泛醇-细胞色素c还原酶)合成样),mccc2(甲基巴豆酰-coa羧化酶2(β)),dkc1(先天性角化病变1,dyskerin),porcn(猪同源物),ebp(依莫帕米结合蛋白(固醇异构酶)),slitrk1(slit和ntrk样家族,成员1),btk(bruton丙种球蛋白缺乏血症酪氨酸激酶),dock6(细胞因子奉献者6(dedicatorofcytokinesis6)),apcdd1(腺瘤性结肠息肉病下调1),zip4(锌转运蛋白4前体),casr(钙感测受体),tert(端粒末端转移酶逆转录酶),edaradd(edar(ectodysplasin-a受体))相关的死亡结构域),atp6v0a2(atp酶,h+转运,溶酶体v0亚基a2),pvrl1(脊髓灰质炎病毒受体相关1(疱疹病毒进入介质c)),mgp(基质gla蛋白),krt85(角蛋白85,ii型),rag2(重组激活基因2),rag-1(重组激活基因1),ror2(受体酪氨酸激酶样孤独受体2),claudi1(claudin7),abca12(atp结合盒,亚家族a(abc1),成员12),sla-dra1(mhcii类dr-α),b4galt7(木糖基蛋白β1,4-半乳糖基转移酶,多肽7),col7a1(胶原vii型,α1),nhp2(nhp2核糖核蛋白),gna11(鸟嘌呤核苷酸结合蛋白(g蛋白),α11(gq类)),wnt5a(无翅型mmtv整合位点家族成员5a),usb1(u6snrna生物发生1),lmna(lamina/c),eps8l3(eps8样3),nsdhl(nad(p)依赖性类固醇脱氢酶样),trpv3(瞬时受体电位阳离子通道亚家族v,成员3),kras(kirsten大鼠肉瘤病毒癌基因同源物),tinf2(terf1-相互作用核因子2),tgm1(转谷氨酰胺酶1),dclreic(dna交联修复1c),pkp1(plakophilin1),wrap53(含有wd重复与tp53反义),kdm5c(赖氨酸(k)特异性脱甲基酶5c),ecm1(细胞外基质蛋白1),tp63(肿瘤蛋白p63),krt14(角蛋白14),ripk4(受体相互作用丝氨酸-苏氨酸激酶4),prkdc(蛋白激酶,dna活化的,催化多肽),bcl11a(b-细胞cll/淋巴瘤11a(锌指蛋白)),bmi1(bmi1原癌基因,多梳环指),ccr5(趋化因子(cc基序)受体5(基因/假基因)),cxcr4(趋化因子(c-x-c基序)受体4),dkk1(dickkopfwnt信号传导途径抑制剂1),etv2(ets变体2),flu(fli-1原癌基因,ets转录因子),flk1(激酶插入结构域受体),gata2(gata结合蛋白2),gata4(gata结合蛋白4),hhex(造血表达同源盒),kit(kit癌基因),lmx1a(lim同源框转录因子1α),myf5(肌原性因子5),myod1(肌原性分化1),myog(肌形成蛋白),nkx2-5(nk2同源框5),nr4a2(核受体亚家族4,a组,成员2),pax3(配对框3),pdx1(胰腺和十二指肠同源盒1),pitx3(配对样同源结构域转录因子3),runx1因子(runt-相关转录因子1),rag2(重组激活基因2),ggta(双功能头孢菌素酰酶/γ-谷氨酰转肽酶),handii(心脏和神经嵴衍生物表达蛋白2),tbx5(t框5),etv2(ets变体2),pdx1(胰腺和十二指肠同源盒1),tbx4(t盒4),id2(dna结合抑制剂2),sox2(sry(性别决定区y)-盒2),ttf1/nkx2-1(nk2同源框1),mesp1(中胚层后部1),nkx2-5(hk2同源盒5),fah(烟酰基乙酰乙酸水解酶),prkdc(蛋白激酶,dna活化的,催化多肽),runx1(runt相关转录因子1),fli1(fli-1原癌基因,ets转录因子),pitx3(配对样同源结构域转录因子3),lmx1a(lim同源盒转录因子1α),dkk1(dickkopfwnt信号传导途径抑制剂1),nr4a2/nurr1(核受体亚家族4,a组,成员2),flk1(激酶插入结构域受体),hhex1(造血表达同源框蛋白hhex),bcl11a(b细胞cll/淋巴瘤11a(锌指蛋白),rag2(重组激活基因2),rag1(重组激活基因1),il2rg(白介素2受体,γ链),c-kit/scfr(v-kithardy-zuckerman4猫肉瘤病毒癌基因同源物),bmi1(bmi1原癌基因多梳环指),tbx5(t框5),olig1(少突胶质细胞转录因子1),olig2(少突胶质细胞转录因子2),它们的杂合子,纯合子及它们的组合。
33.在原代脊椎动物细胞或胚胎中做出多重基因敲除的方法,其包括在与不同靶基因具有同源性的hdr模板存在下,将靶向所述不同靶基因的多种talen导入细胞或胚胎中。
34.制备包含1-33中任一项的动物并且还包括克隆所述细胞或将所述胚胎置于妊娠母体中的方法。
35.通过1-34中任一项的方法制备的动物。
36.通过1-34中任一项的方法制备的嵌合胚胎或动物,其中所述细胞被编辑并且还包括克隆所述细胞,从所述细胞制备宿主胚胎,以及将供体细胞添加到所述宿主胚胎以形成嵌合胚胎。
37.在宿主细胞和供体细胞方面嵌合的脊椎动物胚胎,其包含
在不同染色体dna位点处具有多个宿主细胞遗传编辑的宿主胚胎,和
与宿主细胞整合以形成嵌合胚胎的供体细胞。
38.脊椎动物缺陷载体,其包含在不同染色体dna基因位点处具有多个多重遗传编辑的胚胎,所述编辑提供用于由供体细胞互补的遗传小生境。
39.37-38中任一项的胚胎或载体,其中所述供体细胞是来自灵长类,啮齿动物或偶蹄动物的胚胎干细胞,多能干细胞,卵裂球等。
40.37-39中任一项的胚胎,其中所述宿主或载体细胞遗传编辑包括敲除基因或或用脊椎动物的另一种品种或动物的另一种物种的外源等位基因替换天然等位基因。
41.37-41中任一项的胚胎,其中多个宿主细胞遗传编辑是或至少为2,3,4,5,6或7个。
42.37-41中任一项的胚胎,其中多个用脊椎动物的另一种品种或动物的另一种物种的外源等位基因替换天然等位基因是,或者至少是2,3,4,5,6,或7个。
43.37-42中任一项的胚胎,其中所述胚胎不含可表达的报告基因和/或合成基因和/或外源荧光蛋白。
44.37-43中任一项的胚胎,其中所有基因编辑是双等位的,所述编辑中的至少2,3,4或5个是双等位的,其中所述基因编辑的至少2,3,4或5个是单等位的,或其任何组合。
45.37-44中任一项的胚胎,其中供体细胞是宿主细胞的互补物。
46.37-45中任一项所述的胚胎,其中所述宿主胚胎注定为长势不能(ftt)表型。
47.46的胚胎,其中供体细胞从ftt表型拯救胚胎。
48.37-47中任一项的胚胎,其中所述供体细胞包含一种或多种遗传编辑。
49.37-47中任一项的胚胎,其选自下组:大型脊椎动物,家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,山羊,绵羊和偶蹄动物。
50.在宿主细胞和供体细胞方面嵌合的脊椎动物,其包含在不同染色体dna位点处的多个宿主细胞遗传编辑,以及与宿主细胞整合以形成嵌合动物的供体细胞。
51.50的动物,其选自下组:大型脊椎动物,家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,山羊,绵羊和偶蹄动物。
52.制备在宿主细胞和供体细胞方面嵌合的脊椎动物胚胎的方法,包括:
对宿主脊椎动物细胞中导入:
针对第一靶染色体dna位点的第一靶向内切核酸酶和与所述第一靶位点序列同源的第一同源性指导修复(hdr)模板;和
针对第二靶染色体dna位点的第二靶向内切核酸酶和与所述第二靶位点序列同源的第二hdr模板,
其中所述第一hdr模板序列替换所述第一靶位点处的天然染色体dna序列,并且所述第二hdr模板序列替换所述第二靶位点序列处的天然染色体dna序列,
克隆所述细胞以形成宿主胚胎,并且
将供体细胞置于所述宿主胚胎中。
53.52的方法,其中所述细胞是原代细胞。
54.52-53中任一项的方法,其选自下组:大型脊椎动物,家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,山羊,绵羊和偶蹄动物。
55.1-54中任一项的方法,细胞,胚胎或动物,其不含可表达的报告基因和/或合成基因和/或外源荧光蛋白。
56.包含宿主细胞和供体细胞的嵌合大型脊椎动物,其中所述宿主细胞包含对由所述供体细胞的基因互补的配子发生或精子发生基因的至少一个非减数分裂基因编辑,其中所述动物包括具有所述供体细胞的基因型的配子。
57.56的动物,其不含具有宿主细胞基因型的功能性配子。
58.包含宿主细胞和供体细胞的嵌合大型脊椎动物,其中所述宿主细胞包含至少一个非减数分裂基因编辑以建立长势不能(ftt)宿主细胞基因型,其中所述ftt基因型由所述供体细胞互补。
59.58的动物,其中所述宿主细胞包含建立长势不能(ftt)宿主细胞基因型的多个非减数分裂基因编辑。
60.58或59中任一项的动物,其中ftt表型是免疫缺陷。
61.大型脊椎动物,其包含多种基因编辑。
62.61的动物,所述动物是猪的第一品种或牛的第一品种,其具有用第二品种或另一种物种的相应外源等位基因替换的至少三种天然等位基因,所述外源等位基因是在没有减数分裂重组的情况下相应天然等位基因的替换,其中动物没有外源标志物基因。
63.61或62的动物,其包含至少3、4、5、6、或7种所述外源替换等位基因,每种没有减数分裂重组。
64.61-63中任一项的动物,其选自下组:家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,山羊,绵羊和偶蹄动物。
65.61-64中任一项的动物,其具有3至25的编辑数目。
66.61-65中任一项的动物,其是就多重编辑而言的f0世代。
67.61-66中任一项的动物,其具有2-25的等位基因替换数目。
68.61-67中任一项的动物,其具有2-25的ko基因编辑的数目
69.61的动物,所述动物是猪的第一品种或牛的第一品种,其具有用第二品种或另一种物种的相应外源等位基因替换的至少三种天然等位基因,所述外源等位基因是在没有减数分裂重组的情况下相应天然等位基因的替换,其中动物没有外源标志物基因。
70.69的动物,其包含至少3、4、5、6、或7种所述外源替换等位基因,每种没有减数分裂重组。
本发明还提供以下内容:
1.包含多重基因编辑的大型脊椎动物。
2.项1的动物,所述动物是牛的第一品种或猪的第一品种,所述动物具有用第二品种或另一物种的相应的外源等位基因替换的至少三种天然等位基因,所述外源等位基因是没有减数分裂重组的相应天然等位基因的替换,其中所述动物不含外源标志物基因。
3.项2的动物,其中所述三种等位基因中的每种用于三种不同基因。
4.项2或3的动物,所述动物包含至少三种,四种,五种,六种或七种所述外源替换等位基因,各自没有减数分裂重组。
5.项1的动物,所述动物是具有用第二品种或另一物种的相应外源等位基因替换的至少两种天然等位基因的第一动物,所述外源等位基因是没有减数分裂重组的相应的天然等位基因的替换。
6.项1-5中任一项的动物,所述动物包含3-25的等位基因替换数目或包含2-25的敲除基因编辑数目。
7.项1-6中任一项的动物,其中所述基因编辑包括纯合编辑,杂合编辑或其组合。
8.项1-7中任一项的动物,所述动物是来自宿主动物的宿主细胞和来自供体动物的供体细胞的嵌合体,所述宿主细胞包含多重基因编辑。
9.项8的动物,其中所述动物的有性繁殖将具有所述供体细胞的基因型的配子传递给后代。
10.项1-9中任一项的动物,其不含标志物基因。
11.项1-10中任一项的动物,所述动物选自下组:家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,山羊,绵羊和偶蹄动物。
12.项1-11中任一项的动物,其中在下列基因的一种或多种中进行所述多重基因编辑:il2rg-,rag2,il2rg;rag2,il2rgy,rag2,il2rg,rag2,il2rg;rag2,il2rg;rag2,dgat,abcg2,acan,amely,blg,bmp1b(fecb),dazl,dgat,eif4gi,gdf8,horn-poll基因座,igf2,cwc15,kissr/grp54,ofd1y,p65,prlr,prmd14,prnp,rosa,socs2,sry,zfy,β-乳球蛋白,clpg,mody1(hnf4α),mody2(gck),mody3(hnf1α),mody4(pdx1),mody5(hnf-1β),mody6(eurogenic分化1),mody7(klf11),mody8(cel),mody9(pax4),mody10(ins),mody11(blk),apc,apoe,dmd,ghrhr,hr,hsd11b2,ldlr,nf1,nppa,nr3c2,p53,pkd1,rbm20,scnnig,tp53,dazl,fah,hbb,il2rg,pdx1,pitx3,runx1,rag2,ggta,dazl,vasa,miwi,piwi,dcaf17,vdr,pnpla1,hras,端粒末端转移酶-vert,dsp,snrpe,rpl21,lama3,urod,edar,ofd1,pex7,col3a1,alox12b,hlcs,nipal4,cers3,antxr1,b3galt6,dsg4,ubr1,ctc1,mbtps2,uros,abhd5,nop10,alms1,lamb3,eogt,sat1,rbpj,arhgap31,acvr1,ikbkg,lpar6,hr,atr,htra1,aire,bcs1l,mccc2,dkc1,porcn,ebp,slitrk1,btk,dock6,apcdd1,zip4,casr,tert,edaradd,atp6v0a2,pvrl1,mgp,krt85,rag2,rag-1,ror2,claudin1,abca12,sla-dra1,b4galt7,col7a1,nhp2,gna11,wnt5a,usb1,lmna,eps8l3,nsdhl,trpv3,kras,tinf2,tgm1,dclreic,pkp1,wrap53,kdm5c,ecm1,tp63,krt14,ripk4,prkdc,bcl11a,bmi1,ccr5,cxcr4,dkk1,etv2,fli1,flk1,gata2,gata4,hhex,kit,lmx1a,myf5,myod1,myog,nkx2-5,nr4a2,pax3,pdx1,pitx3,runx1,rag2,ggta,hr,handii,tbx5,etv2,pdx1,tbx4,id2sox2,ttf1/nkx2-1,mesp1,gata4,nkx2-5,fah,prkdc,runx1,fli1,pitx3,lmx1a,dkk1,nr4a2/nurr1,flk1,hhex1,bcl11a,rag2,rag1,il2rg,c-kit/scfr,bmi1,handii,tbx5,gata2,dazl,olig1,olig2,它们的杂合子,它们的纯合子,及它们的组合。
13.在脊椎动物细胞或胚胎中多个靶染色体dna位点处进行体外遗传编辑的方法,包括
对脊椎动物细胞或胚胎中导入:
针对第一靶染色体dna位点的第一靶向内切核酸酶和与所述第一靶位点序列同源的第一同源性指导修复(hdr)模板;和
针对第二靶染色体dna位点的第二靶向内切核酸酶和与所述第二靶位点序列同源的第二hdr模板,
其中所述第一hdr模板序列替换所述第一靶位点处的天然染色体dna序列,并且所述第二hdr模板序列替换所述第二靶位点序列处的天然染色体dna序列。
14.项13的方法,所述方法还包括
对所述细胞或胚胎中导入下列一项或多项:
分别针对第三,第四,第五,第六和第七靶染色体dna位点的第三,第四,第五,第六和第七靶向内切核酸酶,和
分别与第三,第四,第五,第六和第七靶染色体dna位点同源的第三,第四,第五,第六和第七hdr模板。
15.项13-14中任一项的方法,其中所述靶向内切核酸酶包含talen,锌指核酸酶,rna引导的内切核酸酶,或cas9。
16.项13-15中任一项的方法,其中至少所述第一靶染色体dna位点是等位基因的基因座。
17.项16的方法,其中所述hdr模板中的至少一种编码与模板关联的所述dna靶位点的敲除。
18.项16的方法,其中所述hdr模板中的至少一种编码用于替换与所述模板关联的所述dna靶位点处的等位基因的外源等位基因。
19.项13-18中任一项的方法,其中所述细胞或胚胎是家畜的第一物种或第一品种,并且多个所述编辑包括用来自动物的第二物种或第二品种的外源等位基因替换天然等位基因。
20.项13-19中任一项的方法,其中所述细胞或胚胎在所述靶dna位点处的多个基因编辑上是纯合的,所述编辑由与所述靶dna位点关联的hdr模板编码。
21.项13-20中任一项的方法,其中所述细胞或胚胎在所述靶dna位点处的多个基因编辑上是杂合的,所述编辑由与所述靶dna位点关联的hdr模板编码。
22.项13-21中任一项的方法,其中所述细胞或胚胎选自下组:大型脊椎动物,家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,绵羊和偶蹄动物。
23.项13-22中任一项的方法,其中所述细胞选自下组:合子,干细胞,成体干细胞,多能细胞,祖细胞和原代细胞。
24.项13-22中任一项的方法,其中所述胚胎是合子,胚泡,桑椹胚或具有1-200个细胞数。
25.项13-24中任一项的方法,其中所述靶向内切核酸酶是talen和crispr的组合。
26.项13-25中任一项的方法,其中所述靶位点序列中的一种或多种选自下组:il2rgy/-,rag2-/-,il2rg-/-,rag2-/-,il2rgy/-,rag2-/-,il2rg+/-,rag2+/-,il2rgy/+,rag2+/-,il2rg+/-,rag2+/-,dgat,abcg2,acan,amely,blg,bmp1b(fecb),dazl,dgat,eif4gi,gdf8,horn-poll基因座,igf2,cwc15,kissr/grp54,ofd1y,p65,prlr,prmd14,prnp,rosa,socs2,sry,zfy,β-乳球蛋白,clpg,mody1(hnf4α),mody2(gck),mody3(hnf1α),mody4(pdx1),mody5(hnf-1β),mody6(eurogenic分化1),mody7(klf11),mody8(cel),mody9(pax4),mody10(ins),mody11(blk),apc,apoe,dmd,ghrhr,hr,hsd11b2,ldlr,nf1,nppa,nr3c2,p53,pkd1,rbm20,scnn1g,tp53,dazl,fah,hbb,il2rg,pdx1,pitx3,runx1,rag2,ggta,dazl,vasa,miwi,piwi,dcaf17,vdr,pnpla1,hras,端粒末端转移酶-vert,dsp,snrpe,rpl21,lama3,urod,edar,ofd1,pex7,col3a1,alox12b,hlcs,nipal4,cers3,antxr1,b3galt6,dsg4,ubr1,ctc1,mbtps2,uros,abhd5,nop10,alms1,lamb3,eogt,sat1,rbpj,arhgap31,acvr1,ikbkg,lpar6,hr,atr,htra1,aire,bcs1l,mccc2,dkc1,porcn,ebp,slitrk1,btk,dock6,apcdd1,zip4,casr,tert,edaradd,atp6v0a2,pvrl1,mgp,krt85,rag2,rag-1,ror2,claudin1,abca12,sla-dra1,b4galt7,col7a1,nhp2,gna11,wnt5a,usb1,lmna,eps8l3,nsdhl,trpv3,kras,tinf2,tgm1,dclre1c,pkp1,wrap53,kdm5c,ecm1,tp63,krt14,ripk4,prkdc,bcl11a,bmi1,ccr5,cxcr4,dkk1,etv2,fli1,flk1,gata2,gata4,hhex,kit,lmx1a,myf5,myod1,myog,nkx2-5,nr4a2,pax3,pdx1,pitx3,runx1,rag2,ggta,hr,handii,tbx5,etv2,pdx1,tbx4,id2sox2,ttf1/nkx2-1,mesp1,gata4,nkx2-5,fah,prkdc,runx1,fli1,pitx3,lmx1a,dkk1,nr4a2/nurr1,flk1,hhex1,bcl11a,rag2,rag1,il2rg,c-kit/scfr,bmi1,handii,tbx5,gata2,dazl,olig1,olig2,它们的杂合子,它们的纯合子,及它们的组合。
27.在原代脊椎动物细胞或胚胎中产生多重基因敲除的方法,所述方法包括在hdr模板的存在下,将靶向不同靶基因的多种talen导入所述细胞或胚胎中,所述hdr模板与所述不同靶基因具有同源性。
28.宿主细胞和供体细胞嵌合的脊椎动物胚胎,其包含
在不同染色体dna位点处具有多个宿主细胞遗传编辑的宿主胚胎,和
与所述宿主细胞整合以形成嵌合胚胎的供体细胞。
29.项28的胚胎,其中所述供体细胞是来自灵长类,啮齿动物或偶蹄动物的胚胎干细胞,多能干细胞,卵裂球等。
30.项28-29中任一项的胚胎,其中所述宿主或载体细胞遗传编辑包含基因的敲除或用脊椎动物的另一种品种或动物的另一种物种的外源等位基因替换天然等位基因。
31.项28-30中任一项的胚胎,其中所述宿主细胞遗传编辑的数目是或至少为2,3,4,5,6或7。
32.项28-31中任一项的胚胎,其中用脊椎动物的另一种品种或动物的另一种物种的外源等位基因替换天然等位基因的数目是或至少为2,3,4,5,6或7。
33.项28-32中任一项的胚胎,其中所述胚胎不含可表达的报告基因和/或合成基因和/或外源荧光蛋白。
34.项28-33中任一项的胚胎,其中所有所述基因编辑是双等位的,或所述编辑中的至少2,3,4或5个是双等位的,或其中所述编辑中的至少2,3,4或5个是单等位的,或其任何组合。
35.项28-34中任一项的胚胎,其中所述宿主胚胎注定为长势不能(failuretothrive)(ftt)表型。
36.宿主细胞和供体细胞嵌合的脊椎动物,其包含在不同染色体dna位点处的多个宿主细胞遗传编辑,以及与所述宿主细胞整合以形成嵌合动物的供体细胞。
37.制备宿主细胞和供体细胞嵌合的脊椎动物胚胎的方法,包括:
对宿主脊椎动物细胞中导入:
针对第一靶染色体dna位点的第一靶向内切核酸酶和与所述第一靶位点序列同源的第一同源性指导修复(hdr)模板;和
针对第二靶染色体dna位点的第二靶向内切核酸酶和与所述第二靶位点序列同源的第二hdr模板,
其中所述第一hdr模板序列替换所述第一靶位点处的天然染色体dna序列,并且所述第二hdr模板序列替换所述第二靶位点序列处的天然染色体dna序列,
克隆所述细胞以形成宿主胚胎,并且
将供体细胞置于所述宿主胚胎中。
38.项37的方法,其中所述细胞是原代细胞。
39.项37-38中任一项的方法,其选自下组:大型脊椎动物,家畜,猿,犬,猫,禽类,鸟,鱼,兔,猪,牛,水牛,山羊,绵羊和偶蹄动物。
40.包含宿主细胞和供体细胞的嵌合大型脊椎动物,其中所述宿主细胞包含对配子发生或精子发生基因的至少一个非减数分裂基因编辑,其由所述供体细胞的基因互补,其中所述动物包括具有所述供体细胞的基因型的配子。
41.包含宿主细胞和供体细胞的嵌合大型脊椎动物,其中所述宿主细胞包含至少一个非减数分裂基因编辑以建立长势不能(ftt)宿主细胞基因型,其中所述ftt基因型由所述供体细胞互补。
序列表
<110>重组股份有限公司
<120>多重基因编辑
<130>5054.28-wo-01
<150>61/985,327
<151>2014-04-28
<160>38
<170>patentinversion3.5
<210>1
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>1
ctcttttcgcaggcacaggtctacgagctggagcgacgcttctaagcttgcagcagcggt60
acctgtcggctcccgagcgtgaccagttgg90
<210>2
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>2
aaccctgtgtcgtttcccacccagtagatatgtttgatgactaagcttctcggaaggcag60
agagtgtgtcaactgcggggccatgtccac90
<210>3
<211>60
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>3
tgcggttgctcccccgcctcgtccccgtaagcttgactcctggtgcagcgccccggccag60
<210>4
<211>36
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>4
hisasphisasphisaspasnileasnileasnileasnasnasnasn
151015
asnglyasnglyhisaspasnileasnasnasnglyasnasnasngly
202530
asnglyasngly
35
<210>5
<211>40
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>5
hisasphisaspasnileasnileasnasnasnglyasnasnhisasp
151015
asnileasnileasnglyasnglyhisaspasnileasnglyasnasn
202530
asnglyasnilehisaspasngly
3540
<210>6
<211>36
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>6
asnilehisasphisaspasnglyasnglyhisasphisaspasngly
151015
hisasphisaspasnglyhisaspasnglyhisasphisaspasnasn
202530
hisaspasngly
35
<210>7
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>7
hisaspasnglyasnileasnileasnasnhisaspasnglyasnasn
151015
hisaspasnglyasnglyasnglyasnglyasnasnasnileasnile
202530
asngly
<210>8
<211>36
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>8
asnasnasnasnasnileasnileasnasnasnileasnileasnasn
151015
asnglyasnileasnglyhisaspasnileasnasnhisasphisasp
202530
asnileasngly
35
<210>9
<211>32
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>9
asnasnasnilehisasphisasphisaspasnileasnasnasnile
151015
asnileasnglyasnglyasnglyhisaspasnglyasnasnasngly
202530
<210>10
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>10
asnasnasnasnhisaspasnilehisasphisasphisaspasnasn
151015
asnglyasnasnasnglyhisasphisaspasnasnhisaspasnasn
202530
hisasp
<210>11
<211>30
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>11
hisaspasnileasnglyasnasnasnglyasnilehisaspasngly
151015
hisaspasnglyasnasnasnilehisaspasnglyasngly
202530
<210>12
<211>30
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>12
asnasnhisaspasnglyhisaspasnglyasnilehisaspasngly
151015
hisaspasnglyasnilehisasphisasphisasphisasp
202530
<210>13
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>13
asnasnhisaspasnilehisaspasnileasnglyasnasnasnile
151015
asnileasnasnasnglyhisaspasnasnhisasphisasphisasp
202530
asnile
<210>14
<211>36
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>14
hisasphisaspasnasnasnglyhisasphisaspasnglyasngly
151015
asnglyasnasnhisasphisaspasnileasnilehisasphisasp
202530
asnglyasngly
35
<210>15
<211>36
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>15
asnglyasnasnasnasnasnasnasnasnasnasnhisasphisasp
151015
hisaspasnilehisaspasnasnasnasnasnglyasnglyasnasn
202530
hisaspasngly
35
<210>16
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>16
hisaspasnglyhisasphisaspasnglyasnilehisaspasnile
151015
asnileasnasnasnglyasnasnasnasnasnileasnglyasngly
202530
asngly
<210>17
<211>36
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>17
hisaspasnasnasnasnasnilehisasphisasphisaspasnasn
151015
asnglyhisasphisaspasnglyasnglyasnasnhisaspasnile
202530
hisaspasngly
35
<210>18
<211>30
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>18
asnasnasnasnasnilehisaspasnglyasnasnasnilehisasp
151015
hisaspasnilehisaspasnglyasnileasnglyasngly
202530
<210>19
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>19
asnileasnasnasnileasnasnasnileasnileasnglyasnasn
151015
asnglyasnasnasnasnasnglyhisasphisaspasnileasnasn
202530
hisasp
<210>20
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>20
hisaspasnasnhisaspasnileasnasnasnasnhisaspasnile
151015
hisaspasnileasnasnasnasnasnglyhisaspasnglyasnile
202530
hisasp
<210>21
<211>30
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>21
asnilehisasphisaspasnasnhisaspasnglyasnasnhisasp
151015
asnglyasnasnhisaspasnglyasnglyasnasnasnile
202530
<210>22
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>22
asnasnhisaspasnasnasnasnasnglyasnglyasnasnhisasp
151015
asnglyhisasphisasphisasphisasphisaspasnasnhisasp
202530
hisasp
<210>23
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>23
asnasnasnasnhisasphisaspasnasnasnasnasnasnasnasn
151015
hisaspasnasnhisaspasnglyasnasnhisaspasnilehisasp
202530
hisasp
<210>24
<211>30
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>24
asnileasnglyasnasnasnglyasnglyasnglyasnasnasnile
151015
asnglyasnasnasnilehisaspasnglyasnglyhisasp
202530
<210>25
<211>34
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>25
asnasnasnasnhisasphisasphisasphisaspasnasnhisasp
151015
asnileasnasnasnglyasnglyasnasnasnilehisaspasnile
202530
hisasp
<210>26
<211>23
<212>prt
<213>人工序列
<220>
<223>合成重复可变二残基(rvd)代码
<400>26
cysglythrcysalacyscysalaalacysglyglythrcysthrcys
151015
cysthrcysthrcysglygly
20
<210>27
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>27
ttccactctaccccccccaaaggttcagtgttttgtgtaagcttcaatgttgagtacatg60
aattgcacttgggacagcagctctgagctc90
<210>28
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>28
ctctaaggattcctgccaccttcctcctctccgctacccagactaagctttgcacattca60
aaagcagcttagggtctgaaaaacatcagt90
<210>29
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>29
ccagatcgccaaagtcacggaagaagtatcagccattcatccctcccagtgaagcttaca60
gaaattctgggtcgaccacggagttgcact90
<210>30
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>30
agctcgccacccccgccgggcacccgtgtccgcgccatggccatctaagcttaaagaagt60
cagagtacatgcccgaggtggtgaggcgct90
<210>31
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>31
gtgctgcgtgccctttactgctctactctaccccctaccagcctaagcttgtgctgggcg60
acttcatgtgcaagttcctcaactacatcc90
<210>32
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>32
cccagacttcactccgtcctttgccgacttcggccgaccagcccttagcaaccgtgggcc60
cccaaggggtgggccaggtggggagctgcc90
<210>33
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>33
ccgagacgggaaatgcacctcctacaagtggatttgtgatggatccgaacaccgagtgca60
aggacgggtccgctgagtccctggagacgt90
<210>34
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>34
aaagtggcctggcccaacccctggactgaccactcgagtattgaagcacgtaagtatgct60
ggaccacattctctatggctgtagacattc90
<210>35
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>35
ctcttttcgcaggcacaggtctacgagctggagcgacgcttctaagcttgcagcagcggt60
acctgtcggctcccgagcgtgaccagttgg90
<210>36
<211>60
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>36
tgcggttgctcccccgcctcgtccccgtaagcttgactcctggtgcagcgccccggccag60
<210>37
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>37
aaccctgtgtcgtttcccacccagtagatatgtttgatgactaagcttctcggaaggcag60
agagtgtgtcaactgcggggccatgtccac90
<210>38
<211>90
<212>dna
<213>人工序列
<220>
<223>合成同源性指导的修复模板
<400>38
gctcccactcccctgggggcctctgggctcaccaacggtctcctcccgggggacgaagac60
ttctcctccattgcggacatggacttctca90
- 还没有人留言评论。精彩留言会获得点赞!