一种定量高通量测序文库的制备方法及其配套试剂盒与流程
本发明涉及生物技术领域,更具体地,涉及一种精确定量制备高通量测序文库的方法及其配套试剂盒。
背景技术:
随着高通量测序技术的普及,针对各种不同来源样品的高通量测序文库制备方法及商业试剂盒也得到大量应用。市场上主流的高通量文库制备试剂盒诸如illumina公司的truseq系列dna/rna文库制备试剂盒,kapa公司的hyper系列建库试剂盒,neb公司用于二代测序的nebnextdna/rna文库制备试剂等,这些种类繁多、功能各异的试剂盒能应对不同测序平台、不同样本来源等各种需求,最大程度地满足科研和临床等实际应用。不过,目前还没有一种完全定量化的文库制备方法,无法满足精准医学和定量生物学的实际需要。
因此,本领域尚缺乏一种专门针对精确定量需求的高通量测序文库制备方法。
技术实现要素:
本发明的目的是提供一种精确定量化的针对dna样品的高通量测序文库制备方法。
本发明的第一方面提供了一种衔接子,所述衔接子具有式i或ii所示的结构:
5'-s1─s2─s3─s4─s5─s6-3'(i)
5'-ps1─s2─s3─s4─s5─s6-3'(ii)
各式中,
s1为任选地引导部(n)m,n为a、t、g、c中任一碱基,m为1-150的正整数;
ps1为磷酸化的s1;
s2为茎部1,具有seqidno.:1所示的核苷酸序列;
s3为环部,其中含有至少一个碱基u;
s4为茎部2,具有seqidno.:2所示的核苷酸序列;
s2与s4完全互补或部分互补;
s5为无或与引导部s1互补的延伸部;
s6为无或含有至少一个碱基t的结合部;
若s5为无,则s6为无;
“─”为化学键。
在另一优选例中,所述的衔接子为线性结构、或茎环结构。
在另一优选例中,所述的衔接子具有式iii或iv所示结构:
在另一优选例中,m为1-100,更佳地1-50,最佳地5-20的任一正整数。
在另一优选例中,m为5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49或50。
在另一优选例中,所述环部s3具有seqidno.:3所示的核苷酸序列。
在另一优选例中,所述s6含有1个碱基t。
在另一优选例中,所述衔接子的s2具有seqidno.:1所示的核苷酸序列;s3具有seqidno.:3所示的核苷酸序列;s4具有seqidno.:2所示的核苷酸序列。
在另一优选例中,s2与s4是完全互补的,或除了未互补的1或2个碱基之外均为是互补的。
本发明的第二方面提供了一种基于核酸样品构建测序文库的方法,包括步骤:
(a)提供一用于构建测序文库的核酸样品;
(b)对所述的核酸样品进行末端修复反应,获得末端经修复的核酸样品;
(c)对所述的末端经修复的核酸样品进行3'末端加da尾反应,获得经加尾的核酸样品;
(d)将所述经加尾的核酸样品与权利要求1-5中任一所述的衔接子混合,并进行连接反应,从而形成含“衔接子-核酸-衔接子”复合物的第一混合物;
(e)将步骤(d)中获得的“衔接子-核酸-衔接子”复合物与user酶混合,使得衔接子中的u被降解,形成含末端分叉不互补的“衔接子-核酸-衔接子”复合物的第二混合物;
(f)将步骤(e)中获得的含所述复合物的第二混合物与片段分选磁珠混合,使得所述片段分选磁珠吸附多余的衔接子,并将所述被吸附的衔接子去除,获得第三混合物;
(g)以步骤(f)获得的所述复合物为模板,用特异性结合于衔接子的第一引物和特异性结合于衔接子的第二引物进行pcr反应,获得扩增产物;
(h)以将步骤(g)中获得的扩增产物为原料,制得测序文库。
在另一优选例中,在步骤(h)中,还包括对所述扩增产物进行纯化的步骤。
在另一优选例中,所述的纯化包括用片段分选磁珠去除多余的引物。
在另一优选例中,所述步骤(c)和(d)之间还包括步骤:
(i)对式i所示的衔接子进行5'末端磷酸化反应,使其形成式ii所示结构;
或对式iii所示的衔接子进行5'末端磷酸化反应,使其形成式iv所示结构。
在另一优选例中,所述步骤(c)和(d)之间还包括步骤:
(j)对式i或所示的衔接子进行退火,使其形成式iii所示结构;
或对式ii或所示的衔接子进行退火,使其形成式iv所示结构。
在另一优选例中,所述步骤(c)和(d)之间还包括步骤:
(k)当s5为无时,对式i-iv任一所示的衔接子进行链延伸反应,补齐简并碱基部分形成互补双链。
在另一优选例中,所述步骤(c)和(d)之间还包括步骤:
(l)当s5不为无时,对i-iv任一所示的衔接子进行3'末端加dt尾反应;或
当s5为无时,对步骤(k)中获得的衔接子进行3'末端加dt尾反应。
在另一优选例中,所述片段分选磁珠选自下组:ampurexp磁珠、hieffngsdna分选磁珠、imag片段分选磁珠。
在另一优选例中,所述测序文库可用于illunima高通量测序平台直接测序。
在另一优选例中,所述测序文库可用于精确定量。
在另一优选例中,所述步骤(a)中核酸样品总量为500pg~1μg。
本发明的第三方面提供了一种基于核酸样品构建测序文库的试剂盒,所述试剂盒包括:
一末端修复/加da尾复合酶及其缓冲液;
一t4dna连接酶;
一衔接子,所述的衔接子如本发明的第一方面中任一所述;
和说明书,所述的说明书记载了使用方法。
在另一优选例中,所述试剂盒还包括:特异性结合于衔接子的第一引物和第二引物。
在另一优选例中,所述第二引物带有测序标记(barcode)。
在另一优选例中,所述第一引物为通用引物p5,其序列如seqidno.:5所示。
在另一优选例中,所述第二引物为特异引物p7。
在另一优选例中,所述第二引物为特异引物p7,其序列如seqidno.:6所示。
在另一优选例中,所述试剂盒还包括酶缓冲液。
在另一优选例中,所述试剂盒还包括pcr反应预混液。
应理解,在本发明范围内中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。
附图说明
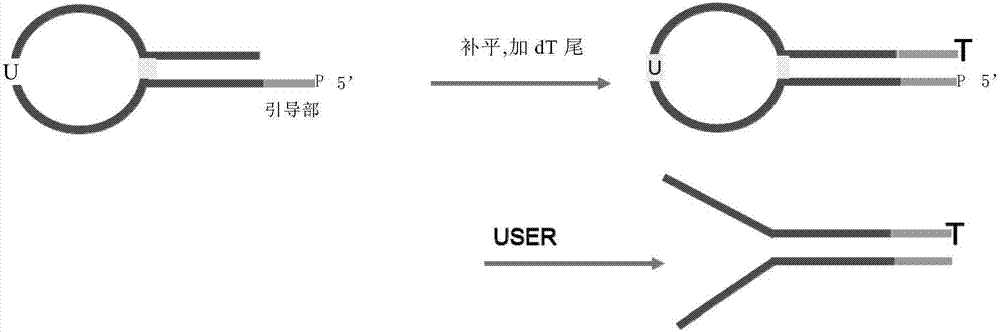
图1是衔接子制备过程的示意图。
具体实施方式
本发明人经过长期而深入的研究,意外开发出了一种具有式i-iv中任一所示的结构的衔接子,其能够用于制备dna高通量测序文库;以及使用该衔接子的构建dna高通量测序文库的方法和相应试剂盒,使用所述方法,能够制备精确定量的高通量测序文库。基于上述发现,完成了本发明。
针对dna样品制备精确定量的高通量测序文库方法
本发明提供了一种基于核酸样品制备定量化高通量测序文库的方法,所述的方法包括步骤:
(a)提供一用于制备测序文库的核酸样品,总量为500pg~1μg(或1-200ng,或0.5-10ng);
(b)对所述的核酸样品进行末端修复反应;
(c)对所述的核酸样品进行3'末端加da尾反应;
(d)提供一用于制备衔接子(adaptor)的单链核酸样品,序列为附件所示,其5'末端包含有5~20个简并碱基,3'末端倒数第34个碱基为u;
(e)对上述单链核酸样品进行5'末端磷酸化反应;
(f)对上一步获得的核酸样品进行退火,使其形成茎环结构;
(g)对上一步获得的核酸样品进行链延伸反应,补齐简并碱基部分形成互补双链;
(h)对上一步获得的核酸样品进行3'末端加dt尾反应,至此茎环结构衔接子(adaptor)制备完成,结构如式iv所示,其中s6为碱基t;
(i)将末端修复后加da尾的核酸样品与衔接子混合进行连接反应,从而形成“衔接子-核酸-衔接子”的复合物;
(j)将上一步获得的“衔接子-核酸-衔接子”复合物与user酶混合,使得衔接子中的u被降解,形成末端分叉不互补的“衔接子-核酸-衔接子”复合物;
(k)将上一步获得的复合物与适量片段分选磁珠混合,吸附去除多余的衔接子;
(l)将上一步获得的复合物与特异性结合于衔接子的通用引物(p5)和特异性结合于衔接子的特异引物(p7)混合,进行pcr反应,获得扩增产物;
(m)将上一步获得的扩增产物与适量片段分选磁珠混合,以去除多余的引物,此即制备完成的测序文库,经长度范围检测和浓度定量之后即可用于illunima高通量测序平台直接测序。
(n)测序后得到的每一个读长(reads)两端都个带有一个5~20个简并碱基的标签,此标签的复杂度取决于简并碱基的数量,理论上足够覆盖所有的核酸样品,并且在扩增放大过程中被忠实保留,因此可以用于精确定量。
基于微量核酸样品构建测序文库的试剂盒
本发明还提供了一种基于核酸样品制备高通量测序文库的试剂盒,所述试剂盒包括:
一末端修复/加a尾复合酶及其缓冲液;
一t4dna连接酶;
一衔接子,所述的衔接子为茎环结构,单链环状部分带有一个碱基u,互补双链末端带有5~20个简并碱基,
和说明书,所述的说明书记载了使用方法。
典型地,本发明试剂盒还包括:一通用引物和/或一特异引物。
典型地,本发明试剂盒中,所述特异引物带有测序标记(barcode),所述测序标记选自表1中所列出的序列。
典型地,本发明试剂盒还包括:一pcr反应预混液。
本发明的主要优点包括:
(1)本发明通过特殊设计的衔接子(adaptor),引入一段长度为5~20个简并碱基,作为每一条核酸片段的独有标签,且不会在放大、测序以及后期信息学分析过程中混淆,能够追溯原始样品中每一条核酸片段的数量和种类,可以实现完全精确定量。
(2)与现有技术相比,本发明利用简单易行的操作实现高通量测序文库的制备。对低至500pg的核酸样品也能顺利建库,通过常规片段分选磁珠的纯化,文库质量高,杂质少,可以直接上机测序。
(3)本发明适合于各种dna和rna样品制备高通量测序文库,且所需都是常规实验技术以及容易购买到的试剂和药品,条件易得,且操作简便,一般实验技术人员皆可独立操作完成。
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如sambrook等人,分子克隆:实验室手册(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数按重量计算。
实施例1dna高通量测序文库的构建
采用式i所示衔接子(其中s5为无,s6为无)为例(参见图1),构建dna高通量测序文库,衔接子预处理流程如下:
1、衔接子磷酸化
将商业合成的单链dna样品溶于纯水得到浓度为100μm的溶液,取5μl溶液到一只200μlpcr薄壁管,加入1μl10×t4连接酶缓冲液(终浓度为50mmtris-hcl,10mmmgcl2,1mmatp,10mmdtt),1μlt4多聚核苷酸激酶(pnk)(10u/μl),补水至总体积为10μl。
37℃反应60分钟,然后70℃反应25min使酶失活。
2、退火
上述反应中加入1μl10×nebuffer2(终浓度为50mmnacl,10mmtris-hcl,10mmmgcl2,1mmdtt),补水至总体积为20μl。
95℃加热10分钟,然后以0.1℃/秒的降温速度缓慢降温至4℃,冰上保存。
3、补平
上述体系中加入2μl10×nebuffer2(终浓度为50mmnacl,10mmtris-hcl,10mmmgcl2,1mmdtt),2μl浓度为10mm的dntp,3μl浓度为5u/μl的klenow酶,补水至总体积为40μl。
25℃反应30分钟,然后用qiagen公司的qiaquicknucleotideremovalkit回收反应产物,总体积为60μl。
4、加dt尾
上述溶液中加入10μl10×nebuffer2(终浓度为50mmnacl,10mmtris-hcl,10mmmgcl2,1mmdtt),3μl浓度为10mm的dttp,5μl浓度为5u/μl的klenow(exo-)酶,补水至总体积为100μl。
37℃反应30分钟,然后用qiagen公司的qiaquicknucleotideremovalkit回收反应产物,总体积为30μl。至此衔接子预处理完成,可分装后-20℃保存。
建库方法流程如下,起始样品dna范围是500pg~1μg:
1、末端修复/加a尾
取200μlpcr管,加入起始样品dna,末端修复/加da尾复合酶3μl,10×末端修复缓冲液6.5μl,补水至65μl。
20℃反应30分钟,然后65℃反应30分钟,4℃保存。
2、连接
上述反应中加入t4dna连接酶5μl,加入制备好的衔接子1μl(如果起始样品dna总量<100ng,衔接子须以水稀释10倍后使用),补水至总体积为80μl。
25℃反应2小时。
3、上述体系中加入3μluser酶,然后37℃反应15分钟。
上述体系中加入80μlampurexp磁珠,混匀后室温下孵育5分钟,然后置磁架上静置5分钟,待溶液变澄清透明后吸弃上清。将磁珠以新配的80%乙醇溶液洗三遍,吸弃上清,置磁架上静置干燥10分钟。然后加入28μl10mmtris-hcl,ph8.0,混匀后置磁架上静置5分钟,然后吸取23μl上清到另一200μlpcr管中,继续加入下面的溶液:
2×pcr预混液25μl,带有测序标记(barcode)的浓度为25μm的特异引物1μl,浓度为25μm的通用引物1μl,总体积为50μl。
在pcr仪上执行下述反应程序:
98℃初始变性30秒,然后98℃变性10秒,65℃退火30秒,72℃延伸30秒,此程序执行5~16个循环,最后72℃延伸5分钟,4℃保存。
如果起始dna样品接近1μg,那么pcr循环数可控制在5~7;如果起始样品为50ng,pcr循环数是10左右;如果起始样品数是500pg,那么pcr循环需要13~16。
用ampurexp磁珠清出产物
上述体系中加入45μlampurexp磁珠,混匀后室温下孵育5分钟,然后置磁架上静置5分钟,待溶液变澄清透明后吸弃上清。将磁珠以新配的80%乙醇溶液洗三遍,吸弃上清,置磁架上静置干燥10分钟。然后加入33μl10mmtris-hcl,ph8.0,混匀后置磁架上静置5分钟,然后吸取28μl上清到另一新管中,此即制备好的可用于上机测序的文库。
本发明中,衔接子中各组成部分s1-s6的序列如下:
s1为n5-20(简并碱基(n)长度为5~20);
s2的序列:5'-agatcggaagagc-3'(seqidno.:1);
s4的序列:5'-gctcttccgatct-3'(seqidno.:2);
s3的序列:5'-acacgtctgaactccagtcuacactctttccctacacgac-3'(seqidno.:3)。
本发明的一个具体实施方式中,衔接子序列结构为z1-z2,
其中,z1为n5-20;
z2为5'-agatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttccgatct-3'(seqidno.:4)。
本发明的一个具体实施方式中,引物序列如下:
通用引物p5为seqidno.:5:
5'-aatgatacggcgaccaccgagatctacactctttccctacacgacgctcttccgatct-3';
特异引物p7为
p1-b-p2
式中,
p1为caagcagaagacggcatacgagattg(seqidno.:6中第1-26位);
b为测序标记(barcode)序列,例如ttgact;
p2为gtgactggagttcagacgtgtgctcttccgatct(seqidno.:6中第33-66位)。
在另一具体实施方式中,所述b的长度为6个nt。
在另一具体实施方式中,所述b选自下表1:
表1illumina高通量测序标记barcode编号及对应序列
在另一具体实施方式中,特异引物p7的序列为seqidno.:6:
5'-caagcagaagacggcatacgagattgttgactgtgactggagttcagacgtgtgctcttccgatct-3'。
在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
序列表
<110>上海交通大学
<120>一种定量高通量测序文库的制备方法及其配套试剂盒
<130>p2017-0449
<160>6
<170>patentinversion3.5
<210>1
<211>13
<212>dna
<213>人工序列
<400>1
agatcggaagagc13
<210>2
<211>13
<212>dna
<213>人工序列
<400>2
gctcttccgatct13
<210>3
<211>40
<212>dna
<213>人工序列
<400>3
acacgtctgaactccagtcuacactctttccctacacgac40
<210>4
<211>66
<212>dna
<213>人工序列
<400>4
agatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttc60
cgatct66
<210>5
<211>58
<212>dna
<213>人工序列
<400>5
aatgatacggcgaccaccgagatctacactctttccctacacgacgctcttccgatct58
<210>6
<211>66
<212>dna
<213>人工序列
<400>6
caagcagaagacggcatacgagattgttgactgtgactggagttcagacgtgtgctcttc60
cgatct66
- 还没有人留言评论。精彩留言会获得点赞!
- 一种构建Hi‑C高通量测序文库的方法与制造工艺
- 桑葚病原菌高通量鉴定及种属分类方法及其应用与制造工艺
- 基于高通量测序技术检测乳腺癌/卵巢癌易感基因的多重PCR特异性引物、试剂盒及方法与制造工艺
- 基于高通量测序检测人EGFR基因变异的质控方法及试剂盒与制造工艺
- 基于高通量测序技术的小麦病原微生物检测方法及其应用与制造工艺
- 一种基于二代高通量测序技术的地中海贫血症的基因检测试剂盒的制造方法与工艺
- 一种基于集群的高通量数据分析方法与制造工艺
- 高通量双折射干涉成像光谱仪装置及其成像方法与制造工艺
- 高通量测序检测人循环肿瘤DNA EGFR基因的捕获探针及试剂盒的制造方法与工艺
- 一种高通量测序检测无创亲子鉴定的方法与制造工艺