一种预测结直肠癌风险的微生物标志物及其应用的制作方法
本发明涉及微生物领域,具体为一种预测结直肠癌风险的微生物标志物及其应用。
背景技术:
结直肠癌(colorectalcancer)是我国发病率仅次于肺癌和胃癌的第三大高发癌症,根据2018年《中国结直肠肿瘤早诊筛查策略专家共识》的统计数据显示,结直肠癌已成为我国发病率增长最快的恶性肿瘤之一,每年新发病例42.92万人,死亡病例28.1万人,防控形势严峻。结直肠癌的发病与年龄、环境等因素相关,约90%左右的患者发病年龄在40岁以上,但近年来随着人们生活水平的提高和饮食习惯的改变,结直肠癌的年轻患者比例逐渐升高,有年轻化趋势。
美国联合癌症委员会(ajcc)根据结直肠癌肿瘤的发生阶段将结直肠癌分为5个时段:0、ⅰ、ⅱ、ⅲ、ⅳ期。结直肠癌早期没有明显症状,等到发现问题时,基本已是晚期,治愈率仅有5%—40%,0/ⅰ期结直肠癌的5年存活率高达90%以上,而ⅳ期的5年成活率仅为5%-7%,因此早期筛查可以大幅降低结直肠癌发病率和死亡率。结直肠癌也是目前最可预防的肿瘤之一,它通常起源于结肠或直肠上皮的非癌性新生物“息肉”。如果通过筛查,早期发现并摘除,就能阻止它变成肿瘤。医学界认为,如果及早发现,肠癌是最易治愈的癌症,因此结直肠癌的早期筛查对于后续的治疗和预后都有重要意义。
随着结直肠癌早筛技术不断发展,目前主要有三种筛查技术:结肠镜检查、fobt/fit检测技术、基于血液或粪便dna的筛查技术。1985年,世界上出现首个肠癌筛查技术:刚性乙状结肠镜,经过数十年的发展,结肠镜技术不断进步,虽然这项技术作为肠癌检查的金标准,是一种较为准确的筛查手段,但是该技术存在侵入性、肠道准备繁琐,以及可能对受检者造成一定的创伤等缺点,令许多结直肠癌风险人群难以忍受或拒绝筛查;第一种非侵入性筛查技术粪便潜血试验(fobt)于1967年提出,十几年后,其改进版粪便免疫化学试验(fit)技术问世,这两项技术虽然具有无创、快速、非侵入性等优点,但前者存在采样次数多、敏感性较低(仅能检测30~50%的大肠癌和10~30%的癌前腺瘤)的缺陷,而后者也同样存在敏感性较低(只能检测50~60%的大肠癌和30%左右的癌前腺瘤)以及价格昂贵等缺点;20世纪90年代,基于dna的肠癌筛查技术出现,同时兼具非侵入性和高敏感性的优点,但是该检测技术假阳率比fit还要高,同时其价格高昂,因而性价比教低。
随着人类基因组计划的完成以及高通量测序技术的发展,基因筛查技术已成为一种新的结直肠癌诊断方法,在结直肠癌的早期诊断中有显著的优势,但是由于结直肠癌在疾病早期没有明显症状,潜在患者仍然需要通过肠镜检查进一步确诊。因此,针对结直肠癌的早期诊断和筛查,提供一种结直肠癌标志物,辅助结直肠癌的早期诊断,具有重要意义。
专利cn108064273a虽然公开了一种用于预测与微生物相关的疾病的生物标志物,但该发明的生物标志物组合存在随机性,且对疾病的预测需要宏基因组测序分析读段的丰度,只限定于特定片段,对数据要求较高,实验过程和操作成本高,不利于技术的应用。
专利cn110408699a虽然公开了一种肠癌肠道菌群标志物及其应用,但是该发明所述方法需要根据肠道菌群16srrna基因的测序数据进行相应的聚类以及注释等分析,从而进行结直肠癌的风险预测,分析步骤繁琐以及所需费用较高,也不利于该技术的广泛应用。
专利cn107904286a虽然公开了一种结直肠癌微生物标志物及其应用,其列举出来的微生物标志物也有4种,但是该发明专利在最终使用时可能只是使用其中的1种微生物标志物,无法保证所有微生物标志物都能参与其结直肠癌风险的评估,其微生物临界值的标准也相对简单,没有考虑不同微生物标志物对结直肠癌的影响因子大小,另外此发明专利使用的背景参考人群相对较少,结直肠癌样本只有64例,健康对照样本只有50例,其检测结果精确度有待进一步大数目人群确认,而本发明专利背景参考人群要大得多,其中结直肠癌样本435例,健康对照样本513例,而且本发明不会基于1种标志物就给出预测,而是综合3种标志物的丰度值以及其在背景人群中的影响因子大小进行风险评分,可靠性相比较要高得多。
专利cn112210602a虽然公开了基于粪便样本的结直肠癌筛查方法,其使用的数据也较多,有血红蛋白含量、基因突变、甲基化位点和细菌含量,然而其最终使用时可能用到的数据只是其中的一部分,如其列举了4个细菌,可能最终只用到其中某1个细菌,同时其收集的样本数也相对偏少,结直肠癌样本只有108例,健康样本只有36例,结直肠腺瘤样本仅18例,最终测试集中腺瘤只有5个样本,此时结果的误差会非常大,因而此专利评价结果精确度也有待进一步大数目人群确认,本发明专利中获取的样本数量相比较而言大得多,其中结直肠癌样本435例,健康对照样本513例,结果会更加可靠。另外需要注意的是,此发明专利使用的多个输入数据虽然包含了多个维度,但是其数据获取难度和成本也是成倍增加,如血红蛋白含量需要特殊的粪便隐血检测方法或者试剂盒进行检测,基因突变也需要对应的二代测序方法或者试剂盒进行检测,dna甲基化以及细菌丰度值等也都需要专业的方法和试剂盒进行检测,因而此方法检测成本会非常高,不利于其应用的广泛推广和应用。
因此,临床上需要一种能够兼具准确性、非侵入性且高性价比的结直肠癌早筛方法。同时肠道中的微生物菌群含有巨大的作为分子标志物的潜能,如具核梭杆菌(fusobacterium_nucleatum),已有大量研究表明,此核菌可作为无创结直肠癌的诊断分子标志物。在此本发明提出一种预测结直肠癌风险的微生物标志物及其应用。
技术实现要素:
针对上述现有技术的不足及实际的需求,本发明提供一种预测结直肠癌风险的微生物标志物及其应用,本发明的微生物标志物预测结直肠癌风险精度高,灵敏性好,操作难度低,性价比高,可用作辅助诊断结直肠癌,指导肠道微生物环境的调整。
为实现上述目的,本发明提供如下技术方案:
第一方面,本发明提供一种预测结直肠癌风险的微生物标志物,所述微生物标志物包括以下3种:
微生物标志物1)fusobacteriumnucleatum;
微生物标志物2)parvimonasmicra;
微生物标志物3)solobacteriummoorei。
研究证实上述微生物标志物在结直肠癌患者组中表达丰度均显著性比正常健康人群高,因而在本专利中综合了此3种微生物标志物对结直肠癌风险进行预测评估。
本发明中的相关结直肠癌微生物标志物灵明度高,特异性好,三个标志物的配合即可有进行辅助诊断或预测结直肠癌的患病风险,可用于肠癌的早期筛查,具有良好的应用前景和现实意义。
其中,所述微生物标志物的丰度是基于对其基因序列片段的计算所提供的。
其中,所述微生物标志物的丰度使用taqman探针法进行qpcr定量检测得到。
其中,所述微生物标志物1具核梭杆菌(fusobacteriumnucleatum)的探针序列和正反引物如seqidno.1~seqidno.3所示。
其中,所述微生物标志物2微小单胞菌(parvimonasmicra)的探针序列和正反引物如seqidno.4~seqidno.6所示。
其中,所述微生物标志物3莫雷梭菌(solobacteriummoorei)的探针序列和正反引物如seqidno.7~seqidno.9所示。
其中,微生物标志物内参对照16srdna的探针序列和正反引物如seqidno.10~seqidno.12所示。
其中,所述微生物标志物的丰度信息用于和参考值进行比较,并进行综合计算,从而确定结直肠癌风险。
第二方面,本发明提供一种检测如第一方面所述的与结直肠癌相关的微生物标志物的试剂。
其中,所述试剂可以是针对所述与结直肠癌相关的微生物标志物的引物探针组合或其他试剂,用来测定所述微生物标志物的丰度。
其中,所述微生物标志物的丰度使用taqman探针法进行qpcr定量检测得到。
第三方面,本发明提供一种如第一方面所述的与结直肠癌相关的微生物标志物或如第二方面所述试剂的用途,所述用途包括用于制备结直肠癌辅助诊断试剂,或制备结直肠癌辅助诊断试剂盒。
第四方面,本发明提供一种基于以上所述微生物标志物丰度预测结直肠癌风险的计算模型,包括以下步骤:
步骤1)收集513例健康个体新鲜粪便样本以及435例结直肠癌患者新鲜粪便样本;
步骤2)从步骤1)中所述个体粪便样本中提取并纯化dna片段;
步骤3)使用taqman探针法进行qpcr实时定量,检测步骤2)样本中如第一方面所述微生物标志物目的基因片段的基因含量以及内部参照16srdna的基因含量,从而比较得到相关微生物标志物的丰度;
步骤4)使用步骤3)中得到的所有样本的相关微生物标志物的丰度信息以及分组信息,多次将收集到的数据有放回的随机分成70%训练组和30%测试组,基于训练组首先使用随机森林算法中randomizedsearchcv算法进行大范围的参数优化选择,然后选择其中最优参数进一步使用gridsearchcv算法进行最终参数选择,从而挑选最优参数进行模型训练,并进行模型结果验证,最后使用测试组进行结果验证。
优选地,本发明中交叉验证是在机器学习建立模型和验证模型参数时常用的办法。重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某个样本再下次可能成为测试集中的样本,即所谓“交叉验证”。
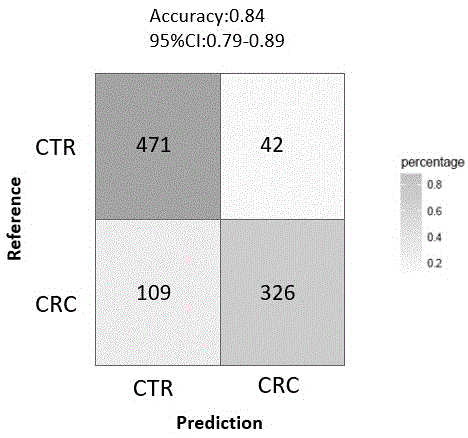
优选地,本发明提供的模型训练最优结果如图1所示。其中,精准率(precision=正确阳性分组数量/(正确阳性分组数量+错误阳性分组数量))达到88%,特异性(truenegativerate=正确阴性分组数量/(正确阴性分组数量+错误阳性分组数量))达到92%,总准确率达到84%,与专利号为cn112210602a的专利相比,虽然其实施例6中提供的测试数据说明其测试集灵敏度达到100%,特异性为94.4%,但是从其测试集样本数目可以看出,其测试集样本数明显偏少,十几个甚至几个测试样本,这种测试结果误差是非常大的,可能一个样本的影响直接将测试结果百分比增加/降低10%~20%,同时根据其专利说明书描述,其专利提供的准确性、灵敏度、特异性至少达到75%及以上,说明其专利提供的模型在具体使用中相关指标不是很稳定,只能保证75%及以上,而本发明测试集较大,最终测试结果精准率达到88%,特异性能达到92%,而且相比较而言本发明在具体使用时不用测试多个不同维度数据,花费时间少,费用也要低得多,在临床使用中有着很高的性价比,具有良好的应用前景和现实意义,可用于评估结直肠癌风险。
第五方面,本发明提供一种基于以上所述微生物标志物丰度预测结直肠癌风险的计算方法,包括以下步骤:
步骤1)从受试者个体新鲜粪便样本中提取并纯化dna片段;
步骤2)使用taqman探针法进行qpcr实时定量,检测步骤1)样本中如第一方面所述微生物标志物目的基因片段的基因含量以及内部参照16srdna的基因含量,从而比较得到相关微生物标志物的丰度;
步骤3)将步骤2)得到的微生物标志物的丰度信息输入第四方面所述的结直肠癌风险计算模型中,经过模型综合计算后给出风险打分,从而辅助诊断评估个体患结直肠癌的风险。
优选地,经过上述模型计算给出打分,相关结果评价如下:
(1)打分值<0.5,则可以判定为健康人群,打分值越接近0,说明结直肠癌风险越低;
(2)打分值>=0.5,则初步判定为结直肠癌高风险人群,打分值越接近1,结直肠癌风险越高,此时后续需要进行其他临床技术进一步确认。
本发明中,利用如第五方面所述的预测个体结直肠癌风险的方法为早期诊断结直肠癌提供了一种非侵入性的辅助检测方法。
与现有技术相比,本发明具有如下有益效果:
1.本发明提供一种预测结直肠癌风险的微生物标志物,此3种微生物经研究证实在患病人群中均显著高表达,因此具有作为结直肠癌诊断标志物的潜能,可用于结直肠癌的辅助诊断和风险预测,同时特异性好,灵敏度高,性价比高,揭示肠道微生物菌群状况,指导微生物环境的调整,降低结直肠癌发生的可能性;
2.本发明提供一种预测个体结直肠癌风险的方法,使用粪便样本便于运输且取样无创,可增加患者依从性。同时,使用粪便样本具有准确性和安全性;
3.本发明提供一种预测个体结直肠癌风险的模型以及其应用,在大数目背景人群以及多次参数优化选择的训练下,模型精确度有较大程度的可靠性,同时不依赖其他指标,依靠此3种微生物标志物的丰度信息即可个体预测结直肠癌的风险,成本较低,精确度也有一定保证,其性价比较高,具有良好的应用前景和现实意义。
附图说明
图1为本发明最终使用模型预测评估结直肠癌风险的相关结果参数。
具体实施方式
为进一步阐述本发明所采取的技术手段及其效果,以下结合实施例对本发明做进一步的说明,但本发明的保护范围不受具体的实施方式所限制,以权利要求书为准,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
本发明所用数据具有相关领域普通技术人员通常理解的含义。然而,为了更好地理解本发明,对一些定义和相关术语的解释如下:
“生物标志物”,指可以标记系统、器官、组织、细胞及亚细胞结构或功能的改变或可能发生改变的生化指标,可用于疾病诊断、判断疾病分期或评价新药新疗法在目标人群中的安全性和有效性。在本发明中,“生物标志物”指肠道微生物标志物,也可用“肠道微生物”、“肠道菌群”表示,因为本发明中使用的与结直肠癌相关的微生物标志物均来自经受试者肠道代谢后的粪便样本。
实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件,或者按照产品说明书进行。所用的试剂或仪器未注明生产厂商者,均为可通过正规渠道商购获得的常规产品。
实施例1,dna样本的提取
(1)收集受试者的新鲜粪便样本,立刻进行冷冻处理,实验前置于冰上;
(2)分别称取200mg固定粪便于2ml离心管中,加入800μl粪便dna提取缓冲液,充分震荡混匀5min,1800g离心1min;
(3)从中取出50μl悬液于1.5ml离心管中,加入800μl裂解液旋涡震荡混匀,70℃裂解5min,离心5min后转移上清至干净的1.5ml离心管中;
(4)加入20μl混匀的磁珠,旋涡震荡20s,室温静置4min,置于磁架上,静置20s,吸取上清;
(5)加入500μl洗涤液ⅰ,旋涡震荡20s,混匀磁珠,置于磁架上,静置20s,弃上清;
(6)加入750μl洗涤液ⅱ,旋涡震荡20s,混匀磁珠,置于磁架上,静置20s,弃上清,重复一次或多次,尽量除去所有液体;
(7)置于磁力架上开盖干燥7-8min,尽量除去所有液体;
(9)加入50μl缓冲液或双蒸水,旋涡震荡15s,混匀磁珠,65℃下加热7min(期间旋涡震荡10s),旋涡震荡15s,置于磁架上,静置2min,吸上清于收集管中,得到所述粪便dna。
实施例2,微生物标志物的定量检测
微生物标志物的定量检测采用taqmanqpcr方法,其中使用的探针和引物如表1所示:
表1.微生物标志物及内参对照的探针和引物
下面以苏州新海生物科技股份有限公司taqmanmastermix试剂盒产品为例,描述本实施例的具体步骤:
(1)按照表2所示的qpcr反应体系进行反应配制pcr反应液;
表2.qpcr反应体系
(2)pcr反应液配置完成后,上下颠倒混匀并离心,分装至96孔pcr反应板中,2000g离心2min,封口后置于pcr仪中进行反应;
(3)使用两步pcr反应法进行qpcr反应,设定程序为表3所示;
表3.两步pcr反应法程序
(4)根据仪器输出的ct值,以内部参照16srdna作为内参,对样本中的微生物标志物的目的片段含量进行相对定量计算,结果即为所述微生物标志物的丰度。
实施例3,结直肠癌风险评估计算模型的训练
结直肠癌风险评估计算模型的建立使用随机森林算法对收集到的513例健康个体以及435例结直肠癌患者样本中如上所述3种微生物标志物丰度信息以及其分组信息进行训练及内部数据测试,最终从多个训练模型中挑选最优模型作为后续结直肠癌风险计算模型,具体步骤如下所示:
步骤1)收集513例健康个体新鲜粪便样本以及435例结直肠癌患者新鲜粪便样本;
步骤2)从步骤1)中所述个体粪便样本中提取并纯化dna片段;
步骤3)使用taqman探针法进行qpcr实时定量,检测步骤2)样本中如第一方面所述微生物标志物目的基因片段的基因含量以及内部参照16srdna的基因含量,从而比较得到相关微生物标志物的丰度;
步骤4)使用步骤3)中得到的所有样本的相关微生物标志物的丰度信息以及分组信息,多次将收集到的数据有放回的随机分成70%训练组和30%测试组,基于训练组首先使用随机森林算法中randomizedsearchcv算法进行大范围的参数优化选择,然后选择其中最优参数进一步使用gridsearchcv算法进行最终参数选择,从而挑选最优参数进行模型训练,并进行模型结果验证,最后使用测试组进行结果验证。
其中,dna片段的提取以及纯化如实施例1所述。
其中,相关微生物标志物丰度的定量如实施例2所述。
其中,模型的验证使用十次十倍交叉验证,避免一次验证造成的误差。
其中,模型训练最优结果如图1所示。其中,精准率(precision=正确阳性分组数量/(正确阳性分组数量+错误阳性分组数量))达到0.88,特异性(truenegativerate=正确阴性分组数量/(正确阴性分组数量+错误阳性分组数量))达到0.92,总正确率达到84%,与专利号为cn112210602a的专利相比,虽然其实施例6中提供的测试数据说明其测试集灵敏度达到100%,特异性为94.4%,但是从其测试集样本数目可以看出,其测试集样本数明显偏少,十几个甚至几个测试样本,这种测试结果误差是非常大的,可能一个样本的影响直接将测试结果百分比增加/降低10%~20%,同时根据其专利说明书描述,其专利提供的准确性、灵敏度、特异性至少达到75%及以上,说明其专利提供的模型在具体使用中相关指标不是很稳定,只能保证75%及以上,而本发明测试集较大,最终测试结果精准率达到88%,特异性能达到92%,而且相比较而言本发明在具体使用时不用测试多个不同维度数据,花费时间少,费用也要低得多,在临床使用中有着很高的性价比,具有良好的应用前景和现实意义,可用于评估结直肠癌风险。
实施例4,结直肠癌风险评估预测
经过实施例3的模型训练并得到最优模型,此时将待测个体的相关微生物标志物丰度参数输入此模型进行计算,综合计算后给出打分,相关结果评价如下:
(1)打分值<0.5,则可以判定为健康人群,打分值越接近0,说明结直肠癌风险越低;
(2)打分值>=0.5,则初步判定为结直肠癌高风险人群,打分值越接近1,结直肠癌风险越高,此时后续需要进行其他临床技术进一步确认。
需要说明的是,在本专利中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
以上所述仅为本发明的优选实例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
序列表
<110>天津奇云诺德生物医学有限公司
<120>一种预测结直肠癌风险的微生物标志物及其应用
<160>12
<170>siposequencelisting1.0
<210>1
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>1
actaagcagttcgcaggagatccagcac28
<210>2
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>2
gccgttataatctcaggcttgatg24
<210>3
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>3
tggtattctggtagctccattacg24
<210>4
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>4
aactcaagatccagaccttgctacgcctca30
<210>5
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>5
aagaatggagagagttgttagagaaagaa29
<210>6
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>6
ttgtgataattgtgaagaaccgaaga26
<210>7
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>7
caccaagagcaggaacaaccggca24
<210>8
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>8
tgaaaatggtttatgcggttgt22
<210>9
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>9
acagcgacggaataggcatatt22
<210>10
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>10
agcttctattggttcttctcgtccagtggc30
<210>11
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>11
ttgtaagtgctggtaaagggattg24
<210>12
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>12
cattcctacataacggtcaagaggta26
- 还没有人留言评论。精彩留言会获得点赞!